Особенности функционирования интерактивных web-ориентированных картографических систем
Введение
Проблема навигации в окружающем пространстве встает перед
нами с момента нашего рождения и непрерывно усложняется всю последующую жизнь.
Способствует этому усложнению как увеличение обозримого ареала обитания (т.е.
посещенных локаций), так и рост числа объектов, наполняющих эти ареалы. В
попытках облегчить навигацию издревле применялись астролябии, компасы, карты,
приборы оптического видения, но все они имеет слабую эффективность при
навигации в густонаселенном городе. Мегаполисы же содержат сотни тысяч объектов
недвижимости (зданий), в каждом из которых может находиться большое количество
потенциальных пунктов назначения (квартир, компаний, общественных мест и др.).
На этом фоне естественным образом развиваются информационные системы,
охватывающие всё больший объем информации о находящихся в городской среде
объектах. И если еще десятилетие назад такие системы по большей части
представляли справочники (желтые страницы, адресные и телефонные книги и др.),
то к настоящему времени рынок захватили комплексные геоинформационные системы
(ГИС), сочетающие справочник, картографический сервис, систему навигации
(GPS-метка) и систему оптимизации маршрута (в том числе с учётом скорости
перемещения транспорта на всём протяжении маршрута). Последние опросы населения,
проводимые как государственными фондами изучения общественного мнения, так и
различными негосударственными организациями (в том числе Интернет-ресурсами),
показывают устойчивый тренд на вытеснение геоинформационными системами
традиционных способов навигации.
Настоящая работа рассматривает проблему совершенствования
существующих геоинформационных сервисов для упрощения навигации в городской
среде на примере мест общественного питания, как одном из самых посещаемых
типов заведений.
В первой главе подробно рассмотрена существующая проблематика
на рынке потребительских интерактивных web-ориентированных геоинформационных
систем. Показана актуальность проблемы актуализации и полноты справочника
организаций. Формулируется гипотеза о возможности создания META-справочника,
консолидирующего данные об организациях сразу нескольких ГИС. Предлагается один
из способов апробации гипотезы.
Во второй главе подробно разобрана реализация предложенного
способа выгрузки, сведения и отображения полученного META-справочника.
Третья глава посвящена заключительным выводам и
результирующим положениям.
Цель данной работы - консолидация данных крупнейших
источников информации о местах общественного питания города Москвы в целях
обеспечения максимальной полноты и актуальности получаемой пользователем
информации в процессе подбора соответствующих заведений.
Для достижения данной цели поставлены следующие задачи:
Исследовать рынок навигационных веб-приложений:
· ознакомиться с наиболее популярными
навигационными веб-приложениями,
· оценить их преимущества и недостатки,
· оценить потребности людей, понять основную
проблематику, понижающую эффективность пользования подобными системами,
· Тщательно изучить предметную область:
· ознакомиться с технологиями,
использующимися для разработки подобных приложений,
· оценить сложность и трудоемкость
реализации поставленной задачи,
· спроектировать оптимальное решение на
стыке результатов исследования рынка навигационных веб-приложений и
технологических и ресурсных возможностей,
· Разработать веб-приложение,
консолидирующее данные об организациях общественного питания г. Москва:
· спроектировать прототип будущего
веб-приложения, основываясь на выявленных решениях,
· разработать функциональную составляющую,
· выгрузить данные из отобранных источников,
· разработать алгоритм сведения данных,
· разработать алгоритм визуализации
полученного справочника организаций.
1. Предметная область и анализ существующих решений
.1 Предметная область
Одним из основных способов решения навигационных задач для
современных web-ориентированных картографических сервисов является совмещение
(наложение) картографических данных рассматриваемой местности с информацией о
субъектах экономической деятельности. Такого рода наложение позволяет создать в
глазах пользователя неразрывную пространственно-информационную модель
окружающего мира, формирующую новую практику ориентирования в городской среде.
Подобная практика ориентирования включает изменение предпосылок, влияющих на
принятие решения о выборе того или иного заведения в качестве пункта
назначения. Так с ростом количества возможных альтернатив растет значимость
фактора стоимости перемещения (расстояния, времени и затраченных средств) и
уменьшается влияние факторов различия между самими заведениями. Неразрывно с
возрастающей сложностью и стоимостью перемещения (связанную в первую очередь с
ростом населения мегаполисов и заметно отстающим от него развитием транспортной
инфраструктуры) растёт и цена навигационных ошибок. Таким образом,
актуальность, полнота и корректность предоставляемой информации становится
важнейшим критерием эффективности использования пользовательских
картографических сервисов (Google Maps, Яндекс.Карты, 2GIS и т.д.).
При рассмотрении проблемы актуальности и полноты
геоинформационных данных следует разделять картографическую информацию и данные
о хозяйствующих субъектах. Так как указанные проблемы затрагивают их в разной
степени.
Динамика изменений городского ландшафта
(появление/исчезновение зданий, дорог, мостов, развязок, переездов и прочих
объектов инфраструктуры) относительно невысока, что позволяет картографическим
сервисам обеспечивать приемлемую для пользователя скорость актуализации данных.
Кроме того, источниками информации о подобных изменениях зачастую являются
официальные представители муниципальных органов, что позволяет добиться не
только высокой скорости актуализации (ведь данные о предстоящих изменениях
городской инфраструктуры и плановой застройки/сноса зданий отражаются в
генеральных планах и становятся публично доступной информацией задолго до
фактического начала работ), но и высокой достоверности предоставляемых
пользователю картографических данных.
Динамика появления/закрытия новых организаций, их филиалов и
представительств, равно как и изменение существенной информации о них (область
деятельности, режим работы, контактная информация и т.п.) на порядки выше
скорости изменения городского ландшафта. Прямые и косвенные подтверждение этому
можно найти в отчетах органов государственной регистрации и учета организаций
(ФНС), из которых следует, что за один рабочий день в 2017 году в Москве в
среднем появляется 379 организаций, а прекращает свою деятельность 371. Еще
большие темпы изменений динамики демонстрируют данные провайдеров телефонной
связи по выделению организациям телефонных номеров и данные “Координационного
центра национального домена” по регистрации и использованию доменных имён в
сети Интернет.
Кроме того, в отличие от изменений в городском ландшафте,
планировке улиц, плановой застройке, учет которых ведут муниципальные органы,
отражая в стандартизованной форме в открытых источниках, информация о
расположении, характере экономической деятельности и графике работы
коммерческих организаций не заносится в обязательном порядке в государственные
реестры. Соответственно у картографических сервисов нет аналогичного по уровню
достоверности источника информации, который позволил бы отслеживать и
безоговорочно актуализировать информацию о присутствующих на карте города
организациях.
Значительно более высокая динамика изменений исходных данных,
подлежащих визуализации, и отсутствие достоверных источников информации в учете
организаций, по сравнению с изменением данных о городском ландшафте ставит
перед картографическими сервисами задачу поиска и развития принципиально иных
подходов к ведению (сбору и актуализации) справочника организаций.
Таким подходом стал VGI (Volunteered geographic information), которую (ввиду
отсутствия аналогов в русском языке) близко к смыслу можно перевести как
“географические данные, собираемые волонтёрами”. По существу данный подход
является подмножеством UGC (User-generated content) подхода, при котором
информационное содержимое ресурса в значительной мере наполняется
пользователями ресурса. Сильной стороной данных подходов является существенное
снижение затрат в процессе сбора и актуализации справочника организаций, слабой
- отсутствие контроля над уровнем актуальности справочника и достоверности,
предоставляемой пользователями информации.
Снижение затрат происходит за счет отсутствия необходимости
содержать большой штат сотрудников, отвечающих за ручной (или
полуавтоматический) сбор и поддержку актуальности информации о действующих
заведениях. Вместо этого информацию о заведениях вносят в систему пользователи
и, в первую очередь, это сами владельцы бизнеса или представители компаний,
отвечающих за маркетинг (бизнес-пользователи), так как современные
интерактивные картографические сервисы являются одним из важнейших источников
появления новых клиентов. К сожалению, как показывает обширная практика
пользования интерактивными картографическими сервисами, очень часто
бизнес-пользователи забывают отражать или отражают с большим отставанием
информацию об изменении графика работы, контактных данных, закрытии или
переезде заведения, не говоря уже об описании характера оказываемых услуг.
Отдельной проблемой является информационный вандализм, который выражается во
внесении пользователями заведомо ложной информации.
Чем больше в справочнике данных, не соответствующих реальной
ситуации, тем больше ошибок навигации совершат пользователи сервиса. А именно
экономия времени при выборе точек назначения и навигации до них, с точки зрения
пользователя, является одним из основных критериев эффективности интерактивного
картографического сервиса.
1.2
Анализ существующих решений и проблематика
За годы эволюции сервисы картографии обзавелись различными
решениями, позволяющими повышать скорость актуализации базы данных заведений. В
основном все они работают по принципу более настойчивого получения обратной
связи от пользователя. Так пользователи получают запрос на подтверждение
корректности телефона в карточке организации сразу после совершения звонка по
нему. Кроме того, все карточки снабжены заметными элементами управления,
позволяющими сообщить о неактуальности представленной в них информации. К сожалению,
не происходит запроса о корректности представленного адреса заведения (и его
фактического существования) после того как пользователь с помощью интерактивной
карты закончил навигацию до места назначения. Технически это реализовывается
ненамного сложнее, чем аналогичный запрос на корректность телефонного номера.
Фактически же это позволило бы заметно уменьшить частоту ошибок навигации за
счет своевременного отражения информации о закрытии или переезде заведений.
Еще одним способом актуализации являются рассылки по базе
бизнес-пользователей с напоминанием о необходимости своевременного обновления
данных и введения платных подписок на размещение информации на карте. И если
эффективность рассылочного метода вызывает большие сомнения, как и в целом
данный канал коммуникации с пользователями, то покупка платного размещения
является хорошим мотиватором для владельцев компаний следить за качеством
предоставляемой информации.
На основных рынках присутствия (США, ЕС) компания Google
практикует методичное повышение квалификации волонтеров, занимающихся
актуализацией данных картографического сервиса Google Maps. Достигается это за
счет создания вокруг данного сервиса большого пользовательского сообщества с
элементами социальной сети и обширной мотивационной программы, повышающей
уровень вовлеченности волонтеров в деятельность по обновлению данных,
представленных на карте. К сожалению, преимущественно деятельность именно этого
VGI-сообщества сосредоточена на внесение правок непосредственно в
картографическую составляющую сервиса, практически не затрагивая работу со
справочником организаций.
Стоит отметить, что методы, направленные на повышение
актуализации и корректности существующей в справочнике информации, не решают
другую важную проблему - проблему полноты представленной информации.
1.3
Поиск возможных решений
веб
картографический пользовательский
В целом компании, занимающиеся развитием картографических
сервисов, прикладывают достаточно усилий для развития инструментария повышения
актуальности и корректности представленной информации внутри базы данных
сервиса. В целях дальнейшего повышения эффективности данного инструментария
картографическим сервисам имеет смысл заимствовать практику сервиса Google Maps
по созданию VGI-сообщества и повышению его вовлеченности в процесс
редактирования карт, особенно в разрезе, так называемых, локальных
географических правок. Такой способ дает жителям районов и домов приоритет при
внесении правок в пределах своего места жительства. Это позволяет получать
более достоверную и актуальную информацию. Также имеет смысл распространять
данный подход на работу со справочником организаций, отображаемых на карте.
Такой подход позволит косвенно повысить и уровень полноты представленной в базе
информации, так как жители района, как правило, быстрее остальных узнают о
появлении новых организаций рядом с их местом проживания. Однако, если не
ограничивать себя экономическими интересами одного сервиса, проблему полноты,
достоверности и актуальности можно решать совсем на другом уровне.
С учетом того факта, что VGI-сообщество в том или ином виде
сформировалось вокруг каждого из популярных сервисов, внесение и актуализация
данных представленных в каждом из них происходит параллельно и независимо друг
от друга, а это означает, что все существующие сервисы охватывают разный (но
безусловно пересекающийся) срез доступной информации о существующих
организациях. Даже ручной анализ выдачи популярных картографических сервисов
показывает, что уровень пересечения баз данных организаций популярных сервисов
варьируется на уровне 70-80%, а это означает, что подавляющий объем работы
сообществами проделывается повторно. Объединение сообществ и создание единого
справочника естественным образом бы сократило издержки, за счет высвобождения
того человеко-ресурса, который сейчас уходит на внесение и корректировку одного
пересекающегося объема информации. В свою очередь высвободившийся ресурс смог
бы обеспечить более широкое покрытие базы организаций в справочнике. Но такой
модельный вариант развития событий негативным образом скажется на конкуренции
сервисов, ведь конечной задачей любого подобного сервиса является генерация
прибыли для компании-разработчика. В такой модели остается открытым вопрос о
системе взаиморасчетов и взаимоотношений между картографическими сервисами, подключенными
к единому справочнику организаций и сервисом обеспечивающим функционирование
самого справочника.
Более того, текущий (уже накопленный) объем данных по
организациям каждый из сервисов справедливо считает своей коммерческой тайной.
Учитывая, что Google Maps является абсолютным лидером в глобальном масштабе и
проигрывает в полноте и актуальности базы лишь некоторым локальным игрокам
(таким как Яндекс.Карты и 2GIS), коммерческой заинтересованности в реализации
подобного сценария в обозримом будущим в корпоративной среде ожидать не стоит.
С другой стороны, возможно создание объединенной версии
справочника организаций в виде стороннего сервиса, агрегирующего информации из
текущих картографических сервисов в единую базу данных с последующей
репрезентаций полученного множества организаций. Такой подход похож на
популярный ранее подход по улучшению текстовой поисковой выдачи систем
посредством создания мета-поисковиков, которые повышали релевантность выдачи за
счет агрегации результатов поиска существующих поисковых машин: Google, Яндекс,
Рамблер, Bing, Yahoo. В настоящее время мета-поисковики по текстовой выдаче
утратили свою актуальность, так как исходные поисковые системы смогли нарастить
качество выдачи и охват поискового индекса до такой степени, что дальнейшие
улучшения за счет манипуляции результатами их поиска практически не приносят
заметных улучшений в плане повышения релевантности.
В случае с задачей повышения полноты и скорости актуализации
справочника организаций, решение техническими средствами (увеличением серверных
мощностей или повышением эффективности алгоритмов обработки данных) не
представляется возможным в обозримом будущем. В любом случае основным
поставщиком информации о происходящих изменениях в реальном мире являются
конечные пользователи сервиса. Соответственно задача по консолидации данных из
существующих источников информации об организациях в целях обеспечения
максимальной полноты и актуальности информации, получаемой пользователем,
выглядит перспективным решением описанной проблемы.
Подробное изучение доступного публичного API коммерческих
сервисов Яндекс.Карты, Google Maps и 2ГИС показало, что бесплатная
(некоммерческая) версия существенно лимитирована по количеству выдаваемых
данных. Как правило, это постраничный доступ с размером страницы от 20 до 50
записей и общим ограничением в несколько десятков или сотен страниц.
Доступ к API для осуществления исследовательских целей на
коммерческих условиях стоит слишком дорого (сотни тысяч рублей в год).
Некоторые компании (2ГИС), в случае описания целей и характера проводимых
исследований, могут предоставить ограниченный по времени, но не ограниченный по
количеству запросов доступ к API.
Единственный достаточно популярный сервис интерактивной
web-ориентированной картографии, представляющий свою базу в открытом виде для
пользования всем желающим (в том числе через API) является OpenStreetMap.
Миссия сервиса заключается в предоставлении всем желающим не только полного
доступа к картографии и базе объектов на ней размещенных но и создания целой
экосистемы инструментов, позволяющих любому пользователю вносить изменения в
существующие набор данных и карты.
С другой стороны, любая компания - это в первую очередь
организация, а любая организация до начала ведения деятельности обязана пройти
обязательные процедуры постановки на учет в налоговых органах, фондах и органах
статистики, а в случае попадания ее деятельности под лицензируемые виды
экономической деятельности (как в случае с продажей алкогольных напитков) еще и
получить соответствующие лицензии и разрешения. Причем, важно отметить, что за
несвоевременное предоставление информации об открытии/прекращении деятельности
организацией предусмотрены значительные штрафы. То есть за актуальностью данной
информации следят контролирующие государственные органы, отделы по взысканию
штрафов, которые обладают более чем достаточным персоналом и полномочиями. Эта
цепочка размышлений приводит нас к мысли о возможности получать информацию: по
правовому статусу организации, дате ее регистрации и дате прекращения деятельности
от наиболее авторитетного источника - единого государственного реестра
юридических лиц и индивидуальных предпринимателей (ЕГРЮЛ и ЕГРИП).
Синхронизация данных между справочником организаций картографических сервисов и
базами данных указанных реестров позволила бы в значительной мере решить
проблему своевременной актуализации большого пласта информации об отображаемых
организациях.
Изучение возможностей сервиса egrul.nalog.ru показало, что,
несмотря на техническую возможность получения информации о любой организации
действующей или действовавшей на территории РФ, использовать его для решения
проблемы актуализации затруднительно по двум причинам:
. База ЕГРЮЛ не содержит указаний на название
заведения, а оно редко соответствует названию юридического лица. Если в случае
АО «Макдоналдс Рус» пользователь легко догадается, о каком заведении идет речь,
то название ООО «Кэпиталфуд» никаких ассоциаций не вызывает.
. База ЕГРЮЛ не содержит другой важной для
пользователя информации о заведении (часы работы, телефон, количество мест,
является ли заведение сетевым и пр.).
Однако наличие подобной информации в открытом доступе наводит
на мысль о том, что в сети также могут быть и базы с расширенными данными по
организациям, полученные от лицензирующих органов или органов статистики.
Продолжительный поиск в итоге приводит нас на портал открытых данных
Правительства Москвы - #"896980.files/image001.jpg">
Рис. 1. Структура таблицы Features справочника организаций
Таким образом, для сохранения всего объема полученных данных
нам необходимо разработать механизм сохранения информации из объектов класса
Feature в таблицу Features с последующим обратным восстановлением данных из таблицы в
набор объектов класса Feature (например, для вывода объектов на карту).
Конечно, для такого сценария можно использовать базовые механизмы для работы с
базами данных в .NET Framework, такие как ADO.NET. Это позволяет реализовать
весь необходимый набор CRUDL запросов к подготовленной базе данных (БД).
Однако, тот уровень тонкого контроля над происходящими обращениями к базе,
который открывается в случае использования ADO.NET в данном проекте будет
избыточен по причине небольшого объема данных, содержащихся в БД. В таком
случае следует выбрать такое средство доступа к данным, которое обеспечит
максимальную скорость и удобство разработки. Обоим этим требованиям отвечают
системы класса ORM (Object Relational Mapping), которые осуществляют
объектно-реляционное отображение данных из объектов в таблицы и обратно в
автоматическом режиме. Достигается это за счет скрытия от разработчика уровня
отработки CRUDL запросов с попутным повышением уровня абстракций используемых в
коде. ORM системы не только ускоряют работу программных продуктов, но и в
значительной мере упрощают их отладку, рефакторинг (за счет исключения из кода
T-SQL запросов в текстовом виде и повышения уровня их типизации) и поддержку.
За долгие годы развития подобного класса систем появились различные их
разновидности, в том числе разрабатываемый и продвигаемый компанией Microsoft
проект EntityFramework.
К сожалению, подобного рода библиотеки требуют от
разработчика создания большого количества промежуточных сущностей (схем
отображения объектов в таблицы) и вынуждают программиста наследовать свои
классы от класса определенного типа. В целях настоящего проекта подобные
системы будут избыточны, так как нам необходимо решить задачу отображения всего
одного класса в одну таблицу. Для решения этой задачи идеально подходит
подмножество ORM систем, поддерживающих работу с POCO (Plain Old CLR Objects,
традиционные объекты общеязыковой среды выполнения), так как они не требуют
создания промежуточных сущностей и специальных схем или классов разметки. Из
всего многообразия подобных систем (более полусотни) была выбрана библиотека
DAL как удовлетворительное решение по сумме факторов: простота подключения,
производительность, прозрачность работы.
Для использования класса Feature в целях отображения значений
его объектов в таблицe Features отнаследуем его от generic-класса
TransactObject<Feature>, после чего библиотека DAL при первом запуске
создаст одноименную таблицу с набором столбцов, полностью соответствующем
набору полей (свойств) класса Feature. В случае обнаружения уже существующей
таблицы и при эквивалентности ее структуры полям (свойствам) класса, структура
таблицы останется без изменений.
При соответствии названий свойств класса и столбцов таблицы
библиотека DAL не требует дополнительной атрибутивной разметки для
осуществления отождествления между свойствами и столбцами и во всех операциях
отображения данных (из объектов в таблицу и наоборот) будет считать их
эквивалентами.операции в библиотеке DAL запускаются посредством вызовов методов
Update(), Insert(), Delete() и Select (через конструктор) у объектов класса,
наследованных от базового класса TransactObject и их множественные аналоги:
SelectMany(), UpdateMany(), InsertMany(), DeleteMany().
К примеру, для выбора объекта Feature с уникальным
идентификатором 14, достаточно просто передать числовое значение идентификатора
в конструктор: new Feature(14), а выборка всех объектов Feature, содержащих в
названии подстроку KFC, будет выглядеть как:
List<Feature> result =
Feature.Instance.SelectMany(f =>f.Name.Contains(“KFC”));
Где result - итоговый список объектов класса Feature,
содержащих в названии подстроку “KFC”, а f => f.Name.Contains(“KFC”) -
условие отбора записей в Feature, заданное в форме Lambda-выражения, которое
будет автоматически сконвертировано библиотекой DAL в T-SQL запрос вида:
SELECT * FROM Features WHERE Name like '%KFC%'
Для каждой строки в результатах выполнения запроса будет
автоматически сгенерирован новый объект класса Feature, в свойства которого
будут занесены значения соответствующих столбцов из результирующей таблицы. В
случае с изменением значений свойств объектов Feature и последующим вызовом
методов Update или UpdateMany, DAL автоматически проверит, какие именно
свойства объекта подверглись изменению и сгенерирует запрос вида:
UPDATE Features SET Name = ‘КФС’ WHERE ID =
14
Где 14 - идентификатор обновляемого объекта (строки таблицы),
а КФС - новое значение поля (столбца) Name.
Таким образом, с использованием ORM DAL функция выгрузки всех
заведений общественного питания города Москвы с сервера Портала открытых данных
Правительства Москвы принимает весьма компактный вид:
public static List<Feature> Download(long
dataSet)
{
WebClient wc = new WebClient();
wc.Encoding = Encoding.UTF8;
string json =
wc.DownloadString("https://apidata.mos.ru/v1/datasets/{" + dataSet +
"}/features");
dynamic list =
((dynamic)JsonConvert.DeserializeObject(json)).features;
List<Feature> res = new
List<Feature>();
foreach (var obj in list)
res.Add(new Feature().FromJSON1(obj));
Feature.Instance.InsertMany(res);
return res;
}
Благодаря оптимально подобранным абстракциям, функция,
которая организовывает GET запрос к серверам apidata.mos.ru, преобразовывает
полученный JSON в динамические объекты языка C# и производит сохранение
полученных объектов Feature в базу данных, умещается всего в 8 строк.
Суммарно из базы OpenStreetMap было выгружено 4 328 заведений
общественного питания города Москвы, а из базы Портала открытых данных
Правительства Москвы 11 884 заведения.
2.3
Сведение данных
Ключевой проблемой, выявленной после загрузки данных из обоих
источников в БД проекта, стало пересечение общей части справочников
организаций, полученных из двух различных источников. В случае попытки сведения
по точному сравнению названий и координат заведений, пересечений между двумя
заведениями не обнаруживается вовсе. Объясняется это тем, что заведения
отличаются как по способу именования, например, встречаются подобные
наименования одного и того же заведения, пришедшего из двух различных
источников: “KFC”, “Ресторан KFC”, так и по координатам расположения, которыми,
как известно, каждое заведение маркируется вручную.
Соответственно для составления итогового справочника
заведений крайне важно разработать оптимальный алгоритм сопряжения одного и
того же заведения для случая, когда оно присутствует сразу в двух базах. Как
уже упоминалось ранее, на примере лис. 2 и 3 видно, что единственной
информацией о заведении, позволяющей его однозначно идентифицировать является
его название и расположение. Причем по отдельности ни название, ни расположение
заведения не дают возможности его точной идентификации. Так ресторанов
“Шоколадница” в Москве более 450 и все они в поле Name в пределах одного
источника данных содержат одно и то же наименование, что не позволяет отличить
одно заведение от другого без привязки к их фактическим координатам. В то же
время плотность ресторанов в торговых центрах такова, что попытка их
идентификации только по координатам без учета наименования так же лишена
всякого смысла. Таким образом, алгоритм сведения должен основываться на
рассмотрении координат и названия заведения в качестве составного ключа
однозначно идентифицирующего заведение. При этом, так как точное сравнение ни
координат, ни названий заведений не даёт никакого результата (т.е. пересечением
множества заведений из двух источников по строгому соответствию является пустое
множество), имеет смысл рассматривать алгоритмы нечеткого сравнения.
Алгоритм нечеткого сравнения координат тривиален. Все что нам
нужно сделать - допустить возможность незначительного отклонения в координатах
заведений, которые рассматриваются как потенциальные кандидаты на сопряжение.
Единственная важная особенность в данном случае это тот факт, что
картографические координаты задаются в градусах (широта и долгота), а расстояние
на плоскости принято измерять в метрах. Для перехода от метров к градусов будем
использовать следующую формулу:
LongDifGrad = 50 / 111134.861111;
double LatDifGrad = 50 / 71240.3572324;
Где LongDifGrad - 50 метров, выраженных в градусах долготы,
LatDifGrad - 50 метров, выраженных в градусах широты.
Теперь для того, чтобы определить близость двух заведений на
карте в радиусе 50 метров достаточно произвести линейные сравнения, как
показано в функции Near:
private bool Near(Feature d)
{CoordX < d.CoordX + LongDifGrad &&
CoordX > d.CoordX - LongDifGrad
&& CoordY < d.CoordY + LatDifGrad
&& CoordY > d.CoordY - LatDifGrad;
}
Задание нестрогого сравнения позволяет снять проблему
незначительно различающихся координат заведений, поступивших из различных источников.
При этом для их полноценного сведения необходимо также решить проблему
различных способов написания названий одного и того же заведения (“iL Patio”,
“iL'Pation”, “Кафе IL PATIO”, и т.п.).
Первичный поиск возможных решений в сети показал возможность
использования алгоритмов класса Soundex - алгоритмов сравнения двух строк по их
звучанию. Они устанавливают одинаковый индекс для строк, имеющих схожее
звучание в английском языке. Оригинальный алгоритм Soundex, запатентованный еще
в 1918 году, имел значительное количество ложноположительных срабатываний,
когда несколько слов с совершенно различным фактическим звучанием определялись
алгоритмом как похожие. Это привело к появлению улучшенных версий данного
алгоритма, в том числе с поддержкой других языков. К сожалению, в SQL Server
встроена только англоязычная версия алгоритма, что подтолкнуло к поиску
алгоритмов по сравнению наименований, которые бы работали на стороне C#.
Обзорные статьи по нечетким алгоритмам сравнения строк
показывают, что наиболее простым способом сравнения двух строк на предмет
схожести являются n-граммные алгоритмы.
public static double FuzzyCompare(int gramm,
string left, string right)
{
if (left != null)
left = left.ToLower();
if (right != null)
right = right.ToLower();
if (left == right || left == null || left.Length
< 3)
return 1;
return Math.Max(_compare(gramm, left, right),
_compare(gramm, right, left));
}
private static double _compare(int gramm, string
left, string right)
{
double foundCnt = 0;
for (int i = 0; i < left.Length - (gramm -
1); i++)
foundCnt += right.Contains(left.Substring(i,
gramm)) ? 1 : 0;
return foundCnt / (left.Length - (gramm - 1));
}
Где gramm - количество подряд стоящих символов, подлежащих
выделению (в нашем случае оптимальное число 3), left - первая строка, right -
вторая строка.
Суть алгоритма отраженного в приведенном выше листинге:
. Выделение из первой строки всех последовательностей
из трех стоящих рядом символов (триграммы). Получаем общее количество триграмм.
. Подсчет количества уникальных вхождений триграмм во
вторую строку.
. Отношение количества вхождений во вторую строку к
общему количеству триграмм отражает в численном виде близость заданных строк
(чем больше, тем ближе).
Так как алгоритм не симметричен, то для точной проверки
схожести двух строк необходимо вызывать его дважды с разным порядком операндов.
Максимальное из полученных значений и будет являться искомым результатом
численной оценки близости строк.
Применение описанного алгоритма определения близости строк
действительно позволяет установить факт схожести названия таких заведений как
«Кафе Песто» и «Песто». Итоговый алгоритм показан в лис. 8. После его
применения к исходным базам, множество сведенных (т.е. обнаруженных в обоих
источниках) заведений выросло с нуля до двух тысяч (больше половины всех кафе и
ресторанов, полученных из базы OpenStreetMap).
private static List<Feature>
Merge(List<Feature> src)
{
var features = Feature.Instance.SelectMany();
List<Feature> res = new
List<Feature>();
foreach (Feature s in src)
{
bool found = false;
foreach (Feature d in features)
{
if (s.Near(d) &&
XgramCompare.FuzzyCompare(3, s.Name, d.Name) > 0.4)
{
found = true;
break;
}
}
if (!found)
res.Add(s);
}
return res;
}
Однако оба алгоритма: и алгоритм определения картографической
близости, и алгоритм определения схожести строк, являются алгоритмами
нечеткими, результаты их работы в большей степени зависят от пороговых значений
«чувствительности» алгоритма. Для алгоритма, таким пороговым значением является
константа 50 метров, для алгоритма таковой константой является 0,4 (40%
пересечений в двух строках), которая используется в лис. 8. Числовые значения
50 и 0,4 определены с помощью выборочного визуального контроля полученного
результата, поэтому не могут считаться оптимальными до тех пор, пока не
показано, что остальные возможные значения для данных констант уменьшают
процент корректно сведенных заведений. Для определения оптимальных (или
субоптимальных) значений пороговой чувствительности указанных алгоритмов,
необходимо изучить остальные допустимые значения указанных констант.
Так для критерия картографической близости область допустимых
значений распространяется от нуля метров до бесконечности. Однако оба крайних
случая лишены смысла. Слишком малое значение приведет к низкому объему
сводимости (при нуле метров, количество сведенных заведений равно нулю).
Слишком большое значение приведет к ложноположительным срабатываниям алгоритма,
когда схожие по названию, но находящиеся на большом удалении (несколько сотен
метров) заведения будут сведены. Но для разумного диапазона значений (от десяти
до ста метров) разброс в количестве сведенных заведений достаточно
значительный, а зависит это количество от значения второй вариативной
постоянной - коэффициента близости строк. Получаем задачу двухкритериальной
оптимизации, при которой целевая функция представляет из себя максимизацию
количества сведенных заведений при минимизации количества ложноположительных
срабатываний. Для визуального решения данной задачи предлагается построить
таблицу результатов отработки алгоритма сведения с последовательным перебором
всех возможных значений обоих констант в диапазоне от 0 до 100 для константы
картографической близости и от 0 до 1 для константы близости строк. Шаг изменения
обеих констант возьмем равным 5.
public static void CalcMerges()
{
var all = Feature.Instance.SelectMany();
var from = all.Where(x =>
x.SourcesStr.Contains("data.mos.ru")).ToList();
var to = all.Where(x =>
x.SourcesStr.Contains("OpenStreetMap.ru")).ToList();
double distStep = 10;
double wordStep = 0.05;
Parallel.For(0, 10, di => {
for (int wi = 20; wi > 0; wi++)
{
Merge2(from, to, "", distStep * di,
wordStep * wi);
}
});
}
private static long Merge2(List<Feature>
from, List<Feature> to,
string source, double dDist, double dNames)
{
long cnt = 0;
List<Feature> res = new
List<Feature>();
List<Feature> toUpdate = new
List<Feature>();
foreach (Feature s in to)
{
foreach (Feature d in from)
{
if (s.Near2(d, dDist) &&
XgramCompare.FuzzyCompare(3, s.Name, d.Name)
> dNames)
{
cnt++;
break;
}
}
res.Add(s);
}
return cnt;
}
Как видно из листинга, построение результирующей таблицы
происходит посредством построения множества всех возможных комбинаций значений
переменных постоянных, которое получается декартовым произведением множеств
значений констант. Таким образом, имеем (100 / 5) двадцать значений каждой из
констант, что в итоге приводит к 400 запускам модифицированного алгоритма
сведения организаций, описанного в функции Merge2, в которой нет
предопределенных констант, в отличие от оригинальной функции, описанной в лис.
8. Для ускорения отработки такого количества запусков в коде функции
CalcMerges() используется конструкция Parallel.For, которая распараллеливает
выполнение описанного лямбда-выражения (по сути вызова функции Merge2).

Рис. 2. Таблица распределения количества сведенных заведений
в зависимости от значений варьируемых переменных
Результат отработки алгоритма из лис. 9, представлен в виде
таблицы на рис. 2, где столбцы представляют из себя значения константы,
задающей коэффициент близости строк, а строки - значения константы
картографической близости. В ячейках, находящихся на пересечении выбранного
столбца и строки, содержится численный результат выполнения функции сведения
(Merge2), который представляет из себя количество сведенных заведений. Таблица
раскрашена в виде «тепловой карты», где ячейки с большим количеством сведенных
заведений имеют большую интенсивность зеленого цвета в фоне. Максимальное
количество сведенных заведений ожидаемо наблюдается при максимальном количестве
допущений (т.е. максимально возможное расстояние между сравниваемыми объектами при
минимально возможном требовании к идентичности строк - 0%). Однако визуальный
контроль списка сведенных заведений показывает, что процент ложных срабатываний
при этом также крайне велик. Дальнейшее изучение таблицы результатов и
визуальный контроль соответствующих им списков сведенных заведений показал, что
уменьшение коэффициента близости строк до уровня меньшего 40% приводит к
заметному росту количества ложноположительных сведений. При этом увеличение
коэффициента близости до 100 метров практически не влияет на количество
ложноположительный сведений. Связано это, прежде всего, с наличием на
территории Москвы большого количества торговых центров, в которых расстояние
между ресторанами зачастую превышает 50 метров. Обнаруженные новые значения
констант использовались для дальнейших расчетов.
Стоит отметить, что описанный метод подбора пороговых
значений все же является экспертным и его результаты нельзя считать
оптимальными, так как ручной контроль количества ложноположительных
срабатываний не является статистически значимым инструментом. Для дальнейшего
улучшения подбора пороговых значений следует выделить критерии
ложноположительного сведения заведений и автоматизировать их определение таким
образом, чтобы итоговая целевая функция могла быть оптимизирована по обоим
целевым значениям (количество сведенных заведений и количество
ложноположительных срабатываний). После этого поиск оптимальных решений свелся
бы к хорошо изученным алгоритмам многокритериальной оптимизации (например,
методу градиентного спуска). Однако выделение критерия ложноположительных
срабатываний выходит за рамки данной работы.
Отдельной особенностью сведения двух и более справочников
организаций является сценарий устранения расхождения в атрибутах сводимых
организаций. В случае отличий между источниками в значениях любого из атрибутов
возникает вопрос, какое из значений отображать пользователю в карточке
организации. Один из возможных подходов:
. Для случая с нечетным количеством источников (3, 5,
7 и т.д.) пользоваться правилом простого большинства. Если значения атрибута в
источниках 1, 2 эквивалентны, но отличаются от значения из источника 3, то
отображается информация из источников 1, 2.
. Для случая с четным количеством источников (2, 4, 6
и т.д.) используем правило приоритетов. До проведения процедуры сведения
вычисляется или задается вручную рейтинг доверия источнику. Далее в процессе
сведения, при наличии разночтений в значении атрибутов источников, сравниваются
суммы рейтингов источников для каждого из вариантов значения атрибута. В итоговую
карточку попадает значение с максимальной суммой рейтинга.
В нашем случае количество источников ограничено двумя,
следовательно, имеет смысл использовать 2-е правило. Так как информация Портала
открытых данных Правительства Москвы имеет гораздо большую частоту обновлений,
чем у OSM, считаем данный источник приоритетней и выводим информацию из него.
2.4
Визуализация данных
По результатам тестирования гибкости и функциональности API
различных картографических сервисов было принято решение использовать API
Яндекс.Карт в качестве сервиса для отображения полученной (сведенной на
предыдущем этапе) базы организаций.
Исследование способов отображения большого (>10 000)
количества объектов на карте единовременно, показало, что в API Яндекс.Карт для
этого предусмотрено два базовых сценария:
. Генерация на сервере полупрозрачной картинки,
которая накладывается поверх карты, делая изображенные на ней объекты видимыми
для пользователя (рис. 1) и создание отдельного слоя активных областей,
очерчивающих контуры объектов, представленных на сгенерированной картинке
(картиночный слой). После чего на каждую отдельную активную область необходимо
«навесить» различные обработчики событий (например - клик).
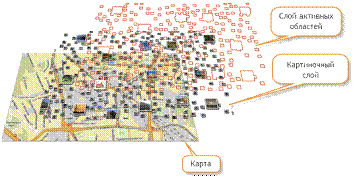
Рис. 3. Overlay техника оптимизации отображения большого
количества объектов на Яндекс.Картах
. Использование встроенных объектов Яндекс.Карт:
RemoteObjectManager или LoadingObjectManager, которые разработаны специально
для отображения большого количества объектов. Они умеют самостоятельно
подгружать с сервера информацию для карты с учётом координат видимого участка
карты и обладают таким важным дополнительным функционалом как кластеризация
отображаемых объектов при отдалении (рис. 2).
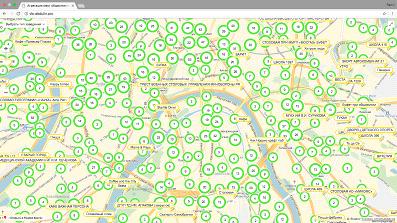
Рисунок 4. Пример автоматической кластеризации, выполняемой
на клиенте
Первый из описанных подходов крайне сложен в реализации: при
любом перемещении пользователем отображаемой области карты необходимо на
сервере генерировать новую картинку с метками. Более того, так как метка по
сути нарисована и не является объектом, интерактивное взаимодействие с ней на
стороне клиента практически невозможно.
Второй подход более гибок и прост в реализации, однако, он
требует от серверной части web-приложения возврата данных в формате JSONP,
который отличается от формата JSON тем, что в случае с JSONP результатом
интерпретации JSON'а является не объект, а вызов callback-функции с передачей
ей объекта с геоданными сгенерированными на сервере.
Пример JSON:
{
"type": "FeatureCollection",
"features": [
{
"type": "Feature",
"id": 2,
"geometry": {
"type": "Point",
"coordinates": [55.763338, 37.565466]
},
"properties": {
"balloonContent": "Содержимое балуна",
"clusterCaption": "Метка 2",
"hintContent": "Текст подсказки"
}
}
]
Пример JSONP:
myCallback_x_1_y_2_z_5(
{
"type": "FeatureCollection",
"features": [
...
]
})
Помимо указанного функционала агрегации, в рамках данной
работы также реализован дополнительный функционал по фильтрации (рис. 5)
справочника заведений общественного питания по типам (кафе, ресторан, бар,
закусочная, предприятие быстрого питания, буфет, столовая и т.д.) и отображение
на карте известных сетевых предприятий в виде корпоративной символики (рис. 6).
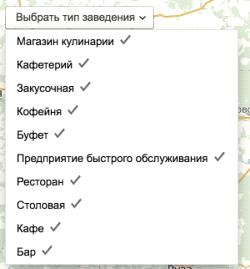
Рис. 5. Фильтр
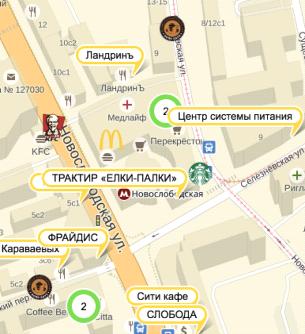
Рис.6. Брендирование
Карточка объекта выглядит следующим образом:
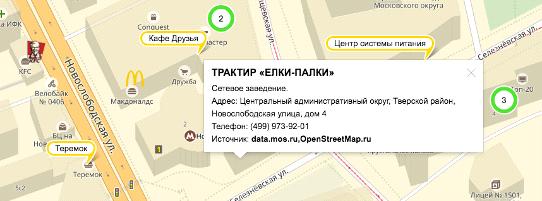
Рис.7. Карточка объекта
Разработанное веб-приложение доступно на сайте vkr.abdulin.pro.
Заключение
В рамках данной работы выполнен анализ различных аспектов
функционирования существующих на рынке интерактивных web-ориентированных
картографических систем (ГИС). Указана основная проблематика использования их
для повседневного решения навигационных задач. Сформулирована гипотеза по
повышению эффективности использования ГИС посредством повышения скорости
актуализации базы данных организаций и увеличения ее полноты.
Изучены особенности лицензирования данных каждым из
популярных ГИС. Определены ГИС, допускающие свободное обращение с
предоставляемыми данными и не ограничивающие доступ к ним в автоматическом
режиме. Изучены API данных сервисов и форматы выгрузки данных.
Произведена выгрузка данных о заведениях общественного
питания г. Москвы из источников data.mos.ru и OpenStreetMap. Обнаружена
проблема большого процента дублей в итоговой выгрузке.
Разработан двухкритериальный алгоритм сведения данных о
заведениях общественного питания, полученных из справочников обоих ГИС.
Разработан алгоритм вычисления субоптимальных пороговых значений для обоих
критериев. По результатам отработки алгоритма уточнены исходные пороговые
значения для обоих критериев. Используя разработанный алгоритм, построен
итоговый сводный справочник заведений.
Изучено картографическое API популярных ГИС. Разработан
механизм вывода сводного справочника организаций (>10000) на Яндекс.Карты.
Реализованы дополнительные опции для демонстрации возможностей системы.
При реализации программного решения были учтены различные
особенности функционирования сервисов, найдены оптимальные способы их
использования, показаны как правильные, так и субоптимальные решения, родившиеся
в процессе работы над проектом.
В целях дальнейшего развития проекта имеет смысл реализовать:
гибкую систему фильтров заведений по дополнительным параметрам (тип кухни,
средний чек, наличие wi-fi и т.п.), систему сбора обратной связи от конечного
пользователя (внесение корректировки в существующие данные), разработку
критерия поиска ложноположительных сведений.
Полученные алгоритмы без дополнительной адаптации могут быть
применены как для любых других типов заведений, так и для других источников
данных.
Приложения
.cs
using
Newtonsoft.Json;System;System.Collections.Generic;System.Linq;System.Net;System.Text;System.Threading.Tasks;DAL;FuzzySearch;
EPA
{
public class Feature :
DAL.TransactObject<Feature>
{
public Feature() : base() { }
public Feature(long id) : base(id) { }
public override CachingType CacheType
{
get { return CachingType.None; }
}
public Feature FromJSON1(dynamic obj)
{
CoordX = obj.geometry.coordinates[0];
CoordY = obj.geometry.coordinates[1];
DatasetId = obj.properties.DatasetId;
VersionNumber = obj.properties.VersionNumber;
ReleaseNumber = obj.properties.ReleaseNumber;
RowId = obj.properties.RowId;
GlobalId = obj.properties.Attributes.global_id;
Name = obj.properties.Attributes.Name;
OperatingCompany = obj.properties.Attributes.OperatingCompany;
IsNetObject =
obj.properties.Attributes.IsNetObject == "да";
AdmArea = obj.properties.Attributes.AdmArea;
District = obj.properties.Attributes.District;
Address = obj.properties.Attributes.Address;
if (PublicPhone != null)
PublicPhone = obj.properties.Attributes.PublicPhone[0].PublicPhone;
SeatsCount =
obj.properties.Attributes.SeatsCount;
SocialPrivileges =
obj.properties.Attributes.SocialPrivileges == "да";
return this;
}
public Feature FromJSON2(dynamic obj)
{
CoordX = obj.lon;
CoordY = obj.lat;
GlobalId = obj.id;
Name = obj.tags.name;
PublicPhone =
obj.tags["contact:phone"];
return this;
}
public static List<Feature>
Download2(string path, string source)
{
WebClient wc = new WebClient();
wc.Encoding = Encoding.UTF8;
string json = wc.DownloadString(path);
//Newtonsoft.Json.Serialization.ser
dynamic list =
((dynamic)JsonConvert.DeserializeObject(json)).elements;
List<Feature> res = new
List<Feature>();
foreach (var obj in list)
{
res.Add(new Feature().FromJSON2(obj));
}
res = Merge(res, source);
Feature.Instance.InsertMany(res);
return res;
}
public static void Counts()
{
long mosRu =
Feature.Instance.InvokeScalar<long>("select count(*) from Features
where SourcesStr like '%mos.data.ru%'");
long osmRu =
Feature.Instance.InvokeScalar<long>("select count(*) from Features
where SourcesStr like '%OpenStreetMap.ru%'");
long mix =
Feature.Instance.InvokeScalar<long>("select count(*) from Features
where SourcesStr like '%mos.data.ru%' and SourcesStr like
'%OpenStreetMap.ru%'");
}
private static List<Feature>
Merge(List<Feature> src, string source)
{
var features = Feature.Instance.SelectMany();
List<Feature> res = new
List<Feature>();
List<Feature> toUpdate = new
List<Feature>();
foreach (Feature s in src)
{
bool found = false;
foreach (Feature d in features)
{
if (s.Near(d) &&
XgramCompare.FuzzyCompare(3, s.Name, d.Name) > 0.4)
{
if (!d.Sources.Contains(source))
{
toUpdate.Add(d);
d.Sources = d.Sources.Concat(new[] { source
}).ToArray();
}
found = true;
break;
}
}
if (!found)
res.Add(s);
}
Feature.Instance.UpdateMany(toUpdate);
return res;
}
// M/(m/Grad)
double LongDifGrad = 50 / 111134.861111;
double LatDifGrad = 50 / 71240.3572324;
private bool Near(Feature d)
{
return CoordX < d.CoordX + LongDifGrad
&& CoordX > d.CoordX - LongDifGrad
&& CoordY < d.CoordY + LatDifGrad
&& CoordY > d.CoordY - LatDifGrad;
}
public static List<Feature> Get(double
lng1, double lat1, double lng2, double lat2)
{
return Feature.Instance.SelectMany(x=>x.CoordX
< lng2 && x.CoordX > lng1
&& x.CoordY < lat2 && x.CoordY
> lat1);
}
public object ToJSONObj()
{
dynamic[] nets = new dynamic[] {
new { name= "макдоналдс", logo=
"mcdonalds.svg", size=new Int32[] { 32, 32 } },
new { name= "старбакс", logo=
"starbucks.png", size= new Int32[] {32, 32}},
new { name= "якитория", logo=
"yakitoriya.png", size= new Int32[] {52, 32}},
new { name= "бургер кинг", logo= "bk.png", size= new
Int32[] {32, 32}},
new { name= "кфс", logo=
"kfc.png", size= new Int32[] {52, 52}},
new { name= "суши wok", logo=
"shushivok.png", size= new Int32[] {62, 32}},
new { name= "суши сет", logo= "sushiset.png", size= new
Int32[] {62, 32}},
new { name= "стардогс", logo=
"stardogs.png", size= new Int32[] {62, 32}},
new { name= "суши шоп", logo= "sushishop.png", size=
new Int32[] {62, 32}},
new { name= "тануки", logo=
"tanuki.png", size= new Int32[] {32, 32}},
new { name= "шоколадница", logo=
"shoko.png", size= new Int32[] {42, 32}},
new { name = "кофе хаус", logo = "coffehouse.png", size =
new Int32[] { 32, 32 } }
// { name: 'суши сет', logo: 'sushiset.png', size: [32, 32}},
};
dynamic net = nets.FirstOrDefault(x => (Name
!= null ? Name.ToLower().Contains(x.name) : false) );
return new
{
id = Id,
geometry = new
{
coordinates = new double[] { CoordX, CoordY },
type = "Point"
},
properties = new
{
type = TypeStr.ToString().ToLower(),
DatasetId = DatasetId,
VersionNumber = VersionNumber,
ReleaseNumber = ReleaseNumber,
RowId = RowId,
iconContent = Name,
balloonContentHeader = Name,
balloonContentBody = (IsNetObject ? "Сетевое заведение. " :
"") +
(!String.IsNullOrWhiteSpace(Address) ?
"<br/> Адрес: " + AdmArea + ", " + District + ",
" + Address : "") +
(!String.IsNullOrWhiteSpace(PublicPhone) ?
"<br/> Телефон: " + PublicPhone : "") +
"<br/> Источник: <b>" +
SourcesStr + "</b>",
hintContent = Address == null ? "" :
Address,
Attributes = new
{
global_id = GlobalId,
Name = Name,
IsNetObject = IsNetObject ? "да" :
"нет",
OperatingCompany = OperatingCompany,
AdmArea = AdmArea,
District = District,
Address = Address,
PublicPhone = new object[] { new { PublicPhone =
PublicPhone } }
},
},
options = (net == null ? null : new
{
iconLayout = "default#image",
iconImageHref = "img/" + net.logo,
iconImageSize = net.size
}),
type = "Feature"
};
}
public static string ToJson()
{
List<Feature> features =
Feature.Instance.SelectMany();
return JsonConvert.SerializeObject(new { features
= features.Select(x => x.ToJSONObj()).ToArray() });
}
public static List<Feature> Download(long
dataNumber)
{
WebClient wc = new WebClient();
wc.Encoding = Encoding.UTF8;
string json =
wc.DownloadString("https://apidata.mos.ru/v1/datasets/{" + dataNumber
+ "}/features");
//Newtonsoft.Json.Serialization.ser
dynamic list =
((dynamic)JsonConvert.DeserializeObject(json)).features;
List<Feature> res = new
List<Feature>();
foreach (var obj in list)
{
res.Add(new Feature().FromJSON1(obj));
}
Feature.Instance.InsertMany(res);
return res;
}
//37 long
public double CoordX
{
get { return Get<double>(); }
set { Set(value); }
}
//55 lat
public double CoordY
{
get { return Get<double>(); }
set { Set(value); }
}
public long DatasetId
{
get { return Get<long>(); }
set { Set(value); }
}
public long VersionNumber
{
get { return Get<long>(); }
set { Set(value); }
}
public long ReleaseNumber
{
get { return Get<long>(); }
set { Set(value); }
}
public string RowId
{
get { return Get(); }
set { Set(value); }
}
public long GlobalId
{
get { return Get<long>(); }
set { Set(value); }
}
public string Name
{
get { return Get(); }
set { Set(value); }
}
public string OperatingCompany
{
get { return Get(); }
set { Set(value); }
}
public bool IsNetObject
{
get { return Get<bool>(); }
set { Set(value); }
}
public string AdmArea
{
get { return Get(); }
set { Set(value); }
}
public string District
{
get { return Get(); }
set { Set(value); }
}
public string Address
{
get { return Get(); }
set { Set(value); }
}
public string PublicPhone
{
get { return Get(); }
set { Set(value); }
}
public string SeatsCount
{
get { return Get(); }
set { Set(value); }
}
public bool SocialPrivileges
{
get { return Get<bool>(); }
set { Set(value); }
}
public string SourcesStr
{
get { return Get(); }
set { Set(value); }
}
public string[] Sources
{
get { return SourcesStr.Split(new string[] {
"," }, StringSplitOptions.RemoveEmptyEntries); }
set { SourcesStr = string.Join(", ",
value); SourcesCnt = value.Length; }
}
public long SourcesCnt
{
get { return Get<long>(); }
set { Set(value); }
}
public long Type
{
get { return Get <long>(); }
set { Set(value); }
}
public object TypeStr {
get
{
switch (this.Type)
{
case 1797:
return "Предприятие быстрого обслуживания";
case 1794:
return "Кафетерий";
case 1793:
return "Столовые";
case 1792:
return "Кафе";
case 1790:
return "Магазины кулинарии";
case 1786:
return "Кофейни";
case 1784:
return "Буфеты";
case 1798:
return "Закусочные";
case 1788:
return "Рестораны";
case 1796:
return "Бары";
case 0:
return "";
default:
return "";
}
}
}
}
}
.ashx:
<%@ WebHandler Language="C#"
Class="Handler" %>
using System;
using System.Collections.Generic;
using System.Globalization;
using System.Web;
using EPA;
using Newtonsoft.Json;
using System.Linq;
public class Handler : IHttpHandler {
public void ProcessRequest (HttpContext context)
{
context.Response.ContentType =
"text/html";
if (context.Request["update"] ==
"true")
{
Feature.Download2("http://overpass.osm.rambler.ru/cgi/interpreter?data=[out:json];node[%22amenity%22=%22restaurant%22](55.625282274095,37.345962524414,55.875696039004,37.889099121094);out;",
"OpenStreetMap.ru");
Feature.Download2("http://overpass.osm.rambler.ru/cgi/interpreter?data=[out:json];node[%22amenity%22=%22cafe%22](55.625282274095,37.345962524414,55.875696039004,37.889099121094);out;",
"OpenStreetMap.ru");
return;
}
string bbox = context.Request["bbox"];
string[] arr = bbox.Split(',');
List<Feature> features =
Feature.Get(double.Parse(arr[0], CultureInfo.InvariantCulture),
double.Parse(arr[1],
CultureInfo.InvariantCulture),
double.Parse(arr[2],
CultureInfo.InvariantCulture),
double.Parse(arr[3],
CultureInfo.InvariantCulture));
string result = JsonConvert.SerializeObject(
features.Select(x => x.ToJSONObj()).ToArray(), Formatting.Indented );
context.Response.Write("/**/ typeof "
+ context.Request["callback"] + " === \"function\"
&& " + context.Request["callback"] +
"({ \"error\": null, \"data\": "+ result +
"});");
}
public bool IsReusable {
get {
return false;
}
}
}
.cs:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace FuzzySearch
{
public static class XgramCompare
{
public static double FuzzyCompare(int gramm,
string left, string right)
{
if (left != null)
left = left.ToLower();
if (right != null)
right = right.ToLower();
if (left == right || left == null || left.Length
< 3)
return 1;
return Math.Max(_compare(gramm, left, right),
_compare(gramm, right, left));
}
//Gramm = 2 or 3
private static double _compare(int gramm, string
left, string right)
{
double foundCnt = 0;
for (int i = 0; i < left.Length - (gramm -
1); i++)
foundCnt += right.Contains(left.Substring(i,
gramm)) ? 1 : 0;
return foundCnt / (left.Length - (gramm - 1));
}
}
}
Index.html:
<!DOCTYPE html>
<html>
<head>
<title>Агрегация мест общественного питания</title>
<script
src="//yandex.st/jquery/2.1.1/jquery.min.js"
type="text/javascript"></script>
<script
src="//api-maps.yandex.ru/2.1/?lang=ru-RU&coordorder=longlat"></script>
<script type="text/javascript">
/*global ymaps*/
ymaps.ready(function () {
// инициируем объект карты
var myMap = window.map = new ymaps.Map('YMapsID',
{
center: [37.633265, 55.761384],
zoom: 18,
controls: ["zoomControl",
"fullscreenControl"]
}, {
// minZoom: 5
});
// инициируем менеджер объектов на карте и настраиваем его на
// автоматическую загрузку данных с нашей прокси-страницы
var objectManager = new
ymaps.LoadingObjectManager('/handler.ashx?bbox=%b&zoom=%z', {
clusterHasBalloon: true, // у кластеров будут свои балуны
clusterize: true, // включаем автоматическую кластеризацию
});
// Задаем стиль иконок для одиночных меток.
objectManager.objects.options.set('preset',
'islands#yellowStretchyIcon');
// Стиль иконок кластеров.
objectManager.clusters.options.set('preset',
'islands#greenClusterIcons');
// добавляем менеджер объектов на карту
myMap.geoObjects.add(objectManager);
// инициируем элемент управления - список типов заведений
(фильтр)
var placeType = new ymaps.control.ListBox({
data: {
content: 'Выбрать тип заведения'
},
items: [
new ymaps.control.ListBoxItem({data: {content: 'Магазины
кулинарии'}}),
new ymaps.control.ListBoxItem({data: {content:
'Кафетерий'}}),
new ymaps.control.ListBoxItem({data: {content:
'Закусочные'}}),
new ymaps.control.ListBoxItem({data: {content: 'Кофейни'}}),
new ymaps.control.ListBoxItem({data: {content: 'Буфеты'}}),
new ymaps.control.ListBoxItem({data: {content: 'Предприятие быстрого обслуживания'}}),
new ymaps.control.ListBoxItem({data: {content: 'Рестораны'}}),
new ymaps.control.ListBoxItem({data: {content: 'Столовые'}}),
new ymaps.control.ListBoxItem({data: {content: 'Кафе'}}),
new ymaps.control.ListBoxItem({data: {content: 'Бары'}}),
]
});
// отмечаем все значения фильтра в позицю выбрано
for (var i = 0; i < placeType.getAll().length;
i++)
{
placeType.getAll()[i].select();
}
// добавляем элемент управления на карту
myMap.controls.add(placeType);
// обработчик клика по списку (т.е. по конкретному типу
общепита)
var filterPlaces = function (e) {
e.preventDefault();
// формируем строку для фильтраиции объектов на карте по
принадлежности к типу общепита
var filterStr = '';
for (var i = 0; i < placeType.getAll().length;
i++)
{
var li = placeType.getAll()[i];
if (li.isSelected()) // если данный тип заведения выбран в
списке, добавляем для него условие фильтрации
filterStr += (filterStr != '' ? ' || ' : '') +
'properties.type == "' + li.data.get('content').toLowerCase() + '"';
}
if (filterStr == '') // не выбран ни один из типов заведений
filterStr = 'properties.type == 9999'; // ... отфильтровываем
вообще все объекты
objectManager.setFilter(filterStr);
};
placeType.events.add('select', filterPlaces);
placeType.events.add('deselect', filterPlaces);
});
<style type="text/css">
html, body, #YMapsID {
width: 100%;
height: 100%;
padding: 0;
margin: 0;
}
</style>
</head>
<body>
<!-- Див в котором будет отображена Яндекс.Карта -->
<div id="YMapsID"></div>
</body>
</html>