Компьютерная реализация информационно-моделирующей системы для процессов химической очистки теплоэнергетического оборудования
ВВЕДЕНИЕ
Актуальность темы: обработка статистических данных уже давно используется
в самых разных видах человеческой деятельности. На данный момент трудно назвать
ту сферу, в которой она бы не могла использоваться. Также обработка
статистических данных может играть большую роль на производстве, где
основополагающими являются технологические процессы, в дальнейшем
рассматриваются процессы химической очистки. Разносторонний и углубленный
анализ такой информации, так называемых статистических данных, полагает
использование различных специальных методов, алгоритмов, важное место среди
которых занимают корреляционно-регрессионный и дисперсионный анализы обработки
статистических данных. Помимо анализов статистической обработки для процессов
химической очистки теплоэнергетического оборудования будет актуально и
моделирование, необходимыми входными данными для которого не будут являться
собранные экспериментальные данные, что также будет разрабатываться в выпускной
квалификационной работе. В настоящий момент в сфере программного обеспечения
представлено большое количество разнообразных программ и пакетов, позволяющих
обрабатывать статистические данные, но большинство из них являются
универсальными в своем роде, требовательны к ресурсам персонального компьютера,
дорого стоят. Многие не направлены на простых пользователей, не способных
оперировать методами и анализами, которые им необходимы для решения конкретных
задач.
Цель данной работы: целью выпускной квалификационной работы является
разработка информационно-моделирующей системы для процессов химической очистки
теплоэнергетического оборудования.
Задачи работы: разработка информационно-моделирующей системы, которая
проводит математическое моделирование корреляционно-регрессионным анализом
(регрессия от одного параметра, множественная регрессия), дисперсионным
анализом (однофакторный, двухфакторный, латинский квадрат, греко-латинский
квадрат, гипер-греко-латинский квадрат, латинский куб), моделирование на основе
теории конечных автоматов.
Научная новизна работы:
) обобщены алгоритмы построения математических моделей
корреляционно-регрессионного анализа для процессов химической очистки
теплоэнергетического оборудования;
) обобщены алгоритмы построения математических моделей дисперсионного
анализа для процессов химической очистки теплоэнергетического оборудования;
) разработан алгоритм на основе теории конечных автоматов для процессов
химической очистки теплоэнергетического оборудования.
Практическая значимость работы: корреляционно-регрессионный анализ дает
возможность прогнозирования результатов процессов химической очистки на основе
собранных статистических данных. Дисперсионный анализ проводит качественную
оценку факторов, участвующих в процессах химической очистки. Анализ на основе
теории конечных автоматов проводит количественную оценку показателей,
необходимых для процессов химической очистки.
Апробация работы. Результаты выпускной квалификационной работы
обсуждались на Межрегиональной научной конференции IX ежегодной научной сессии аспирантов и молодых ученых в 2015
году в г. Вологда.
Публикации. Результаты изложены в двух работах.
Выпускная квалификационная работа содержит четыре разделов.
В первом разделе описывается обзор и анализ систем интеллектуальной
обработки данных. Раздел содержит описание систем поддержки принятия решений,
экспертных систем, систем на основе теории конечных автоматов, также
рассмотрены примеры моделирования конечных автоматов.
Во втором разделе описываются основные аспекты процессов химической
очистки теплоэнергетического оборудования предметная область автоматизации,
дается постановка задачи автоматизации, выявляется структура, назначение
системы, описываются модули. Рассматриваются математическое моделирование
технологических процессов на основе корреляционно-регрессионного и
дисперсионного анализов, и на основе теории конечных автоматов.
В третьем разделе представлены модель IDEF0, диаграммы IDEF3, указана разработка информационно-моделирующей системы, описывая это
основными этапами и алгоритмами, представлена информационная модель данных.
В четвертом разделе указываются требования к системе в целом, требования
к функциональным возможностям. Представлено описание компьютерной реализации и
приведены примеры анализа и оценки технологических процессов. Описаны
структурное тестирование и функциональное тестирование. Оценивается надежность
на основе модели Нельсона.
данные
алгоритм интеллектуальный теплоэнергетический
1. ОБЗОР И
АНАЛИЗ СИСТЕМ ИНТЕЛЛЕКТУАЛЬНОЙ ОБРАБОТКИ ДАННЫХ
1.1 Системы поддержки принятия решений
В книге Черноруцкого И.Г. «Методы принятия решений» [1] описываются
системы поддержки принятия решений. Такие системы, созданные с помощью
компьютерных технологий, являются в большинстве случаев интерактивные системы,
которые разработаны для оказания помощи менеджеру либо руководителю в принятии
определенных решений. Такие системы приравниваются к автоматизированным
информационным системам, работающие с пользователями по принципу диалога с
ними.
Системы поддержки принятия решений можно разделить на два вида:
) информационные системы управления предприятиями;
) системы анализа и исследования данных, которые предусмотрены для
руководителей, за плечами которых есть знания в рассматриваемой предметной
области обследования.
В книге Баллод Б.А. «Методы и алгоритмы принятия решений в экономике» представлена
основная структура систем поддержки принятия решений, и приведены примеры [2].
Информационно-управляющие системы, относящиеся ко второму виду систем поддержки
принятия решений, могут занять неотъемлемую часть в организации решения в
управлении предприятием. Один из возможных видов таких систем представлен на
рисунке 1.1. Согласно модели, представленной на рисунке 1.1, данную
информационно-управляющую систему можно разделить на следующие взаимосвязанные
между собой части: аналитическая подсистема, подготавливающая отчеты
управленческим органам предприятия; система поддержки принятия решений;
информационная система; база данных, включающая в себя архив и необходимые
показатели для работы СППР.
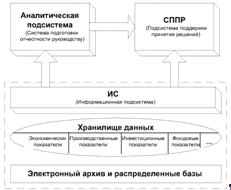
Рисунок 1.1 - Информационно-управляющая система на основе СППР
Работа системы поддержки принятия решений для информационно-управляющей
системы представлена на рисунке 1.2.
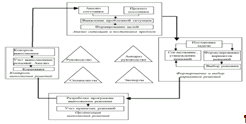
Рисунок 1.2 - Работа СППР
На рисунке 1.2 указано, что в систему поддержки принятия решений входят
такие основные блоки функционирования, как проведение анализа и постановки
проблем, проведение и выбор возможных вариантов решений проблем, организация
решений проблем, проведение контроля решений проблем.
В книге Дорогова В.Г. «Введение в методы и алгоритмы принятия решений»
[3] представлена классификация систем поддержки принятия решений представлена
на рисунке 1.3.
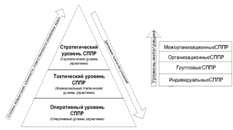
Рисунок 1.3 - Классификация СППР
Согласно классификации системы поддержки принятия решений можно разделить
по уровню интеграции (в порядке возрастания):
) индивидуальные СППР;
) групповые СППР;
) организационные СППР;
) межорганизационные СППР.
Также в системе поддержки принятия решений можно выделить определенные
уровни, критерием которых будет являться тип принимаемых решений системой:
) оперативный уровень СППР;
) тактический уровень СППР;
) стратегический уровень СППР.
Оперативный уровень необходим для принятия решений проблем, которые
повторяются многократно, интервал между ними не велик, может измеряться в днях,
неделях. Так как необходимо часто решать возникающие задачи в организационных
вопросах предприятиях, на этом уровне большое количество выполняемых операций,
а также прослеживается динамика в принятии решений предприятия по созданию
большой выборки проблем за короткий промежуток времени.
Тактический уровень необходим для решения поставленных проблем и задач,
которые требуют первоначального анализа данных, разработанных на первом
оперативном уровне по ходу его выполнения. Решения проблем тактического уровня
разрабатываются уже на большем интервале времени, нежели для оперативного
уровня, здесь промежутки между решениями могут исчисляться кварталами,
полугодиями и годами. Поэтому количество решаемых задач сокращается на этом
уровне, но сложность поиска управленческий решений повышается, следовательно,
оценивать относительно оперативного уровня количество выполняемых операций не
стоит, они могут как розниться, так и быть примерно одинаковыми.
1.2 Экспертные системы
В книге Элти Дж. «Экспертные системы: концепции и примеры» [4] дается
определение и основные положения по экспертным системам. Экспертные системы
являются такими системами, которые используют знания экспертов для того, чтобы
обеспечить необходимое эффективное решение поставленных проблем, не имеющей
конкретной формализации, преобладающие в основном в узкой предметной области.
В книге Попова Э.В. «Экспертные системы. Решение неформализованных задач
в диалоге с ЭВМ» [5] описываются свойства экспертных систем. В качестве основы
всех экспертных систем выступает база знаний, которая имеет свойство накопления
как в процессе построения данной системы, так и уже при ее внедрении и
использовании. Это является основным свойством всех экспертных систем, ее
разбиение и представлено на рисунке 1.4.
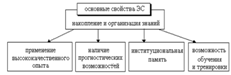
Рисунок 1.4 - Накопление и организация знаний в экспертной системе
Основное свойство экспертных систем делится на следующие свойства:
) использование опытов высокого качества;
) есть возможности составления прогноза;
) институциональная память;
) наличие возможности обучаться и тренироваться.
Использование опытов высокого качества говорит о том, что для решения
определенных проблем используются соответствующие высококвалифицированные эксперты
в данной предметной области, что делает решение проблемы более точным и, как
правило, эффективным.
Экспертные системы могут выдавать ответы не только для определенной
проблемы, но и предугадывать другие результаты при отличных условиях проблем.
Что дает возможность разъяснить, к каким последствиям привела бы новая
поставленная проблема.
Институциональная память является архивом мнений экспертов, которые
постоянно обновляются, дополняются для более точного выбора стратегии решения
проблем в дальнейшем.
Наличие возможности обучаться и тренироваться подает пользователям
накапливаемый со временем опыт выбора решений, по которому есть возможность
обследовать необходимый метод поиска решений поставленной проблемы.
В книге Поспелова Д.А. «Моделирование рассуждений. Опыт анализа
мыслительных актов» [6] представлены участники в экспертных системах. В
разработке и дальнейшем использовании экспертных систем принимают участие:
) непосредственно сама экспертная система;
) эксперты;
) инженер знаний;
) средство построения экспертной системы;
) конечный пользователь.
Схема взаимосвязи участников разработки и использования экспертных систем
представлена на рисунке 1.5.
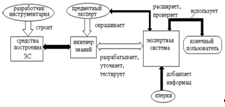
Рисунок 1.5 - Схема взаимосвязи участников разработки и использования
экспертных систем
Ранее уже говорилось об эксперте, участвующем в создании экспертной
системы, но не давалось определение. Экспертом является специалист в
исследуемой предметной области, у которого есть определенная репутация среди
других, умеет находить нужные решения в разных ситуациях. Экспертная система
строит модели на основе всех вариантов ответа каждого эксперта.
Инженером знаний является человек, который имеет навыки в разработке
экспертных систем. Он проводит опрос среди экспертов, организуя и структурируя
полученные знания, инженер определяет, как именно они должны быть занесены в
экспертную систему.
Средством построения экспертных систем является выбранное программное
средство, которое будут использовать для разработки экспертной системы. Это
средство будет отличаться от стандартных языков программирования, так как
необходимым условием для него является удобство представления сложных
высокоуровневых знаний.
Конечным пользователем является человек, которому необходима экспертная
система на этапе ее использования. В качестве пользователей могут также быть и
программисты, разрабатывающие экспертную систему, инженер знаний, эксперты.
В книге Литвака Б.Г. «Экспертные оценки и принятие решений» [7] говорится
про коэффициент доверия. Одной из особенностей экспертных систем является
коэффициент доверия, что является количественной оценкой, означающее
уверенность, показывающее на сколько определенное знание можно считать и
принять правильным для данной ситуации.
В книге Нейлора К. «Как построить свою экспертную систему» [8]
описываются виды экспертных систем: статические и динамические. Структура
статической экспертной системы представлена на рисунке 1.6.
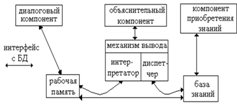
Рисунок 1.6 - Структура статической экспертной системы
В статической экспертной системе все знания о предметной области поделены
на типы: общие знания о том, как решать задачи (связаны с механизмом ввода,
который содержит интерпретатор, он определяет применимость определенного
правила для показа новых данных, и диспетчер, который устанавливает
последовательность применения этих правил) и выделенные знания (связаны с базой
знаний, которая содержит факты и правила).
Структура динамической экспертной системы представлена на рисунке 1.7.
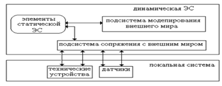
Рисунок 1.7 - Структура динамической экспертной системы
В отличие от статической экспертной системы в динамическую входят
дополнительно две подсистемы:
) подсистема, которая моделирует внешний мир;
) подсистема, имеющая взаимосвязь с внешним миром.
В книге Братко И. «Программирование на языке Пролог для искусственного
интеллекта» [9] указана схема разработки экспертных систем, представленная
рисунке 1.8.
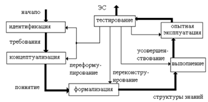
Рисунок 1.8 - Схема разработки экспертных систем
1.3 Системы на основе теории конечных автоматов
В книге А. Гилла «Введение в теорию конечных автоматов» [10] приводятся
некоторые примеры применения теории конечных автоматов, а именно то, что она
имеет дело с математическими моделями, предназначенными для приближенного
отображения физических или абстрактных явлений. А. Гилл в своей книге
представляет основную модель конечного автомата, по которому можно представить,
по его представлению, все остальные, более детальные модели конечного автомата.
Его представление основной модели показано на рисунке 1.9.
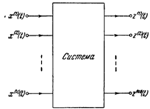
Рисунок 1.9 - Представление системы основной модели конечных автоматов А.
Гилла
Как видно из схемы, систему он представляет как «черный ящик», что в свою
очередь является фундаментальной структурой для многих моделей. Входные
переменные представляют собой воздействия, генерируемые другой системой (не
подлежащей исследованию), и которые влияют на поведение исследуемой системы.
Выходные переменные (реакции) представляют собой те величины, характеризующие
поведение данной системы, которые интересуют исследователя. Промежуточные
переменные - те величины, которые не являются ни входными, ни выходными. Также
предполагаются, что все переменные зависят от времени, что видно на рисунке
1.9.
В книге Н.И. Поликарповой и А.А. Шалыто «Автоматное программирование»
[11] представлены виды систем конечных автоматов, которые чаще всего
используются по данной теории. Соответственно каждую систему можно явно или
косвенно отнести к одному из следующих классов: трансформирующие системы,
интерактивные системы, реактивные системы:
) трансформирующие системы осуществляют некоторое преобразование входных
данных, и после этого завершают свою работу;
) интерактивные системы взаимодействуют с окружающей средой в режиме
диалога (например, текстовый редактор);
) реактивные системы взаимодействуют с окружающей средой путем обмена
сообщениями в темпе, задаваемом средой.
По мнению авторов Н.И. Поликарповой и А.А. Шалыто, критерий применимости
автоматного подхода лучше всего выражается через понятие «сложное поведение».
Сущности с простым поведением и сложным представлены на рисунке 1.10.
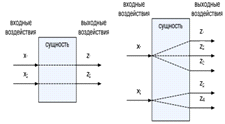
Рисунок 1.10 - Сущности с простым поведением (слева) и сложным (справа)
В этой книге «Автоматное программирование» представлена схема конечного
автомата, что является одной из видов возможных моделей, построенных на основе
основной модели А. Гилла (рисунок 1), схема представлена на рисунке 1.11.
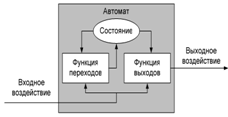
Рисунок 1.11 - Конечный автомат по мнению Н.И. Поликарповой и А.А. Шалыто
В книге М. И. Дехтяря «Конечные автоматы» [12] автор характеризует
автоматы двумя особенностями: отсутствие предвосхищения, конечная память.
Отсутствие предвосхищения указывает на то, что выходной сигнал,
выдаваемый автоматом в определенный момент времени, зависит лишь от полученных
к этому времени входов.
Конечная память указывает на то, что в каждый момент времени информация в
автомате о полученных к этому моменту входных значений конечна.
М. И. Дехтярь в своей книге приводит пример конечного
автомата-преобразователя, который по своей структуре похож с конечным
автоматом, представленной в книге «Автоматное программирование», схема которой
представлена на рисунке 1.11.
Конечный автомат-преобразователь - это система вида
A=<∑x, ∑y, Q, q0,
Φ, Ψ>,
где ∑x={a1,…,am} (m>=1)
- конечное множество - входной алфавит;
∑y={b1,…,br} (r>=1) - конечное множество -
выходной алфавит;
Q={q0,…,qn-1} (n>=1)
- конечное множество - алфавит внутренних состояний;
q0 є Q - начальное состояние автомата;
Ф: Q x ∑x → Q - функция переходов, Ф(q,a) - это состояние, в которое переходит из состояния q, когда получает на вход символ a.
Ψ: Q x ∑x → ∑y - функция выхода, Ψ(q,a) - это символ из ∑y, который выдает на выход автомат в состоянии q, когда получает на вход символ a.
Удобный способ задания функций переходов Ф и выхода Ψ
является табличный.
Каждая из них определяется таблицей n x m, строки которой соответствуют
состояниям из Q, а стоблцы - символах входного
алфавита ∑x. В первой из них
на пересечении строки и стобца состояние Ф(qi,aj), а во второй -
выходной символ Ψ(qi,aj). Пример такого
способа задания функций представлен на рисунке 1.12.
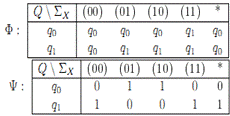
Рисунок 1.12 - Табличный способ задания функций переходов и выхода
Еще один способ представления конечного автомата основан на использовании
ориентированных размеченных графов. Диаграмма автомата на основе табличного
способа задания функций переходов и выхода (рисунок 1.12) представлена на
рисунке 1.13.
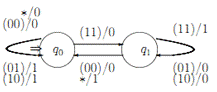
Рисунок 1.13 - Диаграмма автомата с 0 и 1
В отличие от определения на рисунке 1.5 нет меток a/b, роль их выполняют 0 и 1. Широкая стрелка, ведущая в q0, указывает на начальное состояние.
Пример диаграммы с метками a/b представлен на рисунке 1.14.
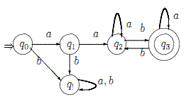
Рисунок 1.14 - Диаграмма автомата с метками a/b
Такие методы задания автоматов легко применимы с работой со словами,
каждой метке можно провести соответствие с рассматриваемой буквой исследуемого
слова.
В методическом указании А. Г. Кокина и В. Н. Кузнецова «Конечные
автоматы: языки и грамматики» [13] представлены некоторые характеристики
автоматов: неотличимость автоматов (любое автоматное отображение, реализуемое
одним из них, может быть реализовано другим), эквивалентность автоматов (имеют
наименьшее возможное число состояний, называется минимальным), частичный
автомат (если хотя бы одна из его двух функций не полностью определена).
В книге «Теория автоматов» [14] автор В. С. Выхованец дает понятие
автоматного отображения, что является соответствием, отображающее входные
строки конечного автомата в выходные.
Также автор поясняет, что конечный автомат является полным, если в
автоматной таблице не существует пустых клеток, кроме столбца соответствующего
заключительному состоянию.
Состояние q2 является
достижимым состоянием q1,
если на пересечении входного значения a и состояния q1 стоит q2. Это видно на рисунке 4. На
диаграмме из состояния q1
идет стрелка в состояние q2 ,
что видно на рисунках 1.13, 1.14.
Сильно связный автомат - это такой автомат, когда из любого его состояния
достижимо его любое другое состояние, то есть на графе автомата существует
путь, соединяющий любые его две вершины. Примером такого автомата является
ориентированный граф, представленный на рисунке 1.15. Также примером сильно
связного автомата будет являться модель, представленная на рисунке 1.13.
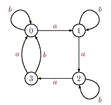
Рисунок 1.15 - Пример сильно связного автомата
Автоматный автомат (генератор) - это автомат, у которого входной алфавит
состоит из одного знака, иногда говорят, что это вход синхронизаций, задающий
такты работы автомата. Возможный вид задания генератора представлен в таблицах
1.1 и 1.2.
Таблица 1.1 - Функция переходов автоматного автомата (генератора)
|
Состояния
|
Входной знак (0)
|
|
q0
|
q1
|
|
q1
|
q2
|
|
q3
|
q4
|
|
q5
|
q6
|
|
q7
|
q8
|
Таблица 1.2 - Функция выхода автоматного автомата (генератора)
|
Состояния
|
Входной знак (0)
|
|
q0
|
1
|
|
q1
|
0
|
|
q3
|
0
|
|
q5
|
1
|
|
q7
|
1
|
В книге Ожиганова А.А. «Теория автоматов» [15] представлены автоматы Мили
и Мура.
Дан абстрактный автомат вида
S=<Z, W, A, a1,
Φ, Ψ>
где Z={z1,…,zf} -
конечное множество - входной алфавит;
W={w1,…,wg} - конечное множество - выходной алфавит;
A={a1,…,am} - конечное множество - алфавит внутренних состояний;
a1 є A - начальное состояние автомата;
δ - функция переходов;
λ - функция выхода.
Работа абстрактного автомата представлена на рисунке 1.16.
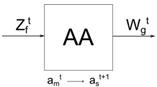
Рисунок 1.16 - Работа абстрактного автомата
Графический способ задания автомата Мили представлен на рисунке 1.17.
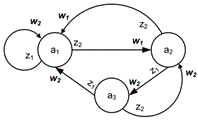
Рисунок 1.17 - Графический способ задания автомата Мили
Графический способ задания автомата Мура представлен на рисунке 1.18.
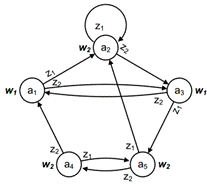
Рисунок 1.18 - Графический способ задания автомата Мура
Автомат Мура переходит в автомат Мили, если всем переходам в состояние
поставить выходные воздействия этого состояния. После таких преобразований
получим эквивалентный автомат Мили.
В книге Котова В. Е. «Сети Петри» [16] представлена характеристика сетей
Петри, их виды и особенности.
Сети Петри представляют собой двудольный ориентированный мультиграф.
События и условия представлены абстрактными символами из двух непересекающихся
алфавитов, называемых соответственно множеством переходов (T) и множеством мест (P). В графическом представлении сетей
переходы изображаются «барьерами», а места «кружками», что представлено на
рисунке 1.19.
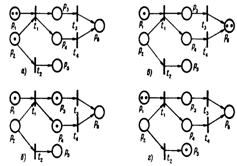
Рисунок 1.19 - Примеры сетей Петри
Сеть Петри можно задать как графическим способом, так и табличным
способом. Графический способ задания сетей Петри представлен на рисунке 1.20
(также этому же способу соответствует рисунок 1.19).
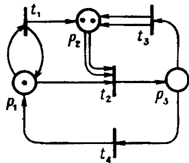
Рисунок 1.20 - Графический способ задания сетей Петри
Табличный способ задания сетей Петри (согласно графическому способу
рисунка 1.20) представлен в таблицах 1.3 и 1.4.
Таблица 1.3 - Табличный способ задания сетей Петри из входного места в
переход
|
t1
|
t2
|
t3
|
t4
|
|
P1
|
1
|
1
|
0
|
0
|
|
P2
|
0
|
2
|
0
|
0
|
|
P3
|
0
|
0
|
1
|
1
|
Таблица 1.4 - Табличный способ задания сетей Петри из перехода в выходное
место
|
P1
|
P2
|
P3
|
|
t1
|
1
|
1
|
0
|
|
t2
|
0
|
0
|
1
|
|
t3
|
0
|
2
|
0
|
|
t4
|
1
|
0
|
0
|
В книге «Теория автоматов» автора В. С. Выхованец описывается
двухстековый автомат.
Это формальная система, задаваемая объектами
D =
<A, B, Q, S, F, P, I>,
где A - конечный входной алфавит;
B -
конечный выходной алфавит;
Q -
множество состояний двухстекового автомата;
S -
стек просмотра назад;
F -
стек просмотра вперед;
P -
система команд. Есть отображение множества декартового произведения множеств
состояний двухстекового автомата, стека просмотра назад, входного алфавита и
стека просмотра вперед в множество декартового произведения множеств состояний
двухстекового автомата, стека просмотра вперед и стека просмотра назад.
P: Q x S x A x F → Q x F x S*
- начальная конфигурация двухстекового автомата.
Структура двухстекового автомата представлена на рисунке 1.21.
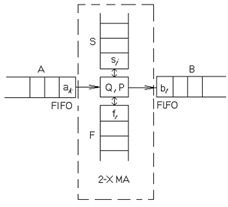
Рисунок 1.21 - Структура двухстекового автомата
В статье «Клеточно-автоматная модель формирования порошковой струи» Ю.Г.
Медведева представлен пример построения клеточно-автоматной модели.
Под клеточным автоматом автор понимает тройку объектов <K, N, Q>.
K
является множеством клеток с заданными координатами в дискретном пространстве.
Каждая клетка характеризуется состоянием и координатами на Декартовой
плоскости. Состояние зависит от дискретного времени, а координаты остаются
неизменными.
Для каждой клетки определено упорядоченное множество N из семи элементов. Первый элемент -
есть сама клетка, остальные 6 - соседи клетки, нумерация соседей представлена
на рисунке 1.22.
Q
является функцией переходов. Автором были проведены два эксперимента: газ без
порошка, композиция газа и порошка. Результаты его экспериментов представлены
на рисунке 1.23, что наглядно показывает работу клеточно-автоматной модели.
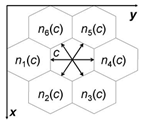
Рисунок 1.22 - Нумерация соседей клеточно-автоматной модели

Рисунок 1.23 - Результаты работы клеточно-автоматной модели
2. РАЗРАБОТКА
ПРИНЦИПОВ И СТРУКТУРЫ ИНФОРМАЦИОННО-МОДЕЛИРУЮЩЕЙ СИСТЕМЫ ДЛЯ ПРОЦЕССОВ
ХИМИЧЕСКОЙ ОЧИСТКИ ТЕПЛОЭНЕРГЕТИЧЕСКОГО ОБОРУДОВАНИЯ
2.1 Информационные аспекты процессов химической очистки
теплоэнергетического оборудования
Есть два основных вида химических очисток: предпусковая и
эксплуатационная [17].
Задачей предпусковой химической очистки является удаление из вновь
смонтированного оборудования большого количества обычно содержащихся в нем
разнообразных загрязнений: ржавчины, сварочного грата, песка, земли, окалины,
масла и смазки, набивочного и прокладочного материала и т.п.
Эксплуатационная химическая очистка предназначена для удаления из
оборудования отложений самого различного состава, возникших во время его
работы. Отложения, удаляемые при эксплуатационных очистках, сравнительно
разнообразны по своему составу, тогда как загрязнения котлов, удаляемые
предпусковыми очистками, имеют более или менее одинаковый состав.
Критерии качества очистки:
) состояние поверхности после очистки, т.е. степень удаления с нее
имевшихся отложений;
) количество вымытых отложений.
Общие условия для очистки:
1) скорость промывочных растворов должна быть достаточной для
предотвращения выпадения в осадок взвеси на горизонтальных участках;
2) целесообразно, чтобы обеспечивалось проведение очистки различными
моющими реагентами;
3) схема предпусковой очистки должна обеспечить проведение в
дальнейшем эксплуатационных очисток;
) схема должна быть максимально увязана со схемой паровой продувки
котла в целях максимального использования одних и тех же трубопроводов.
Отложения, образующие при эксплуатации теплоэнергетического оборудования,
приведены в таблице 2.1.
Таблица 2.1 - Отложения, образующие при эксплуатации оборудования
|
Элемент оборудования
|
Характеристика отложений в
процессе эксплуатации
|
|
Барабанные котлы,
работающие без фосфатирования
|
Накипь и различные
силикаты, алюмосиликаты и ферросиликаты Органические вещества, окислы железа
|
|
Котлы, работающие с
фосфатированием
|
Накипь: медь металлическая,
магнетит, иногда, силикаты железа, алюмосиликаты, соединения цинка Шлам:
гидроксилапатит, окислы железа
|
|
Прямоточные котлы
|
Окислы железа, мель и её
окислы, кремнекислые соли. Силикаты, алюмосиликаты и ферросиликаты,
органические вещества, соединения цинка
|
|
Пароперегреватели
|
Окислы железа, содержащие
также окислы легирующих металлов. Соли натрия - фосфорнокислые, кремнекислые,
сернокислые. Феррит натрия
|
|
Водяные экономайзеры
|
Окислы железа,
металлическая медь, фосфорит, реже карбонат кальция и основной карбонат
магния
|
Этапы химической очистки:
) скоростные водные промывки, которые проводятся для удаления из котла
случайных и слабо сцепленных с поверхностью металла загрязнений (сварочный
грат, песок, ржавчина, отслоившиеся куски окалины);
) щелочение для удаления масел и разрыхления отложений (обезжиривание);
) обработка отложений основными реагентами. Обработка отложений раствором
основных реагентов может сопровождаться рядом явлений, связанных с коррозией
основного металла, поэтому независимо от вида применяемого реагента необходимо
в промывочный раствор добавлять ингибиторы коррозии;
) удаление отработанного промывочного раствора. Осуществляется обычно
вытеснением раствора водой;
) нейтрализация остатков реагента
) пассивация очищенных поверхностей для образования равномерной пленки
окислов, предохраняющей металл в дальнейшем от атмосферной коррозии. Водные
промывки, проводимые после химической очистки технической водой, насыщенной
большим количеством кислорода, хлоридами и сульфатами, которые способствуют
интенсивной коррозии (ржавлению) металла. Поэтому пассивирующие растворы
приготовляются обязательно на обессоленной воде, так как присутствие в растворе
хлоридов или сульфатов препятствует созданию защитной пленки на металле.
Принципы химической очистки:
) превращение нерастворимого отложения в соль, хорошо растворимую в воде;
) связывание катионной части нерастворимого вещества отложения в прочный
комплекс, хорошо растворимый в воде;
) превращение вещества отложения в другое вещество, также нерастворимое в
воде, но способное растворяться в кислоте, других реагентах согласно первому
или второму принципу очистки или легко уноситься потоком воды;
) разрушение подслоя отложений, прочно связанного с поверхностью металла,
с последующим удалением разрыхленных и отставших от поверхности нагрева
отложений потоком воды;
) растворение основной части отложений, после чего оставшиеся
нерастворенными отложения удаляются потоком воды;
) эмульгирование или диспергирование нерастворимых веществ (или части их)
с последующим удалением тонкодисперсной эмульсии или взвеси потоком воды.
Типы реагентов:
) щелочи (едкий натр, кальционированная сода, тринатрийфосфат, аммиак или
специальные детергенты);
) минеральные кислоты;
) органические кислоты;
) комплексоны.
2.2 Структура
информационно-моделирующей системы, назначение и описание модулей системы
Разработана функциональная структура информационно-моделирующей системы,
которая представлена на рисунке 2.1, состоящая из 5-х подсистем: информационная
подсистема, моделирующая подсистема по корреляционно-регрессионному анализу,
моделирующая подсистема по дисперсионному анализу, моделирующая подсистема на
основе теории конечных автоматов, подсистема анализа моделей.
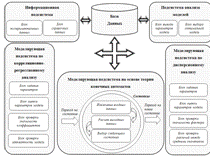
Рисунок 2.1 - Функциональная структура информационно-моделирующей системы
Информационная подсистема проводит ввод экспериментальных данных
процессов химической очистки теплоэнергетического оборудования и включает в
себя справочные данные. Моделирующие подсистемы проводят
корреляционно-регрессионный анализ, дисперсионный анализ, анализ на основе
теории конечных автоматов. Подсистема анализа моделей выдает показатели модели,
реализует выборку оптимальной модели.
Корреляционно-регрессионный анализ информационно-моделирующей системы
включает регрессию от одного параметра и множественную регрессию. В регрессии
от одного параметра по результатам построения модели рассчитываются коэффициент
корреляции, который показывает на сколько тесно связаны входной и выходной
данные, показатели уравнений различных видов регрессий (линейная,
параболическая, гиперболическая, полулогарифмическая, показательная,
степенная), проверка значимости коэффициентов по критерию Стьюдента
(информационная подсистема включает в себя справочные данные критических
значений распределения Стьюдента согласно уровню значимости α=0,05), проверка адекватности модели
по критерию Фишера (информационная подсистема включает в себя справочные данные
критических значений распределения Фишера согласно уровню значимости α=0,05). Во множественной регрессии по
результатам построения модели производится расчет коэффициента корреляции,
расчет показателей уравнений регрессии разных видов (линейная, с парными
взаимодействиями, с квадратичными взаимодействиями), проверка адекватности
модели.
Дисперсионный анализ информационно-моделирующей системы строит модели
следующий анализов: однофакторный анализ, двухфакторным, латинский квадрат (3
фактора), греко-латинский квадрат (4 фактора), гипер-греко-латинский квадрат (5
факторов), латинский квадрат (5 факторов, различие в расположении и
комбинаторике факторов). Включает в себя подсчеты общей суммы факторов, а также
факторной суммы и остаточной суммы, подсчет степеней свободы для всех трех
типов сумм, расчет общей, остаточной и факторной дисперсий, проверка значимости
фактора реализуется по критерию Фишера (информационная подсистема включает в
себя справочные данные критических значений распределения Фишера согласно
уровню значимости α=0,05), проверка различий между
средними значениями реализуется по критерию Дункана (информационная подсистема
включает в себя справочные данные рангов критерия Дункана).
Анализ на основе теории конечных автоматов проводит расчет необходимого
количества выбранных реагентов для очистки определенного вида отложений на
основе данных о количестве и занимаемой площади отложений. Должна быть создана
графическая реализация, представляющая наглядное моделирование
клеточно-автоматной модели, а именно где каждой клетке присваивается
соответствующее состояние, исходя из входных данных, присутствие или отсутствие
отложений, по достижению определенной клетке алгоритм определяет нужное
количество реагента для ее очистки (если требуется) и меняет ее состояние.
2.3 Математическое моделирование на основе
корреляционно-регрессионного анализа
Во многих задачах порой необходимо определить на сколько случайная
величина Y зависит от случайной величины Х, и
зависит ли вовсе. У этих показателей иногда проявляется связь друг с другом
функционально, но чаще видна между ними статистическая зависимость - при этом
изменение одного показателя подразумевает изменение среднего значения другого
показателя, что называется корреляционной зависимостью [18].
Для регрессии от одного параметра входные и выходные данные указываются
из условий: нет параллельных опытов, есть параллельные опыты, есть параллельные
опыты, и их количество фиксировано. Когда нет параллельных опытов, одному
значению входных данных соответствует одно значение выходных данных, что
представлено в таблице 2.2.
Таблица 2.2 - Экспериментальные данные при отсутствии параллельных опытов
|
Входные данные X
|
Выходные данные Y
|
|
x1
|
y1
|
|
x2
|
y2
|
|
…
|
…
|
|
xn
|
yn
|
Когда есть параллельные опыты, то одному значению входного параметра
соответствует несколько значений выходного параметра, что представлено в
таблице 2.3, если количество выходных значений неопределенно, и в таблице 2.4
при фиксированном количестве значений.
Таблица 2.3 - Экспериментальные данные при наличии параллельных опытов
|
Входные данные X
|
Выходные данные Y
|
|
x1
|
y11
|
y12
|
…
|
|
x2
|
y21
|
y22
|
…
|
|
…
|
…
|
…
|
…
|
|
xn
|
yn1
|
yn2
|
…
|
Таблица 2.4 - Экспериментальные данные при наличии параллельных опытов
|
Входные данные X
|
Выходные данные Y
|
|
x1
|
y11
|
y12
|
…
|
y1m
|
|
x2
|
y21
|
y22
|
…
|
y2m
|
|
…
|
…
|
…
|
…
|
…
|
|
xn
|
yn1
|
yn2
|
…
|
ynm
|
Для определения тесноты связи между показателями есть коэффициент
корреляции, который определяется по формуле:
где
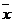 - среднее значение входных значений;
- среднее значение входных значений;
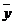 -
среднее значение выходных значений;
-
среднее значение выходных значений;
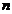 -
количество опытов;
-
количество опытов;
 -
дисперсия входных данных;
-
дисперсия входных данных;
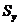 -
дисперсия выходных данных.
-
дисперсия выходных данных.
Средние
значения определяются по формулам:

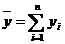
Дисперсии определяются по формулам:
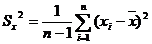
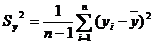
Когда есть параллельные опыты, вместо yi берутся средние значения по строкам из таблицы данных.
Коэффициент корреляции лежит в интервале от -1 до 1. Чем ближе по модулю
к единице его значение, тем сильнее теснота связи между данными. Отрицательный
знак коэффициента говорит об обратной зависимости входных параметров от
выходных.
Линейная форма связи между экспериментальными данными имеет вид:
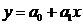
Коэффициенты a0 и a1 (и для последующих форм связи)
определяются методом наименьших квадратов и в конечном итоге определяются по
формулам:
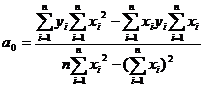
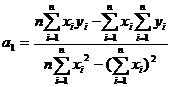
Параболическая форма связи между экспериментальными данными имеет вид:
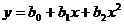
Коэффициенты b0, b1 и b2 определяются по формулам:

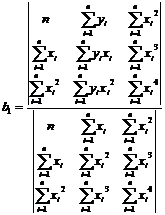

Гиперболическая форма связи между экспериментальными данными имеет вид:
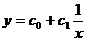
Коэффициенты c0 и c1 определяются по формулам:

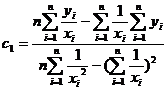
Полулогарифмическая форма связи имеет вид:
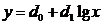
Коэффициенты d0 и d1 определяются по формулам:
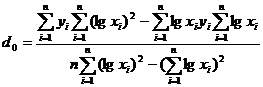
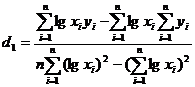
Показательная форма связи между экспериментальными данными имеет вид:
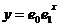
Коэффициенты e0 и e1 определяются по формулам:
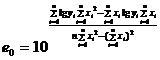
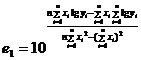
Степенная форма связи имеет вид:
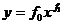
Коэффициенты f0 и f1 определяются по формулам:
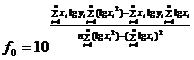
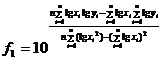
Дисперсия воспроизводимости определяется из условий характера проведения
опытов. При отсутствии параллельных опытов она находится по формуле:
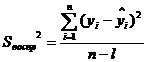 , (2.1)
, (2.1)
где l - количество коэффициентов в
уравнении регрессии.
При наличии параллельных опытов с неопределенным количеством дисперсия
воспроизводимости определяется по формуле:
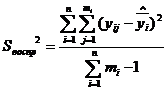 ,
,
где mi - количество параллельных опытов
каждой серии.
При наличии параллельных опытов с одинаковым количеством дисперсия
воспроизводимости определяется по формуле:
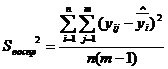
где
m - количество параллельных опытов;
В
знаменателе оценки дисперсии воспроизводимости указывается степень свободы
данной дисперсии (fвоспр).
Значимость
коэффициентов проверяют по критерию Стьюдента. Для линейной формы уравнения
регрессии (аналогично и для остальных форм связи) критерий будет иметь вид:
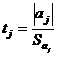
где
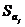 - среднее квадратичное отклонение j-го
коэффициента.
- среднее квадратичное отклонение j-го
коэффициента.
Если
tj больше табличного значения для уровня значимости α=0,05 и числа степеней свободы fвоспр,
то коэффициент aj значимо отличается от нуля. Среднее квадратичное
отклонение определяется по формуле:
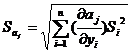 ,
,
где Si2 - выборочные дисперсии.
Если выборочные дисперсии однородны, то используют вместо них дисперсию
воспроизводимости.
Адекватность модели проверяется по критерию Фишера, указанном в формуле:
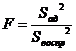 , (2.2)
, (2.2)
где
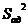 - дисперсия адекватности.
- дисперсия адекватности.
Она
определяется по формуле:
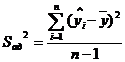 , (2.3)
, (2.3)
где
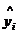 - расчетное значение по определенной форме связи.
- расчетное значение по определенной форме связи.
В
знаменателе указана степень свободы дисперсии адекватности (fад).
Если наблюдаемое значение критерия Фишера для уровня значимости α=0,05 и степеней свободы fвоспр и fад
меньше критического, то модель адекватна. Чем больше превышает критическое
значение наблюдаемое, тем эффективнее уравнение регрессии.
Если
необходимо исследовать корреляционную связь между многими величинами, то есть
возможность построить следующие модели множественной регрессии:
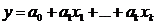 (2.4)
(2.4)
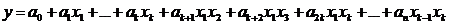 (2.5)
(2.5)
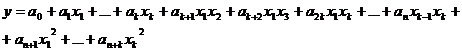 (2.6)
(2.6)
Исходные экспериментальные данные представлены в таблице 2.5.
Таблица 2.5 - Экспериментальные данные для множественной регрессии
|
Номер опыта
|
x1
|
x2
|
…
|
xk
|
y
|
|
1
|
x11
|
x21
|
…
|
xk1
|
y1
|
|
2
|
x12
|
x22
|
…
|
xk2
|
y2
|
|
…
|
…
|
…
|
…
|
…
|
…
|
|
n
|
x1n
|
x2n
|
…
|
xkn
|
yn
|
Для построения модели множественной регрессии, имеющей вид (2.4),
необходимо перейти от натурального масштаба к новому, проведя нормировку всех
значений случайных величин по формулам:
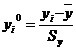 ,
,
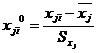 ,
,
где
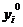 ,
, 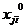 -
нормированные значения соответствующих факторов;
-
нормированные значения соответствующих факторов;
, 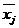 - средние значения факторов;
- средние значения факторов;
, 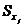 - среднеквадратичные отклонения факторов.
- среднеквадратичные отклонения факторов.
Среднеквадратичные
отклонения определяются по формулам:
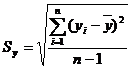
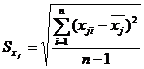
Исходные экспериментальные данные в нормированном виде представлены в
таблице 2.6.
Таблица 2.6 - Экспериментальные данные в нормированном виде
|
Номер опытаx10x20…xk0y0
|
|
|
|
|
|
|
1
|
x110
|
x210
|
…
|
xk10
|
y10
|
|
2
|
x120
|
x220
|
…
|
xk20
|
y20
|
|
…
|
…
|
…
|
…
|
…
|
…
|
|
n
|
x1n0
|
x2n0
|
…
|
xkn0
|
yn0
|
В новом масштабе xj0 =
0, y0 = 0.
Выборочные коэффициенты корреляции будут определяться по формулам:
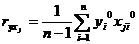
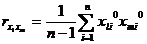 ,
, 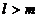
Коэффициенты уравнения также как и в регрессии от одного параметра
находятся по методу наименьших квадратов из условия. В результате для их нахождения
необходимо решить систему уравнений, которая имеет вид:
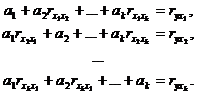 (2.7)
(2.7)
В
системе уравнений (2.7) 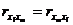 . Решив систему, необходимо определить коэффициент
множественной корреляции, который определяется по формуле:
. Решив систему, необходимо определить коэффициент
множественной корреляции, который определяется по формуле:

Коэффициент множественной корреляции определяет оценку силы связи для
множественной регрессии. Также лежит в интервале от 0 до 1. Для маленького
объема входных данных в величину R
нужно занести корректировку на систематическую ошибку. Чем менее количество
степеней свободы входных данных, тем более завышает сила связи, которая
определяется коэффициентом множественной корреляции, его скорректированное
значение определяется по формуле:
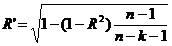
Адекватность модели определяется по критерию Фишера, аналогичным образом,
как и для регрессии от одного параметра при отсутствии параллельных опытов,
используя формулы (2.1), (2.2), (2.3).
Для расчета коэффициентов уравнений вида (2.5) и (2.6) используется метод
градиентов. Задаются первоначальные значения параметров модели, рассчитывается
дисперсия отклонений, после определяется направление изменения каждого
коэффициента, сравнивая получившиеся после дисперсии отклонений. По нахождению
направления изменения коэффициента, он изменяется до тех пор, пока дисперсия
отклонений не станет минимальной. Коэффициент корреляции и проверка
адекватности моделей для данных видов проводятся аналогичным образом, как и для
линейной множественной регрессии без взаимодействий.
В результате изучения математического моделирования на основе
корреляционно-регрессионного анализа была разработана идентификация параметров
математических моделей, которая представлена на рисунке 2.2.
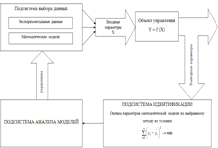
Рисунок 2.2 - Идентификация параметров математических моделей
Оценка параметров математических моделей производится из условия, что
сумма квадратов отклонений от экспериментальных данных стремится к минимуму.
Подсистема анализа моделей выбирает оптимальную модель, исходя из условия
оценки параметров математических моделей, которая представлена в идентификации
параметров.
2.4 Математическое моделирование на основе дисперсионного анализа
Математическое моделирование на основе дисперсионного анализа в
информационно-моделирующей системе для процессов химической очистки
теплоэнергетического оборудования исследует значимость факторов на изменение
средних значений наблюдаемых качественных величин [18].
Для однофакторного дисперсионного анализа экспериментальные данные
представлены в таблице 2.7.
Таблица 2.7 - Экспериментальные данные для однофакторного анализа
|
Номер измерения
|
Уровни фактора А
|
|
a1
|
a2
|
…
|
ap
|
|
1
|
y11
|
y12
|
…
|
y1p
|
|
2
|
y21
|
y22
|
…
|
y2p
|
|
…
|
…
|
…
|
…
|
…
|
|
q
|
yq1
|
yq2
|
…
|
yqp
|
Для каждого уровня фактора необходимо найти групповые средние значения,
определяющиеся по формуле:
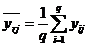 (2.8)
(2.8)
Общее среднее определяется по формуле:
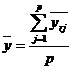 (2.9)
(2.9)
Остаточная сумма отражает влияние случайной величины, определяется по
формуле:
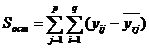 (2.10)
(2.10)
Факторная сумма показывает воздействие фактора, находится по формуле:
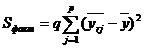 (2.11)
(2.11)
Общая сумма определяется по формулам:
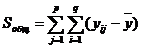 (2.12)
(2.12)
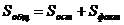 (2.13)
(2.13)
Общая, остаточная и факторная дисперсии определяются по формулам:
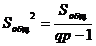 (2.14)
(2.14)
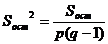 (2.15)
(2.15)
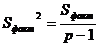 (2.16)
(2.16)
В знаменателях указаны степени свободы fобщ, fфакт
и fост соответственно.
Значимость фактора определяется по критерию Фишера:
 (2.17)
(2.17)
Если наблюдаемое значение критерия Фишера для уровня значимости α=0,05 и степеней свободы fфакт и fост меньше критического, то фактор значим.
Для двухфакторного дисперсионного анализа экспериментальные данные
представлены в таблице 2.8.
Таблица 2.8 - Экспериментальные данные для двухфакторного анализа
|
Уровни фактора B
|
Уровни фактора А
|
|
a1
|
a2
|
…
|
ap
|
|
b1
|
y11
|
y12
|
…
|
y1p
|
|
b2
|
y21
|
y22
|
…
|
y2p
|
|
…
|
…
|
…
|
…
|
…
|
|
bq
|
yq1
|
yq2
|
…
|
yqp
|
Для фактора А используют те же формулы, что и для однофакторного
дисперсионного анализа (2.8)-(2.17).
Для фактора В аналогично считаются групповые средние, факторная сумма,
остаточная и факторная дисперсии.
Групповые средние для фактора В определяются по формуле:
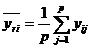
Факторная сумма для фактора В находится по формуле:
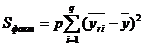
Остаточная и факторная дисперсии для фактора В определяются по формулам:
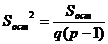

Значимость фактора В также определяется по критерию Фишера по формуле
(2.17).
Различие между средними значениями определяется при помощи множественного
рангового критерия Дункана. Рассмотрим его на факторе А двухфакторного
дисперсионного анализа, аналогичным образом он определяется и для фактора В.
У
нас рассчитаны все групповые средние 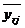 .
Необходимо расположить их в порядке возрастания. Дальше следует определить
ошибку воспроизводимости с соответствующим числом степеней свободы. Нужно
определить ошибку для каждого среднего по формуле:
.
Необходимо расположить их в порядке возрастания. Дальше следует определить
ошибку воспроизводимости с соответствующим числом степеней свободы. Нужно
определить ошибку для каждого среднего по формуле:
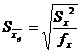
где
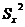 - дисперсия воспроизводимости;
- дисперсия воспроизводимости;
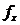 -
степень свободы.
-
степень свободы.
Дальше
надо выписать из таблицы Дункана p-1 значений рангов с выбранным уровнем значимости,
умножить эти значения на ошибку для каждого среднего и таким образом определить
p-1 наименьших значимых рангов. После следует проверить
значимость различия между средними, начиная с крайних в ранжировочном ряду;
разность максимального и минимального значений среднего сравнить с наименьшим
значимым рангом, затем найти разность максимального среднего и второго среднего
в ранжировочном ряду и сравнить ее с наименьшим значимым рангом и так далее.
Это сравнение продолжить для второго по величине среднего, которое сравнивается
с наименьшим, и так далее, пока не будут исследованы на значимость различия
между всеми парами.
В
латинском квадрате в одной таблице данных находятся три фактора, расчеты для
них осуществляются аналогично однофакторному и двухфакторному анализам,
расположение данных для каждого фактора представлено на примере в таблице 2.9.
Таблица
2.9 - Данные для латинского квадрата
|
Уровни фактора В
|
Уровни фактора А
|
|
a1
|
a2
|
a3
|
|
b1
|
c1
|
c2
|
c3
|
|
b2
|
c2
|
c3
|
c1
|
|
b3
|
c3
|
c1
|
c2
|
То есть первому уровню фактора А соответствуют клетки (1,1), (2,1),
(3,1), где первое число - строка, второе число - столбец. Для первого уровня
фактора В соответствуют клетки (1,1), (1,2), (1,3). Для фактора С первый
уровень содержит данные клеток (1,1), (3,2), (2,3).
В греко-латинском квадрате в таблице данных находятся четыре фактора.
Расчеты каждого фактора также аналогичны, пример расположения четырех факторов
представлен в таблице 2.10.
Таблица 2.10 - Данные для греко-латинского квадрата
|
Уровни фактора В
|
Уровни фактора А
|
|
a1
|
a2
|
a3
|
|
b1
|
c1 d1
|
c2 d2
|
c3 d3
|
|
b2
|
c2 d3
|
c3 d1
|
c1 d2
|
|
b3
|
c3 d2
|
c1 d3
|
c2 d1
|
В гипер-греко-латинском квадрате в таблице данных находятся пять
факторов. Пример расположения пяти факторов представлен в таблице 2.11.
Таблица 2.11 - Данные для гипер-греко-латинского квадрата
|
Уровни фактора В
|
Уровни фактора А
|
|
a1
|
a2
|
a3
|
a4
|
a5
|
|
b1
|
c1 d1 e1
|
c2 d2 e2
|
c3 d3 e3
|
c4 d4 e4
|
c5 d5 e5
|
|
b2
|
c2 d3 e4
|
c3 d4 e5
|
c4 d5 e1
|
c5 d1 e2
|
c1 d2 e3
|
|
b3
|
c3 d5 e2
|
c4 d1 e3
|
c5 d2 e4
|
c1 d3 e5
|
c2 d4 e1
|
|
b4
|
c4 d2 e5
|
c5 d3 e1
|
c1 d4 e2
|
c2 d5 e3
|
c3 d1 e4
|
|
b5
|
c5 d4 e3
|
c1 d5 e4
|
c2 d1 e5
|
c3 d2 e1
|
c4 d3 e2
|
2.5 Принципы построения информационно-моделирующей системы на основе
теории конечных автоматов
Конечные автоматы в целом подразумевают наличие входного потока данных, с
помощью которых обрабатывается ограниченное количество состояний алгоритма, по
достижению одного конечного состояния алгоритм и вычисления завершаются.
В данной реализации для решения поставленной задачи используется
клеточно-автоматная модель, где каждая клетка имеет свое состояние, которое
определяется наличием или отсутствием отложений в ней. На основе входных данных
происходят переходы по состояниям с целью расчета количества необходимого
реагентов для очистки определенного вида отложений. Клеточно-автоматная модель
в графической реализации представляет собой поле, что будет являться неким
разрезом теплоэнергетического оборудования. Коэффициент занятых отложением
клеток данного поля определяется по формуле:
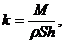
где
М - масса отложений;
ρ - плотность отложений;
S - занимаемая
площадь;
h - единица
высоты для определенного отложения.
Если
коэффициент по расчету больше одного, то ему присваивается значение единицы,
что говорит о том, что вся площадь поля занята отложением. Если коэффициент
меньше единицы, то с учетом его значения будет заполнено только определенная
часть поля отложением.
Общий
вид расположения отложения на клеточном поле представлен в таблице 2.12.
Таблица
2.12 - расположение отложений на поле
|
m11
|
m12
|
…
|
m1b
|
|
m21
|
m22
|
…
|
m2b
|
|
…
|
…
|
…
|
…
|
|
ma1
|
ma2
|
mab
|
Очистка выбранного вида отложений реагентами происходит на основе
протекаемых химических реакций, общий вид записи для каждой клетки-состояния
представлен в формуле:
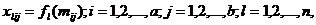
где
xl - количество определенного реагента для очистки
клетки;
fl - функция
расчета для определенного реагента;
n - количество
используемых реагентов для очистки.
Алгоритм
проходит по всем клеткам поля, при обнаружении чистой клетки ее состояние
сохраняется, при обнаружении отложений в клетке производится расчет, а после
меняется состояние клетки.
По
завершению расчетов и смены состояний в клетках поля рассчитывается общее
количество необходимых реагентов для очистки определенного выбранного вида
отложения, что представлено в формуле:
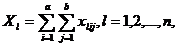
Конечные
данные для каждого реагента выводятся в таблице результатов моделирования.
3. ПОСТРОЕНИЕ
ИНФОРМАЦИОННО-МОДЕЛИРУЮЩЕЙ СИСТЕМЫ
3.1 Проектирование ИМС с использованием CASE-средств
Одними из самых затратных пунктами и моментов разработки
информационно-моделирующей системы являются этапы проектирования и анализа
систем, вследствие которых CASE-средства
обеспечивают результат принимаемых решений технического характера и подготовку
проектной документации.
Для проектирования информационно-моделирующей системы для процессов
химической очистки теплоэнергетического оборудования применяется такое
CASE-средство (Computer Aided System/Software Engineering - автоматизация
процесса разработки сложных информационных систем) как BPwin - средство
функционального проектирования, которое реализует методологию IDEF и DFD. Методология IDEF0 применяется для
проектирования моделей широкого круга предметных областей и применяется как
технологический способ проектирования систем на информационно-логическом
уровне. Эта технология описывает информационно-моделирующую систему в целом как
множество взаимосвязанных функций или действий. Процесс построения модели
какой-нибудь системы в IDEF0 начинается с построения контекстной диаграммы, она
является главной в структуре диаграмм и представляет собой самое общее описание
системы и ее взаимодействие с внешней средой [19].
Для данной модели входной информацией (Input) являются данные о процессе химической очистки.
Управляющими механизмами (Control)
являются методики расчета и справочные данные. Исполняющим механизмом (Mechanism) является информационно-моделирующая
система. В качестве выходной информации (Output) служат математическая модель и результаты анализа.
Контекстная диаграмма модели информационно-моделирующей системы
представлена на рисунке 3.1.
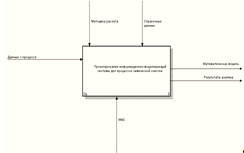
Рисунок 3.1 - Контекстная диаграмма информационно-моделирующей системы
Стрелки контекстной диаграммы представлены в таблице 3.1.
Таблица 3.1 - Стрелки контекстной диаграммы
|
Наименование стрелки
|
Описание
|
Тип
|
|
Данные о процессе
|
Перечень всех необходимых
данных о процессе химической очистки (наименование, входные и выходные
экспериментальные данные)
|
Input
|
|
Методики расчета
|
Все необходимые для
расчетов алгоритмы и методы, используемые в информационно-моделирующей
системе
|
Control
|
|
Справочные данные
|
Все необходимые справочные
данные для расчетов
|
Control
|
|
ИМС
|
Информационно-моделирующая
система
|
Mechanism
|
|
Математическая модель
|
Построенная математическая
модель по технологическому процессу
|
Output
|
|
Результаты анализа
|
Все произведенные расчеты
по построенной математической модели
|
Output
|
Процесс проектирования информационно-моделирующей системы для процессов
химической очистки теплоэнергетического оборудования состоит из пяти основных
этапов: «Ввод информации», «Корреляционно-регрессионный анализ», «Дисперсионный
анализ», «Конечные автоматы», «Анализ модели».
Диаграмма декомпозиции первого уровня «Проектирование
информационно-моделирующей системы для процессов химической очистки
теплоэнергетического оборудования» представлена на рисунке 3.2.
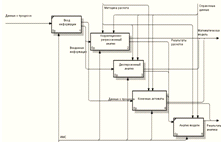
Рисунок 3.2 - Диаграмма декомпозиции первого уровня
Основные модели IDEF0
представлены в таблице 3.2.
Таблица 3.2 - Основные модели IDEF0
|
Название проекта:
Проектирование информационно-моделирующей системы для процессов химической
очистки теплоэнергетического оборудования.
|
|
Цель проекта: Реализация
структурной функциональной модели информационно-моделирующей системы.
|
|
Технология моделирования:
метод функционального моделирования IDEF0.
|
|
Инструментарий: программный
продукт BP Win 4.0.
|
|
Список данных
|
Перечень функций
|
|
Данные о процессе Методики
расчета Справочные данные Информационно-моделирующая система Математическая
модель Результаты анализа
|
А0: Проектирование
информационно-моделирующей системы для анализа и оценки технологических
процессов на основе корреляционно-регрессионного и дисперсионного анализа
|
|
Данные о процессе Введенная
информация Методики расчета Справочные данные Информационно-моделирующая
система Результаты расчетов Математическая модель Результаты анализа
|
А1: Ввод информации А2:
Корреляционно-регрессионный анализ А3: Дисперсионный анализ А4: Конечные
автоматы А5: Анализ модели
|
Описание функциональных блоков представлено в таблице 3.3.
Таблица 3.3 - Описание функциональных блоков
|
Наименование функционального
блока
|
Описание решаемых задач
|
|
А1: Ввод информации
|
По данным о технологическом
процессе происходит занесение соответствующей информации в
информационно-моделирующую систему.
|
|
А2:
Корреляционно-регрессионный анализ
|
По завершению ввода
информации происходит моделирование корреляционно-регрессионным анализом.
|
|
А3: Дисперсионный анализ
|
По завершению ввода
информации происходит моделирование дисперсионным анализом.
|
|
А4: Конечные автоматы
|
По завершению ввода
информации происходит моделирование на основе теории конечных автоматов.
|
|
А4: Анализ модели
|
По результатом
моделирования и расчетов происходит анализ полученных результатов.
|
3 - метод функционально проектирования и построения моделей
бизнес-процесса. Он используется для построения моделей таких процессов, в
которых необходимо определить последовательность выполнения действий и взаимную
зависимость между ними. У данного способа проектирования нет статуса
федерального стандарта, но его используют как дополнение к IDEF0 [20]. Диаграмма бизнес-процесса
«Корреляционно-регрессионный анализ» представлена на рисунке 3.3. Основные
элементы в модели IDEF3 представлены
в таблице 3.4. Описание действий IDEF3
представлено в таблице 3.5. Диаграмма бизнес-процесса «Дисперсионный анализ»
представлена на рисунке 3.4. Основные элементы в модели IDEF3 представлены в таблице 3.6.
Описание действий IDEF3 представлено
в таблице 3.7. Диаграмма декомпозиции второго уровня «Конечные автоматы»
представлена на рисунке 3.5. Описание функциональных блоков представлено в
таблице 3.8.

Рисунок 3.3 - Диаграмма бизнес-процесса «Корреляционно-регрессионный
анализ»
Таблица 3.4 - Основные элементы модели IDEF3
|
Название проекта:
Проектирование информационно-моделирующей системы для процессов химической очистки
теплоэнергетического оборудования.
|
|
Цель проекта: Реализация
структурной функциональной модели ИМС.
|
|
Технология моделирования:
метод моделирования IDEF3.
|
|
Инструментарий: программный
продукт BP Win 4.0.
|
|
Перечень действий
|
Тип соединения
|
|
Название
|
Вид
|
|
1
|
2
|
3
|
|
Построить модель уравнения
регрессии Построить множественную регрессию
|
Соединение «Эксклюзивное
ИЛИ»
|
Разворачивающий
|
|
Построить линейную модель
Построить параболическую модель Построить гиперболическую модель Построить
полулогарифмическую модель Построить показательную модель Построить степенную
модель
|
Соединение «И»
|
Разворачивающий
|
|
Построить линейную модель
Построить параболическую модель Построить гиперболическую модель Построить
полулогарифмическую модель Построить показательную модель Построить степенную
модель
|
Соединение «И»
|
Сворачивающий
|
|
Построить модель без
взаимодействий Построить модель с парными взаимодействиями Построить модель с
квадратичными взаимодействиями
|
Соединение «И»
|
Разворачивающий
|
|
Построить модель без
взаимодействий Построить модель с парными взаимодействиями Построить модель с
квадратичными взаимодействиями
|
Соединение «И»
|
Сворачивающий
|
|
|
|
|
Таблица 3.5 - Описание действий IDEF3
|
Наименование действий
|
Описание решаемых задач
|
|
1. Построить модель
уравнения регрессии
|
Согласно введенным данным
происходит выбор определенного вида модели уравнения регрессии.
|
|
2. Построить множественную
регрессию
|
Согласно введенным данным
происходит выбор определенного вида модели множественной регрессии.
|
|
3. Построить линейную
модель
|
После выбора соответствующего
вида модели строится линейная модель.
|
|
4. Построить параболическую
модель
|
После выбора
соответствующего вида модели строится параболическая модель.
|
|
5. Построить
гиперболическую модель
|
После выбора
соответствующего вида модели строится гиперболическая модель.
|
|
6. Построить
полулогарифмическую модель
|
После выбора
соответствующего вида модели строится полулогарифмическая модель.
|
|
7. Построить показательную
модель
|
После выбора
соответствующего вида модели строится показательная модель.
|
|
8. Построить степенную
модель
|
После выбора
соответствующего вида модели строится степенная модель.
|
|
9. Построить модель без
взаимодействий
|
После выбора
соответствующего вида модели строится линейная множественная модель без
взаимодействий.
|
|
10. Построить модель с парными
взаимодействиями
|
После выбора
соответствующего вида модели строится множественная модель с парными
взаимодействиями.
|
|
11. Построить модель с
квадратичными взаимодействиями
|
После выбора
соответствующего вида модели строится множественная модель с квадратичными
взаимодействиями.
|
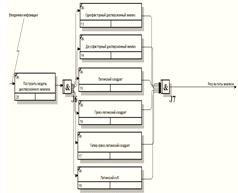
Рисунок 3.4 - Диаграмма бизнес-процесса «Дисперсионный анализ»
Таблица 3.6 - Основные элементы модели IDEF3
|
Название проекта:
Проектирование информационно-моделирующей системы для процессов химической
очистки теплоэнергетического оборудования.
|
|
Цель проекта: Реализация
структурной функциональной модели ИМС.
|
|
Технология моделирования:
метод моделирования IDEF3.
|
|
Инструментарий: программный
продукт BP Win 4.0.
|
|
Перечень действий
|
Тип соединения
|
|
Название
|
Вид
|
|
Построить модель
дисперсионного анализа
|
Соединение «И»
|
Разворачивающий
|
|
Однофакторный дисперсионный
анализ Двухфакторный дисперсионный анализ Латинский квадрат Греко-латинский
квадрат Гипер-греко-латинский квадрат Латинский куб
|
Соединение «И»
|
Разворачивающий
|
|
Однофакторный дисперсионный
анализ Двухфакторный дисперсионный анализ Латинский квадрат Греко-латинский
квадрат Гипер-греко-латинский квадрат Латинский куб
|
Соединение «И»
|
Сворачивающий
|
Таблица 3.7 - Описание действий IDEF3
|
Наименование действий
|
Описание решаемых задач
|
|
1. Построить модель
дисперсионного анализа
|
Согласно экспериментальным
данным происходит выбор определенного вида модели дисперсионного анализа.
|
|
2. Однофакторный
дисперсионный анализ
|
Расчет параметров модели
однофакторного дисперсионного анализа
|
|
3. Двухфакторный
дисперсионный анализ
|
Расчет параметров модели
двухфакторного дисперсионного анализа
|
|
4. Латинский квадрат
|
Расчет параметров модели
латинского квадрата
|
|
5. Греко-латинский квадрат
|
Расчет параметров модели
греко-латинского квадрата
|
|
6. Гипер-греко-латинский
квадрат
|
Расчет параметров модели
гипер-греко-латинского квадрата
|
|
7. Латинский куб
|
Расчет параметров модели
латинского куба
|
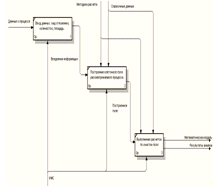
Рисунок 3.5 - Диаграмма декомпозиции второго уровня
Таблица 3.8 - Описание функциональных блоков
|
Наименование
функционального блока
|
Описание решаемых задач
|
|
А1: Ввод данных
|
Производится ввод данных о
процессе химической очистки на основе теории конечных автоматов. Заполняются
данные о виде отложения, количестве и занимаемой площади, а также выбранных
реагентов для произведения очистки.
|
|
А2: Построение клеточного
поля
|
По завершению ввода
информации происходит первоначальное построение и заполнение клеточного поля
для рассматриваемого процесса.
|
|
А3: Выполнение расчетов
|
После построения
первоначального клеточного поля на основе теории конечных автоматов
происходит расчет необходимого количества выбранных реагентов.
|
3.2 Разработка ИМС
.2.1 Основные этапы разработки ИМС
Согласно предметной области автоматизации, поставленной задаче,
выявленных требований к ней и проектированию информационно-моделирующей системы
с использованием CASE-средств
разработку системы можно разделить на три отдельных, независимых друг от друга
модуля:
) корреляционно-регрессионный анализ;
) дисперсионный анализ;
) анализ на основе теории конечных автоматов.
Модули включают в себя соответствующие подсистемы, описанные в
функциональной структуре информационно-моделирующей системы, а также
взаимосвязь между ними с информационной подсистемой и базой данных.
Информационная подсистема включает блок справочных данных, который
содержит:
) справочные данные по критерию Стьюдента;
) справочные данные по критерию Фишера;
) справочные данные по критерию Дункана;
) справочные данные по влиянию реагентов на виды отложений.
Корреляционно-регрессионный анализ из информационной подсистемы берет
данные из первого и второго пункта справочных данных. Дисперсионный анализ берет
данные из второго и третьего пункта. Анализу на основе теории конечных
автоматов требуются данные из четвертого пункта.
Информационная подсистема содержит блок экспериментальных данных. Для
работы с корреляционно-регрессионным анализом требовалась разработка форм ввода
экспериментальных данных:
) разработка ввода экспериментальных данных для уравнения регрессии от
одного параметра для следующих условий: нет параллельных опытов, есть
параллельные опыты, есть параллельные опыты и их количество одинаково,
отдельная серия опытов для дисперсии воспроизводимости;
) разработка ввода экспериментальных данных для множественной регрессии.
Для работы с дисперсионным анализом требовалась разработка форм ввода
данных для однофакторного дисперсионного анализа, двухфакторного анализа,
латинского квадрата, греко-латинского квадрата, гипер-греко-латинского
квадрата, латинского куба.
Для работы с анализом на основе теории конечных автоматов требовалась
разработка формы ввода данных, где указывается вид отложений, количество
отложений, площадь, выбранные реагенты для очистки отложений.
Все вышеперечисленные формы относятся согласно функциональной структуре
информационно-моделирующей системы к информационной подсистеме, которая
взаимодействует с другими при помощи базы данных.
После завершения разработки информационной подсистемы требовалась
разработка форм моделирования анализов:
) разработка формы результатов для регрессии от одного параметра:
графическая реализация, расчет параметров моделей линейной, параболы,
гиперболы, полулогарифмической, показательной, степенной;
) разработка формы результатов для множественной регрессии: расчет
параметров для моделей без взаимодействий, с парными взаимодействиями, с
квадратичными взаимодействиями;
) разработка формы результатов для дисперсионного анализа: расчет
параметров для однофакторного дисперсионного анализа, двухфакторного анализа,
латинского квадрата, греко-латинского квадрата, гипер-греко-латинского
квадрата, латинского куба;
) разработка формы результатов для анализа на основе теории конечных
автоматов: графическая реализация в виде клеточного поля, где цвет клетки
указывает на наличие или отсутствие отложений, расчет параметров.
Согласно функциональной структуре информационно-моделирующей системы
также есть подсистема анализа моделей. Для ее работы требовалось разработать
следующие алгоритмы:
) разработка алгоритма выбора оптимальной модели уравнения регрессии от
одного параметра на основе остаточной дисперсии;
) разработка алгоритма выбора оптимальной модели уравнения множественной
регрессии на основе общей дисперсии отклонений расчетных значений от
экспериментальных данных;
) передача результатов моделирования и оценки модели в базу данных путем
сохранения параметров модели.
Для просмотра сохраненных моделей требовалась разработка соответствующих
форм для всех трех видов анализа, просмотр осуществляется по виду моделирования
и его названию, также требовалась разработка формы удаления сохраненных
моделей.
Для работы информационно-моделирующей системы для процессов химической очистки
теплоэнергетического оборудования на основе корреляционно-регрессионного,
дисперсионного анализов и на основе теории конечных автоматов разработаны 59
форм.
3.2.2 Алгоритмы работы ИМС
В результате анализа предметной области автоматизации и постановки задачи
разработана структурная схема информационно-моделирующей системы,
представленная на рисунке 3.6.
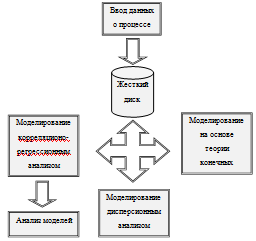
Рисунок 3.6 - Структурная схема ИМС
Обобщенная функционально-технологическая схема корреляционно-регрессионного
анализа представлена на рисунке 3.7. Обобщенная функционально-технологическая
схема дисперсионного анализа представлена на рисунке 3.8. Обобщенная
функционально-технологическая схема анализа на основе теории конечных автоматов
представлена на рисунке 3.9. Обобщенная функционально-технологическая схема
анализа моделей представлена на рисунке 3.10.
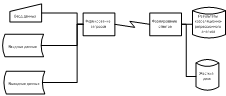
Рисунок 3.7 - Обобщенная функционально-технологическая схема
корреляционно-регрессионного анализа
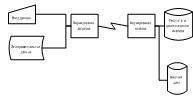
Рисунок 3.8 - Обобщенная функционально-технологическая схема
дисперсионного анализа
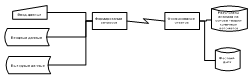
Рисунок 3.9 - Обобщенная функционально-технологическая схема анализа на
основе теории конечных автоматов
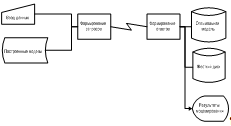
Рисунок 3.10 - Обобщенная функционально-технологическая схема анализа
моделей
В результате анализа предметной области автоматизации, исследования
постановки задачи и математического моделирования процессов химической очистки
теплоэнергетического оборудования разработана схема последовательности этапов
построения математических моделей на основе теории конечных автоматов, которая
представлена на рисунке 3.11.
Рисунок 3.11 - Схема последовательности этапов построения моделей на
основе конечных автоматов
Алгоритм построения математической модели на основе теории конечных
автоматов представлен на рисунке 3.12.
Рисунок 3.12 - Алгоритм построения математической модели на основе теории
конечных автоматов
В результате анализа предметной области автоматизации, исследования
постановки задачи и математического моделирования процессов химической очистки
теплоэнергетического оборудования разработана схема последовательности этапов
построения математических моделей на основе корреляционно-регрессионного
анализа, которая представлена на рисунке 3.13.
Основными этапами являются сбор данных, корреляционный анализ, построение
моделей, проверка значимости коэффициентов модели, проверка адекватности
модели, применение модели.
Алгоритм построения математической модели для линейного уравнения
регрессии (в качестве примера) представлен на рисунке 3.14, согласно которому
по введенным экспериментальным данным, на основе корреляционно-регрессионного
анализа формируется математическая модель, вычисляются параметры модели,
значимость параметров модели оценивается по критерию Стьюдента, адекватность модели
проверяется по критерию Фишера. Для остальных видов уравнений регрессии
(парабола, гипербола, полулогарифмическая, показательная, степенная) алгоритм
построения модели выглядит аналогичным образом.
Алгоритм построения линейной математической модели для множественного
уравнения регрессии без взаимодействий представлен на рисунке 3.15. По
введенным экспериментальным данным, на основе корреляционно-регрессионного
анализа формируется математическая модель, вычисляются параметры модели,
адекватность модели проверяется по критерию Фишера. Для остальных видов
уравнений регрессии (множественная модель с парными взаимодействиями, с
квадратичными взаимодействиями) алгоритм построения модели выглядит аналогичным
образом.
Характер и сила связи определяется коэффициентом корреляции,
Расчет параметров модели включает в себя расчет коэффициентов разных
видов уравнения регрессий.
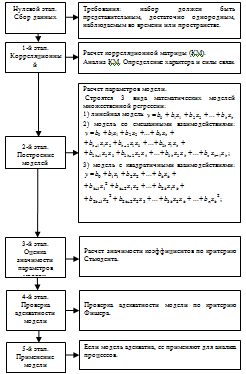
Рисунок 3.13 - Схема последовательности этапов построения моделей на
основе корреляционно-регрессионного анализа
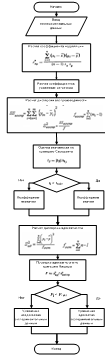
Рисунок 3.14 - Алгоритм построения математической модели для линейного
уравнения регрессии
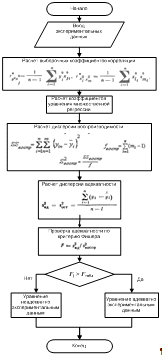
Рисунок 3.15 - Алгоритм построения математической модели для
множественного уравнения регрессии
В результате анализа предметной области автоматизации, исследования
постановки задачи и математического моделирования процессов химической очистки
теплоэнергетического оборудования разработана схема последовательности этапов
построения математических моделей на основе дисперсионного анализа, которая
представлена на рисунке 3.16.

Рисунок 3.16 - Схема последовательности этапов построения моделей на
основе дисперсионного анализа
Основными этапами являются выбор вида модели, определение общей,
межгрупповой, остаточной сумм; расчет степеней свободы вариаций, проверка
значимости фактора; проверка различий между средними значениями.
Алгоритм построения математической модели для однофакторного
дисперсионного анализа представлен на рисунке 3.17. По введенным данным
вычисляются параметры, значимость фактора оценивается по критерию Фишера,
значимость различия между средними значениями проверяется по критерию Дункана.
Алгоритм построения математической модели для двухфакторного
дисперсионного анализа, латинского квадрата, греко-латинского квадрата,
гипер-греко-латинского квадрата, латинского куба производится по аналогии с
однофакторным дисперсионным анализом: вычисляются параметры, проверка
значимости факторов и проверка значимости между средними значениями.

Рисунок 3.17 - Алгоритм построения математической модели для
однофакторного дисперсионного анализа
3.3 Построение информационной модели данных
Согласно предметной области автоматизации, поставленной задаче,
функциональной структуре и структурной схеме разработана информационная модель
данных, которая представлена на рисунке 3.18.
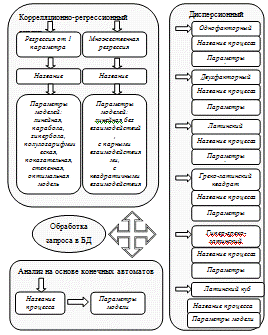
Рисунок 3.18 - Информационная модель данных
Под обработкой запросов в базе данных подразумевается сохранение данных
по завершению моделирования процессов химической очистки теплоэнергетического
оборудования либо извлечение данных из базы данных для повторного просмотра уже
сохраненных моделей.
В корреляционно-регрессионном анализе при обработке запроса происходит
переход в один из двух информационных блоков (регрессия от одного параметра,
множественная регрессия), а дальше идет обращение к названию процесса данного
вида, после чего идет переход на параметры модели.
В дисперсионном анализе (в конкретных видах дисперсионного анализа) и в
анализе на основе теории конечных автоматов аналогичный принцип. По названию
необходимого процесса химической очистки в информационно-моделирующей системе
идет обращение к соответствующим параметрам моделей.
4.
КОМПЬЮТЕРНАЯ РЕАЛИЗАЦИЯ ИНФОРМАЦИОННО-МОДЕЛИРУЮЩЕЙ СИСТЕМЫ ДЛЯ ПРОЦЕССОВ
ХИМИЧЕСКОЙ ОЧИСТКИ ТЕПЛОЭНЕРГЕТИЧЕСКОГО ОБОРУДОВАНИЯ
4.1 Разработка структуры программной реализации системы
Для разработки структурны программной реализации
информационно-моделирующей системы для процессов химической очистки
теплоэнергетического оборудования были выявлены требования к системе в целом и
к функциональным возможностям системы.
4.1.1 Основные требования к разрабатываемой системе
К системе предъявляют следующие требования:
) информационно-моделирующая система должна хранить по требованию
результаты моделирования процессов химической очистки теплоэнергетического
оборудования;
2) система должна иметь понятный интерфейс;
) работа системы не должна зависеть от установленной операционной
системы, не должна требовать больших аппаратных ресурсов;
) система должна быть надежной и безопасной в эксплуатации.
4.1.2 Требования к функциональным возможностям системы
Информационно-моделирующая система должна реализовывать следующие
функции:
) ввод экспериментальных данных процессов химической очистки
теплоэнергетического оборудования;
) моделирование процесса химической очистки на основе
корреляционно-регрессионного анализа;
) моделирование процесса химической очистки на основе дисперсионного
анализа;
) моделирование процесса химической очистки на основе теории конечных
автоматов;
) просмотр и сохранение результатов моделирования;
4.2 Описание программной реализации системы
Информационно-моделирующая система для процессов химической очистки
теплоэнергетического оборудования работает с данными из файлов, следовательно,
изменение местоположения каталогов приведет к неработоспособности системы. Для
функционирования информационно-моделирующей системы нужны: персональный
компьютер, клавиатура, манипулятор типа мышь, операционная система Windows XP и
выше.
Установки система не предполагает, в основном каталоге присутствует файл
для запуска системы. Для удаления системы нет необходимости в каких-либо
программных средствах типа «Uninstal Tool», также не требуется удаление через
стандартные возможности (Панель управления), необходимо обычным способом
удалить каталог с системой.
Для запуска информационно-моделирующей системы нужно открыть
соответствующий файл в основном каталоге системы, либо создать его ярлык на
рабочем столе. После запуска будет видна заставка, внизу которой идет загрузка,
по ее завершению будет открыта форма с выбором моделирования, представленная на
рисунке 4.1.
Первоначально после запуска также открываются три формы проводимых
анализов: корреляционно-регрессионный анализ, дисперсионный анализ, анализ на
основе теории конечных автоматов. В итоге по закрытию заставки видны четыре
формы.
Форма корреляционно-регрессионного анализа представлена на рисунке 4.2.
Форма дисперсионного анализа представлена на рисунке 4.3. Форма анализа на
основе теории конечных автоматов представлена на рисунке 4.4

Рисунок 4.1 - Форма с выбором моделирования
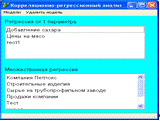
Рисунок 4.2 - Форма корреляционно-регрессионного анализа

Рисунок 4.3 - Форма дисперсионного анализа
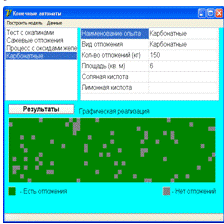
Рисунок 4.4 - Форма анализа на основе теории конечных автоматов
На всех трех формах можно просмотреть сохраненные результаты
моделирования, выбирая из необходимого анализа нужный процесс по химической
очистке. Пункт меню «Модели» для корреляционно-регрессионного анализа содержит
«Регрессия от 1 параметра» с выбором вида проведения опытов (нет параллельных
опытов, есть параллельные опыты и их количество неопределенно, есть
параллельные опыты с определенным количеством), «Множественная регрессия»
(линейная модель, с парными взаимодействиями, с квадратичными
взаимодействиями), для дисперсионного анализа содержит «Однофакторный
дисперсионный анализ», «Двухфакторный дисперсионный анализ», «Латинский
квадрат», «Греко-латинский квадрат», «Гипер-греко-латинский квадрат»,
«Латинский куб».
В форме удаления данных для корреляционно-регрессионного и дисперсионного
анализов, что представлено на рисунке 4.5, после выбора необходимого вида
анализа выводятся все сохраненные в базу данных наименования технологических
процессов, после удаления нужных в соответствующей форме следует сохранить
изменения, нажав на необходимую кнопку.
Рисунок 4.5 - Форма удаления данных
4.2.1 Подсистема «Корреляционно-регрессионный анализ»
На главной форме корреляционно-регрессионного анализа, выбрав пункт
«Модели» - «Регрессия от 1 параметра» - «Нет параллельных опытов», переходим на
форму ввода наименования процесса (следует указывать уникальное наименование,
который не сохранен в базу данных) и ввода количества измерений. Сохраненные в
базе данных наименования процессов повторно информационно-моделирующая система
использовать не даст, будет выведена соответствующая ошибка (такая же ошибка
выдаст при аналогичном повторном использовании наименования процесса в
остальных видах анализов корреляционно-регрессионного, дисперсионного, анализа
на основе теории конечных автоматов). После будет показана форма заполнения
экспериментальных данных, представленная на рисунке 4.6. Изначально вводятся
экспериментальные данные для первого опыта (входной параметр X и выходной параметр Y), после чего по нажатию кнопки
«Задать» переходим к вводу экспериментальных данных для второго опыта и так
далее. Форма будет показана до тех пор, пока все опыты не будут занесены в
информационно-моделирующую систему, после чего будет показана соответствующая
форма моделирования.

Рисунок 4.6 - Форма заполнения экспериментальных данных без параллельных
опытов
Выбрав вид анализа «с параллельными опытами», также после ввода
наименования технологического процесса и ввода количества измерений будет
показана форма заполнения экспериментальных данных, представленная на рисунке
4.7. На форме ввода экспериментальных данных с параллельными опытами следует
ввести соответствующее значение входного параметра Х и все выходные параметры Y (каждое значение с новой строки).
Аналогично вводятся экспериментальные данные для регрессии от одного параметра
с одинаковым количеством параллельных опытов, для множественной регрессии
(вводится соответствующее значение выходного параметра Y и все входные параметры Х), для однофакторного (вводятся все
значения, расположенных на разных уровнях фактора, для каждого опыта) и
двухфакторного дисперсионных анализов (вводятся все значения для каждого уровня
первого фактора).

Рисунок 4.7 - Форма заполнения экспериментальных данных с параллельными
опытами
Форма вывода результатов для регрессии от одного параметра представлена
на рисунке 4.8. С помощью пункта «Данные» можно вывести результаты моделирования
либо изменить экспериментальные данные. С помощью пункта «График» можно
построить либо убрать графики с разными видами регрессий (линейная,
параболическая, гиперболическая, полулогарифмическая, показательная,
степенная), а также построить либо убрать точечный график с введенными
экспериментальными данными. С помощью пункта «Файл» можно сохранить график,
сохранить полученные данные о технологическом процессе в базу данных,
распечатать график, установить настройки принтера, выйти из формы.
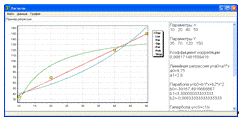
Рисунок 4.8 - Форма вывода результатов для регрессии от одного параметра
Форма ввода экспериментальных данных для множественной регрессии после
ввода названия процесса и количества опытов и факторов имеет следующий вид, который
представлен на рисунке 4.9.
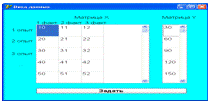
Рисунок 4.9 - Форма ввода данных для множественной регрессии
Форма результатов для множественной регрессии представлена на рисунке
4.10. С помощью пункта «Данные» можно вывести результаты моделирования либо
изменить экспериментальные данные.
Рисунок 4.10 - Форма результатов для множественной регрессии
Формы показа сохраненной модели для корреляционно-регрессионного анализа
имеют аналогичный вид, что и формы результатов моделирования.
Первый пример. В таблице 4.1 собраны экспериментальные данные для
регрессии от одного параметра. Необходимо составить модели регрессии и найти
оптимальную модель.
Таблица 4.1 - Экспериментальные данные для регрессии
|
Номер опыта
|
x
|
y1
|
y2
|
y3
|
|
1
|
4,5
|
9,6
|
9,9
|
9,7
|
|
2
|
6,3
|
14
|
15
|
-
|
|
3
|
8,9
|
18
|
-
|
-
|
|
4
|
10
|
20
|
20
|
-
|
Результаты моделирования представлены на рисунке 4.11.
Коэффициент корреляции получился равным 0,989, что говорит о сильной
связи фактора.
Оптимальной моделью оказалась гипербола, которая имеет вид:
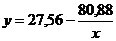
Оба коэффициента уравнения по критерию Стьюдента значимы (критическое
значение 2,78, а наблюдаемые значения 18,05 и 8,26 соответственно).
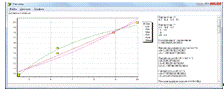
Рисунок 4.11 - Результаты моделирования регрессии
Второй пример. В таблице 4.2 представлены экспериментальные данные для
множественной регрессии. Необходимо составить модели множественной регрессии и
найти оптимальную модель.
Таблица 4.2 - Экспериментальные данные для множественной регрессии
|
Номер опытаx1x2x3y
|
|
|
|
|
|
1
|
0,5
|
0,4
|
0,3
|
1,5
|
|
2
|
1,5
|
1,2
|
1,4
|
4,5
|
|
3
|
2,5
|
3,1
|
2,3
|
7,5
|
|
4
|
3,1
|
2,8
|
3,3
|
9,2
|
|
5
|
4,1
|
4,5
|
3,9
|
|
6
|
4,6
|
5,1
|
5,2
|
15,3
|
|
7
|
5,3
|
6,2
|
5,4
|
16,4
|
|
8
|
2,8
|
3,9
|
4,2
|
9,1
|
|
9
|
6,3
|
7,1
|
8,3
|
20,6
|
|
10
|
10,5
|
3,5
|
15,2
|
27,6
|
|
11
|
2,1
|
12,6
|
3,5
|
18,4
|
Результаты моделирования представлены на рисунке 4.12.
Коэффициент корреляции равен 0,99, что говорит о сильной связи факторов.
Уравнение множественной регрессии имеет вид:
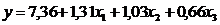
По критерию Фишера наблюдаемое значение равно 1,36, критическое значение
равно 5,3. В результате построенная модель множественной регрессии адекватна.
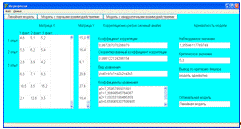
Рисунок 4.12 - Результаты моделирования множественной регрессии
4.2.2 Подсистема «Дисперсионный анализ»
Компьютерная реализация ввода данных и просмотра результатов для
дисперсионного анализа ниже приведена на гипер-греко-латинском квадрате в
качестве примера. Для остальных видов дисперсионного анализа ввод данных и
просмотр результатов выглядят аналогичным, схожим образом. Форма ввода
экспериментальных данных для дисперсионного анализа уже после ввода уникального
наименования процесса для данного вида моделирования и ввода количества уровней
факторов представлена на рисунке 4.13. Уровни первого фактора представляются в
виде столбцов, уровни второго фактора указаны в строках таблицы данных. Чтобы
узнать адреса ячеек третьего, четвертого и пятого уровней факторов необходимо
нажать на соответствующую кнопку. После нажатия кнопки «Задать» открывается
форма вывода параметров моделирования, что представлено на рисунке 4.14. По
нажатию на кнопку с названием определенного фактора выводятся таблица данных,
показатели критерия Фишера и Дункана.

Рисунок 4.13 - Форма ввода данных дисперсионного анализа
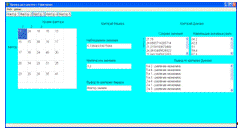
Рисунок 4.14 - Форма вывода результатов моделирования дисперсионного
анализа
Третий пример. Имеются данные для однофакторного анализа, представленные
в таблице 4.3. Необходимо составить модель дисперсионного анализа.
Таблица 4.3 - Экспериментальные данные для дисперсионного анализа
|
Уровни
|
Фактор
|
|
1
|
2,8
|
2,6
|
2,5
|
2,1
|
|
2
|
2,4
|
2,8
|
2,8
|
2,7
|
|
3
|
2,3
|
2,4
|
2,6
|
2
|
|
4
|
2,9
|
2,8
|
2,8
|
2,4
|
Результаты моделирования представлены на рисунке 4.15.
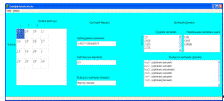
Рисунок 4.15 - Результаты моделирования дисперсионным анализом
По критерию Фишера наблюдаемое значение получилось равным 1,96, а
критическое 3,5. В результате получаем, что фактор значим. По критерию Дункана
только одно различие между средними значениями незначимо.
4.2.3 Подсистема «Моделирование на основе конечных автоматов»
Формы ввода данных для анализа на основе теории конечных автоматов
представлены на рисунках 4.16 и 4.17.
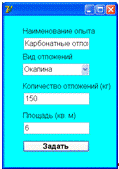
Рисунок 4.16 - Первая форма ввода данных для анализа конечных автоматов
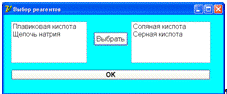
Рисунок 4.17 - Вторая форма ввода данных для анализа конечных автоматов
На второй форме ввода из списка возможных реагентов (слева) для очистки
определенного вида отложений, выбранного на первой форме, выбираются
необходимые, которые заносятся в правый список. Начальные данные на форме
результатов моделирования представлены на рисунке 4.18.
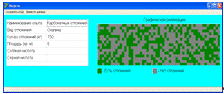
Рисунок 4.18 - Начальные данные результатов моделирования
После нажатия на кнопку «Вывести данные» происходят расчеты, конечные
результаты моделирования представлены на рисунке 4.19.
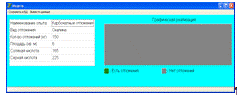
Рисунок 4.19 - Конечные результаты моделирования
Вывод сохраненных данных моделирования на основе теории конечных
автоматов виден на рисунке 4.4.
Четвертый пример. Имеются данные количества отложений, представленных на
рисунке 4.20. Необходимо рассчитать количество реагентов для очистки.
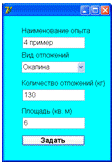
Рисунок 4.20 - Данные отложений
Результаты представлены на рисунках 4.21 и 4.22.

Рисунок 4.21 - Результаты моделирования

Рисунок 4.22 - Результаты моделирования
4.3 Тестирование и оценка надежности системы
Тестирование - метод работы с программным средством, информационной
системой с целью выявить в ходе работы ошибки. Одним из видов тестирования
является структурное, иначе говорится тестирование «белого ящика», оно
определяет оценку сложности системы в комплексе и может использовать эту оценку
для нахождения необходимого минимума тестовых вариантов (ТВ). Данные тестовые
варианты (ТВ) приведены для поверки основного, базового множества путей путем
гарантий, что будет выполняться каждый оператор в тестировании только один раз.
Для проведения структурного тестирования необходимо знать внутреннюю структуру
системы, поэтому изучаются элементы системы и взаимосвязи между ними. В
качестве объекта тестирования будет выступать внутреннее поведение программы и
ее реакция. Система будет считаться проверено полно, если проведено
исчерпывающее тестирование маршрутов или путей ее графа управления. При проверке
используются тестовые варианты, в которых:
1) используется проверка всех независимых путей программы;
2) выполнение всех циклов в пределах их границ и диапазонов;
) проход ветви имеет значение истины или ложи для всех видов
логических путей решений;
) проводится анализ правильности структуры данных внутри системы.
В данной системе будем проводить тестирование с помощью тестирования
базового пути. Этот способ дает возможность определить оценку сложности системы
в комплексе, использующая для оценки нужного количества тестовых вариантов
(ТВ). Для показа системы используется потоковый граф.
Ниже представлена процедура программы для расчета коэффициента корреляции
для регрессии от одного параметра:
1. xsred:=0;
. ysred:=0;
. for j:=1 to z do
. begin
. xsred:=xsred+x0[j];
. ysred:=ysred+y0[j];
. end;
. xsred:=xsred/z;
. ysred:=ysred/z;
. ch:=0;
. for j:=1 to z do
. begin
. ch:=ch+(x0[j]-xsred)*(y0[j]-ysred);
. end;
. sx0:=0;
. sy0:=0;
. for j:=1 to z do
. begin
. sx0:=sx0+sqr(x0[j]-xsred);
. sy0:=sy0+sqr(y0[j]-ysred);
. end;
. sx0:=sqrt(sx0/(z-1));
. sy0:=sqrt(sy0/(z-1));
. R:=ch/((z-1)*sx0*sy0);
. s:=#13+'Коэффициент корреляции:'+#13+floattostr(R)+#13;
26. RichEdit.Lines.Add(s);
Потоковый граф представлен на рисунке 4.23.
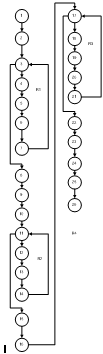
Рисунок 4.23 - Потоковый граф
Для количественной оценки сложности информационно-моделирующей системы
будем применять метрику цикломатической сложности. В способе тестирования
базового пути эту сложность оценивает количество независимых друг от друга
путей в базовом множестве системы, а еще верхнюю оценку количества тестовых
вариантов, гарантирующее работу всех операторов только один раз.
Цикломатическая сложность вычисляется тремя способами:
) цикломатическая сложность равна количеству регионов потокового графа
(G)=4,
) цикломатическая сложность вычисляется по формуле:
(G)=E-N+2,
где E - количество дуг графа;- количество узлов графа.
(G)=28-26+2=4,
) цикломатическая сложность вычисляется по формуле:
(G)=р+1,
где р - количество предикатных узлов потокового графа (3, 11, 17).
(G)=3+1=4.
Перечислим независимые пути для потокового графа:
Путь 1: 1 - 2 - 3 - 4 - 5 - 6 - 7 - 3 - 4 - 5 - 6 - 7 - 3 - 4 - 5 - 6 - 7
- 3 - 8 - 9 - 10 - 11 - 12 - 13 - 14 - 11 - 12 - 13 - 14 - 11 - 12 - 13 - 14 - 11
- 15 - 16 - 17 - 18 - 19 - 20 - 21 - 17 - 18 - 19 - 20 - 21 - 17 - 18 - 19 - 20
- 21 - 17 - 22 - 23 - 24 - 25 - 26.
Путь 2: 1 - 2 - 3 - 4 - 5 - 6 - 7 - 3 - 4 - 5 - 6 - 7 - 3 - 4 - 5 - 6 - 7
- 3 - 4 - 5 - 6 - 7 - 3 - 8 - 9 - 10 - 11 - 12 - 13 - 14 - 11 - 12 - 13 - 14 -
11 - 12 - 13 - 14 - 11 - 12 - 13 - 14 - 11 - 15 - 16 - 17 - 18 - 19 - 20 - 21 -
17 - 18 - 19 - 20 - 21 - 17 - 18 - 19 - 20 - 21 - 17 - 18 - 19 - 20 - 21 - 17 -
22 - 23 - 24 - 25 - 26.
Путь 3: 1 - 2 - 3 - 4 - 5 - 6 - 7 - 3 - 4 - 5 - 6 - 7 - 3 - 4 - 5 - 6 - 7
- 3 - 4 - 5 - 6 - 7 - 3 - 4 - 5 - 6 - 7 - 3 - 8 - 9 - 10 - 11 - 12 - 13 - 14 -
11 - 12 - 13 - 14 - 11 - 12 - 13 - 14 - 11 - 12 - 13 - 14 - 11 - 12 - 13 - 14 -
11 - 15 - 16 - 17 - 18 - 19 - 20 - 21 - 17 - 18 - 19 - 20 - 21 - 17 - 18 - 19 -
20 - 21 - 17 - 18 - 19 - 20 - 21 - 17 - 18 - 19 - 20 - 21 - 17 - 22 - 23 - 24 -
25 - 26.
Тестовые варианты представлены ниже.
Первый тестовый вариант:
Исходные данные: массив X=(1,
4, 6), массив Y=(6, 14, 16)
Ожидаемый результат: 0,95.
Второй тестовый вариант:
Исходные данные: массив X=(1,
4, 6, 8), массив Y=(6, 14, 16, 22)
Ожидаемый результат: 0,98.
Третий тестовый вариант:
Исходные данные: массив X=(1,
4, 6, 8, 10), массив Y=(6,
14, 16, 22, 32)
Ожидаемый результат: 0,98.
Расчетные показатели каждого тестового варианта сравниваются с ожидаемыми
результатами. После выполнения всех тестовых вариантов дается гарантия, что все
операторы системы работали хотя бы один раз.
Также есть помимо «белого ящика» тестирование «черного ящика» (проверка
функций), оно используется в интерфейсе системы. Здесь известны функции
программы, определяется значимость каждой функции на всей области определения.
При проведении тестов рассматриваются системные характеристики систем и
является неважным их внутренняя логическая структура.
К видам функционального тестирования, или «черного ящика», относятся
методы эквивалентного разбиения, анализа граничных значений, метод
функциональных диаграмм.
Метод эквивалентного разбиения описывается в два этапа - выделение
классов эквивалентности, построение тестов для проверки. Классом
эквивалентности является множество входных данных, которые по вероятности
обнаружить определенный тип ошибки в системе равны.
Анализ граничных значений подразумевает рассмотр ситуаций, которые
возникают на границах и рядом с границами эквивалентных разбиений.
Метод функциональных диаграмм состоит в преобразовании входной специфики
системы в диаграмму функций (диаграмму причинно-следственных связей) с помощью
обычных булевых отношений, разработка таблицы решений (методом обратной
трассировки).
Способ разбиения по эквивалентности - самый часто применяемый способ
тестирования функций системы. Входные показатели делятся на классы
эквивалентности. Для каждого такого класса эквивалентности составляется только
один тестовый вариант. При использовании любого набора из класса
эквивалентности в программе используется один и тот же набор операторов и
связей между ними.
Разработка тестов методом эквивалентного разбиения осуществляется в два
этапа:
1) определение классов эквивалентности;
2) разработка тестов.
Тестовый вариант проверяется таким образом, чтобы оценить изначально
наибольшее число свойств класса эквивалентности.
Выделим классы эквивалентности в таблице 4.4.
Таблица 4.4 - Классы эквивалентности
|
Входные условия
|
Правильный класс
эквивалентности
|
Неправильный класс
эквивалентности
|
|
Количество элементов
массива
|
[1; + ∞), целые значения
|
(- ∞; 1), нецифровые
значения, вещественные значения
|
|
Массив входных данных
|
Числовые значения
|
Нецифровые значения
|
|
Массив выходных данных
|
Числовые значения
|
Нецифровые значения
|
Тестовые наборы представлены в таблице 4.5.
Таблица 4.5 - Тестовые наборы
|
Показатель
|
Входные данные для
тестирования
|
Предполагаемый результат
|
Результат тестирования
|
|
Количество элементов в
массивах Массив входных данных Массив выходных данных
|
3 (1, 4, 6) (6, 14, 18)
|
0,95
|
+
|
|
Количество элементов в
массивах Массив входных данных Массив выходных данных
|
4 (1, 4, 6, 8) (6, 14, 16,
22)
|
0,98
|
+
|
|
Количество элементов в
массивах Массив входных данных Массив выходных данных
|
2 (3, 2, 4) (2, 6, 5)
|
Ошибка ввода
|
+
|
|
Количество элементов в
массивах Массив входных данных Массив выходных данных
|
1.5 (3, 5, 9) (13, 17, 10)
|
Ошибка ввода
|
+
|
|
Количество элементов в
массивах Массив входных данных Массив выходных данных
|
4 (a, b, c, d)
(1, 2, 9, 5)
|
Ошибка ввода
|
+
|
|
Количество элементов в
массивах Массив входных данных Массив выходных данных
|
четыре (3.5, 1.6, 4.4, 7.2)
(6.3, 8.2, 15.4)
|
Ошибка ввода
|
+
|
|
Количество элементов в
массивах Массив входных данных Массив выходных данных
|
-4 (2, 3.4, 5.6) (10.4, 9,
4.7)
|
Ошибка ввода
|
+
|
Надежность - свойство системы держать свою работоспособность в течение
определенного периода времени, в определенных условиях эксплуатации системы, не
исключая последствий для пользователя каждого отказа [20].
Работоспособное состояние системы называется таким, при котором оно может
выполнить заданные функции с показателями, определяющиеся требованиями
технического задания. С переходом в другое, обратное состояние системы
происходит отказ.
Для определения надежности информационно-моделирующей системы используем
модель Нельсона. В этой модели при оценке надежности необходимо учитывать
вероятность определенного тестового набора для последующей работы программы.
Предполагается, что область показателей, которые нужны для того, чтобы провести
тестирование, разделяется на k
исключающих друг друга подобластей zi (i = 1, 2, … k).
Пусть Pi - вероятность, что набор данных zi будет выбран для очередной работы
системы. Пусть к моменту определения надежности было выполнено Ni прогонов системы на zi наборе данных. Из них ni прогонов завершилось отказом.
Надежность определяется по формуле:
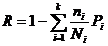
В
системе использовалось 50 наборов исходных данных, которые равновероятно
использовались для прогона 50 тестов. В 2 тесте есть дефекты. Тогда надежность
составляет:
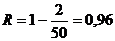
ЗАКЛЮЧЕНИЕ
В выпускной квалификационной работе разработана
информационно-моделирующая система для процессов химической очистки
теплоэнергетического оборудования.
В первом разделе описывается обзор и анализ систем интеллектуальной
обработки данных. Раздел содержит описание систем поддержки принятия решений,
экспертных систем, систем на основе теории конечных автоматов, также
рассмотрены примеры моделирования конечных автоматов.
На этапе разработке принципов и структуры информационно-моделирующей
системы выявлены основные аспекты процессов химической очистки
теплоэнергетического оборудования. Разработана функциональная структура,
состоящая из пяти подсистем: информационная подсистема, моделирующая подсистемы
по корреляционно-регрессионному анализу, моделирующая подсистема по
дисперсионному анализу, моделирующая подсистема на основе теории конечных
автоматов, подсистема анализа моделей. При описании математического
моделирования процессов химической очистки теплоэнергетического оборудования
представлены модели на основе корреляционно-регрессионного (регрессия от одного
параметра, и его виды; множественная регрессия, и его виды) и дисперсионного
(все шесть видов) анализов, а также клеточная модель на основе теории конечных
автоматов. Приведена схема идентификации параметров математических моделей.
На этапе построения информационно-моделирующей системы с помощью
методологий IDEF0 и IDEF3 разработана контекстная диаграмма и ее декомпозиции,
представляющие этапы создания моделей и работу системы. Указаны основные этапы
разработки информационно-моделирующей системы, описаны алгоритмы работы:
структурная схема информационно-моделирующей системы, схемы последовательности
этапов построения моделей и алгоритмы построения моделей на основе
корреляционно-регрессионного, дисперсионного анализов, на основе теории
конечных автоматов. Приведена информационная модель данных.
На этапе компьютерной реализации информационно-моделирующей системы
указаны основные требования к системе и требования к функциональным
возможностям. Представлено описание трех подсистем: корреляционно-регрессионный
анализ, дисперсионный анализ, анализ на основе теории конечных автоматов,
приведены примеры построения моделей на основе данных анализов. Проведено
тестирование информационно-моделирующей системы: структурное и функциональное
тестирование. Оценена надежность системы.
СПИСОК
ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
1.Черноруцкий,
И.Г. Методы принятия решений / И.Г. Черноруцкий. - СПб: БХВ-Петербург, 2005. -
416 с.
.Баллод, Б.А.
Методы и алгоритмы принятия решений в экономике / Б.А. Баллод, Н.Н. Елизарова.
- Москва: Инфра-М, 2009. - 224 с.
. Дорогов,
В.Г. Введение в методы и алгоритмы принятия решений / В.Г. Дорогов, Я.О.
Теплова. - Москва: Инфра-М, 2012. - 240 с.
. Элти, Дж.
Экспертные системы: концепции и примеры / Дж. Элти, М. Кумбс. - Москва: Финансы
и статистика, 1987. - 191 с.
. Попов, Э.В.
Экспертные системы. Решение неформализованных задач в диалоге с ЭВМ / Э.В.
Попов. - Москва: Наука, 1987. - 288 с.
. Поспелов,
Д.А. Моделирование рассуждений. Опыт анализа мыслительных актов / Д.А.
Поспелов. - Москва: Радио и связь, 1989. - 184 с.
. Литвак,
Б.Г. Экспертные оценки и принятие решений / Б.Г. Литвак. - Москва: Патент,
1996. - 271 с.
. Нейлор, К.
Как построить свою экспертную систему / К. Нейлор. - Москва: Энергоатомиздат,
1991. - 286 с.
. Братко, И.
Программирование на языке Пролог для искусственного интеллекта / И. Братко. -
Москва: МирЮ 1990ю - 560 с.
. Гилл, А.
Введение в теорию конечных автоматов / А. Гилл - Москва: Наука, 1966. - 272 с.
.
Поликарпова, Н.И. Автоматное программирование / Н.И. Поликарпова, А.А. Шалыто -
Санкт-Петербург: СПБГУ, 2008. - 167 с.
. Дехтярь,
М.И. Введение в схемы, автоматы и алгоритмы / М.И. Дехтярь - Москва: НОУ
«ИНТУИТ», 2016. - 169 с.
. Кокин, А.Г.
Конечные автоматы: языки и грамматики / А.Г. Кокин, В.Н. Кузнецов - Курган:
КГУ, 1996. - 35 с.
. Выхованец,
В.С. Теория автоматов: учеб. пособие / В.С. Выхованец - Тирасполь: РИО ПГУ,
2001. - 87 с.
. Ожиганов,
А.А. Теория автоматов: учеб. пособие / А.А. Ожиганов - СПб: НИУ ИТМО, 2013. -
84 с.
. Котов, В.Е.
Сети Петри / В.Е. Котов - Москва: Наука, 1984. - 160 с.
. Липов, Ю.М.
Котельные установки и парогенераторы / Ю.М. Липов, Ю.М. Третьяков -
Москва-Воронеж: НИЦ «Регуляторная и хаотичная динамика», 2003. - 592 с.
. Ахназарова,
С.Л. Методы оптимизации эксперимента в химической технологии: учеб. пособие /
С.Л. Ахназарова, В.В. Кафаров. - Москва: Высш. шк., 1985. - 327 с.
. Вендров,
А.М. CASE-технологии. Современные методы и средства проектирования
информационных систем / А.М. Вендров. - Москва: Финансы и статистика, 1998.
-176 с.
. Липаев,
В.В. Надежность программных средств / В.В. Липаев. - Москва: Синтег, 1998. -
232 с.