Статистичне дослідження
Вступ
Статистика - це наука, яка вивчає кількісну сторону масових суспільних,
соціально-економічних та інших явищ в нерозривному зв'язку з їх якісною
стороною в певних умовах місця і часу.
Отже, предмет статистики - кількісна сторона масових суспільних, соціально-економічних
та інших явищ в нерозривному зв'язку з їх якісною стороною в певних умовах
місця і часу.
Об'єктом статистики є людське суспільство, явища і процеси суспільного
життя.
Особливості статистики:
) статистика говорить мовою цифр, але ці цифри якісно визначені;
) масовість явищ (статистика не вивчає поодинокі явища, оскільки в них не
проявляються закономірності, які досліджуються статистикою); використовується
математичний закон великих чисел, основним принципом якого є те, що
закономірність масових явищ може проявлятися при достатньо великому числі
випадків;
) статистика вивчає структуру явища і його динаміку;
) статистика вивчає явища в їх взаємозв'язку.
Закономірності проявляються в таких своїх різновидах:
) закономірності розвитку (динаміка явищ);
) закономірності структурних зрушень;
) закономірності розподілу елементів сукупності (розподіл населення за
віком, за статтю);
) закономірності співзалежності (зв'язку між явищами).
Статистична сукупність - це маса однорідних в певному відношенні
елементів, мають єдину якісну основу, але різняться між собою певними ознаками
і підлягають певному закону розподілу.
Статистична сукупність - це певна множина елементів, поєднана умовами
існування і розвитку.
Сукупність може бути однорідною і різнорідною.
Однорідна сукупність - якщо одна чи декілька ознак, що вивчаються, є
загальними для всіх одиниць. Різнорідна сукупність об'єднує явища різного типу.
Сукупність складають окремі елементи, які називаються одиницями
сукупності.
Одиниця сукупності - це первинний елемент статистичної сукупності, який є
носієм ознак, що підлягають реєстрації і є основою обліку. Ознака - властивість
окремої одиниці сукупності. Ознаки можуть бути (за характером виявлення)
якісними і кількісними.
Якісні ознаки (атрибутивні ознаки) виражаються в вигляді понять,
визначень, які характеризують їх суть, стан або якість. Наприклад, сорт
продукції, професія, сімейний статус.
Кількісні ознаки виражають окремі значення якісних ознак у числовому
виразі, окремі значення яких називаються варіантами.
Кількісні варіанти за характером виразу можуть бути первинними і
вторинними.
Первинні варіанти - характеризують одиницю сукупності в цілому: абсолютні
значення, вимірені, розраховані.
Вторинні варіанти (похідні, розрахункові) - дані, що не можливо
перевірити тому що вони взяті з певних джерел.
По відношенню до об'єкту кількісні ознаки можуть бути прямими і
непрямими. Прямі - характеризують об'єкт дослідження безпосередньо (вік осіб,
кількість присутніх в аудиторії). Непрямі - ознаки, що не належать
безпосередньо досліджуваному об'єкту (чи сукупності), а які належать іншій
сукупності, що входить в дану.
За характером варіації кількісні ознаки можуть бути дискретними
(перервні), безперервними; а якісні - багатоваріантними, альтернативними.
Дискретні - ознаки, виражені окремими цілими числами, без проміжних значень.
Безперервні - ознаки, що можуть набувати будь-яких значень у певних чисел.
Багатоваріантні - перш за все характеризуються рангами (шкалою рангів) від
більшого до меншого (напр. дуже низький, низький, середній, високий, дуже
високий). Альтернативні - взаємовиключаючі значення: так-ні,
позитивне-негативне.
По відношенню до часу ознаки можуть бути інтервальні і моментні.
Інтервальні - це ознаки, які характеризують результат процесів. Моментні - характеризують
об'єкт в певний момент часу.
В залежності між зв'язку між ознаками вони бувають факторними і
результативними. Та ознака, яка впливає на іншу, називається факторною. Та
ознака, яка підлягає впливу, називається результативною. Наприклад: від рівня
кваліфікації робітника залежить його продуктивність. Тут кваліфікація робітника
є факторною ознакою, а продуктивність - результативна. В свою чергу від
продуктивності залежить заробітна плата. Тут продуктивність вже стала факторною
ознакою, а заробітна плата - результативна.
Методологічною основою статистики є:
) теорія пізнання, яка визначає наукові підходи до вивчення явищ природи
і суспільства;
) діалектична логіка, загальнонаукові прийоми синтезу і аналізу;
) системний підхід;
) основи економічної теорії;
) специфічні, властиві лише статистиці, методи (статистичне групування,
зведення і групування, середні, узагальнюючі і аналітичні показники, індекси,
вибірковий метод, балансовий метод, регресійно-кореляційний метод і т.д.).
Будь-яке статистичне дослідження має 4 етапи (всі вони об'єднуються
єдиним - метою дослідження):
) статистичне спостереження - збір даних шляхом первинного (вимірення,
опитування, підрахування) або вторинного збору;
) зведення і групування даних та результатів спостережень;
) узагальнюючі показники (можуть бути абсолютні, середні і відносні);
4) аналіз.
Функції статистики:
) пізнавальна функція - статистика вивчає кількісне співвідношення і
взаємозв'язки, встановлює закономірності розвитку;
) контрольно-організаційна функція;
) керуюча функція - на основі наявних даних проводиться планування і
керування.
Завданнями статистики відповідно до Закону України "Про державну
статистику" є (мається на увазі державна статистика):
реалізація державної політики в галузі статистики;
збирання, розробка, узагальнення та всебічний аналіз статистичної
інформації про процеси, що відбуваються в економічному і соціальному житті
України та її регіонів;
розробка і впровадження статистичної методології, яка базується на
результатах наукових досліджень, міжнародних стандартах та рекомендаціях;
забезпечення достовірності, об'єктивності, оперативності, стабільності та
цілісності статистичної інформації;
забезпечення доступності, гласності і відкритості зведених статистичних
даних в межах чинного законодавства.
статистичний варіація кореляційний ряд
1. Статистичний метод групування
У результаті статистичного спостереження отримують матеріал, який
характеризує окремі елементи сукупності. Постає потреба у спеціальній обробці
статистичних даних - зведенні матеріалів спостереження.
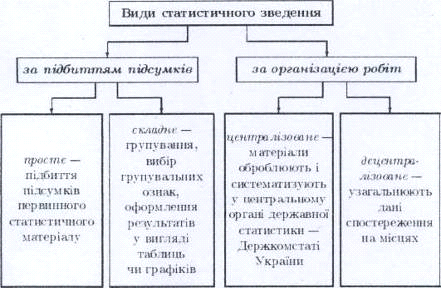
Статистичне зведення - це упорядкування, систематизація і наукова обробка
статистичних даних. Воно включає такі основні етапи:
групування матеріалу;
розробку системи показників для характеристики типових груп і підгруп;
підбиття групових і загальних підсумків, оформлення результатів у вигляді
таблиць.
Статистичне групування - утворення однорідних груп одиниць
сукупності за першою суттєвою ознакою, а також тих, що мають однакові або
близькі значення групової ознак, яку взято за основу утворення груп у процесі
групування. За допомогою статистичного групування розв’язують три основних
завдання:
- поділ неоднорідної сукупності на якісно однорідні групи або
виокремлення соціально-економічних типів - типологічні групування;
- вивчення складу однорідної сукупності за різними ознаками -
структурні групування;
виявлення та вивчення взаємозв’язку явищ та їх ознак -
аналітичні групування.
Групування за однією ознакою називають простими. Якщо
ж для виокремлення груп беруть по дві і більше ознак, то такі групування
називають комбінованими.
Класифікація (у статистиці) - це систематизований розподіл явищ і об’єктів на групи,
класи, розряди на основі їх схожості або відмінностей.
В аналітичних групуваннях здебільшого застосовують кількісні
ознаки. У групуваннях за кількісними ознаками постає питання про кількість груп
і величину інтервалу.
Величина інтервалу - це різниця між максимальним та
мінімальним значеннями ознаки в кожній групі.
Інтервали можуть бути рівними і нерівними. Рівні інтервали
застосовуються тоді, коли ознака групування розподілена в сукупності більш-менш
рівномірно. Величину рівних інтервалів (h) визначають за формулою
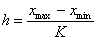 ,
,
де Хтах> Хтіп _ значення ознаки в
сукупності відповідно максимальне і мінімальне;
К-кількість груп.Кількість груп залежить від обсягу сукупності. Якщо
сукупність велика, то кількість груп за рівних інтервалів можна визначити за
формулою, яку запропонував американський вчений Стерджес:
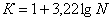 ,
,
де N - кількість одиниць сукупності.
Іноді при невеликій кількості спостережень застосовують принцип рівних
частин. За такого принципу одиниці сукупності розташовуються у порядку
зростання, а в кожній групі міститься однакова їх кількість. Це виключає
утворення численних груп.
В окремих випадках здійснюють перегрупування даних з метою утворення
нових груп на основі наявних, якщо останні не задовольняють меті аналізу.
У результаті групування отримують ряди розподілу.
Ряди розподілу - це сукупність значень групової ознаки (варіант) та
відповідних частот (часток).
Варіанти - це окремі значення групувальної ознаки, а частоти - числа,
які показують, скільки разів окремі значення варіант повторюються в ряді
розподілу. Замість частот може бути частка, виражена коефіцієнтом або
відсотком. Накопичену частоту (частку) називають кумулятивною.
Залежно від статистичної природи групувальної ознаки розрізняють
атрибутивні та варіаційні ряди розподілу.
В атрибутивних рядах одиниці сукупності розподіляються за атрибутивними
(якісними) ознаками, у варіаційних рядах - за кількісними ознаками.
Варіаційні ряди можуть бути дискретними або інтервальними. Характер
варіаційного ряду визначається характером варіації. Варіація може бути
дискретною (перервною) або неперервною.
Дискретними називають ряди розподілу, у яких варіанти є цілими числами.
Інтервальними називають ряди розподілу, в яких варіанти мають вигляд
інтервалів.
У результаті статистичного спостереження ми отримали матеріал по
цукровим заводам в кількості 20 підприємств. Спостереження велося за такими
критеріями:
- вартість основних фондів, тис. грн.
- валова продукція, тис. грн.
- середньоспискова чисельність
працівників, чол.
- в тому числі робітників, чол.
- перероблено цукросировини,
тис. ц.
- вироблено цукру, тис. ц.
середньодобова переробка буряків, тис.
Таблиця 1 - Дані завдання.
|
№ п/п
|
Вартість осн
фондів, тис. грн
|
Валов. Прод.
Тис. грн
|
Середспискова чисел
працівн. чол
|
В т.ч. робітників,
чол..
|
Перероб. цукросир.
Тис.ц
|
Виробл. цукру,
тис.ц
|
Середньодобова
перероб. буряків
|
|
4
|
10097
|
7249
|
883
|
789
|
1528
|
166
|
18
|
|
5
|
8097
|
5256
|
433
|
359
|
938
|
120
|
10,7
|
|
6
|
11116
|
14090
|
839
|
724
|
1253
|
158
|
12
|
|
7
|
4880
|
3525
|
933
|
821
|
1385
|
171
|
14,2
|
|
8
|
7355
|
5431
|
526
|
428
|
818
|
101
|
12,1
|
|
9
|
10066
|
7680
|
676
|
607
|
1353
|
154
|
20,8
|
|
10
|
7884
|
8226
|
684
|
619
|
1425
|
188
|
21
|
|
11
|
7038
|
4081
|
1291
|
1196
|
1688
|
196
|
20,7
|
|
12
|
4850
|
10473
|
556
|
492
|
1943
|
244
|
18,5
|
|
13
|
4350
|
6097
|
496
|
438
|
1248
|
134
|
17,1
|
|
14
|
3427
|
5307
|
367
|
311
|
1101
|
122
|
12,4
|
|
15
|
6062
|
7400
|
706
|
625
|
1470
|
169
|
21,3
|
|
16
|
6113
|
7079
|
555
|
491
|
1189
|
165
|
18,4
|
|
17
|
9787
|
6339
|
623
|
556
|
1202
|
139
|
22,1
|
|
18
|
3849
|
1544
|
371
|
314
|
285
|
33
|
10,7
|
|
19
|
10826
|
11430
|
977
|
886
|
2082
|
256
|
45,3
|
|
2О
|
6695
|
4105
|
738
|
639
|
1297
|
172
|
16,9
|
|
21
|
6633
|
13366
|
922
|
917
|
1104
|
145
|
17,7
|
|
22
|
6472
|
6340
|
495
|
416
|
1138
|
142
|
20,6
|
|
23
|
6083
|
3624
|
456
|
403
|
552
|
84
|
13,9
|
Для подальших розрахунків необхідно виконати первинне
групування вихідних даних за основною ознакою - валова продукція. Так як
групування проводимо по одній ознаки, то воно у нас вважається простим.
Таблиця 2 - Сортування (впорядкування) даних.
|
№ п/п
|
Валов. прод.
Тис. грн
|
Вартість осн.
фондів, тис. грн
|
Серед. спискова
чисел працівн. чол
|
В т.ч. робітників,
чол
|
Перероб. цукросир.
тис.ц
|
Виробл. цукру,
тис.ц
|
Середньодобова
перероб, буряків
|
|
18
|
1544
|
3849
|
371
|
314
|
285
|
33
|
10,7
|
|
7
|
3525
|
4880
|
933
|
821
|
1385
|
171
|
14,2
|
|
23
|
3624
|
6083
|
456
|
403
|
552
|
84
|
13,9
|
|
11
|
4081
|
7038
|
1291
|
1196
|
1688
|
196
|
20,7
|
|
2О
|
4105
|
6695
|
738
|
639
|
1297
|
172
|
16,9
|
|
5
|
5256
|
8097
|
433
|
359
|
938
|
120
|
10,7
|
|
14
|
5307
|
3427
|
367
|
311
|
1101
|
122
|
12,4
|
|
8
|
5431
|
7355
|
526
|
428
|
818
|
101
|
12,1
|
|
13
|
6097
|
4350
|
496
|
438
|
1248
|
134
|
17,1
|
|
17
|
6339
|
9787
|
623
|
556
|
1202
|
139
|
22,1
|
|
22
|
6472
|
495
|
416
|
1138
|
142
|
20,6
|
|
16
|
7079
|
6113
|
555
|
491
|
1189
|
165
|
18,4
|
|
4
|
7249
|
10097
|
883
|
789
|
1528
|
166
|
18
|
|
15
|
7400
|
6062
|
706
|
625
|
1470
|
169
|
21,3
|
|
9
|
7680
|
10066
|
676
|
607
|
1353
|
154
|
20,8
|
|
10
|
8226
|
7884
|
684
|
619
|
1425
|
188
|
21
|
|
12
|
10473
|
4850
|
556
|
492
|
1943
|
244
|
18,5
|
|
19
|
11430
|
10826
|
977
|
886
|
2082
|
256
|
45,3
|
|
21
|
13366
|
6633
|
922
|
917
|
1104
|
145
|
17,7
|
|
6
|
14090
|
11116
|
839
|
724
|
1253
|
158
|
12
|
Визначаємо кількість груп за формулою Стерджес:
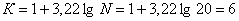
- кількість підприємств дорівнює 20.
Отже, кількість груп 6.
Визначаємо крок інтервалу:
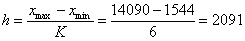
Межі груп мають такі інтервали
|
1544
|
3635
|
|
3635
|
5726
|
|
5726
|
7817
|
|
7817
|
9908
|
|
9908
|
11999
|
|
11999
|
14090
|
Після визначення інтервалів групування, побудуємо таблицю
допоміжного групування.
Таблиця 3 - Допоміжна таблиця групування
|
№ п/п
|
Валов. прод.
Тис. грн
|
Вартість осн.
фондів, тис. грн..
|
Серед. спискова
Чисел. працівн. чол
|
В т.ч. робітників,
чол
|
Перероб. цукросир.
Тис.ц
|
Виробл. цукру,
тис.ц
|
Середньодобова
перероб, буряків
|
|
18
|
1544
|
3849
|
371
|
314
|
285
|
33
|
10,7
|
|
7
|
3525
|
4880
|
933
|
821
|
1385
|
171
|
14,2
|
|
23
|
3624
|
6083
|
456
|
403
|
552
|
84
|
13,9
|
|
Σ
|
8693
|
14812
|
1760
|
1538
|
2222
|
288
|
38,8
|
|
11
|
4081
|
7038
|
1291
|
1196
|
1688
|
196
|
20,7
|
|
2О
|
4105
|
6695
|
738
|
639
|
1297
|
172
|
16,9
|
|
5
|
5256
|
8097
|
433
|
359
|
938
|
120
|
10,7
|
|
14
|
5307
|
3427
|
367
|
311
|
1101
|
122
|
12,4
|
|
8
|
5431
|
7355
|
526
|
428
|
818
|
101
|
12,1
|
|
Σ
|
24180
|
32612
|
2064
|
1737
|
4154
|
515
|
52,1
|
|
13
|
6097
|
4350
|
496
|
438
|
1248
|
134
|
17,1
|
|
17
|
6339
|
9787
|
623
|
556
|
1202
|
139
|
22,1
|
|
22
|
6340
|
6472
|
495
|
416
|
1138
|
142
|
20,6
|
|
16
|
7079
|
6113
|
555
|
491
|
1189
|
165
|
18,4
|
|
4
|
7249
|
10097
|
883
|
789
|
1528
|
166
|
18
|
|
15
|
7400
|
6062
|
706
|
625
|
1470
|
169
|
21,3
|
|
9
|
7680
|
10066
|
676
|
607
|
1353
|
154
|
20,8
|
|
Σ
|
48184
|
52947
|
4434
|
3922
|
9128
|
1069
|
138,3
|
|
10
|
8226
|
7884
|
684
|
619
|
1425
|
188
|
21
|
|
Σ
|
8226
|
7884
|
684
|
619
|
1425
|
188
|
21
|
|
12
|
10473
|
4850
|
556
|
492
|
1943
|
244
|
18,5
|
|
19
|
11430
|
10826
|
977
|
886
|
2082
|
256
|
45,3
|
|
Σ
|
21903
|
15676
|
1533
|
1378
|
4025
|
500
|
63,8
|
|
21
|
13366
|
6633
|
922
|
917
|
1104
|
145
|
17,7
|
|
6
|
14090
|
11116
|
839
|
724
|
1253
|
158
|
12
|
|
Σ
|
27456
|
17749
|
1761
|
1641
|
2357
|
303
|
29,7
|
Для зручності зробимо підсумкову таблицю первинного
групування.
Таблиця 4 - Підсумкова таблиця первинного групування
|
Номер групи
|
Межа інтервалуа
|
Середина інтервала
|
Валов. прод.
тис. грн
|
Вартість осн
фондів, тис. грн
|
Середспискова чисел
працівн. чол
|
В тч робітників,
чол
|
Перероб. цукросир.
тис.ц
|
Виробл. цукру,
тис.ц
|
Середньодобова
Перероб. буряків
|
|
1
|
1544-3635
|
2589,5
|
8693
|
14812
|
1760
|
1538
|
2222
|
288
|
38,8
|
|
2
|
3635-5726
|
4680,5
|
24180
|
32612
|
2064
|
1737
|
4154
|
515
|
52,1
|
|
3
|
5726-7817
|
6771,5
|
52947
|
4434
|
3922
|
9128
|
1069
|
138,3
|
|
4
|
7817-9908
|
8862,5
|
8226
|
7884
|
684
|
619
|
1425
|
188
|
21
|
|
5
|
9908-11999
|
10953,5
|
21903
|
15676
|
1533
|
1378
|
4025
|
500
|
63,8
|
|
6
|
11999-14090
|
13044,5
|
27456
|
17149
|
1761
|
1641
|
2357
|
303
|
29,7
|
|
|
|
138642
|
141080
|
12236
|
10835
|
23311
|
2863
|
343,7
|
Таблиця 5 - Ряд розподілу
|
Номер групи
|
Межа інтервала
|
Середина інтервала
|
Частота
|
Частка
|
Накопичена частка
|
Відносна щільність
|
|
1
|
1544-3635
|
2589,5
|
3
|
0,15
|
3
|
0,000072
|
|
2
|
3635-5726
|
4680,5
|
5
|
025
|
8
|
0,00012
|
|
3
|
5726-7817
|
6771,5
|
7
|
0,35
|
15
|
0,00017
|
|
4
|
7817-9908
|
8862,5
|
1
|
0,05
|
16
|
0,000024
|
|
5
|
9908-11999
|
10953,5
|
2
|
0,1
|
18
|
0,000048
|
|
6
|
11999-14090
|
13044,5
|
2
|
0,1
|
20
|
0,000048
|
У даній таблиці варіанта - середина кожного інтервального
ряду, беремо з попередніх розрахунків. Частота показує кількість підприємств,
що входять в кожен інтервал. Частку знаходимо за формулою:
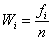 ,
,
де f - відповідна частота групи;- загальна кількість підприємств.
Накопичена частота - це сума частот:
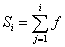 .
.
відносна щільність:
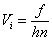 ,
,
де f - відповідна частота;- крок інтервалу.
За сформованим рядом розподілу будуємо статистичні графіки.
Статистичний графік - спосіб наочного подання і викладання даних за допомогою
геометричних знаків та інших графічних символів з метою їх узагальнення і
аналізу.
Полігон розподілу - графічне зображення варіаційного ряду в системі
координат у вигляді ламаної, що послідовно з’єднує точки. По осі абсцис
відкладається значення варіант, по осі ординат - частоти.
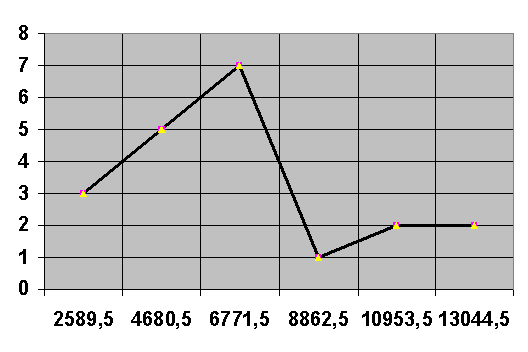
Рисунок 1 - Полігон розподілу
Гістограма - найпоширеніший вид графічного зображення інтервальних
рядів. Вона будується за відносною щільністю у вигляді прямокутників так, щоб
площа їх дорівнювала 1.
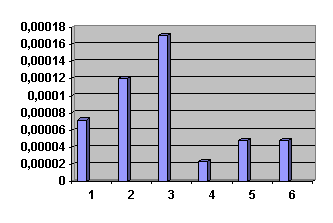
Рисунок 2 - Гістограма
Кумулята - графічне порівняння двох або більше варіаційних розподілів з
рівними чи нерівними інтервалами. Вона будується за кумулятивним розподілом
накопичених частот, при цьому використовуються праві кінці інтервалів.
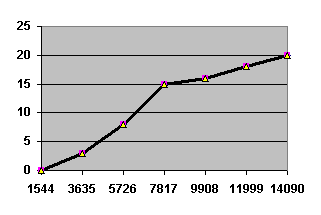
Рисунок 3 - Кумулята
Огіва - це різновид кумулятивного розподілу. Вона є дзеркальним
відображенням кумуляти. На осі ординат відкладаємо межі інтервалів, по осі
абсцис - накопичені частоти.
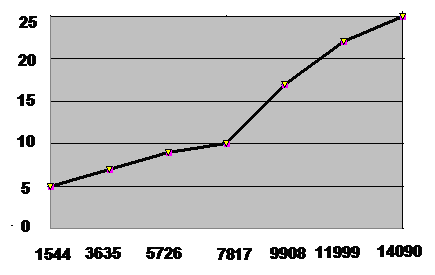
Рисунок 4 - Огіва
2. Середні величини та показники варіації
Найважливішою характеристикою варіаційного ряду розподілу є
середня величина, яка здатна відображати характерний рівень ознаки притаманний
усім елементам сукупності.
Статистичні середні відображають активну наявність певних
умов, що проявляються в кожній одиниці досліджуваної сукупності; вони дають
узагальнюючу кількісну характеристику статистичним сукупностям однотипних явищ
за варіаційною ознакою.
Середньою величиною в статистиці називаються кількісні
показники характерного, типового рівня масових однорідних явищ, який
складається під впливом загальних причин і умов розвитку. В зв’язку з цим
середні величини належать до узагальнюючих статистичних показників, які дають
зведену, підсумкову характеристику масових суспільних явищ. У середній величині
гасяться (розчиняються) всі відмінності та особливості індивідуальних значень
ознак, і вона є «рівнодіючою» значень цих ознак. Розрахунок середніх передбачає
обов’язковість урахування умов виникнення кожної індивідуальної величини,
інакше обчислення можуть призвести до фіктивних середніх. Щоб середня величина
відображувала типове і загальне для всієї сукупності, остання повинна бути
якісно однорідною.

Середня арифметична - застосовують тоді, коли обсяг варіюючої
ознаки для сукупності є сумою індивідуальних значень її окремих елементів.

Середня гармонійна - застосовують тоді, коли відсутні безпосередні дані
про вагу, а відомі варіанти ознак, що усереднюються (х), і добутки значень
варіантів на кількість одиниць, які мають значення 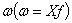 . Розраховують на основі зворотних значень ознаки.
. Розраховують на основі зворотних значень ознаки.

Середня геометрична - застосовується тоді, коли визначальна
властивість сукупності формується як добуток індивідуальних значень ознаки
(аналіз динаміки для визначення середнього темпу зростання).

де Π - символ добутку;
хі - відносні величини динаміки;
Σ1nj = ni - часовий інтервал.
Середня квадратична - використовують у розрахунку показників
віріації.

Ми використовуємо середню арифметичну зважену:
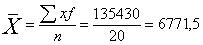
Таблиця 6 - Розрахунок середніх величин
|
Номер п/п
|
Середина інтервала
(х)
|
Частота f
|
xf
|
(x-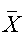 )2 )2
|
|
1
|
2589,5
|
3
|
7768,5
|
17489124
|
|
2
|
4680,5
|
5
|
23402,5
|
4372281
|
|
3
|
6771,5
|
7
|
47400,5
|
0
|
|
4
|
8862,5
|
1
|
8862,5
|
4372281
|
|
5
|
10953,5
|
2
|
21907
|
17489124
|
|
6
|
13044,5
|
2
|
26089
|
39350529
|
|
Сума
|
|
20
|
135430
|
83073339
|
|
середнє
|
|
|
6771,5
|
4153667
|
Структурні середні величини
У ряді розподілу важливе значення мають структурні середні
величини, які характеризують структуру аналізованих сукупностей - мода і
медіана.
Мода (М0) - варіанта, що найчастіше повторюється в
ряді розподілу і розраховується за формулою:
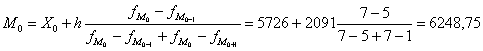
де Х0 - нижня межа модального інтервалу;- величина
модального інтервалу;Mo - частота модального інтервалу;Mo-1
- частота попереднього інтервалу;Mo+1 - частота інтервалу,
наступного за модальним.
Медіана (Ме) - варіанта, що ділить ранжований ряд на дві рівні
частини і розраховується за формулою:
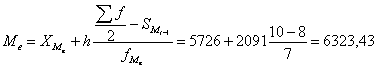
де ХМе - нижня межа медіанного інтервалу;- величина
медіанного інтервалу;
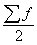 -
півсума частот медіанного інтервалу;
-
півсума частот медіанного інтервалу;
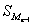 -
сума частот перед медіанним інтервалом;
-
сума частот перед медіанним інтервалом;
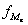 -
частота медіанного інтервалу.
-
частота медіанного інтервалу.
Основні показники варіації
Середні величини характеризують рівень однорідних масових
явищ і процесів, але не дають ніякого уявлення про коливання ознаки, тому
середні величини доповнюють показниками варіації. Вимірювання степеня коливання
ознаки, її варіації - невід’ємна складова аналізу закономірностей розподілу.
Варіація будь-якої ознаки формується під впливом двох причин
(факторів):
основна, що наявна і тісно пов`язана з природою самого явища;
другорядна - випадкова для цієї сукупності в цілому.
Середні величини характеризують типовий рівень варіюючої
ознаки. Крім даних характеристик, обчислюються ще й наступні:
Розмах варіації - Являє собою різницю між максимальною і мінімальною
варіацією.
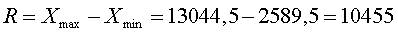 .
.
Середнє лінійне відхилення - це сума, або зважена сума абсолютних величин
відхилень варіант від середнього значення.
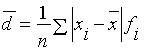
Основною характеристикою варіацій є дисперсія, за
допомогою якої оцінюється відхилення варіаційної ознаки від середнього
арифметичного.
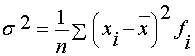
Недоліком дисперсії є те, що вона завжди представлена у
квадраті, що не придатне для аналізу. Тому дисперсія має недолік - одиницю
виміру. Щоб ліквідувати цей недолік, розраховується:
Середнє квадратичне відхилення:
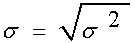
При порівнянні варіації різних ознак або однієї ознаки в різних
сукупностях використовуються коефіцієнти варіації:
а) 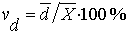 - лінійний;
- лінійний;
б) 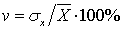 - квадратичний;
- квадратичний;
в) - осциляції.
- осциляції.
Таблиця 7 - Показники варіації
|
варіанти
|
частоти
|
розрахунки
|
|
Xi
|
fi
|
Xifi
|
|Xi-||Xi-|fi(Xi-)2(Xi-)2fi
|
|
|
|
|
2589,5
|
3
|
7768,5
|
4182
|
12546
|
17489124
|
52467372
|
|
4680,5
|
5
|
23402,5
|
2091
|
10455
|
4372281
|
21861405
|
|
6771,5
|
7
|
47400,5
|
0
|
0
|
0
|
0
|
|
8862,5
|
1
|
8862,5
|
2091
|
2091
|
4372281
|
4372281
|
|
10953,5
|
2
|
21907
|
4182
|
8364
|
17489124
|
34978248
|
|
13044,5
|
2
|
26089
|
6273
|
12546
|
39350529
|
78701058
|
|
Сума
|
20
|
135430
|
|
46002
|
83073339
|
192380364
|
|
середнє
|
|
6771,5
|
|
2300,1
|
4153667
|
9619018,2
|
Згідно розрахунків із таблиці 7 знаходимо:
=
2300,1
=
9619018,2
=
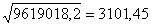
лінійний коефіцієнт варіаціїї
=(2300,1/6771,5)·100%
= 33,97%
квадратичний коефіцієнт варіації
=(3101,45/6771,5)·100%
= 45,8%
- коефіцієнт варіації оселяції
=
(10455/6771,5)·100% = 154,4%
. Кореляційний аналіз
Кореляцією називається неповний зв’язок між досліджуваними явищами. Це
така залежність, коли будь-якому значенню однієї змінної величини може
відповідати декілька різноманітних значень іншої змінної величини. Вона
відображає закон множини причин і наслідків і є вільною неповною залежністю.
Модель кореляційно-регресійного аналізу (лінійної регресії) є
найбільш розповсюдженою регресійною моделлю. По-перше, вона приваблює своєю
простотою, тому що немає простіше функції, ніж лінійна (рівняння прямої лінії).
По-друге, при лінійній апроксимації легко вдається одержати мінімальну
середньоквадратичну помилку.
У кореляційно-регресивному аналізі оцінювання лінії регресії
для добавлення ряду «лінія регресії» здійснюється не в окремих точках, як в
аналітичному групуванні, а в кожній точці інтервалу зміни факторної ознаки х.
Тобто лінія регресії в цьому випадку безперервна і зображується у вигляді
певної функції, яка називається рівнянням регресії, а У- це теоретичні значення
результативної ознаки.
Парною лінійною регресією Y на X називається одностороння
стохастична залежність між випадковими величинами показника Y і фактора X, які
знаходяться у причиново-наслідкових відношеннях, причому зміна фактора викликає
пропорціональну зміну показника.
Нехай ми маємо набір значень двох змінних xi, yi,
i=1,…,n. Пари (xi,yi) можна зобразити точками на площині
X-Y:
Уведемо гіпотезу, що між показником Y і фактором X існує
стохастична лінійна залежність. Суть задачі полягає в тому, щоб знайти
(підібрати, підігнати) лінію, яка найкраще описує залежність Y від X.
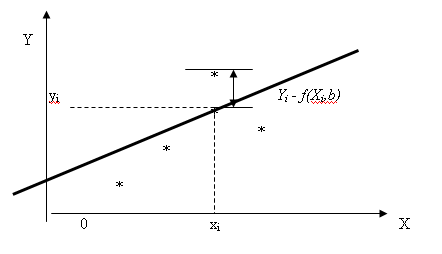
Модель лінійної регресії є, власне кажучи, лінійною
апроксимацією (наближенням) реальної лінії регресії y(x). Вона описується
рівнянням прямої
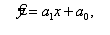
де множник
а1 називається коефіцієнтом регресії. Пряма повинна проходити так,
щоб стосовно крапок вибірки
{Xi,Yi}(n)={ (x1,y1),
(x2,y2),…(xn,yn)}
забезпечити мінімальне
квадратичне відхилення. Для кожної крапки вибірки помилка результативної ознаки
дорівнює 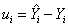
Ця модель є найбільш розповсюдженою регресійною моделлю. По-перше, вона
залучає своєю простотою, оскільки немає простіше функції, ніж лінійна (рівняння
прямої лінії). По-друге, при лінійній апроксимації легко вдається одержати
мінімальну середньоквадратичну помилку.
Модель лінійної регресії є, власне кажучи, лінійною апроксимацією
(наближенням) реальної лінії регресії y(x). Вона описується рівнянням прямої, 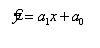 де
множник а називається коефіцієнтом регресії. Пряма (6.2) повинна проходити так,
щоб стосовно крапок вибірки
де
множник а називається коефіцієнтом регресії. Пряма (6.2) повинна проходити так,
щоб стосовно крапок вибірки
{Xi,Yi}(n)={ (x1,y1),
(x2,y2),…(xn,yn)}
забезпечити мінімальну
СКО. Для кожної крапки вибірки помилка
результативної ознаки дорівнює
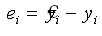
Середній квадрат помилки апроксимації пропорційний сумі квадратів
помилок
(a,b)=n-1Si ei2=n-1Si(a1xi+а0-yi)2
Визначення параметрів a і b моделі здійснюється методом найменших
квадратів (МНК). Тому що мінімум функції Е при варіації a і b має місце в
крапці нульових часток похідних, то одержимо систему двох лінійних відносно a і
b рівнянь.
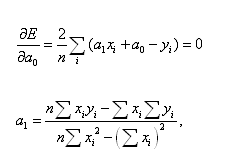
Ця система носить назву система нормальних рівнянь.
Рішення системи рівнянь має вигляд
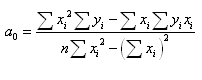
Знаменники в цих вираженнях пропорційні дисперсії факторної ознаки
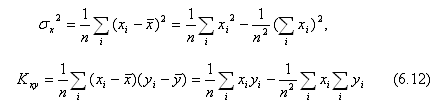
а чисельник пропорційний моменту кореляції між ознаками X і
Y.
Тут використана властивість незміщеності оцінок x та y. З урахуванням
співвідношень коефіцієнт регресії можна виразити як

Після визначення a1 для розрахунку a0
зручніше скористатися формулою:
Вибираючи формулу кореляційного зв’язку, насамперед виходять
з економічної природи явищ, простоти аналітичної функції і вимог до обмеженої
кількості параметрів.
Рівняння кореляційного зв’язку є аналітичним. За його
допомогою відображається взаємозв’язок ознак, а саме залежність між варіаціями
результативної і факторної ознак.
Найчастіше використовують такі рівняння:
- прямої лінії 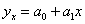 ;
;
- гіперболи 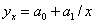 ;
;
- параболи другого порядку  ;
;
- експоненти 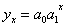 .
.
де у - значення результативної ознаки, що залежить тільки від
факторної;
х - значення факторної ознаки;
а0, а1, а2 - сталі величини,
які називаються параметрами рівняння.
Аналітичне рівняння кореляційного зв’язку і його параметри
визначають методом найменших квадратів, використовуючи систему нормальних
рівнянь. Так, для прямої лінії використовують таку систему нормальних рівнянь:
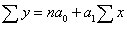
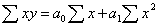
Таблиця 8 - Кореляційно-регресійний аналіз
|
Факторна ознака, х
|
Результативна
ознака, у
|
х*у
|
х2
|
у2
|
Х-Хсер
|
(Х-Хсер)2
|
У-Усер
|
(У-Усер)2
|
|
7249
|
10097
|
73193153
|
52548001
|
101949409
|
316,9
|
100425,61
|
3013
|
9078169
|
|
5256
|
8097
|
42557832
|
27625536
|
65561409
|
-1676,1
|
2809311,21
|
1013
|
1026169
|
11116
|
156624440
|
198528100
|
123565456
|
7157,9
|
51235532,4
|
4032
|
16257024
|
|
3525
|
4880
|
17202000
|
12425625
|
23814400
|
-3407,1
|
11608330,4
|
-2204
|
4857616
|
|
5431
|
7355
|
39945005
|
29495761
|
54096025
|
-1501,1
|
2253301,21
|
271
|
73441
|
|
7680
|
10066
|
77306880
|
58982400
|
101324356
|
747,9
|
559354,41
|
2982
|
8892324
|
|
8226
|
7884
|
64853784
|
67667076
|
62157456
|
1293,9
|
1674177,21
|
800
|
640000
|
|
4081
|
7038
|
28722078
|
16654561
|
49533444
|
-2851,1
|
8128771,21
|
-46
|
2116
|
|
10473
|
4850
|
50794050
|
109683729
|
23522500
|
3540,9
|
12537972,8
|
-2234
|
4990756
|
|
6097
|
4350
|
26521950
|
37173409
|
18922500
|
-835,1
|
697392,01
|
-2734
|
7474756
|
|
5307
|
3427
|
18187089
|
28164249
|
11744329
|
-1625,1
|
2640950,01
|
-3657
|
13373649
|
|
7400
|
6062
|
44858800
|
54760000
|
36747844
|
467,9
|
218930,41
|
-1022
|
1044484
|
|
7079
|
6113
|
43273927
|
50112241
|
37368769
|
146,9
|
21579,61
|
-971
|
942841
|
|
6339
|
9787
|
62039793
|
40182921
|
95785369
|
-593,1
|
351767,61
|
2703
|
7306209
|
|
1544
|
3849
|
5942856
|
2383936
|
14814801
|
-5388,1
|
29031621,6
|
-3235
|
10465225
|
|
11430
|
10826
|
123741180
|
130644900
|
117202276
|
4497,9
|
20231104,4
|
3742
|
14002564
|
|
4105
|
6695
|
27482975
|
16851025
|
44823025
|
-2827,1
|
7992494,41
|
-389
|
151321
|
|
13366
|
6633
|
88656678
|
178649956
|
43996689
|
6433,9
|
41395069,2
|
-451
|
203401
|
|
6340
|
6472
|
41032480
|
40195600
|
41886784
|
-592,1
|
350582,41
|
-612
|
374544
|
|
3624
|
6083
|
22044792
|
13133376
|
37002889
|
-3308,1
|
10943525,6
|
-1001
|
1002001
|
|
138642
|
141680
|
1054981742
|
1165862402
|
1105819730
|
|
204782194
|
|
102158610
|
|
6932,1
|
7084
|
52749087,1
|
|
|
|
|
|
|
Для знаходження невідомих параметрів складаємо систему
нормальних рівнянь використовуючи дані таблиці:
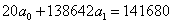
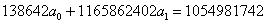
Звідси знаходимо шукані величини:
а0 = 4588,4
а1 = 0,36
Отримавши потрібні параметри, складаємо рівняння, за допомогою якого
знаходимо теоретичне значення допоміжної ознаки Y:
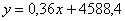
ГРАФІК
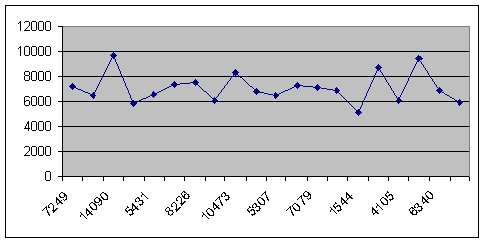
Рисунок 5 - Відображає зв'язок між факторною і результативною ознаками
Знайдемо загальну, залишкову та факторну суми квадратів і перевіримо
правильність складання таблиці.
Таблиця 9
|
Дані величини
|
Розрахункові
величини
|
|
Х
|
У
|
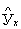 (У-)2(-Усер)2 (У-)2(-Усер)2
|
|
|
|
7249
|
10097
|
7198,04
|
8403969,082
|
13005,1216
|
|
5256
|
8097
|
6480,56
|
2612878,274
|
364139,8336
|
|
14090
|
11116
|
9660,8
|
2117607,04
|
6639898,24
|
|
3525
|
4880
|
5857,4
|
955310,76
|
1504547,56
|
|
5431
|
7355
|
6543,56
|
658434,8736
|
292075,3936
|
|
7680
|
10066
|
7353,2
|
7359283,84
|
72468,64
|
|
8226
|
7884
|
7549,76
|
111716,3776
|
216932,3776
|
|
4081
|
7038
|
6057,56
|
961262,5936
|
1053579,074
|
|
10473
|
4850
|
8358,68
|
12310835,34
|
1624809,102
|
|
6097
|
4350
|
6783,32
|
5921046,222
|
90408,4624
|
|
5307
|
3427
|
6498,92
|
9436692,486
|
342318,6064
|
|
7400
|
6062
|
7252,4
|
1417052,16
|
28358,56
|
|
7079
|
6113
|
7136,84
|
1048248,346
|
2792,0656
|
|
6339
|
9787
|
6870,44
|
8506322,234
|
45607,8736
|
|
1544
|
3849
|
5144,24
|
1677646,658
|
3762668,858
|
|
11430
|
10826
|
8703,2
|
4506279,84
|
2621808,64
|
|
4105
|
6695
|
6066,2
|
395389,44
|
1035916,84
|
|
13366
|
6633
|
9400,16
|
7657174,466
|
5364597,146
|
|
6340
|
6472
|
6870,8
|
159041,44
|
45454,24
|
|
3624
|
6083
|
5893,04
|
36084,8016
|
1418385,722
|
|
138642
|
141680
|
141679,12
|
76252276,28
|
26539772,36
|
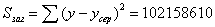
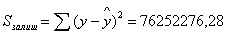
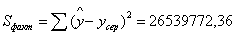
Перевірка 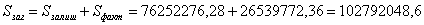
Похибка 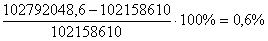
Знаходимо загальну, залишкову та регресійну дисперсію, а
також перевіримо адекватність рівняння регресії:
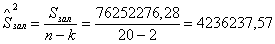 -
залишкова.
-
залишкова.
- кількість невідомих параметрів у рівнянні, дорівнює 2.
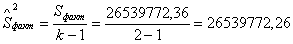 -
факторна
-
факторна
Для перевірки адекватності рівняння регресії застосуємо критерій
Фішера:
обчислюємо спостирежувальне значення критерія
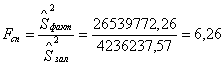
за таблицею знаходимо критичне (табличне) значення
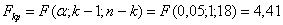
порівняння Fcn>Fkp (6,26>4,41) - немає
підстав відхилити тестуючу гіпотезу, тобто вона є адекватною.
Оцінка щільності зв´язку
Оцінка щільності зв’язку - це характеристика ступеня залежності між
ознаками. Показниками щільності зв’язку є коефіцієнти парної, часткової і
множинної кореляції та детермінації, рангові коефіцієнти, коефіцієнти
асоціації, взаємної спряженості та ін.
Вибір відповідного коефіцієнта залежить від виду випадкової величини,
форми їх залежності, закону розподілу. Для оцінки суттєвості зв’язку
використовують критерій значущості.
Найчастіше використовують лінійний коефіцієнт кореляції, який
обчислюється за формулою (модифікація):
σ - середнє квадратичне
відхилення.
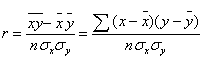
Використовуються також такі формули:
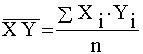 ;
;
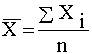 ;
; 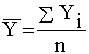 .
.

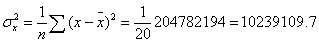
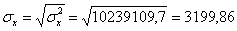
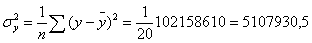
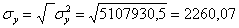
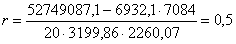
Коефіцієнт r змінюється в межах ±1. Додатнє значення цього показника
свідчить про прямий зв'язок. Що більше його значення, то щільніший зв'язок між
у та х і навпаки. Отже, у нас додатнє значення коефіцієнта і тому маємо прямий
зв'язок.
У літературі пропонуються різні оцінки коефіцієнта кореляції, але
найчастіше застосовують такі оцінки:=0 зв’язок відсутній=0,1-0,3 зв’язок
слабкий=0,3-0,5 зв’язок помірний=0,5-0,7 зв’язок суттєвий (середній)=0,7-0,9
зв’язок тісний (високий)=1 зв’язок функціональний.
Оскільки коефіцієнт лежить в межах 0,5 - 0,7, можемо зробити висновок,
що зв'язок суттєвий.
Знаходимо коефіцієнт детермінації. Значення R2 показує
скільки відсотків варіації результативної ознаки у залежить від варіації
факторної ознаки х.
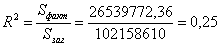
Це означає, що 25% даних підпорядковані лінійній залежності.
Індекс кореляції:
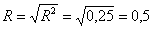
У разі лінійної залежності R=|r|
,5 = 0,5 - умова виконується.
. Ряди динаміки
Динамічний ряд - це послідовність чисел, які характеризують
зміну того чи іншого соціально-економічного явища у часі. Елементами
динамічного ряду є перелік хронологічних дат (моментів) або інтервалів часу і
конкретні значення відповідних статистичних показників, котрі називаються
рівнями ряду (у).
При вивченні динаміки важливі не лише числові значення
рівнів, а і їх послідовність. Як правило, часові інтервали між рівнями однакові
(доба, декада, календарний місяць, квартал, рік). Узявши будь-який інтервал за
одиницю, послідовність рівнів записуємо так: у1, у2, у3,...,уn.
Залежно від статистичної природи показника-рівня розрізняють
динамічні ряди первинні й похідні, ряди абсолютних, середніх і відносних
величин. За ознакою часу динамічні ряди поділяються на інтервальні та моментні.
Рівень моментного ряду фіксує стан явища на певний момент часу t, наприклад,
кількість працюючих на початок року, студентів - на 1 вересня. В інтервальному
ряді рівень - це агрегований результат процесу, що залежить від тривалості
часового інтервалу.
Динамічні ряди характеризуються низкою показників.
1 . Абсолютний приріст, тобто різниця двох рівнів ряду -
наступного і попереднього:
базисний 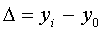 ;
;
ланцюговий 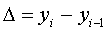 ,
,
де y0 yi - відповідно початковий і кінцевий
рівень ( yi-1 - попередній рівень ряду).
. Коефіцієнт зростання - це відношення наступного рівня до
попереднього:
базисний 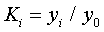 ;
;
ланцюговий 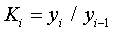 .
.
3. Темп зростання - це процентне співвідношення двох
рівнів ряду:
базисний 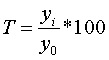 ;
;
ланцюговий 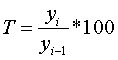 .
.
Темп зростання можна розрахувати, помноживши відповідний коефіцієнт
зростання на 100:
Т = К * 100.
Темп приросту - це відношення абсолютного приросту до попереднього або
першого рівня, виражене у відсотках:
ланцюговий 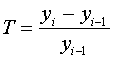 (або Кi - 1).
(або Кi - 1).
5 . Абсолютна величина одного процента визначається як
відношення абсолютного приросту до темпу приросту або діленням базисного чи
попереднього рівня на 100:
6
базисний 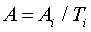 (або yi / 100);
(або yi / 100);
ланцюговий (або yi-1 / 100).
Оскільки показники ряду динаміки змінюються за роками, виникає
необхідність їх узагальнення і розрахунку середніх показників.
Середній рівень інтервального ряду визначається за середньою
арифметичною простою
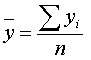 .
.
У моментному ряді динаміки середній рівень визначається за середньою
хронологічною
 .
.
Середній абсолютний приріст знаходять як середню ланцюгових
абсолютних приростів
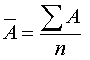 .
.
Середній коефіцієнт зростання розраховують за середньою
геометричною
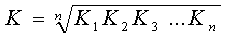 ,
,
де Кi - ланцюгові коефіцієнти зростання, або за
формулою
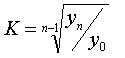 .
.
Середньорічний темп зростання:
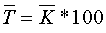 .
.
Обрахування характеристики ряду динаміки
В якості досліджуваного ряду динаміки можна обрати ранжирования ряд
основної ознаки.
Проведемо розрахунки показників ряду динаміки за основною ознакою -
валова продукція.
Таблиця 9 - Розрахунок показників ряду динаміки
|
Період
|
Ріень ряду
|
Абсолютний приріст
|
Темп зростання
|
Темп приросту
|
Абсолютний вміст 1%
приросту
|
|
|
ланцюговий
|
базисний
|
ланцюговий
|
базисний
|
ланцюговий
|
базисний
|
|
|
t
|
y
|
∆i=yi-yi-1
|
∆i=yi-y0
|
Tp=(yi/yi-1)100%
|
Tp=(yi/y0)·
100%
|
Tnp=Tp
- 100%
|
|A%|=yi/yi-1
|
|
1
|
1544
|
-
|
-
|
-
|
-
|
-
|
-
|
-
|
|
2
|
3525
|
1981
|
1981
|
228,3
|
228,3
|
128,3
|
128,3
|
2,28
|
|
3
|
3624
|
99
|
2080
|
102,81
|
234,72
|
2,81
|
134,72
|
1,03
|
|
4
|
4081
|
457
|
2537
|
112,61
|
264,31
|
12,61
|
164,31
|
1,13
|
|
5
|
4105
|
24
|
2561
|
100,59
|
265,87
|
0,59
|
165,87
|
1,01
|
|
6
|
5256
|
1151
|
3712
|
128,04
|
340,41
|
28,04
|
240,41
|
1,28
|
|
7
|
5307
|
51
|
3763
|
100,97
|
343,72
|
0,97
|
243,72
|
1,01
|
|
8
|
5431
|
124
|
3887
|
102,34
|
351,75
|
2,34
|
251,75
|
1,02
|
|
9
|
6097
|
666
|
4553
|
112,26
|
394,88
|
12,26
|
294,88
|
1,12
|
|
10
|
6339
|
242
|
4795
|
103,97
|
410,56
|
3,97
|
310,56
|
1,04
|
|
11
|
6340
|
1
|
4796
|
100,02
|
410,62
|
0,02
|
310,62
|
1,0002
|
|
12
|
7079
|
739
|
5535
|
111,66
|
458,48
|
11,66
|
358,48
|
1,12
|
|
13
|
7249
|
170
|
5705
|
102,4
|
469,49
|
2,4
|
369,49
|
1,024
|
|
14
|
7400
|
151
|
5856
|
102,08
|
479,27
|
2,08
|
379,27
|
1,02
|
|
15
|
7680
|
280
|
6136
|
103,78
|
497,41
|
3,78
|
397,4
|
1,038
|
|
16
|
8226
|
546
|
6682
|
107,11
|
532,77
|
7,11
|
432,77
|
1,07
|
|
17
|
10473
|
2247
|
8929
|
127,32
|
678,3
|
27,32
|
578,30
|
1,27
|
|
18
|
11430
|
957
|
9886
|
109,14
|
740,28
|
9,14
|
640,28
|
1,091
|
|
19
|
13366
|
1936
|
11822
|
116,94
|
865,67
|
16,94
|
765,67
|
1,17
|
|
20
|
14090
|
724
|
12546
|
105,42
|
912,56
|
5,42
|
812,56
|
1,054
|
|
Σ
|
138642
|
|
|
yсер
|
6932,1
|
|
|
∆у
|
660,3
|
|
|
Тр
|
112,34
|
|
|
Тпр
|
12,34
|
|
Оскільки показники ряду динаміки змінюються за періодами, то
виникає необхідність їх узагальнення і розрахунку середніх показників. Середній
рівень ряду визначається за середньою арифметичною простою, тобто
.
Отже, маємо 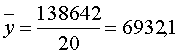
Середній абсолютний приріст
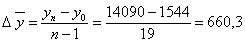
Середній темп зростання
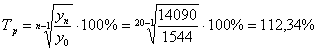
Середній приріст
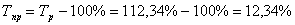
Розрахувавши середні показники ряду динаміки, ми можемо зробити
висновок, що середній темп зростання - 112,34%, а середній темп приросту -
12,34%. Таким чином говоримо, що даний ряд динаміки проявляє тенденцію до
збільшення на 12,34%.
Вирівнювання рядів динаміки
Вирівнювання рядів динаміки проводиться для виявлення тенденції
(тренду).
При розрахунку п’ятичленної ковзаючої
середньої кожен наступний інтервал утворюється на основі попереднього із
заміною одного рівня.
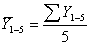 ;
;
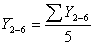 і т.д.
і т.д.
Середній темп зростання розраховується за допомогою коефіцієнта, який
знаходиться за формулою середньої геометричної
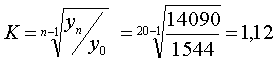 .
.
Розрахований коефіцієнт множимо на перший рівень ряду Y1 та отримуємо
середній рівень ряду Y2, помноживши даний Y2 на коефіцієнт K, отримуємо середній
рівень ряду Y3 і т.д., поки не отримаємо Yn.
Таблиця 10 - Вирівнювання ряду динаміки методом укрупнення періодів і
середньої плинної
|
Період
|
Рівень ряду
|
Метод укрупнення
середніх
|
Розрахунки
|
|
|
|
Середня ковзаюча
|
Середній темп
зростання
|
|
1
|
1544
|
3375,8
|
3375,8
|
-
|
|
2
|
3525
|
|
4118,2
|
1729,28
|
|
3
|
3624
|
|
4474,6
|
3948
|
|
4
|
4081
|
|
4836
|
4058,88
|
|
5
|
4105
|
|
5239,2
|
4570,72
|
|
6
|
5256
|
5686
|
5686
|
4597,6
|
|
7
|
5307
|
|
5902,8
|
5886,72
|
|
8
|
5431
|
|
6257,2
|
5943,84
|
|
9
|
6097
|
|
6620,8
|
6082,72
|
|
10
|
6339
|
|
6881,4
|
6828,64
|
|
11
|
6340
|
7149,6
|
7149,6
|
7099,68
|
|
12
|
7079
|
|
7526,8
|
7100,8
|
|
13
|
7249
|
|
8205,6
|
7928,48
|
|
14
|
7400
|
|
9041,8
|
8118,88
|
|
15
|
7680
|
|
10235
|
8288
|
|
16
|
8226
|
11517
|
11517
|
8601,6
|
|
17
|
10473
|
|
9871,8
|
9213,12
|
|
18
|
11430
|
|
7777,2
|
11729,76
|
|
19
|
13366
|
|
5491,2
|
12801,6
|
|
20
|
14090
|
|
2818
|
14969,92
|
Ряд динаміки
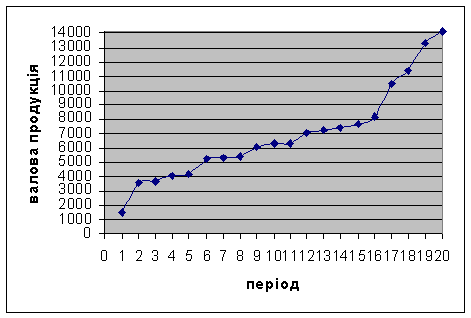
Проведемо згладжування даного ряду за п´ятичленною середньою таблиці
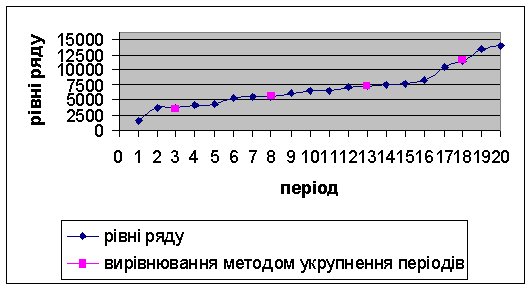
10. Отримаємо вирівнювання ряду методом укрупнення періоду.
Проводимо вирівнювання також методом середньої плинної.
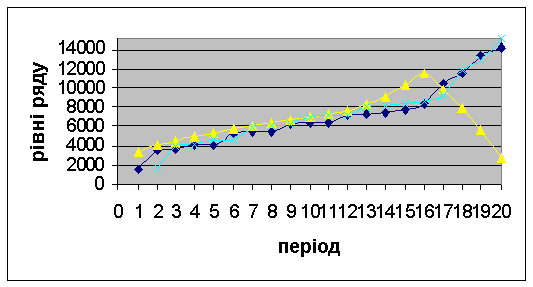
Для вирівнювання методом мінімальних квадратів або
аналітичним методом побудуємо таблицю.
Таблиця 11 - Вирівнювання методом мінімальних квадратів
y
|
t2
|
ty
|
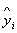
|
|
|
1
|
1544
|
1
|
1544
|
1932,9
|
|
|
2
|
3525
|
4
|
7050
|
2459,1
|
|
|
3
|
3624
|
9
|
10872
|
2985,3
|
|
|
4
|
4081
|
16
|
16324
|
3511,5
|
|
|
5
|
4105
|
25
|
20525
|
4037,7
|
|
|
6
|
5256
|
36
|
31536
|
4563,9
|
|
|
7
|
5307
|
49
|
37149
|
5090,1
|
|
|
8
|
5431
|
64
|
43448
|
5616,3
|
|
|
9
|
6097
|
81
|
54873
|
6142,5
|
|
|
10
|
6339
|
100
|
63390
|
6668,7
|
|
|
11
|
6340
|
121
|
69740
|
7194,9
|
|
|
12
|
7079
|
144
|
84948
|
7721,1
|
|
|
13
|
7249
|
169
|
94237
|
8247,3
|
|
|
14
|
7400
|
196
|
103600
|
8773,5
|
|
|
15
|
7680
|
225
|
115200
|
9299,7
|
|
|
16
|
8226
|
256
|
131616
|
9825,9
|
|
|
17
|
10473
|
289
|
178041
|
10352,1
|
|
|
18
|
11430
|
324
|
205740
|
10878,3
|
|
|
19
|
13366
|
361
|
253954
|
11404,5
|
|
|
20
|
14090
|
400
|
281800
|
11930,7
|
|
|
210
|
138642
|
2870
|
1805587
|
138636
|
Сума
|
|
-
|
6932,1
|
143,5
|
90279,35
|
6932,1
|
середні
|
|
|
|
|
|
|
|
|
|
Для побудови рівняння тенденцій або рівняння тренду виду  скористаємося методом кореляційно-регресійного
аналізу і знайдемо коефіцієнти а0, а1 з системи:
скористаємося методом кореляційно-регресійного
аналізу і знайдемо коефіцієнти а0, а1 з системи:

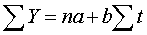 ;
;
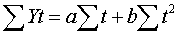 .
.
Для знаходження невідомих параметрів складаємо систему нормальних
рівнянь використовуючи дані таблиці:
а0 + 210а1 = 138642
а0 +2870а1 = 1805587
Із даної системи рівнянь знаходимо шукані параметри а0, а1:
а0 = 1406,7
а1 = 526,2
Отримавши потрібні параметри, складаємо рівняння, за допомогою якого
знаходимо теоретичне значення допоміжної ознаки Y.
Отже, маємо рівняння тренду 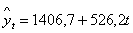
Аналітичне вирівнювання
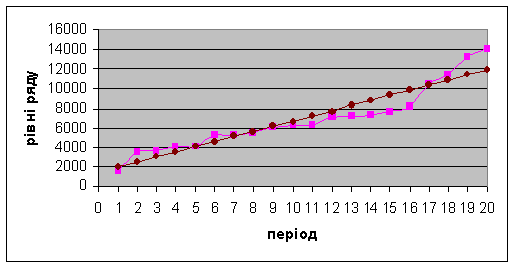
. Індекси ряду
Цей метод широко використовується під час статистичного
аналізу роботи підприємств, галузей усього народного господарства.
Індексний метод дає можливість визначити ступінь впливу
окремих факторів на загальний результат.
Індекси - це відносні величини, які характеризують явище у
розвитку, динаміці, часі і просторі. Індекси поділяються на індивідуальні та
загальні.
Для розрахунку індивідуальних індексів необхідно величину
одного елемента складного явища за один період віднести на його величину в
другому періоді, прийнятому за базу для порівняння. У статистиці позначають
кількість буквою q; ціну буквою Р; собівартість буквою Z; затрати часу на
виробництво продукції буквою Т [або t].
Індивідуальні індекси визначаються такими формулами:
індекс фізичного обсягу iq=q1/q0;
індекс цін iр=р1/р0;
індекс собівартості iz=z1/z0;
індекс трудомісткості it=t1/t0.
Загальні індекси показують
співвідношення сукупності явищ, котрі складаються з різнорідних, безпосередньо
не порівнюваних елементів. Загальний індекс розраховується за формулою
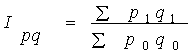 .
.
Це агрегатна формула індексів. Чисельник та знаменник тут приводять до
порівняльного вигляду за допомогою таких сумірників, як ціна, собівартість,
трудомісткість одиниці продукції.
У формулі 1 обсяг продукції в натуральних показниках, а ціна
- в грошовій формі змінюється як у базисному, так і в звітному періоді, тому
таку формулу називають агрегатний індекс перемінного складу.
Якщо зафіксувати ціну на продукцію на базисному рівні,
одержимо індекс, який показує зміну тільки обсягу виробництва в базисних цінах
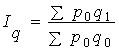 .
.
Такий індекс називають індексом фізичного обсягу виробленої продукції в
порівняльних цінах.
Якщо зафіксувати обсяг виробництва продукції на рівні звітного періоду,
а ціни змінювати в кожному періоді, то отримаємо індекс, котрий показує вплив
цін на загальний індекс
 .
( 3 )
.
( 3 )
Ці індекси зв’язані між собою
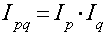 .
( 4 )
.
( 4 )
Щоб визначити вплив окремих факторів на результативний показник в
абсолютних величинах, коли фактори співзалежні між собою, застосовуються
формули
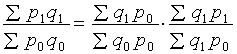 .
.
Абсолютний вираз, який характеризує зміну обсягу виробництва в
грошовому вигляді у звітному періоді порівняно з базисним, має вигляд
Sq1p1-Sq0p0=Spq.
Щоб визначити вплив тільки обсягу виробництва, застосовують формулу
підстановок
Dq= (q1-q0)
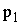 .
.
Вплив ціни на абсолютний обсяг виробництва знаходимо за формулою
Dp=q0(p1-p0),
звідси Dpq=Dq+Dp.
Співзалежні величини досить часто зустрічаються в статистичних
розрахунках. Тому при аналізі це враховується, і вплив кожного фактора
визначають за допомогою індексних систем.
Список використаної літератури
1. Фінансова статистика (з основами теорії статистики):
Навч. посіб./ Головач А.В., Захожай В.Б. -К.:МАУП, 2002. - 224с.
2. Опря А.Т. Статистика. Математична статистика.
Теорія статистики. Навчальний посібник. - Київ: Центр навчальної літератури,
2005. - 472с.
3. Методичні рекомендації та вихідні
дані до контрольної роботи з дисципліни «Статистика» для слухачів центру
післядипломної освіти економічних спеціальностей усіх форм навчання. - Полтава:
ПолтНТУ, 2006. -33с.