Тестирование и отладка программного обеспечения
Курсовая работа
Тестирование и отладка программного
обеспечения
Цели и задачи
курсовой работы
Для достижения поставленной цели в ходе работы необходимо выполнить
следующие задачи:
. Разработать программу превращения, обращения, противопоставления
предикату произвольного суждения. Операции выполнять над общеутвердительными
(A), и общеотрицательными (E)
суждениями.
. Разработать спецификацию задачи и выполнить тестирование
программы методом «черного ящика», описав классы эквивалентности.
. Выполнить тестирование двух модулей разработанной программы,
имеющих среднюю или высокую логическую сложность, методом «белого ящика».
. Выполнить интеграционное тестирование не менее трех модулей
разработанной программы.
. Описать методику выполнения регрессионного тестирования.
Отчет по курсовой работе должен содержать:
- код разработанной программы;
- спецификацию программы; описание классов эквивалентности;
- программный код и результаты выполнения модульных и
интеграционных тестов;
- выводы по работе
Часть 1.
Разработка программы
Предметная
область.
Суждения - это форма мышления, в которой утверждается или отрицается
связь между предметом и его признаком, отношения между предметами или факт
существования предмета и которая может быть либо истинной, либо ложной.
Языковой формой выражения суждения является повествовательное предложение.
Вопросительные и побудительные предложения суждениями не являются.
Простое (атрибутивное) суждение - это суждение о принадлежности предметам
свойств (атрибутов), а также суждения об отсутствии у предметов каких-либо
свойств. В атрибутивном суждении могут быть выделены термины суждения -
субъект, предикат, связка, квантор.
Для упрощения записи операций над суждениями введем следующие
обозначения:
- символ «S»
используется для обозначения субъекта;
- символ «P»
используется для обозначения предиката;
- символ «:» применяется для обозначения связки «есть»;
- символ «~» используется для обозначения отрицательной частицы
«не»;
- символ «» применяется для обозначения терминов «все»,
«всякий», «любой»;
- символ «#» обозначает термин «ни один»;
- символ «!» применяется для обозначения термина «только»;
- символ «» обозначает термины «существует»,
«некоторый».
Тогда
результат выполнения операций в общем виде может быть представлен в виде
таблицы (см. Таблица 1).
модульный
эквивалентность тестирование регрессионный
Таблица
1. Правила выполнения операций над суждениями
|
Операция
|
Суждение
|
|
Общеутвердительное S : P
|
Общеотрицательное # S ~: P
|
|
Превращение
|
# S ~: ~P
|
S : ~P
|
|
Обращение
|
Р : S
|
# P ~: S
|
|
Противопоставление предикату
|
# ~P ~: S
|
Р : S
|
Описание
алгоритма.
На вход программе подается одна или несколько строк. Эти строки
представляет собой простое категорическое суждение, над которым следует
выполнить три требуемые операции. Для удобства дальнейшей работы строка
разбивается на компоненты (квантор, субъект, связка, предикат).
Дополнительными входными данными для работы программы являются словари,
которые хранят используемые кванторы, субъекты, связки и предикаты (то есть все
компоненты суждения).
В случае, если формат строки не удовлетворяет требованиям, или тип
суждения не соответствует указанному в задании (в соответствии с
классификацией, приведенной выше), генерируется исключение (ошибка времени
выполнения).
При успешном разборе суждения последовательно выполняются требуемые
операции и их результат возвращается пользователю в виде строки на естественном
языке. При этом реализация грамматической точности построенного предложения не
является приоритетной задачей.
Входные данные могут быть считаны из текстового файла (файл input.txt находится в той же директории, что и исполняемый
файл). В случае отсутствия указанного файла пользователю предлагается ввести
исходные данные с клавиатуры. Выходные данные выводятся на экран и дублируются
в текстовом файле (файл output.txt находится также в той же директории,
что и исполняемый файл). Данные словарей находятся в текстовых файлах,
расположенных в подкаталоге Data
(сам подкаталог располагается в том же каталоге, что и исполняемый файл) и
имеют имя:
<Название_компонента>.txt
Описание
реализации.
Ниже
приведена диаграмма классов для разработанной программы, созданная с
использованием средств интегрированной среды разработки (IDE) Visual Studio (см. Рисунок 1).
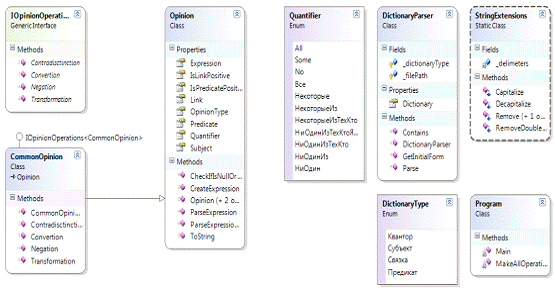
Рисунок
1. Диаграмма классов
На диаграмме приведены только значимые классы и перечисления, с которыми
наиболее активно ведется работа и которые будут задействованы в тестировании.
Также программа содержит ряд классов-утилит и классов, расширяющих класс Exception из .NET Framework.
Процесс
выполнения операций над суждениями представлен в виде блок-схемы на Рисунок 2:
выполняется построчное чтение данных из потока ввода (файл или консоль), для
каждой строки определяет тип суждения и выполняются допустимые операции над
ним.
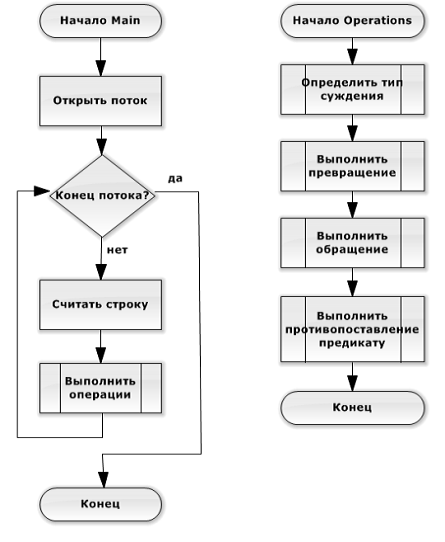
Рисунок
2. Схема работы программы
Часть 2.
Тестирование методом «черного ящика»
Спецификация
программы.
Написать консольную программу выполнения операций превращения, обращения
и противопоставления предикату над общеутвердительными и общеотрицательными
суждениями.
Входные данные находятся в текстовых файлах (расширение .txt). Каждая строка файла содержит
единственную запись - суждение. При отсутствии входного файла осуществляется
пользовательский ввод. Словари компонентов суждений так же хранятся в текстовых
файлов в соответствии с определенным форматом.
Результаты выполнения операций записываются в текстовый файл (расширение
.txt). Также осуществляется вывод
результатов на экран.
Программа должна быть написана на алгоритмическом языке высокого уровня C#. Требуемая версия .NET Framework - 4.0 и выше. Программа должна
выполняться на операционных системах семейства Windows версии XP и
выше.
При ошибках пользовательского ввода или внутренних ошибках программа
должна осуществлять вывод соответствующего сообщения.
Ограничения.
1. По умолчанию, суждения записываются на русском языке. Для записи
суждений на английском языке следует изменить строку 11 в файле app.config. Допустимые значения: Ru - русский зык (по умолчанию), En - английский язык.
. Формат записи суждений:
<Квантор> <Субъект> <Логическая связка>
<Предикат>
Все компоненты являются обязательными. Компоненты Субъект и Логическая
связка должны состоять из единственного слова.
. Формат записи элементов словарей:
<Начальная_форма> ([Форма_слова] [,Форма_слова] … [,Форма_слова])
То есть, в файле должна быть записана начальная форма фразы (слово или
словосочетание), затем в скобках через запятую перечислены формы этой фразы,
используемые в суждениях.
. Предикат должен иметь положительный характер (не должен иметь
отрицательной частицы «не»)
. При записи результата все компоненты новых суждений должны иметь
либо начальную форму фразы, как она указана в словарях компонентов, либо ту же
форму, что и в записи исходного суждения. Знаки препинания игнорируются.
Выходные суждения записываются в верхнем регистре.
. Текстовые файлы должны кодироваться UTF-8 и иметь расширение .txt.
. Требование к структуре файловой системы: текстовые файлы для
ввода и вывода данных должны находиться в том же каталоге, что и исполняемый
файл. Текстовые файлы со словарями компонентов должны располагаться в
подкаталоге Data в том же каталоге, что и исполняемый
файл и именоваться в формате <Компонент>.txt
. При возникновении любой ошибки выполнение программы
останавливается.
Классы
эквивалентности.
Классы
эквивалентности будем представлять в виде таблицы (см. Таблица 2)
Таблица
2. Классы эквивалентности
|
№
|
Ситуация
|
Классы эквивалентности
|
|
|
Допустимые
|
Недопустимые
|
|
1
|
Ввод данных
|
Данные успешно считаны из файла
|
|
|
|
Файл не найден, пользователь вводит данные
|
|
|
2
|
Синтаксический анализ
|
Запись суждения соответствует формату, обнаружены все
компоненты в словарях
|
Отсутствует любой (любые) из компонентов суждения
|
|
|
|
Все компоненты присутствуют, но не могут быть распознаны
|
|
|
|
Тип суждения не соответствует заявленному в задании
|
|
|
|
Файл со словарем для какого-либо компонента не обнаружен
|
|
3
|
Выполнение операций
|
Операции выполнены успешно
|
|
|
4
|
Вывод данных
|
Данные успешно записаны в существующий файл
|
|
|
|
Данные успешно записаны в созданный файл
|
|
Покрытие
тестами классов эквивалентности.
Тесты,
покрывающие классы эквивалентности, приведены в нижеследующей таблице (Таблица 3).
Таблица
3. Используемые тесты
|
№
|
Значение входных данных
|
Значение выходных данных
|
Тип ошибки
|
Причина
|
|
1
|
Файл пустой
|
Пустая строка
|
Ошибки нет
|
|
|
2
|
Файл не существует, пользователь вводит пустую строку
|
Пустая строка
|
Ошибки нет
|
|
|
3
|
Все студенты учатся хорошо
|
I > Входные данные: ВСЕ СТУДЕНТЫ УЧИТЬСЯ ХОРОШО I >
Тип: Общеутвердительное I > Превращение: НИ ОДИН ИЗ ТЕХ КТО СТУДЕНТЫ НЕ
УЧИТЬСЯ НЕ ХОРОШО I > Обращение: НЕКОТОРЫЕ ИЗ ТЕХ КТО УЧАТСЯ ХОРОШО
СТУДЕНТЫ I > Противопоставление: НИ ОДИН ИЗ ТЕХ КТО НЕ УЧАТСЯ ХОРОШО НЕ
СТУДЕНТЫ
|
Ошибки нет
|
|
|
4
|
Студенты учатся хорошо
|
E > Квантор не определен
|
Неверный формат ввода
|
Отсутствует квантор суждения
|
|
5
|
Почти все студенты учатся хорошо
|
E > Не могу считать данные для объекта: Квантор, так как
Не обнаружена требуемая форма
|
Неверный формат ввода
|
Квантор суждения не определен
|
|
6
|
Все учатся хорошо
|
E > Субъект не определен
|
Неверный формат ввода
|
Отсутствует субъект суждения
|
|
7
|
Все студенты хорошо
|
E > Не могу считать данные для объекта: Связка, так как
Не обнаружена начальная форма
|
Неверный формат ввода
|
Отсутствует логическая связка
|
|
8
|
Все студенты учатся
|
E > Предикат не определен
|
Неверный формат ввода
|
Отсутствует предикат суждения
|
|
9
|
Некоторые студенты учатся хорошо
|
I > Входные данные: НЕКОТОРЫЕ СТУДЕНТЫ УЧИТЬСЯ ХОРОШО I
> Тип: Частноутвердительное W > Данное суждение не является
общеутвердительным или общеотрицательным
|
Несоответствие типа
|
Тип суждения не соответствует указанному в задании
|
|
10
|
Все студенты учатся хорошо
|
E > Не могу считать данные для объекта: Предикат, так
как Файл со справочиком не обнаружен
|
Файл не найден
|
Отстутствует файл со справочником
|
При выполнении тестов использовались следующие записи в словарях
компонентов:
) Кванторы (Квантор.txt)
Все (Вся, Всё, Всех)
Некоторые (Некоторых, Некоторым, Некоторыми)
Ни один (Ни одного, Ни одному, Ни одна, Ни одно)
Ни один из (Ни одного из, Ни одному из, Ни одна из, Ни одно из)
Ни один из тех кто (Ни одного из тех кто, Ни одному из тех кто, Ни одна
из тех кто, Ни одно из тех кто)
) Субъекты (Субъект.txt)
Студент (Студента, Студенту, Студентом, Студенте)
Студенты (Студентов, Студентам, Студентами, Студентах)
) Логические связки (Связка.txt)
Учиться (учусь, учимся, учишься, учится, учатся)
Быть (есть, был, была, было, были, будет, будут)
Бывать (бывает, бывают, бывал, бывала, бывало, бывали)
) Предикаты (Предикат.txt)
Хорошо ()
Плохо ()
Умный (умная, умное, умные, умного, умную, умных, умному, умной, умным,
умными, умном, умных)
Используемые
тесты покрывают следующие классы эквивалентности (см. Таблица 4):
Таблица
4. Соотношение классов эквивалентности и тестов
|
№
|
Описание класса эквивалентности
|
Допустимый класс?
|
Номер(-а) тестов
|
|
1
|
Данные успешно считаны из файла
|
+
|
1, 3-9
|
|
2
|
Файл не найден, пользователь вводит данные
|
+
|
2-9
|
|
3
|
Запись суждения соответствует формату, обнаружены все
компоненты в словарях
|
+
|
3
|
|
4
|
Отсутствует любой (любые) из компонентов суждения
|
-
|
4,6-8
|
|
5
|
Все компоненты присутствуют, но не могут быть распознаны
|
-
|
5,7
|
|
6
|
Тип суждения не соответствует заявленному в задании
|
-
|
9
|
|
7
|
Файл со словарем для какого-либо компонента не обнаружен
|
-
|
10
|
|
8
|
Операции выполнены успешно
|
+
|
3
|
|
9
|
Данные успешно записаны в существующий файл
|
+
|
1-10
|
|
10
|
Данные успешно записаны в созданный файл
|
+
|
1-10
|
Часть 3.
Тестирование методом «белого ящика». Модульное тестирование
Модуль DictionaryParser.Parse().
Алгоритм и
код
Программный код модуля приведен в листинге 1.
Листинг
1
|
1
|
public void Parse()
|
|
|
2
|
{
|
|
|
3
|
using (FileStream stream = new
FileStream(_filePath, FileMode.Open, FileAccess.Read))
|
1
|
|
4
|
{
|
|
|
5
|
StreamReader reader = new
StreamReader(stream);
|
2
|
|
6
|
while (!reader.EndOfStream)
|
3
|
|
7
|
{
|
|
|
8
|
string line =
reader.ReadLine().ToLower();
|
4
|
|
9
|
int openBracket;
|
|
|
10
|
string initialForm = "";
|
|
|
11
|
try
|
|
|
12
|
{
|
|
|
13
|
openBracket = line.IndexOf('(');
|
5
|
|
14
|
if (openBracket == -1)
|
6
|
|
15
|
throw new DictionaryException(_dictionaryType,
|
7
|
|
16
|
DictionaryExceptionReason.
НевозможноПроанализироватьВариантыФорм);
|
|
|
17
|
initialForm = string.Concat(line
.Where((c, i) => i < openBracket)).Trim().ToUpper();
|
8
|
|
18
|
}
|
|
|
19
|
catch
|
9
|
|
20
|
{
|
|
|
21
|
throw new DictionaryException(_dictionaryType,
|
|
|
22
|
DictionaryExceptionReason. НеОбнаруженаНачальнаяФорма);
|
|
|
23
|
}
|
|
|
24
|
Dictionary[initialForm] = new
List<string>() {initialForm};
|
10
|
|
25
|
Dictionary[initialForm].AddRange(line.Substring(openBracket
+ 1)
|
|
|
26
|
.Split(new string[] {",", ")"},
|
|
|
27
|
StringSplitOptions. RemoveEmptyEntries)
|
|
|
28
|
.Select(s => s.Trim().ToUpper())
|
|
|
29
|
.ToList());
|
|
|
30
|
}
|
11
|
|
31
|
reader.Close();
|
12
|
|
32
|
}
|
13
|
|
33
|
}
|
|
Блок-схема
метода приведена на рисунке ниже (Рисунок 3).
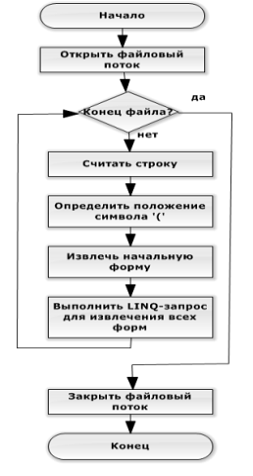
Рисунок
3. Блок-схема модуля DictionaryParser.Parse
Приведенный алгоритм использует язык интегрированных запросов для
облегчения чтения и преобразования данных. Все считанные данные хранятся в
свойстве Dictionary класса.
Тестирование
базового пути.
1. Построение
потового графа
Потоковый
граф рассматриваемого модуля с указанием регионов и выделенными предикаторными
узлами приведен ниже (см. Рисунок 4).
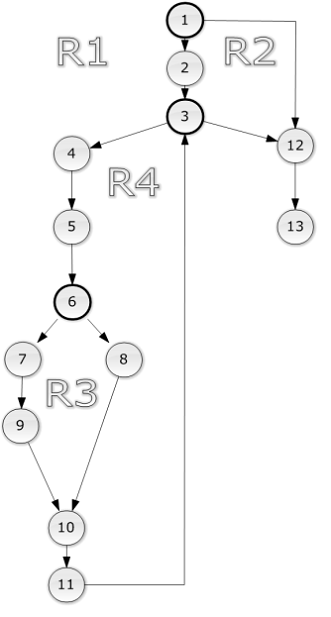
Рисунок
4. Потоковый граф модуля DictionaryParser.Parse
2. Оценка
цикломатической сложности
Приведенный граф позволяет оценить минимальное количество тестов, которые
должны быть проведены. Оценку цикломатической сложности будем производить тремя
указанными методами:
) V(G) = количество регионов = 4
) V(G) = количество дуг - количество узлов + 2 = 15 - 13 + 2 = 4
) V(G) = количество предикатных узлов +1 = 3 + 1 = 4
Таким образом, необходимо составить 4 теста, охватывающих независимые
пути в графе.
3. Определение
базового множества независимых путей
Путь начинается в начальном узле, а заканчивается в конечном узле графа.
Независимые пути необходимо разрабатывать в порядке от самого короткого к
самому длинному.
Были выявлены следующие независимые пути:
) 1-12-13
) 1-2-3-12-13
) 1-2-3-4-5-6-8-10-11-3-12-13
) 1-2-3-4-5-6-7-9-10-11-3-12-13
В представленном списке не учитывался факт наличия цикла (отрезки путей
3-4…-…-11могут повторяться неоднократно)
4. Подготовка
тестовых вариантов
Для
тестирования каждого из независимых путей были созданы тестовые варианты
исходных данных. Сами данные (ИД), ожидаемый от них результат (ОЖ. РЕЗ.) и
результат, полученный фактически при выполнении программы (Ф. РЕЗ.), приведены
в Таблица 5. Тестирование выполняется для справочника «Субъекты».
Таблица
5. Тестовые варианты для метода базового пути
|
№
|
ИД
|
ОЖ. РЕЗ.
|
|
1
|
Файл
Субъекты.txt отсутствует
|
Выброшено исключение FileNotFoundException, которое затем перехвачено в
методе Program.Main.
|
|
2
|
Файл Субъекты.txt не содержит данных
|
Свойство DictionaryParser.Dictionary инициализировано пустым словарем.
|
|
3
|
Файл Субъекты.txt содержит одну или несколько корректных строк: Студент (Студента,
Студенту, Студентом, Студенте) Студенты (Студентов, Студентам, Студентами,
Студентах)
|
Свойство DictionaryParser.Dictionary содержит словарь: СТУДЕНТ -> [0]: "СТУДЕНТ" [1]:
"СТУДЕНТА" [2]: "СТУДЕНТУ" [3]: "СТУДЕНТОМ"
[4]: "СТУДЕНТЕ" СТУДЕНТЫ -> [0]: "СТУДЕНТЫ" [1]:
"СТУДЕНТОВ" [2]: "СТУДЕНТАМ" [3]: "СТУДЕНТАМИ"
[4]: "СТУДЕНТАХ"
|
|
4
|
Файл Субъекты.txt содержит одну или несколько некорректных строк: Студент Студента,
Студенту, Студентом, Студенте) Примечание: отсутствует символ ‘(‘
|
Выброшено исключение DictionaryException, которое затем перехвачено в
методе Program.Main.
|
Тестирование
ветвей и операторов отношений.
В рассматриваемом модуле есть три условных оператора, условия для которых
записаны операторами 1, 3, 6. Метод ветвей и операторов отношений будем
выполнять только в последнем случае, так как первый реализован средствами .NET Framework, а второй задает условие цикла и
будет протестирован позднее:
(openBracket == -1)new
DictionaryException(_dictionaryType,.НевозможноПроанализироватьВариантыФорм);
В этом случае, очевидно, достаточно рассмотреть два случая:
) Переменная openBracket имеет значение -1, то есть строка в файле имеет неверный формат
(отсутствует символ ‘(‘ как разделитель начальной формы слова и используемых
форм). Тогда будет сгенерировано исключение DictionaryException, которое затем будет обработано в
главном цикле программы.
) Переменная openBracket имеет значение, отличное от -1. Тогда программа будет успешно
продолжена.
Тестирование
потоков данных.
Определим
DU-цепочки и представим их в виде информационного графа
программы, наложенного на управляющий граф (см. Рисунок 5).
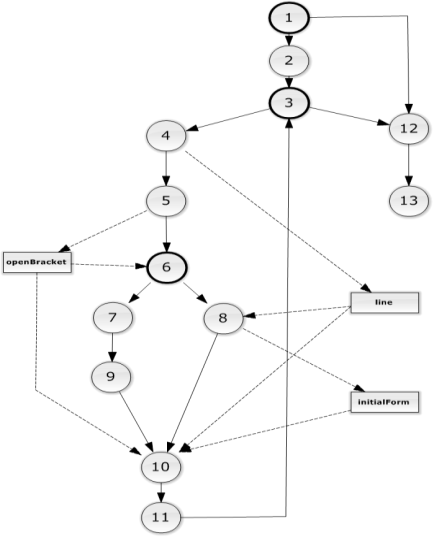
Рисунок
5. Наложение ИГ на УГ для модуля DictionaryParser.Parse
Получены следующие цепочки:
1) [line, 4, 8]
2) [line, 4, 10]
3) [openBracket, 5, 6]
4) [openBracket, 5, 10]
5) [initialForm, 8, 10]
Исходя из полученного списка цепочек, необходимо проанализировать поведение
трех переменных (локальных переменных метод). Так как значения переменной openBracket зависит от line, а значения initialForm - от line и
openBracket, то достаточно рассмотреть все
требуемые варианты переменной line:
1) null
) “”
3) Студент (Студента, Студенту, Студентом, Студенте)
) Студент Студента Студенту Студентом Студенте
Тестирование
циклов.
В модуле представлен единственный цикл типа «ПОКА <условие>
ВЫПОЛНЯТЬ <действие>».
) Единственная строка в файле
) Две строки в файле
) Более двух строк в файле.
Корректность записанных строк не принципиальна, так как условие
некорректной записи было протестировано выше.
Набор
модульных тестов.
Каждый тест сопровождается XML-комментарием,
который описывает ситуацию и требуемое поведение программы.
#region Parser itself
/// <summary>
/// Проверяет случай отсутствия файла со справочником:
все исключения перехвачены
/// </summary>
[Test]static void
Dictionary_FileNotFound_ExceptionCaught()
{.Move("Data/Субъект.txt", "Data/Субъект1.txt");.Throws<DictionaryException>(()
=> new DictionaryParser(DictionaryType.Субъект));.Move("Data/Субъект1.txt", "Data/Субъект.txt");
}
/// <summary>
/// Проверяет случай пустого файла: корректное
завершение работы
/// </summary>
[Test]static void
Dictionary_EmptyFile_NoExceptions()
{.Move("Data/Субъект.txt", "Data/Субъект1.txt");.Delete("Data/Субъект.txt");writer =
File.CreateText("Data/Субъект.txt");.Close();
parser = null;.DoesNotThrow(() =>
parser = new DictionaryParser(DictionaryType.Субъект));<string, List<string>> dictionary = new
Dictionary<string,
List<string>>();.AreEquivalent(parser.Dictionary, dictionary);
.Delete("Data/Субъект.txt");.Move("Data/Субъект1.txt", "Data/Субъект.txt");
}
/// <summary>
/// Проверяет случай любого числа корректных строк в
файле: корректное заверешение работы
/// </summary>
[Test]static void
Dictionary_AllLinesParsedSuccessfully_NoExceptions()
{();
parser = null;.DoesNotThrow(() =>
parser = new DictionaryParser(DictionaryType.Субъект));<string, List<string>> dictionary = new
Dictionary<string, List<string>>();
dictionary["СТУДЕНТ"] = new
List<string>() {"СТУДЕНТ", "СТУДЕНТА",
"СТУДЕНТУ", "СТУДЕНТОМ", "СТУДЕНТЕ"};
dictionary["СТУДЕНТЫ"] = new List<string>()
{"СТУДЕНТЫ", "СТУДЕНТОВ",
"СТУДЕНТАМ", "СТУДЕНТАМИ", "СТУДЕНТАХ"};
foreach (var key in dictionary.Keys)
{.AreEquivalent(parser.Dictionary[key].OrderBy(x
=> x),[key].OrderBy(x => x));
}
.Delete("Data/Субъект.txt");.Move("Data/Субъект1.txt", "Data/Субъект.txt");
}
/// <summary>
/// Проверяет случай некорректной записи строки в
файле: все исключения перехвачены
/// </summary>
[Test]static void
Dictionary_InvalidRecord_ExceptionCaught()
{.Move("Data/Субъект.txt", "Data/Субъект1.txt");.Delete("Data/Субъект.txt");writer =
File.CreateText("Data/Субъект.txt");
writer.WriteLine("Студент Студента, Студенту,
Студентом, Студенте)");
writer.Close();
parser =
null;.Throws<DictionaryException>(() => parser = new
DictionaryParser(DictionaryType.Субъект));
.Delete("Data/Субъект.txt");.Move("Data/Субъект1.txt", "Data/Субъект.txt");
}
#endregion
#region Containing
/// <summary>
/// Проверяет случай наличия формы слова в словаре:
корректное завершение работы
/// </summary>
[Test]static void
Dictionary_ContainsSpecificForm_NoExceptions()
{();
parser = new
DictionaryParser(DictionaryType.Субъект);.AreEqual(true, parser.Contains("студентов"));
.Delete("Data/Субъект.txt");.Move("Data/Субъект1.txt", "Data/Субъект.txt");
}
/// <summary>
/// Проверяет случай отсутствия формы слова в словаре:
корректное завершение работы
/// </summary>
[Test]static void
Dictionary_DoesNotContainSpecificForm_ExceptionCaught()
{();
parser = new
DictionaryParser(DictionaryType.Субъект);.AreEqual(false, parser.Contains("стьюдентс"));
.Delete("Data/Субъект.txt");.Move("Data/Субъект1.txt", "Data/Субъект.txt");
}
#endregion
#region Initial form
/// <summary>
/// Проверяет случай наличия начальной формы слова в
словаре: корректное завершение работы
/// </summary>
[Test]static void
Dictionary_InitialFormRevealed_NoExceptions()
{();
parser = new
DictionaryParser(DictionaryType.Субъект);.AreEqual("студенты".ToUpper(), parser.GetInitialForm("студентов"));
.Delete("Data/Субъект.txt");.Move("Data/Субъект1.txt", "Data/Субъект.txt");
}
/// <summary>
/// Проверяет случай отсутствия начальной формы слова
в словаре: корректное завершение работы
/// </summary>
[Test]static void
Dictionary_InitialFormDidNotReveal_ExceptionCaught()
{();
parser = new
DictionaryParser(DictionaryType.Субъект);.AreEqual("стьюдентов", parser.GetInitialForm("стьюдентов"));
.Delete("Data/Субъект.txt");.Move("Data/Субъект1.txt", "Data/Субъект.txt");
}
/// <summary>
/// Проверяет случай отсутствия начальной формы слова
в пустом файле: корректное завершение работы
/// </summary>
[Test]static void
Dictionary_InitialFormDidNotRevealFromEmptyFile_ExceptionCaught()
{.Move("Data/Субъект.txt", "Data/Субъект1.txt");.Delete("Data/Субъект.txt");writer =
File.CreateText("Data/Субъект.txt");.Close();
parser = new
DictionaryParser(DictionaryType.Субъект);.AreEqual("стьюдентов", parser.GetInitialForm("стьюдентов"));
.Delete("Data/Субъект.txt");.Move("Data/Субъект1.txt", "Data/Субъект.txt");
}
#endregion
/// <summary>
/// Вспомогательный метод для подготовки стандартных
файлов
/// </summary>static void
CreateFake()
{.Move("Data/Субъект.txt", "Data/Субъект1.txt");.Delete("Data/Субъект.txt");writer =
File.CreateText("Data/Субъект.txt");
writer.WriteLine("Студент (Студента, Студенту,
Студентом, Студенте)");.WriteLine("Студенты (Студентов, Студентам,
Студентами, Студентах)");
writer.Close();
}
Модуль String.Capitalize()
Алгоритм и
код
Программный код модуля приведен в листинге 2.
Листинг
2
|
1
|
public static string
Capitalize(this string s)
|
|
|
2
|
{
|
|
|
3
|
if (String.IsNullOrEmpty(s))
|
1
|
|
4
|
return "";
|
2
|
|
5
|
|
|
|
6
|
string res = "";
|
3
|
|
7
|
res += s[0];
|
|
|
8
|
|
|
|
9
|
for (int i = 1; i < s.Length;
i++)
|
4
|
|
10
|
{
|
|
|
11
|
res += (_delimeters.Contains(s[i -
1])
|
5
|
|
12
|
? Char.ToUpper(s[i])
|
6
|
|
13
|
: s[i]);
|
7
|
|
14
|
}
|
8
|
|
15
|
res = res.Remove(" ");
|
9
|
|
16
|
|
|
|
16
|
return res;
|
10
|
|
16
|
}
|
11
|
Нижеприведенный
Рисунок 6 отражает блок-схему метода. Посимвольно перебирая строку, этот метод
исключает все пробелы и знаки препинания из строки и заменяет следующие за ними
символы их заглавными вариациями.
Например,
строка «Это строка из НЕСКОЛЬКИХ слов» будет преобразована к виду
«ЭтоСтрокаИзНесколькихСтрок».
Данный
метод является методом расширения для стандартного класса String
из .NET Framework. Он используется в
качестве вспомогательного для работы с перечислением Quntifier
(Квантор) - см. полный программный код в Приложении (или электронном приложении
к отчету).
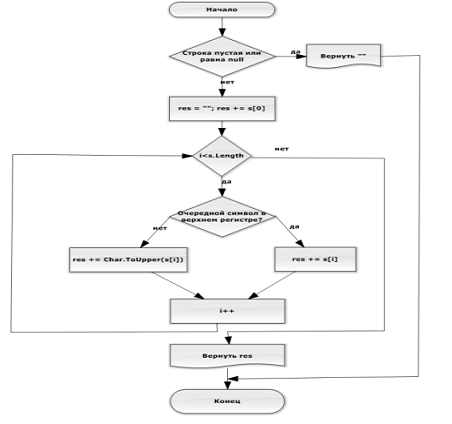
Рисунок
6. Блок-схема модуля String.Capitalize
Тестирование
базового пути.
1. Построение
потового графа
Потоковый
граф рассматриваемого модуля с указанием регионов и выделенными предикаторными
узлами приведен ниже (см. Рисунок 7).
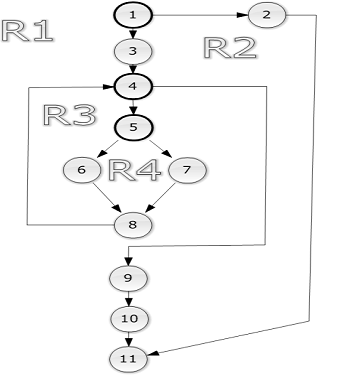
Рисунок
7. Потоковый граф модуля String.Capitalize
2. Оценка
цикломатической сложности
Приведенный граф позволяет оценить минимальное количество тестов, которые
должны быть проведены. Оценку цикломатической сложности будем производить тремя
указанными методами:
) V(G) = количество регионов = 4
) V(G) = количество дуг - количество узлов + 2 = 13 - 11 + 2 = 4
) V(G) = количество предикатных узлов +1 = 3 + 1 = 4
Таким образом, необходимо составить 4 теста, охватывающих независимые
пути в графе.
3. Определение
базового множества независимых путей
Путь начинается в начальном узле, а заканчивается в конечном узле графа.
Независимые пути необходимо разрабатывать в порядке от самого короткого к
самому длинному.
Были выявлены следующие независимые пути:
) 1-2-11
) 1-3-4-9-10-11
) 1-3-4-5-6-8-10-4-…-4-9-10-11
) 1-3-4-5-7-8-10-4-…-4-9-10-11
В представленном списке не учитывался факт наличия цикла (отрезки путей
3-4…-…-8 могут повторяться неоднократно)
4. Подготовка
тестовых вариантов
Для
тестирования каждого из независимых путей были созданы тестовые варианты
исходных данных. Сами данные (ИД), ожидаемый от них результат (ОЖ. РЕЗ.) и
результат, полученный фактически при выполнении программы (Ф. РЕЗ.), приведены
в Таблица 6.
Таблица
6. Тестовые варианты для метода базового пути
|
№
|
ИД
|
ОЖ. РЕЗ.
|
|
1
|
null
|
Пустая строка
|
|
2
|
Пустая строка
|
Пустая строка
|
|
3
|
Это другая строка
|
ЭтоДругаяСтрока
|
|
4
|
Это Еще Одна Строка
|
ЭтоЕщеОднаСтрока
|
Тестирование
ветвей и операторов отношений.
В рассматриваемом модуле есть три условных оператора, условия для которых
записаны операторами 1, 4 (условие выхода из цикла) и 5 (в формате тернарного
оператора - логической операции). Выполним тестирование для последнего
оператора:
+= (_delimeters.Contains(s[i - 1])
? Char.ToUpper(s[i]) : s[i]);
В этом случае, очевидно, достаточно рассмотреть два случая (для
некоторого индекса символа в строке i):
) Предыдущий символ есть символ-разделитель, то есть пробел или
знак препинания. Тогда к результирующей строке добавляем текущий символ,
выведенный в верхний регистр.
) Иначе, добавляем сам символ.
Достаточными будут следующие тест со строкой, в которой присутствуют как
символы-разделители, так и буквенно-числовые символы.
Тестирование
потоков данных.
Выполнение
тестов потоков данных не представляется целесообразным, так как единственная
используемая локальная переменная (кроме переменной итерации) изменяется на
каждой итерации цикла и будет протестирована позднее (см. раздел «Тестирование
циклов»).
Тестирование
циклов.
В модуле представлен единственный цикл типа «ДЛЯ КАЖДОГО <переменная_итерации>
ВЫПОЛНЯТЬ <действие>».
Для тестирования этого цикла будем проверять следующие варианты,
основанные на длине строки (так как условие выхода из цикла есть сравнение
переменной итерации с этой величиной):
) Строка из единственного символа-разделителя;
) Строка из единственного символа число-буквенной
последовательности;
) Строка из двух и более любых символов
Пустая строка не тестируется, так как в этом случае цикл не запускается.
Набор
модульных тестов.
/// <summary>
/// Проверяет случай null-строки: корректное
завершение работы (пустая строка)
/// </summary>
[Test]static void
String_NullStringPassed_EmptyReturned()
{pass = null;res = pass.Capitalize();
Assert.AreEqual("", res);
}
/// <summary>
/// Проверяет случай пустой строки: корректное
завершение работы (пустая строка)
/// </summary>
[Test]static void
String_EmptyStringPassed_EmptyReturned()
{pass = "";res =
pass.Capitalize();
Assert.AreEqual("", res);
}
/// <summary>
/// Проверяет случай строки, содержащей единственный
символ-разделитель:
/// корректное завершение работы (пустая строка)
/// </summary>
[Test]static void
String_DelimeterOnlyStringPassed_EmptyReturned()
{pass = " ";res =
pass.Capitalize();
Assert.AreEqual("", res);
}
/// <summary>
/// Проверяет случай строки, содержащей единственный
символ-НЕ разделитель:
/// корректное завершение работы (пустая строка)
/// </summary>
[Test]static void
String_NotDelimeterOnlyStringPassed_CapitalizedStringReturned()
{pass = "X";res =
pass.Capitalize();.AreEqual("X", res);
}
/// <summary>
/// Проверяет случай любой строки, пригодной к
капитализации:
/// корректное завершение работы (катитализированная
строка)
/// </summary>
[Test]static void
String_AnyCorrectStringPassed_CapitalizedStringReturned()
{pass = "Это тест Строки";
string res =
pass.Capitalize();.AreEqual("ЭтоТестСтроки", res);
}
Часть 4.
Интеграционное тестирование
Определение
модулей и способа тестирования.
Модульные тесты будут разрабатываться для следующих модулей:
1) M1 = Opinion.ParseExpression() - модуль синтаксического анализа
суждения
2) M2 = DictionaryParser.Parse() - извлечение данных из файла словаря.
3) M3 = DictionaryParser.Contains() - проверка на наличие формы слова
в словаре
4) M4 = DictionaryParser.GetInitialForm() - получение начальной формы слова
на основе данных, хранящихся в словаре
Результат
работы этих модулей используется в методе M5 = Opinion.CreateExpression(), поэтому структурная схема модулей выглядит так,
как показано на Рисунок 8. Линии направлены от модуля, содержащего
данные/функциональность к модулю, которые их использует.
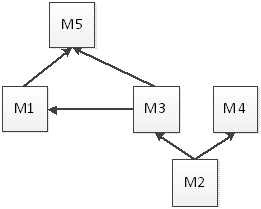
Рисунок
8. Структурная схема используемых модулей
Как видно из рисунка, зависимости между модулями определяют порядок их
тестирования:
1. M2
2. M4
3. M3
4. M1
5. M5
Набор
юнит-тестов.
В данном разделе будет приведен список юнит-тестов для модуля чтения и
использования данных словаря (модули M2-M4).
Для модуля M2 (получение
данных из файла):
- public static void
Dictionary_FileNotFound_ExceptionCaught()
Проверка работы модуля чтения данных из файла при отсутствии файла
- public static void
Dictionary_EmptyFile_NoExceptions()
Проверка работы модуля чтения данных из файла при файле, в котором не
содержится данных
- public static void
Dictionary_AllLinesParsedSuccessfully_NoExceptions()
Проверка работы модуля чтения данных из файла при файле с корректными
данными
- public static void
Dictionary_InvalidRecord_ExceptionCaught()
Проверка работы модуля чтения данных из файла при файле, данные в котором
хранятся в некорректной форме
Подробно
эти методы рассмотрены в разделе Часть 3. Тестирование методом «белого ящика».
Модульное тестирование: Модуль DictionaryParser.Parse() .
Для
модуля M3 (проверка наличия формы слова):
- public static void
Dictionary_ContainsSpecificForm_NoExceptions()
Проверка работы модуля проверки наличия формы слова при файле, который
содержит слово, переданное в качестве параметра.
- public static void
Dictionary_DoesNotContainSpecificForm_ExceptionCaught()
Проверка работы модуля проверки наличия формы слова при файле, который не
содержит слово, переданное в качестве параметра.
Для модуля M4 (получение
начальной формы слова):
- public static void
Dictionary_InitialFormRevealed_NoExceptions()
Проверка работы модуля получения начальной формы слова при файле, который
содержит слово, переданное в качестве параметра.
- public static void
Dictionary_InitialFormDidNotReveal_ExceptionCaught()
Проверка работы модуля получения начальной формы слова при файле, который
не содержит слово, переданное в качестве параметра.
- public static void
Dictionary_InitialFormDidNotRevealFromEmptyFile_ExceptionCaught()
Проверка работы модуля получения начальной формы слова при пустом файле.
Полный код тестов хранится в файле DictionaryParserTests.cs проекта Opinions.Test (подкаталог Tests).
Набор
интеграционных тестов.
Основное предназначение интеграционных тестов - проверить взаимодействие
модулей. В качестве тестируемой части программы был выбран метод CreateExpression() класса Opinion. Выбор был обусловлен двумя причинами:
- метод использует свойства класса, значения которым
присваивается в методе ParseExpression (модуль M1) и
явно вызывает метод Contains класса DictionaryParser (модуль M3);
- метод неявно вызывает метод GetInitialForm (модуль M4) класса DictionaryParser, а тот, в свою очередь, зависит от метода Parse того же класса (модуль M2).
Полный
код метода приведен в Листинг 3.
Листинг
3
|
1
|
public string CreateExpression()
|
|
2
|
{
|
|
3
|
this.Expression = this.ToString();
|
|
4
|
return this.Expression.Remove(new
string[] {"(", ")", "[",
"]"}).RemoveDoubleSymbols(' ');
|
|
5
|
}
|
|
6
|
|
|
7
|
|
|
8
|
public override string ToString()
|
|
9
|
{
|
|
10
|
return string.Format("{0} ({1}) {2}{3} [{4}{5}]",
|
|
11
|
this.Quantifier.ToString().Decapitalize().ToUpper(),
|
|
12
|
new
DictionaryParser(DictionaryType.Субъект).GetInitialForm(this.Subject),
|
|
13
|
(this.IsLinkPositive) ?
"" : (LocalizationHelper.GetString(Variables.Not) + " "),
|
|
14
|
new
DictionaryParser(DictionaryType.Связка).GetInitialForm(this.Link),
|
|
15
|
(this.IsPredicatePositive) ?
"" : (LocalizationHelper.GetString(Variables.Not) + " "),
|
|
16
|
new
DictionaryParser(DictionaryType.Предикат).GetInitialForm(this.Predicate));
|
|
17
|
}
|
Все тесты расположены в файле OpinionCreateExpressionTests.cs проекта Opinions.Test (подкаталог Tests).
/// <summary>
/// Проверяет случай пустого суждения: корректное
завершение работы
/// </summary>
[Test]static void
CreateExpression_SuccessEmpty_ExceptionsCaught()
{opinion = new
CommonOpinion("");
{.ParseExpression();
}(InvalidOpinionFormatException e)
{(e.Reason != FormatExceptionReason.СубъектНеОпределен).Fail("Subject is
not defined Exception required");
}
.Throws<NullReferenceException>(()
=> opinion.CreateExpression());
}
/// <summary>
/// Проверяет случай общеутвердительного суждения:
корректное завершение работы
/// </summary>
[Test]static void
CreateExpression_SucessPositive_NoExceptions()
{opinion;
{= new CommonOpinion("Все студенты учатся хорошо");.ParseExpression();.AreEqual("ВСЕ СТУДЕНТЫ УЧИТЬСЯ ХОРОШО",
opinion.CreateExpression());
}(Exception e)
{.Fail("Тест провален:
" + e.Message);
}
}
/// <summary>
/// Проверяет случай отсутвия файла словаря:
/// все исключения перехвачены, корректное завершение
работы
/// </summary>
[Test]static void
CreateExpression_DictionaryDoesNotExist_ExceptionCaught()
{.Move("Data/Субъект.txt", "Data/Субъект1.txt");opinion = new
CommonOpinion("Все студенты учатся хорошо");.Throws<DictionaryException>(opinion.ParseExpression);
.Move("Data/Субъект1.txt", "Data/Субъект.txt");
}
/// <summary>
/// Проверяет случай некорректной формы слова в
суждении:
/// все исключения перехвачены, корректное завершение
работы
/// </summary>
[Test]static void
CreateExpression_InvalidForm_ExceptionCaught()
{opinion = new CommonOpinion("Все стьюденты учатся хорошо");
{.ParseExpression();.Throws<InvalidOpinionFormatException>(()
=> opinion.CreateExpression());
}(Exception e)
{(e is DictionaryException ||
(e is InvalidOpinionFormatException
&&
(e as InvalidOpinionFormatException).Reason
== FormatExceptionReason.СубъектНеОпределен))
Assert.Pass();
}
}
Часть 5.
Регрессионное тестирование
Понятие
регрессионного тестирования. Основные положения.
Регрессионное тестирование (англ. regression testing, от лат. regressio -
движение назад) - собирательное название для всех видов тестирования
программного обеспечения, направленных на обнаружение ошибок в уже
протестированных участках исходного кода.
Из опыта разработки ПО известно, что повторное появление одних и тех же
ошибок - случай достаточно частый. По данным зарубежных авторов количество
ошибок, возникающих в процессе изменения кода (исправления багов, внедрения
новой функциональности и т.п.) колеблется от 50% до 80%.
Иногда это происходит из-заслабой техники управления версиями или по
причине человеческой ошибки при работе с системой управления версиями. Наконец,
при переписывании какой-либочасти кода часто всплывают те же ошибки, что были в
предыдущей реализации.
Поэтому считается хорошей практикой при исправлении ошибки создать тест
на неё и регулярно прогонять его при последующих изменениях программы. Хотя
регрессионное тестирование может быть выполнено и вручную, но чаще всего это
делается с помощью специализированных программ, позволяющих выполнять все
регрессионные тесты автоматически. В некоторых проектах даже используются
инструменты для автоматического прогона регрессионных тестов через заданный
интервал времени. Обычно это выполняется после каждой удачной компиляции (в
небольших проектах) либо каждую ночь или каждую неделю.
Выявить эти ошибки и помогают тесты регрессии. Обычно используемые методы
регрессионного тестирования включают повторные прогоны предыдущих тестов, а
также проверки, не попали ли регрессионные ошибки в очередную версию в
результате слияния кода.
Регрессионное тестирование может быть использовано не только для проверки
корректности программы, часто оно также используется для оценки качества
полученного результата. Так, при разработке компилятора, при прогоне
регрессионных тестов рассматривается размер получаемого кода, скорость его
выполнения и время компиляции каждого из тестовых примеров.
Определение успешности регрессионных тестов (IEEE 610-90 “Standard Glossary
of Software Engineering Terminology”) гласит: “повторное выборочное
тестирование системы или компонент для проверки сделанных модификаций не должно
приводить к непредусмотренным эффектам”. На практике это означает, что если
система успешно проходила тесты до внесения модификаций, она должна их
проходить и после внесения таковых. Основная проблема регрессионного тестирования
заключается в поиске компромисса между имеющимися ресурсами и необходимостью
проведения таких тестов по мере внесения каждого изменения. В определенной
степени, задача состоит в том, чтобы определить критерии “масштабов” изменений,
с достижением которых необходимо проводить регрессионные тесты.
Виды тестов
регрессии.
Верификационные
тесты (Verification Test).
1. Тесты верификация багов (Bug Verification Test) представляют
собой тесты проверки исправления багов. Допустим, что тест с номером 1 выявил баг,
что было зафиксровано и передано разработчику для исправления. Через
определенное время от разработчика была получена новая версия программы, с
информацией о том, что баг исправлен. Тогда возникает необходимость провести
тест с номером 1 повторно - для того, чтобы убедиться, что баг действительно
больше не проявляется. В случае успешного прохождения теста такой баг
помечается как Verified, в противном случае - как re-do, о чем сообщается
разработчику и передается на доработку. Проведение таких тестов является
обязательным. Так как причин, из-за которых исправленный баг может сохраниться
в программе - множество (от ошибочного описания, а, возможно, и понимания
проблемы, до ошибочного утверждения о том, что исправление имело место).
. Тесты верификации версии (Build Verification Test; Build Acceptance Test, smoke test,
quick check). Представляют
собой набор тестов для проверки сохранности основной функциональности в каждой
новой версии программы. Иными словами - это краткое тестирование всех основных
функций разрабатываемого ПО, цель которого - убедится, что программа
"работает нормально", что основная функциональность программы не
нарушена. Если хотя бы один из тестов верификации версии выявляет баг - то
тестер возвращается к предыдущей (последней "рабочей"), дальнейшей
тестирование новой версии не проводится, а информация об ошибке вносится в базу
и отправляется разработчику. Т.о. тесты верификации версии представляют собой
краткий набор основных тестов функциональности.
Тесты
регрессии (Regression Test
Pass).
Под этим понятием объединяют те тесты, которые уже проводились с
предыдущими версиями программы, притом успешно, т.е. не выявили багов и были
отмечены (например в Test Control
Matrix - матрица контроля тестов) как pass
(passed, пройденный). Необходимость проведения таких тестов очевидна. Допустим,
что ранее проведенный тест № 2, который обеспечивал проверку в программе
участка кода (назовем его условно кодом-А) не выявил ошибок в программе, и был
отмечен как pass. В ходе разработки возникла необходимость изменить участок
кода-А (например, при исправлении какого-либо иного бага или же в процессе
разработки новой функциональности). В результате этот участок кода требует
дополнительной проверки, что и будет сделано при повторном проведении теста №
2. Среди собственно тестов регрессии можно выделить две группы. Первая - тесты,
входящие в набор (т.н. Regression Test Pass with Regression Test Suit), другие
- тесты не входящие в набор (т.н. Regression Test Pass without Regression Test
Suit). Существенные отличия между ними в следующем: первые - вносятся в базу и
описываются, для них могут и должны быть созданы скрипты, которые позволяют
автоматизировать процесс тестирования; вторые - существуют только "в
голове" тестировщика и проводятся вручную. Причин последнего может быть
много - от малых сроков тестирования, до отсутствия необходимого ПО для
автоматизации процесса.
Тесты
регрессии на "закрытых" багах.
Рассмотрим пример. Допустим, что тест № 3, выявивший баг, после
исправления этого бага разработчиком был проведен повторно, при том успешно.
Тест был отмечен как pass, а баг - как Verified. Такой баг будет считаться
"закрытым". Допустим теперь, что в ходе разработки, участок кода, где
был исправлен этот баг, оказался изменен, или сменился разработчик, который
случайно удалил часть в коде, исправлявшую этот баг и т.п. В этом случае баг
проявится снова. Чтобы не допустить подобного, бета-тестеру время от времени
необходимо проводить тесты, выявлявшие ранее баги в измененном участке кода,
исправление которых уже было проверено ранее и зафиксировано в базе. Это и есть
тесты регрессии на "закрытых" багах.
Классификация
С. Канера
Следует отметить, что приведенный выше способ разделения тестов по
категориям не является единственным. Так, Сэм Канер, описал 3 других основных
типа регрессионного тестирования:
. Регрессия багов (Bug regression) - попытка доказать, что
исправленная ошибка на самом деле не исправлена
. Регрессия старых багов (Old bugs regression) - попытка доказать,
что недавнее изменение кода или данных сломало исправление старых ошибок, т.е.
старые баги стали снова воспроизводиться.
. Регрессия побочного эффекта (Side effect regression) - попытка
доказать, что недавнее изменение кода или данных сломало другие части
разрабатываемого приложения
Классификация
по способу сопровождения.
Другой способ классификации видов регрессионного тестирования связывает
их с типами сопровождения, которые, в свою очередь, определяются типами
модификаций.
Выделяют три типа сопровождения:
- корректирующее сопровождение, называемое обычно исправлением
ошибок, - выполняется в ответ на обнаружение ошибки, не требующей изменения
спецификации требований;
- адаптивное сопровождение - осуществляется в ответ на
требования изменения данных или среды исполнения;
- прогрессивное сопровождение - включает любую обра-ботку в
целях повышения эффективности работы системы или эффективности ее
сопровождения.
Определяют два типа регрессионного тестирования: прогрессивное и
корректирующее.
Прогрессивное регрессионное тестирование предполагает модификацию технического
задания. В большинстве случаев при этом к системе программного обеспечения
добавляются новые модули.
При корректирующем регрессионном тестировании техническое задание не
изменяется, а модифицируются только некоторые операторы программы и, возможно,
конструкторские решения.
Выбор тестов
регрессии.
На вопрос когда и как проводить регрессионное тестирование, и какие тесты
ставить в первую очередь ответить не просто. Все определяется видом
разрабатываемого ПО, продолжительностью жизненного цикла, сроками тестирования,
количеством членов команды.
. Регрессионное тестирование проводится в каждой новой версии.
. Начинают регрессионное тестирование с Тестов верификации версии.
Если программа приходит от разработчика в виде полноценной инсталляции, то Тесты
верификации начинаются с проверки инсталляции, после чего проводится краткий
набор тестов функциональности. Если хотя бы один из тестов failed, версия
передается на доработку, регрессионное тестирование прекращается, а тестер
возвращается к тестированию последней "рабочей" версии.
. После успешного прохождения тестов верификации версии, проводят
серию Тестов верификации багов.
. Из Собственно тестов регрессии проводят лишь те, которые
сопряжены с измененным в новой версии участком кода.
. Аналогичным образом (см. пункт 4 ) отбираются тесты в группу
регрессии на "закрытых" багах.
. Тесты регрессии, выполненные успешно (pass) дважды считаются
"закрытыми". Дальнейшее их использование производится так как описано
в пункте 4.
. Для тестов регрессии, которые предполагается проводить более 3-5
раз рекомендуется писать скрипты для автоматизации процесса. Это относится ко
всем группам тестов регрессии.
. Отбор тестов для Финального регрессионного тестирования
осуществляется по следующим принципам:
- В первую очередь отбирают тесты забракованные (failed) два и
более раз. В том числе и те, которые выявляли баги, требующие доработки
(re-do).
- Во вторую очередь отбираются тесты забракованные один раз, и
успешно пройденные повторно.
- Далее отбираются все тесты, которые были пройдены успешно
(pass), но проводились только один раз.
- Затем проводятся все остальные тесты, в зависимости от
поставленной задачи.
- Для наглядности при проведении Регрессионного тестирования
можно использовать следующую таблицу:
Таблица
7. Пример таблицы контроля тестов регрессионного тестирования
|
№ теста
|
Версия 1
|
№ бага
|
Версия 2
|
№ бага
|
Версия 3
|
№ бага
|
|
1
|
Pass
|
|
|
|
|
|
|
2
|
Fail
|
1
|
Pass
|
1 - verified
|
|
|
|
3
|
Pass
|
|
|
|
|
|
|
4
|
Fail
|
4
|
Fail
|
4 - re-do
|
Pass
|
4-verified
|
|
5
|
|
|
Fail
|
5
|
Pass
|
5-verified
|
|
…
|
…
|
…
|
…
|
…
|
…
|
…
|
Автоматизация
тестирования.
Автоматизация функционального регрессионного тестирования позволяет
существенным образом сократить затраты на тестирование ПО и значительно снизить
сроки данных работ.
Одной из основных задач обеспечения качества ПО является проведение
регрессионного тестирования, ресурсоемкость которого может доходить до 90% от
общего объема работ, связанных с тестированием новых версий.
В ходе автоматизации выполняются следующие задачи:
- анализ объектов автоматизации,
- выбор средств автоматизации тестирования,
- определение автоматизируемых компонент,
- разработка архитектурного решения,
- разработка и отладка скриптов,
- проведение регрессионного тестирования;
- обучение специалистов проектных команд работе со средствами
автоматизации, а также практикам эксплуатации разработанной инфраструктуры
тестирования.
Автоматизация тестирования дает ряд ощутимых преимуществ, таких как:
- снижение стоимости итерации тестирования,
- увеличение скорости тестирования без ущерба для результата,
- повышение надежности систем за счет улучшения качества
тестирования,
- уменьшение количества дефектов в функциональности систем,
- обеспечение возможности многократного использования
разработанных тестовых сценариев без увеличения стоимости тестирования,
- обеспечение прозрачности информации о качестве принимаемых
изменений к программному обеспечению,
- усиление контроля процесса обеспечения качества,
- прозрачность и простота планирования времени для проведения
тестирования программного обеспечения,
- использование передовых технологий в сфере обеспечения
качества,
- сокращение времени на проведение тестирования программного
обеспечения,
- минимизация влияния человеческого фактора на процесс
тестирования.
В большинстве проектов по разработке и тестированию программного обеспечения
применяется автоматическое тестирование с использованием как коммерческих
инструментов: QuickTest Pro, WinRunner, TestComplete, Rational Functional
Tester, Rational Robot, - так и opensource-продуктов: Selenium, Watir, WatiN и
др.
Заключение
В ходе выполнения работы были закреплены методы тестирования программного
обеспечения. На основе спецификации с использованием метода «черного ящика»
были сформированы допустимые и недопустимые классы эквивалентности, то есть
набор ситуаций, в которых программа ведет себя одинаковым
(корректным/некорректным, соответственно) образом.
Несколько модулей программы (в терминах объектно-ориентированного
программирования - методов класса) были протестированы методом «белого ящика».
При этом для написания модульных тестов использовался фреймворк NUnit. Несколько объединенных, уже
протестированных модулей были подвергнуты интеграционному тестированию для
проверки их взаимодействия.
Дополнительно были рассмотрены методика проведения регрессионного
тестирования и некоторые средства автоматизации проведения тестов.
Рисунок
9 подтверждает, что все созданные тесты выполняются успешно, то есть программа
работает в соответствии со своей спецификацией.
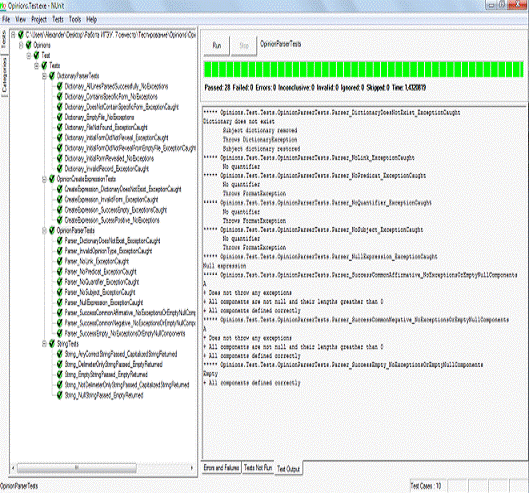
Рисунок
9. Результаты запуска тестов в среде NUnit