|
Тип данных MPI
|
Тип данных C
|
|
MPI_CHAR
|
Signed char
|
|
MPI_SHORT
|
Signed short
int
|
|
MPI_INT
|
Signed int
|
|
MPI_LONG
|
Signed long int
|
|
MPI_UNSIGNED_CHAR
|
unsigned char
|
|
MPI_UNSIGNED_SHORT
|
unsigned short
int
|
|
MPI_UNSIGNED
|
unsigned int
|
|
MPI_UNSIGNED_LONG
|
unsigned long
int
|
|
MPI_FLOAT
|
Float
|
|
MPI_DOUBLE
|
Double
|
|
MPI_LONG_DOUBLE
|
long double
|
|
MPI_BYTE
|
Нет
соответствия
|
|
MPI_PACKED
|
Нет
соответствия
|
Основные
понятия MPI
Коммуникатор представляет собой структуру, содержащую либо
все процессы, исполняющиеся в рамках данного приложения, либо их подмножество.
Процессы, принадлежащие одному и тому же коммуникатору, наделяются общим
контекстом обмена. Операции обмена возможны только между процессами, связанными
с общим контекстом, то есть, принадлежащие одному и тому же коммуникатору
(рис.1). Каждому коммуникатору присваивается идентификатор. В MPI есть
несколько стандартных коммуникаторов:_COMM_WORLD - включает все процессы
параллельной программы;_COMM_SELF - включает только данный процесс;_COMM_NULL -
пустой коммуникатор, не содержит ни одного
процесса.
В MPI имеются процедуры, позволяющие создавать новые
коммуникаторы, содержащие подмножества процессов.
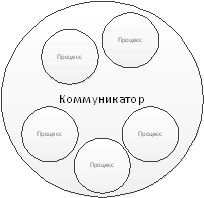
Рис.1. Коммуникатор
Ранг процесса представляет собой уникальный числовой
идентификатор, назначаемый процессу в том или ином коммуникаторе. Ранги в
разных коммуникаторах назначаются независимо и имеют целое значение от 0 до
число_процессов - 1 (рис.2).
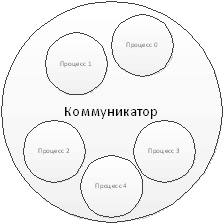
Рис.2. Ранги
процессов
Тег (маркер) сообщения - это уникальный числовой идентификатор,
который назначается сообщению и позволяет различать сообщения, если в этом есть
необходимость. Если тег не требуется, вместо него можно
использовать конструкцию MPI_ANY_TAG.
Различные
подпрограммы MPI
Подключение к MPI:
int MPI_Init (int *argc, char **argv)
Аргументы argc и argv требуются только в программах на C, где
они задают количество аргументов командной строки запуска программы и вектор
этих аргументов. Данный вызов предшествует всем прочим вызовам подпрограмм MPI.
Завершение работы с MPI:
int MPI_Finalize ()
После вызова данной подпрограммы нельзя вызывать подпрограммы
MPI. MPI_FINALIZE должны вызывать все процессы перед завершением своей работы.
Определение размера области взаимодействия:
int MPI_Comm_size (MPI_Comm comm, int *size)
Входные параметры:
· comm - коммуникатор.
Выходные параметры:
· size - количество процессов в области
взаимодействия.
Определение ранга процесса:
int MPI_Comm_rank (MPI_Comm comm, int *rank)
Входные параметры:
· comm - коммуникатор.
Выходные параметры:
· rank - ранг процесса в области
взаимодействия.
Время, прошедшее с произвольного момента в
прошлом
double MPI_Wtime ()
Двухточечный
обмен
Участниками двухточечного обмена являются два процесса:
процесс-отправитель и процесс - получатель (рис.3).
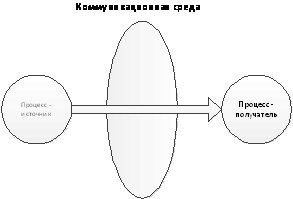
Рис.3. Двухточечный обмен
Стандартная блокирующая передача
int MPI_Send (void *buf, int count, MPI_Datatype datatype,
int dest, int tag, MPI_Comm comm)
Входные параметры:
· buf - адрес первого элемента в буфере
передачи;
· count - количество элементов в буфере
передачи;
· datatype - тип MPI каждого пересылаемого элемента;
· dest - ранг процесса-получателя сообщения
(целое число от 0 до n - 1, где n - число процессов в области взаимодействия);
· tag - тег сообщения;
· comm - коммуникатор;
Стандартный блокирующий прием
int MPI_Recv (void *buf, int count, MPI_Datatype datatype,
int source, int tag, MPI_Comm comm, MPI_Status *status)
Входные параметры:
· count - максимальное количество элементов
в буфере приема. Фактическое их количество можно определить с помощью подпрограммы
MPI_Get_count;
· datatype - тип принимаемых данных.
Напомним о необходимости соблюдения соответствия типов аргументов подпрограмм
приема и передачи;
· source - ранг источника. Можно
использовать специальное значение
MPI_ANY_SOURCE, соответствующее произвольному значению ранга.
В программировании идентификатор, отвечающий произвольному значению параметра,
часто называют "джокером". Это наименование будет использоваться и в
дальнейшем.
· tag - тег сообщения или "джокер"
MPI_ANY_TAG, соответствующий произвольному значению тега;
· comm - коммуникатор. При указании
коммуникатора "джокеры" использовать нельзя.
Выходные параметры:
· buf - начальный адрес буфера приема. Его
размер должен быть достаточным, чтобы разместить принимаемое сообщение, иначе
при выполнении приема произойдет сбой - возникнет ошибка переполнения;
· status - статус обмена.
Если сообщение меньше, чем буфер приема, изменяется
содержимое лишь тех ячеек памяти буфера, которые относятся к сообщению.
Коллективный
обмен
Участниками коллективного обмена являются более двух
процессов.
Широковещательная рассылка выполняется выделенным процессом,
который называется главным (root). Все остальные процессы, принимающие участие
в обмене, получают по одной копии сообщения от главного процессаMPI_Bcast (void
*buffer, int count, MPI_Datatype datatype, int root, MPI_Comm comm)
Параметры этой процедуры одновременно являются входными и
выходными:
· buffer - адрес буфера;
· count - количество элементов данных в
сообщении;
· datatype - тип данных MPI;
· root - ранг главного процесса,
выполняющего широковещательную рассылку;
· comm - коммуникатор.
Схема распределения данных представлена на рис.4.
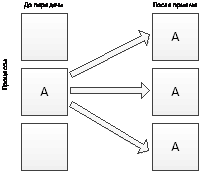
Рис.4. Распределение данных при широковещательной
рассылке
1.2
Технология OpenMP
OpenMP - это интерфейс прикладного программирования для
создания многопоточных приложений, предназначенных в основном для параллельных
вычислительных систем с общей памятью [7]. OpenMP состоит из набора директив
для компиляторов и библиотек специальных функций. Стандарты OpenMP
разрабатывались в течение последних 15 лет применительно к архитектурам с общей
памятью. Описание стандартов OpenMP и их реализации при программировании на
алгоритмических языках Fortran и C/C++ можно найти в [8].позволяет легко и
быстро создавать многопоточные приложения на алгоритмических языках Fortran и
C/C++. При этом директивы OpenMP аналогичны директивам препроцессора для языка
C/C++ и являются аналогом комментариев в алгоритмическом языке Fortran. Это
позволяет в любой момент разработки параллельной реализации программного
продукта при необходимости вернуться к последовательному варианту программы.
В настоящее время OpenMP поддерживается большинством
разработчиков параллельных вычислительных систем: компаниями Intel,
Hewlett-Packard, Silicon Graphics, Sun, IBM, Fujitsu, Hitachi, Siemens, Bull и
другими. Многие известные компании в области разработки системного программного
обеспечения также уделяют значительное внимание разработке системного
программного обеспечения с OpenMP. Среди этих компаний можно отметить Intel,
KAI, PGI, PSR, APR, Absoft и некоторые другие. Значительное число компаний и
научно-исследовательских организаций, разрабатывающих прикладное программное
обеспечение, в настоящее время использует OpenMP при разработке своих
программных продуктов. Среди этих компаний и организаций можно отметить ANSYS,
Fluent, Oxford Molecular, NAG, DOE ASCI, Dash, Livermore Software, а также и
российские компании ТЕСИС, Центральную геофизическую экспедицию и российские
научно-исследовательские организации, такие как Институт математического
моделирования РАН, Институт прикладной математики им. Келдыша РАН, Вычислительный
центр РАН, Научно-исследовательский вычислительный центр МГУ, Институт
химической физики РАН и другие.
Принципиальная
схема программирования в OpenMP
Принципиальная схема параллельной программы изображена на
рис.5.
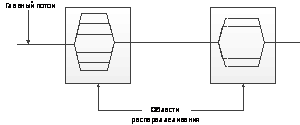
Рис.5. Принципиальная
схема параллельной программы
При выполнении параллельной программы работа начинается с
инициализации и выполнения главного потока (процесса), который по мере
необходимости создает и выполняет параллельные потоки, передавая им необходимые
данные. Параллельные потоки из одной параллельной области программы могут
выполняться как независимо друг от друга, так и с пересылкой и получением
сообщений от других параллельных потоков. Последнее обстоятельство усложняет
разработку программы, поскольку в этом случае программисту приходится
заниматься планированием, организацией и синхронизацией посылки сообщений между
параллельными потоками. Таким образом, при разработке параллельной программы
желательно выделять такие области распараллеливания, в которых можно
организовать выполнение независимых параллельных потоков. Для обмена данными
между параллельными процессами (потоками) в OpenMP используются общие
переменные. При обращении к общим переменным в различных параллельных потоках
возможно возникновение конфликтных ситуаций при доступе к данным. Для
предотвращения конфликтов можно воспользоваться процедурой синхронизации. При
этом надо иметь в виду, что процедура синхронизации - очень дорогая операция по
временным затратам и желательно по возможности избегать ее или применять как
можно реже.
Выполнение параллельных потоков в параллельной области программы
начинается с их инициализации. Она заключается в создании дескрипторов
порождаемых потоков и копировании всех данных из области данных главного потока
в области данных создаваемых параллельных потоков. Эта операция чрезвычайно
трудоемка.
После завершения выполнения параллельных потоков управление
программой вновь передается главному потоку. При этом возникает проблема
корректной передачи данных от параллельных потоков главному. Здесь важную роль
играет синхронизация завершения работы параллельных потоков, поскольку в силу
целого ряда обстоятельств время выполнения даже одинаковых по трудоемкости
параллельных потоков непредсказуемо (оно определяется как историей конкуренции
параллельных процессов, так и текущим состоянием вычислительной системы). При
выполнении операции синхронизации параллельные потоки, уже завершившие свое
выполнение, простаивают и ожидают завершения работы самого последнего потока.
Естественно, при этом неизбежна потеря эффективности работы параллельной
программы. Кроме того, операция синхронизации имеет трудоемкость, сравнимую с
трудоемкостью инициализации параллельных потоков.
Синтаксис
директив в OpenMP
Все рассматриваемые ниже директивы приведены в синтаксисе
языка С/С++.
Основные конструкции OpenMP - это директивы компилятора или
прагмы (директивы препроцессора) языка C/C++. Ниже приведен общий вид директивы
OpenMP прагмы.
#pragma omp конструкция [предложение [предложение] …]
Для обычных последовательных программ директивы OpenMP не
изменяют структуру и последовательность выполнения операторов. Таким образом,
обычная последовательная программа сохраняет свою работоспособность. В этом и
состоит гибкость распараллеливания с помощью OpenMP.
В следующем фрагменте программы показан общий вид основных
директив OpenMP.
# pragma omp parallel \(var1, var2, …) \(var1, var2, …)
\(var1, var2, …) \(var1, var2, …) \(var1, var2, …) \(operator: var1, var 2, …)
\(expression) \(shared | none) \
{
[Структурный блок программы]
}
В рассматриваемом фрагменте предложение OpenMP shared
используется для описания общих переменных. Как уже отмечалось ранее, общие
переменные позволяют организовать обмен данными между параллельными процессами
в OpenMP. Предложение private используется для описания внутренних (локальных)
переменных для каждого параллельного процесса. Предложение firstprivate
применяется для описания внутренних переменных параллельных процессов, однако
данные в эти переменные импортируются из главного потока. Предложение reduction
позволяет собрать вместе в главном потоке результаты вычислений частичных сумм,
разностей и т.п. из параллельных потоков. Предложение if является условным
оператором в параллельном блоке. Предложение default определяет по умолчанию
тип всех переменных в последующем параллельном структурном блоке программы.
Далее механизм работы этих предложений будет рассмотрен более подробно.
Предложение copyin позволяет легко и просто передавать данные из главного
потока в параллельные.
Рассмотренные в настоящем разделе директивы OpenMP не
охватывают весь спектр директив. В следующем разделе будут рассмотрены
некоторые из директив OpenMP и механизмов их работы.
Особенности
реализации директив OpenMP
В этом разделе рассмотрим некоторые специфические особенности
реализации директив OpenMP.
Количество потоков в параллельной программе определяется либо
значением переменной окружения OMP_NUM_THREADS, либо специальными функциями,
вызываемыми внутри самой программы. Определить номер текущего потока можно с
помощью функции omp_get_thread_num ().
Каждый поток выполняет структурный блок программы, включенный
в параллельный регион. В общем случае синхронизации между потоками нет, и
заранее предсказать завершение потока нельзя. Управление синхронизацией потоков
и данных осуществляется программистом внутри программы. После завершения
выполнения параллельного структурного блока программы все параллельные потоки
за исключением главного прекращают свое существование.
Пример ветвления во фрагменте программы, написанной на языке
C/C++, в зависимости от номера параллельного потока показан в примере ниже.
#pragma omp parallel
{= omp_get_thread_num ();(myid == 0)_something
();_something_else (myid);
}
В этом примере в первой строке параллельного блока вызывается
функция omp_get_thread_num, возвращающая номер параллельного потока. Этот номер
сохраняется в локальной переменной myid. Далее в зависимости от значения
переменной myid вызывается либо функция do_something () в первом параллельном
потоке с номером 0, либо функция do_something_else (myid) во всех остальных
параллельных потоках.
Директивы
OpenMP
Теперь перейдем к подробному рассмотрению директив OpenMP и
механизмов их реализации.
Директивы
shared, private и default
Эти директивы (предложения OpenMP) используются для описания
типов переменных внутри параллельных потоков.
Предложение OpenMP(var1, var2, …, varN)
определяет переменные var1, var2, …, varN как общие
переменные для всех потоков. Они размещаются в одной и той же области памяти
для всех потоков.
Предложение OpenMP(var1, var2, …, varN)
определяет переменные var1, var2, …, varN как локальные
переменные для каждого из параллельных потоков. В каждом из потоков эти
переменные имеют собственные значения и относятся к различным областям памяти:
локальным областям памяти каждого конкретного параллельного потока.
Предложение OpenMP(shared | private | none)
задает тип всех переменных, определяемых по умолчанию в
последующем параллельном структурном блоке как shared, private или none.
Директива
if
Директива (предложение) OpenMP if используется для
организации условного выполнения потоков в параллельном структурном блоке.
Предложение OpenMP(expression)
определяет условие выполнения параллельных потоков в
последующем параллельном структурном блоке. Если выражение expression принимает
значение TRUE (Истина), то потоки в последующем параллельном структурном блоке
выполняются. В противном случае, когда выражение expression принимает значение
FALSE (Ложь), потоки в последующем параллельном структурном блоке не
выполняются.
Директива
reduction
Директива OpenMP reduction позволяет собрать вместе в главном
потоке результаты вычислений частичных сумм, разностей и т.п. из параллельных
потоков последующего параллельного структурного блока.
В предложении OpenMP(operator | intrinsic: var1 [, var2,.,
varN])
определяется operator - операции (+, - , *, / и т.п.) или
функции, для которых будут вычисляться соответствующие частичные значения в
параллельных потоках последующего параллельного структурного блока. Кроме того,
определяется список локальных переменных var1, var2,., varN, в котором будут
сохраняться соответствующие частичные значения. После завершения всех
параллельных процессов частичные значения складываются (вычитаются,
перемножаются и т.п.), и результат сохраняется в одноименной общей переменной.
В языке C/C++ в качестве параметров operator и intrinsic в
предложениях reduction допускаются следующие операции и функции:
· параметр operator может
быть одной из следующих арифметических или логических операций: +, - , *,
&, ^, &&, ||;
· параметр intrinsic может
быть одной из следующих функций: max, min;
· указатели и ссылки в
предложениях reduction использовать строго запрещено!
Директива
for
Директива OpenMP for используется для организации параллельного
выполнения петель циклов в программах.
Предложение OpenMP
#pragma omp for
означает, что оператор for, следующий за этим предложением,
будет выполняться в параллельном режиме, т.е. каждой петле этого цикла будет
соответствовать собственный параллельный поток.
Директива
sections
Директива OpenMP sections используется для выделения участков
программы в области параллельных структурных блоков, выполняющихся в отдельных
параллельных потоках.
Описание синтаксиса предложения OpenMP sections приведено в примере
ниже.
#pragma omp sections [предложение [предложение …]]
{
#pragma omp sectionblock
[#pragma omp sectionblock
…
]
}
Каждый структурный блок (structured block), следующий за
прагмой
#pragma omp sections
выполняется в отдельном параллельном потоке. Общее же число
параллельных потоков равно количеству структурных блоков (section),
перечисленных после прагмы
#pragma omp sections [предложение [предложение …]]
В качестве предложений допускаютcя следующие OpenMP
директивы: private (list), firstprivate (list), lastprivate (list), reduction
(operator: list) и nowait.
.3Технология
Posix Threads
Стандарт POSIX допускает различные
подходы к реализации многопоточности в рамках одного процесса. Возможны три
основных подхода:
. В пользовательском адресном
пространстве, когда нити в пределах процесса переключаются собственным
планировщиком.
2. Реализация при помощи системных
нитей, когда переключение между нитями осуществляется ядром, так же, как и
переключение между процессами.
. Гибридная реализация, когда
процессу выделяют некоторое количество системных нитей, но процесс имеет
собственный планировщик в пользовательском адресном пространстве.
Как правило, при этом количество
пользовательских нитей в процессе может превосходить количество системных
нитей. [9]
Пользовательские нити
Реализация планировщика в пользовательском
адресном пространстве не представляет больших сложностей; наброски реализаций
таких планировщиков приводятся во многих учебниках по операционным системам.
Главным достоинством пользовательского планировщика считается тот факт, что он
может быть реализован без изменений ядра системы.
При практическом применении такого
планировщика, однако, возникает серьезная проблема. Если какая-то из нитей
процесса исполняет блокирующийся системный вызов, блокируется весь
процесс. Устранение этой проблемы требует серьезных изменений в механизме
взаимодействия диспетчера системных вызовов с планировщиком операционной
системы. То есть главное достоинство пользовательского планировщика при этом
будет утеряно. Другим недостатком пользовательских нитей является то, что они
не могут воспользоваться несколькими процессорами на многопроцессорной машине,
потому что процесс всегда планируется только на одном процессоре.
Наиболее известная реализация
пользовательских нитей - это волокна (fibers) в Win32. Волокна могут
использоваться совместно с системными нитями Win32, но при этом волокна
привязаны к определенной нити и исполняются только в контексте этой нити.
Волокна не должны исполнять блокирующиеся системные вызовы; попытка сделать это
приведет к блокировке нити. Некоторые системные вызовы Win32 имеют
неблокирующиеся аналоги, предназначенные для использования в волокнах, но
далеко не все. Это резко ограничивает применение волокон в реальных
приложениях.
Системные нити
Ядро типичной современной ОС уже имеет
планировщик, способный переключать процессы. Переделка этого планировщика для
того, чтобы он мог переключать несколько нитей в пределах одного процесса,
также не представляет больших сложностей. При этом возможны два подхода к такой
переделке.
В рамках первого подхода, системные нити
выступают как подчиненная по отношению к процессу сущность. Идентификатор нити
состоит из идентификатора родительского процесса и собственного идентификатора
нити. Идентификатор нити локален по отношению к процессу, т.е. нити разных
процессов могут иметь одинаковые идентификаторы. Такой подход реализует
большинство систем, реализующих системные нити - IBM MVS-OS/390-zOS, DEC
VAX/VMS - OpenVMS, OS/2, Win32, многие Unix-системы, в том числе и Solaris. В
Solaris и других Unix системах (IBM AIX, HP/UX) системные нити называются LWP
(Light-Weight Process, "легкие процессы").10 использует системные
нити, так что каждой нити POSIX Threads API соответствует собственный LWP.
Старые версии Solaris использовали гибридный подход, который рассматривается в
следующем разделе.
В рамках другого подхода, системные нити
являются сущностями того же уровня, что процесс. Иногда все, что объединяет
нити одного процесса - это общее адресное пространство. Наиболее известная ОС,
использующая такой подход - Linux. В Linux, нити выглядят как отдельные записи
в таблице процессов и отдельные строки в выводе команд top (1) и ps (1), имеют
собственный идентификатор процесса.
В старых версиях Linux это приводило к
своеобразным проблемам при реализации POSIX Threads API; так, в большинстве
Unix-систем завершение процесса системным вызовом exit (2) приводит к
немедленному завершению всех его нитей; в Linux вплоть до 2.4 завершалась
только текущая нить. В Linux 2.6 был внесен ряд изменений в ядро, приблизивших
семантику многопоточности к стандарту POSIX. Эти изменения известны как NPT
(Native POSIX Threads).
Разрабатываемый лабораторный практикум
рассчитан на стандартную семантику POSIX Threads API. При программировании для
старых (2.4 и младше) версий ядра Linux необходимо изучить особенности
поведения этих систем по документации, поставляющейся с системой, или по другим
источникам.
Гибридная реализация
В гибридной реализации многопоточный
процесс имеет несколько LWP и планировщик в пользовательском адресном
пространстве. Этот планировщик переключает пользовательские нити между
свободными LWP, подобно тому, как системныйпланировщик в многопроцессорной
системе переключает процессы и системные нити между свободными процессами. При
этом, как правило, процесс имеет больше пользовательских нитей, чем у него есть
LWP.
Причина, по которой этот подход нашел
практическое применение - это убеждение разработчиков первых многопоточных
версий Unix, что пользовательские нити дешевле системных, требуют меньше
ресурсов для своего исполнения.
При планировании пользовательских нитей
возникает проблема блокирующихся системных вызовов. Когда какая-то нить
вызывает блокирующийся системный вызов, соответствующий LWP блокируется и на
некоторое время выпадает из работы. В старых версиях Solaris эта проблема
решалась следующим образом: многопоточная библиотека всегда имела выделенную
нить, которая не вызывала блокирующихся системных вызовов никогда. Когда ядро
системы обнаруживало, что все LWP процесса заблокированы, оно посылало процессу
сигнал SIGWAITING. Библиотечная нить перехватывала этот сигнал и, если это
допускалось настройками библиотеки, создавала новый LWP. Таким образом, если
все пользовательские нити исполняли блокирующиеся системные вызовы, то количество
LWP могло сравняться с количеством пользовательских нитей. Можно предположить,
что компания Sun отказалась от гибридной реализации многопоточности именно
потому, что обнаружилось, что такое происходит со многими реальными прикладными
программами. В старых версиях Solaris поддерживался довольно сложный API,
позволявший управлять количеством LWP и политикой планирования нитей между
ними. Так, можно было привязать нить к определенному LWP. Этот API был частью
Solaris NativeThreads и нестандартным расширением POSIX Threads API. В рамках
данного курса этот API не изучается. Многие современные Unix-системы, в том
числе IBM AIX, HP/UX, SCO UnixWare используют гибридную реализацию POSIX Thread
API.
Создание и
завершение нитей
В POSIX Thread API нить создается библиотечной
функцией pthread_create ().
Параметры этой функции:
· pthread_t * thread -
Выходной параметр. Указатель на переменную, в которой при успешном завершении
будет размещен идентификатор нити.
· const pthread_attr_t *
attr - Входной параметр. Указатель на структуру, в которой заданы атрибуты нити
(рассматривается на следующей лекции). Если этот указатель равен
· NULL, используются
атрибуты по умолчанию.
· void * (*start_routine)
(void*) - Входной параметр. Указатель на функцию, которая будет запущена во
вновь созданной нити.
· void *arg - Входной
параметр. Значение, которое будет передано в качестве параметра start_routine.
Возвращаемое значение:
· 0 при успешном завершении
· Код ошибки при неудачном
завершении
Большинство других функций POSIX Threads
API используют аналогичное соглашение о кодах возврата.
Для завершения нити используется функция
pthread_exit (). Эта функция всегда завершается успешно и принимает
единственный параметр, указатель на код возврата типа void *. Как и в случае с
pthread_create (), библиотека никогда не пытается обращаться к значению этого
параметра как к указателю, поэтому его можно использовать для передачи
скалярных значений.
Другой способ завершения нити - это
возврат управления из функции start_routine при помощи оператора return.
Поскольку функция start_routine должна возвращать тип void *, все ее операторы
return должны возвращать значение. Этот способ практически полностью
эквивалентен вызову pthread_exit () с тем же самым значением.
Для ожидания завершения нити и получения
ее кода возврата используется библиотечная функция pthread_join (). Эта функция
имеет два параметра, идентификатор нити типа pthread_t, и указатель на
переменную типа void *, в которой размещается значение кода возврата. Если в
качестве второго параметра передать нулевой указатель, код возврата
игнорируется.
Если требуемая нить еще не завершилась, то
нить, сделавшая вызов pthread_join (), блокируется. Если такой нити (уже) не
существует, pthread_join () возвращает ошибку ESRCH.
Когда нить завершается, то связанные с ней
ресурсы существуют до того момента, пока какаято другая нить не
вызоветpthread_join (). Однако к тому моменту, когда pthread_join завершается,
все ресурсы, занятые нитью (стек, thread local data, дескриптор нити)
уничтожаются.
В отличие от процессов Unix, где системный
вызов wait () может использовать только родитель по отношению к потомкам, любая
нить может ждать завершения любой другой нити того же процесса. Если несколько
нитей ждут завершения одной и той же нити, которая еще не завершилась, все эти
нити блокируются. Однако при завершении нити одна из ожидавших нитей получает
код возврата, а остальные ошибку ESRCH.
Если нить пытается ожидать сама себя, она
получает ошибку EDEADLK.
Еще одна важная функция, связанная с
ожиданием завершения нити - это функция pthread_detach (). Эта функция
указывает, что все ресурсы, связанные с нитью, необходимо уничтожать сразу
после завершения этой нити. При этом уничтожается и код возврата такой нити -
при попытке сделать pthread_join () на нить, над которой перед этим сделали
pthread_detach (), возвращается код ошибки EINVAL.
В руководстве по pthread_detach () в
системе Solaris 10 сказано, что главное применение pthread_detach () - это
ситуация, когда родитель, ожидавший завершения дочерней нити, получает
pthread_cancel (). В действительности, существуют и другие применения
"отсоединенных" нитей.
Не обязательно делать pthread_detach () на
уже запущенную нить; в атрибутах нити (pthread_attr_t) можно указать, что нить
следует запускать в уже "отсоединенном" состоянии.
Библиотечная функция pthread_cancel ()
принудительно завершает нить. В зависимости от свойств нити и некоторых других
обстоятельств, нить может продолжать исполнение некоторое время после вызова
pthread_cancel (3C).
Атрибуты
нитей и управление нитями
При создании нити можно указать блок
атрибутов нити при помощи второго параметра функции pthread_create (). Этот
блок представляет собой структуру pthread_attr_t.
Стандарт POSIX требует рассматривать эту
структуру как непрозрачный тип и использовать для изменения отдельных атрибутов
функции просмотра и установки отдельных атрибутов. Для инициализации
pthread_attr_t следует использовать функцию pthread_attr_init (). Эта функция
имеет единственный параметр - pthread_attr_t *attr. Она устанавливает атрибуты
в соответствии с табл.2.
Табл.2. Атрибуты нити.
|
Атрибут
|
Значение по
умолчанию
|
Объяснение
|
|
scope
|
PTHREAD_SCOPE_PROCESS
|
Нить использует
процессорное время, выделяемое процессу. В Solaris 9 и последующих версиях
Solaris этот параметр не имеет практического значения
|
|
detachstate
|
PTHREAD_CREATE_JOINABLE
|
Нити создаются
присоединенными (для освобождения ресурсов после завершения нити необходимо
вызвать pthread_join (3C)).
|
|
stackaddr
|
NULL
|
Стек нити
размещается системой
|
|
stacksize
|
0
|
Стек нити имеет
размер, определяемый системой
|
|
priority
|
0
|
Нить имеет
приоритет 0
|
|
inheritsched
|
PTHREAD_EXPLICIT_SCHED
|
Нить не
наследует приоритет у родителя
|
|
schedpolicy
|
SCHED_OTHER
|
Нить использует
фиксированные приоритеты, задаваемые ОС. Используется вытесняющая
многозадачность (нить исполняется, пока не будет вытеснена другой нитью или
не заблокируется на примитиве синхронизации)
|
Кроме этих атрибутов, pthread_attr_t
содержит некоторые другие атрибуты. Некоторые из этих атрибутов игнорируются
Solaris 10, и введены для совместимости с другими реализациями POSIX Thread
API.
Для изменения значений атрибутов
необходимо использовать специальные функции. Для каждого атрибута определены
две функции, pthread_attr_set%ATTRNAME% и pthread_attr_get%ATTRNAME%.
При создании нити используются те значения
атрибутов, которые были заданы к моменту вызова pthread_create (). Изменения в
pthread_attr_t, внесенные уже после запуска нити, игнорируются системой.
Благодаря этому один и тот же блок атрибутов нити можно использовать для
создания нескольких разных нитей с разными атрибутами.
Некоторые из атрибутов, например
detachstate и priority, могут быть изменены у уже работающей нити. Для этого
используются отдельные функции. Так, detachstate в атрибутах нити изменяется
функцией pthread_attr_setdetachstate (), а у исполняющейся нити - функцией
pthread_detach (). Pthread_detach () изменяет значение атрибута с JOINABLE на
DETACHED; способа изменить этот атрибут с DETACHED на JOINABLE у работающей
нити не существует.
Многие из атрибутов, например размер или
местоположение стека, не могут быть изменены у работающей нити.
Перед уничтожением структуры
pthread_attr_t необходимо вызвать функцию pthread_attr_destroy ().
.4 Выводы
В данном разделе проведен анализ основных современных
технологий параллельного программирования для разных типов архитектур ЭВМ и
различных операционных систем. По результатам анализа определены те технологии
параллельного программирования, которые будут представлены для изучения в
рамках лабораторного практикума, а именно MPI, OpenMP и Posix Threads. Данные
технологии охватывают все основные классы современных параллельных компьютеров,
такие как массивно-параллельные системы, симметричные мультипроцессорные
системы, системы с неоднородным доступом к памяти и кластерные системы, а также
основные операционные системы (Windows и Unix-подобные системы). Обозначены
основные директивы и функции вышеупомянутых технологий, которые могут быть
предложены для освоения студентами.
2.
Практическая часть
2.1 Выбор
инструментальных средств
При разработке лабораторного практикума стояла задача
минимизировать количество программных продуктов, необходимых для проведения
лабораторных работ. Для этого преподаватель и студент должны иметь возможность
работать в единой программе, совмещающей функции генератора тестов, задачника и
инструмента для получения зависимостей.
Исходя из вышеуказанных задач, к программному обеспечению
лабораторного практикума, предъявлялись следующие функциональные требования:
возможность авторизации студента и преподавателя.
возможность редактирования преподавателем списка
пользователей.
возможность фиксации преподавателем действий студентов.
возможность удаления, редактирования и добавления новых
вариантов заданий произвольной сложности.
возможность проведения вступительного теста.
возможность редактирования преподавателем вопросов, входящих
в тест, и вариантов ответа.
банк тестов должен быть устойчивым к взлому студентами.
возможность написания студентами кода для решения
поставленных задач.
возможность занесения студентами созданного кода в программу
и получения результатов выполнения программы с последующей автоматической
обработкой.
возможность отображения ошибок компиляции, могущих возникать
при внесении кода, написанного студентами, в программу.
Для реализации функциональных требований целесообразно
использовать два программных продукта. Это среда разработки, поддерживающая
разработку, компиляцию и исполнение последовательных и параллельных программ, и
программа, реализующая лабораторный практикум, которая предоставляет прочие
возможности из перечисленных выше.
Готовой программы, реализующей лабораторный практикум, не
существует, поэтому было принято решение разработать новую программу,
удовлетворяющую функциональным требованиям, указанным выше.
Для написания программы было решено использовать язык C++.
Данное решение вызвано необходимостью компилировать код на языке C/C++,
написанный студентами. Таким образом, и код студентов, и программа, реализующая
лабораторный практикум, написаны на едином языке. Программа была разработана в
среде программирования Borland C++ Builder XE.
В качестве среды разработки, поддерживающей разработку,
компиляцию и исполнение программ, использующих технологию OpenMP, была выбрана
среда Microsoft Visual Studio 2008.
К достоинствам данной среды разработки можно отнести то, что
данная среда полностью поддерживает параллельные библиотеки MPI, OpenMP и Posix
Threads. Существуют и другие среды разработки, поддерживающие вышеуказанные
библиотеки (Dev C++, Eclipse CDT), но принимается во внимание факт, что на компьютерах
учебных классов обычно установлены операционные системы семейства Windows от
компании Microsoft, поэтому Microsoft Visual Studio 2008 требует минимальной
настройки для работы с операционной системой. Также следует учесть то, что
существует программа поставки бесплатных продуктов Microsoft НИЯУ МИФИ
[10].Visual Studio 2008предъявляет следующие системные требования:
· Visual Studio 2008 можно
установить на следующие операционные системы:
o Windows Vista (x86 и x64)
- все выпуски, кроме Starter Edition
o Windows XP (x86 и x64) с
пакетом обновления 2 или более поздней версии - все выпуски, кроме Starter
Edition
o Windows Server 2003 (x86
и x64) с пакетом обновления 1 или более поздней версии (все выпуски)
o Windows Server 2003 R2
(x86 и x64) или более поздней версии (все выпуски)
· ОЗУ не менее 384 МБ (ОЗУ
не менее 768 МБ для Windows Vista)
· 2,2 ГБ свободного
дискового пространства
· Жесткий диск 5400 об/мин
· Дисплей с разрешением не
менее 1024х768
· Дисковод DVD-ROM
Для того чтобы использовать Visual Studio 2008 в работе с
лабораторным практикумом, требуется подключить библиотеки параллельного
программирования: MPI, OpenMP, Posix Threads. О том, как это сделать, подробно
написано в источниках [11], [12] и [13].
Таким образом, для реализации лабораторного практикума
необходимо:
Разработать методику проведения лабораторных работ.
Разработать варианты заданий к лабораторному практикуму.
Разработать программу, реализующую лабораторный практикум.
Протестировать и отладить лабораторные работы практикума.
.2 Проведение
лабораторных работ
Лабораторные работы проводятся в следующем порядке:
. Выполнение домашнего задания, включающего:
Изучение студентом теоретических основ технологий MPI, OpenMP
и Posix Threads.
Изучение работы в среде разработки.
Составление последовательной программы согласно полученному
варианту задания.
Составление параллельных программ на основе последовательной.
. Работа в дисплейном классе, включающая:
Прохождение вступительного теста в программе, реализующей
лабораторный практикум.
Загрузка решений в программу, реализующую лабораторный
практикум.
Построение зависимостей времени выполнения программы и
занимаемой оперативной памяти от параметров программы для каждой технологии
параллельного программирования и последовательной программы.
. Написание отчета, включающего выводы об оптимальной
технологии для решения поставленной задачи и параметрах этой технологии.
Учебные
задания
В программу, реализующую лабораторную работу, можно вносить
любые задания на программирование с применением библиотек MPI, OpenMP и Posix
Threads. Предполагается, что это будут задания, которые можно разработать
изменением готовой последовательной программы. Примеры предполагаемых заданий
приведены в Приложении 2.
Подготовка к
выполнению
Для подготовки к выполнению лабораторных работ необходимо:
· Изучить теоретический материал по
библиотекам MPI, OpenMP и Posix Threads.
· Изучить особенности работы в среде
программирования.
· Составить последовательную программу
согласно полученному варианту задания. Варианты домашних заданий приведены в
Приложении 2.
· На основе последовательной программы
составить варианты параллельных программ. Там, где это возможно, следует
разработать несколько вариантов параллельной программы в рамках одной
технологии параллельного программировния (например, для Posix Threads можно
представить решения с использованием мьютексов и без).
Выполнение
лабораторных работ
Работы выполняются с использованием среды разработки и
программы, реализующей лабораторный практикум.
Для выполнения работ необходимо:
) Зайти в программу, реализующую практикум, под своей
учетной записью.
2) Успешно пройти вступительный тест.
) Загрузить код последовательной и трех параллельных
программ, разработанных дома, в соответствующие вкладки программы, реализующей
практикум.
) Для последовательной программы снять зависимости
времени выполнения и объема оперативной памяти, занимаемой программой, от
размерности программы.
) Для параллельных программ снять зависимости времени
выполнения и объема оперативной памяти, занимаемой программой, от размерности
программы и числа запущенных параллельных процессов (потоков). Если разработано
несколько вариантов программы в рамках одной технологии, то следует выбрать
оптимальный вариант и обосновать свой выбор.
) По полученным зависимостям сделать вывод об
оптимальной технологии для решения данной задачи, оптимальном количестве
запущенных параллельных процессов (потоков) и оптимальной размерности задачи
для достижения заданной точности вычислений (в тех вариантах, где размерность
влияет на точность).
Для сдачи лабораторных работ необходимо иметь отчеты,
включающие коды последовательной и параллельных программ согласно варианту,
зависимости, описанные в задании и выводы по результатам этих зависимостей.
2.3
Алгоритмическое обеспечение
Прежде чем студенты смогут выполнять лабораторные работы,
лабораторный практикум должен быть подготовлен к работе. Для этого
администратор системы должен авторизоваться, занести в программу справочную
информацию по технологиям параллельного программирования и заполнить таблицу
вариантов с подробным описанием варианта и указанием имен программных
переменных. Затем администратор должен заполнить таблицу пользователей с
указанием варианта, присвоенного пользователю. Затем администратор должен
заполнить банк вопросов предварительного тестирования, введя в программу
вопросы и ответы к ним, указав правильный ответ (ответы), для каждой из
технологий параллельного программирования. В случае, если администратора
устраивают существующие варианты, справочные данные, вопросы предварительного
тестирования и списки студентов, уже существующие в программе, данный этап
может быть пропущен.
Алгоритм работы администратора с программным обеспечением,
реализующим лабораторный практикум, представлен на рис.6.
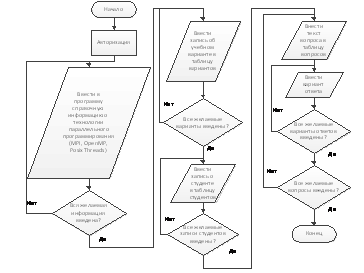
Рис.6. Алгоритм
работы администратора с программой
Студент должен авторизоваться, ответить на вопросы вступительного
тестирования, получить вердикт программы о том, допущен он до выполнения
лабораторных работ или нет. В случае допуска студент должен ввести в систему
последовательную программу, разработанную дома, и варьируя программные
переменные, снять две зависимости - зависимость времени выполнения от
размерности задачи и использованной оперативной памяти от размерности задачи.
На соответствующей вкладке студент вводит программу с использованием MPI в
систему. Варьируя программные переменные, он должен снять четыре зависимости -
времени выполнения и использованной оперативной памяти от размерности задачи,
времени выполнения и использованной оперативной памяти от числа параллельных
процессов (потоков). Затем вводятся программы с использованием OpenMP и Posix
Threads, по ним также снимаются четыре зависимости.
Алгоритм работы студента с программным обеспечением, реализующим
лабораторный практикум, представлен на рис.7.
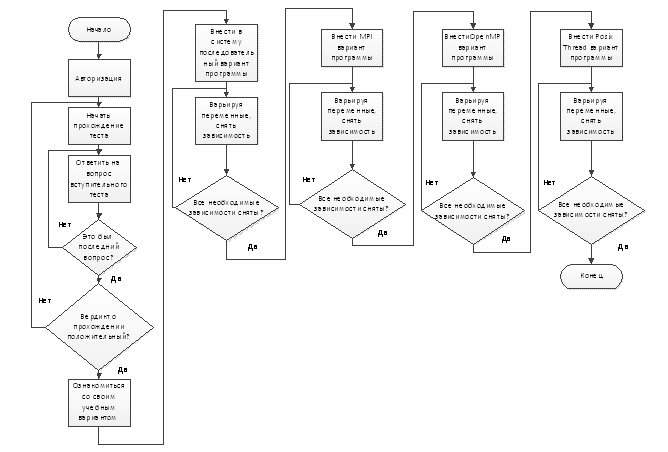
Рис.7. Алгоритм
работы студента с программой
В алгоритм заложено различие действий при обращении с
программой преподавателя и студента, авторизация доступа, функции добавления
пользователей, вариантов, вопросов теста, справочных данных, компиляции
программ, изменения переменных внутри разработанных программ и построения
зависимостей.
Структура разработанного алгоритма удовлетворяет функциональным
требованиям к программе, изложенным в предыдущем разделе.
Схематичный алгоритм работы программы представлен на рис.8.
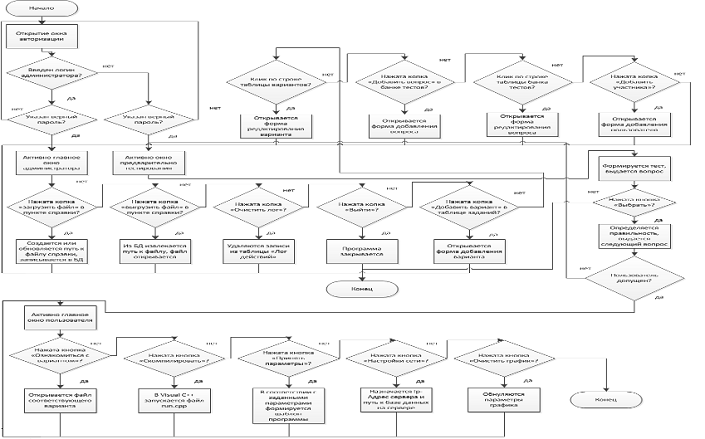
Рис.8. Алгоритм работы программы
В данной схеме представлены реакции программы на действия
пользователей - администратора и студента. Описаны основные результаты
возможных действий, порядок возникновения и закрытия элементов интерфейса,
основные функции, выполняемые программой.
.4
Функциональная структура программы лабораторного практикума
Функциональная структура программы представлена на рис.9.
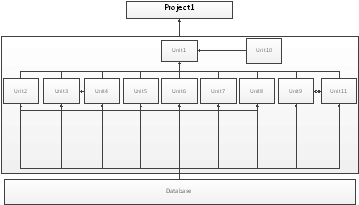
Рис.9. Функциональная
структура программы
В структуре программы можно выделить следующие функциональные
части:
Project1. cpp - модуль, инициализирующий модули Unit1…Unit11.
Database - база
данных программы.
Unit1 - главное окно программы, которое содержит
рабочие области студента и администратора, а также построение графиков и
компиляцию написанных студентом программ.
Unit2 - авторизация пользователей.
Unit3 - добавление нового пользователя.
Unit4 - редактирование учетной записи пользователя.
Unit5 - добавление варианта учебных заданий.
Unit6 - добавление вопросов и ответов в
предварительный тест.
Unit7 - редактирование варианта учебных заданий.
Unit8 - предоставление студенту вопросов, проверка
правильности ответов и подсчет результатов.
Unit9 - редактирование содержимого тестов.
Unit10 - настройка программы.
Unit11 - добавление ответов в вопросы предварительного
теста.
В модуле Project1. cpp происходит создание всех форм
программы как для администратора, так и для администратора.
Таблица auth (таблица пользователей) имеет поля id,
login, password, variant и superuser, где id - идентификатор пользователя,
login - учетная запись пользователя, password - пароль пользователя, variant -
учебный вариант, закрепленный за пользователем, superuser - логическое поле,
для администратора оно имеет значение "True". Для администратора
атрибут "variant" остается пустым.
Таблица files (таблица справочных файлов) имеет поля
kod, filepath и info, где kod - идентификатор справочного файла, filepath -
путь к справочному файлу, info - технология, к которой относится справочный
файл.
Таблица variant (таблица учебных вариантов) имеет поля
nomervariant, namevariant, filepath, perpot и perraz, где nomervariant - номер
учебного варианта, namevariant - название варианта, filepath - путь к файлу
варианта, perpot - имя переменной числа процессов (потоков), perraz - имя
переменной размерности.
Таблицы vopros (таблица вопросов и ответов
вступительного теста) имеет поля id, kat, tekst, var и bool, где id - номер
ответа, kat - название технологии, к которой относится вопрос, tekst -
непосредственно вопрос, var - текст ответа и bool - логическое поле, для
правильного ответа оно имеет значение "True".
В модуле Unit1. cpp содержатся интерфейсы главных форм
студента и администратора, а также средства компиляции программ, написанных
студентами, с нахождением времени выполнения программы, оперативной памяти,
занимаемой программой, построением зависимостей времени и памяти от параметров
программ.
В модуле Unit2. cpp содержится функция авторизации
пользователей. Пользователю предлагается ввести учетную запись и пароль. В
зависимости от учетной записи откроется интерфейс студента или администратора.
В модуле Unit3. cpp содержится функция добавления новых пользователей.
При добавлении пользователя с ролью "Студент", добавляемому
пользователю присваивается учебный вариант.
В модуле Unit4. cpp содержится функция редактирования записи
пользователя. Также присутствует возможность удаления записи.
В модуле Unit5. cpp содержится функция добавления нового
учебного варианта. Присутствует возможность загрузки файла с текстовым
описанием варианта и системных переменных для данного варианта.
В модуле Unit6. cpp содержится функция добавления вопросов и
ответов в предварительный тест. Каждый вопрос может иметь несколько правильных
ответов.
В модуле Unit7. cpp содержится функция редактирования
вариантов учебных заданий. Можно изменять название, описание и системные
переменные для выбранного варианта.
В модуле Unit8. cpp содержатся функции проведения
предварительного теста у студента. Случайным образом выбирается 9 вопросов. При
ответе на 6 или более вопросов студент считается допущенным к выполнению
лабораторных работ.
В модуле Unit9. cpp содержится функция редактирования вопросов.
Реализована возможность добавлять, удалять и назначать правильными ответы на
вопросы. Также можно редактировать текст самого вопроса.
В модуле Unit10. cpp содержатся функции настройки программы,
а именно ip-адрес сервера и путь к базе данных на сервере.
В модуле Unit11. cpp содержится функция вставки записи о
вопросе в таблицу базы данных vopros.
2.5 Интерфейс
разработанной программы
По функциональной структуре, изложенной в п.2.4, была
разработана программа, реализующая лабораторный практикум. Листинг программы
приведен в Приложении 1. Ниже представлен пример работы с разработанной
программой для администратора и студента. Делается допущение, что ярлык
приложения располагается на Рабочем Столе.
Работа с
программой (преподаватель)
На Рабочем Столе выбрать ярлык Parallel и дважды щелкнуть по
нему. Появится форма входа в систему
После введения логина и пароля администратор попадает на
главную форму работы с программой
Далее администратор может просматривать и загружать
справочные материалы. См. пункт "Содержимое справки".
Редактировать и удалять существующие варианты заданий и
добавлять новые с указанием названий переменных числа потоков и размерности
Редактировать и удалять существующие записи пользователей и
добавлять новые с указанием присваиваемого учебного варианта
Просматривать список действий пользователей и при
необходимости очищать его.
Редактировать и удалять существующие вопросы предварительного
теста и добавлять новые с привязкой к конкретной технологии параллельного
программирования
Задавать настройки программы, такие как IP-адрес сервера и
путь к базе данных на сервере.
Работа с
программой (студент)
На Рабочем Столе выбрать ярлык Parallel и дважды щелкнуть по
нему. Появится форма входа в систему (рис. 11). После введения логина и пароля
студент попадает в форму предварительного теста (рис. 17).
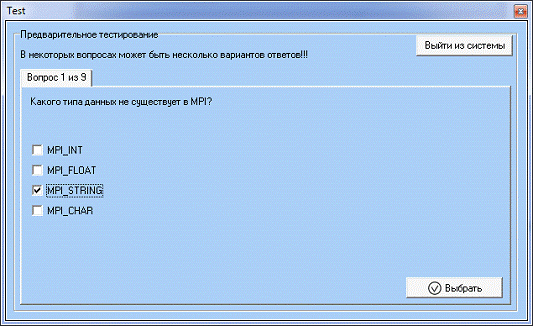
Рис. 17. Вопрос предварительного теста
После прохождения теста студент получает вердикт о
допуске/недопуске его к работам лабораторного практикума (рис. 18).
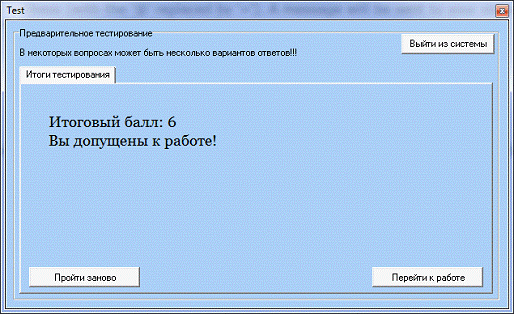
Рис. 18. Вердикт программы о допуске/недопуске
После допуска студент попадает на главную форму работы с
программой (рис. 19).
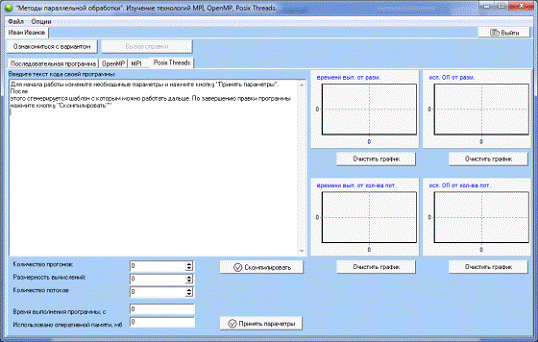
Рис. 19. Главная форма работы студента с программой
Для последовательной программы студент меняет размерность
вычислений и снимает две зависимости - времени выполнения от размерности и
использования оперативной памяти от размерности (рис. 20).
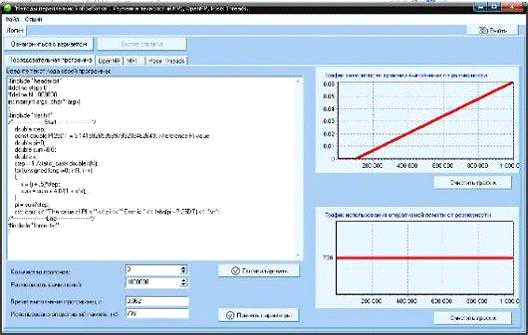
Рис. 20. Окно последовательной программы
Для параллельных программ студент меняет размерность
вычислений и количество параллельных процессов (потоков). По полученным
значениям студент снимает четыре зависимости - времени выполнения от
размерности, использования оперативной памяти от размерности, времени
выполнения от числа процессов (потоков), использования оперативной памяти от
числа процессов (потоков). Этот пример представлен на рис. 21.
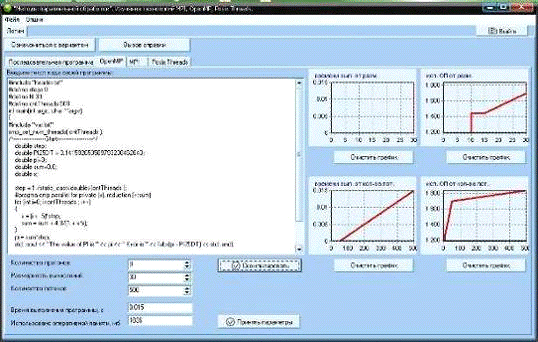
Рис. 21. Окно параллельной программы
2.6
Тестирование и отладка
Методика тестирования заключалась в том, что сначала была
проверена правильность реакции программы на действия администратора, а затем
студента.
Для этого была пройдена авторизация под учетной записью
администратора, в программу была занесена справочная информация по технологиям
параллельного программирования и заполнена таблица вариантов с подробным
описанием варианта и указанием имен программных переменных. Затем была
заполнена таблица пользователей с указанием варианта, присвоенного пользователю.
Затем был заполнен банк вопросов предварительного тестирования, для каждой из
технологий параллельного программирования в программу введены вопросы и ответы
к ним, указан правильный ответ (ответы). В процессе проведения вышеописанных
действий ошибок не выявлено.
Была пройдена авторизация под студентом, пройдены варианты
успешного и неуспешного выполнения студентом предварительного теста. Проверена
корректность просмотра варианта задания и справочной информации. Затем в
систему были занесены разработанные программы. Программы были разработаны
согласно заданию, изложенному в варианте 1 Приложения 2.
Были разработаны следующие решения:
Последовательное решение.
#include <iostream>
#include <iomanip>
#include <cmath>
int main (int argc, char**
argv)
{
const unsigned long cntSteps=500000000;
/* # of rectangles */
double step;
const double PI25DT =
3.141592653589793238462643; // reference Pi value
double pi=0;
double sum=0.0;
double x;:: cout<<
"calculating pi on CPU single-threaded\n";= 1. /static_cast<double>
(cntSteps);
for (unsigned long i=0; i<cntSteps;
i++)
{= (i +.5) *step;= sum +
4.0/ (1. + x*x);
}= sum*step;:: cout <<
"The value of PI is " << pi << " Error
is " << fabs (pi - PI25DT) << "\n";
return 0;
}
Решение с применением MPI.
#include <iostream>
#include <cmath>
#include <mpi. h>
int main (int argc, char* argv
[])
{
int idCurrentThread, cntThreads;
int lenNameProcessor;
char nameProcessor [MPI_MAX_PROCESSOR_NAME];
double localPi, step, sum, x;
double PI25DT = 3.141592653589793238462643;
long cntSteps = 500000000;:: Init
(argc,argv);= MPI:: COMM_WORLD. Get_size ();= MPI:: COMM_WORLD.
Get_rank ();:: Get_processor_name (nameProcessor,lenNameProcessor);::
cout << "Process " << idCurrentThread <<
" of " << cntThreads << " is on "
<<nameProcessor << std:: endl;= 1. /static_cast<double>
(cntSteps);= 0.0;
long cntStepsPerThread= cntSteps /
cntThreads;
long limitRightCurrentThread =
(idCurrentThread+1) *cntStepsPerThread;
// std:: cout <<
"limitLeftCurrentThread" << idCurrentThread*cntStepsPerThread
<< std:: endl;
// std:: cout <<
"limitRightCurrentThread" << limitRightCurrentThread <<
std:: endl;
for (long i = idCurrentThread*cntStepsPerThread;
i < limitRightCurrentThread; i ++)
{= step * (i + 0.5);= sum +
4.0/ (1.0 + x*x);
}= step * sum;
double pi=0.;:: COMM_WORLD. Reduce (&localPi,
&pi, 1, MPI_DOUBLE, MPI_SUM, 0);
if (idCurrentThread == 0)
{:: cout << "The value of PI is
" << pi << " Error is " <<
fabs (pi - PI25DT) << std:: endl;
}:: Finalize ();
return 0;
}
Решение с применением OpenMP.
#include <iostream>
#include <iomanip>
#include <cmath>
#include <omp. h>
int main (int argc, char**
argv)
{
const unsigned long numSteps=500000000;
/* default # of rectangles */
double step;
double PI25DT = 3.141592653589793238462643;
double pi=0;
double sum=0.0;
double x;
#pragma omp parallel
{
#pragma omp master
{
int cntThreads=omp_get_num_threads ();:: cout<<"OpenMP.
number of threads = "<<cntThreads<<std:: endl;
}
}= 1. /static_cast<double> (numSteps);
#pragma omp parallel for private (x), reduction
(+: sum)
for (int i=0; i<numSteps; i++)
{= (i +.5) *step;= sum +
4.0/ (1. + x*x);
}= sum*step;:: cout <<
"The value of PI is " << pi << " Error
is " << fabs (pi - PI25DT) << std:: endl;
return 0;
}
Решение с применением Posix Threads.
#include <iostream>
#include <iomanip>
#include <cmath>
#include <cstdlib>
#include <pthread. h>
#define cntThreads 4
struct ArgsThread
{
long long left,right;
double step;
double partialSum;
};
static void *worker (void *ptrArgs)
{* args = reinterpret_cast<ArgsThread
*> (ptrArgs);
double x;
double sum=0.;
double step=args->step;
for (long long i=args->left;
i<args->right; i++)
{= (i +.5) *step;= sum +
4.0/ (1. + x*x);
}->partialSum=sum*step;
return NULL;
}
int main (int argc, char**
argv)
{
const unsigned long num_steps=500000000;
const double PI25DT =
3.141592653589793238462643;
pthread_t threads [cntThreads];arrArgsThread [cntThreads];::
cout<<"POSIX threads. number of threads = "<<cntThreads<<std::
endl;
double step = 1. / (double)
num_steps;
long long cntStepsPerThread= num_steps /
cntThreads;
for (unsigned int idThread=0;
idThread<cntThreads; idThread++)
{[idThread]. left = idThread*cntStepsPerThread;[idThread].
right = (idThread+1) *cntStepsPerThread;[idThread]. step =
step;
if (pthread_create (&threads [idThread],
NULL, worker, &arrArgsThread [idThread])! = 0)
{
return EXIT_FAILURE;
}
}
double pi=0.;
for (unsigned int idThread=0;
idThread<cntThreads; idThread++)
{
if (pthread_join (threads [idThread], NULL)! =
0)
{
return EXIT_FAILURE;
}+=arrArgsThread [idThread]. partialSum;
}:: cout << "The value of PI is
" << pi << " Error is " <<
fabs (pi - PI25DT) << std:: endl;
return 0;
}
Данные решения были занесены в систему и путем изменения
параметров получены следующие зависимости:
Для последовательной программы (рис. 22)
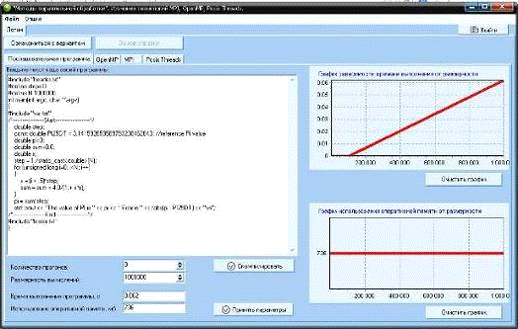
Рис. 22. Полученные зависимости последовательной программы
Для программы с использованием MPI (рис. 23)
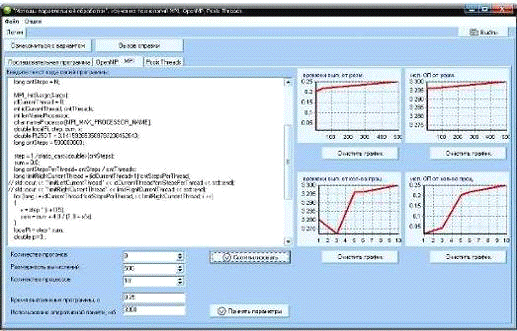
Рис. 23. Полученные зависимости программы с использованием
MPI
Для программы с использованием OpenMP (рис.24)
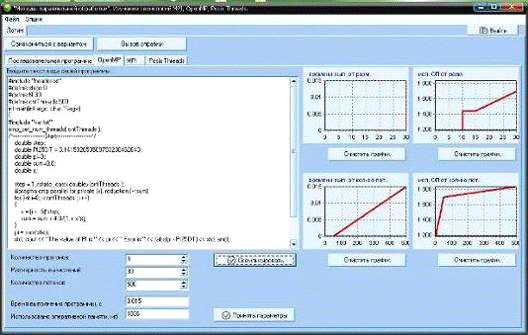
Рис. 24. Полученные зависимости программы с использованием
OpenMP
Для программы с использованием Posix Threads (рис.25)
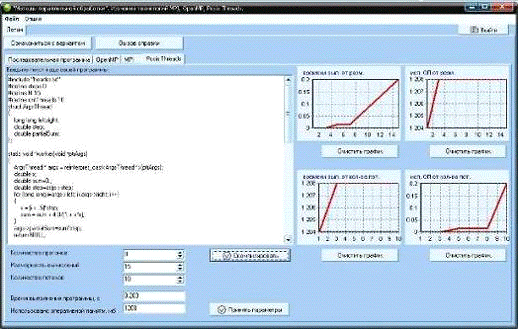
Рис. 25. Полученные зависимости программы с использованием
Posix Threads
Полученные зависимости совпадают с теоретически ожидаемыми с
поправкой на случайные отклонения, которые могут возникать при работе
параллельных программ. Результаты тестирования показали, что программа работает
верно.
2.7 Выводы
В данном разделе выбраны программные средства, реализующие
лабораторную работу. Это среда разработки, поддерживающая разработку,
компиляцию и исполнение программ, использующих технологии параллельного
программирования MPI, OpenMP и Posix Threads, и разрабатываемое в рамках
данного дипломного проекта программное обеспечение, позволяющее реализовать
лабораторный практикум. Также было разработано методическое обеспечение
лабораторного практикума, а именно учебные задания, методика подготовки и
выполнения лабораторных работ, входящих в практикум, варианты домашних заданий.
По методике выполнения лабораторного практикума были сформулированы
функциональные требования к программе, реализующей практикум. Исходя из этих
требований, было разработано алгоритмическое обеспечение, составлена
функциональная структура разрабатываемой программы, разработано программное
обеспечение, после чего произведено тестирование и отладка разработанного
программного обеспечения.
Заключение
Задачей данного дипломного проекта была разработка лабораторного
практикума по курсу "Методы параллельной обработки". В качестве
изучаемых технологий были выбраны MPI, OpenMP и Posix Threads. Данные
технологии охватывают все основные классы современных параллельных компьютеров,
такие как массивно-параллельные системы, симметричные мультипроцессорные
системы, системы с неоднородным доступом к памяти и кластерные системы. В
рамках дипломного проекта составлена методика проведения лабораторных работ,
разработаны задания для учащихся. Исходя из методики проведения лабораторных
работ, были составлены функциональные требования. Разработано алгоритмическое
обеспечение лабораторного практикума, выбраны инструментальные средства
разработки и проведения лабораторной работы, разработана функциональная
структура программы, по которой разработано программное обеспечение для
проведения лабораторных работ, проведено тестирование и отладка программного
обеспечения.
Выполнив лабораторные работы, студент будет иметь
представление о технологиях параллельного программирования MPI, OpenMP и Posix
Threads, знать об основных директивах и функциях, применяемых в вышеуказанных
технологиях, а также сможет оценить зависимость времени выполнения программы и
занимаемой программой оперативной памяти от числа параллельных процессов
(потоков) и размерности вычислений. После этого, проанализировав полученные
зависимости, студент сможет сделать вывод о наиболее целесообразной технологии
для решения поставленной задачи, где критическим ресурсом может являться как
время выполнения, так и оперативная память.
После выполнения данной лабораторной работы студент сможет
самостоятельно создавать несложные приложения с использованием любой
параллельной технологии из вышеперечисленных.
Пробные лабораторные работы были проведены в мае 2013 года с
привлечением технических средств кафедры. Стендовый доклад о лабораторных
работах, связанных с технологиями параллельного программирования, был
представлен на Научной Сессии НИЯУ МИФИ 2013.
Объем разработанного программного обеспечения составил 22,7
Мбайт.
Список литературы
1. Гергель
В.П. Высокопроизводительные вычисления для многоядерных многопроцессорных
систем. Издательство нижегородского госуниверситета, 2010.
2. Developing
Parallel Programs - A Discussion of Popular Models. An Oracle White Paper,
September 2010.
3. <#"656580.files/image019.gif"> 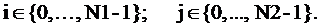
где A - двухмерный массив размерностью N1ЧN2 а
массивы C и B одномерные, размерностью N1. N1 - переменная
размерности задачи. Составить последовательную программу и параллельные
программы с применением библиотек MPI, OpenMP и Posix Threads. Снять
зависимости времени выполнения программы и объема оперативной памяти, занятой
программой, от размерности задачи и количества запущенных потоков (процессов)
для параллельных программ (для последовательной программы - две зависимости,
для параллельных программ по четыре зависимости). По полученным зависимостям
сделать выводы об оптимальной в данном случае технологии, оптимальном
количестве параллельных процессов (потоков) при различной размерности
вычислений.
6. Требуется создать программу, реализующую выполнение
операций над элементами массивов A, B и C по следующей
формуле:
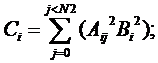
где A - двухмерный массив размерностью N1ЧN2 а
массивы C и B одномерные, размерностью N1. N1 - переменная
размерности задачи. Составить последовательную программу и параллельные программы
с применением библиотек MPI, OpenMP и Posix Threads. Снять зависимости времени
выполнения программы и объема оперативной памяти, занятой программой, от
размерности задачи и количества запущенных потоков (процессов) для параллельных
программ (для последовательной программы - две зависимости, для параллельных
программ по четыре зависимости). По полученным зависимостям сделать выводы об
оптимальной в данном случае технологии, оптимальном количестве параллельных
процессов (потоков) при различной размерности вычислений.
7. Требуется создать программу, реализующую выполнение
операций над элементами массивов A, B и C по следующей
формуле:
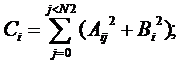
где A - двухмерный массив размерностью N1ЧN2 а массивы
C и B одномерные, размерностью N1. N1 - переменная размерности
задачи. Составить последовательную программу и параллельные программы с
применением библиотек MPI, OpenMP и Posix Threads. Снять зависимости времени
выполнения программы и объема оперативной памяти, занятой программой, от
размерности задачи и количества запущенных потоков (процессов) для параллельных
программ (для последовательной программы - две зависимости, для параллельных
программ по четыре зависимости). По полученным зависимостям сделать выводы об
оптимальной в данном случае технологии, оптимальном количестве параллельных
процессов (потоков) при различной размерности вычислений.
8. Требуется создать программу, реализующую выполнение
операций над элементами массивов A, B и C по следующей
формуле:

где A - двухмерный массив размерностью N1ЧN2 а
массивы C и B одномерные, размерностью N1. N1 - переменная
размерности задачи. Составить последовательную программу и параллельные
программы с применением библиотек MPI, OpenMP и Posix Threads. Снять
зависимости времени выполнения программы и объема оперативной памяти, занятой
программой, от размерности задачи и количества запущенных потоков (процессов)
для параллельных программ (для последовательной программы - две зависимости,
для параллельных программ по четыре зависимости). По полученным зависимостям
сделать выводы об оптимальной в данном случае технологии, оптимальном
количестве параллельных процессов (потоков) при различной размерности
вычислений.
9. Требуется вычислить сумму чисел от 1 до k, где k -
переменная размерности задачи. Составить последовательную программу и
параллельные программы с применением библиотек MPI, OpenMP и Posix Threads.
Снять зависимости времени выполнения программы и объема оперативной памяти, занятой
программой, от размерности задачи и количества запущенных потоков (процессов)
для параллельных программ (для последовательной программы - две зависимости,
для параллельных программ по четыре зависимости). По полученным зависимостям
сделать выводы об оптимальной в данном случае технологии, оптимальном
количестве параллельных процессов (потоков) при различной размерности
вычислений.
10. Требуется вычислить произведение чисел от 1 до k, где
k - переменная размерности задачи. Составить последовательную программу и
параллельные программы с применением библиотек MPI, OpenMP и Posix Threads.
Снять зависимости времени выполнения программы и объема оперативной памяти,
занятой программой, от размерности задачи и количества запущенных потоков
(процессов) для параллельных программ (для последовательной программы - две
зависимости, для параллельных программ по четыре зависимости). По полученным
зависимостям сделать выводы об оптимальной в данном случае технологии,
оптимальном количестве параллельных процессов (потоков) при различной
размерности вычислений.
. Требуется вычислить сумму квадратов чисел от 1 до k,
где k - переменная размерности задачи. Составить последовательную программу и
параллельные программы с применением библиотек MPI, OpenMP и Posix Threads.
Снять зависимости времени выполнения программы и объема оперативной памяти,
занятой программой, от размерности задачи и количества запущенных потоков
(процессов) для параллельных программ (для последовательной программы - две
зависимости, для параллельных программ по четыре зависимости). По полученным
зависимостям сделать выводы об оптимальной в данном случае технологии,
оптимальном количестве параллельных процессов (потоков) при различной
размерности вычислений.
. Требуется вычислить сумму кубов чисел от 1 до k, где
k - переменная размерности задачи. Составить последовательную программу и
параллельные программы с применением библиотек MPI, OpenMP и Posix Threads.
Снять зависимости времени выполнения программы и объема оперативной памяти,
занятой программой, от размерности задачи и количества запущенных потоков
(процессов) для параллельных программ (для последовательной программы - две
зависимости, для параллельных программ по четыре зависимости). По полученным
зависимостям сделать выводы об оптимальной в данном случае технологии,
оптимальном количестве параллельных процессов (потоков) при различной
размерности вычислений.
. Требуется вычислить произведение квадратов чисел от
1 до k, где k - переменная размерности задачи. Составить последовательную
программу и параллельные программы с применением библиотек MPI, OpenMP и Posix
Threads. Снять зависимости времени выполнения программы и объема оперативной
памяти, занятой программой, от размерности задачи и количества запущенных
потоков (процессов) для параллельных программ (для последовательной программы -
две зависимости, для параллельных программ по четыре зависимости). По
полученным зависимостям сделать выводы об оптимальной в данном случае
технологии, оптимальном количестве параллельных процессов (потоков) при различной
размерности вычислений.
. Требуется написать программу, реализующую
транспонирование матрицы n*n, где n - переменная размерности задачи. Составить
последовательную программу и параллельные программы с применением библиотек
MPI, OpenMP и Posix Threads. Снять зависимости времени выполнения программы и
объема оперативной памяти, занятой программой, от размерности задачи и
количества запущенных потоков (процессов) для параллельных программ (для
последовательной программы - две зависимости, для параллельных программ по
четыре зависимости). По полученным зависимостям сделать выводы об оптимальной в
данном случае технологии, оптимальном количестве параллельных процессов
(потоков) при различной размерности вычислений.
. Требуется найти максимальный и минимальный элементы
массива размером n*n, где n - переменная размерности задачи. Элементы массива
задаются случайным образом. Составить последовательную программу и параллельные
программы с применением библиотек MPI, OpenMP и Posix Threads. Снять
зависимости времени выполнения программы и объема оперативной памяти, занятой
программой, от размерности задачи и количества запущенных потоков (процессов)
для параллельных программ (для последовательной программы - две зависимости,
для параллельных программ по четыре зависимости). По полученным зависимостям
сделать выводы об оптимальной в данном случае технологии, оптимальном
количестве параллельных процессов (потоков) при различной размерности
вычислений.
. Требуется найти сумму элементов главной диагонали
массива размером n*n, где n - переменная размерности задачи. Элементы массива
задаются случайным образом. Составить последовательную программу и параллельные
программы с применением библиотек MPI, OpenMP и Posix Threads. Снять
зависимости времени выполнения программы и объема оперативной памяти, занятой
программой, от размерности задачи и количества запущенных потоков (процессов)
для параллельных программ (для последовательной программы - две зависимости,
для параллельных программ по четыре зависимости). По полученным зависимостям
сделать выводы об оптимальной в данном случае технологии, оптимальном
количестве параллельных процессов (потоков) при различной размерности
вычислений.
. Требуется отсортировать элементы массива размером
n*n по возрастанию, где n - переменная размерности задачи. Элементы массива
задаются случайным образом. Составить последовательную программу и параллельные
программы с применением библиотек MPI, OpenMP и Posix Threads. Снять
зависимости времени выполнения программы и объема оперативной памяти, занятой
программой, от размерности задачи и количества запущенных потоков (процессов)
для параллельных программ (для последовательной программы - две зависимости,
для параллельных программ по четыре зависимости). По полученным зависимостям
сделать выводы об оптимальной в данном случае технологии, оптимальном
количестве параллельных процессов (потоков) при различной размерности
вычислений.
. Требуется отсортировать элементы массива размером
n*n по убыванию, где n - переменная размерности задачи. Элементы массива задаются
случайным образом. Составить последовательную программу и параллельные
программы с применением библиотек MPI, OpenMP и Posix Threads. Снять
зависимости времени выполнения программы и объема оперативной памяти, занятой
программой, от размерности задачи и количества запущенных потоков (процессов)
для параллельных программ (для последовательной программы - две зависимости,
для параллельных программ по четыре зависимости). По полученным зависимостям
сделать выводы об оптимальной в данном случае технологии, оптимальном
количестве параллельных процессов (потоков) при различной размерности
вычислений.
. Требуется найти сумму элементов побочной диагонали
массива размером n*n, где n - переменная размерности задачи. Элементы массива
задаются случайным образом. Составить последовательную программу и параллельные
программы с применением библиотек MPI, OpenMP и Posix Threads. Снять
зависимости времени выполнения программы и объема оперативной памяти, занятой
программой, от размерности задачи и количества запущенных потоков (процессов)
для параллельных программ (для последовательной программы - две зависимости,
для параллельных программ по четыре зависимости). По полученным зависимостям
сделать выводы об оптимальной в данном случае технологии, оптимальном количестве
параллельных процессов (потоков) при различной размерности вычислений.
. Требуется найти решение системы линейных
алгебраических уравнений:
11x1 + a12x2 + … +
a1nxn = f121x2 + a22x2
+ … + a2nxn = f2
....n1x1 + an2x2
+ … + annxn = fn,
где n - переменная размерности задачи. Составить
последовательную программу и параллельные программы с применением библиотек
MPI, OpenMP и Posix Threads. Снять зависимости времени выполнения программы и
объема оперативной памяти, занятой программой, от размерности задачи и количества
запущенных потоков (процессов) для параллельных программ (для последовательной
программы - две зависимости, для параллельных программ по четыре зависимости).
По полученным зависимостям сделать выводы об оптимальной в данном случае
технологии, оптимальном количестве параллельных процессов (потоков) при
различной размерности вычислений.