Разработка программно-аппаратного комплекса для анализа видеоизображения и управления видеокамерой средствами языка C/C++ и библиотеки Open CV в среде разработки QT Creator
Введение
Данная работа посвящена разработке
программно-аппаратного комплекса для анализа видеоизображения и управления
движением роботизированной видеокамерой. Под анализом видеоизображения будем
подразумевать обработку цифрового изображения, полученного с камеры с целью
слежения (трекинга) за движением объекта.
На сегодняшний день задача трекинга
объектов на видео является неотъемлемой частью многих прикладных областей,
таких как построение систем видеонаблюдения, отслеживания дорожного трафика,
создание интерфейсов человек-компьютер, различных программ и т.п. За последние
годы было предложено множество успешных подходов к решению данной задачи. Тем
не менее, многие из них накладывают определенные ограничения на обрабатываемые
данные, как то статичный фон и фиксированный ракурс, знания о типе наблюдаемого
объекта или даже наличие множества камер. Большая часть предлагаемых подходов
уделяет мало внимания возможности проводить анализ в реальном времени, хотя и
некоторые из них наоборот ориентированы на строгие ограничения по ресурсам.
Целью данной работы является
разработка программно-аппаратного комплекса, особенностями которого можно
считать способность обнаруживать и отслеживать объекты в режиме реального
времени путем управления поворотом роботизированной камеры, которая находится в
помещении. Система должна удовлетворять следующим требованиям: камера подвижна,
возможен аддитивный шум при регистрации данных, скачки яркости входных
растровых данных; высокая производительность при обработке в реальном времени.
Программный комплекс будет реализовываться на языке C/C++ в среде разработки QT
Creatorс поддержкой библиотеки компьютерного зрения Open CV. Для работы будем
использовать роботизированную камеру Sony BRCH 900P, которая будет передавать
изображение на персональный компьютер, через который и будет осуществляться
управление камерой.
Постановка задачи.
Цель работы: создать
программно-аппаратный комплекс для реализации слежения за человеком с помощью
анализа видеоизображения и перемещением камеры в режиме реального времени.
На основе поставленной цели
сформируем следующие задачи:
) Выбор математических
алгоритмов для анализа изображения.
) Построение технической
системы.
) Реализация алгоритма поиска
лица человека на изображении;
) Отслеживание положения лица
в режиме реального времени;
) Реализация алгоритма
смещения камеры в зависимости от положения объекта на изображении;
) Оценка полученных
результатов.
Требования к системе:
) Работа в режиме реального
времени
) Устойчивость к смене
освещения
) Устойчивость алгоритма
слежения при появлении других движущихся объектов
) Устойчивость при частичном
перекрытии объекта
) Работа с изображением
плохого качества, очень низкого или очень высокого разрешения
1. Аналитический обзор предметной
области
.1 Компьютерное зрение
Компьютерное зрение (машинное
зрение, computer vision) - совокупность программно-технических средств,
обеспечивающих считывание в цифровой форме видеоизображений, их обработку и
выдачу результата в форме, пригодной для его практического использования в
реальном масштабе времени.
Система компьютерного зрения
(computer vision system) - комплекс программно-технических средств,
обеспечивающий обработку данных, снимаемых на выходе оптико-электронных
устройств, например, цифровой фотокамеры, телевизионной или видеокамеры и
выдачу полученных результатов в форме, пригодной для практического применения.
Важной составляющей частью является подсистема оптического распознавания
образов. В 2002 году фирма Canesta продемонстрировала малогабаритную систему
компьютерного зрения, работающую на принципах светового радара, способного
измерять дальность до окружающих предметов и отслеживать их перемещение. В
комплект входит 3D-камера со встроенной микросхемой датчика изображения
(Equinox), работающего на излучение световых импульсов, прием и измерение
времени возвращения отраженных сигналов; USB-интерфейс и программируемый модуль
для Windows. Одной из предлагаемых разработчиками областей применения системы
является дистанционное управление бытовой электроникой с помощью жестов.
Интерес к компьютерному зрению
возник одним из первых в области искусственного интеллекта. Даже архитектура
первой искусственной нейронной сети - перцептрона - была предложена Фрэнком
Розенблаттом, исходя из аналогии с сетчаткой глаза, а ее исследование
проводилось на примере задачи распознавания изображений символов.
Значимость проблемы компьютерного
зрения никогда не вызывала сомнения, но одновременно ее сложность существенно
недооценивалась. К примеру, легендарным по своей показательности стал случай,
когда в 1966 г. один из основоположников области искусственного интеллекта,
Марвин Минский, даже не сам собрался решить проблему искусственного зрения, а
поручил это сделать одному студенту за ближайшее лето. При этом на создание
программы, играющей на уровне гроссмейстера в шахматы, отводилось значительно
большее время. Однако сейчас очевидно, что создать программу, обыгрывающую
человека в шахматы, проще, чем создать адаптивную систему управления с
подсистемой компьютерного зрения, которая бы смогла просто переставлять
шахматные фигуры на произвольной реальной доске.
Прогресс в области компьютерного
зрения определяется двумя факторами: развитие теории, методов, и развитие
аппаратного обеспечения. Долгое время теория и академические исследования
опережали возможности практического использования систем компьютерного зрения.
Условно можно выделить ряд этапов развития теории.
К 1970-м годам сформировался
основной понятийный аппарат в области обработки изображений, являющийся основой
для исследования проблем зрения. Также были выделены основные задачи,
специфические для машинного зрения, связанные с оценкой физических параметров
сцены (дальности, скоростей движения, отражательной способности поверхностей и
т. д.) по изображениям, хотя ряд этих задач все еще рассматривался в весьма
упрощенной постановке для «мира игрушечных кубиков».
К 80-м сформировалась теория уровней
представления изображений в методах их анализа. Своего рода отметкой окончания
этого этапа служит книга Дэвида Марра «Зрение. Информационный подход к изучению
представления и обработки зрительных образов».
К 90-м оказывается сформированным
систематическое представление о подходах к решению основных, уже ставших
классическими, задач машинного зрения.
С середины 90-х происходит переход к
созданию и исследованию крупномасштабных систем компьютерного зрения,
предназначенных для работы в различных естественных условиях.
Текущий этап наиболее интересен
развитием методов автоматического построения представлений изображений в
системах распознавания изображений и компьютерного зрения на основе принципов
машинного обучения.
В то же время прикладные применения
ограничивались вычислительными ресурсами. Ведь чтобы выполнить даже простейшую
обработку изображения, нужно хотя бы один раз просмотреть все его пиксели (и
обычно не один раз). Для этого нужно выполнять как минимум сотни тысяч операций
в секунду, что долгое время было невозможно и требовало упрощений.
К примеру, для автоматического
распознавания деталей в промышленности могла использоваться черная лента конвейера,
устраняющая необходимость отделения объекта от фона, или сканирование
движущегося объекта линейкой фотодиодов со специальной подсветкой, что уже на
уровне формирования сигнала обеспечивало выделение инвариантных признаков для
распознавания без применения каких-либо сложных методов анализа информации. В
оптико-электронных системах сопровождения и распознавания целей использовались
физические трафареты, позволяющие «аппаратно» выполнять согласованную
фильтрацию. Некоторые из этих решений являлись гениальными с инженерной точки
зрения, но были применимы только в задачах с низкой априорной
неопределенностью, и поэтому обладали, в частности, плохой переносимостью на
новые задачи.
Не удивительно, что на 1970-е годы
пришелся пик интереса и к оптическим вычислениям в обработке изображений. Они
позволяли реализовать небольшой набор методов (преимущественно корреляционных)
с ограниченными свойствами инвариантности, но весьма эффективным образом.
Постепенно, благодаря росту
производительности процессоров (а также развитию цифровых видеокамер), ситуация
изменилась. Преодоление определенного порога производительности, необходимого
для осуществления полезной обработки изображений за разумное время, открыло
путь для целой лавины приложений компьютерного зрения. Следует, однако, сразу
подчеркнуть, что этот переход не был мгновенным и продолжается до сих пор.
В первую очередь, общеприменимые
алгоритмы обработки изображений стали доступны для спецпроцессоров - цифровых
сигнальных процессоров (ЦСП) и программируемых логических интегральных схем
(ПЛИС), нередко совместно использовавшихся и находящих широкое применение до
сих пор в бортовых и промышленных системах.
Однако действительно массовое
применение методы компьютерного зрения получили лишь менее десяти лет назад, с
достижением соответствующего уровня производительности процессоров у
персональных и мобильных компьютеров. Таким образом, в плане практического
применения системы компьютерного зрения прошли ряд этапов: этап индивидуального
решения (как в части аппаратного обеспечения, так и алгоритмов) конкретных
задач; этап применения в профессиональных областях (в особенности в
промышленности и оборонной сфере) с использованием спецпроцессоров,
специализированные системы формирования изображений и алгоритмы, предназначенные
для работы в условиях низкой априорной неопределенности, однако эти решения
допускали масштабирование; и этап массового применения.
Как видно, система машинного зрения
включает следующие основные компоненты:
) подсистему формирования
изображений (которая сама может включать разные компоненты, например объектив и
ПЗС- или КМОП-матрицу);
) вычислитель;
) алгоритмы анализа
изображений, которые могут реализовываться программно на процессорах общего
назначения, аппаратно в структуре вычислителя и даже аппаратно в рамках
подсистемы формирования изображений.
Наиболее массового применения
достигают системы машинного зрения, использующие стандартные камеры и
компьютеры в качестве первых двух компонент (именно к таким системам больше
подходит термин «компьютерное зрение», хотя четкого разделения понятий
машинного и компьютерного зрения нет). Однако, естественно, прочие системы
машинного зрения обладают не меньшей значимостью. Именно выбор «нестандартных»
способов формирования изображений (включая использование иных, помимо видимого,
спектральных диапазонов, когерентного излучения, структурированной подсветки,
гиперспектральных приборов, времяпролетных, всенаправленных и быстродействующих
камер, телескопов и микроскопов и т. д.) существенно расширяет возможности систем
машинного зрения. В то время как по возможностям алгоритмического обеспечения
системы машинного зрения существенно уступают зрению человека, по возможностям
получения информации о наблюдаемых объектах они существенно превосходят его.
Исследуя различные решения в области
компьютерного зрения, можно упомянуть следующие системы:
Программно-аппаратный комплекс Axxon
Next. Данное программное обеспечение применяется в сфере охранного
видеонаблюдения и позволяет отслеживать перемещение объектов в пространстве и
времени. Видеоаналитика фиксирует в базе данных информацию об объекте: его
относительные размеры, скорость и траекторию движения, а также дату и время
события. Данный функционал помогает оператору работать с системой максимально
эффективно и в считанные минуты найти нужную информацию.
Подсчет людей в магазине и
транспорте. Данная видеоаналитика выделяет в потоке кадров объекты (входящие и
выходящие люди) и ведет подсчет потоков людей. Это мощное средство позволяет
формировать информативные отчеты, крайне полезные для маркетологов. На основе
этих данных можно сделать выводы о рентабельности автобусных рейсов и вносить
необходимые поправки в расписание движения или маршрут. В Украине реализуется
подобная система - DL-Bus. Данные системы подсчета передаются каналам GPRS, и
руководство автопарка в режиме реального времени получает информацию о потоках
пассажиров.
.2 Обзор методов детектирования
объектов
Существующие алгоритмы обнаружения
лиц можно разбить на четыре категории:
) эмпирические методы;
) методы характерных инвариантных
признаков;
) распознавание с помощью шаблонов,
заданных разработчиком;
) метод обнаружения по внешним
признакам, обучающиеся системы.
Рассмотрим каждую категорию более
подробно.
Эмпирические методы.
Эмпирический подход «базирующийся на
знаниях сверху-вниз» предполагает создание алгоритма, реализующего набор
правил, которым должен отвечать фрагмент изображения, для того чтобы быть
признанным человеческим лицом. Этот набор правил является попыткой
формализовать эмпирические знания о том, как именно выглядит лицо на
изображениях и чем руководствуется человек при принятии решения: лицо он видит
или нет. Самые простые правила:
центральная часть лица имеет
однородную яркость и цвет;
разница в яркости между центральной
частью и верхней частью лица значительна;
лицо содержит в себе два симметрично
расположенных глаза, нос и рот, резко отличающиеся по яркости относительно
остальной части лица.
Метод сильного уменьшения
изображения для сглаживания помех, а также для уменьшения вычислительных операций
предварительно подвергает изображение сильному уменьшению. На таком изображении
проще выявить зону равномерного распределения яркости (предполагаемая зона
нахождения лица), а затем проверить наличие резко отличающихся по яркости
областей внутри: именно такие области можно с разной долей вероятности отнести
к «лицу».
Метод построения гистограмм для
определения областей изображения с «лицом» строит вертикальную и горизонтальную
гистограммы. В областях-кандидатах происходит поиск черт лица. Данный подход
использовался на заре развития компьютерного зрения ввиду малых требований к
вычислительной мощности процессора для обработки изображения.
Рассмотренные выше методы имеют
неплохие показатели по выявлению лица на изображении при однородном фоне, они
легко реализуемы с помощью машинного кода. Впоследствии было разработано
множество подобных алгоритмов. Но эти методы абсолютно непригодны для обработки
изображений, содержащих большое количество лиц или сложный задний фон. Также
они очень чувствительны к наклону и повороту головы.
Методы характерных инвариантных
признаков.
Методы характерных инвариантных
признаков, базирующиеся на знаниях снизу-вверх, образуют второе семейство
способов детекирования лиц. Здесь виден подход к проблеме с другой стороны: нет
попытки в явном виде формализовать процессы, происходящие в человеческом мозге.
Сторонники подхода стараются выявить закономерности и свойства изображения лица
неявно, найти инвариантные особенности лица, независимо от угла наклона и
положения.
Основные этапы алгоритмов этой
группы методов:
) детектирование на
изображении явных признаков лица: глаз, носа, рта
) обнаружение: границы лица,
форма, яркость, текстура, цвет;
) объединение всех найденных
инвариантных признаков и их верификация.
Метод обнаружения лиц в сложных
сценах предполагает поиск правильных геометрических расположений черт лица. Для
этого применяется гауссовский производный фильтр с множеством различных
масштабов и ориентаций. После этого производится поиск соответствия выявленных
черт и их взаимного расположения случайным перебором. Суть метода группировки
признаков в применении второй производной гауссовского фильтра для поиска
интересующих областей изображения.Далее группируются края вокруг каждой такой
области при помощи порогового фильтра. А затем используется оценка при помощи
байесовской сети для комбинирования найденных признаков, таким образом
происходит выборка черт лица.
Методы этой группы в качестве
достоинств имеют возможность распознавать лицо в различных положениях. Но даже
при небольшом загромождении лица другими объектами, возникновении шумов или
засветке процент достоверного распознавания сильно падает. Большое влияние
также оказывает сложный задний фон изображения. Основа рассмотренных подходов -
эмпирика, является одновременно их сильной и слабой стороной. Большая
изменчивость объекта распознавания, зависимость вида лица на изображении от
условий съемки и освещения позволяют без колебаний отнести обнаружение лица на
изображении к задачам высокой сложности. Применение эмпирических правил
позволяет построить некоторую модель изображения лица и свести задачу к
выполнению некоторого количества относительно простых проверок. Однако,
несмотря на безусловно разумную посылку - попытаться использовать и повторить
уже успешно функционирующий инструмент распознавания - человеческое зрение,
методы первой категории пока далеки по эффективности от своего прообраза,
поскольку исследователи, решившие избрать этот путь, сталкиваются с рядом
серьезных трудностей.
Во-первых, процессы, происходящие в
мозгу во время решения задачи распознавания изображений изучены далеко не
полностью, и тот набор эмпирических знаний о человеческом лице, которые
доступны исследователям на сознательном уровне, далеко не исчерпывает
инструментарий, используемый мозгом подсознательно. Во-вторых, трудно
эффективно перевести неформальный человеческий опыт и знания в набор формальных
правил, поскольку чересчур жесткие рамки правил приведут к тому, что в ряде
случаев лица не будут обнаружены, и, напротив, слишком общие правила приведут к
большому количеству случаев ложного обнаружения.
Распознавание с помощью шаблонов,
заданных разработчиком.
Шаблоны задают некий стандартный
образ изображения лица, например, путем описания свойств отдельных областей
лица и их возможного взаимного расположения. Обнаружение лица с помощью шаблона
заключается в проверке каждой из областей изображения на соответствие заданному
шаблону.
Особенности подхода:
) два вида шаблонов:
а) недеформируемые;
б) деформируемые;
) шаблоны заранее запрограммированы,
необучаемы;
) используется корреляция для
нахождения лица на изображении.
Метод детектирования лица при помощи
трехмерных форм предполагает использование шаблона в виде пар отношений
яркостей в двух областях. Для определения местоположения лица необходимо пройти
всё изображение на сравнение с заданным шаблоном. Причём делать это необходимо
с различным масштабом (рис. 1). Модели распределения опорных точек являются
статистическими моделями, которые представляют объекты, форма которых может
измениться. Их полезная особенность метода - способность выделить форму
переменных объектов в пределах учебного набора с небольшим количеством
параметров формы. Эта компактная и точная параметризация может использоваться
для разработки эффективных систем классификации.
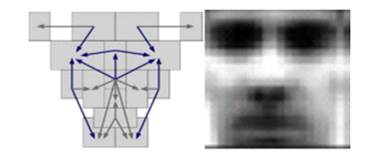
Рис. 1. Метод детектирования при
помощи трехмерных форм
К достоинствам распознавания с
помощью шаблонов можно отнести относительную простоту реализации и неплохие
результаты на изображениях с не очень сложным задним фоном. А главным
недостатком является необходимость калибровки шаблона вблизи с изображением
лица. Большая трудоёмкость вычисления шаблонов для различных ракурсов и
поворотов лица ставят под вопрос целесообразность их использования.
Методы обнаружения лица по внешним
признакам.
Изображению (или его фрагменту)
ставится в соответствие некоторым образом вычисленный вектор признаков, который
используется для классификации изображений на два класса - лицо или не лицо.
Обычно поиск лиц на изображениях с помощью методов, основанных на построении
математической модели изображения лица, заключается в полном переборе всех
прямоугольных фрагментов изображения всевозможных размеров и проведения
проверки каждого из фрагментов на наличие лица. Поскольку схема полного
перебора обладает такими безусловными недостатками, как избыточность и большая
вычислительная сложность, авторами применяются различные методы сокращения
количества рассматриваемых фрагментов. Основные принципы методов:
) Схоластика: каждый
сканируется окном и представляется векторами ценности.
) Блочная структура:
Изображение разбивается на пересекающиеся или непересекающиеся участки (Рис. 2)
различных масштабов и производится оценка с помощью алгоритмов оценки весов
векторов.

Рис. 2. Примеры разбиения
изображения на участки
Для обучения алгоритмов требуется
библиотека вручную подготовленных изображений лиц и «не лиц», любых других
изображений.
Стоит отметить, что важнейшей
задачей является выделение сильных классификаторов. Именно они будут иметь
наивысший приоритет для проверки найденных признаков в изображении. Количество
же более слабых классификаторов стоит уменьшать за счёт похожести друг на
друга, а также удалении классификаторов, возникших за счёт шумовых выбросов.
Перечислим основные методики
выполнения этих задач:
) Искусственные нейронные
сети (Neural network: Multilayer Perceptrons);
) Метод главных компонент (Princiapl Component Analysis (PCA));
3) Факторного анализа (Factor
Analysis);
) Линейный дискриминантный
анализ (Linear Discriminant Analysis);
) Метод опорных векторов (Support Vector Machines (SVM));
6) Наивный байесовский
классификатор (Naive Bayes classifier);
) Скрытые Марковские модели
(Hidden Markov model);
) Метод распределения (Distribution-based method);
9) Совмещение ФА
и метода главных компонент (Mixture of PCA, Mixture of factor analyzers);
10) Разреженная сеть
окон (Sparse network of
winnows (SNoW));
11) Активные модели (Active Appearance Models);
12) Адаптированное улучшение и
основанный на нём Метод Виолы-Джонса и др.
Рассмотрим особенности некоторых из
них. На сегодняшний день метод искусственных нейронных сетей является наиболее
распространенным способом решения задач распознавания лиц на изображении.
Искусственная нейронная сеть (ИНС) - это математическая модель, представляющая
собой систему соединённых и взаимодействующих между собой нейронов. Нейронные
сети не программируются в привычном смысле этого слова, они обучаются.
Технически обучение заключается в нахождении коэффициентов связей (синапсов)
между нейронами.
Метод опорных векторов (Support
Vector Machines) применяется для снижения размерности пространства признаков,
не приводя к существенной потере информативности тренировочного набора
объектов. Применение метода главных компонент к набору векторов линейного
пространства, позволяет перейти к такому базису пространства, что основная
дисперсия набора будет направлена вдоль нескольких первых осей базиса,
называемых главными осями. Натянутое на полученные таким образом главные оси
подпространство является оптимальным среди всех пространств в том смысле, что
наилучшим образом описывает тренировочный набор. Это набор алгоритмов схожих с
алгоритмами вида «обучение с учителем», использующихся для задач классификации
и регрессионного анализа. Этот метод принадлежит к семейству линейных
классификаторов. Метод опорных векторов основан на том, что ищется линейное
разделение классов.
Цель тренировки большинства
классификаторов - минимизировать ошибку классификации на тренировочном наборе
(называемую эмпирическим риском). В отличие от них, с помощью метода опорных
векторов можно построить классификатор, минимизирующий верхнюю оценку ожидаемой
ошибки классификации (в том числе и для неизвестных объектов, не входивших в
тренировочный набор). Применение метода опорных векторов к задаче обнаружения
лица заключается в поиске гиперплоскости в признаковом пространстве, отделяющий
класс изображений лиц от изображений «не-лиц». Возможность линейного разделения
столь сложных классов, как изображения лиц и «не-лиц» представляется
маловероятной. Однако, классификация с помощью опорных векторов позволяет
использовать аппарат ядерных функций для неявного проецирования
векторов-признаков в пространство потенциально намного более высокий
размерности (еще выше, чем пространство изображений), в котором классы могут
оказаться линейно разделимы. Неявное проецирование с помощью ядерных функций не
приводит к усложнению вычислений, что позволяет успешно использовать линейный
классификатор для линейно неразделимых классов.
Самым перспективным на сегодняшний
день в плане высокой производительности и низкой частоты ложных срабатываний и
большим процентом верных обнаружений лиц выглядит метод Виолы-Джонса.
Основные принципы, на которых
основан метод, таковы:
) используются изображения в
интегральном представлении, что позволяет вычислять быстро необходимые объекты;
) используются признаки
Хаара, с помощью которых происходит поиск нужного объекта (в данном контексте,
лица и его черт);
) используется бустинг (от
англ. boost - улучшение, усиление) для выбора наиболее подходящих признаков для
искомого объекта на данной части изображения;
) все признаки поступают на
вход классификатора, который даёт результат «верно» либо «ложь»;
) используются каскады
признаков для быстрого отбрасывания окон, где не найдено лицо.
Обучение классификаторов идет очень
медленно, но результаты поиска лица очень быстры. Алгоритм хорошо работает и
распознает черты лица под небольшим углом, примерно до 30 градусов. При угле
наклона больше 30 градусов процент обнаружений резко падает. И это не позволяет
в стандартной реализации детектировать повернутое лицо человека под
произвольным углом, что в значительной мере затрудняет или делает невозможным
использование алгоритма в современных производственных системах с учетом их
растущих потребностей.
В результате своей работы алгоритм
должен определить лица и их черты и пометить их - поиск осуществляется в
активной области изображения прямоугольными признаками, с помощью которых и
описывается найденное лицо и его черты.
Иными словами, применительно к
рисункам и фотографиям используется подход на основе сканирующего окна
(scanning window): сканируется изображение окном поиска (так называемое, окно
сканирования), а затем применяется классификатор к каждому положению. Система
обучения и выбора наиболее значимых признаков полностью автоматизирована и не
требует вмешательства человека, поэтому данный подход работает быстро.
Выбор алгоритма
Сформируем набор критериев выбора
алгоритма:
) Возможность работы в режиме
реального времени: 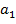 .
.
) Высокая точность
детектирования: 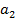 .
.
) Инвариантность к малым
поворотам и масштабированию объекта: 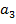 .
.
) Инвариантность к изменению
освещения сцены: 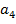 .
.
) Возможность работы при
неоднородном фоне: 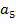 .
.
Составим системную матрицу оценки
критериев (таблица 1), где положительному ответу будет соответствовать 1, а
отрицательному - 0.
Таблица 1. Системная матрица оценки
критериев
|
Методы
|
Работа в режиме реального времени
|
Высокая точность
|
Инвариантность к малым поворотам и масштабированию объекта
|
Инвариантность к изменению освещения сцены
|
Неоднородный фон
|
|
эмпирические методы 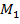
|
1
|
0
|
0
|
0
|
0
|
|
методы характерных инвариантных признаков 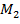
|
1
|
1
|
1
|
0
|
0
|
|
Распознавание с помощью шаблонов, заданных разработчиком 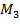
|
1
|
0
|
1
|
0
|
0
|
|
метод обнаружения по внешним признакам 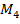
|
1
|
1
|
1
|
1
|
1
|
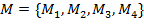 -
множество методов-кандидатов.
-
множество методов-кандидатов.
Для каждого метода-кандидата имеется
набор критериев:
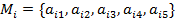
Условие выбора оптимального решения:
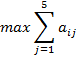
Найдем оптимальное решение,
соответствующее максимальному значению множества M:
Таким образом, метод обнаружения по
внешним признакам наиболее полно удовлетворяет критериям, которые формируют
требования для эффективного решения задачи детектирования лиц в данной работе.
.3 Обзор методов детектирования
движения
Так как в работе нам необходимо
реализовать слежение за движущимся объектом, то необходимо выбрать метод,
который будем использовать. Под понятием слежения за объектом можно выделить
два подхода: первый заключается в итеративном использовании методов
детектирования объекта на каждом кадре, определяя таким образом смещение
объекта, а второй - в детектировании движения выделенного объекта и определение
его нового положения. Естественно, что второй способ будет более правильным с
точки зрения вычислительных затрат. Поэтому рассмотрим существующие методы
детектирования движения в видеопотоке.
Межкадровая разность.
Вычисление межкадровой разности
является очень распространённым методом первичного обнаружения движения, после
выполнения которого, вообще говоря, уже можно сказать, присутствует ли в потоке
кадров движение. До недавнего времени многие детекторы движения функционировали
именно по такому принципу. Однако такой подход даёт достаточно грубую оценку,
приводя к наличию неизбежной ложной реакции детектора на шум регистрирующей
аппаратуры, смену условий освещения, лёгкое качание камеры и пр. Таким образом,
видеокадры должны быть предварительно обработаны перед вычислением разности
между ними. Алгоритм вычисления межкадровой разности двух кадров для случая
обработки цветного видео в формате RGB выглядит следующим образом:
) На вход алгоритма поступают два
видео кадра, представляющие собой две последовательности байт в формате RGB.
) Производится вычисление
попиксельных межкадровых разностей по следующей схеме:
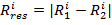 ,
,
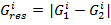 ,
,
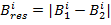 ,
,
где 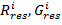 ,
, 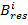 -
значения красной, зелёной и синей компонент цвета i-го пикселя результирующего
растра,
-
значения красной, зелёной и синей компонент цвета i-го пикселя результирующего
растра,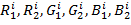 - значения красной, зелёной и синей компонент цвета i-го пикселя
на первом и втором кадре.
- значения красной, зелёной и синей компонент цвета i-го пикселя
на первом и втором кадре.
) Для каждого пикселя
вычисляется среднее значение между значениями трёх компонент цвета:
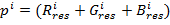 .
.
) Среднее значение
сравнивается с заданным порогом. В результате сравнения формируется двоичная
маска:
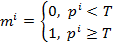 ,
,
где 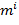 - значение i-го элемента маски, Т - порог сравнения, иногда
называемый также порогом или уровнем чувствительности.
- значение i-го элемента маски, Т - порог сравнения, иногда
называемый также порогом или уровнем чувствительности.
Таким образом, на выходе алгоритма
формируется двоичная маска, одному элементу которой соответствуют три
компоненты цвета соответствующего пикселя исходных двух кадров. Единицы в маске
располагаются в областях, где, возможно, присутствует движение, однако на
данном этапе могут быть и ложные срабатывания отдельных элементов маски,
ошибочно установленных в 1. В качестве двух входных кадров могут использоваться
два последовательных кадра из потока, однако возможно использование кадров с
большим интервалом, например, равным 1-3 кадра. Чем больше такой интервал, тем
выше чувствительность детектора к малоподвижным объектам, которые испытывают
лишь крайне малый сдвиг за один кадр и могут отсекаться, будучи отнесёнными к
шумовой составляющей изображения.
Достоинством данного метода является
простота и нетребовательность к вычислительным ресурсам. Метод широко
применялся ранее по причине того, что в распоряжении разработчиков не было
достаточных вычислительных мощностей. Однако и сейчас он широко используется,
особенно в многоканальных охранных системах, когда необходимо обрабатывать
сигнал от нескольких камер на одной ЭВМ. Ведь трудоёмкость алгоритма имеет
порядок O(n) и осуществляется всего за один проход, что очень важно для растров
большой размерности, таких как 640х480 точек, 768х576 точек, с которыми часто
работают современные видеокамеры.
Описывая метод межкадровых
попиксельных разностей с построением маски движения, в качестве двух входных
кадров мы задавали либо два соседних кадра, либо два кадра, взятых с небольшим
интервалом. Однако использование этого метода оставляет возможность вычислять
разность с некоторым кадром, который бы содержал исключительно неподвижные
области фона (базовый кадр). Такой подход дал бы нам существенное увеличение
вероятности обнаружить любой объект, как самый медленный, так и быстрый, причём
именно в той точке, в которой он находился в данный момент. Иначе данный метод
называется методом вычитания или сегментации фона. Работа метода полностью
аналогична работе алгоритма межкадровой разности с той лишь разницей, что
разность вычисляется между текущим и базовым кадром. Большой проблемой здесь
является способ построения базового кадра, поскольку он должен обладать
несколькими свойствами:
• Если кадр представляет собой кадр
реального изображения, он должен минимально отстоять по времени от текущего
кадра. Заметим, что в реальных условиях это не всегда возможно по той причине,
что съёмка может вестись в местах частого появления в кадре движущихся
объектов, поэтому система будет очень редко фиксировать сцену с полным
отсутствием в ней движения, вследствие чего она не будет иметь возможности
обновлять базовый кадр достаточно часто.
• Если базовый кадр подготавливается
искусственно, он должен содержать минимальное количество движущихся элементов,
иначе неизбежны ложные срабатывания на объекты, которых на текущем кадре уже
нет, однако базовый кадр содержит какие-то их элементы.
• Минимальный уровень шума. Перед
обновлением базового кадра необходимо проводить фильтрацию.
Существует два подхода к построению
базового кадра. Первый основан на кумулятивном его накоплении с использованием
всех кадров потока. При таком способе построения базовый кадр неизбежно
содержит элементы движущихся объектов, однако при вычислении разности между
текущим и базовым кадром различия в интенсивности соответствующих пикселей,
принадлежащих движущемуся объекту, всё же являются значительным и позволяют
обнаружить движение. Плюсом такого способа является его простота. Однако при
вычислении разности необходимо использовать дополнительные методы
шумоподавления, поскольку порог сравнения при построении маски движения в
данном случае не может быть высоким (в силу специфики базового кадра). В
противном случае движение будет просто упущено, а при небольших значениях
порога маска движения будет неизбежно фиксировать большое количество пикселей
шума.
Второй подход выглядит более
интеллектуальным, поскольку при его использовании базовый кадр строится
исключительно из неподвижных областей, взятых с каждого из текущих кадров. Для
этого на входе алгоритма необходимо иметь выходные данные детектора движущихся
объектов от обработки предыдущего кадра. Используя эту информацию, алгоритм
помечает области, где на предыдущем кадре были обнаружены движущиесяобъекты,
после чего, при попиксельном копировании текущего кадра в базовый пиксели
помеченных областей пропускаются. Таким образом, базовый кадр никогда не
содержит никаких элементов движущихся объектов, что достигается ценой
сравнительно небольшого усложнения алгоритма.
Возможен и третий подход, основанный
на обновлении базового кадра текущим в те моменты, когда на текущем кадре нет
движения. Однако в силу очень ограниченной применимости такого подхода (лишь
для случаев малоподвижных сцен, когда само по себе движение в кадре -
исключительный случай) мы его не рассматриваем.
Очевидно, что данные методы
межкадровой разности не подходят для слежения за движущимся объектом, так как
фон не будет стационарным в связи с движением камеры. Поэтому рассмотрим третий
метод, который и будем использовать с работе.
Оптический поток (ОП) - изображение
видимого движения, представляющее собой сдвиг каждой точки между двумя изображениями.
По сути, он представляет собой поле скоростей (т. к. сдвиг с точностью до
масштаба эквивалентен мгновенной скорости). Суть ОП в том, что для каждой точки
изображения 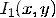 находится
такой сдвиг (dx, dy), чтобы исходной точке соответствовала точка на втором
изображении
находится
такой сдвиг (dx, dy), чтобы исходной точке соответствовала точка на втором
изображении 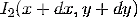 . Как
определить соответствие точек - отдельный вопрос. Для этого надо взять какую-то
функцию точки, которая не изменяется в результате смещения. Обычно считается,
что у точки сохраняется интенсивность (т. е. яркость или цвет для цветных
изображений), но можно считать одинаковыми точки, у которых сохраняется
величина градиента, гессиан, его величина или его определитель, лапласиан,
другие характеристики.
. Как
определить соответствие точек - отдельный вопрос. Для этого надо взять какую-то
функцию точки, которая не изменяется в результате смещения. Обычно считается,
что у точки сохраняется интенсивность (т. е. яркость или цвет для цветных
изображений), но можно считать одинаковыми точки, у которых сохраняется
величина градиента, гессиан, его величина или его определитель, лапласиан,
другие характеристики.
Очевидно, сохранение интенсивности
дает сбои, если меняется освещенность или угол падения света.
Тем не менее, если речь идет о
видеопотоке, то, скорее всего, между двумя кадрами освещение сильно не
изменится, хотя бы потому, что между ними проходит малый промежуток времени.
Поэтому часто используют интенсивность в качестве функции, сохраняющейся у
точки.
Есть два варианта расчета
оптического потока: плотный (dense) и выборочный (sparse). Sparse поток
рассчитывает сдвиг отдельных заданных точек (например, точек, выделенных
некоторым feature detector'ом), dense поток считает сдвиг всех точек
изображения.
Естественно, выборочный поток
вычисляется быстрее, однако для некоторых алгоритмов разница не такая уж и
большая, а для некоторых задач требуется нахождение потока во всех точках
изображения.
Суть оптического потока в том, что
он не ищет какие-то особенные точки, а по параметрам изображений пытается
определить, куда сместилась произвольная точка.
В основе всех дальнейших рассуждений
лежит одно очень важное и не очень справедливое предположение: значения
пикселей переходят из одного кадра в следующий без изменений. Таким образом, мы
делаем допущение, что пиксели, относящиеся к одному и тому же объекту, могут
сместиться в какую либо сторону, но их значение останется неизменным.
Конечно же это предположение имеет
мало общего с реальностью, потому что от кадра к кадру могут меняться
глобальные условия освещения и освещенность самого движущегося объекта.
Масса проблем связана с этим
допущением, но, как ни странно, вопреки всему оно достаточно хорошо работает на
практике.
На математическом языке это
допущение можно записать так:
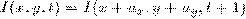 .
.
Где I - это функция яркости пикселей
от положения на кадре и времени. Другими словами x и y - это координаты пикселя
в плоскости кадра, 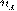 и
и 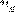 - это смещение, а t - это номер кадра в последовательности.
- это смещение, а t - это номер кадра в последовательности.
В данной работе будет использоваться
именно этот метод, так как он позволяет работать при нестационарном фоне.
.4 Обзор инструментальных средств
для разработки программного продукта
В настоящий момент существует
большое количество специализированных программных библиотек компьютерного
зрения как общего, так и специального назначения. Чтобы отобрать наилучшие из
них, сформулирован набор предъявляемых требований:
) разнообразие решаемых
задач;
) широкое распространение;
) активное развитие и
поддержка продукта компанией-разработчиком либо открытым сообществом;
) высокое качество
технической документации;
) высокоуровневая
иерархическая структура компонентов;
) относительная простота
использования;
) стабильность и
удовлетворительная скорость работы;
) кроссплатформенность и
переносимость.
Несмотря на упомянутое выше
многообразие средств, для создания программного продукта были выбраны два
наиболее полно соответствующих изложенным требованиям продукта.(open source
computer vision library) - это библиотека компьютерного зрения с открытым
исходным кодом. Также, она существует для некоторых других языков, например,
для Java. Включает в себя различные алгоритмы компьютерного зрения,
распознавания изображений и многое другое, работающих в реальном режиме
времени. Все желающие могут использовать библиотеку OpenCV бесплатно, как в
образовательных целях, так и в коммерческих проектах.
Она включает в себя следующие
алгоритмы:
· Распознавание
объектов в видеопотоке.
· Распознавание
печатного и рукописного текста.
· Устранение
искажений картинки.
· Выявление
сходства и формы объектов.
· Слежение
за перемещением объекта.
· Распознавание
движений, жестов и многое другое.
Поддерживаемые платформы и
инструменты для OpenCV.
Сами библиотеки:
· Windows:
компиляторыMicrosoftVisualC++ (6.0, .NET 2003), Intel Compiler, Borland C++,
Mingw (GCC 3.x).
· Linux:
GCC (2.9x, 3.x), Intel Compiler: "./configure-make-make install", RPM
(spec файлвключенвпоставку).
· Используются
C и "облегченный" C++. Прагмы и условная компиляция используются
очень ограниченно.
Средства GUI, захват видео:
· Windows:
DirectShow, VFW, MIL, CMU1394.
· Linux:
V4L2, DC1394, FFMPEG.
Документация: статический HTML.
Функциональность OpenCV:
• Ядро cxcore, также частично
используется в Intel Open Source Probabilistic Network Library:
· Базовые
операции над многомерными числовыми массивами;
· Матричная
алгебра, математические ф-ции, генераторы случайных чисел;
· DFT,
DCT;
· Запись/восстановление
структур данных в/из XML/YAML;
· Базовые
функции 2D графики;
· Поддержка
более сложных структур данных: разреженные массивы, динамически растущие
последовательности, графы.
Модуль обработки изображений и
компьютерного зрения CV:
· Базовые
операции над изображениями (фильтрация, геометрические преобразования,
преобразование цветовых пространств и т.д.);
· Анализ
изображений (выбор отличительных признаков, морфология, поиск контуров,
гистограммы);
· Структурный
анализ (описание форм, плоские разбиения и т.д.);
· Анализ
движения, слежение за объектами;
· Обнаружение
объектов, в частности лиц;
· Калибровка
камер, элементы восстановления пространственной структуры;
Модуль для ввода/вывода изображений
и видео, пользовательского интерфейса highgui:
· Захват
видео с камер и из видео файлов, чтение/запись статических изображений;
· Функции
для организации простого UI (сейчас все демо приложения используют HighGUI);
Экспериментальные и устаревшие
функции cvaux:
· Пространственное
зрение: стереокалибрация, самокалибрация;
· Поиск
стереосоответствия, клики в графах;
· Нахождение
и описание черт лица;
· Сравнение
форм, построение скелетонов;
· Скрытые
Марковские цепи;
· Описание
текстур.
Развитие библиотеки:
• Стратегия смещается и расширяется
- от настольных приложений HCI к более актуальным задачам (встроенные системы
(камерафоны), цифровой дом, безопасность, медицинские приложения, поиск в
домашних и промышленных цифровых библиотеках изображений и видео и т.д.) ;
• Библиотека останется свободной;
• Улучшится стабильность и скорость;
• Улучшится интеграция с IPP для еще
большей производительности;
• Переход к более открытой модели
разработки;
• Перенос некоторой функциональности
из прошлых и текущих исследовательских проектов.
Библиотека OpenCV достаточно мощный
инструмент для решения задач как в научной, так и промышленной областях.
Среда разработки MathWorks MATLAB.
Продукт MATLAB, разработанный
компанией MathWorks, включает высокоуровневый интерпретируемый язык
программирования, интерактивную среду разработки и большое количество
инструментов, предназначенных для решения задач самых разных отраслей науки.
Среда разработки MATLAB обладает
всеми необходимыми инструментами для ра-работки объектно-ориентированных
программ, включая отладчик, профилировщик, набор встроенных средств
визуализации данных, а также удобный конструктор графических интерфейсов. Код,
созданный на языке MATLAB, может исполняться отдельно от среды разработки,
будучи собранным в независимое приложение с помощью компоненты MATLAB Compiler.
Созданный на языке MATLAB код
предназначен для исполнения в большинстве современных операционных систем
общего назначения: Microsoft Windows, GNU Linux, Apple OS X на базе аппаратной
архитектуры x86. Кроме того, с помощью компонентов MATLAB Coder и Embedded
Coder программы на языке MATLAB могут бы транслированы в код на языках C и C++
с соблюдением стандартов ANSI/ISO и в дальнейшем скомпилированы для других
архитектур (например, для встраиваемых устройств на базе процессоров ARM). Эта
функция обеспечивает высокую переносимость разработанных в среде MATLAB
приложений.
Кроме того, имеется возможность
взаимодействия MATLAB-кода с кодом, написанным на других языках, таких как C,
C++, программной платформой Microsoft .NET, а также веб-сервисами по протоколам
SOAP и WSDL.
Официальная документация MATLAB
отличается полнотой и наглядностью, содержит большое количество практически
полезных примеров использования функций и дает возможность осваивать язык
максимально быстро.
Наибольший интерес в данном случае
представляет набор инструментов MATLAB, предназначенный для решения задач
компьютерного зрения, который выделен в библиотеку Computer Vision System
Toolbox. В ее состав включены следующие возможности:
) обработка изображений:
методы улучшения, фильтрации, геометрических и цветовых преобразований;
) распознавание объектов:
метод Виолы - Джонса, обучаемые классификаторы, средства OCR и др.;
) отслеживание объектов:
фильтр Кальмана, алгоритмы CAMShift, Kanade-Lucas-Tomasi (KLT) и др.;
) обнаружение и сопоставление
признаков: детекторы углов (Harris, Shi & Tomasi), дескрипторы SURF, MSER,
обнаружение HOG-признаков, сопоставление призна-ков и др.;
) автоматическая калибровка
камер, в том числе стереокамер;
) работа со
стереоизображениями, в том числе восстановление трехмерных сцен;
) работа с видео: чтение,
запись, воспроизведение, деинтерлейсинг, наложение и комбинирование кадров и
т.д.;
) средства визуализации
результатов обработки;
) поддержка генерации кода
на языке ANSI/ISO C.
Таким образом, данная библиотека в
частности и пакет MATLAB в целом функционально полностью соответствуют
приведенным требованиям.
.5 Интерфейсы последовательной
передачи данных
Так как в работе будет необходимо
реализовать передачу сигналов между объектом управления (камерой) и управляющим
устройством, то соответственно рассмотрим существующие интерфейсы передачи
данных.
Для передачи данных все устройства
оборудованы тем или иным интерфейсом, подсоединение к которому позволяет
считывать информацию по заданному протоколу.
Физически это означает наличие
определенных разъемов на оборудовании и кабельные изделия, способные обеспечить
передачу информации в диспетчерский пункт. Чаще всего это:
o RS-232
(EIA-232).
o RS-422
(EIA-422).
o RS-485
(EIA-485).в названии протокола означает Recommended Standard (рекомендованный
стандарт). Все три протокола относятся к физическому уровню (по модели OSI
(англ. Open Systems Interconnection Basic Reference Model, базовая эталонная
модель взаимодействия открытых систем)). Физический уровень является самым
нижним уровнем модели OSI, т.е. поток информации передается на нижнем уровне -
в двоичной системе - в виде последовательности 0 и 1.
Протоколы передачи данных можно
классифицировать по разным признакам:
1) По направлению сигнала:
- Симплексные (simplex) протоколы
позволяют передавать данные только в одну сторону. Это, например, телевизионные
и радио-сигналы. Используется одножильный провод с оплеткой.
Полудуплексные (half-duplex)
протоколы позволяют передавать данные в обе стороны, но не одновременно.
Используется двужильный провод (витая пара) с оплеткой. Пример - RS-485.
Дуплексные (full-duplex) протоколы
позволяют передавать данные в обе стороны одновременно. Используется
четырехжильный провод (двойная витая пара) с оплеткой. Пример - RS-232, RS-422,
в некоторых случаях RS-485.
2) Сбалансированность.
- Небалансный протокол передает
сигнал по одной жиле всю информацию (серию из 0 и 1). При этом сигнал подвержен
наводкам и тем больше, чем длиннее провод. Пример: RS-232.
Балансный протокол передает
информацию по двум жилам, т.е. используется витая пара проводов, по которым
транслируется дифференциальный сигнал. По одному проводу идет оригинальный
сигнал, а по второму - инверсия сигнала, а разность между ними создает
передающую разность потенциалов. Это является и защитой от помех: при наводке
на оба провода сигнал каждого из них деформируется, но разность сигналов
остается прежней. Это позволяет значительно удлинить допустимую протяженность
провода. Пример: RS-422, RS-485.
Таким образом, уже стали проясняться
принципиальные отличия протоколов серии RS.
RS-232 позволяет устройствам
передавать и получать информацию одновременно, но он ограничен по длине (15м).
RS-422 придуман на замену RS-232,
если последний не удовлетворяет требованиям по скорости и дальности (до
10Мбит/сек на 15м и до 100кбит/сек на 1220м).
RS-485 - самый распространенный
протокол с высокими характеристиками (до 10Мбит/сек на 15м и до 100кбит/сек на
1220м) и выигрывающий у RS-422 в капитальных затратах: две жилы - это дешевле
четырех.
Для камеры SonyBRC передача возможна
либо через RS-422, либо через RS-232, поэтому остановимся подробнее на этих
двух стандартах.- это стандарт последовательной синхронной и асинхронной
передачи двоичных данных между терминалом и коммуникационным устройством.был
введён в 1962 году.представляет собой простой интерфейс для передачи данных
между двумя объектами на расстояние до 15 метров (на практике может не
достигаться). Устойчивость к помехам обеспечивается отказом от стандартного
уровня сигналов 5В. От отправителя поступает последовательность 1 и 0
получателю, который их запоминает и «осознает» полученную информацию.
Существует понятие стартового бита,
получив который получатель понимает, что сеанс передачи информации открыт.
Далее через равные промежутки времени отправляются информационные биты.
Передача пакетная, длина пакета равна одному байту.
Разъем RS-232 представляет собой 9-
или 25-штырьковый трапецеидальный разъем. Изначально применялись 25 контактов,
но со временем большинство устройств стало обходиться меньшим их числом и
разъем «урезали».является полностью дуплексным интерфейсом (full duplex),
поэтому передача данных может одновременно осуществлять в обоих направлениях.
Например, подтверждение приёма пакетов данных происходит одновременно с приёмом
последующих пакетов.
Максимальная дальность действия
интерфейса RS-422 составляет 1200 метров. Дуплексность обеспечивается за счёт
того, что используется одновременно два приёмопередатчика, один из которых работает
на приём, другой - на передачу. RS-422 поддерживает создание только
одномастерных сетей, в которых в качестве передатчика может выступать только
одно устройство, а остальные способны лишь принимать сигнал. В отличие от
устаревшего также полнодуплексного RS-232, RS-422 характеризуется большими
возможностями по дальности линии 1200 метров против 15 метров и значительно
большей скоростью передачи данных.
К каждому передатчику RS-422
возможно подключение до 10 приёмников. Максимальная скорость передачи данных
достигает 10 Мбит/секунду. На самой большой удалённости от передатчика скорость
может составлять 10 кб/с. В качестве провода используется витая пара. Для
организации передачи данных на дистанции свыше 500 метров рекомендуется
использовать экранированную витую пару, чтобы избежать влияния сторонних
электромагнитных полей. Передача данных осуществляется посредством измерения
дифференциального напряжения между двумя проводами витой пары. Оба провода
симметричны по напряжению относительно земли. Рабочие напряжения: от -10 В до
+10 В. Как правило используются номинальные значения +6...+8 В.
Так как, во-первых, нам необходимо
передавать данные на расстояние большее 15м, а, во-вторых, передача будет
осуществляться нескольким приемникам одновременно, то, очевидно, что в нашей
работе мы воспользуемся интерфейсом RS-422.
2. Оборудование и аппаратная
реализация
Первым этапом на пути создания
программно-аппаратного комплекса является анализ имеющегося оборудования,
программных средств и определения способов их взаимодействия.
Характеристики камеры.
Объектом управления является
роботизированная PTZ камера модели SONYBRCH900P (рис. 3), способная
поворачиваться вокруг своей оси от 0 до 360 градусов.

Рис. 3. Камера SonyBRCH900P
Рассмотрим ее характеристики,
которые описаны в руководстве по эксплуатации, представленные в таблице 2.
Таблица 2. Технические
характеристики камеры Sony BRCH900P
|
Датчик изображения
|
1/2-дюймовая CMOS матрица Exmor х3
|
|
Датчик изображения (число эффективных пикселей)
|
2,07 мегапикселя Ч3
|
|
Датчик изображения (общее число пикселей)
|
Прибл. 3,01 мегапикселя
|
|
Система сигналов
|
60 Гц: 1080/59.94i, 720/59.94P, NTSC 50 Гц: 1080/50i, 720/50P,
PAL
|
|
Чувствительность
|
F10
|
|
Минимальная освещенность (50 IRE)
|
4 лк (50 IRE, F1,9, +24 дБ)
|
|
Горизонтальная четкость
|
> 1000 твл (на выходе HD-SDI)
|
|
Отношение С/Ш
|
50 дБ
|
|
Усиление
|
Автоматический/Ручной режим (от -3 до +24 дБ)
|
|
Скорость затвора
|
1/8000 - 1/60 с или 1/8000 - 1/50 с
|
|
Регулировка экспозиции
|
Режимы Auto (Автоматический), Manual (Ручной), Priority
(Приоритет) (приоритет затвора и приоритет диафрагмы), Back light
(Компенсация встречного освещения), Spot light (Местное освещение)
|
|
Функция Color AE (Цветовая коррекция экспозиции)
|
Нет
|
|
Баланс белого
|
Auto (Автоматический)/Indoor (Внутри помещения)/Outdoor (Вне
помещения)/One-push (Одним нажатием на кнопку)/Manual (Ручной)
|
|
Оптическое масштабирование
|
14x
|
|
Цифровое масштабирование
|
-
|
|
Система фокусировки
|
Автоматический/Ручной режим
|
|
Горизонтальный угол обзора
|
59,6° (широкий угол)
|
|
Фокусное расстояние
|
f = 5,8 - 81,2 мм F1,9 (Wide), F2,8 (Tele)
|
|
Минимальное расстояние до объекта
|
800 мм (31 Ѕ дюйма)
|
|
Угол панорамирования/наклона
|
Панорамирование: ±170° Наклон: +90°/-30°
|
|
Скорость панорамирования/наклона
|
|
Предустановки положения
|
16
|
|
Выход HD видеосигнала
|
HD/SD-SDI (переключение) Компонентный (Y/Pb/Pr) или RGB, HD, VD
или SYNC
|
|
Выход SD видеосигнала
|
Композитный, Y/C
|
|
Интерфейс управления камерой
|
RS-232C/RS-422(протокол VISCA)
|
|
Внешняя синхронизация Вход
|
Да
|
|
Auto ICR (Автоматически сдвигаемый режекторный ИК фильтр)
|
Нет
|
|
Wide-D
|
Нет
|
|
Стабилизация изображения
|
Да
|
|
Image Flip (Переворот изображения)
|
Вкл./ Выкл.
|
|
ND (нейтральный) фильтр
|
Нет
|
|
Color Gain (Усиление цвета)
|
Нет
|
|
Color Hue (Цветовой тон)
|
Нет
|
|
Color Matrix (Цветовая матрица)
|
Вкл./Выкл.
|
|
Color Detail (Цветовые детали)
|
Вкл./Выкл.
|
|
Skintone Detail (Детали телесного тона)
|
Нет
|
|
Гамма
|
STD1/STD2/STD3/STD4/CINE1/CINE2/CINE3/CINE4
|
|
Gamma Level (Уровень гаммы)
|
-99 ... 0 ... +99
|
|
Черный
|
-99 ... 0 ... +99
|
|
Black Gamma (Гамма черного)
|
-99 ... 0 ... +99
|
|
Knee Point (Точка колена)
|
50 ... 90 ... 109
|
|
Knee Slope (Наклон колена)
|
-99 ... 0 ... +99
|
|
Knee Sat Level (Уровень насыщенности в области колена)
|
0 ... 50 ... 99
|
|
Функция помощи при автофокусировке
|
Нет
|
|
Flicker Cancel (Подавление мерцаний)
|
Вкл./ Выкл.
|
|
B&W (Черно-белое изображение)
|
Нет
|
|
Color Bar (Сигнал цветных полос)
|
Вкл./ Выкл.
|
Камера может управляться через пульт
управления, либо через интерфейсы RS232/RS422. Так как необходимо
автоматизировать управление камерой без участия человека, то управлять камерой
будет реализуемая программа с персонального компьютера с помощью интерфейса
RS422, который описывался в предыдущей главе. Способ передачи по данному
интерфейсу осуществляться с помощью особого протокола VISCA, который
поддерживают только камеры модели SONY. Рассмотри данный протокол более
детально.
С помощью протокола VISCA можно
обеспечить полное управление функциями камеры, например, такими как, наклон,
поворот, масштабирование, увеличение/уменьшение фокусного расстояния и т.п.
Для обмена данными по протоколу
VISCA необходимо задать следующие параметры соединения, которые установлены в
камере:
) Скорость передачи бит в
секунду: 9600 bps;
) Число бит данных: 8;
) Количество стартовых битов:
1;
) Количество стоповых битов:
1;
) Бит четности: нет. (Бит
четности определяет четное или нечетное количество передаваемых единичных
битов. На принимающей стороне проводится анализ этого бита, и если бит четности
не соответствует количеству единичных битов, то пакет данных пересылается
снова).
) Контроль потока: нет
(механизм, который притормаживает передатчик данных при неготовности
приёмника).
Последовательная передача данных
будет реализовываться асинхронным способом. Это подразумевает использование
специальных битов, маркирующих начало и конец данных - стартового (логический
ноль) и стопового (логическая единица) бита. Таким образом, каждый передаваемый
байт будет выглядеть, как представлено на рис. 4.
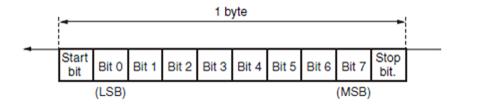
Рис. 4 Формат одного передаваемого
байта в протоколе VISCA.
Управление осуществляется с помощью
отправки пакетов команд. Рассмотрим общую структуру пакета (рис. 5).

Рис. 5
Пакет может быть размером от 3х до
16 байт. Каждый пакет состоит из заголовка, который занимает 1 байт. В него
входит адрес отправителя (контроллера) и адрес получателя (фактически, это
номер камеры). Далее идет сама команда, которая может быть от 1 до 14 байт.
Последний байт пакета всегда одинаковый, состоящий из восьми единиц в двоичном
формате.
Далее рассмотрим основные команды,
которые понадобятся в работе (таб. 3). Все команды представлены в
шестнадцатеричном формате. Вместо “x” во всех командах указывается номер камеры
(то есть ее адрес). После отправления команды, которая предполагает конкретное
действие, приходит ответ:
) z0 4y FF - команда принята;
) z0 5y FF - команда
выполнена, где z = адрес устройства + 8, y - номер разъема.
Если команда по каким-то причинам не
выполнена, то приходит соответствующее сообщение об ошибке.
Таблица 3. Команды VISCA
|
Название команды
|
Действие
|
Пакет команды
|
Комментарии
|
|
POWER
|
Включение/выключение камеры
|
8x 01 04 00 0p FF
|
(p:2 - ON, 3 - OFF)
|
|
FOCUS
|
Ручная/автофокусировка
|
8x 01 04 38 0p FF
|
(p: 2 - Auto, 3 - Manual)
|
|
IF_Clear (Broadcast)
|
Очищает буфер
|
88 01 00 01 FF
|
|
|
Command Cancel
|
Отмена текущей команды
|
8x 2y FF
|
|
|
PAN-TILT Drive
|
Вверх
|
8x 01 06 01 VV WW 03 01 FF
|
WW - скорость наклона камеры вверх/вниз: 00-18; VV - скорость
панорамирования (движения вправо/влево): 00-18
|
|
Вниз
|
8x 01 06 01 VV WW 03 02 FF
|
|
|
Вправо
|
8x 01 06 01 VV WW 02 03 FF
|
|
|
Влево
|
8x 01 06 01 VV WW 01 03 FF
|
|
|
Стоп
|
8x 01 06 01 VV WW 03 03 FF
|
|
|
Zoom
|
Приближение
|
8x 01 04 07 03 FF
|
|
|
Отдаление
|
8x 01 04 07 02 FF
|
|
|
Остановка
|
8x 01 04 07 00 FF
|
|
Для интерфейса RS-422 передача
данных идёт по двум линиям, TXDIN- и TXDIN+, представляющим собой витую пару
(два скрученных провода). Используется принцип дифференциальной передачи одного
сигнала. По проводу TXDIN- идет исходный сигнал, по проводу TXDIN+
противофазный. Когда на одном проводе логическая 1, на другом логический 0 и
наоборот. Этим достигается высокая устойчивость к синфазной помехе, действующей
на оба провода одинаково. Электромагнитная помеха, проходя через участок линии
связи, наводит в каждом проводе одинаковый потенциал, при этом информативная
разность потенциалов остается без изменений.
На рис. 6 представлено обозначение
выводов для интерфейса RS-422, где TXD (TransmittedData) - передающая линия;
RXD (ReceivedData) - принимающая линия; GND - заземление.

Рис. 6 Обозначение выводов
интерфейса RS-422
На рис. 7 представлена схема
соединения по интерфейсу RS-422 между ПК и периферийным устройством.

Рис. 7 Соединение контроллера (ПК) и
камеры через интерфейс RS-422
Получение изображения с камеры.
Для получения изображения с камеры
использовалось программное обеспечение ManyCam, которое транслировало
изображение с сервера управления камерой на персональный компьютер и
представляло полученный видеопоток в виде передачи с виртуальной веб-камеры.
Изображение транслировалось со скоростью 30 fps.
Таким образом, общая структура
аппаратной реализации комплекса, представлена на рис.8 и 9. Отличие между двумя
схемами в том, что в первой будет задержка получения изображения порядка 1
секунды. Во второй схеме задержка будет значительно меньше, что означает, что
работу в режиме реального времени вполне можно реализовать. При разработке и
тестировке использовалась первая схема из рисунка 8. Изображение с камеры
поступает на персональный компьютер и через ManyCamразрабатываемая программа
будет захватывать изображение, обрабатывать его, детектировать лицо человека и
следить за ним, путем передачи команд камере через интерфейс RS422.
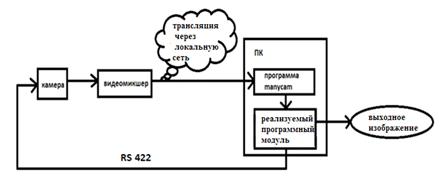
Рис. 8. Схема подключения на
тестируемом оборудовании
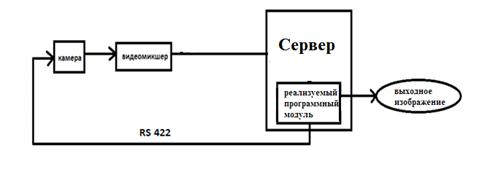
Рис. 9. Схема подключения на
реальном оборудовании
Работа с портом.
Открытие и инициализация порта.
Сначала откроем выбранный com порт
на чтение-запись:
>open(QSerialPort::ReadWrite);
Зададим необходимые параметры для
передачи по протоколу VISCA:
serial->setBaudRate(QSerialPort::Baud9600);>setDataBits(QSerialPort::Data8);>setParity(QSerialPort::NoParity);>setStopBits(QSerialPort::OneStop);>setFlowControl(QSerialPort::NoFlowControl);
Передача/чтение данных.
Передачу данных в com-порт будем
осуществлять с помощью функции:
>write(command),
где command - это массив байтов,
содержащий требуемую команду.
После передачи команды в порт
поставим ограничение на запись на 200 мсек. Именно столько времени необходимо
для передачи команды видеокамере. Считывание данных с com-порта будем проводить
с помощью метода:
(serial,&QSerialPort::readyRead,this,&MainWindow::readData).
По сигналу readyRead(), который
означает, что данные готовы к чтению, мы переходим к слоту readData(), где и
осуществляется чтение с порта:
command_read.append(serial->readAll());
QByteArrayy=command_read.toHex();
Закрытие порта: serial->close();
3. Анализ видеоизображения. Детектор
лица
.1 Постановка задачи
Пусть 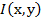 - изображение с камеры в момент времени t, которое представляет
собой совокупность изображений отдельных объектов (лиц) и фона:
- изображение с камеры в момент времени t, которое представляет
собой совокупность изображений отдельных объектов (лиц) и фона:
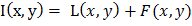 ,
,
где  - лицо человека, F(x,y) - изображение фона; (x,y) ∈ G - область определения изображения.
- лицо человека, F(x,y) - изображение фона; (x,y) ∈ G - область определения изображения.
 определён
только на дискретном множестве точек D скоординатами
определён
только на дискретном множестве точек D скоординатами 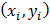 ∈ G. При этом,
∈ G. При этом,
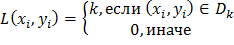
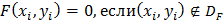 ,
,
где 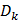 - дискретная область лица; D =
- дискретная область лица; D = 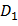 ∪
∪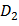 ∪… ∪
∪… ∪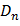 ∪
∪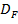 ; D - дискретная прямоугольная решётка, в узлах которой определён
снимок . Узлы решётки определяются координатами или их номерами (i,j), в которых задаётся цвет снимка в данной
точке, что в совокупности определяет пиксель снимка.
; D - дискретная прямоугольная решётка, в узлах которой определён
снимок . Узлы решётки определяются координатами или их номерами (i,j), в которых задаётся цвет снимка в данной
точке, что в совокупности определяет пиксель снимка.
Таким образом, исходное изображениеможно рассматривать как прямоугольную целочисленную решётку P,
узлы которой являются пикселями:
P ={p(i, j) | i = 1,N, j = 1,M},
где i, j - целочисленные координаты
(номера) пикселя; p(i, j)∈{0, 1}
- цветовой компонент пикселя.
Задача: найти множество точек (i,j)∈, для которых 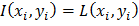 .
.
.2 Метод Виолы-Джонса
По итогам проведенного обзора было
принято решение использовать метод категориального распознавания объектов на
изображении. В настоящий момент самым популярным в силу высокой скорости и
эффективности является представленный в 2001 году метод Виолы - Джонса. Этот
детектор обладает низкой вероятностью ложного обнаружения лица. Алгоритм также
хорошо работает и распознает черты лица под небольшим углом, примерно до 30
градусов, а так же при различных условиях освещенности. На момент написания
алгоритм является основополагающим для поиска объектов на изображении в
реальном времени в большинстве существующих методов распознавания и
идентификации.
В 2001 году Виола и Джон предложили
алгоритм для распознавания лиц, который стал прорывом в области распознавания
лиц. Метод использует технологию скользящего окна. То есть рамка, размером,
меньшим, чем исходное изображение, двигается с некоторым шагом по изображению,
и с помощью каскада слабых классификаторов определяет, есть ли в
рассматриваемом окне лицо. Метод скользящего окно эффективно используется в
различных задачах компьютерного зрения и распознавания объектов.
Метод состоит из 2-х подалгоритмов:
алгоритм обучения и алгоритм распознавания. На практике скорость работы
алгоритма обучения не важна. Крайне важна скорость работы алгоритма
распознавания. По введенной ранее классификации можно отнести к структурным,
статистическим и нейронным методам.
Метод имеет следующие преимущества:
· возможно
обнаружение более одного лица на изображении;
· использование
простых классификаторов показывает хорошую скорость и позволяет использовать
этот метод в видеопотоке.
Однако метод сложно обучаем, так как
для обучения требуется большое количество тестовых данных и предполагает
большое время обучения, которое измеряется днями.
Изначально алгоритм был предложен
для распознавания только лиц, но его можно использовать для распознавания
других объектов. Одним из вкладов Виолы и Джонса было применение таблицы сумм,
которую они назвали интегральным изображением, детальное описание которого
будет дано ниже.
Обобщенная схема распознавания в
алгоритме Виолы-Джонса показана на рисунке 10.
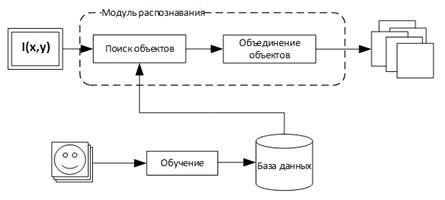
Рис. 10. Обобщенная схема
распознавания метода Виолы-Джонса
Обобщенная схема алгоритма выгляди
следующим образом: перед началом распознавания алгоритм обучения на основе
тестовых изображений обучает базу данных, состоящую из признаков, их паритета и
границы. Подробнее о паритете, признаке и границе будет рассказано в следующих
пунктах. Далее алгоритм распознавания ищет объекты на разных масштабах
изображения, используя созданную базы данных. Алгоритм Виолы-Джонса на выходе
дает всё множество найденных необъединенных объектов на разных масштабах.
Следующая задача - принять решение о том, какие из найденных объектов
действительно присутствуют в кадре, а какие - дубли.
В качестве признаков для алгоритма
распознавания авторами были предложены признаки Хаара, на основе вейвлетов
Хаара. Они были предложены венгерским математиком Альфредом Хааром в 1909 году.
В задаче распознавания лиц, общее
наблюдение, что среди всех лиц области глаз темнее области щек. Рассмотрим
маски, состоящие из светлых и темных областей.

Рис. 11. Признаки Хаара
Каждая маска характеризируется
размером светлой и темной областей, пропорциями, а также минимальным размером.
Совместно с другими наблюдениями были предложены следующие признаки Хаара, как
пространство признаков в задаче распознавания для класса лиц.

Рис. 12. Признаки Хаара
Признаки Хаара дают точечное
значение перепада яркости по оси X и Y соответственно. Поэтому общий признак
Хаара для распознавания лиц представляет набор двух смежных прямоугольников,
которые лежат выше глаз и на щеках. Значение признака вычисляется по формуле:
=X-Y
где X - сумма значений яркостей
точек закрываемых светлой частью признака, а Y - сумма значений яркостей точек
закрываемых темной частью признака. Видно, что если считать суммы значений
интенсивностей для каждого признака это потребует значительных вычислительных
ресурсов. Виолой и Джонсом было предложено использовать интегральное
представление изображения, подробнее о нем будет далее. Такое представление
стало довольно удобным способом вычисления признаков и применяется также и в
других алгоритмах компьютерного зрения, например SURF. Обобщенная схема
алгоритма обучения выглядит следующим образом. Имеется тестовая выборка
изображений. Размер тестовой выборки около 10 000 изображений. На рисунке 13
показан пример обучающих изображений лиц. Алгоритм обучения работает с
изображениями в оттенках серого.

Рис. 13. Пример обучающих
изображений
При размере тестового изображения 24
на 24 пикселя количество конфигураций одного признака около 40 000 (зависит от
минимального размера маски). Современная реализация алгоритма использует
порядка 20 масок. Для каждой маски, каждой конфигурации тренируется такой
слабый классификатор, который дает наименьшую ошибку на всей тренировочной
базе. Он добавляется в базу данных. Таким образом алгоритм обучается. И на
выходе алгоритма получается база данных из T слабых классификаторов. Обобщённая
схема алгоритма обучения показана на рисунке 14.
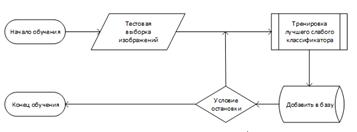
Рис. 14. Обобщенная схема алгоритма
обучения
Обучение алгоритма Виола-Джонса -
это обучение алгоритма с учителем. Для него возможно такая проблема как
переобучение. Показано, что AdaBoost может использоваться для различных
проблем, в том числе к теории игр, прогнозировании. В данной работе условие
остановки является достижение заранее заданного количества слабых
классификаторов в базе.
Для алгоритма необходимо заранее
подготовить тестовую выборку из l изображений, содержащих искомый объект и n не
содержащих. Тогда количество всех тестовых изображений будет:
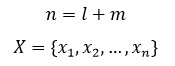
где X - множество всех тестовых
изображений, где для каждого заранее известно присутствует ли искомый объект
или нет и отражено во множестве Y.
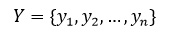
где:

Под признаком j будем понимать
структуру вида:
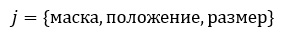
Тогда откликом признака будет f_j
(x), который вычисляется как разность интенсивностей пикселей в светлой и
темной областях. Слабый классификатор имеет вид:
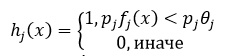
Задача слабого классификатора -
угадывать присутствие объекта в больше чем 50% случаев. Используя процедуру
обучения AdaBoost создается очень сильный классификатор состоящий из T слабых
классификаторов и имеющий вид:
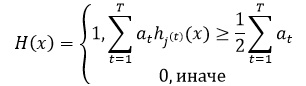
Целевая функция обучения имеет
следующий вид:

Интегральное представление можно
представить в виде матрицы, размеры которой совпадают с размерами исходного
изображения I, где каждый элемент рассчитывается так:
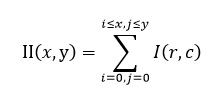
где I(r,c) - яркость пиксела
исходного изображения.
Каждый элемент матрицы II[x,y]
представляет собой сумму пикселов в прямоугольнике от (0,0) до (x,y). Расчет
такой матрицы занимает линейное время. Для того, чтобы вычислить сумму
прямоугольной области в интегральном представлении изображения требуется всего
4 операции обращения к массиву и 3 арифметические операции. Это позволяет
быстро рассчитывать признаки Хаара для изображения в обучении и распознавании.
Например, рассмотрим прямоугольник
ABCD.
Сумму внутри прямоугольника ABCD
можно выразить через суммы и разности смежных прямоугольников по формуле:
Перед началом обучения
инициализируются веса  , где q
- номер итерации, i-номер изображения.
, где q
- номер итерации, i-номер изображения.
После процедуры обучения получится T
слабых классификаторов и T значений.
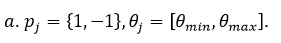

На каждой итерации цикла происходит
обновление весов так, что их сумма будет равна 1. Далее для всех возможных
признаков происходит подбор таких значений p,θ,j
что значение ошибки  будет минимально на этой итерации. Полученный признак J(t) (на
шаге t) сохраняется в базу слабых классификаторов, обновляются веса и
вычисляется коэффициент
будет минимально на этой итерации. Полученный признак J(t) (на
шаге t) сохраняется в базу слабых классификаторов, обновляются веса и
вычисляется коэффициент  .
.
В предложенном в 2001 году оригинальном
алгоритме не была описана процедура получения оптимального признака на каждой
итерации. Предполагается использование алгоритма AdaBoost и полный перебор
возможных параметров границы и паритета.
После обучения на тестовой выборке
имеется обученная база знаний из T слабых классификаторов. Для каждого
классификатора известны: признак Хаара, использующийся в этом классификаторе,
его положение внутри окна размером 24х24 пикселя и значение порога E.
На вход алгоритму поступает
изображение I(r,c) размером WхH, где I(r,c) - яркостная составляющая
изображения. Результатом работы алгоритма служит множество прямоугольников
R(x,y,w,h), определяющих положение лиц в исходном изображении I.
Алгоритм сканирует изображение I на
нескольких масштабах, начиная с базовой шкалы: размер окна 24х24 пикселя и 11
масштабов, при этом каждый следующий уровень в 1.25 раза больше предыдущего, по
рекомендации авторов. Алгоритм распознавания выглядит следующим образом:

Для поиска объекта на цифровом
изображении используется обученный классификатор, представленный в формате xml.
Структура классификатора:

где maxWeakCount - количество слабых
классификаторов;- максимальный порог яркости;- набор слабых классификаторов, на
основе которых выносится решение о том, находится объект на изображении или
нет;и leafValues - параметры конкретного слабого классификатора.
Первые два значения в internalNodes
не используются, третье - номер признака в общей таблице признаков (она
располагается в XML-файле под тегом features), четвертое - пороговое значение
слабого классификатора. Если значение признака Хаара меньше порога слабого
классификатора, выбирается первое значение leafValues, если больше - второе.
На основе этого базиса строится
каскад классификаторов, принимающих решение о том, распознан объект на
изображении или нет. Наличие или отсутствие предмета в окне определяется
разницей между значением признака и порогом, полученным в результате обучения.
После применения данного алгоритма
на выходе получаем интересующую область изображения, содержащую лицо человека.
3.3 Программная реализация
Для реализации метода трекинга будем
использовать две обученные модели детектирования фронтального лица и лица в
профиль:
*cascade_frontal_face=(CvHaarClassifierCascade*)cvLoad("D:/openCV/opencv/sources/data/haarcascades/haarcascade_frontalface_alt.xml",0,0,0);*cascade_profile_face=(CvHaarClassifierCascade*)cvLoad("D:/openCV/opencv/sources/data/haarcascades/haarcascade_profileface.xml",0,0,0);
Далее нам необходимо получить
изображение с камеры для поиска лица на нем. Для работы алгоритма будем использовать
цикл while(), на каждой итерации которого будем получать изображение в текущий
момент времени. Выход из цикла будет означать, что изображение найдено и
передавать управление модулю слежения за объектом.
Захватив изображение с камеры
переводим в градации серого:
(frame,gray,CV_RGB2GRAY);
· frame -
входное изображение,
· gray -
выходное,
· CV_RGB2GRAY-
конвертирование из RGB-пространства в оттенки серого (значение интенсивности
вычисляется как взвешенная линейная свертка интенсивностей по всем трем каналам
R, G, B):
= 0.3R + 0.59G + 0.11B
Далее полученное изображению
передаем в функцию, реализующую детектор лица Виолы-Джонса:
cvHaarDetectObjects(gray, cascade,
MemStorage, 1.1, 3, CV_HAAR_FIND_BIGGEST_OBJECT|CV_HAAR_SCALE_IMAGE, cvSize(50,
50))
) gray - целевое изображение, к
которому применяется каскад;
2) cascade - обученная модель
) MemStorage - хранилище
памяти
) 1.1 - коэффициент
увеличения масштаба
) 3 - минимальный соседний
порог
) CV_HAAR_FIND_BIGGEST_OBJECT
- находит наибольшее лицо
) CV_HAAR_SCALE_IMAGE
) cvSize(50, 50) -
минимальный размер, по которому производится поиск, нужно задать как можно
меньше, так как какой масштаб лица будет - не определено.
На выходе функции получаем
минимальный ограничивающий прямоугольник, содержащий лицо человека и передаем
его модулю слежения:
(x,y,width,height),
где (x,y) - координаты нижней левой
точки прямоугольника, width- ширина, height - высота.
В общем, алгоритм в цикле while()
можно представить следующими шагами:
. Получение нового
изображения.
. Детектирование лица в
фронтал
. Если лицо не найдено, то
используется другая модель для поиска лица в профиль.
. Если лицо не найдено, то
возвращение к шагу 1, иначе выход из цикла и передача управления в модуль
слежения за объектом.
4. Анализ видеоизображения. Слежение
за лицом
.1 Постановка задачи
Пусть  - полученная прямоугольная область изображения лица от детектора
лиц с камеры в момент времени t. Множество точек лица
- полученная прямоугольная область изображения лица от детектора
лиц с камеры в момент времени t. Множество точек лица  .
.
Пусть множество I=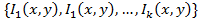 - это изображение в каждый момент времениt от 0 до k, где
tдискретно.
- это изображение в каждый момент времениt от 0 до k, где
tдискретно.
Рассмотрим:
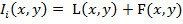 ,
,
где 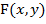 - изображение фона; (x,y) ∈ G - область определения изображения.
- изображение фона; (x,y) ∈ G - область определения изображения.
Задача: найти 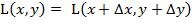 на изображении
на изображении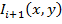 .
.
Таким образом, на вход алгоритма
подается последовательность кадров и координаты точек, которые необходимо
отслеживать. На выходе алгоритма мы должны получить траекторию точек как набор
смещений точки между кадрами.
.2 Метод Лукаса-Канаде
Одномерный случай.
Для начала рассмотрим одномерный
случай.
Представим себе два одномерных кадра
1 пиксель в высоту и 20 пикселей в ширину. На втором кадре изображение немного
будет смещено вправо. Именно это смещение мы и хотим найти. Для этого
представим эти же кадры в виде функций (рисунок 15). На входе позиция пикселя,
на выходе - его интенсивность. В таком представление искомое смещение (d) видно
еще более наглядно. В соответствии с нашим предположением, 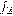 это просто смещенная
это просто смещенная 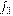 , то есть можем сказать, что
, то есть можем сказать, что 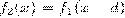 .
.
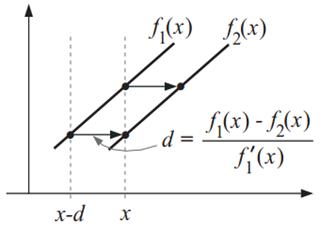
Рис. 15
Обратите внимание, что и при
желании можно записать и в общем виде:  ;
;  где y
и t зафиксированы и равны нулю.
где y
и t зафиксированы и равны нулю.
Для каждой координаты нам известны
значения и в этой
точке, кроме того мы можем вычислить их производные. Свяжем известные значения
со смещением d. Для этого запишем разложение в ряд Тейлора для  :
:
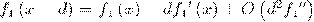
Сделаем второе важное предположение:
предположим, что достаточно
хорошо аппроксимируется первой производной. Сделав это предположение, отбросим
всё, что после первой производной:
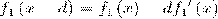
Тут мы теряем в точности, если
только наша функция/изображение не строго линейна, как в нашем искусственном
примере. Зато это существенно упрощает метод, а для достижения требуемой
точности можно сделать последовательное приближение, которое мы рассмотрим
позже.
Смещение d - это наша искомая
величина, поэтому надо что-то сделать с . Как мы условились ранее, , поэтому просто перепишем:
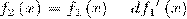
То есть:
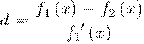
Теперь перейдем от одномерного
случая к двумерному. Запишем разложение в ряд Тейлора для 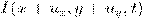 и сразу отбросим все старшие производные. Вместо первой
производной появляется градиент:
и сразу отбросим все старшие производные. Вместо первой
производной появляется градиент:
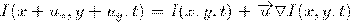
Где  - вектор смещения.
- вектор смещения.
В соответствии со сделанным
допущением .
Обратите внимание, что это выражение эквивалентно 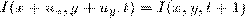 . Это то, что нам нужно. Перепишем:
. Это то, что нам нужно. Перепишем:
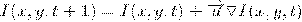
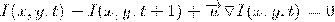
Поскольку между двумя кадрами
проходит единичный интервал времени, то можно сказать, что 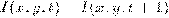 есть не что иное, как производная по времени.
есть не что иное, как производная по времени.
Перепишем:
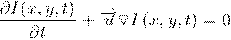
Перепишем ещё раз, раскрыв градиент:
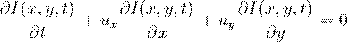
Мы получили уравнение, которое
говорит нам о том, что сумма частных производных должны быть равна нулю.
Проблема только в том, что уравнение у нас одно, а неизвестных в нем два: и . На
этом моменте начинается полет фантазии и разнообразие подходов.
Сделаем третье предположение:
предположим, что соседние пиксели смещаются на одинаковое расстояние. Возьмем
фрагмент изображения, скажем 5 на 5 пикселей, и условимся, что для каждого из
25 пикселей и равны. Тогда вместо одного уравнения мы получим сразу 25
уравнений! Очевидно, что в общем случае система не имеет решения, поэтому будем
искать такие и , которые минимизируют ошибку:
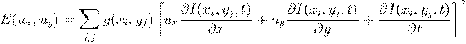
Здесь g - это функция, определяющая
весовые коэффициенты для пикселей. Самые распространенный вариант - двухмерная
гауссиана, которая дает наибольший вес центральному пикселю и все меньший по
мере удаления от центра.
Чтобы найти минимум  воспользуемся методом наименьших квадратов, найдем её частные
производные по и :
воспользуемся методом наименьших квадратов, найдем её частные
производные по и :
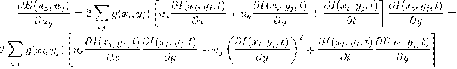
Перепишем в более компактной форме и
приравняем к нулю:
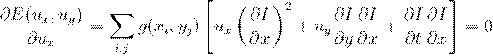
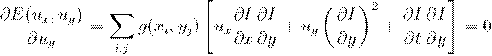
Перепишем эти два уравнения в
матричной форме:
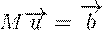
где
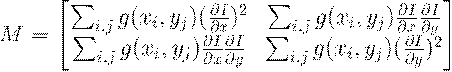
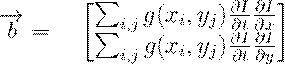
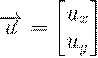
Если матрица М обратима (имеет ранг
2), можем вычислить и , которые минимизируют ошибку E:
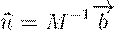
Вот собственно и все. Мы знаем
приблизительное смещение пикселей между двумя соседними кадрами.
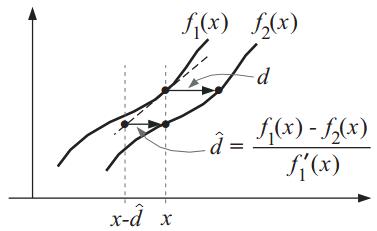
Рис. 16
Поскольку в нахождении смещения
каждого пикселя участвуют также соседние с ним пиксели, при реализации данного
метода целесообразно предварительно посчитать производные кадра по горизонтали
и вертикали.
Описанный выше метод основан на трех
значительных допущениях, которые с одной стороны дают нам принципиальную
возможность определить оптический поток, но с другой стороны вносят
погрешность. Мы предполагали, что для аппроксимации смещения нам будет
достаточно первой производной. В общем случае это конечно же не так (рисунок
16). Для достижения требуемой точности смещение для каждой пары кадров (назовём
их  и
и  ) можно
вычислять итеративно. В литературе это называется искажением (warping). На
практике это означает, что, вычислив смещения на первой итерации, мы перемещаем
каждый пиксель кадра в
противоположную сторону так, чтобы это смещение компенсировать. На следующей
итерации вместо исходного кадра мы
будем использовать его искаженный вариант
) можно
вычислять итеративно. В литературе это называется искажением (warping). На
практике это означает, что, вычислив смещения на первой итерации, мы перемещаем
каждый пиксель кадра в
противоположную сторону так, чтобы это смещение компенсировать. На следующей
итерации вместо исходного кадра мы
будем использовать его искаженный вариант  . И так далее, пока на очередной итерации все полученные смещения
не окажутся меньше заданного порогового значения. Итоговое смещение для каждого
конкретного пикселя мы получаем как сумму его смещений на всех итерациях.
. И так далее, пока на очередной итерации все полученные смещения
не окажутся меньше заданного порогового значения. Итоговое смещение для каждого
конкретного пикселя мы получаем как сумму его смещений на всех итерациях.
По своей природе данный метод
является локальным, то есть при определении смещения конкретного пикселя
принимается во внимание только область вокруг этого пикселя - локальная
окрестность. Как следствие, невозможно определить смещения внутри достаточно
больших (больше размера локальной окрестности) равномерно окрашенных участков
кадра. К счастью на реальных кадрах такие участки встречаются не часто, но эта
особенность все же вносит дополнительное отклонение от истинного смещения. Ещё
одна проблема связана с тем, что некоторые текстуры в изображении дают
вырожденную матрицу М, для которой не может быть найдена обратная матрица.
Соответственно, для таких текстур мы не сможем определить смещение. То есть
движение вроде есть, но непонятно в какую сторону. В общем-то от этой проблемы
страдает не только рассмотренный метод. Даже глаз человека воспринимает такое
движение не однозначно.
.3 Выбор оптимальных параметров
Для реализации алгоритма на C/С++
понадобится функция вычисления оптического потока:
cvCalcOpticalFlowPyrLK(prev_img,
current_img, previous_pyramid, current_pyramid, prev_points, current_points,
count_point, cvSize(20, 20), n, status, 0, tc, flags);
Рассмотрим ее параметры:
) prev_img - изображение,
полученное на предыдущей итерации
2) current_img - изображение на
текущей итерации
) previous_pyramid - буфер
для пирамиды предыдущего изображения
) current_pyramid - буфер для
хранения пирамиды текущего изображения
) prev_points - точки,
положение которых необходимо определить
) current_points - новые
координаты точек
) count_point - количество
найденных точек
) cvSize - размер окна поиска
на каждом уровне пирамиды
) n - количество используемых
уровней пирамид
) Status - массив, элементы
которого равны либо 1 (поток есть), либо 0 (потока нет).
) 0 - массив, содержащий
значения изменений в окрестности между исходной точкой и новой точкой, может
быть равен нулю
) Tc - критерии прекращения
итерационного алгоритма поиска на пирамиде (после указанного максимального
числа итераций criteria.maxCount, или когда окно поиска станет меньше, чем
criteria.epsilon)
) Flags:
CV_LKFLOWPyr_A_READY - пирамида для
первого изображения вычисляется до вызова функции;_LKFLOWPyr_B_READY - пирамида
для второго изображения вычисляется до вызова функции;_LKFLOW_INITIAL_GUESSES -
исходный массив B, содержащий текущие координаты точек создается до вызова.
Задача: определить, при каких
значениях входных параметров n,cvSize и Tc алгоритм будет иметь минимальную
ошибку вычисления и минимальное время обработки на заданном множестве возможных
значений параметров. Так как требование минимальной ошибки и минимального
времени обработки противоречивы, то необходимо оптимальное соотношение между
этими величинами. То есть необходимо решить задачу многокритериальной
оптимизации.
Сначала необходимо исказить
изображения, чтобы создать выборку для исследования алгоритма трекинга.
Алгоритм этих преобразований описан ниже:
. Выбор 10 произвольных изображений,
на каждом из которых случайным образом отмечена точка (её координаты
записываются в файл).
. Выбор одного изображения выборки.
. К выбранному изображению
последовательно применяются аффинные преобразования (масштабирование и параллельный
перенос). В результате получается новое изображение. Новые координаты точки,
отмеченной в п. 1 на исходном изображении, сохраняются в файл.
. К полученному в предыдущем пункте
изображению применяются аффинные преобразования. В результате получается новое
изображение и новые координаты точки.
. Процесс продолжается по аналогии
еще 98 раз. Таким образом, получается 100 новых изображений (и отмеченных на
них точек) для одного изображения исходной выборки
. Выбор следующего изображения из
исходной выборки и для него повторяются действия пунктов 3-5. В итоге
получилось 10 выборок по 100 изображений в каждой. После применения аффинных
преобразований вычисляются координаты точек: аналитически и с помощью алгоритм
трекинга Lucas-Kanade.
Для каждой пары точек ошибка
вычислялась следующим образом: пусть (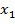 ,
,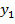 ) -
координаты точки, полученной с помощью аналитического расчёта, а (
) -
координаты точки, полученной с помощью аналитического расчёта, а (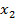 ,
,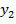 ) -
координаты точки, полученной с помощью алгоритма трекинга. Тогда ошибка
eвычисляется как среднеквадратичное расстояние между аналитическим расчётом
координат точки и расчётом координат этой же точки с помощью алгоритма
Lucas-Kanade, по формуле:
) -
координаты точки, полученной с помощью алгоритма трекинга. Тогда ошибка
eвычисляется как среднеквадратичное расстояние между аналитическим расчётом
координат точки и расчётом координат этой же точки с помощью алгоритма
Lucas-Kanade, по формуле:
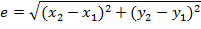
Ниже приведена общая
последовательность действий по анализу значений параметров алгоритма трекинга:
. Фиксируются параметры алгоритма
трекинга.
. Берется множество из 100
искаженных изображений, сгенерированных ранее и соответствующих одному из
изображений исходной выборки, и для каждых двух последовательных изображений
множества вычисляется ошибка и время работы алгоритма. В конце вычисляется
средняя ошибка и среднее время работы алгоритма.
. Шаг 2 повторяется для каждых 100
изображений, соответствующих изображениям исходной выборки. В итоге мы имеем 10
значений средней ошибки и 10 значений среднего времени работы алгоритма.
. Усредняются средние значения,
полученные на предыдущем шаге. Результаты заносятся в таблицу (см. Таблица 3).
. Изменяется значение одного из
параметров алгоритма (n,cvSize), а затем повторяются шаги 2-5 до тех пор, пока
все возможные сочетания параметров алгоритма (из заданных интервалов) не будут
перебраны.
Параметр n будем изменять от 1 до 4
с шагом 1, а параметр cvSize от 3 до 59 с шагом 2. В таблице 3 приведена часть
полученных результатов.
Таблица 3. Зависимость ошибки и
времени работы алгоритма слежения от входных параметров
|
n
|
CvSize
|
Среднее отклонение
|
Среднее время
|
|
1
|
118,594124
|
0,001825
|
|
1
|
5
|
115,657422
|
0,001594
|
|
1
|
7
|
72,6525211
|
0,001363
|
|
1
|
9
|
68,7998512
|
0,001132
|
|
1
|
11
|
64,9471813
|
0,000901
|
|
1
|
13
|
61,0945114
|
0,00067
|
|
1
|
15
|
57,2418415
|
0,000439
|
|
1
|
17
|
53,3891716
|
0,00067
|
|
1
|
19
|
49,5365017
|
0,000901
|
|
1
|
21
|
45,6838318
|
0,001132
|
|
1
|
23
|
41,8311619
|
0,001363
|
|
1
|
25
|
37,978492
|
0,001594
|
|
1
|
27
|
34,1258221
|
0,001825
|
|
1
|
29
|
30,2731522
|
0,002056
|
|
1
|
31
|
26,4204823
|
0,002287
|
|
1
|
33
|
22,5678124
|
0,002518
|
|
1
|
35
|
18,7151425
|
0,002749
|
|
1
|
37
|
14,8624726
|
0,00298
|
|
1
|
39
|
11,0098027
|
0,003211
|
|
1
|
3
|
138,594124
|
0,001825
|
|
1
|
5
|
124,657422
|
0,001594
|
|
1
|
7
|
72,6525211
|
0,001363
|
|
1
|
9
|
68,7998512
|
0,001132
|
Выберем оптимальные параметры по
критерию Парето.
Опр. Решение X2 называется доминируемым, если существует решение X1, не
хуже чем X2, т.е. для любой оптимизируемой функции Fi, I=1, 2, …, m,(X2)£Fi(X1) при максимизации функции Fi,(X2)³Fi(X1) при минимизации Fi.
В случае доминирования при переходе
от X2 к X1 ничего не будет проиграно ни по одному из частных критериев, но в
отношении j - го частного критерия точно будет получен выигрыш. Говорят, что
решение X1 лучше (предпочтительнее) решения X2[20].
Согласно данному определению получим
следующие параметры:=4, winSize=(20; 20).
.4 Программная реализация алгоритма
Определившись с выбором оптимальных
параметров функции вычисления оптического потока, перейдем к непосредственной
реализации модуля слежения за объектом в разрабатываемой системе.
На вход модуля поступают координаты
минимального ограничивающего прямоугольника, полученного от модуля-детектора
лица:
(x,y,width,height).
Задача: найти смещение лица, находящегося
внутри этой области.
Далее работа, как и для детектора
лиц, будет проходить в бесконечном цикле while(), выход из которого возможен
либо нажатием клавиши пользователя, либо при потере объекта слежения.
Алгоритм в цикле while():
. Получение нового изображение.
. Покроем прямоугольник лица
равномерной сеткой:
int step_x = face_rect.width*s /
16;int step_y = face_rect.height *s/ 16;
где s -коэффициент масштабирования.
В узлах этой сетки как раз те точки,
для которых будет вычисляться оптический поток.
. Вычислим оптический поток в
вышеописанной функции, на выходе получаем новое положение точек в текущей
итерации.
. Проверяем количество точек
соответствию порогу:
_point<30.
То есть если количество точек меньше
30, то объект считается потерянным, и тогда происходит выход из цикла и
возвращение к модулю-детектору лица. Данное число подбиралось экспериментально.
При количестве точек, меньших 30, точность слежения пропадала.
. Удаляем точки, не найденные
на текущей итерации.
. Вычисляем координаты
централица на изображении C(x,y):
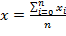 ,
,
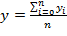 ,
,
где 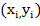 - координаты точек, для которых найден оптический поток,n - их
количество.
- координаты точек, для которых найден оптический поток,n - их
количество.
. Строим новую ограничивающую
прямоугольную область, а точнее смещаем вычисленный детектором лица
прямоугольник на новое положение с центром C(x,y).
. Удаляем точки, которые не
попали в новый прямоугольник. Таким образом, решаем проблему «отставших» точек.
. Выводим на экран найденные
точки.
. Возвращаемся к шагу один.
В результате на каждой итерации
будем получать два изображения (рис. 17): первое (справа) - цветное с
ограничивающим прямоугольником, определяющий положение лица на картинке, а
второе (слева) - изображение в градациях серого с изображением всех точек, для
которых вычислен оптический поток.
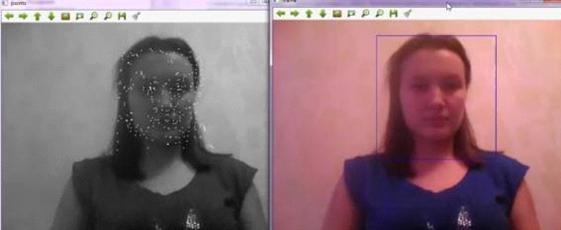
Рис. 17. Выходное изображение
5. Управление поворотом камеры
Цель настоящей главы - создание
математической модели перенацеливания используемой поворотной камеры,
экспериментальная проверка ее адекватности и внедрение ее в разрабатываемый
комплекс.
.1 Постановка задачи
Рассмотрим постановку задачи в
терминах ТАУ. Пусть g - координата центра изображения, а x(t) - положение
объекта в текущий момент времени на плоскости изображении, тогда величина
рассогласования будет равна:

Связь между скоростью перемещения
камеры на изображении и угловой скоростью вращения можно выразить через
следующую формулу:
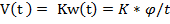 ,
,
где K - коэффициент
пропорциональности. 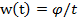 -угловая
скорость вращения камеры, постоянная величина
-угловая
скорость вращения камеры, постоянная величина
Скорость движения объекта на
изображении:
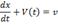
Цель управления:
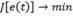
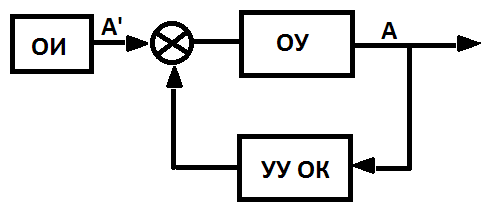
Рис. 18. Математическая модель
камеры
Для наблюдения за целевым объектом
на заданном участке местности необходимо выработать соответствующие управления
поворотной камерой так, чтобы в каждый текущий момент времени камера была
направлена в сторону целевого объекта, например в его «центр». Видеокамера
имеет две степени свободы, которая устроены следующим образом: камера крепится
на одном приводе (привод 1), который в свою очередь крепится на другом приводе
(привод 2). Камера установлена на приводе 1 таким образом, что оптическая ось
ее объектива пересекает ось вращения этого привода и перпендикулярна ей; оси
вращения приводов взаимно перпендикулярны. Примем, что привод 1 предназначен
для вращения камеры по азимуту («влево-вправо»), а привод 2 - для вращения
камеры по склонению («вверх-вниз»). При работе с поворотной камерой при помощи
команд можно изменять направление объектива, вращая камеру вокруг осей двух
приводов. В данной работе для упрощения задачи будем управлять только смещением
привода 1.
Требуется решить задачу
перенацеливания камеры на подвижный объект с известными координатами (x,y) на
поверхности наблюдения, то есть, найти такой угол α поворота привода 1,
которые переведут вектор наблюдения на точку (x,y). Полагаем, что y=const.
5.2 Перенацеливание на заданную
точку поверхности
Далее будем считать, что наблюдаемая
поверхность, то есть изображение с камеры представляет собой плоскость. Введем
декартову систему координат для камеры 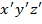 так, что ось вращения первого привода совпадает с
так, что ось вращения первого привода совпадает с 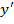 . Положим, что вращение камеры, если рассматривать его по
направлению оси вращения, осуществляется по часовой стрелке вокруг оси . Зафиксируем начальное положение камеры таким образом, чтобы она
была расположена (под расположением камеры будем понимать точку пересечения
оптической оси объектива камеры и оси вращения первого привода) на известном
расстоянии H от плоскости наблюдения и направлена перпендикулярно к ней, а оси
. Положим, что вращение камеры, если рассматривать его по
направлению оси вращения, осуществляется по часовой стрелке вокруг оси . Зафиксируем начальное положение камеры таким образом, чтобы она
была расположена (под расположением камеры будем понимать точку пересечения
оптической оси объектива камеры и оси вращения первого привода) на известном
расстоянии H от плоскости наблюдения и направлена перпендикулярно к ней, а оси 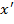 и были
параллельны этой плоскости. Выберем декартову прямоугольную систему координат
так, чтобы в начальном положении камера располагалась на оси Oz в точке C = (0,
0, H) и была направлена в начало координат (плоскость наблюдения при этом
совпадет с плоскостью Oxy), а оси Ox и Oy были сонаправлены осям и соответственно.
и были
параллельны этой плоскости. Выберем декартову прямоугольную систему координат
так, чтобы в начальном положении камера располагалась на оси Oz в точке C = (0,
0, H) и была направлена в начало координат (плоскость наблюдения при этом
совпадет с плоскостью Oxy), а оси Ox и Oy были сонаправлены осям и соответственно.
Пусть требуется направить камеру,
находящуюся в начальном положении, на некоторую точку 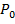 =(
=(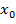 ,
, 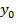 , 0), расположенную на плоскости Oxy. Для этого необходимо
повернуть камеру сначала вокруг оси на некоторый угол A (|A| <p/2). Вычислим углы поворота A. Абсцисса точки легко вычисляется из треугольника
, 0), расположенную на плоскости Oxy. Для этого необходимо
повернуть камеру сначала вокруг оси на некоторый угол A (|A| <p/2). Вычислим углы поворота A. Абсцисса точки легко вычисляется из треугольника 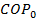 : =(HtgA,
, 0). Так как нас интересует только смещение вдоль оси x, то
: =(HtgA,
, 0). Так как нас интересует только смещение вдоль оси x, то .
.
Величина нам известна - это смещение относительно центра, получаемое в
результате работы алгоритма слежения за объектом в момент времени t. Таким
образом, можно найти угол A:
 .
.
Рис. 19. Нахождение угла поворота
.3 Модель принятия решений
Данная глава будет посвящена
построению модели принятия решений для управления движением камеры.
На предыдущих этапах производилось детектирование
лица и затем отслеживание его смещения на изображении. Но одновременно с
трекингом лица необходимо смещать камеру так, чтобы объект всегда находился в
центре.
В данном случае мы будем
рассматривать смещение на изображении центра области лица 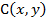 по координатам x. Под центром лица подразумевается сумма
координат всех точек, где есть оптический поток в момент времени t, разделенная
на их количество n:
по координатам x. Под центром лица подразумевается сумма
координат всех точек, где есть оптический поток в момент времени t, разделенная
на их количество n:
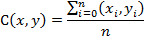
Так как управление будет происходить
только по координате x, то обозначим просто 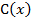 .
.
Таким образом, на входе будут
следующие исходные данные:
) 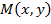 - центр изображения, где
- центр изображения, где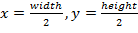 ,
, 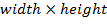 -
разрешение изображения.
-
разрешение изображения.
) 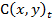 -положение центра лица в текущий момент времени
-положение центра лица в текущий момент времени
) 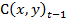 - положение центра лица в предыдущий момент времени.
- положение центра лица в предыдущий момент времени.
Теперь необходимо сформулировать
правила, по которым будет приниматься решение куда смещать камеру.
Введем систему координат на
плоскости изображения, центром в точке .
Рассмотрим значение d: в данном
случае эторегулируемая величина, по сути это «коридор», находясь в котором
центр объекта считается расположенной в центре экрана.
В общем, алгоритм принятия решений
можно представить в виде модели дерева (рис. 20).
Есть три 4 варианта действий:
) 0 - остановка камеры;
) 1 - смещение камеры вправо;
) 2- смещение камеры влево
) 4 - никаких действий не
предпринимается.
Данный алгоритм легко реализуется
наC++.
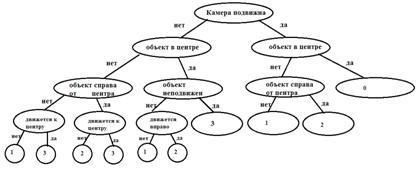
Рис. 20. Алгоритм принятия решений
6. Исследование системы
.1 Оценка точности перенацеливания
Рассмотрим расхождения значений
положения центра экрана и центра лица, вычисленные при наведении на неподвижный
объект.
Отклонение:
.06415
.70325
.80161
.72842
.26971
.73123
.85681
.43057
.98102
.77615
.58008
.75018
Среднее отклонение = 3,6394 пикс.
.2 Проверка на устойчивость к смене
освещения
Было проведено 100 испытаний, в ходе
которых происходила резкая смена освещения при слежении за объектом. В
результате в 94 случая из 100 объект детектировался заново и успешно
отслеживался. В 6 случаях и 100 программа не могла заново найти объект.
6.3 Время задержки
Время задержки измерялось с момента
подачи команды управления на поворот камеры и до момента появления смещения на
изображении:
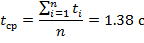
Данная задержка измерялась на
тестируемом оборудовании, где изображение передавалось через локальную сеть,
чем и объясняется такая величина. В технической среде, где будет внедрен
комплекс, измеренная средняя задержка составила:
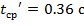
Данная величина вполне соответствует
условиям выполнения в режиме реального времени.
.4 Устойчивость при частичном
перекрытии объекта
В ходе экспериментов было
определено, что максимально возможная область перекрытия при устойчивом
слежении за объектом получилась  .
.
.5 Анализ влияния шумов
Рассмотрим видеоизображение,
полученное с веб-камеры с разрешением 640x480. Будем вычислять значение заранее
заданной неподвижной точки в каждый момент времени и сравнивать ее значение в
предыдущий момент.
Как наглядно показывают результаты
эксперимента на таблице 4, эта разница никогда не равна нулю. К таким
зашумленным изображениям целесообразно применять функцию сглаживания для
уменьшения влияния шумов и тем самым увеличения точности прогноза.
Таблица 4. Результаты наблюдений
|
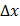
|
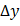
|
|
1.02921
|
0.115829
|
|
1.48715
|
0.295242
|
|
1.3222
|
1.09048
|
|
0.992188
|
0.382339
|
|
1.0459
|
0.894623
|
|
1.3714
|
1.3714
|
|
0.786346
|
1.1476
|
|
1.45007
|
1.28172
|
|
1.03217
|
1.22472
|
|
0.734528
|
0.68219
|
|
0.671539
|
0.737686
|
|
1.22433
|
0.452148
|
|
1.21979
|
0.807755
|
|
0.661194
|
1.25108
|
|
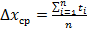 = 1.0734 пикс. = 1.0734 пикс.
|
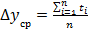 =0,8382 пикс. =0,8382 пикс.
|
Из данных результатов можно сделать
вывод, что детектирования мелких объектов, а тем более их смещение в таком
изображении не будет осуществляться с требуемой точностью.
7. Листинг программы
программный нейронный видеопоток детектирование
Файл Mainwindow.h
#ifndefMAINWINDOW_H
#defineMAINWINDOW_H
#include<opencv2/core/core.hpp>
#include<opencv2/features2d/features2d.hpp>
#include<opencv2/highgui/highgui.hpp>
#include<opencv2/imgproc/imgproc.hpp>
#include<opencv2/nonfree/nonfree.hpp>
#include<opencv2/objdetect/objdetect.hpp>
#include<QtSerialPort/QSerialPort>
#include<QtSerialPort/QSerialPortInfo>
#include"cv.h"
#include"highgui.h"
#include<stdio.h>
#include<ctype.h>
#include<QMainWindow>
#include<opencv\cv.h>
#include<iostream>
#include<stdlib.h>
#include<QDebug>
#include<algorithm>
#include<limits>
#include<time.h>
#include<math.h>
#include"myport.h"
#include<QThread>
#include"tracking.h"
#undefmin
#undefmax{;
}:publicQMainWindow
{_OBJECT:(QWidget*parent=0);
~MainWindow();*first_img;
//intadd_pt;*port422;
//CvPoint2D32f*window_center;*image;//длядетектированиялица;//интересующаяобласть;D32fwindow_center;D32fprev_mass_center;D32fmass_center;_moving;;
//CvPoint2D32fmass_center_next;
//CvRectface_size;_face(IplImage*gray,CvHaarClassifierCascade*haar_cascade,CvMemStorage*mem_storage,CvRect&face_rect);*serial;_read;;
//unsignedcharcamera_id;(constIplImage*gray,constCvRect&face_rect);();_tracking(IplImage*gray,CvRect&face_rect);:_command(QByteArraycommand);:_pushButton_up_clicked();_pushButton_down_clicked();_pushButton_left_clicked();_pushButton_right_clicked();_pushButton_clicked();:::MainWindow*ui;*prev_img;*current_img;*previous_pyramid;*current_pyramid;_point;D32f*current_points;D32f*prev_points;*status;;;
};
#endif//MAINWINDOW_H
Файлmyport.h
#ifndefMYPORT_H
#defineMYPORT_H
#include<QObject>
#include<QDebug>
#include<QtSerialPort/QserialPort>//Обьявляемработуспортом
#include<QMainWindow>
#include"math.h"
#include<unistd.h>{//Структураснастройкамипорта;
////qint32baudRate;
//QSerialPort::DataBitsdataBits;
//QSerialPort::Parityparity;
//QSerialPort::StopBitsstopBits;
//QSerialPort::FlowControlflowControl;
//QSerialPort::setSettingsRestoredOnClosesetSettingsRestoredOnClose;
};:publicQObject
{_OBJECT:(QObject*parent=0);
~MyPort();//хз;;
//QByteArraycommand;_read;_id=0x83;;:_Port();//Сигналзакрытиякласса_(QStringerr);//Сигналошибокпорта(QStringdata);//Сигналвыводаполученныхданных:();//Слототключенияпорта(void);//Слотподключенияпорта();();();
//voidWrite_Settings_Port();//Слотзанесениенастроекпортавкласс_Port();//Тело_action(floatprev,floatnext,floatwindow_center);(QByteArraydata);//Слототправкиданныхвпорт:(QSerialPort::SerialPortErrorerror);//Слотобработкиощибок();//СлотчтенияизпортапоReadyRead
};
#endif//MYPORT_H
ФайлMain.cpp
#include"mainwindow.h"
#include<QApplication>
#include<QCoreApplication>
#include<opencv2/imgproc/imgproc.hpp>
#include<opencv2/highgui/highgui.hpp>(intargc,char*argv[])
{(argc,argv);;.show();.exec();
}
Файл Mainwindow.cpp
#include"mainwindow.h"
#include"ui_mainwindow.h"
#include<QFileDialog>
#include<QDebug>
#include<QtDebug>
#include<QString>
#include<windows.h>
#include<iostream>;;::MainWindow(QWidget*parent):(parent),(newUi::MainWindow)
{>setupUi(this);
/*дляпортаипередачикоманд*/
//camera_id=0x83;
//serial=newQSerialPort(this);
//serial->setPortName("COM1");_img=NULL;_img=NULL;_pyramid=NULL;_pyramid=NULL;_point=0;=0;_points=NULL;_points=NULL;=NULL;_moving=false;=0;*my_thread=newQThread;//Создаемпотокдляпортаплаты*port422=newMyPort();//Создаемобьектпоклассу->moveToThread(my_thread);//помешаемклассвпоток->thisPort.moveToThread(my_thread);//Помещаемсампортвпоток
//port422->
//Загружаемобученныеданныедляклассификатора*cascade_frontal_face=(CvHaarClassifierCascade*)cvLoad("D:/openCV/opencv/sources/data/haarcascades/haarcascade_frontalface_alt.xml",0,0,0);
//"D:/openCV/opencv/sources/data/haarcascades/haarcascade_mcs_upperbody.xml"(!cascade_frontal_face)
{()<<"Errortoloadmodel"<<endl;();
}*MemStorage=cvCreateMemStorage(0);=cvTermCriteria(CV_TERMCRIT_ITER|CV_TERMCRIT_EPS,20,0.03);
//connect(port422,SIGNAL(error_(QString)),this,SLOT(Print(QString)));//Логошибок(my_thread,SIGNAL(started()),port422,SLOT(process_Port()));//Переназначенияметодаrun(port422,SIGNAL(finished_Port()),my_thread,SLOT(quit()));//Переназначениеметодавыход(my_thread,SIGNAL(finished()),port422,SLOT(deleteLater()));//Удалитькчертямпоток(port422,SIGNAL(finished_Port()),my_thread,SLOT(deleteLater()));//Удалитькчертямпоток(this,SIGNAL(send_command(QByteArray)),port422,SLOT(WriteToPort(QByteArray)));//отправкавпортданных
//Захватываемвидео(можноискамеры)слицами->ConnectPort();*capture_web=cvCaptureFromCAM(0);(capture_web);(capture_web==NULL)
{()<<"Errortocatchthecamera!!!!"<<endl;(MemStorage);((void**)&cascade_frontal_face);();
}("frame",1);
//cvNamedWindow("points",1);*gray=NULL;_center=cvPoint2D32f(0.f,0.f);_mass_center=cvPoint2D32f(0.f,0.f);_center=cvPoint2D32f(0.f,0.f);
//mass_center_next=cvPoint2D32f(0.f,0.f);
//Прямоугольникнайденноголица_rect=cvRect(0,0,0,0);
//Controlcontrol_action;_states//Состояниянашегодетектора
{_object,_object
};_statesstate=find_object;*frame=cvQueryFrame(capture_web);_thread->start();(true)
{=cvQueryFrame(capture_web);(frame==NULL)
{()<<"Error"<<endl;;
}
//Всяработаведётсянаизображениивградацияхсерого(!gray)
{=cvCreateImage(cvSize(frame->width,frame->height),IPL_DEPTH_8U,1);
//CvPoint2D32fwindow_center=cvPoint2D32f(0.f,0.f);_center.x=float(frame->width/2);_center.y=float(frame->height/2);
//qDebug()<<"Centerx:"<<prev_mass_center.x<<endl;
//qDebug()<<"Centery:"<<prev_mass_center.y<<endl;
}(frame,gray,CV_RGB2GRAY);
//Нашпримитивныйавтомат(state)
{_object://Поисклица(detect_face(gray,cascade_frontal_face,MemStorage,face_rect)==false)
{
//cvShowImage("frame",frame);
//cvShowImage("points",gray);(cvWaitKey(33)>0);=cvQueryFrame(capture_web);
//gray=cvCreateImage(cvSize(frame->width,frame->height),IPL_DEPTH_8U,1);(frame,gray,CV_RGB2GRAY);
}(gray,face_rect);=track_object;;_object://Сопровождениелица(!object_tracking(gray,face_rect))
{[]={0x83,0x01,0x06,0x01,0x00,0x00,0x03,0x03,0xFF};//8x010601VVWW0303FF.clear();.append((char*)stop,sizeof(stop));_command(command);_moving=false;//Лицопотеряно,деинициализируемданныесопровожденияименяемсостояние()<<"lost"<<endl;_mass_center.x=NULL;_mass_center.y=NULL;();=find_object;
}
{(prev_mass_center.x!=NULL)
//qDebug()<<"next-prev"<<delta_x<<endl;(object_moving==false)//есликамеранеподвижна
{=delta_x+sum;((sum)>10)//объектдвижетсявлево
{
//if(window_center-next>0)//движетсяоткраякцентра
//break;//ничегонеделаем((window_center.x-next)<-30)//движетсяотцентраккраю
{_right[]={0x83,0x01,0x06,0x01,0x03,0x00,0x02,0x03,0xFF};.clear();.append((char*)move_right,sizeof(move_right));_command(command);
//right();//камерусмещаемвправо_moving==true;=0;
//qDebug()<<"next-prev"<<delta_x<<endl;
}
//qDebug()<<"next-prev"<<next-prev<<endl;
}((sum)<-10)//объектдвижетсявправо
{((window_center.x-next)>0)
{_left[]={0x83,0x01,0x06,0x01,0x03,0x00,0x01,0x03,0xFF};
//8x010601VVWW0103FF
//QByteArraycommand;.clear();.append((char*)move_left,sizeof(move_left));_command(command);
//left();//камерусмещаемвлево_moving==true;=0;
}
}
}(fabs(window_center.x-next)<50)//есликамераподвижна
{[]={0x83,0x01,0x06,0x01,0x00,0x00,0x03,0x03,0xFF};//8x010601VVWW0303FF.clear();.append((char*)stop,sizeof(stop));_command(command);_moving==false;()<<"rastoyaniedocentra"<<window_center.x-next<<endl;
}
}//moving(prev_mass_center.x,mass_center.x,window_center.x);
}
//};
}(frame,cvPoint(face_rect.x,face_rect.y),cvPoint(face_rect.x+face_rect.width,face_rect.y+face_rect.height),cvScalar(255,0,0));("frame",frame);(cvWaitKey(8)>0);
}(&capture_web);("frame");("points");(MemStorage);((void**)&cascade_frontal_face);->ClosePort();->finished_Port();
//serial->close();
//my_thread->exit();
}::~MainWindow()
{;
}::detect_face(IplImage*gray,CvHaarClassifierCascade*cascade,CvMemStorage*MemStorage,CvRect&face_rect)
{(MemStorage);*faces=cvHaarDetectObjects(gray,cascade,MemStorage,1.1,3,CV_HAAR_FIND_BIGGEST_OBJECT|CV_HAAR_SCALE_IMAGE
,cvSize(50,50));
////Поисклиц(!faces||!faces->total);
//Возвращаемпервоенайденное_rect=*(CvRect*)cvGetSeqElem(faces,0);;
//}
}
Файлmyport.cpp
#include"myport.h"::MyPort(QObject*parent):(parent)
{
}::~MyPort()
{()<<"finish!!"<<endl;_Port();//Сигналозавершенииработы
}::process_Port(){//Выполняетсяпристартекласса()<<"Hello!"<<endl;(&thisPort,SIGNAL(error(QSerialPort::SerialPortError)),this,SLOT(handleError(QSerialPort::SerialPortError)));//подключаемпроверкуошибокпорта(&thisPort,SIGNAL(readyRead()),this,SLOT(ReadInPort()));//подключаемчтениеспортапосигналуreadyRead()
}::ConnectPort(void){//процедураподключения.setPortName("COM6");()<<"connecting.........."<<endl;.setSettingsRestoredOnClose(false);.open(QIODevice::ReadWrite);.setBaudRate(QSerialPort::Baud9600);.setDataBits(QSerialPort::Data8);//DataBits.setParity(QSerialPort::NoParity);.setStopBits(QSerialPort::OneStop);.setFlowControl(QSerialPort::NoFlowControl);
//{(thisPort.isOpen()){()<<"open"<<endl;
}else{.close();()<<"errortoopenport"<<endl;;
}
//object_moving=false;
//s=0;
//}else{
//thisPort.close();
//error_(thisPort.errorString().toLocal8Bit());
//}
}::handleError(QSerialPort::SerialPortErrorerror)//проверкаошибокприработе
{
//if((thisPort.isOpen())&&(error==QSerialPort::ResourceError)){
//error_(thisPort.errorString().toLocal8Bit());
//DisconnectPort();
//}
}//::ClosePort(){//Отключаемпорт[]={camera_id,0x01,0x06,0x01,0x00,0x00,0x03,0x03,0xFF};//8x010601VVWW0303FF;//command.clear();.append((char*)stop,sizeof(stop));(command);.waitForBytesWritten(200);.close();()<<"portclosed!!!"<<endl;;
//if(thisPort.isOpen()){
//thisPort.close();
//error_(SettingsPort.name.toLocal8Bit()+">>Закрыт!\r");
//}
}::StopMoving()
{[]={camera_id,0x01,0x06,0x01,0x00,0x00,0x03,0x03,0xFF};//8x010601VVWW0303FF;//command.clear();.append((char*)stop,sizeof(stop));(command);
}::ReadInPort()
{_read.append(thisPort.readAll());=command_read.toHex();_read.clear();()<<"answer"<<y<<endl;
}::left()
{_left[]={camera_id,0x01,0x06,0x01,0x03,0x00,0x01,0x03,0xFF};
//8x010601VVWW0103FF;.append((char*)move_left,sizeof(move_left));(command);
}::right()
{_right[]={camera_id,0x01,0x06,0x01,0x03,0x00,0x02,0x03,0xFF};
//command.clear();;.append((char*)move_right,sizeof(move_right));(command);
}::WriteToPort(QByteArraydata){//Записьданныхвпорт
//if(thisPort.isOpen()){
//sleep(7);.write(data);()<<"commandiswritten"<<endl;.waitForBytesWritten(200);
//}
}
Файлtracking.cpp
#include"mainwindow.h"
//слежениезалицом::object_tracking(IplImage*gray,CvRect&face_rect)
{(gray,current_img);
//ВычислениеновогоположенияточекспомощьюпирамидальногоалгоритмаанализаоптическогопотокаЛукаса-Канаде(prev_img,current_img,previous_pyramid,current_pyramid,_points,current_points,count_point,cvSize(20,20),3,status,0,tc,flags);|=CV_LKFLOW_PYR_A_READY;(count_point<30);
//Удалениененайденныхточек,атакжевычислениекоординатописывающегопрямоугольника=std::numeric_limits<float>::max();=std::numeric_limits<float>::max();=std::numeric_limits<float>::min();=std::numeric_limits<float>::min();
//Центрмасс
//CvPoint2D32fmass_center=cvPoint2D32f(0.f,0.f);
//CvPoint2D32fprev_mass_center=cvPoint2D32f(0.f,0.f);_mass_center=mass_center;=0;(inti=0;i<count_point;++i)
{(status[i])
{_points[k]=current_points[i];(current_points[k].x<left)=current_points[k].x;(current_points[k].x>right)=current_points[k].x;(current_points[k].y<top)=current_points[k].y;(current_points[k].y>bottom)=current_points[k].y;_center.x+=current_points[k].x;_center.y+=current_points[k].y;
++k;
}
}_point=k;
//MainWindowwind;_center.x/=(float)count_point;_center.y/=(float)count_point;
//mass_center_next=mass_center;
//Вычислениерасстоянияотцентрамасс,доближайшихсторонописывающегопрямоугольника_x=std::min(mass_center.x-left,right-mass_center.x);_y=std::min(mass_center.y-top,bottom-mass_center.y);
//Границыописывающегопрямоугольникапересчитываютсясучётомполученныхминимальныхзначений+небольшойотступнавсякийслучай=mass_center.x-min_x-min_x/4.f;=mass_center.x+min_x+min_x/4.f;=mass_center.y-min_y-min_y/4.f;=mass_center.y+min_y+min_y/4.f;
//Удалениеточек,которыенепопаливновый прямоугольник=0;(inti=0;i<count_point;++i)
{(current_points[i].x>left&&_points[i].x<right&&_points[i].y>top&&_points[i].y<bottom)
{_points[k]=current_points[i];
//Выводточек(gray,cvPoint((int)current_points[k].x,(int)current_points[k].y),1,cvScalar(255,0,255));
++k;
}
}_point=k;
//printf("points_count=%i\n",count_point);//записываемсколькоточекнашлось_rect.x=(int)left;_rect.y=(int)top;_rect.width=(int)(right-left);_rect.height=(int)(bottom-top);
//Сменауказателейнапараметры::swap(prev_img,current_img);::swap(previous_pyramid,current_pyramid);::swap(prev_points,current_points);("points",gray);;
}
Заключение
В данной работе был разработан
программно-аппаратный комплекс, который осуществляет анализ видеоизображения,
путем поиска лица человека с помощью алгоритма Виолы-Джонса в режиме реального
времени, а затем осуществляет слежение методом пирамидального оптического
потока Лукаса-Канаде. В процессе слежения осуществляется движение видеокамеры в
сторону движения объекта. Программа была написана на языке C/C++ в среде
разработки QTCreatorс использованием библиотеки компьютерного зрения OpenCV.
Преимущества разработанной системы:
Работа в режиме реального времени.
Возможность обучить модель на поиск
определенного объекта или определенного человека.
Устойчивость поиска при смене
освещенности.
Устойчивость слежения при частичном
перекрытии объекта (не более чем 50%).
Возможность работы с изображением
низкого качества.
Недостатки:
Работа в двумерном пространстве без
учета пространственной ориентации объекта.
Существенное время задержки
получения изображения.
Неустойчивость алгоритма слежения к
аффинным преобразованиям.
Рекомендации по улучшению работы
программно-аппаратного комплекса:
Переход от двумерной системы
координат к пространственной системе координат.
Работа одновременно с двумя и более
камерами для создания 3D-модели объекта и распознавание при любой ориентации
объекта в пространстве.
Улучшение работы алгоритма слежения
за объектом путем учета аффинных преобразований.
Для повышения быстродействия и
сокращения времени отклика программы рекомендуется распараллеливание вычислений
алгоритмов.
Список литературы
1. Сойфер В.А. Компьютерная обработка изображений. Часть 2. Методы
и алгоритмы. Соросовский образовательный журнал, №3, 1996, с. 110 - 121.
. Р. Гонсалес, Р. Вудс, «Цифровая обработка изображений», изд-во:
Техносфера, Москва, 2005. - 1072с.
. Козлов В.Н., Функциональный анализ, Санкт-Петербург: СПбГПУ,
2012, 461с.
. Тули М. Справочное пособие по цифровой электронике: Пер. с англ.
- М.: Энергоатомиздат, 1990.
. Sony BRC H900 Command List
. Sony BRC H900 Operating Manual
. Bechtel W. The Cardinal Mercier Lectures at the Catholic
University of Louvain: An Exemplar Neural Mechanism: The Brain’s Visual
Processing System. 2003
. G. Yang and Thomas S. Huang. «Human face detection in a complex
background. Pattern Recognition», 27(1):53-63, 1994
. Татаренков Д. А. Анализ методов обнаружения лиц на изображении
// Молодой ученый. - 2015. - №4. - С. 270-276.
. Lanitis, A.; Taylor, C.J.; Ahmed, T.; Cootes, T.F.; Wolfson
«Image Anal. Classifying variable objects using a flexible shape model» Image
Processing and its Applications, 1995., p.70-74.
. Горбунов В.М. Теория принятия решений. Учебное пособие, Томск,
2010, с.67.
. Прейко М., Устройства управления роботами: схемотехника и
программирование - М.: Издательство ДМК, 2004, 202с.