Разработка сервиса агрегации открытых данных
Оглавление
Введение
Глава 1. Теоретическая часть
.1 Обзор существующих решений на основе открытых данных
.2 Социальные сети
.3 Анализ исследуемой проблемы
.4 Технологии обработки данных
.5 Методы визуализации данных
Глава 2. Разработка системы
.1 Выбор источника открытых данных
.2 Выбор наборов открытых данных
.3 Социальные сети для извлечения данных
.4 Ограничение географической локации
.5 Формат хранения данных
.6 Архитектура системы
.7 Построение системы
Глава 3. Результаты
.1 Описание и анализ полученных результатов
.2 Обобщение результатов и практические рекомендации
.3 Новизна и практическая значимость исследования
Заключение
Список используемых источников
Приложение
Введение
За всю историю все сферы жизни человека переживали колоссальные
изменения. Считается, что человечество уже давно достигло той отметки, когда
главным ресурсом на планете является информация. Соответственно, владение
информацией представляет собой основную ценность в бизнесе, политике, военных
действиях и множестве других сфер. Именно из этих соображений появилась
знаменитая крылатая фраза "Кто владеет информацией, тот владеет
миром" Н.М. Ротшильда.
С каждый годом эта фраза становится все более актуальной. В современном
мире не редкость является компания, которая в качестве бизнес модели имеет
продажу или обработку информации. Основной причиной популярности и успеха
такого вида бизнеса является тот факт, что он доступен практически каждому.
Низкий порог входа обуславливает распространение этого вида электронного
бизнеса, а широкий охват всемирной паутины является преимуществом для простой
доставки информации [24]. Однако самым важным здесь является то, что информация
способна повлиять на деятельность индивидуальных предпринимателей, компаний и
даже государств. С помощью нее можно корректировать существующие процессы и
эффективно принимать решения. Последствия этого могут иметь исключительно
положительный эффект на прибыльности предпринимательской деятельности [23].
Еще одним аспектом повышения важности информации является ее объем. На
сегодняшний день генерируется настолько огромное количество информации, что
даже появился термин "информационный стресс". Количество информации,
которое человек потребляет ежедневно, отличается в тысячи раз по сравнению с
тем, сколько потреблял человек полвека назад. По данным IDC, количество информации удваивается
каждые два года [26]. Настолько стремительный рост объема данных ставит вопрос
о способах их обработке. Именно технологии по работе с большим количеством
данных и получили название "большие данные" (BigData). Они положили начало качественно новым подходам к
анализу данных. В своей основе они также используют последние достижения в
области компьютерных технологий и постоянно снижающуюся стоимость
вычислительных ресурсов.
Стоит отметить, что результатом анализа данных является информация. Можно
сказать, что обработка существующей информации порождает новую информацию. В
некоторых случаях оказывается, что пользу приносит именно сгенерированная
информация, поскольку содержит результаты анализа данных. Поскольку информации
с каждым днем становится все больше, а технологии по их обработке все более
доступными, становится возможным производить анализ из различных источников
информации. Это может быть информация разного формата, собранной для своих
целей, однако при их совместном использовании можно получить более полную
информацию об интересующем явлении или процессе. Такой процесс объединения
источников называется обогащением данных. В таком случае в результате обработки
агрегированных данных может получиться совершенно новая информация, которая
может быть полезна для использования, в то время как каждый источник по
отдельности практически бесполезен. Это еще одно направление развития больших
данных, поскольку появилась возможность извлекать полезную информацию из
огромных массивов данных, которые раньше не несли никакой пользы.
Как уже было сказано, владение и грамотное использование информации могут
положительно сказаться на экономическом аспекте той ли иной организации. Однако
здесь встает вопрос о качестве данных, их полноте и актуальности. В 2005 году
Тим О’Рейли предложил новую концепция построения информационных систем, которая
была названа "Веб 2.0". Главной особенностью ее являлось то, что
контент должен генерироваться и модерироваться самими пользователями. Он
считал, что при таком подходе должно увеличиться количество полезной
информации, она будет проверенной, а качество будет зависеть от числа
пользователей. На данный момент крупнейшими источниками пользовательского
контента являются социальные сети. Сам контент в социальных сетях может
показаться бесполезным, тем не менее, анализ этих данных может выявить
различные закономерности или модели поведения пользователей [12].
Экономическая сторона вопроса также интересует и государство. Влияние на
экономику полезной информации заставляет страны развивать концепцию открытого
государства. Для этого продвигается идея открытых данных, ставшая популярной во
всем мире. Для этого страны публикуют различные документы, статистику, наборы
данных, которые не являются секретными и гарантируют их достоверность,
актуальность и полноту [5].
Как можно заметить, существует великое множество источников данных в
современном мире. В данной работе будут рассмотрены источники в виде наиболее
популярных социальных сетей и одним из самых перспективных - открытых данных. сеть социальный сообщение
Цели и
задачи исследования
Цель исследования: разработка сервиса агрегации открытых данных и данных
из социальных сетей.
Задачи исследования:
· анализ предметной области;
· анализ существующих решений;
· выбор источника и наборов открытых данных;
· выбор социальных сетей для извлечения данных;
· ограничение геолокации сообщений из социальных сетей;
· разработка формата хранения данных;
· разработка сервиса сбора данных из социальных сетей;
· визуализация собранных данных методом теплой карты.
Глава 1. Теоретическая часть
Открытые
данные
Впервые термин открытых данных появился в далеком 1995 году, когда в
научном сообществе набирала популярность идея свободного обмена данными через
интернет. Идея набирала популярность вместе с ростом всемирной паутины и ее
доступностью. Уже в 2007 году на встрече активистов интернета в городе
Сан-Франциско были определены основные принципы, лежащие в основе открытых
данных. Открытые данные определялись как идея о доступной каждому информации в
формате, понятном машинам (компьютерам), без ограничений авторского права. Это
значило ровно то, что никакие механизмы контроля не могут быть применены к
использованию открытых данных, разумеется, если это не противоречит
законодательству государства. Также можно выделить основные принципы открытых
данных:
· свободный доступ;
· отсутствие ограничений по использованию данных;
· машиночитаемый формат;
· свободный формат файлов (CSV, XML, JSON);
· актуальность [31].
Сам факт того, что многие страны мира движутся в направлении открытых
данных, свидетельствует о том, что они стремятся к максимально открытому
государственному управлению. Делая данные открытыми, органы государственной
власти стремятся к прозрачной работе, формируя также контроль со стороны
граждан страны, а также способствуя созданию новых продуктов и сервисов. Наряду
с этим, публикация данных о государственной деятельности является фундаментом
для построения системы "Открытое правительство" [6].
Теперь стоит рассмотреть вопрос, как же могут пригодиться открытые
данные. На первый взгляд неясно, какие сервисы можно разрабатывать и как их
можно использовать для извлечения выгоды, как себе, так и пользователям
сервисов. Правительство в ряде стран проделывает огромную работу по обработке
данных, находящихся в их распоряжении. Работа заключается в переводе данных в
открытый формат и публикация их на сайте. Очевидно, что никакая секретная
информация не может быть подобным образом получена. Тем не менее, существует целый
ряд наборов данных обязательных для публикации. В разных странах данный список
может варьироваться в зависимости от законодательства. Таким образом, в США
обязаны быть опубликованы финансовые показатели каждого штата в отдельности. В
России же обязательным является публикация деклараций о доходах госслужащих.
Тем не менее, власти не ограничиваются публикацией только лишь обязательных
наборов данных. Также публикуются и списки парков и скверов, адреса городских
аптек и их режима работы, максимально допустимые цены на лекарства, пути
патрулирования машин-эвакуаторов и многие другие. Все эти данные могут быть
использованы бизнесом в качестве источника информации, которая является
бесплатной и доступна каждому. Более того, использование этих данных не накладывает
никаких ограничений по их использованию, поэтому они могут лежать в основе
новых продуктов и сервисов, в том числе платных.
Несмотря на широкую популярность в мире темы открытых данных, в России
существует немного проектов на их основе. С использованием открытых данных
связано несколько проблем. Во-первых, некоторые проекты, использующие открытые
данные, не осведомлены, что это именно "открытые данные". Такие
проекты просто используют ту информацию, которую легко найти на сайте и
скачать. Во-вторых, часть проектов используют открытые данные для обогащения
имеющейся информации. Такая информация может быть закрытой и платной, что не
позволяет точно оценить, какое влияние в данном случае оказали именно открытые
данные. И в заключение, существует стереотип, согласно которому крайне
нежелательно делиться информацией об источнике данных. Такая информация может
быть выгодна либо конкурентам для создания аналогичного продукта, либо
поставщика данных, который может начать взимать плату за использование данных.
В последнем случае крайне важно повышать осведомленность бизнеса об открытых
данных, что само понятие подразумевает свободное использование информации без
ограничений.
Практика использования открытых данных в бизнесе распространена по всему
миру. Существуют даже сайты, где перечислены наиболее популярные проекты,
реализованные в виде сервисов. Например, наиболее популярный портал в таком
формате - это "OpenData
500", где содержатся тысячи проектов из таких стран, как США, Канада,
Австралия, Мексика, Корея и Италия [14]. Также существуют бизнес-инкубаторы для
небольших бизнес-компаний, стремящихся построить бизнес на открытых данных.
Примером такого бизнес-инкубатора является "ODINE" (Open Data Incubator Europe) [13]. На их сайте можно найти множество компаний из
стран Европы, чей бизнес основан на использовании открытых данных. Также он
осуществляет поддержку проектов на начальных этапах, что крайне важно для
развития бизнеса. Все компании, которые участвуют в программе
бизнес-инкубатора, работают по схеме B2B, таким образом, их заказчиками
является также бизнес. Можно выделить наиболее показательные проекты: Farm Dog работает с сельскохозяйственным бизнесом и
предоставляет свои решения на основе открытых данных. Существует решение Brightbook, нацеленное на облегчения работы с
бухгалтерией. CommoPrices дает возможность пользователям в
удобной форме следить за ценами на товары. Есть сервис по совместному
использованию велосипедов Bike Citizens для
горожан велосипедистов.
Открытые данные используются компаниями из многих отраслей. Такие
компании представлены почти всеми сферами экономики: от транспорта и
здравоохранения до технологий и страхования. На портале "OpenData500" можно найти визуализацию,
какие именно открытые данные используются компаниями. Например, проекты в
консалтинге, инвестициях и финансах используют данные казначейства [14].
В России открытые данные также широко распространены, и самым значимым
поставщиком данных является само государство. На данный момент порталам
открытых данных есть куда развиваться, и прогресс действительно не стоит на
месте. Открытые данные непрерывно развиваются, и их качество и полнота
постоянно растет.
Однако, простого размещения открытых данных на сайтах правительства
отнюдь не достаточно для развития этой идеи. Для эффективного использования
открытых данных необходимо постоянно производить работу по популяризации данной
темы среди бизнеса и самостоятельных разработчиков. Таким образом, максимальный
эффект может быть достигнут только при широком сообществе пользователей открытых
данных, поэтому необходимо постоянно вовлекать новых людей в данную проблему.
Также развитию открытых данных может способствовать финансирование проектов на
их основе, стимулирование разработку новых приложений с их использованием.
Касательно российских реалий, получить гранты на развитие своего проекта вполне
возможно. Основным источником начального капитала являются различные хакатоны
[25]. Такой формат проведения конкурсов среди разработчиков получил широкое
распространение не только в России, но и по всему миру. Все проекты делятся на
номинации, в каждой жюри выявляет лучшие работы, которым и достанутся денежные
призы. Важным моментов здесь является то, что большинство хакатонов проводятся
либо самими государственными учреждениями, либо при их поддержке. Так, уже не
один год подряд хакатон проводит "Аналитический центр при правительстве
Российской Федерации". Таким образом, можно сказать, что в России
поощряется создание проектов на основе открытых данных, постепенно создаются
условия для бизнеса на их основе [29].
1.1 Обзор существующих решений на основе открытых данных
Популярность открытых данных сложно переоценить. Существуют целые
портала, посвященные проектам на основе открытых данных. Самым крупным из них
является сайт OpenData500. Тот факт, что проект был
опубликован на этом портале, уже означает, что он был признан комиссией как
подающий надежды или потенциально успешный. Стоит рассмотреть наиболее
популярные проекты на основе открытых данных [14].
Проект "Cerner".
Проект в области здравоохранения, является крупным поставщиком информационных
технологий для медицинских учреждений, который оптимизирует клинические и
финансовые показатели. Проект предлагает своим клиентам уделить особое внимание
здравоохранению, комплексному решению составления портфеля услуг и проверенному
лидерству на рынке.
Проект "Garmin"
является глобальным поставщиком навигации, который стремится создавать
информационные продукты в области геолокации для автомобильных, авиационных,
морских и спортивных компаний. Бизнес-модель строится на вертикальной
интеграции сервисов, которая сохраняет эти функции внутри компании, что дает
больший контроль над сроками и качеством обслуживания.
Проект "OptumInsight"
предоставляет аналитику и консультационные услуги для повышения производительности
систем в области здравоохранения. Компания является одной из крупнейших в США
по предоставлению медицинских данных и помогает своим клиентам принимать более
точные и экономически эффективные решения о медицинском лечении и медицинском
страховании. Также проект преследует цель предоставить информацию о том, где
сосредоточить свои маркетинговые стратегии исследовательские усилия для
удовлетворения потребностей рынка. Его информационные услуги включают в себя
управление базами данных, включая электронные медицинские записи, аналитику и
различные консультации для поставщиков медицинских услуг, страховых компаний,
государственных учреждений и деятелей науки.
Проект "Splunk"
является ведущей программной платформой для оперативной разведки в режиме
реального времени. Их программное обеспечение и облачные сервисы позволяют
организациям искать, отслеживать и анализировать генерируемые компьютерами
большие данные, поступающие с веб-сайтов, приложений, серверов, мобильных и
носимых устройств. Предприятия, правительственные учреждения, университеты и
поставщики услуг по всему миру использует этот проект для углубления понимания
бизнеса и клиентов, повышения кибербезопасности, предотвращения мошенничества,
повышения эффективности обслуживания и снижения стоимости услуг.
Проект "OpenAid"
наследует давние шведские традиции открытости, демократии и общественного
доступа к информации. Он преследует цель повышения прозрачности донорского
финансирования за счет возможностей, создаваемых технологическими достижениями.
Проект получил государственную поддержку и был включен в программу реформ,
гарантирующих получение прозрачной помощи, которая требовала от
правительственных органов предоставление всей документации и общественной
информации, связанной с международным сотрудничеством в области развития.
Информационный портал обеспечивает пользователей информацией о том, когда, кому
и зачем была профинансирована медицинская помощь, и каковы были результаты.
Также стоит отметить, что существуют и отечественные разработки. В
основном такие проекты стимулируются за счет проведения хакатонов. Тем не
менее, их существование нельзя игнорировать. Хакатоны проводятся при поддержке
Министерства финансов Российской Федерации, Министерстве экономического
развития Российской Федерации и Аналитического центра при правительстве
Российской Федерации a[3].
Проект "Datatron"
представляет собой экспертную систему, в основе которой лежит нейронная сеть,
обученная на открытых данных. Отличительной особенностью программы является то,
что она способна отвечать на голосовые вопросы пользователей. Разумеется,
тематика вопроса должна быть строго связана с данными о бюджете страны.
Проект "Не оставляйте долги детям" преследует цель создания
рейтинга регионов по единственному критерию - величине долга. Данные собираются
из данных Минфина России, Росстата и Центрального банка. Также имеется
возможность визуализировать тренд величины долго по субъектам Российской
Федерации. Так, можно уловить тенденцию к сокращению или, наоборот, к
увеличению долга региональных бюджетов. В целом сервис показывает динамику
изменений долгов перед главами регионов.
Проект "Жалобин" представляет собой мобильное приложение для
отслеживания цен в аптеках. Пользователь имеет возможность сравнивать цену в
той или иной аптеке с максимально допустимой и помогать пресекать нарушения
ценовой политики. Достигается это путем отправки обращения в Управление
Роспотребнадзора.
Проект "OpenDataSearcher"
преследует идею о получении максимально простого и открытого доступа к данным.
Это достигается путем полнотекстового поиска с последующей визуализацией
полученных результатов. Кроме этого, у сервиса имеется возможность мгновенно
обратиться к конкретному ведомству за дополнительной информацией.
Последним будет проект по исследованию велодорожек Москвы. Цель
исследования заключается в том, чтобы выявить несоответствие между реальным
движением велосипедистов и существующими велодорожками. Результаты можно
назвать ожидаемыми: часть существующих дорожек для велосипедистов лежит не в
местах основного скопления любителей данного вида транспорта. Отсюда можно
сделать вывод, что сервис может быть весьма полезен для планирования
строительства новых дорожек и анализа интенсивности движения.
Как можно заметить, в основном наиболее популярные приложения и сервисы
на основе открытых данных направлены на совершенствование государственного
управления, в первую очередь за счет борьбы с коррупцией и повышения
прозрачности государственной деятельности, а также расширения государственных
услуг и распределения ресурсов. Открытые данные дают возможность гражданам
контролировать свою жизнь и требовать изменений, позволяя принимать более
обоснованные решения и новые формы социальной мобилизации, которые, в свою
очередь, способствуют новым способам общения и доступа к информации. Более
того, открытые данные создают новые возможности для граждан и организаций,
способствуя инновациям и экономическому росту, а также созданию рабочих мест.
Кроме этого, они играют все более важную роль в решении крупных общественных
проблем, в первую очередь, позволяя гражданам и политикам получить доступ к
новой форме оценки на основе открытых документов и статистики. Также подобные
сервисы позволяют более точно ориентироваться на основе открытых данных,
обеспечивая эффективное использование информации и расширение сотрудничества.
Тем не менее, существует ряд проблем, которые необходимо преодолеть для
достижения наилучшего результата. До сих пор существует недостаток спроса и
предложения на сервисы на основе открытых данных, что затрудняет его воздействие.
Открытые данные могли бы быть значительно более эффективными, если бы их
публикация дополнялась обязательством действовать на основе сформированного
понимания. К сожалению, открытые данные создают риски, особенно для обеспечения
конфиденциальности и безопасности. Если они не будут контролироваться должным
образом со стороны уполномоченных органов, их публикация может иметь весьма
пагубные последствия. В заключение стоит отметить, что распределение ресурсов
является недостаточным и ненадежным, что становится одной из основных причин
ограничения успеха или вовсе провала сервисов на основе открытых данных [10].
Социальные сети в современном представлении это интернет-площадка, где
пользователи могут заполнять свои профили, обмениваться друг с другом
сообщениями, основывать сообщества или состоять в них. Основной идеей таких
порталов было создание именно сетей, то есть двунаправленных графов друзей и
знакомых. Каждый пользователь имеет возможность находить в поиске людей, с
которыми он общается, с которыми он когда-либо учился, работал. Также это
распространяется не только на тех людей, с которыми человек знаком в реальной
жизни, но и способствует к возникновению новых связей. Социальные сети стирают
географические границы и позволяют свободно поддерживать связь с людьми из
любой точки мира, а также делиться своими новостями и мыслями. Более того, для
того что бы находить этих самых людей, с которыми необходимо установить
контакт, существуют мощные инструменты поиска. С помощью него можно выставить
фильтры не только по имени человека, его возрасту или дате рождения, но и по
городу, школе и других учебных заведениях, в которых он учился, а также по увлечениям,
мировоззрениям, работе или месту военной службы. Все это позволяет с легкостью
найти человека и восстановить связь при необходимости [1].
Наряду с этим социальные сети содержат огромное количество информации. С
каждым годом поток нового контента, который генерируют сами пользователи,
только растет. В основном это достигается путем увеличения активных
пользователей социальных сетей. По состоянию на июль 2016 года в самой крупной
социальной сети мира Facebook насчитывалось более 1,7 миллиарда пользователей [30]. Это почти
неограниченный источник данных для анализа поведения пользователей. Существуют
различные виды анализа поведения, одним из которых является анализ активности
пользователей. Его можно назвать одним из ключевых показателей, который характеризует,
сколько людей выражает свои мысли. Выражение собственной позиции может быть
проанализировано и является важнейшим и одним из основных источников поиска и
отслеживания трендов. Это своего рода индикаторы общественных интересов и
настроений, которые позволяют улавливать назревающие проблемы еще на этапе их
формирования. Помимо этого, активность в социальных сетях помогает компаниям
оценивать количество упоминаний брендов. С точки зрения рекламных кампаний
такой анализ позволяет понять, по каким каналам и каким образом лучше
взаимодействовать с потенциальными покупателями. Чаще всего такими компаниями
являются производители одежды и парфюмерии, тем не менее, подобный анализ может
быть полезен почти во всех отраслях. Более того, активность пользователей в
социальных сетях позволяет применять семантический анализ текстов, которые они
публикуют. В результате такого анализа можно вынести множество полезной
информации. Например, выделение ключевых слов позволяет построить корреляцию
между тем, какие темы затрагиваются в тексте и количеством просмотров и отметок
"мне нравится". Однако главное, что можно извлечь из семантического
анализа - это тональность текста. Другими словами, это то, как люди реагируют
на то или иное событие или проблему. С помощью такого анализа можно выявлять
интересы и позицию пользователей. Такая информация в первую очередь полезна
государству с точки зрения безопасности, тем не менее, она может найти
применение и в бизнесе.
Еще одной особенностью социальных сетей является тот факт, что они
представляют собой нечто большее, чем просто большая база данных. Прогресс в
информационных технологиях сделал огромный шаг вперед, благодаря чему
социальные сети позволяют следить за активностью пользователей в реальном
времени. Сейчас такая информация может быть доступна каждому пользователю
интернета. Применение такой возможности можно найти в сфере предиктивного
поведения [10]. Отслеживание формирования и динамики трендов становится
возможным в реальном времени. В контексте маркетинга анализ активности
пользователей может предсказывать, будет ли размещение рекламы эффективным в
конкретное время или же оно не достигнет своей цели. Также с помощью такой
аналитики можно строить прогнозы относительно того, какие настроения будут
преобладать в следующий момент времени. Помимо вышеперечисленных примеров
использования такой возможности, существует еще один неочевидный способ
использования аналитики в реальном времени. Речь идет о предсказывании
природных катаклизмов. В настоящее время современные способы заблаговременного
оповещения населения о приближающейся природной катастрофе попросту
отсутствуют. До сих пор человечеству не удалось найти способ определять
землетрясения или извержения вулканов с высокой степенью вероятности. Однако в
результате анализа социальных сетей на предмет упоминания природных катастроф
было выявлено, что некоторые сообщения были опубликованы до их возникновения.
Это может быть объяснено тем, что хозяева питомцев реагировали на странное
поведение своих любимцев и делились этим со своими подписчиками в социальной
сети. Подобные сообщения были зафиксированы за несколько минут до возникновения
землетрясений или извержений вулканов. Исходя из этого, можно сказать, что
анализ сообщений пользователей на предмет упоминания природных катастроф в
реальном времени может оповестить о надвигающейся угрозе местных жителей, в
результате чего это может спасти человеческие жизни.
В данной работе будет использована именно эта особенность социальных
сетей - возможность отслеживать активность пользователей в режиме реального
времени. Сообщения могут содержать в себе множество дополнительной информации,
например метку о географическом расположении пользователя в момент отправки.
Такую информацию можно использовать для визуализации данных. Польза от такой информации
может быть в сопоставлении географического места активности пользователей
социальных сетей и дополнительных объектов, например, парков и скверов.
1.3 Анализ
исследуемой проблемы
Проанализировав вышеперечисленные примеры приложений и сервисов на основе
открытых данных, можно заметить одну общую черту. Дело в том, что все они
выполнены как статические сервисы. Несмотря на то, что на сегодняшний день
существует огромное количество открытых данных, частота их обновления остается
крайне низкой. Самым частым можно назвать ежедневное обновление данных о
чем-либо, однако даже она является редкостью на порталах открытых данных.
Частота может варьироваться от одного дня до года, что свидетельствует о
статическом характере данных. Этого вполне может хватить, чтобы зарекомендовать
себя на хакатоне, но в реальной жизни вряд ли такое приложение или сервис
найдет активное применение.
Все-таки целью проведения хакатонов в России и не только является
популяризация использования открытых данных, Это может быть как сведения о
муниципальных и государственных финансах, так и прочая информация о текущем
положении дел в каждом субъекте страны. При этом популяризация должна проходить
не только среди разработчиков, но и среди журналистов, средств массовой
информации и исследователей. Еще одной целью можно назвать формирование
общественности, которая информационно образована, которая хочет дальнейшего
продвижения идеи открытых данных в массы. Наряду с этим, увеличение количества
проектов и привлечение внимания общественности будет вести к повышению
прозрачности финансовой информации, а также ее доступности. Более того,
создание информационных проектов будет стимулировать развитие общественно
важных проектов и общественных благ. Кроме этого, увеличение вовлеченности
граждан во внутренние дела государства неуклонно повысит уровень финансовой и
правовой грамотности среди населения.
Одним из способов привлечение внимания общественности к открытым данным -
это агрегация их с данными из социальных сетей. Социальные сети развиваются
высокими темпами, имеют широкий охват аудитории и высокую вовлеченность
пользователей. Более того, пользователи проявляют высокую активность в
социальных сетях. Такие сайты входят в топ ресурсов по генерации трафика в
интернете по всему миру. Идея состоит в том, чтобы соединить открытые данные с
данными об активности пользователей социальных сетей. Во-первых, существуют
способы производить мониторинг активности в режиме реального времени.
Во-вторых, сразу будет видно, какие наборы из открытых данных коррелируют с
активностью пользователей, а какие нет. Например, если отслеживать активность
пользователей по их месторасположению, то можно наложить на одну карту эти
данные и адреса парков и скверов. Это даст возможность проанализировать, что
интересует пользователей социальных сетей в том или ином месте, что вызывает
всплеск активности, а к чему они равнодушны. Еще одним пример может стать
исследование поведения пользователей. Допустим, если назначить на каждый парк
или сквер ответственного за него человека, то можно контролировать процесс
ухода за ним. Скорее всего, в более ухоженные парки и скверы будет ходить
большее число посетителей, а установленные арт-объекты и прочие украшения
только увеличат интерес к этому месту. К тому же, если производить мониторинг активности
пользователей социальных сетей по их месторасположению, можно будет легко
определить, произвело это какой-то эффект или нет. Разумеется, вся информация
будет доступна в режиме реального времени на сайте проекта. Все это придаст
сервисам динамику, то есть повысит интерес пользователей и, скорее всего,
заставит их вернуться как минимум еще один раз.
.4
Технологии обработки данных
На сегодняшний день технологии обработки данных сделали большой скачок в
своем развитии. Существует два основных направления: развитие аппаратного
обеспечения, то есть совершенствование процессоров и параллельной работы ядер
компьютера, и разработка программного стека. Первое направление уже добилось
выдающихся результатов даже в небольших устройствах. Если рассмотреть современные
мобильные телефоны, можно увидеть, что они уже обогнали по мощности компьютеры
пятилетней давности [20][9]. В скором времени стоит ожидать примерно равных
показаний производительности у мобильных устройств и настольных персональных
компьютеров. Все это достигается путем развития новых технологий производства
микросхем, позволяющих добиться более компактного размещения элементов на
плате. Также стоит отметить, что стоимость производства комплектующих
компьютеров постоянно падает. Самым дорогим элементом серверов всегда являлась
оперативная память. На данный момент она по-прежнему остается таковой, однако
ее цена позволяет закупаться в достаточном количестве под конкретные задачи.
Наряду с этим, можно заметить, что развитие аппаратного обеспечения шло
плавными темпами, причем самые высокие темпы роста выпали на конец прошлого
века.
Развитие же программного обеспечения в обработке данных можно назвать
скачкообразным, поскольку оно во многом связано с развитием сопутствующих
технологий. Изначально был один единственный подход - все вычисления
производить на одной машине. Такой способ просуществовал ровно до того момента,
когда появились сетевой стек надежные протоколы передачи данных. Сразу же стало
ясно, что вычислительных ресурсов персональных машин недостаточно для
трудоемких задач, поэтому целесообразно было использовать центральный сервер
исключительно для вычислений, а локальные компьютеры оставить пользователям
только для взаимодействия и манипуляцией данных [4]. При таком подходе
необходимо было иметь только один мощный сервер и локальную сеть. Такая
архитектура была названа клиент-серверной, и существует она и по настоящий
момент. Оператор компьютера мог написать инструкции по обработке данных, то
есть откуда их загрузить, что с ними сделать и куда сохранить, а программный
стек осуществлял отправку загруженных данных на сервер, там их обрабатывал и
отдавал результат. Наиболее известные программные реализации такого подхода -
это RPC (Remote Procedure Call), Java RMI (Java Method Invocation) и CORBA [8].
Следующим витком развития стало использование кластеров вместо одного
центрального сервера. В какой-то момент времени даже мощного центрального
сервера перестало хватать для определенных видов вычислений. Резко встал вопрос
о распараллеливании вычислений между несколькими физическими серверами. Так
появился новый фреймворк Hadoop.
Появление Hadoop’а стало началом эпохи больших
данных, поскольку это был настоящий прорыв в обработке больших массивов
информации. Это фреймворк с открытым исходным кодом, написанным на Java. Это обуславливает широкую
распространенность за счет огромного сообщества Java-разработчиков и сторонников открытого программного
обеспечения. Hadoop спроектирован таким образом, что он
способен работать в распределенной среде и обрабатывать такое количество
данных, объем которых ограничивается лишь дисковым пространством [19]. В основе
этого фреймворка лежит революционный подход к распределенным вычислениям:
поскольку при больших объемах данных много времени тратится на транспортировку
их по сети, было решено отправлять не данные к обработчику, а код к данным. Это
позволило добиться качественного увеличения скорости обработки данных,
поскольку обработчики занимают меньше 200Кб и передаются по сети почти
мгновенно. Также в стек технологий Hadoop входит распределенная файловая система HDFS (Hadoop Distributed File System). Она позволяет хранить данные на нескольких сетевых
узлах, обеспечивая тем самым распределенную работу с данными. HDFS считается надежной распределенной
файловой системой, поскольку обеспечивает отказоустойчивую работу в
распределенной среде с поддержкой резервного копирования и репликации данных.
Это значит, что если какой-либо узел станет недоступен, его с легкостью сможет
заменить другой, где продублированы все данные. В качестве основной
вычислительной технологии Hadoop
использует алгоритм MapReduce, который
изначально был разработан компанией Google. Главный принцип этого алгоритма - это принцип "разделяй и
властвуй", то есть большие задачи разбивать на подзадачи, и так до тех
пор, пока каждая отдельная единица не станет считаться достаточно просто. После
разбиения задач на подзадачи необходимо произвести сбор результатов в одно
целое, что и будет являться конечным результатом выполнения программы. Еще
одной характерной чертой Hadoop
является тот факт, что он не зависит от какой-либо компании. Другими словами,
это лишь фреймворк с открытым исходным кодом, предоставляющий возможности
распределенной платформы по обработке больших массивов данных. Существуют
несколько основных поставщиков продуктов на основе Hadoop: это Apache,
Hortonworks, Cloudera и MapR. Всех их объединяет то, что, в конечном счете, они
выполняют одну и ту же задачу - распределенную обработку данных. Тем не менее,
у каждой компании свой подход к построению информационных систем. Более точно,
каждой компании требуется решение, ориентированное на эффективное использование
вычислительных мощностей их конкретных задач. В то время как Apache предлагает более общий вариант
использования Hadoop под широкий спектр задач, Hortonworks стремится к пакетной обработке
данных, причем как можно реже. Например, каждый день в базу данных поступают
миллионы записей, причем не так важно с какой частотой. Пакетная обработка
данных подразумевает, что стоит все поступающие данные сохранять в хранилище
данных, где они будут ждать дальнейшей обработки. После того, как система
решает, что данных накопилось достаточно, на этом этапе вступает Hadoop. Кластер Hadoop отвечает за загрузку данных из источника (в общем
случае из HDFS), производит предопределенные
разработчиками операции над данными и сохраняет их в нужном виде обратно в
распределенную файловую систему. При таком подходе достигается существенная
экономия времени на поднятие кластера и развертывания приложений. Гораздо
эффективнее накапливать данные, а потом з один проход осуществлять вычисления
над ними, чем каждый раз при поступлении данных их обрабатывать. Это и
называется пакетной обработкой информации (batch processing). Тем не менее, также необходимо
понимать, что минимальный размер окна расчета данных здесь исчисляется часами,
чаще всего это 1 сутки. Проблемы такого подхода очевидны: компании с каждым
годом все более ужесточают требования к частоте построения отчетности и
аналитики. Из-за этого все чаще встречается требование к анализу в виде
обработки данных в реальном времени или в режиме близкому к реальному времени.
С такими задачами решения на основе чистого Hadoop справляются крайне плохо. Их можно назвать
тяжеловесными и неповоротливыми технологиями, которым нужно время для старта,
для развертывания. В современном мире информационных технологий такие решения
начинают вытеснять более быстрые фреймворки.
Несмотря на все достоинства использования Hadoop, в современном мире он имеет ряд недостатков. Дело в
том, что дизайн его системы проектировался тогда, когда оперативная память была
очень дорогой. Из-за недостатка оперативной памяти все результаты вычислений
вынуждены сохраняться на диске. Любые операции с диском являются самым
медленным звеном в цепочке вычислений. На сегодняшний день цена на оперативную
память стала более доступной, а ее скорость в тысячи раз превышает скорость
работы с дисковыми накопителями. Именно это дало толчок к развитию новых
технологий, производящих вычисления в оперативной памяти. Наиболее популярным
решением, которое стремится избавиться от подобной проблемы, является Apache Spark [3]. Данный фреймворк также является проектом с
открытым исходным кодом, написан на Scala. Главной особенностью является то, что Spark сочетает в себе гибридную технологию, которая
способна при достаточном количестве оперативной памяти весь массив данных
держать как можно "ближе" к процессору. За счет этого экономится
время на транспортировку данных к обработчику и сохранение результатов
вычислений. Тем не менее, если вдруг окажется, что во время выполнения
программы памяти оказалось недостаточно, фреймворк сможет перейти на режим
работы с диском. Данная особенность позволяет работать максимально быстро при
относительно небольших объемов данных, которые ограничены лишь размером
оперативной памяти. В то же время Spark является отказоустойчивым решением, поскольку даже при нехватке памяти
он будет способен продолжить работу по обработке. Данная технология считается
надстройкой над Hadoop, однако это
мнение ошибочно. Разработчики этого фреймворка решили в корне пересмотреть
подход к обработке данных. В ходе посроения архитектуры системы они ушли от
повсеместно используемого классического алгоритма MapReduce и оставили его только на
специфический ряд задач. В результате масштабной переработки и переосмысления
произведения вычислений синтетические тесты показали, что решения на основе Spark в 100 раз превосходят аналогичные
решения на основе Hadoop.
Достигается это не только путем максимального использования возможностей оперативной
памяти, поскольку если переключить фреймворк в режим работы с диском, то
достигается ускорение до 10 раз. Все эти показания справедливы для пакетной
обработки данных, но разработчики ввели новую технологию. Поскольку все чаще
можно встретить у компаний требования к продукту в виде построения отчетности и
аналитике систем в реальном времени, было решено внедрить потоковую обработку
данных. Реализована она была в виде модуля Spark Streaming. Основная идея была в том, чтобы
эффективно перевести пакетную обработку данных на потоковую обработку путем
создания микро пакетов. Здесь необходимо ввести понятие скользящего окна. Было
решено, что окном будет называться единица времени, которая важна для
приближения анализа к режиму близкому к реальному времени. Другими словами, она
равняется количеству времени, сколько готов ждать бизнес для получения
результатов после получения данных. Во многих случаях хватает одной минуты,
однако создатели фреймворка не ограничивают в величине окна и оставляют его
определения на разработчика. Таким образом, данные в течение времени не
складируются в хранилище, где ожидают дальнейшей обработки, а поступают сразу к
обработчику. Такой потоковый режим значительно упрощает объем вычислений,
поскольку существует ряд задач, где легче обрабатывать данные "на
лету", чем держать их в хранилище. Еще одним преимущества данного
фреймворка является простота в использовании. Из расчета на массовое
использование этой технологии создатели позаботились о мультиплатформенности и
наличии программных реализации на нескольких языках программирования: Java, Scala, R и Python [22]. Также вниманием не обделили и
синтаксис описания обработки данных. Он в чем-то похож на синтаксис
структурированного языка запросов SQL. Этот язык является стандартом в отрасли информационных технологий и
знаком практически каждому человеку, кто в ней работает. Не смотря на то, что в
коде описывается набор данных как единое целое, фреймворк позволяет обращаться
к данным, которые располагаются на разных серверах или узлах так, как будто все
они расположены локально. Создатели фреймворка также сделали модули для
находящихся в тренде технологий: это потоковая обработка данных и машинное
обучение. Хоть машинное обучение и не получило до сих пор широкого
распространения среди пользователей фреймворка, этот модуль продолжает активно
развиваться и, возможно, в ближайшем будущем составит конкуренцию текущим
лидерам в этой области. Данный факт является еще одним преимуществом данной
технологии: все эти модули идет "из коробки", они легки в настройке и
использовании и органично сочетаются между собой. Как уже было сказано, Spark не является надстройкой над Hadoop и может запускаться в
самостоятельном режиме. Тем не менее, если требуется запускать Spark задачи на существующем Hadoop кластере, он также умеет это делать.
Помимо этого, Spark может запускаться совместно с Cassandra, Mesos, HBase
и другими популярными продуктами по распределенной обработке данных и дополнять
их. В технологии Spark также не
обходится без недостатков. Преимущества фреймворка могут обернуться и большой
проблемой для небольших компаний. Заключаются они в том, что для эффективного
использования технологии обработки данных внутри оперативной памяти до сих пор
узким местом является ее цена и объем. Небольшие компании на сегодняшний день
не способны купить дорогостоящую память в достаточном количестве, чтобы
обрабатывать даже не очень крупные по меркам больших данных массивы. Это не
говоря уже о самостоятельных разработчиках, которые пользуются стационарными
компьютерами, где максимальный объем памяти не превышает 16Гб. В какой-то
степени проблема может решиться с массовым распространением облачных вычислений
и их дальнейшим удешевлением, однако на данный момент она остается.
У всех решений на основе Hadoop
или Spark есть один общий недостаток - они
преимущественно для масштаба предприятий. Когда речь идет о технологическом
стеке Hadoop или Spark, подразумевается, что должна быть развитая
информационная инфраструктура. Имеется в виду, что должна быть развернута
распределенная файловая система HDFS,
распределенные базы данных, например Cassandra, для потоковой обработки данных в качестве источника
сообщений используется Kafka.
Касательно Kafka также следует отметить, что должен
быть еще сервис, который преобразовывает сообщения в записи нужного формата для
загрузки в очередь, чаще всего это самостоятельные приложения, на разработку и
тестирование которых также необходимо ресурсы и время. Проблема в том, что
установка и развертывание всей инфраструктуры - задача сложная и требующая
релевантного опыта. К тому же время на развертывание может занимать недели. А
поскольку это критически важно для произведения эффективных распределенных
вычислений, инфраструктура является ключевым фактором для использования
технологий Hadoop и Spark. Еще одним аспектом является не только их
развертывание, но и грамотная настройка каждого компонента в отдельности. В
распоряжении могут иметься различные сервера с разными характеристиками.
Необходимо подобрать подходящую конфигурацию сервера на каждый узел, а не
копировать одну и ту же настройку на всех. Иначе может возникнуть ситуация,
когда один мощный сервер производит расчеты очень быстро, и дет время простоя,
когда ждет результаты от медленного узла. Крайне важно давать релевантную
нагрузку на каждый узел с учетом их технических характеристик и вычислительной
мощности. Более того, для получения временной выгоды от распределенных
вычислений необходимо иметь более одного узла в своей инфраструктуре. Это
значит, что для эффективного использования параллельных операций нужно иметь
как минимум два физических сервера. Разумеется, это не проблема для компаний
любых масштабов, тем не менее, индивидуальным разработчикам не всегда является
возможным иметь такую конфигурацию машин. Кроме этого, существуют такие операции
над данными, которые плохо подвергаются параллельным вычислениям или невозможны
вообще. Такие виды вычислений должны выполняться на одной машине без
использования технологий, наподобие Hadoop или Spark.
Еще одним решением по обработке данных стало Java Stream API. Он стал доступен в Java с версии 1.8 и получил широкое распространение в виду
ряда причин. В качестве основной идеи данная технология выделила термин канала
(pipeline) [2]. Идея в том, что на входе в
поток данные могут проходить различные обработчики, которые выполняются
исключительно последовательно, но внутренняя реализация каждого допускает и
параллельное выполнение. Также характерной особенностью является то, что
использование "ленивых" вычислений может радикально сократить время
выполнения вычислений. Так, к примеру, если в ходе описания обработчиков на
выходе ожидается получить только один элемент, когда на входе был целый массив,
нет необходимости проделывать весь ряд операций над всеми элементами массива.
Такой обработчик вступает в силу только после выполнения терминальной операции,
которая дает понять, что необходимо начать вычисления. В ходе анализа некоторые
обработчики могут игнорироваться, если система решит, что они бесполезные.
Например, если разработчик по ошибке напишет метод сортировки более одного
раза, система проигнорирует остальные обработчики, поскольку появится статус
потока как сортированный. Более того, если учитывать архитектурные особенности
построения процессора, то можно также получить ощутимый прирост в производительности.
Например, требуется над входным массивом провести операцию фильтрации ненужных
элементов с последующей сортировкой. В таком случае можно сначала массив
отсортировать, а потом, используя правило выбора ветки в процессоре (branch prediction), без проблем пройтись по всем
элементам массива и определить, подходят ли они по критерию или нет. Еще одним
преимуществом технологии является ее расширяемость. Разработчики могут
самостоятельно разрабатывать нужные компоненты, которые сразу же можно будет
использовать в потоковой обработке данных. Такой возможности нет ни у Hadoop, ни у Spark, поскольку все возможности фреймворков определяются
их создателями. Уже существуют отдельные бесплатные библиотеки с открытым
исходным кодом, которые стремятся разнообразить стандартный программный
интерфейс и расширить его базовые возможности. Одной из таких является StreamEx, которая сочетает в себе простоту
использования и полезные функции. Несмотря на перечисленные преимущества,
данная технология не лишена недостатков. Внутреннее устройство Java Stream довольно сложное, и не всегда поведение оказывается
очевидным при выполнении. Даже когда версия языка стала публично доступной и
имела статус релиза, разработчики находили такие особенности реализации,
которые в некоторых случаях оказывались ошибками. Самое опасное для тех
разработчиков, которые только начинают знакомиться с возможностями языка и этой
технологии в частности, является тот факт, что некоторые ошибки исправляются
добавление строки в документацию с пояснением, какие именно странности могут
возникнуть при использовании. Дело в том, что не все опытные разработчики
прибегают к чтению документации, не говоря уже о спецификации языка, которая
изложена на сотнях страниц. Это сделано по одной единственной причине, что Java возлагает на себя ответственность за
обратную совместимость версий. Это значит ровно то, что любое написанное
приложение должно работать абсолютно одинаково и на новых версиях языка. Также
недостатком является тот факт, что Java Stream не
определяет, откуда брать данные и куда их складывать. Очень многие функции эта
технология перекладывает на разработчика. В таком случае технология может
сосредоточиться на качественном выполнении одной конкретной задачи и не нести
ответственности за то, что будет дальше. Такой подход содержится в дизайне
языка в целом, и здесь это не исключение. Также в потоках существует
возможность параллельного выполнения операций, тем не менее такой подход далеко
не всегда может принести временную выгоду, к тому же он более требователен к
ресурсам компьютера. Дело в том, что технология сама старается распределить
вычисления по физическим ядрам процессора, и не всегда она делает это
эффективно.
Рассмотрев основные виды обработки данных можно увидеть, что главной
задачей обработки данных является преобразование их к удобному для
использования виду. В конечном итоге, какую бы технологию ни выбрать, их
результат должен быть одинаков. Каждая технология имеет свои преимущества и
свои недостатки, требуют свою настройку и конфигурацию оборудования. Можно
сказать, что эти технологии были созданы специально под определенный круг
задач, который они успешно выполняют. Тем не менее, главным выводом можно
считать то, что развитие технологий обработки данных должно идти в непрерывной
связанности аппаратного и программного обеспечения для достижения максимальных
результатов. Крайне важно, чтобы развитие технологий шло параллельно, органично
дополняя друг друга.
1.5 Методы
визуализации данных
Выбор правильного метода визуализации данных трудно переоценить.
Доказано, что визуальная информация воспринимается в сотни раз быстрее, чем при
чтении. В современном мире, где темп жизни с каждым годом становится все
быстрее, становится критически важным максимально сократить время на получение
новой информации без потери смысла. В данном разделе работы будут
рассматриваться возможные виды визуализации данных на географической карте.
Сервис агрегации данных предусматривает визуализацию данных на карте.
Дело в том, что сообщения из социальных сетей могут содержать в себе
специальные метки, которые означают географическое положение на планете. Такие
метки называются геотеги [17]. Они могут проставляться как пользователем
вручную, так и автоматически устройством, с которого совершен вход в социальную
сеть. Это может быть и мобильный телефон при отправке сообщения, и при
фотосъемке, и автоматическое определение местоположение по Wi-Fi сетям. Стоит отметить, что GPS навигация на сегодняшний день достаточно точно
определяет месторасположение устройств с точностью до 3 метров. Такой точности
вполне достаточно для определения адреса или объекта, откуда производится
отправка сообщения. Социальная сеть может соотносить координаты на карте и
объекты из базы данных, например, ночные клубы, музеи, выставки, театры и кино.
Это делается для более удобного восприятия информации о месте, где находился
пользователь на момент публикации сообщения.
Что касается портала открытых данных, то там есть наборы данных, которые
содержат в себе списки различных объектов. Это могут быть парки, скверы,
кинотеатры, магазины, аптеки, маршруты патрулирования машин эвакуации. Каждый
из объектов содержит в себе такие же метки о географическом месторасположении.
Более того, для определенных наборов данных, чья площадь достаточно большая,
может указываться не точка координат, а целый полигон. Полигон представляет
собой массив координат, последовательно упорядоченных против часовой стрелки.
Это сделано для того, что в некоторых случаях используется технология
рендеринга изображения с помощью видеокарт, где такая последовательность
является строго определенной.
В итоге мы имеем информацию об объектах из открытых данных и
месторасположение, где был сделан пост в социальной сети. Такую информацию
очень удобно анализировать не в текстовом виде, а на карте. Если рассматривать
вопрос в общем, то спектр задач с географическими картами постоянно
расширяется. Уже давно стали обыденностью сервисы по визуализации пробок, по
построению маршрутов, по поиску такси в реальном времени. Именно поэтому
развиваются новые технологии инфографики и карт. Существуют несколько типов
визуализации точек на карте. К первому виду можно отнести обычную метку. Метка
может быть в виде точки, маркера или любого другого изображения, определенного
разработчиком. Это самый простой вид визуализации, поскольку не требует никаких
специальных программных требований, так как представляет собой только лишь пару
координат. Ко второму виду можно отнести линию на карте. Самый простой вариант
- это отрезок, который характеризуется двумя точками, а в общем случае - массив
точек, соединенных последовательно. На карте такой тип широко распространен в
интернете. Его можно встретить на картах маршрутов, на картах пробок. Карты,
которые поддерживают панорамный вид, выделяют линиями те участки дорог, на
которых есть снятые панорамы. К третьему виду относятся более сложные
структуры, которые содержат в себе не только координаты точек, но и
дополнительную информацию. На карте они могут быть изображены как круги с
изменяемым радиусом. Иногда такой тип используется для визуализации населения
городов, где радиус круга соотносится с числом жителей города. Такой вид хоть и
считается распространенным, но все поставщики карт в интернете его
поддерживают. Следующим видом визуализации данных на карте является тепловая
карта. Изначально она использовалась только для обозначения температуры в
какой-либо точке пространства, о чем свидетельствует ее название. Однако она
получила применение и во многих других сферах деятельности, в том числе и на
географических картах. С помощью нее, например можно наглядно показать
неравномерную плотность населения планеты. Для обозначения различной плотности
используется не ее координаты и не ширина линий, а цвет. Именно параметр цвета
несет в себе дополнительную информацию, привязанную к координатам. Последним
видом визуализации является граф. Ребра графа могут нести в себе дополнительную
информацию об объекте описания. В дискретной математике эту величину называют
весом ребра. На географических картах такой вид также нашел применение.
Например, граф с весами может изобразить все аэропорта страны или мира, где вес
ребра будет означать время перелета. В виду сложной программной реализации, а
также неоднозначного формата входных данных, далеко не все существующие
поставщики карт в интернете поддерживают такой формат визуализации.
Далее следует рассмотреть, какие поставщики карт бывают. Существует
несколько решений, которые являются наиболее популярными среди пользователей
карт в интернете. Ими являются Google Maps, Яндекс.
Карты и OpenStreetMap [7][32][15]. У каждого решения есть
свои достоинства и свои недостатки. Начнем с карт от Google, поскольку они является самыми распространенными в
мире в виду своей огромной аудитории. Карты впервые появились в 2005 году,
поэтому имеют наибольший опыт среди всех остальных рассмотренных вариантов.
Корпорация Google уделяет пристальное внимание мелочам
на своих картах и каждый год старается улучшить качество своего сервиса. Помимо
визуализации схемы и вида со спутника, в этих картах доступны построение
маршрутов, размещение фотографий в привязке к месторасположению, панорамные
виды и многое другое. К тому же Google Maps предложила
пользователям возможность пройтись по улицам городов в виде функции
"Просмотр улиц" (Google Street View). В настоящее время выполнена съемка
большинства крупных и средних по размеру городов мира, а также некоторые
достопримечательности. Далее рассмотрим Яндекс. Карты. Во многом они повторяют
функционал карт от Google, поскольку
почти всегда выступали в роли "догоняющих". Тем не менее, все элементы
сервиса выполнены качественно, а в надежности работы не уступают своим
конкурентам. В России существует ряд сервисов, которые завязаны на картах от
Яндекс и используют его как основную технологию бизнеса. К ним относятся в
основном транспортные компании и таксопарки. На них также существует
возможность просматривать панорамы улиц, добавлять фотографии с привязкой к
геолокации. Более того, кому-то даже больше нравятся смотреть карты от Яндекс,
которые показывают загруженность дорог в больших городах, чем на картах
конкурентов. Затем идут карты OpenStreetMap. Основной чертой этих карт является использование только свободного
программного обеспечения, а также весь проект выполнен как проект с открытым
исходным кодом. Поскольку он был основан некоммерческой организацией, его целью
никогда не было получение прибыли. Главной идеей этого проекта стало свободный
доступ каждого пользователя в интернете к достоверной карте мира, так как не
существет организации, которая бы контролировала бы ее содержание и активность
пользователей. На этих картах также имеется возможность просмотра карты мира,
рельефа со спутников, панорам улиц. Тем не менее, скорость работы сервиса
оставляет желать лучшего. Это можно понять, поскольку хостинг серверов
оплачивается, в том числе и за счет добровольцев, кто не равнодушен к идее
свободного программного обеспечения. Это влияет и на разработку собственных
сервисов на их основе. В лицензии сказано, что запрещается использование карт в
качестве основы для коммерческого продукта, и это невозможно без разрешения
правообладателя. Однако не это является препятствием для разработки новых
сервисов, а отсутствие механизма расширения базового функционала. Любые
изменения должны быть отражены в исходном коде OpenStreetMap, после тщательного рассмотрения
заявок, которые выполняются месяцами, к тому же их могут отклонить. Именно
поэтому они не используются в качестве средства визуализации нестандартной
информации на картах в интернете. Далее в работе этот сервис не будет
рассматриваться.
Сравнивая оставшихся поставщиков картографических сервисов можно выявить
и различия. В основном они кроются в программном интерфейсе сервиса. Для
разработчиков дают одинаковые точки расширения карт путем подключения своих или
сторонних плагинов, однако некоторый функционал доступен только для владельцев
платного доступа к картам. Таким образом, для пользователя не будет никакой
разницы, посмотрит от на те или иные карты, но для разработчика, как для
поставщика сервиса, стоимость будет разной. В основном стоимость будет складываться
из числа запросов в сутки; если определенный порог был превышен, за каждый
следующий запрос будет взиматься плата. Это распространенная практика ведения
бизнеса в виде предоставления программного обеспечения как сервиса. Величина
этого порога регулирует характер бесплатного использования. Если порог будет
низкий, то приложение можно будет использовать лишь в ознакомительных целях.
Если порог будет выше, то он прекрасно подойдет для небольших сервисов с
небольшим количеством пользователей. Наконец, если порог будет высоким, то
такой подход подойдет и среднему, и малому бизнесу, однако плата будет
взиматься с крупных предприятий. Проанализировав ценовую политику Google и Яндекс, можно сказать, что Яндекс
допускает большее число бесплатных запросов, нежели его конкурент. Из этого
можно сделать вывод, что именно это карты лучше всего подойдут для сервиса
агрегации открытых данных и данных из социальных сетей с последующей
визуализацией в виде веб сервиса.
Рассмотрев основные способы визуализации данных на карте, можно сделать
вывод, что для задачи сервиса агрегации данных лучше всего подходит метод
построения тепловых карт. Он отвечает следующим условиям: этот метод сохраняет
информацию о географическом месторасположении, что крайне важно, когда пользователи
имеют дело с геотэгами. Также метод тепловых карт показывает плотность
сообщений на карте. Это достигается за счет градации цветов, которые передают
плотность активности в той или иной точке карты. Где активности нет, там цвет
не выделяется, показывается только карта. Там где активность есть низкая, там
используется спокойные зеленные оттенки. По мере роста активности цвет будет
постепенно меняться к агрессивному красному, что покажет максимальную
концентрацию активности на карте. Здесь стоит отметить, почему не подходит
метод агрегации в виде кружков. Во-первых, размер круга должен зависеть от
степени активности пользователей в социальных сетях. Однако это можно достичь
только за счет схлопывания нескольких точек в одну, вследствие чего теряется точность
данных о месторасположении. К тому же на карте будет показываться только одна
точка вместо площади, как будет на самом деле. Более того, смотря на карту,
невозможно сразу сказать, где находится максимальная активность пользователей,
поскольку размер круга легко спутать, если они похожи. К тому же возможна
ситуация, когда можно просто не заметить круг большей площади где-нибудь в
другом месте карты. С тепловой картой такая ситуация почти невозможна, так как
цвет воспринимается однозначно, и сразу можно сказать, где место максимального
скопления активности пользователей социальных сетей.
Google Maps и Яндекс.
Карты поддерживают возможность отображения тепловых карт [7][32]. В первом
случае такой тип карт поддерживается корпорацией официально. Это значит, что Google не только гарантирует стабильную
работу сервиса при использовании тепловых карт, но и поддержку по любым
вопросам, связанным с ними. К тому же это говорит о том, что они были тщательно
протестированы. Однако доступ к ним имеется только у владельцев платного
доступа. Другая ситуация обстоит у Яндекса. Они еще не добавили тепловую карту
как базовый функционал сервиса, однако разработчики-энтузиасты опубликовали
свободное расширение для их построения. Таким образом, тепловые карты можно
строить путем добавления стороннего плагина, который поставляется бесплатно.
Недостатком такого способа является тот факт, что разработчики пользуется им на
условиях "как есть" и не могут претендовать на поддержку в случае
возникновения проблем или вопросов. Тем не менее, это расширение хорошо себя
показало, и было рекомендовано Яндексом к использованию. Таким образом, выбор
технологии остановился на использовании Яндекс. Карт и визуализацией с помощью
тепловых карт, поскольку этот вид является наиболее релевантным данной работе.
Глава 2. Разработка системы
.1 Выбор
источника открытых данных
В России существует небольшое количество порталов открытых данных.
Большая часть из них является проектами, реализованными самим государством.
Дело в том, что в нашей стране у каждого субъекта Российской Федерации ест свой
портал открытых данных. На этих сайтах правительство публикует множество
наборов данных. Во многом они представлены различными наборами на тему
демографии, здравоохранения, культуры, ЖКХ и безопасности. Главной целью
создания подобных порталов является упрощение доступа к данным, которые
являются необходимым для современного общества. Также целью является
предоставление прозрачного контроля действий органов исполнительной власти.
Двумя крупнейшими порталами является "портал открытых данных
Правительства Москвы" и "портал открытых данных Российской
Федерации". Это можно объяснить тем, что столица должна подавать пример
остальным субъектам страны, как должна происходить публикация данных, какие
примеры таких наборов могут быть опубликованы и поощрять эту деятельность.
Помимо того, что эти два сайта являются наиболее крупными, наборы данных в них
регулярно обновляются и расширяются. Несмотря на то, что "портал открытых
данных Российской Федерации" содержит в себе большое количество наборов
данных, они представляют всю страны в целом. Дело в том, что визуализация на
карте будет крайне непоказательная из-за масштаба страны. Активность
пользователей будет сокращаться до точки, что, в свою очередь, не даст
представления о распределении месторасположении пользователей и объектов из
открытых данных. Исходя из того факта, что масштаб карты для визуализации не
должен быть слишком большим, было решено ограничиться одним городом.
"Портал открытых данных Правительства Москвы" как раз содержит
различные наборы данных о нашей столице, которые удобно накладывать на карту и
совмещать с активностью пользователей. Некоторые наборы данных пересекаются с
первым порталом, тем не менее, именно этот сайт содержит наиболее полную и
релевантную информацию об объектах различных сфер жизни. Таким образом, в
качестве источника открытых данных был выбран "Портал открытых данных
Правительства Москвы" [27][28].
.2 Выбор
наборов открытых данных
После определения источника открытых данных, необходимо выбрать, какие
именно объекты будут показываться на карте сервиса. На "Портале открытых
данных Правительства Москвы" существует множество наборов открытых данных,
от здравоохранения до пешеходной инфраструктуры. Касательно сервиса агрегации,
в первую очередь будут интересны разделы, в которых присутствует перечень
объектов с геолокацией. К ним относятся различные места досуга, объекты
культурного наследия, заведения питания. Одним словом, места, где люди могут
проявить свою активность в социальных сетях. На данном портале можно выделить
следующие категории:
· Досуг и отдых;
· культура;
· общественное питание.
В каждой из этих категорий есть более двух десятков наборов данных.
Однако не каждый набор подходит для использования в сервисе агрегации. Так,
некоторые разделы содержат лишь перечень объектов, среди полей которых
отсутствует информация об их географическом расположении. Наиболее интересные
разделы, которые имеют данные о геолокации в категории "Культура":
· музеи;
· театры;
· объекты культурного наследия;
· выставочные залы.
В категории "Досуг и отдых" можно выделить несколько наиболее
релевантных сервису агрегации:
· кинотеатры;
· места для досуга и отдыха с детьми;
· места для пикника;
· парковые территории.
В категории "Общественное питание" наиболее интересными и
содержащими в себе информацию о расположении являются:
· кафе;
· кофейни;
· рестораны;
· бары.
После выделения нужного перечня объектов из источника открытых данных,
необходимо обеспечить их загрузку в базу данных разрабатываемой системы. Для
этого нужно привести их к универсальному формату, который будет понятен сервису
агрегации, а также будет един для всех объектов из портала открытых данных.
Сложность заключается в том, что исходный формат данных в некоторых случаях
предполагает, что объект выражен в виде полигона точек. Другими словами, за его
месторасположение отвечает целая область на карте. Дело в том, что при большом
количестве отображаемых объектов, они будут смешиваться и мешать восприятию
целостной картины. Из этого следует, что нужно учитывать только координаты
центра области, чтобы на карте этот объект отображался как точка. Более того,
программный интерфейс карт располагает необходимым функционалом для обозначения
точек на карте и обеспечивает высокую производительность даже с большим
массивом данных. Подводя итог, следует отметить, что в результате загрузки
данных из портала открытых данных, вся информация будет конвертироваться в
единый формат. После этого она будет сохранена в базе данных системы, для того,
чтобы потом она могла быть загружена на карту пользователя для последующей
визуализации.
.3
Социальные сети для извлечения данных
В мире существует множество социальных сетей на любой вкус. Вероятно,
даже самый искушенный пользователь интернета найдет социальную сеть по своим
интересам. Тем не менее, на мировой арене уже давно наметились явные лидеры
данного сегмента. Речь идет о бессменном лидере Facebook, набирающем обороте Instagram, крайне популярном Twitter и всемирно известном видео хостинге YouTube. Каждая социальная сеть заполнила
свою нишу и удерживает там лидирующие позиции. Например, Facebook является универсальной сетью,
которая сочетает в себе элементы микроблога, сообщества, возможность делиться
видео и фото, широкие возможности общения между пользователями. В то же время
остальные сети более четко выделили для себя целевую аудиторию. Так, изначально
Twitter был нацелен исключительно на обмен
короткими сообщениями. Впоследствии там добилась возможность публикации фото,
тем не менее, эта функция является дополнительной опцией. Социальная сеть Instagram ориентирована на пользователей с
активной жизненной позицией. Сервис направлен на обмен фотографиями и короткими
видео. Дело в том, что фотографии являются центральной сущностью портала;
невозможно выложить пост, состоящий исключительно из текста. Далее расположился
YouTube, известный как сервис видео
хостинга. Несмотря на то, что данная платформа является социальной сетью,
рассматривать в данной работе она не будет по причине отсутствия геолокации.
Учитывая популярность вышеперечисленных социальных сетей, стоит отметить,
что в России существуют локальные игроки, которые с успехом замещают мировых
лидеров. Ими являются социальные сети "Вконтакте",
"Одноклассники", "Мой Мир" и "RuTube". Самой посещаемой в России является социальная
сеть "Вконтакте" с месячной аудиторией более 46 миллионов человек.
Принимая во внимание тот факт, что в России, а в частности в Москве, большей
популярностью пользуются локальные социальные сети, необходимо рассмотреть все
возможные варианты подключения социальных сетей к сервису агрегации.
Следующим этапом будет сравнение программных интерфейсов социальных
сетей. Дело в том, что простота и удобство в использовании играют важную роль
при разработке сервисов, работающих в режиме реального времени. Также важное
место занимает надежность платформы и обновление версий. Каждая социальная сеть
заинтересована в том, чтобы как можно больше разработчиков создавали новые
сервисы на основе их программных интерфейсов. Из-за этого зачастую сами
компании поставляют фреймворки для самых востребованных языков
программирования. Лидером по удобству и функциональности является социальная
сеть Twitter. Она поддерживает множество
фильтров, в том числе отсечение по месторасположению. Более того, там
предусмотрен потоковый режим извлечения контента. Потоковый программный
интерфейс является идеальным решением для сервиса в режиме реального времени.
Кроме этого, существуют программные реализации интерфейсов под все популярные
языки программирования, в частности Java. Именно этот язык программирования используется при реализации данного
проекта. Далее следует социальная сеть Instagram с максимально понятной, доступной и
полной документацией. Наряду с этим, у нее присутствуют клиенты под различные
языки программирования, в том числе под Java. Что касается остальных социальных сетей, с
реализацией клиентов под эти платформы связаны некоторые трудности. Они могут
проявляться в жесткой политике социальной сети в отношении количества запросов
в минуту, отсутствия фреймворка под нужный язык программирования или отсутствие
официальной поддержки. Также они могут выражаться в постоянно меняющихся
версиях программного интерфейса без сохранения обратной совместимости, что
затруднит поддержку проекта в дальнейшем. В итоге для первого варианта сервиса
агрегации данных были выбраны социальные сети Twitter и Instagram.
2.4
Ограничение географической локации
Ежедневно количество сообщений в социальных сетях увеличивается и на
сегодняшний день исчисляется миллионами. Чтобы снизить нагрузку на сервис и
отсеивать информационный шум в виде нерелевантных сообщений из социальных
сетей, необходимо поставить фильтры на пользовательскую активность. Поскольку в
качестве источника открытых данных был выбран сайт открытых данных
правительства Москвы, было решено ограничить все сообщения территорией этого
города. Во всех крупных социальных сетях у программного интерфейса есть
возможность выставить фильтр по географическому месторасположению. Как правило,
это достигается добавлением двух параметров к запросу: широты и долготы. Две
точки координат однозначно задают прямоугольник на карте, в рамках которого
будут отсеиваться нерелевантные сообщения.
Стоит отметить, что социальные сети, поддерживающие геотеги, имеют
собственную привязку координат к объектам из своих баз данных. Для реализации
сервиса агрегации данных из социальных сетей необходимо иметь координаты,
которые можно привязать к какому-либо объекту или точке. Например, человек
сделал фотографию и хочет поделиться ею со своими подписчиками. В результате на
опубликованном фото будет метка о расположении с названием места, где оно было
сделано. То есть другие пользователи вместо двух абстрактным чисел координат,
которые большинству людей будут непонятны, будет виднеться надпись "ПКиО
им. Горького". Формат, который понятен любому пользователю, является
крайне важным элементом любой социальной сети. Тем не менее, для того, чтобы
система могла оперировать с географическим положением пользователя, текстовый
формат является неприемлемым. Во-первых, список таких объектов даже в небольших
городах может составлять десятки тысяч записей. Во-вторых, этот список является
динамическим, поскольку он может время от времени пополняться и
модернизироваться. Более того, такой список необходимо постоянно отправлять
программному интерфейсу социальной сети для фильтрации нерелевантных записей.
Решением данной проблемы является использование исключительно числовых
параметров координат. При таком подходе будет полностью игнорироваться
текстовое обозначение мест и привязки к объектам. Они попросту будут
отсеиваться при извлечении данных из социальной сети. Как уже было сказано
выше, две координаты на плоскости будут задавать ту область, которая
соответствует городу на карте. Разумеется, город Москва имеет не прямоугольные
границы, однако прямоугольная форма полностью покрывает ее территорию и
захватает близлежащие немногочисленные жилые поселки. С таким допущением легко
смириться, поскольку оно никак не влияет на визуализацию пользовательской
активности и не несет в себе большую дополнительную загрузку. Более того,
выставления фильтра в виде только одного набора координат повышает временную
эффективность инструментов поиска социальной сети, поэтому фильтр по геолокации
будет срабатывать быстро. Несмотря на то, что алгоритм поиска является внешней
системой по отношению к сервису агрегации, необходимо учитывать, что на стороне
социальной сети существуют дополнительные системы мониторингов против действий,
направленных на дестабилизацию портала. К таким действиям можно отнести и запросы,
время выполнения которых превышает установленные нормы. При точном выделении
границ города Москвы, набор координат будет насчитывать несколько сотен пар.
Чтобы каждое сообщение соответствовало фильтрам, выставленным сервисов
агрегации, необходимо проверить геолокацию по каждой паре координат. Из-за
того, что система разрабатывается с функционированием в реальном времени, время
выполнения таких запросов может превысить установленные ограничения. Превышение
по времени выполнения запроса может повлечь за собой обрыв связи в лучшем
случае и блокировку аккаунта сервиса в наихудшем. В любом случае, такой риск
является неприемлемым при разработке сервиса агрегации.
Также необходимо учитывать, что некоторые сообщения отправляются без
геотегов, однако они автоматически заполняются социальной сетью. Даже при
выключенной GPS-навигации в мобильных устройствах
социальная сеть способна распознать расположение пользователя с точностью до
населенного пункта. Автоматическое заполнение геотегов в таком случае является
еще одной проблемой для визуализации данных агрегации. Дело в том, что подобные
сообщения попадают под критерии запроса по месторасположению пользователя,
однако не обладают достаточной точностью координат. В таких случаях социальная
сеть проставляет вместо расположения пользователя координаты центра населенного
пункта. Несмотря на то, что пользователи проявили свою активность в
интересующем нас городе, такие сообщения нельзя визуализировать на карте,
поскольку методу тепловых карт нужны точные координаты. Исходя из этого, такие
геотеги будут также фильтроваться, даже если они будут соответствовать городу
Москве.
2.5 Формат
хранения данных
Определившись с фильтрами в запросе к социальной сети, необходимо
проанализировать формат считываемых данных. Некоторые социальные сети
предоставляют программный интерфейс для ограничения получаемых полей сообщения.
Это сделано не только для удобства разработчиков и адаптации для конкретных
сервисов, но и по соображениям эффективности передачи данных. В некоторых
случаях количество полей может достигать нескольких десятков полей, из которых
полезную нагрузку для сервиса несут лишь несколько. Однако не все социальные
сети предоставляют программный интерфейс для фильтрации полей. Например, Twitter транслирует весь список полей сообщения,
описывающие его наиболее полно.
Далее следует проанализировать формат сообщений, который приходит от
социальных сетей, а также данные, которые нужны сервису агрегации для
корректного хранения и визуализации информации о расположении. Как правило,
большое количество сервисов в интернете использует формат JSON в пересылаемых сообщениях.
Социальные сети не исключение. Такое распространение обуславливается широкой
поддержкой данного формата, а также тем, что для языка программирования JavaScript, который является стандартом в мире
веб-программирования, он является родным. Во-первых, необходимо выделить все
поля, которые являются общими для социальных сетей. К ним относятся время
публикации, текст сообщения, геотег, автор сообщения. Во-вторых, необходимо
установить, какие поля нужны разрабатываемому сервису. Помимо вышеперечисленных
свойств, объект должен быть уникальным, то есть обладать идентификатором.
Поскольку у всех социальных сетей формат идентификаторов разный, и,
теоретически, они могут пересекаться, было решено генерировать его
автоматически на стороне разрабатываемого сервиса. Также необходимо добавить
поле источника, откуда было получено сообщение. С помощью него можно будет в
дальнейшем проводить анализ, в каких пропорциях поступают сообщения из каждой
социальной сети.
В результате работы сервиса необходимо адаптировать каждый источник
данных в универсальный формат. Во-первых, необходимо корректно конвертировать
время публикации сообщения. Самым распространенным форматом времени в интернете
является "Unix Timestamp", который представляет собой
число секунд, прошедших с 1 января 1970 года. Его широкое распространение
обуславливает простота формата, так как время выражено одним числом. Тем не
менее, он не учитывает часовые пояса в явном виде, поэтому среди разработчиков
принято указывать время по Гринвичу, то есть с нулевым сдвигом. Однако
социальная сеть Twitter не
поддерживает такой формат и передает время в текстовом формате UTC [18]. В сообщении от социальной сети
можно получить следующее:
"created_at":"Wed Apr 08 13:08:45 +0000 2017"
В результате сервис должен автоматически приводить время публикации
сообщения из разных социальных сетей к общему виду формата Unix Timestamp. Также у всех социальных сетей
разные форматы отображения геолокации пользователя. На примере Twitter можно показать, какой вид имеет
сообщение от этой сети [18]:
"place":
{
"attributes":{},
"bounding_box":
{
"coordinates":
[[
[-77.119759,38.791645],
[-76.909393,38.791645],
[-76.909393,38.995548],
[-77.119759,38.995548]
]],
"type":"Polygon"
"country":"United States",
"country_code":"US",
"full_name":"Washington, DC",
"id":"01fbe706f872cb32",
"name":"Washington",
"place_type":"city",
"url":
"#"897142.files/image001.jpg">
Рисунок 1. Архитектура системы
Глава 3. Результаты
.1
Описание и анализ полученных результатов
После проведенного анализа предметной области и реализации системы, был
разработан сервис агрегации открытых данных и данных из социальных сетей. В его
основе легла техника визуализации данных с помощью тепловой карты. Сервис имеет
микросервисную архитектуру, что означает наличие нескольких независимых
программных модулей, работающих параллельно и составляющих единую систему.
Общий вид сервиса представляет собой веб-сайт, центральной сущностью
которого является тепловая карта активности пользователей социальных сетей. В
общем виде карта выглядит следующим образом (рис. 2):
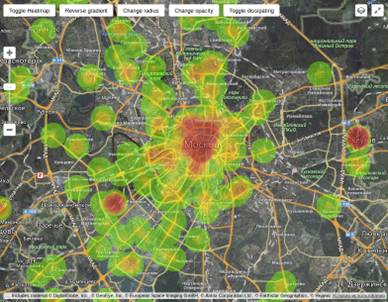
Рисунок 2. Общий вид тепловой карты
Как видно на тепловой карте, цвет в каждой точке характеризует плотность
пользовательской активности. Зеленый цвет соответствует низкой активности,
красный - высокой, бесцветные участки говорят о том, что там не было проявлено
активности в социальных сетях в целом. Стоит отметить, что практическую
значимость сервиса сложно переоценить. Карта может показывать, какие участки
города Москвы чаще всего оказываются в центре внимания среди пользователей
социальных сетей. Глядя на карту, можно сказать, какие достопримечательности и
объекты всегда пользуются спросом, по количеству сообщений и постов с меткой о
расположении, сделанных в этих местах. Еще одним применением сервиса может быть
выявление явных статистических отклонений от среднего количества сообщений в
каждом конкретном объекте из набора открытых данных. Разберем подробнее этот
способ на примере праздника Дня победы 9 мая. На этом случае стоит
остановиться, поскольку он является наглядным примером того, как визуализация
данных помогает выявлять резкие всплески активности пользователей. На рис. 3
изображена активность пользователей социальных сетей 9 мая 2017 года в период с
22:00 до 23:59. На изображении четко видно, что в "Парке Победы" на
Поклонной горе было сделано множество постов в социальных сетях. Это
объясняется тем, что городские власти в честь праздника устраивали салют в
нескольких точках Москвы, в частности в этом месте.
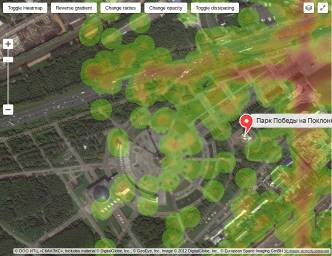
Рисунок 3.Активность пользователей в Парке Победы на
Поклонной горе 9 мая
Скорее всего, данный всплеск активности связан с тем, что люди хотели
запечатлеть салют в честь Дня Победы и поделиться своим постом со своими
друзьями в сети. Тем не менее, это стоит проверить. На следующий день, 10 мая,
ровно в точно такой же временной период было установлено, что количество
сообщений с географической меткой из этого места было в 17 раз меньше (рис. 4).
Дело в том, что, судя по собранным данным, это обычная активность в это время
суток в этом месте. Количество постов здесь колеблется в среднем от 30 до 50
единиц. Вероятнее всего, москвичи и гости столицы делятся здесь впечатлениями
непосредственно о самом парке. В случае же салюта, такое событие собирает
множество людей, но интерес для них представляет не сам парк, а именно
особенное событие в нем.
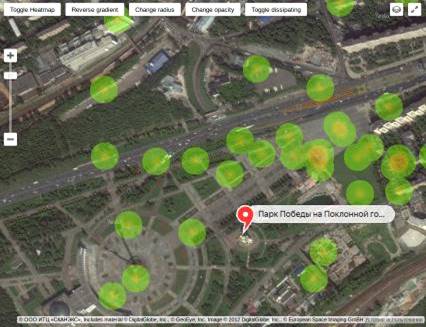
Рисунок 4. Активность пользователей в Парке Победы на
Поклонной горе 10 мая
Еще одним способом применения данного сервиса является тот факт, что его
можно использовать для выявления корреляции активности пользователей с
месторасположением объектов из набора открытых данных. Это можно объяснить на
примере парков и скверов. В Москве существуют более 650 официальных парковых
территорий. Из них лишь несколько являются действительно крупными и популярными
среди посетителей. В частности, к ним можно отнести ЦПКиО им. Горького и
Измайловский парк, которые ежедневно собирают в себе тысячи людей. Тем не
менее, для проявления пользовательской активности важен не размер парковых
территорий, а то, какие впечатления можно оттуда вынести. Так, парк Царицыно
ежедневно открыт для всех посетителей. Судя по тепловой карте сервиса и
среднему значению количества сообщений, он вызывает больше эмоций, нежели
Измайловский парк. Скорее всего, это вызвано тем, что там располагается
красивый и ухоженный пруд, а также Большой дворец, который изначально был
спроектирован для царицы в 18 веке, а сейчас является музеем. Очевидно, наличие
таких отличительных особенностью привлекает посетителей, а также вызывает у них
желание поделиться своими фотографиями или мыслями на этот счет. В этом случае
сервис даст понять, какие парки и скверы люди находя наиболее интересными. С
другой стороны, это также дает понимание менее популярным паркам, что для того,
чтобы там было больше посетителей и пользовательской активности, необходимо
завлекать людей с помощью необычных арт-объектов, памятников и прочих
заслуживающих внимания вещей.
Более того, разработанный сервис позволяет изучать такое понятие, как
сезонность. Дело в том, что пользователи проявляют свою активность в социальных
сетях крайне неравномерно по времени и по месторасположению. Разберем этот
случай на примере тех же парков и скверов. Рассматривая суточную сезонность на
тепловой карте, можно заметить, что количество постов в парках в ночное и
утреннее время крайне мало. В то время как это количество постепенно возрастает
в течение дня, вечером оно достигает своего суточного максимального значения и
к ночи опять идет на спад. Тем не менее, существует еще и недельная сезонность,
которая во многом появляется из-за наличия будних и выходных дней. Стоит
отметить, что пользовательская активность в выходные дни значительно превышает
в остальные дни. Такая сезонность обусловлена тем, что множество людей в
свободные от работы или учебы дни посещают различного рода заведения или парки,
где можно отдохнуть и весело провести время. Таким образом, можно сказать, что
сервис способен также и выявлять сезонность пользовательской активности среди
объектов из набора открытых данных.
3.2
Обобщение результатов и практические рекомендации
Помимо выполнения всех поставленных задач, попутно были решены также и
задачи, которые не были поставлены изначально. К ним относятся такие
результаты, которые вытекают из выбора гибких и современных технологий, которым
сейчас стараются придерживаться многие передовые корпорации. Речь идет о
кроссплатформенной разработке, а именно о языке программирования Java. За счет использования этого языка в
создании сервиса, удалось достичь независимости от платформы, на котором
необходимо развертывать приложения. Благодаря этому, становится возможным
запускать сервис на любой операционной системе, где была предустановлена
виртуальная машина JRE (Java Runtime Environment). Помимо этого, микросервисная
архитектура позволяет выделять отдельные независимые программные компоненты. Из
этого следует, что каждый программный модуль может быть запущен более чем в
одном экземпляре. Таким образом, становится возможным горизонтальное
масштабирование системы. Другими словами, с ростом количества посетителей на
сайт или с ростом количества сообщений из социальных сетей можно почти линейно
увеличивать вычислительные мощности. Более того, из-за того, что в системе
выделены отдельные модули, становится простым процесс их контейнеризации. В
качестве этой технологии можно выбрать самый популярный фреймворк для создания
и запуска контейнером - Docker.
Все это сделало данных сервис более гибким к развертыванию и устойчивым к
нагрузкам, что является важной деталью для систем мониторинга в реальном
времени.
На данный момент в сервисе реализованы клиенты для двух социальных сетей:
Twitter и Instagram. Это одни из самых популярных на
сегодняшний день платформ в мире. Они имеют развитый и технически сложный
программный интерфейс, позволяющие выстраивать гибкие запросы к своим базам данных.
Интеграция с другими сетями была осложнена рядом факторов, которые ранее уже
были описаны в данной работе. Тем не менее, ограничение клиентов было вызвано
только ограничением по времени написания сервиса. Стоит отметить, что
количество клиентов под разные социальные сети является хорошей точкой роста и
развития для сервиса. Дело в том, что чем больше сообщений будет обрабатывать и
сервис агрегации, тем точнее должна получаться визуализация активности
пользователей. В последствие можно будет добавить другие социальные сети,
например, мирового лидера в лице Facebook и более успешного игрока на российском рынке - Вконтакте.
Использование современных технологий разработки оставляет возможность для
расширения функционала. Есть масса идей, которые позволят качественно улучшить
сервис и развить в нем свой потенциал. Каждый день или любой другой отрезок
времени отслеживать, где пользователи наиболее активно себя проявляют в
социальных сетях. Далее с помощью загруженных наборов открытых данных можно
сопоставлять их географическое положение и определять, какой объект является
самым популярным на это время. Это может послужить своего рода рекомендательной
системой для отслеживания трендов посещений пользователями различных заведений,
музеев или выставок.
3.3 Новизна и практическая значимость исследования
Отличительной особенностью среди всех сервисов на основе открытых данных
является тот факт, что визуализация информации является динамической. Это
достигается за счет агрегации потоков данных из социальных сетей в реальном
времени. Недостатком сервисов, которые основываются только лишь на открытых
данных, является их редкое обновление на порталах. Как правило, такие наборы
данных статические и модифицируются крайне редко. Это влечет за собой такие
последствия, как проблемы с удержанием интернет аудитории у веб-ресурса.
Большинство пользователей, которые заходят на подобные сайты, редко
возвращаются или пользуются им повторно. Это объясняется тем, что сервис был
спроектирован таким образом, чтобы обратить внимание на какую-либо проблему или
явление. После того, как люди, пришедшие на интернет портал, изучили поднятый
вопрос, необходимость в нем сразу отпадает. Примером может послужить проект,
участвовавший в хакатоне по открытым данным. Проект заключается в том, чтобы
показать общественности и властям, что некоторые велодорожки были проложены не
там, где движутся велосипедисты в реальной жизни. Такие проекты можно считать
одноразовыми, поскольку они полностью статичны. После посещения такого сайта
интерес к данной теме теряется, а в случае повторного посещения ресурса
пользователь не обнаружит ничего нового.
Иначе дело обстоит с сервисом агрегации данных. Дело в том, что сама
природа социальных сетей автоматически избавляет данный сервис от подобных
недостатков. Благодаря тому, что все наполнение сетей целиком и полностью
генерируется пользователями, такая экосистема сразу становится динамической.
Соответственно, все сервисы, которые используют пользовательскую активность в
своей работе, также становятся динамическими. Все это ведет к тому, что в
каждый момент времени состояние сервиса уникально. Именно это и дает
преимущество перед статическими веб ресурсами, ограниченных определенным
набором открытых данных. Дело в том, что с точки зрения пользователей гораздо
выше вероятность повторного посещения подобного рода сайтов, поскольку они не
знают наверняка, что там увидят. Изучение активности пользователей в привязке к
наборам открытых данных теперь может быть растянуто по времени. Другими
словами, можно выявлять значимые тренды поведения пользователей в социальных
сетях, определять связь между местами скопления пользователей и объектами
города, такими как парки, скверы, места общественного питания и прочие. На
момент написания работы разработанный сервис не имеет аналогов.
Заключение
В результате выполнения выпускной квалификационной работы был реализован
сервис агрегации открытых данных и данных из социальных сетей. При этом была
достигнута основная цель данной работы. Стоит отметить, что автором были решены
все поставленные задачи. Данная система состоит из ряда отдельных независимых
модулей, выполненных согласно микросервисной архитектуре. Это клиенты под
каждую поддерживаемую социальную сеть, адаптеры для конвертации сообщений в
единый универсальный формат, сервис базы данных и веб-сервер для предоставления
доступа к данным пользователю. Сервис представляет собой веб-сайт, который
можно использовать с помощью браузера. Разработанный программный комплекс,
сочетающий в себе средства для визуализации и агрегации открытых данных и
данных из социальных сетей, не имеет аналогов на момент написания данной
работы.
Главной особенностью данного проекта является тот факт, что с помощью
сервиса можно выявлять зависимости между географическим положением
пользовательской активности, ее интенсивностью и объектами из набора открытых
данных. Так, благодаря интуитивно понятной визуализации вышеперечисленных
данных, можно анализировать места скопления людей, которые являются
пользователями социальных сетей. С помощью данного сервиса можно выявлять
закономерности в расположении объектов города, например парков и музеев, и
пользовательской активностью. Благодаря ему можно понять, какие места
пользуются спросом у людей, а какие являются непопулярными. Например, каким
паркам, помимо ухода за территорией, стоит обратить внимание на наполнение
запоминающимися объектами. К ним можно отнести арт-объекты или памятники. Все
это будет вести к повышению вовлеченности посетителей, что в свою очередь
приведет к их желанию поделиться своими впечатлениями со своими друзьями и
знакомыми в социальных сетях. Более того, данный сервис поможет выявить такое
явление как сезонность. Такая информация может быть полезна во многих сферах
жизни, например, представителям рекламных агентств или сетей общественного
питания.
Также следует обратить внимание, что в связи с использованием самых
современных инструментов и технологий индустрии разработки программного
обеспечения, разработанный сервис получился очень гибким в плане поддержки и
развертывания. Дело в том, что система является независимой от платформы.
Другими словами, она может выполняться на любой операционной системе, где есть
виртуальная машина Java. Также в виду
использования микросервисной архитектуры, отдельные независимые сервисы легко
поддаются контейнеризации. Такой подход сейчас стараются поддерживать все
передовые корпорации, занимающиеся разработкой программного обеспечения и
облачными технологиями. Самым распространенным способом является использование
технологии Docker, позволяющей без проблем производить
горизонтальное масштабирование приложений и удобное администрирование систем.
Несмотря на то, что сервис представляет собой готовый к использованию
программный продукт, существует несколько способов для его улучшения. В первую
очередь, в систему может быть добавлена автоматическая рекомендательная
система, которая способна распознавать тренды активности пользователей в
социальных сетях, сопоставлять с наборами открытых данных и делать выводы о
том, какие места в данный момент пользуются популярностью. Также стоит
отметить, что с помощью добавления в систему новых клиентов для других
социальны сетей, точность работы сервиса должна увеличиться. Это можно
объяснить тем, что такая тепловая карта будет еще более показательная, а
визуализация даст наиболее полную картину. Таким образом, у проекта существует
потенциал для развития и роста.
Список используемых источников
1. Boyd D., Ellison N.B. Social Network sites:
Definition, history and scholarship // Journal of Computer-Mediated
Communication, 2011, №11.
. Chan Y. "A Distributed Stream Library
for Java 8," Ph.D. dissertation, University of York, 2016.
. Chowdhury M., Zaharia M., Stoica I.,
Performance and Scalability of Broadcast in Spark. 2010.
. Dewire D.T. Client-server computing.
McGrawHill, Singapore, 1993.
. Digital Fuel of the 21st Century: Innovation
through Open Data and the Network Effect, Harvard University, 2011.
. Eur-Lex, Open data An engine for innovation,
growth and transparent governance, 2011.
. Google Maps Documentation [Электронный ресурс] // URL:https://developers.google.com/maps/documentation (Дата обращения 02.03.2017).
8. Grosso W. Java RMI. First Edition. O'Reilly
and Associates, USA, 2001.
. Kumar K., Liu J., Lu Y., Bhargava B., "A
survey of computation offloading for mobile systems," Mobile Networks and
Applications, vol. 18, no. 1, pp. 129-140, 2013.
. Lahiri M., Berger-Wolf T., "Mining
Periodic Behavior in Dynamic Social Networks," Proceedings of the 8th IEEE
Inter-national Conference on Data Mining, 2008, pp. 373-382.
. Microservices [Электронный ресурс] // URL: http://microservices.io/patterns/microservices.html (Дата обращения 20.04.2017).
12. O’Reilly T., What Is Web 2.0 [Электронный ресурс] // URL: http://www.oreillynet.com/pub/a/oreilly/tim/news/2005/09/30/what-is-web-20.html (Дата обращения 16.02.2017).
13. Open Data Incubator Europe [Электронный ресурс] // URL: https://opendataincubator.eu/ (Дата
обращения 16.02.2017).
14. OpenData 500 [Электронный ресурс] // URL: http://www.opendata500.com/ (Дата обращения 16.02.2017).
15. OpenStreetMap [Электронный ресурс] // URL: https://www.openstreetmap.org/ (Дата обращения 02.03.2017).
16. Ricardo T., Marco T.V., Roberto S.B. An
approach for extracting modules from monolithic software architectures.
Workshop, pages 1-18, 2012.
. Scharl, A. Towards the Geospatial Web: Media
Platforms for Managing Geotagged Knowledge Repositories. The Geospatial Web
Geobrowsers, Social Software and the Web 2.0 are Shaping the Network Society
(pp. 3-14). London: Springer, 2007.
. Twitter Developer Documentation [Электронный
ресурс] // URL: https://dev.twitter.com/overview/api/tweets (Дата обращения
18.04.2017).
. Venner J., Pro Hadoop. Apress, June 22, 2009.
. Wang G., Xiong Y., Yun J., Cavallaro J.
"Accelerating computer vision algorithms using OpenCL framework on the
mobile GPU-a case study," in Proceedings of the 38th IEEE International
Conference on Acoustics, Speech, and Signal Processing (ICASSP ’13), IEEE,
Vancouver, Canada, May 2013.
21. Бегтин И.В. Проблема открытых данных в России // Земля
из космоса. 2011.
№11. С.20-25.
22. Борисенко О.Д., Турдаков Д.Ю., Кузнецов С.Д.,
Автоматическое создание виртуальных кластеров Apache Spark в облачной среде OpenStack. Труды Института системного
программирования РАН, том 17, 2009 г. Стр 31-50.
23. Катков Е.В., Сорочайкин А.Н. Моедирование процессов
инновационного развития предприятий // Вестник Самарского государственного
университета. 2012.
№10. С.33-39.
24. Остервальдер А., Пинье И. Построение бизнес-моделей.
Настольная книга стратега и новатора. - М.: Альпина Паблишер, 2011.
. Открытые государственные финансовые данные
[Электронный ресурс] // URL: http://budgetapps.ru (Дата обращения 16.02.2017).
. Парамонов В., ГОС: Объем информации в интернете
удваивается каждые полтора года [Электронный ресурс] // URL: http://www.newsland.ru/news/detail/id/367158/ (Дата обращения 15.02.2017).
. Портал открытых данных правительства Москвы
[Электронный ресурс] // URL: https://data.mos.ru/ (Дата обращения 18.04.2017).
. Портал открытых данных Российской Федерации
[Электронный ресурс] // URL: http://data.gov.ru/ (Дата обращения 18.04.2017).
. Хакатон портала открытых данных data.gov.ru
[Электронный ресурс] // URL: http://data.gov.ru/hackathon (Дата обращения 16.02.2017).
. Число пользователей Facebook превысило 1,71 миллиарда
[Электронный ресурс] // URL: https://rg.ru/2016/07/28/chislo-polzovatelej-facebook-prevysilo-171-milliarda.html (Дата обращения 16.02.2017).
. Что такое открытые данные? [Электронный ресурс] // URL: https://opengovdata.ru/definition/ (Дата обращения 16.02.2017).
. Яндекс. API карт. Документация. [Электронный ресурс] // URL: https://tech.yandex.ru/maps/doc/jsapi/2.1/quick-start/tasks/quick-start-docpage/
(Дата обращения 02.03.2017).
Приложение
Текст программы
MapController.java
package com.alexcodes.web.controller;
import
com.alexcodes.web.dto.MapDTO;com.alexcodes.web.service.MapService;org.springframework.beans.factory.annotation.Autowired;org.springframework.http.MediaType;org.springframework.util.Assert;org.springframework.web.bind.annotation.RequestMapping;org.springframework.web.bind.annotation.RequestMethod;org.springframework.web.bind.annotation.RestController;
@RequestMapping("/map")class MapController {final
MapService mapService;
@AutowiredMapController(MapService mapService)
{.notNull(mapService, "Cannot be null");.mapService = mapService;
}
@RequestMapping(value = "/coordinates",=
RequestMethod.GET,= MediaType.APPLICATION_JSON_VALUE)MapDTO getCoordinates()
{mapService.getMap();
}
}
CoordinatesService.java
package com.alexcodes.web.service;java.util.List;interface
CoordinatesService {<List<Double" findCoordinates();
}
MapService.java
package
com.alexcodes.web.service;com.alexcodes.web.dto.MapDTO;org.springframework.beans.factory.annotation.Autowired;org.springframework.stereotype.Service;org.springframework.util.Assert;
@Serviceclass MapService {final CoordinatesService
coordinatesService;
@AutowiredMapService(CoordinatesService coordinatesService)
{.notNull(coordinatesService, "Cannot be null");.coordinatesService =
coordinatesService;
}MapDTO getMap() {dto = new MapDTO();.coordinates =
coordinatesService.findCoordinates();dto;
}
}
SimpleCoordinatesService.java
package
com.alexcodes.web.service;com.alexcodes.common.dao.GeoPostRepository;com.alexcodes.common.domain.GeoPost;com.google.common.collect.Lists;org.springframework.beans.factory.annotation.Autowired;org.springframework.context.annotation.Profile;org.springframework.stereotype.Service;java.util.Arrays;java.util.List;java.util.Objects;java.util.stream.Collectors;
@Service
@Profile("default")class SimpleCoordinatesService
implements CoordinatesService {final GeoPostRepository geoPostRepository;
@AutowiredSimpleCoordinatesService(GeoPostRepository
geoPostRepository) {.geoPostRepository = geoPostRepository;
}
@OverrideList<List<Double" findCoordinates()
{<GeoPost> posts =
Lists.newArrayList(geoPostRepository.findAll());posts.stream()
.map(post -> post.location)
.filter(Objects::nonNull)
.filter(location -> location.latitude != 55.7547875
&& location.longitude != 37.427642500000005)
.map(location -> Arrays.asList(location.latitude,
location.longitude))
.collect(Collectors.toList());
}
}
CoordinateDTO.java
package com.alexcodes.web.dto;class CoordinateDTO {double
longitude;double latitude;CoordinateDTO() {
}CoordinateDTO(double longitude, double latitude) {.longitude
= longitude;.latitude = latitude;
}
}
MapDTO.java
package
com.alexcodes.web.dto;java.time.Instant;java.util.List;class MapDTO {Instant
lastModified;List<List<Double" coordinates;
}
WebMain.java
package
com.alexcodes.web;org.springframework.boot.SpringApplication;org.springframework.boot.autoconfigure.SpringBootApplication;org.springframework.context.annotation.ComponentScan;
@SpringBootApplication
@ComponentScan(basePackages =
"com.alexcodes.*")class WebMain {static void main(String[] args)
{.run(WebMain.class);
}
}
Index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport"
content="width=device-width, initial-scale=1, shrink-to-fit=no">
<title>Social Parks</title>
<link
href="https://yandex.st/bootstrap/2.3.2/css/bootstrap.min.css"
rel="stylesheet">
<style type="text/css">, body, .hero-unit
{height: 100%;: 100%;: 0;
}
#YMapsID {: 900px;: 700px;
}
#YMapsCode {: 880px;
}
</style>
<script src="js/jquery-3.2.1.min.js"
type="text/javascript"></script>
<script
src="http://api-maps.yandex.ru/2.1/?lang=ru_RU"
type="text/javascript"></script>
<script src="js/heatmap.min.js"
type="text/javascript"></script>
<script
type="text/javascript">.ready(function () {
$.get("/map/coordinates", function (response) {data
= response.coordinates;map = new ymaps.Map('YMapsID', {: [55.751588,
37.617861],: ['zoomControl', 'typeSelector', 'fullscreenControl'],: 11, type:
'yandex#satellite'
}),= {: new ymaps.control.Button({: {: 'Toggle dissipating'
},: {: false,: 150
}
}),: new ymaps.control.Button({: {: 'Change opacity'
},: {: false,: 150
}
},: {: false,: 150
}
}),: new ymaps.control.Button({: {: 'Reverse gradient'
},: {: false,: 150
}
}),: new ymaps.control.Button({: {: 'Toggle Heatmap'
},: {: false,: 150
}
})
},= [{
.1: 'rgba(128, 255, 0, 0.7)',
.2: 'rgba(255, 255, 0, 0.8)',
.7: 'rgba(234, 72, 58, 0.9)',
.0: 'rgba(162, 36, 25, 1)'
}, {
.1: 'rgba(162, 36, 25, 0.7)',
.2: 'rgba(234, 72, 58, 0.8)',
.7: 'rgba(255, 255, 0, 0.9)',
.0: 'rgba(128, 255, 0, 1)'
}],= [5, 10, 20, 30],= [0.4, 0.6, 0.8,
1];.modules.require(['Heatmap'], function (Heatmap) {heatmap = new
Heatmap(data, {: gradients[0],: radiuses[1],: opacities[2]
});.setMap(map);.dissipating.events.add('press', function ()
{.options.set(
'dissipating', !heatmap.options.get('dissipating')
);
});.opacity.events.add('press', function () {current =
heatmap.options.get('opacity'),= opacities.indexOf(current);.options.set(
'opacity', opacities[++index == opacities.length ? 0 : index]
);
});.radius.events.add('press', function () {current =
heatmap.options.get('radius'),= radiuses.indexOf(current);.options.set(
'radius', radiuses[++index == radiuses.length ? 0 : index]
);
});.gradient.events.add('press', function () {current =
heatmap.options.get('gradient');.options.set(
'gradient', current == gradients[0] ? gradients[1] :
gradients[0]
);
});.heatmap.events.add('press', function ()
{.setMap(.getMap() ? null : map
);
});(var key in buttons) {(buttons.hasOwnProperty(key))
{.controls.add(buttons[key]);
}
}
});
});
});
</script>
</head>
<body>
<div>
<div>
<p>Yandex Maps API <a
href="https://github.com/yandex/mapsapi-heatmap">Heatmap
Module</a></p>
<div id="YMapsID"></div>
</div>
</div>
</body>
</html>
MongoConfiguration.java
package com.alexcodes.common.config;com.mongodb.Mongo;com.mongodb.MongoClient;org.springframework.beans.factory.annotation.Value;org.springframework.context.annotation.Configuration;org.springframework.data.mongodb.config.AbstractMongoConfiguration;org.springframework.data.mongodb.repository.config.EnableMongoRepositories;
@Configuration
@EnableMongoRepositories({"com.alexcodes.common.dao"})class
MongoConfiguration extends AbstractMongoConfiguration {
@Value("${spring.data.mongodb.host}")String host;
@Value("${spring.data.mongodb.port}")int port;
@Value("${spring.data.mongodb.database}")String
database;
@OverrideString getDatabaseName() {database;
}
@OverrideMongo mongo() throws Exception {new
MongoClient(host, port);
}
}
GeoPost.java
package com.alexcodes.common.domain;com.google.common.base.MoreObjects;org.springframework.data.annotation.Id;java.time.Instant;class
GeoPost {
@IdString id;SourceType sourceType;String text;Location
location;Instant timestamp;
@OverrideString toString() {MoreObjects.toStringHelper(this)
.add("sourceType", sourceType)
.add("text", text)
.add("location", location)
.toString();
}
}
Location.java
package
com.alexcodes.common.domain;com.google.common.base.MoreObjects;class Location
{Type type;double longitude;double latitude;Location() {}Location(Type type,
double longitude, double latitude) {.type = type;.longitude =
longitude;.latitude = latitude;
}
@OverrideString toString() {MoreObjects.toStringHelper(this)
.add("longitude", longitude)
.add("latitude", latitude)
.toString();
}enum Type {, CITY
}
}
AppConfig.java
package
com.alexcodes.twitter.config;com.twitter.hbc.core.endpoint.Location;org.springframework.beans.factory.annotation.Value;org.springframework.context.annotation.Bean;org.springframework.context.annotation.Configuration;
@Configurationclass TwitterConfig {
@Value("${twitter.location.southwest.longitude}")double
southWestLongitude;
@Value("${twitter.location.southwest.latitude}")double
southWestLatitude;
@Value("${twitter.location.northeast.longitude}")double
northEastLongitude;
@Value("${twitter.location.northeast.latitude}")double
northEastLatitude;
@BeanLocation location() {new
Location(Location.Coordinate(southWestLongitude,
southWestLatitude),Location.Coordinate(northEastLongitude, northEastLatitude));
}
}
LocationExtractor.java
package
com.alexcodes.twitter.logic;com.alexcodes.common.domain.Location;com.google.gson.JsonArray;com.google.gson.JsonElement;com.google.gson.JsonObject;org.slf4j.Logger;org.slf4j.LoggerFactory;org.springframework.stereotype.Service;java.util.ArrayList;java.util.List;
@Serviceclass LocationExtractor {static final Logger log =
LoggerFactory.getLogger(LocationExtractor.class);static final String
COORDINATES = "coordinates";static final String PLACE =
"place";static final String PLACE_TYPE =
"place_type";static final String CITY = "city";static final
String BOUNDING_BOX = "bounding_box";static final String TYPE =
"type";static final String POLYGON = "Polygon";Location
getLocation(JsonObject root) {coordinates = root.get(COORDINATES);(coordinates
!= null &&
!coordinates.isJsonNull())extractCoordinates(coordinates);place =
root.get(PLACE);(place != null &&
!place.isJsonNull())extractPlace(place);.error("Cannot extract location
from {}", root);null;
}Location extractCoordinates(JsonElement coordinates) {array
= coordinates.getAsJsonObject().getAsJsonArray(COORDINATES);longitude =
array.get(0).getAsDouble();latitude = array.get(1).getAsDouble();new
Location(Location.Type.POINT, longitude, latitude);
}Location extractPlace(JsonElement place) {placeType =
place.getAsJsonObject().get(PLACE_TYPE).getAsString();boundingBox =
place.getAsJsonObject().getAsJsonObject(BOUNDING_BOX);(!placeType.equals(CITY))
{.warn("Unknown placeType: {}", placeType);null;
}point = extractBoundingBox(boundingBox);new Location(Location.Type.CITY,
point.longitude, point.latitude);
}Point extractBoundingBox(JsonObject boundingBox) {type =
boundingBox.getAsJsonPrimitive(TYPE).getAsString();(type) {POLYGON:
{coordinates = boundingBox.getAsJsonArray(COORDINATES)
.get(0)
.getAsJsonArray();<Double> longs = new
ArrayList<>(coordinates.size());<Double> lats = new
ArrayList<>(coordinates.size());(int i = 0; i < coordinates.size();
i++) {point = coordinates.get(i).getAsJsonArray();.add(point.get(0).getAsDouble());.add(point.get(1).getAsDouble());
}avgLong = longs.stream()
.mapToDouble(Double::doubleValue)
.average()
.getAsDouble();avgLat = lats.stream()
.mapToDouble(Double::doubleValue)
.average()
.getAsDouble();new Point(avgLong, avgLat);
}:.error("Unknown format: {}", boundingBox);new
Point(0.0, 0.0);
}
}static class Point {double longitude;double
latitude;Point(double longitude, double latitude) {.longitude =
longitude;.latitude = latitude;
}
}
}
PostConverter.java
package com.alexcodes.twitter.logic;com.alexcodes.common.domain.GeoPost;com.alexcodes.common.domain.SourceType;com.alexcodes.common.logic.PostConverter;com.google.gson.JsonElement;com.google.gson.JsonObject;com.google.gson.JsonParser;org.springframework.beans.factory.annotation.Autowired;org.springframework.stereotype.Service;java.time.Instant;java.time.format.DateTimeFormatter;
@Serviceclass TweetConverter implements PostConverter {static
final String TEXT = "text";static final String CREATED_AT =
"created_at";static final DateTimeFormatter formatter
=.ofPattern("E MMM dd HH:mm:ss Z yyyy");final LocationExtractor
locationExtractor;
@AutowiredTweetConverter(LocationExtractor locationExtractor)
{.locationExtractor = locationExtractor;
}
@OverrideGeoPost convert(String message) {parser = new JsonParser();root
= parser.parse(message).getAsJsonObject();post = new GeoPost();.sourceType =
SourceType.TWITTER;.text = getText(root);.location =
locationExtractor.getLocation(root);.timestamp = getTimestamp(root);post;
}String getText(JsonObject root) {root.getAsJsonPrimitive(TEXT).getAsString();
}Instant getTimestamp(JsonObject root) {createdAt =
root.get(CREATED_AT);(createdAt == null) return null;timestamp =
createdAt.getAsString();formatter.parse(timestamp).query(Instant::from);
}
}
PostProcessor.java
package
com.alexcodes.twitter.logic;com.alexcodes.common.dao.GeoPostRepository;com.alexcodes.common.domain.GeoPost;com.alexcodes.common.logic.PostProcessor;org.slf4j.Logger;org.slf4j.LoggerFactory;org.springframework.beans.factory.annotation.Autowired;org.springframework.stereotype.Service;
@Serviceclass TweetProcessor implements PostProcessor {static
final Logger log = LoggerFactory.getLogger(TweetProcessor.class);final
TweetConverter tweetConverter;final GeoPostRepository geoPostRepository;
@AutowiredTweetProcessor(tweetConverter,geoPostRepository)
{.tweetConverter = tweetConverter;.geoPostRepository = geoPostRepository;
}
@Overridevoid process(String message) {{post =
tweetConverter.convert(message);.debug("Tweet: {}",
post);.save(post);
} catch (RuntimeException e) {.error("Exception during
tweet processing:", e);
}
}
}
Listener.java
package
com.alexcodes.twitter.service;com.alexcodes.twitter.logic.TweetProcessor;com.twitter.hbc.ClientBuilder;com.twitter.hbc.core.Client;com.twitter.hbc.core.Constants;com.twitter.hbc.core.Hosts;com.twitter.hbc.core.HttpHosts;com.twitter.hbc.core.endpoint.Location;com.twitter.hbc.core.endpoint.StatusesFilterEndpoint;com.twitter.hbc.core.event.Event;com.twitter.hbc.core.processor.StringDelimitedProcessor;com.twitter.hbc.httpclient.auth.Authentication;com.twitter.hbc.httpclient.auth.OAuth1;org.slf4j.Logger;org.slf4j.LoggerFactory;org.springframework.beans.factory.annotation.Autowired;org.springframework.beans.factory.annotation.Value;org.springframework.boot.CommandLineRunner;org.springframework.stereotype.Service;org.springframework.util.Assert;java.util.Collections;java.util.List;java.util.concurrent.BlockingQueue;java.util.concurrent.LinkedBlockingQueue;
@Serviceclass TwitterListener implements CommandLineRunner
{static final Logger log =
LoggerFactory.getLogger(TwitterListener.class);static final int QUEUE_SIZE =
1000;
@Value("${twitter.consumerKey}")String consumerKey;
@Value("${twitter.consumerSecret}")String
consumerSecret;
@Value("${twitter.tokenSecret}")String tokenSecret;
@Value("${twitter.client.name}")String
clientName;final Location location;final TweetProcessor tweetProcessor;
@AutowiredTwitterListener(Location location, TweetProcessor
tweetProcessor) {.notNull(location, "Location cannot be
null");.notNull(tweetProcessor, "Cannot be null");.location =
location;.tweetProcessor = tweetProcessor;
}void run(String... strings) throws Exception {
// Set up your blocking queues: Be sure to size these
properly based on expected TPS of your stream<String> msgQueue = new
LinkedBlockingQueue<>(QUEUE_SIZE);<Event> eventQueue = new
LinkedBlockingQueue<>(QUEUE_SIZE);
// Declare the host you want to connect to, the endpoint, and
authentication (basic auth or oauth)hosebirdHosts = new HttpHosts(Constants.STREAM_HOST);hosebirdEndpoint
= new StatusesFilterEndpoint();
// Optional: set up some followings and track
terms<Location> locations =
Collections.singletonList(location);.locations(locations);
// These secrets should be read from a config filehosebirdAuth
= new OAuth1(consumerKey, consumerSecret, token, tokenSecret);builder = new
ClientBuilder()
.name(clientName)
.hosts(hosebirdHosts)
.authentication(hosebirdAuth)
.endpoint(hosebirdEndpoint)
.processor(new StringDelimitedProcessor(msgQueue))
.eventMessageQueue(eventQueue);hosebirdClient =
builder.build();.connect();i = 0;time = System.currentTimeMillis();
// on a different thread, or multiple different
threads....(!hosebirdClient.isDone()) {message = msgQueue.take();
// log.debug("Receive: {}", message);.process(message);++;
// if (System.currentTimeMillis() - time > 60_000L) break;
}.info("{} TPS", i);.stop();
}
}