|
Clearswift
|
Info Watch
|
IPLocks
|
ISS
|
Liquid
Machines
|
Port
Authority
|
Surf
Control
|
Инфо-системы Джет
|
Raytown Corp. LLC
|
|
Комплексность
решения
|
Да
|
Да
|
Да
|
Да
|
Нет
|
Да
|
Да
|
Нет
|
Нет
|
|
Функциональность
|
|
Защита от
утечки посредством ресурсов электронной почты и Web-каналов
|
Да (только
e-mail)
|
Да
|
Нет
|
Да (только
e-mail)
|
Да
|
Да
|
Да
|
Да
|
Нет
|
|
Защита от
утечки посредством мобильных носителей и ресурсов рабочей станции
|
Нет
|
Да
|
Нет
|
Нет
|
Да
|
Нет
|
Нет
|
Нет
|
Нет
|
|
Анализ
текстовых файлов
|
Да
|
Да
|
Нет
|
Да
|
Да
|
Да
|
Да
|
Да
|
Нет
|
|
Анализ файлов
Microsoft Office
|
Да
|
Да
|
Нет
|
Да
|
Да
|
Да
|
Да
|
Да
|
Нет
|
|
Анализ файлов
формата PDF
|
Да
|
Да
|
Нет
|
Да
|
Да
|
Да
|
Да
|
Нет
|
Нет
|
|
Метод анализа
|
На совпадение с
образцами по сигнатурам файлов
|
Лингвистические
алгоритмы; поддержка нескольких языков;
|
Нет
|
На совпадение с
образцами по сигнатурам файлов
|
Алгоритм
цифровых отпечатков
|
По ключевым
словам и фразам, словарям, на совпадение с образцами, по сигнатурам файлов
|
Лингвистические
алгоритмы
|
Эвристический
анализ слов
|
Нет
|
|
Разработка
методов анализа в unix-подобной
среде
|
Нет
|
Нет
|
Нет
|
Нет
|
Нет
|
Нет
|
Нет
|
Нет
|
Нет
|
|
Архивирование
электронной почты
|
Нет
|
Да
|
Нет
|
Нет
|
Да
|
Да
|
Нет
|
Да
|
Нет
|
|
Уведомление
офицера безопасности об инцидентах
|
Нет
|
Да
|
Да
|
Да
|
Да
|
Да
|
Да
|
Да
|
Нет
|
|
Централизованное
управление
|
Да
|
Да
|
Да
|
Да
|
Да
|
Да
|
Да
|
Да
|
Да
|
|
Внедрение
|
|
Модернизация ПО
в соответствии с задачами заказчика
|
Нет
|
Да
|
Нет
|
Нет
|
Нет
|
Нет
|
Нет
|
Нет
|
Нет
|
|
Разработка
политики обращения с конфиденциальной информацией
|
Да
|
Да
|
Нет
|
Да
|
Нет
|
Нет
|
Нет
|
Нет
|
Нет
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Комплексность решений в сфере предотвращения утечек
конфиденциальных данных подразумевает не только перекрытие всех путей кражи
чувствительных сведений, но и целый ряд сопроводительных услуг. Некоторые
поставщики помогают своим клиентам внедрять решения, проводить аудит
ИТ-безопасности, составлять политику внутренней ИТ-безопасности, готовить
нормативные документы и улаживать возникающие юридические трудности, связанные,
например, с перлюстрацией корпоративной корреспонденции, а также обучать
персонал.
Заключение
Многие выше приведенные продукты обладают следующим
недостатком: отсутствуют компоненты, контролирующих утечку конфиденциальной
информации через ресурсы рабочих станций (мобильные накопители, принтеры и
т.д.). Средства печати, USB-накопители и мобильные устройства - одни из самых
распространенных путей утечки секретных данных, наряду с почтовым и
Web-трафиком. Этим же недостатком будет обладать и программа КонфДетект. В тоже
время у нее будет ряд преимуществ перед другими программными решениями. Ни в
одном из продуктов метод анализа текстовых файлов не реализован в unix-подобной среде. В
программе КонфДетект это будет новизной перед остальными решениями.
1.2
Аналитический обзор существующих методов сравнения текстовых файлов
На текущий момент вопрос обнаружения
сходства документов хорошо проработан в области обнаружения плагиата. Это
обнаружение основано на различных алгоритмах и подходах к поиску плагиата
(автоматическому поиску). Чтобы проанализировать эффективность поиска плагиата,
необходимо ввести некоторую функцию качества для оценки результата. Прежде
рассмотрим что такое плагиат.
1.2.1
Различные понимания и определения плагиата
1. Плагиат - буквальное заимствование из
чужого литературного произведения без указания источника;
. Плагиат (от лат. plagio - похищаю) - вид
нарушения прав автора или изобретателя. Состоит в незаконном использовании под
своим именем чужого произведения (научного, литературного, музыкального) или
изобретения, рационализаторского предложения (полностью или частично) без
указания источника заимствования;
. Плагиат - присвоение плодов чужого
творчества: опубликование чужих произведений под своим именем без указания
источника или использование без преобразующих творческих изменений, внесенных
заимствователем;
. Плагиат - умышленное присвоение
авторства на чужое произведение науки, литературы или искусства. Не считается
плагиатом заимствование темы или сюжета произведения либо научных идей,
составляющих его содержание, без заимствования формы их выражения;
. Плагиат - вид нарушения авторских прав,
состоит в незаконном использовании под своим именем чужого произведения
(научного, литературного, музыкального) или изобретения, рационализаторского
предложения (полностью или частично) без указания источника заимствования.
Принуждение к соавторству также рассматривается как плагиат.
Разрабатываемая программа КонфДетект
обнаруживает плагиат в том смысле, что проверяет на сходство документы с
файлами, запрещенными к копированию. Документы отправляются на проверку с
помощью программы сторонних разработчиков.
1.2.2 Специфика
автоматического поиска плагиата
Автоматический поиск - это поиск без
участия человека, как эксперта, поэтому все критерии должны быть заданы заранее
и кроме того, быть достаточно четкими. В случае поиска плагиата, некоторые
специфические нечеткие критерии обычно отбрасываются, такие как:
. вопрос о соответствии законодательству
(является ли совершенное действие преступлением?);
. вопрос об умышленности деяния (было ли
совершенное деяние, совершено намеренно?).
Таким образом, если не рассматривать
смежные вопросы, описанные выше, задача поиска плагиата сводится к задаче -
определить была ли использована некоторая, чужая идея в документе.
На практике некоторым образом задается функция близости (или
метрика) и некоторый порог, по которому можно определить насколько вероятно,
что часть документа, в частности, текстового файла была украдена.
1.2.3 Общая
схема поиска
1. Различные представления. Выше было
рассказано про основные характеристики, которые учитываются при поиске
плагиата. Процесс выделения основных характеристик - это введение
представления, то есть из модели, с большим количеством избыточной
информации, переходим в более компактную модель, где незначимая информация
удалена. Выбирая разные представления, выбираем характеристики, которые
для данного случая являются основными и оставляем их. После этого вводим
функцию близости (или метрику), чтобы определить, какие характеристики из
оставшихся более, а какие менее значимы. То, какие характеристики являются
основными - это вопрос понимания плагиата.
. Метрики. Следующими качествами должны
обладать метрики, чтобы быть полезными на практике:
.1 Они должны представлять такие
характеристики, которые достаточно трудно изменить, пытаясь замаскировать
копию;
.2 Должны быть устойчивы к незначительным
изменениям текстового файла;
.3 Необходимо обеспечить простоту
сравнения, используя эти метрики.
Изначально обнаружение плагиата
использовалось среди исходных кодов программ. Устройство детектора плагиата
документов разработано на основе детектора для программ.

Рисунок 2.1 - Устройство детектора
плагиата документов
В качестве методов сравнения текстовых
файлов можно выбрать общие алгоритмы сравнения текстовых файлов, а именно
сравнение строк, такие как: стандартный алгоритм, алгоритм
Кнута-Морриса-Пратта, алгоритм Бойера-Мура.
1.2.4
Стандартный алгоритм
Задача состоит в том, чтобы найти первое
вхождение некоторой подстроки в длинном тексте. Поиск последующих вхождений
основан на том же подходе. Это сложная задача, поскольку совпадать должна вся
строка целиком. Стандартный алгоритм начинает со сравнения первого символа
текста с первым символом подстроки. Если они совпадают, то происходит переход
ко второму символу текста и подстроки. При совпадении выравниваются следующие
символы. Так продолжается до тех пор, пока не окажется, что подстрока целиком
совпала с отрезком текста, или пока не встретятся несовпадающие символы. В
первом случае задача решена, во втором - сдвигается указатель текущего
положения в тексте на один символ и заново начинается сравнение с подстрокой.
Этот процесс изображен ниже.
Здесь поиск образца they в тексте there
they are. При первом проходе три первых символов подстроки совпадают с
символами текста. Однако только седьмой проход дает полное совпадение (оно
находится после 13 сравнений символов).

Из алгоритма получается, что основная операция - сравнение
символов, а именно число сравнений и следует подсчитывать.
Недостаток стандартного алгоритма заключается в том, что он
затрачивает много усилий впустую. Если сравнение начала подстроки уже
произведено, то полученную информацию можно использовать для того, чтобы
определить начало следующего сравниваемого отрезка текста. Например, при первом
проходе в выше приведенном примере расхождение с образцом осуществляется на
четвертом символе, а в первых трех символах произошло совпадение. При взгляде
на образец видно, что третий символ встречается в нем лишь однажды, поэтому
первые три символа текста можно пропустить и начать следующее сравнение с
четвертого, а не со второго символа текста. Существуют различные способы
использования этой возможности, например: алгоритм Кнута-Морриса-Пратта, алгоритм
Бойера-Мура.
1.2.5
Алгоритм Кнута-Морриса-Пратта
При построении конечного автомата для
поиска подстроки в тексте легко построить переходы из начального состояния в
конечное принимающее состояние: эти переходы помечены символами подстроки (рис.1).
Проблема возникает при попытке добавить другие символы, которые не переводят в
конечное состояние.
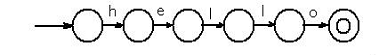
Рисунок 2.2 - Начало построения автомата
для поиска подстроки hello
Алгоритм Кнута-Морриса-Пратта основан на
принципе конечного автомата, однако он использует более простой метод обработки
неподходящих символов. В этом алгоритме состояния помечаются символами,
совпадение с которыми должно в данный момент произойти. Из каждого состояния
имеется два перехода: один соответствует успешному сравнению, другой -
несовпадению. Успешное сравнение переводит в следующий узел автомата, а в
случае несовпадения - в предыдущий узел, отвечающий образцу. Пример автомата
Кнута-Морриса-Пратта для подстроки ababcb приведен на рисунке 2.3.
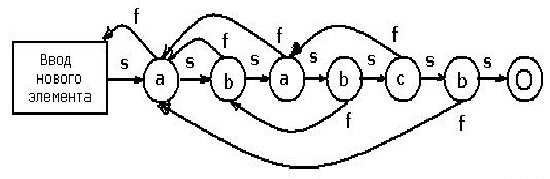
Рисунок 2.3 - Полный автомат
Кнутта-Морриса-Пратта для подстроки ababcb
При любом переходе по успешному сравнению
в конечном автомате Кнутта-Морриса-Пратта происходит выборка нового символа из
текста. Переходы, отвечающие неудачному сравнению, не приводят к выборке нового
символа; вместо этого они повторно используют последний выбранный символ. Если
был переход в конечное состояние, то это означает, что искомая подстрока
найдена. Можно проверить текст abababcbab на автомате, изображенном на рисунке
2.3, и посмотреть, как происходит успешный поиск подстроки.
Прежде, чем перейти к анализу этого
процесса, рассмотрим как задаются переходы по несовпадению. Заметим, что при
совпадении происходит переход к следующему узлу. Напротив, переходы по
несовпадению определяются тем, как искомая подстрока соотносится сама с собой.
Например, при поиске подстроки ababcb нет необходимости возвращаться назад на
четыре позиции при необнаружении символа c. Если достигнут пятый символ в образце,
то первые четыре символа совпали, и поэтому символы ab в тексте, отвечающие
третьему и четвертому символам образца, совпадают также с первым и вторым
символами образца.
К достоинствам данного алгоритма относится
стабильная скорость работы на длинных строках. Эффективность не снижается и при
сравнении "не удачных" данных.
1.2.6 Алгоритм
Бойера-Мура
В отличие от двух выше описанных
алгоритмов сравнения строк алгоритм Бойера-Мура осуществляет сравнение с
образцом справа налево, а не слева направо. Исследуя искомый образец, можно
осуществить более эффективные прыжки в тексте при обнаружении несовпадения.
В примере ниже сначала сравниваются y с r
и обнаруживается несовпадение. Поскольку буква r вообще не входит в образец,
можем сдвинуть текст на целых четыре буквы (то есть на длину образца) вправо.
Затем сравниваются буквы y с h и вновь обнаруживается несовпадение. Однако
поскольку на этот раз h входит в образец, можно сдвинуться вправо только на две
буквы так, чтобы буквы h совпали. Затем начинается сравнение справа и
обнаруживается полное совпадение кусочка текста с образцом. В алгоритме
Бойера-Мура проводится 6 сравнений вместо 13 в стандартном алгоритме.
Пример 1. Поиск образца they в тексте
there they are (совпадение находится после 6 сравнений символов):

Пример 2. Проблема со сдвигом:

Алгоритм Бойера-Мура обрабатывает образец двумя способами.
Во-первых, можно вычислить величину возможного сдвига при несовпадении
очередного символа. Во-вторых, вычисляется величина прыжка после того, как
выделены в конце образца последовательности символов, уже появлявшиеся раньше.
Перед подсчетом величины прыжка, посмотрим, как используются результаты этого
подсчета.
Массив сдвигов содержит величины, на которые может быть сдвинут
образец при несовпадении очередного символа. В массиве прыжков содержатся
величины, на которые можно сдвинуть образец, чтобы совместить ранее совпавшие
символы с вновь совпадающими символами строки. При несовпадении очередного
символа образца с очередным символом текста может осуществиться несколько
возможностей. Сдвиг в массиве сдвигов может превышать сдвиг в массиве прыжков,
а может и нет. (Совпадение этих величин - простейшая возможная ситуация.) О чем
говорят эти возможности? Если элемент массива сдвигов больше, то это означает,
что несовпадающий символ оказывается "ближе" к началу, чем повторно
появляющиеся завершающие символы строки. Если элемент массива прыжков больше,
то повторное появление завершающих символов строки начинается ближе к началу
образца, чем несовпадающий символ. В обоих случаях следует пользоваться большим
из двух сдвигов. Так, например, если значение сдвига равно 2, а значение прыжка
4, то сдвиг на два символа не позволит найти соответствие образцу:
несовпадающий символ все равно окажется невыровненным. Однако, если сдвинуть на
четыре символа, то под ранее несовпадающим символом окажется подходящий символ
образца, и при этом сохраняется возможность того, что завершающие символы
образца будут совпадать с новыми соответствующими символами текста.
Выполнив этот алгоритм на образце datadata, получается slide [d] =
3, slide [a] = 0 и slide [t] = 1; для всех остальных букв алфавита значение
сдвига будет равно 8.
Массив jump, размер которого совпадает с длиной образца, описывает
взаимоотношение частей образца. Этот массив позволяет, например, при
несовпадении символа h образца с символом t текста в примере 2 сдвинуть образец
целиком за сравниваемый символ. Этот новый массив также отслеживает повторение
символов в конце образца, которые могут заменять сравниваемые символы. Пусть, например,
образец имеет вид abcdbc, и в процессе сравнения два последних символа образца
совпали с символами текста, а в третьем символе обнаружилось расхождение. Тогда
массив jump говорит, насколько следует сдвинуть образец, чтобы символы bc в
позициях 5 и 6 совпали с символами bc в позициях 2 и 2. Таким образом, массив
jump содержит информацию о наименьшем возможном сдвиге образца, который
совмещает уже совпавшие символы с их следующим появлением в образце. Положим,
что в некотором образце несовпадение очередного символа означает, что образец
следует сдвинуть целиком на место начало сравнения. В примере 4 изображены
отрезок текста и образец. Символы X в образце могут быть произвольными; они
призваны проиллюстрировать процедуру.
Пример 4. Определение величины прыжка:
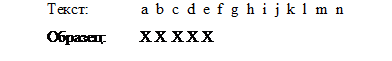
Если образец нужно сдвинуть целиком на всю длину, то символы X
должны соотнестись с символами от f до j, то есть новое значение переменной
textLocбудет равно 10. Если несовпадение произошло на символе, когда textLoc =
5, то для сдвига образца нужно к textLoc прибавить 5.
Если же несовпадение произошло на символе d, то есть при textLoc =
4, то для сдвига нужно увеличить textLoc на 6. При несовпадении на символах c,
b или a увеличение составит соответственно 7, 8 или 9. В общем случае при
несовпадении последнего символа увеличение составляет длину образца, а при
несовпадении первого символа - удвоенную длину без единицы. Эти соображения и
служат основой для инициализации массива jump.
Достоинствами данного алгоритма на "хороших" данных
является высокая скорость и крайне низкая вероятность появления
"плохих" данных. Поэтому он оптимален в большинстве случаев, когда
нет возможности провести предварительную обработку текста, в котором проводится
поиск. Разве что на коротких текстах выигрыш не оправдает предварительных
вычислений.
Недостатки алгоритма следующие:
. Сравнение не является "чёрным ящиком", поэтому при
реализации наиболее быстрого поиска приходится либо рассчитывать на удачную
работу оптимизатора, либо вручную оптимизировать поиск на ассемблерном уровне;
. Если текст изменяется редко, а операций поиска проводится много
(например, поисковая машина), в тексте стоило бы провести индексацию, после
чего поиск можно будет выполнять быстрее, чем даже алгоритмом Бойера-Мура;
. На больших алфавитах (например, Юникод) таблица стоп-символов
может занимать много памяти. В таких случаях либо обходятся хэш-таблицами, либо
разбивают алфавит, рассматривая, например, 4-байтовый символ как пару
двухбайтовых;
. На искусственно подобранных "плохих" текстах
(например, needle="колоколоколоколоколокол") скорость алгоритма
Бойера-Мура серьёзно снижается. Существуют попытки совместить присущую
алгоритму Кнута-Морриса-Пратта эффективность в "плохих" случаях и
скорость Бойера-Мура в "хороших" - например, турбо-алгоритм.
1.2.7
Нейросетевые методы обнаружения плагиата
Поиск плагиата можно свести к задаче
классификации, когда набор документов требуется разбить на несколько классов, в
каждом из которых будут содержаться только списанные друг с друга документы.
Как известно, нейронные сети - это один из лучших инструментов для решения
задачи аппроксимации функций, и в частности, классификации.
Нейронную сеть можно представить как
черный ящик, на вход которому подается известная информация, а на выходе
выдается информация, которую хотелось бы узнать. Например, входной информацией
может служить набор программ, а выходной, являются ли программы плагиатом.
Базовые элементы искусственных нейросетей - формальные нейроны - изначально
нацелены на работу с широкополосной информацией. Каждый нейрон нейросети, как
правило, связан со всеми нейронами предыдущего слоя обработки данных. Рисунок
иллюстрирует наиболее широко распространенную в современных приложениях
архитектуру многослойного персептрона. Типичный формальный нейрон производит
простейшую операцию - взвешивает значения своих входов со своими же локально
хранимыми весами и производит над их суммой нелинейное преобразование. Из-за
нелинейности функции активации всю нейросеть нельзя свести к одному нейрону и
возможности нейросети существенно выше возможностей отдельных нейронов.
Состояние сети характеризуется набором весов, которые меняются в процессе
поступления входной информации. Данный процесс называется обучением сети.
Принцип обучения нейросетей основан на минимизации эмпирической ошибки. Функция
ошибки, оценивающая данную конфигурацию сети, задается извне - в зависимости от
того, какую цель преследует обучение. Но далее сеть начинает постепенно
модифицировать свою конфигурацию - состояние всех своих весов - таким образом,
чтобы минимизировать эту ошибку. В итоге, в процессе обучения сеть все лучше
справляется с возложенной на нее задачей. Характерной особенностью нейросетей
является их способность к обобщению, позволяющая обучать сеть на ничтожной доле
всех возможных ситуаций, с которыми ей, может быть, придется столкнуться в
процессе функционирования.
1.2.7.1 Виды
нейронных сетей
Различие в подходах при решении задачи
поиска плагиата и смежных с ней, таких как определения авторства и классификация
текстов, заключается, в основном, в использовании той или иной разновидности
сети. Все нейросети можно разделить на два класса по методу обучения: обучение
с учителем и обучение без учителя (самообучение).
При обучении с учителем реальные выходы
сети сравниваются с эталонными, и процесс обучения сводится к задаче
максимального приближения выходов сети к эталону.
Многослойный персептрон - это один из
самых распространенных видов сетей с учителем. При решении задачи классификации
при обучении на вход сети подаются примеры, а на выход принадлежность к классу.
После обучения на вход сети можно подавать новые примеры, и сеть будет выдавать
принадлежность к классу.
Еще одним видом сетей с учителем являются
байесовские или вероятностные сети. Это сети, чей принцип действия основан на
байесовской статистике. Обычная статистика по заданной модели говорит, какова
будет вероятность того или иного исхода. Байесова статистика зеркально отражает
вопрос: правильность модели оценивается по имеющимся достоверным данным. В более
общем плане, байесова статистика дает возможность оценивать плотность
вероятности распределений параметров модели по имеющимся данным. Вероятностная
сеть представляет собой реализацию методов ядерной аппроксимации оценки
плотности, оформленных в виде нейронной сети. В отличае от персептрона,
вероятностная сеть на выходе дает не принадлежность примера к какому-либо
классу, а вероятность принадлежности к каждому из классов. Применение
байесовских сетей к задаче обнаружения плагиата не найдено.
Другой разновидностью нейронных сетей
являются самоорганизующиеся карты. В данном виде нейросетей используется метод
обучения без учителя. В этом случае сети предлагается самой найти скрытые
закономерности в массиве данных и результат обучения зависит только от структуры
входных данных. То есть классы не известны априори и определяются согласно
схожести входной информации при обучении. После обучения на вход сети можно
подавать новые примеры, и они будут отнесены к одному из классов или не
отнесены вообще. В последнем случае можно говорить, что появился новый класс.
Несмотря на большие возможности,
существует ряд недостатков, которые все же ограничивают применение
нейросетевого метода. Во-первых, нейронные сети позволяют найти только
субоптимальное решение, и соответственно они неприменимы для задач, в которых
требуется высокая точность. Функционируя по принципу черного ящика, они также
неприменимы в случае, когда необходимо объяснить причину принятия решения.
Обученная нейросеть выдает ответ за доли секунд, однако относительно высокая
вычислительная стоимость процесса обучения как по времени, так и по объему
занимаемой памяти также существенно ограничивает возможности их использования.
1.2.8 Жадное
строковое замощение
Рассмотрим эвристический алгоритм
получения жадного строкового замощения (жадного (общего) покрытия строк). На
вход подаётся две строки символов над определенным алфавитом, а на выходе
получается набор их общих непересекающихся подстрок, близкий к оптимальному.
Подстрока, входящая в этот набор, будет называться тайлом (Tile).
Пусть Р и Т - представления сравниваемых
текстовых файлов.
Определения:
. MinimumMatchLength - минимальная длина
наибольшего общего префикса строк Рр и Tt, при которой он
учитывается алгоритмом;
. Длина самого большого из пока найденных
на текущей итерации алгоритма общих префиксов строк Рр и Tt обозначается MaxMatch;
. Набор тайлов будет обозначаться как Tiles.
. Множество, содержащее кандидаты на
попадание в набор тайлов, обозначется Mathes.
Алгоритм можно разделить на две фазы:
. Ищутся наибольшие общие подстроки Р и Т,
состоящие только из непомеченных элементов (вначале алгоритма все элементы
непомечены). Для этого используются три вложенных цикла: первый пробегает по
всем возможным Рр, второй по всем Tt, а третий находит
наибольший общий префикс Рр и Tt. Далее существует три
варианта в зависимости от соотношения величин MaxMatch и найденного префикса:
.1 если MaxMatch меньше, то мы удаляем из
списка общих подстрок Matches все до этого добавленные и помещаем туда
найденный префикс;
.2 если MaxMatch больше, то ничего не
меняем;
.3 если они равны, то добавляем наибольший
общий префикс Рр и Tt к списку Matches.
. Просматривается список. Если текущий
элемент списка - подстрока, не содержащая помеченных элементов, то она
помещается в выходной набор Tiles (теперь эту подстроку называют Tile - отсюда и название
алгоритма), маркируются все элементы рассматриваемой строки, входящие в Р и Т.
Если длины строк в списке (MaxMatch) больше MinimumMatchLength, то соуществляется переход
к первой фазе.
Достоинства:
. Общие подстроки меньшей длины, чем MinimumMatchLength, игнорируются, поэтому
алгоритм не принимает в расчет небольшие случайно совпавшие области текста;
. При разбиении совпавшего участка текста
на две и более части вставкой одного-нескольких блоков функция схожести слабо
изменяется. (Длина совпадения должна быть значительно больше MinimumMatchLength);
. Алгоритм нечувствителен к перестановкам
больших фрагментов кода.
Недостатки:
. Возможноть совпадения представлений
текстовых файлов, но отсутствия совпадения в самих текстах;
. Разбиение совпадения на блоки вставкой
или заменой на похожий, каждый длиной меньшие MinimumMatchLength, ведет к полному
игнорированию совпадения;
. Из-за эвристик, используемых в
алгоритме, совпадения, длиной меньшей чем MinimumMatchLength, будут проигнорированы.
1.2.9 Метод
идентификационных меток
При поиске плагиата требуется находить
копии и частичные копии файла в тестовой базе большого объема. В этом случае
непосредственное сравнение файлов не эффективно.
Рассматриваемая техника позволяет
перевести файл (документ) в более краткое представление: документу
сопоставляется набор идентификационных меток (fingerprints), так чтобы для близких
документов эти наборы пересекались. Рассмотрим произвольный текст:
abracadabra, (он состоит из 11
символов; т = 11)
k-граммом называются любые
k символов стоящих подряд.
Построим всевозможные k-граммы для нашего текста при, например, k = 3:
abr, bra, гак, ака, kad, ada, dab, abr, bra
Количество k-граммов, которые можно
построить для текста длины т обозначим п, п = (т - (k - 1)) (в примере = 9)
Хешируются все k-граммы. Получившийся
набор хеш-значений (h1. hn) характеризует исходный
документ. Для рассмотренного текста могла получиться, например, такая
последовательность хеш-значений:
12, 35, 18, 3, 26, 48,
55, 12, 35
На практике, использовать все значения не
целесообразно, поэтому выбирают небольшое их подмножество. Выбранные
хеш-значения становятся метками (fingerprints) документа. Вместе с самой меткой хранится
информация о том, какому файлу она принадлежит и в каком месте этого файла
встречается. Если хеш-функция гарантирует малую вероятность коллизий, то
одинаковая метка в наборах двух файлов свидетельствует о том, что у них есть
общая подстрока. По количеству общих меток можно судить о близости файлов.
Чтобы выбрать те хеш-значения, которые
будут представлять документ, используют следующие подходы:
. Наивный подход - выбрать каждое i-тое из п значений.
Однако, такой способ не устойчив к вставке и удалению символов, изменению их
порядка (действительно, если добавить в начало файла 1 символ, позиции всех k-граммов сдвинутся, ни
одна из меток нового файла со старыми не совпадет). Поэтому опираться на
позицию внутри документа нельзя.
. По Хайнце следует назначать метками
минимальных хеш-значений, их количество для всех документов будет постоянно. С
помощью этого метода нельзя найти частичные копии, но он хорошо работает на
файлах примерно одного размера, находит похожие файлы, может применяться для
классификации документов.
. Манбер предложил выбирать в качестве
меток только те хеш-значения, для которых h = 0 mod р, так останется только п/р
меток (объем идентификационного набора для разных файлов будет отличаться,
сами метки будут зависеть от содержимого файла). Однако, в этом случае расстояние
между последовательно выбранными хеш-значениями не ограничено и может быть
велико. В этом случае совпадения, оказавшиеся между метками, не будут учтены.
. Метод просеивания (winnowing) не имеет этого
недостатка. Алгоритм гарантирует, что если в двух файлах есть хотя бы одна
достаточно длинная общая подстрока, то как минимум одна метка в их наборах
совпадет.
Алгоритм просеивания для построения меток
При поиске общей подстроки в файлах
руководствуются следующими условиями:
. если длина совпадающей подстроки больше
или равна гарантированной длине (guarantee threshold) t, то совпадение будет
обнаружено;
. совпадения короче шумового порога (noise threshold) k, игнорируются. (Параметры t и k задают в зависимости от
необходимой точности). Пункт 2 обеспечен выделением из текста k-граммов. Чем больше k, тем менее вероятно, что
совпадения случайны. Но с ростом k падает устойчивость
метода к перестановкам. В художественных текстах обычно за k принимают среднюю длину
устойчивых выражений.
Чтобы удовлетворить пункту 1 необходимо (и
достаточно), чтобы из каждых последовательно идущих (t - k + 1) хеш-значений хотя бы одно
было выбрано в качестве метки.
Идея алгоритма такова. Продвигается окно
размера w = (t - к + 1) вдоль последовательности h1. hn, на каждом шаге окно перемещается
на одну позицию вправо. Назначаем меткой минимальное hj в окне. Если в одном окне
два элемента принимают минимальное значение, правый назначается меткой.
Пример для выше рассмотренного процесса.
Тексту abracadabra соответствует
последовательность хеш-значений:
12, 35, 78, 3, 26, 48,
55, 12, 35
Пусть интересуют совпадения длины 4 и
более, т.е. t = 4. Тогда w = (4 - 3 + 1) = 2, и окна получатся
(12,35), (35, 78),
(78,3), (3, 26), (26,48), (48, 55), (55,12), (12, 35)
Жирным выделены значения, назначенные
метками. Для данного текста итоговый набор меток будет следующим:
(12, 35, 3, 26, 48,12)
Выбор метки определяется только содержимым
окна, такой алгоритм называется локальным. Любой локальный алгоритм выбора
меток корректен. Действительно, если в двух файлах есть достаточно большая
общая подстрока, то будут и одинаковые окна, а значит, будут назначены
одинаковые метки. По ним определяется, что в файлах есть совпадения.
Показателем эффективности алгоритма может
служить плотность d - доля хеш-значений, выбранных в качестве меток,
среди всех хеш-значений документа. Можно показать, что при просеивании d = 2/ (w+l).
Достоинством данного алгоритма является
его линейная трудоемкость. Количество сравнений зависит от заданного
пользователем уровня точности.
.2.10
Алгоритм Хескела
Представим два текстовых файла в виде
строк a
и b соответственно. Одним из
критериев сходства строк считается длина их наибольшей общей
подпоследовательности. Всегда можно найти такой элемент строки аi, что НОП строк a' = a|a|a|a|-1…aia1…ai-1 и b будет значительно меньше
(максимум в два раза), чем НОП (а, b) (если НОП (а, b) > 1). Чтобы избежать
этого явления можно воспользоваться алгоритмом сравнения строк Хескела, он
требует нескольких проходов, но работает за линейное время. Разобьем строки а и
b на k-граммы (подстроки длины k). Найдем те k-граммы, которые
встречаются в а и b только по одному разу. Для каждой такой пары проверим совпадают
ли элементы строк, непосредственно лежащие над ними; если это так, то проведем
ту же проверку и для них и так далее, пока несовпадение не будет найдено.
Аналогично для строк, лежащих ниже соответствующих k-граммов. Получаем набор
общих непересекающихся подстрок а и b. Их общая длина может служить мерой схожести
программ соответвующих а и b.
Достоинства:
. Линейная трудоемкость (количество
сравнений) алгоритма.
Недостатки:
1. Небольшое количество уникальных k-граммов в больших
текстовых областях, соответственно, многие совпадения, не содержащие в себе
таких k-граммов,
будут проигнорированы;
. Вставка в найденный блок или изменение на семантический
эквивалентен во многих случаях будет приводить к игнорированию той части блока,
в которой не содержится уникальной k-граммы.
Существует ещё ряд методов таких как Conceptual graph или Abstract Syntax tree и поиск на XML представлении. Но их
применение целесообразно только в случае обнаружения плагиата в программах,
поскольку вся информация, проверяемая на сходство, представляется в виде
дерева. Во втором алгоритме описание хранится в XML формате.
Заключение
Стандартный алгоритм и нейросетевые методы обладают рядом
существенных недостатков, чтобы их использовать. Алгоритмы Кнута-Морриса-Пратта
и Бойера-Мура уже реализованы. Реализация метода идентификационных меток
существует в похожей с разрабатываемой библиотекой обнаружения утечки
конфиденциальной информации. После оценки достоинств и недостатков следующих
методов: Жадное строковое замощение и алгоритм Хескела, на рассмотрение к
реализации выбран алгоритм Хескела.
1.3
Постановка задачи
Целью проекта является предотвращение несанкционированного
распространения конфиденциальной информации посредством документов. Для
достижения данной цели необходимо:
Реализовать алгоритм, выбранный на основании аналитического
обзора существующих методов сравнения текстовых файлов, поиска плагиата в
передаваемом документе на языке С++;
Разработать модуль обнаружения утечки конфиденциальной
информации на основании алгоритма поиска плагиата. Модуль будет представлен в
виде библиотеки;
Разработать рекомендации по использованию библиотеки;
Разработать руководство программиста.
В качестве исходных данных, используемых для выполнения
проекта, будут определены конфиденциальные и не конфиденциальные документы,
представленные в виде текстовых файлов. На вход библиотеки будут поступать
проверяемые на предмет плагиата документы.
В качестве выходных данных, представляющих результаты
выполнения проекта, будет сообщение о результате проверки документа.
Глава 2.
Разработка алгоритма сравнения текстовых файлов
2.1 Выбор и
обоснование алгоритма
На основании проведённого анализа представляется использовать
следующий алгоритм оценки сходства документов - алгоритм сравнения строк
Хескела, что повышает эффективность обнаружения утечки конфиденциальной
информации. Данный алгоритм уже реализован в двух программах обнаружения
плагиата исходных кодов программ. Этими программами являются следующие
детекторы: Plague, YAP, которые построены по модели токенов.
Сходство в детекторах определяется не по смыслу и без
использования XML форматов, а по совпадению последовательности символов. Поэтому
возможно применение данного алгоритма для сравнения текстовых файлов. Алгоритм
Хескела требует нескольких проходов, но работает за линейное время - для
каждого прохода требуется одинаковое время. Также он характеризуется линейной
трудоемкостью (количество сравнений). Все это достоинства, к недостаткам
относится следующее. Даже в больших текстовых областях содержится небольшое
количество уникальных k-граммов, соответственно, многие совпадения, не содержащие в
себе таких k-граммов,
будут проигнорированы. С учетом всех достоинств и недостатков будут разработаны
две различные схемы работы данного алгоритма. В первой схеме будет
непосредственно использован алгоритм Хескела, а во второй будут формироваться
списки сигнатур документов, которые записываются в базу данных и используются в
дальнейшем при оценки исходящей информации.
2.2
Разработка алгоритма
Использовать алгоритм сравнения строк
Хескела в разрабатываемом модуле обнаружения утечки информации в документах
возможно по 2 двум различным схемам. Но их объединяют одинаковые типы данных,
поступающих на вход библиотеки. К ним относятся 3 типа текстовых файлов: с
конфиденциальной, не конфиденциальной и проверяемой информацией. Эти файлы
представляются в виде строк. Рассмотрим две из них, например с конфиденциальной
и не конфиденциальной информацией. Обозначим их a и b соответственно. В
строках a
и b из всех имеющихся
символов сохраняются только буквы, пробелы и знаки препинания удаляются. Далее
а и b
разбиваются на подстроки длиной k (k-граммы). Целесообразно, чтобы минимальное количество символов в k-граммах было равно 3.
В качестве объяснения получения k-грамм рассмотрим текст: конфиденциальный,
(он состоит из 16 символов; m = 16). K-граммой называются любые k символов стоящих подряд.
Всевозможные k-граммы
для рассматриваемого текста при, например, k = 5, строятся следующим
образом: конфи, онфид, нфиде, фиден, иденц, денци, енциа, нциал, циаль,
иальн, альны, льный. Количество k-граммов, которые можно построить для текста
длиной m
обозначаются n,
n = (m - (k - 1)) (в примере n = 12). Чем больше, тем
менее вероятно, что совпадения случайны. Но с ростом k-граммы падает
устойчивость метода к перестановкам. В художественных текстах обычно за длину k-граммы принимают среднюю
длину устойчивых выражений.
Возможно, что и в а, и в b, будут присутствовать
дублирующиеся части, поэтому удаляются повторяющиеся наборы k-грамм в каждой строке.
Сравнение строк a и b проводится следующим образом. Выполняется поиск пар уникальных k-грамм, т.е. тех которые
встречаются в a
и b только по одному разу.
Для каждой пары проверяется, совпадают ли символы в k-граммах, которые
располагаются над ними, затем сравнивается сама пара. Далее проводится проверка
для k-грамм,
лежащих ниже соответствующей пары. И так до тех пор, пока совпадение не будет
найдено. В результате получается набор общих непересекающихся подстрок в a и b. Общие - т.е.
присутствует сходство подстрок между a и b. Непересекающиеся - т.е. отсутствует сходство между
подстроками каждой строки: a и b. Как раз для получения непересекающихся подстрок и
проводилось удаление повторяющихся наборов k-грамм в каждой строке.
Набор общих непересекающихся подстрок формируется для каждой строки: a и b. Их общая длина может
служить мерой сходства документов соответствующих a и b.
Вторая схема вначале работает по тому же принципу, что и
первая. Файлы также представляются в виде строк. Из всех имеющихся символов
удаляются пробелы и знаки препинания, остаются только буквы. Проводится
разбиение на k-граммы.
Если присутствуют дублирующиеся части, то удаляются повторяющиеся наборы k-грамм в каждой строке.
Далее алгоритм Хескела дополняется соответствующим образом. С использованием
хеш-функции формируются списки сигнатур a и b, которые записываются в
базу данных. С помощью такой функции происходит преобразование входного массива
данных произвольной длины в выходную битовую строку фиксированной длины.
Хеш-функция также называется функцией свёртки, а ее результаты называют хешем,
хеш-кодом или дайджестом сообщения. В разрабатываемом алгоритме хеши будут
присваиваться каждой k-грамме. Хеш-коды не являются уникальными, поэтому если есть
повторяющиеся k-граммы,
то и хеши тоже совпадают. Одной из характеристик множества алгоритмов
хеширования является разрядность. Рассмотрим следующие хеш-функции:
. На выходе CRC-16 (контрольной суммы) - хеш-код, максимальный
размер которого равен 16 бит или 2 байта, об этом свидетельствует имя
хеш-функции;
. На выходе MD5 - хеш-код, максимальный размер которого равен
128 бит или 16 байт;
. На выходе SHA-1 - хеш-код, максимальный размер которого равен
160 бит или 20 байт.
Размер одного символа составляет 1 байт. Если длина k-граммы варьируется в
диапазоне от 3 до 16 символов, то объему k-граммы соответствует
диапазон от 3 до 16 байт. Выбор той или иной хеш-функции определяется
спецификой решаемой задачи. Но в общем случае однозначного соответствия между
исходными данными и хеш-кодом нет. Поэтому существует множество массивов
данных, дающих одинаковые хеш-коды - так называемые коллизии. Вероятность возникновения
коллизий играет немаловажную роль в оценке "качества" хеш-функций. В
связи с этим можно выбрать хеш-функцию с наименьшим объемом хеш-кода. В данном
случае это контрольная сумма CRC-16. Каждой k-грамме будет
присваиваться двухбайтовый хеш-код, будет происходить хеширование k-граммы по хеш-функции CRC-16.
CRC-16 или контрольная сумма - несложный, крайне
быстрый и легко реализуемый алгоритм. Может использоваться в качестве защиты от
непреднамеренных искажений. Платой за столь высокую скорость является легкая
возможность подогнать сообщение под заранее известную сумму. Обычно разрядность
контрольных сумм (типичное число: 32 бита) ниже, чем у таких хеш-функций как MD5 или SHA (типичные числа: 128,
160 и 256 бит), что означает возможность возникновения непреднамеренных
коллизий. Простейшим случаем такого алгоритма является деление сообщения на 32
- или 16-битные слова и их суммирование. Как правило, к такому алгоритму
предъявляются требования отслеживания типичных ошибок, таких, как несколько
подряд идущих ошибочных бит до заданной длины. Семейство алгоритмов т. н.
"циклических избыточных кодов" удовлетворяет этим требованиям. К ним
относится, например, CRC32.
В качестве применения хеширования можно использовать:
. Сверку данных. В общем случае это применение можно описать,
как проверка некоторой информации на идентичность оригиналу, без использования
оригинала. Для сверки используется хеш-код проверяемой информации. Различают
два основных направления этого применения:
. Проверка на наличие ошибок. Например, контрольная сумма
может быть передана по каналу связи вместе с основным текстом. На приёмном
конце, контрольная сумма может быть рассчитана заново и её можно сравнить с
переданным значением. Если будет обнаружено расхождение, то это значит, что при
передаче возникли искажения и можно запросить повтор. Бытовым аналогом
хеширования в данном случае может служить приём, когда при переездах в памяти
держат количество мест багажа. Тогда для проверки не нужно вспоминать про
каждую кладь, а достаточно их посчитать. Совпадение будет означать, что ни одна
кладь не потеряна. То есть, количество мест багажа является его хеш-кодом;
. Проверка парольной фразы. В большинстве случаев парольные
фразы не хранятся на целевых объектах, хранятся лишь их хеш-коды. Хранить
парольные фразы нецелесообразно, так как в случае несанкционированного доступа
к файлу с фразами злоумышленник узнает все парольные фразы и сразу сможет ими
воспользоваться, а при хранении хешей он узнает лишь хеши, которые не обратимы
в исходные данные, в данном случае в парольную фразу. В ходе процедуры
аутентификации вычисляется хеш-значение введённой парольной фразы, и
сравнивается с сохранённым. Примером в данном случае могут служить ОС GNU/Linux
и Microsoft Windows XP. В них хранятся лишь хеш-значения парольных фраз из
учётных записей пользователей.
. Ускорение поиска данных. Например, при записи текстовых
полей в базе данных может рассчитываться их хеш-код и данные могут помещаться в
раздел, соответствующий этому хеш-коду. Тогда при поиске данных надо будет
сначала вычислить хеш-код текста и сразу станет известно, в каком разделе их
надо искать, то есть, искать надо будет не по всей базе, а только по одному её
разделу (это сильно ускоряет поиск). Бытовым аналогом хеширования в данном
случае может служить помещение слов в словаре по алфавиту. Первая буква слова
является его хеш-кодом, и при поиске просматривается не весь словарь, а только
нужная буква.
После преобразования строк в сигнатуры проводится их
сравнение следующим образом. Каждое хеш-значение строки a сравнивается с
хеш-значением строки b. Количество совпавших комбинаций является мерой схожести
документов. Для того, чтобы проверяемый файл был признан конфиденциальным и
соответственно запрещенным к передаче, устанавливается пороговое значение
количества схожих сравнений.
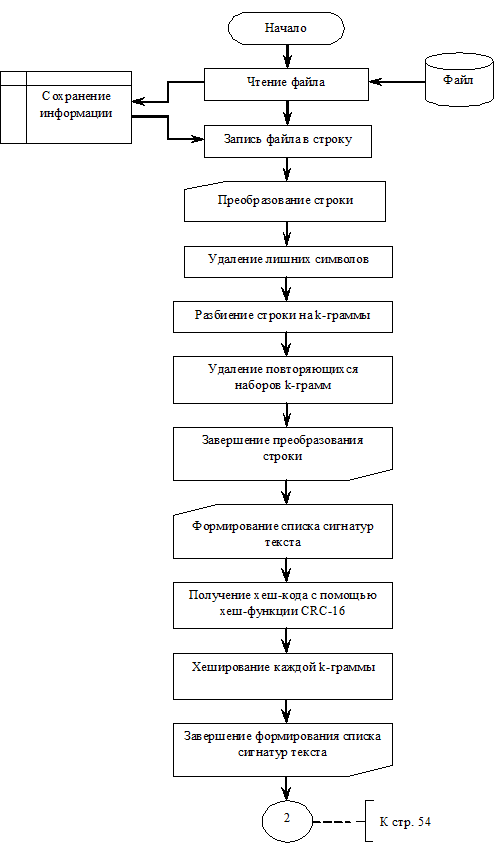
2.2.1 Схема
алгоритма
Схема 1
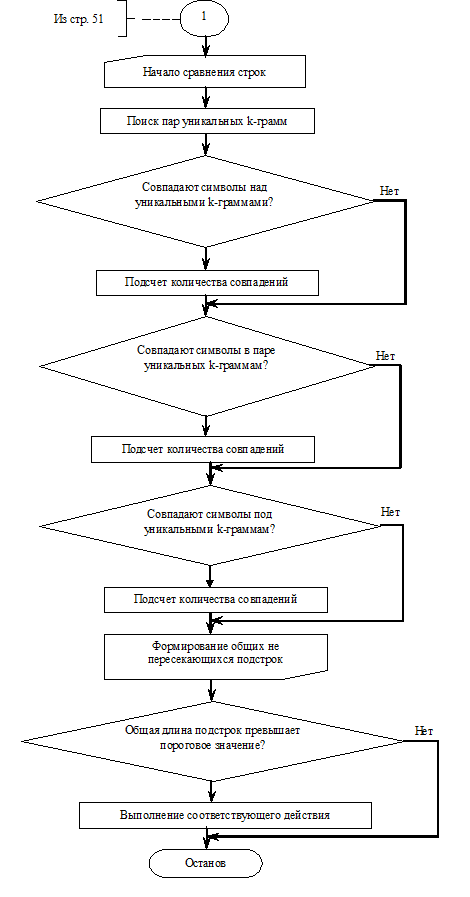
Схема 2
К шагу "Выполнение соответствующего действия” может
относиться следующее:
. Удаление сигнатур не конфиденциальных файлов из базы сигнатур
конфиденциальных файлов. Процесс удаления будет подробно описан в главе 3,
пункте 1;
. Оповещение о конфиденциальности документа, которое
сопровождается записью в журнал безопасности.
2.3 Выбор
методики верификации
В качестве методики верификации экспериментальной системы
обнаружения утечки информации было выбрано тестирование, результатом которого
будет построение ROC-кривой.кривая (Receiver Operator Characteristic - функциональные
характеристики приемника) - кривая, которая наиболее часто используется для
представления результатов бинарной классификации в машинном обучении. Название
пришло из систем обработки сигналов. Поскольку классов два, один из них
называется классом с положительными исходами, второй - с отрицательными
исходами. ROC-кривая показывает зависимость количества верно классифицированных
положительных примеров от количества неверно классифицированных отрицательных
примеров. В терминологии ROC-анализа первые называются истинно положительным,
вторые - ложно отрицательным множеством. При этом предполагается, что у
классификатора имеется некоторый параметр, варьируя который, будет получаться
то или иное разбиение на два класса. Этот параметр часто называют порогом, или
точкой отсечения (cut-off value). В зависимости от него будут получаться
различные величины ошибок I и II рода.
В логистической регрессии порог отсечения изменяется от 0 до
1 - это и есть расчетное значение уравнения регрессии. Будем называть его
рейтингом.
Для понимания сути ошибок I и II рода рассмотрим
четырехпольную таблицу сопряженности (confusion matrix), которая строится на
основе результатов классификации моделью и фактической (объективной)
принадлежностью примеров к классам.
Таблица 3.1 - Четырехпольная таблица сопряженности
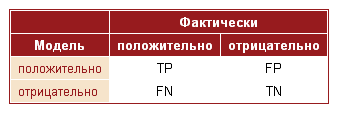
Примеры маркируются как положительный (p), так и
отрицательный (n). На выходе сопряженности возможны четыре случая:
. Положительные примеры (р) (так называемые истинно
положительные случаи) верно классифицированы (TP - True Positives);
. Положительные примеры (р) классифицированы как
отрицательные (ошибка I рода). Это так называемый "ложный пропуск" -
когда интересующее нас событие ошибочно не обнаруживается (ложно отрицательные
примеры) (FN - False Negatives);
. Отрицательные примеры (n) (так называемые истинно
отрицательные случаи) верно классифицированны (TN - True Negatives);
. Отрицательные примеры (n) классифицированы как
положительные (ошибка II рода). Это ложное обнаружение, т.к. при отсутствии
события ошибочно выносится решение о его присутствии (ложно положительные
случаи) (FP - False Positives).
Что является положительным событием, а что - отрицательным,
зависит от конкретной задачи. В качестве примера можно продемонстрировать
диагностический тест, который определяет наличие у человека болезни. В этом
случае ложный пропуск происходит, когда по результатам теста человек здоров, но
фактически болезнь есть (ошибка I рода). Ложное обнаружение происходит, когда у
человека определяется болезнь, но фактически ее нет (ошибка II рода).
Все четыре случая: True Positives, False Negatives, True Negatives, False Positives - это количественные
характеристики. Также рассчитываются относительные показатели - доли (rates):
. Доля истинно положительных примеров среди всех
положительных образцов (True Positives Rate), еще называется чувствительностью
(Sensitivity): TPR=TP/ (TP+FN);
. Доля ложно положительных примеров среди всех отрицательных
образцов (False Positives Rate): FPR=FP/ (FP+TN), FPR=1-Sp, Sp - cпецифичность (или представительность - Specificity): Sp=TN/ (TN+FP).
Модель с высокой чувствительностью часто дает истинный
результат при наличии положительного исхода (обнаруживает положительные
примеры). Наоборот, модель с высокой специфичностью чаще дает истинный
результат при наличии отрицательного исхода (обнаруживает отрицательные
примеры). Если рассуждать в терминах медицины - задачи диагностики заболевания,
где модель классификации пациентов на больных и здоровых называется
диагностическим тестом, то получится следующее:
. Чувствительный диагностический тест проявляется в
гипердиагностике - максимальном предотвращении пропуска больных;
. Специфичный диагностический тест диагностирует только
доподлинно больных. Это важно в случае, когда, например, лечение больного
связано с серьезными побочными эффектами и гипердиагностика пациентов не
желательна.
2.3.1
Построение ROC-кривой
ROC-кривая получается следующим образом:
. Для каждого значения порога отсечения, которое меняется от
0 до 1 с шагом dx (например, 0.01) рассчитываются значения чувствительности Se
и специфичности Sp. В качестве альтернативы порогом может являться каждое
последующее значение примера в выборке;
. По оси 0y откладывается чувствительность Se или TPR - доля истинно
положительных примеров, по оси 0x - (1-представительность) (1-Sp) или FPR - доля ложно
положительных случаев.
В результате получается некоторая кривая:
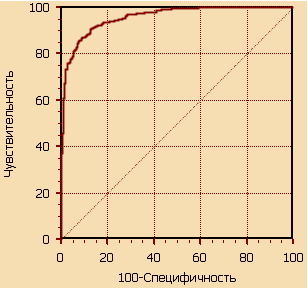
Рисунок 3.1 - ROC-кривая
График часто дополняют прямой f (x) =x. На рисунке 3.1
представлена ROC-кривая для идеального классификатора, так как график проходит
через верхний левый угол, где доля истинно положительных случаев составляет
100% или 1.0 (идеальная чувствительность), а доля ложно положительных примеров
равна нулю. Поэтому чем ближе кривая к верхнему левому углу, тем выше
предсказательная способность модели. Чем меньше изгиб кривой и чем ближе она
расположена к диагональной прямой, тем менее эффективна модель. Диагональная
линия соответствует "бесполезному" классификатору, т.е. полной
неразличимости двух классов.
Визуальный анализ ROC-кривой не всегда позволяет определить,
насколько эффективна модель. Своеобразным методом такого определения является
оценка площади под кривой. Теоретически она изменяется от 0 до 1.0, но,
поскольку модель всегда характеризуются кривой, расположенной выше
положительной диагонали, то обычно говорят об изменениях от 0.5
("бесполезный" классификатор) до 1.0 ("идеальная" модель).
Эта оценка может быть получена непосредственно вычислением площади под
многогранником, ограниченным справа и снизу осями координат и слева вверху -
экспериментально полученными точками (рисунок 3.3). Численный показатель
площади под кривой называется AUC (Area Under Curve). Вычислить его можно,
например, с помощью численного метода трапеций:
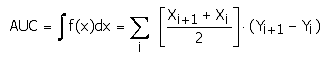
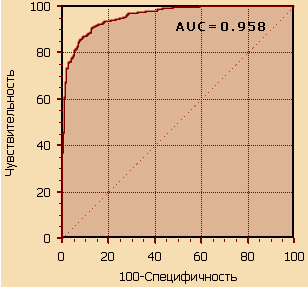
Рисунок 3.3 - Площадь под ROC-кривой
С большими допущениями можно считать, что чем больше
показатель AUC, тем лучшей прогностической силой обладает модель. AUC обладает
следующими свойствами:
. показатель AUC предназначен скорее для сравнительного
анализа нескольких моделей;
. AUC не содержит никакой информации о чувствительности и
специфичности модели.
По следующей экспертной шкале для значений AUC можно судить о
качестве модели:

Идеальная модель обладает 100% чувствительностью и
специфичностью. Однако на практике добиться этого невозможно, более того,
невозможно одновременно повысить и чувствительность, и специфичность модели.
Компромисс находится с помощью порога отсечения, т.к. пороговое значение влияет
на соотношение Se и Sp. Можно говорить о задаче нахождения оптимального порога
отсечения (optimal cut-off value).
Порог отсечения нужен для того, чтобы применять модель на
практике: относить новые примеры к одному из двух классов. Для определения
оптимального порога нужно задать критерий его определения, т.к. в разных
задачах присутствует своя оптимальная стратегия. Критериями выбора порога
отсечения могут выступать:
. Требование минимальной величины чувствительности
(специфичности) модели. Например, нужно обеспечить чувствительность теста не
менее 80%. В этом случае оптимальным порогом будет максимальная специфичность
(чувствительность), которая достигается при 80% (или значение, близкое к нему
"справа" из-за дискретности ряда) чувствительности (специфичности);
. Требование максимальной суммарной чувствительности и
специфичности модели: Cut_offo=maxk (Sek+Spk);
. Требование баланса между чувствительностью и
специфичностью, в случае Se≈Sp: Cut_offo=mink|Sek-Spk|.
Глава 3.
Экспериментальное обоснование результатов исследования
3.1
Архитектура экспериментальной системы обнаружения утечки информации
На рисунке 3.1.1 представлена работа модуля обнаружения
утечки конфиденциальной информации в документах. Она начинается с чтения
информации из конфиденциальных и не конфиденциальных файлов, которые определяет
руководитель организации, и проверяемых документов. На основании анализа данных
типов документов формируются списки сигнатур, которые записываются в базу
данных и используются в дальнейшем при оценки исходящей информации. Преобразование
в сигнатуры файлов происходит тем способом, который описан в главе 2, пункте 2
(разработка алгоритма). Сигнатуры конфиденциальных и не конфиденциальных файлов
записываются в соответствующие базы данных и сравниваются по алгоритму,
описанному в том же пункте 2 главы 2. Если найдены совпадения, то
соответствующие сигнатуры удаляются из конфиденциальной базы и формируется
общая база без учета сигнатур не конфиденциальных файлов. В качестве удаляемой
не конфиденциальной информации может выступать шапка документа. Это удаление
предотвращает ложные обнаружения. После преобразования текста проверяемого
файла в сигнатуры не происходит записи в базу данных. Эти сигнатуры после
помещения в оперативную память сравниваются с общей базой и удаляются.
Напротив, необходимо хранение сигнатур конфиденциальных и не конфиденциальных
файлов в базах данных, поскольку каждая из этих баз периодически дополняется и
прежняя информация очень важна.
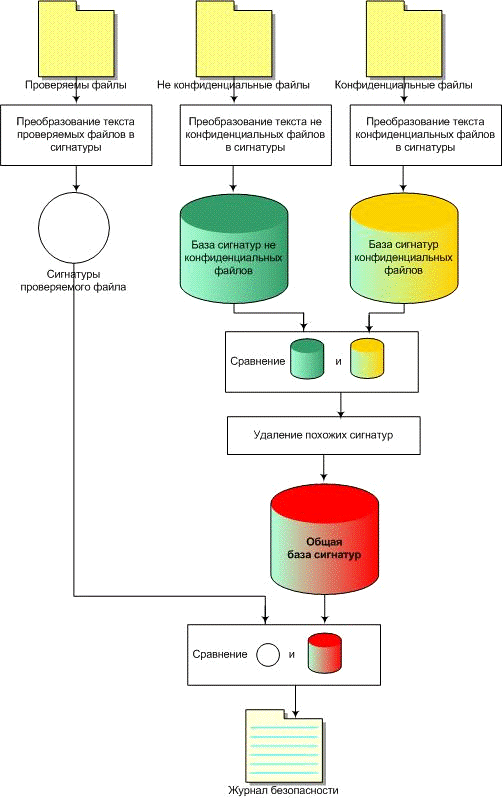
Рисунок 3.1.1 - Архитектура экспериментальной системы
3.2
Технология проведения эксперимента
В основе проведения эксперимента над системой обнаружения
утечки информации лежит технология построения ROC-кривой. Эта кривая будет
построена по 14 точкам. Для расчета координат необходимы показатели, представленные
в следующей таблице.
Таблица 3.2.1 - Четырехпольная таблица сопряженности
Это четырехпольная таблица сопряженности (confusion matrix),
которая строится на основе результатов классификации моделью и фактической
(объективной) принадлежностью примеров к классам.
Примеры классифицируются как положительный (p), так и
отрицательный (n). На выходе сопряженности возможны четыре случая:
. Положительные примеры (р) (так называемые истинно
положительные случаи) верно классифицированы (TP - True Positives);
. Положительные примеры (р) классифицированы как
отрицательные (ошибка I рода). Это так называемый "ложный пропуск" -
когда интересующее нас событие ошибочно не обнаруживается (ложно отрицательные
примеры) (FN - False Negatives);
. Отрицательные примеры (n) (так называемые истинно
отрицательные случаи) верно классифицированны (TN - True Negatives);
. Отрицательные примеры (n) классифицированы как
положительные (ошибка II рода). Это ложное обнаружение, т.к. при отсутствии
события ошибочно выносится решение о его присутствии (ложно положительные
случаи) (FP - False Positives).
В этом случае положительным примером будут конфиденциальные
файлы, а отрицательным - не конфиденциальные файлы. На базе фактических данных
все показатели делятся на две группы:
. Доля ложных обнаружений - характеризует ошибку II рода и
означает, что не конфиденциальные файлы определились как конфиденциальные.
Рассчитывается по формуле: FPR=FP/ (FP+TN). При построении ROC-кривой является
координатой точки по оси 0х;
. Доля истинных обнаружений - означает, что конфиденциальные
файлы определились как конфиденциальные, т.е. произошло правильное
срабатывание. Рассчитывается по формуле: TPR=TP/ (TP+FN). При построении ROC-кривой является
координатой точки по оси 0y.
Возникновение ошибок I и II рода зависят от следующих
критериев:
. Особенность работы алгоритма - если разбивать строки на
подстроки как можно большей длины (минимальная длина равна 3-м символам), то
уменьшается вероятность ложного пропуска (конфиденциальные файлы определяются
как не конфиденциальные), что является ошибкой I рода;
. Особенность работы системы - в случае обновления базы
конфиденциальных файлов информацией как конфиденциальной, так и не
конфиденциальной, необходимо обновить и базу не конфиденциальных файлов, иначе
возрастает вероятность ложного обнаружения. Т.е. не конфиденциальные файлы
будут определяться как конфиденциальные. Это ошибка II рода.
Проверяемые файлы будут относится к двум классам -
конфиденциальный и не конфиденциальный. В каждом классе будут по 150 файлов.
Для меньшей вероятности возникновения ошибок I рода в алгоритме будет
задаваться параметр разбиения на подстроки различной длины, начальное значение k=3 (подстрока из 3-х
символов). В ходе проведения тестирования использовалась эмуляция ложных
обнаружений. Для большей вероятности возникновения ошибок II рода - из базы не
конфиденциальных файлов будет постепенно удаляться информация, в то время как в
базе конфиденциальных файлов эта информация сохраняется.
3.3
Результаты тестирования
Изменение параметров выше рассмотренных критериев будет
приводить к получению координат каждой из 14 точек.
-я точка. Первоначальная длина k-граммы равна 3 символам.
В базе не конфиденциальных файлов присутствует вся информация. После запуска
программы была получена информация о подозреваемых документах, сохранившаяся в
журнале безопасности (файл с расширением txt), на основе которой
приведен следующий результат проверки:
. Ни одного правильно обнаруженного конфиденциального файла, TP=0;
. Абсолютный ложный пропуск, FN=150;
. Все 150 не конфиденциальных файла правильно определились
как не конфиденциальные, TN=150;
. Ни одного ложно обнаруженного конфиденциального файла, FP=0.
Итак, все проверяемые файлы, фактически являющиеся
конфиденциальными, определились как не конфиденциальные. Появилась ошибка I
рода. В реальной системе проверяемый файл был бы разрешен к передаче. Все
проверяемые файлы, фактически являющиеся не конфиденциальными, определились как
не конфиденциальные.
TPR=0/150=0, Se=TPR=0, FPR=0/150=0, Sp=1-FPR=1
2-я точка. Длина k-граммы равна 4 символам. Из базы не конфиденциальных
файлов удален 1 абзац.
Результат проверки документов:
.4 правильно обнаруженных конфиденциальных файла, TP=4;
.146 конфиденциальных файла определились как не
конфиденциальные, FN=146;
.149 не конфиденциальных файла определились как не конфиденциальные,
TN=149;
.1 ложно обнаруженный конфиденциальный файл, FP=1.
TPR=4/150=0,03, Se=TPR=0,03, FPR=1/150=0,01,
Sp=1-FPR=0,99
3-я точка. Длина k-граммы равна 5 символам. Из базы не
конфиденциальных файлов удалены 2 абзаца.
Результат проверки документов:
.11 правильно обнаруженных конфиденциальных файла, TP=11;
.139 конфиденциальных файла определились как не
конфиденциальные, FN=139;
.147 не конфиденциальных файла определились как не
конфиденциальные, TN=147;
.3 ложно обнаруженных конфиденциальных файла, FP=3.
TPR=11/150=0,07, Se=TPR=0,07, FPR=3/150=0,02,
Sp=1-FPR=0,98
4-я точка. Длина k-граммы равна 6 символам. Из базы не
конфиденциальных файлов удалены 4 абзаца.
Результат проверки документов:
.21 правильно обнаруженных конфиденциальных файла, TP=21;
.129 конфиденциальных файла определились как не
конфиденциальные, FN=129;
.144 не конфиденциальных файла определились как не
конфиденциальные, TN=144;
.6 ложно обнаруженных конфиденциальных файла, FP=6.
TPR=21/150=0,14, Se=TPR=0,14, FPR=6/150=0,04,
Sp=1-FPR=0,96
5-я точка. Длина k-граммы равна 7 символам. Из базы не
конфиденциальных файлов удалены 6 абзацев.
Результат проверки документов:
.36 правильно обнаруженных конфиденциальных файла, TP=36;
.114 конфиденциальных файла определились как не
конфиденциальные, FN=114;
.140 не конфиденциальных файла определились как не
конфиденциальные, TN=140;
.10 ложно обнаруженных конфиденциальных файла, FP=10.
TPR=36/150=0,24, Se=TPR=0,24, FPR=10/150=0,07,
Sp=1-FPR=0,93
6-я точка. Длина k-граммы равна 8 символам. Из базы не
конфиденциальных файлов удалены 8 абзацев.
Результат проверки документов:
.56 правильно обнаруженных конфиденциальных файла, TP=56;
.94 конфиденциальных файла определились как не
конфиденциальные, FN=94;
.134 не конфиденциальных файла определились как не
конфиденциальные, TN=134;
.16 ложно обнаруженных конфиденциальных файла, FP=16.
TPR=56/150=0,37, Se=TPR=0,37, FPR=16/150=0,11,
Sp=1-FPR=0,89
7-я точка. Длина k-граммы равна 9 символам. Из базы не конфиденциальных
файлов удалены 12 абзацев.
Результат проверки документов:
.71 правильно обнаруженных конфиденциальных файла, TP=71;
.79 конфиденциальных файла определились как не
конфиденциальные, FN=79;
.126 не конфиденциальных файла определились как не конфиденциальные,
TN=126;
.24 ложно обнаруженных конфиденциальных файла, FP=24.
TPR=71/150=0,47, Se=TPR=0,47, FPR=24/150=0,16,
Sp=1-FPR=0,84
8-я точка. Длина k-граммы равна 10 символам. Из базы не
конфиденциальных файлов удалены 16 абзацев.
Результат проверки документов:
.82 правильно обнаруженных конфиденциальных файла, TP=82;
.68 конфиденциальных файла определились как не
конфиденциальные, FN=68;
.119 не конфиденциальных файла определились как не
конфиденциальные, TN=119;
.31 ложно обнаруженных конфиденциальных файла, FP=31.
TPR=82/150=0,55, Se=TPR=0,55, FPR=31/150=0,26,
Sp=1-FPR=0,74
9-я точка. Длина k-граммы равна 11 символам. Из базы не
конфиденциальных файлов удалены 20 абзацев.
Результат проверки документов:
.89 правильно обнаруженных конфиденциальных файла, TP=89;
.61 конфиденциальных файла определились как не
конфиденциальные, FN=61;
.107 не конфиденциальных файла определились как не
конфиденциальные, TN=107;
.43 ложно обнаруженных конфиденциальных файла, FP=43.
TPR=89/150=0,59, Se=TPR=0,59, FPR=43/150=0,29,
Sp=1-FPR=0,71
10-я точка. Длина k-граммы равна 12 символам. Из базы не
конфиденциальных файлов удалены 25 абзацев.
Результат проверки документов:
.96 правильно обнаруженных конфиденциальных файла, TP=96;
.54 конфиденциальных файла определились как не
конфиденциальные, FN=54;
.99 не конфиденциальных файла определились как не
конфиденциальные, TN=99;
.51 ложно обнаруженных конфиденциальных файла, FP=51.
TPR=96/150=0,64, Se=TPR=0,64, FPR=51/150=0,34,
Sp=1-FPR=0,66
11-я точка. Длина k-граммы равна 13 символам. Из базы не
конфиденциальных файлов удалены 27 абзацев.
Результат проверки документов:
.103 правильно обнаруженных конфиденциальных файла, TP=103;
.47 конфиденциальных файла определились как не
конфиденциальные, FN=47;
.90 не конфиденциальных файла определились как не
конфиденциальные, TN=90;
.60 ложно обнаруженных конфиденциальных файла, FP=60.
TPR=103/150=0,69, Se=TPR=0,69, FPR=60/150=0,4,
Sp=1-FPR=0,6
12-я точка. Длина k-граммы равна 14 символам. Из базы не
конфиденциальных файлов удалены 32 абзаца.
Результат проверки документов:
.121 правильно обнаруженных конфиденциальных файла, TP=121;
.29 конфиденциальных файла определились как не
конфиденциальные, FN=29;
.82 не конфиденциальных файла определились как не
конфиденциальные, TN=82;
.68 ложно обнаруженных конфиденциальных файла, FP=68.
TPR=121/150=0,8, Se=TPR=0,8, FPR=68/150=0,45,
Sp=1-FPR=0,55
13-я точка. Длина k-граммы равна 15 символам. Из базы не
конфиденциальных файлов удалены 54 абзаца.
Результат проверки документов:
.136 правильно обнаруженных конфиденциальных файла, TP=136;
.14 конфиденциальных файла определились как не
конфиденциальные, FN=14;
.49 не конфиденциальных файла определились как не
конфиденциальные, TN=49;
.101 ложно обнаруженных конфиденциальных файла, FP=101.
TPR=136/150=0,91, Se=TPR=0,91, FPR=101/150=0,67,
Sp=1-FPR=0,33
14-я точка. Длина k-граммы равна 16 символам. Из базы не
конфиденциальных файлов удалены 75 абзацев.
Результат проверки документов:
.148 правильно обнаруженных конфиденциальных файла, TP=148;
.2 конфиденциальных файла определились как не
конфиденциальные, FN=2;
.10 не конфиденциальных файла определились как не
конфиденциальные, TN=10;
.140 ложно обнаруженных конфиденциальных файла, FP=140.
Итак, все проверяемые файлы, фактически являющиеся конфиденциальными,
определились как конфиденциальные. Все проверяемые файлы, фактически являющиеся
не конфиденциальными, определились как конфиденциальные. Появилась ошибка II рода. В реальной системе
проверяемый файл был бы запрещен к передаче.
TPR=148/150=0,99, Se=TPR=0,99, FPR=140/150=0,93,
Sp=1-FPR=0,07
По полученным точкам построена следующая ROC-кривая:
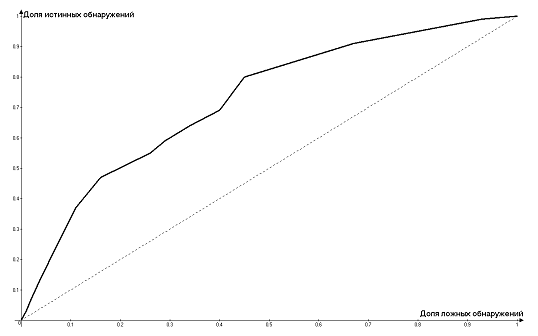
Рисунок 3.3.1 - Оценка эффективности обнаружения утечки
информации
Для идеального классификатора график ROC-кривой проходит
через верхний левый угол, где доля истинно положительных случаев составляет
100% или 1.0 (идеальная чувствительность), т.е. модель устойчива к
возникновению ошибок I рода (ложных пропусков), а доля ложно положительных
примеров равна нулю, т.е. устойчива к ошибкам II рода (ложных обнаружений). Чем
меньше изгиб кривой и чем ближе она расположена к диагональной прямой, тем
менее эффективна модель. Диагональная линия соответствует
"бесполезному" классификатору, т.е. полной неразличимости двух
классов. Данный график проходит между идеальной кривой и кривой неразличимости
двух классов, но все же ближе к идеальной.
На основании проведенного тестирования получен массив точек,
представленный в таблице "Чувствительность (доля истинных обнаружений) -
Представительность”.
Таблица 3.3.1 - Чувствительность (доля истинных обнаружений)
- Представительность
|
Порог
|
Se,
%
|
Sp,
%
|
Se + Sp
|
|Se - Sp|
|
|
0,075
|
0
|
100
|
0
|
0
|
|
0,15
|
3
|
99
|
102
|
96
|
|
0,225
|
7
|
98
|
105
|
91
|
|
0,3
|
14
|
96
|
110
|
82
|
|
0,375
|
24
|
93
|
117
|
69
|
|
0,45
|
37
|
89
|
126
|
52
|
|
0,525
|
47
|
84
|
131
|
37
|
|
0,6
|
55
|
74
|
129
|
19
|
|
0,675
|
59
|
71
|
130
|
12
|
|
0,75
|
64
|
66
|
130
|
02
|
|
0,825
|
69
|
60
|
129
|
09
|
|
0,9
|
80
|
55
|
135
|
25
|
|
0,975
|
91
|
33
|
124
|
58
|
|
1
|
7
|
106
|
92
|
Из таблицы 3.1 следует, что оптимальным порогом
классификации, обеспечивающим максимум чувствительности и специфичности теста
(или минимум ошибок I и II рода), является точка 0,9. В ней чувствительность
равна 80%, что означает: 80% конфиденциальных файлов будут правильно определены
как конфиденциальные. Специфичность равна 55%, следовательно, 55% файлов,
которые являются не конфиденциальными, будут определены как не
конфиденциальные.
Точкой баланса, в которой чувствительность и специфичность
примерно совпадают, является 0,75.
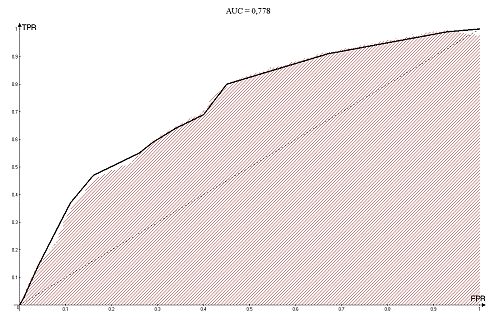
Рисунок 3.3.2 - Площадь под ROC-кривой
Так как численный показатель площади под кривой - AUC = 0,778 (рисунок 3.2),
то предсказательную способность системы обнаружения утечки конфиденциальной
информации на основании экспертной шкалы можно охарактеризовать как хорошую.
Итак, разработанный модуль обнаружения утечки
конфиденциальной информации в документах можно считать работоспособной и
применять как средство интеграции в общую систему, так как величина ложного
пропуска равна 1,3% (допустимое значение в пределах 1%) при длине k-граммы равной 16
символов, а ложного обнаружения - 0,7%. Данная величина ложного обнаружения
получается, если не добавлен в базу не конфиденциальных файлов один абзац
текста, который присутствует в базе конфиденциальных файлов. Такая ситуация
может произойти по не внимательности.
3.4 Разработка
рекомендаций по использованию разработанного алгоритма
3.4.1
Назначение и условия применения программы
Назначение программы обнаружения утечки конфиденциальной
информации в документах - проверка файла на предмет конфиденциальности.
Проверка может осуществляться по двум алгоритмам, соответствующим различным
схемам. Программа включает следующие процедуры и функции:
. to_upper - перевод буквы в верхний регистр для
win-кодировки;
. make_file_list - составление списка файлов по заданному
пути;
. input_file - ввод данных из файла в строку и составление
списка хэш-кодов;
. remove_repeats - удаление повторяющихся k-грамм;
. remove_allowed - удаление не конфиденциальной информации из
конфиденциальных файлов;
. cmp_strings - сравнение содержимого проверяемого файла с
конфиденциальным;
. cmp_hashes - сравнение информации проверяемого файла с
конфиденциальным;
. Crc16 - функция, возвращающая двухбайтовый код;
. init_hl - инициализация сервиса шифрования;
. close_hl - завершение сервиса шифрования;
. get_hash - получение хеш-кода;
. main - инициализация библиотеки.
Условия необходимые для выполнения библиотеки:
. PC-совместимая система;
. Объем оперативной памяти - 15МБ и больше;
. НМЖД объемом 500 КБ и больше;
. Процессоры семейства Intel x86, а также IA-64, AMD64,
PowerPC, ARM;
. От используемого исполняемого файла зависит выбор
операционной системы:
.1 Ms Windows 95/98/МЕ/2000/ХР;
.2 Операционная система Linux с дистрибутивами
Slackware, Debian, Red Hat, Fedora, Mandriva, SuSE, Gentoo, Ubuntu.
3.4.2
Характеристика программы
К основным характеристикам и особенностям программы
относятся:
. Временная характеристика - при объеме всей информации в
файлах равной 15КБ время работы составляет 2-3 с. Время работы программы будет
возрастать на 1 с, в том случае, если объем информации увеличивается больше чем
на 15КБ. График зависимости количества данных от времени выполнения программы
будет больше приближен к оси 0х, что говорит о достаточной скорости работы;
. Режим работы. Программа разработана в виде библиотеки и
может быть встроена в системы с почтовыми серверами, где не требуется работы в
консольном или графическом режиме. Настоящая реализация программы предполагает
запуск исполняемого файла и сохранение отчета в файл;
. Правильность выполнения. Ошибка ложного пропуска файла
составляет 1,3%, ложного обнаружения - 0,7%.
3.4.3
Обращение к программе
При запуске исполняемого файла происходит обращение к функции
main (), инициализирующей
работу программы.
3.4.4 Входные
и выходные данные
Входными данными являются конфиденциальные, не
конфиденциальные и проверяемые файлы. Текст каждого файла кодируется с помощью
хеш-функции CRC-16. Информация конфиденциальных и не конфиденциальных файлов
записывается в базу данных. Данные проверяемых файлов хранятся в оперативной памяти
в ходе выполнения программы. В качестве выходных данных служит отчет о
конфиденциальности файла, отправляемого на проверку.
3.4.5
Сообщения
Результатом программы является запись отчета о
конфиденциальности проверяемого файла в журнал безопасности. Если файл
конфиденциальный, то напротив его имени появляется соответствующее сообщение. В
случае интеграции разработанной библиотеки в систему предотвращения утечки
конфиденциальной информации, передача файла блокируется, сообщение о блокировки
передается офицеру безопасности. Если файл содержит только разрешенную или
информацию, которая не запрещена, то в отчете напротив его имени ничего не
появляется.
3.5
Разработка рекомендаций по использованию разработанной системы
В текущей реализации разработанный модуль использует
документы, проходящие через почтовые сервера. Эти серверы работают под
операционными unix-подобными системами. Например, QMail сервер (рисунок 4.1)
предназначен для Linux. Для работы с этим сервером распространяется бесплатная лицензия
в случае использования базового функционального набора. Если нужна расширенная
функциональность, то лицензия становится платной. Разработанный модуль можно
интегрировать в QMail, который используется и для архива электронной почты. Прежде чем
складировать информацию необходимо ее заархивировать соответствующим образом.
Подобную информацию в дальнейшем можно использовать для отчетности. Объектом
анализа являются письма, отправляемые работниками данной организации. При
получении письма на вход модуля последовательно подаётся текст письма и
вложенные файлы. Для извлечения текстовой информации из письма и файлов
используются модули сторонних разработчиков. Для снятия сигнатур с извлеченного
текста используется хеш-функция CRC-16. Библиотека разработана как open source проект.
Рисунок 3.5.1 - Рекомендации по использованию разработанной
системы
B.
Экологическая часть и БЖД
Экологическая часть и безопасность жизнедеятельности состоит
из следующих основных разделов: техники безопасности, производственной
санитарии, эргономики, промышленной эстетики и правовой базы.
Техника безопасности представляет собой систему средств и
методов, предотвращающих или снижающих до безопасного уровня воздействие
опасных факторов. Производственная санитария призвана устранить или снизить до
безопасного уровня воздействие вредных факторов.
Опасные факторы - это производственные факторы, воздействие
которых на человека ведет к травме или другому резкому и внезапному ухудшению
здоровья.
Вредные факторы - это производственные факторы, воздействие
которых в определенных условиях ведет к возникновению профессионального
заболевания или снижению трудоспособности.
В связи с научно-техническим прогрессом проблема
взаимодействия человека и современной техники стала весьма актуальной. В
настоящее время все большую роль во взаимодействии с техникой приобретает
человек-оператор, на которого возлагается роль управления не только отдельными
машинами, но и целыми системами технических объектов. Человек-оператор должен перерабатывать
большой объем технической информации и принимать ответственные решения. Поэтому
в целях рационализации технического процесса возникает задача согласования
особенностей конструкции машин и технического оборудования с психологическими и
физическими характеристиками человека, поскольку эффективное применение даже
наиболее совершенной техники зависит, в конечном итоге, от правильности
действий людей, управляющих этой техникой.
Глава 1.
Исследование опасных и вредных факторов при эксплуатации ЭВМ
При выполнении дипломной работы используются следующие
элементы вычислительной техники:
. переносной персональный компьютер (ППК) ASUS A8Sr с диагональю экрана
14,1” и разрешением 1280 х 800;
. персональный компьютер (ПК) Pentium IV, 800 MHz;
. монитор LG L1730P с диагональю экрана 17” и разрешением 1280 х 1024, частоты
развертки: fверт = 56-75 Гц, fгоризонт = 30-83 кГц;
. лазерный принтер HP LaserJet 1020;
. сканер HP ScanJet G3010.
При работе с перечисленными элементами вычислительной техники
нужно учитывать следующие обстоятельства:
. ППК и ПК питаются от сети переменного тока напряжением 220
В и частотой 50 Гц, а это превышает безопасное напряжение для человека (40 В),
поэтому появляется опасный фактор - поражение электрическим током.
. При работе за экраном дисплея пользователь попадает под
воздействие ультрафиолетового излучения (УФИ) с длинами волн менее 320 нм и
излучения электромагнитных полей частотой до 400 кГц. УФИ, испускаемое
монитором, соединяясь с УФИ, излучаемым люминесцентными лампами и УФИ,
проникающим сквозь оконные проемы, может повысить нормируемую плотность УФИ (10
Вт/м2). Возникает вредный фактор - ультрафиолетовое излучение.
. При работе ППК, ПК (а также принтера, сканера и других
периферийных устройств) и при передвижении людей возникает статическое
электричество, которое при превышении нормированного значения 15 кВ/м
становится вредным фактором.
. Для получения изображения на экране дисплея необходимо
иметь вертикальную и горизонтальную развертки, которые соответствуют напряжению
с частотами вертикальной и горизонтальной развертки: fверт = 56-75
Гц, fгоризонт = 30-83 кГц. Появляется вредный фактор - излучение
электромагнитных полей низких частот.
Таким образом, пользователь, работающий с ППК и ПК,
подвергается воздействию следующих опасных и вредных факторов:
. поражение электрическим током;
. ультрафиолетовое излучение;
. статическое электричество;
. излучение электромагнитных полей низких частот.
Глава 2.
Воздействие опасных и вредных факторов на организм пользователя ЭВМ
2.1 Поражение
электрическим током
Воздействие на человека электрического тока носит
термический, электролитный, биологический характер, что может привести к общим
травмам (электроудары) и местным (ожоги, металлизация кожи, электрические
знаки, электроофтальмия, механические повреждения).
Различают электроудары четырех степеней сложности:
. Электроудары I степени: сопровождаются судорожным
болезненным сокращением мышц без потери сознания;
. Электроудары II степени: сопровождаются судорожным
болезненным сокращением мышц с потерей сознания, но с сохранением дыхания и
сердцебиения;
. Электроудары III степени: сопровождаются судорожным
болезненным сокращением мышц, c потерей сознания, нарушением работы сердца
и/или дыхания;
. Электроудары IV степени: наступает клиническая смерть, то
есть прекращается дыхание и кровообращение.
2.2
Ультрафиолетовое излучение
Ультрафиолетовое излучение может послужить причиной
возникновения или обострения следующих заболеваний:
. заболевания кожи: угревая сыпь, себорроидная экзема,
розовый лишай, меломанный рак кожи и другие;
. катаракта глаз;
. нарушение терморегуляции организма.
2.3
Статическое электричество
Под действием статических электрических полей дисплея пыль в
помещении электризуется и переносится на лицо пользователя (так как тело человека
имеет отрицательный потенциал, а частички пыли заряжены положительно). При
подвижности воздуха в помещении вычислительного центра выше 0, 2 м/с пыль,
скопившаяся на поверхности экрана, сдувается с нее и также переносится на лицо
пользователя (разработчика), что приводит к заболеваниям кожи.
С точки зрения технического влияния следует отметить
следующее: электронные компоненты персонального компьютера (ПК) или ППК
работают при низких значениях напряжения (5-12 В). При большом значении
напряженности электростатического поля возможны замыкания клавиатуры, реле и
потеря информации на экране. Нормируемая величина напряженности
электростатического поля E = 15 кВ/м.
2.4 Излучение
электромагнитных полей низких частот
Воздействие этого фактора может привести к следующим
последствиям:
. обострение некоторых кожных заболеваний: угревая сыпь,
себорроидная экзема, розовый лишай, рак кожи и другие;
. нарушение метаболизма;
. изменение биохимической реакции крови на клеточном уровне,
что ведет к стрессу;
. нарушения в протекании беременности (увеличение в два раза
вероятности выкидыша у беременных);
. нарушение репродуктивной функции и возникновению
злокачественных образований (в случае воздействия низкочастотных полей);
. изменения в нервной системе (потеря порога
чувствительности).
2.5 Вывод
Из анализа воздействия опасных и вредных факторов видно, что
пользователь персонального компьютера (ПК) или ППК нуждается в защите от них.
Глава 3.
Способы защиты пользователей от опасных и вредных факторов
3.1 Защита от
поражения электрическим током
На корпусе оборудования может образовываться напряжение, если
возникает пробой изоляции, обрыв токоведущего провода и касание его корпуса и
т.п. Это может привести к воздействию электрического тока на человека, если
человек коснется корпуса оборудования (прямое или косвенное прикосновение).
Прямое прикосновение - электрический контакт людей или
животных с токоведущими частями, находящимися под напряжением. Косвенное
прикосновение - электрический контакт людей или животных с открытыми
проводящими частями, оказавшимися под напряжением при повреждении изоляции.
Напряжение прикосновения - напряжение между двумя проводящими
частями или между проводящей частью и землей при одновременном прикосновении к
ним человека или животного.
Согласно общим требованиям ПУЭ [21, гл.1.7,
пп.1.7.49-1.7.51], токоведущие части электроустановки не должны быть доступны
для случайного прикосновения, а доступные прикосновению открытые и сторонние
проводящие части не должны находиться под напряжением, представляющим опасность
поражения электрическим током, как в нормальном режиме работы электроустановки,
так и при повреждении изоляции.
Для дополнительной защиты от прямого прикосновения в
электроустановках напряжением до 1 кВ, при наличии требований других глав ПУЭ,
следует применять устройства защитного отключения (УЗО) с номинальным
отключающим дифференциальным током не более 30 мА.
Зануление - преднамеренное соединение нетоковедущих частей с
нулевым защитным проводником (НЗП). Оно применяется в трехфазных четырех
проводных сетях с глухо-заземленной нейтралью в установках до 1.000 Вт и
является основным средством обеспечения электробезопасности.
Принцип защиты при занулении заключается в следующем: ток
короткого замыкания вызывает перегорание предохранителя (срабатывание автомата)
и, следовательно, отключение пользователя от сети, предотвращая перегрев и
самовозгорание токоведущих частей сети электропитания. Кроме того, устройство
защитного отключения (УЗО) срабатывает при возникновении утечки из сети
электропитания величиной не более 30 мА, предотвращая поражение электрическим
током в случае прямого прикосновения.
Схема подключения ПЭВМ к электрической сети показана ниже (R0
- сопротивление заземлителя).
Рисунок 3.1 - Схема подключения ПЭВМ к электросети
Определим ток короткого замыкания Iкз по заданным
параметрам:
Iкз = Uф / ( (rт / 3) + Rобщ), где
Iкз - ток короткого замыкания;ф - фазное напряжение:
Uф = 220 В;
rт - паспортная величина сопротивления обмотки
трансформатора:
rт = 0, 412 Ом;
Rобщ = R1 + R2 + Rнзп = p1 * L1/S1 + pнзп * Lнзп / Sнзп + p2 * L2/S2
- удельное сопротивление проводника:
. p1 = 0, 0280 (Ом * мм2/м) (алюминий);
. pнзп = p2 = 0, 0175 (Ом * мм2/м) (медь).- длина проводника (L1
= 600 м, L2 = 100 м; Lнзп = 50 м);- площадь поперечного
сечения проводника (S1 =2 мм2; S2 =1 мм; Sнзп
=1 мм2).
R1 = (0,0280 (Ом * мм2/м) * 600 м) / 2
мм2 = 8,4 Ом
R2 = (0,0175 (Ом * мм2/м) * 100 м) / 1
мм2 = 1,75 Ом
Rнзп = (0,0175 (Ом * мм2/м) * 50 м) / 1 мм2
= 0,875 Ом
Rобщ = 8, 4 Ом +1, 75 Ом +0, 875 Ом = 11 Ом;
Iкз = 220 B / ( (0,412/3) Ом + 3,24 Ом) = 19,75 А
Устройство защиты от короткого замыкания срабатывает при
выполнении следующего условия:
Iкз ≥ k * Iном => Iном ≤ Iкз / k, где
- коэффициент, учитывающий тип защитного устройства: k = 3
для автомата с электромагнитным расцепителем;ном - номинальный ток
срабатывания защитного устройства.
Iном ≤ 19,75А / 3 = 6,6 А ≈ 7 А
Указанному условию удовлетворяет защитное устройство УЗО
22-05-2-030 с номинальным током срабатывания Iном = 7 А и номинальным
отключающим дифференциальным током IΔ = 30 мА.
Вывод: во избежание поражения электрическим током,
возникновения пожара в помещении и выхода из строя ПЭВМ и периферийного
оборудования, в случае возникновения короткого замыкания или других причин
появления напряжения прикосновения Uпр, в цепь питания ПЭВМ необходимо включить
устройство защитного отключения с Iном = 7 А и IΔ = 30 мА.
3.2 Защита от
ультрафиолетового излучения
Синий люминофор экрана монитора вместе с ускоренными в электронно-лучевой
трубке электронами являются источниками ультрафиолетового излучения.
Воздействие ультрафиолетового излучения сказывается при длительной работе за
компьютером. Основными источниками поражения являются глаза и кожа.
Для защиты от ультрафиолетового излучения используют:
. обычную побелку стен и потолка (ослабляет излучение на
45-60%);
. электролюминесцентные лампы, мощностью не более 40 Вт;
. рекомендуемый материал одежды персонала - фланель, поплин.
3.3 Защита от
статического электричества
Для защиты от статического электричества необходимо выполнять
следующие требования:
. использовать контурное заземление;
. использовать нейтрализаторы статического электричества;
. применять антистатическое покрытие полов;
. использования экранов для снятия статики;
. обеспечить регулярное проведение влажной уборки;
. проветривать помещения при подвижности воздуха 0,1 - 0,2
м/сек без присутствия в нем пользователей.
Наиболее эффективным способом нейтрализации статического
электричества является применение нейтрализаторов, создающих вблизи
наэлектризованного диэлектрического объекта положительные и отрицательные ионы.
Различают 4 типа нейтрализаторов:
. коронного разряда (индуктивные и высоковольтные);
. радиоизотопные;
. комбинированные;
. аэродинамические.
3.4 Защита от
излучения электромагнитных полей низких частот
Защита от излучения электромагнитных полей низких частот
осуществляется выбором расстояния от экрана монитора, длительности работы с
компьютером и экранированием.
При разработке дипломного проекта используется монитор LG L1730P. Данный монитор
соответствует стандартам MPR-II, ТСО ‘03, стандарту по эргономичности ISO
13406-2. Уровень напряженности полей низкой частоты соответствует нормам,
поэтому единственным параметром, требующим соблюдения, является расстояние
между мониторами в 1,5 м и более.
Ниже приведены схемы зон компьютерного излучения. Из них
видно, что компьютерное излучение в горизонтальной проекции испускается с
большей интенсивностью в направлении, перпендикулярном оси просмотра изображения,
поэтому необходимо устанавливать экраны с боковых сторон монитора для защиты
пользователей, работающих в том же помещении. В вертикальной плоскости
компьютерное излучение имеет наивысшую напряженность в секторах А-С и С-В,
поэтому необходимо также устанавливать защитный экран с задней стороны
монитора. Кроме того, необходимо строго соблюдать безопасное расстояние до
экрана монитора.
Рисунок 3.2 - Схемы зон компьютерного излучения
Для защиты от излучения электромагнитных полей низких частот
необходимо выполнять следующие требования:
. время работы на персональном компьютере не должно превышать
4 - 6 часов;
. запрещается работать при открытых корпусах персональных
компьютеров;
. располагаться от экрана дисплея следует не ближе, чем на
расстоянии вытянутой руки;
. при выборе рабочего места необходимо располагаться от
боковых и задних стенок мониторов соседних компьютеров не ближе 1,5 м.
3.5 Вывод
Выбранные способы защиты пользователей от воздействия на них
опасных и вредных факторов при соблюдении эргономических требований
обеспечивают их безопасную работу.
Заключение
В процессе разработки дипломного проекта:
. Проведен аналитический обзор существующих решений для
защиты от утечки информации;
. Проведен аналитический обзор существующих методов сравнения
текстовых файлов;
. Разработана схема алгоритма сравнения текстовых файлов;
. Разработана архитектура программного модуля обнаружения
утечки информации в документах;
. Реализован программный модуль обнаружения утечки информации
в документах на языке С++ в виде open source проекта;
. Проведение тестирования над экспериментальной системой
установило, что достигнута высокая эффективность обнаружения утечки информации
в текстовых файлах - ошибка работы программы в пределах 1%. Разработанную
библиотеку можно интегрировать в системы защиты от утечки информации в
документах.
Список
использованных источников
1. Комплексные
решения для защиты от утечек конфиденциальных данных, BYTE/Россия, 2005
(http://www.bytemag.ru/articles/detail. php? ID=9068
<http://www.bytemag.ru/articles/detail.php?ID=9068>).
. <http://www.clearswift.com>.
. Интеллектуальные
решения по защите информации, ЗАО "ИнфоВотч", 2009
(<http://www.infowatch.ru>.)
4. Why
Iplocks?, IPLocks, Inc. All Rights Reserved Worldwide, 2007
(<http://www.iplocks.com>).
. Why
Compromise?, © IBM Corporation 1994 - 2008. All rights reserved
(<http://www.iss.net>).
. ©
2009, Liquid Machines, Privacy Statement Site Map Site by Newfangled Web
Factory and Nowspeed Marketing (<http://www.liquidmachines.com>).
. ©
2007, Websense, Inc. All Rights Reserved
(<http://www.portauthoritytech.com>).
. ©
2009, Websense, Inc. All Rights Reserved (<http://www.surfcontrol.com>).
9. © 2002 -
2006, Инфосистемы Джет (<http://www.jetinfosoft.ru>).
10. ©
1998-2009, Global Information Technology (UK) Limited. All Rights Reserved
(<http://www.pcacme.com>).
11. Обзор
автоматических детекторов плагиата в программах, 2006 (http://logic. pdmi.
ras.ru/~yura/detector/survey. pdf)
. Большая
советская энциклопедия.
. Авторы
проекта AlgoLib, Алгоритмы сравнения строк, © 2004-2005 "AlgoLib.
narod.ru" (http://algolib. narod.ru/Search/Standart.html).
. Алексей
Котов, Связь между детекторами плагиата и нейронными сетями, 2006
(http://detector. spb. su/bin/view/Sandbox/NeuralNetworks
<http://detector.spb.su/bin/view/Sandbox/NeuralNetworks>).
. Страуструп
Б., Язык программирования С++, Специальное изд. - М.: "Издательство
Бином”, СПб.: "Невский диалект”, 1999.
16.
Receiver operating characteristic, Wikimedia Foundation, Inc., 2009 (http://en.
wikipedia.org/wiki/Receiver_operating_characteristic
<http://en.wikipedia.org/wiki/Receiver_operating_characteristic>).
17. Николай
Паклин, Логистическая регрессия и ROC-анализ - математический аппарат, © 1995 -
2009 BaseGroup Labs (<http://www.basegroup.ru/library/analysis/regression/logistic/>).
18. Кривые ROC, Copyright legioner © spssbase.com,
2008 (<http://www.spssbase.com/Glava22/Index35.html>).
19. Гост ССБТ
12.1.045-84 "Электростатические поля. Допустимые уровни на рабочих местах”.
. Гост ССБТ
12.4.124-83 "Средства защиты от статического электричества”.
. Гигиенические
требования к видеотерминалам персональных ЭВМ и организация работы с ними.
СанПиН 2.2.2 542-96.
. Гост
12.0.003-86 "Опасные и вредные производственные факторы”.
. Нормы
радиационной безопасности. НРБ 76/87.
. Гост
12.1.030-81 "Электробезопасность. Защитное заземление, зануление”.
. Гост 19.504-79
"Руководство программиста”.
. Гост 19.401-78
"Текст программы”.
Приложения
Приложение №
1
Текст программы
Листов 15
// Модуль утечки конфиденциальной информации с реализацией
алгоритма по схеме 1
#include <fstream>
#include <iostream>
#include <string>
#include <vector>
#include <io. h>
using namespace std;k;<string>
allowed_files,secured_files,checked_files;
// Перевод в заглавную букву для win-кодировки
char to_upper (unsigned char c)
{( (c>=97 && c<=122) || c >=
224)=32;
// Буква ё(c == 184)= 168;c;
}
// Составление списка файлов по заданному пути
void make_file_list (vector<string>
&list,const char *path)
{search_path = path,tmp_st;
_finddata_t fdata;i;
// Поиск текстовых файлов_path+="*. txt";
int h = _findfirst (search_path. c_str
(),&fdata);(h! = - 1)
{_st = path;_st+=fdata. name;. push_back
(tmp_st);= _findnext (h,&fdata);
}while (i == 0);
_findclose (h);
}
// Ввод данных из файла в строку
string input_file (const char *fname)
{st;c;fin (fname);(! fin. fail ())
{(fin >> c,! fin. eof ())
{
// Проверка, являются ли символы в тексте буквами
if (c < 0 || (c>='a' && c<='z')
|| (c>='A' && c<='Z') || (c>='0' && c<='9'))+=to_upper
(c);
}
}. close ();
return st;
}
// Удаление повторяющихся k-грамм
string remove_repeats (string st, int k)
{i = 0,j;st2;(i < st. length () - k-1)
{
// выделение текущей k-граммы= st. substr (i,k);(j = st. find (st2,
i+1),j! =-1). erase (j,k);++;
}st;
}
// Удаление не конфиденциальной информации из
конфиденциальной
void remove_allowed (string &st1,string
&st2, int k)
{i=0,to_delete;(i <= st1. length () - k)
{tmp = st1. substr (i,k);
// Поиск k-граммы в разрешенном файле
int j = st2. find (tmp,0);(j! = - 1)
{_delete = k;
// Расширение вперед(i<st1. length () - k && j<st2.
length () - k && st1 [i+k] == st2 [j+k])
{++;++;_delete++;
}. erase (i,to_delete);
}++;
}
}
// Сравнение содержимого защищенного файла с проверяемым
void cmp_strings (string &st1,string
&st2, int k, int &total_len,string &same_st)
{i=0;_len = 0;(i <= st1. length () - k)
{tmp = st1. substr (i,k);j = st2. find
(tmp,0);(j! = - 1)
{_len+=k;_st+=tmp;(i<st1. length () - k
&& j<st2. length () - k && st1 [i+k] == st2 [j+k])
{_st+=st1 [i+k];++;++;_len++;
}_st+=' ';
}++;
}
}main ()
{sec_st,alw_st,chk_st,tmpst,same_st;fout
("result. txt");total_len;<string>:: iterator
sec_it,alw_it,chk_it;
// Составление списков имеющихся файлов_file_list
(secured_files,"secret\\");_file_list
(allowed_files,"unsecret\\");_file_list
(checked_files,"check\\");(chk_it = checked_files. begin (); chk_it!
= checked_files. end (); ++chk_it)
{_st = input_file ( (*chk_it). c_str ());<<
"*****Проверяемый файл: "
<< (*chk_it) << "*****\n";(k=15; k<=16; k++)
{= remove_repeats (chk_st,k);
fout << "k = " << k << endl;
// Удаление из конфиденциального файла не конфиденциальные
k-граммы
for (alw_it = allowed_files. begin (); alw_it! =
allowed_files. end (); ++alw_it)
{_st = input_file ( (*alw_it). c_str ());_st =
remove_repeats (alw_st,k);_allowed (tmpst,alw_st,k);
}
// Проверка конфиденциальных файлов с проверяемыми(sec_it =
secured_files. begin (); sec_it! =secured_files. end (); ++sec_it)
{_st = input_file ( (*sec_it). c_str ());
fout << "Сравнение с файлом " <<
(*sec_it) << ": \n";
sec_st = remove_repeats (sec_st,k);_st =
"";_strings (tmpst,sec_st,k,total_len,same_st);. precision
(2);<< total_len << " " << (float)
total_len/sec_st. length () *100.0 << "%\n";<< same_st
<< endl;
}<< endl;
}
}
return 0;
}
// Модуль утечки конфиденциальной информации с реализацией
алгоритма по схеме 2
#include <fstream>
#include <iostream>
#include <string>
#include <list>
#include <algorithm>
#include <io. h>
#include "hashlib. h"namespace
std;list<unsigned short> thash_vec;k;<string>
allowed_files,secured_files,checked_files;
// Перевод в заглавную букву для win-кодировки
char to_upper (unsigned char c)
{( (c>=97 && c<=122) || c >=
224)=32;
// Буква ё(c == 184)= 168;c;
}
// Составление списка файлов по заданному пути
void make_file_list (list<string>
&l,const char *path)
{search_path = path,tmp_st;
_finddata_t fdata;i;
// Поиск текстовых файлов_path+="*. txt";
int h = _findfirst (search_path. c_str
(),&fdata);(h! = - 1)
{_st = path;_st+=fdata. name;. push_back (tmp_st);=
_findnext (h,&fdata);
}while (i == 0);
_findclose (h);
}
// Ввод данных из файла в строку и составление списка
хеш-кодов
void input_file (const char *fname, int
k,thash_vec &hash_vec)
{st;c;*c_st;_vec:: iterator it;short crc;fin
(fname);(! fin. fail ())
{(fin >> c,! fin. eof ())
{
// Проверка, что символы в тексте это буквы
if (c < 0 || (c>='a' && c<='z')
|| (c>='A' && c<='Z') || (c>='0' &&
c<='9'))+=to_upper (c);
}_st = (char*) st. c_str ();(size_t i=0;
i<=st. length () - k; i++)
{= Crc16 ( (unsigned char*) c_st,k);
// Если такое же значение уже есть в массиве,
// не добавляем его= lower_bound (hash_vec. begin (),hash_vec. end (),crc);(it
== hash_vec. end () || (*it! = crc))_vec. insert (it,crc);
c_st++;
}
}. close ();
}
// Удаление повторяющихся хеш-кодов
// sec_hash - список с конфиденциальными хеш-кодами
// alw_hash - список с не конфиденциальными хеш-кодами
void remove_allowed (thash_vec
&sec_hash,thash_vec &alw_hash)
{_vec:: iterator sec_it;_it = sec_hash. begin
();(sec_it! = sec_hash. end ())
{(binary_search (alw_hash. begin (),alw_hash. end
(), (*sec_it)))_it = sec_hash. erase (sec_it);
else_it++;
}
}
// Сравнение с содержимым защищенного файла
void cmp_hashes (thash_vec
&chk_hash,thash_vec &sec_hash, int &total_len)
{_vec:: iterator chk_it;_len = 0;(chk_it =
chk_hash. begin (); chk_it! = chk_hash. end (); ++chk_it)
{(binary_search (sec_hash. begin (),sec_hash. end
(),*chk_it))_len++;
}
}main ()
{_vec sec_hash,alw_hash,chk_hash;fout
("result. txt");total_len;<string>:: iterator
sec_it,alw_it,chk_it;
// Составление списков имеющихся файлов_file_list
(secured_files,"secret\\");_file_list
(allowed_files,"unsecret\\");_file_list
(checked_files,"check\\");
// init_hl ();(k=15; k<16; k++)
{<< "k = " << k << endl;
// Ввод информацию из конфиденциальных и не конфиденциальных
файлов
for (sec_it = secured_files. begin (); sec_it!
=secured_files. end (); ++sec_it)_file ( (*sec_it). c_str
(),k,sec_hash);(alw_it = allowed_files. begin (); alw_it! = allowed_files. end
(); ++alw_it)_file ( (*alw_it). c_str (),k,alw_hash);
// Удаление не конфиденциальных комбинаций из базы
конфиденциальных хеш-кодов
remove_allowed (sec_hash,alw_hash);(chk_it =
checked_files. begin (); chk_it! = checked_files. end (); ++chk_it)
{<< "*****Проверяемый файл: "
<< (*chk_it) << "*****\n";_file ( (*chk_it). c_str
(),k,chk_hash);_hashes (chk_hash,sec_hash,total_len);
if (total_len > 450)
{<< "Количество совпавших комбинаций: "
<< total_len << " - Файл запрещен к передаче!" <<
endl;<< endl;_hash. clear ();
}
{<< "Количество совпавших комбинаций: "
<< total_len << endl;
fout << endl;_hash. clear ();
}
}_hash. clear ();_hash. clear ();
}
// close_hl ();0;
}
/*Реализация хеш-функции CRC-16: CRC-16: 0x8005 x^16 + x^15 + x^2 + 1:
0x0000: true: 0x0000: 0x4B37
("123456789"): 4095 байт (32767 бит) - обнаружение
одинарных, двойных, тройных и всех нечетных ошибок*/
const unsigned short Crc16Table [256] = {
0x0000, 0xC0C1, 0xC181, 0x0140, 0xC301, 0x03C0, 0x0280, 0xC241,0xC601, 0x06C0, 0x0780, 0xC741, 0x0500, 0xC5C1, 0xC481, 0x0440,0xCC01, 0x0CC0, 0x0D80, 0xCD41, 0x0F00, 0xCFC1, 0xCE81, 0x0E40,0x0A00, 0xCAC1, 0xCB81, 0x0B40, 0xC901, 0x09C0, 0x0880, 0xC841,0xD801, 0x18C0, 0x1980, 0xD941, 0x1B00, 0xDBC1, 0xDA81, 0x1A40,0x1E00, 0xDEC1, 0xDF81, 0x1F40, 0xDD01, 0x1DC0, 0x1C80, 0xDC41,0x1400, 0xD4C1, 0xD581, 0x1540, 0xD701, 0x17C0, 0x1680, 0xD641,0xD201, 0x12C0, 0x1380, 0xD341, 0x1100, 0xD1C1, 0xD081, 0x1040,0xF001, 0x30C0, 0x3180, 0xF141, 0x3300, 0xF3C1, 0xF281, 0x3240,0x3600, 0xF6C1, 0xF781, 0x3740, 0xF501, 0x35C0, 0x3480, 0xF441,0x3C00, 0xFCC1, 0xFD81, 0x3D40, 0xFF01, 0x3FC0, 0x3E80, 0xFE41,0xFA01, 0x3AC0, 0x3B80, 0xFB41, 0x3900, 0xF9C1, 0xF881, 0x3840,0x2800, 0xE8C1, 0xE981, 0x2940, 0xEB01, 0x2BC0, 0x2A80, 0xEA41,0xEE01, 0x2EC0, 0x2F80, 0xEF41, 0x2D00, 0xEDC1, 0xEC81, 0x2C40,0xE401, 0x24C0, 0x2580, 0xE541, 0x2700, 0xE7C1, 0xE681, 0x2640,0x2200, 0xE2C1, 0xE381, 0x2340, 0xE101, 0x21C0, 0x2080, 0xE041,0xA001, 0x60C0, 0x6180, 0xA141, 0x6300, 0xA3C1, 0xA281, 0x6240,0x6600, 0xA6C1, 0xA781, 0x6740, 0xA501, 0x65C0, 0x6480, 0xA441,0x6C00, 0xACC1, 0xAD81, 0x6D40, 0xAF01, 0x6FC0, 0x6E80, 0xAE41,0xAA01, 0x6AC0, 0x6B80, 0xAB41, 0x6900, 0xA9C1, 0xA881, 0x6840,0x7800, 0xB8C1, 0xB981, 0x7940, 0xBB01, 0x7BC0, 0x7A80, 0xBA41,0xBE01, 0x7EC0, 0x7F80, 0xBF41, 0x7D00, 0xBDC1, 0xBC81, 0x7C40,0xB401, 0x74C0, 0x7580, 0xB541, 0x7700, 0xB7C1, 0xB681, 0x7640,0x7200, 0xB2C1, 0xB381, 0x7340, 0xB101, 0x71C0, 0x7080, 0xB041,0x5000, 0x90C1, 0x9181, 0x5140, 0x9301, 0x53C0, 0x5280, 0x9241,0x9601, 0x56C0, 0x5780, 0x9741, 0x5500, 0x95C1, 0x9481, 0x5440,0x9C01, 0x5CC0, 0x5D80, 0x9D41, 0x5F00, 0x9FC1, 0x9E81, 0x5E40,0x5A00, 0x9AC1, 0x9B81, 0x5B40, 0x9901, 0x59C0, 0x5880, 0x9841,0x8801, 0x48C0, 0x4980, 0x8941, 0x4B00, 0x8BC1, 0x8A81, 0x4A40,0x4E00, 0x8EC1, 0x8F81, 0x4F40, 0x8D01, 0x4DC0, 0x4C80, 0x8C41,0x4400, 0x84C1, 0x8581, 0x4540, 0x8701, 0x47C0, 0x4680, 0x8641,0x8201, 0x42C0, 0x4380, 0x8341, 0x4100, 0x81C1, 0x8081, 0x4040
};short Crc16 (unsigned char * pcBlock, unsigned
short len)
{short crc = 0;(len--)= (crc >> 8) ^
Crc16Table [ (crc & 0xFF) ^ *pcBlock++]; crc;
}
// Библиотека для получения хеш-кодов
#include <windows. h>
#include <Wincrypt. h>
#include "hashlib. h"HCRYPTPROV hProv =
0;
// Инициализация сервиса шифрования
DWORD init_hl ()
{dwStatus = 0;(! CryptAcquireContext
(&hProv,,,_RSA_FULL,_VERIFYCONTEXT))
{= GetLastError ();
}dwStatus;
}close_hl ()
{(hProv, 0);
}get_hash (const char *data, int len,BYTE *hash)
{dwStatus = 0;hHash = 0;cbHash = 0;
// Создание объекта(! CryptCreateHash (hProv, CALG_MD5, 0, 0,
&hHash))
{= GetLastError ();dwStatus;
// Добавление данных для хеширования(!
CryptHashData (hHash, (const BYTE*) data, len, 0))
{= GetLastError ();(hHash);dwStatus;
}= HASH_LEN;
// Получение хеш-кода(! CryptGetHashParam (hHash, HP_HASHVAL, hash,
&cbHash, 0))
{= GetLastError ();
}(hHash);dwStatus;
}