|
13.48%
2.2 Создание модели поведения пользователя
2.2.1 Выбор ссылок
Рассмотрим логику поведения пользователей. То, как они попадают на ту или
иную страницу:
. Переход по ссылке, с одной страницы на другую
. Использование поисковых систем
. Прямой переход (например, из закладок в браузере)
Необходимо учитывать, что в целях стоит размытие профиля пользователя -
соответственно необходимо генерировать запросы к очень большому количеству различных
сайтов. В связи с этим делается допущение, что для второго и третьего пункта
можно рассматривать сайты отдельно. Далее рассмотрены разработанные алгоритмы
для симуляции выбора ссылок для каждого из приведённых пунктов:
. Переход по ссылке с одной страницы на другую. Если существует
такой переход, значит в HTMLкоде
страницы существует соответствующий тэг. Таким образом, алгоритм действий
таков: загрузка первой страницы, парсинг HTMLразметки, выбор всех тэгов-ссылок (<a>). Далее случайным образом выбор
из получившегося списка ссылки, переход по ней и повторение действий с начала.
Другой вариацией этого подхода, является переход по нескольким ссылкам на одной
странице (симуляция возврата пользователя назад, и переход в другое место)
. Использование поисковых систем. Подразумевается отправка
пользователем запроса и переход по нескольким наиболее популярным ссылкам. С
которыми, далее, возможен повторения сценария из пункта 1. В качестве основной
поисковой системы был выбран Google
- см. описание пакета google
1.9. в Python package Index [21], в связи с тем, что его использует практически
90% пользователей сети (Рис. 5) А так же у него есть функция отображения
наиболее популярных, среди поисковых выдачей страниц. Два способа работы с
поисковой системой:
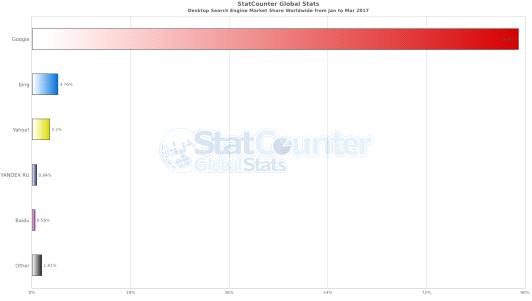
Рисунок 5. Распределение использования поисковых систем пользователями ПК
за последние три месяца [14]
. Запрос вида site:<адрес_сайта>
- в данном случае выбираются наиболее релевантные страницы на заданном сайте. Задаётся
список любых возможных запросов к поисковой системе, и с выдачей по каждому
запросу идёт отдельная генерация (проход по первым N ссылкам из выдачи с
возможностью углубления по каждой ссылке)
. Прямой переход. Для реализации данного метода (а также желание
не повторяться с предыдущими) было выбрано использование sitemaps (описание протокола [22]). Это, в
основном, xml файл, предоставляемый большинством
сайтов, в котором находится информация обо всех страницах сайтах и, зачастую, с
проставленным приоритетом страниц (= популярностью среди пользователей).
Соответственно из данного списка, определённым образом выбираются страницы для
дальнейшего открытия. Механизм выбора - настраиваемый: случайным образом или
последовательно.
2.2.2
Распределение времени ожидания
Стиль поведения в сети различных пользователей - разный. Некоторым
необходимо большое количество времени, чтобы понять подходит ли им тот или иной
сайт, и стоит ли вчитываться внимательнее. Другим для этого хватает пары
секунд. В связи с этим распределение времени просмотра страницы было решено
делать конфигурируемым, с возможностью выбора распределения для отдельных
сайтов, больших наборов сайтов или унифицированный алгоритм для всех сайтов. В
качестве самых базовых распределений были выбраны:
. Константа
. Равномерное
. Нормальное (с обрезкой отрицательного конца)
Далее делается предположение, что существует два типа просмотра страницы
пользователем:
. Беглый, при котором пользователей определяет, стоит ли ему
углубляться в изучение материала, или необходимо искать другой источник -
происходит в течении нескольких секунд (редко превышает временной промежуток в
10-20 секунд) - при большом количестве сайтов и усреднении пользователей можно
предположить нормальное распределение с математическим ожиданием в районе 10, и
дисперсией около 3,5 (= график распределения выглядит как вытянутая колба)
. Глубокий просмотр - происходит после беглого осмотра, время,
затраченное на него, сильно зависит от пользователя и содержания конкретной
страницы. Снова, при большом количестве сайтов и усреднении пользователя
логичным является использование нормального распределения, но в этот раз с
большой дисперсией - из-за сильного разброса в содержимом сайтов. Колба
распределения становится гораздо более пологая.
Объединяя два упомянутых распределения - получается сумма нормальных
распределений - новое распределение с 5ю параметрами. В программе реализована
его упрощённый вид, с предположением что p = ½.
Сумму двух нормальных распределений с весами p и 1-p соответственно можно
вычислить по формуле:
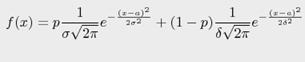
Далее было проведено исследование на реальных значениях, по данным
ресурса WebStat [23] (которые создатели сайта выложил в открытом доступе). В их
базе данных представлены значения - сколько времени пользователь находился на
сайте, и сколько страниц он за этот временной промежуток просмотрел. Формат
данных представлен в Таблице 3.
Таблица. 3. Часть статистики пользователей сайта web-stat.com [23]
|
Time
|
Visit Depth
|
Visit Duration (sec)
|
|
13/05/2017 10:09
|
1
|
3
|
|
13/05/2017 10:09
|
2
|
2
|
|
13/05/2017 10:09
|
2
|
10
|
|
13/05/2017 10:09
|
2
|
3
|
|
13/05/2017 10:09
|
1
|
2
|
|
13/05/2017 10:09
|
4
|
14
|
|
13/05/2017 10:09
|
1
|
38
|
|
13/05/2017 10:08
|
2
|
59
|
|
13/05/2017 10:08
|
2
|
28
|
|
13/05/2017 10:08
|
1
|
7
|
|
13/05/2017 10:08
|
1
|
34
|
|
13/05/2017 10:08
|
4
|
13
|
|
13/05/2017 10:08
|
1
|
75
|
|
13/05/2017 10:08
|
1
|
11
|
1
|
2
|
На Рисунках 6 и 7 представлено распределение времени на каждой странице и
количество посещённых страниц пользователями. Статистика основана на данных по
8000 пользователям. Синие линии показывают реальные значения количества
пользователей. Красные линии - усреднённые значения (в первом случае -
полиноминально среднее, во втором - среднее). Данные усреднённые линии
напоминаю экспоненциальное распределение. Подтверждение данной гипотезы на
Рисунке 8. Синяя линия - распределения вероятностей для каждой секунды в
промежутке от 1 до 50 - полученное путём деления количества пользователей,
которые были на странице данное количество времени и делёное на общее
количество пользователей.
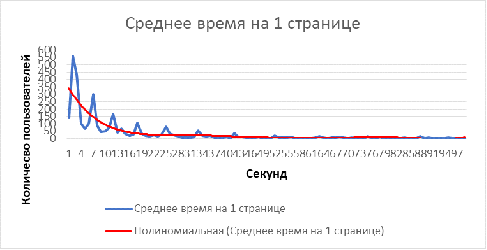
Рисунок 6 Среднее время просмотра 1 страницы пользователём на сайте www.web-stat.com [23]
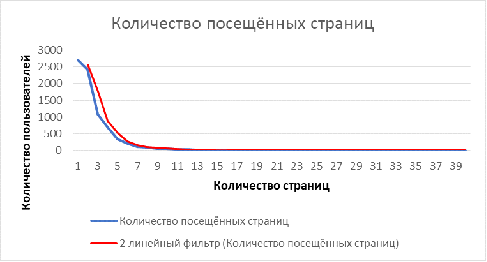
Рисунок 7 Количество посещённых страниц пользователями сайте www.web-stat.com [23]
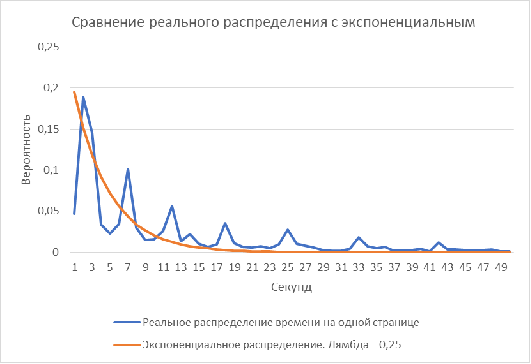
Рисунок 8. Сравнение реального распределения времени на одной странице (с
сайта www.web-stat.com [23]) с экспоненциальным
распределением
Основываясь на гипотезе о схожести данных в программу была добавлена
возможность задавать время просмотра страниц с помощью экспоненциального
распределения с варируемой лямбдой.
Но статистические критерии схожести, например, критерий 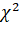 описанный на Рисунке 9, показывают,
что гипотеза о схожести не верна. Т.к. после вычисления значение получилось 162499,3412 (при
количестве степеней свободы = 50). Что отвергает гипотезу о схожести даже при
самых высоких уровнях значимости. описанный на Рисунке 9, показывают,
что гипотеза о схожести не верна. Т.к. после вычисления значение получилось 162499,3412 (при
количестве степеней свободы = 50). Что отвергает гипотезу о схожести даже при
самых высоких уровнях значимости.

Рисунок 9 Описание способа вычисления критерия хи-квадрат
(#"896971.files/image012.gif"> (количество степеней свободы - 20) =
1211,81087 - статистически нельзя говорить о схожести этих распределений.
Но эти две характеристик раздельные - т.е. возможно для одного сайта
использовать различные распределения для времени ожидания и для количества
страниц.
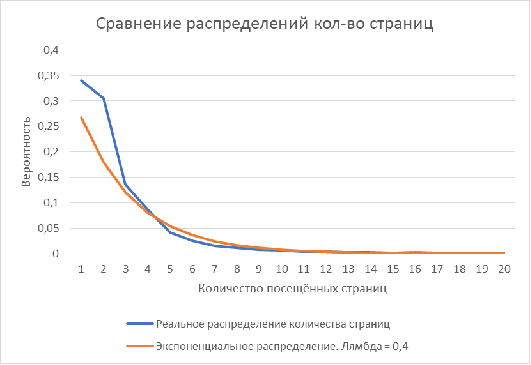
Рисунок 10. Сравнение реального и экспоненциального распределения (лямбда
= 0.4) на количество просмотренных пользователем страниц сайта www.web-stat.com
Ещё вводится дополнительная особенность: режим обхода страниц в сети
«бесконечный сёрфинг» - когда нет ограничений на количество открываемых
страниц. Данный режим работает по следующему алгоритму:
. Задаётся начальная ссылка, открывается и добавляется время
ожидания;
. Сбор с данной страницы всех активных ссылок;
. Выбор из списка ссылок одну (случайным образом);
. Переход по выбранной ссылке, ожидание;
. Повторение п.2.
Выводы по
второй главе
В второй главе был представлен способ моделирования поведения
пользователя, какие статистические распределения к этому применяются. Какие
способы выбора набора сайтов и страниц на сайтах, как они коррелируют с
реальным поведением пользователя в сети. Так же был представлен способ
генерации обращений к выбранным сайтам.
Глава 3.
Выбор средств реализации программного продукта, проект/прототип программного
продукта
Выбор средств реализации во многом зависел исключительно от Технического
Задания, поскольку разрабатываемая система в дальнейшем должна будет стать уже
подсистемой другой системы, разрабатываемой в Институте Системного
Программирования РАН, которая включает в себя в целом работу с трафиком, с
возможностью его захвата на различном оборудовании (в том числе и на
специализированных высокоскоростных сетевых картах), его сохранение, обработка
(снятие определённых заголовком с пакетов, классификация различными способами и
т.д.). И, соответственно, следующим этапом является добавление функциональности
по генерации нового, реалистичного сетевого трафика (возможность простого копирования
ранее сохранённой трассы уже реализована).
Поэтому базовым технологическим стеком является:
1. Python 3.4
. PyGTK 3
. WebKitGtk
В дополнении к нему, для обеспечения работы логгирования и сбора и
отображения статистик:
1. Rsyslog
2. Logstash
3. Elasticsearch 1.4
4. Kibana 3.0
Вся функциональная часть системы разработана в модульном архитектурном
подходе.
3.1 Описание модулей
Launcher
Модуль для запуска всей системы в целом. На вход принимает путь к
конфигурационному файлу системы, в котором указано количество запускаемых
генераторов, их имена и пути к конфигурационным файлам. По полученным данным
этот модуль запускает генераторы, как отдельные процессы. Пример конфигурационного файла:
{
"time_to_live": 10000,
"processes": [
{
"name":"Yandex_catalog",
"config":"config/yandex_catalog.json"
},
{
"name":"Surfing",
"config":"config/surfing.json"
}
]
}
Generator
На вход передаётся конфигурационный файл для генерации сетевого трафика,
в котором указываются используемые распределения для времени и числа страниц на
сайтах, методы выбора ссылок, списки сайтов и методы их генерации.
Пример конфигурационного файла:
{
“user_agen”: “Mozilla/5.0
(Macintosh; Intel Mac OS X 10_12_4) AppleWebKit/603.1.30 (KHTML, like Gecko) Version/10.1
Safari/603.1.30”
“max_time_loading”: 50
"schemes": {
"fast_going": {
"page_generator": "site-scraping",
"time_between_page": {
"type": "uniform",
"low_boundary": 1,
"up_boundary": 5
},
"page_number":{
"type": "uniform",
"low_boundary": 1,
"up_boundary": 10
}
}
"sites":[
{
"type": "loaded_list",
"file_type": "xlsx",
"file_name":
"support_files/sitelist.xlsx",
"worksheet":"List",
"column":"A",
"count_for_visit": 0,
"scheme": "fast_going"
}
]
}
Здесь необходимо ввести понятие «схема сайта» - будем подразумевать как JSON-объект, описывающий схему обхода
некоторого количества сайтов (от одного и более), или описывающий метод
бесконечного сёрфинга. Под каждую схему сайта создаётся отдельный поток. Одним
общим окном для всех потоков, для симуляции графического отображения создаётся
GTK окно.
Worker
Можно рассматривать как интерфейс. В общем случае подразумевает получение
схемы сайта, и отвечает за его обработку, и генерацию последовательности ссылок
и пауз. Затем отправляет полученные ссылки на Opener, и отвечает за корректную расстановку пауз. Имеет
четыре наследника (во вложенном списке перечислены параметры для данной схемы
сайта):
. Infinity_surfing - задаётся начальная ссылка и распределение
времени пауз между открытиями страниц. Далее до остановки переходит от страницы
к другой странице, ссылка на которую находилось на предыдущей.
1.1. file_type - расширения файла
.2. file_name - относительный путь к файле
.3. worksheet - имя листа, на котором находится список
.4. column - имя колонки в которой находится список
.5. count_for_visit -
количество сайтов из списка для посещения. Если 0 - то бесконечно открывать
сайты по-кругу
.6. scheme - схема обхода (из листа schemes)
2. Loaded_list - задаётся
список сайтов (в текущем виде ожидает exel таблицу), и совершает
последовательный обход сайтов из этого списка. Так же подразумевается открытие
нескольких ссылок на каждом сайте
2.1. url - начальный сайт, точка входа в сёрфинг
2.2. scheme - схема обхода
3. Usual_site - открытие
одного сайта, для которого совершается обход в соответствии с заданной схемы
3.1. url - сайт для обхода
3.2. scheme - схема обхода
4. Google Engine - задаётся
список запросов (человеко-читаемых) к поисковой системе, количество сайтов для
каждой выдачи и способ обхода каждого сайта из выдачи.
4.1. queries - лист запросов к поисковой системе
4.2. site_count - объект задающий распределение,
определяющее количество сайтов из выдачи для посещения
4.3. scheme - схема обхода сайта
Utils
Различные методы, которые используется в других модулях. Например: сбор
ссылок со страницы сайта, отправка запроса к google и т.п.
Distribution
Интерфейс для реализации различных распределений. В общем случае - на
вход приходит описание распределения. Затем, при каждом обращении к объекту
класса соответствующего распределения возвращается следующее число.
Параметры распределения задаются с помощью конфигурационного файла,
являясь составной частью параметра «scheme». Пример конфигурации для
распределения времени между загрузкой отдельных страниц:
"time_between_page":
{
"type": "uniform",
"low_boundary": 1,
"up_boundary": 5
},
- На данный момент реализованы все, указанные в п. 2.2
распределения: (в скобках указаны параметры для каждого распределения):
1. Fix (value)
. Uniform (low_boundary, up_boundary)
. Positive-normal (M,D)
. Dual-normal (M1,D1,M2,D2)
. Exponential (L)
. Custom (array)
Logger
Вывод в rsyslog статистик о том, какие страницы открывались, время между
страницами, и количество страниц на сайте (найденных и открытых). Вывод
информации о неисправностях и ошибках в работе.
Кофигурационный файл rsyslog:
:msg,startswith,"PRCSS" /var/log/prcss.log
:msg,startswith,"PRCSS" @@localhost:5544
:msg,startswith," PRCSS" /var/log/prcss.log
:msg,startswith," PRCSS" @@localhost:5544
Конфигурационный файл Logstash:
input {
tcp {
port => 5544
type => syslog
}
udp {
port => 5544
type => syslog
}
}{
if [type] == "syslog" {
grok {
overwrite => "message"
"message" =>
"^(?:<%{POSINT:syslog_pri}> ?)?%{SYSLOGTIMESTAMP:timestamp}
%{IPORHOST:host} (?:%{PROG:program}(?:\[%{POSINT:pid}\])?:) ?PRCSS %{PROG:mess_type}%{GREEDYDATA:message}"
}
}
syslog_pri { }
date {
# season to taste for your own syslog format(s)
match => [ "timestamp", "MMM d
HH:mm:ss", "MMM dd HH:mm:ss", "ISO8601" ]
}
}
}{
stdout {codec => rubydebug}
elasticsearch {
host => localhost
protocol => http
}
}
Конфигурационный файл Elasticsearch:
node.local: true.cors.allow-origin: "/.*/".cors.enabled:
true
3.2 Описание работы журналирования и сбора статистик

Диаграмма
3. Схема работы логирования и сбора статистик
Рисунок 11. Логи работы

Рисунок12. Отображение статистик работы системы
На диаграмме 3 представлена последовательность работы элементов
подсистемы журналирования и сбора статистик. На Рисунках 11 и 12 представлен
пример результата работы системы в целом, выраженный в логах и графиков
статистик.
Выводы по
третьей главе
В третьей главе были представлены разработанные модули системы с
описанием выполняемых функций и ограничения, накладываемые на входные и
выходные данные.
Заключение
Генерация сетевого трафика - динамично развивающаяся область знаний,
идущая параллельно с развитием остальных сетевых технологий и используется, в
основном, для тестирования нового сетевого оборудования и сетевых протоколов.
В рамках выпускной квалификационной работы был представлен новый взгляд в
этой области, и решалась новая задача - предотвращение атак типа «watering hole» путём размытия профиля пользователя в сети, который
достигается за счёт генерации значительного объёма реалистичного трафика. Для
реализации поставленной цели были разработаны алгоритмы моделирования поведения
пользователя в сети - задающие методы генерации посещённых сайтов и страниц,
распределения количества открываемых страниц на каждом сайте и количество
времени, отводимое на задержку на данной странице. Был применён метод загрузки
страниц, на котором основано большинство современных браузеров - WebKit.
Таким образом, в процессе выполнения ВКР были решены следующие задачи:
. Изучена область по генерации трафика. В первой главе был
произведён подробный анализ существующих методов генерации и способов оценки
качестве генерируемого трафика;
. Разработан механизм statefull-генерации HTTP запросов к
серверам с ожиданием ответа и генерацией на его основе следующих запросов путём
использования библиотеки WebKit
в связке с GTK+
. Собраны статистические данные по поведению пользователей в сети
интернет. Получены распределения времени проведённого на страницах сайта и количества
посещённых страниц;
. Разработаны методы моделирования поведения пользователя в сети
путём реализации нескольких способов генерации списка страниц и различных
распределений для количественных характеристик
. Разработана модульная архитектура, с возможностью её дальнейшей
интеграции в существующую в ИСП РАН систему работы с сетевым трафиком;
. Разработана программа генерации сетевого трафика с параметрами,
задаваемыми через конфигурационные файлы;
. Разработана техническая документация к созданной программе.
После выполнения всей работы были произведены испытания получившейся
системы. Реальные результаты запусков программы показывают, что удалось достичь
вероятностных распределений, описанных в разделе 2.2 Создание модели поведения
пользователя. Программа и Методика испытаний в разделе 6 Методика Испытаний.
Направления дальнейшей работы включают в себя следующие задачи:
- Интеграция разработанной программы в систему работы с сетевым
трафиком Института Системного Программирования РАН;
- Расчёт экономической стоимости внедрения и поддержки
разработанной системы на предприятиях различных отраслей;
- Реализация методов определения времени на странице через
анализ содержимого страницы.
Основные
определения, термины и сокращения
DNS (Domain Name System) - протокол
для системы доменных имён. Используется для получения IP-адреса по имени хоста
DPDK (Data Plane Development Kit) - набор
библиотек и драйверов для высокоскоростной обработки данных (обработки сетевых
пакетов)
Framework - программная платформа, определяющая структуру программной
системы; программное обеспечение, облегчающее разработку и объединение разных
компонентов большого программного проекта
GUI (Graphical User Interface) - графический пользовательский интерфейс
HTML (HyperText Markup Language) - «язык гипертекстовой разметки» - стандартизированный язык разметки
документов во Всемирной паутине.
HTTP (Hyper Text Transport Protocol) -
протокол прикладного уровня передачи данных в сети. Существует набор состояний
клиента и сервера при обмене данных (например, 200 - сервер успешно принял и
обработал сообщение клиента). Statefull - поддержка всех состояний работы
протокола
HTTPS (Hyper Text Transport Protocol Secure) - расширение
протокола HTTP, для поддержки шифрования в целях
повышения безопасности. Данные в протоколе HTTPS передаются поверх криптографических протоколов SSL (Secure Sockets Layer) или TLS (Transport Layer Security)
ICMP (Internet Control Message Protocol) - протокол межсетевых управляющих сообщений. Используется для передачи сообщений
об ошибках и других исключительных ситуациях, возникших при передаче данных,
например, запрашиваемая услуга недоступна, или хост, или маршрутизатор не
отвечают.
IDS (Intrusion Detection System) - устройство
или приложения для мониторинга сети или системы и обнаружения случившихся
вторжений или вирусов
IPS (Intrusion Prevention Systems) - приложение для сетевой безопасности, не допускающее в сеть или систему
запросы или файлы, которые могут быть вредоносными
JS (JavaScript) - язык программирования, в основном используется на веб-сайтах
REST (Representational state transfer) запрос - HTTP Get или Post
запрос, соответствующий общим архитектурным принципам взаимодействия
распределённого приложения.
Statefull HTTP запросы - загрузка html-кода страницы и последующая
обработка js-скриптов, поддержка сертификатов для HTTPS, загрузка картинок и иного медиа-контента. Например,
в случае страницы отдельного видео на youtube - должна происходить его полная загрузка - как это
происходит у пользователей, т.к. включается авто-проигрывание при открытии
страницы.
URL (Uniform Resource Locator) - текстовое значение, служит стандартизированным способом записи адреса
ресурса в сети Интернет.
Watering Hole - тип сетевых атак, при которых доступ к системе жертвы
достигается путём заражения стороннего ресурса.
Wireshark - приложение
для захвата и анализа сетевого трафика. На данный момент считается стандартов в
данной области
WWW (World Wide Web) - всемирная
паутина. Набор всех сайтов, входящих в сеть интернет
Сетевой пакет - последовательный набор байт, передаваемых по сети. Включает в
себя несколько заголовков различных уровней. В модели TCP/IP
выделяют 4 уровня - канальный, сетевой, транспортный, прикладной. Протоколы
канального уровня называют также низкоуровневыми протоколами, последние два -
высокоуровневыми. Для каждого из уровней существует определённый набор
протоколов.
Список
использованных источников
[1] Abendan Oscar Celestino Angelo Watering Hole 101 [Электронный
ресурс] // Trend Micro. - 13 02 2013 г.. - 25 01 2017 г.. -
https://www.trendmicro.com/vinfo/us/threat-encyclopedia/web-attack/137/watering-hole-101.
[2] Alessio Botta
Alberto Dainotti, Antonio Pescapé A tool for the generation of realistic network workload for
emerging networking scenarios [Журнал] // Elsevier. - Napoli : Elsevier, 24
March 2012 г.. - 80125 : Т. 21.
[3] Aymen Hafsaoui Navid Nikaein, Lusheng Wang OpenAirInterface Traffic Generator
(OTG): A Realistic Traffic Generation Tool for Emerging Application Scenarios.
[Отчет] / Mobile Communications Department ; Eurocom. - Sophia : [б.н.], 2012.
[4] Data plane development kit [Электронный ресурс]. - Febuary 2017
г.. - http://dpdk.org.
[5] Field-programmable gate array [Электронный ресурс] // Wikipedia. -
2017 г.. - Febuary 2017 г.. - https://en.wikipedia.org/wiki/Field-programmable_gate_array.
[6] J. Sommers H. Kim, P. Barford Harpoon: a flow-level traffic
generator for router and network tests [Отчет]. - [б.м.] : SIGMETRICS, 2013.
[7] Nicola Bonelli Andrea Di Pietro, Stefano Giordano,
Gregorio Procissi
Flexible High Performance Traffic Generation on Commodity Multi-Core Platforms
[Отчет] / Universit`a di Pisa. - Pisa : Universit`a di Pisa, 2014.
[8] P. Srivats Ostinato [Электронный ресурс] // Ostinato. - 2010 г.. -
January 2017 г.. - http://ostinato.org.
[9] Paul Emmerich
Sebastian Gallenmüller, Daniel Raumer, Florian Wohlfart, Georg Carle MoonGen: A Scriptable High-Speed
Packet Generator [Отчет] / Department of Computer Science ;
Technische Universität München. - [б.м.] : Technische Universität
München.
[10] Raffaele Bolla Roberto Bruschi, Marco Canini A High Performance IP Traffic
Generation Tool Based on the Intel IXP2400 Network Processor [Журнал]. - [б.м.]
: Distributed Cooperative Laboratories: Networking, Instrumentation, and
Measurements Signals and Communication Technology, 206 г.. - стр. 127-142.
[11] Sandor Molna Geza Szabo How to Validate Traffic Generators
[Конференция] // IEEE International Conference on Communications. - [б.м.] :
IEEE ICC'13, 2013.
[12] Shalvi Srivastava Sweta Anmulwar, A.M.Sapkal Comparative Study of Various Traffic
Generator Tools [Конференция] // RAECS UIET. - Chandigarh : Panjab University
Chandigarh, 2014.
[14] StatCounter Statcounter [Электронный ресурс] // Statcounter. -
StatCounter. - March 2017 г.. - https://statcounter.com.
[15] Stefano Avallone
Antonio Pescapè, Giorgio Ventre Analysis and Experimentation of Internet Traffic Generator
[Конференция] // Distributed Computing Systems. - [б.м.] : 10th IEEE
International Workshop, 2004. - стр. 277- 283.
[16] Sudhakar Mishra Shefali Sonavane, Anil Gupta Study of Traffic Generation Tools
[Журнал] // International Journal of Advanced Research in Computer and
Communication Engineering. - 6 2015 г.. - 6 : Т. 4.
[17] The WebKitGTK+ team [Электронный ресурс]. - Febuary 2017 г.. -
https://webkitgtk.org.
[18] Xin Su Dafang Zhang, Wenjia Li, Xiaofei Wang AndroGenerator: An automated and
configurable android app network traffic generation system [Журнал] // SECURITY
AND COMMUNICATION NETWORKS. - [б.м.] : Wiley Online Library, 15 September 2015
г.. - 4273 : Т. 8.
[19] Yeongrak Choi Jae Yoon Chung, Byungchul Park, Paul
Barford Automated
Classifier Generation for Application-Level Mobile Traffic Identification
[Отчет] / Division of IT Convergence Engineering. - Pohang : POSTECH, 2012.
[20] Нефёдова Мария Недавняя атака на польские банки связана с хак-группой
Lazarus, взломавшей Sony Picture [Электронный ресурс] // Хакер. - 14 02 2017
г.. - 20 02 2017 г.. - https://xakep.ru/2017/02/14/lazarus-new-campaign/.
[21] Google 1.9.3 Python Package Index [Электронный ресурс]. -
March 2017 г.. - https://pypi.python.org/pypi/google.
[22] XML-формат файла Sitemap [Электронный ресурс]. -
Febuary 2017 г.. - https://www.sitemaps.org/ru/protocol.html.
[23] Web-Stat / Live Web Traffic
Analysis and Visitors Details [Электронный ресурс]. - Febuary 2017 г.. - http://www.web-stat.com.
Похожие работы на - Разработка программы для генерации сетевого трафика с заданными параметрами
|