Проектирование информационных систем
Введение
Информационные системы (ИС) в современном понимании - это основанные на
средствах вычислительной техники автоматизированные системы, предназначенные
для сбора, хранения, обработки, передачи и отображения информации в некоторой
предметной области. ИС относятся к классу так называемых сложных систем и их
проектирование - это трудоемкий и слабо формализуемый процесс.
Эффективность разработки ИС в решающей степени зависит от соблюдения
определенной системы принципов и методик, образующих методологию проектирования
ИС. Составной частью методологии является использование моделей для
формализации и фиксации информации о предметной области ИС, ее функциях,
структуре и составе информационных объектов, которые должны быть представлены в
ИС.
Описываемые в пособии структурно-функциональная и информационная модели
представляют собой в совокупности концептуальный уровень описания ИС. Далее на
базе концептуальных моделей осуществляется логическое проектирование ИС.
Функциональный аспект ИС на уровне логического проектирования
представляется набором алгоритмов, соответствующих детализированным до
необходимой степени информационным процессам. Детализация процессов,
осуществляемая в функциональной модели в соответствии с принципом
последовательной декомпозиции, должна обеспечить возможность их достаточно
простого алгоритмического описания для последующей реализации.
Информационная модель логического уровня для ИС строится на основе
реляционной модели данных, используемой в большинстве современных СУБД.
Существенную роль при этом играет получение эффективной структуры базы данных,
которое основано на принципе нормализации отношений.
Необходимо отметить, что в настоящее время кроме вышеописанной
методологии проектирования ИС широко используется объектно-ориентированная методология.
Она сформировалась позже структурно-функционального подхода к моделированию ИС,
но на базе тех же самых общих принципов системного анализа.
Существует специальный класс программных систем для поддержки построения
разных типов концептуальных моделей ИС и автоматизации проектирования на их
основе логических моделей ИС, а также разработки различной документации и
генерации отчетов. Эти программные средства называются CASE-системами, к ним относятся такие известные продукты
как CASE-Аналитик, BPWin, ERWin и многие другие. Кроме того, CASE-средства разработки входят в состав
таких мощных СУБД как Oracle.
CASE-системы
существенно ускоряют и делают более эффективным процесс разработки сложных ИС
масштаба крупного предприятия или организации.
В данном пособии рассматривается процесс концептуального проектирования
без использования CASE-средств и
объектно-ориентированных методов. Изложение рассматриваемых вопросов
согласовано с содержанием учебного пособия «Информационные системы», изданного
в ПетрГУ в 2005 г. [1]
Одной из широко распространенных современных СУБД является Microsoft SQL
Server, различные версии которой выпускаются с 1994 г. В своем составе система
имеет средства создания баз данных, работы с информацией баз данных,
перенесения данных из других систем и в другие системы, резервного копирования
и восстановления данных, развитую систему транзакций, систему репликации
данных, реляционную подсистему для анализа, оптимизации и выполнения запросов
клиентов, систему безопасности для управления правами доступа к объектам базы
данных и другие компоненты.
В
учебном процессе ПетрГУ используется версия SQL Server 2005.
<#"551811.files/image001.gif">
Рис.1
Функции проектируемой ИС в DFD-модели
должны быть представлены в виде процессов, преобразующих входные потоки данных
в выходные в соответствии с определенными алгоритмами. Сами потоки данных
является механизмом, моделирующим передачу информации от некоторого источника к
приемнику (из одной части системы в другую). Поток данных на диаграмме
изображается линией, оканчивающейся стрелкой, которая показывает направление
потока. Каждый поток данных должен иметь имя, отражающее его содержание.
Например, функция ИС, предназначенная для формирования заказа мебели и
заключения договора на ее изготовление, на диаграмме может быть представлена
процессом «заказ мебели». Этот процесс в качестве входных данных должен
получать информацию о заказчике, необходимую для заключения договора и
информацию о заказываемой им мебели (тип, описание, размеры и др.). Графическое
изображение этого процесса и соответствующих потоков данных:
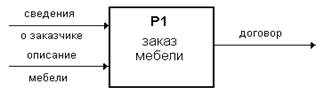
Рис.2
Накопитель (хранилище) данных представляет собой абстрактное устройство
для хранения информации, которую можно в любой момент поместить в накопитель и
извлечь для дальнейшего использования. Информация в накопитель может поступать
от внешних сущностей и процессов, они могут быть и потребителями информации,
хранящейся в накопителе. Графическое изображение накопителя:

Рис.3
Контекстная диаграмма
Диаграмма верхнего уровня иерархии, фиксирующая основные процессы или
подсистемы ИС и их связи с внешними сущностями (входами и выходами системы),
называется контекстной диаграммой. Обычно при проектировании относительно
простых ИС строится единственная контекстная диаграмма со звездообразной
топологией, в центре которой находится главный процесс, соединенный с
приемниками и источниками информации (пользователи и другие внешние системы).
Хотя контекстная диаграмма может казаться тривиальной, несомненная ее
полезность заключается в том, что она устанавливает границы анализируемой
системы и определяет основное назначение системы. Тем самым задается тот
контекст, в котором существуют диаграммы нижних уровней с их процессами,
потоками и накопителями.
Контекстная диаграмма для описанного выше примера представлена на рис.4.
Необходимо отметить, что в учебных целях далее рассматривается упрощенный
вариант моделей системы, в которых не будут представлены потоки данных и
процессы, связанные с финансовой стороной деятельности компании. Хотя, конечно,
для любой компании своевременная, полная и достоверная информация о ее
финансовом состоянии является жизненно необходимой. В данном примере
«финансовая составляющая» очевидно, присутствует во взаимодействии компании со
всеми внешними сущностями, представленными на контекстной диаграмме.

Рис.4
Представленные на этой диаграмме внешние сущности выступают как источники
информации, которая хранится и обрабатывается в ИС фирмы, и как потребители
этой информации. В данной модели выделены две сущности «клиент», являющиеся
образами реальных клиентов фирмы: «заказчик» и «покупатель», так как имеются
существенные различия в содержании информации, которой они обмениваются с ИС.
Для «клиента-заказчика» поток данных «каталог» - это описание типовой
мебели, производимой фирмой. Поток данных «заказ» может включать в себя
информацию о заказе мебели, выбранной из каталога и/или описание заказчиком
отсутствующей в каталоге мебели и также, возможно, информацию о старой мебели,
продаваемой заказчиком фирме.
Для «клиента-покупателя» поток данных «каталог старой мебели» - это
сведения о имеющейся в наличии старой мебели, принятой от заказчиков. Поток
«покупка/прокат старой мебели» - это информация о выбранной клиентом старой
мебели, которую он желает приобрести или взять на прокат.
В то же время на практике возможны ситуации, когда «клиент-заказчик» и
«клиент-покупатель» будут одним и тем же лицом.
Декомпозиция процессов
В соответствии с общим принципом построения DFD-модели диаграммы следующих уровней детализируют
процессы, представленные на диаграммах более высокого уровня. При этом процесс
разделяется на составляющие его подпроцессы, и связанные с ним потоки данных
также могут быть разделены. Также появляются новые потоки данных между
подпроцессами. Такая декомпозиция продолжается, создавая многоуровневую
иерархию диаграмм, до тех пор, пока не будет достигнут уровень детализации, на
котором процессы становятся достаточно элементарными.
Первым шагом в декомпозиции контекстной диаграммы на рис.4 может быть
декомпозиция основного процесса на несколько подпроцессов, каждый из которых
соответствует определенной внешней сущности (декомпозиция по внешним
сущностям). Результат такой декомпозиции представлен на рис.5.
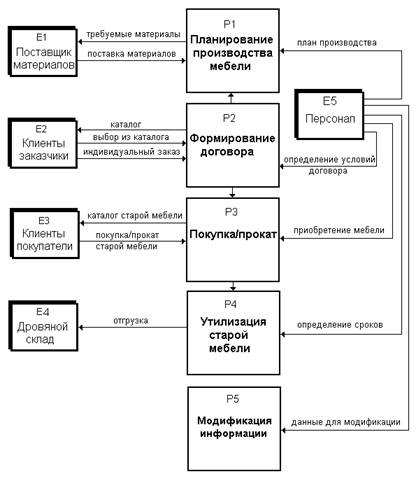
Рис.5
В результате декомпозиции на диаграмме появились новые потоки данных
между подпроцессами: от Р2 к Р1 - «мебель, которая должна быть изготовлена», от
Р2 к Р3 - «приобретенная старая мебель», от Р3 к Р4 «невостребованная старая
мебель».
Каждый из процессов Р1 - Р4 в свою очередь состоит из нескольких процедур
по обработке информации, которые должны рассматриваться как отдельные процессы
на следующем уровне декомпозиции. Эти процессы имеют дело с данными
(поступающими в качестве входной информации или являющимися результатом
выполнения самого процесса), которые должны сохраняться в ИС для их
использования как рассматриваемыми, так и, возможно, некоторыми другими процессами.
Таким образом, на следующем уровне декомпозиции появляется необходимость явного
представления в модели нескольких накопителей данных.
Дадим краткое описание декомпозиции процессов Р1, Р2, Р3 и Р4.
На рис. 6 показана декомпозиция процесса Р1 и используемые этим процессом
накопители данных.
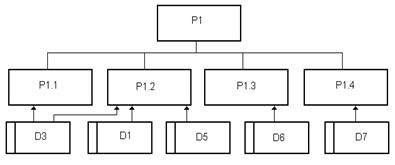
Рис. 6
Р1.1 - определение мебели, которая должна быть изготовлена в соответствии
с заключенными договорами в течение определенного времени.
Р1.2 - определение потребности в материалах.
Р1.3 - формирование заказа на приобретение материалов у конкретных
поставщиков.
Р1.4 - распределение работ по изготовлению мебели между исполнителями.
Используемые накопители:
D1 -
каталог типовой мебели.
D3 -
текущие заключенные договоры.
D5 -
имеющийся в наличии материал и комплектующие.
D6 -
сведения о поставщиках.
D7 -
сведения об исполнителях.
На рис. 7 показана декомпозиция процесса Р2 и используемые этим процессом
накопители данных.
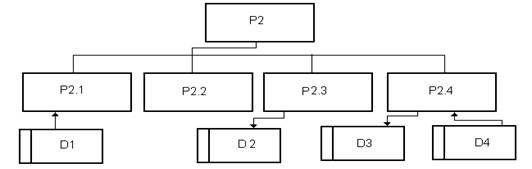
Рис. 7
Р2.1 - выбор клиентом-заказчиком мебели из каталога типовой мебели.
Р2.2 - заказ мебели, отсутствующей в каталоге.
Р2.3 - покупка старой мебели у клиента.
Р2.4 - оформление договора на изготовление мебели.
Используемые накопители:
D1 -
каталог типовой мебели.
D2 -
каталог старой мебели.
D3 -
текущие заключенные договоры.
D4 -
выполненные договоры.
На рис. 8 показана декомпозиция процесса Р3 и используемые этим процессом
накопители данных.
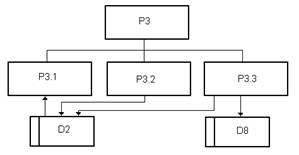
Рис. 8
Р3.1 - выбор мебели по каталогу наличия старой мебели.
Р3.2 - приобретение старой мебели покупателем.
Р3.3 - прокат старой мебели.
D2 -
каталог имеющейся в наличии старой мебели.
D8 -
договора на прокат старой мебели.
На рис. 9 показана декомпозиция процесса Р4 и используемые этим процессом
накопители данных.
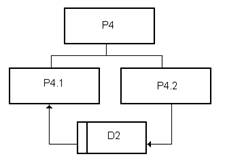
Р4.1 - определение мебели, подлежащей утилизации по истечении срока
хранения.
Р4.2 - внесение изменений в каталог старой мебели.
Используемые накопители:
D2 -
каталог имеющейся в наличии старой мебели.
На рис. 10 показана декомпозиция процесса Р5 и используемые этим
процессом накопители данных.
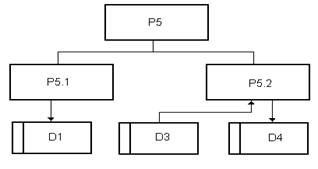
Рис. 10
Р5.1 - обновление каталога типовой мебели.
Р5.2 - перенос информации о законченных договорах в накопитель выполненных
договоров.
Используемые накопители:
D1 -
каталог типовой мебели.
D3 -
текущие заключенные договоры.
D4 -
выполненные договоры.
Представленные на рис. 5 - 10 варианты декомпозиции процессов могут быть
оформлены в виде набора диаграмм потоков данных, образующих очередной уровень
представления DFD-модели ИС. Для этого необходимо
определить и указать все потоки данных, как внешние, связанные с находящимися
за пределами конкретной диаграммы сущностями и процессами, так и между
процессами внутри диаграммы.
Такая диаграмма декомпозиции для процесса Р2 представлена на рис. 11.
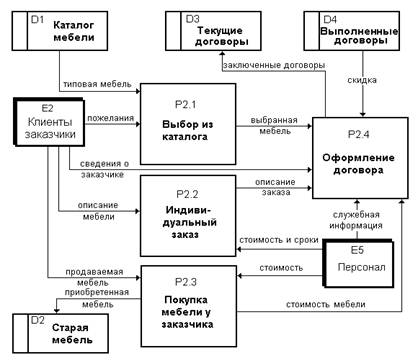
Рис.11
Дальнейшая декомпозиция представленных на рисунке 11 подпроцессов Р2.1 -
Р2.4 в виде диаграмм вряд ли целесообразна, так как их содержание достаточно
понятно и может быть описано несложными алгоритмами.
Словарь данных
Модель ИС, использующая DFD, должна также содержать словарь данных
системы. Словарь представляет собой определенным образом организованный список
всех элементов данных с их точными определениями, что дает возможность
различным категориям пользователей и разработчиков иметь общее понимание всех
входных и выходных потоков и компонентов накопителей.
Определения элементов данных в словаре осуществляются следующими видами
описаний:
· описанием значений потоков и хранилищ, изображенных на DFD,
· описанием композиции агрегатов данных, движущихся вдоль
потоков, т.е. комплексных данных, которые могут расчленяться на элементарные
символы (например, АДРЕС ПОКУПАТЕЛЯ содержит ПОЧТОВЫЙ ИНДЕКС, ГОРОД, УЛИЦУ и
т.д.),
· описанием композиции групповых данных в хранилище.
Для каждого потока данных в словаре хранится имя потока, его тип и
атрибуты. Относительно типа потока в словаре содержится информация,
классифицирующая потоки на:
· простые (элементарные) или групповые (комплексные);
· внутренние (существующие только внутри системы) или внешние
(связывающие систему с другими системами);
· потоки данных или потоки управления;
· непрерывные (принимающие любые значения в пределах
определенного диапазона) или дискретные (принимающие определенные значения).
Основные атрибуты потока данных включают:
· имена-синонимы потока данных (если они используются);
· определение в виде формы Бекуса - Наура в случае группового
потока;
· единицы измерения потока;
· диапазон значений для непрерывного потока;
· список значений и их смысл для дискретного потока.
Далее в качестве примера приведен словарь данных для диаграммы,
представленной на рис. 11. В данном примере словарь включает только основной
набор показателей, относящихся к типу потока и его атрибутам.
|
Имя потока
|
Тип потока
|
Атрибуты
|
Комментарий
|
|
E2 → P2.1 пожелания
|
Простой Внешний Данные
Дискретный
|
Безразмерный Значения -
номера мебели в каталоге
|
Выбор заказчиком мебели из
каталога
|
|
E2 → P2.4 сведения о заказчике
|
Комплексный Внешний Данные
Дискретный
|
ФИО, адрес, телефон
Безразмерный Значения - строки
|
|
|
E2 → P2.2 описание мебели
|
Простой Внешний Данные
Дискретный
|
Безразмерный Значения - строка
|
Произвольный текст с
описанием заказываемой мебели, отсутствующей в каталоге
|
|
E2 → P2.3 продаваемая мебель
|
Простой Внешний Данные
Дискретный
|
Безразмерный Значения - строка
|
Произвольный текст с
описанием старой мебели, покупаемой у заказчика
|
|
E5 → P2.2 стоимость и сроки
|
Комплексный Внешний Данные
Непрерывный
|
Размерный: Рубли для
стоимости Дата для срока
|
Стоимость индивидуального
заказа и срок изготовления мебели
|
|
E5 → P2.3 стоимость
|
Простой Внешний Данные
Непрерывный
|
Размерный: Рубли для
стоимости
|
Цена, по которой старая
мебель приобретается у заказчика
|
|
E5 → P2.4 служебная информация
|
Комплексный Внешний Данные
и управляющая информация Непрерывный
|
Безразмерный Значения
числовые и строки
|
Тип договора Процент скидки
Учет стоимости старой мебели срок выполнения заказа
|
|
D1 → P2.1 типовая мебель
|
Комплексный Внутренний
Данные Дискретный
|
Безразмерный Значения -
строки
|
Описание мебели из каталога
|
Комплексный Внутренний
Данные Дискретный
|
Безразмерный Значения -
коды заказчика и мебели Размерный: Стоимость рубли Срок выполнения дата
|
Информация о заключенных
договорах
|
|
D4 → P2.4 скидка
|
Простой Внутренний Данные
Непрерывный
|
Размерность: Рубли
|
Суммарная стоимость ранее
выполненных договоров данного заказчика
|
|
P2.1 → P2.4 выбранная
мебель
|
Комплексный Внутренний
Данные Дискретный
|
Безразмерный Значения -
числа Размерный: Рубли
|
Код выбранной мебели из
каталога и ее стоимость
|
|
P2.2 → P2.4 описание
заказа
|
Простой Внутренний Данные
Дискретный
|
Безразмерный Значения -
строки
|
Описание мебели,
изготавливаемой по инд. заказу
|
|
P2.3→ D2 приобретенная мебель
|
Комплексный Внутренний
Данные Непрерывный
|
Безразмерный Значения -
строки Размерный: Стоимость Рубли Срок списания дата
|
Информация о старой мебели,
приобретенной у заказчиков
|
|
P2.3 → P2.4 стоимость
мебели
|
Простой Внутренний Данные
Непрерывный
|
Размерный: Стоимость Рубли
|
Стоимость старой мебели,
учитываемая в стоимости заказа
|
Миниспецификации
Алгоритмические описания процессов, представленных на последнем уровне
декомпозиции, в DFD-модели называются миниспецификациями. Их назначение -
обеспечить разработчика системы информацией, достаточной для понимания логики
процесса и реализации алгоритмов процессов, описанных миниспецификациями, в
виде программных модулей и процедур.модель не предписывает какой-либо
специальной обязательной формы для представления миниспецификаций. Одно из
требований (и одновременно признак того, что дальнейшая декомпозиция процесса
не нужна) - текст миниспецификации процесса должен быть объемом не более 20-30
строк, а соответствующий язык может варьироваться от структурированного
естественного языка или псевдокода до визуальных языков проектирования.
Миниспецификация должна содержать номер и/или имя процесса, списки
входных и выходных данных и тело (описание) процесса, являющееся спецификацией
алгоритма или операции, трансформирующей входные потоки данных в выходные.
Независимо от используемой нотации спецификация процесса должна
начинаться с ключевого слова (например, @СПЕЦПРОЦ). Требуемые входные и
выходные данные должны быть специфицированы следующим образом:
@ВХОД = <имя символа данных>
@ВЫХОД = <имя символа данных>
@ВХОДВЫХОД = <имя символа данных>,
где <имя символа данных> - соответствующее имя из словаря данных.
Иногда в миниспецификации задаются пред- и постусловия выполнения данного
процесса. В предусловии записываются объекты, значения которых должны быть
истинны перед началом выполнения процесса, что обеспечивает определенные
гарантии безопасности для пользователя. Аналогично, в случае наличия
постусловия гарантируется, что значения всех входящих в него объектов будут
истинны при завершении процесса.
При описании миниспецификаций на структурированном естественном языке
могут быть использованы:
· глаголы, ориентированные на действие и применяемые к
объектам;
· термины, определенные на любой стадии проектирования
(например, задачи, процедуры, символы данных и т.п.);
· предлоги и союзы, используемые в логических отношениях;
· общеупотребительные математические, физические и технические
термины;
· формулы, таблицы, диаграммы, графы и т.п.;
· комментарии.
К управляющим структурам относятся:
последовательная конструкция:
ВЫПОЛНИТЬ функция1
ВЫПОЛНИТЬ функция2
конструкция выбора:
ЕСЛИ <условие> ТО
ВЫПОЛНИТЬ функция1
ИНАЧЕ
ВЫПОЛНИТЬ функция2
КОНЕЦЕСЛИ
итерация:
ДЛЯ <условие>
ВЫПОЛНИТЬ функция
КОНЕЦДЛЯ
или
ПОКА <условие>
ВЫПОЛНИТЬ функция
КОНЕЦПОКА
В качестве примеров приведем варианты миниспецификаций процессов Р2.1
«Выбор заказчиком типовой мебели из каталога» и P2.3 «Покупка мебели у заказчика»..
Пример 1.
@P2.1_выбор_по_каталогу
@ВХОД = пожелания// номер мебели в каталоге
@ВЫХОД = выбранная мебель// номер мебели и ее стоимость
ВЫПОЛНИТЬ открыть окно формы с каталогом мебели
ВЫПОЛНИТЬ зафиксировать выбор заказчика
ЕСЛИ выбор подтвержден ТО
ВЫПОЛНИТЬ передать номера мебели и ее стоимость процессу P2.2
ИНАЧЕ
ВЫПОЛНИТЬ отменить выбор заказчика
КОНЕЦЕСЛИ
ВЫПОЛНИТЬ закрыть окно формы с каталогом
@P2.3_покупка_старой_мебели
ПРЕДУСЛОВИЕ заказчик оформляет договор на изготовление мебели
@ВХОД = продаваемая мебель//описание старой мебели,
покупаемой у заказчика
@ВХОД = стоимость//стоимость,
назначаемая персоналом
@ВЫХОД = приобретенная мебель// описание старой мебели, приобретенной у
заказчика
@ВЫХОД = стоимость мебели//стоимость,
согласованная с заказчиком
ВЫПОЛНИТЬ открыть окно формы диалога с заказчиком
ВЫПОЛНИТЬ получить описание старой мебели, предлагаемой
заказчиком
ВЫПОЛНИТЬ предложить стоимость
ЕСЛИ стоимость согласована ТО
ВЫПОЛНИТЬ передать описание старой мебели, приобретенной
у заказчика в накопитель D2
ВЫПОЛНИТЬ передать стоимость старой мебели, приобретенной
у заказчика процессу P2.4
КОНЕЦЕСЛИ
ВЫПОЛНИТЬ закрыть окно формы диалога с заказчиком
Информационное моделирование ИС
Информационная модель предметной области (и информационной системы)
разрабатывается с целью получения концептуальной схемы базы данных в форме
одной модели или нескольких локальных моделей, которые относительно легко могут
быть реализованы далее в рамках какой-либо реляционной СУБД или другой
инструментальной системы, поддерживающей реляционную модель данных.
Модель “сущность - связь”
Наиболее распространенным средством моделирования данных являются
диаграммы “сущность - связь” (ERD Entity - Relationship Diagrams). Основное
назначение ERD - семантическое описание предметной области и представление
информации для выбора структур данных на этапе логического проектирования.
Модель “сущность - связь” строится с использованием трех конструктивных элементов:
сущность, атрибут и связь. С их помощью определяются важные для предметной
области информационные объекты (сущности), их свойства (атрибуты) и отношения
друг с другом (связи).
Сущность (Entity) - это некоторая абстракция (модель) реально существующего либо
воображаемого объекта, процесса или явления, имеющего существенное значение для
рассматриваемой предметной области, информация о котором подлежит хранению. С
сущностью связаны понятия: тип - набор однородных предметов, явлений,
выступающий как единое целое, и экземпляр - конкретный элемент набора данного
типа. Каждый экземпляр сущности должен однозначно идентифицироваться и
отличаться от всех других экземпляров данного типа сущности.
Связь (Relationship) - средство для представления отношений между сущностями.
Каждая сущность может обладать любым количеством связей с другими сущностями
модели. Семантически отношения могут объединять любое количество сущностей, но
в ERD-модели используются только бинарные связи, которыми моделируются любые
n-арные отношения. Различают связи трех типов - один-к-одному (когда существует
взаимно однозначное соответствие экземпляров двух сущностей); один-ко-многим
(когда соответствие однозначно со стороны одной из сущностей); многие-ко-многим
(когда это соответствие многозначно).
Атрибут (attribute) - это поименованная характеристика сущности, являющаяся
средством для описания ее свойств, значимых для рассматриваемой предметной
области (т.е. средством для моделирования свойств объекта). (Пример: сущность -
книга, а автор, название, издательство, год издания, тираж - атрибуты этой
сущности.) Атрибут предназначен для квалификации, идентификации, классификации,
количественной характеристики или выражения состояния сущности.
Атрибут представляет тип характеристик или свойств, ассоциированных с
множеством реальных или абстрактных объектов (людей, мест, событий, состояний,
идей, предметов и т.д.). Экземпляр атрибута - это определенная характеристика
отдельного элемента множества экземпляров сущности, которой принадлежит атрибут.
Атрибут может быть либо обязательным, либо необязательным. Обязательность
означает, что атрибут не может принимать неопределенных значений.
Для идентификации конкретных экземпляров сущностей, принадлежащих
некоторому типу, используются специальные атрибуты или наборы атрибутов,
называемые ключом. Каждая сущность должна обладать хотя бы одним возможным
ключом. Возможный ключ сущности - это один или несколько атрибутов, чьи
значения однозначно определяют каждый экземпляр сущности. При существовании
нескольких возможных ключей один из них выбирается в качестве первичного ключа,
а остальные рассматриваются как альтернативные ключи.
На рис.12 представлена основная часть информационной модели для
рассматриваемого в пособии примера в виде диаграммы “сущность - связь”.
Сущностям этой ER-диаграммы
соответствуют накопители и внешние сущности ранее представленных DF-диаграмм. Основным типом связи на
этой диаграмме является связь один-ко-многим (за исключением связи «Текущий
договор-Материалы» типа многие-ко-многим).
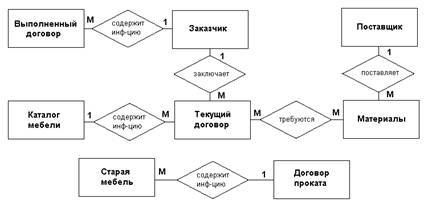
Рис.12
На рис.13 показаны атрибуты сущностей, представленных на рис.12. Для
однозначной идентификации экземпляров сущностей каждая из них снабжена
атрибутом Номер, который используется в качестве первичного ключа. Атомарность
таких искусственных ключей облегчает в дальнейшем получение эффективной схемы
базы данных на основе реляционной модели.
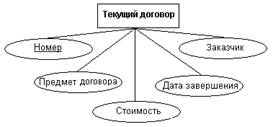
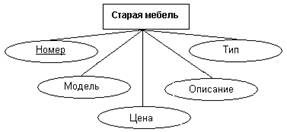
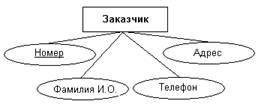
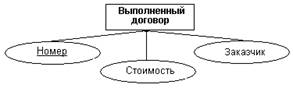
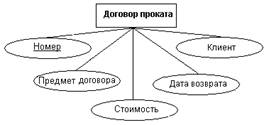
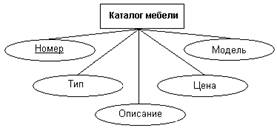
Рис.13
Реляционная модель
Реляционная модель является основной логической моделью данных,
используемых современными СУБД. Формальное определение реляционной модели
данных основано на понятии отношения, которое представляет собой подмножество
декартово произведения доменов (т.е. множеств, элементами которых являются все
возможные значения некоторого набора атрибутов).
Проектирование схемы реляционной базы данных может начинаться с формального
преобразования концептуальной модели сущность-связь в логическую реляционную
модель путем замены каждой сущности соответствующим отношением. Связи, в
которых нескольким экземплярам одной сущности соответствует один экземпляр
другой сущности, реализуются с помощью внешних ключей. Внешним ключом
называется первичный ключ некоторого отношения при использовании его в качестве
атрибута другого отношения.
На рис. 14 представлен фрагмент схемы реляционной базы данных,
построенной в соответствии с представленной выше концептуальной моделью
сущность-связь.
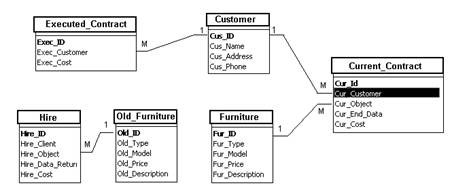
Рис.14
В списке атрибутов каждого отношения первым стоит его первичный ключ.
Идущие от первичного ключа отношения линии соединяют его с атрибутами -
внешними ключами других отношений, с которыми у данного отношения существует
связь один-ко-многим.
Для реализации связи многие-ко-многим необходимо создать дополнительное
отношение, атрибутами которого являются первичные ключи отношений, участвующих
в связи. В нашем примере такая ситуация возникает для связи «Текущий
договор-Материалы»
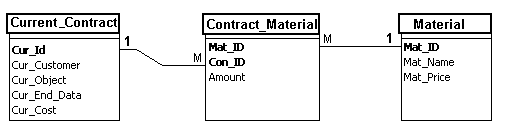
Рис.15
Нормализация
Нормализация - это процесс преобразования схемы реляционной БД,
позволяющий получить более эффективную структуру БД. Реляционная БД считается
эффективной, если она обладает следующими характеристиками:
· отсутствие избыточности (аномалии обновления, добавления);
· минимальное использование null-значений;
· предотвращение потери информации (аномалия удаления).
Основополагающее понятие теории нормализации - понятие функциональной
зависимости. Функциональные зависимости отражают определенную семантическую
связь между атрибутами отношения.
Пусть в отношении существует множество атрибутов X. Некоторый атрибут или
множество атрибутов A является функционально зависимым от X тогда и только
тогда, когда каждой комбинации значений X соответствует одно и только одно
значение A.
Атрибут A находится в полной функциональной зависимости от множества
атрибутов {X,Y}, если он функционально зависим от этого множества атрибутов, и
не существует функциональной зависимости ни от какого подмножества данного
множества. Если же существует функциональная зависимость A от X, то A находится
в частичной функциональной зависимости от {X,Y}.
В теории реляционных БД выделяют следующую последовательность нормальных
форм:
· первая нормальная форма (1NF);
· вторая нормальная форма (2NF);
· третья нормальная форма (3NF);
· нормальная форма Бойса-Кодда (BCNF);
· четвертая нормальная форма (4NF);
· пятая нормальная форма, или форма проекции-соединения (5NF или PJNF).
Последовательность нормальных форм должна удовлетворять следующим
требованиям:
· каждая следующая нормальная форма в некотором смысле улучшает
свойства предыдущей;
· при переходе к следующей нормальной форме свойства предыдущих
нормальных форм сохраняются.
Каждой нормальной форме соответствует некоторый определенный набор
ограничений.
Отношение находится в первой нормальной форме, если значения всех
атрибутов атомарные и указан ключ (из определения реляционного отношения
следует, что любое такое отношение находится в 1NF).
Отношение находится во второй нормальной форме, если оно находится в
первой нормальной форме и не содержит неключевых атрибутов, находящихся в
частичной функциональной зависимости от первичного ключа. Для отношения с
атомарным первичным ключом наличие 2NF обеспечено.
Отношение находится в третьей нормальной форме, если оно находится во
второй нормальной форме и не содержит транзитивных зависимостей.
Для БД, количество отношений в которых не превышает нескольких десятков,
наличие 3NF считается достаточным для
эффективности ее структуры.
В приведенном выше примере (рис. 14) первичные ключи всех отношений
атомарные, поэтому отношения находятся во 2NF. Анализ функциональных зависимостей между атрибутами этих
отношений показывает, что транзитивные зависимости отсутствуют, следовательно,
отношения находятся также и в 3NF.
Очевидно, что отношения на рис. 15 тоже находятся в 3NF.
Реализация макета системы средствами MS SQL Server 2005
База данных в SQL Server 2005 с логической точки зрения представляет
собой набор реляционных отношений или таблиц. Указанные таблицы содержат
данные, а также могут содержать элементы управления данными. У таблиц есть
несколько типов элементов управления: ограничения, значения по умолчанию, а
также пользовательские типы данных. Кроме того у таблицы могут быть и такие
объекты, как представления, индексы, хранимые процедуры, пользовательские
функции и триггеры, заданные для поддержки операций с данными. Кроме того, база
данных может содержать процедуры, которые используют программный код
Transact-SQL или .NET Framework для выполнения операций над данными в базе
данных. Сюда относится создание представлений пользовательского доступа к
данным таблицы или пользовательским функциям, которые производят сложные
вычисления над подмножеством записей.
· master. Хранит информацию уровня всей системы, информацию инициализации SQL
Server и настройки конфигурации SQL Server. Эта база данных также хранит все
учетные записи для входа в систему, информацию о наличии всех остальных баз
данных и о местоположении первичного файла для всех пользовательских баз
данных. Всегда имейте свежую копию базы данных master - главной базы данных.
· tempdb. Хранит временные таблицы и временные хранимые процедуры. Эта базы
данных используется также для хранения прочей временной информации, нужной для
работы SQL Server, например для сортировки данных. При каждом запуске SQL
Server создается новая чистая копия базы данных tempdb. Затем, если нужно, эта
база данных растет автоматически. Если для хранения ваших временных данных
требуется много места, то можно увеличить стандартный размер этой базы данных,
применив команду ALTER DATABASE.
· model. Служит образцом (шаблоном) для всех остальных баз данных, создаваемых на
данной системе, в том числе и для tempdb. При создании базы данных ее начало
создается как копия содержимого базы данных model, а всё остальное заполняется
пустыми страницами. База данных model обязательно должна иметься в системе,
потому что она применяется для воссоздания базы данных tempdb при каждом
запуске SQL Server. Вы можете изменять базу данных model, добавляя туда пользовательские
(определяемые пользователем) типы данных, таблицы и т.д. Если вы измените базу
данных model, то каждая созданная вами база данных будет иметь измененные
атрибуты.
· msdb. Содержит таблицы, которые SQL Server Agent применяет для планирования
заданий и оповещений и для записи операторов (здесь операторы - это люди,
которые отвечают за работу заданий и оповещений). Эта база данных также хранит
таблицы, применяемые для репликации.
Физически база данных SQL Server состоит из набора файлов операционной системы.
Файл базы данных может быть либо файлом данных, либо файлом журнала. Файлы
данных служат для хранения таблиц и таких объектов, как индексы, представления,
триггеры и хранимые процедуры. Имеется два типа файлов данных: первичные и
вторичные. Файлы журналов служат только для хранения информации из журналов
транзакций.
Каждая база данных должна создаваться хотя бы с одним файлом данных и с
одним файлом журнала; файлы не могут быть использованы более чем в одной базе
данных - т.е., базы данных не могут разделять файлы (использовать файлы
совместно). В приведенном ниже перечне указаны три типа файлов, которые могут
быть использованы в базах данных:
· Первичные файлы данных. Первичные файлы данных содержат всю информацию для
запуска базы данных и ее системных таблиц и объектов. Они указывают на другие
файлы, созданные в базе данных. Они могут также содержать таблицы и объекты,
задаваемые пользователем, хотя это и не обязательно. Каждая база данных может
иметь только один первичный файл. Для этих файлов рекомендуется применять
расширение .mdf.
· Вторичные файлы данных. Вторичные файлы данных не являются обязательными. Они могут
хранить данные и объекты, которые отсутствуют в первичном файле. База данных
может вообще не иметь ни одного вторичного файла (если все ее данные хранятся в
первичном файле). Для этих файлов рекомендуется применять расширение .ndf.
· Файлы журналов транзакций. Файлы журналов транзакций хранят всю информацию из
журнала транзакций, служащую для восстановления базы данных. Каждая база данных
должна иметь хотя бы один файл журнала, а может иметь и несколько файлов
журналов. Для этих файлов рекомендуется применять расширение .ldf.
Для управления базами данных SQL Server существует полнофункциональный
инструмент с графическим интерфейсом SQL Server Management Studio.
Создание базы данных
информационный база данный скалярный
Рассмотрим основные шаги построения БД в среде SQL Server Management
Studio.
После запуска Management Studio и установления соединения с SQL Server
появляется основное окно программы. Нажатие на правую кнопку мыши на строке
«Базы данных» обозревателя объектов вызывает контекстное меню, содержащее
команду «Создать базу данных». Появляется окно «Создание базы данных», в
котором необходимо задать имя и местоположение базы на диске (см. рис. 16).
Файлы базы данных создаются имеющими некоторый начальный размер. После
того как этот начальный размер заполнится, SQL Server увеличит размер файла на
некоторую заданную величину, называющуюся приращение роста (growth increment).
Когда это добавленное свободное место заполнится, SQL Server добавит еще одно
приращение роста. При необходимости, файл продолжит свой рост с заданным темпом
до тех пор, пока не заполнится весь диск или пока его размер не достигнет
ограничения на максимальный размер файла (если таковое ограничение задано).
Параметры начальный размер и приращение задаются в том же окне «Создание базы
данных» В учебных примерах для этих параметров рекомендуется использовать
значения, установленные по умолчанию.
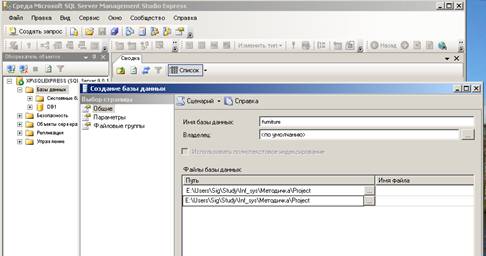
Рис.16
Таблицы. Типы данных
Нажатие на правую кнопку мыши на строке «Таблицы» вызывает контекстное
меню, содержащее команду «Создать таблицу…». Появляется вкладка, на которой
задаются имена столбцов, выбираются для них типы данных и устанавливается
флажок «Разрешить значения null». Для сохранения структуры необходимо нажат
правую кнопку мыши находясь на заголовке вкладки. В появившемся контекстном
меню выбирается команда «Сохранить…» и задается имя таблицы (см. рис. 17).
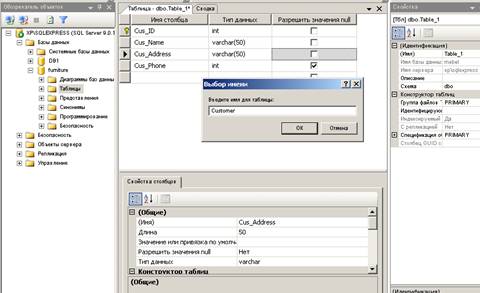
Рис.17
Для атрибутов (полей) таблиц SQL Server 2005 предоставляет следующие типы
данных которые могут быть выбраны при создании таблицы:
Двоичные данные
|
binary [ ( n ) ]
|
максимальная длина 8 000
байт (n)
|
|
varbinary [ ( n ) ]
|
данные переменной длины,
максимальная длина 8 000 байт (n)
|
|
image
|
максимальная длина 2 147
483 647 байт
|
|
bit
|
тип данных, который
принимает значения 1 или 0
|
Символьные данные
|
сhar [(n)]
|
максимальная длина 8 000
символов (n)
|
|
varchar [(n)]
|
тип переменной длины, максимально
8 000 символов (n)
|
|
text
|
максимальная длина 1 073
741 823 символов
|
Символьные данные в кодировке Unicode
|
nchar (n)
|
максимальная длина 4 000
символов (n)
|
|
nvarchar (n)
|
переменной длины в
кодировке Unicode максимальная длина 4 000 символов (n)
|
|
ntext
|
максимальная длина 1 073
741 823 символов
|
Числовые целые данные
|
igintдиапазон от -922 337
203 685 4775808 до 922 337 203 685 4775807
|
|
|
Int
|
диапазон от -2 147 483 648
до 2 147 483 647
|
|
smallint
|
диапазон от - 32 768 до 32
767
|
|
tinyint
|
диапазон от 0 до 255
|
Числовые данные с дробной частью числа
|
decimal[(p[, s])]
|
диапазон от -1038-1 до
1038-1 с задание фиксированного количества знаков (p - всего и s -дробной
части), максимальное общее количество знаков 38
|
|
numeric
|
то же, что и decimal
|
|
float [ ( n ) ]
|
диапазон от +2.29*10-308 до
+1.79*10308
|
|
real
|
числа с 7-значной точностью
в диапазоне от +1.18*10-38 до +3.40*1038.
|
Тип дата и время
|
datetime
|
диапазон от 1.01.1753 до
31.12.9999 с точностью 3.33 мс
|
|
smalldatetime
|
диапазон от 1.01.1900 до
6.06.2079 с точностью 1 мин.
|
Денежный тип
|
moneyдиапазон от
|
7 203 685 477.5808 до +922
337 203 685 477.5807
|
|
smallmoneyдиапазон от
|
214 748.3648 до +214
748.3647
|
timestamp
|
Пометка времени, SQL Server автоматически увеличивает значение поля этого типа
на 1 при внесении любых изменений в таблицу. Имеет уникальное значение для
базы данных, не может быть ключом.
|
|
uniqueidentifier
|
тип, который содержит
уникальный идентификационный номер (GUID), сохраняемый как 16-битная двоичная
строка
|
|
sql_variant
|
тип, который сохраняет
значения различных типов, кроме text, ntext, timestamp и sql_variant.
|
|
sysname
|
тип - синоним nvarchar,
используется для ссылок на имена объектов базы данных
|
|
xml
|
Тип для хранения документов
в формате XML
|
Схема базы данных
Для создания схемы базы данных используется объект Диаграммы бах данных
(см. рис. 18).
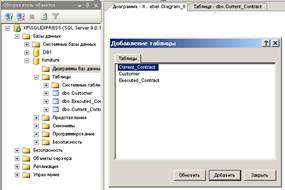
Рис.18
На соответствующей вкладке после добавления таблиц курсором при нажатой
левой клавише мыши устанавливаются связи между таблицами. В появляющихся при
этом вспомогательных окнах указываются названия связей и имена используемых для
связи атрибутов, являющихся первичными или внешними ключами (см. рис. 19).
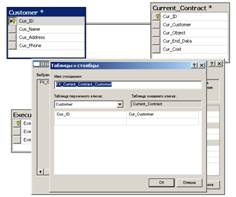
Рис.19
Фрагмент полученной для рассматриваемого в пособии примера диаграммы базы
данных показан на рис. 20.
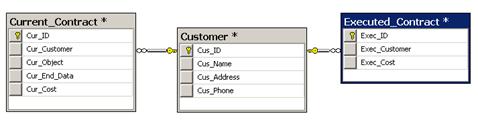
Рис.20
Создание запросов
В состав SQL Server Management Studio входят инструменты для создания
SQL-запросов. Для создания запроса на основе текущей (открытой) таблицы с
помощью пункта меню «Конструктор запросов» или кнопки  на панели инструментов «Редактор
SQL» на вкладке текущей таблицы открывается окно с областью SQL-кода,
содержащее шаблон запроса. Этот запрос может быть дописан вручную или
сформирован с помощью Конструктора запросов. Элементами конструктора являются
окна: Область схемы, Область условий, Область результата, Добавления таблицы,
которые вызываются соответствующими кнопками на панели инструментов «Редактор
SQL» на вкладке текущей таблицы открывается окно с областью SQL-кода,
содержащее шаблон запроса. Этот запрос может быть дописан вручную или
сформирован с помощью Конструктора запросов. Элементами конструктора являются
окна: Область схемы, Область условий, Область результата, Добавления таблицы,
которые вызываются соответствующими кнопками   . Для выполнения запроса используется кнопка . Для выполнения запроса используется кнопка  . .
На рис. 21 показан пример созданного таким образом запроса к таблицам
Customer и Executed_Contract.
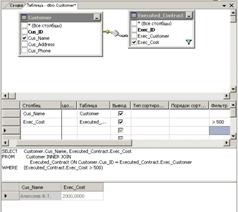
Рис. 21.
Для создания запроса в отдельной вкладке используется кнопка «Создать
запрос» панели инструментов «Стандарт» или пункт «Создать запрос» контекстного
меню, вызываемого для выбранной БД. Далее запрос пишется вручную или создается
в Конструкторе запросов (меню Запрос/Создать запрос в редакторе, см. пример на
рис.21).
После формирования запроса и нажатия на кнопку «Ok» текст запроса
переносится на вкладку. После чего он может быть выполнен, а также сохранен в
отдельном файле с расширением sql. Пример показан на рис.22.
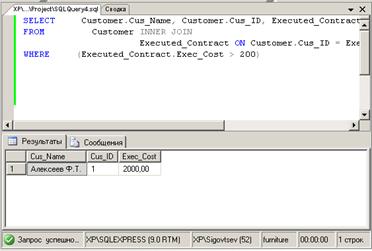
Рис. 22.
Для того чтобы ранее сохраненный запрос мог быть выполнен, надо открыть
файл с запросом. При открытии файла (меню Файл/Открыть/Файл) устанавливается
соединение с сервером. Для выполнения запроса необходимо указать полные имена
используемых в запросе таблиц (Имя_БД.dbo.Имя_таблицы). Например,
furniture.dbo.Customer.
Другой вариант указания для какой именно базы данных предназначены
SQL-команды - использование команды use < имя базы данных>, которая
пишется до других SQL-команд. (В этом случае префикс dbo не указывается.)
Запрос с группровкой и агрегатными функциями
Для включения в запрос секции GROUP BY в конструкторе запросов в
контекстном меню «Области схемы» выбирается пункт «Добавить группу по». При
этом в «Области условий» добавляется столбец «Группировка». Выбор агрегатной
функции для требуемого поля происходит из выпадающего списка (см. рис. 23).

Рис. 23.
Сформированный запрос и результат его выполнения показан на рис.24.
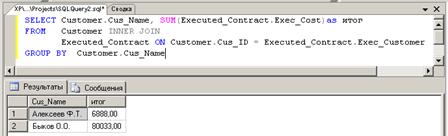
Рис. 24.
Результат выполнения запроса может быть сохранен в отдельный текстовый
файл двумя способами:
. Вызвать контекстное меню «Области запроса» и выбрать команду
«Отправить результат в → в файл» (см. рис. 25);
. Вызвать контекстное меню «Области результата» и выбрать команду
«Сохранить результаты как…».
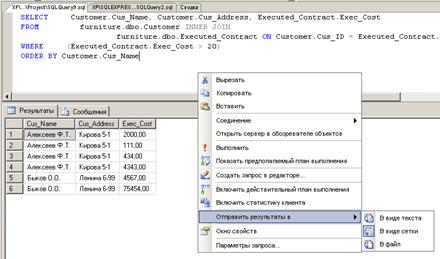
Рис. 25.
Запросы на изменение данных
Существуют три вида запросов, изменяющих содержимое таблиц базы данных:
· запрос на добавление (insert);
· запрос на обновление (update);
· запрос на удаление (delete).
В качестве примера создадим запрос на добавление в таблицу Executed_Contract
записей о выполненных контрактах. Выполненными считаются контракты из таблицы
Current_Contract, у которых дата завершения меньше текущей.
Для этого в Конструкторе запросов после добавления таблицы
Current_Contract и выбора необходимых полей в контекстном меню «Области схемы»
выбирается пункт «Изменить тип» → «Вставить результаты». Затем из списка
таблиц выбираем таблицу-адресат «Executed_Contract» и добавляем фильтр для поля
Cur_End_Data (см. рис. 26).
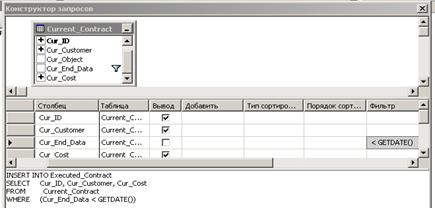
Рис. 26.
Записи, добавленные в таблицу Executed_Contract, должны быть удалены из
таблицы Current_Contract. Для этого аналогичным образом создатется запрос на
удаление.Server использует расширенную версию языка SQL, которая называется
Transact-SQL, или T-SQL. T-SQL позволяет создавать пакеты из нескольких
запросов, которые последовательно выполняются на сервере и их результаты вместе
возвращаются клиенту.
Команда GO определяет, когда пакет передается на сервер. Пример пакета из
указанных выше запросов на вставку и удаление показан на рис. 27.
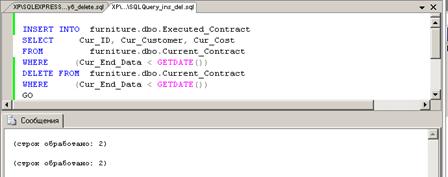
Рис. 27.
Вложенные запросы
Пример. Найти заказчиков, имеющих максимальное количество заказов.
Вначале создается запрос, возвращающий количество заказов, имеющихся у
каждого заказчика. (Рис. 28)
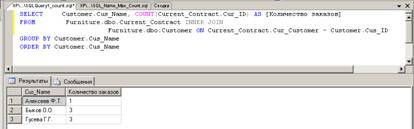
Рис. 28.
Далее этот запрос используется в секции FROM запроса, определяющего максимальное количество
заказов у одного заказчика
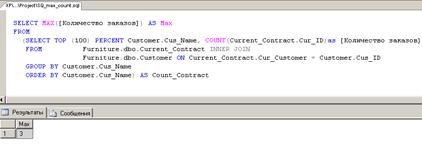
Рис. 29.
Окончательный вид запроса, дающего ответ на вопрос, сформулированный в
примере, представлен на рис. 30. Здесь запрос, показанный на рис.29,
используется в секции WHERE
при определении условия для выбора фамилии заказчика с максимальным количеством
заказов; при этом запрос на подсчет количества заказов у каждого заказчика
используется дважды.
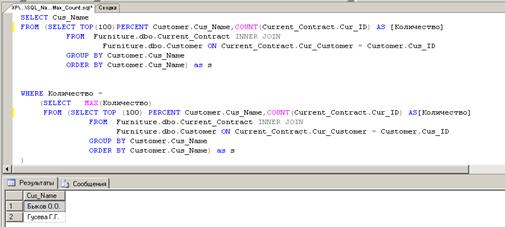
Рис. 30.
Получить в результате выполнения одного запроса список пользователей с
количеством заказов, сделанных каждым из них, и максимальное количество
заказов, сделанных одним пользователем, позволяет запрос на рис. 31. В этом
запросе использована секция COMPUTE,
в которой возможна подстановка одной агрегатной функции в другую (что запрещено
делать в других секциях запросов).
Выражения в секции COMPUTE
должны совпадать с выражениями в списке выборки команды SELECT и в этой секции нельзя использовать
псевдонимы столбцов.

Рис. 31.
В запросе на рис.32 используются три агрегатные функции, вычисляющие
количество заказов, общую стоимость заказов и среднюю стоимость одного заказа
для каждого клиента. При этом используется информация как о текущих заказах,
находящаяся в таблице с именем Current_Contract, так и о выполненных ранее заказах
из таблицы с именем Executed_Contract. Для этого в секции FROM помещена команда UNION, объединяющая в один набор данных
результаты двух отдельных запросов к указанным выше таблицам.
Списки выборки в каждой команде SELECT, входящей в состав команды UNION, должны содержать одинаковое число столбцов и соответствующие столбцы
должны иметь одинаковые (или преобразующиеся один к другому) типы данных.
Заголовки столбцов результата команды UNION совпадают с заголовками столбцов первой команды SELECT.
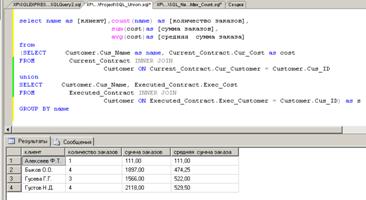
Рис. 32.
Кроме отдельных SQL-запросов СУБД MS SQL Server позволяет использовать для обработки данных и
такие средства как системные и пользовательские хранимые процедуры, триггеры,
пользовательские функции.
Пользовательские функции
Пользуясь средствами языка T-SQL, пользователь может создавать
собственные функции, которые будут сохраняться в его базе данных. Эти функции
затем могут вызываться в командах SELECT и других выражениях языка T-SQL. Функции могут иметь входные
параметры любого типа кроме text, image, table.
Существует три типа пользовательских функций. Функция типа inline возвращает в качестве результата
значение типа table и тело этой функции должно состоять
из одной команды SELECT. Рассмотрим
создание и вызов функции такого типа на примере вычисления стоимости
выполненных заказов для заказчика с данной фамилией и инициалами. (Имена
заказчиков находятся в столбце Cus_name таблицы Customer, а стоимости в столбце Exec_cost таблицы Executed_Contract.)
Создание функции происходит при выполнении команды Create Function. Для получения текста этой команды в
обозревателе объектов последовательно выбирается база данных, для нее пункты
Программирование, Функции, Функции, возвращающие табличное значение. Для
последнего пункта вызывается контекстное меню, содержащее команду «Создать
встроенную функцию, возвращающую табличное значение…». Эта команда выводит на
экран окно с шаблоном команды Create Function, в
которой должен быть размещен код создаваемой функции. После удаления из шаблона
комментариев и вставки необходимых команд и конкретных имен получаем код
команды создания пользовательской функции типа inline на языке T-SQL, представленный на рис. 33. (При
этом для создания запроса SELECT,
который находится в теле функции, был использован редактор запросов.)
Пользовательская функция добавляется в базу данных после запуска команды
создания функции на выполнение. Имя функции появляется в обозревателе объектов
после его обновления.
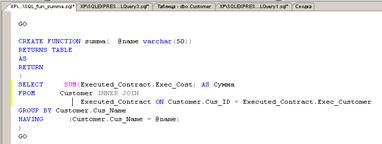
Рис. 33.
После создания пользовательская функция может быть использована,
например, следующим образом. В обозревателе объектов для имени этой функции
вызывается контекстное меню, в котором находится команда «создать сценарий для
функции». Затем через подменю происходит конкретизация команды →
«используя SELECT» → «В новом окне редактора
запросов». В результате на экране появляется окно с кодом команды SELECT, которая в нашем примере после
замены входного параметра функции summa на конкретное значение ‘Быков О.О.’ получает вид, показанный на рис. 34.
Результат выполнения этого запроса показан в нижней части рис. 34.
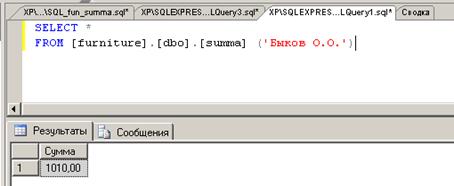
Рис. 34.
По существу, созданная в рассмотренном примере пользовательская функция в
приведенном выше варианте ее использования, может быть интерпретирована как
«Запрос с параметром» в терминологии СУБД Access.
Скалярные функции
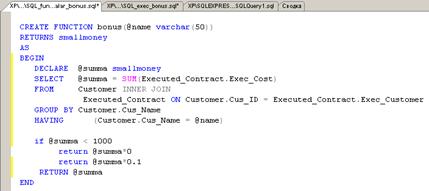
Рис. 35.
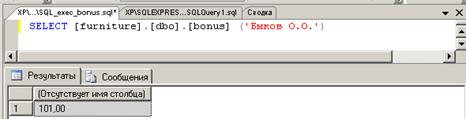
Рис. 36.
Хранимые процедуры
Хранимая процедура - это последовательность компилированных операторов
T-SQL, хранящихся в системной базе данных SQL Server. Хранимые процедуры
предварительно откомпилированы, поэтому эффективность их выполнения выше, чем у
обычных запросов. После первого выполнения компилированный план процедуры
хранится в быстродействующем кэше в оперативной памяти, что существенно
повышает скорость выполнения запросов. Другое их преимущество состоит в том,
что пользователь может получить право выполнения хранимой процедуры, даже если
он не имеет права доступа к тем объектам, к которым обращается процедура.
Хранимая процедура создается с помощью оператора CREATE PROCEDURE. Для
создания хранимой процедуры соответствующей командой контекстного меню
открывается шаблон кода, в котором задаются имя, параметры и SQL-код тела процедуры.
Затем созданный код запускается на выполнения для проверки синтаксиса и
компиляции.
На рис. 37 приведен код процедуры, вычисляющей количество имеющихся в
каталоге вариантов мебели заданного типа.
После обновления в обозревателе объектов добавляется ярлык созданной
процедуры.
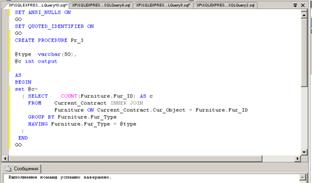
Рис. 37.
Для выполнения процедуры контекстное меню предлагает два варианта:
выполнить хранимую процедуру или создать сценарий для хранимой процедуры,
используя команду execute.
В первом случае появляется окно с таблицей параметров процедуры, в
котором задаются значения входных параметров (в рассматриваемом примере
значение параметра @type=стол, рис.
38).
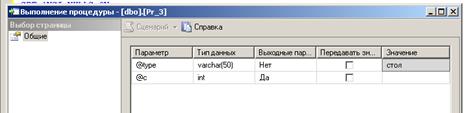
Рис. 38.
После этого появляется код сценария выполнения процедуры, запуск которого
дает результат (рис.39).
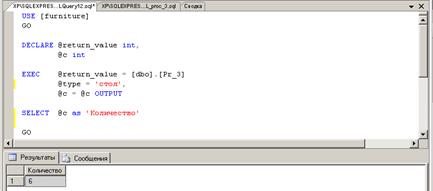
Рис. 39.
Триггеры
Триггер - это специальный тип хранимой процедуры, которая автоматически
выполняется при каждой попытке изменить защищаемые его данные. Триггеры
обеспечивают целостность данных, предотвращая несанкционированное или
неправильное их изменение. Триггеры не имеют параметров и не выполняются явно.
Это значит, что триггер запускается только при попытке изменения данных.
По умолчанию все триггеры (INSERT, DELETE и UPDATE) срабатывают после
выполнения оператора изменения данных. Эти триггеры называются триггерами AFTER
(после),. Кроме того в SQL Server используются триггеры INSTEAD OF (вместо),
которые выполняются вместо оператора предполагаемого изменения данных.
Создание триггера, аналогично пользовательским функциям и процедурам,
можно осуществить на основе шаблона, вызываемого контекстным меню. На рис. 40
приведен пример триггера, созданного для контроля бизнес-правила: «нельзя
удалять сведения о выполненном заказе, если его стоимость превышает 100».
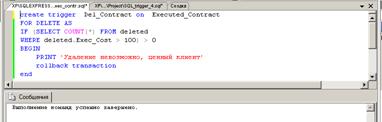
Рис. 40.
При попытке удалить информацию из таблицы Executed_Contract о выполненном
заказе на сумму, превышающую 100, появляется окно-сообщение (см. рис. 41).
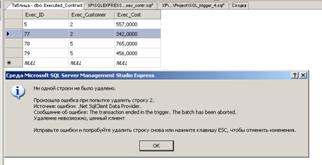
Рис. 41.
Заключение
Описанные выше и проиллюстрированные действия по созданию макета
информационной системы представляют собой только начальный этап разработки
полноценной ИС. При этом информационная модель системы служит основой для
проектирования схемы базы данных, а функциональная модель определяет набор
SQL-запросов и процедур.
Следует отметить, что описанных выше возможностей недостаточно для
разработки ИС, ориентированной на конечного пользователя. Во-первых, такая ИС
должна обладать удобным для конечного пользователя интерфейсом и максимально
облегчать выполнение некоторых рутинных операций (ввод исходных данных,
формирование отчетов и др.). Во-вторых, необходимую для конечного пользователя
функциональность трудно реализовать в полном объеме в рамках языка
SQL-запросов.
Поэтому для разработки прикладной части ИС используют такие современные
системы программирования, как Delphi, Visual Studio, обладающие
большими наборами компонент для создания пользовательских интерфейсов и
библиотеками для реализации необходимой функциональности.
Приложение
Требования к проекту по курсу «Информационные системы»
Разработка прототипа ИС в среде SQL Server 2005
1. Анализ предметной области с учетом ПО-информации и гипотетической
ПП-информации и построение концептуальных моделей:
· создать информационную модель в виде ER-диаграммы;
· создать функциональная модель в виде набора DF-диаграмм, со
словарем данных и миниспецификацией одного из процессов.
. Построение логической модели ИС:
· описать структуру реляционных таблиц;
· проанализировать функциональные зависимости между атрибутами
отношений ;
· привести отношения к третьей нормальной форме.
. Реализация прототипа ИС в SQL Server 2005:
· создать структуру и заполнить данными таблицы БД средствами
SQL Server Management Studio Express;
· создать диаграмму БД;
· создать несколько SQL-запросов (с использованием агрегатных функций; сортировка; удаление,
добавление данных и т.д.);
· разработать несколько пользовательских функций (возвращающих
табличное значение, скалярное значение).
. Отчет о проделанной работе в виде действующего макета ИС и
текстового документа, содержащего информацию по указанным выше пунктам.
Литература
1. Сиговцев
Г. С. Информационные системы. Учебное пособие. Петрозаводск. Изд-во ПетрГУ,
2005. - 220 с.
. Красильникова
М. В. Проектирование информационных систем. Учебное пособие. М.: МИСиС, 2004. -
106 с
. Жилинский
А.А. Самоучитель Microsoft SQL Server 2005. СПб. Изд-во БХВ-Петербург, 2007. - 224 с.
4. Microsoft® SQL ServerTM 2005. Практические методы работы.
Серия «Шаг за шагом»; пер. с англ. - М.: ЭКОМ Паблишерз, 2007. - 464 с.
5. Информация о
бесплатной версии Microsoft SQL Server
2005 Express
<http://www.microsoft.com/rus/msdn/vstudio/express/sql/default.mspx>
Похожие работы на - Проектирование информационных систем
|