Влияние подкрепления и наказания на поведение
Министерство
образования и науки Российской Федерации
федеральное
государственное бюджетное образовательное учреждение
высшего
профессионального образования
«Российский
государственный гуманитарный университет»
ДИПЛОМНАЯ
РАБОТА
на
тему:
«Влияние
подкрепления и наказания на поведение»
Выполнил студент
Руссков Степан
Андреевич
Института
психологии им. Выготского
Факультета
Психологии (бакалавриат)
Группа: ИП-133
Научный
руководитель: Тихомирова И.В.
Москва,
2017 год
Оглавление
Введение
.
Теоретические основания исследования
.1
Награды, подкрепление и наказание
.2
Планирование режима подкрепления
.3
Какой режим подкрепления является "наилучшим"
.4
Система наград в типичных приключенческих видеоиграх
.5
Параллельные режимы подкрепления
.6
Практические вопросы реализации системы вознаграждения в игре
.7
Какие награды может предложить наука
.8
Позитивное и негативное подкрепление и наказание как факторы воздействия на
поведение
.
Эмпирическое исследование
.1
Проблемы и цели
.2
Процедура эксперимента
.3
Результаты исследования
.4
Научение посредством подкрепления
Выводы
Список
использованных источников
Приложения
Введение
Когда после поведения следуют приятные
последствия, появляется тенденция к его повторению, а если следуют неприятные
или неудовлетворительные последствия, происходит отказ от повторения. Торндайк
Э.Л.
Одной из основных задач психологии является
возможность предсказания поведения человека. Необходимое и обязательное условие
научного метода проявляется в способности интерпретировать результаты
экспериментов, основываясь на собственной теоретической базе. В психологии для
подтверждения теории обязательными требованиями являются:
Непротиворечивость
Соответствие экспериментальным данным
Возможность предсказывать новые явления
Возможность описывать известные явления
Фальсифицируемость
Актуальность проблемы: Целью данной работы
является анализ литературных данных по проблемам подкрепления и практической
оценки влияния подкрепления и наказания на поведение. Большая часть работы
посвящена исследованию поведения человека в медиа и видеоигровых пространствах,
так как это позволяет повысить экономность исследования, провести анализ новых
актуальных тем, нуждающихся в освещении. Поведение человека представляет собой
направленные к чему-то или от чего-то, в какой-то мере осмысленные и
целесообразные социально или личностно значимые действия, источником которых
является сам человек и ответственность за которые возлагается на него.
Видеоигрой считается игра между человеком и вычислительной системой (либо между
множеством людей) с использованием изображений, сгенерированных электронной
аппаратурой. Первая запатентованная игра появилась в 1968 году, то есть менее
50 лет назад. В настоящий момент невозможно определить точное количество людей,
играющих в видеоигры, только США в 2010 году насчитывало более 150 миллионов
людей играющих в видеоигры и, согласно исследованию Spil Games в 2013 году в
мире играют в игры на различных электронных платформах более 1.2 миллиарда
людей, что на тот момент равнялось 17% населения планеты Земля. Прибыль игровой
индустрии в 2015 году составила 91.8 миллиарда долларов США. Для работы данной
индустрии крайне необходим всесторонний научный анализ, исследователи работают
над этой проблемой "по обе стороны баррикад". С одной стороны -
разработчики игр, перед ними стоит задача создать игру, которая принесёт как
можно больше прибыли. С другой стороны - исследователи, целью которых является
объяснение популярности игр, проблема игровой аддикции и другие.
Видеоигры сильно повлияли на геополитическую
ситуацию в мире - объединяя множество игроков по всему миру и развивая
киберспортивную отрасль. Многие страны (в том числе США, Южная Корея и Россия,
во время проведения этого исследования - в июне 2016 года) признали киберспорт профессиональным
видом спорта. Процесс оформления визы в США для киберспортсменов из разных
стран заметно упростился. Игровые компании осуществляют свою деятельность на
трансмедийных платформах, регулярно киберспортивные мероприятия собирают
аудиторию в сотни тысяч зрителей. По играм снимаются фильмы, пишутся книги, в
месяц прямые трансляции видеоигр от самих игроков собирают более 100 миллионов
просмотров и многое другое.
Среди исследователей растет число приверженцев
людологии. Только в последние десятилетия появилась соответствующая наука,
которая занимается всеми вопросами, связанными с компьютерными играми.
Людология - наука, занимающаяся исследованиями игр как современной формы
коммуникации и творчества. Эта дисциплина представляет собой нечто большее, чем
просто математическая модель, если сравнивать её с теорией игр, она поднимает и
философские, и теоретические, и практические вопросы, касающиеся компьютерных
игр
В западных странах наука людология получила
официальный статус уже более 10 лет назад, в начале 2000-х годов. В России, к
настоящему моменту, над этой наукой трудятся лишь несколько
одиночек-энтузиастов.
Людология ставит во главу угла целый ряд важных
вопросов: Почему человек играет, зачем ему это? Какое влияние оказывают игры на
играющих? Почему процесс разработки всё время усложняется, а игры становятся
всё проще и проще? Какое будущее у индустрии, и какие ещё есть пути развития?
Почему игры подразделяются на такие жанры? Почему одни жанры популярнее других?
Почему у различных жанров сформировались свои шаблоны игровых интерфейсов? Как
реагирует игровая публика на те или другие нововведения? Что в игре
действительно нужно игроку, а что просто добавляется по традиции и висит
балластом?
Наибольший успех в исследовании видеоигр среди
разработчиков в настоящее время показывает Бихевиоризм, что объяснятся
сущностью индустрии. Анализ игрового процесса, исследование подкрепления в
видеоиграх, объяснение и предсказание поведения игрока - вот на чем
специализируется данная теория. Несмотря на ошеломительный успех бихевиоризма
данное исследование рассматривает несколько теоретических точек зрения на
проблему подкрепления в видеоиграх.
Цель исследования: Анализ эффекта подкрепления в
видеоиграх в целом, и у представителей разных социальных групп разработка психодиагностического
метода для исследования влияния подкрепления и наказания в видеоиграх.
Объект исследования: влияние подкрепления и
наказания на поведение. видеоигра социальный
психодиагностический наказание
Предмет исследования: подкрепление и наказание в
видеоиграх как детерминанты поведения человека.
Задачи исследования: исследование механизмов
функционирования подкрепления и наказания в привычной среде, анализ
литературных данных, изучение подкрепления с обучением, разработка метода для
исследования влияния подкрепления и наказания в видеоиграх, проведение
практической части работы, сопоставление полученных данных с известными
математическими моделями предсказывающими эффект влияния наказания и
подкрепления в видеоиграх на поведение человека.
Гипотеза исследования: Ненаправленная гипотеза
Н1 о существовании различий в эффектах, оказываемых подкреплением и наказанием
на поведение у представителей разных социальных групп.
Научная новизна исследования: создание и
применение на практике нового психодиагностического метода в рамках
предварительного исследования, анализ моделей обучения с подкреплением в рамках
видеоигр.
Теоретическая значимость исследования: данные,
полученные исследователем, развивают и дополняют ряд существенных аспектов
теорий, в которых имеет место подкрепление и наказание, теории классического
обуславливания, теории социального научения, теория оперантного научения и др.
Основные теоретические результаты исследования могут стать основой для
дальнейшего изучения механизма влияния подкрепления и наказания не только в
видеоиграх, но и в других сферах человеческой деятельности.
Практическая значимость работы. Выводы,
содержащиеся в работе, могут быть использованы при разработке теоретической
модели обучения с помощью подкрепления и наказания, основанной на поведенческой
и математической психологии, благодаря этому на основе заключений работы может
состоятся пересмотр этих факторов как влияющих на поведение. Полученные данные
могут быть использованы как в дизайне игровой среды, так для создания
терапевтических моделей, снижающих игровую активность.
Структура исследования. Курсовая работа включает
в себя следующие разделы: введение, теоретическую часть, практическую часть,
заключение, список использованной литературы и приложения.
1. Теоретические основания исследования
.1 Награды, подкрепление и наказание
Наградой считается всё, что увеличивает частоту
поведения. Так наградой может быть позитивное событие, следующее за ответом,
или уход от аверсивного события. Точно так же наказание является чем-либо, что
снижает частоту поведения, и может принимать форму аверсивного события, или
ухода от позитивного события Thorndike E. L. Human learning. NY.: Century
Company, 1931. Как уже говорилось, ранее психологи, как правило, имели
тенденцию относиться к чему-либо, что увеличивает частоту поведения как к
подкреплению. Следовательно, награды называют позитивным подкреплением, а уход
от наказания называют негативным подкреплением. Реакции испытуемого на стимулы
отражены в таблице №1.
Таблица 1 - Влияние позитивных и негативных
стимулов на поведение.
|
Итоги
обуславливания
|
|
Увеличение
частоты поведения
|
Снижение
частоты поведения
|
|
Позитивные
стимулы
|
Предъявление
положительного подкрепления
|
Удаление
аверсивного стимула
|
|
Негативные
стимулы
|
Удаление
положительного стимула (запрещают)
|
Предъявление
аверсивного стимула
|
Основным фактором, в определении того, будет ли
поведение оперантным или нет являются последствия, вытекающие из этого
поведения. Если следствием поведения является не то, что признается субъектом
подкрепляющим, поведение не будет подкрепляться. Одна группа последствий,
которые явно являются подкрепляющими это те, которые удовлетворяют
биологические потребности. Пища является очевидным примером подобного
подкрепления. Для голодного человека, еда всегда будет иметь подкрепляющий
эффект. Подкрепления, которые удовлетворяют биологическую потребность или драйв
известны как первичное подкрепление. Они включают в себя еду, воду, и избегание
боли.
Некоторые условные подкрепления особенно эффективны,
поскольку они могут быть связанными со многими другими подкреплениями. Они
называются генерализованным подкреплением. Деньги, жетоны, одобрение и
привязанность являются генерализованным подкреплением, так как они могут быть
связаны с различными событиями, которые сами по себе являются подкрепляющими.
Основной принцип оперантного обуславливания
прост - частота поведения возрастает, если она вознаграждается, и она будет
уменьшаться, если такое поведение наказывается. Например, голодная крыса в
коробке Скиннера будет в сначала вести себя в манере, которая является
естественной для голодных крыс; например, бегать по клетке, пищать, пытаться
спастись, и т.д. Если во время выполнения ею этих действий, один ответ - в этом
случае, нажатие на рычаг, - приводит к награде обеспечения едой, крыса
постепенно узнает, что, нажатие на рычаг приводит к награде пищей. Поведение
будет повторяться и, таким образом, выучено. Поведение, которое приводит к
награде становится особенно важным для крысы. Тот же самый процесс может быть
применен к действию, что позволяет крысе уйти или избежать нежелательных
раздражителей.
Другой принцип оперантного обуславливания
состоит в том, что как только поведение выучено, частота награды может быть
уменьшена. Для научения определённому поведению необходимо сначала подкреплять
каждое появление поведения. Когда поведение выучено, с течением времени можно
уменьшить частоту подкрепления и по-прежнему вызывать такое же поведение. К
примеру, количество нажатий на рычаг для получения подкрепления может
изменяться каждый раз, каждые десять раз, или изменить правила таким образом,
то что рычаг должен быть нажат непрерывно, и т.д. Бихевиористы провели много
экспериментов исследуя какой эффект оказывают различные режимы подкрепления на
поведение. Эти режимы подкрепления имеют особое значение для гейм-дизайнера.
Последним из основных принципов оперантного
обуславливания является то, что возможно обусловить индивида исполнять
определённое поведение за пределами его обычного поведения. Если поведение является
особенно сложным, например, это действие, которое требует нескольких шагов, или
для его выполнения необходимо особое умение существует вероятность того, что
такое поведение невозможно подкрепить напрямую. Вместо этого, можно подкрепить
поведение, которое близко к желаемому, и шаг за шагом подкрепляя более похожее
поведение на необходимое нам, мы получим желаемое поведение. Этот принцип
известен как "формирование поведения". К примеру, видеоигры могут
включать в себя различные уровни сложности, и каждый последующий уровень
требует, чтобы игрок выполнил более сложный набор действий, чтобы добиться
успеха.
.2 Планирование режима подкрепления
Основной принцип оперантного обуславливания
гласит: "возможно увеличить частоту поведения подкрепляя его". Изучение
оперантного обуславливания становится более интересным, когда мы посмотрим на
то, как системы подкрепления могут быть структурированы таким образом, чтобы
оказать наибольшее влияние на поведение Ferster, C. B. & Skinner, B. F.
"Schedules of Reinforcement", 1957 New York: Appleton-Century-Crofts.
Исследователи изучают как подкрепления могут быть выданы, чтобы быть наиболее
эффективным.
Существует три типа режима подкрепления -
непрерывный, угасающий и периодический. В непрерывном каждое повторение поведения
покрепляется, угасающий является противоположностью непрерывного. Как правило,
угасание часто вызывает гнев и разочарование со стороны субъекта. Мы ожидаем,
что Вселенная имеет смысл и цель быть последовательной, и при появлении
непредвиденных обстоятельств мы можем вспылить. Интересно, что эта реакция
также наблюдалась и у многих животных. Это называется "поведенческий
контраст". В одном из экспериментов шимпанзе выполняли простое задание -
потянуть за рычаг. Выполнив его, шимпанзе вознаграждались кусочками листьев
салата, который они любят употреблять в пищу. После выполнения серии проб
шимпанзе 1 раз вознаграждали виноградом, который они любят ещё больше чем
листья салата. Далее, при следующей пробе, их опять награждали листьями салата,
и они были очень огорчены этим, бросая салат в экспериментатора. Новый стимул,
более приятный чем предыдущий создает новые ожидания от награды, и когда эти
ожидания не оправдываются, (у животных) неизбежно наступает фрустрация и гнев.
Подобные эксперименты проводились на голубях, и многих других животных. Между
этими двумя экстремумами лежит периодический режим, что только некоторые из
повторений поведения подкрепляются. Периодический режим подкрепления включает в
себя:
Режим соотношения: в этом режиме подкрепление
появляется если поведение осуществляется Х раз. Х может быть вариативным
числом.
Интервальный режим - в этом режиме первая
реакция в любое время по истечении определенного промежутка времени
подкрепляется.
Режим длительности - в этом режиме поведение
должно происходить на протяжении какой-либо длительности времени чтобы
подкрепиться.
Все эти графики подкрепления могут быть
фиксированными или вариативными. В фиксированном графике подкрепление будет
появляться в течении заданного периода времени, или после фиксированного числа
ответов. В вариативном графике подкрепления, время или количество ответов будет
меняться вокруг определенного числа; например, подкрепление будет даваться
когда действие будет выполнено от 10 до 20 раз. Если мы примем, что постоянный
режим и угасающий режим подкрепления являются ничем иным как двумя экстремумами
периодического режима то мы получаем восемь базовых режимов подкрепления
Herrnstein, R. J. (1970). On the law of
effect. Journal of the Experimental Analysis of Behavior, 13, 243-266. В
примерах режимов подкрепления значительное внимание уделяется примерам как из
реальной жизни, так и в игровой среде.
Фиксированное соотношение - подкрепление дается
после точно определенного количества верных ответов. На рис. №1 изображен
график динамики поведения животного в режиме фиксированного соотношения. Полосы
перекрывающие линию динамики поведения означают момент получения подкрепления.
Буквой А отмечена пост-подкрепляемая пауза (Bernstein, Roy, Srull, &
Wickens, 1991; Bootzin, Bower, Crocker, & Hall, 1991)[13].
Примеры:
Работа на фабрике, оплачиваемая по количеству
произведённых деталей.
Получение премии на работе на каждые (х)
проданных товаров.
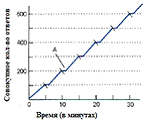
Сбор жетонов в игре. Многие игры требуют от
игрока сбора определенного количества жетонов для перехода на следующий
уровень, чтобы получить дополнительное очко жизни, или другое подкрепление.
Достижение нового уровня в RPG - ролевой игре
(или "РПГ"). Некоторые RPG показывают в точности, сколько требуется
опыта для достижения нового уровня. Высокий показатель определенности того,
сколько потребуется работы для достижения нового уровня, заключает игрока в
режим фиксированного соотношения подкрепления.
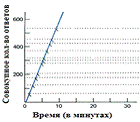
Вариативное соотношение - подкрепление дается
после заданного количества верных ответов.
На рисунке №2 изображен график динамики
поведения животного в режиме вариативного соотношения. Полосы перекрывающие
линию динамики поведения означают момент получения подкрепления.
Примеры:
Игровые автоматы в казино. [13].
Покупка лотерейных билетов (Pettijohn, 1992).
Поочерёдное закидывание и сматывание удочки
перед тем как поймать рыбу. Bootzin, Bower, Crocker, & Hall, 1991;
Сбор жетонов. Некоторые игры требуют от игрока
собирать жетоны чтобы чего-то достичь, но варьируют количество требуемых
жетонов.
Получение нового уровня в РПГ. Некоторые РПГ не
дают точной информации о том, сколько требуется опыта для достижения следующего
уровня. Это заключает игрока в режим вариативного соотношения подкрепления.
Крафтинг (производство каких-либо вещей или
экипировки самим игроком) в РПГ. Может потребоваться множество попыток, чтобы
достичь успеха, и чтобы вещь получила новый уровень, но чем больше раз вы
пытаетесь, тем более вероятно что ваше поведение подкрепится.
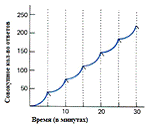
Фиксированный интервал - первый ответ после
фиксированного временного интервала подкрепляется.
На рис. №3 изображен график динамики поведения
животного в режиме фиксированного интервала. Полосы перекрывающие линию
динамики поведения означают момент получения подкрепления. (Peterson, 1991).
Примеры:
Получение зарплаты каждую неделю.[13]
Проверка почтового ящика по утрам.
Ожидание респауна (возрождения) монстров, где
респаун происходит после заданного периода времени. Заметка: в онлайн-играх
другие игроки также могут ожидать этого монстра, и в этом случае они находятся
в режиме фиксированного интервала и ограниченного удержания.
Получение объектов, сокровищ, или усилений в
игре, которые появляются только в фиксированные интервалы времени.
Вариативный интервал - режим, где первый ответ
после вариативного временного интервала подкрепляется (Gleitman, 1981).
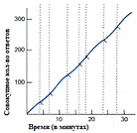
На рис. №4 изображен график динамики поведения
животного в режиме вариативного интервала. Полосы перекрывающие линию динамики
поведения означают момент получения подкрепления.
Примеры:
Сотрудники ГАИ, следящие за соблюдением
скоростного режима за чертой города.
Ожидание приезда такси. (Baron,1992).
Ожидание респауна монстров в игре, где респаун
происходит только в вариативные интервалы времени. Заметка: в мультиплеерных
играх другие игроки могут также ожидать этого монстра, и в таком случае они
находятся в режиме фиксированного интервала и ограниченного удержания.
Фиксированный интервал с ограниченным удержанием
- первый ответ после фиксированного интервала времени подкрепляется,
обеспечивая осуществление реакции в течении заданного периода до его окончания.
Примеры:
Ожидание респауна монстров в заполненном мире
онлайн игры. Если монстр респаунится в регулярные интервалы времени - игрок
должен ждать фиксированный период времени чтобы его убить. Тем не менее если
монстра после определенного периода ожидания нету - высока вероятность того,
что его убил другой игрок.
Получение объектов, сокровищ, или усилений,
которые появляются только в ограниченный период фиксированных временных
интервалов.
Вариативный интервал с ограниченным удержанием -
первый ответ после вариативного интервала времени подкрепляется, обеспечивая
осуществление реакции в течении заданного периода до его окончания.
Примеры:
Получение наград, объектов, или усилений которые
появляются только на ограниченное время в случайный момент.
Ожидание респауна монстра в заполненном людьми
онлайн мире - если монстр респаунится в вариативные интервалы времени игрок
должен ожидать фиксированное количество времени чтобы убить монстра, тем не
менее, если монстра нету после определенного периода ожидания - вероятно что
его убил другой игрок.
Фиксированная длительность - чтобы быть подкрепленным,
поведение должно осуществляться непрерывно на протяжении всего фиксированного
временного интервала.
Примеры:
Игры с ограниченным временем на прохождение
уровня. Для продвижения, игроку требуется постоянно проявлять активность на
протяжении фиксированного периода, к примеру стрелять в инопланетян или
зачищать все предметы на уровне.
Вариативная длительность - чтобы быть
подкрепленным, поведение должно осуществляться непрерывно на протяжении всего
вариативного интервала времени.
Примеры:
Симуляторы охоты. Игроку необходимо сидеть в
засаде. Для успешного итога вариативной длительности поведение должно
продолжаться неопределённое количество времени, и игрок должен продолжать
сидеть в засаде в течении всего периода.
Симуляторы гонок. Игрок должен водить средство
передвижения всю гонку, чтобы выиграть.
.3 Какой режим подкрепления является
"наилучшим"
Если целью является генерация наибольшего
количества повторений поведения в течении наибольшей длительности - в таком
случае, осознанное применение режимов соотношения подкрепления является
наилучшим способом. Кроме того, вариативное соотношение подкрепления
демонстрирует более длительную сопротивляемость затуханию (снижению
эффективности) любого режима подкрепления, и это означает, что возможно
значительно увеличить время между подкреплениями без снижения количества
ответов. Таким образом, осуществляя вариативное соотношение режима
подкрепления, гейм-дизайнер может обуславливать игроков продолжать совершать
поведение на протяжении очень долгих интервалов времени без получения
какого-либо подкрепления Ferster, C. B. & Skinner, B. F. "Schedules of
Reinforcement", 1957 New York: Appleton-Century-Crofts. . Неудивительно,
что игры ,которые считаются как затягивающими, или которые становятся причиной
зависимости более чем вероятно пользуются вариативным соотношением режима
подкрепления. Это, как бы то ни было, не означает, что этот режим подкрепления
- наилучший, и могут существовать веские причины для того, чтобы пользоваться
другими коэффициентами режима подкрепления.
В то время как режимы соотношения подкрепления
вырабатывают наибольший уровень ответов, не означает, что этот тип подкрепления
является наиболее приятным для игрока. Работники на фабриках часто получают
оплату согласно режиму соотношения, то есть их зарплата зависит от количества
произведённых ими деталей. Владельцы фабрик предпочитают такой способ оплаты.
Работники, однако, находят такой режим зарплаты нежелательным, потому что они
заставляют их работать перенапрягаясь, оставляя их нервными и истощенными после
рабочего дня. Давление профсоюзов часто приводит к смене режима заработка на
почасовую систему, т.е. на режим длительности. Злоупотребление вариативным
соотношением в игре может привести к тому, что игроки будут чувствовать себя
перегоревшими, уставшими, и безрадостными независимо от их игрового опыта даже
если они осознают что их вынуждают играть. Эта реакция - не то, чего хочет
гейм-дизайнер для своих игроков. Дизайнер также желает использовать другие
режимы подкрепления - интервальные, которые продолжат мотивировать игрока, но
оставят его менее истощенным к концу игровой сессии.
Другие режимы подкрепления хорошо подходят для
определенных ситуаций. Пока вариативное соотношение подкрепления - лучшее в
поддержании поведения, фиксированное соотношение и режимы длительности - лучшие
для усвоения новых видов подкрепления Ferster, C. B. & Skinner, B. F.
"Schedules of Reinforcement", 1957 New York: Appleton-Century-Crofts.
Экспериментаторы часто используют режим фиксированного соотношения, когда с
самого начала научают поведению, и только потом переключаются на вариативный
режим соотношения подкрепления. К примеру, во многих видеоиграх дизайнеру
требуется сначала научить или натренировать игрока как играть в игру, и для
этого фиксированное соотношение и режимы длительности - лучшие способы этого
достичь.
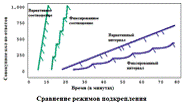
На рисунке №5 показано сравнение динамики
подкрепления поведения такими режимами как Вариативное соотношение,
Фиксированное соотношение, Вариативный интервал и Фиксированный интервал. Как
мы можем увидеть, количество ответов за временной период увеличивается при
переходе от Фиксированного интервала к Вариативному интервалу, и от
Фиксированного соотношения к Вариативному. Как уже было сказано выше,
интервальные режимы имеют слабую сопротивляемость росту напряжения в системе, а
следовательно им тяжелее вызывать всё более высокий уровень ответов. В
дополнение, фиксированные интервалы вызывают пост-подкрепляемые паузы, таким
образом они проигрывают вариативным режимам подкрепления по количеству
повторений поведения Kazdin, A.E. Behavior Modification in Applied Settings,
Belmont, Brooks/Cole, 1989.
.4 Система наград в типичных приключенческих
видеоиграх
Типичная система совершенствования в играх, от
ранних "ручка-бумага", таких как "Dungeons and Dragons", до
таких РПГ как "World of Warcraft" и "Dark age of Camelot",
в которых персонажи игрока должны улучшать свой уровень и способности. Чтобы
получить уровень, персонажи должны заработать очки опыта, которые обычно даются
за убийство монстров, или получение сокровища. Способности обычно получаются
посредством практики, каждое успешное применение способности увеличивает шанс,
что игрок станет лучше пользоваться этой способностью, или сам уровень
способности повысится. В дополнение к убийству монстров и улучшению
способностей, игроки могут получить объекты и сокровища, выучить новые
заклинания, исследовать игровой мир, заводить друзей и достигать статуса.
Вариативные награды часто взаимосвязаны. Ниже
даны примеры подобных событий.
Игроку может потребоваться получить определенный
уровень, чтобы выучить новую способность или заклинание.
Наилучшие заклинания, броня и оружие позволяют
игрокам убивать монстров, а следовательно получать опыт быстрее и легче.
Лучшие способности позволяют игрокам убивать
более сильных монстров, и, создавать лучшее оружие, получать внутриигровую
валюту, и т.д.
На высоких уровнях игроки могут убивать более
сильных монстров, получая больше опыта и зарабатывать больше наград
Получение редкого или востребованного предмета и
получение большего уровня увеличивает статус игрока в игре.
Для того, чтобы поддерживать дружеские
отношения, игрок должен продвигаться по уровням с той же скоростью что и его
друзья, иначе, они останутся позади (или наоборот) и не смогут пережить
сражение с монстрами, которых их друзья берут на себя. Для игр без сетевой
поддержки это также работает, но в другом виде социального подкрепления.
Для многих игроков достижение новых уровней (или
продвижение по игре) и следственно увеличение статуса, становятся
первостепенным подкреплением, и причиной, по которой они продолжают играть.
Если достижение новых уровней будет простым, их ценность как подкрепления (за
единицу) снизится. Игроки смогут быстро достичь максимального уровня, и статус
получения самого высокого уровня снизится. Дизайнеры, следовательно, должны
внедрить систему уровней, так, что достижение каждого уровня требует больших
усилий, и получение высочайших уровней потребует огромного количества усилий.
В классической версии игры World of Warcraft,
игрок в среднем способен прокачаться с 1 до 4 уровня за несколько часов игры, а
прокачка с 5 до 10 уровня может занять несколько дней игры. Достижение самых
высоких уровней, занимало месяцы, или даже годы усилий. Тем более немаловажен
сам способ повышения уровня персонажа.
Экспоненциальный рост игрового времени, которое
требуется для того, чтобы достичь следующего уровня имеет следующее
преимущество.
Он убеждает игроков, что игроку требуется больше
времени, чтобы достичь больших уровней, и призывает их продлить подписку на
игру
Он гарантирует игроку, что высокие уровни -
редкое явление, и это является сильным подкреплением для игроков, стремящихся к
статусу.
Тем не менее быстрый рост сложности условий,
требуемых для получения подкрепления - (получение нового уровня) вызывает
относительное напряжение. Напряжение режима включает в себя риск, что игрок в
какой-то момент найдет усилия, затрачиваемые на достижение нового уровня непропорциональными
самой награде, и может просто отказаться от этих усилий, и, соответственно,
отказаться от игры Medler, B., John, M. and Lane, J. Data Cracker: Developing a
Visual Game Analytic Tool for Analyzing Online Gameplay. In Proceedings of CHI
2011. Vancouver, BC Canada. Неудивительно, что геймдизайнеры выбирают режимы
соотношения подкрепления для продвижения по уровням, потому что эти режимы
имеют наименьшую восприимчивость к напряжению режима. Как мы можем увидеть, все
фиксированные режимы подкрепления вызывают пост-подкрепляемые паузы - временное
снижение частоты поведения после подкрепления, длительность которого зависит от
величины подкрепления, и длительности временного интервала, после которого
поведение будет снова подкреплено. Геймдизайнеры также часто не дают точной
информации, сколько усилий потребуется для достижения следующего уровня,
устанавливая продвижение по уровням на режим вариативного соотношения, Такой
режим, показывает наибольшую сопротивляемость угасанию поведения, режим,
который не производит никаких пост-подкрепляемых пауз, и который наиболее
эффективен в производстве высокого уровня ответа в течении длительного периода
времени Toma, C. L. Affirming the Self through Online Profiles: Beneficial
Effects of Social Networking Sites. In Proceeding of CHI 2010, р. 1749-1752.
В дополнение к увеличению опыта, необходимого
для получения следующего уровня, другие методы часто используются, чтобы
сделать достижение следующего уровня более сложным. К примеру:
Игрок может получать опыт только от монстров
(убийства), которые находятся близко по уровню к игроку или выше, так что
игроки должны искать более сильных монстров, чтобы получить опыт, и
продвинуться. Либо получать валюту\опыт только за те задания, которые
предназначены примерно для его уровня (в среднем стандартное отклонение
равняется 2,24).
На ранних уровнях игроки могут убить монстра
близкого к ним по уровню (разброс в играх колеблется ±5 уровней), в то время
как на высоких уровнях для убийства монстра может потребоваться группа игроков,
поэтому на более высоких уровнях игроку придется найти группу других игроков
для совместных приключений.
В то время как игра в группе обычно более
веселая, часто занимает много времени найти подходящую группу, с которой можно
сойтись. Им надо быть не только такого же уровня как и вы, им также необходимо
играть за другие классы. К примеру, обычно желательно иметь в группах бойцов,
лекарей и волшебников. Логистика поиска групп может быть сложным и длительным
процессом.
При борьбе в группе вы делитесь опытом, это
означает что вы получаете меньше опыта за убийство монстра. Чем больше игроков
в группе, тем меньше опыта вы получите, однако тем проще будет убить этого
монстра.
.5 Параллельные режимы подкрепления
В жизни нам часто представляются множественные
режимы подкрепления, и наши действия в любой момент - результат выбора между
альтернативами. Психологи пытались понять, как организмы выбирают между
множествами типами режима подкрепления, и отметили поразительную
согласованность наших выборов. Они обнаружили, что организмы выбирают режим
подкрепления в точной пропорции по отношению к частоте, величие, или задержке
подкрепления для каждого из режимов. К примеру, если голубь получает одну
порцию еды за то, что ударит по синему ключу пять раз, но две порции еды за 5
ударов по красному, голуби будут бить красную кнопку в два раза чаще чем синюю.
Точно также, если режим предусматривает подкрепление в два раза чаще другого,
организмы выбирают этот режим над другим в соотношении 2:1. Эта связь известна
под названием "закон соответствия", который гласит, что относительная
скорость реакции на альтернативный выбор приблизительно равна отношению к
частоте, величие и незамедлительности подкрепления получаемого за выбор этой
альтернативы Miltenberger, R. G. "Behavioral Modification: Principles and
Procedures". Thomson/Wadsworth, 2008. p. 86 .
Исследования пищевого поведения животных в их
естественной среде дали результаты, согласующиеся с этим законом. Позже была
разработана теория оптимального фуражирования, в 1966 году Р. Макартуром.
Теория оптимального фуражирования гласит, что пищевое поведение зависит от
соотношения между количеством энергии, затрачиваемом при поиске, получении и
употреблении пищи, и количеством энергии которое обеспечивает питание. Чистая
прибыль энергии определяет размер, качество, дефицит, и работу, затраченную на
завладение добычей. Когда дается выбор между едой, животные выберут в точной
пропорции к чистой прибыли энергии из различных вариантов питания (т.е.
применяет этот закон). Постулат теории звучит так - животное стремится
максимально увеличить скорость потребление энергии, которую оно получает из
добычи. Поведение фуражирования животных, как например пчел, сов, и грызунов
были рассчитаны с высокой точностью благодаря теории оптимального фуражирования,
и её формуле 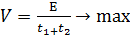 , где
, где 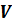 -
скорость потребления пищи,
-
скорость потребления пищи, 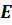 - количество
энергии данного вида добычи, t1 - время поиска добычи, t2 - время обработки добычи.
- количество
энергии данного вида добычи, t1 - время поиска добычи, t2 - время обработки добычи.
.6 Практические вопросы реализации системы
вознаграждения в онлайн-игре
При анализе дизайна онлайн-игры со стороны
оперантного научения (обуславливания), необходимо определить
Какой режим подкрепления применяется?
Какие награды (будут) использованы в игре?
Какое поведение подкрепляется?
В некоторых играх этот процесс прост. К примеру,
очевидно, что онлайн-покер следует режиму переменного подкрепления. В других
играх разгадать режим подкрепления гораздо сложнее. К примеру разные игроки
могут находить различные части одной игры подкрепляющими. Например некоторые
игроки в онлайн-тетрис могут находить подкрепляющим: ставить блоки идеально,
другие - заполнять ряды. При этом оба игрока пользуются разным вариативным
режимом подкрепления.
Вопрос о внедрении систем вознаграждения
осложняет факт научения вторичным подкреплениям. Игрок, которому нравится
заполнять ряды, наверняка научится наслаждаться от идеальной постановки блоков,
и теперь будет оперировать двумя режимами подкрепления. Немного подкреплений выучивается,
но главенствующие мотивы игры из-за них могут измениться. К примеру новые
игроки могут быть мотивированы шансом исследовать игру и протестировать
возможности, ею предлагаемые. Когда они исчерпывают свое первоначальное
любопытство, они могут перейти к попыткам заработка очков, еще позже, они могут
приступить к попыткам получить больше очков чем другие игроки.
Следующее осложнение состоит в том, что может
измениться не только система наград, но и тип режима подкрепления используемый
по ходу игры. К примеру, награда может изначально быть предусмотрена с
фиксированным соотношением, но по ходу игры режим может измениться на
переменный тип. Анализ дизайна игровых наград требуется с обеих сторон -
новичка и опытного игрока.
Для примера рассмотрим онлайн-тетрис - это
простая игра, но она использует множество типов подкрепления. Все они оперируют
на вариативном режиме.
Позитивное подкрепление - получение очков и
заполнение рядов, высокий счет очков и его улучшение, заполнение пространства
блоками, выигрыш или переход на след уровень.
Негативное подкрепление - избегание проигрыша,
построение столбцов из блоков, неудача в увеличении рекорда очков.
.8 Позитивные и негативные стимулы как факторы
воздействия на поведение
Существует два основных вида подкрепления и
наказания. В предыдущей части работы мы говорили только о положительных
стимулах. Существуют также негативные подкрепления и наказания. Стимул
считается негативным, если после определённого поведения происходит удаление
аверсивного стимула (подкрепление), или удаление подкрепляющего стимула
(наказание). Наглядная классификация представлена в табл.№99
Таблица
|
Позитивное
|
Негативное
|
|
Подкрепление
|
Получение
награды
|
Удаление
аверсивного стимула
|
|
Наказание
|
Потеря
награды
|
Удаление
подкрепляющего стимула
|
Тем не менее, современная наука обладая
определением данного вида стимула, несмотря на активное употребление его в
научной литературе не смогла установить однозначную зависимость и связь между
позитивными и негативными факторами подкрепления. Негативное подкрепление
активно используется в нашей повседневной жизни. Например:
Неприятный звук при не пристёгнутом пассажире в
автомобиле является негативным стимулом, а наградой считается исчезновение
этого звука, если пассажир пристегнётся (Gredler, 1992).
Приём таблетки аспирина при головной боли.
Головная боль как негативный стимул, который удаляется при приёме аспирина
Buskist & Gerbing, 1990; Gerow, 1992.
Подкрепление и наказание являются природным
арсеналом в управлении подведением. Хорошо известно, что подкрепляющие и нет
стимулы оказывают критически сильное влияние на поведение. Как уже говорилось
выше, с начала прошлого века психология сделала неизмеримо большой шаг в
изучении поведения человека и животных. Были разработаны тысячи теорий,
проведены десятки тысяч экспериментов и многое другое. Затраченные усилия не
прошли даром, полученные данные были использованы в множестве ситуаций, в том
числе на первый взгляд не относящиеся к психологии. Примером того может служить
проектировка вокзалов, где особое расположение "препятствий"
рассеивает толпу, улучшает инфраструктуру и т.п. Несмотря на то, что
фундаментальные законы подкрепления были сформулированы относительно давно, и
претерпели за время своего существования мало изменений, существует насущная
потребность в постоянном совершенствовании теоретического аппарата, не в
последнюю очередь благодаря специфике нашего постоянно развивающегося и
изменяющегося мира. До настоящего времени неизвестно об однозначном различии
подкрепления и наказания и их влияния на поведение. С одной стороны,
приверженцы однофакторной теории предполагали (как и сам Торндайк), согласно
закону эффекта, что подкрепление и наказание, грубо говоря, являются стимулами,
симметрично расположенными на отрезке [-1;1], где положительный стимул является
подкреплением, а отрицательный - наказанием. Иначе говоря - подкрепление
увеличивает частоту поведения, наказание её снижает, и величины этих эффектов
равны Miltenberger, R. G. "Behavioral Modification: Principles and
Procedures". Thomson/Wadsworth, 2008. p. 86 . С другой стороны, к этому
утверждению стоит относиться лишь как к допущению, ибо оно не подкреплено
достаточными эмпирическими данными. Виной тому - недостаточно совершенная
экспериментальная среда, и нехватка креативных методов по оценке влияния
подкрепления и наказания. В прошлом веке из-за недостаточно развитого
технического оснащения, и невозможности стандартизации в одной шкале измерения
положительного и отрицательного подкрепления оставалось только избегать данных
вопросов. Оставался неразрешённым вопрос: "Оказывают ли эти факторы
симметричное, или качественно различное влияние на поведенческие реакции".
В противоположность однофакторной теории, приверженцы двухфакторных теорий
смотрят на подкрепление и наказание как качественно различные факторы, влияющие
на поведение.
Немногие источники базовой литературы по
вопросам науки о поведении поддержали больший уклон в прикладное применение
полученных знаний, чем исследовании и совершенствовании теории о аверсивном
контроле (наказание и негативное подкрепление) поведения. Вероятно, наиболее
наглядно это продемонстрировал Skinner (1953, 1971, 1974) Skinner, B.F. (1953).
Science and human behavior. New York:
Macmillan. doi: Skinner, B.F. (1971). Beyond freedom and dignity. New York:
Knopf.Skinner, B.F. (1974). About behaviorism. New York: Knopf. и
Сидман
idman, M. (1989). Coercion and its fallout. Boston:
Authors Cooperative. Они экстраполировали эту работу, чтобы выдвинуть обширное
заключение о предполагаемых опасностях аверсивного контроля поведения в
повседневной жизни, что повлекло за собой уточнение учебников по прикладному
бихевиоризму.( Cooper, J.O., Heron, T.E.,
& Heward, W.L. (2007). Applied behavior analysis (2nd ed.). Upper
Saddle River, NJ: Pearson.)и другие трактаты о роли контроля за поведением в
повседневной жизни. Baum, W.M. (2005).
Understanding behaviorism: Behavior, culture, and evolution (2nd Ed.). Malden,
MA: Blackwell. Daniels, A. (1984). Bringing out the best in people: How to
apply the astonishing power of positive reinforcement. New
York: McGraw Hill.1чтобы повторить их заключения с дополнением результатов
прикладного бихевиоризма. Однако, вплоть до этого момента, фундамент отрасли
поведенческой психологии - о аверсивном контроле поведения, на которой основаны
практические советы, ещё далек от однозначного и устоявшегося построения.
Действительно, на протяжении многих десятилей наука о поведении погрязла в
классических рассуждениях об аверсивном контроле поведения, которые мало
свидетельствуют о окончательном разрешении этой проблемы . Baron,
A. (1991). Avoidance and punishment. In I.H. Iverson & K.A. Lattal (Eds.),
Experimental analysis of behavior, Part 1 (pp. 173-217). Amsterdam:
Elsevier.Baron, A., & Galizio, M. (2005). Positive and negative
reinforcement: Should the distinction be preserved? The Behavior Analyst, 28,
85-98.Critchfield, T.S., Paletz, E., MacAleese, K., & Newland, M.C. (2003).
Punishment in human choice: Direct or competitive suppression? Journal of the
Experimental Analysis of Behavior, 80, 1-27.
Таким образом, стандартные рекомендации по
контролю поведения с упоминанием аверсивного контроля могут представлять собой
случаи натягивания практики на теорию. В связи с этим возникает насущная
потребность вернуться к наиболее фундаментальным вопросам об управлении аверсивными
стимулами для прогресса в поведенческой психологии. Critchfield,
T.S., & Farmer-Dougan, V.F. (2014). Isolation from the mainstream: Recipe
for an impoverished science. European Journal of Behavior
Analysis, 15, 6-13. Что касается негативного подкрепления, центральный вопрос
до сих пор остающийся без ответа касается того, как оно отличается от
положительного подкрепления, в частности, являются ли эти подкрепления
различными на фундаментальном уровне, или же позитивное и негативное
подкрепление остаются "двумя сторонами одной монеты" Mowrer, O.H.
(1947). On the dual nature of learning-a
re-interpretation of “conditioning” and “problem solving.” Harvard
Educational Review, 17, 102-148.. Периодические обновления и расширения этих
двух концепций не привели ни к консенсусу враждующие стороны Baron, A., &
Galizio, M. (2005). Positive and negative
reinforcement: Should the distinction be preserved? The Behavior Analyst, 28,
85-98... Dinsmoor, J.A. (2001). Stimuli inevitably generated by behavior that
avoids electric shock are inherently reinforcing. Journal
of the Experimental Analysis of Behavior, 75, 311-333., ни к какому либо
коллективному исследованию этих факторов, которые обычно необходимы для
разработки и продвижения научной теории Critchfield, T.S., & Rasmussen,
E.B. (2007). It's aversive to have an incomplete
science of behavior. Mexican Journal of Behavior Analysis, 33, 1-6..
Барон и Галицио Baron, A., & Galizio, M.
(2005). Positive and negative reinforcement:
Should the distinction be preserved? The Behavior
Analyst, 28, 85-98 отметили, что прежде, чем спросить, как различаются
положительное и отрицательное подкрепления, нужно установить, что они
различаются. Это замечание обращает внимание на историческую двусмысленность, в
отношении того, что выражается терминологическим различием между положительным
и отрицательным подкреплением. Действительно ли позитивное и негативное
подкрепление по-разному контролируют поведение? К сожалению, в течении почти
века эмпирических исследований положительное и отрицательное подкрепление
изучалось главным образом в отдельных экспериментах, а это означается, что
анализ в основном требует сравнения результатов, генерируемых неидентичными
процедурами. В подавляющем большинстве случаев процедуры, используемые для изучения
положительного и отрицательного подкрепления не являются достаточно схожими для
проведения значимых сопоставлений поведенческих эффектов Hineline, P.N. (1984).
Aversive control: A separate domain? Journal of
the Experimental Analysis of Behavior, 42,pp..1984.42-495. Филипп
Хинелин отмечает, что сходство положительного и отрицательного подкрепляющих
эффектов более велико, чем их различия. В дополнение, в начиная с середины
прошлого века исследователями неоднократно предпринимались попытки разработки
негативных подкрепляющих процедур, которые были бы параллельны позитивным
Azrin, N.H., Holz, W.C., Hake, D.F., & Ayllon, T. (1963). Fixed-ratio
escape reinforcement. Journal of the Experimental Analysis of Behavior, 6,
449-456. Dinsmoor, J.A. (1962). Variable-interval escape from stimuli
accompanied by shocks. Journal of the Experimental Analysis of Behavior, 5,
41-47. Verhave, T. (1962). The functional properties of a time out from an
avoidance schedule. Journal of the Experimental Analysis
of Behavior, 5, 391-422.. Тем не менее их выводы в большинстве своём
основывались на сравнении различных экспериментов исследовавших позитивное и
негативное подкреплению, и зачастую сравниваемые эксперименты не были
процедурно идентичными, или хотя бы достаточно схожими, чтобы можно было с
некоторыми допущениями однозначно утверждать о наличии сходств и различий. В
ходе исследования данного вопроса мы обнаружили основные препятствия и шаги,
которые нужно предпринять для оценки сходства и различия позитивного и
негативного подкрепления. В их число входят:
Необходимость сравнения позитивных и негативных
подкреплений и наказаний в рамках одного исследования.
Необходимость оперировать вторичными
подкреплениями и наказаниями повсеместно в ходе исследования.
Необходимость проведения оценки влияния на
поведение как позитивных, так и негативных стимулов на каждом из испытуемых, а
не отдельно.
Необходимость в качестве испытуемых использовать
уравненную выборку людей.
Последний фактор особенно интересен в рамках
поведенческой психологии. Исторически так сложилось, что эта наука, ставившая
приоритет изначально исследовать элементарные элементы поведения, все
эксперименты изначально предлагала проводить на животных, или по крайней мере
допускать возможность предварительного исследования на животных, чаще всего
голубей или шимпанзе. В нашем случае становится очевидным, что провести
однозначную стандартизацию позитивных и негативных подкреплений к одной шкале
для животных не представляется возможным, или по крайней мере, это создаст
исключительную сложность при доказательстве валидности эксперимента, вдобавок к
очень низкому показателю экономичности.
Эта дискуссия о сходстве и различии позитивного
и негативного подкрепления остается, по большей части, неразрешённой, главным
образом, по двум причинам. Во-первых, трудно сравнивать качественно различные
факторы, к примеру подкрепление в виде еды и электрический шок как наказание в
общем масштабе. Решением этой проблемы является работа с подкреплением и
наказанием которые однородны. Во-вторых, предыдущие исследования ставившие
перед собой этот вопрос использовали чрезмерно сложные парадигмы. Сложность
научной парадигмы сильно затрудняет исследование влияния награды и наказания на
поведение. Следовательно, для проведения объективного научного исследования
необходимо использовать простую парадигму, с наименьшим количеством факторов
Cronbach Lee J. Essentials of Psychological Testing (Third Edition). NY.:
Harper and Row, 1970
2. Эмпирическое исследование
.1 Проблемы и цели
Проблема исследования. Различия во влиянии
подкрепления и наказания на поведение между людьми с различной мотивацией.
Цель исследования. Предложить новый
психодиагностический метод, с помощью которого будет возможно измерить
имеющиеся различия в реакции на позитивное и негативное подкрепление и
наказание.
Объект исследования. Подкрепление и наказание
как факторы, влияющие на поведение.
Предмет исследования. Подкрепление и наказание
(положительные и отрицатенльные) как качественно различные факторы, по разному
влияющие на поведение людей.
Гипотеза исследования: Н1- ненаправленная
гипотеза, утверждающая о различном влиянии позитивного и негативного
подкрепления и наказания как качественно различных факторов на поведение.
Гипотеза об отличном друг от друга влиянии на выборку людей, разделённых с
помощью комплекса опросников Эллерса и Шуберта.
В предыдущей главе этой работы было описано то,
как влияет на наше поведение подкрепление и наказание, их режимы и временные
интервалы, однако, возникает вопрос - различается ли влияние этих факторов на
людей между собой? Возможно ли, что человек, привыкший играть, будет
реагировать на стимулы отлично от человека, не играющего в видеоигры? Целью
исследования является попытка ответить на эти вопросы.
Несмотря на то, что теоретические дискуссии
зачатую предполагают различие между положительным и отрицательным
подкреплением, в настоящее время литература содержит мало однозначных
доказательств того, что они оказывают различные эффекты на поведение. Чтобы
проверить, по-разному ли два вида последствий действий влияют на поведение, мы
воспользовались данной нам возможностью измерить относительное влияние на
поведение позитивных и негативных подкреплений и наказаний на поведение, в
режиме распределения "фиксированный интервал с ограниченным удержанием"
с помощью современных технологий программирования. Позже мы сопоставили
результаты прохождения методики для оценки связи результатов с батареей
психодиагностических методик, призванных измерить мотивацию испытуемого на
успех, на избегание неудач, и готовность к риску. В эту психодиагностическую
батарею входили опросники Эллерса (2 части: мотивация успеха + мотивация
избегания неудач) вместе с методикой Шуберта- «Склонность к риску». Эти
методики основаны на предположении, что мотивация успеха и мотивация избегания
неудач - две отдельные мотивации, и их соотношение в разных ситуациях может
быть различно.
Для проведения данного исследования мы
воспользовались простой парадигмой. За методологическую основу был выбран метод
исследования, опубликованного в 2015 году Яном Кубанеком (Cognition. 2015
Jun; 139: 154-167) Kubanek. J., L. H. Snyder., R. A. Abrams. Reward and
punishment act as distincs factors in guiding behavior // J. Kubanek. Elsevier
Cognition. NY.: CrossMark, 2015. Метод Яна был всесторонне усовершенствован практически
во всех его частях, результатом чего явилась возможность как более точно
отслеживать эффект диспропорции во влиянии различного подкрепления и наказания
на поведение человека, так и отслеживать это влияние всесторонне, а не только
со стороны позитивного подкрепления и наказания. Целью исследования было
выявление различий между влияниями позитивным подкреплением и наказанием в
зависимости от их величины. Основным методом воздействия на испытуемого было
изменение величины награды и наказания после каждой пробы и автоматическое
динамическое изменение сложности поставленных задач в зависимости от уровня
правильных ответов (60%) испытуемого. Этот метод позволил нам измерить
тенденцию испытуемых к повторению предыдущего выбора в зависимости от изменения
величины награды и наказания. Эти простые условия позволяют проверить
однофакторные и двухфакторные теории на возможность к предсказанию поведения. В
этой парадигме, однофакторные теории предсказывают, что награды и штрафы
приведут к симметричным, противоположным реакциям на поведение. В
противоположность им, двухфакторные теории предсказывают, что тенденция к
повторению результата в зависимости от величины награды или наказания, и будут
качественно различными для этих двух факторов. В данном эксперименте было
использовано два режима подкрепления: фиксированный и вариативный интервал
подкрепления с ограниченным удержанием. Фиксированный интервал использовался
при прохождении проб с предъявлением стимулов, вариативный интервал применялся
при прохождении проб без предъявления стимулов. В этом исследовании не были
использованы дополнительные различные комбинации режимов подкрепления, а только
основные реакции на подкрепление и наказание, отрицательное и положительное,
так как это потребовало бы значительно больших временных и вычислительных
инвестиций. В силу того, что эта работа является дипломной, и это исследование
ещё не прошло необходимой полной валидизации, полученные результаты нельзя
считать однозначно верными, и ведущими к подтверждению H1. Данная гипотеза
является ненаправленной, что характерно для предварительного исследования с
применением новых методик. Необходимость предварительного исследования
диктуется новизной методики, отсутствием высоковалидных способов анализа
конструктной валидности в связи с отсутствием методик, измеряющих тот же
параметр, что и новая методика, а также возможности экспертной оценки со
стороны, как поступают с тестами достижений. Также предварительное исследование
позволяет обнаружить ошибки и недочёты в новой методике, в том числе и
негативный "эффект потолка", который не наблюдался в эксперименте.
2.2 Процедура эксперимента
Испытуемый садился за стол перед компьютером, на
расстоянии 50-80 см от монитора. Первоначально испытуемый проводил серию из 20
проб, чтобы привыкнуть к заданию. Перед испытуемыми открывалось графическое
изображение, в котором на светло-сером фоне по двум сторонам экрана, на
расстоянии около 8 см друг от друга располагалось 2 круга, размером в 2
зрительных градуса или |2о|. Эти условия были необходимы для избегания
попадания кругов в области слепых пятен испытуемых. Во время проведения проб
координаты кругов были неизменны. В дополнение, были отобраны испытуемые без
астигматизма и косоглазия, во избежание попадания кругов в зоны слепых пятен.
Эксперимент выглядел следующим образом: До
исследования всем испытуемым, было объявлено, что игроки, набравшие наибольшее
количество баллов получат приз, который будет объявлен после 26 июня. В начале
испытуемому было необходимо заполнить информацию о себе, перейти к правилам
игры, которые даны в приложении №1. После того, как было установлено, что
испытуемый понял все правила, он получал возможность приступить к
психодиагностической игре. Образец того, как выглядели пробы 1 типа приведён в
приложении №2, 3 типа - в приложении №3.
Суть игры состояла в наборе наибольшего
количества очков путем ответа на последовательно появляющиеся друг за другом
пробы. Всего испытуемый проходил 240 проб, первые 20 из которых считались
обучающими, и не брались в учёт при оценке уровня влияние позитивных и
негативных подкреплений и наказаний. В ходе пробы испытуемому было необходимо
выявить сторону (правую или левую), на которой круги мигали чаще. Для дачи
ответов использовалась кнопки, появляющиеся после предъявления пробы под полем
предъявления кругов.
Всего в эксперименте насчитывалось 4 вида задач.
Проба, в которой предъявлялись синие круги. При
правильном ответе испытуемый получал 1, 2 или 4 балла. При неправильном - терял
1, 2 или 4 балла.
Проба, в которой не предъявлялось кругов. При
переходе на эту пробу поле предъявления окрашивалось в синий цвет, и от
испытуемого требовалось сделать выбор в пользу той или иной стороны. При
правильном ответе испытуемый получал 1, 2 или 4 балла. При неправильном - терял
1, 2 или 4 балла.
Проба, в которой предъявлялись зелёные круги.
При правильном ответе испытуемый получал баллы, предотвращающие потерю 1, 2 или
4 баллов в будущем. При неправильном - получал баллы, предотвращающие получение
1, 2 или 4 баллов в будущем.
Пробы с синим цветом представляли собой
"Позитивное подкрепление и наказание", в котором наградой считается
получение баллов, а наказанием - потеря. Пробы с зелёным цветом представляли
собой "Негативное подкрепление и наказание", в котором наградой
считается удаление аверсивного стимула (потери баллов) а наказанием - удаление
подкрепляющего стимула (получения баллов).
Всего предусмотрено 12 различных исходов проб.
Для синих проб исход исчисляется в итоговом изменении кол-ва баллов
{-4;-2;-1;1;2;4}. Для зелёных проб исход исчисляется в баллах, которые
предотвращают изменение баллов исходами синих проб {4,2,1,-1,-2,-4}. Подобные
величины были взяты неслучайно. Основанием для их выбора послужил "Закон
Стивенса", доказанный в 1957 го Стенли Стивенсоном, модифицировавший
психофизиологический "закон Вебера-Фехнера" (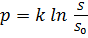 ).
Этот закон постулирует о том, что зависимость силы ощущения от интенсивности
раздражителя описывается степенной функцией
).
Этот закон постулирует о том, что зависимость силы ощущения от интенсивности
раздражителя описывается степенной функцией 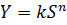 (где
Y - сила субъективного ощущения, S - интенсивность стимула, n - показатель
степени функции и k - константа, зависящая от единиц измерения), а не
логарифмической, как считалось ранее. Целью подбора возможных изменений
количества баллов было составление экономного (во избежание излишне большого
количества дополнительных переменных, которые бы потребовали заметно увеличить
количество проб в исследовании), и соотносимого состава целых величин, так,
чтобы каждая следующая ощущалась в 2 раза больше предыдущей, и в целом отвечала
генерализованному восприятию соотношения величин. В качестве константы была
выбрана "протяжённость линии", как самая наглядная в плане восприятия.
В результате мы получили величины (1,2,4), которые затем перевели в
отрицательные. Так мы добились удобного представления величин, отвечавшее
требованию экономности. В результате каждая из проб получила 25 возможных
результатов. Величина награды для каждого отдельного задания присваивалась
методом подбора случайных чисел, (1;3), где 1 - 1 балл, 2 - 2 балла, 3 - 4
балла. За каждым из заданий закреплялась величина |1;2;4|, которая уже во время
проведения методики изменяла свой знак на отрицательный или положительный, в
зависимости от ответа испытуемого. Испытуемые не были проинформированы о том,
что изначально за каждым заданием закреплялась случайная величина награды и
наказания соответственно.
(где
Y - сила субъективного ощущения, S - интенсивность стимула, n - показатель
степени функции и k - константа, зависящая от единиц измерения), а не
логарифмической, как считалось ранее. Целью подбора возможных изменений
количества баллов было составление экономного (во избежание излишне большого
количества дополнительных переменных, которые бы потребовали заметно увеличить
количество проб в исследовании), и соотносимого состава целых величин, так,
чтобы каждая следующая ощущалась в 2 раза больше предыдущей, и в целом отвечала
генерализованному восприятию соотношения величин. В качестве константы была
выбрана "протяжённость линии", как самая наглядная в плане восприятия.
В результате мы получили величины (1,2,4), которые затем перевели в
отрицательные. Так мы добились удобного представления величин, отвечавшее
требованию экономности. В результате каждая из проб получила 25 возможных
результатов. Величина награды для каждого отдельного задания присваивалась
методом подбора случайных чисел, (1;3), где 1 - 1 балл, 2 - 2 балла, 3 - 4
балла. За каждым из заданий закреплялась величина |1;2;4|, которая уже во время
проведения методики изменяла свой знак на отрицательный или положительный, в
зависимости от ответа испытуемого. Испытуемые не были проинформированы о том,
что изначально за каждым заданием закреплялась случайная величина награды и
наказания соответственно.
Ход пробы: Испытуемый переходил к новой пробе,
затем, если она представляла 1 или 3й тип задач, то в течении четырёх секунд на
правой и левой сторонах поля для пробы появлялись и исчезали круги со статичной
для каждого из кругов частотой. После того как предъявление кругов
заканчивалось, поле предъявления окрашивалось в цвет кругов, предъявляемых в
этой пробе. У испытуемого было 2 секунды на то, чтобы сделать выбор в пользу
правой или левой стороны. После ответа немедленно следовал результат пробы и на
месте кнопок "С левой" и "С правой" появлялся текст
величиной в 30 пикселей, соответствовавший результату ответа. Для подтверждения
ответа испытуемому было необходимо нажать левой кнопкой мыши на один из
вариантов ответа. Если был дан правильный ответ, то текст результата был с
белой рассеянной обводкой величиной в 3 пикселя. Если был дан неверный ответ,
то обводка была красной, толщиной в 3 пикселя. Если проба представляла 2 или 4й
тип задач, то в течении двух секунд после перехода к пробе поле предъявления
окрашивалось в цвет, соответствовавший типу задания, под которым появлялся
текст "Сделай выбор наугад" и испытуемому требовалось выбрать сторону
без предъявления стимулов. Далее следовало предъявление результатов ответа и на
месте кнопок "С левой" и "С правой" появлялся текст
величиной в 30 пикселей, соответствовавший результату ответа. Если был дан
правильный ответ, то текст результата был с белой рассеянной обводкой величиной
в 3 пикселя. Если был дан неверный ответ, то обводка была красной, толщиной в 3
пикселя. В случае если испытуемый за данные ему 3 секунды на ответ не выбирал
какой либо из вариантов, то проба считалась проваленной и испытуемый переходил
к следующему испытанию. Общее количество валидных проб в итоге составило
99.58%.
После начала пробы испытуемому демонстрировали
серию появляющихся и исчезающих кругов с частотой начиная от 0.1мс и заканчивая
1000 мс. Частота мигания кругов была неизменна для каждого из них в каждой
пробе. Частота смены кадров, была скорректирована в соответствии с частотой
обновления монитора, чтобы время смены кадров отклонялось на минимально
возможную величину, при этом сохраняя высокую концентрацию испытуемых на
задании не давая им расслабиться.
Всего изначально было создано 400 различных
вариантов задач, в которых варьировалась частота появления и исчезновения
кругов, и количество баллов, которые несёт собой исход задачи, из которых,
путём отбора были удалены 260, и выбраны те задачи, которые наилучшим образом
отвечали требованиям к их составлению: относительный уровень сложности,
наглядность, и понятность испытуемому. После, из получившегося списка, задачи
были ранжированы по уровню сложности, от 1 до 10. В определении уровня
сложности принимали участие 3 испытуемых, каждый из которых проходил все
отобранные задачи и ранжировал их по уровню сложности. Данные испытуемые позже
не использовались в качестве выборки в основном эксперименте. Всего было
составлено 10 уровней сложности, в каждом из которых было по 24 задачи. В
дальнейшем, при прохождении методики, программа через каждые 3 пробы проверяла
результаты испытуемых на соотношение полученных правильных и неправильных
ответов. Если соотношение отклонялось от стандарта в 6:4, где 6 - верные
ответы, а 4 - неверные. Сложность заданий была заранее составлена таким
образом, чтобы количество правильных ответов испытуемых составляло около (60%).
Целью подобной корректировки количества правильных ответов было соблюдение
баланса между подкреплением и наказанием, и сохранение интереса испытуемых к
проводимому исследованию.
Количество показываемых кругов было фиксировано,
соответствуя формуле
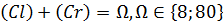 ,
,
где 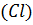 является
количеством предъявлений левого круга, а
является
количеством предъявлений левого круга, а
(Cr) - количество предъявлений правого круга.
При этом, выражения
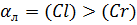 и
и 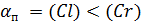 ,
,
где αx-проба,
в которой чаще предъявлялся круг определённой стороны (правой или левой) в
течении создания эксперимента выбирались случайно из 24 на уровень сложности, и
независимо от испытуемых.
Всего в методике было использовано четыре вида
заданий. У каждого из них изначально была выставлена своя пропорция появления в
серии испытаний. Количество задач первого и третьего видов составляло по 37% из
100. Для задач второго и четвертого видов была выставлена пропорция появления
по 13% из 100. При этом была задана невозможность предъявления задач типа 2 или
4 друг за другом, после них всегда следовали задачи типа 1 и 3. Сложность
заданий была заранее составлена таким образом, чтобы количество правильных
ответов испытуемых составляло около (60%). Целью подобной корректировки
количества правильных ответов было сохранение интереса испытуемых к проводимому
исследованию. Этого удалось достичь благодаря ранжированию заданий по сложности
до эксперимента, распределению заданий в потоке эксперимента.
Выборка в исследовании составила 2 человека.
Испытуемыми являлись разнополые люди, возрастом от 20 до 26 лет, студенты,
которые не были знакомы друг с другом, тем не менее этот фактор остаётся
незначимым в данном исследовании, так как методика проводилась с использованием
двойного слепого метода, а опросники испытуемые заполняли уже после прохождения
методики. Так как в этом исследовании выдвигается гипотеза о различиях между
группами, не включающую в себя котнрольную, то исследователь мог бы повлиять на
испытуемых, если бы знал заранее о распределении групп. Благодаря слепому
методу исследователь также во время эксперимента не обладал данными о
распределении групп и отношении испытуемого к той или иной группе, которые
образовывались посредством обработки результатов трёх опросников, и не мог
повлиять на прохождение методики испытуемым осознанно или неосознанно с целью
исказить данные. Таким образом, испытуемые могли получить возможность
догадаться об исследуемом факторе только после того, как они уже заполнили методику.
Применение слепого метода среди испытуемых в данном случае очень важно, потому
что это позволяет в полной мере отследить исследуемый фактор с минимальным
риском появления таких частых ошибок как "ошибка положительного
испытуемого". Уже после проведения эксперимента, во время беседы с
испытуемым раскрывалась цель эксперимента, и ни один из испытуемых, по их
словам, не был близок к правде в поисках смысла исследования.
Всего в исследовании приняло участие Х человек.
Выборка испытуемых была уравнена в показателях возраста, пола, рода занятий,
социального положения, работе зрительного аппарата.
Процедура проводилась в домашних условиях у
испытуемого с помощью персонального компьютера, перед экспериментом не
проводились какие-либо предварительные психологические методики, для снижения
вероятности появления эффекта "истощения Эго", предложенного на
основе психодинамической теории Роем Баумейстером (by Roy F. Baumeister, 1994,
ACADEMIC PRESS, San Diego, 307 pp.). Каждая серия проб длилась 20 минут, при
этом первые 20 проб (~2 минуты) уделялись на пробные попытки, в которых
проводилось ознакомление с видами задач и временными рамками проб. Изначально
перед испытуемыми ставилась задача набрать как можно больше очков - это, самая
частая форма подкрепления, встречающаяся в играх.
С учётом того, что эксперимент построен на
основе другого, но существенно изменён по большинству параметров, встаёт вопрос
о валидности исследования. Первоначально, задания были заметно упрощены, таким
образом давая эффекту влияния подкрепления и наказания возможность проявится в
гораздо более приближённых к реальности условиям. Тем не менее, была соблюдена
цель в сохранении уровня правильных ответов в 60%. Был использован другой метод
изменения сложности в соответствии с уровнем правильных ответов испытуемых,
позволяющий более полно отразить прогресс испытуемых. Благодаря этому уровень
правильных ответов среди всех испытуемых составил Х со стандартным отклонением
Х. Во время разработки эксперимента была проведена его стандартизация, что
можно заметить в описании эксперимента. Соответственно, как уже было сказано, в
данном методе используют фиксированный и вариативный интервал подкрепления с
ограниченным удержанием. Фиксированный интервал используется при прохождении
проб с предъявлением стимулов, вариативный интервал применяется при прохождении
проб без предъявления стимулов.
Валидность данного экспериментального метода
необходимо рассматривать сразу с нескольких сторон, как и для всех других
стандартизированных психодиагностических методик. Наиболее важная -
конструктная валидность данной методики - до сегодняшнего дня остаётся
неопределённой до конца, и для её подтверждения необходимы методики, измеряющие
то же свойство что и оригинальная Романова Е.С. Психодиагностика. МСК.: Кнорус,
2015.. Известно, что при анализе константной валидности методики обычно
формулируют ряд гипотез о том, как будет коррелировать разрабатываемая методика
с массивом других методик, направленных на конструкты, находящиеся в
теоретически известной или предполагаемой связи с исследуемыми. Также
ограниченность во времени не позволяет провести мета-анализ дискриминантной и
конвергентной валидностей. Тем не менее, на основании полученных данных и их
соотношения с "экспериментом Кубанека" Kubanek. J.,
L. H. Snyder., R. A. Abrams. Reward and punishment act as distincs factors in
guiding behavior // J. Kubanek. Elsevier Cognition.
NY.: CrossMark, 2015 можно заключить, что обе методики имеют относительно
устойчивую корреляцию, и обладают схожей текущей и прогностической валидностью.
Положение внутренней валидности исследования скорее благоприятное, и несмотря
на невозможность изучения какого-либо отдельного психического процесса отдельно
от психики в целом, данная методика уделяет много внимания минимизации
разнообразных факторов, угрожающих внутренней валидности. Внешняя валидность,
как возможность обобщения данных пока не исследована, и для её соблюдения
необходимо, по крайней мере, проведение эксперимента с участием 200 или более
человек. Данная методика имеет потенциально высокую инкрементную валидность не
в последнюю очередь благодаря случайности нескольких переменных и слепому
методу, позволяя, в перспективе, обнаружить подверженность испытуемого внешним
факторам, выраженность выученной беспомощности, и др.
Уже на стадии разработки метод удовлетворяет
двум из трёх требований, необходимых для соблюдения критерия объективности, в
их число входит доступность и удобство, относительная простота процедуры
тестирования и оценивания, отсутствие высоких требований к квалификации
персонала, и дешевизна стимульной части метода. Это утверждённые высказано с
допущением того, что у каждого испытуемого будет наличествовать собственный
персональный компьютер дома. Как бы то ни было, мы не видим препятствий для
проведения эксперимента в лаборатории. Процедура оценки результатов в данном
исследовании заняла много времени, но только из-за несовершенства
вычислительного аппарата. В будущем данную часть исследования будет возможно
перенести на ЭВМ, таким образом, многократно увеличив экономность метода.
Прогностическая ценность данной методики пока не установлена, и для её
определение потребуется провести ещё как минимум одну процедуру с большинством
испытуемых, уже проходивших её.
Анализ ложной валидности достоин отдельного
упоминания. В неё входит: очевидная валидность, валидность исходящая из опыта,
валидность опирающаяся на убеждения, и валидность основанная на желании. В ходе
исследования был подтверждён высокий уровень очевидной валидности среди
испытуемых, что, безусловно является положительным фактором для метода.
Валидность, исходящая из опыта неприменима к данному методу в её первоначальном
смысле, что является плюсом методики, в которой использовался односторонний
слепой метод. Валидность, опирающаяся на убеждение слабо применима к данному
методу, так как при его разработке были использованы, грубо говоря, все
однофакторные и двухфакторные теории подкрепления, и её целью было определение
"одного из двух", что является плюсом метода. Единственным наиболее
вероятным минусом данного метода является "валидность, основанная на
желании" - она предполагает наличие предубеждений исследователя
относительно возможностей метода. Тем не менее её уровень минимизируется
благодаря изначальному принятию факта того, что практическая часть с
использованием данного метода носит характер простого пилотного исследования, и
того, что методу в любом случае потребуется доработка - стандартизация,
увеличение надежности, пересмотр взглядов на проблему константной валидности и
др.
В дальнейшем, при совершенствовании данного
метода планируется уделить особое внимание переменным модераторам, которые
зачастую оказывают заметное влияние на результаты валидизации любого метода. К
примеру, при прогностической валидизации теста способностей было обнаружено,
что наивысшую валидность имели тесты у интравертов, в то время как у
экстравертов корреляция находилась за пределами значимости результатов.
.3 Результаты исследования
По итогам проведения 240 проб с каждым из
испытуемых были получены результаты, на основании которых были построены
графики, которые приведены в приложении. Результаты эксперимента представлены в
таблицах 1 и 3 для первого испытуемого - игрока, результаты контрольной выборки
показаны в таблицах 2 и 4 (стр 51-53). Графики 3 и 4 (стр. 56) представляют собой
графическое отображение общей тенденции к повтору и избегания предыдущего
выбора в зависимости от того, получил ли испытуемый награду или наказание.
Результаты применения t-критерия Стьюдента и U-критерия Манна-Уитни на реакцию
после наказания указывают на значимые различия между эмпирическим и
теоретическим распределением.
Полученные результаты могут указывать на две
причины. Первая - реакция на подкрепление и наказание несимметрична из-за того
что это два качественно различных фактора. Вторая - на основании полученных
данных можно подтвердить предварительную гипотезу Н1 - гипотезу о различиях в
восприятии подкрепления и наказания между игроками в видеоигры и обычными
людьми. Для сравнения, во второй части графиков приведено графическое
отображение влияния подкрепления и наказание на следующий выбор в пробах, где
не было предъявления стимулов, в которых также присутствует тенденция
повторения поведения при подкреплении и избегания при наказании. Тем не менее,
нельзя однозначно утверждать о подтверждении Н1 в силу того, что выборка
составила 2 человека.
На основании полученных данных были построены
графики 2 и 4, приведённые в приложении. Целью графиков было отображение
влияния на поведение величины подкрепления. Впоследствии, на основании
полученных данных были проведены средние линии, для графического отображения
влияния подкрепления и наказания на поведение в зависимости от величины награды
и наказания. Общая тенденция выглядит так: подкрепление, независимо от своей
величины оказывает меньшее влияние на поведение, чем наказание. Среди всех
полученных данных, ни одна из величин подкрепления не вызывала сопоставимого
влияния на поведение, как такая же величина наказания. Вероятно, подкрепление и
наказание являются качественно различными факторами, оказывающими различное
влияние на поведение человека. Скорее всего, это обусловлено эволюционными
факторами. Вероятно, для нахождения оптимального решения проблемы и поведения
необходима несимметричная реакция на факторы подкрепления и наказание. Человек
искал лучшее поведение, и продолжал его повторять при подкреплении неизбежно
внося небольшие изменения в процесс, а при наказании следовал немедленный
пересмотр стратегии поведения, первоочередной задачей которого являлось
избегание любого наказания, вне зависимости от его величины, и сравнимой
величины потенциального подкрепления.
На основании полученных данных, можно выдвинуть
заключение для предварительного исследования. С вероятностью 95% следует
заключить, что ненаправленная гипотеза о различном влиянии подкрепления и
наказания, в и вне зависимости от величины награды и наказания оказывают
различные эффекты на поведении человека. Тем не менее, здравый смысл и
статистические методы в лице U и t-критериев не позволяют вынести заключения о
различном влиянии этих факторов на поведение между выборкой игроков и
контрольной группы. Таким образом, первая из двух гипотез Н1 была подтверждена,
а вторая гипотеза не получила подтверждения.
.4 Научение посредством подкрепления
Множество исследований фокусируются на процессах
принятия решений, которые люди и животные употребляют при выборе действий перед
лицом награды и наказания. Всё чаще анализ поведения на уровне вычислительных
операций опирается на идеи обучения с подкреплением, которое обеспечивает
удобную теоретическую основу в рамках которой процесс принятия решений может
быть проанализирован.
Фундаментальный вопрос в поведенческой
нейробиологии касается процессов принятия решений благодаря которым люди и
животные выбирают действия перед лицом награды и наказания, и их нейронным
осуществлением. В бихевиоризме этот вопрос был подробно исследован с помощью
классической и оперантной парадигмы обуславливания. С их помощью было собрано
множество данных, в отношении того, как ассоциации контролируют различные
аспекты выученного поведения. Вычислительная сторона обучения с подкреплением
обеспечила нормативную структуру, в рамках которой можно понять такое обучение.
Здесь оптимальный выбор действий основан на прогнозах долгосрочных последствий,
например, что принятие решения направлено на достижение максимальной выгоды и
минимизации потерь.
Научные данные, полученные от нейрологии,
физиологии, фармакологии, и т.д. о поведении животных позволили обозначить
(предварительно) нервные структуры, лежащие в основе ключевых вычислительных
конструкций в этих моделях. С вычислительной точки зрения Павловское
обуславливание рассматривается как прототип - экземпляр обучения предсказанию -
обучение построения прогностических связей между событиями в окружающей среде.
Инструментальное обуславливание, с другой стороны, включает в себя обучение
выбору действий, которые увеличат вероятность полезных событий, и уменьшат
вероятность аверсивных событий. С математической точки зрения, такой процесс
принятия решений рассматривается как попытка оптимизировать последствия
действий со стороны долгосрочной перспективы, исчисляющиеся в общем количестве
вознаграждений, и/или избегания наказания.
Научение посредством подкрепления (далее - НПП)
- это обучение посредством взаимодействия с окружающей средой. Субьект НПП
обучается благодаря обсервации последствий своих действий, вместо простого
эксплицитного обучения, субъект выбирает действия на основе прошлого опыта, и
новым выборам, которое по сути своей представляет метод проб и ошибок.
Различные модели предполагают разные механизмы увеличения ассоциативной связи.
В данной работе мы упомянем о двух из них. Первая из них - модель
Рескорлы-Вагнера является самой перспективной из всех математических моделей
обучения, которая уже неоднократно применялась в эмпирических исследованиях с
большим успехом. Р. Рескорла и А. Вагнер совместно разработали математическую
модель процесса обучения на основе теории подкрепления, с использованием
разностного уравнения. При этом они оперировали теоретической физиологической
переменной, названной ими "ассоциативная сила" и обозначенной через
V. Они предполагали, что после каждого сочетания условного и безусловного
раздражителей. Их предположение состояло в том, что после каждого сочетания
условного и безусловного раздражите лей новое значение изменяется ассоциативной
силы Vnew и равно предшествующему значению, плюс прирост "ассоциативной
силы" ∆V за счет сочетания условного и безусловного раздражителей.
Иными словами:  . Они
постулировали, что
. Они
постулировали, что 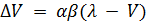 , где V - текущее
значение ассоциативной силы; α - относительная
сила влияния условного раздражителя, варьирующаяся между 0 и 1; λ
- максимум
ассоциативной силы; β - относительная
сила влияния безусловного раздражителя, также варьирующая между 0 и 1.При
эмпирических расчетах по этой формуле необходимо задать начальное значение V0,
значения α, β и λ.
Тогда
после первого сочетания условного и безусловного раздражителей
, где V - текущее
значение ассоциативной силы; α - относительная
сила влияния условного раздражителя, варьирующаяся между 0 и 1; λ
- максимум
ассоциативной силы; β - относительная
сила влияния безусловного раздражителя, также варьирующая между 0 и 1.При
эмпирических расчетах по этой формуле необходимо задать начальное значение V0,
значения α, β и λ.
Тогда
после первого сочетания условного и безусловного раздражителей 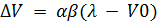 и
и
 .
Аналогичноiвычисляется значение "ассоциативной силы" при каждом из
следующих сочетаний условного раздражителя и безусловного раздражителя.
Особенно важным в этой модели является тот факт, что авторы допускали ненулевое
начальное значение "ассоциативной силы" V0. В рамках данного
исследования не предполагается адаптация этой модели поведения на полученных
результатах, и их сравнение, по нескольким причинам. Первая - полученные
результаты, какими бы они ни были не могут считаться валидными из-за репрезентативности
выборки. Вторая - адаптация модели, с учётом имеющихся данных потребует
использования специального программного обеспечения, использующегося в
математических вычислениях, иначе - сложность задачи далеко выходит за рамки
возможностей исследователя.
.
Аналогичноiвычисляется значение "ассоциативной силы" при каждом из
следующих сочетаний условного раздражителя и безусловного раздражителя.
Особенно важным в этой модели является тот факт, что авторы допускали ненулевое
начальное значение "ассоциативной силы" V0. В рамках данного
исследования не предполагается адаптация этой модели поведения на полученных
результатах, и их сравнение, по нескольким причинам. Первая - полученные
результаты, какими бы они ни были не могут считаться валидными из-за репрезентативности
выборки. Вторая - адаптация модели, с учётом имеющихся данных потребует
использования специального программного обеспечения, использующегося в
математических вычислениях, иначе - сложность задачи далеко выходит за рамки
возможностей исследователя.
Тем не менее, в рамках данной работы возможен
анализ одной из математических моделей, адаптация под решения которых не
требует больших вычислительных мощностей. Это модель "win-stay,
lose-switch", успешно применявшаяся при решении проблем, связанных с
"игровыми автоматами", "дилеммой заключённого" и др. Модель
утверждает, что выбор следующего действия зависит только от исхода предыдущего
акта поведения. Исходы подразделяются на успешные (награды) и неудачные
(наказания). Если поведение в предыдущем раунде было подкреплено, тогда субъект
повторяет стратегию поведения, если поведение было наказано - то субъект
переключается на другую стратегию поведения. Вероятность, с которой повторение
и изменение поведение будет происходить определяется двумя свободными
параметрами, Preward и Ppenalty. При адаптации метода со значением переменных
Preward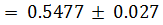 и
Ppenalty
и
Ppenalty 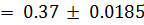 для
группы игроков, и Preward
для
группы игроков, и Preward 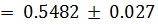 и Ppenalty
и Ppenalty 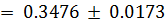 для
контрольной группы. Были получены результаты, приведённые в таблицах 5 и 6 в
приложении. Как можно увидеть, данная модель оказалась неспособной предсказать
реакции испытуемых, в первую очередь благодаря тому, что модель не учитывает
величину подкрепления и наказания.
для
контрольной группы. Были получены результаты, приведённые в таблицах 5 и 6 в
приложении. Как можно увидеть, данная модель оказалась неспособной предсказать
реакции испытуемых, в первую очередь благодаря тому, что модель не учитывает
величину подкрепления и наказания.
Подводя итог, вычислительные модели обучения
многое сделали для улучшения нашего понимания процесса принятия решений за
последние несколько десятилетий благодаря своей способности к предсказанию
поведения. Совершенствование математических моделей обучения с подкреплением
продолжается до сих пор, и продолжится в будущем, как и изучение данного метода
исследования подкрепления и наказания.
Выводы
Применение общих правил к конкретному случаю
редко обходится без потерь, особенно в ситуациях, когда существует более чем
одна непредвиденная переменная. Большинство экспериментов в поведенческой
психологии предназначены для освещения одного, определённого явления, подобно
рентгену, просвечивающему кости руки. Кожа, мускулы в этом случае не видны, и в
результате картина будет являться неполной. Но даже видя только кости, мы
способны выдвинуть жизнеспособные предположения о том, как работает рука, её
возможности и ограничения. Принципы Бихевиоризма, обсуждаемые здесь должны
иметь схожие преимущества и ограничения. Существует огромное множество других
факторов, которые влияют на игроков, но базовые паттерны поведения и
математические модели формируют фундамент. Понимая фундаментальные
закономерности, которые лежат в основе игры, мы сможем сформировать более полно
не только модели подкрепления игр, мотивации игроков, но и более успешные
модели поведения и обучения.
Список использованной литературы
1. Thorndike
E. L. Human learning. NY.: Century Company, 1931.
2. Cronbach
Lee J. Essentials of Psychological Testing (Third Edition). NY.:
Harper and Row, 1970
3. Kubanek.
J., L. H. Snyder., R. A. Abrams. Reward and punishment act as distincs factors
in guiding behavior // J. Kubanek. Elsevier Cognition.
NY.: CrossMark, 2015.
4. Sharma,
M., Ontañón, S., Mehta, M. and Ram, A. Drama Management and
Player Modeling for Interactive Fiction Games.
Computational
Intelligence Journal, 26(2), 2010. р. 183-211.
5. Toma,
C. L. Affirming the Self through Online Profiles: Beneficial Effects of Social
Networking Sites. In Proceeding of CHI 2010, р.
1749-1752.
6. Walther,
J. B. Selective self-presentation in computer-mediated communication:
Hyperpersonal dimensions of technology, language, and cognition. Computers
in Human Behavior, 2007.р. 1 - 23, 2538-2557.
7. Bates,
B. Game Design: The Art & Business of Creating Games. Prima
Publishing, Roseville, CA, 2001.
8. Kazdin,
A.E. Behavior Modification in Applied Settings, Belmont, Brooks/Cole, 1989.
. Martin,
G., Pear, J., Behavior Modification, New Jersey, Prentice Hall, 1992.
. Medler,
B., John, M. and Lane, J. Data Cracker: Developing a Visual Game Analytic Tool
for Analyzing Online Gameplay. In Proceedings of CHI 2011.
Vancouver, BC Canada.
11. Few,
S. Now You See It: Simple Visualization Techniques for Quantitative Analysis. Analytics
Press, 2009.
12. Spence,
R. Information Visualization. ACM Press, 2001.Age and Sex Composition: 2010. [Электронный
ресурс] URL: #"898217.files/image023.gif">
Приложение 3
Образец того, как выглядела проба типа 3.

Приложение 4
График наглядного представления результатов
методики одним из испытуемых. В случае, если какая либо из величин исхода пробы
не повторялась более 7 раз, результаты её влияния на поведение не учитывались. На
графике это выражено пунктирными линиями. Линия обозначенная синими кругами
представляет результаты задания №1, с зелёными - задания №2, сплошная синяя
линия - задания №3, сплошная зелёная - задания №4.
Результаты прохождения методик.
Опросник Эллерса для оценки мотивации избегания
неудач: 19 баллов, умерено высокий уровень мотивации избегания неудач.
Опросник Эллерса для оценки мотивации к успеху:
18 баллов, умеренно высокий уровень мотивации к успеху.
Опросник Шуберта для оценки готовности к риску:
25 баллов,
Приложение 5
График общего представления результатов
методики, без учётов типов задач и величин баллов, закреплёнными за заданиями.
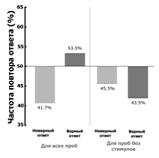
Приложение 6
График представления результатов методики по
каждому из типов заданий, без учёта величин баллов.