Разработка службы мониторинга для решения проблемы обеспечения экспертных линий поддержки
Содержание
Введение
. Архитектура IT сервисов и роль инженеров поддержки в
обеспечении доступности систем
.1 Связь качества IT сервисов и бизнес стратегии поставщика
услуг
.2 Структура многоуровневой службы технической поддержки
.3 Шаблоны проектирования информационных систем
.4 Уровни системы мониторинга информационной инфраструктуры
. Моделирование мониторинга элементов информационной
инфраструктуры
.1 Архитектура системы мониторинга
.2 Диаграмма состояний службы мониторинга
.3 Структура приложения службы мониторинга
. Тестирование сценариев взаимодействия со службой
мониторинга
.1 Диаграмма вариантов использования
.2 Тестирование сценариев запуска и остановки службы
.3 Тестирование сценария просмотра статуса проверки
.4 Тестирование сценария отключения настроенной проверки
Заключение
Список использованной литературы
Приложения
Введение
Внедрение и развитие информационных технологий способствует повышению
качества и производительности различных бизнес-процессов компании.
Использование информационных технологий (ИТ) в деятельности предприятия
позволяет повышать качество производимых товаров и предоставляемых услуг.
Автоматизация отдельных участков производства может способствовать получению
экономических выгод за счет снижения издержек и трудозатрат, а также
увеличивает производительность. Большинство компаний вынуждено внедрять,
обновлять и поддерживать информационную инфраструктуру для сохранения
собственной конкурентоспособности. Однако организации не всегда выгодно
выполнять перечисленные функции самостоятельно, а более целесообразно получить
это в виде услуги у стороннего предприятия, специализирующегося на конкретном
виде деятельности.
Понятие «аутсорсинга ИТ» появилось в 70-х годах прошлого века и набрало
значительную популярность после выпуска технологии Active Server Pages компанией Microsoft для создания Web
приложений. Под аутсорсингом ИТ понимается передача функций по управлению
информационной инфраструктурой сторонней организации.
Согласно исследованию, проведенному аналитическим агентством TAdviser рынок аутсорсинга ИТ в России
является один из наиболее перспективных направлений и его рост в 2015 году
составляет 15%. Наибольшей популярностью пользуются в России такие виды услуг,
как офисная печать и видеонаблюдение, телекоммуникации. Также в последние годы
наблюдается значительное повышение спроса на контракты «инфраструктура как
сервис» и «инженерные системы» (корпоративные системы и центры обработки
данных). К компаниям, занимающимся предоставлением аутсорсинговых услуг,
относят консалтинговые предприятия, которые специализируются на автоматизации
процессов за счет внедрения корпоративных систем; предприятия из сферы
телефонии и Интернет-провайдеров; организации, предоставляющих «облачные»
услуги и хранилища данных.
В последней версии библиотеки ITILv3 (IT Infrastructure Library) IT-услуга
определяется как «совокупность информационных систем, обеспечивающих выполнение
бизнес-процессов; IT-услуга включает
в себя информационные технологии, процессы и людей».
Поставщик услуги берет на себя ответственность за качество работы сервиса
для содействия в получении конечного результата заказчику. Обращаясь к
терминологии ITIL, отношения между исполнителем и
заказчиком регулируются на основе формального договора - Service Level Agreement (сокращённо SLA). Документ включает в себя требования по доступности
сервиса, производительности при определенном количестве пользователей, а также
сроки по разрешению обращений или инцидентов.
Таким образом, перед поставщиком информационных услуг стоит задача
обеспечить доступность сервиса в рамках установленных SLA и иметь возможность устранять сбои в работе системы в
максимально сжатые сроки. Как правило, служба технической поддержки провайдера
услуг должна знать о проблемах в работе сервиса еще до того, как она окажет воздействие
на конечных пользователей. Эту задачу можно частично решить при помощи
внедрения систем автоматизированного мониторинга.
Сегодня существует ряд Open Source продуктов и
готовых решений, которыми могут пользоваться системные администраторы для отслеживания
сбоев на различных участках и уровнях ИС. Однако на практике чаще всего
используется наиболее известное программное обеспечение компании Microsoft - System Center Operations Manager (SCOM)
и программа Nagios с открытым кодом. Эти решения
предназначены не только для мониторинга устройств, центров обработки данных
(ЦОД), но и управления частными облаками, службами и обеспечения безопасности.
Процесс обработки событий мониторинга является частью процесса управления
событиями. При возникновении события мониторинга в системе управления
обращениями должен быть зарегистрирован инцидент, который назначается на
соответствующую команду поддержки. Далее специалисты технической поддержки
устраняют возникший сбой и закрывают инцидент.
Основная проблема заключается в том, что экспертные линии поддержки также
хотят иметь доступ к просмотру отдельных событий мониторинга и наблюдать
состояние конкретных участков системы в режиме реального времени. Выдавать
доступ к менеджеру системы мониторинга не корректно с точки зрения процесса
управления событиями и безопасности. Обходным решением может послужить доступ к
файловому журналу событий, но такой подход не обеспечивает пользователей
удобным интерфейсом и возможностью настраивать собственные проверки системы,
необходимые для процесса устранения проблем (troubleshooting). Настройка внутри командных
«мониторов» может быть необходима для сбора статистики по здоровью отдельных
компонентов сервиса, а также отслеживания работы других ресурсов, которые
специалисты используют в работе для выполнения функций поддержки. Существующие
на сегодняшний день решения являются достаточно сложными для развертывания, а
также дорогостоящими в случае продукта от компании Microsoft. Интерфейс менеджера систем
мониторинга зачастую требует дополнительных временных затрат на обучение со
стороны сотрудников и может содержать излишние данные.
Таким образом, целью данной работы является разработка службы мониторинга
для решения проблемы обеспечения экспертных линий поддержки информацией о
состоянии элементов поддерживаемой инфраструктуры в режиме реального времени,
которая обладает свойствами:
. Быстрое развертывание и конфигурация, не требующие построения
массивных деревьев здоровья сервиса;
. Модификация состава и настроек уже существующих командных
«мониторов»;
. Пользовательский интерфейс, который позволит в реальном времени
наблюдать состояние сервиса и получать необходимую информацию;
. Хранение исторических данных работы сервиса мониторинга для
сбора статистики и последующего анализа.
Для достижения поставленной цели необходимо выполнить следующие задачи:
. Изучить существующие алгоритмы и подходы к организации
мониторинга систем для применения этих практик в разрабатываемой службе
мониторинга;
. Проанализировать существующие шаблоны проектирования и способы
взаимодействия компонентов информационной инфраструктуры;
. На основе полученного анализа выявить основные компоненты для
мониторинга и составить требования к функционалу системы;
. Разработать архитектуру системы мониторинга;
. Разработать компоненты системы мониторинга: базу данных и сервис
мониторинга;
. Проверить работу компонентов системы на примере сценариев
взаимодействия с системой.
1.
Архитектура IT сервисов
и роль инженеров поддержки в обеспечении доступности систем
1.1 Связь качества IT сервисов и бизнес стратегии поставщика
услуг
Аутсорсинг информационных технологий является достаточно актуальной темой
для исследования на сегодняшний день. Как заметил в одной из своих работ
профессор Дж. Гу (Университет Флорида Атлантик, департамент информационных
технологий и управления операциями) в 2007 году, научные работы, где объектом
исследования выступают отношения между заказчиками и провайдерами ИТ услуг,
можно разделить на три основных направления: изучение социальных, экономических
и стратегических аспектов подобных взаимоотношений. Так, работы по
стратегической концепции ставят перед собой в качестве основной цели
исследование причин, по которым организации приходится выделять аутсорсинговую
стратегию, а также самого процесса её разработки.
Говоря об экономической стороне предмета исследования, авторы анализируют
эффективность транзакций между участниками отношений, а также подходы к
управлению подобными транзакциями на основе теории транзакционных издержек и
агентской теории. Например, для проектов в сфере информационных технологий
зачастую характерно неполное понимание заказчиком его реальных потребностей или
возможностей исполнителя. Это приводит к появлению искажений (издержек) при
обмене информацией и заключении контракта между обеими сторонами. По этой
причине исполнителю следует в большинстве случаев стремиться использовать
наиболее масштабируемые, универсальные и гибкие решения, чтобы иметь
возможность удовлетворить изменяющиеся потребности клиента.
В качестве социальных аспектов взаимоотношений «вендор-заказчик»
исследованию подлежат управленческие подходы к организации обмена ценными
ресурсами между сторонами соглашения. Проекты по аутсорсингу информационных
технологий предполагают выполнение последовательных действий каждого из
участников, именно поэтому важно эффективно организовать процесс передачи
информации и построения взаимоотношений между сотрудниками.
В своей работе «Исследование факторов, которые влияют на
продолжительность отношений в ИТ аутсорсинге» («An investigation of factors that influence the duration of IT outsourcing relationships», 2007) Дж. Ку построил модель из
семи ключевых аспектов, которые оказывают наибольшее влияние на такой
показатель, как длительность взаимоотношений между заказчиком и исполнителем в
области ИТ аутсорсинга. В модель вошли сбор знаний, стратегическая значимость
ИТ, наличие специфических инвестиций, неопределенность требований, круг
заменителей функций для передачи на аутсорсинг, оппортунистическое поведение и
удовлетворенность клиента итоговым качеством. Все перечисленные переменные
глобально могут быть разделены на два типа: известные заранее и постусловия.
Например, клиент формирует свое отношение к сервису именно в момент его
непосредственного использования, поэтому фактор удовлетворенности качеством
относится ко второму типу. Процесс использования сервиса включает в себя
обращения в службу поддержки. Отсюда, удовлетворенность уровнем обслуживания Service Desk напрямую влияет на репутацию провайдера и
длительность взаимоотношений с заказчиками.
Позднее в 2014 году была опубликована статья «Уроки из Голландского ИТ
аутсорсинга» («Lessons
from Dutch IT outsourcing», G.P.A.J. Delen и другие).
Работа была посвященная исследованию метрик и переменных, при помощи которых
можно было определить вероятность успеха аутсорсинговой сделки на примере
выборки из 30 реальных проектов. Авторы разделили все возможные факторы на два
основных вида: неизменные и контролируемые. Под «неизменными» аспектами
понимаются те, которые были определены в самом начале проекта и не могут быть
преобразованы в последствие. Например, совместимость корпоративных культур
организаций исполнителя и заказчика или мотивы обеих сторон к участию в сделке.
«Контролируемые» показатели напротив могут меняться и принимать различные формы
на протяжении всего проекта. Так, в качестве данных показателей в работе были
исследованы процесс управления спросом, коммуникации внутри фирмы провайдера
услуг и заказчика, выполнение работ в соответствии с планом передачи функций на
аутсорсинг и т.д. Не смотря на утверждение исследователей о том, что тип
выполняемых работ по аутсорсингу не оказывает ни положительное, ни негативное
влияние на исход сделки, они отмечают необходимость исполнителя стремиться к
построению долгосрочных отношений, а также уметь выявлять потребности и
возможности своего клиента. Как уже было отмечено ранее, уровень
удовлетворенности качеством поддержки предоставляемых услуг напрямую влияет на
длительность контракта. Отсюда следует, что успех проекта по аутсорсингу
информационной инфраструктуры также зависит от этой составляющей.
Не менее важное направление исследований в области аутсорсинга
информационных технологий - процесс управления рисками. Филип де Са-Соарес
(профессор Университета Миньо департамента программной инженерии) в своей
работе «Навстречу теории рисков аутсорсинга информационных систем» («Towards a theory of information systems outsourcing risk», 2014) привел все возможные факторы, которые могут
оказывать негативное влияние на организации, выступающие в качестве заказчиков
ИТ услуг. В представленной им рисковой модели выделено пять основных
компонентов: факторы риска, угрозы, действия по снижению негативного влияния,
негативные исходы и нежелательные последствия. При помощи этой модели, автор
объяснил природу возникновения рисков и связал их с аспектами, непосредственно
характерными для проектов по аутсорсингу информационных технологий.
Обращаясь к компонентам представленной модели, угроза является причиной
(или возможной причиной) какого-либо негативного исхода. Негативный исход можно
определить как неблагоприятный (нежелательный) результат определённых действий,
который далее перетекает в нежелательные последствия. Нежелательные последствия
представляют собой явную потерю ценных ресурсов для организации. При этом
первопричиной негативного исхода является фактор риска, то есть некоторая
ситуация, усиливающая угрозы. Однако организация может снижать уровень
причиненного вреда или размер потерь за счет применения определенных действий и
инструментов на этапе возникновения негативного исхода. Для каждого из
перечисленных компонентов автор собрал и представил возможные примеры,
характерные для исследуемой предметной области. Так для составленных примеров,
больший процент угроз для клиента составляют проблемы с производительностью и
стабильностью информационной инфраструктуры провайдера услуг, плохое качество
предоставляемых сервисов и низкий уровень взаимодействия между организациями.
Одним из более конкретных примеров таких негативных аспектов является
недостаточный уровень оказания технической поддержки, проблемы с
телекоммуникационной сетью провайдера или сбои в компонентах информационной
инфраструктуры провайдера. Перечисленных проблем можно частично избежать за
счет внедрения метрик по контролю качества и закреплению данных показателей в
формальном договоре об уровне оказываемых услуг - Service Level Agreement (SLA).
Не смотря на то, что термин «Соглашение об уровне услуг» (SLA) зачастую воспринимается лишь как
формальный договор, описывающий инструкции и обязанности участников отношений,
он имеет гораздо более широкое значение. Понятие «дополнительной валюты»
появилось около века назад и может быть определено как ресурс, добавляющий
ценность к национальной валюте или способный полностью её заменить. В 2012 году
Иоаном Петри было проведено исследование возможности использовать SLA в качестве такой валюты, которое он
описал в своей работе «Service level agreement as a complementary currency in peer-to-peer markets». Заключение в его работе было построено на основе
тезиса о том, что соглашение между двумя сторонами в рамках подобных договоров
направлено на результат в будущем. Этот результат может быть оценен лишь по
истечении срока подобного договора.
Процесс внедрения соглашения и его жизненный цикл в работе разделены на
несколько основных этапов. Во-первых, клиенту необходимо сформировать заявку на
получение контракта (SLA).
После обработки заявки, провайдер услуг формирует условия, которые он готов
предложить клиенту, и направляет их в ответ. На третьем этапе клиент принимает
решение о подписании договора, и далее участники действуют в соответствии с
установленными положениями и сроками контракта. Также в исследовании сделана
предпосылка, о том, что за клиентом остается возможность платить на основе
моделей «плати перед использованием» (pay-before-use) или «плати после использования» (pay-after-use).
Заключительным этапом жизненного цикла контракта является дата его истечения,
при наступлении которого клиент принимает решение о проведении очередной
итерации заключения соглашения с провайдером.
Это исследование показало, что доход провайдера и размер базы лояльных
клиентов напрямую зависит от качества и уровня услуг, которые провайдер
предоставил в период действия соглашения с клиентом. Автор также отмечает в
своей работе способность SLA
минимизировать риски, которые могут оказать непосредственное негативное влияние
на процессы организации-заказчика.
В последней версии библиотеки ITIL (IT Infrastructure Library), опубликованной в 2011 году, приводятся примеры
структуры и положений Договора об уровне услуг в третьей книге серии IT Service Design. Особое место в договоре занимают положения о
доступности сервиса. Под доступностью в данном случае понимается время, в
рамках которого сервис должен предоставлять полный спектр своего функционала
конечным пользователям на определенном соглашением уровне. Авторы книги
рекомендуют использовать для этого показателя метрики в процентном выражении за
определенный период. Однако, как уже было отмечено ранее, клиент может оценить
уровень исполнения провайдером зафиксированных метрик лишь по истечении срока
договора, поэтому чаще всего в первую очередь участники договора рассчитывают
уровень «недоступности» сервиса. Помимо этого положения в приведенном примере
договора выделяются разделы для показателей надежности - максимального
количества сбоев в системе за период договора, - и производительности системы.
При помощи SLA также
регулируется время разрешения и реакции на пользовательские обращения в службу
поддержки провайдера услуг. Снижение производительности и сбои в системе могут
приводить к резкому увеличению потока инцидентов и загрузке инженеров
поддержки. Именно поэтому использование службы автоматизированного мониторинга
непосредственно инженерами технической поддержки позволит снизить риски
возникновения более масштабных проблем в работе систем, а также ускорит время
реакции на возможные перебои и их исправление.
Таким образом, достижение целевых значений ключевых экономических
показателей (например, прибыли, эффективности использования ресурсов)
организации - поставщика ИТ услуг, напрямую зависит от качества предоставляемых
сервисов, уровня и скорости обслуживания конечных клиентов и способности
обеспечить требуемую производительность систем. Контроль исполнения всех
перечисленных показателей может быть обеспечен за счет внедрения систем
автоматизированного мониторинга. Более того, наличие возможности у инженеров
поддержки конкретного приложения или сервиса самостоятельно наблюдать за
состоянием отдельных участков системы в режиме реального времени позволяет
обеспечить улучшение этих показателей, снижение эффекта от нежелательных
воздействий и прозрачность исполнения условий соглашения об уровне услуг.
1.2 Структура многоуровневой службы технической поддержки
Одним из основных процессов управления ИТ услугами, согласно ITIL v3 2011 Edition,
является управление эксплуатацией сервисов (IT Service Operations). Основной целью этого процесса
является контроль над эффективностью и качеством предоставляемых услуг на
уровне, согласованном между заказчиком и провайдером.
Авторы библиотеки выделяют три типа провайдеров услуг (service provider): внутренний поставщик услуг,
объединенный центр обслуживания и внешний поставщик услуг. Под внутренним
провайдером понимается поставщик, предоставляющий услуги в рамках одного бизнес
подразделения, в то время как для второго типа провайдера характерно
обслуживание нескольких департаментов. Последний тип провайдеров предполагает
работу с внешними пользователями системы. На сегодняшний день для большинства
организаций характерно наличие нескольких типов поставщиков услуг или их смесь,
когда провайдер одновременно занимается обслуживанием внутренних и внешних
пользователей системы напрямую. Особенно это характерно для компаний,
занимающихся предоставлением онлайн сервисов.
Эксплуатация ИТ услуг включает в себя такие операции, как управление
событиями, инцидентами, запросами на обслуживание, проблемами и доступом к
системам. Все перечисленное является частью функций службы технической
поддержки и управления приложениями. Авторы библиотеки называют службу
поддержки (service desk) «единой точкой контакта между поставщиком услуг и
пользователями». Основной целью службы поддержки является оказание помощи
пользователям с возникшими проблемами во время использования сервиса и
выполнение запросов на обслуживание. Процесс обработки инцидентов и запросов
состоит из следующих этапов:
. Пользователь заводит обращение в системе при помощи специальной
онлайн системы, звонка и сообщения;
. Сотрудник первой линии регистрирует обращение в системе,
определяет его тип и конкретный сервис, к которому относится заявка;
. Сотрудник первой линии выполняет инструкции для данного типа
обращения: предоставляет пользователю поддержку самостоятельно или передает
(эскалирует) заявку в соответствующую команду на второй линии поддержки;
. Если заявка была передана сотрудникам второй линии, они могут
провести более детальную диагностику и оказать более широкий спектр услуг
пользователю. Сотрудники этой линии могут также решать инциденты посредством
привлечения сотрудников смежных команд. Под смежными командами понимаются
системные администраторы, специалисты (в том числе разработчики) по конкретному
программному обеспечению, администраторы платежных систем и т.д.
В больших организациях принято разделение службы технической поддержки на
уровни. В основном для Service Desk характерно
выделение трех уровней поддержки:
1. Первый уровень. Первый уровень технической поддержки включает в себя
диспетчеров, которые занимаются регистрацией запросов в системе и
предоставлением поддержки в простых случаях, которые можно покрыть стандартными
инструкциями. Для внутренней службы поддержки организации в основном это
предоставление доступа к корпоративным системам, настройка рабочего места
нового сотрудника, иногда установка ПО. Сотрудники этого уровня поддержки
обладают общими знаниями о сервисах компании, поэтому при возникновении сложных
задач и запросов они передают их соответствующим специалистам на более высокий
уровень. Однако перед передачей заявок инженерам второй линии поддержки
сотруднику первого уровня необходимо собрать детальную диагностику у
пользователя и всю необходимую информации согласно типу заявки и сервиса.
2. Второй уровень. Сотрудники второго уровня являются специалистами в
конкретной системе или продукте и имеют доступ к некоторым её внутренним
компонентам, например, базам данных, web API, логам системы
и т.д. Для инженеров второй линии поддержки характерно решение усложненных
технических задач, требующих проведения более глубокой аналитики. Специалисты
второго уровня также имеют определенных инструкций по работе с системой и по
выполнении заявок на обслуживание, требующих конфигурации определенных
параметров внутри сервиса. Сотрудники второй линии поддержки помогают младшей
линии в решении нестандартных обращений и запросов, требующих наличия
определенного уровня доступа к элементам информационной инфраструктуры компании
и поддерживаемого продукта.
3. Третий уровень. На самом последнем уровне поддержки сотрудники занимаются
исследованием наиболее сложных и ранее неизвестных проблем в работе систем,
зачастую это специалисты в конкретной технологии. На этом уровне поддержки
специалисты могут передавать проблемы в команды разработки программного
обеспечения или внешним производителям.
Иногда в структуре технической поддержки выделяют четвертый уровень,
который предполагает поддержку сторонних поставщиков (вендоров) физических
элементов цифровой инфраструктуры или технологий разработки. В этом случае
отношения между внутренней поддержкой и последней линией регулируются на основе
договора об уровне услуг (SLA).
В зависимости от особенностей предоставляемого компанией сервиса задачи
сотрудников второй и третьей лини могут смешиваться, возможны ситуации, когда
определенная команды поддержки не может быть явно отнесена к одному из уровней
на основе представленного описания. Поэтому в рамках данной работы
предполагается, что сотрудники экспертных линий выполняют (или могут выполнять)
следующие задачи:
. Конфигурация определенных параметров системы для выполнения
заявок на обслуживание пользователей;
. Проведение сетевой диагностики при возникновении инцидентов
доступности сервиса;
. Чтение и модификации данных в БД поддерживаемого приложения;
. Проведение анализа проблем и исследования логики обработки запросов
за счет доступ к Web API поддерживаемого приложения;
. Анализ логов отдельных компонентов для исследования проблем и
сбоев в работе системы;
. Получение информации из веб интерфейса системы;
. Предоставление доступа пользователей к участкам системы, если
это требует конфигурации настроек безопасности системы;
. Передача кейсов в команды разработки, если это требует
исправления ошибок в программном коде, аппаратной части сервиса или анализа
кода приложения;
. Получение нотификации от администраторов системы о проблемах или
сбоях, выявленных при помощи системы автоматизированного мониторинга.
1.3 Шаблоны проектирования информационных систем
Качество предоставляемых услуг, в данном случае качество ИТ сервисов,
является их неотъемлемым свойством. На сегодняшний день существует достаточно
большое количество метрик, которые могут быть использованы для определения
качества программного обеспечения. Как уже было отмечено в работе, на рынке
информационных технологий все подобные метрики закрепляются в формальном
договоре об уровне предоставляемых услуг между поставщиком и заказчиком
приложения (системы). Например, в роли этих метрик могут выступать время
загрузки страницы с контентом или количество пользовательских запросов, которые
должен обрабатывать сервер за определенный временной интервал. Все эти аспекты
должны быть учтены при проектировании информационной системы.
В частности, перед архитектором сервиса и командой разработки стоит
задача достичь максимальных показателей таких измерений, как масштабируемость,
доступность и производительность.
Под масштабируемостью понимается способность системы выдерживать пиковые
нагрузки без потери эффективности. Компания-заказчик планирует увеличить штат
сотрудников в несколько раз: это приведет к росту количества пользователей и,
соответственно, увеличит количество запросов к сервису. Бизнес проводит
масштабную маркетинговую акцию по продаже продукции, что повлечет за собой
резкое увеличение числа клиентов, желающих приобрести товары онлайн. В обоих
случаях система должна иметь способность расширяться до определенного числа
пользователей или выдерживать нагрузку на самом её пике, иначе это находит своё
прямое отражение в прибыли компании и производительности её бизнес-процессов.
Однако это не говорит о том, что при увеличении масштаба системы приходится
прибегать к пересмотру SLA.
Как правило, такие нагрузки должны быть учтены заранее и значения метрик
приводятся в виде диапазонов значений при различных условиях.
Доступность - это способность системы быть постоянно доступной конечным
пользователям без потери основных функций. Важно донести до заказчика, что
невозможно обеспечить стопроцентную доступность сервисов.
Выделяют два основных вида причин «бездействия» системы: плановые и
внеплановые. Например, на этапе внедрения система может поставляться отдельными
компонентами, при этом необходимо начать обучение пользователей заранее и
поэтапно. В момент поставки новой функциональности может появиться
необходимость в плановом отключении тех компонентов, что уже были предоставлены
заказчику ранее. К плановым остановкам работы системы можно также отнести
исправление ошибок в предыдущих поставках, которые были выявлены конечными
пользователями или тестировщиками, обновление программного обеспечения или
профилактические работы. К внеплановым перебоям относятся проблемы с сетевым
обеспечением, оборудованием, инциденты безопасности, сбои в приложениях и
программном обеспечении, а также природные катастрофы. Все перечисленные риски
и аспекты учитываются бизнесом при планировании доступности системы,
составлении требований, определении критичных процессов, транзакций и функций.
На этом этапе планирования составляются схемы отката, архивирования и
бэкапирования данных. Ранее было отмечено, что метрики в формальном договоре -
это, как правило, диапазоны значений. Для компонентов системы, сбои в которых
могут оказывать наибольшее влияние на бизнес и стратегию, значения этих метрик
могут быть более узкими и жесткими.
Отдельную роль в проектировании занимает оптимизация производительности,
в особенности, если речь идет о веб приложениях. Скорость обслуживания
пользователей посредством информационных ресурсов крайне важна для бизнеса. На
сегодняшний день требования к времени обработки пользовательских запросов
крайне высокие. Чем быстрее у клиента загружается страница, обрабатывается
транзакция, выполняется поисковой запрос, тем больше конкурентное преимущество
компании. Это напрямую влияет на впечатление пользователя от использования
сервиса и удовлетворенность качеством, повышает вероятность того, что он снова
вернется на этот ресурс или приобретет на нем товар (если речь идет о торговой
онлайн площадке).
Для решения задач по обеспечению доступности, масштабируемости и
оптимизации производительности существует достаточно большое количество подходов
к организации взаимодействия компонентов как между собой внутри системы, так и
с внешними сервисами и интерфейсами. Для последующего использования в
построении универсальной модели системы мониторинга необходимо рассмотреть
несколько наиболее распространенных шаблонов (моделей). Выбор именно этих
решений напрямую связан с функциями и задачами, которые находятся в компетенции
инженеров поддержки, которые были рассмотрены в предыдущем разделе.
В современной среде разработки пользовательских сервисов и приложений
перед специалистами в основном стоит задача написания объектно-ориентированного
кода и создания такой архитектуры. Множество современных технологий, платформ и
языков программирования построены именно на принципах ООП. В первую очередь
такой подход позволяет масштабировать системы, а также в большинстве случаев
упрощает анализ кода и процедуры пополнения функциональности сервиса, кроме
того такие системы являются более производительными и эффективными. Одним из
основных аспектов ООП является разделение системы на части и назначение
функционального наполнения каждой из них, то есть ответ на вопросы «что?» и
«для чего?». За более чем сорокалетнюю историю технологии было разработано
множество готовых решений наиболее распространенных задач, которые возникают
перед разработчиками. Для моделирования и определения функциональности службы
мониторинга необходимо рассмотреть следующие шаблоны проектирования:
) Подписчик-издатель (pub-sub pattern)
a) Описание: шаблон проектирования, при котором компоненты
взаимодействуют между собой посредством передачи сообщений через шину. Этот
шаблон является примером реализации параллельной обработки запроса от клиента
несколькими системами.) Принцип работы: в системе выделяются
«издатель» (publisher) и «подписчик» (subscriber). Издатель публикует сообщения в
виртуальные очереди или разделы. Сообщения делятся на классы. Подписчики
забирают сообщения из одного или нескольких разделов и обрабатывают их.
c) Реализация в службе мониторинга: чаще всего такой подход
подразумевает использование готовых шин (интеграторов) между подписчиками и
издателями. Примером такого решения является технология компании Microsoft - Azure Service Bus. Отправители и подписчики могут обмениваться
информацией, как посредством очередей, так и при помощи разделов.
Необработанные сообщения помещаются в специальную очередь - Dead-Letter Queue. Служба мониторинга получает количество сообщений и
их класс из этой очереди.
2) Фасад (Façade)
a) Описание: шаблон проектирования, для которого характерно
наличие интерфейса более высокого уровня для обеспечения доступа к подсистемам.
При помощи такой архитектуры от пользователя скрыта сложность реализации
подсистем. Фасад обеспечивает возможность упрощенного доступа к функционалу
сервиса через единый интерфейс.
b) Принцип работы: клиент осуществляет работу с системой
через Фасад, который выполняет передачу запроса нужному компоненту в
подсистемах. В случае если необходимо обеспечить работу между несколькими
системами, выделяется класс «обертка» для основной системы. При помощи этого
класса другие системы могут взаимодействовать с компонентами основной без
доступа к ее внутренней архитектуре.
c) Реализация в службе мониторинга: взаимодействие с
системой может осуществляться при помощи очереди событий или отправки SOAP запросов к сервису. Мониторинг может
осуществляться за счет проверки количества и типов событий в очередях в БД.
Также возможна генерация SOAP
запросов, отправка их на сервис и проверка возвращаемого значения или кода
ошибки.
3) Адаптер (Adapter)
a) Описание: шаблон Adapter, как и Façade, предполагает создание «обертки» для подсистем с
целью обеспечения доступа к их компонентам. Основное отличие между этими
шаблонами заключается в том, что Adapter
не предусматривает создание нового интерфейса, а лишь преобразование
существующего к необходимому виду. Этот шаблон применяется в случае, если нет
возможности повторно использовать ранее созданный код.
b) Принцип работы: между существующим пользовательским
интерфейсом и некоторым классом, реализующем необходимые функции, вводится
класс-«обертка» (адаптер). Класс-адаптер реализует пользовательский интерфейс и
в него добавляется ссылка на экземпляр функционального класса. Адаптер отвечает
за перенаправление пользовательских запросов в функциональный класс.
c) Реализация в службе мониторинга: интерфейс может
обмениваться информацией с адаптером при помощи SOAP запросов. В этом случае также возможна генерация SOAP запросов, отправка их на сервис и
проверка возвращаемого значения или кода ошибки.
4) Push и Pull модель (push and pull patterns)
a) Описание: наиболее распространенные модели взаимодействия
пользователя с сервисом. При использовании pull-модели пользователь самостоятельно опрашивает сервис
и получает от него ответ. При использовании push-модели сервис обрабатывает события и уведомляет
клиента об изменениях без пользовательского запроса.
b) Принцип работы:
i) Pull-модель. Клиент отправляет запрос на сервер. Сервер обрабатывает
сообщение и возвращает синхронный ответ.
ii) Push-модель. Сервис самостоятельно уведомляет клиента об изменениях на
заданном адресе. Это позволяет снизить частоту клиентских запросов, но
отличается сложностью реализации из-за асинхронности событий.) Реализация в
службе мониторинга: при реализации шаблона Push изменения могут фиксироваться на уровне базы данных
сервиса. Сервис создает запись с изменением статуса события и задачу на его
отправку. Отдельный модуль отвечает за сбор этих задач и нотификацию
пользователей. Служба мониторинга может собирать данные об очереди задач в базе
данных и их статусе. За счет этого инженеры смогут выявлять сбои в работе
сборщика задач.
) Распределение нагрузки на систему (workload distribution)
a) Описание: для высоко нагруженных систем часто применяется
паттерн распределения нагрузки. Реализация архитектурного шаблона заключается в
использовании балансировщиков нагрузки (balancers) и переносе задач на отдельные
компоненты систем.
b) Принцип работы: балансеры распределяют пользовательские
запросы между виртуальными компонентами или зеркалами баз данных, тем самым
позволяя системе обрабатывать большее количество событий. Другим важным
моментом является выявление отдельных функций и задач, которые система может
обрабатывать в определенные интервалы времени. Для этого в системе можно
настроить расписания и автоматизировать выполнение задачи по нему - настроить
задания (jobs).
c) Реализация в службе мониторинга: служба мониторинга может
проверять работоспособность и доступность отдельных заданий за счет получения
даты последнего успешно обработанного события и сравнения с расписанием в
задании.
6) Сервисно-ориентированная архитектура (SOA)
a) Описание: в основе сервисно-ориентированной архитектуры
лежит набор компонентов, которые осуществляют взаимодействие при помощи
стандартизированных протоколов. Чаще всего такой подход используется для
реализации веб-сервисов.
b) Принцип работы: основными составляющими в SOA являются пользователь, поставщик и
реестр сервисов. Пользователь обращается в реестр при помощи запроса - SOAP, HTTP, WSDL и
т.д. Реестр обрабатывает запрос на основе соглашения об интерфейсе и
перенаправляет его к нужному компоненту сервиса. Сервис обрабатывает событие и
передает ответ обратно в реестр. Реестр возвращает пользователю результат
обработки его сообщения. Поставщик отвечает за поддержку веб интерфейсов
сервисов для интеграции и регистрацию сервиса в реестре.
c) Реализация в службе мониторинга: служба мониторинга может
направлять запросы на основе различных протоколов к реестру и сравнивать
полученный ответ с ожидаемым результатом.
Большинство шаблонов разработки предполагают использование очередей
событий и, для веб сервисов, обмен сообщениями на основе таких протоколов, как SOAP, HTTP и WSDL.
Это говорит о необходимости реализации в службе мониторинга возможности
выполнять SQL запросы на серверах и анализировать
полученный набор данных, а также отправлять запросы на основе перечисленных
протоколов на веб ресурсы с последующим извлечением результата из полученного
ответа.
Для анализа запросов и ответов службе мониторинга необходимо уметь
работать с XML дейтаграммами. Так как в большинстве
случаев разработчики стремятся увеличить производительность системы и скорость
обработки событий, при возможности все чаще используется формат JSON. Это говорит о необходимости
извлекать данные из запросов также и в таком формате.
1.4 Уровни системы мониторинга информационной инфраструктуры
В своей книге «Проектирование высокопроизводительных, масштабируемых и
доступных бизнес Web приложений»
Кумар Ш. («Architecting High Performing, Scalable and Available Enterprise Web Applications», 2015) приводит рекомендации по
проектированию системы мониторинга, в основе которой лежат наиболее
распространенные практики и подходы к обеспечению доступности и
производительности систем. Автор акцентирует внимание на том, что часто один и
тот же паттерн может одновременно применяться для обеспечения
производительности, доступности и масштабируемости веб приложения. Например,
при использовании подхода «распределенной нагрузки» и внедрении
«балансировщиков» нагрузки (balancers) архитектор сервиса решает задачу повышения производительности и уровня
доступности при обработке запросов. При выходе из строя какого-либо из
компонентов, пользователи могут быть временно переключены на работу с одним из
доступных компонентов без потери основного функционала системы и нарушения
бизнес-процессов.
Представленная в книге модель системы мониторинга разделена на два
уровня: мониторинг внутренних систем и служб и мониторинг с внешней стороны (со
стороны пользователя). Мониторинг внутренних систем направлен на проверку
состояние физических компонентов, баз данных, служб и исполнение метрик SLA на уровне баз данных и загрузки
компонентов приложения, в то время как мониторинг с внешней стороны
предполагает анализ исполнения метрик производительности и доступности сервиса
со стороны конечных пользователей в режиме реального времени.
На этапе внутреннего анализа система мониторинга может посылать запросы
веб-приложению, серверу или базе данных и анализировать полученный ответ.
Например, любой HTTP-response код, отличный от 200, может стать
сигналом о наличии ошибок в приложении и сбоях. Также пользователи системы
мониторинга могут следить за использованием памяти серверами, базами данных и
веб приложениями, и, в случае превышения порогового значения, получать
нотификацию. Уведомления системы, отчеты о производительности сервисов и
отложенные задания (scheduled jobs) являются неотъемлемыми компонентами
службы мониторинга на внутреннем уровне, так как предоставляют пользователям
возможность интегрировать её с процессами конкретной организации или команды.
Для мониторинга компонентов со стороны инженеров поддержки конкретного
приложения необходимо также рассмотреть такие функции службы, как мониторинг
исполнения метрик SLA в режиме
реального времени и анализ логов систем. В мониторинге исполнения метрик SLA выделяется два направления: уровень
представления приложения клиентам и уровень выполнения бизнес функций. На
первом уровне пользователь системы имеет возможность анализировать
производительность приложения при загрузке отдельных веб страниц сервиса, на
втором - выполнять конкретный запрос к сервису или базе данных и измерять время
обработки. При анализе файлов для логирования событий систем может
осуществляться поиск конкретной записи, наличие которой говорит о потенциальных
сбоях в работе системы.
Мониторинг внешней производительности системы должен быть наиболее
тщательно проработан, так как наличие ошибок на этом уровне проверки говорит о
том, что сбои в системе оказывают непосредственно влияния на конечных
пользователей и невозможности предоставить ИТ услугу в требуемом качестве. Для
организации этого уровня мониторинга могут использоваться различные готовые
решения и инструменты:
1. Google analytics для анализа времени загрузки
страницы, ответа страницы и проходящего через сервис трафика;
. Инструменты мониторинга производительности приложения (Application Performance Monitoring, APM), которые построены на базе географически
распределённых ботов мониторинга;
. Инструменты real-user monitoring (RUM), основанные на подходе пассивного мониторинга
системы.
На сегодняшний день выделяют две основных группы методов мониторинга
трафика в сети: активные и пассивные. При активном мониторинге происходит
анализ передачи пакетов, пропускной способности канала обмена данными и
маршрутов, по которым идут пакеты, между двумя точками. Активные методы
применяют такие утилиты сетевой диагностики, как ping, tracert
и iperf. Пассивные методы напротив
анализируют информацию об одной точке в сети, перехватывая идущие по каналу
пакеты, и не создают дополнительную нагрузку и трафик к тем, что уже есть в
сети. Они занимаются сбором информации о времени между прохождением пакетов,
трафике, количестве переданных битов и протоколах передачи данных. Обе группы
методов в отдельности имеют ряд существенных недостатков. Например, активные
методы создают лишнюю нагрузку и трафик в сети, не всегда можно гарантировать
точность таких измерений, в то время как пассивные методы могут производить
только оффлайн анализ собранных измерений и не имеют инструментов эффективного
анализа больших данных. Именно по этой причине на практике чаще всего
применяются комбинации описанных методов.
Возвращаясь к перечисленным инструментам внешнего мониторинга, стоит
отметить, что RUM решения являются наиболее
распространенными на сегодняшний день, так как имеют достаточно большой набор
доступного функционала. Они позволяют анализировать использование и трафик веб
страниц приложения, получать статистику производительности и выявлять основные
тренды загрузки сервиса, собирать статистические данные по географическим
регионам, для различных браузеров и устройств, измерять скорость загрузки медиа
контента системы (изображения, видео и звук), а также ошибки при загрузке
страниц и JavaScript’ов.
Однако из всего перечисленного функционала в своей работе инженеры
технической поддержки чаще сталкиваются с задачами осуществления сетевой
диагностики и недоступности страниц и их контента. Утилиты сетевой диагностики,
перечисленные для активных методов, удобнее использовать из командной строки Windows, а не стороннего интерфейса, для
анализа пакетов в сети также существуют удобные готовые решения (например, wireshark). Для автоматизации получения данных
по доступности веб страниц реализуемая система мониторинга должна уметь отправлять
HTTP запросы к веб станицам и
анализировать полученный ответ, распознавать ошибки при загрузке JavaScript’ов и уведомлять об этом
пользователей службы в интерфейсе.
Современные системы автоматизированного мониторинга такие, как Nagios, могут формировать выходные данные
по конкретному участку мониторинга и публиковать результаты в виде XML дейтаграмм в файлы на файловом
ресурсе. Служба мониторинга должна реализовывать функционал считывания данных
из XML и JSON файлов по заданным параметрам и анализировать
полученные значения атрибутов и элементов. За счет этого пользователи службы
мониторинга смогут визуализировать результаты основных систем без необходимости
их реализации в собственном инструменте.
Отсюда, функционал службы мониторинга может быть дополнен следующим
образом:
. Измерение времени обработки запроса в базе данных и сравнение с
пороговым значением метрики;
. Измерение времени загрузки веб страницы и сравнение с пороговым
значением метрики;
. Поиск значения в файле с логами приложения и нотификация
пользователя о наличии значения в интерфейсе;
. Отправка HTTP
запроса к веб ресурсу и анализ кода ответа веб ресурса;
. Анализ ошибок при загрузке JavaScript’ов на веб странице приложения;
. Анализ значений элементов в формате XML и JSON
на различных ресурсах для работы с выходными данными основных систем
мониторинга.
2.
Моделирование мониторинга элементов информационной инфраструктуры
2.1 Архитектура системы мониторинга
На основе анализа современных подходов к организации мониторинга компонентов
информационной инфраструктуры, способов интеграции компонентов систем и задач,
решаемых инженерами экспертных линий поддержки можно составить требования к
реализуемым типам проверок разрабатываемой системы и их свойствам.
|
Тип (категория) проверки
|
Описание
|
Дополнительные свойства
|
|
Проверка времени выполнения SQL запроса на сервере
|
Система выполняет заданный запрос на базе данных MS SQL Server и получает статистические данные о
результатах выполнения. В качестве итогового значения система анализирует значение
времени выполнения запроса.
|
Свойства запроса: Не учитываются. Дополнительные параметры: В качестве дополнительных
параметров могут быть получены другие статистические значения выполнения
запроса на сервере. Список таких значений и их ключей описан в статье
библиотеки MSDN - «Статистика поставщика для SQL Server» [URL:
https://msdn.microsoft.com/ru-ru/library/7h2ahss8(v=vs.110).aspx].
|
|
Проверка итогового значения SQL запроса на сервере
|
Система выполняет запрос к базе данных MS SQL Server, получает значение параметра из
определенного столбца по его имени и анализирует результат. Запрос должен
возвращать не более одной строки (значения последующих строк не
анализируются).
|
Свойства запроса: Для выполнения запроса пользователь указывает имя
столбца, значение которого необходимо проанализировать и путь к файлу со
скриптом для выполнения. Файл должен храниться на той же машине, с которой
запускается инструмент мониторинга. Дополнительные параметры: Запрос пользователя может
возвращать несколько столбцов. Для анализа значений дополнительных параметров
необходимо указать имена столбцов.
|
|
Значение атрибута XML из файла
|
Система загружает данные в формате XML из файла на файловом сервере или локальном
компьютере пользователя. В полученной структуре данных выполняется поиск
необходимого элемента XML
и анализ его значения.
|
Свойства запроса: Для поиска элемента в структуре XML пользователь указывает путь в
формате XPath и
перечисляет namespaces. Необходимо указать явно все namespaces, которые присутствуют в элементах
документа на пути к искомому атрибуту. Дополнительные параметры: В качестве дополнительных
параметров может выполняться поиск других атрибутов в полученной XML структуре. Для этих атрибутов
также требуется указать путь в формате XPath.
|
|
Значение атрибута XML с веб страницы
|
Система загружает данные в формате XML с веб страницы. В полученной структуре данных
выполняется поиск необходимого элемента XML и анализ его значения.
|
Свойства запроса и дополнительные параметры аналогичны категории
«Значение атрибута XML
из файла».
|
|
Значение атрибута JSON из файла
|
Система загружает данные в формате JSON из файла на файловом сервере или локальном
компьютере пользователя. В полученной структуре данных выполняется поиск
необходимого элемента и анализ его значения.
|
Свойства запроса: Для поиска элемента в структуре JSON пользователь указывает путь к
элементу формате JSONPath. Дополнительные параметры: В качестве дополнительных параметров может выполняться
поиск других атрибутов полученного JSON. Для этих атрибутов также требуется
путь в формате JSONPath.
|
|
Значение атрибута JSON с веб страницы
|
Система загружает данные в формате JSON с веб страницы. В полученной структуре данных
выполняется поиск необходимого элемента и анализ его значения.
|
Свойства запроса и дополнительные параметры аналогичны категории
«Значение атрибута JSON
из файла».
|
|
Поиск
словосочетания в логах
|
Система получает файл из указанной директории с логами. В
файле осуществляется поиск слова или сочетания слов, результатом проверки
является количество найденных словосочетаний.
|
Свойства запроса: Для поиска файла с логами в директории пользователю
необходимо указать расширение файла, префикс в его имени, необходимость
получить последний измененный файл с такими параметрами. Для выполнения
проверки необходимо указать строку с искомым словосочетанием или
последовательностью символов. Дополнительные параметры: Не учитываются.
|
|
Код ответа web
страницы
|
Система выполняет запрос к указанной странице и получает
код ответа. Код ответа сравнивается с ожидаемым значением проверки.
|
Свойства запроса: В URL станицы могут перечисляться атрибуты, содержащие имена
методов и входящих параметров. Имена атрибутов и их значения должны быть явно
указаны в свойствах запроса. Дополнительные параметры: Не учитываются.
|
|
Код ответа web API
|
Система выполняет запрос к указанному адресу web API и получает код ответа. Код ответа
сравнивается с ожидаемым значением проверки.
|
Свойства запроса: В адресе web API могут перечисляться атрибуты,
содержащие имена методов и входящих параметров. Имена атрибутов и их значения
должны быть явно указаны в свойствах запроса. Дополнительные параметры: Не учитываются.
|
Исходя из описания полученных категорий, можно выделить следующие
свойства правил в системе мониторинга:
) Тип проверки
(правила) - определяет подход к анализу полученных данных и дополнительных
атрибутов. На данном этапе проектирования системы можно выделить следующие типы
проверок:) Значение из дейтаграммы;) Значение из данных в формате JSON;) Значение
из логов (обычного текста);) Значение из таблицы с данными (набора);) Время
выполнения запроса;) Доступность ресурса.
) Тип ресурса -
определяет способ подключения к объекту (компоненту инфраструктуры), на котором
хранится информация для осуществления проверки. Для разрабатываемой службы
можно выделить следующие типы ресурсов:) Файловый сервер;) База
данных на MS SQL Server;
c) Web страница;
d) Web API.
) Тип запроса -
определяет способ выполнения запроса на ресурсе и получения данных для анализа.
Пользователям системы доступны следующие типы запросов:
a) SQL запрос;) Поиск на основе XML Path;) Поиск
на основе JSON Path;
d) HTTP запрос к веб ресурсу;) Поиск значения в
тексте.
При проектировании системы
необходимо учесть, что проверки мониторинга должны быть разделены на несколько
групп по типам итоговых статусов. Например, проверки из категорий «код ответа web
страницы» или «код ответа web API» могут завершиться успешно
(веб ресурс ответил ожидаемым для проверки статус-кодом), либо кодом с ошибкой.
Результат таких проверок будет принимать значение Passed
или Failed в
зависимости от полученного значения. Эти статусы относятся к группе статусов Binary.
Другие проверки могут
переходить в различные состояния. Например, очереди синхронизации между
системами могут обрабатывать определенное количество событий в штатном режиме.
Если число событий в очереди превышает заданный порог, то это может означать
либо передачу данных с задержкой, либо перегрузку и полный отказ одного из
компонентов. В этом случае пользователи системы мониторинга могут заранее
узнать о накоплении событий в очереди и устранить проблему до того, как она
перейдет в критическое состояние. Такие проверки необходимо отнести к группе Stages
и определять статус - Success, Warning или Critical - в зависимости от интервала, в который входит
итоговое значение.
Возможны ситуации, когда
служба мониторинга не может определить итоговое значение из-за сбоя при
установлении соединения с ресурсом или неправильных настройках проверки. В
данном случае проверка переходит в статус Unknown,
относящийся к группе Errors.
В таблице «Таблица 1. Группы
и типы статусов» отражены описанные типы статусов с разбиением по группам.
Таблица 1. Группы и типы
статусов
|
Группа статусов
|
Тип статуса
|
|
Errors
|
Unknown (неизвестно)
|
|
Binary
|
Passed (проверка пройдена)
|
|
Failed (проверка не пройдена)
|
|
Stages
|
Success (функционирование в штатном
режиме)
|
|
Warning (предупреждение о возможном сбое
компонента)
|
|
Critical (сбой компонента)
|
Для того чтобы определить, в каком статусе находится проверка в данный
момент времени, необходимо явно задать соотношение полученного значения с
пороговыми показателями. Между этими значениями может быть как прямая, так и
обратная зависимость, строгое или нестрогое соотношение. Для данной системы
мониторинга определено следующее правило: в левой части выражения сравнения
находится полученное значение, в правой части - пороговое или ожидаемое
значение. Отсюда, правило мониторинга должно обладать одним из следующих
наборов полей (свойств):
) Ожидаемое значение проверки;
) Ожидаемое значение, порог предупреждения (warning) и критический порог (critical);
) Порог предупреждения (warning) и критический порог (critical).
Перечисленные наборы полей составлены именно таким образом на основе
определенных на предыдущем этапе групп и типов статусов. Схематично логика
определения группы статуса, возможного набора полей и операторов сравнения
представлена на схемах - “Схема 1. Доступные операторы сравнения и наборы
определяющих полей для группы Binary”
и “Схема 2. Доступные операторы сравнения и наборы определяющих полей для группы
Stages”.
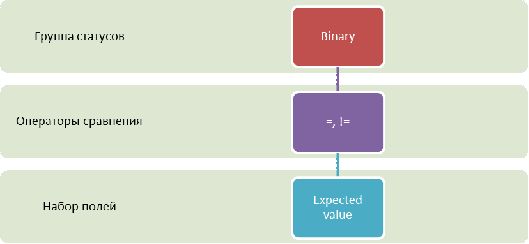
Схема 1. «Доступные операторы сравнения и наборы определяющих полей для
группы Binary»
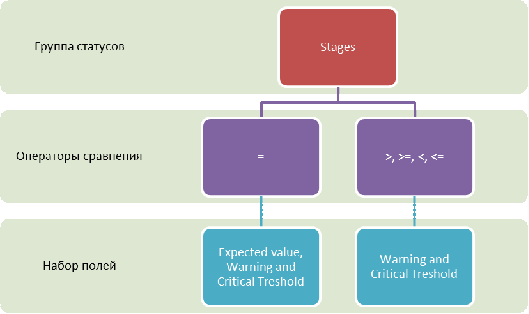
Схема 2. «Доступные операторы сравнения и наборы определяющих полей для
группы Stages»
Для обеспечения регулярной работы системы мониторинга необходимо
определить интервал времени, с которым будет запускаться механизм на сервере.
Пользователи также должны иметь возможность самостоятельно задавать этот
интервал, останавливать и перезапускать инструмент мониторинга, вводить учетные
данные, от имени которых будет осуществляться доступ к компонентам
инфраструктуры организации. Всем перечисленным требованиям отвечает приложение
службы Windows. При помощи интерфейса управления
службами можно определять тип запуска службы, останавливать и запускать
приложение вручную, передавать учетные данные для взаимодействия с внешними
сервисами. Передачу интервала работы службы можно реализовать при помощи
указания значения в миллисекундах в ключе Service Polling Interval в файле конфигурации приложения.
Другим плюсом использования приложения Windows службы является возможность создания журнала событий
для логирования информации о состояниях механизма и сбоях в работе системы. Для
этого журнала можно выделить три типа записей о событиях: информация (information), предупреждение (warning) и ошибка (error). Состав событий и их условия будут определены после
построения диаграммы состояний службы в последующих разделах.
Возвращаясь к требованию об обеспечении регулярной работы службы,
необходимо добавить, что для каждой из проверок, настраиваемых пользователем,
также должна быть возможность определить индивидуальное расписание. Отсюда,
должны быть определены параметры запуска проверки с заданной периодичностью. У
расписания проверки должны быть явно заданы следующие свойства:
) Последнее время запуска проверки - последние дата и время, когда
служба обработала проверку.
) Интервал запуска - целое число, определяющее периодичность
запуска проверки.
) Измерение - определяет показатель, в котором измеряется интервал
запуска. Допустимые значения: секунды, минуты и часы.
) Следующее время запуска проверки - дата и время, когда
необходимо обработать проверку в следующий раз. Рассчитывается на основе
текущей даты и времени и заданной периодичности запуска (интервала и его
измерения).
Таким образом, служба мониторинга опрашивает расписание каждой из настроенных
пользователем проверок с регулярностью определенной в файле конфигурации
приложения. На основе анализа полученного расписания служба находит проверки,
которые необходимо обработать на текущую дату и время в момент очередной
итерации инструмента.
Всю информацию о пользовательских проверках, их параметрах и историю
удобно хранить в базе данных (БД) на сервере. В разрабатываемой системе
используется среда Microsoft SQL Server для управления реляционными базами данных. Модель
базы данных, созданная в этой среде, может быть использована для взаимодействия
с технологией Entity Framework на основе подхода Database First. Использование этой технологии значительно упрощает
взаимодействие с БД. Эта технология может также быть использована в дальнейшем
при разработке пользовательского интерфейса для взаимодействия с системой
мониторинга. Схематично архитектура будущей системы представлена на рис. 1
«Взаимодействие компонентов системы мониторинга».
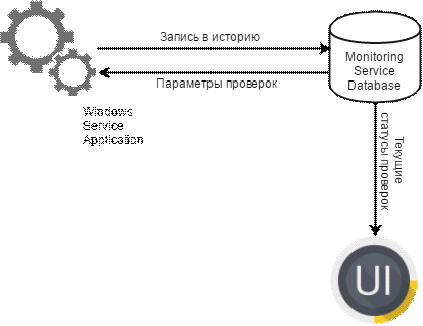
Рис. 1 «Взаимодействие компонентов системы мониторинга»
Служба мониторинга получает всю необходимую информацию из базы и
анализирует полученные параметры проверок. После обработки настроенных
мониторов служба осуществляет запись результатов в историю. Пользовательский
интерфейс отображает наиболее актуальные записи по каждой из активных проверок
из истории.
В разрабатываемой системе необходимо предусмотреть возможность отключения
каждой отдельной проверки. Проверка считается неактивной, если служба
мониторинга не выполняет обновление её расписания, не определяет ее категорию и
не выполняет действия по анализу контрольного значения (которые заданы для
какой-либо категории). Неактивные проверки не отображаются на странице со
статусами мониторинга в пользовательском интерфейсе.
На основе составленных требований к функционалу системы, её архитектуре и
логике работы можно перейти к моделированию каждого из компонентов в
отдельности, которые реализуются в рамках данной работы: базы данных и
приложения службы Windows.
Модель базы данных системы мониторинга и её элементы
На диаграмме ниже (рис. 2 «Логическая модель базы данных») представлена
логическая модель базы данных.
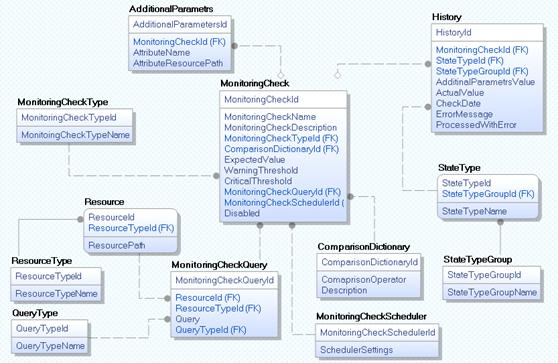
Рис. 2 «Логическая модель базы данных»
База данных состоит из следующего набора сущностей:
· MonitoringCheck (проверка мониторинга). Содержит в себе настройки
пользовательских проверок (мониторов). Связь 1-М с сущностью History.
· MonitoringCheckType (тип проверки мониторинга). Словарь допустимых типов проверок.
Добавление новых значений в эту таблицу должно сопровождаться реализацией
соответствующего функционала в службе мониторинга. Связь М-1 к сущности MonitoringCheck.
· ResourceType (тип ресурса). Словарь реализованных типов ресурсов, на которых могут
выполняться проверки. Например, файловая система, сервер баз данных и т.д.
Связь М-1 с сущностью Resource.
· Resource (ресурс). Описывает ресурс, на котором выполняется
пользовательская проверка. Связь М-1 с сущностью MonitoringCheckQuery.
· QueryType (тип запроса к ресурсу). Словарь реализованных в службе типов
запросов к компонентам информационной инфраструктуры. Например, SQL запрос, XML дейтаграмма или JSON. Связь М-1 c MonitoringCheckQuery.
· MonitoringCheckQuery (запрос проверки). Содержит в себе информацию о
запросе к ресурсу для определенной пользовательской проверки. Связь 1-1 с
сущностью MonitoringCheck.
· MonitoringCheckScheduler (расписание проверки). Содержит в себе информацию о
расписании, по которому проверяется конкретная проверка, и следующем времени
запуска. Связь 1-1 с MonitoringCheck.
· ComparisonDictionary (оператор сравнения). Словарь операторов сравнения
реального значения с ожидаемым значением, а также пороговыми значениями (warning и critical threshold) проверок связь М-1 с MonitoringCheck.
· StateTypeGroup (группа статусов проверок). Словарь допустимых групп типов
статусов проверок. Например, проверка может быть бинарной и результат
сравнивается только с ожидаемым значением или для неё настроены пороговые
значения.
· StateType (статус проверки). Словарь статусов проверок по
группам.
· History (история). Содержит в себе историю по результатам пользовательских
проверок. Историю можно очищать при помощи настройки задания очистки данных из
этой таблиц за определенный период.
В таблице «Таблица 2. Описание полей таблиц базы данных» представлена
информация о полях базы данных: тип данных, допустимые значения и примеры.
мониторинг служба поддержка информационный
Таблица 2. Описание полей таблиц базы данных
|
Поле
|
Описание
|
Тип данных
|
Допустимые значения
|
Пример
|
|
Monitoring Check Type
|
|
MonitoringCheckTypeId
|
Идентификатор типа
проверки (PK)
|
integer
|
Целочисленные положительные значения
|
1
|
|
MonitoringCheckTypeName
|
Название типа проверки
|
varchar(50)
|
Словарь содержит следующие типы проверок, реализованные в
службе: o Value from data set o Query execution time o
Value from
datagram o Value from json o Value from text o
Page
availability
|
Value from data set - анализирует значение из полученного набора
данных
|
|
Resource Type
|
|
ResourceTypeId
|
Идентификатор типа ресурса (PK)
|
integer
|
Целочисленные положительные значения
|
1
|
|
ResourceTypeName
|
Название типа ресурса
|
varchar(50)
|
Словарь содержит следующие типы ресурсов, реализованные в
службе: o File Server o MS SQL server o
Web Page o
Web API
|
MS SQL server - сервер базы данных, на котором
необходимо выполнить запрос
|
|
Query Type
|
|
QueryTypeId
|
Идентификатор типа запроса (PK)
|
integer
|
Целочисленные положительные значения
|
1
|
|
QueryTypeName
|
Название типа запроса
|
varchar(50)
|
Словарь содержит следующие типы запросов, реализованные в
службе: o SQL query o XML path o JSON o
HTTP
request o
Plain text
|
Plain text - получает текст из файла для поиска
словосочетания
|
|
Resource
|
|
ResourceId
|
Идентификатор ресурса (PK, auto increment)
|
integer
|
Целочисленные положительные значения
|
1
|
|
ResourceTypeId
|
Идентификатор типа ресурса (PK, FK)
|
integer
|
Целочисленные положительные значения
|
1
|
|
ResourcePath
|
Путь к ресурсу, строка подключения или URL
|
varchar(250)
|
Символьные значения переменной длины (максимальная длина
250)
|
Data Source = LocalServer; Initial
Catalog = LocalDb; Integrated Security = True - строка подключения к базе данных
|
|
Monitoring Check Query
|
|
MonitoringCheckQueryId
|
Идентификатор запроса для проверки (PK, auto increment)
|
integer
|
Целочисленные положительные значения
|
1
|
|
ResourceId
|
Идентификатор ресурса (FK)
|
integer
|
Целочисленные положительные значения
|
1
|
|
ResourceTypeId
|
Идентификатор типа ресурса (FK)
|
integer
|
Целочисленные положительные значения
|
1
|
|
QueryTypeId
|
Идентификатор типа запроса (FK)
|
integer
|
Целочисленные положительные значения
|
1
|
|
Query
|
Состав запроса к ресурсу
|
varchar(max)
|
Символьные значения переменной длины. Представляют из себя JSON с описанием параметров запроса для
проверки.
|
{ "PathToFile" :
"C:\Users\user\MonitoringService\req1.sql", "ParamName":
"ResultValue" } - путь к файлу с SQL запросом
|
|
Additional Parameters
|
|
AdditionalParametersId
|
Идентификатор запроса дополнительного параметра (PK, auto increment)
|
integer
|
Целочисленные положительные значения
|
1
|
|
MonitoringCheckId
|
Идентификатор проверки мониторинга (FK)
|
integer
|
Целочисленные положительные значения
|
1
|
|
AttributeName
|
Название дополнительного атрибута (Unique)
|
varchar(50)
|
Символьные значения переменной длины (максимальная длина
50)
|
LastErrorDate
|
|
AttributeResourcePath
|
Путь (Path)
к атрибуту в результирующем наборе значений (если формат набора XML или JSON)
|
varchar(max)
|
Символьные значения переменной длины в формате XML Path или JSON Path
|
//CCC/preceding-sibling::* - данные в формате XPath
|
|
Comparison Dictionary
|
|
ComparisonDictionaryId
|
Идентификатор оператора сравнения (PK)
|
integer
|
Целочисленные положительные значения
|
1
|
|
ComaprisonOperator
|
Оператор сравнения
|
varchar(5)
|
Символьные значения переменной длины (максимальная длина
5). Словарь содержит следующие значения: o = o
!= o
> o
>= o
<=
|
“>” - представляет оператор “больше”
|
|
Description
|
Описание оператора сравнения
|
varchar(50)
|
Символьные значения переменной длины (максимальная длина
50) . Словарь содержит следующие значения: o Equal o
Not Equal o
Greater o
Greater or
equal o
Smaller o
Smaller or
equal
|
Smaller or equal - меньше или равно
|
|
Monitoring Check Scheduler
|
|
MonitoringCheckSchedulerId
|
Идентификатор расписания проверки (PK)
|
integer
|
1
|
|
SchedulerSettings
|
Настройки расписания проверки
|
varchar(max)
|
Символьные значения переменной длины. Представляют из себя JSON с описанием параметров: o PollingInterval - интервал проверки
o
IntervalMeasurement -
измерение интервала (допустимые значения: days, hours, minutes, seconds) o LastExecutionTime - последняя дата
запуска (допустимо значение never,
если проверка будет запущена впервые) o NextExecutionTime - следующая
ожидаемая дата запуска
|
{"PollingInterval":"2",
"IntervalMeasurement":"hours",
"LastExecutionTime":"2017-04-22 11:22",
"NextExecutionTime":"2017-04-22 13:22" } - проверка запускается раз в
два часа
|
|
State Type Group
|
|
StateTypeGroupId
|
Идентификатор группы статусов (PK)
|
integer
|
Целочисленные положительные значения
|
1
|
|
StateTypeGroupName
|
Название группы статусов
|
varchar(50)
|
Словарь содержит следующие значения: o
Binary - итоговый статус выводится, как
прошел/не прошел o Stages - проверка может находится на разных стадиях o
Errors - статус выводится, если не
удалось обработать проверку
|
Stages - к этой группе статусов
относятся Success, Warning и Critical
|
|
State Type
|
|
StateTypeId
|
Идентификатор типа статуса
(PK)
|
integer
|
Целочисленные положительные значения
|
1
|
|
StateTypeGroupId
|
Идентификатор группы статусов (FK)
|
integer
|
Целочисленные положительные значения
|
1
|
|
StateTypeName
|
Название типа статуса
|
varchar(50)
|
Символьные значения переменной длины (максимальная длина
50) . Словарь содержит следующие значения: o Passed и Failed (для типа
Binary) o Success, Warning, Critical (для типа
Stages) o Unknown (для типа Errors)
|
Warning - итоговое значение проверки
выходит за границы порога Warning Threshold, но находится в пределах Critical Threshold
|
|
Monitoring Check
|
|
MonitoringCheckId
|
Идентификатор проверки (PK, auto increment)
|
integer
|
Целочисленные положительные значения
|
1
|
|
MonitoringCheckName
|
Название проверки (Unique)
|
varchar(50)
|
Символьные значения переменной длины (максимальная длина
50) .
|
Test Monitoring Check
|
|
MonitoringCheckDescription
|
Описание проверки
|
varchar(max)
|
Символьные значения переменной длины.
|
Tests performance of monitoring
service
|
|
MonitoringCheckTypeId
|
Идентификатор типа
проверки (FK)
|
integer
|
Целочисленные положительные значения
|
1
|
|
ComparisonDictionaryId
|
Идентификатор оператора сравнения (FK)
|
integer
|
Целочисленные положительные значения
|
1
|
|
ExpectedValue
|
Ожидаемое значение (заполняется для проверок с группой
статусов Binary)
|
varchar(250)
|
Символьные значения переменной длины (максимальная длина
250) .
|
200
|
|
WarningTreshold
|
Порог Warning для проверки (заполняется для проверок с группой статусов Stages)
|
varchar(250)
|
Символьные значения переменной длины (максимальная длина
250) .
|
50
|
|
CriticalTreshold
|
Порог Critical для проверки (заполняется для проверок с группой статусов Stages)
|
varchar(250)
|
Символьные значения переменной длины (максимальная длина
250) .
|
Critical - файлы вывода систем
мониторинга могут содержать готовые статусы по проверкам
|
|
MonitoringCheckQueryId
|
Идентификатор запроса для проверки (FK)
|
integer
|
Целочисленные положительные значения
|
1
|
|
MonitoringCheckSchedulerId
|
Идентификатор расписания проверки (FK)
|
integer
|
Целочисленные положительные значения
|
1
|
|
Disabled
|
Флаг, определяющий состояние проверки
|
bit
|
Значение 0 для работающих проверок; 1 - для остановленных
|
1 - выполнение проверки временно остановлено
пользователями
|
|
History
|
|
HistoryId
|
Идентификатор записи в истории (PK, auto increment)
|
integer
|
Целочисленные положительные значения
|
1
|
|
MonitoringCheckId
|
Идентификатор проверки (FK)
|
integer
|
Целочисленные положительные значения
|
1
|
|
StateTypeId
|
Идентификатор типа статуса
(FK)
|
integer
|
Целочисленные положительные значения
|
1
|
|
StateTypeGroupId
|
Идентификатор группы статусов (FK)
|
integer
|
Целочисленные положительные значения
|
1
|
|
AdditinalParametrsValue
|
Значения дополнительных параметров в формате JSON
|
varchar(max)
|
Символьные значения переменной длины формате JSON (имя параметра : значение)
|
{"LastErrorDate":"2017-02-29"}
|
|
ActualValue
|
Реальное значение проверяемого параметра
|
varchar(250)
|
Символьные значения переменной длины (максимальная длина
250) .
|
2000
|
|
CheckDate
|
Дата и время исполнения проверки
|
datetime
|
Значение даты и времени в текущей временной зоне
|
2017-04-22 11:22:00
|
|
ErrorMessage
|
Текст ошибки в случае сбоя
|
varchar(300)
|
Символьные значения переменной длины (максимальная длина
300) .
|
Could not connect to database
“LocalDB”.
|
|
ProcessedWithError
|
Флаг, определяющий наличие ошибок при обработке проверки
|
bit
|
0 - проверка обработана успешно 1 - во время обработки
возник сбой
|
1 - службе мониторинга не удалось подключиться к серве
ру с базой данных для выполнения запроса
|
Скрипт генерации базы данных получен при помощи средств моделирования ERWIN Data Modeling Tools и находится в Приложении 1 - «Скрипт базы данных».
2.2 Диаграмма состояний службы мониторинга
На диаграмме состояний (рис. 3 «Диаграмма состояний службы мониторинга»)
схематично изображен процесс обработки настроенных пользователями проверок
службой мониторинга. После установки служба мониторинга запускается в режиме - Automatically. Запуск службы сопровождается
созданием источника и журнала событий, если они не были настроены ранее, и
записью о запуске службы.
Далее запускается таймер, интервал (в миллисекундах) которого
регулируется настройкой «Service Polling
Interval» в файле конфигурации службы. По
истечении таймера служба мониторинга осуществляет чтение информации о
настроенных проверках из базы. Строка подключения к базе также задается
отдельной настройкой в файле конфигурации. Если проверок в базе нет, служба
возвращается в первоначальное состояние.
Если проверки есть, осуществляется фильтрация полученных проверок по полю
Disabled, то есть поиск активных проверок.
Если активных проверок нет, служба возвращается в первоначальное состояние.
Если активные проверки настроены, осуществляется проверка настроек
расписания из поля SchedulerSettings.
Если среди проверок нет тех, для которых параметр NextExecutionDate меньше текущих значений даты и
времени, служба возвращается в первоначальное состояние.
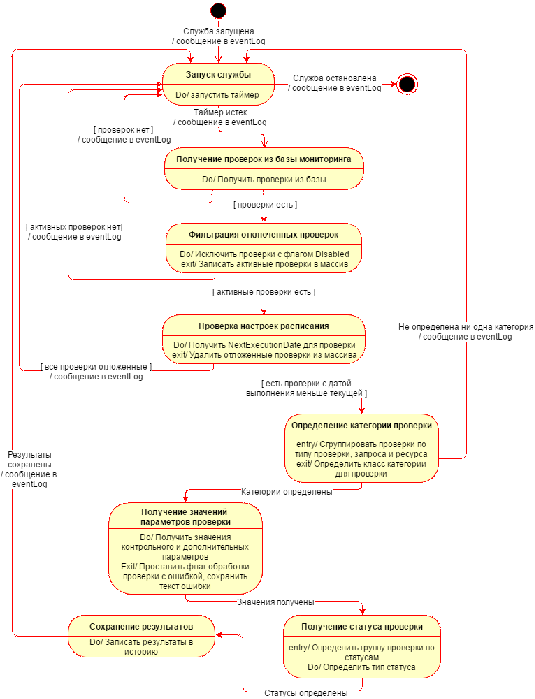
Рис. 3 «Диаграмма состояний службы мониторинга»
Если есть проверки, которые уже необходимо выполнить по расписанию,
служба переходит в состояние определения категории проверки и обновляет
параметр NextExecutionDate в расписании. Проверки делятся на
категории в зависимости от типа проверки, ресурса и запроса:
Таблица 3. Категория проверки в зависимости от типа запроса, ресурса и
проверки
|
Категория
|
Тип запроса
|
Тип ресурса
|
Тип проверки
|
|
Проверка времени выполнения SQL запроса на сервере
|
Query execution time
|
MS SQL Server
|
SQL Query
|
|
Проверка итогового значения SQL запроса на сервере
|
Value from dataset
|
MS SQL Server
|
SQL Query
|
|
Значение атрибута XML из файла
|
Value from datagram
|
File Server
|
XML path
|
|
Значение атрибута XML с веб страницы
|
Value from datagram
|
Web Page
|
XML path
|
|
Значение атрибута JSON из файла
|
Value from json
|
File Server
|
JSON
|
|
Значение атрибута JSON с веб страницы
|
Value from json
|
Web Page
|
JSON
|
|
Поиск
словосочетания в логах
|
Value from plain text
|
File Server
|
Plain Text
|
|
Код ответа web страницы
|
Response Code
|
Web Page
|
HTTP Request
|
|
Код ответа web API
|
Response Code
|
Web API
|
HTTP Request
|
В зависимости от категории проверки происходит вызов соответствующих
методов для получения результатов проверки - контрольного и дополнительных
параметров. Если в результате группировки ни для одной категории не было
выявлено ни одной проверки, служба переходит в первоначальное состояние. Если
во время получения параметров проверки произошел сбой, для нее проставляется
соответствующий флаг ProcessedWithError и фиксируется сообщение ошибки. Полученные значения
дополнительных параметров преобразуются в JSON.
После обработки соответствующего запроса проверки служба мониторинга
переходит в состояние определения статуса на основе той группы, к которой она
относится, и значения контрольного параметра.
Полученные данные сохраняются в таблицу истории. Завершение очередной
итерации службы мониторинга фиксируется в журнале событий.
На основе представленной диаграммы можно определить состав и тип записей
в журнале событий, представленных в таблице 4 «Типы записей в журнале событий
службы мониторинга».
Таблица 4. Типы записей в журнале событий службы мониторинга
|
Иконка
|
Тип события
|
Условие
|
Текст записи
|
|

|
Информация (Information)
|
Запуск службы вручную
|
Monitoring service successfully
started
|
|
|
Очередная итерация службы по истечению таймера
|
Monitoring iteration after start
{iteration}
|
|
|
Начало обработки проверки
|
Start processing check: {Check
name}
|
|
|
Остановка службы вручную
|
Monitoring service stopped
|
|

|
Предупреждение (Warning)
|
В системе нет активных проверок
|
No active Monitoring Checks
retrieved
|
|
|
Все проверки отложенные
|
No Monitoring Checks to be executed
at {current timestamp} retrieved
|
|
|
Не удалось определить категорию отдельной проверки
|
Could not define implemented
category for check {Check Name}. Please ensure correct combination of
resource, category and check types.
|
|
|
Не удалось определить категорию ни для одной проверки
|
No Monitoring Checks categories
could be defined. Check EventViewer log for more information.
|
|

|
Ошибка (Error)
|
Не удалось определить группу статусов
|
Please make sure that the
combination of expected value, War ning threshold, critical threshold and
comparison operator have been set up correctly.
|
|
|
Не удалось получить контрольное значение
|
В журнал записывается сообщение ошибки, inner exception и stack trace.
|
|
|
Не удалось получить проверки из базы
|
|
|
|
Не удалось записать историю в базу
|
|
|
|
Другие ошибки при обработке методов службы мониторинга
|
|
2.3 Структура приложения службы мониторинга
Приложение службы мониторинга разрабатывается в среде Visual Studio 2017 на языке C# 7.0 с использованием шаблона проекта Windows Service. На основе требований, составленных в предыдущих
разделах, приложение осуществляет взаимодействие со спроектированной базой
данных при помощи технологии Entity Framework.
При помощи конструктора ADO.NET в проекте приложения службы
загружена EMD модель Monitoring Service Model (рис. 4 «Модель данных в проекте приложения службы»)
на основе существующей базы. Полученная модель включает в себя классы,
определяющие сущности базы данных, определения таблиц, столбцов и типов данных,
а также сопоставление классов и таблиц из модели. Строка подключения к БД
системы мониторинга задается в файле конфигурации приложения App.config в элементе ConnectionStrings с именем MonitoringServiceEntities.
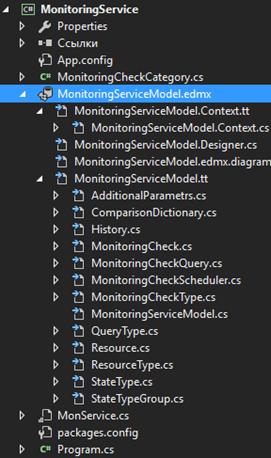
Рис. 4 «Модель данных в проекте приложения службы»
Для установки службы мониторинга в системе и обозначения первоначальной
конфигурации приложения в проекте реализован компонент ProjectInstaller, который состоит из serviceProcessInstallerMS и serviceInstallerMS (рис. 5 «Состав компонента установки
приложения ProjectInstaller»).
Рис. 5 «Состав компонента установки приложения ProjectInstaller»
При помощи serviceProcessInstallerMS (рис. 6 «Настройки компонента serviceProcessInstallerMS») можно задать тип учетной записи,
от которой будет работать служба. В данном случае используется тип учетной
записи «User», то есть при установке приложения
пользователю необходимо будет явно указать учетные данные.
Рис. 6
«Настройки компонента serviceProcessInstallerMS»
Компонент serviceInstallerMS
позволяет настроить имя службы для отображения в системе, добавить описание
службы и выбрать тип запуска (рис. 7 «Настройки компонента serviceInstallerMS»). В этом проекте используется тип
запуска Automatic, так как служба запускается с
заданной пользователями периодичностью.

Рис. 7 «Настройки компонента serviceInstallerMS»
Для каждого из состояний приложения службы реализован набор методов,
представленных в таблице 5 «Описание методов для состояний службы мониторинга».
Таблица 5. Описание методов для состояний службы мониторинга
|
Состояние
|
Метод / Конструктор
|
Описание
|
|
Запуск службы
|
Program.Main()
|
В методе инициализируется объект класса MonService. Объект добавляется в массив типа ServiceBase. Выполняется регистрация
исполняемого файла службы мониторинга.
|
|
MonService.InitializeComponent()
|
В методе инициализируется объект eventLogMS типа System.Diagnostics.EventLog. Объект предназначен для записи в
журнал событий службы мониторинга.
|
|
MonService.MonService()
|
В конструкторе класса MonService создаются и/или определяются параметры журнал службы мониторинга и инициализируются поля класса _checks, _scheduledChecks, _categorizedChecks,
_currentHistoryResults.
|
|
MonService.OnStart(string[] args)
|
В методе инициализируется объект типа Timer. Интервал (interval) таймера задается при помощи ключа
из файла конфигурации Service Polling Interval. Для объекта определяется поведение по истечении интервала времени (Elapsed) - делегату назначается метод T1_Elapsed(object sender, ElapsedEventArgs e).
|
|
MonService. T1_Elapsed(object
sender, ElapsedEventArgs e).
|
Метод вызывается по истечении таймера и задает поведение
службы мониторинга, порядок и логику перехода к другим состояниям и записей в
журнал событий службы.
|
|
Получение проверок из базы и фильтрация отключенных
проверок
|
MonService.RetrieveData()
|
Метод возвращает коллекцию с типом MonitoringCheck, которая передается в _checks. Коллекция содержит данные по
активным проверкам из базы. Фильтрация происходит по значению поля Disabled сущности MonitoringCheck.
|
|
Проверка настроек расписания
|
MonService.GetScheduledChecks()
|
Метод анализирует параметры расписания для объектов из
коллекции _checks и возвращает коллекцию типа MonitoringCheck (_scheduledChecks). Для текущих проверок происходит
присвоение новых значений параметров расписания и вызов метода UpdateDBSchedule() для обновления параметров
расписания. При расчете нового значения NextExecutionTime используется метод GetTimeSpan(string intervalMeasurement, int
pollingInterval).
|
|
MonService.UpdateDBSchedule()
|
Метод обновляет параметры расписания - LastExecutionTime и NextExecutionTime - для проверки в базе.
|
|
MonService.GetTimeSpan(string
intervalMeasurement, int pollingInterval)
|
Метод возвращает объект типа TimeSpan для предоставленного интервала
обработки проверки и его измерения. Этот объект используется для расчета
нового значения параметра NextExecutionTime и передается в метод DateTime.Add().
|
|
Определение категории проверки
|
MonService.DefineCategory()
|
Метод инициализирует объекты классов, реализующих интерфейс
IMonitoringCheckCategory. В каждый из объектов классов
передается соответствующая данной категории проверка из _scheduledChecks. Категорированные проверки хранятся
в коллекции _categorizedChecks.
|
|
Получение значений параметров проверки и получение статуса
проверки
|
MonService.GetHistoryData()
|
Метод определяет необходимые значения параметров проверки
для последующего сохранения в истории. Для каждого объекта коллекции _categorizedChecks происходит вызов метода ObtainActualValue(out proccessedWithError, out
errorMessage), который определен в каждом классе, рализующем интерфейс IMonitoringCheckCategory. Далее для каждого объекта
определяется его группа статусов и текущий тип статуса. Результаты
сохраняются в коллекцию _currentHistoryResults.
|
|
IMonitoringCheckCategory
.ObtainActualValue(out proccessedWithError, out errorMessage),
|
Метод возвращает значение контрольного и дополнительного
параметров проверки на текущий момент, а также определяет обработалась ли
проверка успешно или с ошибками.
|
|
MonService.GetStateType( string
comaprisonOperator, string expectedValue, string warningThreshold, string
criticalThreshold, string actualValue, bool processedWithError)
|
Метод
возвращает идентификатор текущего статуса проверки на основе результата обработки одного из методов: CalculateStagesState(string expectedValue, string
warningThreshold ,string criticalThreshold ,string actualValue ,string
comaprisonOperator) или
CalculateBinaryState(string expectedValue, string actualValue, string
comaprisonOperator).
|
|
MonService.
CalculateStagesState(string expectedValue, string warningThreshold ,string
criticalThreshold ,string actualValue ,string comaprisonOperator)
|
Метод возвращает идентификатор текущего статуса проверки
группы Stages.
|
|
MonService.
CalculateBinaryState(string expectedValue, string actualValue, string
comaprisonOperator)
|
Метод возвращает идентификатор текущего статуса проверки
группы Binary.
|
|
GetStateTypeGroup(int stateTypeId)
|
Метод возвращает идентификатор группы текущего статуса
проверки.
|
|
Сохранения результатов
|
MonService.InsertHistory()
|
Метод сохраняет объекты типа History из коллекции _currentHistoryResults в базе данных.
|
|
Остановка службы мониторинга
|
MonService.OnStop()
|
Метод вызывается при остановке приложения службы вручную. В
журнал событий записывается информацию об остановке работы службы
мониторинга.
|
Для каждой из категорий должен быть определен свой класс, реализующий
интерфейс IMonitoringCheckCategory. Соотношения классов, реализованных
в приложении службы, и категорий приведены в таблице 6 «Соотношения классов
приложения и категорий проверок».
Таблица 6. Соотношения классов приложения и категорий проверок
|
Класс
|
Категория
|
|
SQLQueryResult
|
Время выполнения SQL запроса на сервере
|
|
Проверка итогового значения SQL запроса на сервере
|
|
XMLQueryResult
|
Значение атрибута XML из файла
|
|
Значение атрибута XML с веб страницы
|
|
JSONQueryResult
|
Значение атрибута JSON из файла
|
|
Значение атрибута JSON с веб страницы
|
|
ValueFromLogs
|
Поиск
словосочетания в логах
|
|
WebResourceResponseCode
|
Код ответа web
страницы
|
|
Код ответа web API
|
Диаграмма классов и код проекта добавлены в Приложения 2 - «Диаграмма
классов приложения службы» и 3 - «Код проекта службы мониторинга»
соответственно.
3.
Тестирование сценариев взаимодействия со службой мониторинга
3.1 Диаграмма вариантов использования
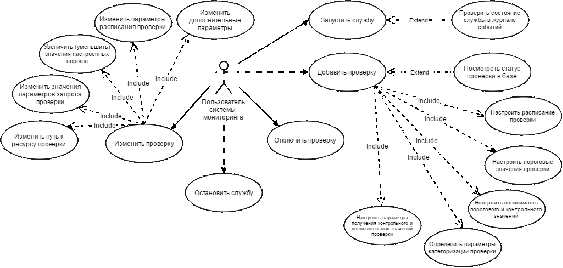
Рис. 8 «Диаграмма вариантов использования»
На рис.8 «Диаграмма вариантов использования» представлены возможные
сценарии взаимодействия пользователя с системой мониторинга.
Для запуска и остановки службы мониторинга необходимо воспользоваться
интерфейсом менеджера служб Windos.
Запуск службы сопровождается созданием журнала событий и позволяет пользователю
наблюдать за состоянием инструмента по записям в журнале.
Настройка и изменение параметров проверки может осуществляться через веб
интерфейс системы или напрямую через базу данных. Настройка новой проверки
включает в себя определение параметров получения контрольного значения
(параметров запроса, пути к ресурсу и т.д.) и категоризации проверки (типа
ресурса, запроса и правила), передачу проговых и контрольного значений, а также
определение периодичности запуска проверки (расписание). Добавление проверки
позволяет просматривать ее текущий статус и значения параметров посредством
получения наиболее актуальной записи из таблицы истории.
Пользователь может отключить проверку, что означает проставление
соответствующего значения для флага Disabled на уровне системы. Для изменения доступны следующие
параметры: настройки расписания, состав и настройки дополнительных параметров,
значения параметров запроса проверки (например, XPath), увеличение или уменьшение пороговых значений (без
изменения их состава) и путь к ресурсу, на котором располагаются данные
компонента инфраструктуры.
Для разработанного прототипа службы мониторинга необходимо проверить
возможность запуска и отключения приложения мониторинга, возможность получения
текущего статуса и отключения настроенной в системе проверки.
3.2 Тестирование сценариев запуска и остановки службы
Компонент установки службы в системе настроен таким образом, что
приложение устанавливается в системе с именем MonitoringService. При первом запуске службы в системе
для нее создается отдельный журнал событий для записи информации о состоянии
приложения. Приложение становится доступно в интерфейсе менеджера служб Windows после его установки на локальном
компьютере / сервере под управлением Windows (рис. 9 «Служба мониторинга в интерфейсе менеджера служб Windows»).
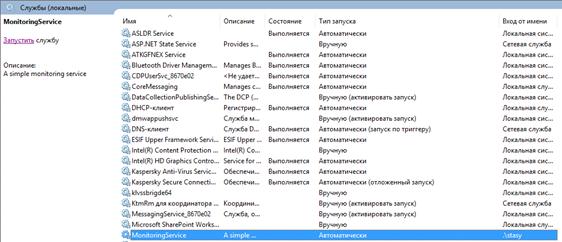
Рис. 9 «Служба мониторинга в интерфейсе менеджера служб Windows»
Успешный запуск приложения через интерфейс сопровождается переходом
службы в состояние «Выполняется» (рис. 10 «Состояние запущенной службы
мониторинга»).
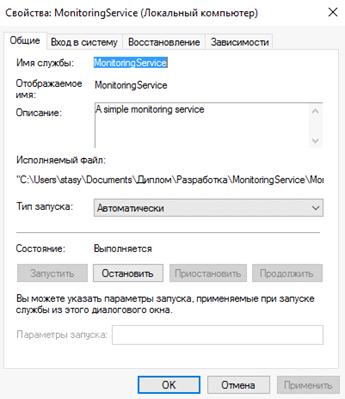
Рис. 10 «Состояние запущенной службы мониторинга»
Согласно составленным требованиям, в системе регистрируется журнал для
ведения записей о событиях приложения мониторинга с именем MonitoringServiceLog (рис. 11 «Журнал событий службы
мониторинга»). Журнал доступен в интерфейсе просмотра событий Windows.
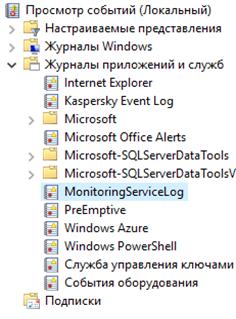
Рис. 11 «Журнал событий службы мониторинга
Запуск и остановка службы мониторинга сопровождаются внесением
соответствующих сообщений в журнал событий (рис. 12 «Сообщение о запуске службы
в журнале» и рис. 13 «Сообщение об остановке службы в журнале»).
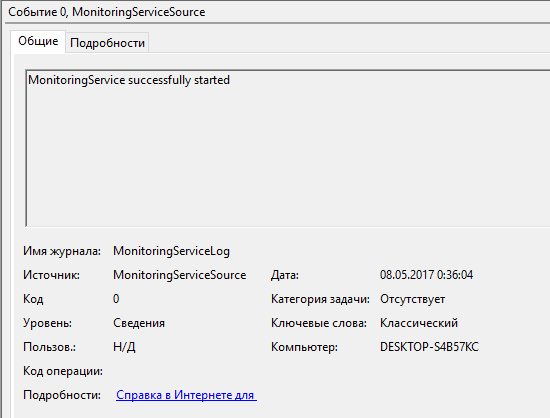
Рис. 12 «Сообщение о запуске службы в журнале»
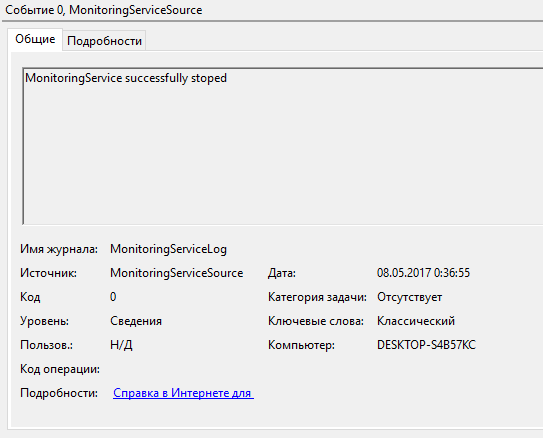
Рис. 13 «Сообщение об остановке службы в журнале»
Успешная остановка приложения через интерфейс управления переводит службу
в состояние «Остановлена» (рис. 14 «Состояние остановленной службы
мониторинга»).
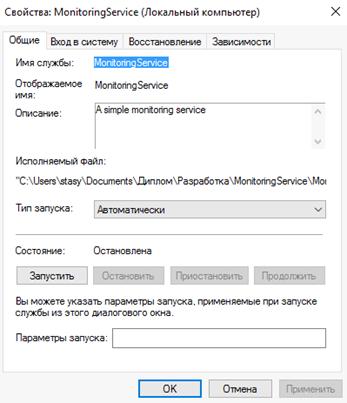
Рис. 14 «Состояние остановленной службы мониторинга»
Таким образом, в разработанном прототипе реализованы механихмы запуска,
создания журнала и источника событий и механизм оставновки приложения в
соответствии с составленными требованиями и диаграммой состояний службы.
3.3 Тестирование сценария просмотра статуса проверки
Для проверки сценария возможности просмотра статуса необходимо добавить в
систему новое правило и заполнить справочники базы данных. Справочники базы
данных заполняются при помощи скрипта из приложения 4 - «Скрипт заполнения
справочников базы данных». Так как разработка пользовательского интерфейса не
входит в задачи данной работы, новая проверка будет добавлена в базу данных
системы мониторинга при помощи выполнения скрипта.
USE MonitoringServiceTRYTRANSACTION@Table_ID INTINTO
dbo.[Resource]
(3, 'https://www.w3schools.com/xml/plant_catalog.xml')INTO
dbo.MonitoringCheckQuery
(IDENT_CURRENT('dbo.[Resource]'), 3
,'{
"XPath":"CATALOG/PLANT[COMMON=''Crowfoot'']/PRICE",
"namespaces":{}}',2)INTO dbo.MonitoringCheckScheduler
('{
"PollingInterval":"5",
"IntervalMeasurement":"minutes",
"LastExecutionTime":"2017-04-29 11:22",
"NextExecutionTime":"2017-04-29 13:22"
}')INTO dbo.MonitoringCheck
(3,1,'$9.34',NULL,NULL,IDENT_CURRENT('dbo.MonitoringCheckQuery')
,'Test check for use case', 'My test check for use case'
,IDENT_CURRENT('dbo.MonitoringCheckScheduler'),0)INTO
dbo.AdditionalParametrs ([MonitoringCheckId], [AttributeName],
[AttributeResourcePath])
(IDENT_CURRENT('dbo.MonitoringCheck'),'Common name',
'CATALOG/PLANT[COMMON=''Crowfoot'']/BOTANICAL')TRYCATCH
END CATCH
При помощи данного скрипта в систему была добавлена проверка категории
«Значение атрибута XML с веб
страницы». Проверка относится к группе статусов Binary и считается успешной, если контрольное значение равно
“$9.34”. У проверки также настроены дополнительный атрибут “Common name” и периодичность запуска каждые пять минут. После
выполнения скрипта, в таблицы добавляются соответствующие значения свойств для
новой проверки, и создается объект MonitoringCheck (рис. 15 «Объект MonitoringCheck в таблице базы»).
Рис. 15 «Объект MonitoringCheck в таблице базы»
При последующей итерации или запуске службы мониторинга в журнале событий
появляется соответствующая запись об обработке настроенной проверки (рис. 16
«Запись об обработке проверки в журнале событий»).
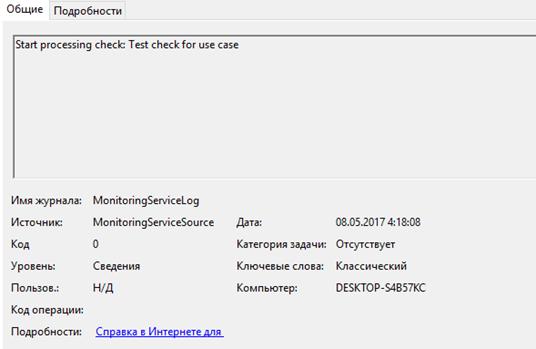
Рис. 16 «Запись об обработке проверки в журнале событий»
Данные об актуальном статусе текущей проверки можно получить при помощи
выполнения SQL запроса к таблице истории мониторинга
History.
USE MonitoringServiceh.*dbo.History AS hh.MonitoringCheckId =
9 --ID of the inserted ruleh.CheckDate = (SELECT MAX(h1.CheckDate)
FROM dbo.History AS h1
WHERE h1.MonitoringCheckId = 9)
Результатом выполнения запроса на момент выполнения тестового сценария
были успешный статус для данной проверки и значение дополнительного атрибута “Ranunculus” (веб страница для загрузки XML содержит информацию о каталоге
цветов).

Рис. 17 «Результат выполнения запроса на получение текущего статуса
проверки»
Таким образом, в службе мониторинга реализован функционал обработки
настроенных пользователем проверок, согласно описанным требованиям. На текущем
этапе разработки системы мониторинга пользователи могут получать информацию о
текущих статусах проверок из базы при помощи выполнения SQL запроса.
USE MonitoringServiceh.HistoryId, mc.MonitoringCheckName,
mc.MonitoringCheckDescription
,st.StateTypeName, h.AdditinalParametrsValue, h.ActualValue
,h.CheckDate, h.ErrorMessage, h.ProcessedWithErrordbo.History
AS hJOIN dbo.StateType AS stst.StateTypeId = h.StateTypeIdJOIN
dbo.MonitoringCheck AS mcmc.MonitoringCheckId = h.MonitoringCheckIdh.CheckDate
= (SELECT MAX(h1.CheckDate)dbo.History AS h1h1.MonitoringCheckId =
h.MonitoringCheckId)
3.4 Тестирование сценария отключения настроенной проверки
Как уже было отмечено ранее, отключение проверки представляет собой
проставление соответствующего значения (true) флага Disabled для неё в базе данных. Для настроенной на предыдущем шаге проверки можно
проставить флаг при помощи выполения SQL запроса.
USE MonitoringServicedbo.MonitoringCheck
SET [Disabled] = 1MonitoringCheckId = 9;
В резальтате выполнения запроса запись в таблице MonitoringCheck для отключенной проверки будет
содержать значение “1” для поля Disabled (рис. 18 «Результат выполнения запроса на отключение проверки»).

Рис. 18 «Результат выполнения запроса на отключение проверки»
Отключение проверки приведет к тому, что для неё не будет выполняться
определение категории, обновление расписания, получение контрольного значение и
статуса. Так как в системе не было настроено других активных проверок, в
журнале событий должно появиться соответствующее предупреждение.
Для выполнения тестирования данного сценария обновим настройки проверки и
зададим параметры нереализованной в службе категории. Запущенная служба
мониторинга не должна выдавать ошибок категоризации.
USE MonitoringServicedbo.MonitoringCheckMonitoringCheckTypeId
= 6--Web Resource AvailabilityMonitoringCheckId = 9;
После очередной итерации службы мониторинга в журнале появляется
соответствующее предупреждение (рис. 19 «Предупреждение об отсутствии активных
проверок в журнале») и переход к следующей итерации по истечении таймера.
Записи об ошибках категоризации отсутствуют. Отсюда, можно сделать вывод, что
служба не переходит в последующие состояния, которые отражены на диаграмме
состояний.
Рис. 19 «Предупреждение об отсутствии активных проверок в журнале»
Таким образом, функционал отключения настроенных пользователем проверок
реализован в прототипе службы мониторинга согласно требваниям: при отсутствии
активных проверок в журнале событий создается запись с соответствующим
предупреждением, неактивные проверки не обрабатываются службой.
Заключение
В рамках данной работы был проведен анализ структуры многоуровневой
технической поддержки организации на основе подходов, описанных в библиотеке ITIL v3. На основе этого анализа были выявлены основные потребности
инженеров экспертных линий функциональном наполнении разрабатываемой системы
мониторинга. Для сужения спектра задач и более точного формулирования
требований к функиональному дизайну службы мониторинга в работе были
проанализированы существующие шаблоны проектирования информационных систем.
Использование наиболее распространенных подходов к интеграции систем и их
архитектуре при проектировании системы позволило определить наиболее общие
подходы к организации мониторинга. В работе были также проанализированы
существующие технологии и виды мониторинга, которые используются в
организациях. Это позволило уточнить требования, выявленные на предыдущем этапе
анализа.
В результате проведенного исследования были определены следующие
категории проверок, которые необходимо реализовать на данном этапе проекта:
. Проверка времени выполнения SQL запроса на сервере
. Проверка итогового значения SQL запроса на сервере
. Значение атрибута XML из
файла
. Значение атрибута XML с
веб страницы
. Значение атрибута JSON
из файла
. Значение атрибута JSON с
веб страницы
. Поиск словосочетания в логах
. Код ответа web
страницы
. Код ответа web API
Для реализации перечисленных категорий были составлены требования к
архитектуре разрабатываемой системы мониторинга, взаимодейтсвию ее компонентов,
структуре данных и функциональному наполнению. На основе требований были
разработы база данных для хранения информации о параметрах пользовательских
проверок и истории и прототип службы мониторинга на базе приложения службы Windows. Функционал разработанных
компонентов был успешно протестирован на основе диаграммы вариантов
использования системы. В результате тестирования было определено, что
разработанный прототип службы мониторинга и его интеграция с базой данных
соответствуют составленным требованиям и решают задачи, поставленные перед
системой мониторинга.
Таким образом, в рамках данной работы были решены все поставленные задачи
и цели. Быстрое развертывание и конфигурация компонентов системы достигаются за
счет использования наиболее распространенных платформ и технологий - Microsoft SQL Server для работы с базой данных и приложение службы Widnows для управления компонентом получения
данных о текущем состоянии поддерживаемых систем. При помощи среды MS SQL Management Studio пользователи могут управлять составом проверок и их
настройками, а также наблюдать за текущим состоянием компонентов
инфраструктуры. За счет разработанной базы данных инженеры поддержки могут
получать статистические данные (отчеты) о состоянии компонентов поддержки и
использовать для выявления наиболее проблемных участков в структуре сервисов.
На последующих этапах развития проекта планируется разрабокта
веб-интерфейса для добавления, изменения и отключения пользовательских проверок
и отображения их текущего состояния на доске. Функционал системы может быть
дополнительными категориями проверок на основе потребностей инженеров
поддержки, выявленных после внедренияразработанной системы, а также сервисом оповещений
о сработавших мониторах. Также для базы данных могут быть настроены отложенные
задания по очистке устаревших исторических данных из таблицы History и отчеты на локальном сервере
репортинга.
Список
использованной литературы
1. Диго Светлана Михайловна. Базы данных: проектировние
и создание. Учебник.
М.:ФиС; 2005 г.; 36,4 п.л.
2. ИТ-аутсорсинг (рынок России). (2017). // TAdviser - портал об ИТ в госуправлении и бизнесе. Крупнейшая в
РФ база знаний о технологиях, ИТ-проектах и профессионалах отрасли.
[Электронный ресурс]. URL: #"897343.files/image025.jpg">
«Диаграмма классов приложения службы мониторинга»