Разработка сигнального микропроцессора для реализации КИХ-фильтров с децимацией
Содержание
Введение
1. Основные положения теории сигнальных микропроцессоров и
ких-фильтров
1.1 ПЛИС и языки описания аппаратуры
1.1.1 Элементы теории ПЛИС
1.1.2 Классификация ПЛИС
1.1.3 Языки описания аппаратуры
1.2 Цифровая фильтрация
1.2.1 Основные понятия теории цифровой фильтрации
1.2.2 Нерекурсивные цифровые фильтры (КИХ-фильтры)
1.2.3 Рекурсивные цифровые фильтры (БИХ-фильтры)
1.3 Цифровые процессоры обработки сигналов
1.3.1 Общие принципы построения ЦПОС и особенности их архитектуры
1.3.2 Архитектура фон Неймана и гарвардская архитектура
1.3.3 Принцип конвейерного выполнения программ
1.3.4 Примеры функциональных узлов ЦПОС
2. Существующие методы реализации ких-фильтров
2.1 Виды рассматриваемых КИХ-фильтров
2.1.1 Первый вид КИХ-фильтров
2.1.2 Второй вид КИХ-фильтров
2.1.3 Третий вид КИХ-фильтров
2.2 Проектирование КИХ-фильтров в базисе ПЛИС фирмы Altera
3. Разработка сигнального микропроцессора для реализации
ких-фильтров с децимацией
3.1 Макетное проектирование на языке высокого уровня
3.2 Примеры реализации КИХ-фильтров с помощью макета ЦСП
3.3 Реализация микропроцессора на языке описания аппаратуры Verilog
3.3.1 Реализация модуля "CounterWithInit"
3.3.2 Реализация модуля "RegRam"
3.3.3 Реализация модуля "RegRamWith2Ports"
3.3.4 Реализация модуля типа "RAM"
3.3.5 Реализация модуля "RamWuth2Port"
3.3.6 Реализация модуля "Subs"
3.3.7 Реализация модуля "Loader"
3.3.8 Реализация модуля "Conveyor"
3.4 Итоговая компиляция проекта
4. Экономическое обоснование
4.1 Расчет трудоемкости НИР
4.2 Расчёт заработной платы работников, принимающих участие в
разработке проекта
4.3 Расчет страховых взносов с заработной платы
4.4 Расчет затрат на электроэнергию
4.5 Расчет стоимости специального оборудования и суммы
амортизационных отчислений
4.6 Расчет накладных расходов
4.7 Расчет полной стоимости проекта
5. Охрана труда и пожарная безопасность
5.1 Анализ опасных и вредных производственных факторов
5.2 Безопасность производственного процесса
5.3 Электробезопасность
5.4 Микроклимат в производственных помещениях
5.5 Естественное и искусственное освещение
5.6 Защита от шума и вибрации
5.7 Организация рабочего места согласно эргономическим требованиям
5.8 Пожарная безопасность
5.9 Выводы
6. Экологичекая безопасность проекта
Заключение
Библиографический список
Приложения
Введение
Прогресс последних десятилетий в области компьютерных
технологий привел к широкому внедрению методов цифровой обработки сигналов
(ЦОС) в самые различные отрасли науки и техники такие, как: коммуникация,
освоение космоса, разведка месторождения полезных ископаемых, диагностика
результатов медицинских исследования и многие другие.
Для реализации алгоритмов цифровой обработки сигналов
применяются цифровые сигнальные процессоры (ЦСП), обладающие высокой
производительностью. Непрерывно возрастающие темпы совершенствования ЦСП в свою
очередь активизируют разработку новых методов ЦОС. Однако разработка цифровых
устройств, обладающих высоким быстродействием зачастую невозможна без
применения специализированных систем автоматизированного проектирования (САПР),
систем моделирования и макетирования. Комплексные требования к готовому изделию
такие, как низкая стоимость, малое время разработки и модернизации,
быстродействие заставляют разработчиков использовать универсальные средства и
методы проектирования. Указанным качествам в настоящее время соответствуют
технология проектирования устройств на основе микропроцессоров, а также
технология проектирования с использованием программируемых логических
интегральных схем (ПЛИС) [1].
Использование микросхем такого типа позволяет конфигурировать
отдельные компоненты и создавать связи между ними путем загрузки в ПЛИС потока
данных, включающего требуемые цепи и узлы коммутации. В результате из имеющихся
в составе микросхемы ресурсов создается требуемая цифровая схема, которая при
необходимости может легко модифицироваться. Многие ПЛИС хранят конфигурацию в
статической памяти, которая может быть неограниченно перезаписана, таким
образом единственная программируемая микросхема может служить для макетирования
целой серии устройств, для чего кроме самой ПЛИС требуется только компьютер, с
установленной САПР.
В результате такого подхода проектирования разработчик на
ранних этапах получает в свое распоряжение аппаратный аналог будущего
устройства, использование которого существенно помогает в отладке и
демонстрации работоспособности принятых проектных решений.
Основой для такого стиля проектирования интегральных схем
является использование специализированных языков описания аппаратуры (Hardware Description Languages, HDL), которые позволяют в
короткие сроки описать желаемое поведение будущего устройства на языке,
приближенном по стилю к языкам программирования. После проверки конструкторских
решений в ПЛИС те же файлы с кодом, описывающим поведение устройства, могут
быть использованы для получения аналогичной интегральной микросхемы. [2].
Особый интерес вызывает применение алгоритмов ЦОС в
радиолокации, где использование новых методов произвело революцию, обеспечив
решение многих задач данной научно-технической отрасли.
Так, к основным задачам, решаемым на базе ЦОС в данной
отрасли, можно отнести задачу линейной фильтрации, решение которой может быть
осуществлено с помощью цифровых фильтров (с конечной или бесконечной
импульсными характеристиками).
Основным преимуществом цифровых фильтров перед аналоговыми
является возможность реализации сложных алгоритмов обработки сигналов, которые
неосуществимы с помощью аналоговой техники, например, адаптивных алгоритмов,
изменяющихся при изменении параметров входного сигнала.
Точность обработки сигнала цифровыми фильтрами может быть
несоизмеримо выше из-за отсутствия погрешностей, вызываемых нестабильностью
параметров аналоговых фильтров (колебаниями температуры, старением, изменением
питающих напряжений и др.)
Цифровые фильтры более компактны в случае обработки
низкочастотных и инфранизкочастотных сигналов.
Недостатками цифровых фильтров по сравнению с аналоговыми
являются:
· Трудность работы с высокочастотными
сигналами. Полоса частот ограничена частотой Найквиста, равной половине частоты
дискретизации сигнала. Поэтому для высокочастотных сигналов применяют
аналоговые фильтры, либо, если на высоких частотах нет полезного сигнала,
сначала подавляют высокочастотные составляющие с помощью аналогового фильтра
нижних частот, затем обрабатывают сигнал цифровым фильтром.
· Трудность работы в реальном времени -
вычисления должны быть завершены в течение периода дискретизации.
· Для большой точности и высокой скорости
обработки сигналов требуется не только мощный процессор, но и дополнительное
аппаратное обеспечение в виде высокоточных и быстрых ЦАП и АЦП.
Различают два вида реализации цифрового фильтра: аппаратный и
программный. Аппаратные цифровые фильтры реализуются на элементах интегральных
схем в том числе ПЛИС, тогда как программные реализуются с помощью программ,
выполняемых процессором или микроконтроллером. В данном дипломном проекте
основное внимание уделено программной реализации фильтров с конечной импульсной
характеристикой (КИХ-фильтров).
САПР крупных компаний (Altera, Xilinx), разрабатывающей ПЛИС,
обладает стандартным средством создания фильтров данного типа. Однако, данный
подход обладает серьезным недостатком: реализация последовательности
КИХ-фильтров или единичного КИХ-фильтра высокого порядка требует больших
ресурсных затрат ПЛИС. И хотя современные интегральные схемы обладают
достаточно большим объемом ресурсов (достигающих миллионов эквивалентных
логических вентилей, составляющих сотни тысяч логических ячеек) нормальной
практикой на производствах считается использование в качестве аппаратной базы
ПЛИС размером 5 000 - 10 000 ЛЭ. Такие ПЛИС помимо их относительно невысокой
стоимости обладают еще и низким энергопотреблением, что позволяет их
использовать в автономных системах. Реализация же единичного КИХ-фильтра с
помощью стандартных средств САПР ПЛИС, например, 150-го порядка может
задействовать около 12 000 логических ячеек ПЛИС, что обусловлено
необходимостью задействования большого числа умножителей.
В качестве задания на дипломный проект выступает одна из
работ в рамках коммерческого заказа, выполняемого сотрудниками ФГБНУ НИРФИ. По
техническому заданию целью указанной работы является создание сигнального
микропроцессора для реализации КИХ-фильтров различных видов высоких порядков
(150 - 200) на базе ПЛИС с ограничением по количеству элементов на кристалле в
5 000 логических ячеек. Данная разработка предполагается к использованию в
качестве составной части серийно-производимого устройства геологической
разведки. В качестве технического задания были выданы схемы КИХ-фильтров
необходимые для реализации на базе создаваемого ЦСП (см. пункт 2.1).
В связи с этим, в дипломном проекте предлагается метод
программной реализации КИХ-фильтров с децимацией на базе разрабатываемого
сигнального микропроцессора с вынесенным умножителем.
Целью данного дипломного проекта является создание
сигнального микропроцессора для реализации КИХ-фильтров с децимацией.
Для достижения заявленной цели дипломного проекта в дипломной
работе решены следующие задачи:
· Разработан алгоритм работы цифрового
сигнального микропроцессора для реализации КИХ-фильтров с децимацией.
· Разработана архитектура цифрового
сигнального микропроцессора для реализации КИХ-фильтров с децимацией.
сигнальный микропроцессор фильтр цифровой
· Выполнено макетное проектирование
сигнального микропроцессора для реализации КИХ-фильтров с децимацией на языке C++.
· Разработан сигнальный микропроцессор для
реализации КИХ-фильтров с децимацией на языке описания аппаратуры Verilog.
При решении вышеперечисленных задач использованы язык
описания аппаратуры Verilog и ПЛИС фирмы Altera DE2-70 семейства Cyclone II с объемом в 70 000
логических ячеек (для тестирования и отладки сигнального микропроцессора).
1. Основные
положения теории сигнальных микропроцессоров и ких-фильтров
1.1 ПЛИС и
языки описания аппаратуры
1.1.1
Элементы теории ПЛИС
Программируемая логическая интегральная схема (ПЛИС, англ. Programmable logic device, PLD) - электронный
компонент, используемый для создания цифровых интегральных микросхем. В отличие
от обычных цифровых микросхем, логика работы ПЛИС не определяется при
изготовлении, а задается посредством программирования. Для программирования
используются программаторы и отладочные среды, позволяющие задать желаемую
структуру цифрового устройства в виде принципиальной электрической схемы или
программы на специальных языках описания аппаратуры: Verilog, VHDL, AHDL и др. [3].
Создание программируемых логических интегральных схем
началось с появления программируемых постоянных запоминающих устройств. Сперва
ПЗУ применялись лишь для хранения данных, однако впоследствии их стали
использовать и для создания цифровых комбинационных устройств с произвольной
таблицей истинности. Однако данный подход имел существенный недостаток -
неизбежный экспоненциальный рост сложности устройства в зависимости от количества
входов. Добавление одного дополнительного входа приводило к увеличению
требуемого количества ячеек ПЗУ вдвое, что не позволяло реализовывать
многовходовые комбинационные цифровые схемы. Для устранения данного недостатка
впервые были разработаны программируемые логические матрицы (ПЛМ). В
иностранной литературе они получили название - PLA (англ. Programmable Logic Arrays). Именно программируемые
логические матрицы можно считать первыми программируемыми логическими
интегральными схемами (Programmable Logic Devices - PLDs).
ПЛМ представляет собой матрицу многовходовых (несколько
десятков входов) логических элементов с триггерами, в которых логика работы
программируется с помощью перемычек между логическими блоками. Вначале
перемычки выполнялись в виде пережигаемых тонких проводников. Теперь они
выполняются в виде МОП-транзистора с плавающим затвором, как в электрически
перепрограммируемом ПЗУ, т.е. ПЛМ изготовляются по технологии флэш-памяти.
На аппаратном уровне ПЛИС представляет собой кристалл, на
котором расположено большое количество не соединенных между собой логических
элементов. Превращение совокупности данных элементов в конкретную электрическую
схему происходит с помощью электронных ключей, расположенных в этом же
кристалле. В ячейки специальной памяти, которая управляет электронными ключами,
заносится код конфигурации цифровой схемы. Таким образом, с помощью
определенных кодов, записанных в память ПЛИС, можно собрать цифровое устройство
любой степени сложности в зависимости от типа ПЛИС. Основное отличие ПЛИС от
микропроцессоров, в том, что здесь можно реализовывать алгоритмы цифровой
обработки на аппаратном (схемном) уровне. При таком подходе быстродействие
создаваемой системы резко возрастает.
Процесс прошивки ПЛИС называется конфигурированием. Прошивка
автоматически переписывается из ПЗУ, находящегося рядом с ПЛИС, после включения
питания или по сигналу сброса.
В отличие от ПЛМ ПЛИС поддерживает неограниченное количество
перепрограммировании, а также обладает большей логической емкостью и меньшим
энергопотреблением. Кроме того, надежность ПЛИС значительно выше надежности
логических матриц.
Программируемые логические интегральные схемы являются одними
из самых востребованных и перспективных элементов цифровой схемотехники.
К недостаткам технологии можно отнести необходимость наличия
внешнего ПЗУ, а также генератора синхроимпульсов.
К достоинствам разработки систем на ПЛИС можно отнести:
· Небольшое количество времени, необходимого
на разработку прошивки ПЛИС
· Отсутствие
необходимости разработки печатных плат
· Так как конфигурирование ПЛИС происходит
лишь с помощью персонального компьютера инженера, занимающегося разработкой, то
отпадает необходимость в сложном технологическом производстве.
К областям применения ПЛИС можно отнести:
· Разработки в области цифровой обработки
сигналов
· Разработки в области создания систем сбора
данных
· Разработки в области создания систем
управления и др.
1.1.2
Классификация ПЛИС
Микросхемы, программирование которых возможно руками
пользователей, явили собой новое направление в истории современной
микроэлектроники и вычислительной техники.
ПЛИС можно классифицировать по многим признакам, в первую
очередь:
· по уровню интеграции и связанной с ним
логической сложности;
· по
архитектуре;
· по числу допустимых циклов программирования;
· по типу памяти
конфигурации;
· по степени зависимости задержек сигналов
от путей их распространения;
· по системным
свойствам;
· по однородности или гибридности (по
признаку наличия или отсутствия в микросхеме областей с различными по методам проектирования
схемами, такими как ПЛИС, БМК, схемы на стандартных ячейках).
Все перечисленные признаки имеют значение и отображают ту или
иную сторону возможных классификаций. Рассмотрим в качестве примера
классификацию ПЛИС по архитектуре.
В классификации по архитектуре (Рисунок 1, а) ПЛИС разделены
на 4 класса.

Рисунок 1 - Классификация ПЛИС по архитектуре
Первый из классов - SPLD, Simple Programmable Logic Devices, т.е. простые
программируемые логические устройства. По архитектуре эти ПЛИС можно разделить
на программируемые логические матрицы ПЛМ (PLA, Programmable Logic Arrays) и схемы с
программируемой матричной логикой ПМЛ (PAL, Programmable Arrays Logic, или GAL, Generic Array Logic).
ПЛМ позволяют реализовать n логических функций от m аргументов и содержат
последовательно соединенные k связями (термами) матрицы элементов "И" и
элементов ИЛИ (рисунок 2). Помимо этого, в матрице "И" могут быть
использованы инвертированные входные сигналы, что позволяет реализовывать
функции в дизъюнктивной нормальной форме (ДНФ). Изготовленная на заводе ПЛМ
содержит матрицы со всеми возможными связями (на рисунке 2 показаны точками):
матрица "И" позволяет получить k конъюнкций входных
сигналов, а матрица ИЛИ - n дизъюнкций термов. В этом случае программирование
заключается в разрушении излишних связей. В другом варианте в исходной ПЛМ все
связи отсутствуют, а программирование заключается в их создании.
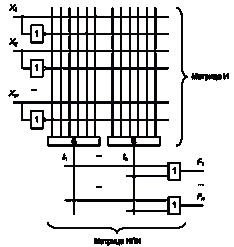
Рисунок 2 - Структура ПЛМ
Структура ИС ПМЛ позволяет более полно использовать ресурсы
кристалла при проектировании простых устройств. В отличие от ПЛМ в таких
микросхемах программирование возможно только для матрицы "И", а
матрица ИЛИ фиксирована (рисунок 3). Ограничения на состав и число термов позволяют
усложнить остальные части ПМЛ.
С момента своего создания функциональные возможности ПЛМ и
ПМЛ были расширены благодаря следующим усовершенствованиям:
введению двунаправленных, обратных и межэлементных связей,
что позволяет наращивать число термов функций (например, отечественные ПЛМ
К1556ХП8);
введению элементов памяти, что позволяет проектировать на
основе ПЛМ и ПМЛ синхронные цифровые автоматы;
программированию выходных буферов для выдачи выходных
сигналов в прямом или инверсном виде;
использованию мультиплексоров для выбора альтернативных путей
прохождения сигналов, репрограммируемых точек связи и памяти конфигурации,
позволяющих разработчикам неоднократно программировать функциональность и
связность частей ПЛМ и ПМЛ.
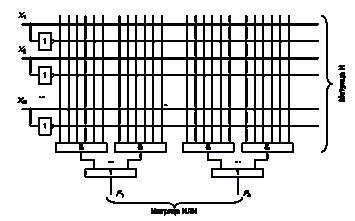
Рисунок 3 - Структура ПМЛ
Результатом эволюции ИС указанных типов стали сложные
программируемые логические устройства (СПЛУ, Complex Programmable Logic Devices, CPLD) [2].
Сложная программируемая логическая схема CPLD состоит из нескольких
макроячеек, расположенных на одном кристалле. Каждая макроячейка соединена с
блоками ввода-вывода, осуществляющими формирование необходимого вида входов или
выходов для работы с внешними схемами. Кроме того, все макроячейки и блоки
ввода-вывода связаны между собой внутренними параллельными шинами. Приведенная
на рисунке 4 микросхема CPLD состоит из четырех макроячеек, которые связаны
между собой внутренними шинами и соединяются с блоками ввода-вывода.
Макроячейка построена подобно ПЛМ микросхеме, к которой на выходе подключен D-триггер.
К недостаткам можно отнести то, что трудно обеспечить
эффективное применение всех макроячеек. Всегда часть макроячеек остается
неиспользуемыми. Часто из макроячейки используется только триггер или
логический элемент "2И" ("2ИЛИ").
Остальная часть схемы зря занимает площадь кристалла и
потребляет ток от источника питания.

Рисунок 4 - Пример внутренней схемы CPLD
Микросхемы программируемых пользователями
вентильных матриц FPGA (Field Programmable Gate Arrays) предназначены для
реализации сложных проектов, и их емкость достигает десятков миллионов
"эквивалентных вентилей". (Данный термин означает, что для реализации
одного и того же проекта на полностью заказной ИС потребовалось бы определенное
число вентилей, называемое при реализации проекта с использованием ИС
"числом эквивалентных вентилей") [2]. Такая высокая функциональность
позволяет объединять на одном кристалле несколько процессорных устройств и
интерфейсную логику.
Заданную при программировании функциональность обеспечивают
конфигурируемые логические блоки (КЛБ), расположенные по всей площади
кристалла. Их число является основным параметром, характеризующим возможность
реализации на конкретной ПЛИС сложных проектов. Связность КЛБ обеспечивается с
помощью переключательной матрицы (рисунок 5), состоящей из цепей различной
длины: от длинных глобальных до коротких прямых, соединяющих соседние КЛБ. Коммутация
цепей переключательной матрицы осуществляется с помощью коммутационных блоков.

Рисунок 5 - Структура FPGA
При реализации на основе ПЛИС сложных устройств, работающих
на высокой тактовой частоте, особые требования предъявляются к глобальным
сигналам синхронизации. В современных ПЛИС типа FPGA система синхронизации
состоит из специально спроектированной сети распределения синхросигналов,
основным свойством которой является одинаковая длина линий от источника
синхросигнала (от специально выделенного для этих целей контакта ПЛИС или от
менеджера синхросигналов) до всех КЛБ.
Также, как и в CPLD, в FPGA предусмотрена возможность использования
нескольких тактовых сигналов. Для реализации функций деления, умножения и
сдвига по фазе синхросигнала на кристалле предусмотрено несколько менеджеров
синхросигналов. Использование обычных цепей передачи информационных сигналов
для передачи синхросигналов не рекомендуется. На кристалле также располагаются
дополнительные устройства - блоки статической памяти и умножители. На периферии
кристалла находятся блоки ввода/вывода.
Блоки ввода/вывода ПЛИС типа FPGA сложнее, чем в ПЛИС типа
CPLD. Основное отличие
заключается в наличии в этих блоках динамических триггеров для хранения
входного и выходного сигналов, а также внутренних сигналов управления третьим
состоянием сигналов. Кроме этого, в последних поколениях FPGA указанные регистры
способны синхронизироваться от двух тактовых сигналов, что позволяет
использовать технологию передачи с удвоенной скоростью (DDR). Для обеспечения
возможности работы ПЛИС с несколькими типами интерфейсов, использующих при
передаче различные уровни сигналов, блоки ввода/вывода подключают к различным
цепям опорного напряжения. Группа блоков ввода/вывода, подключенных к одному и
тому же сигналу опорного напряжения называется банком ввода/вывода. Существенное
расширение области применения FPGA достигается также использованием программируемых
схем параллельного и последовательного согласования волновых сопротивлений,
соответствующих современным стандартам (PCI, PCI-X, LVCMOS, LVTTL, LVDS и др.).
Преимуществами современных ПЛИС являются:
малое время и простота проектирования;
низкая стоимость разработки;
сокращение используемого пространства печатных плат;
более низкая стоимость в расчете на одну микросхему по
сравнению с заказными ИС;
более продолжительное время обращения продукта на рынке
благодаря возможности перепрограммирования;
возможность создания динамически реконфигурируемых устройств.
К недостаткам можно отнести более низкую скорость работы ПЛИС
по сравнению с полностью заказными ИС, а также нерентабельность использования в
крупносерийном производстве.
Крупнейшими производителями ПЛИС являются фирмы Xilinx и Altera.
Xilinx - американский разработчик и производитель
интегральных микросхем программируемой логики (ПЛИС, FPGA). Данная фирма была
основана в 1984 году и на сегодняшний момент является одним из лидеров в
области производства ПЛИС-микросхем. Доля продукции Xilinx на мировом рынке ПЛИС
составляет, по данным самой компании, 51%. На сегодняшний день для различного
рода вычислений у данной компании имеется несколько серий выпускаемой
продукции:
· Virtex. Высокопроизводительные
ПЛИС на основе FPGA, разработанные с целью замены специализированных интегральных
схем при решениях различных ресурсоемких задач.
· Spartan. Более дешевые ПЛИС
разработанные для использования на устройствах, не рассчитанных на решение
ресурсоемких задач.
· CoolRunner и XC9500. Серии ПЛИС типа CPLD с минимальными размерами
и низкой потребляемой мощностью для использования в портативных устройствах.
Компанией Xilinx разработаны также различные системы для
разработки и отладки цифровых схем.
Altera - вторая крупнейшая фирма по производству ПЛИС и
главный конкурент Xilinx, была основана в 1983 г. Одной из последних разработок,
представленных фирмой Altera является новая плата из серии Stratix высокопроизводительных
микросхем типа FPGA - Stratix IV, которая работает на 40нм архитектуре. Для
реализации задач, не требующих больших вычислительных мощностей, Altera предлагает серию ПЛИС FPGA Cyclone.
Основным программным продуктом необходимым для работы с
платами фирмы Altera является пакет программ Quartus II, который предоставляет
различные возможности как для проектирования и анализа структуры микросхем, так
и для оптимизации затрат по потребляемой мощности [4].
1.1.3 Языки
описания аппаратуры
В качестве формальной записи, которая используется на всех
этапах работы по созданию схемы выступают языки описания аппаратуры (Hardware Description Language). В силу того, что
данный язык воспринимается как машиной, так и человеком, использование его
возможно и для проектирования, верификации, тестирования аппаратуры, и для
оформления документации по проекту. В настоящее время ПЛИС фирмы Altera поддерживают три языка
описания аппаратуры: VHDL, Verilog и AHDL.
VHDL (англ. VHSIC (Very high speed integrated circuits) Hardware Description Language) берет свое начало из
80-х годов, когда он был разработан по заказу организации Министерства обороны
США. Сперва он был предназначен в основном для унификации описаний проектов в
различных ведомствах. Однако уже 1987 году язык VHDL был принят Международным
институтом IEEE как стандарт VHDL-87. Данный язык используется для поведенческого,
структурного и потокового описания цифровых систем, а также для проектирования
ПЛИС.
Verilog HDL - это язык описания аппаратуры, применяемый с
целью описания и моделирования электронных систем. Этот язык используется для
проектирования, верификации и реализации как цифровых, так и аналоговых
электронных систем. Был разработан фирмой Gateway Design Automation как внутренний язык симуляции.
В 1989 году язык был открыт для общественного использования. В 1995 году был
определен стандарт языка - Verilog LRM (Language Reference Manual), IEEE1364-1995. Именно поэтому
датой появления языка Verilog можно считать 1995 год.
В отличие от остальных, язык описания аппаратуры AHDL (Altera Hardware Description Language) относится к языкам
описания аппаратуры низкого уровня. Данный язык был разработан фирмой Altera с целью применения его
для описания комбинационных и последовательных логических устройств, цифровых
автоматов на ПЛИС фирмы Altera. Синтаксис языка представляет собой совокупность
универсальных средств по описанию алгоритмов функционирования цифровых
устройств.
Несмотря на распространённое заблуждение о родственности Verilog HDL и VHDL, необходимо отметить,
что это разные языки.
Verilog - язык, напоминающий язык программирования Си -
как по синтаксису, так и по "идеологии". Отличается малым количеством
служебных слов и простотой основных конструкций, что позволяет упростить как
процесс изучения, так и процесс использования языка. Однако, необходимо
отметить высокую эффективность языка.
VHDL отличается большей универсальностью и
возможностью использования не только для описания моделей цифровых электронных
схем, но и для решения других задач. Однако, в виду расширенных возможностей,
данный язык не может похвастаться той же эффективностью и простотой, что и Verilog: для описания одинаковых
конструкций Verilog требует в среднем в 3 - 4 раза меньшего количества символов, чем VHDL. Оба языка поддерживаются
в качестве стандартов большим количеством программных продуктов, в том числе и open source, в области систем
автоматизированного проектирования (САПР). Имеются и компиляторы, и симуляторы
для обоих языков, в том числе, например, и с первого языка на второй. Именно
эти языки используются при проектировании (с помощью современных средств САПР
ведущими производителями FPGA) не только самих СБИС, но и готовых модулей
(ядер), мегафункций, предназначенных для решения достаточно сложных задач
обработки сигналов.
Язык AHDL в сравнении с языками VHDL и Verilog имеет некоторые сходство
с ними, как по командному базису, так и по возможности описания цифровых систем
и ПЛИС. Отличие между ними состоит в том, что VHDL и Verilog создавались как языки
описания цифровых устройств вообще, а AHDL ориентирован на ПЛИС и другие микросхемы фирмы Altera. Это значит, что он
имеет более узкую "специальность", но, поскольку был создан для
микросхем с определенной архитектурой, то позволяет наиболее полно использовать
ее особенности. Таким образом, с точки зрения задачи моделирования устройств,
языки VHDL и AHDL и САПР на их основе обеспечивают логический расчет на ранних
этапах проектирования. Эти языки пригодны также для моделирования цифровых
микросхем. Их достоинствами является наглядность и сравнительная простота,
широкая распространенность и универсальность. Эти языки не предназначены для
расчета электрических схем будущего цифрового узла, но без проведения отладки
функционирования средствами САПР с применением HDL и других подобных языков
создание сложных устройств становится очень затруднительным. Возможность
проведения моделирования цифрового узла на стадии их проектирования -
неоспоримая практическая польза и несомненное достоинство HDL. Проблема в выборе языка
описания аппаратуры для реализации проектов на ПЛИС фирмы Altera заключается в том, что в
открытых источниках нет исследований на тему эффективности использования
ресурсов тем или иным языком описания аппаратуры при проектировании цифрового
устройства [4].
1.2 Цифровая
фильтрация
1.2.1
Основные понятия теории цифровой фильтрации
Цифровая фильтрация является важной операцией цифровой обработки
сигналов, которая нашла широкое применение в самых различных отраслях науки и
техники. Большой спектр задач реализуется здесь с помощью цифровых фильтров
(ЦФ), которые используются для преобразования вида входного сигнала к виду,
необходимому для дальнейшего использования. Связь между входным 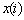 и выходным
и выходным 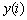 дискретными сигналами в ЦФ в общем виде определяется:
дискретными сигналами в ЦФ в общем виде определяется:
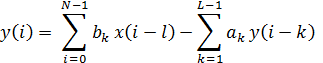 (1)
(1)
где:
· N и L -
пределы суммирования
· 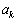 и
и 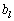 - параметры фильтра (могут быть
константами либо отсчетами решетчатых функций, зависящих от дискретного времени
- параметры фильтра (могут быть
константами либо отсчетами решетчатых функций, зависящих от дискретного времени
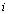 ).
).
Необходимо так же отметить, что сигналы и могут быть как вещественными, так и комплексными.
Уравнение (1) можно рассматривать как алгоритм вычисления , т.е. алгоритм работы ЦФ. Реализация
данного алгоритма в виде устройства приведет к аппаратному методу реализации
ЦФ, а программирование на заданном языке программирования - к программному.
С помощью данного уравнения, при условии, что известны
коэффициенты 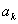 и
и 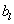 , отсчеты входного сигнала
, отсчеты входного сигнала 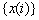 при
при 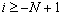 и начальные значения
и начальные значения 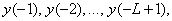 можно так же рассчитать отсчеты для любого
можно так же рассчитать отсчеты для любого 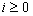 . Таким образом можно говорить, что данное уравнение также дает
аналитическое описание ЦФ во временной области.
. Таким образом можно говорить, что данное уравнение также дает
аналитическое описание ЦФ во временной области.
ЦФ являются системами с постоянными параметрами, в случае если
коэффициенты ak и bl не зависят от дискретного времени i, иначе их можно отнести к системам с переменными параметрами.
В общем случае цифровые фильтры принято разделять на два класса:
рекурсивные (РЦФ) и нерекурсивные (НЦФ). Фильтр называют рекурсивным, если
в уравнении (1), хотя бы один из коэффициентов ak не равен нулю. В противном случае ЦФ
называют нерекурсивным. Разностное уравнение (1) для него имеет вид:
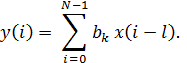 (2)
(2)
Анализируя выражения (1) и (2) можно сделать вывод, что НЦФ
является системой без обратной связи, а РЦФ представляет собой систему с
обратной связью. Сразу же отметим, что все на практике реализуемые НЦФ
представляют собой КИХ-фильтры, а все РЦФ - БИХ-фильтры.
Цифровые фильтры, выполняя операцию частотной фильтрации, по
сравнению с аналоговыми цепями имеют ряд преимуществ:
высокую стабильность параметров;
возможность получать самые разнообразные формы АЧХ и ФЧХ;
не требуется настройка;
легко реализуются на ЭВМ программными методами [5].
Прежде чем подробнее рассмотреть структуру КИХ и БИХ-фильтров
введем понятие импульсной характеристики фильтра, частотного коэффициента
передачи ЦФ и системной функции ЦФ.
Как уже было отмечено ЦФ преобразует входной сигнал x (t) в
выходной y (t),
равный свертке функции x (t) и импульсной характеристики h (t).
Импульсная характеристика системы h (t) - отклик системы на входной сигнал x (t).
Свертка двух функций x
(t), h (t):
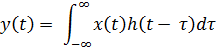 (3)
(3)
Импульсной характеристикой ЦФ называется сигнал, являющийся
реакцией ЦФ на "единичный импульс". Говорят, линейный импульс
"стационарен", если при смещении входного единичного импульса на
любое число интервалов дискретизации импульсная характеристика смещается таким
же образом, не изменяясь по форме. Тогда можно сказать, что выходная
последовательность есть дискретная свертка входного сигнала и импульсной
характеристики фильтра. Т.е. в момент каждого отсчета ЦФ проводит операцию
взвешенного суммирования всех предыдущих значений входного сигнала.
Иными словами, ЦФ обладает "памятью" по отношениям к
прошлым входным воздействиям [5].
Введем понятие частотного коэффициента передачи ЦФ. Пусть на вход
ЦФ подается последовательность вида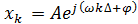 , где k = 0,
±1, ±2, и тд. Найдем
выходной сигнала цифрового фильтра:
, где k = 0,
±1, ±2, и тд. Найдем
выходной сигнала цифрового фильтра:
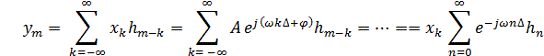 (4)
(4)
Анализируя данное выражение можно сделать вывод, что выходные
отсчеты получаются иp входных умножением на комплексную
величину 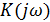 :
:
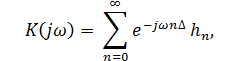 (5)
(5)
где 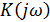 - частотный коэффициент передачи ЦФ.
- частотный коэффициент передачи ЦФ.
Анализируя (5) получаем, что является периодической функцией частоты с периодом, равным
частоте дискретизации 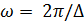 ; Видно, что зависит от импульсной характеристики системы.
; Видно, что зависит от импульсной характеристики системы.
Сопоставим дискретным сигналам {xk}, {yk}, {hk} их Z-преобразования X (z), Y (z), H (z) соответственно.
Выходной сигнал {yk} является сверткой входного сигнала {xk} и импульсной характеристики {hk}, тогда на основании 3-го свойства Z-преобразования выходному сигналу отвечает функция Y (z) = H (z) *X (z).
Системной функцией H (z) стационарного линейного ЦФ называется отношение Z-преобразования выходного сигнала к Z-преобразованию сигнала на входе [5]:
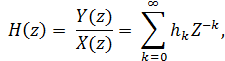 (6)
(6)
то есть системная функция ЦФ - это Z-преобразование импульсной характеристики [5]. Для того чтобы
получить из системной функции частотный коэффициент передачи ЦФ, нужно в (6)
сделать подстановку: 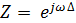 [5].
[5].
1.2.2
Нерекурсивные цифровые фильтры (КИХ-фильтры)
Алгоритм работы таких фильтров можно описать выражением:
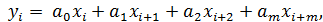 (7)
(7)
где a0, a1, a2, … am - последовательность
коэффициентов, m - порядок ЦФ.
Отметим, что для вычисления текущего отсчета выходного
сигнала КИХ-фильтры используют текущий и предыдущий отсчеты входного сигнала и
совсем не используют выходные отсчеты [6].
Если применить Z - преобразование к обеим частям (7), то получим системную
функцию нерекурсивного ЦФ:
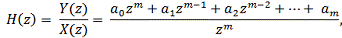 (8)
(8)
КИХ-фильтр состоит из блоков задержки отсчетных значений на
один интервал дискретизации (Z-1), а также блоки умножения на соответствующие
коэффициенты (ai).
Графически алгоритм функционирования КИХ-фильтра можно
изобразить следующим образом:
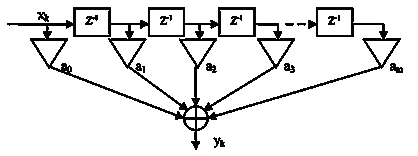
Рисунок 6 - Блок схема нерекурсивного фильтра
Рассмотреть процесс формирования отсчетов выходного сигнала yk можно на следующем
примере: пусть на вход ЦФ подается последовательность входных отсчетов xk:
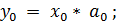
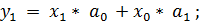
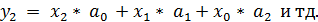
Т.е. при поступлении на вход ЦФ очередного отсчета входного
сигнала предыдущие (прошлые) отсчеты сдвигаются через блоки задержки (Z-1) на одну позицию вправо
и домножаются на соответствующие коэффициенты аk, суммируются и поступают
на выход.
Процесс "заполнения" ЦФ входными отсчетами занимает
некоторое время и называется переходным процессом, длительность которого
зависит от количества коэффициентов ЦФ и частоты дискретизации [5].
Проанализировав (6) можно прийти к выводу, что каждое
слагаемое функции H (z) дает вклад, равный
соответствующему коэффициенту an, смещенному на n позиций в сторону
запаздывания. Тогда импульсная характеристика нерекурсивного ЦФ выражается
уравнением
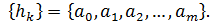 (9)
(9)
Видно, что (7) содержит конечное число членов, именно из-за
этого КИХ-фильтры получили свое название.
В выражение для системной функции введем замену переменной , тогда частотный коэффициент передачи нерекурсивного ЦФ можно
описать уравнением [10]:
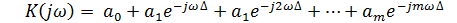 (10)
(10)
1.2.3
Рекурсивные цифровые фильтры (БИХ-фильтры)
В фильтрах данного типа, в отличие от предыдущих, для
вычисления текущего отсчета выходного сигнала КИХ-фильтры используют как
текущие отсчеты входного сигнала, так и выходные отсчеты.
Алгоритм их работы можно описать выражением:
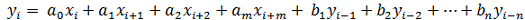 (11)
(11)
где коэффициенты b1, … bn, определяющие рекурсивную часть алгоритма
фильтрации.
Аналогично предыдущему пункту получим выражение для описания
системной функции рекурсивного ЦФ:
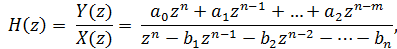 (12)
(12)
Графически алгоритм функционирования БИХ-фильтра можно
изобразить следующим образом:
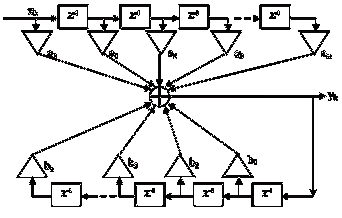
Рисунок 7 - Блок-схема рекурсивного фильтра
Рассмотри процесс формирования выходных отсчетов рекурсивного
цифрового фильтра:
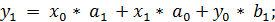
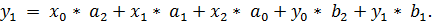
Нерекурсивной части алгоритма фильтрации соответствует
верхняя часть блок-схемы. Как и в прошлом случае здесь необходимы блоки,
реализующие операции умножения (их количество равно m + 1), а также блоки,
отвечающие за хранение входных отсчетов (необходимо m блоков).
Рекурсивной части алгоритма соответствует нижняя часть
структурной схемы, где используется n последовательных значений выходного сигнала,
которые в процессе работы фильтра перемещаются из ячейки в ячейку путем сдвига.
Так как для формирования выходного отсчета рекурсивного ЦФ используются
предыдущие выходные отсчеты, то импульсная характеристика имеет бесконечное
число членов и именно поэтому такие фильтры называют фильтрами с бесконечной
импульсной характеристикой (БИХ) [7].
1.3 Цифровые
процессоры обработки сигналов
Цифровые процессоры обработки сигналов (ЦПОС) или цифровые
сигнальные процессоры (ЦСП), англоязычное сокращение (DSP), предназначены для
реализации алгоритмов цифровой обработки сигналов (ЦОС) и систем управления в
реальном времени.
Свою историю ЦСП ведут с 80-х годов ХХ века, когда фирмой Texas Instruments был разработан первый
сигнальный процессор TMS320C10 с производительностью 5 млн операций в секунду. На
сегодняшний момент производительность ЦПОС достигает нескольких миллиардов
операций в секунду, что в своею очередь стимулирует развитие ЦОС.
Цифровой процессор обработки сигналов чаще всего предназначен
для выполнения обработки данных и решения задач анализа и управления в режиме
реального времени. Для повышения производительности ЦПОС в них используют общие
методы повышения производительности типа увеличения тактовой частоты работы.
Однако основной упор в задаче повышения производительности делается на
разработку новых структурных и архитектурных решений, учитывающих специфику
алгоритмов ЦОС. Исходя из этого можно сделать вывод, что сигнальные процессоры
являются специализированными или проблемно-ориентированными [8].
1.3.1 Общие
принципы построения ЦПОС и особенности их архитектуры
Термин "архитектура" обычно используется для
описания, как аппаратных средств процессоров, так и программного обеспечения, и
их комбинации.
С самого начала появления ЦПОС их архитектура формировалась
алгоритмами ЦОС. Любые особенности данных процессоров определялись
требованиями, возникающими при реализации алгоритмов цифровой обработки
сигналов. Поэтому для того, чтобы определить особенности развития архитектуры
ЦПОС необходимо исследовать типичную задачу цифровой обработки сигналов.
Традиционным примером, показывающим особенности алгоритмов
ЦОС и процессоров ЦПО, является алгоритм реализации КИХ-фильтра.
Как уже было отмечено (см.1.2 Цифровая фильтрация) выходной
сигнал фильтра определяется выражением:
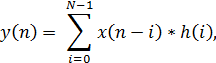
где x (n) - отсчеты входного сигнала;
h (i) - коэффициенты фильтра.
Выборки входного сигнала, в соответствие с данным алгоритмом,
умножаются на коэффициенты фильтра и суммируются. Проанализировав другие
алгоритмы ЦОС, можно прийти к выводу, что подобные вычисления встречаются
повсеместно. Исходя из этого можно сделать вывод, что операция умножения с
накоплением результата являются базовыми в цифровой обработке сигналов.
Подобную операцию часто обозначают мнемоникой МАС.
Для того, чтобы работать с высокой производительностью,
процессор должен выполнять операцию МАС за один цикл работы процессора. Отсчеты
сигнала, коэффициенты фильтра и команды программы хранятся в памяти. Для
достижения быстрой производительности три выборки из памяти необходимо
произвести за один такт работы программы. При этом подразумевается, что
результат не помещается в память, а остается в центральном процессорном
устройстве (ЦПУ). Иногда возникает необходимость в операции записи результата в
память, т.е. необходима еще и 4 операция. Таким образом, производительность
ЦПОС в первую очередь обусловлена возможностью параллельной работы
разнообразных модулей и их взаимодействия.
1.3.2
Архитектура фон Неймана и гарвардская архитектура
На рисунке 8 изображена традиционная структура вычислительной
системы, соответствующая "фон-неймановской" вычислительной машине
[8]. В качестве основных особенностей данной системы можно отметить наличие
единой памяти программ и данных, а также одной шины данных, по которой передаются
и данные и команды программы. Можно сделать вывод, что с помощью такой системы
невозможно осуществить операцию МАС в один такт работы процессора.
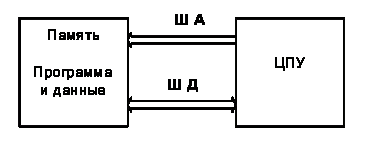
Рисунок 8 - Архитектура фон Неймана
В процессорах ЦПОС применяется гарвардская архитектура
вычислительной системы, изображенная на рисунке 9. Основной ее особенностью
является наличие различных устройств памяти для хранения программы (команд) и
данных. Соответственно в системе имеется два комплекта шин для этих устройств:
шина адреса памяти программ (ШАПП), шина данных памяти программ для работы c памятью программ (ПП) и
шина адреса памяти данных (ШАПМД), шина данных памяти данных (ШДПД) для работы
с памятью данных (ПД) [8]. Использование системы с гарвардской архитектурой
позволяет синхронно обращаться и к памяти программ, и к памяти данных.
Получается, что для выполнения операции МАС требуется 2 такта работы, однако в
реальности получается с помощью дополнительных мер свести время операции к
одному машинному циклу. В таком случае приходится говорить уже о
модифицированной гарвардской архитектуре.
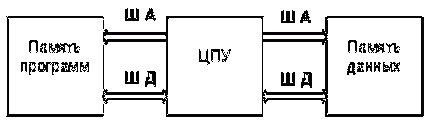
Рисунок 9 - Гарвардская архитектура
Сразу же необходимо отметить, что взаимодействие с внешней
памятью происходит по одному комплекту внешних шин - ВША и ВШД. Поэтому
разработчики стараются максимально увеличить объем внутренней памяти процессора
как ПП так и ПД, так как при использовании внешней памяти для хранения программ
и данных увеличивается время, затрачиваемое на выполнение операций [8].
1.3.3 Принцип
конвейерного выполнения программ
Конвейерный принцип выполнения программ предполагает
одновременное выполнение различных этапов команд в разных функциональных
устройствах.
Время выполнения одного этапы команды, как правило, равно
внутренней тактовой частоте работы процессора и называется командным циклом
работы процессора.
Для пояснения принципа конвейерного выполнения команд
приведем схему выполнения команд во времени.
В общем случае процесс выполнения команды делится на 4 этапа:
· Выборка
команды (ВбК);
· Декодирование
команды (ДК);
· Подготовка
операндов (ПО);
· Выполнение
команды (ВпК).
Каждый из этих этапов в общем случае выполняется за один
машинный цикл.
Приведем диаграмму неконвейерного способа выполнения команд.
В данном случае время выполнения одной команды будет равно четырем машинным
циклам. Соответственно для выполнения m команд, потребуется 4m циклов. Недостатки
данного способа очевидны.
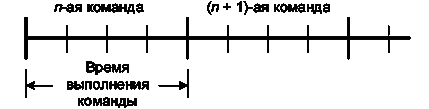
Рисунок 10 - Неконвейерный способ выполнение команд
Приведем теперь диаграмму конвейерного выполнения команд, при
котором различные этапы выполнения различных команд совмещаются [8]. При таком
подходе время выполнения каждой команды остается по-прежнему равным четырем
циклам, однако результаты выполнения, при условии наличия большего числа
последовательно выполняемых команд, будут появляться через один машинный цикл.
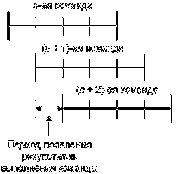
Рисунок 11 - Конвейерный способ выполнение команд
Также приведем распределение во времени различных этапов
разных команд при конвейерном способе выполнения (Таблица 1).
Таблица 1
|
Номер команды
|
Номер цикла
|
|
n-2
|
n - 1
|
n
|
n+ 1
|
n+ 2
|
n+ 3
|
n+ 4
|
|
n - 1
|
|
ВбК
|
ДК
|
ПО
|
ВпК
|
|
|
|
n
|
|
|
ВбК
|
ДК
|
ПО
|
ВпК
|
|
|
n + 1
|
|
|
|
ВбК
|
ДК
|
ПО
|
ВпК
|
|
n + 2
|
|
|
|
|
ВбК
|
ДК
|
ПО
|
Такой принцип выполнения команд возможен при условии наличия
нескольких функциональных узлов, позволяющих выполнять одновременно этапы с
различными данными, относящимися к разным командам. Так гарвардская архитектура
позволяет одновременно выбирать команду из памяти программ и данные из памяти
данных.
В качестве ограничений на функционирование конвейера,
изображенного на рисунке 11, влияет длина команды и вид исполняемой программы.
Длина всех команд должна быть одинаковой, чтобы их исполнение
занимало одно и то же время.
Сама же программа должна носить линейный характер (без команд
условных переходов), чтобы сохранить порядок команд известным для любого этапа
выполнения программы. В случае наличия команды условного перехода следующая за
ней команда определится лишь после вычисления условия. При этом может
оказаться, что должна выполняться команда, не следующая по порядку в записи
программы. В таком случае необходимо заново начинать выборку команд, что
приводит к потере нескольких тактов [8].
1.3.4 Примеры
функциональных узлов ЦПОС
Для обеспечения наибольшего быстродействия работы ЦПОС для
выполнения тех операций, которые обычно в процессорах реализуются программным
образом, реализованы аппаратные способы: различные функциональные узлы и
специализированные модули.
а) Умножитель предназначен для произведения операции
умножения данных в формате "слово" процессора (16х16 для 16-разрядных
процессоров или 32х32 для 32-разрядных) за один цикл, в отличие от программных
методов реализации операции умножения, которые требуют много циклов.
б) Дополнительные арифметические устройства. Использование
дополнительных арифметических устройств в процессорах ЦПОС позволяет
осуществлять различные математические операции одновременно с основным АЛУ,
повышая тем самым производительность систем.
в) Разнообразные устройства ввода/вывода и периферии.
Использование разнообразных устройств ввода/вывода информации и периферийных
устройств в ЦПОС существенно облегчает решение задач ЦОС.
К устройствам ввода/вывода относят:
· параллельные и последовательные порты ввода/вывод,
использующие различные протоколы передачи информации;
· каналы прямого доступа в память DMA, позволяющие
вводить/выводить информацию в память системы без использования мощностей ЦПУ;
· модули АЦП и ЦАП, разрешающие вводить в
процессор аналоговый сигнал;
· генераторы сигналов ШИМ
(широтно-импульсной модуляцией) и др.
2.
Существующие методы реализации ких-фильтров
2.1 Виды
рассматриваемых КИХ-фильтров
В пункте 1.2.2 главы 1 отмечалось, что КИХ-фильтр описывается
разностным уравнением, которое описывает связь между входным и выходным
сигналами фильтра:
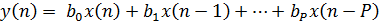
где P - порядок фильтра, (n) - входной сигнал, y (n) - выходной сигнал, а bi - коэффициенты
импульсной характеристики.
Приведем основные виды КИХ-фильтров, которые рассматриваются
в данном дипломном проекте.
2.1.1 Первый
вид КИХ-фильтров
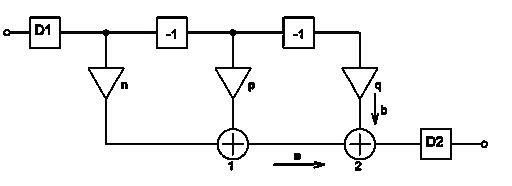
Рисунок 12 - Схема КИХ-фильтра первого вида
На рисунке 12 представлен КИХ-фильтр состоящий из двух блоков
задержки, трех умножителей с коэффициентами n, p, q, двух сумматоров, а
также блоков децимации D1 и постдецимации D2.
Для записи разностного уравнения данного КИХ-фильтра
необходимо знать коэффициенты импульсной характеристики. Для их вычисления
рассмотрим процесс работы данного КИХ-фильтра в произвольный момент времени t.
Пусть на вход первого узла поступает значение ai. Тогда на вход первого
сумматора поступают значения ai, умноженное на коэффициент n - ai*n и значение в предыдущий
момент времени с учетом децимации на входе D1, умноженное на
коэффициент умножителя - p*aiD1-1. На входе второго
сумматора имеем по ветке "а" значение n*ai + p*aiD1-1, а по ветке
"б" - q* aiD1-2, в итоге на выходе
сумматора получаем:
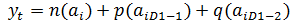 (13)
(13)
Как видно для КИХ-фильтров такого вида, коэффициенты
импульсной характеристики совпадают с коэффициентами фильтра.
2.1.2 Второй
вид КИХ-фильтров
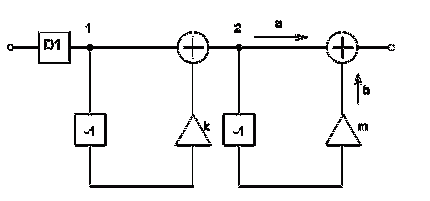
Рисунок 13 - Схема КИХ-фильтра второго вида
Анализируя данную схему строения КИХ-фильтра можно сделать вывод,
что его структура имеет вид отличный от предыдущего варианта.
Данный КИХ-фильтр состоит из двух блоков задержки, двух
умножителей с коэффициентами k, m, двух сумматоров, а
также блока децимации D1.
Приведем разностное уравнения для данного вида фильтров.
Пусть на вход первого узла поступает значение ai. Тогда на вход первого
сумматора поступают значения ai, и значение в предыдущий момент времени с
учетом децимации на входе D1, умноженное на коэффициент умножителя - k*aiD1-1. В итоге на выходе
первого сумматора имеем ai + k*ai D1-1. Данное значение по ветке
"а" поступает на второй сумматор. По ветке "б" имеем
значение в предыдущий момент времени, умноженное на коэффициент умножителя, в
итоге на выходе сумматора получаем:
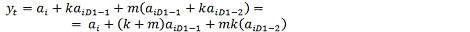 (14)
(14)
Очевидно, что c помощью простейших операций удалось преобразовать исходный
фильтр к предыдущему виду. Изобразим его схему:
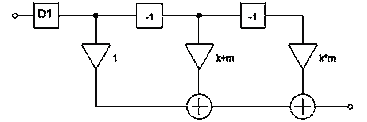
Рисунок 14 - Эквивалентная схема КИХ-фильтра второго вида
2.1.3 Третий
вид КИХ-фильтров
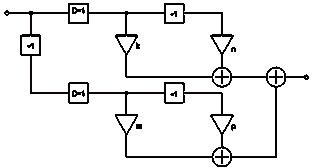
Рисунок 15 - Схема КИХ-фильтра третьего вида
Данный КИХ-фильтр состоит из трех блоков задержки, четырех
умножителей с коэффициентами k, т, n, p, трех сумматоров, а также
двух блоков децимации D = 1.
Аналогично предыдущему случаю постараемся вычислить
разностное уравнение для данного фильтра.
Пусть на вход схемы в момент времени t поступает значение ai. На выходе 1 сумматора
после блока децимации D, двух умножителей с коэффициентами k и n и блока задержки имеем:
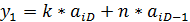
На выходе второго сумматора в этот момент имеем:
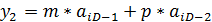
Тогда на выходе третьего сумматора, т.е. на выходе схемы
имеем:
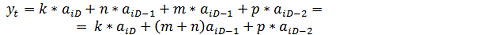 (15)
(15)
Приведем схему КИХ-фильтра, которому соответствует данное
разностное уравнение:
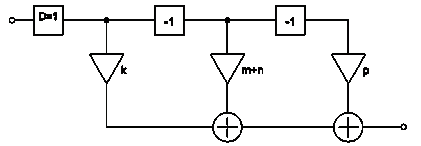
Рисунок 16 - Эквивалентная схема КИХ-фильтра третьего вида
Итак, в данном разделе приведены те виды фильтров, которые
будут реализованы на базе разрабатываемого ЦСП. Для каждого вида выведены
разностные уравнения, описывающие связь между входным и выходным сигналами
фильтра.
2.2
Проектирование КИХ-фильтров в базисе ПЛИС фирмы Altera
Одной из распространённых операций цифровой обработки
сигналов является фильтрация, для реализации которой могут быть использованы:
· программно-аппаратные ресурсы цифровых
сигнальных процессоров;
· ПЛИС по
архитектуре FPGA;
· различные операционные устройства:
регистры, умножители, сумматоры и соответствующее управляющее устройство;
· программная реализация с использованием
высокоуровневых языков.
Использование особенностей архитектуры ПЛИС FPGA позволяет проектировать
компактные и быстрые КИХ-фильтры с использованием распределённой арифметики.
В состав мегафункции "Mega Wizard Plug-In Manger" САПР ПЛИС "Quartus II", входит утилита
"FIR Compiler II v12.1", использование которой позволяет быстро
спроектировать цифровой КИХ-фильтр исходя из заданных параметров. Быстрота и
малая трудоемкость расчетов делает данное программное обеспечение незаменимым
при проектировании КИХ-фильтров в базисе ПЛИС фирмы Altera.
Приведем несколько примеров реализации КИХ-фильтров с помощью
данной утилиты, с целью оценки зависимости количества задействованных
логических элементов ПЛИС от порядка разрабатываемого фильтра.
В качестве примера будем создавать КИХ-фильтры 64, 128 и 256
порядков со следующими характеристиками: Fсреза = 40 Гц, Fдискр = 400 Гц.
Опишем процесс создания КИХ-фильтра 64 порядка.
При запуске "FIR Compiler II v12.1" появляется
окно управления утилитой.
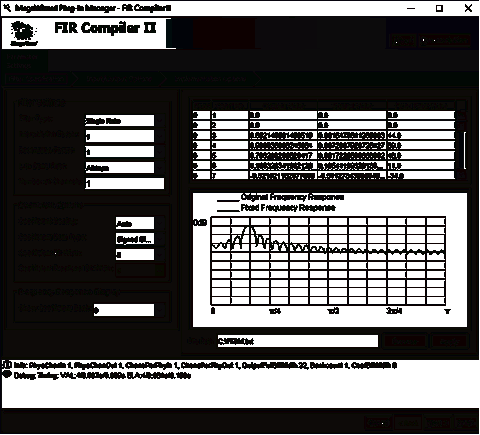
Рисунок 17 - Окно управления утилитой "FIR Compiler II v12.1"
Реализация КИХ-фильтра с помощью данной утилиты происходит в
3 этапа. Во-первых, необходимо задать характеристики фильтра в пункте меню
"Filter Specification".
Приведем основные настраиваемые параметры:
· Параметр "Filter Type" - задает тип
создаваемого фильтра. Есть возможность задания обычного фильтра, фильтра с
децимацией и фильтра с интерполяцией.
· "Interpolation Factor" - задает значение
интерполяции. Для обычного фильтра значение интерполяции равно единице.
· "Decimation Factor" - задает значение
децимации. Для обычного фильтра значение децимации равно единице.
Также в данном меню есть возможность настройки значений
коэффициентов импульсной характеристики.
Параметр "Coefficient Data Type" предоставляет
возможность задания знакового или беззнакового вида представления коэффициентов
импульсной характеристики, а в пункте меню "Coefficient Bit Width" можно задать
количество знаков после запятой. Здесь же можно увидеть значения импульсной
характеристики КИХ-фильтра и его АЧХ.
В следующем пункте меню "Input/Output Options" происходит задание
типов входных и выходных данных. Здесь же есть возможность задание ширины
входной шины данных. Значение ширины выходной шины вычисляется автоматически.
Пункт меню "Implementation Options" дает возможность
настройки основных параметров работы схемы. Например, здесь можно настроить
характеристики тактового генератора.
По окончанию процесса настройки фильтра начинается процесс
его создания, за ходом которого можно наблюдать в отдельном окне. В случае
успешного создания фильтра выводится надпись "Generation Successfull".
После окончания процесса создания фильтра проведем компиляцию
проекта, по окончанию которого будет выведена статистика, где отражается
количество задействованных логических элементов. Отметим, что данный проект
тестовый и содержит лишь один КИХ-фильтр, в то время как для решения конкретных
задач возникает необходимость реализации целой цепочки фильтров, а также ряда
сопутствующих блоков.
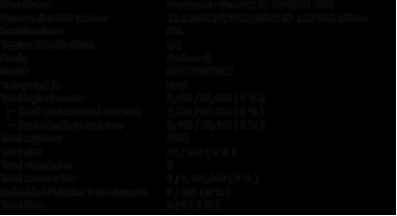
Рисунок 18 - Статистика, задействованных ЛЭ для реализации
КИХ-фильтра 64 порядка
Для реализации проекта, включающего в себя один КИХ-фильтра
64 порядка, с помощью стандартной утилиты "FIR Compiler II v12.1" было
задействовано 3 482 логических ячейки ПЛИС.
Далее приведем статистику, отражающую количество логических
элементов, задействованных для реализации КИХ-фильтра 128 порядка.

Рисунок 19 - Статистика, задействованных ЛЭ для реализации
КИХ-фильтра 128 порядка
Видно, что для реализации фильтра порядка 128, необходимо в
два раза больше логических элементов по сравнению с реализацией КИХ-фильтра
порядка 64.
Для реализации КИХ-фильтра 256-го порядка с помощью данной
утилиты понадобилось уже 12 900 логических элементов.
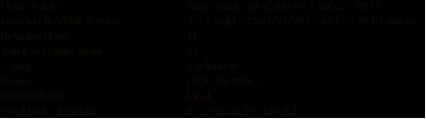
Рисунок 20 - Статистика, задействованных ЛЭ для реализации
КИХ-фильтра 256 порядка
Поясним полученные результаты.
Аппаратная реализация КИХ-фильтров связана с большими
ресурсными затратами, вызванными многократно выполняемой операцией умножения.
Система проектирования Quartus II, используемая для разработки устройств на основе
ПЛИС фирмы Altera, включает библиотеку стандартных подпрограмм, предназначенных для
выполнения основных математических операций. В частности, для реализации
операции умножения используют подпрограмму lpm_mult. Эта подпрограмма
позволяет синтезировать схему устройства, реализующего на аппаратном уровне
умножитель двух двоичных чисел заданной разрядности. Очевидно, что чем больше
разрядность сомножителей, тем сложнее устройство и при его реализации
расходуются большие аппаратные ресурсы ПЛИС и возрастает время вычисления.
Поэтому проблема сокращения аппаратных затрат и времени вычисления является
весьма важной [9].
Проанализировав традиционную схему КИХ-фильтра (рисунок 12) и
его разностное уравнение можно заметить, что количество используемых в данной
схеме умножителей равно количеству коэффициентов импульсной характеристики. А
значит при увеличении порядка фильтра будет пропорционально увеличиваться и
количество задействованных умножителей. Это приводит к тому, что для создания
сколь более реальной схемы, использующей фильтры высоких порядков (порядка 150
- 200), требуются все более мощные ПЛИС с большим количеством логических
элементов на кристалле, что ведет в свою очередь к необоснованному удорожанию
проекта.
В качестве решения проблемы сокращения аппаратных затрат ПЛИС
в данном дипломном проекте выдвигается идея реализации ЦСП с одним умножителем.
Такой подход позволит минимизировать количество логических элементов на
кристалле для решения задачи построения КИХ-фильтров, что особенно актуально
для реализации фильтров высоких порядков.
3. Разработка
сигнального микропроцессора для реализации ких-фильтров с децимацией
3.1 Макетное
проектирование на языке высокого уровня
Перед началом работы по созданию электронной схемы на языке
описания аппаратуры Verilog HDL, с целью апробации метода функционирования ЦСП,
а также для проектирования детальной архитектуры проекта - прежде всего общей
структуры проекта, было проведено макетное проектирование на языке высокого
уровня. В качестве инструментария разработки был выбран кроссплатформенный
Фреймворк на языке программирования C++ - Qt версии 5.7.
Приведем ниже (рисунок 21) блок-схему создаваемой в рамках
макетирования программы, а также проиллюстрируем назначение функциональных
блоков данной схемы. Ознакомиться с полным кодом программы можно в пункте
"Приложение А" данной работы.
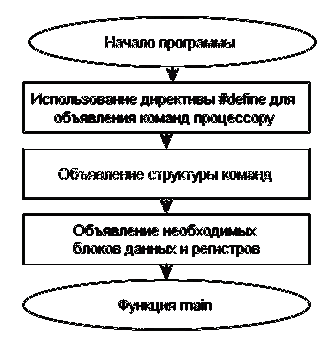
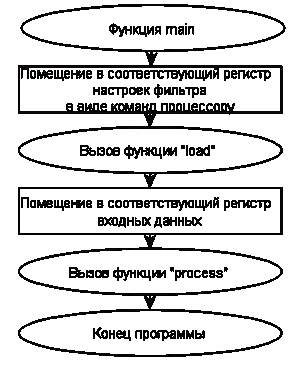
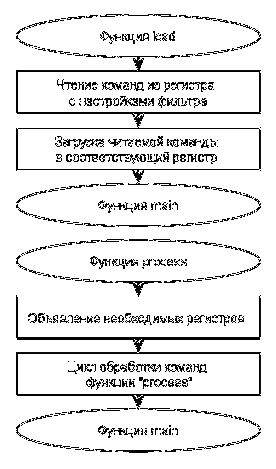
Рисунок 21 - Блок-схема работы макета ЦСП
Как видно из блок-схемы, программа имеет простую структуру,
состоит из одного исполняемого файла и ее функционал реализован всего тремя
функциями: функцией "main", функцией "load" и функцией "process". В процессе
написания программы учитывалась дальнейшая трансляция на язык описания
аппаратуры, поэтому ее архитектура во многом использует подходы, используемые в
Verilog HDL.
Изначально для построения цепочки КИХ-фильтров с децимацией
был определен язык машинных кодов создаваемого процессора, состоящий из четырех
команд:
· LOOK_WCOUNT
<ЗНАЧЕНИЕ>;
· LOOK_SCOUNT
<ЗНАЧЕНИЕ>;
· KOEFF
<ЗНАЧЕНИЕ>;
· RETURN.
Команда LOOK_WCOUNT <ЗНАЧЕНИЕ> задает значение преддецимации.
Так, если значение децимации равно N, то из исходной последовательности отсчетов a0, a1, a2, … будет браться каждый
N-й отсчет. Также с этой
команды начинается описание каждого нового КИХ-фильтра в цепочке.
Команда LOOK_SCOUNT <ЗНАЧЕНИЕ> задает значение постдецимации.
Команда KOEFF <ЗНАЧЕНИЕ> задает значение коэффициентов
разностного уравнения, описывающего КИХ-фильтр, т.е. по сути коэффициенты
импульсной характеристики. Если в фильтре используется m умножителей, то
необходимо использовать m команд KOEFF <ЗНАЧЕНИЕ>, следующих друг за другом.
RETURN - последняя команда, которая ставится после
задания всей цепочки КИХ-фильтров и сигнализирует о конце процесса
конфигурации.
Отметим, что описание фильтров должно происходить с помощью
использования приведенных выше команд в строгом порядке. Вначале конфигурации
каждого нового фильтра должна стоять команда LOOK_WCOUNT <ЗНАЧЕНИЕ>, за ней
должна идти LOOK_SCOUNT <ЗНАЧЕНИЕ>, а затем одна или несколько команд KOEFF <ЗНАЧЕНИЕ>.
Команда RETURN ставится в самом конце после описания всех необходимых фильтров,
составляющих цепочку.
Для того, чтобы сохранить понятную структуру программы на
языке C++,
было решено использовать эти команды и в процессе макетного проектирования.
Вначале исполняемого файла, до функции "main", с помощью
директивы #define создаются макросы, задающие необходимые для функционирования
микропроцессора команды.
Затем создается структура "Command", содержащая
префикс команды и ее значение, а далее происходит создание необходимых для
функционирования программы блоков данных и регистров:
· "datas" - блок данных,
отвечающий за хранение результирующих данных;
· "koeffs" - блок данных,
отвечающий за хранение коэффициентов фильтров;
· "wcounts" - регистры,
отвечающие за хранение счетчиков записи;
· "scounts" - регистры,
отвечающие за хранение счетчиков старта;
· "wcountsinit"
- регистры записи;
· "scountsinit"
- регистры старта;
· "sizes"
- регистры размеров;
· "queues"
- регистры очередей;
· "subs" - регистр,
отвечающий за хранение количества подпрограмм.
Необходимо отметить, что на этапе макетного проектирования
нет принципиальной разницы между блоками данных и регистрами. Практически все
эти объекты, за исключением регистра "subs", реализованы в
виде контейнеров QVector, инициализированных данными типа int. Регистр "subs" же представлен
переменной типа int. Различия в терминологии введены ради дальнейшей трансляции программного
кода на язык описания аппаратуры, где реализация будет существенно отличаться.
В самом начале функции "main" происходит задание
конфигурации цепочки КИХ-фильтров, а затем вызов функции "load", в процессе
выполнения которой происходит чтение всех загруженных команд и поэтапная
инициализация приведенных выше блоков данных и регистров.
В процессе выполнения подпрограммы создается несколько
регистров, данные с которых будут использоваться в качестве адресов для
обращения к ранее созданным блокам данных и регистрам:
· "nr" - регистр,
отвечающий ха хранения номера подпрограммы;
· "dr" - регистр,
отвечающий за хранение указателя на адрес обращения к блокам данных "datas" и "koeffs".
Регистры, отвечающие за хранение счетчиков записи и счетчиков
старта, изначально инициализируются нулями. В регистры записи и старта
заносятся значения исходя из кода программы на языке машинных кодов.
Блок данных, отвечающий за хранение результирующих данных,
изначально также инициализируется нулями, а в блок данных, отвечающий за
хранение коэффициентов фильтров заносятся действительные значения фильтров. В
процессе выполнения данной функции происходит инициализация регистра "subs", куда заносится
действительное количество подпрограмм.
После окончания выполнения функции "load" ход программы
снова продолжается в функции "main", где происходит инициализация входных
данных, которые будут поступать на вход цепочки КИХ-фильтров. В качестве
примера входные данные в программе представлены в виде массива, содержащего
последовательность чисел от 1 до 20. В реальности входные данные будут
представлены в виде внешнего оцифрованного сигнала.
Далее элементы входной последовательности по очереди
передаются на вход функции "process", которая по сути и представляет собой
реализацию цифрового сигнального микропроцессора. В отличие от рассмотренных
выше функций "main" и "load" ход выполнения функции "process"
"нетривиален".
В ее начале происходит создание дополнительных регистров,
используемых лишь в этой функции:
· "rr" - регистр,
предназначенный для хранения результата фильтрации;
· "dr" - регистр,
используемый для адресации к блоку данных с коэффициентами фильтров;
· "nr" - регистр,
используемый для хранения номера подпрограммы;
· "ar" - регистр,
используемый для хранения адреса подпрограммы.
Регистры "dr" и "nr" изначально
инициализируются нулями.
Замечание. Структура данной функции также продумывалась с
учетом ее дальнейшей трансляции на Verilog, где предполагалось использование конечного
автомата. Так, в зависимости от рассматриваемого состояния, необходимо
совершать определённые операции с содержимым блоков данных и регистров. В
качестве состояний должны были выступать команды, которые используются для
построения КИХ-фильтров. Однако приближенный анализ показал, что данных команд
недостаточно для реализации конечного функционала, в связи с чем было решено
добавить несколько дополнительных состояний: начальное состояния BEGIN_STATE и состояние записи
данных WR_STATE. Именно с этим связано использование директивы #define внутри функции "process" для создания
дополнительных макросов. В качестве начального состояния соответственно
выступает состояние BEGIN_STATE.
Затем в процессе выполнения функции "process" начинается цикл
обработки команд. Подобно тому, как это предполагается делать на языке описания
аппаратуры с помощью конечного автомата, здесь обработка команд также
происходит по "состояниям". Благодаря тому, что ранее был установлен
единый порядок следования команд для описания КИХ-фильтров, можно сохранить
линейную структуру цикла обработки команд без дополнительных проверок на
соответствие обрабатываемого "состояния" действительно загруженным
командам.
После начального состояния BEGIN_STATE идет безусловный переход
на состояние LOOK_WCOUNT.
В состоянии LOOK_WCOUNT происходит обращение к "wcounts" по адресу номера
подпрограммы и дальнейшая проверка данных, лежащих в регистре по этому адресу.
Если проверяемое значение больше нуля, то оно декрементируется и выполнение
функции "process" прекращается. Далее в функции "main" происходит вызов
функции "process" уже со следующим значением входных данных. В случае, если
проверяемое значение регистра "wcounts" равно нулю, то в него копируются данные,
лежащие в регистрах записи "wcountsinit" по адресу номера подпрограммы, и идет
переход на состояние записи WR_STATE.
Этот процесс требует дополнительных объяснений. Так как
команда LOOK_WCOUNT задает значение децимации, то прекращение работы функции "process" с рядом входных
значений фактически означает их отбрасывание. И лишь, когда данные, лежащие в
регистре "wcounts" по адресу номера подпрограммы, равны нулю - входное
значение будет пропущено далее "по конвейеру" для обрабатывания
следующими командами.
В состоянии WR_STATE происходит запись данных из регистра "rr" в блок данных
"datas". Для определения адреса, по которому будет происходить
запись, используются данные с регистров "queues" по адресу номера
подпрограммы.
Регистры очередей "queues" хранят адреса
значений, которые будут обрабатываться следующими, для каждой подпрограммы.
Поэтому после записи данных в "datas" происходит смещение очереди: содержимое
регистров "queues" либо декрементируется, либо, если вся очередь была
пройдена, в них записывается адрес последнего для данной подпрограммы значения.
Затем содержимое регистра "rr" обнуляется и происходит безусловный
переход на состояние LOOK_SCOUNT.
Ход выполнения программы в состоянии LOOK_SCOUNT очень похож на процесс
ее выполнения в состоянии LOOK_WCOUNT. Здесь происходит обращение к "scounts" по адресу номера
подпрограммы. Если проверяемое значение больше нуля, то оно декрементируется и
выполнение функции прекращается. Далее происходит вызов функции "process" из функции "main" уже с новыми
входными данными. В случае же, если проверяемое в LOOK_SCOUNT значение равно нулю, то
в него копируются данные, лежащие в регистрах записи "scountsinit" по адресу номера
подпрограммы, и идет переход на состояние KOEFF.
Таким образом можно говорить, что команда LOOK_SCOUNT также реализует некий
вид децимации, а именно постдецимацию.
Основная задача программы в состоянии KOEFF - перемножение данных из
двух блоков: "koeffs" и "datas" с последующим суммированием результата с
содержимым регистра "rr". В качестве параметра, используемого для
адресации к блоку "koeffs", выступают данные регистра "dr". Однако адресация
к "datas" происходит сложнее: логика программы построена таким
образом, что значению, лежащему в "koeffs" всегда
соответствует значение из "datas". Однако в связи со смещением очереди,
адрес записи к "datas" постоянно "плавает", поэтому для
его вычисления необходимы дополнительные действия, которые приведены в
приложении с исходным кодом программы (Приложение А).
После перемножения данных происходит выбор следующего
состояния выполнения программы: если обрабатываемая подпрограмма последняя, то
происходит переход на конечное состояние RETURN. В противном случае
происходит переход на состояние LOOK_WCOUNT для начала работы следующего фильтра в
последовательности. В состоянии RETURN происходит также выдача результирующих данных из
регистра "rr" на выход программы.
Более подробно проследить логику программы можно,
ознакомившись с листингом исходного кода в пункте Приложение А данной дипломной
работы.
Итак, в процессе выполнения данного этапа проекта была
разработана архитектура цифрового сигнального микропроцессора для реализации
КИХ-фильтров с децимацией, также был продуман функционал основных блоков данных
и регистров, был определен язык машинных кодов. На основании результатов
данного этапа была сформирована схема устройства микропроцессора (см.
Приложение Б)
На данной схеме вся архитектура ЦСП разделена на три основных
функциональных блока: Загрузчик, Блок регистров, включающий в себя все
необходимые для работы ЦСП блоки данных и регистров, а также Конвейер - блок,
занимающийся обработкой команд ЦСП.
Загрузчик получает сигнал записи, а также команды на языке
машинных кодов от внешнего устройства. Затем распределяет данные команды по
функциональным блокам микропроцессора, производя тем самым необходимую
начальную инициализацию.
Регистры и блоки данных на схеме структурно не вынесены в
отдельную группу, однако функционально составляют собой Блок регистров. Данный
функциональный блок включает в себя все используемые в программе блоки данных и
регистры.
Конвейер - блок обработки команд микропроцессора. Получает
внешний оцифрованный сигнал - внешние данные напрямую из внешнего устройства. С
выхода конвейера получаем выходные данные после обработки всей
последовательности фильтров.
Также на схеме вынесен в отдельный блок умножитель. На этапе
макетного проектирования данная особенность ЦСП не была отражена, однако
является основной для аппаратной реализации на языке описания аппаратуры.
По окончанию выполнения данного этапа работы были достигнуты
следующие результаты:
· сформулирована общая логика работы
сигнального микропроцессора;
· определен язык машинных кодов ЦСП;
· продуманы основные составные части ЦСП:
блоки данных и регистры;
· реализована схема архитектуры устройства
ЦСП;
· получен
рабочий макет ЦСП.
3.2
Примеры реализации КИХ-фильтров с помощью макета ЦСП
Ранее отмечалось (пункт 2.1) что КИХ-фильтр описывается
разностным уравнением вида:
где P - порядок фильтра, (n) - входной сигнал, y (n) - выходной сигнал, а bi - коэффициенты
импульсной характеристики.
Приведем примеры реализации КИХ-фильтров с помощью макета
ЦСП, а также докажем работоспособность разработанного подхода.
Пример 1. Реализовать КИХ-фильтр следующего вида:
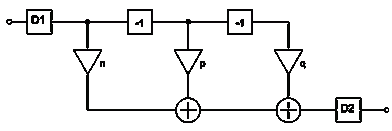
Рисунок 22 - Структура КИХ-фильтра к реализации
Для описания фильтра с помощью разработанной программы
необходимо знать:
· значение
децимации на входе;
· значение
децимации на выходе;
· коэффициенты
импульсной характеристики.
Значение децимации на входе равно D1, а на выходе - D2. Также при рассмотрении
фильтров данного вида в главе 2 отмечалось, что коэффициенты импульсной
характеристики для разностного уравнения совпадают с коэффициентами фильтра.
Приведем пример его реализации на языке машинных кодов
разработанного нами макета ЦСП.
LOOK_WCOUNT <D1>_SCOUNT
<D2><n><p><q>
Работоспособность данного макета ЦСП проще всего доказать
математически, рассмотрев частный случай реализации данного фильтра и
сопоставив результаты компьютерного моделирования результатам, полученном
аналитически.
Пусть D1 = 1, D2 = 0, n = 1, p = 2, q = 3, тогда реализация
фильтра на языке машинных кодов будет иметь вид:
LOOK_WCOUNT 1_SCOUNT 01 2
KOEFF 3
RETURN
Рассмотрим ход работы такого фильтра при условии потактовой
подачи на вход последовательности xi = [1 … 5], при условии
прохождения первого значения без децимации.
В начальный момент времени на вход схемы поступает x1 = 1. Данное значение
умножается на n = 1, а затем поступает на выход. В результате на выходе первого
такта работы схемы имеем y1 = 1.
Так как на входе схемы стоит дециматор на 1, то на вход поступать
будет каждый второй отсчет, поэтому x2 = 2
"отбрасывается". Следующим обрабатываемым значением будет x3 = 3. На входе первого
сумматора будем иметь произведение x3 на n = 1, а также произведение
предыдущего значения схемы x1 на p = 2. В итоге на выход схемы имеем y3 = 5.
Следующим в схему поступает x5 = 5. На выходе первого
сумматора имеем 5 * 1 + 3 * 2 = 11. А на выходе второго сумматора и,
соответственно, на выходе схемы, 11 + 1 * 3 = 14.
В итоге приведем разностное уравнение для данного фильтра для
случая подачи на вход схемы последнего значения их входной последовательности xi = [1 … 5]:
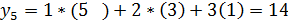
А также представим результаты работы макета ЦСП:
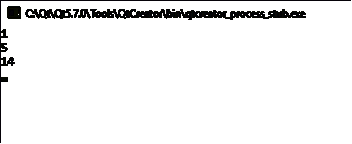
Рисунок 23 - Результат работы макета ЦСП
На рисунке 23 представлен результат работы макета ЦСП для
разных входных значений последовательности. Так, для значения x1 = 1, результат работы равен
1, для x3 = 3, результат работы равен 5, для x5 = 5, результат работы равен
14.
Таким образом можно говорить, что результаты расчета данного
фильтра с помощью созданного макета ЦСП полностью соответствует результатам,
полученным аналитически.
Пример 2. Реализовать КИХ-фильтр следующего вида:
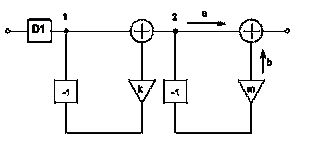
Рисунок 24 - Пример КИХ-фильтра к реализации
Ранее при рассмотрении фильтров данного вида в главе 2
отмечалось, что разностное уравнения для данного вида фильтров имеет вид:
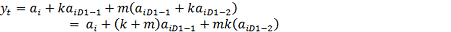
Приведем также эквивалентную схему данного фильтра:
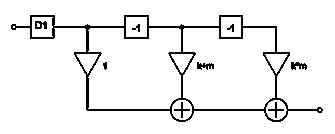
Рисунок 25 - Преобразованный КИХ-фильтр
Очевидно, что коэффициенты данного фильтра имеют значения: 1,
k+m, m*k.
Реализовать данный фильтр на базе созданного макета ЦСП языке
машинных кодов можно следующим образом:
LOOK_WCOUNT D1_SCOUNT 01k + mk * m
Пример 3. Реализовать КИХ-фильтр следующего вида:
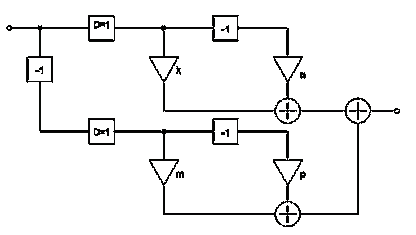
Рисунок 26 - Пример КИХ-фильтра к реализации
Ранее при рассмотрении фильтров данного вида в главе 2
отмечалось, что разностное уравнения для данного вида фильтров имеет вид:
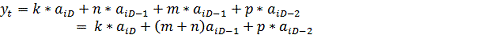
Приведем схему КИХ-фильтра, которому соответствует данное
разностное уравнение:
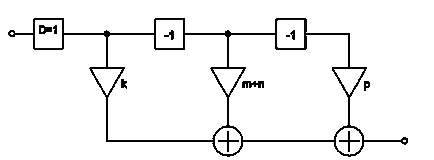
Рисунок 27 - Преобразованный КИХ-фильтр
Очевидно, что коэффициенты данного фильтра имеют значения: k, m+n, p.
Реализовать данный фильтр на базе созданного макета ЦСП языке
машинных кодов можно следующим образом:
LOOK_WCOUNT 1_SCOUNT 0km + np
Таким образом мы проиллюстрировали, что функционала,
реализованного на С++ макета цифрового сигнального микропроцессора, достаточно
для реализации КИХ-фильтров приведенных выше видов. А значит можно утверждать,
что данный подход построения архитектуры ЦСП, а также логику его работы, можно
использовать в качестве основы реализации на языке описания аппаратуры Verilog.
3.3
Реализация микропроцессора на языке описания аппаратуры Verilog
Создание схем с помощью языков описания аппаратуры, в
частности с использованием Verilog, связано с описанием простейших функциональных
блоков, называемых модулями, и их последующим использованием в различных частях
итоговой схемы, где они выполняют различные функции. Несколько небольших
модулей могут быть объединены в один для реализации конечного функционала. Так,
основываясь на функциональных блоках, необходимость наличия которых была
установлена на этапе макетирования, созданная схема разделяется на модули,
каждый из которых реализует конечный функционал:
· модуль "Loader", реализующий
функционал "загрузчика";
· модуль "Conveyor", реализующий
функционал "конвейера";
· модуль "DR", реализующий
функционал регистров "dr";
· модуль "NR", реализующий
функционал регистров "nr";
· модуль "SIZES", реализующий функционал
регистров "sizes";
· модуль "QUEUES", реализующий
функционал регистров "queues";
· модуль "SCounts_Init", реализующий
функционал регистров "scountsinit";
· модуль "WCounts_Init", реализующий
функционал регистров "wcountsinit";
· модуль "SCounts", реализующий
функционал регистров "scounts";
· модуль "WCounts", реализующий
функционал регистров "wcounts";
· модуль "Subs", реализующий
функционал регистров "subs";
· модуль "Koeffs RAM", реализующий
функционал блока данных "koeffs";
· модуль "Datas RAM", реализующий
функционал блока данных "datas".
В данном разделе опишем режимы работы созданной схемы, а
также приведем основные моменты реализации микропроцессора на языке описания
аппаратуры Verilog. С итоговой схемой разработанного ЦСП можно ознакомиться в пункте
"Приложение В" данного дипломного проекта.
Функционирование схемы начинается с этапа ее инициализации.
На данном этапе с внешнего устройства происходит запись кодов команд, задающих
параметры последовательности фильтров, в модули "Koeffs RAM" и "Datas RAM". Все регистры же
инициализируются начальными значениями, которые были определены на этапе
макетирования.
Затем начинается основной этап работы схемы - обработка
команд. По окончанию выполнения данного этапа на выход схемы ЦСП O_DATA выдается результат
фильтрации.
Замечание. Перед началом описания модулей схемы отметим, что
все тактируемые элементы подключены к одному тактовому генератору.
На этапе макетирования была разработана архитектура ЦСП, а
также определено функциональное назначение основных блоков данных и регистров,
входящих в его состав, поэтому работа над созданием микропроцессора началась с
реализации именно этих составных частей.
Анализ исходного кода разработанного макета показывает, что
ряд регистров обладает схожим функционалом, а значит могут быть реализованы
единожды в виде отдельного схемотехнического решения с его последующим
использованием в различных частях итоговой схемы.
3.3.1
Реализация модуля "CounterWithInit"
Регистры "dr" и "nr" по сути реализуют
одни и те же функции: в ходе работы макета ЦСП их содержимое инициализируется
нулями и инкрементируется. Реализовать такой функционал на языке описания
аппаратуры достаточно просто.
Рассмотрим модуль "CounterWithInit". Кроме входа с
тактового генератора I_CLK, данный модуль обладает также: входом сигнала
инкрементации I_INC, и входом сигнала инициализации I_INIT, а также выходом O_DATA. Ширина шины выхода
задается с помощью параметра и может быть различным в зависимости от роли
функционального блока в работе схемы. Также параметром передается значение
инициализации. Приведем схему данного модуля:
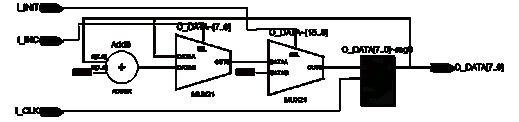
Рисунок 28 - Модуль "CounterWithInit"
Схемотехнически данный модуль выполнен в виде регистра D-триггеров, а также двух
мультиплексоров, необходимых для выбора входного сигнала. Если сигнал поступает
на вход I_INIT, то регистр O_DATA в данном случае
реализации инициализируется нулем. Если сигнал поступает на вход I_INС, то данный модуль начинает
функционировать как счетчик, прибавляя на каждом такте работы единицу к
выходному значению.
3.3.2
Реализация модуля "RegRam"
Регистры "wcounts", "scounts", "wcountsinit", "scountsinit", "sizes", "queues" также обладают
одним и тем же функционалом: в режиме записи позволяют записывать в них данные
по определенному адресу, а также получать данные, лежащие по определённому
адресу, в режиме чтения. Т.е. по сути функционально напоминают память типа RAM.
Известно, что Quartus (среда для проектирования и отладки проектов на
СБИС Altera) позволяет с помощью стандартных методов создавать готовые
схемотехнические решения типа RAM объемом заданным пользователем. Однако из-за
специфики функционирования RAM использовать ее для реализации данных регистров
не оправдано. Дело в том, что процессы записи и чтения данных в автоматически
созданный блок RAM занимают по одному такту. И если для записи значений этот такт
действительно необходим, то продолжительность чтения данных из памяти в один
такт существенно снижает скорость работы ЦСП. Именно поэтому было решено
реализовать аналог RAM с использованием регистров хранения на базе D-триггеров для записи
значений и простой комбинационной схемы на мультиплексорах для чтения значений
по заданному адресу.
Модуль "RegRAM" состоит из двух функциональных частей:
модуля "RegRAMWriteStoreModule" и модуля "RegRAMReadModule".
"RegRAMWriteStoreModule", помимо входа для
подключения генератора тактовых импульсов I_CLK, обладает также адресным
входом I_ADDRESS, входом данных I_DATA и входом для получения
сигнала записи I_WREN. Размер шины данных задается параметром,
и может быть различным в зависимости от роли функционального блока в работе
схемы. Также в качестве параметра передается максимальное количество слов,
которое способна вместить память, исходя из чего с помощью стандартной функции $clog2 (<ЗНАЧЕНИЕ>)
(логарифм по основанию 2 с округлением вверх) вычисляется размер шины адреса.
Также данный модуль обладает единственным выходом O_DUMP, размер шины которого
равен произведению ширины шины данных на количество слов. Схемотехнически
данный модуль выполнен в виде регистра D-триггеров, куда
записываются значения, подаваемые на вход данных, а также целой
"сети" мультиплексоров, служащих для определения адресов (номеров D-триггера) для
записываемых значений.
"RegRAMReadModule" представляет собой комбинационную
схему, предназначенную для получения данных из "RegRAMWriteStoreModule". Данный модуль
обладает входом I_DUMP, куда подключен модуль "RegRAMWriteStoreModule", а также адресным
входом I_ADDRESS, в зависимости от данных на котором происходит
подключение входных ножек к выходным. Размер шины адреса вычисляется аналогично
предыдущему модулю. Выход модуля O_DATA имеет размер ширины шины
данных.
На рисунке 29 приведена схема устройства модуля "RegRAM", а на рисунке 30 -
схема реализации модуля "RegRAMReadModule". Изобразить внутреннее устройство
модуля "RegRAMWriteStoreModule" не представляется возможным в виду
большого размера схемы.

Рисунок 29 - Модуль "RegRAM"
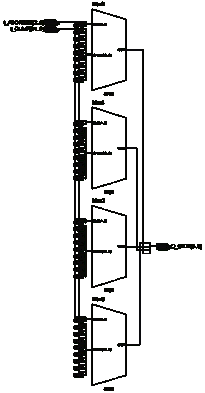
Рисунок 30 - Модуль "RegRAMReadModule"
3.3.3
Реализация модуля "RegRamWith2Ports"
Анализируя приведенную в Приложении Б блочную схему
устройства ЦСП, можно заметить, что данные в ряд регистров, а именно в "wcounts", "scounts", "queues", записываются не
только из загрузчика, но и из конвейера. Т.е. в режиме инициализации схемы в
качестве шин адреса и данных, а также сигнала записи выступают сигналы с одних
блоков, а в режиме обработки команд - другие. Таким образом возникла
необходимость в реализации мультиплексоров выбора входящих сигналов. Данная
задача была решена созданием нового модуля "RegRamWith2Ports". Приведем схему
данного модуля:
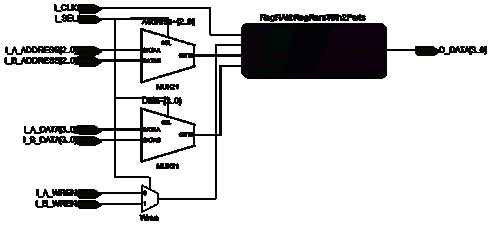
Рисунок 31 - Модуль "RegRamWith2Ports"
Он состоит из трех мультиплексоров, подключенным ко входам
модуля "RegRAM": мультиплексора шины адреса, мультиплексора шины данных, а
также мультиплексора сигнала записи. В качестве управляющего сигнала выступает
сигнал записи внешнего устройства, который дается только в режиме инициализации
схемы.
3.3.4
Реализация модуля типа "RAM"
Рассмотрим далее реализацию модулей "Koeffs RAM" и "Datas RAM". На этапе описания
процесса макетирования мы отмечали, что нет никакой принципиальной разницы в
реализации блоков данных и регистров на языке высокого уровня и, что разница в
терминологии введена в угоду реализации данных составных частей ЦСП на языке
описания аппаратуры. Поясним данное утверждение.
Ранее отмечалось, что функционально регистры напоминают блоки
памяти типа RAM. Однако из-за ограничений по скорости работы ЦСП использовать
модули RAM для реализации регистров нецелесообразно.
Анализ исходного кода макета ЦСП показывает, что в процессе
работы схемы нет необходимости в частом обращении к блокам данных "datas" и "koeffs". Именно поэтому
для аппаратной реализации данных блоков были выбраны автоматически-созданные
модули RAM, схема которых приведена на рисунке 32:
Рисунок 32 - Модуль типа "RAM"
Данный модуль обладает рядом неиспользуемых ножек, которые
были подключены автоматически самой системой. К используемым нами относятся
входы: "clock0", "wren_a", "data_a", "address_a", а также выход "q_a". Размер шин адреса
и данных, как и объем памяти (максимальное количество слов, которые может
вместить RAM) задаются пользователем на этапе создания модуля. Однако есть
возможность вручную исправить код описания данного модуля, реализовав
возможность задания данных величин параметрами, что и было сделано. Внутренне
устройство данного модуля имеет сложную автоматически-сгенерированную структуру
(см. Рисунок 33) и описание его работы приводить не будем.

Рисунок 33 - Внутреннее устройство модуля типа "RAM"
3.3.5
Реализация модуля "RamWuth2Port"
Аналогично регистрам "wcounts", "scounts" и "queues" в блок данных
"datas" записываются значения как из загрузчика, так и из конвейера
(см. Приложение Б). Для возможности подключения различных входных сигналов был
создан модуль "RamWith2Ports", функционал которого аналогичен "RegRamWith2Ports".

Рисунок 34 - Модуль "RamWith2Port"
3.3.6
Реализация модуля "Subs"
Модуль "Subs" реализует функционал регистра "subs", который отвечает
за хранение количества подпрограмм. Функционал данного модуля ограничивается
возможностью записи в него значения с последующей возможностью считывания. На
схемном уровне данный модуль выполнен в виде простого регистра из D-триггеров.

Рисунок 35 - Модуль "Subs"
Далее приведем описание оставшихся двух модулей: "Loader" и "Conveyor".
3.3.7
Реализация модуля "Loader"
Ознакомиться со схемой устройства модуля "Loader" можно в пункте
"Приложении Г" данного дипломного проекта.
Данный модуль обладает следующими входами:
· I_PC_LOOK - вход, на который передаются
с внешнего устройств данные команд LOOK_WCOUNT и LOOK_SCOUNT для записи в модули
"WCountsInit" и "SCountsInit";
· I_PC_KOEFF - вход, на который
передаются с внешнего устройства данные команд KOEFF, для записи в модуль
"KoeffsRAM";
· I_PC_CODE - вход, на который с
внешнего устройства передаются коды команд;
· I_PC_WRITEMODE - вход, на который подается
сигнал режима записи. Данный сигнал находится в состоянии логической единицы до
окончания записи;
· I_CLK - вход подключенный к
тактовому генератору;
· I_PC_ENBL - вход, на который подается
строб-сигнал от внешнего устройства.
Также модуль обладает рядом выходов, с наименованием которых
можно ознакомиться в пункте "Приложении Г" данного дипломного
проекта. Здесь приведем лишь их функциональное назначение.
Выходы данного модуля можно разделить на три группы:
1. Выходы, к которым подключены шины данных (O_WCOUNTS_INIT_DATA, O_SCOUNTS_INIT_DATA и др.).
2. Выходы, к которым подключены сигналы, разрешающие
запись в модули (O_SIZES_ENBL, O_SCOUNTS_ENBL, O_WCOUNTS_ENBL и др.).
3. Выходы, к которым подключены сигналы
инициализации и инкрементации модулей (O_DR_INC, O_NR_INC).
Отметим, что каждой шине данных соответствует свой сигнал
типа "ENBL" (например, O_SIZES_DATA - O_SIZES_ENBL и тд), и все пары таких выходов подключены к соответствующим
модулям в блоке регистров. По сути, в сочетании с единым для всей схемы
сигналом I_CLK, такой подход означает, что соединение модулей
из блока регистров с модулем "Loader" происходит с помощью последовательного
интерфейса SPI. И основная задача загрузчика - своевременно давать сигналы,
разрешающие запись значений в модули из блока регистров и сигналы инициализации
и инкрементации модулей.
Кроме стандартных логических элементов "Loader" включает в себя
модуль "CounterWithInit" на базе которого здесь реализован служебный регистр
"SubSize", который необходим для вычисления размера подпрограммы, с
последующей передачей этого значения на выход O_SIZES_DATA и записью данного
значения в регистр "Sizes" по адресу номера подпрограммы.
3.3.8
Реализация модуля "Conveyor"
Модуль "Conveyor" имеет самую сложную структуру, приведем
его описание. Ознакомиться со схемой реализации данного модуля можно в пункте
"Приложение Д" данного дипломного проекта.
Основное функциональное назначение данного модуля - обработка
команд, данные которых хранятся в блоке регистров. А значит для корректного
функционирования данного модуля необходима возможность, как чтения данных из
элементов блока регистров, так и записи новых значений в них.
Анализируя блочную схему устройства ЦСП видно, что на чтение
конвейер принимает значения с регистров "sizes", "wcounts", "scounts", "queues", "wcountsinit", "scountsinit" и "subs". Запись же
значений происходит в регистры "wcounts", "scounts" и блок данных
"datas".
Перечислим основные функциональные блоки данного модуля:
· Модуль "State" является конечным
автоматом;
· Модуль "DR" реализует
функционал регистра "dr";
· Модуль "AR" реализует
функционал регистра "ar";
· Модуль "NR" реализует
функционал регистра "nr";
· Модуль "RR" реализует
функционал регистра "rr";
· Модуль "CommandProcessingSelector" включает в себя
комбинационную схему обработки команд;
· Модуль "DatasAddresSelector" включает в себя
комбинационную схему выбора адреса для обращения к модулю "Datas"
из блока регистров.
Вся обработка команд в конвейере происходит по состояниям
конечного автомата "State". Ознакомиться со схемой его переходов
можно в пункте "Приложение Д" данного дипломного проекта. В
зависимости от текущего состояния выполняются различные действия.
На начальном состоянии BEGIN_STATE происходит загрузка
входных данных с входа I_DATA в модуль "RR" и подаются сигналы
на входы I_INIT модулей "DR" и "NR". На следующем
такте данные модули будут инициализированы заданными начальными значениями (в
данном случае нулями). Затем происходит переход на состояние LOOK_WCOUNT.
На состоянии LOOK_WCOUNT происходит сравнение данных на входе I_WCOUNTS с нулем. В случае
неравенства с помощью комбинационных схем модуля "CommandProcessing" происходит
декрементация данных и "отправление" их на выход O_WCOUNTS с одновременной подачей
сигнала O_WCOUNTS_ENBL. На следующем такте
работы декрементированное значение будет записано в модуль "WCounts" блока регистров по
адресу номера подпрограммы, который берется с выхода O_NR_DATA модуля "Conveyor". Затем происходит
переход на состояние BEGIN модуля "State".
В случае равенства данных на входе I_WCOUNTS нулю, с помощью
комбинационных схем модуля "CommandProcessing" происходит перенаправление данных с
входа I_WCOUNTS_INIT на выход O_WCOUNTS, с одновременной подачей
сигнала O_WCOUNTS_ENBL. На следующем такте
работы данное значение будет записано в модуль "WCounts" блока регистров по
адресу номера подпрограммы, который берется с выхода O_NR_DATA модуля "Conveyor". Затем происходит
переход на состояние WR_STATE модуля "State".
В состоянии WR_STATE происходит запись значений модуля "RR" в модуль "DATAS", по адресу,
который вычисляется с помощью комбинационных схем модуля "DatasAddresSelector". Результат
вычислений подается на выход модуля O_DATAS_ADDR.
Также происходит сравнение данных с входа I_QUEUES с данными с выхода
модуля "AR". В случае их равенства на выход O_QUEUES_DATA подается результат
работы комбинационной схемы модуля "CommandProcessing", а также дается
сигнал O_QUEUES_ENBL. В противном случае
происходит декрементация данных с входа I_QUEUES и последующее
перенаправление декрементированных значений на выход O_QUEUES_DATA с подачей сигнала O_QUEUES_ENBL.
На этом же состоянии подается сигнал I_INIT на модуль "RR", а затем
происходит переход на состояние LOOK_SCOUNT.
Функционирование схемы на состоянии LOOK_SCOUNT напоминает процесс ее
работы на состоянии LOOK_WCOUNT. Аналогично происходит сравнение данных на входе I_SCOUNTS с нулем. В случае
неравенства с помощью комбинационных схем модуля "CommandProcessing" происходит
декрементация данных и "отправление" их на выход O_SCOUNTS с одновременной подачей
сигнала O_SCOUNTS_ENBL. На следующем такте
работы декрементированное значение будет записано в модуль "SCounts" блока регистров по
адресу номера подпрограммы, который берется с выхода O_NR_DATA модуля "Conveyor". Затем происходит
переход на состояние BEGIN модуля "State".
В случае равенства данных на входе I_SCOUNTS нулю, с помощью
комбинационных схем модуля "CommandProcessing" происходит перенаправление данных с
входа I_SCOUNTS_INIT на выход O_SCOUNTS, с одновременной подачей
сигнала O_SCOUNTS_ENBL. На следующем такте
работы данное значение будет записано в модуль "SCounts" блока регистров по
адресу номера подпрограммы, который берется с выхода O_NR_DATA модуля "Conveyor". Затем происходит
переход на состояние KOEFF модуля "State".
На данном состоянии модуля "State" происходит
операция перемножения данных с модулей "Koeffs RAM" и "Datas RAM" с помощью
обращения к вынесенному умножителю.
На этапе описания процесса создания макета ЦСП на языке
высокого уровня было указано, что для корректного обращения к блоку данных
"datas" на данном состоянии необходимо вычисление величины смещения
очереди. В пункте "Приложение А" с исходным кодом макета ЦСП можно
найти формулу расчета данной величины. Здесь же опишем аппаратный способ
расчета корректного адреса для обращения к модулю "Datas RAM".
Во-первых, необходимо вычислить смещение очереди. Для этого
реализуется комбинационная схема с использованием выхода модуля "AR", входов конвейера I_SIZES и I_QUEUES, а также двух
сумматоров. Выход полученной комбинационной схемы подается на вход I_Z модуля "DatasAddresSelector", где происходит
окончательный расчет адреса для обращения к модулю "Datas RAM".
В данном модуле с помощью цепи мультиплексоров сравнивается
разность значений с выходов модулей "DR" и "AR" с величиной на
входе I_Z. В случае, если разность
меньше, то на выход O_DATAS_ADDR подается результат одной комбинационной схемы, если же разность
больше - другой. Проследить логику работы данных комбинационных схем можно в
пункте "Приложение Ж", где приведена схема данного модуля.
В итоге на входы умножителя подаются сигналы с выходов
модулей "KoeffS RAM" и "Datas RAM", где происходит перемножение величин, а
результат, через вход I_MULTIPLIER модуля "Conveyor", поступает на вход I_MULTIPLIER модуля "RR", где суммируется с
его содержимым.
На этом же состоянии происходит подача сигнала на вход I_INC модуля "DR".
Следующее состояние программы выбирается исходя из того, есть
ли еще коэффициенты фильтров к обработке. В случае работы с последним
коэффициентом последнего фильтра происходит переход на состояние RETURN. Если следующая команда
для обработки LOOK_WCOUNT <ЗНАЧЕНИЕ>, то происходит переход на состояние LOOK_WCOUNT, а также подается сигнал
на вход I_INC модуля "NR". Если же следующая
команда обработки KOEFF <ЗНАЧЕНИЕ>, то состояние автомата не меняется.
Состояние RETURN - последнее, и на нем содержимое модуля "RR" подается на выход
конвейера O_DATA. Данный выход является
результирующим, на него подается результат работы всей схемы.
3.4 Итоговая
компиляция проекта
После создания схемы проведем финальную компиляцию
полученного проекта для оценки количества задействованных логических элементов
ПЛИС и сравним результаты разработанного нами подхода с результатами работы
стандартной утилиты "FIR Compiler II v12.1".
Для корректного сравнения результатов проведем компиляцию три
раза: выделим размеры блоков данных равным 64, 128 и 256 для хранения значений
коэффициентов фильтров 64, 128 и 256 порядка соответственно.
Рисунок 36 - Статистика задействованных ЛЭ для реализации
КИХ-фильтра 64 порядка

Рисунок 37 - Статистика задействованных ЛЭ для реализации
КИХ-фильтра 128 порядка

Рисунок 38 - Статистика задействованных ЛЭ для реализации
КИХ-фильтра 256 порядка
Сведем полученные двумя способами результаты в итоговую
таблицу (Таблица 2) и по ее результатам построим график зависимости числа ЛЭ от
порядка разрабатываемого фильтра (рисунок 40).
Таблица 2
|
Порядок
КИХ-фильтров
|
Количество ЛЭ
|
|
64
|
703
|
|
3482
|
|
128
|
764
|
|
6579
|
|
256
|
1047
|
|
12900
|
В данной таблице выделены результаты реализации КИХ-фильтров
с помощью разработанного ЦСП. Для более точного определения вида графика числа
ЛЭ от порядка реализуемого фильтра с помощью разработанного ЦСП, реализуем
также на базе ПЛИС схему для хранения коэффициентов фильтра 512 порядка
(рисунок 39).

Рисунок 39 - Статистика задействованных ЛЭ для реализации
КИХ-фильтра 512 порядка
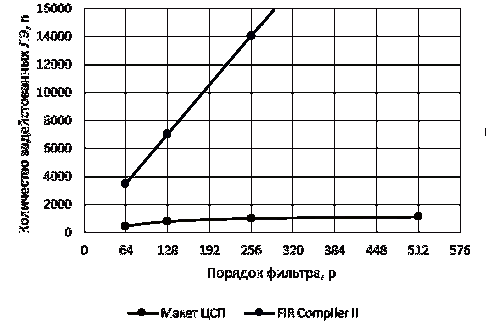
Рисунок 40 - График зависимости числа ЛЭ от порядка
разрабатываемого фильтра
Анализ результатов, полученных с помощью стандартной утилиты
"FIR Compiler II v12.1", демонстрирует линейный рост числа ЛЭ необходимых
для реализации КИХ-фильтров, что приводит к задействованию 12 900 ЛЭ ПЛИС в
случае создания фильтра 256-го порядка.
По сравнению со стандартной утилитой, разработанный макет ЦСП
требует куда меньшее количество ЛЭ ПЛИС для реализации схем КИХ-фильтров.
Анализируя приведенный на рисунке 39 график видно, что рост числа ЛЭ имеет
нелинейный вид. С ростом порядка реализуемого фильтра увеличивается разница в
количестве задействованных ЛЭ.
Таким образом мы наглядно продемонстрировали основное
преимущество разработанного подхода реализации КИХ-фильтров высоких порядков на
базе реализованного ЦСП.
Замечание. Таких результатов удалось достичь за счет
использования лишь одного блока умножителя для реализации всего КИХ-фильтра.
Однако, следует отметить, что использование данного подхода актуально в случае,
если частота дискретизации входного сигнала меньше частоты работы ПЛИС. Иначе
применение разработанного ЦСП для реализации КИХ-фильтров влечет за собой
неминуемую потеряю скорости обработки сигналов.
4.
Экономическое обоснование
В данном разделе необходимо представить расчет рыночной
стоимости и себестоимости разработки [10].
4.1 Расчет
трудоемкости НИР
Расчёт трудоемкости выполненных работ по категориям
работников, представлены в табличной форме (таблица 3). Перечислены этапы
разработки дипломного проекта, исполнители разработки, а также трудоемкость
работы.
Таблица 3
|
№
|
Наименование
этапов
|
Исполнители
|
Трудоемкость,
чел-дн.
|
|
1
|
Выдача задания
на дипломный проект
|
руководитель
|
1
|
|
2
|
Изучение
литературы
|
инженер
|
5
|
|
3
|
Консультация по
выбранной тематике
|
консультант
|
1
|
|
4
|
Проведение
макетного проектирования на языке программирования высокого уровня
|
инженер
|
3
|
|
5
|
Изучение
основных аспектов применения языков описания аппаратуры
|
инженер
|
16
|
|
6
|
Создание
принципиальной схемы на языке описания аппаратуры Verilog
|
инженер
|
21
|
|
7
|
Сравнение и
анализ полученных результатов
|
инженер
|
3
|
|
8
|
Консультация по
выполненной работе
|
консультант
|
2
|
|
9
|
Прием и
проверка выполненного задания
|
руководитель
|
1
|
|
10
|
Оформление
|
инженер
|
4
|
|
11
|
Проверка и
отзыв руководителя
|
руководитель
|
2
|
|
Итого
|
59
|
4.2 Расчёт
заработной платы работников, принимающих участие в разработке проекта
Согласно данным предприятия средняя заработная плата
составляет:
· руководителя:
30000 руб;
· инженера:
25000 руб;
· консультанта:
30000 руб.
Исходя из того, что в среднем в месяце 22 рабочих дня,
получаем дневной заработок исполнителей:
· руководителя:
1363 руб/день;
· инженера: 1136
руб/день;
· консультанта:
1363 руб/день.
Приведем расчеты заработной платы работников, принимающих
участие в разработке проекта (таблица 4).
Таблица 4
|
№
|
Исполнители
|
Дневной
заработок, руб.
|
Участие, дни
|
Заработная
плата, руб.
|
|
1
|
Руководитель
|
1363
|
4
|
5452
|
|
2
|
1136
|
52
|
59 072
|
|
3
|
Консультант
|
1363
|
3
|
4089
|
|
Итого
|
59
|
68 613
|
4.3
Расчет страховых взносов с заработной платы
Страховые взносы с 1 января 2012 года составляют 30 % от
заработной платы:
Sстраховых взносов = 68 613 * 0.3 = 20 584
рубля.
4.4 Расчет
затрат на электроэнергию
Затраты на электроэнергию определяются по формуле
РЭ = W * T * S * КИМ (14)
Где:
· W - мощность всех
приборов, кВт;
· Т - фонд времени работы прибора, час;
· S - стоимость
киловатт-часа электроэнергии, S = 3,32 руб. /час;
· КИМ - коэффициент использования
мощности, КИМ = 0,9.
Результаты расчета затрат на электроэнергию сводятся в
таблицу 5.
В процессе работы над проектом в качестве ЭВМ выступал
ноутбук фирмы Lenovo модели g570 с заявленной потребляемой мощностью 54 Вт.
Так же в процессе работы использовалась ПЛИС фирмы ALTERA семейства Cyclone 2, модели EP2C70 с заявленной
потребляемой мощностью 4 Вт.
Таблица 5
|
Оборудование
|
Потребляемая
мощность, кВт
|
Фонд времени,
час
|
Расход
электроэнергии, кВт∙час
|
Затраты на
электроэнергию, руб.
|
|
ЭВМ
|
0,1
|
354
|
35,4
|
105,7
|
|
ПЛИС
|
0,004
|
2
|
0,008
|
0,023
|
|
Настольная
лампа
|
0,06
|
354
|
21,24
|
64,5
|
|
Принтер
|
0,2
|
1
|
0,2
|
0,6
|
|
Итого
|
169,9
|
4.5
Расчет стоимости специального оборудования и суммы амортизационных отчислений
Расчет стоимости специального оборудования, необходимого для
выполнения работы, и суммы амортизационных отчислений. Результаты расчета
сведены в таблицу 6.
Затраты на специальное оборудование считают по формуле
Зсп. об = (Агод * Тисп) / Тгод
где:
· Агод
- амортизационные отчисления, руб.;
· Тисп - время использования по
теме, год;
· Тгод - длительность работы над
дипломом, лет.
Таблица 6
|
Наименование
оборудования
|
Цена за
единицу, руб.
|
Время
использования, год
|
Норма
амортизации, %
|
Годовая сумма
амортизации, руб.
|
Амортизационные
отчисления, руб.
|
|
ЭВМ
|
21000
|
5
|
20
|
4200
|
350
|
|
ПЛИС
|
22500
|
5
|
20
|
4500
|
375
|
|
Настольная
лампа
|
2500
|
5
|
20
|
250
|
41,66
|
|
Принтер
|
6000
|
5
|
20
|
1200
|
100
|
|
Итого
|
866,6
|
4.6
Расчет накладных расходов
Накладные расходы рассчитываются исходя из суммы всех
предыдущих статей затрат в размере 150 - 200%:
Sнакладных расходов = (169,9 + 68 613 + 20
584 + 866,6) * 1,5 = 135 350 рублей.
4.7 Расчет
полной стоимости проекта
Расчет полной стоимости проекта - сумма всех его
составляющих, представленных в пунктах 1-4. Результаты расчетов
представлены в таблице 7.
Таблица 7
|
№
|
Статьи затрат
|
Сумма, руб.
|
Удельный вес, %
|
|
1
|
Основная
заработная плата
|
68 613
|
33,46
|
|
3
|
Амортизационные
отчисления
|
866,6
|
0,42
|
|
4
|
Затраты на
электроэнергию
|
169,86
|
0,08
|
|
5
|
Накладные
расходы
|
135 350
|
66
|
|
Себестоимость
разработки
|
204 999
|
100
|
5.
Охрана труда и пожарная безопасность
5.1 Анализ
опасных и вредных производственных факторов
На рабочем месте инженера-разработчика, согласно ГОСТ
12.0.003-74 "Опасные и вредные производственные факторы
Классификация", можно выделить следующие опасные и вредные производственные
факторы [11]:
Физические:
· повышенный уровень электромагнитных
излучений, связанный с постоянным, близким нахождением с монитором компьютера;
· физические перегрузки статического
характера, связанные с малой подвижностью в течении всего рабочего дня;
· параметры микроклимата: подвижность
воздуха, влажность, температура.
Психофизиологические:
· перенапряжение анализаторов, в первую
очередь зрения. Опасность связана с тем, что основным источником информации
является монитор компьютера;
· умственное перенапряжение, связанное с
постоянной умственной деятельностью разработчика, поиском решений поставленных
задач и освоением новых технологий, необходимых для реализации их решения;
Источников химической и биологической опасности рабочее место
разработчика не имеет.
5.2
Безопасность производственного процесса
ЭВМ является основным оборудованием, используемым на рабочем
месте разработчика [12]. Данное оборудование удовлетворяет требованиям ГОСТ
12.2.003-91 "Оборудование производственное. Общие требования безопасности".
ЭВМ, материалы и конструкции не оказывают опасного и вредного воздействия на
организм человека на всех заданных режимах работы и предусмотренных условиях
эксплуатации.
5.3
Электробезопасность
Основным используемым на рабочем месте разработчика
оборудованием является ЭВМ.
Кроме того, в помещении сеть с напряжением 220В (50 Гц).
Согласно ГОСТ 12.1.019-79 "Электробезопасность. Общие
требования и номенклатура видов защиты" [14], вероятность поражения
электрическим током снижется при использовании следующих средств защиты:
· изоляции токоведущих частей компьютера (сетевого шнура и
разъемов);
· покрытия рабочего места изоляционным материалом;
· безопасного расположения токоведущих частей.
Также для обеспечения защиты от поражения электрическим током
допускаются к работе с электрооборудованием лица не моложе 18 лет, прошедшие
медицинское освидетельствование и инструктаж по технике безопасности.
5.4
Микроклимат в производственных помещениях
Согласно ГОСТ 12.1.005-88 "Общие санитарно-гигиенические
требования к воздуху рабочей зоны" [15], рабочее место разработчика, по
энергозатратам соответствует категории "Легкая - 1а", с уровнем
энергозатрат до 120 ккал/час. Оптимальные и допустимые параметры микроклимата
для данной категории тяжести работ на постоянных рабочих местах приведены в
таблице 8.
Таблица 8
|
Параметры
|
Период года
|
|
Холодный
|
Теплый
|
|
Температура,°С
|
оптимальная
|
22-24
|
23-25
|
|
допустимая
|
верхняя граница
|
25
|
28
|
|
|
нижняя граница
|
20
|
21
|
|
Относительная
влажность, %
|
оптимальная
|
40-60
|
40-60
|
|
допустимая (не
более)
|
15-70
|
15-75
|
|
Скорость
движения воздуха, м/с
|
оптимальная
|
0,1
|
0,1
|
|
допустимая (не
более)
|
0,1
|
0,2
|
Для обеспечения требуемых параметров микроклимата на рабочем
месте используются системы центрального водяного отопления, кондиционирования и
вентиляции. Проектирование и эксплуатация систем водяного центрального
отопления, вентиляции и кондиционирования удовлетворяют требованиям СНиП
2.04.05-91 "Отопление, вентиляция и кондиционирование воздуха. Нормы
проектирования" [16].
Ежедневно производится влажная уборка всех помещений.
Температура воздуха в холодный и теплый периоды года, помимо системы
центрального водяного отопления, поддерживается в пределах нормы с помощью
кондиционирования. В некоторых комнатах, в жаркий период года, устанавливают
дополнительные кондиционеры или вентиляторы.
5.5
Естественное и искусственное освещение
В производственном освещении используется совмещенное
освещение в соответствии с СанПиН 2.2.2/2.4.1340-03 "Гигиенические
требования к персональным ЭВМ и организации работы" [17].
В соответствие с СанПиН 2.2.2/2.4.1340-03 "Гигиенические
требования к персональным ЭВМ и организация работы" в помещении
используется совмещенное освещение. Светильники располагаются на потолке.
В темное время суток используется искусственное освещение,
которое осуществляется системой общего равномерного освещения. В качестве
источников света при искусственном освещении применяются люминесцентные лампы
типа ЛБ и компактные люминесцентные лампы (КЛЛ).
Согласно СниП 23.05-95 "Естественное и искусственное
освещение. Нормы проектирования" [18] работа разработчика относится к
зрительной работе высокой точности, разряд зрительной работы III. Освещенность на
поверхности стола в зоне размещения рабочего документа находится в пределах 300
лк. Освещение не создает бликов на поверхности экрана. Освещённость поверхности
экрана не превышает 300 лк. Коэффициент запаса для осветительных установок
общего освещения равен 1,4. Нормы освещенности на рабочем месте приведены в
таблице 9.
Таблица 9
|
Искусственное
освещение
|
Совмещенное
|
Естественное
боковое
|
|
Освещенность,
лк
|
Контраст
|
Фон
|
КЕО, %
|
КЕО, %
|
|
300
|
большой
|
светлый
|
1,2
|
2
|
5.6
Защита от шума и вибрации
Обычно шум на рабочих местах создается внутренними
источниками: техническими средствами, установками кондиционирования и
вентиляции воздуха, люминесцентными лампами и другим оборудованием, а также
шумом, проникающим извне.
Длительное воздействие постоянного широкополосного шума на
организм человека приводит к снижению остроты слуха и зрения, а также понижению
внимания, снижению продуктивности умственного труда.
Шум, существующий на рабочем месте, соответствует допустимому
уровню звукового давления и уровня звука для рабочих помещений, согласно ГОСТ
12.1.003 - 83 ССБТ "Шум. Общие требования безопасности" [19], которые
приведены в таблице 10.
Таблица 10
|
Уровни
звукового давления, дБ в октавных полосах со среднегеометрическими частотами,
Гц
|
Уровень звука,
дБА
|
|
31,5
|
63
|
125
|
250
|
500
|
1000
|
2000
|
4000
|
8000
|
50
|
|
86
|
71
|
61
|
54
|
49
|
45
|
42
|
40
|
38
|
|
Шумящее оборудование, уровень шума которого превышает
нормированный, в помещении разработчика отсутствует.
На рабочем месте разработчика вибрация отсутствует, уровень
шума не превышает нормированные значения.
Для защиты от внешнего шума в помещениях используются двери,
окна, жалюзи, пол застелен линолеумом.
5.7
Организация рабочего места согласно эргономическим требованиям
Работа разработчика характеризуется малой подвижностью в
течение рабочего дня, что приводит к малой статической утомляемости.
В соответствии с СанПиН 2.2.2/2.4.1340-03 "Гигиенические
требования к персональным электронно-вычислительным машинам и организации
работы" [20] минимальная площадь рабочего места при использовании в
качестве дисплея мониторов на базе плоских дискретных экранов
(жидкокристаллические, плазменные) должна составлять не менее 4,5 м2.
В
нашем случаем площадь одного рабочего места составляет:
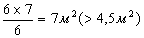
Расположение рабочего места организовано так, что естественный
свет падает сзади. Рабочий стул не регулируется по высоте и углам наклона
сиденья и спинки. Высота поверхности сиденья составляет 500 мм. Высота рабочей
поверхности стола не регулируется и составляет 750 мм.
Органы управления режимом работы монитора сводятся к единой
кнопке, которая расположена в его нижней части. Регулировка яркости и
контрастности возможна от минимального до максимального значения.
Длительность рабочего дня составляет 8 часов с часовым перерывом
на обед и регламентированным перерывом 15 минут через каждый час.
5.8 Пожарная
безопасность
В соответствии с НПБ-105-95 "Определение категории
помещений и зданий по взрывопожарной и пожарной опасности" рабочее
помещение относится к категории “В” (пожароопасная), так как содержит горючие и
трудно горючие вещества и материалы, способные при взаимодействии с водой, кислородом
воздухом или друг с другом только гореть.
В соответствии с ГОСТ 12.1.004-91 "Пожарная
безопасность. Общие требования" [21] источником возникновения пожара на
рабочем месте могут быть: разряд атмосферного электричества (занос высокого
потенциала), электрическая искра (короткое замыкание, электрические лампы
накаливания общего назначения, искры статического электричества).
Для обеспечения пожарной безопасности используются плавкие
предохранители и автоматы защиты. При окончании работы сеть отключается и
проводится проверка помещения.
В помещении отдела установлены пожарные извещатели (типа ДТЛ
с порогом срабатывания +72°С) и комбинированные (типа КИ-1), реагирующие на
тепло и дым в радиусе 5 м.
Кроме технических средств по предупреждению и тушению пожара,
проводятся инструктажи по технике противопожарной безопасности.
Помещение оснащено углекислотным огнетушителем типа ОУБ-7.
5.9 Выводы
В данном разделе (таблица 11) изложены выводы по охране труда
и пожарной безопасности, приведены нормы и стандарты, контролирующие рабочие
факторы и примеры разработанных мероприятий.
Таблица 11
|
Рабочее место
|
Вредные факторы
|
Нормативные
документы
|
Разработанные
мероприятия
|
|
|
Наименование
|
Ограничение
факторов
|
|
|
Рабочее место
инженера-разработчика
|
Шум
|
ГОСТ
12.1.003-83 СН 2.2.4/2.1.8.562-96
|
Максимальный
уровень звука: 50дБА
|
1.
Планировочное (региональное расположение помещений) 2. Звукопоглощение
(облицовка звуко - и вибропоглощающими материалами) 3. Организационные
(предупреждающие надписи)
|
|
Вибрация
|
СН
2.2.4/2.1.8.566-96
|
Виброускорение:
0,014м/с² Виброскорость:
0,028 м/с· 10¯²дБ
|
|
|
Микроклимат
|
ГОСТ
12.1.005-88 СНиП 2.04.05-91
|
Температура: не
более, 25°С, не ниже 20°С. не более, 28°С, не ниже 21°С. Оптимальная
относительная влажность: 40-60% Оптимальная скорость движения воздуха: 0,1
м/с
|
Системы
вентиляции, отопления и кондиционирования воздуха (общеобменная и местная
вентиляция)
|
|
Освещение
искусственное
|
СНиП 23.05-95
|
Общее
освещение: 300 лк Монитор: макс 300 лк
|
1.
Люминесцентные лампы местного давления 2. Дополнительные лампы на рабочих
местах 3. Выбор оптимального монитора по заданным параметрам
|
|
Электробезопасность
|
ГОСТ 12.1.019 -
79 ГОСТ 12.1.030-81
Рациональная
организация рабочих мест.