|
С, им. +
|
как словно будто что точно как будто
|
С, им. «Иван что герой»
|
Корпус примеров.
Там, где есть тире, Синтаксис именует клаузу «ТИРЕ», где тире
нет, там оно восстанавливается и Синтаксис именует клаузу «ТИРЕ». Примеры,
выделенные жирным шрифтом, не обрабатываются в соответствии с указанными после
них правилами.
«Петя - человек»
«вести свое хозяйство на крестьянский лад» (см
правило 5)
«жить все равно что родине служить» (см правило 3)
«дом, построенный на холме, - большой»
«Вчера в лесу мы работали старой пилой, а сегодня
во дворе - новой». Определение типа фрагмента
Типом фрагмента может быть ровно одно значение из списка.
Начиная с первого значения из списка, по порядку проверяется есть ли в данном
фрагменте слово этой части речи. Если такое слово найдено и у него нет омонимов
других частей речи, то дальнейшие поиски прекращаются и тип фрагмента -
значение, на котором остановились. Если для данного значения из списка не
нашлось неомонимичных (с точностью до части речи) подходящих слов, но есть
омонимичные, тогда для фрагмента не устанавливается однозначно тип, а
постулируется несколько вариантов, которые либо уничтожатся на уровне
семантики, либо останутся в выходной структуре.
Пример: на этот раз она не права
Для этого фрагмента есть два варианта:
1. Тип фрагмента - краткое прилагательное (права - ж.р., ед.
ч. от правый)
2. Тип фрагмента - пустыха (права - и.п./в.п. мн. ч.;
р.п. ед. ч. от право)
Пример: мои права забрали в милиции
Для этого фрагмента тип определяется однозначно, т.к. забрали
- неомонимичный глагол в личной форме. Глагол в личной форме стоит в списке на
первом месте, дальнейшие поиски возможных вершин фрагмента не ведутся.
Алгоритм выявления ВВОДНЫХ
Проверка клаузы на наличие вводных слов.
Если найдено слово из списка 1 вводных слов (см. ниже), при
этом оно ограничено с обеих сторон какими-либо знаками препинания из следующих:
1. запятая,
2. точка,
. вскл. знак,
. вопр. знак,
. точка с запятой,
. тире,
. двоеточие,
. начало предложения (Бб),
. конец предложения,
. кавычки.
То это слово «ВВОДН»
Дополнительное правило:
Если слева от вводного слова стоит сочинительный союз или
частица, не отделенные от него знаком препинания, то они включаются в клаузу
«ВВОДН». («Она двинулась в путь, и наверно, быстро бы достигла цели, если бы не
гроза.»)
Определение
союзов и союзных слов фрагмента
Сначала определяется, нет ли такого сложного союза (из файла
оборотов obor.dic), начало которого (слово с пометой Об1) находится в соседнем
слева фрагменте, а конец (помета Об2) в данном. (Это такие сложные союзы,
которые разделяются запятой, часто имеют варианты, при которых запятая стоит
перед всем союзом - для того, чтобы; с тем, чтобы; потому, что и др.) Если
такой союз есть, то он относится к данному фрагменту, т.е. к тому, в котором
заканчивается. Далее все слова фрагмента, у которых есть омоним - союз,
считаются союзами данного фрагмента. Эта процедура несовершенна и требует
доработки с учетом индивидуальных особенностей отдельных союзов.
Работа
с фрагментами
В правилах обработки фрагментов может использоваться как
стандартная информация (см. структура фрагмента), так и сведения об отдельных
словах.
Правила,
устанавливающие иерархию
Здесь мы рассмотрим правила, которые один фрагмент вкладывают
в другой.
) Алгоритм вкладывания «ВВОДН»
Процесс вкладывания, а не слияния клаузы «ВВОДН» происходит
на синтаксисе до объединения всех групп «ГЛ_личн», «КР-прил» и др. Клауза
«ВВОДН» вкладывается в другие клаузы слева или справа следующим образом:
1. Если «ВВОДН» - первая клауза в предложении. Если с правой
стороны от «ВВОДН» стоит Подчиненное предложение любого типа («ГЛ_ЛИЧН когда»,
«Наверно, когда пошла домой, она что-то забыла.»), то «ВВОДН» в него не
вкладывается, в остальных случаях происходит вложение.
2. Если после следующих слов, имеющих омоним «ВВОДН»,
стоит подчинительная клауза со «что» («бесспорно, что это так»), то омоним
«ВВОДН» убивается и ставится «ПРЕДК»:
. Если «ВВОДН» - последняя клауза в предложении. В
таком случае «ВВОДН» всегда вкладывается в левую клаузу.
. Если «ВВОДН» ограничено с одной стороны запятой, а с
другой другим знаком препинания или запятой и еще одним знаком препинания, то
«ВВОДН» вкладывается в клаузу со стороны запятой безотносительно к
иерархическому статусу оной. (» - Не знаю, - прошептал Врумфундель, - наверно,
наши мозги слишком натренированы, Маджиктиз.» «Убийца потерял что-то - наверно,
пальто.»,» - Да нет, конечно, - вздохнул Зафод.»)
. Если обе клаузы слева и справа от «ВВОДН» имеют
союз, то клауза «ВВОДН» вкладывается в левую клаузу независимо от иерархии. («И
пошла Маша домой, наверно, а не в гости.»)
. Если обе клаузы слева и справа без союзов и если в
составе клаузы «ВВОДН» имеется союз или частица («Она пошла в гости, приготовив
ужин, и наверно, поев.»), то клауза «ВВОДН» вкладывается в правую клаузу
независимо от иерархического уровня последней, за исключением случаев конца
предложения и других знаков препинания с правой стороны, кроме запятой.
Имеет место следующая иерархия:
1. ГЛ_ЛИЧН («Она, наверно, пошла гулять», «Зеленые, красные
и сиреневые облака, наверно, плыли над нами.», «Какую, наверно, она возбуждает
зависть у других!» «Такого царственного существа, наверно, больше нигде не
найдешь.») // но: Я думаю, наверно, наши мозги слишком натренированы.
2. ПРЕДК («Возможно, конечно, наши мозги слишком
натренированы.», «Это, наверно, интересно»)
. КР_ПРИЛ («Она, наверно, красива»)
. КР_ПРЧ («Оттого, наверно, наши мозги слишком
натренированы.»)
. ДПР («Она, приготовив, наверно, ужин, пошла в кино»)
. ПРЧ («Она, строящая, наверно, дом, умна», «Дом,
наверно, строящийся рабочими.»)
. ИНФ («Нам, наверно, уходить?»)
. СРАВН («Ему, наверно, было немногим больше двадцати
лет.»)
. ПУСТЫХА («Дом, наверно, который построил Джек,
развалился.»)
. ВВОДН (» - Конечно, конечно, - сказал Зафод.», «Я,
конечно, конечно, с тобой согласен.» «Она пришла, конечно, наверно, министр ее
примет» или «Она пришла, конечно, и конечно же, министр ее примет»)
Вывод: Чем меньше номер у типа клаузы, тем больше связывающей
силы она имеет, но иерархия не работает, если клауза имеет союз. («Стена
джунглей, тянувшаяся покуда хватало глаз и, наверно, еще на добрых две тысячи
миль.», «Если это был и ты, наверно, ты не прав.»), хотя «Но у них, наверно, по
всему лесу рыщут разведчики.», «Это была, наверно, только приписка.»
.1) Дополнительные правила объединения клауз после
вкладывания «ВВОДН»:
Если правая клауза имеет сочинительный союз, то объединения
клауз после вкладывания «ВВОДН» не происходит.
а) Если мы имеем линейную цепочку «Пустыха», «ВВОДН», «Х»,
где «Х» - любая из групп выше по вышеприведенной иерархии («это, конечно,
здорово»), чем «Пустыха», то «Пустыха» присоединяется к получившейся клаузе после
того, как ВВОДН» вольется в правую от себя клаузу.
б) Если мы имеем цепочку «Х», «ВВОДН», «Пустыха», где «Х» -
любая из групп выше по вышеприведенной иерархии, чем «Пустыха» («На этот вот
момент, конечно, главная из новостей - пройдоха Президент.»), то она
(«Пустыха») присоединяется к получившейся слева клаузе после вливания «ВВОДН»
только в том случае, если
) не имеет союза перед собой, («Они пошли, наверно, в лес, а
затем решили остановиться.»)
) если она является последней клаузой в предложении или после
стоит («ГЛ_личн» || «КР_ПРИЛ» || «КР_ПРЧ» || «ПРЕДК») без подчинительного союза
(«Пойдем, наверно, в кино.»)
в) Если с одной стороны от «ВВОДН» (В1) стоит еще одна
«ВВОДН» (В2), а с другой другая клауза Х, то В1 и В2 вкладываются в клаузы в
соответстсвии с иерархией. Мы отказались от правила первичного объединения двух
«ВВОДН» ввиду множества контр примеров типа «Она пришла, конечно, наверно,
министр ее примет» или «Она пришла, конечно, и конечно же, министр ее примет»,
где они относятся к разным клаузам.
Общий корпус примеров на вкладывание «ВВОДН» (подчеркнутый
курсив - противоречит правилу):
«Стена джунглей, тянувшаяся покуда хватало глаз и, наверно,
еще на добрых две тысячи миль.»
«Такого царственного существа, наверно, больше нигде не
найдешь.»
«Убийца потерял что-то - наверно, пальто.»
«Я все любил: и зиму, конечно, и весну.»
) Причастный оборот (применяется к фрагментам с типом
причастие)
а) Проверка, не стоит ли причастие, вершина фрагмента, перед
определяемым словом: поиск существительного, совпадающего с причастием по роду,
числу и падежу. Если такое существительное есть, происходит повторное
определение типа фрагмента (тип причастие исключается) и выход из правила.
Иначе переход к пункту б).
б) Поиск в соседнем левом фрагменте существительного или
местоимения, совпадающего с причастием в роде числе и падеже. Если такое слово
найдено, то данный фрагмент (причастный оборот) вкладывается в соседний левый и
выход из правила. Если слово не найдено, выход из правила.
) Фрагмент со словами который, какой, чей
Если в соседнем левом фрагменте есть существительное или
местоимение, совпадающее с который (какой, чей) в роде и числе, данный
фрагмент вкладывается в соседний левый.
) Фрагмент с союзом что или чтобы
Фрагмент с подчинительным союзом что или чтобы с вершиной не
«пустыха», не «вводное слово», не «инфинитив» (если союз - что) вкладывается в
соседний левый фрагмент с вершиной не «пустыха», не «вводное слово», не
«инфинитив» (если в нем нет союза чтобы).
) Деепричастный оборот (применяется к фрагментам с
типом деепричастие)
Фрагмент с вершиной - «деепричастие» вкладывается в соседний
левый, если у того вершина - глагол в личной форме, иначе - в соседний правый,
если у него вершина - глагол в личной форме, нет подчинительных союзов.
Правила,
объединяющие фрагменты
1) Правило присоединения фрагментов типа «пустыха» к
фрагменту с предикатной вершиной
Если есть цепочка «пустых», разделенная либо запятыми, либо
сочинительным союзом без запятой, и слева от первой «пустыхи» стоит фрагмент не
«пустыха» и не «вводное слово», тогда с этим фрагментом объединяй всю цепочку.
Если с этой цепочки начинается предложение или перед ней стоит точка с запятой
или двоеточие, а справа от этой цепочки стоит фрагмент не «пустыха» и не
«вводное слово» и при этом без подчинительных союзов, тогда с этим фрагментом
объединяем всю цепочку.
Пример: Я знаю Петю, Васю.
На первом этапе «Вася» был отдельной Пустыхой, после же
отработки этого правила «Вася» подсоединиолся к «Я знал Петю».
) Правила для объединения разорванных фрагментов и поиска
слова, управляющего вложениями в них присубстантивных фрагментов.
Работают после анализа сочинения.
Ситуации правил ищутся в предложении справа налево.
Группа правил (4 Правила) соединения
.1 «пустых» без подлежащего в начале предложения или
фрагментов с подчинительным союзом без подлежащего и без сказуемого с
фрагментом со сказуемым.
.2 фрагментов с подлежащим и без ПРЕД в начале предложения
или фрагментов с подчинительным союзом и подлежащим с фрагментом - «пустыхой»
или фрагментом с ПРЕД.
Что: {Фрагмент-k (первый в предложении* или с
подчинит. союзом и в нем нет сущ в именит. п., нет ПРЕД и в него включено
обособленное согласованное определение)+(фрагмент-k+i с ПРЕД) или
{Фрагмент-k (первый в предложении* или с подчинительным
союзом и в нем нет существительного в им. п и нет ПРЕД)+ (фрагмент-k+i с ПРЕД и
со включенным в него деепричастным оборотом)}
Строим: соединяем фрагменты k и k+i в один
Примеры: …когда на столе, покрытом скатертью, они расставили
тарелки…
…если, решая задачу, он ошибся,… Вчера, решая задачу, он
ошибся…
На столе, покрытом скатертью, стояли тарелки.
Что: фрагмент-k: первый в предложении* или с подчинит.
союзом и в нем нет сущ. в им. п и нет ПРЕД)+ (фрагмент k+i с подчинительным
союзом) + фрагмент k+i+n: первый фрагмент справа - не придаточное\деепричастный
оборот\ обособленное определение)
Строим: фрагмент-k объединить с фрагментом k+i+n в
один.
Что: {Фрагмент-k (первый в предложении или с подчинит.
союзом, без предиката и с сущХ или с группой, вершина которой - сущХ:
существительное, или местоимение, или колич. числ в им. п. или с сущХ: группой
сочиненных сущ или групп - в им. падеже, в который вложено согласованное
определение или фрагмент с который) + фрагмент k+i с ПРЕД} или {Фрагмент-k
(первый в предложении или с подчинит. союзом, без ПРЕД и с сущХ) +
(фрагмент-k+i с ПРЕД и вложенным фрагментом с деепричастием)}
Условия: сущХ согласуется с ПРЕД.
Строим: фрагмент-k объединить с фрагментом-k+i
Когда он, пытаясь решить задачу, сделал чертеж, пошел
дождь.
Он увидел, что на столе, над которым висела лампа, были горой
навалены учебники.
Что: (Фрагмент-k: первый в предложении или с
подчинительным союзом, без ПРЕД и с сущХ) + (фрагмент-k+i: ближайщий без
подчинительного союза с ПРЕД)}
Условия: сущХ согласуется с ПРЕД
Строим: фрагмент-k и фрагментК+1 сливаем в один фрагмент.
Примеры: Город, где он никогда не был, казался ему уродливым.
Город, где он, когда учился, жил, был ему дорог.
Город, где башня, когда она строилась, сгорела, был ему дорог.
Алгоритм определения хозяина присубстантивного фрагмента.
Правило ХС-1.
Что: фрагмент-k + (фрагмент-k+1 с где \ чей \ кто\
когда \куда \откуда
Условия: во фрагменте-k есть СУЩ:
существительное со слугою - местоим. прил. (тот, такой, каждый, всякий, любой,
некоторый,)
Строим: СУЩ - хозяин вложенного фрагмента.
Примеры:…тот город, где он жил, расположен….тот город,
где он жил, расположен.
(Если в то время \тот день\, когда он…, приедет его брат…в
том городе, куда \ откуда он едет.,
Правило ХС-2
Что: фрагмент-k + фрагмент-k+1 с кто или чей
Условия: во фрагменте-k контактно к фрагменту-k+1 есть
МЕСТ: местоименное сущ: тот, каждый, всякий, любой, все, никто, кто-нибудь,
кто-то, кое-кто, любой, любая прочие
Строим: ближайшее МЕСТ - хозяин фрагмента-k+1
Примеры:…тот, кто этого не знает, не решит…с каждым, чьими
вычислениями они пользовались, договориться было бы…
Правило ХС-3
Что: фрагмент-k + фрагмент-k+1 со что (в любой форме)
Условия: во фрагменте-k контактно к фрагменту-k+1 есть
МЕСТ: все, ничто, что-нибудь, что-то, кое-что,
Строим: МЕСТ - хозяин вложенного фрагмента.
Примеры: что-то, что было им важно, они не знали
Правило ХС-4.
Что: фрагмент-k + (фрагмент-k+1 со что, в котором нет
сущ. в им. п.
Условия: непосредственно слева от фрагмента со что стоит сущ.
(или группа с вершиной-сущ), согласующееся с ПРЕД вложенного фрагмента
Строим: это сущ - хозяин фрагмента-k+1
Примеры:..стол, что стоял\стоит у окна, был покрыт…об
истории, что была тогда рассказана, он ничего не знал…
Правила
построения фрагмента необособленного согласованного определения
Правила формирования групп с прилагательным\причастием в
препозиции к существительному - вершине со вставлениями (=НСО) и ПГ, где
предлогу подчинен НСО.
Анализирует:
. согласованные определения, выраженные прилагательными и
причастиями в препозиции к существительному-хозяину и осложненные вложениями
предложных оборотов и беспредложных существительных между согласованным
определением и его хозяином (готовый ко всему мальчик) и
. предложные группы со вставлениями между предлогом и его
слугою вложений, задаваемые ситуациями п. 1 (на покрытом скатертью столе).
Правило 7 для анализа именной группы со вложениями ПГ
Что: цепочка (прилагательное или причастие)л
- ПГ - (прил_сущ. или одиночное существительное)n.
Условие: (прил\прич)л согласуется по числу
и падежу, а в ед. ч. - по роду с (прил_сущ. или одиночным сущ.)n.
Строится: 1. группа (прил\прич.)л + ПГ, где
(прил\прич)л - вершина.
. группа (прил\прич)л + (прил_сущ. или один. сущ.)n
с вершиной - существительным.
Примеры:… удобным по всем показателям новым методом…,…
готовый к новому большому и очень трудному походу молодой воин…
Правило 8 для анализа группы прил-сущ со вложениями
между вершиной и прилагательным\ причастием - слугою других групп прил-сущ
Что: цепочка (прилагательное\ причастие)л +
(группа прил_сущ.. или одиночное существительное\местоимение)i
+(прил_сущ. или одиночное сущ.)n
Условия:
. (прил. или прич)к согласуется по падежу и числу
с (прил_сущ или одиночным сущ.)n
. (группа прил_сущ или одиночное существительное\местоимение)i
не в неомонимичном им. падеже.
Строится:
. группа (прилагательное\причастие)л + (прил_сущ.
или одиночное существительное)i с вершиной - прилагательным\
причастием)к.
. группа (прилагательное\причастие)i + (прил_сущ
или одиночное сущ.)n с существительным - вершиной.
Примеры:… видящему всех псу, строящим высокие дома англичанам
Правило 10 для построения ПГ с именными группами,
построенными по правилам 7-9.
Что: цепочка предлог+НСО
Условие: предлог может управлять одним из падежей вершины
НСО.
Строится: группа предлог + НСО, где предлог - вершина.
Примеры: на лежащем под ним ковре, к ожидающему
неприятностей мальчику, для известного всем старшего дворника
2.3.4 Взаимодействие
с синтаксическим анализом
Синтаксический анализ проводится на каждом фрагменте
отдельно. На фрагментах, полученных объединением по правилу о простых случаях
однородности, могут построиться синтаксические группы однородных членов.
Основные механизмы взаимодействия между фрагментами и их синтаксическими вариантами:
1. При объединении фрагментов объединяются их синтаксические
варианты (каждый с каждым, чтобы получить декартово произведение омонимов для
нового фрагмента).
2. При вложении фрагмента в лево- или правостоящий
фрагмент, происходит перемножение типов вкладываемого фрагмента на
синтаксические варианты главного фрагмента. Каждый омоним типа вкладываемого
фрагмента представляется как юнит (см. синтаксис) и добавляется в начало или
конец синтаксического варианта.
. При построении фрагмента необособленного
согласованного определения внутри существующего предложения, фрагмент
необособленного согласованного определения внутри синтаксических вариантов
представляется как юнит.
Существует механизм для объединения дистантных и рядом
стоящих фрагментов, который объединяет лучшие синтаксические варианты и строит
по всем существующим синтаксическим правилам группы для нового варианта, а
затем ищет группы построенные на границе объединения или подлежащее и сказуемое
по разные стороны границы объединения. Если поиск успешен, то объединение двух
фрагментов возможно.
2.4 Морфологический
анализ
синтаксический морфологический текст графематический
Данный блок позволяет получить морфологическую информацию о
словах в тексте.
2.4.1 Структура
морфологического словаря
Морфологический словарь, или лексикон, содержит все
словоформы одного языка, в нашем случае русского.
2.4.2 Русский
морфологический словарь
Русский морфологический словарь базируется на грамматическом
словаре А.А. Зализняка[50]. Включает на данный момент 161 тыс. лемм.
При лемматизации для каждого слова входного текста выдается
множество морфологических интерпретаций следующего вида:
· морфологическая часть речи;
· набор общих граммем
(которые относятся ко всем словоформам парадигмы слова).
· множество наборов
граммем.
Ниже мы приводим полный перечень русских частей речи:
|
Часть речи в системе
|
Пример
|
Расшифровка
|
|
C
|
мама
|
существительное
|
|
П
|
красный
|
прилагательное
|
|
МС
|
он
|
местоимение-существительное
|
|
Г
|
идет
|
глагол в личной форме
|
|
ПРИЧАСТИЕ
|
идущий
|
причастие
|
|
ДЕЕПРИЧАСТИЕ
|
идя
|
деепричастие
|
|
ИНФИНИТИВ
|
идти
|
инфинитив
|
|
МС-ПРЕДК
|
нечего
|
местоимение-предикатив
|
|
МС-П
|
всякий
|
местоименное прилагательное
|
|
ЧИСЛ
|
восемь
|
числительное (количественное)
|
|
ЧИСЛ-П
|
восьмой
|
порядковое числительное
|
|
Н
|
круто
|
наречие
|
|
ПРЕДК
|
интересно
|
предикатив
|
|
ПРЕДЛ
|
под
|
предлог
|
|
СОЮЗ
|
и
|
союз
|
|
МЕЖД
|
ой
|
междометие
|
|
ЧАСТ
|
же, бы
|
частица
|
|
ВВОДН
|
конечно
|
вводное слово
|
Граммема - это элементарный морфологический описатель,
относящий словоформу к какому-то морфологическому классу, например, словоформе
стол с леммой СТОЛ будут приписаны следующие наборы граммем: «мр, ед, им, но»,
«мр, ед, вн, но». Таким образом, морфологический анализ выдает два варианта
анализа словоформы стол с леммой СТОЛ внутри одной морфологической
интерпретации: с винительным (вн) и именительным падежами (им).
Ниже перечислены все используемые граммемы:
мр, жр, ср - мужской, женский, средний род;
од, но - одушевленность, неодушевленность;
ед, мн - единственное, множественное число;
им, рд, дт, вн, тв, пр - падежи: именительный, родительный,
дательный, винительный, творительный, предложный;
св, нс - совершенный, несовершенный вид;
пе, нп - переходный, непереходный глагол;
дст, стр. - действительный, страдательный залог;
нст, прш, буд - настоящее, прошедшее, будущее время;
пвл - повелительная форма глагола;
л, 2 л, 3 л - первое, второе, третье лицо;
- неизменяемое.
кр - краткость (для прилагательных и причастий).
сравн - сравнительная форма (для прилагательных).
имя, фам - имя, фамилия.
лок, орг - локативность, организация.
кач - качественное прилагательное.
вопр, относ - вопросительность и относительность (для
наречий).
дфст - слово обычно не имеет множественного числа.
опч - частая опечатка или ошибка.
жарг - жаргонизм.
Как уже было сказано, одной словоформе может соответствовать
много морфологических интерпретаций. Например, у словоформы стали две
интерпретации:
· {СТАЛЬ, C, «но», («жр, ед, рд», «жр, ед, дт»,
«жр, мн, им», «жр, мн, вн»)};
· {СТАТЬ, Г, «нп, св»,
(«мн, дст, прш»)}.
3.
Разработка базы данных синтаксических правил
База синтаксических правил состоит из двух
сущностей:
· Правила
· Элементы
Структура таблицы «Правила» представлена
на рисунке 3.1.
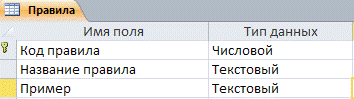
Рис. 3.1
Структура таблицы «Элементы» представлена
на рисунке 3.2.
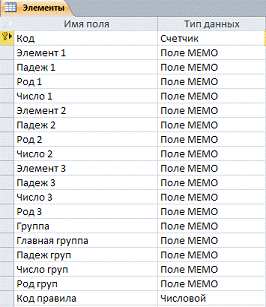
Рис. 3.2
3.1 Построение логической модели базы данных в
рамках методологии IDEF1Х
Логический уровень - это абстрактный взгляд на данные, на нем
данные представляются так, как выглядят в реальном мире, и могут называться
так, как они называются в реальном мире. Объекты модели, представляемые на
логическом уровне, называются сущностями и атрибутами. Логическая модель данных
является универсальной и никак не связана с конкретной реализацией СУБД.X
(IDEF1 Extended) - методология описания данных, использующаяся для
моделирования реляционных баз данных, имеющих отношение к рассматриваемой
системе. Методология IDEF1X определяет стандарты терминологии, используемой при
информационном моделировании, и графического изображения типовых элементов на
диаграммах. Логическая модель базы данных синтаксических правил представлена на
рисунке 3.1.1
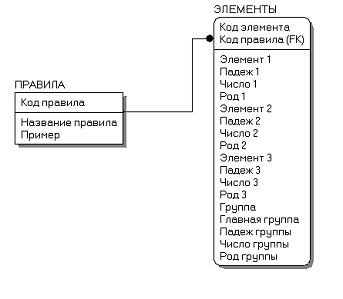
Рис. 3.1.1
Заключение
В ходе практической работы была разработан алгоритм
синтаксического анализа русскоязычных текстов база данных синтаксических правил
русского языка, а так же база данных синтаксических правил. В данной программе
предусмотрена печатная форма отчетности. В дальнейшем этот алгоритм и база
данных могут пригодиться для разработки синтаксического анализатора текста.
Список литературы
1. Синтаксис
современного русского языка. -
http://www.hi-edu.ru/e-books/xbook089/01/part-002.htm
2. Автоматическая
обработка текста. - http://aot.ru/docs/synan.html
3. Гладкий
А.В. Синтаксические структуры естественного языка в автоматизированных системах
общения. М., 1985 г.
4. Панкратов
Д.В., Гершензон Л.М. Описание синтаксического анализа в системе Диалинг. -,
1999.