Разработка библиотеки программных компонентов определения форматов файлов и ее использование в системах безопасности промышленных сетей
Введение
интерфейс программный компьютерный
сеть
Автоматизированные системы
управления различными технологическими процессами современных промышленных
предприятий - это сложные программно-аппаратные комплексы, в которых
применяются серверы приложений, серверы баз данных, автоматизированные рабочие
места на основе персональных компьютеров и мобильных устройств, программируемые
логические контроллеры различных производителей. Информационная безопасность
АСУ ТП стала предметом пристального внимания после появления вируса,
получившего известность как Stuxnet, который нанёс серьёзный ущерб иранской ядерной программе в 2010
году. Stuxnet стал первым компьютерным вирусом, который способен перехватывать
и модифицировать поток данных между ПЛК и рабочими станциями SCADA-систем. Данный инцидент
обратил внимание специалистов по информационной безопасности на весьма новую
для них область, которая ранее казалась недоступной для атак по причине
физической изолированности таких сетей и использования весьма специфичного оборудования.
В настоящее время, для предотвращения нарушения работы промышленного
оборудования создаются различные системы, призванные своевременно обнаружить и
нейтрализовать вредоносное ПО во внутреннем контуре промышленных сетей.
Объектом исследования данной
выпускной квалификационной работы являются некоторые вопросы безопасности
систем АСУТП, к числу которых относятся разработка систем обнаружения вторжений
и аномалий в сетевом трафике. Данные системы позволяют своевременно
обнаруживать и предотвращать инциденты в сфере информационной безопасности
промышленных компьютерных сетей.
Целью ВКР является разработка
библиотеки программных компонентов для определения форматов файлов и
возможностей исполняемых файлов. Данная библиотека является частью системы
обнаружения вторжений и аномалий в сетевом трафике, которая работает на участке
между программируемыми логическими контроллерами и рабочими станциями SCADA-систем. Для достижения
данной цели необходимо провести разработку методики определения форматов
файлов, выполнить поиск существующих аналогов и разработать программный код
библиотеки. Итоговый проект представляет собой библиотеку программных
компонентов, решающих задачу определения форматов файлов, а также задачу
проведения анализа исполняемых файлов на предмет характера их активности.
1. Аналитический обзор
.1 Описание промышленных
компьютерных сетей
Библиотека программных компонентов
для определения форматов файлов является частью системы обнаружения вторжения и
аномалий сетевого трафика для промышленных сетей (англ. Intrusion Detection System (IDS)). Данная система
отслеживает состояние сетевого трафика в промышленных сетях между
программируемыми логическими контроллерами (ПЛК) и рабочими станциями SCADA-систем.
Промышленная сеть Ethernet - это обычная сеть Ethernet, элементами которой
являются в основном ПЛК, установленные на промышленном оборудовании,
взаимодействующие с рабочими станциями SCADA-систем с помощью
промышленных протоколов. К подобным протоколам относятся, например, Modbus, Profibus, Siemens-S7, которые в свою очередь, работают
поверх TCP/IP. Сам контроллер - это миниатюрный компьютер со своей операционной
системой и программой выполнения, предназначенный для управления каким-либо
промышленным агрегатом, станком, насосом, сборочной линией и др. Наиболее
распространёнными контроллерами являются контроллеры фирм Siemens, Shneider, Vipa, Advantech, ABB, Delta Electronics. Операционная система
на ПЛК-либо собственной разработки производителя, информация о которой
малодоступна, либо открытая, например Lunix, VxWorks, либо QNX, WindowsCE или WindowsXP. Архитектура контроллеров обычно является модульной: как правило
существует главный модуль к которому подключаются различные дополнительные
модули ввода-вывода управляющие различными компонентами промышленного
оборудования, различные датчики, элементы человеко-машинного интерфейса.
Основной режим работы ПЛК - это длительное автономное использование, часто в
неблагоприятных условиях окружающей среды, без специального обслуживания и
практически без вмешательства человека.
Система обнаружения вторжений и
аномалий сетевого трафика в данной области обычно устанавливается либо на
рабочей станции SCADA-систем, либо между ней и ПЛК. Одной из её задач является анализ
сетевого трафика, а именно, определение содержимого сетевых пакетов на предмет
выявления попыток передачи исполняемых файлов вредоносного ПО и их компонентов.
Анализ передаваемых по сети файлов
включает в себя этап определения формата файла и, в случае исполняемых файлов,
определение его типа, который может быть драйвером, модулем ядра ОС,
динамической библиотекой или файлом с сетевыми возможностями.
.2 Постановка задачи по
анализу файлов, передаваемых по промышленным сетям и общие требования к
реализуемой библиотеке
При выполнении инспекции сетевого
трафика необходимо выявлять, прежде всего, исполняемые файлы, ибо именно они
могут являться вредоносным программным обеспечением. Так как наиболее
распространёнными операционными системами на ПЛК являются ОС на основе Windows и Linux, то наибольший интерес
представляют исполняемые файлы форматов ELF и PE. Вредоносное
программное обеспечение, как правило, использует сеть для передачи данных и
собственного распространения. Также оно может внедряться в компоненты
операционной системы, либо в компоненты стороннего ПО, установленного на
устройстве. Для выявления таких возможностей необходимо проводить анализ
структуры самого файла, что также входит в круг задач, решаемых библиотекой.
Ещё одной немаловажной задачей является детектирование исполняемых скриптов командной
оболочки типов bash и shell, которые могут выполнять довольно обширный набор команд на
целевой системе.
Данные задачи являются только частью
функционала, необходимого для полноценного анализа трафика на предмет наличия
вредоносных компонентов, поэтому его реализацию необходимо выполнить в виде
отдельной библиотеки программных компонентов. Такой подход к реализации даст
возможность повторного использования полученного программного кода, а также
упростит разработку и тестирование.
Таким образом, создаваемая
библиотека программных компонентов должна выполнять следующие функции:
1) определения формата файла:
выявление исполняемых файлов (форматов ELF и PE), загрузочных
файлов-образов (U-boot image), компонентов файловых систем (Squashfs), структурированных
файлов (ICO, GIF, TAR, GZIP, ZIP), исполняемых скриптов (sh, bash);
2) определение типа
исполняемых файлов: исполняемый файл с сетевыми возможностями, драйвер, модуль
ядра ОС;
Библиотека должна удовлетворять
следующим требованиям:
1) определение следующих
типов файлов: ELF, PE, U-boot, Squashfs.NET, компоненты COM\DCOM, bash, shell, ICO, GIF, TAR, ZIP, GZIP;
2) определение следующих
типов исполняемых файлов по функционалу: файл с сетевыми возможностями,
драйвер, модуль ядра;
) библиотека должна реализовывать
идиому Zero-Copy (не создавать внутри себя копий анализируемых данных), не должна
изменять сами анализируемые данные. Данное требование продиктовано
соображениями безопасности и быстродействия;
) библиотека должна иметь минимум
два уровня абстракции интерфейса для того, чтобы быть максимально гибкой в
использовании. Интерфейс верхнего уровня, скрывающий все детали реализации и
требующий минимальных действий пользователя для получения результата. Интерфейс
нижнего уровня, предоставляющий возможность использовать каждый компонент
библиотеки отдельно по своему усмотрению и более глубоко интегрировать
функционал библиотеки в клиентский код;
) библиотека должна собираться с
помощью системы сборки Сmake для платформ Windows и Linux аналогично с основным приложением, которое её использует;
) для удобства использования в
состав исходного кода библиотеки должен входить набор примеров использования
интерфейсов библиотеки обоих уровней;
.3 Обзор существующих
решений
На данный момент в сети Internet встречаются следующие
библиотеки прикладного программирования, выполняющие похожие задачи: libmagic, Chilkat.
Библиотека libmagic является свободно
распространяемым программным обеспечением с собственной открытой лицензией.
Данный программный продукт располагает функционалом для определения множества
форматов файлов и является кроссплатформенным. В комплекте с библиотекой
поставляются набор примеров использования и описание программного интерфейса
библиотеки. Также большим достоинством данной библиотеки является тот факт, что
она входит в состав официального репозитория Linux Ubuntu, что говорит о её
надёжности и проверенности тестированием. Недостатки библиотеки: она имеет
только один уровень абстракции интерфейса, который не позволяет использовать
отдельные её компоненты самостоятельно; библиотека требует от пользователя
создания и удаления своих собственных структур данных, то есть управляет
ресурсами; функционал для определения типов исполняемых файлов отсутствует.
Библиотека от компании Chilkat позволяет определять различные
типы файлов, по так называемым «magic bytes». Пример размещённый на сайте производителя даёт весьма
ограниченное представление о функционале библиотеки. Данный продукт является
проприетарным и без покупки лицензии определить насколько он соответствует
требованиям проекта не представляется возможным.
Ещё одним, близким по функционалу
программным компонентом является pe-parser от проекта TrailOfBits. Он представляет собой небольшой программный модуль, основной
функцией которого является парсинг файлов формата PE. Основным недостатком
модуля является тот факт, что в процессе своей работы он копирует довольно
много данных, а также в нем отсутствует какой-либо дополнительный функционал,
кроме парсинга формата PE.
Из всего выше сказанного следует,
что ни один из представленных программных продуктов не реализует необходимый
для проекта функционал и не соответствует необходимым требованиям.
.4 Выбор технологий
реализации
Языком программирования для
реализации данного проекта является язык С/С++ с использованием возможностей
стандарта С++11. Выбор данного языка обусловлен его объектно-ориентированными
возможностями с одной стороны и тем фактом, что основной продукт, использующий
разрабатываемую библиотеку также написан на этом языке. С/С++ это компилируемый
язык со статической типизацией, который позволяет реализовывать высокоуровневую
архитектуру проекта с использованием всех возможностей
объектно-ориентированного подхода и строить удобные лаконичны интерфейсы. Также
данный язык подходит для системного и сетевого программирования. Стандарт С++11
добавляет множество новых удобных механизмов и возможностей, облегчающих
написание эффективных и безопасных программ.
В качестве среды разработки выбрана IDE QtCreator. Её основными
достоинствами являются бесплатность использования и широкий набор встроенных
средств, позволяющих эффективно редактировать код. Она включает в себя
графический интерфейс для отладчика и визуальные средства разработки
графического интерфейса. Поддерживает следующие компиляторы: GCC, MSVC, Clang, MinGW и другие. QtCreator поддерживает следующие
системы сборки: autotools, qmake, cmake, а также системы контроля версии Git, Mercurial, Subversion.
В качестве компилятора выбран GCC - набор компиляторов
для различных языков программирования, разработанный проектом GNU. GCC представляет собой
свободное программное обеспечение, распространяемое фондом свободного
программного обеспечения (FSF) на условиях лицензий GNU GPL и GNU LGPL. Он используется в качестве стандартного компилятора для UNIX-подобных операционных
систем.
Отладчик - GDB переносимый отладчик,
созданный также в рамках проекта GNU, который может работать на UNIX-подобных системах и
позволяет выполнять отладку различных языков программирования, включая Си, C++. GDB - свободное программное
обеспечение, распространяемое на условиях лицензии GPL. GDB предлагает обширные
средства для слежения и контроля за выполнением исполняемых файлов.
Пользователю предоставляется возможность изменять внутренние переменные
программы, а также вызывать функции независимо от стандартного поведения
программы. GDB способен выполнять отладку исполняемых файлов в формате a.out, COFF (в том числе
исполняемые файлы Windows), ECOFF, XCOFF, ELF, использовать отладочную информацию в различных форматах, таких
как stabs, COFF, ECOFF, DWARF, DWARF2. Наибольшие возможности отладки предоставляет формат DWARF2. GDB может быть
скомпилирован для поддержки приложений нескольких целевых платформ и может
переключаться между ними во время отладочной сессии. Целевые платформы, на
которых GDB не может быть запущен, в частности встроенные системы, могут
поддерживаться с помощью встроенного симулятора (процессоры ARM, AVR), либо приложения для
них могут быть скомпилированы с участием специальных подпрограмм,
обеспечивающих удаленную отладку под управлением GDB-server, запущенном на
компьютере разработчика.
Система сборки CMake - это
кроссплатформенная система автоматизации сборки программного обеспечения из
исходного кода. CMake не занимается непосредственно сборкой, она генерирует файлы управления
сборкой для разных систем. Для Unix это makefile для системы сборки make, для Windows это файлы projects/solutions (.vcxproj/.vcproj/.sln) для сборки с помощью Visual C++.
.5 Описание форматов
файлов, используемых в промышленных сетях
Описание формата ELF
Описание формата ELF представлено в [1].
Формат ELF - это формат объектных файлов для операционной системы UNIX. Объектные файлы могут
быть трёх видов: релоцируемые(relocatable) - предназначены для статической линковки с другими объектными
файлами; исполняемые (executable) - предназначенные создания образа процесса и его исполнения;
разделяемые (shared object) - предназначенные для динамической линковки в качестве
динамических библиотек. Общая структура файла представлена на рисунке 1.1.
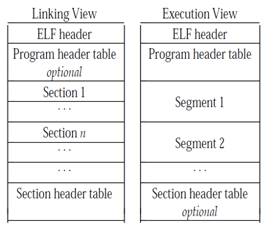
Рисунок 1.1. Структура файла формата
ELF
Файл формата ELF состоит из набора
заголовков и набора секций данных. Заголовки и секции данных содержащих
различную информацию для загрузчика операционной системы, создающего образ процесса
в памяти компьютера.
В самом начале файла расположен
заголовок ELF-header. Набор полей заголовков представлен в таблице 1.1.
Таблица 1.1. Поля заголовка ELF-header
|
Имя
|
Описание
|
|
e_ident[]
|
Массив 16 байт, предназначен для идентификации файла. Первые
четыре байта в массиве содержат сигнатуру файла: 0x7f 0x45 0x4c 0x46.
|
|
e_type
|
Тип файла.
|
|
e_machine
|
Архитектура аппаратной платформы, для которой файл создан.
|
|
e_version
|
Номер версии формата.
|
|
e_entry
|
Точка входа.
|
|
e_phoff
|
Смещение до таблицы заголовков программы.
|
|
e_shoff
|
Смещение до таблицы заголовков разделов.
|
|
e_flags
|
Набор флагов.
|
|
e_ehsize
|
Размер заголовка
файла.
|
|
e_phentsize
|
Размер каждого
заголовка программы.
|
|
e_phnum
|
Число заголовков
программы.
|
|
e_shentsize
|
Размер каждого
заголовка разделов.
|
|
e_shnum
|
Число заголовков
разделов.
|
|
e_shstrndx
|
Индекс записи в таблице разделов, указывающей на таблицу
названий разделов.
|
Поле e_type может принимать
значения, указанные в таблице 1.2.
Таблица 1.2. Значения поля e_type
|
Имя
|
Значение
|
Описание
|
|
ET_NONE
|
0
|
-
|
|
ET_REL
|
1
|
Релоцируемый
|
|
ET_EXEC
|
2
|
Исполняемый
|
|
ET_DYN
|
3
|
Разделяемый
|
|
ET_CORE
|
4
|
Файл ядра
|
|
ET_LOPROC
|
0xff00
|
Зарезервировано
|
|
ET_HIPROC
|
0xffff
|
Зарезервировано
|
По смещению, указанному в поле e_phoff заголока ELF-header расположен массив
заголовков Program header, каждый элемент которого содержит информацию, которая относится
непосредственно к процессу создания образа процесса при его запуске. Каждый
заголовок содержит набор полей, представленный в таблице 1.3.
Таблица 1.3. Поля заголовка Program header
|
Имя
|
Описание
|
|
p_type
|
Тип сегмента и его интерпретация.
|
|
p_offset
|
Смещение от начала
файла.
|
|
p_vaddr
|
Виртуальный адрес, по которому сегмент загружается в память при
запуске процесса.
|
|
p_paddr
|
Не используется.
|
|
p_filesz
|
Размер сегмента в байтах в файле.
|
|
p_memsz
|
Размер сегмента в байтах в памяти процесса.
|
|
p_flags
|
Набор флагов.
|
|
p_align
|
Выравнивание.
|
Таблица секций представляет собой
массив состоящий из заголовков секций. Каждый заголовок описывает одну секцию,
содержащую данные, необходимые для создания образа процесса. Смещение до начала
массива, число записей в массиве и размер каждой записи можно получить из полей
заголовка ELF-header. Каждый заголовок секции содержит следующий набор полей,
указанный в таблице 1.4.
Таблица 1.4. Поля заголовка секции
|
Имя поля
|
Описание
|
|
sh_name
|
Имя секции, представленное индексом в таблице строк.
|
|
sh_type
|
Тип секции.
|
|
sh_flags
|
Набор флагов.
|
|
sh_addr
|
Адрес загрузки секции в память процесса.
|
|
sh_offset
|
Смещение от начала файла до начала секции.
|
|
sh_size
|
Размер секции в байтах.
|
|
sh_link
|
Индекс ссылки.
|
|
sh_info
|
Дополнительная информация. Зависит от поля sh_type.
|
|
sh_addralign
|
Выравнивание.
|
|
sh_entsize
|
Фиксированный размер
секции.
|
- файл может содержать следующие
секции:
1) bss - Служит для хранения неинициализированных переменных или
представления области памяти. В
момент запуска программы заполнена нулями.
2) data - Содержит инициализированные данные программы.
3) debug -
Содержит отладочную информацию.
) dynamic - Содержит информацию для динамической линковки.
5) dynstr - Содержит набор строк, которые представляют собой символьные
имена, необходимые для динамической линковки.
6) dynsym - Содержит символьную таблицу для динамической линковки.
7) init - Содержит информацию, необходимую для инициализации процесса. Используется до вызова точки входа (main).
) shstrtab - Содержит список имён секций.
9) symtab -
Содержит символьную таблицу.
) text - Содержит набор инструкций, составляющих программу.
Таблица символов содержит
информацию, необходимую для использования символьных ссылок используемых в
программе и представляет собой набор структур с полями, представленными в
таблице 1.5.
Таблица 1.5. Поля структуры таблицы
символов
|
Имя
|
Описание
|
|
st_name
|
Индекс строки с именем в таблице строк.
|
|
st_value
|
Значение символа (может быть адресом, индексом и т.п.).
|
|
st_info
|
Информация о типе и связывании символа.
|
|
st_other
|
Зарезервировано.
|
Таблица строк представляет собой
массив нуль-терминированных строк, которые используются для представления
символьных имён. Каждое имя секции и символьное имя функции, используемой в
программе имеет индекс, по которому в таблице строк расположена строка с
соответствующим именем.
Описание формата PE
Формат PE (Portable Executable) - это формат
исполняемых файлов, объектного кода и динамических библиотек, который
используется в различных версиях операционной системы Microsoft Windows. Он представляет собой
структуру данных, содержащую всю информацию, необходимую PE-загрузчику для
отображения файла в память. Исполняемый код включает в себя ссылки для связывания
динамически загружаемых библиотек, таблицы импорта и экспорта API функций, данные для
управления ресурсами и данные локальной памяти потока (TLS). Общая структура файла
представлена на рисунке 1.2.

Рисунок 1.2. Структура файла формата
PE
Файл формата PE состоит из набора
заголовков и секций с данными. К
заголовкам относятся IMAGE_DOS_HEADER, IMAGE_FILE_HEADER,
IMAGE_OPTIONAL_HEADER. Заголовок IMAGE_DOS_HEADER унаследован от
операционной системы MS-DOS и в версиях для ОС Windows большинство его полей не используются. Сразу за ним расположен
набор «магических байт», идентифицирующий формат PE для ОС Windows. Далее расположен
обязательный заголовок IMAGE_FILE_HEADER. Поля данного заголовка перечислены в таблице 1.6.
Таблица 1.6. Поля заголовка
IMAGE_FILE_HEADER
|
Имя
|
Описание
|
|
Machine
|
Тип архитектуры
целевой системы.
|
|
NumberOfSections
|
Число секций в таблице секций.
|
|
TimeDateStamp
|
Время создания файла.
|
|
PointerToSymbolTable
|
Смещение до таблицы
символов.
|
|
NumberOfSymbols
|
Число записей в таблице символов.
|
|
SizeOfOptionalHeader
|
Размер опционального
заголовка.
|
|
Characteristics
|
Набор флагов.
|
Каждый файл-образ должен содержать
заголовок IMAGE_OPTIONAL_HEADER. Слово «OPTIONAL» в имени заголовка говорит о том, что не все файлы формата PE содержат этот
заголовок. Размер этого заголовка не фиксирован, его можно узнать из поля SizeOfOptionalHeader
заголовка IMAGE_FILE_HEADER. В начале содержится набор «магических байт», которые
идентифицируют битность архитектуры: 0x10b для 32-х битной и 0x20b для 64-х битной. Заголовок содержит три основных раздела:
стандартный набор полей (англ. Standard fields), раздел для OC Windows (англ. Windows-specific fields), директории данных (англ. Data directories). Стандартный набор
полей содержит поля определённые для всех реализаций формата COFF (унаследован от UNIX). Раздел для OC Windows содержит поля,
специфичные только для ОС Windows. Директории данных, это набор структур, каждая из которых
содержит адрес и размер тех или иных таблиц (например, таблиц импорта и
экспотра), которые используются операционной системой. Стандартный набор полей
представлен в таблице 1.7.
Таблица 1.7. Стандартный набор полей
|
Имя
|
Описание
|
|
Magic
|
Идентификатор архитектуры: 0x10B при 32-х битной архитектуре, 0x20B при 64-х битной.
|
|
MajorLinkerVersion
|
Старшая версия
линкера.
|
|
MinorLinkerVersion
|
Младшая версия
линкера.
|
|
SizeOfCode
|
Размер секции кода.
|
|
SizeOfInitializedData
|
Размер секции, содержащей инициализированные данные.
|
|
SizeOfUninitialized
|
Размер секции, содержащей неинициализированные данные (BSS).
|
Раздел Windows-specific Располагается сразу
после стандартного набора полей и состоит из 21 поля, данные из которых
используются линкером и загрузчиком операционной системы. В таблице 1.8
представлены поля, которые непосредственно используются библиотекой в процессе
выполнения её основных функций.
Таблица 1.8. Поля раздела Windows-specific
|
Имя
|
Описание
|
|
ImageBase
|
Предпочтительный адрес по которому загружается образ процесса в
память компьютера при его создании.
|
|
SectionAlignment
|
Выравнивание для секций, обычно соответствует размеру страницы
памяти.
|
|
FileAlignment
|
Выравнивание для данных внутри секций. По
умолчанию равно 512 байт.
|
|
SizeOfImage
|
Размер образа процесса создаваемого в памяти при его загрузке.
|
|
SizeOfHeaders
|
Размер всех заголовков
образа.
|
Раздел директорий данных состоит из
набора структур, каждая из которых содержит адрес и размер каждой секции
файла-образа, используемой операционной системой. Адрес представляет собой
смещение относительно адреса загрузки образа процесса в память операционной
системы. Размер указывает размер таблицы в байтах. Набор таблиц, которые может
содержать файл-образ, представлен в таблице 1.9.
Таблица 1.9. Виды таблиц файла-образа
|
Имя
|
Описание
|
|
Export Table(.edata)
|
Таблица экспорта. Содержит символьные имена, экспортируемые
модулем (предоставляемые другим модулям).
|
|
Import Table(.idata)
|
Таблица импорта. Содержит символьные имена, импортируемые из
других модулей.
|
|
Resource Table(.rsrc)
|
Таблица ресурсов.
|
|
Exception
Table(.pdata)
|
Таблица исключений.
|
|
Certificate Table
|
Таблица атрибутов
сертификата.
|
|
Debug(.debug)
|
Содержит отладочную
информацию.
|
|
Architecture
|
Зарезервировано.
Всегда 0.
|
|
Global Ptr
|
Зарезервировано.
Всегда 0.
|
|
TLS Table(.tls)
|
Локальное хранилище
данных потока.
|
|
CLR Runtime
Header(.cormeta)
|
Содержит данные для загрузки окружения для выполнения.NET-компонентов.
|
Сразу за заголовком IMAGE_OPTIONAL_HEADER расположена таблица
секций, состоящая из структур IMAGE_SECTION_HEADER. Число структур в таблице указано в заголовке IMAGE_FILE_HEADER, размер каждой
структуры равен 40 байтам. Поля заголовка содержать информацию, описывающую
каждую секцию, имеющуюся в файле. Поля
перечислены в таблице 10.
Таблица 1.10. Поля структуры
IMAGE_SECTION_HEADER
|
Имя
|
Описание
|
|
Name
|
Имя секции. Содержит либо не нуль-терминированную строку с
именем, либо индекс строки в таблице строк если имя не умещается в 8 байт.
|
|
VirtualSize
|
Размер секции, когда он загружен в память процесса.
|
|
VirtualAddress
|
Смещение в байтах относительно адреса загрузки процесса в
память.
|
|
SizeOfRawData
|
Размер секции в файле на диске.
|
|
PointerToRawData
|
Адрес секции в файле на диске.
|
|
PointerToRelocations
|
Адрес реллокации. Только для объектных файлов.
|
|
Characteristics
|
Набор флагов.
|
Сразу после таблицы секций
расположены сами секции содержащие описанную в заголовках информацию. Как
указано в спецификации, каждая секция представляет собой сплошной набор блоков
байт, начало которого указано в поле PointerToRawData заголовка IMAGE_SECTION_HEADER, а размер в поле SizeOfRawData.
Секция строк расположена сразу после
секции символов, адрес и размер которой можно получить из полей заголовка IMAGE_OPTIONAL_HEADER. В начале секции
находится 4-х байтовое поле, содержащее размер секции, сразу за которым
начинается массив нуль-терминированных строк.
Описание COM - компонентов формата PE
Стандарт COM был разработан в 1993
году корпорацией Microsoft в качестве основы для развития технологии OLE. Основное понятие,
которым оперирует стандарт COM, это COM-компонент. Программы, построенные на стандарте COM, по сути, не являются
автономными программами, а представляют собой набор взаимодействующих между
собой COM-компонентов. Каждый компонент имеет уникальный идентификатор и может
одновременно использоваться во многих программах. Компонент взаимодействует с
другими программами через COM-интерфейсы - наборы абстрактных функций и свойств. Windows API предоставляет различные
базовые функции, которые позволяют использовать COM-компоненты.
Все COM-компоненты имеют формат
PE
описанный ранее. Единственное отличие - это экспорт интерфейса DllGetClassObject, который является
точкой входа компонента.
Описание.NET - компонентов формата PE
NET Framework - это программная платформа, выпущенная компанией Microsoft в 2002 году. В качестве
основы для платформы выступает общеязыковая среда исполнения Common Language Runtime (CLR), которая подходит для
различных языков программирования. Функциональные возможности CLR доступны в любых языках
программирования, использующих указанную среду. Основной идеей при разработке.NET Framework являлось обеспечение
свободы разработчика за счёт предоставления ему возможности создавать
приложения различных типов, способные выполняться на различных типах устройств
и в различных средах. Программа для.NET Framework, написанная на любом поддерживаемом языке программирования,
сначала переводится компилятором в единый для.NET промежуточный байт-код Common Intermediate Language (CIL). В терминах.NET получается сборка (англ.
assembly). Затем код либо
исполняется виртуальной машиной Common Language Runtime (CLR), либо транслируется утилитой в исполняемый код для конкретного
целевого процессора. Архитектура.NET Framework описана и опубликована в спецификации Common Language Infrastructure (CLI), разработанной Microsoft и утверждённой ISO и ECMA. В CLI описаны типы данных.NET, формат метаданных
программы и система исполнения байт-кода. Сами сборки имеют формат РЕ.
Описание формата ZIP
Формат ZIP - это один из наиболее
широко используемых форматов для сжатия данных, был разработан в 1989 году.
Формат описан в [5]. Он может использоваться для агрегации файлов и каталогов,
их сжатия и шифрования. Целостность данных внутри архива обеспечивается
подсчётом контрольной суммы. Архив ZIP может содержать один или несколько файлов и каталогов, которые
могут быть сжаты разными алгоритмами. Наиболее часто в ZIP используется алгоритм
сжатия Deflate. Как указано в спецификации [5], файлы формата ZIP могут иметь разные
расширения, такие как JAR, DOCX, XLXS, PPTX, ODT, и другие. Обычно архивы представляют собой файлы с расширением
«.zip»
или «.ZIP». Если есть необходимость, то ZIP-архив может быть
объединён с модулем-распаковщиком в единый исполняемый файл с расширением.EXE (SFX-архив). Поэтому программы,
работающие с данным форматом должны полагаться на внутренние данные заголовков,
а не на указанное расширение файла. Общая структура файла представлена на
рисунке 1.3.
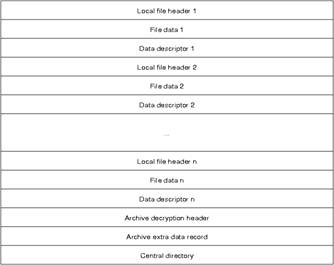
Рисунок 1.3. Структура файла формата
ZIP
В начале каждого файла упакованного
в ZIP-архив
располагается заголовок Local file header. Первым его полем является 4-х байтовый набор «магических байт»,
идентифицирующих заголовок. Далее располагаются поля содержащие информацию о
методе сжатия, дате и времени модификации файла, контрольной сумме, размере
сжатого и распакованного файла и др.
Сразу за заголовком Local file header должны располагаться
сами сжатые данные, но в случае, если они зашифрованы, то сначала располагается
заголовок шифрования, а потом непосредственно данные. После данных
располагается заголовок Data descriptor, но как указано в спецификации, только если установлен
соответствующий бит в поле флагов заголовка Local file header. Он содержит
контрольную сумму, размер сжатого и распакованного файла. Последовательность из
[local file header] [encryption header] [file data] [data descriptor] повторяется для каждого входящего в архив файла.
В конце файла расположен заголовок Archive decryption header, который был введён в
версии формата 6.2 (2004 г.). Его назначение - это поддержка режима шифрования Strong Encryption и структуры Central Directory, которая располагается
далее в файле. Сразу за ней расположен заголовок Archive extra data. Оба этих заголовка
присутствуют в файле, только если структура Central Directory зашифрована.
Структура Central directory была введена в
спецификацию в версии формата 6.2 для поддержки режима шифрования Strong Encryption. Данный режим
предусматривает шифрование с использованием криптографических сертификатов. Она
состоит и набора заголовков, каждый из которых описывает атрибуты одного файла,
входящего в архив. Завершает набор специальная структура, которая содержит
набор «магический баит» и цифровую подпись.
Описание формата TAR
Формат TAR был разработан в 1998
году и первоначально использовался для архивирования данных на магнитной ленте.
Формат описан в [7]. В настоящее время используется для хранения нескольких
файлов внутри одного файла. Также данный формат удобен для сохранения каталогов
и создания архивов файловых систем, так как в файл записываются данные о
владельце, группе владельца, временные метки, структура каталогов. Файл формата
TAR
представляет собой несколько файлов, помещенных в один файл (по умолчанию - без
сжатия). Файл TAR можно сжать другими приложениями, позволяющими сжимать данные
(например, GZIP). Расширение.tar при этом меняется на.tar.gz. Общая структура архива представлена на рисунке 1.4:
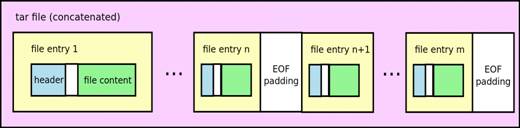
Рисунок 1.4. Общая структура архива TAR.
Файлы с расширением TAR состоят из данных
файла, а также заголовка, округленного до 512 байт. Каждый файл, входящий в
архив начинается с заголовка со списком полей, представленным в таблице 11.
Таблица 1.11. Список полей заголовка
файла, входящего в архив TAR
|
Имя
|
Описание
|
|
name
|
Имя файла.
|
|
mode
|
Режим сжатия.
|
|
uid
|
ID пользователя в
системе.
|
|
gid
|
ID
группы, в которую входит пользователь.
|
|
size
|
Размер файла.
|
|
mtime
|
Время создания файла.
|
|
chksum
|
Контрольная сумма
заголовка.
|
|
typeflag
|
Тип файла.
|
|
linkname
|
Имя файла ссылки.
|
|
magic
|
Набор «магических
байт».
|
|
version
|
Версия формата.
|
|
uname
|
Имя пользователя,
создавшего файл.
|
|
gname
|
Имя группы, в которую входит пользователь.
|
Сразу после заголовка располагается
сам файл, который по умолчанию не сжат. Последовательность из заголовка и
данных файла повторяется до конца архива. Весь файл архива разбит на блоки по
512 байт, поэтому всё структура заголовок+данные также выровнены по 512 байт.
Описание формата GZIP
Формат GZIP описан в [6]. Он был
разработан в 1992 году для UNIX-систем, во многих из которых является стандартом де-факто. GZIP - это формат архива
который использует алгоритм Deflate и может работать только с одним непрерывным файлом. Архивация
нескольких файлов в один архив невозможна. Для этой цели несколько файлов
сначала упаковывают в один файл формата TAR, используя одноимённую
утилита, и лишь потом сжимают. Полученный архив имеет расширение.tar.gz. gzip может работать с
непрерывным потоком данных, упаковывая-распаковывая их «на лету». Данный подход
широко применяется в UNIX-системах: при помощи перенаправления потоков можно работать с
упакованными файлами так же легко, как и с распакованными (распаковка в памяти
при чтении и упаковка при записи). Многие UNIX-утилиты имеют
встроенную поддержку такого механизма.
Файл формата GZIP состоит из набора
записей (сжатых наборов данных). Записи следуют одна за другой до конца файла.
Каждая запись состоит из заголовка и следующих за ним сжатых данных. Поля заголовка описаны в таблице 1.12.
Таблица 1.12. Поля заголовка записи
|
Имя
|
Описание
|
|
Magic
|
Набор «магических байт» для идентификации.
|
|
CM
|
Метод сжатия.
|
|
FLG
|
Набор флагов.
|
|
MTIME
|
Время создания файла.
|
|
XFL
|
Дополнительный набор
флагов.
|
|
OS
|
Операционная система, на которой выполнялось сжатие.
|
|
XLEN
|
Длинна дополнительных
полей.
|
|
CRC32
|
Контрольная сумма.
|
|
ISIZE
|
Размер несжатого
файла.
|
Общая структура файла изображена на
рисунке 1.5.

Рисунок 1.5. Структура файла GZIP
Описание формата U-Boot
Формат U-Boot - это формат файлов
универсального загрузчика Das U-Boot, который представляет собой загрузчик операционной системы,
используемый для встроенных устройств архитектур MIPS, PowerPC, ARM и других. Das U-Boot - это свободное
программное обеспечение, распространяемое по условиям лицензии GNU General Public License и обладающее самым
широким набором возможностей по сравнению с другими загрузчиками. Оно может
применяться на любой поддерживаемой архитектуре с использованием инструментария
кросс-разработки GNU. Как правило, загрузчик хранится в загрузочной ПЗУ и запускается
сразу после подачи питания на плату устройства и прохождения Post-инициализации. Основная
функция загрузчика - произвести загрузку операционной системы в память
устройства. Общая структура файла формата U-Boot представлена на рисунке
1.6.
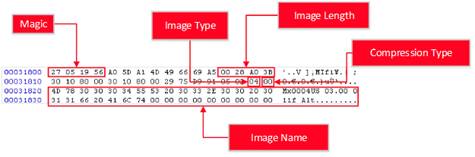
Рисунок 1.6. Структура файла формата
U-Boot
В начале файла расположен заголовок,
назначение полей которого описано только в комментариях к исходному коду
загрузчика [9]. Согласно этим комментариям заголовок содержит поля, описанные в
таблице 1.13.
Таблица 1.13. Поля заголовка файла
формата U-Boot
|
Имя
|
Описание
|
|
ih_magic
|
Набор «магических
байт».
|
|
ih_hcrc
|
|
ih_time
|
Время создания файла.
|
|
ih_size
|
Размер файла.
|
|
ih_load
|
Адрес загрузки образа.
|
|
ih_ep
|
Адрес точки входа.
|
|
m_ih_dcrc
|
Контрольная сумма
файла-образа.
|
|
ih_os
|
Тип операционной
системы.
|
|
ih_arch
|
Архитектура
процессора.
|
|
ih_type
|
Тип образа.
|
|
ih_comp
|
Тип сжатия.
|
|
ih_name
|
Имя образа процесса.
|
Описание формата Squashfs
Squashfs - это файловая система для операционной системы Linux, предоставляющая доступ
к данным в режиме «только для чтения» и располагающая функционалом для сжатия
данных. Squashfs может сжимать файлы, индексные дескрипторы и каталоги, а также
поддерживает блоки данных различных размеров до 1024 Кбайт для лучшего сжатия.
Она является свободным программным обеспечением с лицензией GPL. Squashfs предназначена для
широкого использования в файловых системах с доступом «только для чтения», а
также в ограниченных по размеру блочных устройствах (например, во встраиваемых
системах). Наиболее распространенный пример использования данной файловой
системы, это дистрибутивы LiveCD различных операционных систем на основе Linux: Debian, Ubuntu, Gentoo, Fedora и др.
Описание заголовка файла формата Squashfs взято из исходного
кода, размещённого на официальном сайте проекта [10]. Поля заголовка описаны в
таблице 1.14.
Таблица 1.14. Поля заголовка файла
формата Squashfs
|
Имя
|
Описание
|
|
s_magic
|
Набор «магических
байт».
|
|
inodes
|
Число индексных дескрипторов.
|
|
mkfs_time
|
Время создания файла.
|
|
block_size
|
Размер блока.
|
|
fragments
|
Число фрагментов.
|
|
compression
|
Тип сжатия (доступны алгоритмы Deflate,
LZMA).
|
|
flags
|
Набор флагов.
|
|
s_major
|
Старшая версия
файловой системы.
|
|
s_minor
|
Младшая версия
файловой системы.
|
Описание формата ICO
Формат ICO - это формат хранения
файлов значков в операционной системе Microsoft Windows. Один ICO-файл может содержать один или несколько значков, размер и другие
атрибуты каждого из которых задаются отдельно. Начиная с версии Windows 98/2000, формат
поддерживает хранение изображений в формате JPEG и PNG. Файл состоит из
заголовка фиксированной длины, каталога информации о изображениях и самих
изображений. Данный формат файлов является специфичным для операционной системы
Windows. Заголовок имеет размер 6 байт, его поля описаны в таблице 1.15.
Таблица 1.15. Поля заголовка файла ICO
|
Имя
|
Описание
|
|
reserved
|
Зарезервировано.
Всегда 0.
|
|
Type
|
Тип файла: 1 для значков (.ICO)
2 для курсоров (.CUR) Иные значения
недопустимы.
|
|
count
|
Количество изображений в файле, минимум 1.
|
Каталог информации об изображениях
представляет собой набор структур фиксированного размера, следующие одна за
другой. Их количество указано в поле count заголовка. Изображение в формате GIF хранится построчно, и
поддерживается только формат с индексированной палитрой цветов. Стандарт
разрабатывался только для поддержки 256-цветовой палитры. Формат GIF поддерживает
анимационные изображения. Они представляют собой последовательность из
нескольких статичных кадров и информацию о том, сколько времени каждый кадр
должен быть показан на экране. GIF использует формат сжатия LZW который, является
алгоритмом сжатия без потерь. Поля структур описаны в таблице 1.16.
Таблица 1.16. Поля структуры
описания изображения
|
Имя
|
Описание
|
|
width
|
Ширина изображения в пикселах. Может принимать значения от 0 до
255. Если указано 0, то изображение имеет ширину 256 пикселов.
|
|
height
|
Высота изображения в пикселах. Может принимать значения от 0 до
255. Если указано 0, то изображение имеет высоту 256 пикселов.
|
|
colors
|
Количество цветов в палитре изображения. Для полноцветных
значков должно быть 0.
|
|
reserved
|
Зарезервировано.
Всегда 0.
|
|
planes
|
Количество плоскостей. Может быть 0 или 1.
|
|
bpp
|
В.ICO определяет
количество битов на пиксель (bits-per-pixel).
Это значение может быть 0, так как легко получается из других данных;
например, если изображение не хранится в формате PNG,
тогда количество битов на пиксель рассчитывается на основе информации о
размере растра, а также его ширине и высоте. Если же изображение хранится в
формате PNG, то соответствующая информация хранится в самом PNG.
|
|
size
|
Размер растра в
байтах.
|
|
offset
|
Размер растра в
байтах.
|
Описание файлов
сценариев командной оболочки
Командная оболочка UNIX (англ. Unix shell, sh) - это командный интерпретатор, используемый в операционных
системах семейства UNIX, в котором пользователь может либо давать отдельные команды
операционной системе, либо запускать скрипты, состоящие из списка команд.
Bash - один из наиболее
популярных командных интерпретаторов UNIX, представляет из себя усовершенствованную версию интерпретатора sh. Особенно популярна в
среде Linux, где она часто используется в качестве предустановленной
командной оболочки. Bash - это командный процессор, работающий, как правило, в интерактивном
режиме в текстовом окне. Bash также может читать команды из файла, который называется скриптом
(или сценарием). Данный файл представляет собой обычный текстовый файл,
отличительной особенностью которого является наличие в начале файла строки следующего
содержания #!/usr/bin/ bash либо #!/usr/bin/ sh.
Описание формата GIF
Формат GIF - это растровый формат
графических изображений, который способен хранить данные без потерь качества (с
ограничением не более 256 цветов). Формат был разработан в 1987 году CompuServe. В дальнейшем он был
модифицирован для поддержки прозрачности и анимации, а также использования
компрессии LZW. Данная модификация описана в стандарте GIF89 [17].
Изображение в формате GIF хранится построчно, и
поддерживается только формат с индексированной палитрой цветов. Стандарт
разрабатывался только для поддержки 256-цветовой палитры. Формат GIF поддерживает
анимационные изображения. Они представляют собой последовательность из
нескольких статичных кадров и информацию о том, сколько времени каждый кадр
должен быть показан на экране. GIF использует формат сжатия LZW который, является
алгоритмом сжатия без потерь. Таким образом, хорошо сжимаются изображения,
строки которых имеют повторяющиеся участки, особенно изображения, в которых много
пикселей одного цвета по горизонтали. Формат GIF допускает чересстрочное
хранение данных. При таком способе хранения строки разбиваются на группы, и
меняется порядок хранения строк в файле. При загрузке изображение проявляется
постепенно, в несколько проходов. Используя этот принцип можно имея только
часть файла, увидеть изображение целиком, но в меньшем разрешении.
Файл формата GIF содержит несколько
заголовков, содержащих различную информацию о содержимом файла. В самом начале
файла расположен набор магических байт и заголовок логического дескриптора
экрана (англ. Logical screen descriptor). Набор полей логического дескриптора экрана описан в таблице
1.17. Общая структура представлена на рисунке 1.5.
Таблица 1.17. Поля логического
дескриптора экрана
|
Имя
|
Описание
|
|
Width
|
Ширина экрана.
|
|
Height
|
Высота экрана.
|
|
Fields
|
Набор флагов.
|
|
Background color index
|
Значение цвета фона.
|
|
Pixel aspect ration
|
Индекс
масштабирования.
|
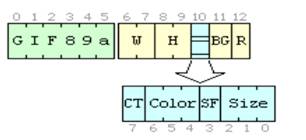
Рисунок 1.5. Общая структура
логического дескриптора экрана
Сразу за данным заголовком
расположена глобальная таблица цветов (англ. Global Color Table). Данная таблица
содержит последовательность байт представляющих цвета в формате RGB. Данная таблица
присутствует в файле только если в заголовке логического дескриптора экрана
установлен соответствующий флаг. Если таблица отсутствует, то описание цветовой
палитры берётся из файлов самих изображений для каждого изображения входящего в
файл
Файл формата GIF может хранить в себе
множество изображений, которые расположены в файле сразу после глобальной
таблицы цветов. Каждое изображение начинается с заголовка, который описан как
дескриптор изображения (англ. Image descriptor). Поля данного заголовка описаны в таблице 1.18. Общая структура
представлена на рисунке 1.6.
Таблица 1.18. Поля заголовка Image Descriptor
|
Имя
|
Описание
|
|
ImageSeparator
|
Идентификатор начала изображения. Значение всегда 0x2C.
|
|
LeftPosition
|
Отступ слева от границы экрана.
|
|
TopPosition
|
Отступ сверху от границы экрана.
|
|
Width
|
Ширина изображения в
пикселах.
|
|
Height
|
Высота изображения в
пикселах.
|
|
Flags
|
Набор флагов.
|
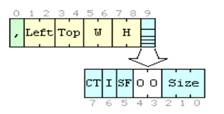
Рисунок 1.6. Общая структура
дескриптора изображения
За данным заголовком расположена
локальная таблица цветов, которая используется вместо глобальной, за которой
расположены блоки данных самого изображения. Внутри изображения также
содержатся ещё несколько структур данных, которые оставлены без описания, так
как они не имеют непосредственного отношения в идентификации формата. Общая
структура файла изображена на рисунке 1.7.
Рисунок 1.7. Описание файла формата GIF
Помимо этой информации в том случае,
если файл содержит анимацию, то кроме самих изображений, составляющих анимацию
в файле хранится информация, необходимая для её «проигрывания». Изображение в
формате GIF хранится построчно, и поддерживается только формат с
индексированной палитрой цветов. Стандарт разрабатывался только для поддержки
256-цветовой палитры. Формат GIF поддерживает анимационные изображения. Они представляют собой
последовательность из нескольких статичных кадров и информацию о том, сколько
времени каждый кадр должен быть показан на экране. GIF использует формат
сжатия LZW который, является алгоритмом сжатия без потерь. Файл формата GIF может хранить в себе
множество изображений, которые расположены в файле сразу после глобальной
таблицы цветов. Каждое изображение начинается с заголовка, который описан как
дескриптор изображения (англ. Image descriptor). Стандарт разрабатывался только для поддержки 256-цветовой
палитры. Формат GIF поддерживает анимационные изображения. Они представляют собой
последовательность из нескольких статичных кадров и информацию о том, сколько
времени каждый кадр должен быть показан на экране.
1.6 Разработка методики
определения форматов файлов
Методика определения
форматов неисполняемых структурированных файлов
Большинство типов файлов содержат в
себе так называемые «магические байты» (англ. - magic bytes). Как правило, это
последовательность байт, которая расположена в начале файла и содержит
какой-либо определённый набор символов. Ниже перечислены основные наборы
«магических байт» для тех форматов, которые библиотека должна детектировать:
Таблица 1.19. Значения magic bytes для форматов файлов
|
Формат файла
|
Hex - значение
|
ASCII - значение
|
|
TAR
|
0x75, 0x73, 0x74,
0x61, 0x72
|
ustar
|
|
GZIP
|
0x1f, 0x8b, 0x08
|
-
|
|
ZIP
|
0x50, 0x4b, 0x03, 0x04
|
PK
|
|
ICO
|
0x00, 0x00, 0x01, 0x00
|
|
|
ELF
|
0x7F, 0x45, 0x4C, 0x46
|
ELF
|
|
PE
|
0x4d, 0x5a
|
MZ
|
|
U-boot
|
0x27, 0x05, 0x19, 0x56
|
-
|
|
Squashfs
|
0x68, 0x73, 0x71, 0x73
|
hsqs
|
Детектирование указанных форматов
производится поиском в начале файла последовательности «магических байт» с
помощью алгоритма, идентичного алгоритму поиска подстроки в строке, но
работающего с потоком байт.
Определение форматов
исполняемых файлов и файлов-образов
Исполняемые файлы являются наиболее
сложными по своей структуре. Также в рамках одного формата они сильно
отличаются между собой по архитектуре целевой системы - это могут быть
архитектура ARM, x86, MIPS и другие. Кроме нахождения «магических байт» также использутся
частичный или полный разбор структуры файла, в ходе которого извлекается ряд
параметров, необходимых для идентификации целевой архитектуры.
Методика определения
формата ELF
Для идентификации данного формата
файла библиотека в процессе своей работы кроме «магических байт» проверяет
набор полей заголовка, указанных в таблице 1.20.
Таблица 1.20. Набор проверяемых
полей для формата ELF.
|
Поле
|
Возможное значение
|
Описание
|
|
EI_CLASS
|
0x01, 0x02
|
Разрядность системы:
32, 64
|
|
EI_DATA
|
0x01, 0x02, 0x10
|
Порядок байт:
little-endian, big-endian, multibyte
|
|
EI_OSABI
|
… 0x03, 0x06, 0x09
|
Операционная система: Linux,
FreeBSD, Solaris
|
|
e_type
|
0x01, 0x02, 0x03
|
Тип файла:
rellocatable, executable, shared
|
|
e_phoff
|
0x34, 0x40
|
Смещение программного заголовка: x86,
x86-64
|
|
e_shoff
|
-
|
Смещение таблицы
секций
|
Методика
определения формата PE
PE-формат (англ.-portable executable) - это формат исполняемых файлов для операционный систем
семейства Windows NT. На данный момент существует два формата PE-файлов: PE32 и PE32+. PE32 формат для x86 систем, а PE32+ для x64. Формат описан в [2]. Структура
файла представляет собой набор заголовков, содержащих в себе данные,
необходимые для создания образа процесса в оперативной памяти компьютера. Как и
формат ELF PE-файл содержит в себе «магические байты» для идентификации.
Для получения информации о файле
проверяются значения полей, указанных в Таблице 1.21.
Таблица 1.21. Набор проверяемых
полей для формата PE
|
Поле
|
Возможное значение
|
Описание
|
|
signature
|
'P', 'E', '\0', '\0'
|
«набор магических
байт»
|
|
size_of_code
|
0 - размер файла
|
Размер исполняемого
файла
|
|
Machine
|
-
|
Идентификатор CPU
целевой машины
|
|
majorOperatingSystemVersion
|
4 - 10
|
Старшая версия
операционной системы
|
Определение исполняемых
скриптов командной оболочки
Для определения того факта, что
текстовый файл является исполянемым скриптом в нём производится поиск подстроки
следующего содержания:
«#!/bin», «#!/usr/bin»,
«#!/bin/sh», «#!/bin/bash», «#!/system/bin/sh».
.7 Обзор методики
определения типов исполняемых файлов
Исполняемый файл, если он не
является драйвером устройства или модулем ядра, работает в пространстве
пользователя. Пространство пользователя - это адресное пространство
виртуальной памяти операционной системы, отводимое для пользовательских
программ. Выполняясь в данном пространстве пользовательский процесс не может
напрямую обращаться к аппаратным ресурсам компьютера, таким как, например,
сетевой адаптер. Данной возможностью обладает только ядро операционной системы.
Для того, чтобы передавать и принимать данные по сети, процесс должен
воспользоваться интерфейсом системных вызовов операционной системы. Системный
вызов - это обращение программы, работающей в пространстве пользователя к ядру
операционной системы для выполнения какой-либо операции. К сетевым системным вызовам относятся следующие: socket, connect,
accept, listen, sendto, recvfrom, select, poll, epoll. Сами системные вызовы скрыты за интерфейсом стандартной библиотеки
libstdc [3]. Набор системных вызовов может отличаться для различных
операционных систем.
Определение возможностей
взаимодействия с сетью для файлов формата ELF
Для того, чтобы определить
использует ли создаваемый из файла процесс сетевые системные вызовы
используется метод поиска символьных имён соответствующих вызовов в секции
строк. Символьное имя функции - это имя, которое присваивается компилятором
каждой функции, описанной программистом в исходном коде или библиотечной
функции, которая является обёрткой над системным вызовом. Секция строк содержит
символьные имена, используемые программой, в строковом виде. Она представляет
собой массив строк, где каждая строка отделена нулевым символом в конце. Для
поиска символьных имён сетевых системных вызовов необходимо найти таблицу строк
по смещению, указанному в заголовке файла и проверить каждое символьное имя на
совпадение со строками, указанными в списке сетевых системных вызовов. Стоит
отметить, что в таблице строк символьные имена функций хранятся в искажённом
виде. Искажение представляет собой добавление различных символов в начало и
конец имени. Это происходит на этапе компиляции и носит название «мэнглинга»
имён (англ. name mangling). Эта процедура необходима для обеспечения уникальности каждого
символьного имени в программе. Например, описанный в стандартной библиотеке
класс char_traits в программе будет иметь символьное имя _ZStlsIcSt11char_traitsIcESaIcEERS, оператор вывода
стандартной библиотеки std:cout будет иметь имя _ZSt4cout@@GLIBCXX_3.4.
Определение модулей ядра
для операционной системы Linux
Определение того факта, что
исполняемый файл формата ELF является модулем ядра операционной системы выполняется также
методом поиска символьных имён. Каждый модуль ядра использует пару системных
вызовов init_module и cleanup_module для своей инициализации и деинициализации. Данный факт является
достаточным для правильной идентификации модуля.
Определение возможностей
взаимодействия с сетью для файлов формата PE
В операционной системе Windows интерфейс
взаимодействия с сетью находиться в динамической библиотеке WinSock, которая загружается в
память при первом обращении к ней. Перед тем как использовать её функционал
пользовательский процесс должен произвести её инициализацию путём вызова
функции WSAStartup [4]. Без вызова данной функции использование WinSock невозможно. Таким
образом, для определения того факта, что создаваемый из PE - файла пользовательский
процесс располагает функционалом для взаимодействия с сетью достаточно
детектировать обращение к функции WSAStartup. Детектирование проводится методом поиска символьного имени «WSAStartup» в таблице строк файла.
Определение драйверов
операционной системы Windows
Для определения драйвера Windows необходимо и достаточно
проверить значение поля Subsystem в опциональном заголовке PE-файла. Для драйвера
установлена константа IMAGE_SUBSYSTEM_NATIVE со значением равным единице.
Определение файлов.NET
Платформа.NET корпорации Microsoft расширила формат PE с помощью функций,
которые поддерживают общеязыковую среду исполнения (Common Language Runtime - CLR). Дополнением является
директория ClrDirectory и секция данных CLR. Идентификация компонентов.NET производится поиском
директории ClrDirectory в таблице директорий, которая располагается в конце опционального
заголовка. В данной директории содержатся виртуальный адрес загрузки и размер
данных. Если PE - файл является.NET - компонентом, то значения данных полей отличны от нуля.
Определение COM-компонентов
COM (англ. Component Object Model - объектная модель компонентов) - это технологический стандарт от
компании Microsoft, предназначенный для создания программного обеспечения на основе
взаимодействующих компонентов, каждый из которых может использоваться во многих
программах одновременно. Стандарт воплощает в себе идеи полиморфизма и
инкапсуляции объектно-ориентированного программирования. Каждый COM-компонент содержит в
своей таблице экспорта функцию DllGetClassObject, которая одновременно является и точкой входа для компонента.
Для идентификации COM-компонента необходимо и
достаточно найти в таблице экспорта файла имя функции «DllGetClassObject».
2. Проектирование и
реализация
.1 Разработка
архитектуры библиотеки
Общий подход к
проектированию и разработке библиотеки
Создание данного программного
продукта производится по спиральной модели. Реализованный в данной работе
функционал является лишь частью задуманного и в будущем разработка библиотеки
будет продолжена. Для того, чтобы дальнейшее развитие программного продукта
было максимально эффективным и не приводило к излишним затратам времени и сил,
был применён подход к разработке, называемый принципами SOLID.
Принципы SOLID - это первые пять
принципов, названных Робертом Мартином в начале 2000-х [5] [6], которые
означают пять основных принципов объектно-ориентированного программирования и
проектирования. Эти принципы предназначены для повышения качества кода и
помогают создать код, который будет легко поддерживать и расширять в течение
долгого времени. Это особенно актуально при спиральном подходе, так как при
правильном проектировании очередной итерации создаются условия для более лёгкой
и быстрой реализации функционала последующей итерации. В свою очередь,
количество затраченного времени на написание кода на каждой итерации определяет
стоимость конечного программного продукта, частью которого является данная
библиотека.
Признаками плохой архитектуры и
реализации программного кода являются следующие [5]:
1) сильная связанность
компонентов (авт. rigidity) - выражается в том, что при внесении изменений в один из
компонентов кода, появляется необходимость вносить каскадные изменения во все
зависимые компоненты;
2) неустойчивость (авт. fragility) - внесение изменений в
один компонент кода приводит к сбоям в работе других, которые могут даже не
иметь прямой связи с изменёнными компонентами;
) сложность повторного использования
(авт. immobility) - систему сложно разделить на отдельные компоненты, которые
можно использовать повторно;
) вязкость (авт. viscosity) дизайна и окружения -
сложность внести что-то новое согласно существующему дизайну интерфейса,
архитектуры. Необходимость использования грубых решений, нарушающих
существующую концепцию;
) неустойчивость к изменениям (авт. Changing Requirements) - под воздействием
новых требований существующая стройная концепция архитектуры быстро
разрушается. Чем больше изменений, тем быстрее происходит разрушение
архитектуры;
Для того, чтобы предотвратить
подобные проблемы применяются следующие принципы:
1) принцип единой
ответственности (англ. The Single Responsibility Principle, SRP) - означает, что каждый
объект должен иметь одну ответственность и эта ответственность должна быть
полностью инкапсулирована в класс. Автор определяет ответственность как причину
изменения и заключает, что классы должны иметь одну и только одну причину для
изменений. На практике ответственность представляет собой задачу, которую
выполняет класс. Основным признаком нарушения данного принципа является тот
факт, что при изменении кода, отвечающего за одну ответственность (задачу), в
приложении появляются исправления кода, отвечающего за другую ответственность
(задачу);
2) принцип открытости /
закрытости (англ. The Open Closed Principle, OCP) - программные сущности (классы, модули, функции и проч.) должны
быть открыты для расширения, но закрыты для изменения. Открыты для расширения
означает, что поведение сущности может быть расширено, путём создания новых
типов сущностей. Закрыты для изменения: в результате расширения поведения
сущности, не должны вноситься изменения в код, который эти сущности используют
(например, унаследованный код);
) принцип подстановки Барбары Лисков
(англ. Liskov Substitution Principle, LSP) - если D является производным типом от B, тогда объекты типа B в программе могут быть замещены
объектами типа D без каких-либо изменений свойств этой программы;
) принцип разделения интерфейса
(англ. Interface Segregation Principle, ISP) - общие интерфейсы с множеством разнонаправленных методов нужно
разделять на узкие и специфические, чтобы их клиенты знали только о тех
методах, которые необходимы им в работе. Как результат, при изменении метода
интерфейса не должны меняться клиенты, которые не используют этот метод;
) принцип инверсии зависимостей
(англ. Dependency inversion principle, DIP) - уменьшение зависимостей различных модулей, сущностей друг от
друга. Модули верхних уровней не должны зависеть от модулей нижних уровней. Оба
типа модулей должны зависеть от абстракций, а не от конкретных реализаций;
Принцип SRP применён в библиотеке
следующим образом: класс FFilter несёт ответственность только за определение формата файла. Его
интерфейс выглядит следующим образом:
интерфейс программный компьютерный
сеть
class FFilter
{
public:(){}bool test
(const char* buffer, size_t buffSize) = 0;FileFormatName getFormatName() =
0;size_t getFileSize (const char* buffer, size_t buffSize) = 0; ~FFilter(){}
};
Единственная задача метода test(…), это ответить на вопрос имеет ли целевой файл формат, указанный
типом производного класса. Получение размера файла - это взаимосвязанная
операция, т.к. её реализация зависит от формата. Метод getFileSize(…) - возвращает размер целевого файла, вычисленный согласно
структуре его формата. Метод getFormatName(…) возвращает идентификатор файла.
Единственным формальным нарушением
данного принципа является класс FileHandler, интерфейс которого предоставляет множество различных функций.
Данный факт не следует считать нарушением, так как данный класс представляет
собой интерфейс самого верхнего уровня, и его цель максимально скрывать
внутреннюю реализацию.
Принцип ISP прослеживается в следующем: базовые классы FFilter и ExecClassifier содержат только те
методы, которые необходимы пользователю при использовании интерфейса нижнего
уровня (непосредственно классов-фильтров и классов-классификаторов конкретных
форматов и типов). Это, в первую очередь, методы для определения формата либо
типа исполняемых файлов. Остальные методы этих интерфейсов являются
взаимосвязанными с основной задачей класса, поэтому их нельзя считать
нарушением принципа ISP. Все специфические для конкретных задач методы и данные
инкапсулированы в промежуточных подклассах и конечных класса-наследниках. Для
примера, набор констант для формата ELF инкапсулирован в выделенный отдельно промежуточный абстрактный
базовый класс FfilterELF. Все подклассы, не связанные с ELF - форматом не видят
этих данных. Аналогичная ситуация с классификаторами NetworkClassifier и DriverModClassifier.
Примером использования принципа DIP является класс DetectPool. Первоначально, в
процессе разработки он выглядел так:
template<typename
T>DetectPool
{typename
std:vector<T>:iterator FPIterator;:(){}~DetectPool()
{(auto i: m_pool)i;
}FPIterator begin()
{return m_pool.begin();}FPIterator end() {return m_pool.end();}:
std:vector<T> m_pool; // < - зависимость на уровне реализации
public:(const DetectPool
&) = delete;DetectPool & operator = (const DetectPool &) = delete;
};
В интерфейс класса помимо открытых
методов входят также и шаблонные параметры. В данном варианте имеется
зависимость на уровне реализации, путём привязки к конкретному виду контейнера std:vector - это закрытый член std:vector<T> m_pool. Если возникнет
необходимость заменить блочный контейнер std:vector, например, на
какой-либо пользовательский, то это приведёт к необходимости внесения изменений
в реализацию класса DetectPool, и, вероятнее всего, его классов-наследников, что является также
нарушением принципа OCP. На практике это выльется в дополнительную работу по отладке и
тестированию всех изменённых классов.
Более правильный вариант выглядит,
таким образом, что зависимость на уровне реализации превращается в зависимость
на уровне интерфейса (контейнер становится параметром шаблона):
template<
template<class…> class Container, typename T>DetectPool
{:typename
Container<T>:iterator FPIterator;(){}~DetectPool()
{(auto i: m_pool)i;
}FPIterator begin()
{return m_pool.begin();}FPIterator end() {return m_pool.end();}:<T>
m_pool;:(const DetectPool &) = delete;DetectPool & operator = (const
DetectPool &) = delete;
};
Также, принцип DIP используется для уменьшения зависимостей на уровне интерфейса.
Методы которые использует клиент при работе с нижним уровнем библиотеки
выполнены с максимально простыми сигнатурами без зависимостей на уровне
интерфейса.
Пример: в процессе разработки метод test(…) выглядел так:
FileFormatName test
(const char* buffer, size_t buffSize, Ffd & ffdOut)
где в объект ffdOut помещался конечный
результат работы, такой как тип (в случае исполняемого файла), размер файла,
смещение и т.д. При этом, получалась дополнительная зависимость на уровне
интерфейса, т.к. метод test(…) должен был знать об устройстве класса Ffd. Что при изменении
структуры Ffd привело бы к необходимости вмешательства в реализацию всех
методов test(…) всех классов-фильтров и их повторному тестированию. В
условиях, когда постоянно появляются новые требования к функциональности
библиотеки, это привело бы к значительным дополнительным затратам. Возвращаемое
значение заменено на bool по той же причине - оно может измениться в будущем, поэтому проще
возвращать его с помощью отдельного метода (который выглядит тривиально), чем
вмешиваться в «дорогой» в разработке метод test(…). Итоговый вариант
сигнатуры метода выглядит так:
bool test (const char*
buffer, size_t buffSize).
Общая архитектура
библиотеки
Основная функциональная часть
библиотеки представлена двумя иерархиями классов: классами-фильтрами и
классами-классификаторами. Классы-фильтры содержат методы для определения
форматов файлов, классы-классификаторы для определения типа исполняемых файлов.
Классы-фильтры унаследованы от абстрактного базового класса FFilter, классы-классификаторы
от ExecClassifier. Общий вид иерархии классов фильтров представлен на рисунке 2.7:
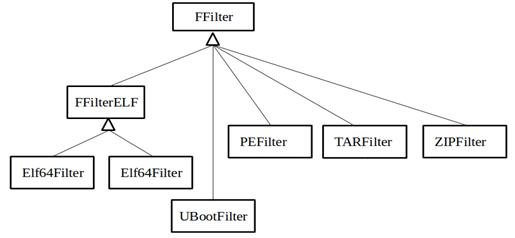
Рисунок 2.7. Общий вид иерархии
классов-фильтров
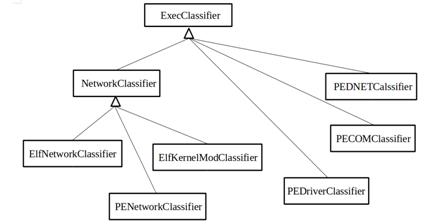
Рисунок 2.8. Общий вид иерархии
классов-классификаторов
Каждая иерархия включает в себя
абстрактный базовый класс-предок, интерфейс которого наследуют классы-потомки.
Интерфейс базового класса иерархии классов-фильтров выглядит следующим образом:
class FFilter
{
public:(){}bool test
(const char* buffer, size_t buffSize) = 0;FileFormatName getFormatName() =
0;size_t getFileSize (const char* buffer, size_t buffSize) = 0; ~FFilter(){}
};
Основным методом классов-фильтров
является виртуальный метод test со следующей сигнатурой:
bool test (const
char* buffer, size_t buffSize),
где buffer - это указатель на
буфер, который содержит целевой файл, формат которого нужно определить, buffSize - его размер. Метод
возвращает булево значение, которое сигнализирует о том, имеет ли целевой файл
указанный формат. Каждый класс-фильтр имеет только один метод test (…) и может определить
только один формат. Метод getFormatName() возвращает
идентификатор формата файла, метод getFileSize(…) вычисляет размер
идентифицированного файла путём разбора полей его заголовка и вычисления
смещения до его конца.
Интерфейс базового класса иерархии
классов-классификаторов выглядит следующим образом:
class ExecClassifier
{:(){}~ExecClassifier(){}bool
detect (const char* buff, size_t buffSize, FileFormatName format) = 0; ExecTypeName getExecTypeName() = 0;
};
Основным методом
классов-классификаторов является виртуальный метод detect со следующей сигнатурой:
bool detect (const
char* buffer, size_t buffSize, FileFormatName format),
где buffer - это указатель на
буфер, который содержит целевой исполняемый файл, тип которого нужно
определить, buffSize - его размер, format - идентификатор формата. Метод возвращает булево значение,
которое сигнализирует о том, имеет ли целевой исполняемый файл указанный тип.
Каждый класс-классификатор имеет только один метод detect (…) и может определить
только один тип исполняемого файла. Метод getExecTypeName() возвращает идентификатор типа исполняемого файла.
Библиотека содержит следующий набор
программных сущностей, описанных в терминах объектно-ориентированного
программирования:
1) класс Ffd представляет собой
описатель конечного результата обработки целевого файла. Он содержит набор
полей, которые необходимы для описания формата файла и его типа если файл
является исполняемым;
2) класс FileHandler реализует интерфейс
верхнего уровня библиотеки и позволяет определить формат файла и тип исполняемого
файла.
) класс FFilter является корнем
иерархии классов-фильтров и предоставляет интерфейс своим потомкам;
) класс FFilterELF инкапсулирует общие для
всех ELF-файлов данные, является промежуточным звеном между
классами-фильтрами и корнем иерархии;
) класс ExecClassifier является корнем
иерархии классов-классификаторов.
) класс NetworkClassifier является
промежуточным звеном в иерархии классов-классификаторов и расширяет интерфейс ExecClassifier общими данными для
всех классификаторов сетевых возможностей;
) класс DriverModClassifier
является промежуточным звеном в иерархии классов-классификаторов и расширяет
интерфейс ExecClassifier общими данными для всех классификаторов драйверов и модулей ядра;
) класс DetectPool содержит контейнер с
указателями на объекты классов-фильтров, предоставляет интерфейс итераторов для
перемещения по контейнеру, является предком для классов FilterPool и ClassifierPool, которые наследуют
его интерфейс;
) набор классов-фильтров и
классов-классификаторов унаследованных от FFilter и ExecClassifier;
Уровни интерфейса
библиотеки
Библиотека имеет два уровня
абстракции интерфейса: интерфейс нижнего уровня и интерфейс верхнего уровня.
Интерфейс нижнего уровня
Интерфейс нижнего уровня
предоставляет возможность использовать каждый компонент библиотеки отдельно по
своему усмотрению и более глубоко интегрировать функционал библиотеки в
клиентский код если это необходимо. Данный интерфейс представлен набором
классов фильтров и классификаторов, каждый из которых можно создать и
использовать в клиентском приложении отдельно от остальных. Пример
использования интерфейса нижнего уровня представлен в Приложении 1.1.
Интерфейс верхнего
уровня
Интерфейс верхнего уровня устроен
таким образом, чтобы скрывать все детали реализации. Такой подход позволяет
получить конечный результат при минимальных действиях пользователя, что, в свою
очередь, способствует минимизации возможных ошибок при разработке приложения с
использованием библиотеки. Основным элементом интерфейса верхнего уровня
является класс FileHandler, интерфейс которого выглядит следующим образом:
class FileHandler
{:();easyCheck (const
char* buff, size_t fileSize);: ExecTypeName parseExecType (const char* buff,
size_t fileSize, LDF: FileFormatName format);:tryFilters (Ffd & ffdOut,
const char* buff, const size_t buffSize);m_filterPool;m_classifierPool;
};
Для определения формата файла
предусмотрен метод easyCheck(), для определения типа
исполняемого файла - метод getExecType(). Для того, чтобы
определить формат файла пользователю достаточно выполнить следующие действия
(Полный код примера использования приведён в Приложении 1.2):
) Создать объект класса FileHandler.
) Вызвать метод easyCheck() класса FileHandler передав ему указатель
на буфер и размер буфера.
В качестве результата метод easyCheck() вернёт объект класса Ffd, который содержит
идентификатор формата файла.
Класс FileHandler содержит в себе два
набора объектов, инкапсулированных в классы FilterPool и ClassifierPool. FilterPool используется в методе easyCheck(). Этот класс является
наследником абстрактного базового класса DetectPool и содержит в себе набор
указателей на объекты классов-фильтров, которые создаются в его конструкторе.
Класс DetectPool выполнен в виде шаблона, который параметризируется типом
указателя на базовый класс фильтра либо классификатора. Указатели хранятся в
объекте std:vector стандартной библиотеки языка С++. Такая компоновка позволяет
используя цикл обойти весь набор объектов вызывая метод test каждого объекта через
указатель. Класс ClassifierPool устроен аналогичным образом и содержит набор указателей на
объекты классов-классификаторов. Он используется в методе getExecType() который определяет тип исполняемого файла.
.2 Реализация алгоритма
определения формата ELF и типов исполняемых файлов
Реализация алгоритма
определения формата ELF
Заголовок файла формата ELF для архитектур х86 и
х86-64 представлен структурой Elf32Ehdr и Elf64Ehdr соответственно, которые описаны в файле библиотеки common.h. Данная структура проецируется на
входной файл через указатель что позволяет выполнять сравнение полей структуры
с заданными константами используя этот указатель. Для определения формата
происходит последовательное сравнение полей структуры с константами, которые
заданы в спецификации на формат ELF. Если значение какого-либо поля не соответствует заданному
значению, то проверка прерывается с возвращением булевого значения false. Код представлен в
Приложении А.
Реализация алгоритма
определения сетевых возможностей исполняемых файлов формата ELF
Определение сетевых возможностей
исполняемого файла сводится к поиску символьных имён сетевых системных вызовов
в таблице символов файла. К
сетевым системным вызовам относятся следующие: socket, connect, accept, listen,
sendto, recvfrom, select, poll, epoll.
Для поиска символьных имён
необходимо проделать следующую последовательность действий:
1) извлечь из поля e_shoff заголовка ElfHeader смещение до таблицы
заголовков секций (англ. - section header table). Данная таблица содержит набор структур, каждая из кторых
описывает одну из секций. В библиотеке данная структура представлена
структурами Elf32Shdr и Elf64Shdr которые описаны в заголовочном файле common.h;
2) найти в таблице
структуру.shstrtab которая содержит список имен всех секций файла. Каждая секция
имеет поле sh_name, которое содержит индекс по которому расположено имя данной
секции внутри секции.shstrtab. Для того, чтобы найти данную секцию, необходимо вычислить
смещение до неё от начала файла. Смещение вычисляется путём сложения значения
из поля e_shoff заголовка ElfHeader со значением, полученным путём умножения размера структуры
заголовка (поле e_shentsize заголовка ElfHeader) на индекс структуры.shstrtab. Значение индекса содержится в поле e_shstrndx заголовка ElfHeader. Вычисление смещения в
общем выглядит следующим образом: offset = e_shoff + (e_shentsize * e_shstrndx);
) найти смещение до секции.strtab, которая содержит
строки, представляющие собой символьные имена используемых функций и системных
вызовов. Поиск смещения происходит путём обхода таблицы заголовков секций, где
из каждого заголовка извлекается индекс имени секции. По данному индексу из
таблицы.shstrtab извлекается строка, которая является именем секции. Данная строка
сравнивается с искомой строкой «.strtab». При совпадении, извлекается смещение до данной секции;
) найти символьные имена сетевых
системных вызовов в секции.strtab, которая представляет собой массив нуль-терминированных строк
символьных имён. Поиск осуществляется с применением алгоритма поиска подстроки
в строке;
Список символьных имён системных
вызовов содержит имена тех системных вызовов, которые могут быть использованы
только для передачи либо приёма данных по сети. Таким образом, нахождение хотя
бы одного совпадения достаточно, чтобы установить тот факт, что данный
исполняемый файл будучи запущен в операционной системе может принимать либо
передавать данные по сети.
Реализация алгоритма определения
драйверов и модулей ядра исполняемых файлов формата ELF
Каждый динамически подгружаемый
драйвер либо модуль ядра должен экспортировать следующие методы для загрузки и
выгрузки: «init_module», «cleanup_module». При отсутствии данных методов в таблице символьных имён
загрузка файла как модуля ядра становится невозможна. Поиск данных символьных
имён происходит аналогично поиску символьных имён сетевых системных вызовов.
.3 Реализация алгоритма
определения формата PE и возможностей исполняемых файлов PE
Реализация алгоритма
определения формата PE
Алгоритм определения формата PE аналогичен алгоритму
для формата ELF. В начале файла PE располагается набор заголовков, которому соответствует следующий
набор структур библиотеки: PeDosHdr, PeNtHdr, PeNtFileHdr, PeDataDir, PeOptHdr32, PeOptHdr64, PeImageSectionHeader, PeExportDirTable. Для определения формата происходит последовательное сравнение
полей структуры с константами, которые заданы в спецификации на формат PE. В начале любого файла
формата PE находится заголовок IMAGE_DOS_HEADER, унаследованный от операционной системы MS-DOS. Далее расположен
заголовок IMAGE_NT_HEADER, поля которого и содержат необходимую для идентификации
информацию. Для идентификации формата производится проверка значения magic bytes, а также ещё некоторых
полей заголовка. Код представлен в Приложении А.
Реализация алгоритма
определения сетевых возможностей исполняемых файлов формата PE
Для определения сетевых возможностей
исполняемого файла формата PE как и в случае с форматом ELF производится поиск
символьных имён сетевых системных вызовов. Кроме этого, производится поиск
символьного имени процедуры WSAStartup, которая является точкой входа в библиотеку WINSOCK.DLL. В ОС Windows интерфейс сетевых
системных вызовов находится в динамической библиотеке WINSOCK.DLL, которую каждое
приложение, которое осуществляет сетевое взаимодействие должно загрузить в
память процесса. Таким образом, нахождение символьного имени точки входа данной
библиотеки является необходимым для установления факта использования сети
запущенным исполняемым файлом.
Для поиска указанных выше символьных
имён необходимо выполнить следующую последовательность действий:
1) получить смещение от
начала файла до заголовка IMAGE_NT_HEADER. Значение данного смещения находится в поле e_lfanew заголовка IMAGE_DOS_HEADER;
2) вычислить смещение до
таблицы символов. Для этого используются поля заголовков IMAGE_FILE_HEADER, который является
частью IMAGE_NT_HEADER. Необходимо извлечь следующие значения: смещение до таблицы
символов и число символьных имён в данной таблице;
) найти в таблице строк символьное
имя «WSAStartup» соответствующее библиотеке WINSOCK.DLL, а также имена сетевых
системных вызовов;
Реализация алгоритма
определения драйверов Windows
Для установления того факта, что
исполняемый файл формата PE является драйвером, необходимо и достаточно проверить значение
поля e_subsystem в заголовке COFF Optional Header. Его значение согласно спецификации должно быть равно 1. Код
представлен в Приложении А.
Реализация алгоритма
определения COM-компонентов Windows
Согласно спецификации [15], каждый COM-компонент должен
содержать функцию загрузки с именем DllGetClassObject, символьное имя которой содержится в таблице экспорта. Для
идентификации COM-компонентов необходимо и достаточно выявить наличие данного
символьного имени в таблице экспорта. Для
этого необходимо выполнить следующую последовательность действий:
4) получить смещение от
начала файла до заголовка IMAGE_NT_HEADER. Значение данного смещения находится в поле e_lfanew заголовка IMAGE_DOS_HEADER;
5) вычислить смещение до
таблицы секций. Для этого используются поля заголовков IMAGE_OPTIONAL_HEADER и IMAGE_FILE_HEADER, которые являются
частью IMAGE_NT_HEADER. Необходимо извлечь следующие значения: число секций в файле;
предпочтительный адрес образа процесса когда он загружается в память; структуру
IMAGE_DATA_DIRECTORY, которая соответствует
таблице экспорта; виртуальный адрес данной таблицы; размер заголовка IMAGE_OPTIONAL_HEADER. Используя эти данные
можно вычислить смещение до таблицы секций и адрес таблицы экспорта;
) используя адрес таблицы экспорта
найти секцию, содержащую эту таблицу в таблице секций;
) перейдя по полученному смещению
получить смещение до таблицы символов таблицы экспорта;
) найти в таблице символов секции
экспорта символьное имя «DllGetClassObject»;
Реализация алгоритма
определения.NET-компонентов Windows
Для определения того факта, что файл
является.NET-компонентом необходимо проверить значение поля таблицы e_dataDirectory заголовка IMAGE_OPTIONAL_HEADER по индексу 14. Если
значение данного поля не равно нулю, то это значит, что в файле присутствует
таблица COM+ Runtime Header, что в свою очередь, позволяет однозначно определить.NET-компонент. Код
представлен в Приложении А.
2.4 Реализация
алгоритмов определения неисполняемых структурированных файлов
Алгоритм определения неисполняемых
структурированных файлов является общим для форматов U-boot, Squashfs, ICO, TAR, GZIP, ZIP, GIF. Он сводится к поиску
набора «магических байт», который, как правило, расположен в начале любого
файла указанных форматов. При совпадении значений «магических байт» с заданными
в спецификациях форматов значениями алгоритм возвращает булево значение true, иначе false.
.5 Реализация алгоритмов
определения файлов исполняемых скриптов командной оболочки
Алгоритм определения фалов
исполняемых скриптов командной оболочки для форматов скриптов bash и sh реализован с помощью
алгоритма поиска подстроки в строке. Для каждой из подстрок, указанных в
параграфе 1.6.3 производится поиск в первой строке целевого файла.
.6 Создание примеров
использования интерфейсов библиотеки
Для более полного понимания методов
и возможностей использования библиотеки при разработке прикладного программного
обеспечения был создан набор примеров использования различных интерфейсов
библиотеки для определения форматов файлов и типов исполняемых файлов. Примеры
описывают использование интерфейсов верхнего и нижнего уровней библиотеки,
применение классов-фильтров и классов-классификаторов. Данный набор является
неотъемлемой частью библиотеки и поставляется вместе с её исходным кодом. Код
примеров представлен в Приложении Б.
2.7 Тестирование кода
библиотеки
Для тестирования библиотеки
применялся метод модульного тестирования.
Данный вид тестирования представляет
собой проверку отдельных классов и их методов нижнего и верхнего уровней
библиотеки. В качестве инструмента тестирования использовался фреймворк Boost Test [16], который является
специализированным инструментом модульного тестирования исходных кодов программ
на языке программирования С++. Данный фреймворк предоставляет удобный интерфейс
для написания тестов и получения результатов тестирования. Для выполнения тестирования
была написана программа, включавшая в себя набор тестов, в которых проверялась
работа основных методов классов-фильтров и классов-классификаторов. Основной
задачей тестов было выявление ложноположительного результата работы этих
методов, а также выявление ошибок сегментации памяти при выполнении операций с
буфером, который содержит исходный файл. На вход программе тестирования
подавались заранее подготовленные файлы различных форматов, в том числе
намеренно искажённые. Тестирование выполнялось в несколько итерации с
последующим устранением выявленных ошибок.
В результате проведённого
тестирования было установлено, что каждый тестируемый модуль работает
корректно, ошибок сегментации нет.
Заключение
В результате работы над проектом
было проведено изучение предметной области систем безопасности промышленных
сетей, в результате которого было выяснено, что наибольший интерес с точки
зрения обеспечения безопасности и предотвращения вторжений представляет поиск в
сетевом трафике исполняемых файлов, файлов архивов, файлов компонентов файловых
систем, файлов изображений. Было проведено изучение методик определения
следующих форматов файлов: ELF, PE, U-boot, ZIP, GZIP, TAR, GIF, ICO. Также, была выполнена разработка методики определения
возможностей исполняемых файлов, изучение существующих решений. Результатом
работы стало проектирование и разработка библиотеки прикладного
программирования, которая реализует функции, заявленные в задании выпускной
квалификационной работы. При проектировании применялись принципы разработки SOLID, основанные на
многолетнем опыте разработки программного обеспечения многих специалистов. Было
проведено успешное тестирование готового программного продукта.
1. Формат ELF [Электронный ресурс]: ELF specification - Режим доступа: http://www.skyfree.org/linux/references/ELF_Format.pdf
. Справка по Linux system calls [Электронный ресурс]: Linux Programmer's Manual - Режим доступа: http://man7.org/linux/man-pages/man2/syscalls.2.html
. Формат PE [Электронный ресурс]: PE pecification - Режим доступа: https://msdn.microsoft.com/ruru/library/windows/desktop/ms680547 (v=vs.85).aspx
. Справка по Winsock.dll [Электронный ресурс]: Microsoft Winsock.dll - Режим доступа: https://support.microsoft.com/ru-ru/help/122928/description-of-the-winsock.dll-file
. Формат ZIP [Электронный ресурс]: ZIP specification - Режим доступа:
https://pkware.cachefly.net/webdocs/casestudies/APPNOTE.TXT
. Формат GZIP [Электронный ресурс]: GZIP specification - Режим доступа: https://tools.ietf.org/html/rfc1952
. Формат TAR [Электронный ресурс]: TAR specification - Режим доступа:
https://www.gnu.org/software/tar/manual/html_node/Standard.html
. Формат ICO [Электронный ресурс]: ICO format - Режим доступа: https://msdn.microsoft.com/ru-ru/library/windows/desktop/gg430024 (v=vs.85).aspx
. Справка по загрузчику Uboot [Электронный ресурс]: Uboot manual - Режим доступа: http://ftp1.digi.com/support/documentation/90000852_K.pdf
. Справка по файловой системе Squashfs [Электронный ресурс]: Squashfs description - Режим доступа: https://www.kernel.org/doc/Documentation/filesystems/squashfs.txt
11. Corbet, J. Linux Device Drivers, 3rd Edition. / J. Corbet, A.
Rubini, G. Kroah-Hartman. - Cambridge: 2005 O'Reilly. - 640 p.
12. Мартин Р.С. Быстрая разработка программ. Принципы, примеры,
практика / Р.С. Мартин, Д.В. Ньюкирк, Р.С. Косс. - Москва: Вильямс, 2004. - 753
стр.
. Майоров А. Проектирование информационных систем. / А. Майоров,
И. Соловьев. - Санкт-Петербург: Академический проект, 2009. - 400 стр.
. Фаулер М. Рефакторинг. Улучшение существующего кода. -
Санкт-Петербург: Символ-Плюс, 2003. - 432 стр.
. Справка по Windows API DllGetClassObject [Электронный ресурс]: Microsoft COM - Режим доступа: https://msdn.microsoft.com/ruru/library/windows/desktop/ms680760 (v=vs.85).aspx
. Справка по фреймворку Boost Test [Электронный ресурс]: Boost Test - Режим доступа: http://www.boost.org/doc/libs/1_64_0/libs/test/doc/html/index.html
. Формат GIF [Электронный ресурс]: GIF89 - Режим доступа: https://www.w3.org/Graphics/GIF/spec-gif89a.txt