Оптическое распознавание символов
ВВЕДЕНИЕ
В настоящее время компьютеризация в нашем обществе растет очень быстрыми
темпами и играет очень значимую роль в повседневной деятельности человека. При
помощи компьютерных технологий сейчас делаются попытки автоматизировать широкий
круг процессов, которые в недалеком прошлом возлагались на умственную
способность человека, поскольку информационные технологии используются
повсеместно, в связи с чем программисты всего мира разрабатывают новые и
совершенствуют уже зарекомендовавшие себя на практике алгоритмы автоматизации
рутинных процессов.
Одной из актуальных проблем на данный момент является неэффективная
работа различных государственных организаций, таких как «Пенсионный Фонд»,
городские поликлиники, различные организации бухгалтерского учета, поскольку
все делается в ручном режиме. Каждый бланк заполняется собственноручно, и если
нужно внести какую-то информацию (например, паспортные данные) в базу данных,
то данная задача выполняется оператором собственноручно. Автоматизация процесса
перевода информации с бумажных документов в электронный вид сейчас актуальна
практически во всех государственных и коммерческих организациях. Также решение
данной проблемы является важным аспектом безопасности и контроля, ведь малейшая
ошибка при вводе данных может дорогого стоить. Избежать этого можно, используя
программное обеспечение, позволяющее автоматизировать данный процесс. Его можно
применять в различных сферах работы, касающихся обработки документов.
Иллюстрацией выше изложенного служит практическая деятельность компаний,
фиксирующих персональные данные граждан: коммунальные службы, паспортные столы,
бухгалтерия по месту работы, т.д. Современные информационные разработки
позволяют нам существенно облегчить доступ к необходимым информационным
ресурсам из любой точки мира, при условии наличия их электронного варианта.
В настоящее время существует достаточно много систем оптического
распознавания символов, но, к сожалению, не все из них являются по-настоящему
качественной продукцией. Так программы OCR «низкого уровня» переводят текст на
бумаге в набор символов и далее предлагают самостоятельно разобраться с тем,
что получилось. Системы, обладающие высоким быстродействием и точностью
распознавания, как правило, очень дороги, что делает их практически
недоступными для внедрения и практического использования в массовом масштабе.
Объектом исследования в данном случае являются алгоритмы распознавания
символов, а предметом исследования - система оптического распознавания символов
с изображений.
Цель работы: разработка алгоритма повышенной точности для оптического
распознавания символов с изображений паспортов за счет комбинирования методов
предварительной обработки с использованием библиотеки OCR Tesseract и словарного контроля полученных
результатов.
Для достижения поставленной цели в ходе выпускной квалификационной работы
были поставлены следующие задачи:
. Изучение и анализ существующих методов по распознаванию печатных
символов и программных решений, базирующихся на данных методах для выявления их
недостатков
. Рассмотреть существующий программный инструментарий для создания
системы оптического распознавания символов
. Сравнить в ходе экспериментов различные движки для распознавания
символов с изображений
. Реализовать рабочий прототип приложения, способный распознавать
данные с паспортов граждан
В главе 1 рассматриваются основы распознавания символов, существующие
приложения и программный инструментарий. В главе 2 рассмотрено реализованное
приложение, поэтапно разобран алгоритм его работы и интерфейс пользователя.
Глава 1. Материалы и методология
В данной главе рассматриваются основные понятия в сфере оптического
распознавания символов, методы распознавания печатных букв, программные
средства для распознавания и приложения, способные распознавать русские
символы. Также сконцентрировано внимание на экспериментальном сравнении трех
основных движков распознавания символов.
1.1 Оптическое распознавание символов
Оптическое
распознавание символов (англ.optical character recognition, OCR) - это
механический или электронный перевод изображений рукописного, машинописного или
печатного текста в последовательность кодов, использующихся для представления в
текстовом редакторе. Оптическое распознавание имеет широкие границы применения:
для конвертации книг и документов в электронный вид, для автоматизации систем
учета в бизнесе или для публикации текста на веб-странице. Над преобразованным
в электронный вид при помощи оптического распознавания текстом можно совершать
множественные манипуляции: редактировать, осуществлять поиск слова или фразы,
хранить его в более компактной форме, демонстрировать или распечатывать
материал, не теряя качества, анализировать информацию, а также применять к
тексту электронный перевод
<#"896877.files/image001.gif">
Рис.1 Процесс обработки поступающего документа
Учитывая перечисленные выше недостатки исходных изображений, перед
непосредственным распознаванием графического файла алгоритмами распознавания
необходимо провести как можно более тщательную предварительная обработка входящего
документа, направленную на улучшение качества изображения[16, 23, 26]. Данная
процедура включает в себя ротацию изображения, преобразование в используемый
системой формат (в основном это 8-битное изображение переведенное градации
серого), последующую фильтрацию изображения от шумов, локальное повышение
резкости и контрастности необходимых участков. Подготовленное изображение
отправляется на вход модуля сегментации областей интереса. Задачей данного
модуля является нахождение и определение основных структурных единиц текста -
строк и слов. Выделение фрагментов наивысших уровней, таких как строки и слова,
может быть осуществлено на основе анализа промежутков между тёмными областями
на бинаризованном изображении. Однако такой подход не может быть успешно
применен для выделения отдельных букв в силу особенностей написания или
различных искажений. Изображения соседних букв могут объединяться в одну
компоненту связанности как показано на рисунке 2, в данной ситуации велика
вероятность того, что «нн» будет принято за «м», или за «ии».

Рис. 2. Объединение нескольких букв в одну компоненту связанности
Еще один частый случай, когда изображение одной единой буквы может
распадаться, как показано на рисунке 3. Человек, в отличие от программы,
способен понять, что это единый символ. Во многих случаях для решения задачи
сегментации отдельных букв используются эвристические алгоритмы повышенной
сложности, затрачивающие слишком большие вычислительные мощности. Для принятия
решения о прохождении границы конкретной буквы на данном этапе обработки
системе распознавания будет недостаточно информации. В разработанном алгоритме
задачей модуля сегментации на уровне букв будет являться нахождение лишь
возможных границ символов внутри каждой буквы, а окончательное решение о
разделении слова принимается на последнем этапе работы модуля распознавания, с
учетом идентификации отдельных фрагментов изображения как букв. Дополнительным
преимуществом такого подхода является возможность работы с начертаниями букв,
состоящих из нескольких компонент связанности благодаря рассмотрению таких
случаев.

Рис. 3. Разделение изображений букв на несвязанные компоненты
В результате работы модуля сегментации мы получаем дерево сегментации.
Дерево сегментации это особая структура данных, организация которой отражает
структуру текста на странице. Самому верхнему уровню соответствует сам исходный
объект - документ. Он содержит в свою очередь массив объектов, описывающих
строки. Каждая строка в свою очередь включает свой набор объектов-слов. Слова
являются листьями получаемого нами на выходе алгоритма дерева. Информация о
возможных местах разделения слова на буквы хранится в самом слове, отдельные
объекты для букв не выделяются. В каждом объекте дерева хранится информация об
области, занимаемой соответствующим объектом на изображении.
.3 Обзор существующих приложений
по оптическому распознаванию символов
На данный момент уже существуют готовые программные решения по
оптическому распознаванию символов.
В данном разделе будет рассмотрено решение безоговорочного лидера в
данной сфере IT технологий, компании ABBYY: Abbyy FineReader, а также некоторые небольшие
приложения по преобразованию печатных символов в электронный вариант на базе собственных
движков распознавания. Следует помнить, что на рынке на сегодняшний день
имеется достаточное количество как бесплатных, так и платных приложений по
распознаванию символов, но в данной работе будут рассмотрены только наиболее
примечательные из них. Об остальных будет упомянуто лишь в сводной
сравнительной таблице, т.к. многие из них являются лишь обертками для уже
упомянутых движков распознавания и не демонстрируют достойных результатов.
1.3.1 Abbyy FineReader
FineReader -
коммерческий продукт для оптического распознавания символов разработанный
российской компанией ABBYY и безусловный лидер в сфере оптического
распознавания символов. В основе FineReader запатентованная технология
оптического распознавания символов ABBYY OCR, которую лицензируют такие мировые
гиганты как Fujitsu <https://ru.wikipedia.org/wiki/Fujitsu>, Panasonic
<https://ru.wikipedia.org/wiki/Panasonic>, Xerox
<https://ru.wikipedia.org/wiki/Xerox> и Samsung
<https://ru.wikipedia.org/wiki/Samsung>. Программа позволяет переводить
изображения печатных документов во множество электронных редактируемых
форматов. Начиная с версии 12, она поддерживает распознавание текста на 190
языках, имеет встроенную проверку орфографии для 48 из них, способна сохранять
исходное форматирование документа, имеет большой набор функций для
предварительной обработки изображения, позволяет проводить настройку множества
параметров. Но основным ее преимуществом является почти безукоризненная
точность распознавания. По некоторым данным, после тщательного обучения система
может распознавать рукописный текст, однако ее нужно будет учить под почерк
каждого конкретного пользователя. На данный момент программа насчитывает более
20 миллионов пользователей по всему миру.
1.3.2 CuneiForm
CuneiForm
- система оптического распознавания текстов российской компании
CognitiveTechnologies. Изначально программа CuneiForm была разработана
компанией CognitiveTechnologies как коммерческий продукт. CuneiForm поставлялся
в комплекте с некоторыми моделями сканеров. Однако после нескольких лет
перерыва в разработке, 12 декабря 2007 года анонсировано открытие исходных
текстов программы, которое состоялось 2 апреля 2008 года. На данный момент
CuneiForm позиционируется как шрифтонезависимая система преобразования
электронных копий бумажных документов и графических файлов в редактируемый вид
с возможностью сохранения структуры и гарнитуры шрифтов оригинального документа
в автоматическом или полуавтоматическом режиме. Система включает в себя две
программы для одиночной и пакетной обработки электронных документов.
1.3.3 OCRopus
OCRopus
- система оптического распознавания символов, изначально направленная на
преобразование в электронный вид большого объема документов на базе
собственного распознающего ядра, начиная с версии 0.4. Это программный пакет
для распознавания текста, развивающийся по принципам OpenSource и
распространяющийся под лицензией ApacheLicense 2.0. Программа позволяет
подключать дополнительные модули для анализа макета содержимого,
предварительного улучшения изображения. По задумке разработчиков, с помощью
OCRopus станет возможным определять текстовое содержимое на графических файлах
построчно и переводить его в обычный текстовый формат для дальнейшего
редактирования. Помимо печатного текста, программа сможет распознавать и рукописные
материалы. По состоянию на альфа-релиз, OCRopus использует код языка
моделирования из другого проекта, поддерживаемого Google - OpenFST. OCRopus в
настоящее время доступна только для GNU/Linux. В настоящее время OCRopus
использует только интерфейс командной строки, принимая указания на входные
изображения с текстом, и выводя данные в формате hOCR (открытый формат на
основе HTML), TXT.
.3.4 Tesseract
Tesseract
- одноименная со своим ядром распознавания, свободно распространяемая программа
для распознавания текстов, разрабатывавшаяся Hewlett-Packard с середины 1980-х
по середину 1990-х, а затем на 10 лет проект был приостановлен.[10,20] В
августе 2006 года компания Google выкупила ее и открыла исходные тексты под
лицензией Apache 2.0 для продолжения работы над перспективным проектом. В
настоящий момент программа работает с UTF-8, поддержка языков (включая, русский
с версии 3.0) осуществляется с помощью установки и настройки дополнительных
модулей. Использует интерфейс командной строки. Начиная с версии 3.04,
выпущенной в 2015 году работает с более чем 100 языками.
1.3.5 Выявленные недостатки приложений
После
рассмотрения четырех наиболее примечательных приложений по распознаванию
символов, были сделаны следующие выводы:
1. Многие из приложений обладают не вполне интуитивно понятным
интерфейсом и слишком большим числом функций, что иногда может оказаться
недостатком
. Приложения не способны работать в фоновом режиме, кроме FineReader(добавлено в последней версии 12)
. Не у всех имеется возможность предварительной обработки
изображения с целью улучшения качества
. Отсутствие графического интерфейса пользователя у некоторых
решений
. Ни одна из программ не демонстрирует 100% результата и
идеального сохранения форматирования
.4 Основные трудности распознавания
символов
Существуют различные проблемы, связанные с распознаванием символов.
Наиболее существенны следующие:
. Разнообразие языков, символов, и способов изображать их. Многие
языки обладают похожими буквами: «N» и «И», «R» и «Я» и др. В
каждом языке имеются символы, обладающие схожими чертами друг с другом и
цифрами. Например, в русском языке: «М», «Н», «И» и «О» и «0», и т.д.
. Искажение изображений символов. Причины могут быть разнообразны.
От минимальных проблем связанных с исходным изображением, заканчивая дефектом
самого источника.
. В случае обработки персональных данных, проблемы могут вызвать
системы защиты источника изображения. В случае паспортов - это невидимые
символы.
4. Разнообразные вариации размеров и масштабов
символов. Каждый отдельный символ может быть написан с использованием различных
шрифтов, как стандартных (Times,
Orator, Arial), а также множеством шрифтов, используемых, например,
в пределах одной страны, для оформления одних и тех же документов.
Искажения цифровых изображений текстовых символов
могут быть вызваны следующими причинами[26]:
1. Шумами печати, в частности, непропечаткой
(разрывами слитных черт символов), «слипанием» соседних символов, пятнами и
ложными точками на фоне вблизи символов и т. п.
2. Смещением символов или частей символов
относительно их ожидаемого положения в строке
. Изменением наклона символов
. Искажением формы символа за счет оцифровки
изображения с «грубым» дискретом
. Эффектами освещения (тени, блики и т. п.) при
съемке камерой.
Многие системы OCR
показывают наилучшие результаты при обработке черного текста на светлом фоне. В
случае текстовых документов - это не критично. Но если применять такую систему
для обработки нестандартных изображений: сканы паспортов, водительских
удостоверений, номерных знаков автомобилей, то мы столкнемся с невозможностью
получить корректные данные без предварительной обработки изображения.
Многие проблемы, описанные выше, можно устранить на этапе
предобработки(1, 2, 3)[23, 26].
Система оптического распознавания текста (OCR) должна:
выделять на цифровом изображении текстовые области, выделять в них отдельные
строки, затем отдельные символы, распознавать эти символы и при этом быть
нечувствительной (устойчивой) по отношению к способу верстки, расстоянию между
строками и другим параметрам печати.
1.5 Методы распознавания символов
Распознавание структурированных (печатных) символов различных изображений
обеспечивает решение ряда научных и прикладных задач при идентификации объектов
различной природы. Современные методы распознавания символов используются для
решения как типовых задач, например, распознавание текста, так и
специализированных задач, ориентированных на распознавание символьной
информации, нанесенной на поверхность различных объектов. Рассмотрим наиболее
известные и распространенные методы распознавания символов.
1.5.1 Структурные методы
Алгоритм работы данных методов заключается в разбиении исходного образа
на составные части, описываемые как стабильные идеальные элементы.
Одни из методов данного направления использует для распознавания
топологическое описание изображений. Иными словами, эталон содержит информацию
о взаимном положении отдельных составных частей символа. При этом становится
неважным размер распознаваемой буквы и даже шрифт, которым она напечатана. Возможные
изображения, составляющие тот или другой класс, можно представить как результат
гомеоморфных преобразований некоторого эталонного изображения, соответствующего
этому классу. Задача распознавания в этом случае может быть сведена к
установлению гомеоморфности предъявленного изображения с одним из эталонных. Ее
можно обнаружить с помощью топологических инвариантов - таких свойств
изображения, которые не изменяются при его гомеоморфных преобразованиях.
Инвариантом, позволяющим дать численное описание изображений, является,
например, количество сходящихся в точке линий. Соответствующее описание
получается обходом в определенном порядке контуров изображения с одновременной
фиксацией индексов точек. Установление гомеоморфности - собственно
распознавания - сводится к сравнению описаний предъявленного изображения и
эталонных изображений классов. Важное достоинство топологического описания -
его нечувствительность к сильным деформациям изображения, включающим все
преобразования подобия, если связывать с каждым изображением некоторую
характерную точку, из которой начинается обход. Обучение топологическому коду
состоит в ведении набора эталонных описаний.
Другие структурные методы реализуют алгоритм событийного распознавания.
Событийный метод опирается на топологическую структуру объекта, состоящую из
линий и не изменяющуюся при малых деформациях образа. Линией называется часть
образа, в каждом сечении которого имеется всего один интервал. Линии,
огрубленные на некоторой сетке, определяют события. Событийное представление
является не только формальным набором признаков, но и адекватным топологическим
описанием. Обучение метода сводится к составлению списка эталонов на достаточно
большой последовательности образов. При распознавании для исходного растра
определяется событийное представление, которому сопоставляется эталонный класс.
Основной проблемой структурных методов распознавания является
идентификация знаков, имеющих дефекты.
Достоинствами метода являются способность распознавания искаженных
символов и быстродействие при малом алфавите.
1.5.2 Шаблонные методы
Алгоритм работы шаблонных методов опирается на сопоставление входного
графического изображения, идеальному шаблону. Первым этапом работы шаблонного
метода является преобразование отсканированного изображение в растровое. В
процессе распознавания, перебираются шаблоны, и вычисляется расстояние от
образа до шаблона. Класс, шаблоны которого находятся на минимальном расстоянии
от входного образа, является результатом распознавания.
Данные методы делятся на два класса шрифтозависимые и шрифтонезавизимые.
Шрифтонезависимые методы используют заранее определенные шаблоны, и
универсальны для всех типов шрифтов. Однако при таком подходе снижается
вероятность правильного распознавания. Шрифтозависимые алгоритмы рассчитаны только
на один тип шрифта, это повышает качество их работы, но они совершенно не
работоспособны при использовании других шрифтов. Были предложены методы для
распознавания больших объемов текста, когда часть символов гарантированно
распознается шрифтонезависимыми методами, а затем на основании распознанных
символов строятся шаблоны для шрифтозависимых алгоритмов.
При существующем изобилии печатной продукции в процессе обучения
невозможно охватить все шрифты и их модификации.
К достоинствам данного алгоритма относятся: простота реализации, надежная
работа в условиях отсутствия помех, высокая точность распознавания дефектных
символов, быстрота при малом алфавите.
К недостаткам можно отнести: сильную зависимость от шаблонов и сложность
подбора оптимальных шаблонов, невозможность распознать шрифт, отличающийся от
заложенного в систему, медленная работа при большом количестве помех,
чувствительность к вращению, шумам и искажениям.
1.5.3 Признаковые методы
Данные методы базируются на том, что изображению ставится в соответствие N-мерный вектор признаков.
Распознавание заключается в сравнении его с набором эталонных векторов той же
размерности. Принятие решения о принадлежности образа тому или иному классу, на
основании анализа вычисленных признаков, имеет целый ряд строгих математических
решений в рамках вероятностного подхода. Тип и количество признаков в немалой
степени определяют качество распознавания. Формирование вектора происходит во
время анализа изображения. Данную процедуру называют извлечением признаков. Эталон
для каждого класса получают путем аналогичной обработки символов обучающей
выборки.
К достоинствам метода можно отнести: простота реализации, высокая
обобщающая способность, устойчивость к изменению формы символов, высокое
быстродействие.
К недостаткам метода относятся: неустойчивость к различным дефектам
изображения, потеря информации о символе на этапе извлечения признаков.
1.5.4 Нейросетевые методы
Нейросетевые методы[8, 9] основаны на применении различных типов
искусственных нейронных сетей. Идея этих методов - моделирование работы мозга
человека. На вход заранее обученной нейронной сети поступает вектор, который
является представлением входного образа (пиксели, частотные характеристики,
вэйвлеты). На выходе нейрон, соответствующий классу распознанного символа,
выдает максимальное значение функции активации. Или же на выход поступает
множество ключевых характеристик изображения, которые затем обрабатываются
другими системами. Обучение нейронных сетей происходит на множестве обучающих
примеров. Причем возможно обучение с учителем (персептрон) или самоорганизация
(сеть Кохонена).
Достоинствами метода являются: способность к обобщению, высокая скорость
работы.
Недостатки: чувствительность к вращению и искажению символов, сложность
подбора обучающей выборки и алгоритма обучения.
1.6 Tesseract OCR
- модуль оптического распознавания образов с открытым исходным кодом,
был разработан HP в промежутке
между 1984 и 1994 годами. В 1995 был представлен как инновация на The Fourth Annual Test of OCR Accuracy - тест точности решений OCR, и показал выдающиеся результаты.
После этого проект был заморожен[20].
Поскольку HP обладает
технологией анализа содержимого страницы, которая используется в продуктах
компании, Tesseract никогда не нуждался в своей системе
подобного анализа. Tesseract
предполагает, что получает на вход бинаризацию изображения с заданными
регионами текста[10, 12]. Распознавание происходит в 2 шага. На первом,
происходит попытка распознать каждое слово по очереди. Каждое слово передается
классификатору являясь его обучающими данными. Благодаря этому адаптивный
классификатор получает возможность более точно распознать текст, лежащий ниже
на странице. Чтобы сделать распознавание более точным в начале страницы, второй
прогон следует за первым из-за того, что классификатор способен обучиться
полезной информацией завершения первого шага. В этой ситуации, слова, которые
были недостаточно хорошо распознаны, обрабатываются повторно. Финальный этап
удаляет случайные пробелы, и находит текст, написанный малыми прописными.
Основная часть данной работы состоит в разработке приложения с использованием
системы OCR Teseract.
Tesseract имеет ряд преимуществ, с чем и связан наш выбор его в качестве модуля
оптического распознавания символов в рамках данной работы:
. Обладает открытым исходным кодом
. Показывает прекрасные результаты при работе с чёрно-белым
текстом
. Позволяет в короткие сроки на своей базе реализовать модуль
способный распознавать текст с, например, водительских прав или
государственного номера автомобиля.
. Обладает обширной документацией.
. Способен к тесной интеграции с библиотеками компьютерного зрения
(openCV).
Ниже будут рассмотрены методы работы Tesseract подробнее.
1.6.1 Метод обнаружения линий
Данный метод разработан для того, чтобы страница, перевернутая под
каким-то углом, могла быть распознана, без устранения наклона - это позволяет
избежать потери качества изображения. Ключевая часть данного процесса -
фильтрация контуров и конструкция линий.Считая, что анализ содержимого страницы
уже предоставил регионы текста, примерно одного размера, простой фильтр высот
удаляет большие заглавные буквы, с которых начинается страница в некоторых
текстовых файлах.

Медиана высот аппроксимирует размер текста в регионах, поэтому нужно
фильтровать контуры, меньшие этой медианы. Данные элементы, с высокой
вероятностью являются пунктуацией или шумом.
Отфильтрованные контуры удовлетворяют модели неперекрывающихся,
параллельных линий. Сортировка и обработка контуров по «x» координате позволяет присвоить
контур уникальной строке, отслеживая наклон по странице, что значительно
уменьшает вероятность присвоения к некорректной строке в случае наличия
перекоса. После того, как отфильтрованные контуры были закреплены за линиями,
меньшая медиана квадратов используется для оценки базовых линий, и
отфильтрованные контуры установлены обратно в соответствующие строки.
Последняя стадия процесса создания линий соединяет контуры, перекрывающие
друг друга по горизонтали хотя бы на половину, накладывая корректную базу и
корректно соотнесенные части поломанных символов.
1.6.2 Метод выбора базовой линии
Как только строки были найдены, базовые линии определяются более точно с
помощью квадратичного сплайна. Это позволяет Tesseract обрабатывать строки, расположенные
под углом - что весьма вероятно при сканировании документов.

Рис. 6. Определенные линии
Рисунок выше, демонстрирует строку текста, с выделенной базовой линией,
нижней границей строки, центральная линия строки, и верхняя границей. Данные
линии параллельны, и немного наклонены.
.6.3 Определение фиксированного шага и сегментация
слов
Tesseract проверяет строки, для обнаружения фиксированных шагов между символами.
При обнаружении tesseract делит
слова на символы используя найденный шаг, и запрещает классификатору проверять
данные слова на этапе распознавания слов.

Рис. 8. Слово, сегментированное с определённым шагом
1.6.4 Обнаружение слов
Не фиксированные шаги, или пропорциональные пробелы - очень нетривиальная
задача. Рисунок 8 демонстрирует типичные проблемы. Разрыв между десятками и
единицами в «11.9%» похож на обычный пробел, и является больше чем разрыв между
«erated» и «junk». Здесь нет горизонтального разрыва между «of» и «financial». Tesseract решает большинство этих проблем
измеряя пробелы в фиксированном вертикальном пределе между базовой линией, и
центральной линией строки. Пробелы, которые слишком близки к порогу на этой
стадии становятся нечеткими, поэтому финальное решение может быть совершено
другим после распознания слов.
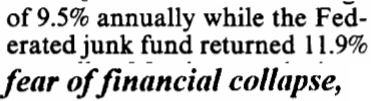
Рис.9. Строки со сложными для обработки разрывами
1.6.5 Распознавание слов
Задача процесса распознавания для любого метода распознавания образов это
определить, как слово должно быть разделено на символы. Первоначальный
результат сегментации по найденным линиям классифицируется первым. Остальная
часть этапа распознавания слов применяется только к тексту с не фиксированным
шагом пробелов.
1.6.6 Разделение соединенных символов
Пока результат неудовлетворителен, tesseract совершает попытки его улучшить,
обрезая контур, основываясь на данных классификатора: удаляются элементы хуже
всех подходящие ему. Кандидатуры точек разделения находятся из вогнутых вершин
полигональной аппроксимации границ, и могут быть как другими вершинами, так и
сегментами линии. Для успешного разделения связанных символов из «ASCII» набора, необходимы три пары таких
точек.
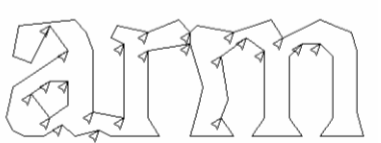
Рис. 10. Возможные точки сегментации
Рисунок демонстрирует набор точек разделения со стрелками, и выбранный
участок разделения, как линию на границе, где «r» касается «m».
Разделение выполняется по порядку. Каждое отсечение, не улучшающее
финальный результат, не будет совершено, но оно не стирается из памяти, поэтому
в дальнейшем может быть использовано заново (в случае необходимости).
1.6.7 Распознавание поврежденных символов
В случае, когда все возможные варианты разделения символов израсходованы,
а слово распознается не достаточно хорошо, оно передается ассоциатору. Данный
модуль совершает «А*» поиск сегментированных символов в возможной комбинации
максимально обрезанных контуров, чтобы найти символ максимально похожий на
обрубленный элемент. Данный алгоритм находит маршрут с наименьшей стоимостью от
одной вершины (начальной) к другой (целевой, конечной).Он предоставляет
кандидату новые состояния из приоритетной очереди и оценивает их, классифицируя
неклассифицированные комбинации фрагментов.
Можно поспорить, является ли данный подход наилучшим, ведь весьма
вероятно исчезновение важных сегментов разделения. Преимущество данного метода
в том, что структура данных, необходимая для обработки целого сегментированного
элемента, упрощается.

Рис. 11. Пример легко распознанного слова
Когда «А*» поиск был впервые разработан в 1989 году, точность Tesseract для обработки искаженных символов
была наголову выше, чем коммерческие разработки того времени. Значительная
часть успеха работы заключается в классификаторе образов, который способен с
легкостью распознавать поврежденные элементы.
1.6.8 Статический классификатор символов
Ранняя версия tesseract
использовала топологический модуль, разработанный по статье Шилмана, и хотя
данный метод не зависит от шрифта и размера, работа данного модуля неустойчива.
Идея была в том, чтобы взять сегмент аппроксимации и использовать его как
особенность элемента, но данный подход также неустойчив к поврежденным
символам.
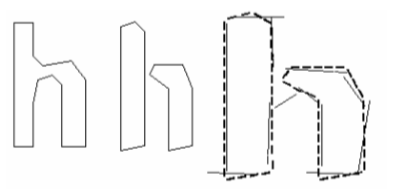
Рис. 12. Четкий, искаженный и совпадающий по признакам прототип
Прорывом оказался следующий подход. Особенности неизвестного символа не
должны совпадать с отличительными чертами в обученных данных. Во время
обучения, сегменты полигональной аппроксимации используются для обнаружения
особенностей, но при распознавании, малые свойства фиксированной длинны
извлекаются из границ и совпадают со многими признаками обученных данных. На
рисунке 11, короткие, тонкие линии - это признаки, извлеченные из неизвестного
символа, а тонкие длинные линии являются сегментами полигональной
аппроксимации, используемой в прототипе обученных данных. Один прототип не
совпадает с двумя связанными признаками, но в этом прототипе находит свое
отражение каждое из этих свойств по отдельности. Получается, что при сравнении
малых признаков с более крупными прототипами, можно добиться хороших
результатов при обработке поврежденных символов. Основная проблема данного
подхода в том, что это требует высоких вычислительных мощностей для сравнения
неизвестного элемента и прототипа.
Признаки, извлеченные из неизвестного символа, определяются тремя
направлениями (xposition, yposition, angle), с 50-100 признаками на символ, а признак прототипа
определяется 4-мя направлениями (xposition, yposition, angle, length),
с 10-20 свойствами на конфигурацию прототипа.
1.6.9 Классификация
Классификация проводится в два шага. На первом, создается короткий список
элементов класса, с которыми могут совпадать неизвестные. Каждый признак
выбирается из битового вектора классов, которым этот признак может
удовлетворять, и битовых векторов просуммированных по всем свойствам. Классы с
большим количеством признаков становятся списком для следующего шага.
Каждый признак неизвестного элемента ищет битовые вектора прототипов
выбранного класса, с которыми может совпадать, а затем высчитывается реальная
похожесть данных. Каждый элемент прототипа класса символов представляет собой
логическую сумму выражения продукта с конфигурацией, таким образом, сохраняется
запись об уровне похожести данных каждого признака в каждой конфигурации,
каждого прототипа. Наивысший уровень сходства, вычисленный из общего числа
признаков, будет лучшим среди всех сохраненных конфигураций класса.
1.6.10 Обучение данных
В виду того, что классификатор способен различать поврежденные символы,
классификатор не был обучен с использованием искаженных символов. Для обучения
применялось объединение 20 образцов по 94 символах одного размера в 8 различных
шрифтах, но с 4 атрибутами (жирный, обычный, курсивный, жирный курсивный).
Таким образом, было 60160 образцов для обучения. Разительное отличие от других
классификаторов, таких как Calera,
с более чем миллионом образцов и Baird
- 100 шрифтовый классификатор с 1175000 элементами для обучения.
1.6.11 Лингвистический анализ
Tesseract обладает относительно малым языковым анализом. Всякий раз, когда модуль
распознавания обрабатывает новую сегментацию, лингвистический модуль выбирает
лучшее из доступных слов в каждой последующей категории: наиболее часто
встречающееся слово, наиболее словарное слово, наиболее часто встречающаяся
цифра, наиболее часто встречающееся слово в верхнем регистре и наиболее часто
встречаемое слово в нижнем регистре. Классификатор выбирает из них слово
максимально похожее на то, которое было подано на вход. Но финальное решение по
выбранной сегментации - это слово с наименьшим дистанционным рейтингом, где
каждая из представленных выше категорий домножена на различные константы.
1.6.12 Адаптивный классификатор
Использование адаптивных классификаторов в OCR модулях приносит немалые плоды. Несмотря на то, что
статичный классификатор хорошо подходит для обработки любого вида шрифта, его
способность различать символы и не-символы не достаточно развита. Более
чувствительные к шрифту классификаторы, обученные с использованием выходных
данных статического классификатора обладают большей способностью к
распознаванию символов в документах, где число шрифтов лимитировано.
Tesseract не использует шаблонный классификатор, но использует те же функции, что
и статический классификатор. Единственное значительное отличие между статичным
и адаптивными классификаторами, если забыть об обученных данных, это то, что
адаптивный классификатор использует нормализацию по базовым линиям.Нормализация
по базовым линиям упрощает обнаружение символов верхнего и нижнего регистров, а
также повышает стойкость к шумам. Основное преимущество нормализации - удаление
зависимости от шрифтов, и от ширины символа для данного шрифта. Следующая
фигура демонстрирует пример форму трех символов в нормализации по базовой
линии, и форму нормализации по моменту.

Рис. 13. Слово в базовых линия, и нормализованные по моменту буквы
1.7 Фильтр Гаусса (gaussianblurring)
Размытие является неотъемлемой частью различных техник коррекции
изображения, направленных на устранение специфических дефектов (излишняя
детализация, дефекты сканирования, пыль, и т.д). Одним из их возможных
применений является шумоподавление, т.е. задача восстановления исходного
изображения, к пикселям которого добавлен случайный шум.
Размытие по гауссу - это характерный фильтр размытия изображения, который
использует нормальное распределение (Гауссово распределение) для вычисления
преобразования, применяемого к каждому пикселю изображения.
Шум в изображении меняется независимо от пикселя к пикселю и, при
условии, что математическое ожидание значения шума равно нулю, шумы соседних
пикселей будут компенсировать друг друга. Чем больше окно фильтрации, тем
меньше будет усредненная интенсивность шума, однако при этом будет происходить
и существенное размытие значащих деталей изображения.
Уравнение распределения Гаусса в N измерениях имеет вид:
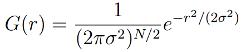 ,
,
Шумоподавление при помощи прямоугольного фильтра имеет существенный
недостаток: пиксели на расстоянии «r» от обрабатываемого оказывают на результат
тот же эффект, что и соседние.
Более эффективное шумоподавление можно, таким образом, осуществить, если
влияние пикселей друг на друга будет уменьшаться с расстоянием (частный случай
- для двух измерений):
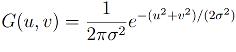 ,
,
где «r» - это радиус размытия, «r2» = «u2» + «v2»
, «σ» - стандартное
отклонение распределения Гаусса. В случае двух измерений - эта формула задает
поверхность, имеющей вид концентрических окружностей с распределением Гаусса от
центральной точки. Пиксели, где распределение отлично от нуля используются для
построения матрицы свертки, которая применяется к исходному изображению.
Значение каждого пикселя становится средне взвешенным для окрестности. Исходное
значение пикселя принимает наибольший вес (имеет наивысшее Гауссово значение),
и соседние пиксели принимают меньшие веса, в зависимости от расстояния до них.
В теории, распределение в каждой точке изображения будет ненулевым, что
потребовало бы вычисление весовых коэффициентов для каждого пикселя
изображения. Но, на практике, когда рассчитывается дискретное приближение
функции Гаусса, не учитывают пиксели на расстоянии свыше 3σ,
т.к. они достаточно
малы. Таким образом, программе, фильтрующей изображение, достаточно рассчитать
матрицу d6σe×d6σe, чтобы гарантировать достаточную
точность приближения распределения Гаусса.
Для применения данного фильтра используется свертка по функции:
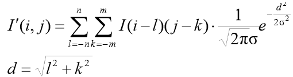
Параметр σ задает степень размытия. На графике функция с σ
= 5
Рис. 13
Результаты свертки по функции Гаусса и по константной функции
(усреднения).
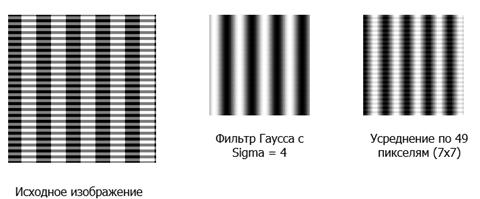
Рис. 14
Фильтр Гаусса хорошо подходит для ситуации, когда зашумленное изображение
имеет большое количество деталей, т.к данный фильтр меньше размывает детали
малого размера и весьма достойно убирает зашумление.
1.8 Алгоритм Канни
Канни изучил математическую проблему получения фильтра, оптимального по
критериям выделения, локализации и минимизации нескольких откликов одного края.
Это означает, что детектор должен реагировать на границы, но при этом
игнорировать ложные, точно определять линию границы (без её фрагментирования) и
реагировать на каждую границу один раз, что позволяет избежать восприятия
широких полос изменения яркости как совокупности границ. Канни ввел понятие
Non-MaximumSuppression (подавление не-максимумов), которое означает, что
пикселями границ объявляются точки, в которых достигается локальный максимум
градиента в направлении вектора градиента.
Для определения граней необходимо сперва воспользоваться фильтром
описанным выше(5х5), так как шум может быть принят за грань изображения.
Для вычисления приближенного значение градиента яркости изображения
применяется оператор Собеля. Результатом его применения в каждой точке
изображения будет либо вектор градиента яркости в этой точке, либо его норма.
Сглаженное изображение фильтруется с помощью матрицы Собеля по горизонтальному
и вертикальному направлениям, чтобы получить первые производные в
горизонтальном и вертикальном направлениях.
Вектор градиента, всегда перпендикулярен к граням.
После получения градиента и направления, необходимо удалить с изображения
все пиксели, которые не являются гранями. Для этого каждый пиксель проверяется
на принадлежность к локальному максимуму в своей окрестности по направлению
градиента (рис. 15). Пикселями границ объявляются пиксели, в которых
достигается локальный максимум градиента в направлении вектора градиента.
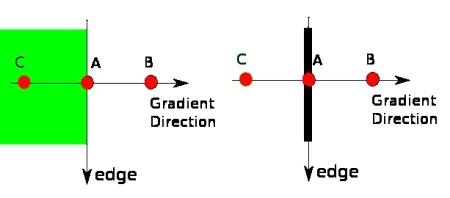
Рис. 15
Точка «А» - грань (вертикальное направление). Направление градиента -
нормаль для этой грани. Точки «В» и «С» лежат на векторе градиента. Поэтому т.
«А» сравнивается с ними, чтобы проверить, является ли она локальным максимумом.
Если да, то переходят к следующей стадии, иначе она обнуляется.
Далее, необходимо проверить: находится или нет граница в данной
точке(применяя порог). Чем меньше порог, тем больше границ будет находиться, но
тем более восприимчивым к шуму станет результат, выделяя лишние данные
изображения. Наоборот, высокий порог может проигнорировать слабые края или
получить границу фрагментами. Для этого необходимы два порога «max_Val» и «min_Val» - верхний и нижний. В программных
реализациях данного алгоритма эти пороги задаются самостоятельно. Один из
возможных вариантов задания этих порогов - это принять их равными :
_Val = 0.66*[среднее значение],
max_Val = 1.33*[среднее значение],
где «cреднее значение» - это усредненная
величина интенсивности пикселей для вашего изображения в «оттенках серого».
Любая грань с интенсивностью большей «max_Val» -
точно грань, меньшие нижнего порога - нет. Грани, интенсивности которых, лежат
между этими порогами, классифицируются в зависимости от принадлежности к
пикселю уже отобранной грани.

Рис. 16. Верхний и нижний пороги интенсивности
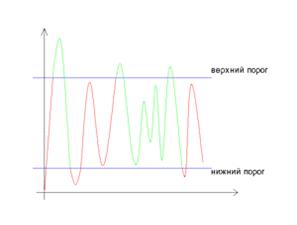
Рис. 16а. Верхний и нижний пороги интенсивности
Грань «А» выше «max_Val» - она точно является гранью. Грань
«C» ниже максимума, но соединена с
гранью «А», поэтому тоже является гранью - мы получили полную кривую. Грань «В»
же лежит ниже максимума, но не соединена ни с гранью «А», ни с гранью «C», поэтому она не является гранью.
Для получения корректного результата, весьма важно, правильно выбрать эти
пороги. На этой стадии, также удаляются шумы на краях граней

Рис. 17. Пример обработки изображания алгоритмом Канни
Глава 2. Описание разработанной системы
В данной главе описан прототип системы, которая была разработана в рамках
данного выпускного проекта. Здесь содержится описание как алгоритма работы
приложения, так и общая информация о возможностях прототипа и результаты его
тестирования.
2.1 Общее описание приложения и принципа его
работы
Разработанный в рамках данной работы прототип реализован в виде
приложения, написанного под платформу Windows. Приложение позволяет распознавать данные с изображений
паспортов. Со сканера поступает изображение паспорта сотрудника. При этом оно
загрязнено невидимыми символами (в случае паспорта Российской Федерации -
гербами) или иметь дефекты. Расположение интересующих нас данных:
· Номер
· Ф.И.О.
· Дата и место рождения
· Пол
· Дата регистрации
Заранее определено, где расположены интересующие нас области, т.к.
имеется единый образец данного документа. Изображение паспорта расположено ровно,
но возможны некоторые отклонения, в зависимости от положения документа во время
сканирования. Данное приложениесчитывания данных состоит из следующих
программных модулей:
· Пользовательский интерфейс
· Модуль ротации изображения;
· Модуль локализации данных
· Модуль распознавания;
· Внешняя база данных
Отсканированное изображение паспорта выбирается через UI непосредственно и подается на вход
алгоритма для устранения дефектов сканирования и ротации изображения. После
этого рабочее изображение поступает для локализации данных. И только после
того, когда было установлено местоположение интересующей нас информации, текст
распознается модулем распознавания символов. Далее следуют алгоритмы
постобработки текста, основанный на словарном контроле результатов.
2.2 Tesseract
Для решения задачи распознавания образов предлагаю использовать OCR модуль для Python: Tesseract.Python-tesseract это обертка для Tesseract-OCR выкупленного Google. Данный модуль может принимать на вход все типы
изображений поддерживаемые PythonImagingLibrary, включая jpeg, png, bmp, tiff.
В то время как tesseract-OCR по умолчанию поддерживает только tiff и bmp.
2.3 Исходные данные
Данная программа работает с изображением скана паспорта (см. рис. 10)

Рис.18. Исходное изображение
2.4 Предварительная обработка изображения
Первым делом производится ротация и предварительная обработка изображения
скана паспорта, на основе представлений о виде изображения в стандартном виде:
на всю рабочую область, без наклона. Для этого производятся следующие
манипуляции над исходным изображением:
. Переводим изображение в оттенки серого

Рис. 19. Изображение в оттенках серого
. Сглаживаем шум на границах при помощи фильтра Гаусса
. Находим границы изображения при помощи алгоритма Канни

Рис. 20. Результат работы алгоритма Канни
. Бинаризация изображения
. Находятся все необходимые линии(как на самом изображении
паспорта, так и на границах: изображение подложка)

Рис. 21. Результат обнаружения линий на изображении
. Находим углы для всех линий
. Кластеризируем углы по двум центрам
. Выбираем кластер с большим количеством элементов
. Находим угол для ротации (подразумеваем, что изображение
обладало отклонением от 0 до 90 градусов)
. После предыдущего пункта могут появиться неотфильтрованные
области (не содержащие изображения паспорта) - отрезаем их

. Получаем финальное изображение

Рис. 22. Финальное изображение
2.5 Распознавание данных
.5.1 Выделение границ нахождения данных
Так как расположение данных в паспорте заранее определено, и для всех
образцов одинаково - получаем области, содержащие только нужную информацию.
Обнаружение зон интересующей информации:
. Бинаризация изображения[5]

Рис. 23. Бинаризация изображения
. Обнаружение контуров в бинаризованном изображении, и получение
контуров ограниченных областей

Рис. 24 Получение контуров
. Сортировка областей интереса (предполагаемое место нахождения
информации) в паспорте

Рис. 25 Области интереса
. Группировка областей по линиям, сортировка по площадям, высотам
и расстояниям между областями
. Разделение областей в поля

Рис. 26 Необходимые поля
2.5.2 Алгоритм локальной адаптивной бинаризации
1. Пороги для поверхности изображения вычисляются, во время скольжения
прямоугольного окна(каждый пиксель бинаризуется основываясь на информации о
своих соседях).
. Порог «T» в
центральном пикселе окна вычисляется по формуле:
T = m -
kα(m - M), α = 1 -  ,
R = max(s),
,
R = max(s),
где
«m» - минимальное значение интенсивности пикселя изображения в «оттенках
серого» в окне, «k» - константа, установленная равной 0.2, «M» - минимальное
значение интенсивности пикселя во всем изображении в «оттенках серого», «S» -
стандартное отклонение, «R» - максимальное из стандартных отклонений по всем
окрестностям.
3. Затем изображение сравнивается с пороговой поверхностью и все
пиксели с интенсивностью большей пороговой, делаются белыми(255), а все
интенсивности меньшие пороговой делаются черными(0)
. Для данного алгоритма единственный входной параметр - размер
окна.
Входной
параметр - размер окна:
1. Экспериментально было установлено, что лучшие результаты
распознавания достигаются с размером окна равным половине высоты текста.
. Таким образом, алгоритм способен обрабатывать образцы с
различным размером текста
. Но требуется система оценивающая высоту текста
2.5.3 Оценка высоты текста
1. Для каждой ячейки на изображении в «оттенках серого» вычисляются
интенсивности. Это позволяет получить массив дисперсий, у которых длина равна
высоте изображения.
. Области дисперсии, у которых расхождение больше порога «Tv» - рассматриваются как текст.(«Tv» - среднее значение всего набора
дисперсии)
. Медианная ширина зон текста большая «Tv» - высота текста.
2.5.4 Удаление линий (через анализ области
вокруг текста)
Шаги алгоритма:
1. Локализация связанных областей текста в бинаризованном
изображении.
. Обнаружение линий на изображении без текста.
. Удаление линий из оригинального изображения.
Связанные области текста:
1. Высота текста нам известна(h)
. Бинаризованное изображение расширяется с помощью следующего
ядра:
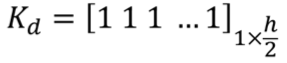
3. Изображение обрабатывается нормализованным hxh ядром:
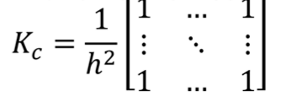
4. Результирующая обработка ограничена порогом в 0.25
. Полученные блобы (Blob -
регион цифрового изображения, обладающий постоянными свойствами) вероятнее
всего были получены из текста, т.о связанные регионы теста найдены.

Обнаружение линий
1. Удаление всех зон текста (все, что находится внутри связанных
регионов)
. Применяем трансформацию Хафа чтобы найти горизонтальные линии
(Линии в большинстве случаев «сломаны» и обладают не одинаковой толщиной,
поэтому трансформация Хафа применяется с порогом равным половине высоты, и
максимальном расстоянию между линиями равному половине ширины)
. Предыдущий шаг найдет список позиций горизонтальных линий
Удаление линий
1. Используем позиции горизонтальных линий и извлекаем пиксели из
оригинального изображения, которые принадлежат линиям, но не к текстовым
символам.
. Предполагаем, что толщина линий не постоянна, но не больше чем h/10.
. Для каждой возможной толщины, и каждой координаты на линии,
накладываем на оригинальное изображение маску и отмечаем все пиксели ,которые
совпадают с маской.
. Создаем отклонение, двигая маску вверх-вниз со стартовой
позиции. Данное перемещение не должно быть больше толщины линии.
Используемая маска:
 ,
,
где «d» - это толщина линии.
. Нули добавлены, чтобы убедиться, что маска не накладывается на
текст.
. Если при наложении маски, найдены пиксели подходящие ей, то он
маркируются для удаления.


Входное изображение должно содержать текст, с окружающей его зоной,
достаточно большой, чтобы иметь фоновые линии после того, как текстовые зоны
будут удалены. Линии могут быть под углом, пока возможно их обнаружение по
кусочкам. При обработке, текст не будет потерян. Иногда небольшие участки
текста остаются, но они могут быть удалены в последующих шагах обработки.
2.6 Обученные данные
Обучающая выборка состоит из стандартного пакета русского языка для tesseract. Результаты обработки с ее помощью
были не идеальны, поэтому были улучшены путем внесения изменений в файлы
обучающей выборки.
2.7 Результат работы программы

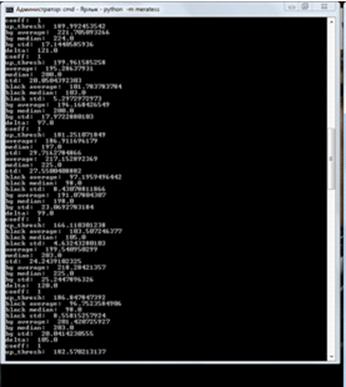
Рис. 27 Результат работы программы

На данный момент, система демонстрирует 94-95% точность распознавания.
2.8 Описание графического интерфейса пользователя
Разработанное приложение обладает простым интуитивно понятным
интерфейсом. При запуске приложения пользователь видит основное окно (рис. 28)

Рис. 28 Стартовый экран приложения
Для того, чтобы система начала свою работу необходимо нажать кнопку «Open» и выбрать изображение паспорта,
затем нажатием кнопки «Recognize» запускается процесс распознавания данных с изображения паспорта.
Результат работы программы будет выведен в соответствующие графы под
изображением (Рис. 29.)
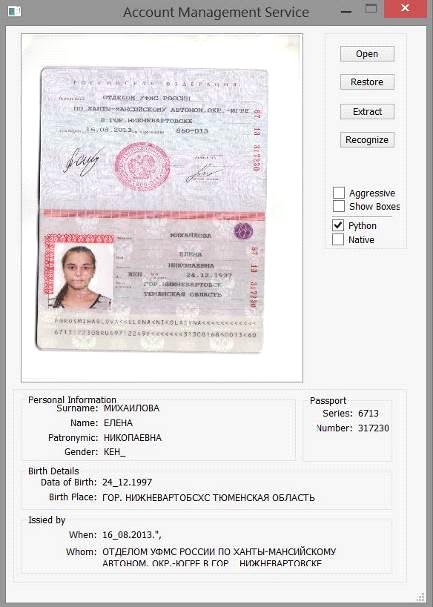
Рис. 29 Результат работы программы
2.9 Тестирование функции распознавания паспортных данных
Исходными данными для тестирования являются сканированные изображения
паспортов и файлы с проверочными данными для каждого изображения в определенном
формате. На данный момент корректные данные заносятся в проверочные файлы
вручную, в дальнейшем планируется разработать GUI для удобного редактирования
данных.
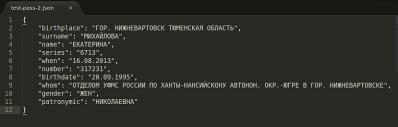
Рис. 30. Проверочные данные для тестирования
2.9.1 Процесс тестирования
В процессе работы утилиты для каждого изображения формируется файл с
распознанными данными в том же формате, что и проверочный файл. Далее
проводится сравнение полученных и корректных данных используя Расстояние
Левенштейна.
2.9.2 Результат тестирования
Результатом тестирования являются сгенерированные статистические файлы
для каждого изображения, и сводный файл в формате html для визуализации
результатов.
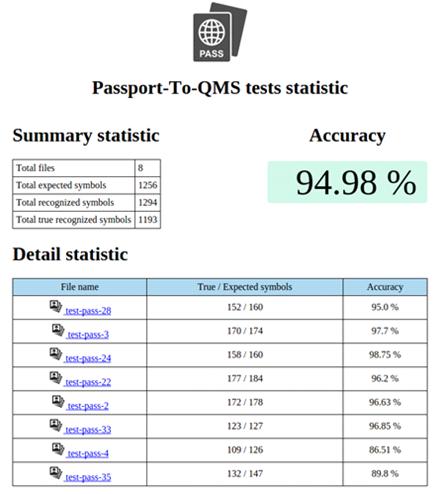
Рис. 31 Результат тестирования.
В целом проводилось тестирование на 50 различных паспортах, ошибка
составила 5%. Данный процент ошибки - в основном результат применения различных
шрифтов в разных регионах нашей страны, и не идеальность алгоритма удаления
фона.
Заключение
распознавание символ документ оптический
В настоящие время качественные системы распознавания текста достаточно
дороги, поэтому недостаточно широко распространены. Например, FineReader 12
показывает лучший результат. Он великолепно распознает как сканированные, так и
сфотографированные изображения. Однако, минимальная его стоимость составляет
80€ за лицензию на 10000 распознаваний в год. Данная же система не имеет таких
ограничений и может быть установлена, например, в бухгалтерии или отделе кадров
любой компании, для автоматизации сбора и обновления данных. Наше OCR
приложение на базе Tesseract
позволяет с достаточно высокой степенью точности распознавать символы, при
наличии различных шумов и помех, благодаря разработанному алгоритму
предварительной обработки изображений и системой постобработки текста,
основанной на словарном контроле результатов. Несомненным преимуществом нашей
системы является возможность быстрой доработки под иной формат документов и
интуитивно понятный интерфейс пользователя. Кроме того, разработанное решение
было успешно внедрено в Территориальный фонд Обязательного медицинского
страхования Нижегородской области, следовательно, имеет практическую
значимость.
На данный момент у данного модуля существует один значительный недостаток
касательно поддержки русского языка: данные недостаточно обучены, что не дает
такого же высокоточного результата, как с международными языками, но со
временем этот недостаток нивелируется.
В дальнейшем планируется разработка web-based
прототипа приложения, расширение возможностей по распознаванию данных:
поддержка других видов документов, борьба с шумами, более качественные метод
удаления фона, видоизменение стандартного алгоритма определения базовой линии
(используя openCV).
Список литературы
1. Богданов
В., Ахметов К. Системы распознавания текстов в офисе. // Компьютер-пресс - 1999
№3, с.40-42.
. Павлидис
Т. Алгоритмы машинной графики и обработки изображений. М:, Радиоисвязь, 1986
. Shani
U. Filling Regions in Binary Raster Images - a Graph-theoretic Approach. //
SIGGRAPH'80, pp 321-327.
. Merrill
R.D. Representation of Contours and Regions for Efficient Computer Search. //
CACM, 16 (1973), pp. 69-82.
. Pavlidis
T. Filling Algorithms for Raster Graphics. // CGIP, 10 (1979), pp. 126141.
6. <https://habrahabr.ru/post/112442/>
7. Lieberman
H. How to Color in a Coloring Book. // SIGGRAPH'78, Atlanta, Georgia, (August,
1978), pp. 111-116. PublishedbyACM.
8. Fuller,
R. (2004). Fuzzy logic and neural nets in intelligent systems. In C. Carlsson
(Ed.)Information Systems Day, pp. 74-94. Turku: Abo Academi University Press.
. Melin
P., Urias J., Solano D., Soto M., Lopez M., Castillo O., Voice Recognition with
Neural Networks, Type-2 Fuzzy Logic and Genetic Algorithms. Engineering Letters, 13:2, 2006.
10. R.W.
Smith, The Extraction and Recognition of Text from Multimedia Document Images,
PhD Thesis, University of Bristol, November 1987.
. R.W.Smith,
“A Simple and Efficient Skew Detection Algorithm via Text Row Accumulation”,
Proc. of the 3rd Int. Conf. on Document Analysis and Recognition (Vol. 2), IEEE
1995, pp. 1145-1148.
. R.W.
Smith, An Overview of the Tesseract OCR Engine, IEEE 2007 pp. 629 - 633
. http://yann.lecun.com/exdb/mnist/
14. International
Journal of Computer Vision 57(2), 137-154, 2004
15. Canny
Edge Detection Tutorial by Bill Green, 2002.
. Shapiro,
L. G. & Stockman, G. C: "Computer Vision", page 137, 150. PrenticeHall, 2001
17. OpenCV
Python tutorials(<http://opencv-python-tutroals.readthedocs.org/>)
18. Багрова И. А., Грицай
А. А., Сорокин С. В., Пономарев С. А., Сытник Д. А. Выбор признаков для распознавания
печатных кириллических символов // Вестник Тверского Государственного
Университета 2010 г., 28, стр. 59-73
19. Journal
of Signal and Information Processing, 2013, 4, 173-175
20. <https://ru.wikipedia.org/wiki/Tesseract>
21. <https://en.wikipedia.org/wiki/Comparison_of_optical_character_recognition_software>
22. Квасников В.П.,
Дзюбаненко А.В. Улучшение визуального качества цифрового изображения путем
поэлементного преобразования // Авиационно-космическая техника и технология
2009 г., 8, стр. 200-204
. <https://habrahabr.ru/company/abbyy/blog/225215/>
24. Mark S. Nixon and Alberto S. Aguado. Feature
Extraction and Image Processing. - Academic Press, 2008. - С. 88.
25. Hsueh,
M. (2011). Interactive text recognition and translation on a mobile device.
Electrical Engineering and Computer Sciences, 57, 47-60.
. Gllavata,
G. & Ewerth, R. (2003). A robust algorithm for text detection in images.
New York: Halstead Press.
. Bieniecki,
W. & Grabowski, S. (2007). Image preprocessing for improving OCR accuracy.
Columbia: Columbia University Press.
Приложение
. Prototype.py:ImageImportError:PIL import
Imagesafepytesseractcv2multiprocessing import
Poolautorotatecleanbgpostactionsfindboxesdo_recognize(img, dbg=''):
""" save image and process with tesseract
"""dbg != '':= dbg + '_tmp.png'.imwrite(filename, img)=
Image.fromarray(img, 'RGB')= safepytesseract.image_to_string(img,
lang='rus')resultrecognize(img, rot, (l1, t1, r1, b1), coeff, post=None,
dbg='', shrinkboxfactor=0):
""" prepares picture for recognition, passes
picturetesseract and does post actions:- image to process
(l, t, r, b) - box to look into- rotation flag for the box
above
(l1, t1, r1, b1) - box to ignore within (l, t, r, b)- debug
flag- array of post actions- by how much factor of height will the box be
shrinked from each side (left and right) aftercleaning and before it is passed
to OCR. Must be >=0
"""
# do rotation if neededrot:= cv2.transpose(img)=
cv2.flip(img, 0)= cleanbg.clean_bg((img, coeff, True))shrinkboxfactor <
0:ValueError("shrinkbox must be >=0")= int(img.shape[0] *
shrinkboxfactor)shrinkpixels > 0:= img[:, shrinkpixels:-shrinkpixels, :]
# wash the box which is to be ignoredl1 != 0 or t1 != 0 or r1
!= 0 or b1 != 0:rr in range(t1, b1):pp in range(l1, r1):[rr][pp] = [255, 255,
255]= do_recognize(img, dbg + str(coeff) if dbg != '' else '')=
postactions.do_post_actions(result, post)dbg != '':resultresult
# noinspection PyArgumentListrecognize_wrapper(args):
""" wrapper function to be passedthe process
pool """recognize(*args)do_box(img, (l, t, r, b), rot, (l1, t1,
r1, b1), post=None, agressive=0, dbg='', expandboxfactor=0):
""" Does recognition for image within given
box """dbg != '':'_do_box (l:%u t:%u r:%u b:%u rot:%u)' % (l, t,
r, b, rot)rot != 0: # don't expand rotated images= 0expandboxfactor != 0:-=
int(expandboxfactor * (b-t))+= int(expandboxfactor * (b-t))
# crop the box= img[t:b, l:r]agressive:frange(x, y, jump):x
< y:x+= jump= frange(0.0, 2.0, (2.0 - 0.0) / agressive)= Pool(4)=
pool.map(recognize_wrapper,
[(img.copy(), rot, (l1, t1, r1, b1),, post, dbg,
expandboxfactor) for coeff in coeffs])= postactions.do_sift(attempts, dbg):=
1.0= recognize(img, rot, (l1, t1, r1, b1), coeff, post, dbg,
expandboxfactor)result
# noinspection PyArgumentListdo_box_wrapper(args):
""" wrapper function to be passedthe process
pool """do_box(*args)= (('surname', (0.44, 0.85, 0.54, 0.62), 0,
(0, 0, 0, 0), [postactions.post_remove_newlines,.post_remove_spaces]),
('name', (0.51, 0.80, 0.62, 0.67), 0, (0, 0, 0, 0),
[postactions.post_remove_newlines,.post_remove_spaces]),
('patronymic', (0.51, 0.80, 0.67, 0.71), 0, (0, 0, 0, 0),
[postactions.post_remove_newlines,.post_remove_spaces]),
('series', (0.92, 0.98, 0.05, 0.25), 90, (0, 0, 0, 0),
[postactions.post_remove_newlines,.post_remove_spaces]),
('number', (0.92, 0.98, 0.25, 0.48), 90, (0, 0, 0, 0),
[postactions.post_remove_newlines,.post_remove_spaces]),
('whom', (0.10, 0.92, 0.09, 0.20), 0, (0.00, 0.16, 0.00,
0.22),
[postactions.newlines_to_spaces,.post_remove_spaces_before_dots,.smart_replacement]),
('when', (0.18, 0.399, 0.20, 0.25), 0, (0, 0, 0, 0),
[postactions.post_remove_newlines,.post_remove_spaces]),
('birthdate', (0.57, 0.90, 0.71, 0.75), 0, (0, 0, 0, 0),
[postactions.post_remove_newlines,.post_remove_spaces,.commas_to_dots]),
('birthplace', (0.36, 0.90, 0.75, 0.86), 0, (0.00, 0.06,
0.00, 0.10), [postactions.newlines_to_spaces,._remove_spaces_before_dots]),
('gender', (0.38, 0.49, 0.71, 0.75), 0, (0, 0, 0, 0),
[postactions.post_remove_newlines,.post_remove_spaces,.remove_dots_and_commas]))process_image(filename,
dbg=0, agressive=0, rotate=1, adaptive_bboxes=False, expandboxfactor=0):
""" innter1 function
"""dbg:filename'agressive = ', agressive
# read and rotate the picture= cv2.imread(filename)rotate:=
autorotate.auto_rotate((img, filename if dbg != 0 else '')), cols, _ =
img.shaperows == 0 or cols == 0:''
# print findboxes.get_boxes(img, dbg)
# print findboxes.get_boxes()adaptive_bboxes:=
findboxes.get_boxes(img, dbg)= ''name, rects, rot, ignore, post in bboxes:
# print rects= name + ': 'r in rects:= do_box(img, r, rot,
ignore, post, expandboxfactor=expandboxfactor)name == 'series':= out[:4]name ==
'number':= out[-6:]+= out+= ' '+= fieldres + '\n'result:=
findboxes.get_boxes()agressive:
# for agressive recognition process boxes one by one;
# do_box() starts its own process for every coeff;
# python doesn't allow to start child processes from childs=
[]name, (l, r, t, b), rot, (l1, r1, t1, b1), post in bboxes:.append(do_box(img,
(int(l1 * r * cols), int(t1 * b * rows), int(r1 * r * cols),
int(b1 * b * rows)),=post,=agressive,=filename + "_" + name if dbg !=
0 else ''))out # [(result,weights),...]:
# for fast recognition start pool of workers and
# and recognize each box in its separate process
'''
# uncomment this and comment the code below for serial
processing= ''name, (l, r, t, b), rot, (l1, r1, t1, b1), post in boxes:+= name
+ ': ' + do_box(img.copy(),
(int(l * cols), int(t * rows), int(r * cols), int(b *
rows)),,
(int(l1 * r * cols), int(t1 * b * rows), int(r1 * r *
cols),(b1 * b * rows)),,
,+ "_" + name if dbg != 0 else '') + '\n'out
'''= Pool(4)= pool.map(do_box_wrapper, [(img.copy(),
(int(l * cols), int(t * rows), int(r * cols), int(b *
rows)),,
(int(l1 * r * cols), int(t1 * b * rows), int(r1 * r *
cols),(b1 * b * rows)),,
,+ "_" + name if dbg != 0 else '')name, (l, r, t,
b), rot, (l1, r1, t1, b1), post in bboxes])= [name for name, _, _, _, _ in
boxes]= [name + ": " + out[names.index(name)] for name in names]reduce(lambda
aa, bb: aa + '\n' + bb, result)
. Cleanbg.pyscipy.ndimage import measurementsnumpy as
npcv2_WIDTH = 10_HEIGHT = 10clean_bg_v1(img, hist_max_ix, deviation, coeff):
""" cleans image bg by washing
colors[hist_max_ix +/- coeff*deviation] """, cols, _ =
img.shape= [coeff * deviation[0], coeff * deviation[1], coeff *
deviation[2]]row in range(0, rows):col in range(0, cols):channel in [0, 1,
2]:img[row][col][channel] > hist_max_ix[channel] -
thres[channel]:[row][col][channel] = 255
# bitwise remaining colorsimg[row][col][0] != 255 or
img[row][col][1] != 255 or img[row][col][2] != 255:[row][col] = [0, 0,
0]clean_bg_v2(img, coeff):
"""
# the algorithm breaks colors on the box on three areas:
# - upper area, which is to be cleaned up, this must be bg
# - middle area, area of interest which colors constructs
characters
# - lowers area, area with colors below characters colors,
nothing must be here in the begging
# upper and lower areas are to be cleaned up and middle area
is to be stretched from 0 up to 225
# upper cutting threshold is fixed for the whole picture
# lower threeshold is floating from pixel to pixel
#
# the idea is that character pixels with overlights from
watermarks should be scaled down to
# more lower value than usual pixels
"""= cv2.cvtColor(img, cv2.COLOR_BGR2GRAY),
cols = img.shape
# statistics for overall box= np.average(img)= np.std(img)=
np.median(img)
# print 'average: ', avr
# print 'median: ', median
# print 'std: ', std
# statistics for character colors
# colors below 110 are considered related to the characters
# TODO: to try calculate 110 dynamically= []row in range(0,
rows):col in range(0, cols):img[row][col] < 110:.append(img[row][col])
# blacks_avr = np.average(blacks)_median =
np.median(blacks)_std = np.std(blacks)
# print 'black average: ', blacks_avr
# print 'black median: ', blacks_median
# print 'black std: ', blacks_std
# statistics for character colors
# colors higher 110 are considered related to the bg
# TODO: to try calculate 110 dynamically= []row in range(0,
rows):col in range(0, cols):img[row][col] > 110:.append(img[row][col])
# bg_avr = np.average(bg)
# bg_median = np.median(bg)
# bg_std = np.std(bg)
# print 'bg average: ', bg_avr
# print 'bg median: ', bg_median
# print 'bg std: ', bg_std
# comparing meadian values for the whole box and for the
characters only
# we can try to assume if the box contains watermarks.
# due to high watermaks colors, diff between above values are
less on
# the pictures with watermaks compared to the ones without
them.
# empirically detected values:
# - with watermaks: bg =~ 200, charaters =~ 100
# - without watermaks: bg =~ 220, charaters =~ 90
# TODO: to be verified on other samples
# watermark detection is needed to set propper upper
threshold.
# the recognition result is very sensitive for the upper
threshold.
# magic numbers 1.1 and 0.7 are also empirically settled and
may not work on othen pictures.
# TODO: is it possible to figure out some common algorith
which would set propper upper threshold?= median - blacks_mediandelta > (100
+ 130) / 2:_thresh = avr - 1.0 * coeff * std:_thresh = median - 0.7 * coeff *
std
# print 'delta: ', delta
# print 'coeff: ', coeff
# print 'up_thresh: ', up_thresh
# print img.shape= cv2.copyMakeBorder(img, BORDER_HEIGHT,
BORDER_HEIGHT, BORDER_WIDTH, BORDER_WIDTH, cv2.BORDER_REPLICATE), cols =
img.shape= np.zeros(img.shape, np.float32)_rows = 10_cols = 10
# the lower threshold is calculated dynamically for each
pixel
# as min value for some locality of that pixelrow in
range(box_rows / 2, rows - box_rows / 2):col in range(box_cols / 2, cols -
box_cols / 2):[row][col] = np.min(img[row - box_rows / 2:row + box_rows / 2,
col - box_cols / 2:col + box_cols / 2])
# scale up colors from 0...up_thresh to 0...255row in
range(box_rows / 2, rows - box_rows / 2):col in range(box_cols / 2, cols -
box_cols / 2):img[row][col] > up_thresh:[row][col] = 255:[row][col] =
img[row][col] * 255 / up_thresh
# scale down colors from mask[row][col]...255 to 0...255row
in range(box_rows / 2, rows - box_rows / 2):col in range(box_cols / 2, cols -
box_cols / 2):img[row][col] < mask[row][col]:[row][col] = 0mask[row][col] !=
255:[row][col] = 255 - (255 - img[row][col]) * 255 / (255 - mask[row][col])
# cut box borders= img[BORDER_HEIGHT:rows-BORDER_HEIGHT,
BORDER_WIDTH:cols-BORDER_WIDTH], cols = img.shape
# this magic stuff is needed to get rid of the noise happened
to appear in the box.
# proper setting of upper threshold could help to clean that
noise also, but
# but there is no common algorithm to calculate upper
threshold for each box personally.
# condition to do cleaning: no watermarks and characters are
fat enoughdelta > (100 + 130) / 2 and blacks_std > 6:
# print 'do noise clean'= np.ones((3, 3), np.float32) / 9=
cv2.filter2D(img, -1, kernel)row in range(0, rows):col in range(0,
cols):dst[row][col] > 255 * (9 - 3) / 9:[row][col] = 255= cv2.cvtColor(img,
cv2.COLOR_GRAY2RGB)imgget_char_dot_height(img):
""" calculates apprx charater heightdot height
on the image """= np.float32(img.copy())= cv2.cornerHarris(fimg,
20, 31, 0.04)= cv2.dilate(dst, None)= img.copy()[dst < 0.01*dst.max()] = 0,
hierarchy = cv2.findContours(fimg.copy(), cv2.RETR_TREE,
cv2.CHAIN_APPROX_SIMPLE)= sorted(contours, key=cv2.contourArea, reverse=True)=
0= 0c in cnts:= cv2.arcLength(c, True)peri > 100:, y, w, h =
cv2.boundingRect(c)+= h+= 1hcount != 0:_height = hsum/hcount/2:_height =
20_height = char_height/3 - 2
# print char_height
# print dot_heightchar_height, dot_heightclean_bg_v3(img,
coeff, clean_noise):
"""
# the algorithm breaks colors on the box on three areas:
# - upper area, which is to be cleaned up, this must be bg
# - middle area, area of interest which colors constructs
characters
# - lowers area, area with colors below characters colors,
nothing must be here in the begging
# upper and lower areas are to be cleaned up and middle area
is to be stretched from 0 up to 225
# upper cutting threshold is fixed for the whole picture
# lower threeshold is floating from pixel to pixel
#
# the idea is that character pixels with overlights from
watermarks should be scaled down to
# more lower value than usual pixels
#
# diff against v2:
# - adaptive upper threshold
# - noise cleaning
"""= cv2.cvtColor(img, cv2.COLOR_BGR2GRAY),
cols = img.shape
# calculate an apprx charater height and dot height on the
orig image
# used later in noise filteringclean_noise:_height,
dot_height = get_char_dot_height(img)
# calculate upper threshold by picking one row and analazing
its colors:
# - filter image saving characters border
# - pick the most black line
# - colors on the line should be easily clasterized into bg
color and char color
# - take upper threshold as charaters color minus one third
from distance between
# bg color and char colors (one third is an empirical coeff)
# apply bilateral filter, TODO: kernel size to be calculated
in runtime= np.std(img.flatten())= cv2.bilateralFilter(img, 51, sigmacolor, 21)
# pick the most black line_per_row = []rr in range(0, rows):
_sum_per_row = 0cc in range(0, cols):
_sum_per_row += (255 -
bltf[rr][cc])_per_row.append(_sum_per_row)= sum_per_row.index(max(sum_per_row))
# print 'row ix: ', rix
# extract the line
# almost sure numpy can do this as well= []cc in range(0,
cols):.append(bltf[rix][cc])
# clusterize color on that line= np.float32(rowx)=
(cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 100, 0.1), labels, centers
= cv2.kmeans(rowx, 2, criteria, 100, cv2.KMEANS_RANDOM_CENTERS)
# print ret, labels, centers
# determine if watermarks are present as it is done in v2
algo= np.median(img)= []row in range(0, rows):col in range(0,
cols):img[row][col] < 110:.append(img[row][col])_median = np.median(blacks)=
median - blacks_median= (delta > (100 + 130) / 2)whatermarks:_thresh =
max(centers) - (max(centers)-min(centers))/2.0*coeff:_thresh = max(centers) -
(max(centers)-min(centers))/4.0*coeffcoeff, up_thresh
# expand the box to be able to do 'convolution' properly=
cv2.copyMakeBorder(img, BORDER_HEIGHT, BORDER_HEIGHT, BORDER_WIDTH,
BORDER_WIDTH, cv2.BORDER_REPLICATE), cols = img.shape
# mask for the lower threshold= np.zeros(img.shape,
np.float32)_rows = 10_cols = 10
# the lower threshold is calculated dynamically for each
pixel
# as min value for some locality of that pixelrow in
range(box_rows / 2, rows - box_rows / 2):col in range(box_cols / 2, cols -
box_cols / 2):[row][col] = np.min(img[row - box_rows / 2:row + box_rows / 2,
col - box_cols / 2:col + box_cols / 2])
# scale up colors from 0...up_thresh to 0...255row in
range(box_rows / 2, rows - box_rows / 2):col in range(box_cols / 2, cols -
box_cols / 2):img[row][col] > up_thresh:[row][col] = 255:[row][col] =
img[row][col] * 255 / up_thresh
# scale down colors from mask[row][col]...255 to 0...255row
in range(box_rows / 2, rows - box_rows / 2):col in range(box_cols / 2, cols -
box_cols / 2):img[row][col] < mask[row][col]:[row][col] = 0mask[row][col] !=
255:[row][col] = 255 - (255 - img[row][col]) * 255 / (255 -
mask[row][col])clean_noise:
# fill the borders with the white, need later
on.rectangle(img, (0, 0), (cols, BORDER_HEIGHT/2), (255, 255, 255),
-1).rectangle(img, (0, rows-BORDER_HEIGHT/2), (cols, rows), (255, 255, 255),
-1).rectangle(img, (0, 0), (BORDER_WIDTH/2, rows), (255, 255, 255),
-1).rectangle(img, (cols-BORDER_WIDTH/2, 0), (cols, rows), (255, 255, 255), -1)
# binarize into tmp image= img.copy()row in range(0,
rows):col in range(0, cols):tmp[row][col] < 255:[row][col] = 0
# find contours on binarized image
# one of returned contours is the box itself, how to get rid
of it?, hierarchy = cv2.findContours(tmp.copy(), cv2.RETR_TREE,
cv2.CHAIN_APPROX_SIMPLE)= float(rows)/cols if rows < cols else
float(cols)/rowscnt in contours[1:]:, y, w, h = cv2.boundingRect(cnt)
# loop over the contours and filter them by the condition
below= float(w)/h if w < h else float(h)/ww < dot_height or h <
dot_height or ((w > 1.5*char_height or h > 1.5*char_height) and cratio
< 0.1) or \
((w < char_height or h < char_height) and cratio <
bratio):
# -1 in the last param fills the contour with given
color.drawContours(img, [cnt], -1, (255, 255, 255), -1)
# else:
# print cratio
# cv2.rectangle(img, (x, y), (x+w, y+h), (0, 255, 0), 1)
# cut box borders= img[BORDER_HEIGHT:rows-BORDER_HEIGHT,
BORDER_WIDTH:cols-BORDER_WIDTH]= cv2.cvtColor(img, cv2.COLOR_GRAY2RGB)img
# noinspection PyPep8Naminglocally_adaptive_binarization(img,
window_size):
"""
__author__ = 'Vladan Krstic'the image according to the
algorithm briefly explained
in://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.19.4933&rep=rep1&type=pdfalgorithm
is better than OpenCV's locally adaptive thresholding because it adopts a
global minimum for. This will leave white areas in the image to be white (it
will not calculate a threshold based on local'at all cost' - half on one side
and half of other side).
:param img: Image array to be binarized. Expecting 8bit gray
image (vals = 0..255, ndims = 2)
:param window_size: Size of the window used to calculate
locally adaptive binarization threshold. Must be odd!
:return: binarized image as np.uint8
"""window_size % 2 == 0 or window_size <=
0:ValueError("window_size must be odd and positive")= (window_size -
1) / 2_expanded = cv2.copyMakeBorder(img, k, k, k, k, cv2.BORDER_REPLICATE),
cols = img_expanded.shape= 0= np.min(img)= np.zeros(img.shape)=
np.zeros(img.shape)= 0.2i in range(k, rows - k):j in range(k, cols - k):=
img_expanded[i - k:i + k + 1, j - k:j + k + 1][i - k, j - k] = np.std(w)[i - k,
j - k] = np.mean(w)s[i - k, j - k] > R:= s[i - k, j - k] # global maximum of
stdevR == 0:ValueError("maximum stdev is zero - this shouldn't happen")
# binarization threshold:= m - c * (1 - s / R) * (m - M) #
per-element matrix operations (avoids having another pair of nested for loops)=
np.zeros(img.shape, dtype=np.uint8)[img > T] =
255resultestimate_text_height(img, print_msg=False):
"""
__author__ = 'Vladan Krstic'text height by looking at the
pixel variance profile. The idea is to go row by row and observe pixel. The
rows with higher variance are assumed to be areas with text information. If
multiple lines of text are, median of their height is taken and returned as
result. Areas smaller than 9px are ignored.image should contain area bigger
than the text who's height is to be determined (text shouldn't touch upper
oredge of the image).
:param img: Grayscale image of the text (dtype=uint8)
:param print_msg: Bool switch - Controls whether debug
messages are printed to console.
:return: Estimated text height in pixels
"""_var = np.var(img, 1)=
np.mean(h_var)h_var[0] >= mh and print_msg:"Warning: text probably
touching the edge of the image."= []= 0i in range(1, h_var.size):h_var[i -
1] < mh <= h_var[i]:= i # top of the texth_var[i - 1] >= mh >
h_var[i]:i-a < 9:
# expect text to be at least 9px high
# todo: this is not universal solution, consider algorithms
for outlier detection on heights list.append(i - a) # bottom of the textnot
heights:print_msg:"Warning: unable to determine text height"
# raise ValueError("Unable to determine text
height.")a == 0: # appears like text height is equal to image
height._height = img.shape[0]: # or text is touching the lower edge of the
image, take helf the image height as text height_height = img.shape[0] /
2:_height = int(np.median(heights)) # text line heightprint_msg:"Estimated
text height:", t_heightt_height
# noinspection
PyPep8Naming,PyUnresolvedReferencesremove_lines(img, textHeight):
"""
__author__ = 'Vladan Krstic'thin horizontal lines from binary
image.
. Take binary image, do the dilatation with a row-vector
kernel to ensure that adjacent letters will be recognizedone blob.
. Take the convolution of the dilated image with a square
kernel size = text height
. Threshold the convolution result to get binary blobs. Find
bounding boxes for those blobs. -> words bboxes
. Remove the bboxes from the image and analyze the rezulting
image to find the lines
. Remove the lines found from the original binary image.image
should contain area wide enough to still have background lines after the text
area is removed.minimum width is two times text height on each (lef/right) side
of the text.
:param img: binarized image, dtype=uint8
:param textHeight: height of text - used as basis for other
parameters
:return: image with lines removed
"""
# image form suitable for operations= 1 - img / 255.
# dilate with a row kernel= np.ones((1, textHeight / 2),
np.float32)_tmp = cv2.dilate(imgbw, kernel)
# convolve with a box xernel= textHeight= np.ones((k, k),
np.float32) / (k * k)= cv2.filter2D(blobs_tmp, -1, kernel)= 0.25 # todo:
experiment with this thresh (must be between 0 and 1)_tmp = boxconv > t
# find bounding boxes, hierarchy =
cv2.findContours(np.uint8(blobs_tmp), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)= []cnt in contours:, y, w, h =
cv2.boundingRect(cnt).append([x, y, w, h])
# get the image without text_notext = imgbw.copy()rect in
rects:, y, w, h = recti in range(y, y + h):j in range(x, x + w):_notext[i, j] =
0
# find lines_lines = np.dstack((np.uint8(255 * img_notext),
np.uint8(255 * img_notext), np.uint8(255 * img_notext)))_notext_8bit =
np.uint8(img_notext * 255)= img.shape[1] / 2= textHeight / 2
# maxgap = int(img.shape[1] * 0.95)
# threshold = int(textHeight * 0.1)=
cv2.HoughLinesP(img_notext_8bit, 1, np.pi / 2, threshold,
maxLineGap=maxgap)_pos = set() # i want unique valueslines is not None:x1, y1,
x2, y2 in lines[0]:.line(img_lines, (x1, y1), (x2, y2), (0, 255, 0), 1)y1 ==
y2:_pos.add(y1)
# for each line found, do the filtering on the image with
text
# during filtering, make variations of the column mask to
accomodate varying thickness of the line_thickness = (textHeight + 5) /
10_padded = np.pad(imgbw, ((max_thickness, max_thickness), (0, 0)),
mode='constant')= np.zeros(imgbw_padded.shape)line_pos:y in line_pos:+=
max_thickness # compensate for paddingt in range(1, max_thickness+1):_mask =
np.ones(t+2)_mask[0] = 0_mask[-1] = 0v in range(0, t):
# variations are formed by moving the column mask up/down by
a number of pixels up
# to the thickness of the line.= imgbw_padded[y-t+v:y+v+2,
:]_rows = deletemask[y-t+v:y+v+2, :] # creates a view of the rows of deletmaskj
in range(0, rows.shape[1]):all(rows[:, j] == col_mask):_rows[:, j] += col_mask=
deletemask[max_thickness:-max_thickness] # remove padding from the mask
# remove line pixels from the original image_cleaned =
img.copy()_cleaned[deletemask > 0] = 255img_cleaned
# noinspection PyUnusedLocalclean_bg_v4(img, a, b):
"""
__author__ = 'Vladan Krstic'steps:
. Text height is estimated.
. Image is locally adaptively binarized with regards to text
height.
. Background lines are removed.algorithm assumes that:
. The text doesn't touch img edges.
. Background lines are horizontal and extend beyond the width
of the text bounding boxes.should have at least 5px area above and below the
text. Image should contain enough of the passport formleft and/or right of the
text so it can be detected when the text is removed.of thumb: image should
contain area bigger than text bounding box by at least two heights of the text
(morebetter, but not too much so it doesn't pick up too much background noise).
"""= cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# blur background while keeping edges (bilateral filter)=
np.std(grayimg.flatten()) / 2= cv2.bilateralFilter(grayimg, 5, sigmacolor, 5) #
todo: calculate kernel size automatically
# determine text height_height =
estimate_text_height(grayimg, True)
# locally adaptive thresholding_size = t_height / 2 # set
window size relative to line height.window_size % 2 == 0: # must be odd_size +=
1_result = locally_adaptive_binarization(grayimg, window_size)_cleaned =
remove_lines(bin_result, t_height)
# remove all blobs smaller than some value...= t_height / 2=
img_cleaned_blobs, num_blobs = measurements.label(blobsies == 0, np.ones((3,
3)))i in range(1, num_blobs + 1):np.sum((labeled_blobs == i) *
np.ones(labeled_blobs.shape)) < minpixels:[labeled_blobs == i] = 255
# labeled_blobs[labeled_blobs == i] = 0=
cv2.cvtColor(blobsies, cv2.COLOR_GRAY2RGB)result
# noinspection PyUnusedLocalclean_bg(arg):clean_bg_v3(*arg)