Система семантического разбора для естественно-языковых текстов
СОДЕРЖАНИЕ
Введение
. Обзор и
анализ существующих средств семантического разбора естественно-языковых текстов
. Постановка
задачи
Анализ
алгоритмов для системы обработки естественно-языковых текстов
.1
Графематический анализ
.1.1 Входные
и выходные данные
.1.2
Графематические дескрипторы
.1.3Деление
на предложения
.2
Морфологический анализ
.3
Синтаксический анализ
.4
Семантический анализ
. Структура
системы построения семантического разбора для естественно-языковых текстов
.1
Графематический анализ
.2 Морфологический
анализ
.4
Статистический анализ
.4
Синтаксический анализ
.5
Семантический анализ
.
Использования н-граммного словаря msr
.1 Методы
хранения словарей
.2 Описание
морфоанализатора для словаря
.3 Таблицы
кодирования постоянных грамматических характеристик
.4 Таблицы
кодирования переменных грамматических характеристик
. Алгоритмы
анализа системы
.1 Алгоритм
графематического разбора
.2 Алгоритм
морфологического разбора
.3 Алгоритм
синтаксическо-семантического разбора и построения сети
.
Проектирование интерфейса
.1 Требования
к разработке интерфейса
.2 Интерфейс
системы
. Структура
программного обеспечения
. Описания
функционирования и тестирование системы
.1 Описания
функционирования
.2
Тестирования программного кода
10.
Требование к оборудованию при эксплуатации ЭВМ
.
Организационно-экономическая часть
Выводы
Список
использованных источников
Приложение А.
Техническое задание
Приложения В.
Экранные формы
Приложение Б.
Листинг программы
ВВЕДЕНИЕ
Наиболее естественным для человека способом общения является естественный
язык (ЕЯ), Предлагаемые методы ориентированы на решение поставленной проблемы
путем создания русскоязычных онтологических информационных систем.
Проблема создания тезаурусов и глоссариев как информационной базы
является ключевым моментом в любой предметной области на определенном этапе ее
развития. При этом в настоящий момент нет русскоязычной ментальной модели
лексикона человека, дающей возможность динамического развития семантических
понятий предметной области, связанной с информационными технологиями.
Разработка автоматизированной системы семантического анализа является
основой программного обеспечения с пользовательским интерфейсом, близким к
естественно-языковому. Построение тезаурусов должно способствовать снятию
проблемы терминологической путаницы в работе информационных систем.
Анализ существующих исследований, посвященных решению задачи
автоматизированного построения тезаурусов, выявил крайне незначительное число
готовых и апробированных решений, что во многом связано с отсутствием
достаточно проработанной теории и практики решения задач анализа
неструктурированной, естественно-языковой текстовой информации. Эффективное
решение задачи разработки программы, реализующей динамическую визуализацию
понятийных окружений, и составляет суть диссертационной работы.
Исследования в области автоматической обработки текста и формализации
естественных языков, планомерно продвигаясь от самых простых методов анализа к
более сложным методам. Данные исследования постепенно приближаются к такому
уровню обработки текста, на котором уже возможно представление текста не просто
в виде последовательности слов, а единым целым, обладающим неким смыслом, что
уже соответствует человеческому восприятию.
Стремительное увеличение вычислительных мощностей сделало возможным
применение трудоёмких лингвистических алгоритмов на больших объемах данных. Но,
несмотря на то, что в области формализации естественных языков и систем
автоматической обработки текста, в частности, задействовано большое количество
людей и мощностей, работающих в самых разных направлениях. Результаты пока
довольно скудны, так как ни одна из существующих моделей не может перекрыть
структуру языка в целом, а объёмы данных, с которыми имеет дело лингвистика,
очень большие.
Такое положение вещей само собой рождает задачу создания системы, удобной
для отработки различных решений анализа с целью нахождения наиболее оптимальных
и эффективных. Этому способствует то, что как сам анализ, так и программные
комплексы, реализующие данные подходы, достаточно легко поддаются фрагментации,
т.е. делению на функциональные блоки, выполняющие изолированную
функциональность. Исходя из данной специфики проблемной области, наиболее
естественной задачей являлось создание модульного программного испытательного
стенда, дающего возможность реализации отдельных функциональных блоков,
применяя для каждого из них последние достижения в данной области, а затем
реализовать их совместную работу путём точной настройки каждого из них в
отдельности и гибкой компоновки между собой.
1. ОБЗОР И АНАЛИЗ СУЩЕСТВУЮЩИХ СРЕДСТВ СЕМАНТИЧЕСКОГО РАЗБОРА
ЕСТЕСТВЕННО-ЯЗЫКОВЫХ ТЕКСТОВ
Перед тем как анализировать различные существующие средства
семантического разбора естественно-языковых текстов, необходимо понять, что
собой представляет семантический разбор.
Семантическим разбором, в данном случае, является извлечение, из текста,
сведений об интересующих объектах, фактах и событиях. Полученные таким образом
сведения представляются в формализованной форме в виде объектов предметной
области и связей между ними, после чего поступают на обработку традиционными
методами в зависимости от текущих задач.
Мы привыкли к тому, что компьютеры, как правило, работают со
структурированными и формализованными данными. Это могут быть базы данных с
таблицами и полями, электронные формы и карточки объектов, тексты программ на
формальных языках и инструкции (программы) в машинных кодах. Вместе с тем, для
человека наиболее естественной формой представления информации является
естественный язык, то есть применительно к компьютеру, это записанный в
документ текст. Какие возможности по обработке текста нам предоставляют
современные информационные средства? Это, прежде всего, хранение, передача,
поиск и проверка орфографии. Но все эти сервисы относятся непосредственно к
текстовому представлению (символам, в лучшем случае - словам и фразам), а не к
информации, которая в этих текстах содержится! В итоге складывается ситуация,
когда в организации накоплен значительный объем текстовых документов, но
информация, содержащаяся в них, не доступна для обработки классическими
автоматизированными средствами. Семантический анализ текстов позволяет
эффективно использовать эти информационные ресурсы для решения различных задач.
Одна из таких систем является информационно-аналитическая система
"АРИОН" - мощное средство работы с разнородными источниками
информации, использующее инновационные технологии извлечения и обработки знаний
[1].
Система позволяет работать как со структурированными (таблицы, базы
данных, xml), так и неструктурированными (документы и тексты на естественном
языке) источниками информации. Пользователь получает эффективный инструмент
аналитики с развитыми механизмами визуализации и большим набором функций по
извлечению, загрузке, очистке и обработке информации.
В состав информационно-аналитической системы "АРИОН" входит
специальный модуль - Лингвистический процессор АРИОН-ЛИНГВО. На вход
Лингвистический процессор получает текстовый документ. Результатом его работы
является массив связной фактографической информации, который далее передается в
модуль идентификации для выделения похожих и слияния совпадающих объектов.
Выделение фактографической информации осуществляется с помощью
специализированных правил, которые описывают процедуры выделения объектов и
связей на внутрисистемном языке лингвистического процессора, построенном на
базе XML. Лингвистический процессор выполняет обработку полнотекстовой
информации в соответствии со следующими этапами изображенных на рисунке 1.1.

Рисунок 1.1 - Этапы обработки полнотекстовой информации
Последний этап заключается в выделении словарных понятий, разборе
объектов предметной области и создании связей между выделенными объектами.
Результатом работы лингвистического процессора является набор объектов и
связей между ними, который традиционно представляют в виде так называемой
фактографической (семантической) сети. Результат работы Лингвистического
процессора изображен на рисунке 1.2.
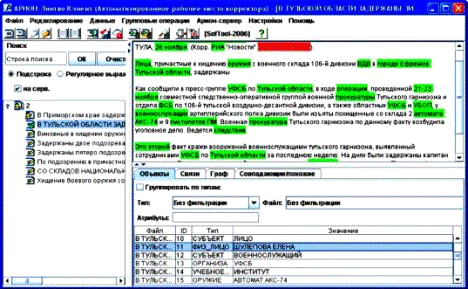
Рисунок 1.2 - Лингвистический процессор, выделение объектов
Данная форма визуализации является удобной и естественной для дальнейшей
работы пользователя с выделенной информацией. Такой интерфейс интуитивно
понятен и не требует длительного освоения и обучения. Каждый объект имеет набор
атрибутов, заданных в рамках описания предметной области. Атрибуты - это
характеристики объекта, например, "Имя", "Фамилия" и
"Дата рождения" для объекта "Человек". Связь имеет
смысловую окраску и тип.
Как
это можно использовать? информационно-аналитическая система "АРИОН"
позволяет эффективно решать <#"531470.files/image003.gif">
Рисунок 1.3 - Крупноблочная схема вопросно-ответного лингвопроцессора
Интерпретация ответного текста происходит следующим образом. Ответ
поступает в лексический процессор (ЛексПР) и на основе экземпляра фрейма (ЭКФ)
модели ответа (МО) переводится в канонизированное представление ответа (КО) в
виде последовательности концептул. Часть информации на лексическом уровне может
представлять интерес для дальнейшего разбора (например, для проверки на
непротиворечивость с ожидаемой частью ответа), поэтому накапливается в
специальных файлах (СФ). Одновременно формируется частичный вектор ситуации
(ЧВС), отражающий промежуточную диагностику ответа. Далее канонический текст
интерпретируется с привлечением ИКГ. Результат формируется в виде некоторого
полного вектора ситуации (ПВС), по которому в блоке управления (БУ) принимается
управляющее действие системы на основе соответствующих опций, заполненных
предварительно преподавателем и содержащихся в базе знаний предметной области
(БЗ ПО). Разработана интерфейсная оболочка, обеспечивающая удобное
взаимодействие при эксплуатации семантического анализатора для преподавателя
(при подготовке базы вопросов, модели ответов и других опций) и обучаемого
(притвете на вопросы системы). На рисунке 1.4 показан фрагмент
автоматизированного рабочего места преподавателя. Программа реализована на
языке Delphi и обеспечивает семантический анализ ответов и интерфейс на
русском, татарском и английском языках.
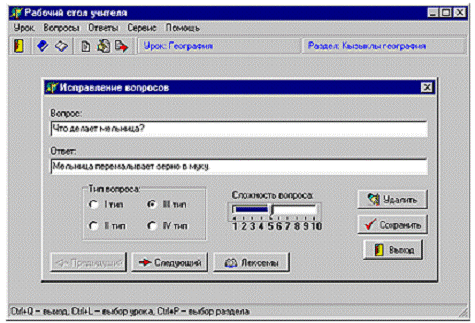
Рисунок 1.4 - Фрагмент интерфейса АРМ преподавателя
В статье предложен подход к разработке семантического анализатора
естественно-языковых текстов в диалоговых обучающих системах в условиях
детерминированного контекста, определяемого заданным вопросом. На ряде
иллюстрированных примеров изложены особенности и преимущества анализа
вопросно-ответных текстов в ситуации "ожидаемого текста" и
"детерминированного контекста". В настоящее время разрабатывается
развитая версия семантического анализатора в условиях двуязычных
вопросно-ответных текстов на татарском и русском языках [4, 5].
Очень
важно упомянуть о рабочей группе AOT [6], которое разрабатывает программное
обеспечение в области автоматической обработки текста. В круг их интересов в
основном входит анализ русского языка. Начиная с 2002 года группа выкладываем
разработки с лицензией LGPL. Теперь каждый может бесплатно использовать
библиотеки <#"531470.files/image005.gif">
Рисунок 2.1 - Обобщенная структура системы семантического разбора
3. АНАЛИЗ АЛГОРИТМОВ ДЛЯ СИСТЕМЫ ОБРАБОТКИ ЕСТЕСТВЕННО-ЯЗЫКОВЫХ ТЕКСТОВ
Общие принципы систем обработки текстов представляют собой компоненты,
составляющие структуру систем анализа текстов - лингвистические процессоры,
которые последовательно обрабатывают входной текст. Вход одного процессора
является выходом другого.
Выделяются следующие компоненты:
- графематический анализ - выделение слов, цифровых комплексов, формул и
т.д.;
- морфологический анализ - построение морфологической
интерпретации слов входного текста;
- синтаксический анализ - построение дерева зависимостей всего
предложения;
- семантический анализ - построение семантического графа
текста.
Для каждого уровня разрабатывается свой язык представления. Язык
представления, как полагается, состоит из констант и правила их комбинирования.
На графематическом уровне константами являются графематические дескрипторы (ЛЕ
- лексема, ЦК - цифровой комплекс и т.д.) На морфологическом уровне - граммемы
(рд - родительный падеж, мн - множественное число). На синтаксическом -
названия отношений (subj -отношение между подлежащим и сказуемым, circ -
обстоятельство).
Основой для построения уровней служат результаты работы предыдущих
компонентов, но, что важно, последующие компоненты также могут улучшить
представление предыдущих. Например, если для какого-то предложения
синтаксический анализатор не смог построить полного дерева зависимостей, тогда,
возможно, семантический анализатор сможет спроектировать построенный им
семантический граф на синтаксис.
3.1 Графематический анализ
Графематический анализ - достаточно простой компонент, выполняющий первые
предварительные анализа над текстом, представленного в виде цепочки ASCII
символов, вырабатывающая информацию, необходимую для дальнейшей обработки
морфологическим и синтаксическим процесорами.
В задачу графематического анализа входят:
- разделение входного текста на слова, разделители и т.д.;
- сборка слов, написанных в разрядку;
- выделение устойчивых оборотов, не имеющих словоизменительных
вариантов;
- выделение ФИО (фамилия, имя, отчество), когда имя и отчество
написаны инициалами;
- выделение электронных адресов и имен файлов;
- выделение предложений из входного текста;
- выделение абзацев, заголовков, примечаний.
.1.1 Входные и выходные данные
На вход графематике подается файл плайн-текста в Windows-кодировке. На
выходе графематика строит таблицу, состоящую из двух столбцов. В первом столбце
стоит некоторый кусок входного текста (выделенный по правилам, о которых мы
скажем ниже), во втором столбце стоят графематические дескрипторы,
характеризующие этот кусок текста. Например, из текста "Иван спал"
будет построена таблица 3.1.
В первый столбец всегда помещается часть входного текста. Если входные
символы являются последовательностью из мягких разделителей (пробел, табуляция,
возврат каретки), тогда используются другие символы, номера которых включены в
описание на языке дискрипторов.
Таблица 3.1
Графематические дескрипторы
|
Кусок входного текста
|
Графематические дескрипторы
|
|
Иван
|
RLE Aa NAM?
|
|
спал
|
RLE aa SENT_END
|
.1.2 Графематические дескрипторы
Сначала приведем перечень главных дескрипторов, один из которых
обязательно должен присутствовать на каждой строке графематической таблицы.
Графематические дескрипторы описаны в таблице 3.2.
Таблица 3.2
Перечень главных дескрипторов
|
Название
|
Русское название
|
Объяснение
|
Примеры
|
|
RLE
|
ЛЕ
|
русская лексема, присваивается последовательностям,
состоящим из кириллицы
|
Иван
|
|
LLE
|
ИЛЕ
|
иностранная лексема, присваивается последовательностям из
латиницы
|
John
|
|
DEL
|
РЗД
|
разделитель.
|
"*", "=", "_"
|
|
PUN
|
ЗПР
|
знак препинания, присваивается последовательностям,
состоящим из одинаковых знаков препинания
|
".", " [","]"," (",
") ", "-", ":", ";"
|
|
DC
|
ЦК
|
цифровой комплекс, присваивается последовательностям,
состоящим из цифр
|
1234
|
|
DSC
|
ЦБК
|
цифро-буквенный комплекс, присваивается
последовательностям, состоящим из цифр и букв
|
34h
|
|
GRAUNK
|
|
сложный узел, присваивается последовательностям, не
обладающим вышеперечисленными признаками
|
|
Таблица 3.3
Разновидности дескриптора DEL
|
SPC
|
ПРБ
|
строка пробелов или табуляций
|
|
EOLN
|
КСТ
|
признак конца строки
|
|
PAR_SYM
|
|
символ параграфа
|
|
EMSYM
|
|
нулевой символ
|
Разновидности дескриптора PUN описаны в таблице 3.4.
Таблица 3.4
Разновидности дескриптора PUN
|
OPN
|
открывающая скобка
|
"{", "[", "("
|
|
CLS
|
закрывающая скобка
|
"}", "]", ")"
|
|
HYP
|
дефис
|
-
|
Разновидности дескриптора ЗПР и РЗД описаны в таблице 3.5.
Таблица 3.5
Разновидности дескриптора ЗПР и РЗД
|
DPUN
|
последовательность одинаковых символов, длина которой
больше 20
|
|
PLP
|
последовательность одинаковых символов, длина которой
больше 1
|
|
DPUN
|
последовательность одинаковых символов, длина которой
больше 20
|
Разновидности дескриптора ЛЕ и ИЛЕ описаны в таблице 3.6.
Таблица 3.6
Разновидности дескриптора ЛЕ и ИЛЕ
|
aa
|
признак того, что все символы лексемы - малые
|
мама
|
|
Aa
|
признак того, что первый символ лексемы - большой
|
Мама
|
|
AA
|
признак того, что все символы лексемы - большие
|
МАМА
|
Теперь опишем дескрипторы, которые появляются на строке в зависимости от
контекста, т.е. они вычисляются не только из текущей строки, но и из номера
текущей строки и строк, которые находятся выше и ниже вычисляемой. Контекстные
дескрипторы описаны в таблице 3.7.
Кроме этого, используются дескрипторы, относящиеся к макросинтаксическому
анализу (анализу расположения абзацев, заголовков). В макросинтакксическом
анализе абзацы, заголовки и т.д. называются условно предложениями (УП).
Макросинтаксические дескрипторы ставятся на конце УП в зависимости от типа УП,
они описаны в таблице 3.8.
Таблица 3.7
Контекстные дескрипторы
|
BEG
|
ставится на начале текста (входного файла), т.е. всегда
стоит на нулевой строке таблице. Причем, важно сказать, что нулевая строка
таблицы используется как служебная ( содержимое первого столбца нулевой
строки не входит во входной текст)
|
|
|
EOP
|
ставится на конце фразы.Концом фразы считается только
";"
|
|
|
SENT_END
|
конец предложения
|
|
|
NAM?
|
признак того, что лексема, возможно, является частьюимени
собственного. Присваивается лексеме, начинающейся с большой буквы и не
имеющей перед собой символа конца предложения
|
|
|
BUL
|
ставится на начале пункта перечисления
|
|
|
Продолжение таблицы 3.7.
|
|
INDENT
|
ставится на начале абзаца
|
|
|
EXPR1
|
ставится на начале оборота
|
типа "во взаимодействии с"
|
|
EXPR2
|
ставится на конце оборота
|
|
|
FAM1
|
ставится на начале ФИО
|
типа "Иванов И.И."
|
|
FAM2
|
ставится на конце ФИО
|
|
|
FILE1
|
начало имени файла
|
c:\test.txt
|
|
FILE1
|
конец имени файла
|
|
|
ABB1
|
начало сокращения
|
и т.п.
|
|
ABB2
|
конец сокращение
|
|
|
KEY1
|
начало последовательности обозначений клавиш
|
Ctrl-F
|
|
KEY2
|
начало последовательности обозначений клавиш
|
|
EA электронный
адрес www.aot.ru <#"531470.files/image006.gif">
Рисунок 3.1 - Пример семантической сети
Традиционный школьный синтаксис, который строится на понятии
согласования, управления и примыкания, позволяет очертить круг синтаксических
отношений. Все алгоритмы, которые ищут эти отношения и их композиции, можно
назвать синтаксисом. Семантикой мы называем те алгоритмы, которые, используя
смысл слов и выражений, устанавливают отношения, которые не вычисляются
напрямую из синтаксических отношений. Конечно, нельзя преувеличивать значение
семантического анализа для систем автоматической обработки текста. Если
попытаться просчитать актуальность семантического анализа как довеска к
традиционному синтаксическому хотя бы на примере системы ДИАЛИНГ, то его помощь
составляет не более десяти-двадцати процентов.
Теперь мы кратко опишем теоретическую базу, на основе которой был
разработан первично семантический процессор - т.е., семантическая система
доктора технических наук Н.Н. Леонтьевой.
В центре этой теории находится Русский общесемантический словар (РОСС),
который включает семантическое описание по следующему шаблону описанному ниже.
1. Семантический класс лексемы (набор семантических характеристик).
2. Грамматический класс лексемы.
. Валентная структура лексемы (в терминах семантических тношений).
. Семантические и грамматические ограничения на выражение каждого
актанта из валентной структуры.
Ниже приведен пример словарной статьи глагола "винить":
ЗГЛ = винить 1
КАТ = 1 ЭТК.СИТ
ГХ = 1 ГЛ:ГГ
СХ = 1 ИНТЕЛ
КОММУНИК
ВАЛ = АГЕНТ , А1 , С
ОБ , А2 , С
СОДЕРЖ , А3 , С
ГХ1 = 1 подл : И
СХ1 = 1 ОДУШ
ГХ2 = 1 п_доп : В
СХ2 = 1 ОДУШ
АБСТР
ГХ3 = 1 к_доп : в+П
к_доп : за+В
АНГ = blame 1
ИЛЛ = Я сам себя винил во всех неудачах.
Винить за это некого.
Опишем кратко понятие семантической характеристики и отношения.
Семантическое отношение - это некая универсальная связь, усматриваемая
носителем языка в тексте.
Формат записи семантического отношения следующий: R(А,B), где R -
название семантического отношения, А - зависимый член отношения, B -
управляющий член отношения.
Для конкретных А,B и отношения R направление выбирается таким образом,
чтобы формула R(А,B) была эквивалентна утверждению, что "А является R для
B". Например, для фразы роман Толстого будет построена формула
АВТОР(Толстой, роман), а не наоборот, потому что верно утверждение "
Толстой является АВТОРом романа".
Соответственно, эта проверка и является базисной оценкой правильности
проведения одного отношения от узла А к узлу B. Если все базисные проверки
пройдены, то и весь граф признается правильным, т.е. отражающим смысл входного
текста.
Семантическое отношение R (A, B) <=> "А является R для
B". Перечень отношений описаны в таблице 3.10.
Таблица 3.10
Семантическое отношение R (A, B)
|
Название(R)
|
Примеры
|
|
АВТОР
|
Роман Толстого
|
|
АГЕНТ
|
Мы сократили отставание
|
|
АДР
|
Я отдал стул отцу.
|
|
ВРЕМЯ
|
Это произошло вчера.
|
|
ИДЕНТ
|
Дом N 20
|
|
ИМЯ
|
Дворник Степанов
|
|
ИНСТР
|
резать ножом
|
|
ИСХ-Т
|
яблоки из Молдавии
|
|
КОЛИЧ
|
два яблока
|
|
КОН-Т
|
уехать в Москву
|
|
ЛОК
|
жить в глуши
|
|
ОБ
|
уничтожить мост
|
|
ОЦЕНКА
|
хорошо относиться
|
|
ПАЦИЕН
|
арест преступника
|
|
ПРИЗН
|
красивый шар
|
|
ПРИНАДЛ
|
дом отца
|
|
ПРИЧ
|
деревья повалены ураганом
|
|
РЕЗЛТ
|
испечь пирог
|
|
СОДЕРЖ
|
рассказать о весне
|
|
СПОСОБ
|
идти босиком
|
|
СРЕДСТВО
|
красить белилами
|
|
СУБ
|
любовь отца
|
|
ЦЕЛЬ
|
забастовка в целях повышения зарплаты
|
|
ЧАСТЬ
|
ножка стула
|
Семантические характеристики (СХ) в словаре РОСС играют важнейшую роль.
В словаре РОСС семантических характеристик около 40. Из этих меток
строятся формулы (с логическими связками и, или). Каждому слову приписана
некоторая формула, составленная из СХ.
СХ используются для сборки валентной структуры. Для каждого i-го актанта
в поле СХi записывается формула, которой он должен удовлетворять.
Хотя изначально СХ вводились как простые селективные ограничения,
отбраковывающие некоторые связи, проведенные синтаксическим анализом, теперь за
каждой из них закреплено определенное значение. Вообще говоря, считается, что
если СХ(А) = СХ (B) <=> "А и В имеют общее семантическое
свойство".
Семантическая характеристика СХ (A) = СХ(B) <=> "А имеет
смысловое сходство с B".
Пример:
) (говорить) = СХ(орать) = КОММУНИК;
) (повар) = СХ(генерал) = ДОЛЖ.
Перечень семантических характеристик описаны в таблице 3.11.
Таблица 3.11
Перечень семантических характеристик
|
Название
|
Примеры
|
|
АБСТР
|
модель, план,
|
|
АРТ
|
хлеб,памятник
|
|
ВЕЩВО
|
бензин,ядохимикат
|
|
ВМЕСТЛ
|
мешок, амбар
|
|
ВОСПР
|
слушать, видеть
|
|
ДВИЖ
|
идти, ронять
|
|
ДОЛЖ
|
повар,партработник
|
|
Д-УСТР
|
карбюратор,валик
|
|
ИЗМ
|
наращивать,реформировать,
|
|
ИНТЕЛ
|
надеяться,изучать,
|
|
ИНФ
|
знание,команда,
|
|
КОММУНИК
|
выражать,выступать
|
|
НОСИНФ
|
книга,газета,
|
|
Н-ТРЕБ
|
закон,инструкция
|
|
ОДЕЯТ
|
|
ОДУШ
|
папа,президент
|
|
ОРГ
|
колхоз,школа
|
|
ПРЕДМ
|
марка, бинокль
|
|
ПРОТЯЖ
|
дорога,граница
|
|
СОБИР
|
библиотека,молодежь
|
|
УСТР
|
компьютер,лифт
|
|
ЭМОЦ
|
мизерный,могучий
|
|
ЯВЛЕН
|
смерч,терроризм
|
Мы описали основные досемантические компоненты системы ДИАЛИНГ и аппарат
семантического анализа, который был взят нами за основу. Теперь перейдем к
описанию первично семантического процессора.
На вход семантического процессора подается синтаксическое дерево, а в
большинстве случаев множество несвязных синтаксических деревьев, т.е. лес.
Задача состоит в том, чтобы по возможности разрешить морфологическую,
лексическую и древесную неоднозначность, описание в таблице 3.12.
Таблица 3.12
Описание семантического процессора
|
Вход: синтаксическое дерево
|
|
Выход: семантический граф
|
|
R(a, b)
|
=>
|
R(A, B)
|
|
генит,иг(дом, отца)
|
=>
|
ПРИНАДЛ(дом, отца)
|
|
генит_иг(чашка, чая)
|
=>
|
КОЛИЧ(чашка, чай)
|
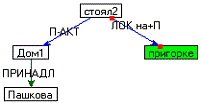
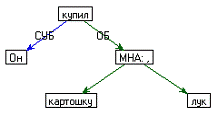
Примеры семантической структуры для предложений преведены на рисунке 3.2.
Но в системе ДИАЛИНГ используют граф с центром в глаголе. То есть,
глаголы соединяются с группой существительного с использованием падежных
отношений. Для данной задачи граф должен быть с центром в существительном, как
изображено на рисунке 3.2.
|
Дом Пашкова стоял на пригорке.
|
|
Он купил картошку, лук.
|
|
|
|
|
|
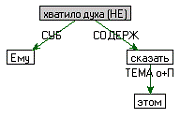
Ему не хватило духа сказать об этом.
|
|
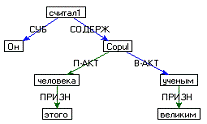
Он считал этого человека великим ученым.
|
|
|
|
|
Рисунок 3.2 - Примеры семантической структуры
4. СТРУКТУРА СИСТЕМЫ ПОСТРОЕНИЯ СЕМАНТИЧЕСКОГО РАЗБОРА ДЛЯ
ЕСТЕСТВЕННО-ЯЗЫКОВЫХ ТЕКСТОВ
Планируемая система будет иметь схожий на систему ДИАЛИНГ структуру.
Следовательно, в обязательном порядке, присутствуют такой компонент как
графематический анализ. Который производит разбор на слова, цифровые комплексы,
электронный адресов, названия файлов, аббревиатуры и деления на абзацы,
предложения.
Далее следует морфологический разбор, предназначенный для построения
морфологической информации слов входного текста, и после следует синтаксический
анализ. Помимо этого будет добавлен статистический анализатор, в данном
компоненте будет реализовываться подсчет повторно встречаемых слов, какой части
речи они относятся, форма слов и т.п. Данный анализатор более упростит и
повысит качество семантического анализа, даст больше данных для построения
семантической сети. Структуру системы построения семантического разбора для
естественно-языковых текстов можно увидеть на рисунке 4.1.

Рисунок 4.1 - Структура системы семантического разбора для
естественно-языковых текстов
.1 Графематический анализ
Графематический анализ - достаточно простая программа, выполняющая первые
предварительные действия над текстом. На вход графематике подается текст в
кодировке Windows, на выходе строится графематическая таблица, в которой на
каждой строке стоит слово или разделитель из входного текста. Кроме деления
текста на слова, графематика разбивает текст на предложения
(макросинтаксический анализ). Данный анализ немного отличатся от ранее
описанного графематического анализа из системы ДИАЛИНГ.
Практическая задача анализа построить графематическую таблицу. В первом
столбце стоит некоторый кусок входного текста, во втором столбце стоят
графематические дескрипторы, характеризующие этот кусок текста. Примером такой
таблице является таблица 4.1.
Таблица 4.1
Графематическая таблица
|
Кусок входного текста
|
Графематические дескрипторы
|
|
Иван
|
ЛЕ Бб НПРД
|
|
_
|
РЗД
|
|
спал
|
ЛЕ бб
|
|
.
|
ЗПР КПРД
|
Перечисление графематических дескрипторов описаны в таблице 4.2.
Таблица 4.2
Графематические дескрипторы
|
Кир.Назв.
|
Объяснение
|
Пример
|
|
ЛЕ
|
русская лексема, присваивается последовательностям,
состоящим из кириллицы
|
Иван
|
|
ИЛЕ
|
иностранная лексема, присваивается последовательностям из
латиницы
|
John
|
|
РЗД
|
разделитель, но не знак препинания.
|
"*", "=", "+", "-",
"_" и т.п.
|
|
ЗПР
|
знак препинания, присваивается последовательностям,
состоящим из одинаковых знаков препинания
|
" . ", "[","]",
"(", ")", " : ", " ; " и т.п.
|
|
ЦК
|
цифровой комплекс, присваивается последовательностям,
состоящим из цифр
|
1234
|
|
ЦБК
|
цифро-буквенный комплекс, присваивается
последовательностям, состоящим из цифр и букв
|
34h
|
Разновидности дескриптора ЛЕ и ИЛЕ описаны в таблице 4.3.
Таблица 4.3
Разновидности дескриптора ЛЕ и ИЛЕ
|
бб
|
признак того, что все символы лексемы - малые
|
мама
|
|
Бб
|
признак того, что первый символ лексемы - большой;
|
Мама
|
|
ББ
|
признак того, что все символы лексемы - большие
|
МАМА
|
Теперь опишем дескрипторы, которые появляются вычисляють начало и конец
предложения. Они описаны в таблице 4.4.
Таблица 4.4
Контекстные дескрипторы
|
НПРД
|
начало предложения
|
|
КПРД
|
конец предложения
|
Деление предложений будет производиться по определенным правилам.
1. Начало текста совпадает с началом предложения.
2. Предложения начинается с заглавной буквы, а если предложения в
середине текста, перед ним должен быть знак препинания ".",
"?" или "!".
. Предложение не может состоять из знаков препинания, цифр или
символа.
. Конец предложения заканчивается знаком препинания ".",
"?" или "!", а следующая лемма начинатся с заглавной буквы,
если это не конец текста
. Конец текста всегда будет концом последнего предложения.
Для полного понимания на рисунке 4.2 изображены блоки графемотического
анализа.

Рисунок 4.2 - Блоки графемотического анализа
Анализ состоит всего и двух модулей.
В первом определяются дискрипторы, которые были описаны в таблице 4.2 и
4.3.
Во втором определяются начало и конец предложения, и соответственно
добавляются дискрипторы контекста из таблицы 4.4.
.2 Морфологический анализ
Морфологический компонент осуществляет морфоанализ и лемматизацию русских
словоформ (лемматизация - приведение текстовых форм слова к словарным;
морфоанализ - приписывание словоформам морфологической информации).
Блоки изображены на рисунке 4.3.
При лемматизации для каждого слова входного текста морфологический
процессор выдает множество морфологических интерпретаций следующего вида:
- лемма (всегда пишется большими буквами);
- морфологическая часть речи;
- множество наборов граммем.
-

Рисунок 4.3 - Блоки морфологического анализа
Так как программная разработка морфологичекого анализа является сложной
задачей, данная система будет спользовать библиотеку mcr.dll позволяющюю
подключать, создавать и сохранять словари в формате mcr, выполнять поиск слов в
этих словарях, морфоанализ, лемматизацию, орфокоррекцию, стемминг и еще
некоторые другие функции.
Морфоанализ данной библеотеки построен на основе словаря А. А. Зализняка
содержащий порядка 100 тысяч слов общеупотребительной лексики языка (в формате
mcr), который прилагается к программным модулям.
.3 Статистический анализ
Статистический анализ - позволяет получить статистику, т.е. какие слова и
сколько раз встретились в тексте. Предусмотрена возможность совместного
подсчета словоформ - то есть слов в разном роде, падеже и пр. (объединяются
похожие слова, которые имеют разное окончание). Есть возможность не учитывать
слова, которые встретились только один раз. Данный анализ даст больше
информации о тексте и упростит задачу семантического анализа.
Данный статистический анализ можно разбить на блоки, которые изображены
на рисунке 4.4.

Рисунок 4.4 - Блоки статистический анализа
Первый блок, данного анализа, осуществляет простой подсчет количества
лемм и предложений в анализируемом тексте.
Во втором блоке осуществляет поиск и количественный подсчет служебных
частей речи, а именно, такие как: предлоги, союзы, частицы, междометия и т.п.
Третий блок позволит выделить группу слов-объектов и определить
количество, встречаемых по каждому из слов. К данной группе относятся частей
речи, как существительные, прилагательные и числительные.
Четвертый блок аналогичен предыдущему, за исключением, что анализируемые
слова относятся к группе слов-отношений. К данной группе относятся такие частей
речи, как глаголы.
И завершающий блок, из группы слов-объектов выделит, и определить их
количество, по форме слова. Имеется виду, слова схожие по своему лексическому
значению (дом - дому, домом, дома).
.4 Синтаксический анализ
На сегодня создание синтаксического анализа является одной из самых
актуальных задач в компьютерной лингвистике, решение которой позволило бы
достичь высокого уровня формализации языковых структур в разнообразных
прикладных целях: от создания систем автоматического распознавания речи до
поисковых систем в Интернете.
Под целью синтаксического анализа понимается вычленение базовых синтаксических
структур и установление синтаксических связей между ними.
На выход поступает цепочка слов, разбитая на группы, причем каждая группа
имеет связь с другими группами. Кроме того, модуль синтаксического анализа
идентифицирует такие синтаксические категории, как подлежащее и сказуемое.
Однако создание синтаксического анализа для русского языка упирается в
большое количество сложностей, связанных с недостаточно разработанной
теоретической базой, в общем, и прикладном языкознании.
Структуры человеческого языка отличаются разнообразием и часто высоким
уровнем сложности, предусмотреть который чрезвычайно тяжело.
Синтаксический анализ был разбит на три блока изображенных на рисунке
4.5.
Из модуля морфологического анализа, в котором для слоаоформы есть все возможные
варианты основ и соответствующие грамматические показатели. Если данной
словоформе соответствует только одна основа, она поступает в процедуру
построения гипотез. В зависимости от части речи и грамматических показателей
выделяется соответствующая синтаксическая группа. В том случае, когда одной
словоформе соответствует несколько основ, построение гипотез осуществляется для
всех вариантов основ. Если словоформа не найдена в словаре, то результатом
будет неразобранное предложение.

Рисунок 4.5 - Блоки синтаксического анализа
После предварительной обработки словоформа поступает в блок генерирования
гипотез. Этот блок является основным. На его вход поступает словоформа. Если
это первое слово в предложении, то в соответствии с частью речи определяется
синтаксическая группа. На основании исходного текста был составлен список
частей речи, которые в нем встречаются. Список включает в себя: имя
существительное, финитный глагол, прилагательное, краткое прилагательное, инфинитив,
наречие, предлог, сочинительный союз "и", вспомогательный глагол
"быть" и другие части речи.
Далее эти гипотезы поступают в блок отсеивания неправильных гипотез.
Данный блок имеет два уровня проверки.
На первом уровне проверяется согласование синтаксических групп в рамках
одного предложения. Это согласование определяется исходя из грамматических
характеристик вершин групп. То есть группа подлежащего и группа сказуемого
должны согласоваться по роду, лицу и числу. Если согласование подтверждается,
то гипотеза поступает на второй уровень проверки. В противном случае гипотеза
отсеивается.
На втором уровне проверяются связи слов внутри каждой группы. В
зависимости от типа связи слов внутри группы (управление, согласование или
примыкание) проверяются соответствующие грамматические характеристики элементов
группы. Если связь не подтверждается - гипотеза отсеивается.
.5 Семантический анализ
Завершающим этапом системы является семантический анализ. На основе
синтаксического и статистического анализов текста, полученные структуры и
количественные данные объектов преобразуются семантическую сеть.
В теории, узлы сети представлены множеством часто встречавшихся термов -
слов и устойчивых словосочетаний, здесь возможно поможет статистический анализ
слов-объектов по форме слова. Связи между ними представлены в группе
слов-отношений. А служебные части речи помогут объединить некоторые связи сети.
Исходя из логичных рассуждений, можно семантический анализ разделить на два
блока, изображенных на рисунке 4.6.

Рисунок 4.6 - Блоки семантического анализа
Коротко говоря, первый блок выделяет все узлы, представляющие собой
концепты предметов (слов-объектов) всего текста.
Следовательно, во втором блоке, производится построение сети, то есть
определение отношений по каждому из предложений, основываясь по данным
результата синтаксического анализа.
5. ИСПОЛЬЗОВАНИЕ Н-ГРАММНОГО СЛОВАРЯ MCR
Многие существующие словари используют модели, основанные на морфологии
описания слов. Унификация морфов позволяет получить компактное и довольно
быстрое решение. В качестве минимальной единицы для описания слова могут
выступать слоги или набор аффиксов, которые сопоставлены с каким-либо корнем. В
данной работе предложен вариант организации словаря с использованием
псевдоморфов - н-грамм.
Системы обработки текстов на естественном языке, как правило, используют
разнообразные словари. Существует несколько подходов и способов организации
электронных словарей[21]. Большинство из них связано с моделями хранения данных,
основанных на различных видах организации морфов или аффиксов.
Для электронного словаря важнейшими свойствами являются скорость анализа
входной последовательности символов и компактность. Эти характеристики особенно
важны при использовании словаря при обработке больших объемов текста.
.1 Методы хранения словарей
Расцвет рынка программного обеспечения для русских словарей был в
середине 90-х годов. Основные модели, которые успешно действуют до сих пор,
были разработаны для слабых, по нынешним меркам, процессоров с небольшим
количеством памяти. Бывало и так, что кодирование слов не всегда было
однозначным (транзитивным). Словарь общей лексики на 100 тысяч лемм умещали в
300-400 кб. при помощи унификации флексий. Проще говоря, из всех слов выделяли
постоянную графическую часть, цепочки изменяющихся префиксов и суффиксов
хранили отдельно. Информация о грамматических характеристиках дополнительно
требовала дополнительно 100-200 кб., в зависимости от принятой классификации
частей речи.
Cтэмменг
<#"531470.files/image017.gif">
Рисунок 6.1 - Алгоритм графематического разбора
Более подробно данный алгоритм приведен в листинге программы дипломного
проекта.
Исходя из рисунка, выходными данными алгоритма будет запись в очередь
буквенные, цифровые лексемы, знаки препинания и комплексные лексемы.
.2 Алгоритм морфологического анализа
Морфологический анализ, входные данные которого является очередь из
лексем и знаков препинания, анализирует только русские лексемы. Алгоритм описан
на рисунке 6.2.

Рисунок 6.2 - Алгоритм морфологического анализа
Всё что качается морфологического анализа библиотеки mcr.dll было описано
ранее. Были изложенные различные методы хранения словаря, и так же текущий
метод Н-граммы, который позволяет хранить сразу целые цепочки корней и аффиксов
длиной N, что дает некоторые преимущества и некоторые особенности при
использовании орфокоррекции или в генетических алгоритмах генерации псевдослов.
А так же библиотека mcr.dll позволяет подключать, создавать и сохранять
словари в формате mcr, выполнять поиск слов в этих словарях, морфоанализ,
лемматизацию, орфокоррекцию, стемминг и еще некоторые другие функции.
.3 Алгоритм синтаксическо-семантического анализа
Конечный, самый важный и сложный анализ системы семантического разбора
естественно-языковых текстов является синтаксическо-семантического анализа.
Упрощенное содержание алгоритма изложено на рисунке 6.3.

Рисунок 6.3 - Алгоритм синтаксическо-семантического аланиза
7. ПРОЕКТИРОВАНИЕ ИНТЕРФЕЙСА
Интерфейс имеет важное значение для любой программной системы и является
неотъемлемой ее составляющей, ориентированной, прежде всего, на конечного
пользователя. Именно через интерфейс пользователь судит о прикладной программе
в целом.
Интерфейс - в широком смысле слова, это способ (стандарт)
взаимодействия между объектами. Интерфейс в техническом смысле слова задаёт
параметры, процедуры и характеристики взаимодействия объектов.
Интерфейсы различают:
– интерфейс пользователя - набор методов взаимодействия
компьютерной программы и пользователя этой программы;
- программный
интерфейс - набор методов для взаимодействия между программами.
7.1 Требования к разработке интерфейса
Основным требованию к интерфейсу служит условия своеобразной пирамиды,
изображенной на рисунке 7.1.
Прежде
чем подняться на следующий уровень пирамиды, нужно соблюсти требования
низлежащего уровня. Например, нету смысла улучшать юзабилити
<javascript:%20void(0)> (что соответствует уровню "удобство"
пирамиды требований), если требования полезности не были учтены или какой смысл
в системе, если она не решает насущных проблем пользователя, то есть не является
полезной.
Система считается полезной, если она предлагает пользователям новые и
ценные услуги или улучшает уже существующие. Определить является ли система
полезной, можно только при помощи ее пользователей: лично поговорив с ними,
осознав сказанное и проанализировав их явные и скрытые потребности. Кроме того,
можно сделать очень ценные выводы, просто наблюдая за тем, как пользователи
работают с системой или c ее прототипом.
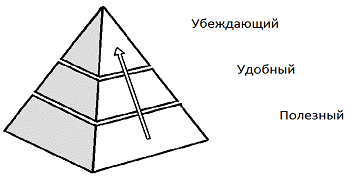
Рисунок 7.1 - Пирамида требований к интерфейсу
К сожалению, не существует верного способа для создания 100%-но удобных
продуктов и поэтому это творческий процесс. Системы, которые делают что-то
полезное, могут быть разработаны только при условии глубокого понимания
пользователей и их нужд. Методы юзабилити по формальному анализу
пользовательских требований и получению обратной связи от пользователей делают
возможным создание таких систем. Кроме того, в юзабилити есть техники и
методики, которые позволяют тестировать концепции и идеи дизайна еще до того,
как они будут прототипированы и разработаны.
Если продукт полезен, это еще не значит, что им будут пользоваться. Чтобы
продуктом пользовались, он должен удовлетворять требованиям оставшихся трех
уровней нашей иерархии.
Удобная система - это та система, которая позволяет своим
пользователям выполнять задачи, которые они хотят выполнить. Юзабилити это
свойство системы, которое можно спроектировать и оценить, привлекая
потенциальных пользователей в процесс разработки.
Юзабилити очень важный (но не единственный) фактор дизайна, который
ориентирован на нужды пользователей. Пользователи системы обязательно должны
быть способны корректно решать свои задачи в системах, в которые они работают
(например, в банках, в кассах по продаже железнодорожных билетов). Однако было
показано, что люди часто предпочитают использовать те системы, которые явно
менее удобны. Факторы, которые влияют на это, обсуждаются на последнем уровне
иерархии.(International Standartization Organization, Интернациональная
организация по стандартизации) определяет юзабилити через комбинацию трех
факторов:
– эффективность (могут ли представители целевой аудитории достичь своих
целей, используя систему);
– продуктивность (какие ресурсы (например, время, физические и
умственные нагрузки) дополнительно нужны этим пользователям, чтобы достичь
своих целей);
– удовлетворение (находят ли пользователи систему комфортабельной и
приятной).
Эти
критерии описаны в стандарте <#"531470.files/image021.gif">
Рисунок 7.2 - Интерфейс системы
Операции соответствующих закладок:
– закладка 1 (загрузки и редоктирования текста);
– закладка 2 (графематический анализ);
– закладка 3 (морфологический анализ);
– закладка 4 (статистический анализ);
– закладка 5 (построение семантической сети).
Экранные формы всех закладок можно увидеть на рисунках Б.1, Б.2, Б.3 Б.4
и Б.5.
В конечном итоге разработанный интерфейс очень прост и удобен в
использовании, несложная навигация по каждому из разделов анализа позволяет
быстро и продуктивно использовать систему любому пользователю.
8. СТРУКТУРА ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ СИСТЕМЫ
Структура программы представляет собой обычное приложения с различными
элементами управления для пользователя. Поэтому программный продукт разработан
с помощью Microsoft Visual C# 2008 Express Edition.
Работа программы осуществляется по диалоговому и событийному режиму, при
этом под диалогом понимается предоставление пользователю нескольких альтернатив
и обработка его выбора. В диалоговую систему входят, всплывающие подменю, диалоговые
окна. Под событиями понимаются процессы активизируемые пользователем, а также
программные события - получение определенным полем фокуса редактирование или
потеря фокуса ввода. На основании данных событий активизируются процедуры
контроля допустимости данных.
Взаимодействие основных файлов системы представлены на рисунке 8.1.
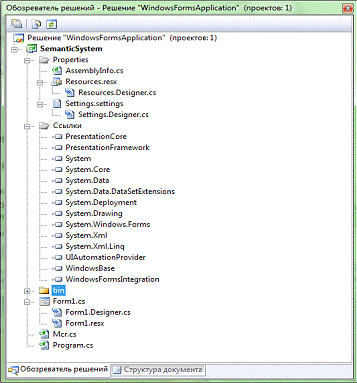
Рисунок 8.1 - Обозреватель решений основных файлов системы
. ОПИСАНИЕ ФУНКЦИОНИРОВАНИЯ И ТЕСТИРОВАНИЕ СИСТЕМЫ
.1 Описание функционирования
Функционирование системы в общем виде можно изобразить на схеме,
представленной на рисунке 9.1.

Рисунок 9.1 - Общий вид функционирования системы
Пользователь взаимодействует с системой, интерфейс которого изображен на
рисунке 7.2. Каждая из закладок интерфейса соответствуют данным модулям
изображенных на рисунке 9.1.
Диаграмма классов - методология объектно-ориентированного проектирования,
предназначенная для представления статической структуры модели системы в
терминологии классов объектно-ориентированного программирования.
Класс - это тип, описывающий устройство объектов. Понятие
"класс" подразумевает некоторое поведение и способ представления.
Понятие "объект"
подразумевает нечто, что обладает определённым поведением и способом
представления. Говорят, что объект - это экземпляр класса. Обычно классы
разрабатывают таким образом, чтобы их объекты соответствовали объектам
предметной области.
На рисунке 9.2 представлено дерево классов проекта.
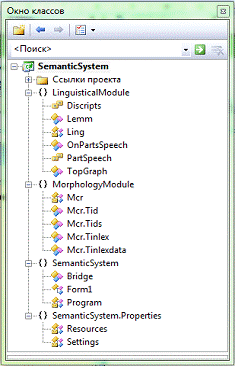
Рисунок 9.2 - Дерево классов проекта
.2 Тестирование программного кода
Уровни тестирования описаны далее
. Модульное тестирование - тестируется минимально возможный для
тестирования компонент, например, отдельный класс или функция. Часто модульное
тестирование осуществляется разработчиками ПО.
2. Интеграционное тестирование - тестируются интерфейсы между
компонентами, подсистемами. При наличии резерва времени на данной стадии
тестирование ведётся итерационно, с постепенным подключением последующих
подсистем.
. Системное тестирование - тестируется интегрированная система на
её соответствие требованиям.
Альфа-тестирование - имитация реальной работы с системой штатными
разработчиками, либо реальная работа с системой потенциальными
пользователями/заказчиком. Чаще всего альфа-тестирование проводится на ранней
стадии разработки продукта, но в некоторых случаях может применяться для
законченного продукта в качестве внутреннего приёмочного тестирования. Иногда
альфа-тестирование выполняется под отладчиком или с использованием окружения,
которое помогает быстро выявлять найденные ошибки. Обнаруженные ошибки могут
быть переданы тестировщикам для дополнительного исследования в окружении,
подобном тому, в котором будет использоваться ПО.
Бета-тестирование - в некоторых случаях выполняется распространение
версии с ограничениями (по функциональности или времени работы) для некоторой
группы лиц, с тем чтобы убедиться, что продукт содержит достаточно мало ошибок.
Иногда бета-тестирование выполняется для того, чтобы получить обратную связь о
продукте от его будущих пользователей.
Часто для свободного/открытого ПО стадия альфа-тестирования характеризует
функциональное наполнение кода, а бета-тестирования - стадию исправления
ошибок. При этом как правило на каждом этапе разработки промежуточные
результаты работы доступны конечным пользователям.
Тестирование программного кода - процесс выполнения программного кода,
направленный на выявление существующих в нем дефектов. Под дефектом здесь
понимается участок программного кода, выполнение которого при определенных
условиях приводит к неожиданному поведению системы. Неожиданное поведение
системы может приводить к сбоям в ее работе и отказам, в этом случае говорят о
существенных дефектах программного кода. Некоторые дефекты вызывают
незначительные проблемы, не нарушающие процесс функционирования системы, но
несколько затрудняющие работу с ней. В этом случае говорят о средних или
малозначительных дефектах.
Задача тестирования при таком подходе - определение условий, при которых
проявляются дефекты системы, и протоколирование этих условий. В задачи
тестирования обычно не входит выявление конкретных дефектных участков
программного кода и никогда не входит исправление дефектов - это задача
отладки, которая выполняется по результатам тестирования системы.
Цель применения процедуры тестирования программного кода - минимизация
количества дефектов в конечном продукте. Тестирование само по себе не может
гарантировать полного отсутствия дефектов в программном коде системы. Однако, в
сочетании с процессами верификации и валидации, грамотно организованное
тестирование дает гарантию того, что система удовлетворяет требованиям и ведет
себя в соответствии с ними во всех предусмотренных ситуациях.
В
рамках проведенного тестирования программы, не было выявлено значительных
ошибок. Программа отменно запускается и функционирует на различных операционных
системах, только с предварительно установленной машинно-независимой платформой
- NET Framework.
<#"531470.files/image025.gif">, (11.5)
где КВ - капиталовложения в проект (стоимость оборудования, используемого
для разработки программного продукта), грн.
Тпл - плановый срок службы оборудования, час.
Плановый срок службы оборудования рассчитывается по формуле:
Тпл = tсм * Драб * Ссл, (11.6)
где tсм - продолжительность смены (8 часов);
Драб - число рабочих дней в году (Драб = 260 дней);
Ссл - срок службы оборудования, годы (Nпл = 5 лет).
Зная продолжительность смены, число рабочих дней в году и срок службы
оборудования, рассчитаем плановый срок службы оборудования, используя формулу
(11.6):
Тпл = 8 * 260 * 5 = 10400 (часов)
Теперь, зная плановый срок службы оборудования и стоимость оборудования,
используемого для разработки программного продукта, рассчитаем числовое
значение амортизационных отчислений, используя формулу (11.5):
А = 2654 / 10400 = 0,2551 (грн./час)
Издержки на оплату израсходовано электроэнергии рассчитываются из
мощности, загрузки и времени работы токоприемников (компьютеров), а также
тарифов на электроэнергию по формуле:
Зопл
= Аэ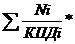 Кзагр, (11.7)
Кзагр, (11.7)
где Аэ - тариф 1кВт час электроэнергии (0,3167 грн./(кВт·ч.));- мощность
i-го токоприемника, кВт;
КПДi - коэффициент полезного действия i-го токоприемника (0,96);
Кзагр - коэффициент загрузки i-го токоприемника (0,8).
Учитывая мощность компьютера N (0,7 кВт), зная стоимость
одного киловатт-часа электроэнергии A(0, 3167 грн./(кВт·ч.)), и приняв
коэффициент полезного действия компьютера равным 0,96, а коэффициент загрузки
компьютера - 0.8, рассчитаем затраты на оплату электроэнергии, используя
формулу (11.7):
Зопл = 0,3167 * (0,7 / 0,96) * 0,8 = 0,1847 (грн./час)
Прочие издержки, связанные с обслуживанием оборудования принимаются
равными 0,09 (грн./час).
Зная сумму амортизационных отчислений, сумму издержек на оплату
электроэнергии и прочие затраты, рассчитаем стоимость машино-часа, используя
формулу (11.4):
См = 0,2551 + 0,1847 + 0,09 = 0,5298 (грн./час)
Для расчета издержек, связанных с эксплуатацией аппаратного обеспечения,
нужно рассчитать время, затраченное на разработку данного проекта (Тразр).
Период разработки приходится на май 2011г., что, с учетом пятидневной рабочей
недели, составляет восемнадцать дней. Работа велась в среднем 8 ч. в день.
Следовательно, общее время разработки составило Тразр=22*8=176ч.
Рассчитаем сумму издержек, связанных с эксплуатацией аппаратного обеспечения,
используя формулу (11.3):
Зэкспл = 0,5298 * 176 = 93,24 (грн.)
Среднечасовая
тарифная ставка - фиксированный размер оплаты труда
<#"531470.files/image027.gif"> (11.11)
где
Р - уровень рентабельности продукта (выражается в %).
Принимая
уровень рентабельности равным 27% и валовые издержки, рассчитаем прибыль,
используя формулу (11.10):
П
= 10380,37 * 0,27 = 2802,70 (грн.)
Зная
валовые издержки и прибыль, рассчитаем оптовую цену созданного ПП на рынке,
используя формулу (11.9):
Цопт
= 10380,37 + 2802,70 = 13183,07 (грн.)
Оптово-отпускная
цена рассчитывается с учетом НДС и определяется по формуле:
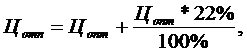 (11.12)
(11.12)
Зная
оптовую цену ПП и НДС, рассчитаем оптово-отпускную цену ПП, используя формулу
(11.11):
Цотп
= 13183,07 + (13183,07 * 0,22) = 16083,34 (грн.)
В
результате проведенных расчетов можно сказать, что отпускная цена программного
продукта составит 16083,34 грн. Исходя из того, что данная система
семантического разбора естественно-языковых текстов занимается анализом и
обработкой текста строя, в конечном итоге, семантическую сеть заданного текста
и представляет собой на данном этапе исследовательскую работу. Но библиотеки
данной системы можно использовать в коммерческих целях, они имеют широкую сферу
применения, от перевода текстов на различные естественные языки, применения в
поисковых системах, лингвистики, так и для представления знаний.
Стоимость
подобных систем изложены в таблице 11.2.
Таблице 11.2
Стоимость подобных систем
|
Наименования программного продукта
|
Цена(грн)
|
|
RCO Fact Extractor Desktop
|
27913
|
|
ИАС "АРИОН"
|
32421
|
|
Morphology Professional SDK
|
74615
|
Сравнив по цене данный ПП с другими похожими, можно сказать, что он
станет вполне конкурентом на рынке подобных продуктов.
ВЫВОДЫ
Был произведен анализ существующих средств семантического разбора
естественно-языковых текстов, их особенности и технологии. Описаны алгоритмы
системы анализа текста и разработана структура системы построения
семантического разбора для естественно-языковых текстов.
Во время работы дипломного проекта разработан законченный продукт,
подходящий для применения его в качестве анализатора текстов, предоставляющий
на выходе семантическую сеть.
На сегодня создание системы семантического разбора естественно-языковых
текстов является одной из самых актуальных задач в компьютерной лингвистике,
решение которой позволило бы достичь высокого уровня формализации языковых
структур в разнообразных прикладных целях: от создания систем автоматического
распознавания речи до поисковых систем в Интернет.
Однако создание подобных систем для русского языка упирается в большое
количество сложностей, связанных с недостаточно разработанной теоретической
базой, в общем, и прикладном языкознании. Дело в том, что структуры
человеческого языка отличаются разнообразием и часто высоким уровнем сложности,
предусмотреть который чрезвычайно тяжело. В связи с этим, в настоящее время,
предлагается структура семантического разбора естественно-языковых текстов
работающего с простыми синтаксическими структурами. Создания системы,
работающей с текстом на русском языке любой сложности, представляется на
настоящем этапе невозможным.
В данной работе рассматривались так же вопросы охраны труда, связанные с
тем, что операторы ЭВМ, операторы по подготовке данных, программисты по
прежнему подвергаются воздействию физически опасных и вредных производственных
факторов. Таких, как повышенный уровень шумов, повышенная температура внешней
среды, отсутствие или недостаток естественного света, недостаточная
освещенность рабочей зоны, электрический ток, статическое электричество и др.
Определялись пути решения этих проблем, чтобы обеспечить безопасные условия
труда для работников.
Особое внимание уделяется пожарной безопасности, так как пожары сопряжены
с опасностью для человеческой жизни и большими материальными потерями.
Немаловажным аспектом являются требования к оборудованию. Такие требование как
поддержка чистоты ЭВМ от накопления пыли и грязи, выяснены стандарты монитора и
требования к настройкам яркости, контраста и других параметров, изложенных в
данном разделе.
Так же проведены расчеты отпускной цены программного продукта, которая
составит 16083,34 грн. И сделаны выводы, что данная система семантического
разбора естественно-языковых текстов в конечном итоге представляет собой на
данном этапе исследовательскую работу. Но библиотеки данной системы можно
использовать в коммерческих целях, они имеют широкую сферу применения, от
перевода текстов на различные естественные языки, применения в поисковых
системах, лингвистики, так и для представления знаний.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
1._SyTech -
разработка программного обеспечения: аналитические системы, электронный
документооборот, корпоративные системы, информационные порталы
//#"531470.files/image029.gif">
Рисунок Б.1 - Форма редактора входного текста
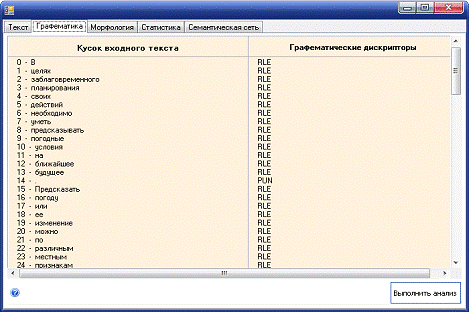
Рисунок Б.2 - Форма графематического разбора
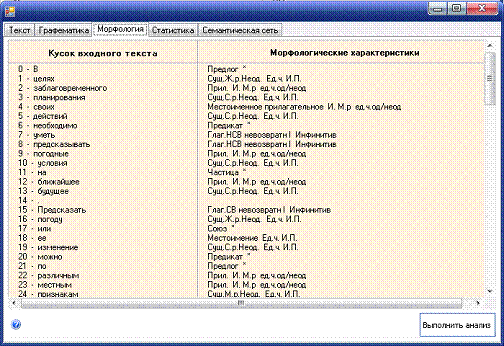
Рисунок Б.3 - Форма морфологического анализа
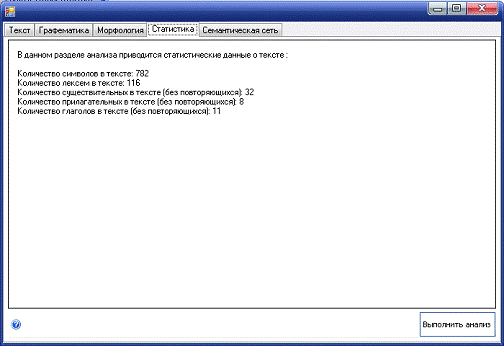
Рисунок Б.4 - Форма статистического анализа
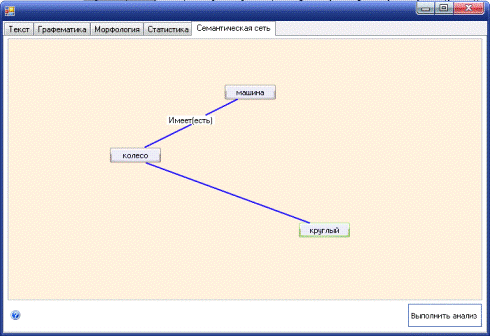
Рисунок В.5 - Форма семантического построения
ПРИЛОЖЕНИЕ В
ЛИСТИНГ ПРОГРАММЫ
//************************************************************
// Programm
//************************************************************System;System.Collections.Generic;System.Linq;System.Windows.Forms;System.Text;MorphologyModule;SemanticSystem
{class Program
{
/// <summary>
/// Главная точка входа для приложения.
/// </summary>
[STAThread]void Main()
{.EnableVisualStyles();.SetCompatibleTextRenderingDefault(false);.Run(new
Form1());
}
}
}LinguisticalModule
{enum PartSpeech { Noun, Ajective, Verb, End, Separator
};struct OnPartsSpeech
{PartSpeech Patr;int iAnword;
}enum Discripts { RLE, LLE, DC, GRAUNK, PUN };struct Lemm
{string Text;Discripts Discript;string Morph;byte MorphCid;
}struct TopGraph //Граф
{int id;string Top; //ВершинаList<string> Relations; //ОтношениеList<int> Relationships; //Связи
}Ling
{[] DEL = { (char)0x9, (char)0xA, (char)0xB, (char)0xC,
(char)0xD, (char)0x20, (char)0xA0, (char)0x2000,
(char)0x2001, (char)0x2002, (char)0x2003,
(char)0x2004, (char)0x2005, (char)0x2006,
(char)0x2007, (char)0x2008, (char)0x2009,
(char)0x200A, (char)0x200B, (char)0x3000,
(char)0xFEFF, };[] SIG = { '.', ',', '-', '!', '?', ';', ':',
'(', ')'};[] RLE = { 'й','ц','у','к','е','н','г','ш','щ','з','х','ъ','ф',
'ы','в','а','п','р','о','л','д','ж','э','я','ч','с',
'м','и','т','ь','б','ю','ё',
'Й','Ц','У','К','Е','Н','Г','Ш','Щ','З','Х','Ъ','Ф',
'Ы','В','А','П','Р','О','Л','Д','Ж','Э','Я','Ч','С',
'М','И','Т','Ь','Б','Ю','Ё' };[] LLE = {
'q','w','e','r','t','y','u','i','o','p','a','s','d',
'f','g','h','j','k','l','z','x','c','v','b','n','m',
'Q','W','E','R','T','Y','U','I','O','P','A','S','D',
'F','G','H','J','K','L','Z','X','C','V','B','N','M' };[] DC =
{ '1', '2', '3', '4', '5', '6', '7', '8', '9', '0' };[] END = {
'.','!','?'};Lemm LemmDiscript(string text)
{lemm = new Lemm();.Text = text;rle, lle, dc;=
text.IndexOfAny(RLE);= text.IndexOfAny(LLE);= text.IndexOfAny(DC);((dc == -1)
& (lle == -1) & (rle != -1))
{.Discript = Discripts.RLE; //RLE
}if ((rle == -1) & (dc == -1) & (lle != -1))
{.Discript = Discripts.LLE; //LLE
}if ((rle == -1) & (lle == -1) & (dc != -1))
{.Discript = Discripts.DC; //DC
}
{(text.IndexOfAny(SIG) != -1)
{.Discript = Discripts.PUN; //PUN
}lemm;
}Queue<Lemm> GraphematicAnalysis(string Text) //
Графематический разбор
{<Lemm> TextLemm = new Queue<Lemm>();starti = 0;deli
= 0, sigi = 0;
{= Text.IndexOfAny(DEL, starti);= Text.IndexOfAny(SIG,
starti);(deli < sigi)
{(deli == starti)
{++;
}if (deli > starti)
{.Enqueue(LemmDiscript(Text.Substring(starti, deli -
starti)));= deli + 1;
}if (deli == -1)
{(sigi > starti)
{.Enqueue(LemmDiscript(Text.Substring(starti, sigi -
starti)));= sigi;
}if (sigi == starti)
{.Enqueue(LemmDiscript(Text.Substring(starti, 1)));++;
}
}
}if (sigi < deli)
{(sigi == starti)
{.Enqueue(LemmDiscript(Text.Substring(starti, 1)));++;
}if (sigi > starti)
{.Enqueue(LemmDiscript(Text.Substring(starti, sigi -
starti)));= sigi;
}if (sigi == -1)
{(deli > starti)
{.Enqueue(LemmDiscript(Text.Substring(starti, deli -
starti)));= deli;
}if (deli == starti)
{++;
}
}
}if (sigi == deli)
{(Text.Length == starti)
{.Enqueue(LemmDiscript(Text.Substring(starti, 1)));++;
}if (Text.Length > starti)
{.Enqueue(LemmDiscript(Text.Substring(starti, Text.Length -
)));= Text.Length + 1;
}
}
}(Text.Length > starti);TextLemm;
}Queue<Lemm> MorphologicAnalysis(Queue<Lemm>
TextLemm)
{Mlemm;strb = new StringBuilder();.Tids ts = new
Mcr.Tids();.Tinlexdata data = new
Mcr.Tinlexdata();.InitMcr();.LoadMcr("zal.mcr");(int i = 0; i !=
TextLemm.Count; i++)
{( TextLemm.Peek().Discript == Discripts.RLE )
{.FindWID(TextLemm.Peek().Text, ref ts);.GetWordById(ts.ids[0],
false, true, ref data);.Text = TextLemm.Peek().Text;.Discript =
TextLemm.Peek().Discript;.MorphCid = data.inlex[0].cid;.Morph =
Mcr.ConstIdToStr(data.inlex[0].cid) + " "
+.VarIdToStr(data.inlex[0].cid, data.inlex[0].vid);.Enqueue(Mlemm);=
TextLemm.Dequeue();
}
{.Enqueue(TextLemm.Dequeue());
}
}TextLemm;
}List<string> NounsSeparation(Queue<Lemm>
TextLemm) // Все
Существительна
{.Tids ts = new Mcr.Tids();.Tinlexdata data = new
Mcr.Tinlexdata();.InitMcr();.LoadMcr("zal.mcr");<string> list =
new List<string>();(int i = 0; i != TextLemm.Count; i++)
{(TextLemm.Peek().Discript == Discripts.RLE
&.Peek().MorphCid >= 1 & TextLemm.Peek().MorphCid <= 15)
{.FindWID(TextLemm.Peek().Text, ref
ts);.GetWordById(ts.ids[0], false, true, ref data);.Add(data.inlex[0].anword);.Enqueue(TextLemm.Dequeue());
}
{.Enqueue(TextLemm.Dequeue());
}
}<string> list2 = new List<string>();(list.Count
> 0)
{j = 0;b;
{.Add(list.ElementAt(0));
{= list.Remove(list2.ElementAt(j));
}(b == true);++;
}(list.Count > 0);
}.Clear();list2;
}List<string> AdjectivesSeparation(Queue<Lemm>
TextLemm) //
Прилагательные
{.Tids ts = new Mcr.Tids();.Tinlexdata data = new
Mcr.Tinlexdata();.InitMcr();.LoadMcr("zal.mcr");<string> list =
new List<string>();(int i = 0; i != TextLemm.Count; i++)
{(TextLemm.Peek().Discript == Discripts.RLE &
((TextLemm.Peek().MorphCid == 20)|
(TextLemm.Peek().MorphCid == 23)|
(TextLemm.Peek().MorphCid == 24)|
(TextLemm.Peek().MorphCid == 25)))
{.FindWID(TextLemm.Peek().Text, ref ts);.GetWordById(ts.ids[0],
false, true, ref data);.Add(data.inlex[0].anword);.Enqueue(TextLemm.Dequeue());
}
{.Enqueue(TextLemm.Dequeue());
}
}<string> list2 = new List<string>();(list.Count
> 0)
{j = 0;b;
{.Add(list.ElementAt(0));
{= list.Remove(list2.ElementAt(j));
}(b == true);++;
}(list.Count > 0);
}.Clear();list2;
}List<string> VerbsSeparation(Queue<Lemm>
TextLemm) // Все Глаголы
{.Tids ts = new Mcr.Tids();.Tinlexdata data = new
Mcr.Tinlexdata();.InitMcr();.LoadMcr("zal.mcr");<string> list =
new List<string>();(int i = 0; i != TextLemm.Count; i++)
{(TextLemm.Peek().Discript == Discripts.RLE
&.Peek().MorphCid >= 40 & TextLemm.Peek().MorphCid <= 51)
{.FindWID(TextLemm.Peek().Text, ref
ts);.GetWordById(ts.ids[0], false, true, ref
data);.Add(data.inlex[0].anword);.Enqueue(TextLemm.Dequeue());
}
{.Enqueue(TextLemm.Dequeue());
}
}<string> list2 = new List<string>();(list.Count
> 0)
{j = 0;b;
{.Add(list.ElementAt(0));
{= list.Remove(list2.ElementAt(j));
}(b == true);++;
}(list.Count > 0);
}.Clear();list2;
}int ScanPart(string str, List<TopGraph> topGraph)
{.Tids ts = new Mcr.Tids();.Tinlexdata data = new
Mcr.Tinlexdata();.InitMcr();.LoadMcr("zal.mcr");.FindWID(str, ref
ts);.GetWordById(ts.ids[0], false, true, ref data);iPart = -1;(int i = 0; i !=
topGraph.Count; i++)
{(topGraph.ElementAt(i).Top == data.inlex[0].anword)= i;
}iPart;
}int ScanPart(string str, List<string> list)
{.Tids ts = new Mcr.Tids();.Tinlexdata data = new
Mcr.Tinlexdata();.InitMcr();.LoadMcr("zal.mcr");.FindWID(str, ref
ts);.GetWordById(ts.ids[0], false, true, ref data);iPart = -1;(int i = 0; i !=
list.Count; i++)
{(list.ElementAt(i) == data.inlex[0].anword)= i;
}iPart;
}List<TopGraph>
SyntaxSemanticAnalysis(Queue<Lemm> )
{Top = new TopGraph();<TopGraph> topGraph = new
List<TopGraph>(); // Граф<string>
list = new List<string>();<string> listVerb = new
List<string>();.AddRange(NounsSeparation(TextLemm));Ni = list.Count; // до данного значения элементы являются
существительными
// полсе следуют
прилагательные.AddRange(AdjectivesSeparation(TextLemm));.AddRange(VerbsSeparation(TextLemm));
//выделения глаголов
for(int i=0; i!=list.Count; i++) //записываем все вершины графа(сети)
{.id = i;.Top = list.ElementAt(i);
topGraph.Add(Top);
}
//Транспанируем текст в структуру TextOnParts выделяя главные
элементы<OnPartsSpeech>
TextOnParts = new List<OnPartsSpeech>();PS = new OnPartsSpeech();(int i =
0; i!=TextLemm.Count; i++)
{(TextLemm.ElementAt(i).Discript == Discripts.RLE & //
Noun.ElementAt(i).MorphCid >= 1 & .ElementAt(i).MorphCid <= 15)
{.Patr = PartSpeech.Noun;.iAnword =
ScanPart(TextLemm.ElementAt(i).Text, topGraph);.Add(PS);
}if (TextLemm.ElementAt(i).Discript == Discripts.RLE & //
Ajective
(TextLemm.ElementAt(i).MorphCid == 20) |
(TextLemm.ElementAt(i).MorphCid == 23) |
(TextLemm.ElementAt(i).MorphCid == 24) |
(TextLemm.ElementAt(i).MorphCid == 25))
{.Patr = PartSpeech.Ajective;.iAnword =
ScanPart(TextLemm.ElementAt(i).Text, topGraph);.Add(PS);
}if (TextLemm.ElementAt(i).Discript == Discripts.RLE & //
Verb.ElementAt(i).MorphCid >= 40 & .ElementAt(i).MorphCid <= 51)
{.Patr = PartSpeech.Verb;.iAnword =
ScanPart(TextLemm.ElementAt(i).Text, listVerb);.Add(PS);
}
}.Patr = PartSpeech.End; //конец текста.iAnword = -1;.Add(PS);
//Транспанируем структуру TextOnPartsTG = new TopGraph(); // для изменений<string> LR = new List<string>();<int> LRs = new
List<int>();(TextOnParts.Count >= 0)
{iP = 0;
{(TextOnParts.ElementAt(iP).Patr == PartSpeech.Noun)
{(TextOnParts.ElementAt(iP + 1).Patr == PartSpeech.Noun) //
Сущь_Сущь
{(topGraph[TextOnParts.ElementAt(iP).iAnword].Relations !=
null)
{
.AddRange(topGraph[TextOnParts.ElementAt(iP).iAnword].Relations);
}.Add("Имеет(есть)");(topGraph[TextOnParts.ElementAt(iP).iAnword].Relationships
!= null)
{ .AddRange(topGraph[TextOnParts.ElementAt(iP).iAnword].Relationshi);
}.Add(TextOnParts.ElementAt(iP + 1).iAnword);.id =
topGraph[TextOnParts.ElementAt(iP).iAnword].id;.Top =
topGraph[TextOnParts.ElementAt(iP).iAnword].Top;.Relations = LR;.Relationships
= LRs;[TextOnParts.ElementAt(iP).iAnword] = TG;++;
}if (TextOnParts.ElementAt(iP + 1).Patr ==
PartSpeech.Ajective) //
Сущь_Прил
{
//
.ElementAt(TextOnParts.ElementAt(iP).iAnword).Relations.Add("
Свойство");
//
.ElementAt(TextOnParts.ElementAt(iP).iAnword).Relationships.A(TextOnParts.ElementAt(iP
+ 1).iAnword);
//
}if (TextOnParts.ElementAt(iP + 1).Patr == PartSpeech.Verb)//
Сущь_Глагал
{<int> iVeber = new List<int>();<int>
iAjective = new List<int>();iP_2 = iP + 1;
{(TextOnParts.ElementAt(iP_2).Patr == PartSpeech.Verb)
//->глагол
{.Add(iP_2);
}if (TextOnParts.ElementAt(iP_2).Patr == PartSpeech.Ajective)
//->прил
{.Add(iP_2);
}_2++;
}(TextOnParts.ElementAt(iP_2).Patr != PartSpeech.Noun |
.ElementAt(iP_2).Patr != PartSpeech.End);(TextOnParts.ElementAt(iP_2).Patr ==
PartSpeech.Noun)
{
}if (TextOnParts.ElementAt(iP_2).Patr == PartSpeech.End)
{
}.ElementAt(TextOnParts.ElementAt(iP).iAnword).Relations.Add(li.ElementAt(TextOnParts.ElementAt(iP
+
1).iAnword));.ElementAt(TextOnParts.ElementAt(iP).iAnword).Relationships.A(TextOnParts.ElementAt(iP
+ 1).iAnword);
}++;
}(TextOnParts.ElementAt(iP).Patr == PartSpeech.End);
}topGraph;
}
}
}
//************************************************************
// Form1
//************************************************************System;System.IO;System.Collections.Generic;System.ComponentModel;System.Data;System.Drawing;System.Linq;System.Text;System.Windows.Forms;System.Collections;MorphologyModule;LinguisticalModule;SemanticSystem
{struct Bridge // Дуги для вершин
{int TopX;Label Attitude; // Отношениеint TopY;Point pointX;Point pointY;Bridge(int tx,
Label At, int ty, Point pX, Point pY)
{= tx;= At;= ty;= pX;= pY;
}
}partial class Form1 : Form
{Text; // Исходный текстmyLing = new Ling(); // Класс анализа<Button>
buttons = new List<Button>(); // Вершины
графа<Bridge> Bridges =
new List<Bridge>(); // Дуги графаactiveButton = -1; // id - активной вершины<Lemm> TextLemm = new Queue<Lemm>(); // Обработаный текст<TopGraph> Graph = new List<TopGraph>();Form1()
{();
}
// Загрузка текстаvoid открытьToolStripButton_Click(object
sender, EventArgs e)
{dlg = new OpenFileDialog();.Filter = "Формат файла
(txt)|*.txt";(dlg.ShowDialog() == DialogResult.OK)
{enc = Encoding.Default;FileName = dlg.FileName;sr = new
StreamReader(FileName, Encoding.Default);= sr.ReadToEnd();.Close();.richTextBox1.Text
= Text;();
}
}
// Графематический анализvoid toolStripButton1_Click(object sender, EventArgs e)
{= this.richTextBox1.Text;.Clear();(this.Text.Length != 0)
{= myLing.GraphematicAnalysis(Text);strb1 = new
StringBuilder();strb2 = new StringBuilder();(int i = 0; i != TextLemm.Count;
i++)
{.Append(" " + i + " - " +
TextLemm.Peek().Text + "\r");.Append(" " +
TextLemm.Peek().Discript + "\r");.Enqueue(TextLemm.Dequeue());
}.label3.Text = strb1.ToString();.label4.Text = strb2.ToString();
}
{.Show("Отсутствует анализируемый текст!");
}
}
// Морфологический анализvoid toolStripButton2_Click_1(object sender, EventArgs e)
{(this.TextLemm.Count != 0)
{= myLing.MorphologicAnalysis(TextLemm);strb1 = new
StringBuilder();strb2 = new StringBuilder();(int i = 0; i != TextLemm.Count;
i++)
{.Append(" " + i + " - " +
TextLemm.Peek().Text + "\r");.Append(" " +
TextLemm.Peek().Morph + "\r");.Enqueue(TextLemm.Dequeue());
}.label6.Text = strb1.ToString();.label9.Text =
strb2.ToString();
}
{.Show("Не выполнен графематический анализ!");
}
}
// Статистический анализvoid toolStripButton6_Click(object sender, EventArgs e)
{.label16.Text = "\n В данном разделе анализа приводится
статистические данные о тексте :\n" +
"\n Количество символов в тексте: " + Text.Length +
"\n Количество лексем в тексте: " + TextLemm.Count +
"\n Количество существительных в тексте (без повторяющихся): "
+ .NounsSeparation(TextLemm).Count +
"\n Количество прилагательных в тексте (без повторяющихся): " +
.AdjectivesSeparation(TextLemm).Count +
"\n Количество глаголов в тексте (без повторяющихся): " +
.VerbsSeparation(TextLemm).Count +
" ";
// "/n/tКоличество существительных в тексте (без повторяющихся):
" +
TextLemm.Count;
}
// Синтаксическо-Семантический анализvoid toolStripButton4_Click(object sender, EventArgs e)
{(buttons.Count > 0) //очистка перед построением графа(сети)
{(int i = 0; i != buttons.Count; i++)
{.ElementAt(i).Dispose();
}.Clear();
}(Bridges.Count > 0)
{(int i = 0; i != Bridges.Count; i++)
{.ElementAt(i).Attitude.Dispose();
}.Clear();
}.Panel1.Controls.Clear();(TextLemm.ElementAt(0).MorphCid !=
null)
{strb = new StringBuilder();mehDown = new
(splitContainer5_Panel1_MouseDown);=
myLing.SyntaxSemanticAnalysis(TextLemm);(int i = 0; i != Graph.Count; i++) // Создания кнопок(вершин)
{.Add(new Button() { Text = Graph.ElementAt(i).Top ,=
Graph.ElementAt(i).id,= new Point(20, 30 * (i + 1)),= Color.Lavender,= false,=
true});.Panel1.Controls.Add(buttons.ElementAt(i));
}(int i = 0; i != buttons.Count; i++) // присвоили события
нажатия
мышки для каждой кнопки(вершине)
{.ElementAt(i).MouseDown += mehDown;
}(int i = 0; i != Graph.Count; i++) // Создания связий
{(Graph[i].Relations != null)
{(int j = 0; j != Graph.ElementAt(i).Relations.Count; j++)
{.Add(new Bridge(i, new Label()
{= true,= new Point(
(int)(buttons.ElementAt(i).Location.X +
.ElementAt(Graph.ElementAt(i).Relationships.ElementAt(j)).Locatio.X)/2,
(int)(buttons.ElementAt(i).Location.Y +
.ElementAt(Graph.ElementAt(i).Relationships.ElementAt(j)).Locatio.Y)/2),=
Color.White,
//BorderStyle = BorderStyle.FixedSingle;
//label.TabIndex = 1;=
Graph.ElementAt(i).Relations.ElementAt(j)
}, j,Point(buttons.ElementAt(i).Location.X,
.ElementAt(i).Location.Y),(buttons.ElementAt(Graph.ElementAt(i).Relationships.ElementAt(j)).L.X,.ElementAt(Graph.ElementAt(i).Relationships.ElementAt(j)).Locatio.Y)));.Panel1.Controls.Add(Bridges[j].Attitude);
}
}
}.richTextBox1.Text = strb.ToString();
}
{.Show("Не выполнен морфологический анализ анализ!");
}.splitContainer5.Panel1.Invalidate();
}
// Реакция на мишь для графа (выбор)
private void splitContainer5_Panel1_MouseDown(object sender,
MouseEventArgs e)
{(MouseButtons.Left == e.Button)
{(int i = 0; i != buttons.Count; i++)
{(buttons.ElementAt(i).Focused == true)
{= i;
}
}
}
{= -1;.splitContainer5.Panel1.Focus();
}();.splitContainer5.Panel1.Invalidate();
}
// Реакция на мишь для графа (перемешение курсора)
private void splitContainer5_Panel1_MouseMove(object sender,
e)
{(MouseButtons.Left == e.Button)
{(activeButton != -1)
{.ElementAt(activeButton).Location =Point(e.Location.X -
(buttons.ElementAt(activeButton).Size.Width / 2)
,e.Location.Y - (buttons.ElementAt(activeButton).Size.Height
/ 2));(int i = 0; i != Graph.Count; i++)
{(Graph.ElementAt(i).Relations != null)
{(int j = 0; j != Graph.ElementAt(i).Relations.Count; j++)
{[0].Attitude.Location = new Point(
(int)(buttons.ElementAt(i).Location.X +
.ElementAt(Graph.ElementAt(i).Relationships.ElementAt(j)).Locatio.X) / 2,
(int)(buttons.ElementAt(i).Location.Y +
.ElementAt(Graph.ElementAt(i).Relationships.ElementAt(j)).Locatio.Y) / 2);
}
}
}
}= -1;
}
}
// Реакция на мишь для графа (установка)
private void splitContainer5_Panel1_MouseUp(object sender, e)
{(MouseButtons.Left == e.Button)
{(activeButton != -1)
{.ElementAt(activeButton).Location =Point(e.Location.X -
(buttons.ElementAt(activeButton).Size.Width / 2)
, e.Location.Y - (buttons.ElementAt(activeButton).Size.Height
/ 2));(int i=0; i!=Graph.Count; i++)
{(Graph.ElementAt(i).Relations != null)
{(int j = 0; j != Graph.ElementAt(i).Relations.Count; j++)
{[0].Attitude.Location = new Point(
(int)(buttons.ElementAt(i).Location.X +
.ElementAt(Graph.ElementAt(i).Relationships.ElementAt(j)).Locatio.X) / 2,
(int)(buttons.ElementAt(i).Location.Y + .ElementAt(Graph.ElementAt(i).Relationships.ElementAt(j)).Locatio.Y)
/ 2);
}
}
}
}
{= -1;
}
}.splitContainer5.Panel1.Invalidate();
}
// Рисование линий отношенийvoid
splitContainer5_Panel1_Paint(object sender, PaintEventArgs e)
{B = new Bridge();gx = e.Graphics;(int i = 0; i !=
Bridges.Count; i++)
{
//B.Attitude = Bridges[i].Attitude;.pointX = new
Point(buttons.ElementAt(Bridges[i].TopX).Location.X,
.ElementAt(Bridges[i].TopX).Location.Y);.pointY = new
Point(buttons.ElementAt(Bridges[i].TopY).Location.X, .ElementAt(Bridges[i].TopY).Location.Y);.DrawLine(new
Pen(Brushes.Blue, 4),.pointX, B.pointY);
}
}
// Помощь1void справкаToolStripButton1_Click(object sender,
EventArgs e)
{str = "\tЗакладка данной системы преднозначена для загрузки" +
"и редоктирования текста, в дальнейшем который будет
обработан!";
MessageBox.Show(str);
}
// Помощь2void справкаToolStripButton_Click(object sender,
EventArgs e)
{str = "\tДанная закладка(этап анализа) системы преднозначена для
графематического" +
" анализа, который разделяет текст на разделители и лексемы, при
этом
определяет" +
" для них свой дескриптор.\n \tПеречень дескрипторов:\n" +
" RLE - русская лексема;\n LLE - английская лексема;\n DC - цифровой
комплекс;\n" +
" GRAUNK - смешаные;\n PUN - разделители и знаки препинания.";
MessageBox.Show(str);
}
}
}
//************************************************************
// Mcr
//************************************************************System;System.Collections.Generic;System.Linq;System.Text;System.Runtime.InteropServices;MorphologyModule
{Mcr
{const int MAX_WORD_LEN = 32;const int MAX_WORD_COUNT = 200;
[System.Runtime.InteropServices.StructLayoutAttribute(System.Runtime.In.LayoutKind.Sequential,
CharSet = .Runtime.InteropServices.CharSet.Ansi)]struct Tinlex
{
/// char[32]
[System.Runtime.InteropServices.MarshalAsAttribute(System.Runtime.Inter.UnmanagedType.ByValTStr,
SizeConst = 32)]string anword;
/// unsigned charbyte cid;
/// unsigned charbyte vid;
/// charbyte virt;
/// unsigned charbyte para;
}
[System.Runtime.InteropServices.StructLayoutAttribute(System.Runtime.In.LayoutKind.Sequential)]struct
Tinlexdata
{
/// Tinlex[200]
[System.Runtime.InteropServices.MarshalAsAttribute(System.Runtime.Inter.UnmanagedType.ByValArray,
SizeConst = 200, ArraySubType
= System.Runtime.InteropServices.UnmanagedType.Struct)]Tinlex[]
inlex;
/// intint count;
}
[System.Runtime.InteropServices.StructLayoutAttribute(System.Runtime.In.LayoutKind.Sequential)]struct
Tid
{
/// unsigned intuint lnk;
/// unsigned charbyte en;
}
[System.Runtime.InteropServices.StructLayoutAttribute(System.Runtime.In.LayoutKind.Sequential)]struct
Tids
{
/// Tid[200]
[System.Runtime.InteropServices.MarshalAsAttribute(System.Runtime.Inter.UnmanagedType.ByValArray,
SizeConst = 200, ArraySubType
= System.Runtime.InteropServices.UnmanagedType.Struct)]Tid[]
ids;
/// intint count;
}
// // InitMcr() - инициализировать словарь mcr
[DllImport("mcr.dll", CharSet =
CharSet.None)]static extern int InitMcr();
// // LoadMcr - загрузить словарь mcr
[DllImport("mcr.dll", CharSet =
CharSet.None)]static extern int ([System.Runtime.InteropServices.InAttribute()]
[System.Runtime.InteropServices.MarshalAsAttribute(System.Runtime.Inter.UnmanagedType.LPStr)]
string s);// // SaveMcr - сохранить словарь mcr
[DllImport("mcr.dll", CharSet =
CharSet.None)]static extern int ([System.Runtime.InteropServices.InAttribute()]
[System.Runtime.InteropServices.MarshalAsAttribute(System.Runtime.Inter.UnmanagedType.LPStr)]
string s);
// // FindID - поиск слова s в словаре mcr, возвращает int количество
найденых слов и ids
//// (уникальный идентификтор слова = уникальный идентификатор
//// Используйте полученные идентификаторы для получения
грамматических характеристик слова или возврата всей парадигмы
[DllImport("mcr.dll", CharSet =
CharSet.None)]static extern int ([System.Runtime.InteropServices.InAttribute()]
[System.Runtime.InteropServices.MarshalAsAttribute(System.Runtime.Inter.UnmanagedType.LPStr)]
string s, ref Tids ids);
// GetByID - для идентификатора id, функция возвращает
грамматические характеристики, лемму или всю парадигмы в outdata
// :: gh_only = true - возвращать только грамматические характеристики
// :: gh_only = false - возвратить грамматические характеристики для id
и лемму (win1251)
// :: all = true - поместить в wout всю парадигму для указанного id с
грамматическими характериситками, доступно только для словарей без
пометы
ReadOnly
[DllImport("mcr.dll", CharSet = CharSet.None,
EntryPoint =
"GetWordById")]static extern int GetWordById(Tid
id,
[System.Runtime.InteropServices.MarshalAsAttribute(System.Runtime.Inter.UnmanagedType.I1)]
bool gh_only,
[System.Runtime.InteropServices.MarshalAsAttribute(System.Runtime.Inter.UnmanagedType.I1)]
bool all, ref Tinlexdata outdata);
// // ROnly Проверка является ли подключенный словарь - словарем
только для чтения
(ReadOnlyDict)
[DllImport("mcr.dll", CharSet =
CharSet.None)]static extern bool ReadOnlyDict();
// // AddPara - добавление парадигмы в словарь
[DllImport("mcr.dll", CharSet =
CharSet.None)]static extern int AddParadigma(ref Tinlexdata indata);
// //3Space - проверка свободного места в словаре, если любой из
аргументов близок к 100% то добавление парадигм будет вскоре
невозможно
[DllImport("mcr.dll", CharSet =
CharSet.None)]static extern int FreeSpace(System.IntPtr ar1, System.IntPtr ar2,
.IntPtr ar3);
// // Информация о версии mcr.dll
[DllImport("mcr.dll", CharSet =
CharSet.None)]static extern int Ver(System.IntPtr s);
// //Строка постоянной грамматической характеристики
[DllImport("mcr.dll", CharSet = CharSet.None)]
public static extern string ConstIdToStr(byte cid);
// //Строка переменной грамматической характеристики
[DllImport("mcr.dll", CharSet = CharSet.None)]
public static extern string VarIdToStr(byte cid, byte vid);
//Нахождение словоформ по заданной грамматической характеристике
(только для не ReadOnly словарей)
//lnk - номер парадигмы
//const_gh - код постоянной грамматическрй характеристики
(const_gh=0 - любая)
// //var_gh - переменная гр. характеристика
// //all=false - вернуть только первую найденную словоформу
[DllImport("mcr.dll", CharSet =
CharSet.None)]static extern int GetBGH(int lnk, byte const_gh, byte var_gh,
[System.Runtime.InteropServices.MarshalAsAttribute(System.Runtime.Inter.UnmanagedType.I1)]
bool all, ref Tinlexdata outdata);
}
}