Разработка онтологии экономических рисков на основе мониторинга информации, получаемой из новостных лент
Оглавление
Введение
Глава 1.
Моделирование предметных областей и решение задач информационного поиска:
анализ методов и средств
1.1 Описание
подхода к решению задачи мониторинга глобальных процессов на основе
Интернет-новостей
.2 Основные
методики, решающие проблему поиска
1.2.1
Семантический поиск
.2.2
Автоматическое реферирование
.2.3
Направления поиска
.2.4
Автоматическое рубрицирование
1.3 Общие
выводы по результатам анализа
Глава 2.
Построение онтологии
2.1 Понятие
онтологии
.2
Существующие исследования по извлечению знаний
.3 Пример
разработки онтологии предметной области в рамках проекта мониторинга глобальных
процессов
Глава 3.
Разработка онтологии экономических рисков
3.1
Расширенная онтология экономических рисков
.2 Апробация
полученной онтологии
Заключение
Библиографический
список
Приложения
Введение
В век информационных технологий в любой сфере деятельности информация
является одним из основных ресурсов, благодаря которому эта деятельность
совершается. Данные об изменении каких-либо числовых показателей (например,
курс валют, коэффициент рождаемости в регионе, рентабельность продаж и прочее),
обзорные статьи о разных исследованиях, таблицы, иллюстрации и многое другое.
Информация в различном представлении используется для анализа предметных областей,
составления прогнозов и прочего. Повседневно мы имеем дело с большими объемами
данных, а наиболее доступным ресурсом для их получения служит Интернет, который
представляет собой доступ к большому количеству источников различных данных.
К сожалению, большая часть таких ресурсов представляет собой электронные
документы, каждый из которых имеет определенную структуру, заложенную
составителем, не всегда подходящую для обработки текстов компьютером. Другими
словами, в таких источниках чаще всего представлена неструктурированная или
слабоструктурированная информация, что в совокупности с большими объемами
данных, содержащихся в документах, затрудняет поиск действительно нужных или
полезных данных именуемых знаниями. Для их извлечения аналитикам помимо собственных
навыков необходимо прибегать к специальным методам, которые позволяют собирать
из разных источников необходимую информацию.
На данный момент существует множество методов, решающих проблему
информационного поиска:
· фактографический поиск информации;
· аннотирование документов;
· рубрицирование или классификация;
· автоматическое реферирование;
· и другие.
Но в основной своей массе они решают проблему сортировки документов и
затрачивают на это большое количество времени и ресурсов, поэтому подходят для
решения ограниченного числа задач и используются чаще всего в информационных
системах с определенным набором электронных документов.
Чаще всего в Интернете эксперты собирают числовую информацию для анализа
показателей деятельности компаний, отраслей, стран и прочего, благодаря которой
они выявляют закономерности, строят числовые ряды, рассчитывают рейтинги и
прочее. Примером аналитической системы является платформа Prognoz Platform, которая позволяет пользователям
производить анализ числовой информации, найденной в Интернет [1]. Для обработки
и анализа структурированной информации существует много инструментов. Числовая
информация как раз обычно является структурированной, что позволяет аналитикам
быстро анализировать ее, строить модели, разрабатывать прогнозы и прочее на
основе современных аналитических платформ, программ и разных ресурсов.
Помимо числовой информации в Интернет представлено большое количество
текстовой информации, содержащей в себе знания, которые могут быть полезны для
использования аналитиками не меньше, чем числовая информация. Для обработки
текстов необходимы более сложные алгоритмы распознавания, поскольку тексты на
естественном языке содержат сложную неоднозначную структуру. Конечно, написание
текстов основывается на определенных правилах построения предложений,
употребления определенных словосочетаний, но помимо них существуют и другие
особенности языка такие как, собственный стиль автора, большое разнообразие
грамматических конструкций, употребление антонимов, синонимов и прочее. Сложность
и разнообразие языка усложняют задачу автоматизации обработки текста. В
настоящее время набирает популярность применение методов fact mining для извлечения знаний из текста, которые чаще всего
применяются для обработки числовой информации. Если структурировать текстовую
информации так, чтобы ее можно было обработать этими методами, то процесс
обработки можно ускорить в разы.
Большую часть данных в Интернет составляет текстовая информация.
Новостные ленты Интернета наполнены публикациями на разные темы о разных
событиях. Из таких публикаций можно извлечь много полезной информации о
происходящих событиях, о датах и времени, местах, где они происходили. Если
научится автоматически извлекать такие факты из текстов Интернет-новостей, на
их основе можно построить модели, описывающие разные предметные области. Уже
готовые модели могут быть использованы в качестве основы для баз знаний
аналитических систем для обработки текстовой информации, ее сбора,
структурирования, нахождения взаимосвязей и прочего. Такой подход уже описан в
[2] и используется в системе RCO Fact Extractor.
Для решения задач поиска информации широко используются онтологии [3].
Они используется для разработки инструментов информационного поиска, которые
решают различные задачи (аннотирование, реферирование текста и так далее).
Онтология чаще всего содержит в себе три основных компонента: концепты
(основные понятия, весь смысловой базис), атрибуты (свойства концептов) и
аксиомы (правила, которые объясняют взаимосвязи концептов между собой и с атрибутами).
Онтология собирает все найденные факты в заданном пользователем порядке,
иерархии, а также ее легко можно редактировать, дополнять, интегрировать с
различными системами и так далее. С помощью нее можно осуществлять поиск
необходимой информации о событиях по заданной предметной области.
Благодаря тому, что в онтологии можно отражать взаимосвязи между
объектами, ее можно использовать для нахождения не просто иерархических связей
для решения тривиальных задач поиска, но и задавать взаимосвязи, указывающие на
последствия и причины. При анализе новостей и формирования модели предметной
области на основе извлеченных из них данных, можно как раз определять
причинно-следственные связи событий и отражать это в онтологии. На основе этих
связей можно строить процессы, в которые входят анализируемые события.
Для построения моделей процессов, отражающих выявленные взаимосвязи и
служащих шаблоном происхождения определенного рода событий, может быть
использовано средство анализа процессов Process Mining. Но это средство служит для обработки
структурированной информации о событиях, представленной в виде журналах
событий. Для того, чтобы воспользоваться методами глубинного анализа процессов
необходимо преобразовать найденную в Интернете информацию о событиях к нужному
формату, предварительно обработав ее. Именно для поиска и предобработки
информации предлагается использовать онтологию в качестве модели предметной
области.
Глобальные процессы могут связывать события, относящиеся к разным
предметным областям, но на данном этапе исследований для апробации
моделирования предметных областей на основе новостных публикаций из Интернета
мы выделяем в качестве предметной области экономические риски и рассматриваем
влияние событий в данной области на другие сферы деятельности, в частности, на
экологию.
Объектом данной работы являются глобальные процессы, связывающие события,
относящиеся к различным предметным областям, в частности, экономике, экологии и
прочее, информация о которых представлена в Интернет.
Предметом исследования являются средства моделирования предметных
областей, в частности, средства разработки онтологий, используемых для решения
задач поиска информации в Интернет.
Целью работы является разработка онтологических моделей предметных
областей, предназначенных для анализа глобальных процессов на основе
информации, получаемой из новостных лент. На данном этапе реализации проекта
выделена предметная область - экономические риски.
Для достижения поставленной цели необходимо выполнить следующие задачи:
. Рассмотреть существующие подходы к моделированию предметных областей
и их использование для задач информационного поиска.
2. Выполнить анализ данных о выделенных для исследования предметных
областях.
. Построить формальные модели предметных областей (онтологии,
включающие как классификацию понятий, так и экземпляры соответствующих событий,
фактов, извлечённых их новостей).
. Провести апробацию онтологии на предмет решения поставленных
задач при помощи современных средств поиска.
В соответствии с поставленными задачами мы будем использовать следующие
методы:
· для анализа источников данных необходимо воспользоваться методами
системного анализа;
· для построения модели предметной области мы выбрали
онтологическое моделирование и средство построения онтологий редактор Protégé;
· поисковые системы.
Первая глава работы содержит анализ методов моделирования предметных
областей, которые позволяют решать задачи информационного поиска. Вторая глава
посвящена описанию онтологического подхода. В третьей главе приведены
построенные онтологии и их апробация.
Глава 1.
Моделирование предметных областей и решение задач информационного поиска:
анализ методов и средств
Интернет-пространство предоставляет доступ к огромному объему информации,
который постоянно растет. Мы можем найти информацию в любом представлении:
текстовом, табличном, аудио, видео и так далее. Помимо того, что объемы
информации настолько велики, что вручную их не обработать, большая часть данных
неструктурирована или слабоструктурирована.
Неструктурированные данные, как правило, представляют собой информацию,
не имеющую установленную структуру данных, понятную для машины, или структура
этих данных не установлена [4], то есть такие данные имеют определенную
структуру, которая характерна для естественного языка.
Очень часто неструктурированная информация представлена в текстовом виде
и для решения задач анализа несёт в себе ценность в виде содержания дат, мест,
различных показателей и прочего. Около 80% полезной для бизнеса информации
содержится в неструктурированных данных, по словам экспертов инвестиционного
банка Меррилл Линч в 1998 году [5]. Многие крупные предприятия занимаются
изучением внешних данных для выявления предпочтений покупателей, состояния
рынка, а также для принятия решения продвижения своего бизнеса. Несмотря на
это, очень много информации практически не попадает во внимание экспертов, так
как не подходит под критерии анализа и является избыточной.
Существует ряд признаков, по которым неструктурированные данные трудно
поддаются обработке стандартными средствами аналитики:
· неструктурированная информация представляет разнообразные данные;
· одна и та же структура данных может означать совершенно
разное в зависимости от особенностей языка, контекста и прочего;
· такая информация динамична, то есть со временем при изменении
структуры данных меняется и её значение.
Основной проблемой обработки неструктурированной информации является
отсутствие понятной для компьютера структуры этих данных. Исходя из этого,
можно сделать вывод, что для обработки подобных массивов неупорядоченной
информации следует понять, как возможно эту структуру создать.
Для представленной работы важной задачей при поиске информации является
извлечение из нее знаний, которые можно использовать для построения базы
знаний, а именно для проектирования выбранных моделей предметных областей:
нужно найти такие методы, которые помогут отобрать нужные публикации в сети
Интернет, для извлечения фактов, принадлежащих предметной области (в частности,
экономические риски: места события, наименования субъектов, даты происшествий и
прочее). Помимо этого, необходимо, чтобы собранные данные об одних объектах,
упомянутые разными словами (например, «США» и «Соединенные Штаты»), не
«размножались», т.е. необходимо решить проблему именования данных. По числу
упоминаний события в разных источниках можно выстраивать рейтинги и
прогнозировать динамику развития подобных событий.
Существуют разные методы для извлечения знаний из неструктурированных
данных. Нельзя сказать, что есть стандартный перечень методов, которые используются
экспертами. Для разных задач выбираются соответствующие методы. В современных
системах используется двухфазная технология аналитической обработки. В первой
фазе производится автоматизированный анализ отдельных документов,
структуризация их содержания и формирование хранилищ исходной и аналитической
информации. Во второй фазе (OLAP, Text Mining, Data Mining) - извлечение знаний
из хранилища или из полученной по запросу подборки документов.
В одном из исследований предлагается обрабатывать источники Интернет
созданием структуры электронного документа с помощью специальной
программы-«обертки» [6]. Вместо разработки сложного программного продукта по
автоматизации обработки и управления информации здесь предлагается с помощью
программы-«обертки» обернуть неструктурированные данные и представить их в
структурированном виде. Суть такого подхода определяется тем, что программа
извлекает информацию с веб-страниц и конвертирует её в структурированный текст.
На сегодняшний день существуют различные подходы к извлечению информации.
Широкое применение находят алгоритмы, используемые в поисковых системах, для
извлечения более точных и полных знаний аналитики разрабатывают новые способы,
комбинируя, дополняя существующие технологии или занимаются созданием новых. Подход,
предложенный Шаляевой И.М. [7], описывает алгоритм обработки информации в
Интернет и на основе этих данных возможность построения моделей глобальных
процессов, их мониторинг, прогнозирование событий и прочее.
1.2 Описание
подхода к решению задачи мониторинга глобальных процессов на основе
Интернет-новостей
Представленные выше методы извлечения информации могут найти применение в
решении различных задач поиска (классификация, кластеризация и другие). Они
используются в разных информационных системах, для реализации поиска на
веб-страницах, порталах и прочее.
Для проведённого исследования необходимо понять, какая технология
извлечения данных подойдет для решения задач проекта, то есть для поиска
Интернет-новостей, извлечения фактов в виде наименования событий, наименования
объектов, дат произошедших событий и прочего, обработки этих фактов и
построение на основании этих знаний полноценной модели предметной области.
Наиболее подходящим инструментом для этих задач является построение
онтологической модели предметной области. Данный подход позволяет аналитику
легко вносить изменения в разработанную модель, интегрировать с другими
онтологиями, многократно использовать ее. Помимо этого, существуют удобные
инструменты для создания онтологий и работы с ними, которые находятся в
открытом доступе.
В работе И.М. Шаляевой, В.В. Ланина и Л.Н. Лядовой описывается подход, в
котором онтология в качестве модели предметной области используется для поиска
фактографической информации [8]. Сам проект посвящен разработке алгоритма
работы системы мониторинга глобальных процессов на основе Интернет-новостей. На
рис. 1.6 представлена схема работы такой
системы.



Рисунок
1.1 Основные этапы подхода [27]
Основные этапы подхода делятся на следующие:
. Первым этапом подхода является формирование пользовательских запросов
к информационной системе.
. Далее полученные результаты поиска в сети Интернет по запросам
извлекаются.
. Затем проходят обработку в соответствии с моделью предметной
области, описанной пользователем. Так происходит наполнение базы знаний.
. После повторения этапов 2-4 происходит формирование набора
данных для автоматического построения моделей процесса. Результаты запроса
представляются в формате, который используется для работы с системами
глубинного анализа процессов (XES).
. Последний этап заключается в подготовке журналов событий и их
передаче в систему автоматического анализа и моделирования процессов ProM [9].
Данная система способна моделировать процессы в необходимой нотации (BPMN, EPC
и другие), а также поддерживает различные методы их анализа.
Для данного подхода многоуровневая онтология была выбрана в качестве
структуры для хранения данных об источниках информации, выбранной предметной
области. Благодаря этому все необходимые данные из документов будут извлекаться
в соответствии с построенной моделью предметной области (онтологией), которая
будет содержать в себе экземпляры событий, факты.
В работе [8] представлено применение описанного подхода для мониторинга
событий связанных с экологическими катастрофами. В ходе работы были получены
модели процессов для предметной области экологические катастрофы.
1.2 Основные методики, решающие проблему поиска
1.2.1 Семантический
поиск
Одним из самых первых подходов считается использование векторной модели.
В основе данного метода лежит представление электронного документа в качестве
точки (вектора) в многомерном пространстве, наполненном множеством таких же
точек (векторов). Расстояние между векторами определяется семантической
близостью документов друг к другу. Чем более схожи документы по семантике, тем
ближе находятся в пространстве точки.
Существует несколько видов матриц, которые строятся на основании данной
модели:
· Матрица, основанная на сходстве между документами. При наличие
определенной коллекции документов можно построить матрицу, в которой в качестве
сроки будет выступать определенный термин, а в качестве столбца берется
соответствующий документ.
· Матрица, основанная на сходстве между словами. В тех случаях,
когда нам необходимо определить семантическое расстояние между словами не во
всем документе, а лишь в его части, мы строим матрицу, в которой отражается
частота вхождения термина во фразу, предложение и прочее.
· Матрица, основанная на сходстве отношений. В данном случае в
строке матрицы описывается пара слов, а столбец определяет их отношения.
Как и векторную модель булеву модель начали использовать достаточно
давно. Этот подход базируется на использовании логических операторов при
построении запроса для поиска информации:
· Оператор AND - логическое
«и» (умножение). При использовании данного оператора система находит только те
документы, в которых обязательно встречаются оба термина из запроса.
· Оператор OR -
логическое «или» (сложение). Данный оператор ставит перед системой поиска
задачу найти все документ, которые могут содержать как оба термина из запроса,
так и один из них.
· Оператор NOT -
логическое отрицание. Логическое отрицание говорит поисковику исключить из
документов поиска те, в которых содержится слово из запроса.
При составлении запросов с использованием булевых операторов размеры
выборки и ее качество может сильно варьировать. На рис. 1.2 изображено
схематически, как выглядят результаты поиска при использовании разных
комбинаций операторов в запросах.
Очень часто при использовании такого подхода можно столкнуться с
проблемой нерелевантной выборки. Бывают ситуации, когда на запрос с оператором AND в поисковой выдаче нам выдается
слишком мало документов, а на запрос с оператором OR наоборот поисковик может найти слишком большое количество
ресурсов.
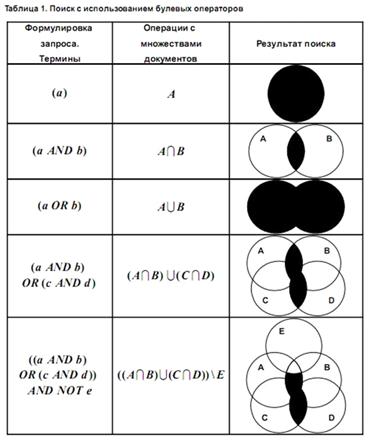
Рисунок
1.2 Таблица с использованием булевых операторов
Также проблемой булевой модели является невозможность ранжировать
результаты поиска. То есть мы не можем задавать веса терминам запроса, и при
логическом «и» нет разницы между документами, содержащими хотя бы одно слово из
запроса и не содержащими их вообще, а при логическом «или» не различаются
документы, содержащие оба термина и только один.
Но такие проблемы научились решать с помощью расширения булевой модели
[10]. В данный момент в профессиональных системах используются модели, которые
работают с разветвленными запросами, контекстными ограничениями на расстояние
между словами и прочее.
Технологии семантического поиска включают в себя использование онтологий.
В отличие от поиска по ключевым словам, который реализуется в поисковых
системах Интернета (Google, Яндекс и
другие), поиск с помощью онтологии основывается на использовании семантике
слов, а не на упоминании терминов в текстах документов. Такой подход позволяет
машине производить более осмысленный поиск с точки зрения человеческого
мышления. Содержание в онтологии помимо классов (понятий) их свойств, а также
связей между ними позволяет усложнить технологию поиска, но при этом добиться
более точных и полных результатов от выборки.
Для разработки онтологии существуют редакторы, которые распространяются
бесплатно. Одним из таких редакторов является Protégé [11]. Он представляет собой
инструмент, который визуализирует действия работы над онтологией, ее создание,
описание связей, задание функции, разработка запросов. Имеется возможность
визуализации иерархии построенной онтологии, внесение в нее изменений и другие
функции.
Исследователи по онтологиям со всего мира занимаются разработкой
Семантической паутины, которая является аналогией Интернета, только целью
создания данного ресурса является упрощение поиска [3]. Документы данного
хранилища представляют собой готовые онтологии или документы со встроенной
разметкой текста. Эти документы распределяются внутри самой технологии по
заданным категориям, что также должно упрощать поиск и распределение ресурсов.
1.2.2 Автоматическое
реферирование
Суть данного метода заключается в составлении небольшого текста, который
еще называют аннотацией. Такой текст должен коротко излагать суть всего
документа. Он часто собирается из отрывов текста документа, определенных
предложений и параграфов, вырванных из контекста, которые могут быть не связаны
между собой, из-за чего подобные тексты нельзя назвать полноценными [12].
Однако для преодоления сложностей данного метода придумали несколько подходов.
Первый подход считается довольно простым в реализации, так как он
предлагает построение модели без добавления правил о новых предметных областях
или языках. Второй подход базируется на знаниях и предлагает создавать более
качественные аннотации за счет понимания текста. Для этого необходимо обладать
большой базой знаний, в которой есть правила, извлеченные и адаптируемые для
новых предметных областей и языков.
Но возникает вопрос реализации такого метода для нескольких источников.
Реферирование документа предусматривает сжатие текста до одной третьей его
части и меньше для одного документа, а для нескольких источников этот процент
должен быть еще меньше. Создание программ, которые смогут воплотить в
реальность такой метод и выдавать в результате качественные рефераты, является
довольно затратным предприятием.
1.2.3 Направления
поиска
Многие программы анализа данных имеют собственные базы документов, с
которыми приходится работать аналитикам. Они могут визуализировать результаты
анализа, взаимосвязи объектов и так далее.
Существует процесс ETL (Extract, Transform, Load), который используется в управлении хранилищами
данных. Это основной процесс обработки источников данных. ETLизвлекает данные из нескольких
источников (нескольких систем), затем обрабатывает их таким образом, чтобы
остались только полезные знания, а потом загружает полученные знания в
хранилище. Тот способ поиска, который используется в процессе ETL, позволяет находить взаимосвязи
между объектами не обращая внимание на содержимое документов. Визуализация
построенной сети зависимостей объектов позволяет аналитику ориентироваться в
пространстве представленных объектов и производить анализ их взаимосвязей в
разных документах. Задача типизации является следующим этапом обработки
полученных объектов и их связей.
При более глубоком анализе данных помогают OLAP-технологии. Представление информации в виде куба (см.
рис. 1.3-1.4), многомерной таблицы, позволяет собрать большие массивы данных
вместе. Обычно формируется таблица, содержащая в себе факты, по которым и
происходит группировка данных. Все остальные таблицы данных присоединены к ней.
Запросы формируются по таблице с фактами. Использование OLAP-кубов позволяет аналитикам
просматривать информацию в разрезе, задавая определенные параметры измерений.
Подобные технологии помогают не только обрабатывать и анализировать большие
объемы данных, но и строить прогнозы на их основе.
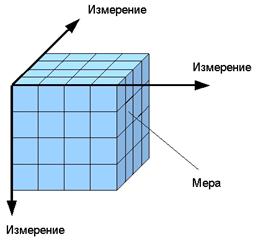
Рисунок 1.3 Представление OLAP-куба
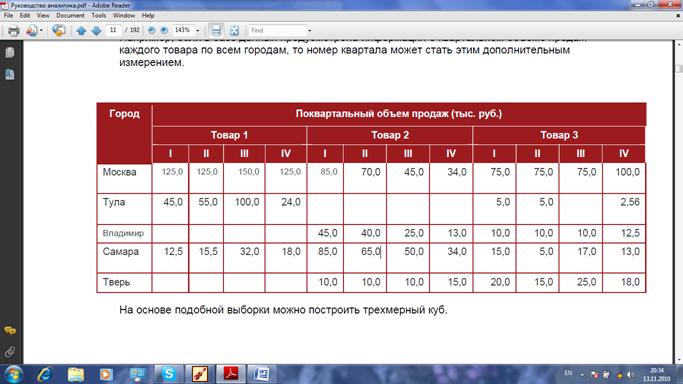
Рисунок
1.4 Пример таблицы с тремя измерениями
События, информация о которых найдена в Интернет, могут быть связаны с
числовой информацией, размещённой в хранилищах данных. Измерения могут быть
привязаны к объектам, местам, где события произошли, и времени, когда они
произошли. Таким образом, можно расширить возможности мониторинга и анализа
процессов.
1.2.4 Автоматическое
рубрицирование
Метод автоматического рубрицирования подразумевает под собой разделение
частей текста на категории, по которым создается их иерархия (классификация).
Рубрицирование используется для упорядочивания знаний и их обмена. Существует
два подхода к автоматическому рубрицированию:
. Методы, которые основываются на знаниях. Суть метода состоит в том,
что аналитики составляют правила обработки данных с помощью полученных знаний,
булевских выражений и прочего.
2. Методы, которые основываются на машинном обучении. Для
использования данного метода необходимо собрать коллекцию документов, которая
будет классифицирована по категориям, отобранным человеком. На базе этой
коллекции машина учится категорировать документы.
В одной исследовательской работе [13] авторы утверждают, что при
использовании больших рубрикаторов (500 и более рубрик) для обработки информации
очень сложно собрать коллекцию документов для качественного обучения машины.
Поэтому чаще всего используются методы, в которых рубрики составляются и
описываются вручную аналитиками.
В данном исследовании авторы также проанализировали разные подходы и
выявили ряд проблем связанные как с составлением рубрик вручную, так и
автоматически. При обработке документов разными аналитиками на выходе могут
получиться сильно отличающиеся результаты. Один эксперт может отнести к
документу определенные рубрики, а другие выберут другой набор рубрик. Такая
ситуация может произойти из-за разного понимания содержания документов, и
разница в рубрикации при обработке одних и тех же документов может оказаться
очень большой. Чем больше берется объем коллекции документов и количество
рубрикаций, тем больше будет различий в рубрицировании коллекции разными
аналитиками.
Помимо этого, ручное рубрицирование сталкивается с проблемой
непоследовательности. Она возникает по нескольким причинам:
· При пользовании большим количеством рубрик аналитик может забыть про
некоторые из них и не указать подходящие из них рубрики для документа.
· Тематика документов не всегда определяется одной предметной
областью, в одном документе может быть пересечение различных областей знаний
из-за чего эксперты в узком кругу вопросов могут растеряться и либо неправильно
выбрать рубрики для документа, либо не выбрать ничего, чтобы лишний раз не
ошибиться.
При использовании методов машинного обучения также возникают проблемы с
рубрицированием. В первую очередь для получения хороших результатов
рубрицировании необходимо наличие большой выборки рубрицированных текстов.
Помимо большого объема коллекции для обучения, документы должны быть
классифицированы качественно, то есть экспертам необходимо придерживаться общих
правил обработки документов и составления рубрик. Часто возникает проблема
неравномерного распределения документов по рубрикам. В некоторые рубрики
попадает небольшое количество документов в отличие от других, из-за чего
обучение машины проходит не очень удачно, и ей сложно отнести документы в такие
рубрики.
Но с проблемами рубрицирования помогают справится специальные технологии.
Для метода с использованием знаний можно использовать уже выявленные знания о
языке и культуре из сторонних ресурсов независимых от данных классификаторов.
При методе машинного обучения принято сочетать его с методом, основанном на
знаниях.
Результаты автоматической рубрикации можно использовать для решения
задачи автоматизации построения онтологий, снижения трудоёмкости разработки
моделей предметных областей.
1.3 Общие
выводы по результатам анализа
Описанные выше методы извлечения информации могут найти применение в
решении различных задач поиска (классификация, кластеризация и другие). Их
можно использовать в разных информационных системах, для реализации поиска на
веб-страницах, порталах и прочее.
Для данного исследования необходимо понять, какая технология извлечения
данных подойдет для решения задач проекта: для поиска Интернет-новостей,
извлечения фактов в виде наименования событий, наименования объектов, дат
произошедших событий и прочего, обработки этих фактов и построение на основании
этих знаний полноценную модель предметной области.
Наиболее подходящим инструментом для этих задач является построение
онтологической модели предметной области. Данный подход позволяет аналитику
легко вносить изменения в разработанную модель, интегрировать с другими
онтологиями, многократно использовать ее. Многие исследователи предлагают
именно такой подход и описывают результаты успешной его реализации. Помимо
этого, существуют удобные инструменты для создания онтологий и работы с ними,
которые находятся в открытом доступе.
Глава 2.
Построение онтологии
Для построения модели предметной области необходимо в первую очередь
определиться с тем, что мы подразумеваем под моделью предметной области и с
помощью каких инструментов мы хотим ее построить. В данной главе даётся понятие
онтологии, приводится формальное определение, которое берётся за основу для
построения модели предметной области для решения задачи моделирования
предметных областей в данной работе, а также описана в качестве примера
онтология, которая ранее построена при реализации проекта (онтология предметной
области экологические катастрофы).
2.1 Понятие
онтологии
В настоящее время все большую популярность набирает построение онтологий
для моделирования предметных областей. Но прежде чем рассказывать об этом
подходе, необходимо дать понятие самой онтологии.
Данный термин начали использовать еще в философии, где он обозначает учение
о сущем, о бытие [14]. То есть онтология - это объяснение причины существования
всего живого и взаимосвязей между всеми объектами мира.
В сфере информационных технологий онтологией считается «структура,
описывающая значения элементов некоторой системы» [15]. Другими словами,
онтология представляет собой классифицированную иерархию объектов, которые
связанны между собой разными видами отношений. Исходя из этого определения,
онтология состоит из объектов, их атрибутов и отношений между ними.
Многие авторы считают одним из основных определений онтологии
определение, которое дал Том Грубер. Он сказал, что онтология - это
спецификация концептуализации [16].
В состав онтологии могут входить следующие элементы:
· Классы или понятия (ранее названные объектами). Эти элементы могут
представлять собой сущность, которая несет какую-либо информацию, или группу
объектов.
· Отношения или атрибуты (ранее названные свойствами). Данные
элементы показывают зависимости между объектами разных областей знаний.
· Функции. Представленный элемент является специальным видом
отношения, при котором объект определяется с помощью предыдущих объектов.
· Аксиомы. Этот вид элементов записывает правила, которые
всегда являются истинными.
Основной целью использования онтологии в настоящее время является
моделирование предметных областей. Многие Интернет-магазины используют
онтологический подход для категоризации продаваемых товаров, а также их
характеристик. В медицине разработаны большие словари SNOMED и семантическая
сеть, которая называется Системы Унифицированного Медицинского Языка (Unified Medical Language System, UMLS).
Существуют веские причины, почему онтологический подход для моделирования
предметных областей получает широкое применение:
. В первую очередь структура онтологии позволяет использование не
только теми людьми, которые ее создали, но и другими исследователями. Это
позволяет людям со всего мира обмениваться важными разработками, создавать
глобальные проекты по созданию глобальной онтологии, которая сможет
смоделировать практически любые знания.
2. Также любую онтологию можно использовать повторно в той
предметной области, для которой она создана, и не только.
. Методы работы с онтологией позволяют пользователям постоянно
вносить какие-либо правки в нее, что упрощает процесс создания такой модели и
дает возможность постоянно ее совершенствовать.
. Благодаря тому, что в онтологии можно отделить оперативные
знания от знаний предметной области, мы можем обобщать данные. То есть общие
знания для определенного объекта всегда можно отделить от его уникальных
свойств, что делает применение онтологии более обширным.
. Одной из особенностей использования онтологии является
реализация анализа предметной области. Благодаря тому, что в онтологию всегда
можно внести изменения, повторный анализ предметной области позволяет расширить
модель на основе выявленных знаний.
Существует несколько классификаций онтологий. Классификация по цели
создания включает в себя 4 вида онтологий:
· Онтология представления (см. рис. 2.1).
Данная онтология разрабатывается с целью создания языка, описывающего
онтологии низшего уровня.
· Онтология верхнего уровня (см. рис. 2.2).
· Онтология предметной области.
Данный вид онтологии походит на предыдущий, но он ограничен всего одной
предметной областью. Такая онтология предназначена для собрания обобщенных
понятий из одной области знаний и для повторного использования другими
экспертами.
· Прикладная онтология.
Подразумевается, что такая онтология должна содержать в себе более
специфическую информацию в отличие от предыдущего вида. Она описывает
концептуальную модель для конкретной задачи предметной области.
Рисунок
2.1 Онтология представления
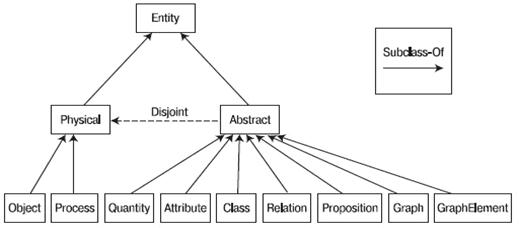
Рисунок
2.2 Онтология верхнего уровня
Еще одной классификацией онтологий по содержимому включает в себя 3 вида:
· Общие онтологии.
В ней содержатся наиболее общие понятия, независимые от предметных
областей и прочего. Она может включать в объекты первых двух онтологий из
предыдущей классификации.
· Онтологии задач.
Такая онтология чаще всего создается для описания конкретных задач при
создании программного продукта.
· Предметные онтологии.
Эта онтология описывает не абстрактные сущности, а объекты реального
мира, например, запчасти автомобиля.
2.2
Существующие исследования по извлечению знаний
Подход к поиску информации с точки зрения построения онтологий относится
к семантическим технологиям. Само по себе понятие онтологии обозначает описание
области знаний, то есть она является совокупностью этих полезных знаний.
Семантический поиск предполагает поиск осмысленных понятий, поиск с логикой,
схожей человеческим суждениям, поиск по семантике текстов [17]. Представление знаний
в электронном виде позволяет автоматизировать процесс поиска новых знаний, их
обработки, анализа, построения прогнозов на их основе и так далее.
Создаются новые алгоритмы извлечения знаний из документов в сети
Интернет, которые реализуются благодаря существующим технологиям. В одной из
своих работ Кириллов А.В. [18], работник НИУ ВШЭ кафедры Инноваций и бизнеса в
сфере информационных технологий, предлагает использование нового подхода к
извлечению данных с помощью запросов на естественном языке. В своей статье
автор описывает проблемы, которые возникают с применением современных
технологий по поиску и извлечению информации из электронных документов.
Одновременно с этим он предлагает новый алгоритм обработки запросов на
естественном языке с помощью семантического преобразования.
Другой автор в своей работе рассматривает применение онтологического
анализа при моделировании сложных систем [19]. На основе метода
экспериментальных данных автор пытается изменить структуру самой онтологической
модели, то есть взаимосвязей между объектами. Он изучает способы автоматизации
построения структуры онтологии.
В еще одной статье авторы описывают онтологически-ориентированный подход
в построении системы поиска информации в коллекции документов [20]. Этот подход
разрабатывался для реальной ИАС (информационную автоматизированную систему) и
внедрен в нее, «Яндекс.Персональный поиск».
2.2 Пример
разработки онтологии предметной области в рамках проекта мониторинга глобальных
процессов
В своей работе И.М. Шаляева предлагает метод извлечения знаний из
Интернет-новостей при помощи онтологии [7]. Суть подхода заключается в том, что
вся информация, собранная из Интернет-новостей, должна будет структурироваться
в виде таблицы журнала событий. Такой вид представления информации чаще всего
бывает представлен в информационных системах предприятий, которые собирают
данные, показатели работы всей деятельности и анализируют их. Как правило,
такая информация уже представлена в структурированном виде и машине не
представляется никакой сложности для ее анализа.
Таблицы событий обрабатываются многими методами, например, инструментами Process Mining. Они помогают находить закономерности между
событиями, представленными в журнале, зависимости объектов и прочее. Но для
приведения данных в такую структуру необходимо предварительно их обработать.
Для решения этой задачи в проекте строится онтология. На основе содержащихся в
ней знаний, компьютер сможет распознавать, какие знания из текстов
Интернет-новостей подходят эксперту, и распределит их по соответствующим
классам, заранее занесенным в онтологию. Благодаря тому, что онтология легко
поддается изменениям, данный проект можно расширять и интегрировать его с
другими онтологиями по другим предметным областям. Данное исследование
представлено в такой предметной области как техногенные катастрофы и по ней уже
построена онтология (см. рис. 2.3). Предварительные результаты реализации
проекта показывают, что применение онтологии позволяет уточнить модели
процессов, выявить скрытые закономерности.
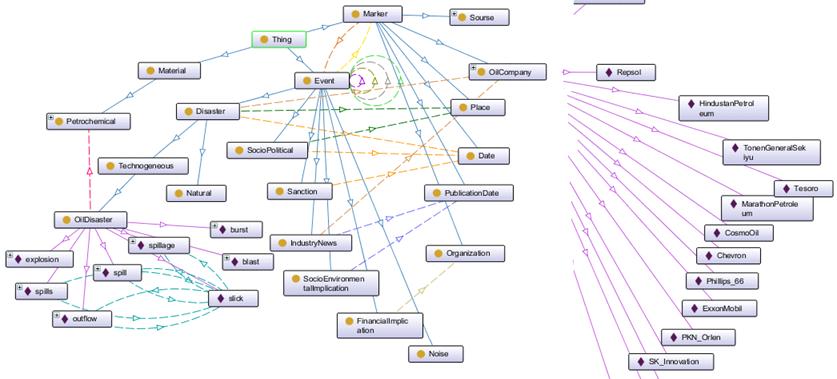
Рисунок
2.3 Онтология предметной области «Экология» [7]
Разработка онтологии в данной работе должна дополнить проект и расширить
возможности поиска не только для экологии, но и для экономики, расширив
«границы» глобальных процессов до нескольких предметных областей.
онтология новостной экономический риск
Глава 3.
Разработка онтологии экономических рисков
В качестве предметной области для построения онтологии выбраны
экономические риски. На начальном этапе создания онтологии требуется собрать
информацию по выбранной предметной области, обработать ее и проанализировать.
Необходимо выделить основные понятия, используемые в предметной области,
определить их свойства, а также связи между объектами.
В первую очередь нам необходимо было выяснить, что собой представляют
экономические риски, другими словами, нужно понять, как распределяются
экономические риски. Для того чтобы понять, какие риски бывают, необходимо
изучить их классификацию. В разных источниках приводятся разные классификации
экономических рисков, то есть не существует общей правильной классификации, а
есть определенные признаки, по которым разделяют виды рисков по разным
классификациям.
Риск для любой сферы деятельности воспринимается с точки зрения экономики
и считается возникновением неблагоприятной для бизнеса ситуацией. Различные
учебные пособия, статьи, книги приводят разные примеры видов рисков, но в то же
время все они имеют схожие характеристики, свойства. В некоторых источниках
имеется небольшое описание существующих типов рисков [21, 22]. Другие же
подробно описывают классификацию рисков, в которых прослеживается пересечение
этих рисков, от чего может возникнуть путаница в понимании того или иного вида
риска [23, 24].
В одной статье выделяют динамическую группу рисков, то есть спекулятивные
[25]. Эти риски связаны как с убытками, потерями, так и с получением прибыли, в
отличие от чистых рисков, которые включают в себя только риски, приносящие
убытки или нулевую доходность. В этой группе выделяют следующие виды рисков:
· финансовые;
· политические;
· технические;
· производственные;
· коммерческие;
· отраслевые;
· инвестиционные.
Большое внимание в литературе уделяется коммерческим рискам. Данный тип
экономических рисков входит в предпринимательскую деятельность. Такие риски
чаще всего описаны с точки зрения одного предприятия, классифицирует риски,
влияющие на деятельность определенной компании.
Каждый из этих видов можно разделить на подвиды в зависимости от
содержимого. Например, практически для каждого вида можно выделить масштаб
происходящего, то есть события для определенного вида риска может иметь
значение в масштабе одного объекта, города, страны или иметь международный
масштаб. Заранее хочется выделить события крупного масштаба в пределах страны в
качестве примера для построения онтологической модели.
В таблице 3 приведены характеристики выбранных типов рисков.
Таблица
3.1
Классификация экономических рисков
|
Название риска
|
Определение
|
Пример события
|
|
Природоестественные
|
Риски, связанные с
природными стихиями
|
Наводнение, цунами, оползни
и др.
|
|
Экологические
|
Риски, связанные с
загрязнением окружающей среды
|
Разлив нефти, охрана
окружающей среды, загрязнение воздуха и прочее.
|
|
Политические
|
Такие риски связанны с
политическими делами страны внутри государства и в мире
|
Расследование о доходах,
протесты, международные конфликты и др.
|
|
Транспортные
|
Риски, связанные с
перевозками
|
Дорожно-транспортные
происшествия и др.
|
|
Коммерческие риски
представляют собой определенные потери при хозяйственной деятельности
|
Имущественные риски
представляют собой риски потери имущества
|
Кража, проявление
халатности, перенапряжение систем и др.
|
|
Производственные риски
связаны с убытками при остановке производства, ущербе, нанесенном
оборудованию, технике, а также риски при внедрении новой технологии и техники
|
Внедрение технологий в
производство, поломка оборудования и прочее.
|
|
Торговые риски связанны с
рисками в торговой деятельности
|
Задержки платежей, отказ в
платеже, непоставка товара и прочее.
|
|
Финансовые риски связанны с
потерями денежных средств.
|
Изменения курса валют,
инвестирование и др.
|
Для этих рисков выделим основные атрибуты, которые будут отражать
свойства выбранных категорий, основные показатели и факты, которые необходимо
извлечь из текста. По аналогии с приведенным во второй главе исследованием И.М.
Шаляевой [7] выделим следующие категории и атрибуты:
. Классификация рисков, которая приведена в таблице 3, является одной
из иерархий классов в онтологии:
a. Natural (Природоестественные
риски).
b. Ecological (Экологические риски).
c. Political (Политические риски).
e. Commercial (Коммерческие риски): Property (Имущественные), Production (Производственные), Trading (Торговые) и Financial (Финансовые).
2. Атрибуты также составляют отдельную иерархию классов и связываются с
типами событий с помощью установленных связей:. Названия фирм, которые
фигурируют в новостях об экономических рисках - Company (Компания, организация).
b. Дата, когда произошло то или иное событие - Date (Дата события).. Дата публикации
новостного события - Publication date (Дата
публикации события в источнике).
3. Экземпляры классов присутствуют в нашей онтологии для того, чтобы
показать, какие именно события могут называться экономические риски:. Для
финансовых рисков возьмем показатели изменения курса валют (exchange rate), также выделим сумму убытка в денежном представлении
(loss).
b. Для природоестественных рисков введем экземпляры наводнение (flood) и оползень (slide).. Для политических рисков возьмем
митинги (rally) и конфликты (dispute).
В итоге мы получили онтологию, отображение которой в виде графа можно
увидеть в приложении А. Данная онтология представляет лишь небольшую часть
предметной области «Экономические риски». Ее необходимо расширять, исследовать
и обрабатывать по мере поступления новых знаний. Предполагается использовать ее
для поиска новых знаний в выбранной предметной области.
3.1 Расширенная
онтология экономических рисков
Первая построенная онтология, граф которой есть в приложении А, отражала
классификацию экономических рисков, интересных для изучения в нашем проекте. Но
данная онтология нуждается в доработке, то есть ее необходимо расширить,
добавив дополнительные классы и экземпляры. Основной целью общего проекта,
описанного в первой главе, а также ссылка на его применение есть во второй
главе, является мониторинг глобальных процессов на основе Интернет-новостей.
Модель предметной области не должна отражать общие понятия, формировать полное
описание области знаний, ее задача показывать описание событий какой-либо
деятельности с точки зрения пользователя. Построенная онтология должна
представлять из себя формальное описание событий определенной предметной
области, например, экономические риски.
В сети Интернет содержится много информации, но нам важно отыскать данные
о событиях, которые нас интересуют. Для этого необходимо было понять, чем для
нас являются события, которые мы хотим описывать с помощью онтологии. Так как в
качестве источника информации для нас служат новостные публикации из сети
Интернет, нужно определить, какие именно объекты, содержащиеся в тексте, могут
быть использованы для нашей модели.
Классификацию экономических рисков необходимо было дополнить экземплярами
событий. Для узла Событий (Events)
на онтологическом графе произошли следующие изменения, которые можно увидеть на
рис. 3.1:
· добавлены экземпляры для политических рисков (Political) конфликты (conflicts) и расследование о доходах (investigationIncome);
· для экологических рисков (Ecological) разлив нефти (oilSpill) и загрязнение воздуха (aiPolution);
· для транспортных рисков (Transport) дорожно-транспортные происшествия (trafficAccident);
· для финансовых рисков (Financial) инвестирование (investing);
· для торговых рисков (Trading) задержка платежей (latePayment) и непоставка товара (non-delivery);
· для имущественных рисков (Property) потеря имущества (lossProperty) и кража в особо крупных размерах (grandTheft);
· для производственных рисков (Production) поломка оборудования (equipmentFailure) и внедрение технологий (deploymentTechnology).
Для анализа новостных публикаций Интернета мы использовали наиболее
распространенные поисковые системы. Основной задачей являлась просмотреть как
можно большее количество новостей и выделить особенно важные атрибуты, которые
войдут в онтологию.
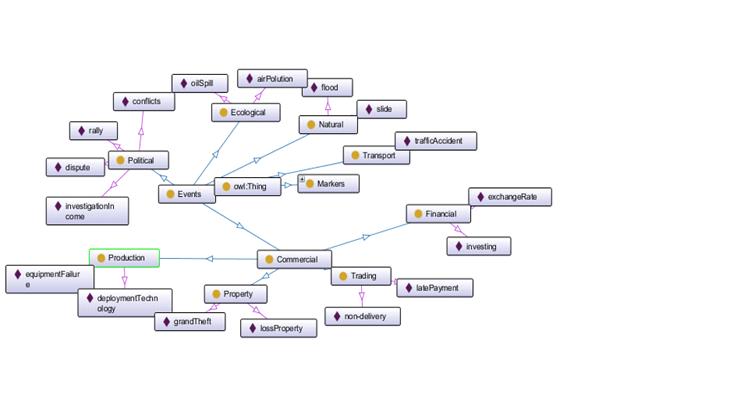
Рисунок
3.1 Часть онтологии экономических рисков. Развернут компонент Events
(События)
После сбора и анализа определенного количества информации мы выделили
следующие атрибуты (Markers):
· В первую очередь необходимо было выделить страны, которые оказывают
наибольшее влияние на мировую экономику. Узел Страны (Countries) содержит следующие наименования:
Азия (Asia), Европа (Europe), Россия (Russia), США (USA), Австралия (Australia), Африка (Africa), Аргентина (Argentina), Бразилия (Brazil), Канада (Canada), Мексика (Mexica). При этом
Азия включает в себя Китай (China),
Индия (India), Индонезия (Indonesia), Иран (Iran), Япония (Japan), Корея (Korea), Саудовская
Арабия (SaudiArabia), Тайвань (Taiwan), Таиланд (Thailand), Турция (Turkey).
Европа включает в себя Бельгия (Belgium),
Франция (France), Германия (Germany), Италия (Italy), Нидерланды (Netherlands), Польша (Poland), Испания (Spain), Швеция (Sweden), Швейцария (Switzerland), Соединенное Королевство (UK).
· Существуют различные организации, контролирующие
экономическую деятельность по всему миру, которые могут быть органом власти
какой-либо страны или союзом стран, объединенных для достижения определенной
цели, а также компании мировые лидеры в своей отрасли. В онтологии узел,
содержащий данные об организациях называется Организации (Organizations). Он включает в себя Европейский
Союз (EU), Всемирный банк (WoldBank), Большую двадцатку (G20), ООН (UN).
В
качестве примера мирового лидера добавлена компания Роснефть (Rosneft),
которая занимается добычей нефти. В ее иерархии разместилась небольшая
организационная структура в виде руководства компании: во главе всех главный
исполнительный директор Игорь Сечин (Sechin), далее идут остальные
представители правления Юрий Калинин (Kalinin), Эрик Морис Лирон (Liron),
Геннадий Букаев (Bukaev), Дидье Касимиро (Casimiro), Юрий
Нарушевич (Nerushevich), Зелько Рунье
<https://www.rosneft.ru/governance/corpmanagement/item/762/> (Runje),
Юрий Курилин (Kurilin), Андрей Шишкин <https://www.rosneft.ru/governance/corpmanagement/item/175279/>
(Shishkin).
· Третий атрибут Люди (People)
предполагает содержание в себе информации о каких-либо известных личностей из
мира экономических рисков. Сюда входят Министры некоторых стран: Силуанов (Siluanov), Мнучин (Mnuchin), Сапен (Sapin), Осборн (Osborne), Падоан (Padoan), Мейрелес (Meirelles), Шойбле (Schauble), Агбал (Agbal), Морно (Morneau).
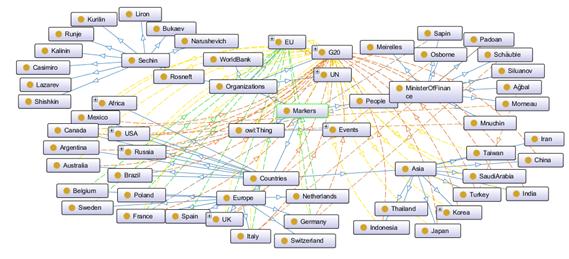
Рисунок
3.2 Часть онтологии экономических рисков. Развернут компонент Markers
(Атрибуты)
Данные атрибуты с нашей точки зрения являются основными для нашей
предметной области. Построение онтологической модели позволяет изменять,
дополнять ее, что позволяет расширять модель, изменять ее, подстраивать под
изменяющиеся предпочтения, обстоятельства и прочее.
Длинные наименования часто имеют аббревиатуру, которую в некоторых
источниках расшифровывают, в некоторых употребляют сокращения. Для избегания
повторений лишней информации и для верной обработки данных для некоторых
атрибутов необходимо было прописывать все возможные их использования в текстах.
Таким образом, для США прописаны еще варианты Соединенные Штаты (UnitedStates), Америка (America), Соединенные Штаты Америки (UnitedStatesOfAmerica). Для Африки есть уточнение Южная
Африка (SouthAfrica), для России Российская Федерация (RussianFedration), для Великобритании Соединенное
Королевство (UnitedKingdom), Англия (England), для Кореи Корейская Республика (RepublicOfKorea), Южная Корея (SouthKorea). Для ЕС Европейский Союз (EuropeanUnion), для Большой двадцатки G-20, GroupOfTwenty, для ООН (UnitedNations).
Помимо иерархических связей в онтологии построены связи между людьми и
странами, есть связи, показывающие какие страны входят в определенный союз или
группа. На данном этапе работы в список стран вошли те, которые занимают
высокие позиции в рейтингах по вычисленному ВВП, то есть считается, что такой
показатель говорит о влиянии экономики страны на экономику мира.
Вся иерархия объектов онтологии представлена в приложении Б, а полный
граф онтологии можно увидеть в приложении В. Получившаяся онтология является
гибким инструментом в использовании и в дальнейшем планируется ее дополнение,
расширение, обязательно внедрение в проект по системе мониторинга глобальных
процессов. На основе этой модели можно создавать модели других предметных
областей или делать более общей получившуюся.
3.2
Апробация полученной онтологии
Основной задачей онтологии для системы мониторинга событий является
наполнение базы знаний системы знаниями по выбранной пользователем предметной
области. А именно онтология должна решать проблему именования, проблему
наполнения базы ненужными знаниями, проблему ограниченного поиска знаний. Очень
распространена ситуация, когда в текстах происходит упоминание одних и тех же
объектов, но разными словами. Например, в одной новости может быть в качестве
страны, где происходили те или иные события, упоминаться ее сокращенное
название «США», «Америка» или «Соединенные штаты», а в другой могут написать
полное наименование «Соединенные штаты Америки» и так далее.
При составлении такого большого запроса для поиска, который смог бы
удовлетворить условию решения проблемы именования, пользователь может учесть не
все. Благодаря онтологии, которая содержит в себе разные названия одного
объекта, пользовательский запрос, например, «падение цен в Америке», можно
дополнить всеми возможными наименованиями, подходящими под него, а также
расширить его, подобрав синонимы для словосочетания «падение цен», например,
«снижение цен», «спад цен» и так далее.
Для того, чтобы избавиться от лишней информации, которую пользователь
может получить при поиске, также можно использовать онтологическую модель
предметной области. Ее пользователь наполняет исключительно для той предметной
области, которую он выбрал, соответственно онтология должна содержать в себе
объекты и их описание конкретно по заданной тематике, а также пользователь
может конкретизировать ее на сколько возможно.
Благодаря построению взаимосвязей между объектами и их свойствами
появляется возможность расширения пользовательского запроса. Это значит, что
его можно уточнить с помощью объектов из онтологии, дополнив изначальный запрос
знаниями про конкретные места, личности, наименования, выставив определенные
временные рамки и так далее. Например, запрос «разлив нефти» можно дополнить
территориальным параметром «в Мексиканском заливе». На запрос «разлив нефти в
Мексиканском заливе» будет выведено меньшее количество новостей и большинство
из них будет связанно именно с событием, когда в Мексиканском заливе была
разлита нефть, по сравнению с первоначальным запросом, который мог вывести
любую информацию по событиям связанными с разливом нефти.
При содержании в онтологии синонимов определенных объектов можно
расширить поисковую область и добавить новые знания в базу знаний. Например,
при задании запроса «снижение зарплаты» поисковая система выведен нам одно
количество новостей, а при задании запроса «падение зарплаты» уже другое. Если
объединить все синонимичные запросы, то количество найденных новостей возрастет,
появится больше информации для анализа и есть возможность найти больше
различных событий, связанных с этим запросом. Чем больше информации о различных
событиях, тем более полную картину о цепочке различных событий можно увидеть.
Какие события предшествуют заданному событию, а какие являются последствиями.
Для апробации нашей онтологии необходимо было проанализировать, каким
образом собранные знания могут помочь при поиске новых фактов, а также при их
извлечении. В первую очередь для примера был выбран запрос «падение доходов».
Для него были придуманы синонимичные запросы «снижение доходов», «спад
доходов», «уменьшение доходов», «падение прибыли», «снижение прибыли», «спад
прибыли», «уменьшение прибыли». В приложении 4 изображено количество выведенных
в поисковой системе результатов по заданным запросам. Можно заметить, что
количество выведенных результатов везде отличается, то есть вполне возможно,
что некоторые публикации встречаются повторно при задании разных запросов.
Однако мы увидели такую картину, где возможно получение большего количества
информации, благодаря использованию синонимов из онтологии.
При уточнении запроса поисковая система должна выдавать нам публикации в
большей степени по теме нашего запроса, что позволяет избавиться от ненужной
информации, которая содержит в себе данные не подходящим для искомого события.
Уточним запрос «падение прибыли» до «падение прибыли роснефть», применение
которого видно на рис. 3.3. Роснефть является одной из крупнейших компаний по
производству нефти. Данную компанию часто подозревают в скрытии информации о
прибыли компании. В течение 2016-2017 против компании идет разбирательство о
доходах топ-менеджеров компании. В качестве события, которое мы возьмем за
исходное для проведения анализа, является падение прибыли компании Роснефть. На
основе уточненного запроса найдем информацию и извлечем ее из новостных
публикаций.
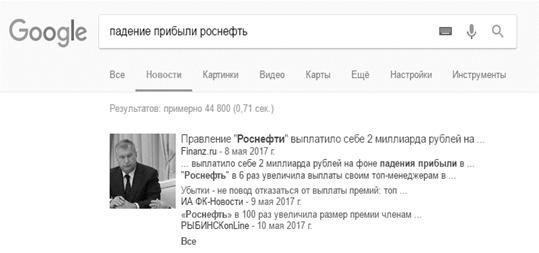
Рисунок
3.3 Количество найденных страниц по запросу «падение прибыли роснефть»
На примере данного запроса сформируем таблицы (см. приложение 5) с
информацией о фактах, извлеченных из текстов публикаций, для того, чтобы
показать, в каком виде должны поступать результаты поиска в систему для
обработки данных. В данную таблицу входят данные о источнике информации, точнее
электронный адрес, наименование источника, сами факты, извлеченные из текстов и
дата публикации. По столбику «факт» можно увидеть, что очень часто встречается
не только название фирмы, но и ее представители. В онтологии для этого мы
прописали неполную иерархию сотрудников для компании Роснефть. Таким образом,
онтология помогает нам кластеризовать записи, в которых речь может идти про
один и тот же объект. В данном случае, если нам важно найти информацию о
событиях, связанных с компанией Роснефть, при упоминании о каком-либо
сотруднике этой компании по онтологии можно будет вычислить о какой копании
идет речь.
Заключение
Обработка информации в Интернете в наши дни набирает популярность, так
как по исследованиям многих аналитиков именно в ресурсах Интернета содержится
много полезной информации, которую могут использовать как ученые, так и
менеджеры крупных предприятий.
В новостных лентах Интернета можно найти много информации о различных
событиях, но для извлечения из них полезной информации необходимо использовать
специальные средства извлечения информации. Существуют различные аналитические
системы, которые содержат в себе методы анализа неструктурированной информации
из Интернета, но они не являются общедоступными. Для построения собственной
аналитической системы необходимо определить подход, благодаря которому такая
система сможет осуществлять поставленные задачи. Этот подход уже придуман и
используется в работе Шаляевой И.М. [7, 8]. Одной из важных составляющих
данного подхода является формирование базы знаний, что послужило основой для
данной работы.
В результате был проведен анализ существующих методов для извлечения
информации из электронных документов и их структурирования. В ходе анализа было
выявлена, что лучше всего для наполнения базы знаний подходит онтология,
которая в качестве модели предметной области применялась как для поиска
информации в Интернете, так и для извлечения новых знаний. Из этого можно
сделать вывод, что онтология может послужить основой для решения сразу
нескольких задач информационного поиска, а также обеспечить максимально гибкие
решения возникающих при поиске информации проблем.
Решена основная задача - на основе проведённой классификации
экономических рисков разработаны модели предметной области. Построенные
онтологии включают понятия о разновидности экономических рисков, а также об
атрибутах публикаций. Построенная модель предметной области позволяет решать
проблему именования в тексте, кластеризации данных. Работа прошла апробацию,
результаты которой были представлены и опубликованы в сборнике на конференции
«Математика и междисциплинарные исследования - 2017» (ПГНИУ), а также на
конференции «Цифровая гуманитаристика: ресурсы, методы, исследования» (ПГНИУ)
[26, 27].
Библиографический
список
1. Prognoz Platform 8. Возможности платформы // Prognoz [Электронный ресурс]
2. Ермаков
А. Е. Поиск фактов в тексте [Электронный ресурс] А. Е. Ермаков // Открытые
системы
. Басипов
А.А. Семантический поиск: проблемы и технологии / А.А Басипов, О.В. Демич //
Вестник АГТУ. Серия: Управление, вычислительная техника и информатика. - 2012.
- №1. - С.104-111.
. Гришковский
А. Интегрированная обработка неструктурированных данных [Электронный ресурс] А.
Гришковский
5. Shilakes
C.C. Enterprise Information Portals / C. C. Shilakes, J. Tylman // Merrill
Lynch. - 16 November, 1998.
6. Лемесев
К.А. Модели и методы извлечения структурированной информации из сети Интернет /
К.А. Лемесев // Вестник МГУЛ - Лесной вестник. - 2012. - №6 (89). - С.113-115.
. Шаляева
И.М. Мониторинг экологических катастроф и их последствий на основе Internet-новостей / И.М. Шаляева // VII Международная научно-техническая
конференция Технологии разработки информационных систем ТРИС-2016. - Таганрог.
- 2016. - С.116-123.
. Шаляева
И.М. О проекте разработки системы мониторинга глобальных процессов на основе
Интернет-новостей / И.М. Шаляева, В.В. Ланин, Л.Н. Лядова // VII Международная научно-техническая
конференция Технологии разработки информационных систем ТРИС-2016. - Таганрог.
-2016. - С.166-170.
9. Van
der Aalst W.M.P. Process Mining Manifesto / W.M.P. van der Aalst, A.
Adriansyah, A.K. de Medeiros // BPM 2011 Workshops, Part I. Т. 99. Springer-Verlag. - 2012. - P.
169-194.
10. Шарапов
Р.В. Расширенная булева модель поиска [Электронный ресурс] Р.В. Шарапов, Е.В.
Шарапова, Т.Е. Меркулова
. Редактор
Protégé // Protégé [Электронный ресурс]
. Ланин
В.В. Система интеллектуального поиска, классификации и реферирования документов
для Интернет-портала / В.В. Ланин // The XV th International Conference “Knowledge-Dialogue-Solution” (KDS’2009). - Varna (Bulgaria). - June-July.
- 2009. - Pp.151-157.
. Агеев
М.С. Автоматическая рубрикация текстов: методы и проблемы / М.С. Агеев, Б.В.
Добров, Н.В. Лукашевич // Учен. зап. Казан. ун-та. Сер. Физ.-матем. науки. -
2008. - №4. - С.25-40.
. Доброхотов
А.Л. Онтология. Гуманитарная энциклопедия [Электронный ресурс] А.Л. Доброхотов,
А.П. Огурцов, М.А. Можейко, В.Е Кемеров
. Добров
Б. Онтологии и тезаурусы: модели, инструменты, приложения [Электронный ресурс]
Б. Добров, В. Иванов, Н. Лукашевич, В. Соловьев // НОУ Интуит
16. Gruber
T.R. A translation approach to portable ontology specifications / T. R. Gruber
// Knowledge Acquisition. - June 1993. -5 (2). - P.199-220.
17. Горшков
С. Введение в онтологическое моделирование / С. Горшков // Тринидата. -
2014-2016. - С.10-15.
. Кириллов
А.В. О новом подходе к семантическому преобразованию естественно-языковых
запросов поисковых систем / А.В. Кириллов, В.А. Фомичев // Бизнес-информатика.
- 2011. - №1 (15). - С.61-68.
. Смирнов
С.В. Онтологический анализ предметных областей моделирования / С.В. Смирнов //
Известия Самарского научного центра РАН. 2001. №1 С.62-70.
. Вдовицын
В. Онтологически-ориентированный подход для построения систем полнотекстового
информационного поиска электронных документов / В. Вдовицын, Н. Крижановская,
В. Старкова // Информационные ресурсы России. - 2014. - №5. - С.33-40.
. Виды
и классификация рисков // Risk24.ru [Электронный ресурс]
. Колмыкова
Т.С. Инвестиционный анализ: Учеб. пособие / Т.С. Колмыкова // М.: ИНФРА-М,
2009. - 204 с.
. Султанов
И.А. Классификация основных видов рисков деловой деятельности [Электронный
ресурс] И.А. Султанов
. Общие
принципы классификации и виды рисков // Страховой консультант [Электронный
ресурс]
. Коммерческий
риск // Grandars
. Ланин
В.В. Мониторинг глобальных процессов на основе данных из Интернет-новостей /
В.В. Ланин, И.М. Шаляева, А.Ю. Скурихина // Международная научная конференция
Цифровая гуманитаристика: ресурсы, методы, исследования. - Пермь. - 2017. - С.
67-70.
Приложение А
Граф онтологии экономических рисков
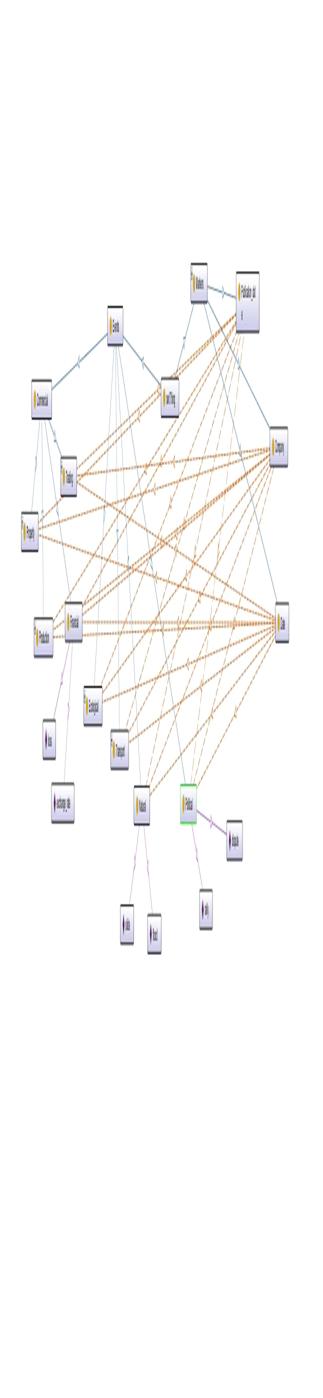
Рисунок А1. Граф онтологии экономических рисков
Приложение
Б
Фрагменты
иерархии классов расширенной онтологии экономических рисков

Рисунок Б1. Фрагмент иерархии классов онтологии экономических рисков,
часть 1
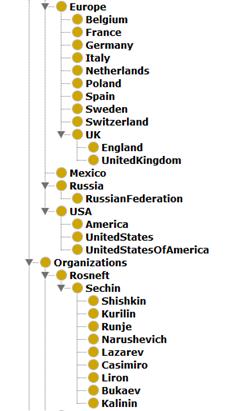
Рисунок Б2. Фрагмент иерархии классов онтологии экономических рисков
часть 2
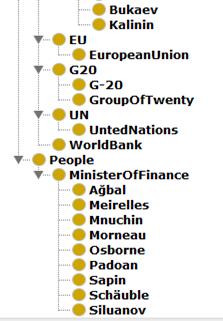
Рисунок Б3. Фрагмент иерархии классов онтологии экономических рисков часть
3
Приложение
В
Граф
расширенной онтологии экономических рисков
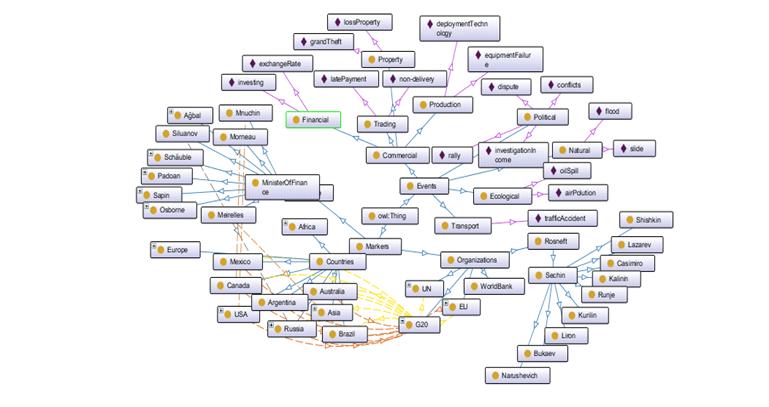
Рисунок В1. Граф расширенной онтологии экономических рисков
Приложение
Г
Иллюстрации
изменения количества источников поиска с синонимичными запросами
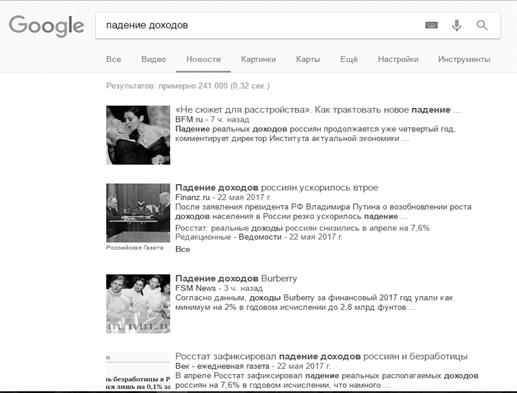
Рисунок Г1. Количество найденных страниц по запросу «падение доходов»
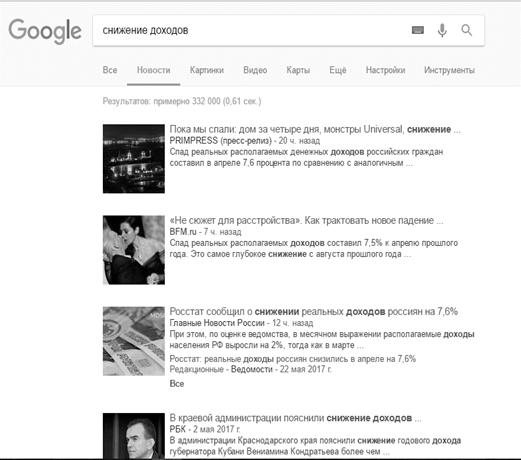
Рисунок Г2. Количество найденных страниц по запросу «снижение доходов»
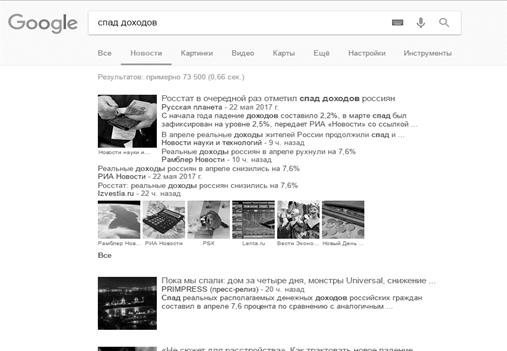
Рисунок Г3. Количество найденных страниц по запросу «спад доходов»
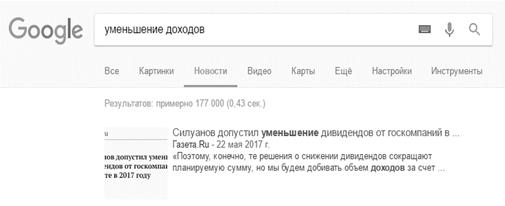
Рисунок Г4. Количество найденных страниц по запросу «уменьшение доходов»
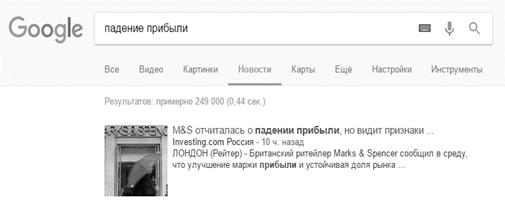
Рисунок Г5. Количество найденных страниц по запросу «падение прибыли»
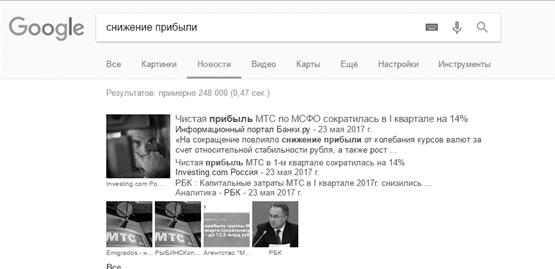
Рисунок Г6. Количество найденных страниц по запросу «снижение прибыли»
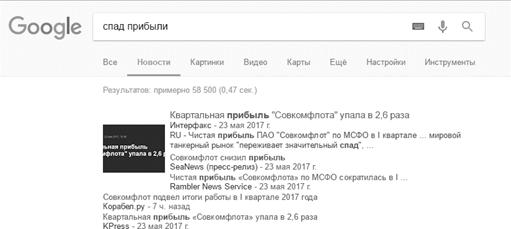
Рисунок Г7. Количество найденных страниц по запросу «спад прибыли»
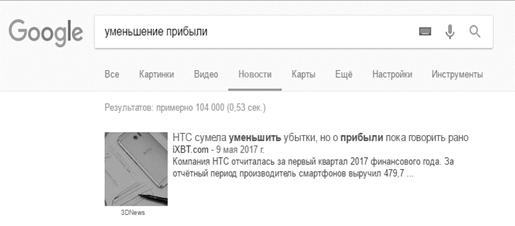
Рисунок Г8. Количество найденных страниц по запросу «уменьшение прибыли»
Приложение
Д
Таблица
извлеченных данных по запросу «падение прибыли роснефть»
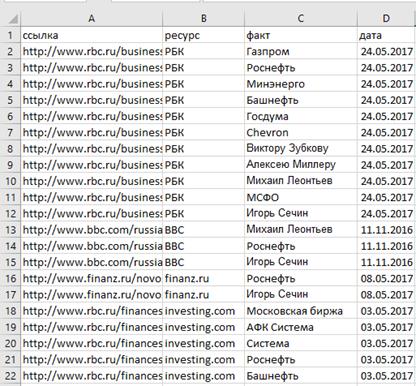
Рисунок Д5. Таблица извлеченных данных по запросу «падение прибыли
Роснефть»