Концепции информационного поиска
Оглавление
Введение
Исследование
основных концепций информационного поиска
Исследование
моделей поиска информации
Булева
модель
Векторная
модель
Меры
подобия
Определение
веса индексных терминов
Исследование
методов оценки качества поиска
Оценка
неранжированных наборов результата поиска
Реализация
векторной модели в среде Matlab
Функция
расчета евклидовой меры
Функция
расчета косинусной меры
Расчет
ранжированных списков документов
Реализация
оценок качества поиска в среде Matlab
Расчет
точности, полноты и F-меры в зависимости от числа найденных документов
Листинг
программы
Расчет
интерполированной средней точности, ROC-кривой и зависимости точности от полноты
Функция
для расчета значений кривой точности в заданных точках
Листинг
программы
Расчет
среднего значения средней точности
Листинг
программы
Выводы
Список
используемой литературы
Введение
Цели прохождения производственной практики:
-изучение
основных концепций информационного поиска;
рассмотрение
базовых моделей поиска информации;
рассмотрение
методов оценки качества поиска информации;
приобретение
практических навыков по реализации изученных моделей и методов в среде Matlab.
Исследование основных концепций информационного
поиска
Информационный поиск занимается представлением, хранением,
организацией и обеспечением доступа к информационным объектам. Представление и
организация информации должны предоставлять пользователю удобный доступ к
интересующей его информации. Основной целью системы ИП является получение
информации, которая может быть полезна и релевантна для пользователя, с
использованием его запроса. Основной акцент делается на том, что поиск
информации - это не поиск данных.
Поиск данных - это извлечение всех объектов, которые
удовлетворяют четко определенным условиям, выраженным через язык запросов.
Данные имеют строго определенную структуру и семантику. Используются формальные
языки запросов (например, регулярные выражения). Результаты обязаны быть
точными, ошибки не допускаются. Нет ранжирования по отношению к информационной
потребности пользователя.
Поиск информации - это нахождение материалов (обычно
документов) неструктурированной природы (обычно текст), которые удовлетворяют
информационной потребности, используя большие коллекции (обычно хранящиеся на
многих компьютерах). Запросы обычно не структурированы (запросы на основе
ключевых слов, контекста, фраз, запросы на естественном языке). Ошибки в
полученных результатах допустимы. Концепция релевантности по отношению к
потребностям пользователя занимает центральное место:
· Осуществляется ранжирование по
релевантности.
· Не ясна «степень релевантности», которой
доволен пользователь. Для системы может быть неизвестно что является для
пользователя более важным - точность или полнота.
· Ранжирование позволяет пользователю
начинать с начала ранжированного списка и исследовать его, пока он не
удовлетворит свои потребности.
Модель поиска информации может быть определена как:
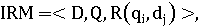
где- набор логических представлений для документов в
коллекции.
Q - набор логических представлений для нужд пользователя
(запросов).
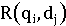 - функция ранжирования, связывающая
действительное число с представлением документа dj для запроса qi. Такой рейтинг
определяет порядок документов по отношению к запросу qi.
- функция ранжирования, связывающая
действительное число с представлением документа dj для запроса qi. Такой рейтинг
определяет порядок документов по отношению к запросу qi.
Релевантность:
· Субъективна: два пользователя могут иметь
одни и те же информационные потребности, но по-разному оценивать одни и те же
найденные документы.
· Динамична в пространстве и времени.
Найденные и отображенные пользователю документы могут повлиять на его оценку
документов, которые будут показаны позднее. В зависимости от своего состояния
пользователь может по-разному оценивать один и тот же документ для одного и
того же запроса.
· Многогранна: релевантность документа
определяется не только темой, но и авторитетностью, специфичностью, полнотой,
новизной, ясностью и т.п.
· Неизвестна системе до оценки пользователя.
Система угадывает релевантность документов по отношению к данному запросу с
помощью расчета , которая зависит от принятой IRM (например, булева,
вероятностная, векторная).
Исследование моделей поиска информации
Модели поиска назначают меру сходства между запросом и
документом. Общая идея: чем чаще термины находятся одновременно в документе и в
запросе, тем более релевантным считается документ по отношению к запросу.
Стратегия поиска - это алгоритм, который принимает запрос q и набор документов
d1, d2,…,dN и определяет коэффициент подобия SC(q,dj) для каждого из
документов 1≤j≤N. Классические модели ИП: булева, вероятностная, векторная.
Каждый документ представляется набором ключевых слов,
называемых индексными терминами. Индексные термины используются для
индексирования и обобщения содержимого документа. Различные индексные термины
отличаются по релевантности, когда используются для описания содержимого
документа. Этот эффект отражается в назначении числовых весов каждому
индексному термину документа.
Пусть ti - индексный термин, dj -
документ, а wi,j≥0 - вес, связанный с парой (ti, dj).
wi,j определяет качество индексного термина для описания смыслового
содержания документа. Каждый документ связан с вектором индексных терминов:
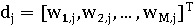
wi,j=g(dj), где g - это функция, которая
вычисляет вес термина ti в документе dj (wi,j=0
обозначает термин ti, который не появляется в dj) и M -
это количество индексных терминов.
Веса индексных терминов, как правило, предполагаются
независимыми друг от друга. Это означает, что знания о весе wi,j, связанном с парой (ti,
dj), ничего не говорят нам о весе wi+1,j связанном с парой (ti+1,
dj). Это является упрощением, потому что вхождения индексных
терминов в документе взаимосвязаны. Более поздние модели ИП (LSI, pLSA, LDA) в явном виде обращаются
к корреляции индексных терминов.
Булева модель
Булева модель поиска информации - это простая поисковая
модель, основанная на теории множеств и булевой алгебре. Значимость индексного
термина представлена с помощью двоичного веса:
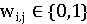 связан с парой (ti, dj).dj
- с набором индексных терминов для документа.ti - с набором
документов для индексного термина.
связан с парой (ti, dj).dj
- с набором индексных терминов для документа.ti - с набором
документов для индексного термина.
Запросы определяются как логические выражения над индексными
терминами (используя логические операции AND, OR и NOT). Например, Brutus AND
Caesar, NOT Calpurnia. Релевантность определяется в виде двоичного свойства
документа:
(q, dj)=0 или SC(q, dj) = 1.
Пример. Пусть
есть коллекция из трех документов:1 = [1,1,1]T2
= [1,0,0]T3 = [0,1,0]T
В коллекции
используются 3 термина. Множества документов, соответствующих терминам:t1
= {d1, d2}, Rt2 = {d1, d3},
Rt3 = {d1}
Тогда
результатами запросов будут: = t1
q = t1 AND t2
q = t1
OR t2= NOT t1t1 = {d1, d2}t1
∩ Rt2 = d1t1 ∪ Rt2 = {d1,
d2, d3}
⌐Rt1 = d3 логический запрос может быть переписан в дизъюнктивной нормальной
форме. Например:
q = ta ∧ (tb ∨ ¬tc) = qdnf = (ta ∧ tb ∧ tc) ∨ (ta ∧ tb ∧ ¬tc) ∨ (ta ∧ ¬tb ∧ ¬tc)
Каждая дизъюнкция
представляет собой идеальный набор документов. Документ удовлетворяет запросу,
если он содержится в терминах дизъюнкции:
qdnf = (ta ∧ tb ∧ tc)∨ (ta ∧ tb ∧ ¬tc)∨ (ta ∧ ¬tb ∧ ¬tc)
qdnf = (1,1,1)∨ (1,1,0)∨ (1,0,0)
SC(q,dj)=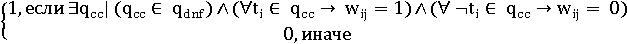
Достоинства
булевой модели:
· Логические выражения имеют точную
семантику.
· Используются структурированные запросы.
· Простой и аккуратный формализм позволял
принять ее во многих ранних коммерческих библиографических системах.
Недостатки
булевой модели:
· Не осуществляется ранжирование. Стратегия
поиска основана на двоичном критерии решения, т.е. документ предполагается либо
релевантным, либо нерелевантным.
· Не просто перевести информационное
требование в логическое выражение.
Векторная модель
Векторная модель представляет документы и запросы в виде
векторов в пространстве терминов. Значимость индексного термина представлена
вещественным весом.
wi,j ≥0 связан с парой
(ti, dj)
Каждый документ представлен вектором в M-мерном пространстве,
где M - это количество индексных терминов
Каждый термин представляет собой единичный вектор
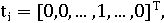
указывающий направление i-ой оси. Множество векторов ti,
i=1,…M
формируют канонический базис для евклидова пространства  M. Любой вектор документа
dj может быть представлен его разложением по каноническому базису
(см. рис.1):
M. Любой вектор документа
dj может быть представлен его разложением по каноническому базису
(см. рис.1):
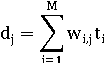
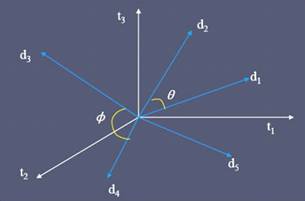
Рисунок 1. Векторное пространство, образованное тремя терминами.
Документы, близкие друг к другу в векторном пространстве,
похожи друг на друга. Запрос так же представляется в виде вектора:
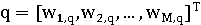
Модель векторного пространства вычисляет сходство SC(q, dj)
между запросом и каждым документом и составляет ранжированный список
документов. Она принимает во внимание документы, которые соответствуют условиям
запроса лишь частично. Ранжированный набор найденных документов более
эффективен (лучше соответствует информационной потребности пользователя), чем
набор документов, найденных булевой моделью. Существуют различные меры, которые
могут быть использованы для оценки сходства документов.
Меры подобия
Мера подобия между документами должна отвечать следующим
требованиям:
· Если d1 рядом с d2,
то d2 рядом с d1.
· Если d1 рядом с d2, а
d2 рядом с d3, то d1 находится недалеко от d3.
· Не существует документов ближе к d, чем сам d.
Примеры мер подобия:
· Евклидова дистанция.
· Косинусное подобие.
· Скалярное произведение.
· Мера Жаккара.
· Коэффициент Дайса.
· Мера Шимкевича-Симпсона.
Евклидова дистанция - это длина разностного вектора:
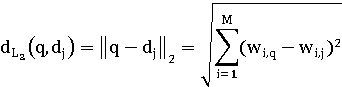
Она может быть преобразована в коэффициент подобия различными
способами:
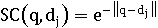
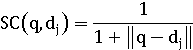
Нужно также решить вопрос нормализации, так как евклидова
дистанция, примененная к ненормированным векторам, как правило, делает любой
большой документ нерелевантным для большинства запросов, так как запросы обычно
имеют короткую длину.
Длинные документы будут похожи друг на друга из-за длины, а
не из-за темы.
Косинусное подобие - это косинус угла между двумя векторами.
Оно показывает сходство, а не дистанцию (см. рис.1). Для косинусного подобия не
выполняется неравенство треугольника.
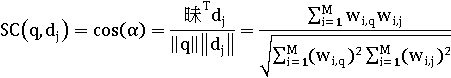
Косинусная мера нормализует результаты с учетом длины вектора
документа. Для двух векторов сходство определяется их направлениями. Для
нормализованных векторов косинусное подобие равно их скалярному произведению.
Меры подобия определяются для двух произвольных множеств A и
B:
Мера Жаккара: 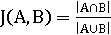
Коэффициент Дайса: 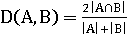
Мера Шимкевича-Симпсона: 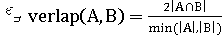
Они могут быть расширены для недвоичных векторов.
Расширенная мера Жаккара.
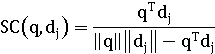
Определение веса индексных терминов
Нам нужно рассмотреть два вопроса. Во-первых, при двоичном
назначении веса похожие термины рассматриваются по-разному. Во-вторых,
нормализация может быть недостаточной для компенсации разницы в длинах документов.
Более длинный документ имеет больше возможностей содержать
релевантные к запросу компоненты.
Поэтому вес индексных терминов должен быть пропорционален
одновременно их важности в документе и во всей коллекции документов.
Вес wi,j может быть рассчитан по
следующей формуле:
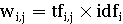
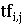 - частота термина ti в документе dj. Обеспечивает меру того,
как хорошо термин описывает содержимое документа.
- частота термина ti в документе dj. Обеспечивает меру того,
как хорошо термин описывает содержимое документа.
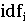 - обратная частота документа для термина ti. Термины, появляющиеся
во многих документах, не очень полезны для отличия релевантных от нерелевантных
документов.
- обратная частота документа для термина ti. Термины, появляющиеся
во многих документах, не очень полезны для отличия релевантных от нерелевантных
документов.
Вес термина 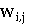 увеличивается с ростом количества его вхождений в
документ и с редкостью появления термина во всей коллекции.
увеличивается с ростом количества его вхождений в
документ и с редкостью появления термина во всей коллекции.
Частота термина в документе:
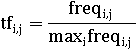
Иногда, чтобы предотвратить смещение в сторону более длинных
документов, рассчитывается как:
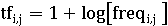
Либо просто:
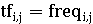
Обратная частота для термина:
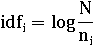
где N - количество документов в коллекции, ni -
количество документов, содержащих ti.
Было произведено множество улучшений в схеме tf- idf. Следующая
формула была определена в качестве хорошей реализации:
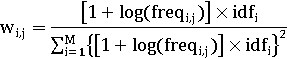
Достоинства векторной модели:
· Схема, определяющая веса терминов,
повышает производительность поиска по отношению к булевой модели.
· Стратегия частичного соответствия
позволяет находить документы, частично удовлетворяющие условиям запроса.
· Ранжированные результаты поиска и контроль
их величины.
· Гибкость и интуитивная геометрическая
интерпретация.
Недостатки векторной модели:
· Невозможность использования
структурированных запросов (нет операторов OR, AND, NOT).
· Термины являются осями (даже с
использованием стемминга может получиться более 20000 измерений).
Исследование методов оценки качества поиска
Главной мерой качества поиска является “счастье”
пользователя. Оно зависит от многих факторов:
· Релевантности результатов.
· Дизайна макета интерфейса пользователя.
· Скорости отклика.
· Целевого приложения:
o Веб-движок: пользователь
находит то, что хочет, и возвращается к движку.
o Сайт продажи онлайн:
пользователь находит то, что хочет, и делает покупку.
o Сайты предприятий,
компаний, государства, образования: забота о “производительности пользователя”
(как много времени он сохраняет, когда ищет информацию).
Качество системы зависит от скорости индексации, скорости
поиска, величины коллекции документов, используемого языка запросов, скорости
при использовании сложных запросов. Чтобы измерить эффективность
информационного поиска, нам необходимы:
· тестовая коллекция документов (должна
иметь разумный размер). Необходимо усреднять производительность, так как
результаты сильно отличаются в зависимости от различных документов и
информационных потребностей.
· тестовый набор информационных
потребностей, выраженный через запросы,
· набор оценок релевантности, обычно это
двоичное обозначение для каждой пары запрос-документ, показывающее релевантен
ли результат.
Релевантность оценивается по отношению к информационной
потребности, а не к запросу. Документ является релевантным, если он относится к
указанной информационной потребности, а не просто содержит все слова из
запроса.
Оценка неранжированных наборов результата поиска.
Точность (P): доля релевантных документов из всех
найденных.(релевантные|найденные) =
= #(найденные релевантные объекты) / #(найденные объекты)
Позволяет определить “степень надежности” системы. Не
учитывает общее количество документов.
Полнота (R): доля найденных релевантных документов из всех релевантных
в коллекции.(найденные|релевантные) =
= #(найденные релевантные объекты) / #(релевантные объекты)
Позволяет определить “степень полноты” системы.
Таблица 1. Обозначения множеств в коллекции обрабатываемых
документов.
|
Relevant (релевантные)
|
Non-relevant (нерелевантные)
|
|
Retrieved (найденные)
|
true positive (TP) (верно положительные)
|
false positive (FP) (ложно положительные)
|
|
Not retrieved (ненайденные)
|
false negative (FN) (ложно отрицательные)
|
true negative (TN) (верно отрицательные)
|
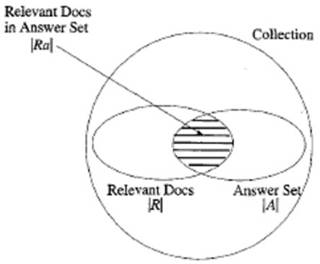
Рисунок 2. Графическое представление обрабатываемой коллекции
документов.
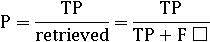
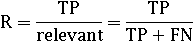
Точность - доля правильных классификаций.
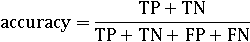
Точность не подходит для использования в контексте ИП. Во
многих случаях данные крайне искажены, например, 99,9% документов являются
нерелевантными. В этом случае система, настроенная на максимизацию точности
будет почти всегда объявлять каждый документ нерелевантным.
Можно получать высокую полноту (но низкую точность), извлекая
все документы для всех запросов. Полнота является неубывающей функцией от
количества найденных документов. Точность обычно падает (в хороших системах).
Точность может быть вычислена на разных уровнях полноты. Пользователи,
ориентированные на высокую точность - веб-серферы, на высокую полноту -
профессиональные исследователи, юристы, аналитики.
F-мера является комбинированной мерой, оценивающей компромисс
между точностью и полнотой (взвешенное среднее гармоническое):
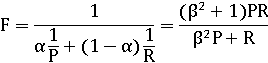
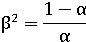
При значении β<1 акцент делается на
точности, при β>1 - на полноте.
Обычно используется сбалансированная F-мера, т.е. β=1 или α=½
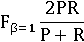
Когда значения двух чисел отличаются, среднее гармоническое
ближе к их минимуму, чем среднее арифметическое или геометрическое. Например,
если 1 из 10000 документов релевантен, мы можем получать 100% полноты, извлекая
все документы. Среднее арифметическое будет 50%, а гармоническое - 0,02%.
Полнота, точность и F-мера являются мерами, основанными на
множествах (например, неупорядоченный набор документов). В ранжированных
поисковых системах значения P и R связаны с позицией в рейтинге. Оценка
производится путем вычисления точности, как функции от полноты. Если (k+1)-ый найденный документ
релевантен, то R(k+1) > R(k), а P(k+1) > P(k). Если (k+1)-ый найденный документ
нерелевантен, то R(k+1) = R(k), но P(k+1) < P(k). Чтобы удалить колебания,
используется интерполированная точность.
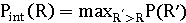
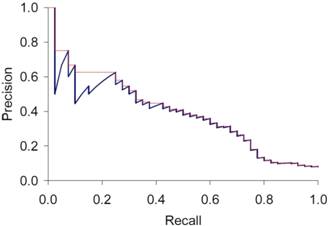
Рисунок 3. Пример графика зависимости точности от полноты. Красным
цветом обозначен график интерполированной точности.
Одиннадцатиточечная интерполированная средняя точность
(11-point interpolated average precision). Измеряется точность на 11 уровнях
полноты {0.0, 0.1, 0.2,…,1.0}, затем рассчитывается среднее арифметическое
уровня точности.
Чтобы найти среднее значение средней точности (mean average
precision (MAP)), вычисляется средняя точность (AP) для каждого
информационного запроса. Затем значение средней точности получается для набора
из первых k документов, имеющихся после каждого нахождения релевантного
документа. MAP = среднее значение AP множества информационных потребностей.
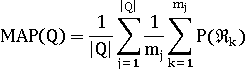
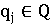 - запрос?
- запрос?
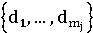 - документы, релевантные запросу
- документы, релевантные запросу 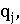
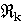 - ранжированный набор первых k найденных
результатов.
- ранжированный набор первых k найденных
результатов.
Для одной информационной потребности AP связана с площадью под
неинтерполированной кривой точности/полноты. Пример:

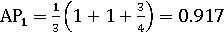
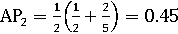
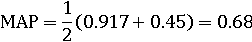
Расчет точности для k. Фиксируется k - количество извлекаемых
результатов, например k=10. Вычисляется точность для первых k объектов.
Достоинство: не требуется множества релевантных документов (полезно для
веб-поиска). Недостаток: общее количество релевантных документов сильно влияет
на точность для k. Например, если количество релевантных документов равно 8, то
точность для 20 будет не более 0,4.
R-точность. Для известного релевантного множества размера Rel
вычисляется количество релевантных документов r среди первых Rel
результатов поиска. Достоинство: идеальная система достигает R-точность = 1,0.
Недостаток: рассматривается только одна точка на кривой точность/полнота.
Операционная характеристика приемника (receiver operating
characteristic). ROC-кривая отображает график зависимости доли верно положительных
классификаций (чувствительности) от доли ложно положительных классификаций (1 -
специфичность).
Доля TP = чувствительность = полнота = TP / (TP + FN)
Доля FP = 1 - специфичность = FP / (FP + TN)
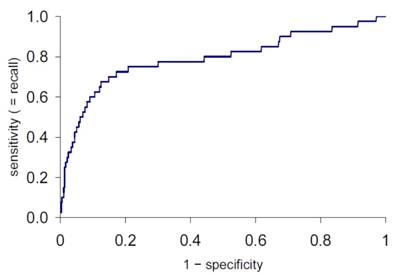
Рисунок 4. Пример графика ROC-кривой.
Реализация векторной модели в среде Matlab
Входные данные:
-terms - множество терминов;
docs - множество документов;
freq - таблица частот терминов.
· answer_euc - ранжированный список при
использовании евклидовой меры;
· answer_cos - ранжированный список при
использовании косинусной меры.
Функция расчета евклидовой меры
function SC = euclideanSM(q,d)
= 1/(1+norm(q-d));
Функция расчета косинусной меры
function SC = cosineSM(q,d)=
q'*d/(norm(q)*norm(d));
Расчет ранжированных списков документов
% Расчет весов документов
= size(docs,1); % Количество документов= size(terms,1); %
Количество терминов
% Частота терминов в документах
= 1 + log(freq);
tf(freq == 0) = 0;= zeros(M,1);i = 1:M(i) =
sum(freq(i,:) > 0);= log(N./df);= zeros(M,N);i = 1:Mj = 1:N(i,j) =
tf(i,j)*idf(i);
end
% Запрос
q = [1;0;0;1]; % Реализация запроса в случае четырех терминов
% Нормализация векторов
for j = 1:N(:,j) = W(:,j)/norm(W(:,j));=
q/norm(q);_euc = zeros(1,N);_cos = zeros(1,N);j = 1:N_euc(j) =
euclideanSM(q,W(:,j));_cos(j) = cosineSM(q,W(:,j));
% Вычисление ранжированного списка документов
[ranked_score_euc,i_euc] =
sort(score_euc,'descend');
[ranked_score_cos,i_cos] =
sort(score_cos,'descend');
% Расчеты для вывода результатов_euc = cell(N,2);
answer_cos = cell(N,2);j = 1:N
%answer_euc{j,1} = docs{i_euc(j)}; % Вывод названия
документа_euc{j,1} = i_euc(j); % Вывод порядкового номера документа
answer_euc{j,2} = ranked_score_euc(j);
%answer_cos{j,1} = docs{i_cos(j)};_cos{j,1} =
i_cos(j);_cos{j,2} = ranked_score_cos(j);
end
% Вывод результатов('Евклидова мера:');
answer_euc('Косинусная мера:');_cos
Реализация оценок качества поиска в среде Matlab
Расчет точности, полноты и F-меры в зависимости от числа
найденных документов
Входные данные:
-список
ранжированных документов;
relevance - массив, указывающий релевантность каждого документа запросу;
Выходные данные:
· precision - массив точности для
фиксированного числа первых документов;
· recall - массив полноты для
фиксированного числа первых документов;
· f_measure_A - F-мера для первых 20
документов;
· f_measure_B - F-мера для первых 50
документов.
Листинг программы
numTot = length(relevance);= round(numTot/10);=
zeros(numStep,1);= zeros(numStep,1);= 10:10:numTot;
% Расчет точности и полноты для фиксированного числа первых
документов
for j = 1:numStep= 0;= 0;= 0;= 0;i =
1:numRet(j)relevance(i) == 1= TP + 1;= FP + 1;i =
numRet(j)+1:numTotrelevance(i) == 1= FN + 1;= TN + 1;(j) = TP / (TP + FP); % Расчет точности(j) = TP / (TP
+ FN); % Расчет полноты
end
% Вывод графиков точности и полноты
figure(numRet,recall,'b'), hold on,
plot(numRet,precision,'r'), hold off
legend('полнота','точность');('Количество найденных
документов');
% Расчет F-меры для первых 20 и 50 документов
% Бета изменяется в диапазоне [0;5]= 0:0.01:5;
f_measure_A = (beta.^2 +
1)*precision(2)*recall(2)./(precision(2)*beta.^2 + recall(2));_measure_B =
(beta.^2 + 1)*precision(5)*recall(5)./(precision(5)*beta.^2 + recall(5));
% Вывод графиков F-мер(beta,f_measure_A,'b'), hold on,
plot(beta,f_measure_B,'r'), hold off('F-мера A','F-мера B');
xlabel('Beta');
Расчет интерполированной средней точности,
ROC-кривой и зависимости точности от полноты.
Входные данные:
-список
ранжированных документов;
relevance - массив, указывающий релевантнос-ть каждого документа запросу;
Выходные данные:
· precision - массив точности для
фиксированного числа первых документов;
· recall - массив полноты для
фиксированного числа первых документов;
· precisionI - интерполированная
точность;
· IAP_11 - 11 точек
интерполированной средней точности;
· fp_rate - доля неверно
положительных;
· tp_rate - доля верно
положительных.
Функция для расчета значений кривой точности в
заданных точках
function i = nearestPoint(v,n)= find(v >= n);=
x(1);
Листинг программы
numTot = length(relevance);= zeros(numTot,1);=
zeros(numTot,1);= zeros(numTot,1);_rate = zeros(numTot,1);numRet = 1:numTot=
0;= 0;= 0;= 0;i = 1:numRetrelevance(i) == 1= TP + 1;= FP + 1;i =
numRet+1:numTotrelevance(i) == 1= FN + 1;= TN + 1;(numRet) = TP / (TP +
FP);(numRet) = TP / (TP + FN);
% Расчет доли ложно положительных документов_rate(numRet) = FP / (FP + TN);
end
% Расчет интерполированной точности(end) = precision(end);i = numTot-1:-1:1(i) =
max(precision(i),precisionI(i+1));
end
% Расчет 11 точек интерполированной средней точности
IAP_11 = zeros(11,1);i = 1:11_11(i) =
precisionI(nearestPoint(recall,0.1*(i-1)));
end
% Вывод графика зависимости точности от полноты
figure(recall,precision,'b'),hold
on,plot(recall,precisionI,'r')(0:0.1:1,IAP_11,'ok'),hold off('точность')('полнота')('неинтерполированная','интерполированная','IAP_{11}')
% ROC-кривая_rate = recall;(fp_rate,tp_rate,'b')('TP_{доля}')('FP_{доля}')
title('ROC')
Расчет среднего значения средней точности
Входные данные:
relevance - Q-мерный массив, указывающий релевантность каждого документа
запросу;
Выходные данные:
· precision - массив точности для
фиксированного числа первых документов;
· AP - массив средних точностей для
запросов;
· MAP - среднее значение
средней точности.
Листинг программы
[numTot,Q] = size(relevance);= zeros(Q,1);=
zeros(Q,1);j = 1:Q(j) = sum(relevance(:,j));= zeros(m(j),1);= 0;= 0;= 0;=
1;index < m(j)relevance(i,j) == 1= TP + 1;= index + 1;(index) = TP / (TP +
FP);= FP + 1;= i + 1;
end
% Расчет средней точности(j) = mean(precision);
% Расчет среднего значения средней точности= mean(AP)
Выводы
Во время прохождения производственной практики:
-изучены
основные концепции информационного поиска;
рассмотрены
базовые модели поиска информации, выделены их основные преимущества и
недостатки, соответственно которым можно определить для решения каких задач
обработки данных наиболее выгодно использовать ту или иную вычислительную
модель;
рассмотрены
методы оценки качества поиска информации, показаны основные случаи их
применения;
-приобретены практические навыки по реализации изученных
моделей и методов в среде Matlab.
Список используемой литературы
· R. Baeza-Yates, B.
Ribeiro-Nieto, “Modern Information Retrieval”, 1999
· C.D. Manning, P. Raghavan
and H. Schütze,
“Introduction to Information Retrieval”, Cambridge University Press. 2008