Системы нечеткого вывода
Федеральное
агентство по образованию
Государственное
образовательное учреждение
высшего
профессионального образования
САРАТОВСКИЙ
ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ
ИМЕНИ.
Н.Г. ЧЕРНЫШЕВСКОГО
Кафедра
теоретических основ компьютерной
безопасности
и криптографии
СИСТЕМЫ
НЕЧЕТКОГО ВЫВОДА
КУРСОВАЯ
РАБОТА
студента 3 курса факультета компьютерных наук
и информационных технологий
Рогова Игоря Алексеевича
Саратов
2010
Содержание
Введение
.
Системы нечеткого вывода
.1
Базовая архитектура систем нечеткого вывода
.1.1
Нечеткие лингвистические высказывания
.1.2
Правила нечетких продукций в системах нечеткого вывода
.1.3
Основные этапы нечеткого вывода
.2
Алгоритм Мамдани
.3
Алгоритм Цукамото
.4
Алгоритм Ларсена
.5
Алгоритм Сугено
.
Реализация нечеткого вывода Мамдани
Заключение
Список
используемой литературы
Введение
Существуют три основных базисных нечетких
логики: логика Лукасевича, логика Гёделя и вероятностная логика. Интересно, что
объединение любых двух из трех перечисленных выше логик приводит к классической
булевозначной логике.
В первой части курсовой работы приведены
основные понятия из теории нечеткой логики, а так же некоторые схемы нечеткого
вывода. Во второй части рассмотрен пример реализации алгоритма Мамдани.
1. Системы нечеткого вывода
Основное определение нечеткой логики включает в
себя понятия объединения, пересечения и дополнения множеств (через
характеристическую функцию; задать можно различными способами), понятие
нечеткого отношения, а также одно из важнейших понятий - понятие лингвистической
переменной. Даже такой минимальный набор определений позволяет использовать
нечеткую логику в некоторых приложениях, для большинства же необходимо задать
ещё и правило вывода (и оператор импликации).
Процесс нечеткого вывода представляет собой некоторую
процедуру или алгоритм получения нечетких заключений на основе нечетких условий
или предпосылок с использованием рассмотренных выше понятий нечеткой логики.
Этот процесс соединяет в себе все основные концепции теории нечетких множеств:
функции принадлежности, лингвистические переменные, нечеткие логические
операции, методы нечеткой импликации и нечеткой композиции.
Под нечетким множеством понимается совокупность
A = 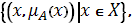
где А - это нечеткое множество, Х -
универсальное множество, а 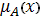 - функция принадлежности
(характеристическая функция), характеризующая степень принадлежности элемента x нечеткому
множеству А.
- функция принадлежности
(характеристическая функция), характеризующая степень принадлежности элемента x нечеткому
множеству А.
Системы нечеткого вывода
предназначены для реализации процесса нечеткого вывода и служат концептуальным
базисом всей современной нечеткой логики. Достигнутые успехи в применении этих
систем для решения широкого класса задач управления послужили основной становления
нечеткой логики как прикладной науки с богатым спектром приложений. Системы
нечеткого вывода позволяют решать задачи автоматического управления,
классификации данных, распознавания образов, принятия решений, машинного
обучения и многие другие.
.1 Базовая архитектура систем
нечеткого вывода
Рассматриваемые системы нечеткого
вывода являются частным случаем продукционных нечетких систем или систем
нечетких правил продукций, в которых условия и заключения, отдельных правил
формируются в форме нечетких высказывания относительно значений тех или иных
лингвистических переменных.
.1.1 Нечеткие лингвистические
высказывания
Нечетким лингвистическим
высказыванием будем называть высказывания следующих видов.
1. Высказывание ”β
есть α”,
где β -
наименование лингвистической переменной, α
- ее значение, которому соответсвует отдельный лингвистический терм из базового
терм-множества T лингвистической переменной β.
2. Высказывание ”β есть 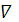 α”, где - модификатор, соответствующий
таким словам, как: ”ОЧЕНЬ”, ”БОЛЕЕ ИЛИ МЕНЕЕ”, ”МНОГО БОЛЬШЕ” и другим, которые
могут быть получены с использованием процедур G и M данной лингвистической
переменной.
α”, где - модификатор, соответствующий
таким словам, как: ”ОЧЕНЬ”, ”БОЛЕЕ ИЛИ МЕНЕЕ”, ”МНОГО БОЛЬШЕ” и другим, которые
могут быть получены с использованием процедур G и M данной лингвистической
переменной.
. Составные высказывания,
образованные из высказываний видов 1 и 2 и нечетких логических операций в форме
связок: ”И”, ”ИЛИ”, ”ЕСЛИ-ТО”, “НЕ”.
Поскольку в системах нечеткого вывода нечеткие
лингвистические высказывания занимают центральное место, далее будем их
называть просто нечеткими высказываниями.
Рассмотрим некоторые примеры нечетких
высказывания. Первое из них - ”скорость автомобиля высокая” представляет собой
нечеткое высказывание первого вида, в рамках которого лингвистической переменной
”скорость автомобиля” присваивается значение ”высокая”. При этом
предполагается, что на универсальном множестве X переменной ”скорость
автомобиля” определен соответствующий лингвистический терм ”высокая”, который
задается в форме функций принадлежности некоторого нечеткого множества.
Нечеткое высказывание второго вида “скорость
автомобиля очень высокая” означает, что лингвистической переменной ”скорость
автомобиля” присваивается значение ”высокая” с модификатором ”ОЧЕНЬ”, который
изменяет значение соответствующего лингвистического терма ”высокая” на основе
использования расчетной формулы.
.1.2 Правила нечетких продукций в системах
нечеткого вывода
Простейший вариант правила нечеткой продукций,
который наиболее часто используется в системах нечеткого вывода, может быть
записан в форме:
ПРАВИЛО <#>: ЕСЛИ “β1
есть α”,
ТО ”β2
есть α”.
Здесь нечеткое высказывание “β1
есть α”
представляет собой условие данного правила нечеткой продукций, а нечеткое
высказывание ”β2
есть α”
- нечеткое заключение данного правила. При этом считается, что β1≠
β2.
Система нечетких правил продукций
или продукционная нечеткая система представляет собой некоторое согласованное
множество отдельных нечетких продукций или правил нечетких продукций в форме
”ЕСЛИ 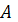 , ТО Β”, где и Β - нечеткие
лингвистические высказывания вида 1,2 или 3.
, ТО Β”, где и Β - нечеткие
лингвистические высказывания вида 1,2 или 3.
.1.3 Основные этапы нечеткого вывода
Основными этапами нечеткого вывода
являются:
Формирование базы правил систем
нечеткого вывода.
Фаззификация входных переменных.
Агрегирование подусловий в нечетких
правилах продукций.
Активизация (композиция)
подзаключений в нечетких правилах продукций.
Вывод заключений нечетких правил
продукций.
Рассмотрим каждый в отдельности.
База правил нечетких продукций
представляет собой конечное множество правил нечетких продукций, согласованных
относительно используемых в них лингвистических переменных. Наиболее часто база
правил представляется в форме структурированного текста:
ПРАВИЛО_1: ЕСЛИ ”Условие_1” ТО
”Заключение_1”
ПРАВИЛО_2: ЕСЛИ ”Условие_2” ТО
”Заключение_2”
…
ПРАВИЛО_n: ЕСЛИ
”Условие_n” ТО
”Заключение_n”.
Согласованность правил относительно
используемых лингвистических переменных означает, что в качестве условий и
заключений правил могут использоваться только нечеткие высказывания вида:
ПРАВИЛО <#>: ЕСЛИ “β1 есть α” И ”β2 есть α”, ТО ”β3 есть 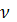 ”
”
или
ПРАВИЛО <#>: ЕСЛИ “β1 есть α” ИЛИ ”β2 есть α”, ТО ”β3 есть ”.
ПРАВИЛО <#>: ЕСЛИ “β1 есть α”, ТО ”β2 есть α” И ”β3 есть ”
ПРАВИЛО <#>: ЕСЛИ “β1 есть α”, ТО ”β2 есть α” ИЛИ ”β3 есть ”.
При этом в каждом из нечетких высказываний
должны быть определены функции принадлежности значений терм-множества для
каждой из лингвистических переменных.
В системах нечеткого вывода
лингвистические переменные, которые используются в нечетких высказываниях
подусловий правил нечетких продукций, часто называют входными лингвистическими
переменными, а переменные, которые используются в нечетких высказываниях
подзаключений правил нечетких продукций, часто называют выходными
лингвистическими переменными.
Таким образом, при задании или
формировании базы правил нечетких продукций необходимо определить: множество
правил нечетких продукций P={ПРАВИЛО_1,ПРАВИЛО_2,…,ПРАВИЛО_n}, множество
входных лингвистических переменных V={β1, β2,…, βm} и
множество выходных лингвистических переменных W={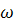 1,
1,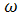 2,…,l}. Тем самым
база правил считается заданной, если заданы множества P,V,W.
2,…,l}. Тем самым
база правил считается заданной, если заданы множества P,V,W.
Под фаззификацией понимается не только
этап выполнения нечеткого вывода, но и собственно процесс или процедура
нахождения значений функций принадлежности нечетких множеств(термов) на основе
обычных(не нечетких) исходных данных. Фаззификацию еще называют введением
нечеткости.
Агрегирование представляет собой
процедуру определения степени истинности условий по каждому из правил системы
нечеткого вывода.
Активизация представляет собой
процедуру или процесс нахождения степени истинности каждого из подзаключений
правил нечетких продукций.
Методы нечеткой композиции:
min-активизация:
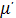 (y) = min{ci,
(y) = min{ci,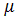 (y)},
(y)},
где C={c1,c2,…,cq} -
множество степеней истинности, q - общее количество подзаключений в
базе правил;
prod-активизация:
(y) = сi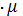 (y);
(y);
average-активизация:
(y) = 0,5 (сi+
(сi+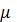 (y)),
(y)),
Где (y) - функция
принадлежности терма, который является значением некоторой выходной переменной .
Вывод заключений нечетких правил
продукций или аккумуляция в системах нечеткого вывода представляет собой
процедуру или процесс нахождения функции принадлежности для каждой из выходных
лингвистических переменных множества W={1,2,…,l}.
Цель аккумуляции заключается в том,
чтобы объединить или аккумулировать все степени истинности заключений
(подзаключений) для получения функции принадлежности каждой из выходных
переменных. Причина необходимости выполнения этого этапа состоит в том, что
подзаключения, относящиеся к одной и той же выходной лингвистической переменной,
принадлежат различным правилам нечеткого вывода.
Дефаззификация в системах нечеткого
вывода представляет собой процедуру или процесс нахождения обычного значения
для каждой из выходных лингвистических переменных множества W={1,2,…,l}.
Цель дефаззификации заключается в
том, чтобы, используя результаты аккумуляции всех выходных лингвистических
переменных, получить обычное количественное значение каждой из выходных переменных,
которое может быть использовано специальными устройствами, внешними по
отношению к системе нечеткого вывода.
Методы дефаззификации:
Метод центра тяжести:
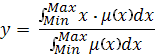 ,
,
где y - результат дефаззификации, x
- переменная, соответствующая выходной лингвистической переменной , 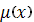 - функция принадлежности нечеткого
множества, соответствующего выходной переменной после этапа аккумуляции, Min и Max - левая и
правя точки интервала носителя нечеткого множества рассматриваемой выходной
переменной ;
- функция принадлежности нечеткого
множества, соответствующего выходной переменной после этапа аккумуляции, Min и Max - левая и
правя точки интервала носителя нечеткого множества рассматриваемой выходной
переменной ;
Метод центра тяжести для
одноточечных множеств:
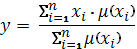 ,
,
где n - число одноточечных
(одноэлементных) нечетких множеств, каждое из которых характеризует
единственное значение рассматриваемой лингвистической переменной;
Метод центра площади:
Центр площади равен y = , где значение определяется из уравнения:
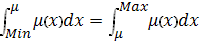 ,
,
другими словами, центр площади равен
абсциссе, которая делит площадь, ограниченную графиком кривой функции
принадлежности соответствующей выходной переменной, на две равные части;
Метод левого модального значения:
y = min{xm} ,
где xm - модальное
значение(мода) нечеткого множества, соответствующего выходной переменной после аккумуляции, другими словами,
значение выходной переменной определяется как мода нечеткого множества для
соответствующей выходной переменной или наименьшая из мод(самая левая), если
нечеткое множество имеет несколько модальных значений;
Метод правого модального значения:
y = max{xm} ,
где xm - модальное
значение(мода) нечеткого множества, соответствующего выходной переменной после аккумуляции, другими словами,
значение выходной переменной определяется как мода нечеткого множества для
соответствующей выходной переменной или наибольшая из мод(самая правая), если
нечеткое множество имеет несколько модальных значений;
.2 Алгоритм Мамдани (Mamdani)
Алгоритм Мамдани является одним из
первых, который нашел применение в системах нечеткого вывода. Он был предложен
в 1975г. Английским математиком Е. Мамдани(Ebrahim Mamdani) в качестве
метода для управления паровым двигателем. По своей сути этот алгоритм порождает
рассмотренные выше этапы, поскольку в наибольшей степени соответствует их
параметрам.
Формально алгоритм Мамдани может
быть определен следующим образом:
Формирование базы правил систем
нечеткого вывода. Совпадают с рассмотренными выше.
Фаззификация входных переменных.
Совпадают с рассмотренными выше.
Агрегирование подусловий в нечетких
правилах продукций. Для нахождения степени истинности условий каждого из правил
нечетких продукций используются парные нечеткие логические операции. Те
правила, степень истинности условий которых отлична от нуля, считаются
активными и используются для дальнейших расчетов.
Активизация подзаключений в нечетких
правилах продукций. Осуществляется по формуле min-активизации, при этом для
сокращения времени вывода учитываются только активные правила нечетких
продукций.
Аккумуляция заключений нечетких
правил продукций. Осуществляется по формуле объединения нечетких множеств,
соответствующих термам подзаключений, относящихся к одним и тем же выходным
лингвистическим переменным.
Дефаззификация выходных переменных.
Традиционно используется метод центра тяжести для многоэлементных или
одноэлементых множеств или метод центра площади.
.3 Алгоритм Цукамото (Tsukamoto)
Формально алгоритм Цукамото может
быть определен следующим образом:
Формирование базы правил систем
нечеткого вывода. Совпадают с рассмотренными выше.
Фаззификация входных переменных.
Совпадают с рассмотренными выше.
Агрегирование подусловий в нечетких
правилах продукций. Для нахождения степени истинности условий всех правил
нечетких продукций используются парные нечеткие логические операции. Те
правила, степень истинности условий которых отлична от нуля, считаются
активными и используются для дальнейших расчетов.
Активизация подзаключений в нечетких
правилах продукций. Осуществляется аналогично алгоритму Мамдани, после чего
находятся обычные значения всех выходных лингвистических переменных в каждом из
подзаключений активных правил нечетких продукций. В этом случае значение выходной
лингвистической переменной 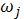 в каждом из подзаключений находится
как решение уравнения:
в каждом из подзаключений находится
как решение уравнения:
ci = () (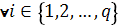 ),
),
где q - общее
количество подзаключений в базе правил.
Аккумуляция заключений нечетких
правил продукций. Фактически отсутствует, поскольку расчеты осуществляются с
обычными действительными числами .
Дефаззификация выходных переменных.
Используется модифицированный вариант в форме метода центра тяжести для
одноточечных множеств:
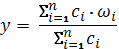 ,
,
где n - общее
количество активных правил нечетких продукций, в подзаключениях которых
присутствует выходная лингвистическая переменная .
.4 Алгоритм Ларсена (Larsen)
Формально алгоритм Ларсена может
быть определен следующим образом:
Формирование базы правил систем
нечеткого вывода. Совпадают с рассмотренными выше.
Фаззификация входных переменных.
Совпадают с рассмотренными выше.
Агрегирование подусловий в нечетких
правилах продукций. Используются парные нечеткие логические операции для
нахождения степени истинности условий всех правил нечетких продукций (как
правило, max - дизъюнкция и min - конъюнкция). Те правила, степень истинности
условий которых отлична от нуля, считаются активными и используются для
дальнейших расчетов.
Активизация подзаключений в нечетких
правилах продукций. Осуществляется использованием формулы prod-активации,
посредством чего находится совокупность нечетких множеств: С1,C2,…,Cq, где q - общее
количество подзаключений в базе правил.
Аккумуляция заключений нечетких
правил продукций. Осуществляется по формуле объединения нечетких множеств,
соответствующих термам подзаключений, относящихся к одним и тем же выходным
лингвистическим переменным.
Дефаззификация выходных переменных.
Может использоваться любой из рассмотренных выше методов дефаззификации.
Алгоритм Сугено(Sugeno)
Формально алгоритм Сугено,
предложенный Сугено и Такаги, может быть определен следующим образом:
Формирование базы правил систем
нечеткого вывода. В базе правил используются только правила нечетких продукций
в форме:
ПРАВИЛО <#>: ЕСЛИ “β1 есть α” И ”β2 есть α”, ТО ”=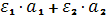 ”.
”.
Фаззификация входных переменных.
Совпадают с рассмотренными выше.
Агрегирование подусловий в нечетких
правилах продукций. Для нахождения степени истинности условий всех правил
нечетких продукций, как правило, используется логическая операция min -
конъюнкции. Те правила, степень истинности условий которых отлична от нуля,
считаются активными и используются для дальнейших расчетов.
Активизация подзаключений в нечетких
правилах продукций. Во-первых, с использованием метода min-активизации
находятся значения степеней истинности всех заключений правил нечетких
продукций. Во-вторых, осуществляется расчет обычных значений выходных
переменных каждого правила. Это выполняется с использованием формулы для
заключения:
ПРАВИЛО <#>: ЕСЛИ “β1 есть α” И ”β2 есть α”, ТО ”=”,
в которую вместо a1 и a2
подставляются значения входных переменных до этапа фаззификации. Тем самым
определяются множество значений C = {c1,c2,…,cn} и
множество значений выходных переменных W={1,2,…,l}, где n -
общее количество правил в базе правил.
Аккумуляция заключений нечетких
правил продукций. Фактически отсутствует, поскольку расчеты осуществляются с
обычными действительными числами .
Дефаззификация выходных переменных.
Используется модифицированный вариант в форме метода центра тяжести для
одноточечных множеств.
нечеткий вывод алгоритм мамдани
2. Реализация нечеткого вывода Мамдани
В обычном светофоре время работы зеленого и
красного света, а также время цикла фиксированы. Это создает некоторые
трудности в движении машин, особенно, при изменении их потоков в часы пик, что
довольно часто приводит к появлению автомобильных пробок.
В предлагаемом нечетком светофоре время цикла
остается постоянным, однако, время его работы в режиме зеленого света должно
меняться в зависимости от количества подъезжающих к перекрестку машин.
Пусть время цикла традиционного и нечеткого
светофоров будет одинаковым и равным 1мин.=60сек. Длительность зеленого света
обычного светофора зададим 30сек., тогда красный свет будет гореть тоже 30сек.
Для работы нечеткого светофора на перекрестке
улиц Север-Юг (СЮ) и Запад-Восток (ЗВ) необходимо установить 8 датчиков (рис.
1), которые считают проехавшие мимо них машины.
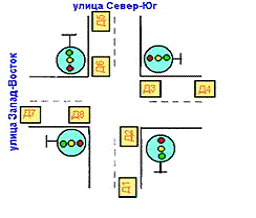
Рис. 1. - Расположение датчиков на перекрестке.
Светофор использует разности показаний четырех
пар датчиков: (Д1-Д2), (Д3-Д4), (Д5-Д6) и (Д7-Д8). Таким образом, если для
улицы СЮ горит зеленый свет, машины проезжают перекресток и показания двух пар
датчиков равны: Д1=Д2, Д5=Д6, а, следовательно, их разность равна нулю. В это
же время на улице ЗВ перед светофором останавливаются машины, которые успели
проехать только Д4 и Д7. В результате можно рассчитать суммарное количество
автомобилей на этой улице следующим образом:
(Д4-Д3)+(Д7-Д8)=(Д4-0)+(Д7-0)=Д4+Д7.
Для сравнения работы обоих светофоров введем
показатель эффективности, в качестве которого будем рассматривать число машин,
не проехавших перекресток за один цикл светофора.
Данную задачу можно сравнить с системой
массового обслуживания (СМО), по двум каналам которой поступают заявки на
обслуживание в виде автомашин. Показатель эффективности в этом случае число
заявок, получивших отказ.
Более подробно рассмотрим проектирование
нечеткой подпрограммы. Здесь однозначно должны быть определены все входы и
выходы.
Поскольку работа светофора зависит от числа
машин на обеих улицах и текущего времени зеленого света, для нашей подпрограммы
предлагается использовать 3 входа: число машин на улице СЮ по окончанию
очередного цикла, число машин на улице ЗВ по окончанию цикла и время зеленого
света нечеткого светофора.
Теперь для каждой переменной надо задать
лингвистические термы, соответствующие некоторым диапазонам четких значений.
Так, для переменной время зеленого света предлагается использовать три терма
(рис. 2):
малое (10-25 секунд);
среднее(20-40 секунд);
большое(35-50 секунд).
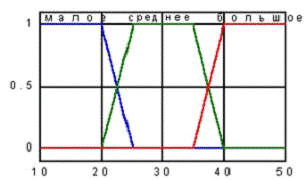
Рис. 2. - Функция принадлежности первой входной
переменной.
Трапециевидная функция принадлежности
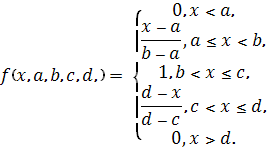
Степень принадлежности четких
значений термам задается с помощью функций принадлежности (в нашем случае эти
функции имеют форму трапеции).
Аналогично, термы для двух
оставшихся переменных будут (рис. 3):
очень малое (0-18);
малое (16-36);
среднее (34-56);
большое (54-76);
очень большое (72-90).
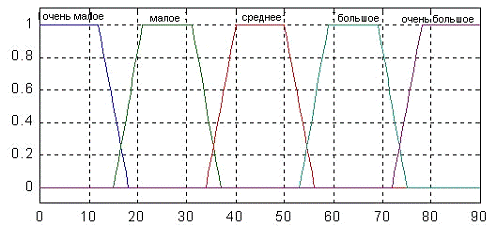
Рис. 3. - Функция принадлежности
второй и третьей входных переменных.
Функции принадлежности здесь также
имеют форму трапеции.
Так как суть работы светофора
состоит в изменении времени зеленого света, в качестве выходного параметра
предлагается использовать величину этого изменения. Термы в этом случае будут
следующие (рис. 4):
уменьшить (-20-0 секунд);
не изменять (-15-15 секунд);
увеличить (0-20 секунд).

Рис. 4. - Функция принадлежности
выходной переменной.
Использовалась функция
принадлежности Гаусса 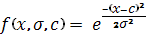 .
.
Кроме того, в подпрограмму
записывается таблица правил на основе условных высказываний, которая формирует
выходное значение исходя из величин входных параметров, например:
Если (число машин на улице
СЮ=малое)&(число машин на улице ЗВ=большое)&(время зеленого света на
улице СЮ=большое), то (время зеленого света=уменьшить).
Заключение
В данной курсовой работе была
рассмотрена основная структура схемы нечеткого вывода. Так же были показаны
алгоритмы: Мамдани, Цукамото, Ларсена и Сугено, и был реализован один из них на
примере работы уличного светофора.
Список использованных источников
1. Заде
Л. Понятие лингвистической переменной и его применение к принятию приближенных
решений. - М.: Мир, 1976.
. Интернет
ресурс
Милосердов
Д. Моделирование работы светофора с нечеткой логикой. Fuzzyfly.chat.ru. <http://fuzzyfly.chat.ru/index.htm>. Верно
на дату 20.06.12.