Проектирование портала для анализа и оценки стиля научных текстов
Введение
Подготовка научных статей на английском языке часто вызывает затруднения
у людей, не являющихся носителями языка. Однако без этого невозможно
распространение научных идей в мировом сообществе, а значит, написание научных
работ и статей на английском языке является необходимым навыком для
исследователей, в частности, для студентов высших учебных заведений.
Однако даже при высоком уровне владения языком формулировка мыслей в
академическом стиле может вызывать затруднения. Существуют стандартные приёмы,
клише, характерные для текста научных публикаций. Данные приёмы можно извлечь
из специальных тематических подборок [21] или многочисленных примеров статей,
написанных носителями языка. В то же время использование клише не гарантирует
идеального соответствия текста академическому стилю речи. Проблема заключается
в том, что избыточное количество приёмов «академизации» текста понижает
читаемость работы, её понятность как для носителей языка, так и для широкой
академической аудитории. При этом не существует общепринятых стандартов,
которых можно придерживаться при написании статьи на английском языке, так как
стилистика и степень читаемости текста оцениваются экспертами.
Существующие инструменты для рецензирования и методы анализа стиля [33]
при оценке качества и читаемости, опираются на ограниченное число признаков
(терминология, формальный стиль речи, читаемость текста), в то время как в
методической литература и научных статьях представлено гораздо больше
характеристик академического стиля. Кроме того, изначально сформулированные
правила определения качества текста не обязательно могут отражать реальную
ситуацию использования различных признаков научного стиля на практике. Именно
такую возможность предоставляют методы корпусной лингвистики.
Корпусная лингвистика основана на использовании корпусов - произвольных
(либо представительных) коллекций текстов по определенной тематике, которые
доступны в электронной форме [18], т.е. набор документов или записей, собранных
по определённому принципу: общего стиля, общего автора, общего жанра и т.д. или
просто общего языка (для национальных корпусов). Таким образом, в отличие от
классической лингвистики, корпусная ориентирована на изучение практического
применения языка, а не его теоретических аспектов. Существует много задач, уже
сейчас решаемых с помощью текстовых корпусов. Например, изучение отдельных
словоупотреблений, общей динамики языка, машинный перевод и обучение языку (computer-assistedlanguage learning), некоторые виды анализа текста.
Существует потребность в создании приложения, которое имело бы
возможность анализировать научные статьи, написанные носителями на английском
языке и одобренные к публикации влиятельными рецензируемыми изданиями
(например, Springer), по некоторым лингвистическим
характеристикам, которые в основном определяют академический стиль письменной
речи. Усреднённые значения встречаемости значимых характеристик, определённые в
ходе исследования корпуса статей по определённой тематике, смогут служить
ориентиром при написании собственного материала.
Для проверки значимости различных лингвистических характеристик при
оценке качества стиля и читаемости текста проводится исследование, основанное
на сравнении встречаемости маркеров стиля в научных статьях, взятых в качестве
эталонных, и учебных работ высокого и низкого качества (по мнению эксперта).
Результаты исследования могут быть использованы для частичной автоматизации
работы эксперта при проверке соответствия статьи стилистическим требованиям, а
также для формирования рекомендаций.
Объектом данного исследования является процесс проверки соответствия
научных статей академическому стилю английского языка.
Предметом исследования являются средства анализа и обработки корпусов.
Целью данной работы является проектирование архитектуры портала для анализа
и оценки стиля научных публикаций на основе методов корпусной лингвистики.
Портал должен предоставлять пользователям возможность изучить результаты
анализа встречаемости маркеров стиля в корпусе текстов для проведения
лингвистических исследований или получить рекомендации, сформированные на
основе сравнения характеристик отдельной работы с эталонным корпусом. Маркеры
стиля выделяются в корпусе с помощью автоматической разметки на основе
специальных шаблонов.
Для достижения цели требуется решить следующие задачи:
. Рассмотреть существующие методы анализа академического стиля и
средства их реализации:. Провести анализ методов и инструментов идентификации
и анализа функционального стиля текста;. Сделать обзор существующих
продуктов для работы с корпусами, оценив возможность их использования для
анализа качества академического стиля текста;
. Разработать требования к порталу:. Формализовать
функциональные и выделить нефункциональные требования для проектируемого
портала;. Рассмотреть возможные средства реализации портала;
. Выполнить эскизное проектирование портала портала, включающее:. Построение
модели предметной области и жизненного цикла системы;. Разработку
архитектуры портала;. Создание прототипов интерфейса портала.
В данном исследовании применяются методы теоретическо-эмпирического
анализа, корпусной лингвистики, объектно-ориентированного проектирования,
сервисно-ориентированный подход для создания распределенных приложений.
Глава 1. Методы и инструменты анализа академического стиля
английского языка
архитектура
английский портал научный
Идентификация функционального стиля текста, в том числе научного
(академического) - одна из базовых задач лингвистики в целом. Использование
методов корпусной лингвистики, основанных на анализе коллекций текстов, позволяет
рассмотреть не только теоретические признаки научных текстов, но и особенности
их применения на практике.
Существуют различные инструменты для работы с корпусами текстов - от
обычных сайтов для простого просмотра и поиска данных до систем, позволяющих
создавать собственные приложения. Некоторые из этих инструментов могут быть
использованы при реализации метода анализа и получения оценки соответствия
статей академическому стилю английского языка, описанного в статье [35].
1.1. Академический стиль речи в английском языке, методы его
идентификации и анализа
Научный (академический) стиль речи представляет научную сферу общения и
речевой деятельности, связанную с реализацией науки как формы общественного
сознания [9]. Иными словами, это особый функциональный стиль речи, который, в
широком смысле, используется для сообщения нового знания о действительности и
доказательства её истинности. Этот стиль используется в научных статьях,
учебной литературе, монографиях и т.д.
В настоящее время у людей, занимающихся научными исследованиями, нередко
возникает необходимость освоения академического стиля английского языка, для
того, чтобы их научные работы и статьи могли быть признаны международным
академическим сообществом. Для помощи в изучении особенностей данного стиля
создаются справочные и учебные материалы, а также обучающие Интернет-ресурсы.
Существует множество учебных пособий на английском языке (guides, coursebooks, etc), предназначенных для обучения академическому письму.
Методические пособия могут быть адресованы исследователям и студентам [34, 40,
41], преподавателям [25, 26, 29, 36, 39], редакторам изданий [27, 38]. Имеются
также учебные пособия от русскоязычных авторов [13, 14, 17].
Кроме того, доступны Интернет-ресурсы, содержащие рекомендации к
написанию научных текстов. В частности, ресурсы, называемые academicphrasebanks, содержат списки конструкций,
которые могут быть использованы в тех или иных ситуациях: когда нужно выразить
критический взгляд, обозначить дистанцию между приводимым мнением и мнением автора,
описать классификацию, привести результаты сравнения и примеры, ввести понятие,
и т.д. Пример подобного ресурса: AcademicPhrasebank-Universityof Manchester [21].
Особенностям академического стиля английского языка были посвящены многие
научные работы, в том числе русскоязычные диссертации и исследования как 80-х
годов, так и относительно недавнего времени. В исследованиях охвачены как общие
структурные и функциональные особенности научных текстов [2], так и узкие темы,
например, выражение экспрессивности [12], причинно-следственных отношений [4] и
др.
Классификация текстов, в том числе по функциональным стилям (разговорный,
научный, художественный и др.) - одна из задач обработки естественного языка. Определение функционального
стиля текста может использоваться в информационном поиске, машинном переводе,
генерации текстов [5, 30] для получения более точных и удовлетворяющих
пользователя результатов.
Как правило, для определения стиля текста используются так называемые
«маркеры стиля». В работе [32]
описаны четыре типа таких маркеров (признаков, features):
- маркеры на уровне токенов (длина слова, слоги, N-граммы и др.);
- маркеры, основанные на синтаксисе (части речи, правила замены
и др.);
- маркеры, основанные на многообразии лексики (соотношение числа
разных слов к общему числу слов, hapax legomena- слова, встречающиеся в контексте один раз, и др.);
- частотность общеупотребительных слов.
В статье [5] представлены методы машинного обучения для классификации
текстов, которые используют в том числе вышеописанные признаки, разделённые
авторами на лексические (количество слов, N-грамм, глубина дерева синтаксического разбора и т.д.) и
квантитативные (количество символов, количество слогов и т.д.).
Классифицируемые документы сопоставляются с векторами признаков.
Подход к анализу академического стиля был представлен в работе [33].
Выделяются признаки текста, отвечающие за формальный стиль речи (пассивный
залог, субъективные выражения, вопросы), читаемость (союзы и другие соединяющие
фразы, использование существительных вместо глаголов) и научный язык (по списку
из 200 научных слов и др.), и на основе выделенных признаков создаётся
самоорганизующаяся карта (Self-OrganizingMap- особая разновидность нейронной
сети).
Ещё один метод был использован для анализа характеристик в заголовках
статей по теме «ComputerScience».
Значения параметров, таких как длина заголовка, использование пунктуации и
предлогов, частота слов, были исследованы на примере корпуса статей из научных
журналов [22].
Метод, рассматриваемый в данной работе, предполагает сравнение статей,
стиль которых признан экспертами качественным, со статьями, которые, несмотря
на соблюдение рекомендаций из методической литературы, являются плохо читаемыми
и не соответствуют стандартам. Сравнение производится по признакам, связанным с
лексическими и синтаксическими характеристиками текста, которые были выделены
при анализе учебных пособий и научных работ об особенностях академического
стиля речи. В качестве опоры для исследования берётся коллекция «эталонных»статей
из рецензируемых источников, каждой из которых сопоставляется вектор,
описывающий встречаемость тех или иных лингвистических характеристик. В
дальнейшем, при сравнении эталонных статей с работами студентов, предлагается
исследовать влияние каждой из этих характеристик на оценку качества и
читаемости текста.
Особенностью этого метода является ориентация на практическое применение
теоретических рекомендаций по соблюдению академического стиля. Проведение
исследований на коллекции текстов, собранных по общим признакам - в данном
случае языку и стилю, - относит метод к области корпусной лингвистики.
1.2. Основные задачи корпусной лингвистики
Корпусная лингвистика направлена на изучение языка и различных его
аспектов в конкретных проявлениях и рассматривает в первую очередь примеры
текстов, а не абстрактные характеристики речи. Такой подход позволяет оценить
разницу между теоретической, идеальной моделью языка и реальным его
употреблением, отследить динамику. В отличие от традиционной, корпусная
лингвистика чаще использует квантитативные методы исследования, опирается на
статистику и теорию вероятностей.
Корпусом называется собрание текстов на некотором языке в электронной
форме (а также основанные на нем информационно-справочные системы) [10]. Тексты
в корпусах, как правило, объединены некоторыми общими признаками. Наибольшая
вариативность документов - в национальных корпусах, где общим признаком
является только язык. В специализированных корпусах берётся более узкий набор,
например, тексты одного жанра, одного стиля, одного автора, на одну тематику и
т.д. Существуют также параллельные корпуса, где хранятся тексты и их переводы
на нескольких языках.
Хранение составляющих корпус документов в электронной форме иногда входит
в определение корпуса [10]. Кроме этого, важной частью корпуса является его
разметка. Разметка или аннотации - множество меток, относящихся к отдельным
словам или частям текста и содержащих некоторую информацию. Одним из базовых
видов разметки для корпуса является разметка по результатам морфологического
анализа. Средство просмотра корпуса в электронном виде должно предоставлять
возможность просматривать или редактировать аннотации к элементам текста.
Разметка бывает разных типов. К первичной разметке текстов относятся
этапы токенизации (разбиения на орфографические слова), лемматизация
(приведение словоформ к словарной форме) и морфологический анализ. Среди
лингвистических типов разметки выделяются следующие:
− морфологическая (part-of-speech tagging);
− синтаксическая (parsing);
− семантическая;
− анафорическая;
− просодическая.
Первые три типа являют собой результат проведения соответствующих типов
анализа и нанесения определённых меток (тэгов, аннотаций) на слова или
словосочетания. Анафорическая разметка текста позволяет указать принадлежность
местоимений к заменяемым ими словам. Просодическая разметка применяется в
корпусах, где необходима информация об особенностях произношения слов:
ударениях, интонации и т.д.
Нанесение разметки вручную требует многих затрат, поэтому разрабатываются
программные средства для решения этой задачи. В частности, морфологический и
синтаксический анализ успешно автоматизирован и производится тэггерами и
парсерами- специальными
программными средствами, осуществляющими морфологическую и синтаксическую
разметку текста соответственно. Однако системы, позволяющие работать с
разметкой текста, допускают возможность пользовательского редактирования меток.
Для решения своих задач могут понадобиться, помимо основных, собственные
типы разметки. В этом случае разметку текста, опять же, можно произвести
вручную, а можно автоматизировать процесс, написав свою программу или
воспользовавшись специализированной средой для работы с документами. Для
автоматического аннотирования часто используют регулярные выражения, основанные
на лексико-синтаксических шаблонах - структурных образцах языковой конструкции,
которые отображают её лексические и поверхностные синтаксические свойства [3].
Шаблоны для каждого вида аннотаций составляются лингвистами с использованием
определённого синтаксиса и стандартных элементов [28].
Корпуса используются в различных исследованиях лингвистов, а также при
создании словарей, автоматическом переводе, создании учебных пособий,
тестировании программ автоматического анализа и синтеза речи [7]. Множество
областей применения корпусов и их анализа продолжает пополняться. Одной из
актуальных сфер является проведение стилистического анализа для оценки качества
научных статей - задача, рассматриваемая в данной работе.
1.3. Анализ существующих инструментальных средств для работы с
корпусами текстов
Поскольку использование корпусов тесно связано с информационными
технологиями, существуют различные инструментальные средства для просмотра и
обработки размеченных коллекций текстов, начиная с библиотек, созданных для
упрощения работы программистов, заканчивая полноценными средами, доступными для
лингвистов без навыков программирования. Далее рассмотрена возможность
применения каких-либо из существующих инструментов при реализации метода
анализа стиля академических текстов на основе сравнения с эталонным корпусом.
Выделяются следующие требования:
− возможность выбора одного из нескольких корпусов;
− загрузка в систему собственного корпуса;
− редактирование разметки корпуса вручную;
− автоматическое нанесение разметки с помощью специальных
расширений или обрабатывающих ресурсов, использующих лексико-синтаксические
шаблоны;
− сбор статистики и создание отчётов или возможность
разработки соответствующего расширения
− возможность одновременной работы большого количества
пользователей.
При анализе инструментальных средств также учитываются аспекты, не
касающиеся непосредственно реализуемого метода. На их основе формируются
нефункциональные требования к разрабатываемому приложению.
Работа с национальными корпусами в некоммерческих и учебных целях, как
правило, осуществляется на специальных сайтах в интернете. В качестве примера
можно привести сайт Национального корпуса русского языка (НКРЯ) [10]. Основной
и единственной доступной функцией для работы с корпусом является поиск. Есть
возможность пользоваться обычным поиском (см. рис. 1.1), просто вводя искомые
словосочетания, также доступен лексико-грамматический поиск, учитывающий
множество параметров.
Тексты в НКРЯ содержат синтаксическую разметку, поэтому параметры поиска
весьма разнообразны (см. рис.1.2).
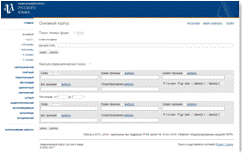
Рисунок
1.1.Поиск по Национальному корпусу русского языка
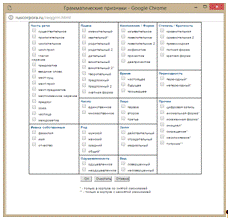
Рисунок
1.2. Параметры поиска по Национальному корпусу русского языка
Поиск словоупотреблений часто является главной и единственной функцией
многих программ для работы с корпусами. Такие программы называются
конкордансерами, и они предназначены для использования лингвистами и людьми с
более низкой квалификацией. Конкорданс - это список всех употреблений заданного
языкового выражения. Специализированные программы позволяют создавать
конкордансы, то есть рассматривать контексты употребления тех или иных
выражений для дальнейших учебных или исследовательских целей.
Конкордансеры могут быть привязаны к определённому корпусу, как,
например, браузерный конкордансер StringNet, который использует для поиска словоупотреблений
национальный корпус английского языка (BritishNationalCorpus, BNC) [20]. Бывают и другие программы, которые позволяют
загружать пользовательские коллекции текстов и работать с ними в режиме
оффлайн. Программы с наиболее широкой функциональностью позволяют, помимо
построения конкордансов, составлять списки слов корпуса (wordlists) и списки ключевых слов (для этого
может использоваться сравнение с неспециализированным корпусом), выполнять
поиск с помощью регулярных выражений, читать и наносить разметку (аннотации).
В качестве примеров продуктов с широкой функциональностью мы рассмотрим
две бесплатные программы - конкордансер AntConc и среду для разработки приложений по обработке
текстов GATEDeveloper. Оба этих продукта являются
универсальными с точки зрения лингвистических задач и не ограничены какой-либо
узкой предметной областью.
AntConc
- основная из семейства программ, созданных Лоренсом Энтони для работы с
корпусами. Помимо AntConc,
предназначенной в основном для выделения конкордансов и анализа текстов,
существуют и другие продукты, например, AntPConc для анализа параллельных корпусов и AntWordProfiler, в котором слова текста соотносятся
с имеющимися списками (wordlists) и разделяются на уровни в зависимости от принадлежности к одному из
этих списков (или отсутствия принадлежности к какому-либо из них), а также
предоставляется статистическая информация. AntConc содержит в себе семь
инструментов[31]:
− поиск конкордансов в формате «ключевое слово с контекстом»
(см. рис 1.3) для исследования стандартных случаев употребления слов в корпусе;
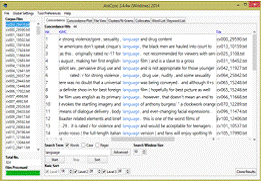
− поиск конкордансов в формате карты («штрих-кода»)для
исследования позиций, в которых встречается искомое выражение(см. рис 1.4);
− просмотр текстовых файлов (в том числе с результатами
работы других инструментов AntConc);
− выделение кластеров (часто встречающихся контекстов на
основе искомого выражения) и N-грамм
(часто встречающихся выражений размером в Nслов) (см. рис. 1.5);
− выделение устойчивых выражений, содержащих искомый термин;
− создание списка слов на основе всех текстов корпуса (с указанием
частотности);
− создание списка ключевых слов (с использованием
неспециализированного корпуса), например, для выделения терминов в корпусе по
определённой предметной области.
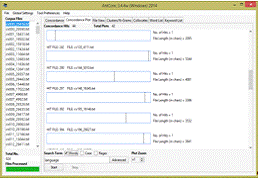
Рисунок
1.4. Поиск конкордансов в формате карты в AntConc
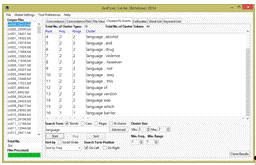
Рисунок
1.5. Выделение кластеров в AntConc
AntConc
представляет собой настольное приложение для однопользовательской работы,
позволяет настраивать некоторые элементы под нужды и предпочтения пользователя.
Однако, являясь удобным инструментом для базовых задач - поиска конкордансов,
создания списков слов и выделения ключевых слов, - он не предоставляет
возможность создания в данном интерфейсе средств для автоматической обработки
корпуса и нанесения разметки.
GATEDeveloper [23] также является одним из представителей целого семейства средств для
работы с корпусами. В отличие от AntConc,
основная функция GATEDeveloper - не
использование готового корпуса текстов для исследовательских и учебных целей, а
создание приложений, собственных обрабатывающих ресурсов для нанесения разметки
и анализа текста. GATEDeveloper -
это интегрированная среда для разработки приложений по обработке текстов,
включающую в себя встроенную систему извлечения информации и множество
плагинов. Существует также фреймворк GATEEmbedded для использования функций GATE Developer при
программировании отдельных приложений, GATE Cloud для облачных вычислений и
веб-приложение GATETeamware для
управления проектами по совместной работе над корпусом.
Приложения в GATEDeveloper
представляют собой конвейеры (Pipelines) - последовательности применения обрабатывающих ресурсов (ProcessingResources) к корпусу или текстовому файлу.
Обрабатывающие ресурсы создаются на основе плагинов, входящих в стандартный
набор или созданных программистами (с помощью библиотек GATE на языке Java). Интерфейс создания конвейера показан на рисунке
1.6.
Стандартные плагины GATE
могут использоваться для нанесения разных видов разметки: токенизации
(выделения отдельных элементов текста, чаще всего слов), разбиения на
предложения, синтаксического и морфологического анализа (определения частей
речи и некоторых характеристик слов) и других. Разметка наносится в виде меток
- аннотаций (Annotations), доступна для просмотра и может
быть отредактирована вручную (см. рис 1.7). Пользователь может создавать метки
любого типа (вручную или с помощью приложения), и разные типы аннотаций будут
отмечены в документах корпуса разными цветами.
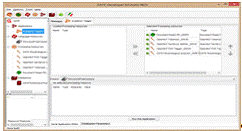
Рисунок
1.6. Создание конвейера для обработки корпуса в GATEDeveloper
Высокий уровень функциональности и универсальности программы негативно
сказывается на удобстве её интерфейса: создание и сохранение даже ручной
разметки, а тем более создание приложений является трудной задачей для
недостаточно знакомых с программой пользователей. Такое приложение подходит
только для решения задач профессиональными лингвистами с некоторыми навыками
программирования. Кроме того, библиотеки GATE могут быть использованы при создании собственного
отдельного сервиса, что является полезным при необходимости создания
специализированного приложения, которое требует выполнения некоторых основных
функций, например, нанесения базовых видов разметки.
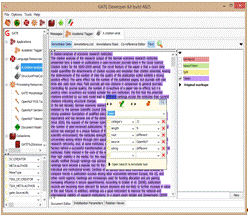
Рисунок
1.7. Ручное редактирование разметки
В целом, рассматривая различные средства анализа корпусов, можно сделать
следующие выводы:
. ПО для обработки корпусов может предоставляться в виде
подключаемых библиотек, приложений, онлайн-сервисов и специализированных сред
разработки.
. Данные виды ПО имеют различные функции, наиболее популярными из
которых являются: работа с конкордансами, выделение ключевых слов и
словосочетаний, лексический анализ (составление wordlists и др.), составление модели текста,
аннотирование текстов (в т.ч. POS-tagging, парсинг и т.п.).
. ПО, используемое в сфере компьютерной лингвистики, в разной
степени автоматизировано. Так, одни ресурсы предназначены для ручного
использования (конкордансеры, средства ручного аннотирования и др.), в то время
как целью других является автоматизация процессов (выделение ключевых слов,
автоматическое аннотирование и т.д.).
. Ресурсы работы с корпусами бывают как коммерческими, так и
открытыми.
При выборе средств, необходимых для анализа корпуса, следует учитывать
цель и специфику решаемых задач, а также квалификацию и возможности
пользователей и программистов, участвующих в проекте.
В таблице 1.1 представлены результаты анализа соответствия рассмотренных
типов инструментальных средств функциональным требованиям.
Таблица 1.1 Результаты анализа инструментальных средств для работы с
корпусами
|
Сайт (на примере НКРЯ)
|
Конкордансеры (на примере AntConc)
|
Среды разработки (на примере GATE)
|
|
Хранение нескольких корпусов
|
Один корпус
|
Корпуса загружаются пользователем по мере необходимости
|
Корпуса загружаются пользователем по мере необходимости
|
|
Загрузка собственного корпуса
|
Нет
|
Есть
|
Есть
|
|
Ручное редактирование разметки
|
Есть возможность (скрытая)
|
Нет
|
Есть возможность
|
|
Автоматическое редактирование разметки
|
Нет
|
Нет
|
Есть возможность
|
|
Возможность разработки расширений
|
Нет открытой возможности
|
Нет
|
Есть возможность создания плагинов на Java, а также обрабатывающих ресурсов Jape[24]
|
|
Одновременная работа пользователей
|
Есть
|
Нет (настольное приложение)
|
Нет (настольное приложение)
|
|
Другие особенности
|
Ограниченные функции
|
Дружественный интерфейс, ограниченные функции
|
Визуализация разметки, сложный интерфейс
|
Наиболее подходящей для реализации метода является среда GATE, однако ввиду отсутствия свободного
одновременного доступа к приложению для большого числа пользователей и
сложности интерфейса в целом она также не может быть использована для полной
реализации сервиса. На примере рассмотренных приложений для работы с корпусами,
их достоинств и недостатков можно выделить требования, которые следует учесть
при реализации собственного продукта.
Вывод по главе
Для изучения особенностей академического стиля английского языка
используются научные работы по данной тематике, методические материалы для
студентов и преподавателей, а также обучающие Интернет-ресурсы. Существуют
разные способы автоматического анализа функционального стиля текста,
использующие подсчёт характеристик текста, в том числе наличие определённых
конструкций, терминологии и т.д. Использование методов корпусной лингвистики
позволяет рассмотреть особенности практического применения признаков
«академизации» речи на примере коллекций текстов. Для реализации предложен
метод анализа и оценки стиля научных текстов на английском языке с помощью
эталонных корпусов.
На данный момент не существует приложений, которые позволили бы
реализовать указанный метод без разработки дополнительных расширений. Наиболее
близкой по функциональности является среда разработки приложений для работы с
корпусами GATE, но она является настольным приложением
с достаточно сложным интерфейсом, поэтому не может быть использована для полной
реализации портала. В целом имеющиеся инструменты лингвистов не предоставляют
достаточной функциональности или не являются достаточно удобными для работы
пользователей, не являющихся специалистами в лингвистике и программировании.
Глава 2. Формирование требований к разрабатываемому приложению
Наиболее подходящей для реализации метода анализа и оценки стиля научных
текстов на английском языке с помощью эталонных корпусов является форма
исследовательского портала. Исследовательские порталы - информационные ресурсы,
размещаемые в сети Интернет с целью предоставления пользователям материалов для
проведения исследований и публикации их результатов. Некоторые порталы предназначены
для совместного решения задач в определённой предметной области [6, 8, 15],
другие размещают результаты работы отдельных научных подразделений -
университетов, кафедр и др. [37]
Для реализации портала необходимо формализовать требования к функциональности
портала, которые основываются на теоретических аспектах метода. Кроме
функциональных требований, выделяются также нефункциональные, касающиеся
особенностей целевой аудитории портала и их целей использования метода.
2.1. Теоретические основы метода анализа и оценки качества стиля на
основе эталонных корпусов
В рассматриваемом методе оценка качества стиля статьи производится на
основе сравнения с корпусом научных статей, написанных носителями на английском
языке и признанных качественными (прошедших рецензирование экспертами), по
некоторым лингвистическим характеристикам, которые в основном определяют
академический стиль письменной речи. Эти характеристики далее в тексте будут
называться качественными критериями или маркерами академического стиля.
Для проверки значимости различных лингвистических характеристик при
оценке качества стиля и читаемости текста будет проводиться исследование,
основанное на сравнении встречаемости маркеров стиля в научных статьях, взятых
в качестве эталонных, и учебных работ высокого и низкого качества (по мнению
эксперта). Результаты исследования смогут быть использованы для формирования
рекомендаций.
В качестве теоретической базы для создания приложения экспертом был
предоставлен список качественных критериев («маркеров») академического стиля
речи. Список составлен на основе справочных и учебных материалов, а также
Интернет-ресурсов по обучению академическому письму (в том числе описанных в
главе 1). В ходе исследования источников учитывался тот факт, что имеющиеся
российские диссертационные исследования не всегда приводят статистически
убедительные данные.
Все вошедшие в список критерии можно условно разделить на несколько
групп:
− грамматические;
− синтаксические.
Внутри групп также возможно разделение критериев, например, по
особенностям их проверки. Рассмотрим критерии, входящие в каждую группу,
подробнее.
Лексические критерии можно условно разделить на три подгруппы:
- Критерии, которые учитывают частотность появления в тексте
конкретных слов, терминологии.
- Критерии, которые учитывают частотность появления в тексте
слов, соответствующих определённым словообразовательным схемам.
- Критерии, которые учитывают частотность появления в тексте
слов определённых частей речи.
К первой подгруппе относятся следующие критерии:
− активное использование терминологии, соответствующей
предметной области, предположительно 15-20% текста;
− близкая к нулевой встречаемость личных местоимений you, he, she;
− использование личного местоимения we (мы) в значении I (я);
− десемантизированные глаголы: be, become, seem,
remain, grow, consider;
− глаголы широкой абстрактной семантики: be, exist, have, appear,
occur, alter, continue, contribute, discuss, involve, investigate, conduct,
consider, illustrate, assume, find calculate, demonstrate, identify, analyze,
support, challenge, examine, affect, provide, include, classify, establish;
− словосочетанияthat of, those of;
− усилительные наречия: clearly, dramatically,
completely, considerably, essentially, significantly, markedly, perfectly.
Вторая группа включает в себя такие маркеры, как:
− наличие абстрактных существительных, образованных с помощью
суффиксов: - ment, - ion: -ation/- ition /- tion / -sion, -f, -ness, -ce/-cy, -
ity, -dom, - th, -ery/-ry, - ise/ -ice, - hood, -ics, -ship;
− наличие суффикса -or, который, как правило, обозначает термины и технические понятия.
Наконец, к третьей группе мы отнесём следующие критерии:
− номинативность текста - преобладание существительных;
− предположительно низкая встречаемость личных местоимений.
В группу грамматических маркеров входят два критерия:
− широкое использование глаголов в пассивном залоге;
− преобладание глаголов настоящего времени (предположительно).
Синтаксические критерии, как и лексические, можно разделить на подгруппы.
- Критерии, описываемые структурами.
- Критерии, учитывающие встречаемость определённых союзов,
предлогов, средств связи и др.
В первую подгруппу входят следующие критерии:
− преобладание предложений с простой, сложноподчинённой или
сложносочинённой структурой;
− наличие постпозитивных и препозитивных определений почти
при каждом существительном.
− преобладание препозитивных определительных групп в
технических текстах (например: vacuumtubes, anti-aircraftfirecontro lsystems).
Препозитивное определение [11] в английском языке может быть выражено
прилагательным, местоимением-прилагательным, количественным или порядковым
числительным, причастием, герундием (без предлога), существительным в
притяжательном падеже и существительным в общем падеже без предлога. Примеры: the old woman, the first
sentence, her sister’s flat, the kitchen door.
Постпозитивное определение [11] может быть выражено существительным в
общем падеже с предлогом, причастным оборотом, герундием с предлогом,
инфинитивом, наречием, количественным числительным, употребленным в значении
порядкового, а также прилагательным с зависящими от него словами. Примеры: door of the room, the
children playing in the yard, the article to translate, the room upstairs, room
ten.
Во второй подгруппе выделяются следующие маркеры:
− использование двойных и составных союзов: not merely, but also, both and, as … as, neither … nor, the
… the, not so … as;
− использование слов thereby, therewith, hereby, являющихся в
литературном языке архаизмами;
− составные предлоги: throughout, within, in
accordance with, instead of, according to, because of, due to, regardless of;
− средства логической связи: since, therefore, (it) follow/s (that), so, thus, leads to,
results in.
Предполагается, что числовые оценки значений вышеописанных характеристик
для определённой предметной области возможно получить, проведя анализ корпуса
текстов, состоящего из статей по соответствующей тематике.
Разрабатываемый сервис для анализа и оценки стиля должен получать на вход
корпус текстов, состоящий из научных статей на английском языке, посвящённых
сходной тематике. Последнее уточнение нужно для более удобного выделения
терминов в тексте, например, с использованием терминологического словаря на
заданную тематику.
После автоматической токенизации текста и нанесения разметки на слова и
конструкции, которые описываются в качественных критериях академической речи,
приложение предоставляет пользователю возможность проверить и редактировать
автоматически нанесённую разметку.
Проанализировав аннотированный корпус, приложение выдаёт по каждому из
критериев, представленных выше, статистическую информацию, например:
− среднее количество маркеров данного типа, встречающееся в документах
корпуса;
− наибольшее и наименьшее количественные значения
характеристики;
− опционально: распределение количества маркеров в каждом
документе;
− для критериев, оценивающих встречаемость частей речи, типов
предложений и др.: процентное соотношение относительно общего количества
слов/предложений.
Должен учитываться тот факт, что размер статей может различаться, поэтому
статистическую информацию необходимо отражать как в абсолютных числах, так и
относительно общего числа слов в документе. Полученная в результате работы
сервиса информация сможет использоваться экспертом для интерпретации и проверки
её валидности.
Для формирования рекомендаций сервис должен получить отдельную статью,
разметить её по тем же типам аннотации (маркерам стиля), которые оцениваются в
корпусе, и сравнить расстояния между значениями статистических характеристик
корпуса и статьи по некоторой метрике.
2.2. Нефункциональные требования к разрабатываемому приложению
Возможность выполнить анализ и оценку на основе описанного в статье [35]
метода не является единственным важным аспектом при создании портала. В
процессе проектирования и выбора средств реализации необходимо учесть
особенности целевой аудитории портала. В данном случае потенциальные
пользователи условно разделяются на профессиональных лингвистов, использующих
портал для анализа корпусов, и авторов статей, которые хотят получить
рекомендации по качеству стиля своего текста.
С учётом специфики метода и результатов анализа популярных приложений для
работы с корпусами, приведённого в главе 1, были выделены изложенные ниже
требования:
−