Разработка системы для видеонаблюдения на основе цифровых процессоров
Министерство образования и науки
Челябинской области
государственное бюджетное
общеобразовательное учреждение
среднего профессионального
образования (ССУЗ)
"Кыштымский радиомеханический
техникум"
Специальность 230113
Разработка системы для видеонаблюдения
на основе цифровых процессоров
Пояснительная записка к курсовому
проекту
по дисциплине: " МДК.02.01
Микропроцессорные системы"
КРМТ.230113.КП.3122.0003.ПЗ
Руководитель
проекта
_________
М.В.Кускова
Нормоконтроль
_________
М.В.Кускова
Содержание
Введение
. Теоретическая часть
1.1 Обзор цифровых процессоров для видеонаблюдения
.2 Конструктивное исполнение процессоров
1.3 Программное и аппаратное обеспечение
Практическая часть
.1 Программное обеспечение разработки
.2 Система команд цифрового процессора
.3 Содержание программного кода
.4 Пояснения к программному коду
.5 Иллюстрация работы эмулятора
.6 Алгоритм программы
Введение
Процессор цифровой обработки сигналов (digital signal processor - DSP) -
это специализированный программируемый микропроцессор, предназначенный для
манипулирования в реальном масштабе времени потоком цифровых данных.
DSP-процессоры широко используются для обработки потоков графической
информации, аудио- и видеосигналов.
Любой современный компьютер оснащен центральным процессором и только
немногие - процессором цифровой обработки сигналов. Центральный процессор,
очевидно, представляет собой цифровую систему и обрабатывает цифровые данные,
поэтому на первый взгляд неясна разница между цифровыми данными и цифровыми
сигналами, то есть теми сигналами, которые обрабатывает
DSP-процессор.процессоры принципиально отличаются от микропроцессоров,
образующих центральный процессор настольного компьютера. По роду своей
деятельности центральному процессору приходится выполнять объединяющие функции.
Он должен управлять работой различных компонентов аппаратного обеспечения
компьютера, таких как дисководы, графические дисплеи и сетевой интерфейс, с
тем, чтобы обеспечить их согласованную работу.
В итоге типичный современный центральный процессор поддерживает несколько
сот команд, которые обеспечивают выполнение всех этих функций.
Набор команд у DSP куда меньше, чем у центрального процессора настольного
компьютера; их число не превышает 80. Это значит, что для DSP требуется
облегченный декодер команд и гораздо меньшее число исполнительных устройств.
Кроме того, все исполнительные устройства в конечном итоге должны поддерживать
высокопроизводительные арифметические операции. Таким образом, типичный
DSP-процессор состоит не более чем из нескольких сот тысяч транзисторов.
Специфические возможности DSP-процессора в части обработки информации
делают его идеальным средством для многих приложений. Используя алгоритмы,
основанные на соответствующем математическом аппарате, DSP-процессор может
воспринимать цифровой сигнал и выполнять операции свертки для усиления или
подавления тех или иных свойств сигнала.
В силу того что в DSP-процессорах значительно меньше транзисторов, чем в
центральных процессорах, они потребляют меньше энергии, что позволяет использовать
их в продуктах, работающих от батарей. Крайне упрощается и их производство,
поэтому они находят себе применение в недорогих устройствах. Сочетание низкого
энергопотребления и невысокая стоимость обусловливает применение
DSP-процессоров в сотовых телефонах и в роботах-игрушках.
Впрочем, спектр их применения этим далеко не ограничивается. В силу
большого числа арифметических модулей, наличия интегрированной на кристалле
памяти и дополнительных шин данных часть DSP-процессоров могут использоваться
для поддержки многопроцессорной обработки. Они могут выполнять
сжатие/распаковку «живого видео» при передаче по Internet. Подобные
высокопроизводительные DSP-процессоры часто применяются в оборудовании для
организации видеоконференций.
1. Теоретическая часть
.1 Обзор цифровых процессоров для видеонаблюдения
1.1.1
Процессор Philips PNX1700 для обработки видео высокой четкости

Рисунок 1-
Микросхема для Philips PNX1700
Компания Philips Electronics 14 марта объявила о выпуске новой микросхемы
PNX1700 из семейства медиапроцессоров Nexperia, поддерживающих видео высокой
четкости (HD). Схема предназначается для использования в телевизионных
приставках, цифровых медиаадаптерах, -,устройствах записи видео, видеотелефонах
и телевизионных приемниках.
В PNX1700 объединены обработка изображений, поддержка работы в сети с
улучшенной поддержкой дисплеев. По сравнению с предыдущими схемами её
производительность удвоена при сохранении аппаратной и программной
совместимости.
Ядром PNX1700 является процессор TriMedia с тактовой частотой 500 Мгц и
многоступенчатым конвейером. Он поддерживает декодирование видео в формате HD,
включая Windows Media Video, DivX, MPEG-4 и MPEG-2. Процессор PNX1700 может
одновременно кодировать и декодировать видео в форматах MPEG-2 и MPEG-4 с
разрешением D1. Это разрешение 720х480 для сигнала в стандарте NTSC и 720х576
для сигнала PAL.
В набор команд процессора PNX1700 добавлены инструкции, специально
предназначенные для оптимизации кодирования и декодирования видео и звука в
стандарте H.264, а также для поддержки декодирования видео нормального (SD) и
высокого разрешения (HD) с деинтерлейсингом.
Дело в том, что в телевизионном сигнале сначала выводятся все четные
строки изображения (первый полукадр), а затем все нечетные (второй полукадр).
При выводе оцифрованного сигнала на монитор используется не чересстрочная, а
прогрессивная развертка, то есть оба полукадра выводятся одновременно. Поэтому
на мониторе на быстро движущихся вдоль горизонтальной оси объектах появляется
так называемая “гребенка”, которая происходит из-за того, что первый полукадр
“ждет”, пока к нему добавятся строки второго полукадра. За это время быстро
движущийся объект успевает немного сместиться, причем длина зубцов “гребенки”
равна этому смещению. - процесс восстановления видеоизображения после оцифровки
с целью минимизации эффекта “гребенки”. Эффект “гребенки” наблюдается только
при полном разрешении. Если размер выводимого изображения составляет 288 строк
или меньше, “гребенки” нет, так как изображение состоит из одного полукадра.
Для разработки устройств PNX1700 имеется пакет программ, в состав которого
входят C-компилятор-отладчик и библиотеки программных кодеков и прикладных
программ.
1.1.2 Микропроцессор TMS320DM64x/Da Vinci

Рисунок 2- Микросхема для TMS320DM64x/Da Vinci
цифровой процессор программный код
Компания Texas Instruments Incorporated (TI) в апреле этого года
представила два новых цифровых сигнальных процессора (ЦСП). ЦСП TMS320DM647 и
TMS320DM648 предназначены для использования во встраиваемых мультимедийных
приложениях - видеорекодерах, DVD-проигрывателях, цифровых фото- и
видеокамерах, IP-видеосерверах, в многоканальных видеосистемах безопасности.
Тенденции роста рынка потребительской мультимедийной электроники
стимулируют производство высокоскоростных программируемых процессоров. По своей
«электронной начинке» мультимедийные устройства незначительно отличаются от
современных информационно-вычислительных систем (высокопроизводительный
процессор, большой объем встроенной памяти, стандартные интерфейсы для обмена
данными - USB, Ethernet и др., интерфейс с ЖК-дисплеем, клавиатурой и т. д.).
Процессоры, ориентированные на применение в мультимедийных устройствах, должны
иметь хорошие показатели соотношения производительности и стоимости,
производительности и уровня потребляемой мощности, а также миниатюрные размеры.
Следуя направлению развития рынка потребительской электроники,
разработчики ведущих компаний создали множество новых модификаций
программируемых мультимедийных процессоров: TMS320DM644x/643x, TMS320DM647/8
(Texas Instruments), семейство Blackfin - ADSP-BF54х (Analog Devices),
процессоры MCIMX31/31L (Freescale Semiconductor), PNX1300/1500/1700 (NXP),
PXA3xx (Marvell) и AT32AP700x (Atmel). Приведем их количественные показатели
производительности при выполнении алгоритмов, которые широко используются в
цифровой обработке видео- и аудиоданных (КИХ и БИХ-фильтров, декодера Витерби,
БПФ и др.). Для такой оценки принято использовать набор тестовых программ BDTI
Benchmark. Набор этих тестов был предложен независимой ассоциацией BDTI
(Berkeley Design Technology, Inc.).
Далее рассмотрим архитектуру и функциональные возможности двух новых
цифровых сигнальных процессоров от Texas Instruments - TMS320DM647 и
TMS320DM648. ЦСП построены на основе ядра TMS320C64x+, что позволяет перенести
уже существующие видеосистемы, например, на базе TMS320DM642, на новую
аппаратную платформу с удвоенной производительностью при существенном снижении
расходов на компоненты системы. Удвоение производительности процессоров DM648 в
сравнении с DM642 обеспечивается рядом решений: на 20% увеличена эффективность
выполнения кода в процессорных циклах, на 20-30% стала выше плотность кода,
вдвое увеличилось количество 16-разрядных операций умножения с накоплением
(MMAC) за один процессорный цикл, в четыре раза увеличилась пропускная
способность EDMA, увеличены тактовые частоты и производительность
интегрированного видеосопроцессора VICP.
Снижение стоимости набора компонентов при создании систем на базе новых
процессоров возможно из-за появления двух дополнительных видеопортов,
интегрированного порта SGMII, позволяющего обойтись без PCI-моста, а также за
счет отказа от микросхемы ПЛИС (FPGA), функции которой выполняет теперь
сопроцессор VICP.
Тактовая частота процессоров DM647 и DM648 - 720 и 900 МГц. Пиковая
производительность - 5760 и 7200 MIPS. За один процессорный цикл (1,39 и 1,11
нс) выполняются восемь 32-битовых инструкций C64x+. Вычислительная часть
процессора содержит шесть АЛУ (32 и 40 бит) и два умножителя. В течение одного
цикла в АЛУ может выполняться либо одна операция с 32-битными операндами, либо
две с 16-битными, либо восемь с 8-битными, а в умножителе - одна операция с
16-битными операндами или восемь с 8-битными. В процессе вычисления все восемь
операционных модулей могут использоваться независимо - это и дает возможность
выполнять одновременно восемь инструкций за один процессорный такт. Все
инструкции могут выполняться с условием. Для уменьшения размера программного
кода инструкции упаковываются. Процессор имеет 64 32-разрядных регистра общего
назначения. Дополнительное улучшение в системе команд С64х+ - работа в
защищенном режиме и обнаружение критических ошибок с программной переадресацией
на обработчик.
Встроенная кэш-память включает два блока объемом по 32 кбайт каждый: L1P
- кэш программного кода и L1D - кэш данных, а также один блок памяти L2 объемом
256/512 кбайт, который является конфигурируемым - либо ОЗУ, либо кэш данных или
программного кода. Процессоры содержат пять 16-разрядных видеопортов. Каждый из
видеопортов содержит два канала (А и В) с 5120-байтовым блоком буферной дисплейной
памяти, используемой раздельно.
С помощью процессора легко осуществить дублирование видеопотоков, которое
используется в видеоприложениях систем безопасности, когда высококачественный
поток видеоданных должен быть сохранен на носителе информации, а
низкокачественный поток видео используется для отображения на мониторе текущего
видеонаблюдения. Видеопорт поддерживает различные разрешения и видеостандарты
(CCIR601, ITU-BT.656, BT.1120, SMPTE 125M, 260M, 274M, 296M). Процессоры
содержат специализированный видеосопроцессор VICP (Video Imaging Co-processor).
Сопроцессор VICP проводит обработку данных, работая параллельно с главным
ядром ЦСП. Его работа обеспечивается библиотекой VICP Functional Library,
поддерживающей эффективные алгоритмы стандартов MPEG4/H.264, преобразования
цвета, масштабирования изображений, организации развертки. Эта библиотека
распространяется с платформой разработчика DM648 Digital Video Development
Platform (DVDP). На рис. 2 показана функциональная блок-схема процессоров, которая
отображает множество интерфейсов для связи с периферийными устройствами.
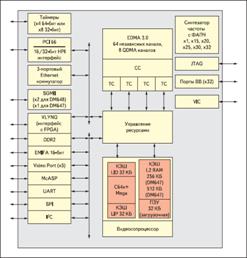
Рисунок 3-Функциональная блок-схема TMS320DM647/TMS320DM648
.2 Конструктивное исполнение процессоров
.2.1 Типы корпусов процессоров
BGA
(англ.
<https://ru.wikipedia.org/wiki/%D0%90%D0%BD%D0%B3%D0%BB%D0%B8%D0%B9%D1%81%D0%BA%D0%B8%D0%B9_%D1%8F%D0%B7%D1%8B%D0%BA>
Ball grid array - массив шариков) - тип корпуса
поверхностно-монтируемых
<https://ru.wikipedia.org/wiki/%D0%9F%D0%BE%D0%B2%D0%B5%D1%80%D1%85%D0%BD%D0%BE%D1%81%D1%82%D0%BD%D1%8B%D0%B9_%D0%BC%D0%BE%D0%BD%D1%82%D0%B0%D0%B6>
интегральных микросхем
<https://ru.wikipedia.org/wiki/%D0%98%D0%BD%D1%82%D0%B5%D0%B3%D1%80%D0%B0%D0%BB%D1%8C%D0%BD%D0%B0%D1%8F_%D0%BC%D0%B8%D0%BA%D1%80%D0%BE%D1%81%D1%85%D0%B5%D0%BC%D0%B0>.
<https://commons.wikimedia.org/wiki/File:BGA_RAM.jpg?uselang=ru>произошёл
от PGA <https://ru.wikipedia.org/wiki/Pin_grid_array>. BGA выводы
представляют собой шарики из припоя
<https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%B8%D0%BF%D0%BE%D0%B9>,
нанесённые на контактные площадки с обратной стороны микросхемы. Микросхему
располагают на печатной плате
<https://ru.wikipedia.org/wiki/%D0%9F%D0%B5%D1%87%D0%B0%D1%82%D0%BD%D0%B0%D1%8F_%D0%BF%D0%BB%D0%B0%D1%82%D0%B0>,
согласно маркировке первого контакта на микросхеме и на плате. Затем микросхему
нагревают с помощью паяльной станции
<https://ru.wikipedia.org/wiki/%D0%9F%D0%B0%D1%8F%D0%BB%D1%8C%D0%BD%D0%B0%D1%8F_%D1%81%D1%82%D0%B0%D0%BD%D1%86%D0%B8%D1%8F>
или инфракрасного источника, так что шарики начинают плавиться. Поверхностное
натяжение <https://ru.wikipedia.org/wiki/%D0%9F%D0%BE%D0%B2%D0%B5%D1%80%D1%85%D0%BD%D0%BE%D1%81%D1%82%D0%BD%D0%BE%D0%B5_%D0%BD%D0%B0%D1%82%D1%8F%D0%B6%D0%B5%D0%BD%D0%B8%D0%B5>
заставляет расплавленный припой зафиксировать микросхему ровно над тем местом,
где она должна находиться на плате и не позволяет шарикам деформироваться.

Рисунок 4- Микросхемы памяти, установленные на планку,
имеющие выводы типа BGA
BGA
- это решение проблемы производства миниатюрного корпуса ИС с большим
количеством выводов. Массивы выводов при использовании поверхностного монтажа
«две линии по бокам» (SOIC <https://ru.wikipedia.org/wiki/SOIC>)
производятся всё с меньшим и меньшим расстоянием и шириной выводов для
уменьшения места, занимаемого выводами, но это вызывает определённые сложности
при монтаже данных компонентов. Выводы располагаются слишком близко, и растёт
процент брака по причине спаивания припоем соседних контактов. BGA не имеет
такой проблемы - припой наносится на заводе в нужном количестве и месте.
Следующим преимуществом перед микросхемами с ножками
является лучший тепловой контакт между микросхемой и платой, что в некоторых
случаях избавляет от установки теплоотводов, поскольку тепло уходит от
кристалла на плату более эффективно (также, в некоторых случаях, по центру корпуса
создаётся одна большая контактная площадка-радиатор, которая припаивается к
дорожке-теплоотводу).
Если
BGA-микросхемы рассеивают достаточно большие мощности и теплоотвод по всем
шариковым выводам недостаточен, то к корпусу микросхемы прикрепляется (иногда
приклеивается) радиатор
<https://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D0%B4%D0%B8%D0%B0%D1%82%D0%BE%D1%80>.
В качестве примера можно привести видеоплаты для ПК, микросхемы „северных
мостов <https://ru.wikipedia.org/wiki/%D0%A1%D0%B5%D0%B2%D0%B5%D1%80%D0%BD%D1%8B%D0%B9_%D0%BC%D0%BE%D1%81%D1%82_(%D0%BA%D0%BE%D0%BC%D0%BF%D1%8C%D1%8E%D1%82%D0%B5%D1%80)>“
на материнских платах ПК и т. д.
Чем
меньше длина выводов, тем меньше наводки и излучение. У BGA длина проводника
очень мала и может определяться лишь расстоянием между платой и микросхемой,
так что применение BGA позволяет увеличить диапазон рабочих частот и, для
цифровых приборов (см. Цифровая обработка сигналов
<https://ru.wikipedia.org/wiki/%D0%A6%D0%B8%D1%84%D1%80%D0%BE%D0%B2%D0%B0%D1%8F_%D0%BE%D0%B1%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%BA%D0%B0_%D1%81%D0%B8%D0%B3%D0%BD%D0%B0%D0%BB%D0%BE%D0%B2>),
увеличить скорость обработки информации.
Основным
недостатком BGA является то, что выводы не являются гибкими. Например, при
тепловом расширении или вибрации некоторые выводы могут сломаться. Поэтому BGA
не является популярным в военной технике или авиастроении.
Отчасти
эту проблему решает залитие микросхемы специальным полимерным веществом -
компаундом
<https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BC%D0%BF%D0%B0%D1%83%D0%BD%D0%B4>.
Он скрепляет всю поверхность микросхемы с платой. Одновременно компаунд
препятствует проникновению влаги под корпус BGA-микросхемы, что особенно
актуально для некоторой бытовой электроники (например, сотовых телефонов
<https://ru.wikipedia.org/wiki/%D0%A1%D0%BE%D1%82%D0%BE%D0%B2%D1%8B%D0%B9_%D1%82%D0%B5%D0%BB%D0%B5%D1%84%D0%BE%D0%BD>).
Также осуществляется и частичное залитие корпуса, по углам микросхемы, для
усиления механической прочности.
Другим
недостатком является то, что после того как микросхема припаяна, очень тяжело
определить дефекты пайки. Обычно применяют рентгеновские снимки или специальные
микроскопы, которые были разработаны для решения данной проблемы, но они
дороги. Относительно недорогим методом локализации неисправностей, возникающих
при монтаже, является периферийное сканирование
<https://ru.wikipedia.org/wiki/%D0%9F%D0%B5%D1%80%D0%B8%D1%84%D0%B5%D1%80%D0%B8%D0%B9%D0%BD%D0%BE%D0%B5_%D1%81%D0%BA%D0%B0%D0%BD%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5>.
Если решено, что BGA неудачно припаяна, она может быть демонтирована
термовоздушным феном или с помощью инфракрасной паяльной станции; может быть
заменена новой. В некоторых случаях из-за дороговизны микросхемы шарики
восстанавливают с помощью паяльных паст и трафаретов; этот процесс называют
ребо́ллинг.

Рисунок
5 - Микросхема корпуса FCBGA для TMS320DM64x/Da Vinci

.3 Программное и аппаратное обеспечение
Программатор
- аппаратно-программное устройство
<https://ru.wikipedia.org/wiki/%D0%90%D0%BF%D0%BF%D0%B0%D1%80%D0%B0%D1%82%D0%BD%D0%BE-%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%BD%D0%BE%D0%B5_%D1%83%D1%81%D1%82%D1%80%D0%BE%D0%B9%D1%81%D1%82%D0%B2%D0%BE>,
предназначенное для записи/считывания информации в постоянное запоминающее
устройство
<https://ru.wikipedia.org/wiki/%D0%9F%D0%BE%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D0%BD%D0%BE%D0%B5_%D0%B7%D0%B0%D0%BF%D0%BE%D0%BC%D0%B8%D0%BD%D0%B0%D1%8E%D1%89%D0%B5%D0%B5_%D1%83%D1%81%D1%82%D1%80%D0%BE%D0%B9%D1%81%D1%82%D0%B2%D0%BE>
(однократно записываемое <https://ru.wikipedia.org/wiki/PROM>,
флэш-память
<https://ru.wikipedia.org/wiki/%D0%A4%D0%BB%D0%B5%D1%88-%D0%BF%D0%B0%D0%BC%D1%8F%D1%82%D1%8C>,
ПЗУ, внутреннюю память микроконтроллеров
<https://ru.wikipedia.org/wiki/%D0%9C%D0%B8%D0%BA%D1%80%D0%BE%D0%BA%D0%BE%D0%BD%D1%82%D1%80%D0%BE%D0%BB%D0%BB%D0%B5%D1%80>
и ПЛК
<https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D1%83%D0%B5%D0%BC%D1%8B%D0%B9_%D0%BB%D0%BE%D0%B3%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9_%D0%BA%D0%BE%D0%BD%D1%82%D1%80%D0%BE%D0%BB%D0%BB%D0%B5%D1%80>).
Для
программирования микросхем с корпусами, отличными от DIP и/или с большим числом
выводов, используются специальные адаптеры под соответствующий тип корпуса.
Одной стороной эти адаптеры устанавливаются в DIP-колодку программатора, другая
сторона представляет собой колодку под соответствующий тип корпуса (SDIP, PLCC,
SOIC, SOP, PSOP, TSOP, TSOPII, TSSOP, QFP, TQFP, VQFP, QFN, SON, BGA, CSP и т.
д.).
1.3.1 Отладочные платы для процессора TMS320DM64x/Da Vinci
Семейство DaVinci «родилось» с появлением процессоров TMS320DM644x на
базе двух ядер, ARM и DSP. При реализации приложений видеообработки на этом
процессоре, ARM-ядро берет на себя задачи управления (периферийными
устройствами, операционной системой и др.), а DSP-ядро отвечает за
вычислительную часть (кодирование-декодирование видео). Среди TMS320DM644x
существуют модификации процессоров, поддерживающие кодирование-декодирование
видео (DM6446), только декодирование видео (DM6443), а также модификация для
приложений с низким энергопотреблением (DM6441).
Для приложений, в которых ARM-ядро избыточно, т.е. когда для задач
управления не требуется много ресурсов, компания Texas Instruments выпустила
семейство процессоров DM643x.
Процессоры представляют собой версию семейства DM644x без ARM-ядра. За
счет «урезания» ARM-ядра, сократилась также цена решения. Кроме того, это
семейство стандартизовано для автомобильных приложений, работает в диапазоне
температур от -40 до 125°С и содержат CAN-интерфейс.
Начинать разработку приложения на базе TMS320DM355 рекомендуется с
помощью отладочного комплекта TMDXEVM355, изображенного на рисунке 2
(TMDSEVM355 в будущем).
В отладочный комплект TMDXEVM355 входит:
· Отладочная плата с процессором TMS320DM355 TMS320DM64x/Da
Vinci (рисунок 8);

Рисунок 7- Отладочная плата TMDXEVM355 TMS320DM64x/Da Vinci
· Пульт дистанционного управления;
· Документация для отладочной платы (гербер, схематика,
спецификация);
· 2 Гб NAND Flash;
· Документация для реализованного на плате контроллера
Ethernet;
· Демонстрационная версия MontaVista Linux Pro 4.0;
· Драйвера для периферийных устройств, включая UART, I2C, SPI,
EDMA, NAND, MMC, SDIO, USB HS;
· Программное обеспечение для отладочной платы (BSP);
· Загрузчик U-boot;
· Кодеки JPEG, HD MPEG4 SP и G.711;
· Техническое описание.
2. Практическая часть
.1 Программа VisualDSP++
Интегрированная среда VisualDSP++ является основным
средством разработки и отладки приложений для процессоров компании Analog
Devices. Последняя версия VisualDSP++ имеет номер 5.0, работает под ОС Windows
2000 SP4, Windows XP SP2, Windows Vista или Windows 7
Business/Enterprise/Ultimate edition и поддерживает семейства процессоров
TigerSHARC, SHARC и Blackfin.
При запуске установочного файла, загруженного с
веб-сайта или находящегося на компакт-диске, вызывается программа установки,
которая распаковывает все необходимые для работы VisualDSP++ файлы и драйверы,
а также примеры программ и файлы справочной системы, в указанный пользователем
каталог (по умолчанию это каталог Program Files\Analog Devices\VisualDSP 5.0\
на системном диске). Кроме того, программа установки автоматически создает папку
Программы →Analog Devices → VisualDSP++ 5.0 в меню Пуск ОС Windows.
Среда VisualDSP++ обладает всеми средствами,
необходимыми для максимально быстрого создания приложений на базе процессоров
компании Analog Devices.
.2 Система команд цифрового процессора
ADSP-21160 - первый процессор нового семейства SHARC®.
Оптимизированный для применения в приложениях, таких как телефония, медицина,
радарная электроника, связь, 3D графика, процессор представляет новую
архитектуру Single-Instruction-Multiple-Data ( SIMD ).использует два
вычислительных блока (ALU, Barrel Shifter, MAC, регистровые файлы) и имеет
принципиально новый уровень производительности по сравнению с
процессорамиADSP-2106x в множестве DSP-алгоритмов. Новое семейство является
программно-совместимым с популярным первым поколением SHARC-процессоров -
ADSP-2106x. Сохраняя текущий вклад SHARC® в развитие программных средств,
первое поколение SHARC® может привести к скорому появлению второго поколения
SHARC-систем на рынке. Как и другие процессоры, процессор ADSP-21160 является
32-разрядным процессором, оптимизированным для применения в
высокопроизводительных DSP-приложениях. ADSP-21160 имеет ядро 100 МГц для
поддержки как 32-разрядной фиксированной точки, так и (32-разрядной,
40-разрядной) плавающей точки, встроенное двухканальное СЗУПВ размером 4 Мбит,
интегрированный процессор ввода/вывода с поддержкой мультипроцессорных систем и
множественные внутренние шины для устранения критических параметров
ввода/вывода.построен с использованием многопроцессорных топологий; SHARC®
поддерживает многопроцессорную обработку через link -порты или внешний порт.
Через внешний порт можно подключить до шести процессоров ADSP-21160 без
использования дополнительных логических схем.
Арбитраж для этой разделенной шины интегрирован на
кристалле. Каждый SHARC-процессор в группе имеет доступ к внутренней памяти
каждого SHARC-процессора. Используя внешний порт можно также разделить внешнюю
память.
При небольших размерах и высокой производительности
ADSP-21160, его потребляемая мощность устанавливает новый уровень отношения
MFLOPS/Вт. Типичное значение для потребляемой мощности ADSP-21160M составляет 2
Вт при быстродействии 300 MFLOPS. Это позволяет разработчикам использовать
несколько процессоров на PCI-плате с ограничением мощности 25 Вт. С восемью
сигнальными процессорами ADSP-21160, каждый из которых обеспечивает
быстродействие 600 MFLOPS, стандартная PCI-плата может поддерживать
производительность 4.8 GFLOPS и иметь запас мощности 9 Вт.
Система команд поддерживает прямой и косвенный режимы
адресации. Прямая адресация возможна только для памяти данных и использует
непосредственное выражение в качестве адреса памяти: ДМ(<addr>).
Косвенная адресация памяти программ и памяти данных
использует индексные регистры генераторов адресов.
Набор инструкций процессора разделен на следующие
группы:
) Вычислительные инструкции
(инструкция ALU, инструкция умножителя накопителя MAC, инструкция устройства циклического сдвига Shifter).
Пример: mrf=r3*r0(ssi) - результат
умножения содержимого регистров r0 и r3 запишется в регистр результата АЛУ;
r1=ROTr1 by 4 -
сдвигаем значение, хранящееся в r1 на
4 бита (на 1 позицию влево);
) Пересылки данных
Пример: r2=dm(0x050006) - в регистр r2 из памяти данных запишется элемент массива, находящийся по адресу 0x050006; dm(0x050006)=r2 - в памяти данных по адресу
запишется число , хранящееся в регистре r2;
) Управление программой (DO UNTIL, IDLE);
) Многофункциональная:
· двойное сложение/вычитание
· параллельная операция умножителя и ALU (MAC).
Пример: mrf=mrf+r0*r3(ssi)- сложение с умножением(результат
произведения r0 и r3 просуммируется со значением, находящимся в памяти).
.3 Содержание программного кода
Изучить порядок обработки прерывания и написать
процедуру обработки для прерывания LP2I, заключающуюся в том, чтобы в 16-ти
битном числе поменять местами 1-ый и 3-ий элементы.
2.4 Пояснения к программному коду
1) #define n h#1234 - Объявляем константу n=1234, в 16-и битной системе.
) #include <def21160.h>Подключаем файл стандартной библиотеки.
) .section/dm seg_dmda; Объявляем секцию памяти данных.
) .section/pm seg_rth; Объявляем секцию обработки прерываний.
5) _reset:_1: NOP; NOP; NOP; NOP; //
0x0-0x3_Reset: NOP; JUMP _START; NOP; NOP; // 0x4-0x7; JUMP _IRQ; NOP; RTI; //
0x8-0xB; NOP; NOP; NOP; // 0xC-0xF; NOP; NOP; NOP; //
0x10-0x13; NOP; NOP; NOP; // 0x14-0x17; NOP; NOP; NOP; //
0x18-0x1B; NOP; NOP; NOP; // 0x1C-0x1F; NOP; NOP; NOP; // 0x20; NOP; NOP; NOP; //
0x24; NOP; NOP; NOP; // 0x28; NOP; NOP; NOP; //
0x2C; NOP; NOP; NOP; // 0x30; NOP; NOP; NOP; // 0x34
RTI; NOP; NOP; NOP; // 0x40; NOP; NOP; NOP; //
0x44; NOP; NOP; NOP; // 0x48; NOP; NOP; NOP; //
0x4C; NOP; NOP; NOP; // 0x50; NOP; NOP; NOP; // 0x54; NOP;
NOP; NOP; // 0x58; NOP; NOP; NOP; // 0x5C; NOP;
NOP; NOP; // 0x60; NOP; NOP; NOP; // 0x64; NOP; NOP;
NOP; // 0x68
6).section/pm seg_pmco
-Объявляем секцию программного кода
)_START: - метка «START»
) bit set mode1 IRPTEN-
Разрешаем обработку прерываний
) bit set IMASK LP2I- Накладываем
маску на прерывание LP2I
) r1=1- в регистр r1записываем единицу
) r2=2- в регистр r2 записываем двойку
12) bit set IRPTL LP2I- вызываем прерывание LP2I
13) nop - пустая операция
) r3=3- в регистрr3 записываем тройку
) r4=4- в регистр r4 записываем четверку
) idle - переводим процессор в энергосберегающее
состояние
)_IRQ:- метка
) r0=n- в регистр r0
записывается число 1234
) i0=0x050000- резервируем область памяти
) r2=0x000F-накладываем
маску на число ,т.е выбираем 4
)r1=r0 and r2-Логическое умножение r0 и r2, обнуляем все цифры, кроме 4
)r3=0x00F0-Накладываем
маску на число, т.е выбираем цифру 3
)r4=r0 and r3-Логическое умножение r0и r3,обнуляем все, кроме 3
) r5=r1 or r4-Логическое сложение
) r6=0xF000-Накладываем маску на число, т.е выбираем цифру 1
) r7=r0 and r6-Обнуляем все, кроме 1
) r7 = ROT r7 by -8 -Сдвиг
вправо на два шаг
) r8=r5 or r7-Логическое сложение
) r9=0x0F00-накладываем
маску на число, т.е выбираем цифру 2
) r10=r0 and r9-Обнуляем все, кроме 2
) r11=r8 or r10- Логическое сложение
33) bit clr mode2 LP2I- Очистка
регистра mode2
34) rti -Возврат в основную программу.
2.5 Иллюстрация работы эмулятора
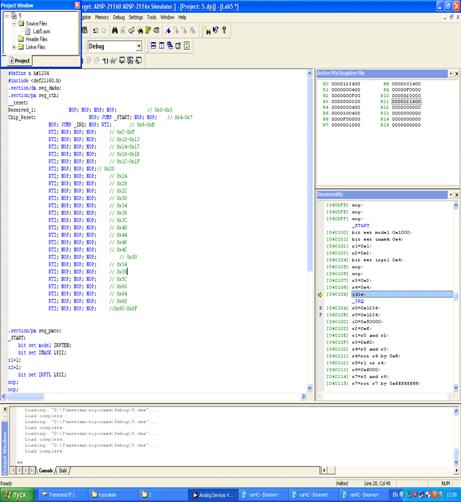
Рисунок 8- Работа эмулятора
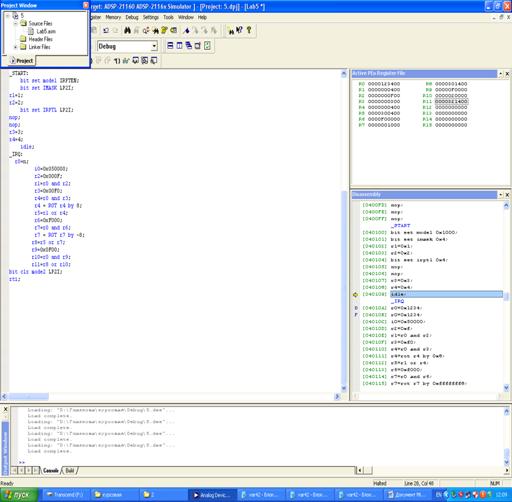
Рисунок 9- Работа эмулятора
2.6 Алгоритм программы


Рисунок 10- Алгоритм программы


Рисунок11- Алгоритм подпрограммы
Заключение
В данной работе была разработана система для видеонаблюдения на основе
цифровых процессоров. В ней представлены два вида микропророцессоров.