Приведение КС-грамматики к нормальному виду
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РФ
Филиал ФГБОУ "ДГТУ" в г.
Каспийск
Кафедра ПОВТ и АС
Курсовая работа
По дисциплине:
"Теория языков
программирования"
на тему:
"Приведение КС-грамматики к
нормальному виду"
Выполнила:
студент 4 курса гр. М831
Магомедов К.К.
Приняла: Сулейманова О.Ш.
Каспийск 2011г.
Аннотация
Целью данной курсовой работы является разработка программы,
позволяющей осуществить приведение КС-грамматики к нормальному виду, т.е.:
1. Удалить бесплодные символы
2. Удалить недостижимые символы
3. Устранить правила с пустой правой частью
4. Исключить цепные правила
Работа содержит:
_____ страниц машинописного текста
рисунков
3 библиографических источника
Содержание
Введение
Задание
Приведение КС-грамматики к нормальному виду
Преобразования грамматик
Алгоритм удаления недостижимых символов
Исключение цепных правил
Описание процедур
Литература
Приложение
Введение
Формальные грамматики и языки
Формальные грамматики как математический аппарат появились
именно по необходимости представления синтаксиса в трансляторах и автоматизации
синтаксического анализа. В отличии от лексики и семантики, которые можно
реализовать используя содержательные средства, синтаксический анализатор почти
не возможно сделать руководствуясь здравым смыслом. Здесь необходимо иметь
промежуточный уровень между синтаксисом языка и программируемой системой, таким
уровнем являются формальные грамматики.
Формальные грамматики являются не только синтаксисом, но и
основным инструментом для синтаксического анализатора. Самая общая схема
синтаксического анализатора, построенная на основе формальных методов:
. Описание синтаксиса языка дается исключительно
средствами формальных грамматик.
2. Формальный метод синтаксического анализа
устанавливает свойства формальных грамматик, которые определяются исходя из
правил, составляющих формальные грамматики.
. Правила, множества различных символов и отношения
представляются табличными данными, на основе которых функционирует
распознаватель.
. Распознаватель представляет собой алгоритм
(управляющий автомат), который наряду с входной строкой, в качестве элемента
использует стек.
. Распознаватель, используя данные извлеченные из
формальной грамматики, выполняет действия, которые соответствуют синтаксической
структуре самого текста.
Стековая структура является процессом определенного набора
действий, соответствующих синтаксическому анализу. Полученные формальным
методом табличные данные являются программой его работы.
Описание синтаксиса в виде формальных грамматик является ее
исходным текстом.
Взаимосвязь синтаксиса и формальных грамматик
После предварительного анализа свойств формальных грамматик
нужно отметить, что они в целом играют роль синтаксиса. Синтаксис языка
программирования, представленный в виде конкретной формальной грамматики своеобразный
аналог исходного текста программы.
Одна и та же программа может быть написана разными способами,
т.е. идея воплощенная и реализованная на формальном языке можно реализовать
множеством способов. Программа пишется содержательно, не существует формальных
методов разработки программ. Не возможно определить формальными методами -
эквивалентны ли две программы с точки зрения результата программы. Один и тот
же синтаксис можно реализовать в виде множества формальных грамматик. Синтаксис
преобразуется в формальную грамматику содержательно. Общим недостатком
формальных языков является отрыв формальных грамматик от синтаксиса. Обычно
формальная грамматика изучается как некоторая данность, а не результат
программирования определенного синтаксиса.
Из всех классов формальных грамматик только КС грамматики
продуктивно используются в синтаксическом анализе. Они дают дополнительный
смысл понятию нетерминальный смысл.
Нетерминальный символ - обозначение элемента синтаксиса и
место его вхождения в другие элементы синтаксиса. Кроме нетерминалов, явно
обозначающих синтаксические единицы, для многих элементов синтаксиса
используются вспомогательные нетерминалы.
Основные понятия и определения.
Алфавит - это конечное множество символов.
Например, алфавит A = {a, b, c, +,! } содержит 5 букв, а алфавит B = {00, 01, 10, 11}
содержит 4 буквы, каждая из которых состоит из двух символов.
Цепочкой символов в алфавите V называется любая
конечная последовательность символов этого алфавита.
Цепочка, которая не содержит ни одного символа, называется
пустой цепочкой. Для ее обозначения будем использовать символ l.
Более формально цепочка символов в алфавите V определяется следующим
образом:
) l - цепочка в алфавите V;
) если α - цепочка в алфавите V и a - символ этого алфавита,
то αa или аa - цепочка в алфавите V;
) β - цепочка в алфавите V тогда и только тогда,
когда она является таковой в силу (1) и (2).
Если α и β - цепочки, то цепочка αβ называется конкатенацией
(или сцеплением) цепочек α и β.
Например, если α = ab и β = cd, то αβ = abcd.
Для любой цепочки α всегда αl = lα = α.
Обращением (или реверсом) цепочки α называется цепочка, символы которой записаны в обратном порядке.
Например, если α = abcdef, то αR = fedcba.
Для пустой цепочки: l = lR.
n-ой степенью цепочки α (будем обозначать αn) называется конкатенация
n цепочек α
α0 = l;
αn = ααn-1 = αn-1α.
Длина цепочки - это число составляющих ее символов.
Например, если α = abcdefg, то длина α равна 7.
Длину цепочки α будем обозначать |α|. Длина l равна 0.
Язык в алфавите V - это подмножество цепочек конечной длины в этом
алфавите.
Обозначим через V* множество, содержащее все цепочки в алфавите V, включая пустую цепочку l.
Например, если V={0,1}, то V* = {l, 0, 1, 00, 11, 01, 10,
000, 001, 011,. }.
Обозначим через V+ множество, содержащее все цепочки в алфавите V, исключая пустую цепочку
l.
Следовательно, V* = V+ U {l}.
Ясно, что каждый язык в алфавите V является подмножеством
множества V*.
Известно несколько различных способов описания языков. Один
из них использует порождающие грамматики. Именно этот способ описания языков
используется чаще всего.
Задание
Приведение
КС-грамматики к нормальному виду
Приведенные грамматики
Приведенные грамматики - это КС-грамматики, которые не
содержат недостижимых и бесплодных символов, циклов и l-правил
("пустых" правил). Приведенные грамматики называют также
КС-грамматиками в каноническом виде.
Для того, чтобы преобразовать произвольную КС-грамматику к
приведенному виду, необходимо выполнить следующие действия:
·
удалить все бесплодные символы;
·
удалить все недостижимые символы;
·
удалить l-правила;
·
удалить цепные правила.
Следует подчеркнуть, что шаги преобразования должны
выполняться именно в указанном порядке, и никак иначе.
Преобразования
грамматик
В некоторых случаях КС-грамматика может содержать
недостижимые и бесплодные символы, которые не участвуют в порождении цепочек
языка и поэтому могут быть удалены из грамматики.
Определение: символ A є VN называется бесплодным
в грамматике G
= (VT, VN, P, S), если множество { a
| a є VT*, A => a} пусто.
Определение: символ x є (VT U VN) называется недостижимым
в грамматике G
= (VT, VN, P, S), если он не появляется ни в одной сентенциальной форме этой
грамматики.
Алгоритм удаления бесплодных символов
Вход: КС-грамматика G = (VT, VN, P, S).
Выход: КС-грамматика G’ = (VT, VN’, P’, S), не содержащая
бесплодных символов, для которой L (G) = L (G’).
Метод:
Рекурсивно строим множества N0, N1,.
1. N0 = Æ, i = 1.
2. Ni = {A | (A → a) є P и a є (Ni-1 U VT) *}
U Ni-1.
3. Если Ni ≠ Ni-1, то i = i+1 и переходим к шагу 2,
иначе VN’ = Ni; P’ состоит из правил множества P, содержащих только
символы из VN’ È VT; G’ = (VT, VN’, P’, S).
Алгоритм
удаления недостижимых символов
Вход: КС-грамматика G = (VT, VN, P, S)
Выход: КС-грамматика G’ = (VT’, VN’, P’, S), не содержащая
недостижимых символов, для которой L (G) = L (G’).
Метод:
1. V0 = {S}; i = 1.
. Vi = {x | x є (VT U VN), (A →
axb) Î P и A є Vi-1} U Vi-1.
3. Если Vi ≠ Vi-1, то i = i+1 и переходим к шагу 2,
иначе VN’ = Vi Ç VN; VT’ = Vi Ç VT; P’ состоит из правил множества P, содержащих только
символы из Vi; G’ = (VT’, VN’, P’, S).
Удаление символов сопровождается удалением правил вывода,
содержащих эти символы.
Если в этом алгоритме переставить шаги (1) и (2), то не
всегда результатом будет правильным.
В качестве примера рассмотрим контекстно-свободную грамматику
G с правилами S → U, S → VZ, T → aa, T → bb, U → aUa, U → bUb, V → aTb, V → bTa, W → YZY, W → aab, X → Xa, X → Xb, X → ε, Y → YY, Y → aU, Y → ε, Z → W, Z → b. Удалив четыре правила,
содержащие бесплодный символ U, получим грамматику G1: S → VZ, T → aa, T → bb, V → aTb, V → bTa, W → YZY, W → aab, X → Xa, X → Xb, X → ε, Y → YY, Y → ε, Z → W, Z → b.
В ней символ X является недостижимым. Удалив три правила, содержащие X, получим грамматику G2 с правилами: S → VZ, T → aa, T → bb, V → aT b, V → bT a, W → YZY, W → aab, Y → YY, Y → ε, Z → W, Z → b. Очевидно, L (G) = L (G2) и грамматика G2 не содержит бесплодных и недостижимых символов.
Преобразование неукорачивающих грамматик
Последний вид рассматриваемых преобразований связан с
удалением из грамматики правил с пустой правой частью.
Определение. Правило вида A → l называется "пустым"
(аннулирующим) правилом.
Определение. Грамматика называется неукорачивающей
или грамматикой без "пустых" правил, если либо
) схема грамматики не содержит аннулирующих правил,
) либо схема грамматики содержит только одно правило вида S → l, где S - начальный символ
грамматики, и символ S не встречается в правых частях остальных правил грамматики.
Для грамматик, содержащих аннулирующие правила, справедливо
следующее утверждение.
Утверждение. Для каждой КС-грамматики G', содержащей
аннулирующие правила, можно построить эквивалентную ей неукорачивающую грамматику
G, такую что L (G') =L (G).
Построение неукорачивающей грамматики приведет к увеличению
числа правил заданной грамматики из-за построения дополнительных правил,
получаемых в результате исключения нетерминалов аннулирующих правил. Чтобы
построить дополнительные правила необходимо выполнить все возможные подстановки
пустой цепочки вместо аннулирующего нетерминала во все правила грамматики.
Если же в грамматике есть правило вида S → l, где S - начальный символ
грамматики, и символ S входит в правые части других правил грамматики, то следует
ввести новый начальный символ S’ и заменить правило S → l двумя новыми правилами: S' → l
и S'→ S.
В качестве иллюстрации способа построения неукорачивающих
грамматик, исключим аннулирующие правила из следующей грамматики:
G ({a,b}, {S}, P = { S → aSbS, S →
bSaS, S → l }, S).
Выполняя все возможные замены символа S в первом правиле
грамматики, получаем четыре правила вида:
S → aSbS, S → abS, S → aSb, S →
ab.
Поступая аналогично со вторым правилом, имеем:
S → bSaS, S →baS, S → bSa, S →
ba.
Учитывая, что начальный символ, образующий аннулирующее
правило, входит в правые части других правил грамматики, заменим правило S → l правилами вида S' → l
и S' → S.
Построенная совокупность правил образует множество правил
искомой неукорачивающей грамматики.
S' → S | l, S → aSbS | abS | aSb | ab | bSaS |baS | bSa | ba
Все приведенные выше преобразования грамматик могут быть
использованы при построении как конечных, так и магазинных автоматов.
Исключение
цепных правил
Определение. Правило грамматики вида A → B, где A, B є VN, называется цепным.
Для КС-грамматики G, содержащей цепные
правила, можно построить эквивалентную ей грамматику G', не содержащую цепных
правил.
Идея доказательства заключается в следующем.
Если грамматика G имеет правила A → B, B → C, C → aX, то такие правила могут
быть заменены одним правилом А → aX, поскольку вывод А =>
B
=> C => aX цепочки aX в грамматике G может быть получен в
грамматике G'
с помощью правила A → aX.
. Для каждого А є N построить NA={B│A =>*B} следующим образом:
а) Положить N0 = {A} и i=1.
в) Если Ni ≠ Ni-1, положить i = i+1 и повторить шаг (б).
В противном случае положить NA = Ni.
. Построить Р’ так: если В → α принадлежит Р и не является цепным правилом, включить в Р’
правило А → α для всех таких А, что В
є NА.
. Положить G’ = (VT, VN, P’, S).
В качестве примера выполним исключение цепных правил из
грамматики G:
G = ({+,*, (,),a}, {E,T,F},
P={E → E+T | T, Т → T*F | F, F → (E) | a}, E).
Разобьем правила грамматики на два подмножества:
P1 = {E → T, T →
F},2 = {E → E+T, T → T*F, F → (E) |
a }
На шаге (1) NЕ = {E, T, F},
NT = {T, F}, NF = {F}. После шага (2)
множество Р’ станет таким
E → T+T | T*F | (E) | a→
T*F | (E) | a
F → (E) | a
Описание процедур
1) Анализ
Входные данные: правила, введенные в Memo1.
Выходные данные: правила, выведенные в Memo2.
procedure TForm1. btn1Click (Sender: TObject);l;.
Clear;i: =0 to mmo1. Lines. Count doLength (mmo1. Lines [i]) >2 then begin:
= []; s: =mmo1. Lines [i];j: =0 to Length (s) do begin(s [j] in ['А'. 'Я']) or
(s [j] in ['а'. 'я']) then mmo1. Lines. Delete (i);: =mm+ [s [j]]; end;(not (s
[1] in ['A'. 'Z'])) or (s [2] <>'-') or (' ' in mm) then mmo1. Lines.
Delete (i);else mmo1. Lines. Delete (i);i: =0 to mmo1. Lines. Count do begin:
=mmo1. Lines [i];: =Pos ('/',s); Delete (s,n,1);: =Pos ('/',s); Delete
(s,m,1);(n>0) and (m>0) and (n<m) then begin. Lines. Add (Copy
(s,1,n-1));. Lines. Add (Copy (s,1,2) +Copy (s,n,m-n));. Lines. Add (Copy
(s,1,2) +Copy (s,m,Length (s) - m+1));l;;n>0 then begin. Lines. Add (Copy
(s,1,n-1));. Lines. Add (Copy (s,1,2) +Copy (s,n,Length (s) - n+1));l;;(n=0)
and (Length (s) >2) then mmo2. Lines. Add (s);:;i: =0 to mmo2. Lines. Count
do begin p [i]: =mmo2. Lines [i];[i]: = [];j: =3 to Length (p [i]) do if p
[i,j] in ['A'. 'Z'] then mn [i]: =mn [i] + [P [i,j]];;
END;
Пример выполнения:
Введем в Мемо1 следующие правила и нажмем на кнопку 1
грамматика алгоритм символ правило

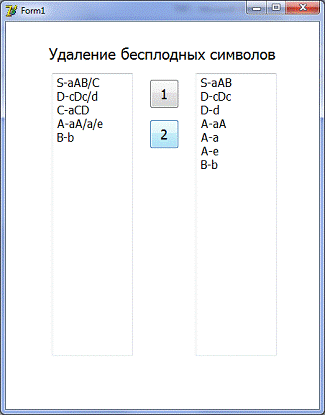
2) Удаление бесплодных символов
Входные данные: правила из
Мемо2
Выходные данные: правила в Мемо2 (без
бесплодных символов)
procedure TForm1. btn2Click (Sender:
TObject);vn2: set of Char;: =mmo2. Lines. Count;i: =0 to v do p [i]: ='';i: =0
to v do begin p [i]: =mmo2. Lines [i];[i]: = [];j: =3 to Length (p [i]) dop
[i,j] in ['A'. 'Z'] then mn [i]: =mn [i] + [P [i,j]];;. Clear;: = [];i: =0 to
v-1 do if mn [i] = [] then vn: =vn+ [p [i,1]];: = [];: =0;vn<>vn2 do
begin: =vn2;i: =0 to V-1 do(mn [i] - vn= [])vn2: =vn2+vn+ [p [i,1]];;i: =0 to v
doj: =1 to Length (p [i]) doLength (p [i]) >2 then if (not (p [i,j] in vn))
and (p [i,j] in ['A'. 'Z']) then p [i]: ='';i: =0 to v do begin mn [i]: = [];j:
=3 to Length (p [i]) do if p [i,j] in ['A'. 'Z'] then mn [i]: =mn [i] + [p
[i,j]];Length (p [i]) >2 then mmo2. Lines. Add (p [i]);;i: =0 to v do p [i]:
='';i: =0 to mmo2. Lines. Count do begin p [i]: =mmo2. Lines [i];[i]: = [];j:
=3 to Length (p [i]) dop [i,j] in ['A'. 'Z'] then mn [i]: =mn [i] + [P
[i,j]];;;
Пример использования:
. Введем в Мемо1 правила
2. Нажмем на кнопку 1
. Нажмем на кнопку 1
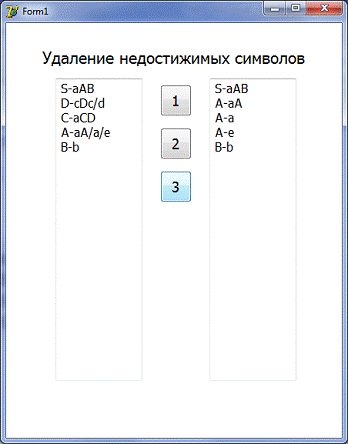
3) Удаление недостижимых символов
Входные данные: правила из
Мемо2
Выходные данные: правила в Мемо2 (без
недостижимых символов)
procedure TForm1. btn3Click (Sender: TObject);
: =mmo2. Lines. Count;i: =0 to v do p [i]: ='';i:
=0 to v do begin p [i]: =mmo2. Lines [i];[i]: = [];j: =3 to Length (p [i]) dop
[i,j] in ['A'. 'Z'] then mn [i]: =mn [i] + [P [i,j]];;. Clear;: = [];i: =0 to 3
doLength (p [i]) >1 then begin vn: =vn+ [p [i,1]] +mn [0]; Break; end;:
=0;m<4 do begini: =0 to v doLength (p [i]) >2 thenp [i,1] in vn then vn:
=vn+mn [i];(m);;i: =0 to v doj: =0 to Length (p [i]) doLength (p [i]) >2
then if (not (p [i,j] in vn)) and (p [i,j] in ['A'. 'Z']) then p [i]: ='';i: =0
to v doLength (p [i]) >2 then mmo2. Lines. Add (p [i]);i: =0 to v do p [i]:
='';i: =0 to mmo2. Lines. Count do begin p [i]: =mmo2. Lines [i];[i]: = [];j:
=3 to Length (p [i]) dop [i,j] in ['A'. 'Z'] then mn [i]: =mn [i] + [P
[i,j]];;;
Пример использования:
. Введем правила в Мемо1
2. Нажмем на кнопку 1
. Нажмем на кнопку 3
4) Устранение правил с пустой правой частью
Входные данные: правила из Мемо2
Выходные данные: правила в Мемо2
procedure TForm1. btn4Click (Sender: TObject);:
=mmo2. Lines. Count;i: =0 to v do p [i]: ='';i: =0 to v do begin p [i]: =mmo2.
Lines [i];[i]: = [];j: =3 to Length (p [i]) dop [i,j] in ['A'. 'Z'] then mn
[i]: =mn [i] + [P [i,j]];;. Clear;: =0;i: =0 to v doLength (p [i]) >2 thenp
[i,3] ='e' then begin(j); r [j]: =p [i,1]; p [i]: ='';;: =j; k: =0;i: =1 to n
doj: =0 to v do beginLength (p [j]) >1 thenr [i] in mn [j] then begin: =p
[j];(s,1,2);: =s;: =Pos (r [i],s);(s,m,1);: =Pos (r [i],s);(m>0) and
(l>0) then begin(k);[k+v]: =Copy (p [j],1,2) +s;(k); l: =Pos (r [i],s);
Delete (s1,l+1,1);[k+v]: =Copy (p [j],1,2) +s1;(k); l: =Pos (r [i],s1); Delete
(s1,l,1);[k+v]: =Copy (p [j],1,2) +s1;;(m>0) and (l=0) then begin(k);[k+v]:
=Copy (p [j],1,2) +s;;; end;i: =0 to v+ (k-1) doj: =i+1 to v+k do beginp [i] =p
[j] then p [j]: ='';(Length (p [i]) =3) and (p [i,1] =p [i,3]) then p [i]:
='';;i: =0 to v+k doLength (p [i]) >2 then mmo2. Lines. Add (p [i]);i: =0 to
v do p [i]: ='';i: =0 to mmo2. Lines. Count do begin p [i]: =mmo2. Lines
[i];[i]: = [];j: =3 to Length (p [i]) dop [i,j] in ['A'. 'Z'] then mn [i]: =mn
[i] + [P [i,j]];;;
Пример использования:
. Вводим правила в Мемо1
2. Нажимаем на кнопку 1
. Нажимаем на кнопку 4

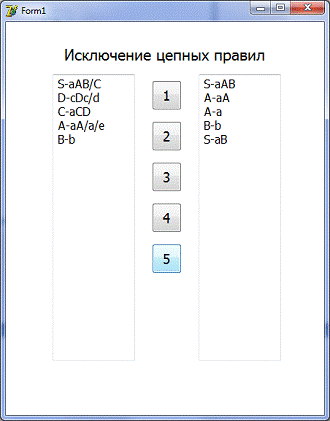
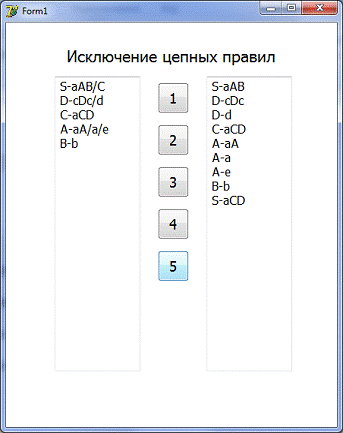
5) Исключение цепных правил
Входные данные: правила из
Мемо2
Выходные данные: правила в
Мемо2
procedure TForm1. btn5Click (Sender: TObject);:
=mmo2. Lines. Count;i: =0 to v do p [i]: ='';i: =0 to v do p [i]: =mmo2. Lines
[i];. Clear;i: =1 to 5 do r [i]: =' '; k: =0;i: =0 to v doLength (p [i]) =3
then(p [i,1] in ['A'. 'Z']) and (p [i,3] in ['A'. 'Z']) and (p [i,1] <>p
[i,3]) then begin(k); r [k]: =p [i,1]; r [k+1]: =p [i,3]; p [i]: ='';;i: =1 to
k do begin[i]: = [];j: =i+1 to k+1 do[i]: =mn [i] + [r [j]];;: =0; l: =0;i: =1
to k do begin(m);j: =0 to v do(Length (p [j]) >2) and (p [j,1] in mn [m])
then begin(l); p [v+l]: =p [j];[v+l,1]: =r [m]; end;;i: =0 to v+l doLength (p
[i]) >2 then mmo2. Lines. Add (p [i]);;
Пример использования:
. Ведем правила в Мемо1
2. Нажмем на кнопку 1
. Нажмем на кнопку 5
Литература
1. "Теория
и реализация языков программирования" Серебряков В. А. Издательство
М3-Пресс, 1999г., 174 стр.
2. "Давайте
создадим компилятор!" Джек Креншоу Издательство Самиздат, 1995г., 135 стр.
. "Алгоритмы,
языки, автоматы и компиляторы" М. Мозговой Издательство Наука и техника,
2006г., 316 стр.
Приложение
unit Unit1;
interface
uses
Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms,
Dialogs, StdCtrls, ComCtrls, Grids, jpeg, ExtCtrls, XPMan, Menus, Buttons;
type= class (TForm): TButton;: TMemo;: TMemo;:
TButton;: TButton;: TButton;: TButton;: TLabel;: TXPManifest;btn1Click (Sender:
TObject);btn2Click (Sender: TObject);btn3Click (Sender: TObject);btn4Click
(Sender: TObject);btn5Click (Sender: TObject);btn1MouseMove (Sender: TObject;
Shift: TShiftState; X,: Integer);btn2MouseMove (Sender: TObject; Shift:
TShiftState; X,: Integer);FormMouseMove (Sender: TObject; Shift: TShiftState;
X,: Integer);btn3MouseMove (Sender: TObject; Shift: TShiftState; X,:
Integer);btn4MouseMove (Sender: TObject; Shift: TShiftState; X,:
Integer);btn5MouseMove (Sender: TObject; Shift: TShiftState; X,: Integer);
{ Private declarations }
{ Public declarations };: TForm1;,m,n,j,v,k,l:
Integer;,s1: string;: array [0.40] of string;,vt,k1,k2,mm: set of Char;: array
[0.25] of set of Char;: Char;: array [1.5] of Char;
{$R *. dfm}TForm1. btn1Click (Sender:
TObject);l;. Clear;i: =0 to mmo1. Lines. Count doLength (mmo1. Lines [i]) >2
then begin: = []; s: =mmo1. Lines [i];j: =0 to Length (s) do begin(s [j] in
['А'. 'Я']) or (s [j] in ['а'. 'я']) then mmo1. Lines. Delete (i);: =mm+ [s
[j]]; end;(not (s [1] in ['A'. 'Z'])) or (s [2] <>'-') or (' ' in mm)
then mmo1. Lines. Delete (i);else mmo1. Lines. Delete (i);i: =0 to mmo1. Lines.
Count do begin: =mmo1. Lines [i];: =Pos ('/',s); Delete (s,n,1);: =Pos ('/',s);
Delete (s,m,1);(n>0) and (m>0) and (n<m) then begin. Lines. Add (Copy
(s,1,n-1));. Lines. Add (Copy (s,1,2) +Copy (s,n,m-n));. Lines. Add (Copy
(s,1,2) +Copy (s,m,Length (s) - m+1));l;;n>0 then begin. Lines. Add (Copy
(s,1,n-1));. Lines. Add (Copy (s,1,2) +Copy (s,n,Length (s) - n+1));l;;(n=0)
and (Length (s) >2) then mmo2. Lines. Add (s);:;i: =0 to mmo2. Lines. Count
do begin p [i]: =mmo2. Lines [i];[i]: = [];j: =3 to Length (p [i]) do if p
[i,j] in ['A'. 'Z'] then mn [i]: =mn [i] + [P [i,j]];;;TForm1. btn2Click
(Sender: TObject);vn2: set of Char;: =mmo2. Lines. Count;i: =0 to v do p [i]:
='';i: =0 to v do begin p [i]: =mmo2. Lines [i];[i]: = [];j: =3 to Length (p
[i]) dop [i,j] in ['A'. 'Z'] then mn [i]: =mn [i] + [P [i,j]];;. Clear;: =
[];i: =0 to v-1 do if mn [i] = [] then vn: =vn+ [p [i,1]];: = [];: =0;vn<>vn2
do begin: =vn2;i: =0 to V-1 do(mn [i] - vn= [])vn2: =vn2+vn+ [p [i,1]];;i: =0
to v doj: =1 to Length (p [i]) doLength (p [i]) >2 then if (not (p [i,j] in
vn)) and (p [i,j] in ['A'. 'Z']) then p [i]: ='';i: =0 to v do begin mn [i]: =
[];j: =3 to Length (p [i]) do if p [i,j] in ['A'. 'Z'] then mn [i]: =mn [i] +
[p [i,j]];Length (p [i]) >2 then mmo2. Lines. Add (p [i]);;i: =0 to v do p
[i]: ='';i: =0 to mmo2. Lines. Count do begin p [i]: =mmo2. Lines [i];[i]: =
[];j: =3 to Length (p [i]) dop [i,j] in ['A'. 'Z'] then mn [i]: =mn [i] + [P
[i,j]];;;TForm1. btn3Click (Sender: TObject);: =mmo2. Lines. Count;i: =0 to v
do p [i]: ='';i: =0 to v do begin p [i]: =mmo2. Lines [i];[i]: = [];j: =3 to
Length (p [i]) dop [i,j] in ['A'. 'Z'] then mn [i]: =mn [i] + [P [i,j]];;.
Clear;: = [];i: =0 to 3 doLength (p [i]) >1 then begin vn: =vn+ [p [i,1]]
+mn [0]; Break; end;: =0;m<4 do begini: =0 to v doLength (p [i]) >2 thenp
[i,1] in vn then vn: =vn+mn [i];(m);;i: =0 to v doj: =0 to Length (p [i])
doLength (p [i]) >2 then if (not (p [i,j] in vn)) and (p [i,j] in ['A'.
'Z']) then p [i]: ='';i: =0 to v doLength (p [i]) >2 then mmo2. Lines. Add
(p [i]);i: =0 to v do p [i]: ='';i: =0 to mmo2. Lines. Count do begin p [i]:
=mmo2. Lines [i];[i]: = [];j: =3 to Length (p [i]) dop [i,j] in ['A'. 'Z'] then
mn [i]: =mn [i] + [P [i,j]];;;TForm1. btn4Click (Sender: TObject);: =mmo2.
Lines. Count;i: =0 to v do p [i]: ='';i: =0 to v do begin p [i]: =mmo2. Lines
[i];[i]: = [];j: =3 to Length (p [i]) dop [i,j] in ['A'. 'Z'] then mn [i]: =mn
[i] + [P [i,j]];;. Clear;: =0;i: =0 to v doLength (p [i]) >2 thenp [i,3]
='e' then begin(j); r [j]: =p [i,1]; p [i]: ='';;: =j; k: =0;i: =1 to n doj: =0
to v do beginLength (p [j]) >1 thenr [i] in mn [j] then begin: =p
[j];(s,1,2);: =s;: =Pos (r [i],s);(s,m,1);: =Pos (r [i],s);(m>0) and
(l>0) then begin(k);[k+v]: =Copy (p [j],1,2) +s;(k); l: =Pos (r [i],s);
Delete (s1,l+1,1);[k+v]: =Copy (p [j],1,2) +s1;(k); l: =Pos (r [i],s1); Delete
(s1,l,1);[k+v]: =Copy (p [j],1,2) +s1;;(m>0) and (l=0) then begin(k);[k+v]:
=Copy (p [j],1,2) +s;;; end;i: =0 to v+ (k-1) doj: =i+1 to v+k do beginp [i] =p
[j] then p [j]: ='';(Length (p [i]) =3) and (p [i,1] =p [i,3]) then p [i]:
='';;i: =0 to v+k doLength (p [i]) >2 then mmo2. Lines. Add (p [i]);i: =0 to
v do p [i]: ='';i: =0 to mmo2. Lines. Count do begin p [i]: =mmo2. Lines
[i];[i]: = [];j: =3 to Length (p [i]) dop [i,j] in ['A'. 'Z'] then mn [i]: =mn
[i] + [P [i,j]];;;TForm1. btn5Click (Sender: TObject);: =mmo2. Lines. Count;i:
=0 to v do p [i]: ='';i: =0 to v do p [i]: =mmo2. Lines [i];. Clear;i: =1 to 5
do r [i]: =' '; k: =0;i: =0 to v doLength (p [i]) =3 then(p [i,1] in ['A'.
'Z']) and (p [i,3] in ['A'. 'Z']) and (p [i,1] <>p [i,3]) then begin(k);
r [k]: =p [i,1]; r [k+1]: =p [i,3]; p [i]: ='';;i: =1 to k do begin[i]: = [];j:
=i+1 to k+1 do[i]: =mn [i] + [r [j]];;: =0; l: =0;i: =1 to k do begin(m);j: =0
to v do(Length (p [j]) >2) and (p [j,1] in mn [m]) then begin(l); p [v+l]:
=p [j];[v+l,1]: =r [m]; end;;i: =0 to v+l doLength (p [i]) >2 then mmo2.
Lines. Add (p [i]);;TForm1. btn1MouseMove (Sender: TObject; Shift: TShiftState;
X,: Integer);. Caption: ='Анализ грамматики';;TForm1. btn2MouseMove (Sender:
TObject; Shift: TShiftState; X,: Integer);
begin
end;TForm1. FormMouseMove (Sender: TObject;
Shift: TShiftState; X,: Integer);. Caption: ='Приведение грамматики';;TForm1.
btn3MouseMove (Sender: TObject; Shift: TShiftState; X,: Integer);
begin
lbl1. Caption: ='Удаление недостижимых символов';
end;TForm1. btn4MouseMove (Sender: TObject;
Shift: TShiftState; X,: Integer);
begin
lbl1. Caption: ='Преобразование неукорачивающих правил';
end;TForm1. btn5MouseMove (Sender: TObject;
Shift: TShiftState; X,: Integer);. Caption: ='Исключение цепных правил';;
end.
Пример работы программы:
Шаг 1: вводим правила в Мемо1

Шаг 2: нажимаем на кнопку 1
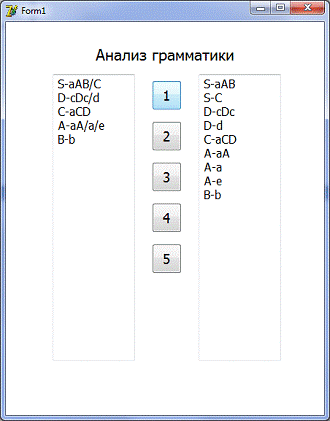
Шаг 3: нажимаем на кнопку 2

Шаг 4: нажимаем на кнопку 3
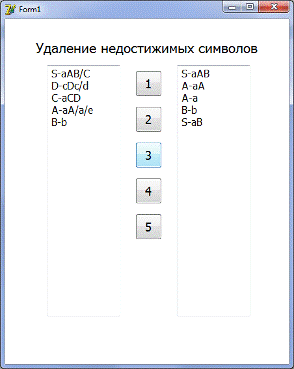
Шаг 5: нажимаем на кнопку 4
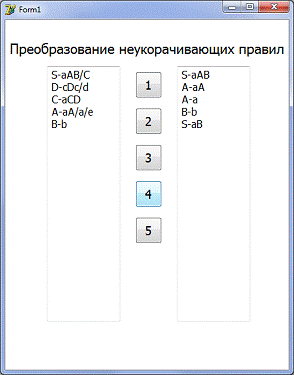
Шаг 6: нажимаем на кнопку 5