Построение математической модели для использования в различных ситуациях в рамках анализа данных о госзакупках
1. Актуальность открытых данных
В последнее время все чаще и чаще рассматриваются вопросы, связанные с
использованием открытых данных. В ходе данной работы обрабатывается информация,
основанная на открытых данных о расходах государственных организаций в России
за период с января по октябрь 2015.
Рассмотрим более подробно концепцию открытых данных. Она основана на
представлении о том, что данные должны находиться в свободном и открытом
доступе без ограничений на их использование и распространение.
Открытые данные - информация о деятельности государственных органов и
органов местного самоуправления, размещенная в сети Интернет в формате,
обеспечивающем ее автоматическую обработку в целях повторного использования без
предварительного изменения человеком (информация должна иметь единый
машиночитаемый формат). Эта информация может свободно использоваться в любых
соответствующих закону целях любыми лицами независимо от формы ее размещения
[12].
По словам И. Бегтина «Самая главная возможность,
которую дает такая информация - это возможность понять, как устроено наше
государство. Это вещи, которые далеко не очевидны. Это не только то, что
касается непосредственно денег. Это очень многие вопросы, которые касаются
качества нашей жизни. Это позволяет нам быть более информированными. Что-то
можно выявить просто вручную: вбить в поисковую строку сайта, найти информацию
по ключевому слову и посмотреть.
Когда мы смотрим на это более системно, и эти же
данные у нас доступны в виде цельной базы, то мы можем не просто посмотреть
информацию по конкретному случаю. Мы можем взять какую-нибудь определенную
тему, взять любой город или муниципальный район и узнать всю карту госрасходов
по всем учреждениям. Потом это можно наложить на карту, узнать, как устроены
госрасходы вокруг вас, а также вы можете физически сходить туда и посмотреть,
что там на самом деле делается» [10].
В ходе работы рассматривается набор данных [14],
который содержат информацию о расходах бюджетных организаций в России за 2015
год (с января по октябрь) в рамках государственных закупок, проводимых в
соответствии с федеральным законом ФЗ № 44[1]. Кстати, стоит отметить, что
российские данные в секторе госзакупок имеют значительно более высокий уровень
открытости, чем в большинстве западных стран. Однако в целом Россия занимает
пока лишь 119 место (2015 г.) в рейтинге ИВК (индекс восприятия коррупции),
опубликованным международной антикоррупционной организацией Transperancy International. Все же положительная динамика по
раскрытию информации присутствует, поскольку страна сделала большие шаги в
области раскрытия данных благодаря пропаганде открытых данных, хоть и
лимитированной, но существующей государственной политике, а в основном за счет
естественного хода автоматизации власти в условиях рыночной экономики [11]. К раскрытию
и публикации данных в свободном доступе обязывает, в частности, ФЗ № 44. Далее
опишем сферу распространения данного закона.
Федеральный закон № 44 - это ФЗ от 05.04.2013 “О
контрактной системе в сфере закупок, товаров, услуг для обеспечения государственных
и муниципальных нужд”. Данный закон регулирует отношения, направленные на
обеспечение государственных и муниципальных нужд в целях повышения
эффективности, результативности осуществления закупок товаров, работ услуг,
обеспечения гласности и прозрачности осуществления этих закупок, предотвращения
коррупции и других злоупотреблений в сфере данных закупок. Закон имеет широкую
сферу применения, включая [1, гл. 1, ст.1]:
1) планирование закупок товаров, работ, услуг;
) определение поставщиков (подрядчиков, исполнителей);
) заключение гражданско-правового договора, предметом которого являются
поставка товара, выполнение работы, оказание услуги (в том числе приобретение
недвижимого имущества или аренда имущества), от имени Российской Федерации,
субъекта Российской Федерации или муниципального образования, а также
бюджетного учреждения согласно частям 1, 4 и 5 статьи 15 настоящего
Федерального закона;
) особенности исполнения контрактов;
) мониторинг закупок товаров, работ, услуг;
) аудит в сфере закупок товаров, работ, услуг;
) контроль за соблюдением законодательства Российской Федерации и иных
нормативных правовых актов о контрактной системе в сфере закупок товаров,
работ, услуг для обеспечения государственных и муниципальных нужд.
Документ имеет достаточно сложную историю принятия, он был принят
Госдумой в третьем чтении 22.03.2013. За двухлетнюю редакцию в закон было
внесено более 800 поправок. В конечном счете, на смену ФЗ № 94 пришла новая
контрактная система, более понятная и открытая, обеспечивающая широкие
возможности для общественного контроля.
Сформулируем основные цели работы:
) Выявление выбросов с математической точки зрения, то есть
нетипичных групп-регионов с отклонением от стандартного поведения.
) Типизация (классификация) регионов по типу использования
государственных средств, то есть выделение нескольких основных групп регионов с
выявлением их общих характеристик, как, например, территориального и
экономического устройства.
Этих целей можно добиться путем удаления выбросов, кластеризации полученной
прямоугольной матрицы и анализа результатов. Более подробно о исходном наборе
данных и методе получения из этого набора прямоугольной матрицы, содержащей
информацию по сумме контрактов, заключенных в каждом регионе, будет рассказано
во 2 разделе работы.
1.1 Выявление выбросов
Практически любые данные содержат в себе выбросы, так называемые
нетипичные данные, которые по своему поведению выделяются из выборки. Выбросы
характеризуются малым числом и должны быть выявлены и удалены из выборки для дальнейшего
корректного разбиения на кластеры.
Существует три основные причины возникновения выбросов [6].
Самая распространённая из них - ошибка измерений / некорректная запись
результата. Следующим фактором может являться не типичность рассматриваемого объекта
по сравнению с остальными, представленными в выборке. Также выбросы могут быть
часть распределения.
Оценки, на которые влияние выбросов не значительно, в статистике называют
робастными. Самым простым примером робастной оценки является медиана выборки, в
то время как стандартные характеристики мат. ожидания и стандартного отклонения
не являются робастными.
Основные типы выбросов:
) Точечные выбросы
Самый легко определимый тип выброса. Точка считается выбросам, если она
«аномально» располагается по сравнению с остальными точками выборки.
Например, если вся выборка разбивается на 3 кластера, один из которых
содержит только одну точку, то эта точка, скорее всего, и является выбросом.
) Контекстные выбросы
Такой тип выбросов появляется, когда отдельный предмет в выборке сильно
отличается от остальных по своим свойствам. В таком случае на этапе описание
данных необходимо указать о наличие контекстных выбросов и описать 1)
местоположение подобных экземпляров или их окрестность и 2) свойства поведения
объекта.
Контекстные выбросы определяются по свойствам поведения описанных
объектов. Следует отметить, что такие объекты обычно не являются выбросами в
другом контексте или наборе данных.
) Массовые выбросы
В этом случае набор, состоящий из нескольких точек, проявляет нетипичное
поведение в совокупности. Естественно, что такой тип выбросов появляется в
наборах данных, где имеется некая связь между точками их этого набора.
Наличие выбросов также связано с распределением данных. Если данные
распределены по нормальному закону распределения, то по «правилу трех сигм»
каждое 375-ое значение будет отличаться от стандартного отклонения в 3 раза (а
каждое 22-ое - в 2 раза).
Существует множество причин для возникновения выбросов: человеческий
фактор; механический кратковременный сбой, приведший к возникновению
аномального значения; ошибка, возникшая в кодировании при передаче информации
или транскрипции данных и т.д.
Вопрос обнаружения выбросов далеко не тривиален, потому что до сих пор не
сформулировано математического определения объекта, который должен считаться
выбросом.
Одной из робастных мер для определения выбросов является статистика
Тьюки. Таким образом, выбросами считаются наблюдения (элементы выборки), не
входящие в интервал
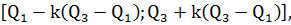
где 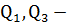 нижняя (25-ая) и верхняя (75-ая) квантили.
нижняя (25-ая) и верхняя (75-ая) квантили.
Значение k=1.5 указывает на
выброс, а k=3 на «хвосты» выборки.
Существующие алгоритмы, определяющие выбросы, основаны на предположении,
что данные имеют нормальное распределение, а маловероятные данные определяются
на основе подсчета таких статистических характеристик как математическое
ожидание и стандартное отклонение.
Способ обработки выбросов зависит от того, каких целей хочет достичь
исследователь.
) Сохранение
В данных с нормальным распределением и большим объемом выборки
возникновение выбросов ожидаемо. Поэтому при классификации данных важно
использовать алгоритмы, устойчивые к выбросам.
) Исключение
Самый интересный и сложный вопрос. Существует множество споров о том, стоит
ли исключать выбросы и если да, то как правильно это делать. Например, в [9]
рассматривается нахождения выбросов для многомерных числовых данных в
Евклидовом пространстве. В работе описаны способы определения выбросов в
многомерном пространтсве, где в качестве оценки эффективности исключения
выбросов предлагается использовать ROC-кривую, а точнее площадь под графиком этой кривой.
) Негауссовские распределения
В реальных данных нормальное распределение встречается не так часто, а
поэтому появление «тяжелых хвостов» выборки весьма типично (например, у
распределения Коши). И число выбросов растет с гораздо большей скоростью, чем в
нормальном распределении.
.2 Методы кластеризации
Задача классификации объектов на основе их сходства друг с другом, когда
не задана принадлежность обучающих объектов каким-либо конкретным классам,
называется задачей кластеризации. Наиболее распространённый метод кластеризации
- объединение объектов с меньшим между собой расстоянием, вычисленным по
определенной метрике, в один класс.
Задача кластеризации (или обучения без учителя) заключается в следующем.
Имеется выборка 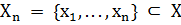 и функция расстояния между объектами
и функция расстояния между объектами 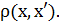 Требуется разбить выборку на
непересекающиеся подмножества, называемые кластерами, так, чтобы каждый кластер
состоял из объектов, близких по метрике
Требуется разбить выборку на
непересекающиеся подмножества, называемые кластерами, так, чтобы каждый кластер
состоял из объектов, близких по метрике 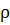 , а объекты разных кластеров
существенно отличались. При этом каждому объекту
, а объекты разных кластеров
существенно отличались. При этом каждому объекту 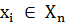 приписывается номер кластера
приписывается номер кластера 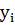 . Также нетривиальным является вопрос
определения оптимального числа кластеров.
. Также нетривиальным является вопрос
определения оптимального числа кластеров.
Цели кластеризации:
· Понять структуру множества объектов 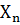 , разбив это множество на группы
схожих объектов
, разбив это множество на группы
схожих объектов
· Выделить нетипичные объекты, которые не схожи ни с одним из
выделенных кластеров
Алгоритмы кластеризации можно условно разбить на две классификации
· Иерархические и плоские
Иерархические алгоритмы (таксономичекие) представляют собой систему
вложенных разбиений на непересекающиеся кластеры и выводятся в виде дерева
кластеров, корнем которого является вся выборка, а листьями - наиболее мелкие
кластеры.
В свою очередь плоские алгоритмы строят только одно разбиение объектов на
кластеры.
· Четкие и нечеткие
Четкие (непересекающиеся) алгоритмы [3] каждому объекту выборки
сопоставляют номер кластера, т.е. получается сюръективное отображение. Нечеткие
(соответственно, пересекающиеся) алгоритмы каждому объекту ставят в
соответствие некий набор вещественных значений, отражающих вероятность объекта
быть отнесенным к определенному кластеру.
Прежде чем перейти к основным алгоритмам кластеризации стоит описать
требования к входным данным:
) Признаковые характеристики объектов
В данном случае каждый объект описывается присущими ему характеристиками,
которые могут быть как количественными, так и качественными.
) Матрица расстояний
Квадратная матрица, которая отражает расстояние между объектами
метрического пространства.
) Матрица сходства
Также квадратная матрица, которая отличается от предыдущей тем, что
учитывает степень сходства между объектами.
Перечислим самые популярные методы кластеризации. Отметим, что существует
около 00 различных алгоритмов, из чего можно сделать, что выбор метода кластеризации
не универсален и для каждой задачи выбирается экспериментально.
) Иерархическая кластеризация
) Кластеризация с выбором центроидов
В данном виде кластеризации каждый кластер имеет свой центр (причем этот
центр-вектор не обязательно должен являться каким-либо объектом выборки). При
фиксированном числе кластеров k
можно формально сформулировать задачу: найти k центров кластеров и присвоить
объекты этим кластером так, чтобы квадрат расстояния от центра до объекта было
минимальным:
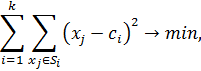
где 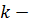 число кластеров,
число кластеров, 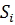 - полученные кластеры,
- полученные кластеры,  центроиды кластеров.
центроиды кластеров.
Самой известной реализацией является алгоритм k-means,
разработанный в середине 20 века одновременно Гуго Штейнхайзом и Стюардом
Ллойдом. Основным недостатком является необходимость заранее указать число
кластеров, также результат кластеризации очень сильно зависит от начального
выбора центроидов, поэтому усовершенствованные алгоритмы повторяют алгоритм
несколько раз, затем выбирая наилучшую реализации.
) Кластеризация на основе распределения
Модель кластеризации наиболее тесно связана с выборками с известной
статистикой. Кластеры могут быть определены как объекты, принадлежащие к
заданной функции распределения. Данный тип алгоритмов имеет хорошее
теоретическое обоснование, однако ключевой проблемой является постоянное
переобучение модели и в связи с этим увеличивается сложность алгоритма. Более
сложная модель, как правило, будет в состоянии объяснить данные лучше. В связи
с этим важно задать алгоритмическую сложность модели в соответствии с ее
реальной сложностью, что весьма не просто.
Алгоритмы данного типа задают сложные модели для кластеров, которые могут
учесть даже корреляцию между объектами. Тем не менее, эти алгоритмы не всегда
применимы на практике: для многих наборов реальных данных невозможно четко
сформулировать математическую модель (например, предположение о нормальном
распределении чаще всего является довольно грубым).
) Кластеризация на основе плотности
В алгоритмах данного типа кластеры определяются как области с наиболее
высокой плотностью по сравнению с остальной частью набора данных. Самым
популярным представителем данного класса является алгоритм DBSCAN [7]. Большинство алгоритмов,
основанных на плоском разбиении, создают кластеры приблизительно сферической
формы, поскольку минимизируют расстояние от объектов до центров кластеров.
Экспериментальным путем показано, что алгоритм DBSCAN распознает кластеры
различной формы. Идея алгоритма формулируется следующим образом: каждый кластер
имеют некую плотность, причем плотность объектов внутри кластера выше, чем
плотность объектов снаружи, а плотность в областях с шумовыми данными ниже, чем
плотности любого кластера. Более того для каждой точки кластера её соседство
заданного радиуса 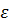 должно содержать не менее некоторого порогового числа точек.
Для работы данному алгоритму не требуется указывать число кластеров, однако
нужно указать -окрестность и пороговое значение для числа точек, входящих в
указанную окрестность.
должно содержать не менее некоторого порогового числа точек.
Для работы данному алгоритму не требуется указывать число кластеров, однако
нужно указать -окрестность и пороговое значение для числа точек, входящих в
указанную окрестность.
В этой главе была обоснована актуальность использования набора данных,
приведен обзор литературы, освещающий понятие выбросов в выборке, и описаны различные
алгоритмы кластеризации. В ходе работы во 2 разделе будут подробно описаны
исходные данные и их обработка с целью получения итогового набора, над которым
будет произведен дальнейший анализ. Раздел 3 посвящен описанию математической
модели, которая содержит 3 различных вида матриц. В 4 разделе отражены
полученные результаты для задач нахождения выбросов и разбиения данных на
кластеры. Приложение 1 содержит подробное описание полей.csv файлов набора данных.
2. Описание данных
.1 Содержание исходного набора данных
Обратимся к детальному описанию набора данных. Он состоит из большого
перечня файлов. Любой файл содержит информацию о контрактах, заключенных по
каждому из 9-значных кодов продукции ОКПД.
Все контракты, как уже было сказано ранее, проведены в соответствии с 44
ФЗ.
ОКПД - это общероссийский классификатор продукции по видам экономической
деятельности. Введен в действие с 01.01.2008г. В ОКПД использованы
иерархический метод классификации и последовательный метод кодирования. Код
состоит из 2 - 9 цифровых знаков, и его структура может быть представлена в
следующем виде:

В рассматриваемом наборе данных все контракты объединены по
подкатегориям.
Таблица 2.1. Пример иерархии кода на примере 22 класса
|
Класс
|
22
|
Продукция печатная и носители информации записанные
|
|
Подкласс
|
22.1
|
Книги, газеты и прочие материалы печатные и носители
информации записанные
|
|
Группа
|
22.14
|
Звукозаписи
|
|
Подгруппа
|
22.14.1
|
Грампластинки, ленты, компакт-диски (CD), видео-диски
цифровые (DVD) и прочие носители для записи звука
|
|
Вид
|
22.14.12
|
Ленты магнитные только со звукозаписью
|
|
Категория
|
22.14.12.110
|
Ленты магнитные записанные шириной не более 4 мм
|
|
Подкатегория
|
22.14.12.111
|
Ленты магнитные записанные шириной не более 4 мм в кассетах
|
Ссылка
на данные: <#"896825.files/image015.jpg">
Рис
2.1. Гистограмма размера файлов, содержащихся в наборе данных
Все
файлы имеют расширение.csv. В каждом файле первая строчка состоит из имен
полей, подробное описание которых приведено в Приложении 1.
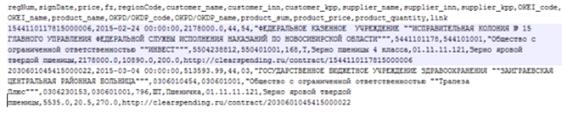
Рис.
2.2. Пример содержания файла (первые 3 строки)
2.2 Обработка и очистка
Из каждого файла выделена релевантная информация - код региона, сумма
контракта, ИНН заказчика, ИНН поставщика.
Информация сгруппирована в 62 группы в соответствии с классами ОКПД,
встречающимися в наборе данных (первые 2 цифры кода ОКПД, являющегося именем
файла). Заметим, что классы с номерами от 1 до 50 описывают товары, а с 50 до
99 - услуги.
В ходе подготовки данных к дальнейшему анализу были выполнены следующие
действия:
) Удаление незначимых файлов, размер которых - 228 КБ (они
содержат только строку с описанием полей). После удаления осталось 21016
файлов.
) При считывании не были учтены лишние разрывы в строках. Порой
строки содержали лишние переходы на новую строку, которые мешали корректно
обрабатывать данные входной строки.

Рис. 2.3. Пример строки c
разрывом
) Данные считаны с условием уникальности реестрового номера
контракта. То есть не принимались во внимание так называемые строки-дубликаты.

Рис. 2.4. Пример строк-дубликатов
4) Некоторые сделки проводились по устаревшим кодам регионов.
Такие коды заменены на те, которые актуальны сейчас.
Таблица 2.2. Соответствие старых кодов субъектов РФ действующим
|
Старый код
|
Действующий код субъекта
|
Наименование субъекта РФ
|
|
80
|
75
|
Забайкальский край
|
|
81
|
59
|
Пермский край
|
|
82
|
91
|
|
85
|
38
|
Иркутская область
|
|
88
|
24
|
Красноярский край
|
|
93
|
23
|
Краснодарский край
|
|
97, 99
|
77
|
Москва
|
.3 Итоговый набор данных
После обработки данных получены:
Матрица 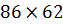 - суммарная стоимость договоров (контрактов), заключенных в
каждом из 86 регионов для каждого представленного класса классификатора (из
перечня в 100 различных категорий контракты заключены по 62 категориям
товаров/услуг).
- суммарная стоимость договоров (контрактов), заключенных в
каждом из 86 регионов для каждого представленного класса классификатора (из
перечня в 100 различных категорий контракты заключены по 62 категориям
товаров/услуг).
Число различных поставщиков и покупателей товаров/услуг в каждом регионе.
Данный раздел был посвящен описанию исходного набора данных, обработке и
очистке этих данных и выделению существенной информации, которая позволит
провести дальнейший анализ разбиения регионов на группы.
3. Математическая модель
На основе обработанных данных может быть построено несколько моделей.
.1 Прямоугольная вещественнозначная матрица
После обработки данных получена прямоугольная вещественная матрица 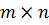 . Данная матрица отражает информацию
о суммарной стоимости контрактов, заключенных в m регионах (напомним, что m=86) для n
классов классификатора ОКПД (все контракты проведены по 62 различным кодам
классификатора). Итак, полученная матрица состоит из m n-мерных векторов.
. Данная матрица отражает информацию
о суммарной стоимости контрактов, заключенных в m регионах (напомним, что m=86) для n
классов классификатора ОКПД (все контракты проведены по 62 различным кодам
классификатора). Итак, полученная матрица состоит из m n-мерных векторов.
Элементы матрицы имеют сильный разброс в диапазоне от 0 до 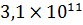 рублей. Такой большой диапазон может
создать проблемы для дальнейшего анализа данных. Тем более что некоторые
классификаторы являются «популярными» и по ним проводятся частые и большие
объемы закупок, как, например, по классификатору с кодом 45. В то же время код
классификатора 12 (Руды урановые и ториевые) содержит очень редкие закупки на
небольшие суммы. В связи с вышеописанным важно каким-то образом уравнять вклад
этих величин и произвести нормировку данных. Нормировка данных - это процесс
изменения исходных данных и приведения их к безразмерному виду. Данный процесс
приводит к повышению качества данных.
рублей. Такой большой диапазон может
создать проблемы для дальнейшего анализа данных. Тем более что некоторые
классификаторы являются «популярными» и по ним проводятся частые и большие
объемы закупок, как, например, по классификатору с кодом 45. В то же время код
классификатора 12 (Руды урановые и ториевые) содержит очень редкие закупки на
небольшие суммы. В связи с вышеописанным важно каким-то образом уравнять вклад
этих величин и произвести нормировку данных. Нормировка данных - это процесс
изменения исходных данных и приведения их к безразмерному виду. Данный процесс
приводит к повышению качества данных.
В качестве нормировки этой матрицы может быть выбран один из следующих
способов: нормировка в долях от общей суммы контрактов по каждому региону,
нормировка в долях от общей суммы по каждому коду классификатора, население
региона.
) Нормировка по регионам
Для любого региона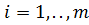 нахождение доли участия каждого классификатора в
формировании суммы стоимости контрактов в регионе i.
нахождение доли участия каждого классификатора в
формировании суммы стоимости контрактов в регионе i.
) Нормировка по кодам классификатора
Для любого кода классификатора 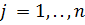 нахождение доли участия каждого
региона в формировании суммы стоимости контрактов по кодам классификатора j.
нахождение доли участия каждого
региона в формировании суммы стоимости контрактов по кодам классификатора j.
) Нормировка по численности регионов
Необходимо разделить каждый элемент матрицы на численность
соответствующего региона.
Также можно рассмотреть стандартные способы нормирования данных [13]:
) Мини-максная линейная
нормализация
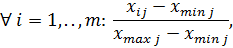
где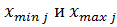 - минимальное и максимальное
значения затрат для каждого региона i в векторе
- минимальное и максимальное
значения затрат для каждого региона i в векторе 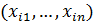 .
.
Эта нормализация приводит все данные к значениям в диапазоне 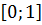 .
.
) Приведение к распределению вида N[0,1] (стандартизация данных)
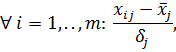
где 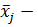 матем. ожидание,
матем. ожидание,
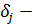 среднеквадратическое отклонение вектора .
среднеквадратическое отклонение вектора .
) Нелинейная нормализация
Этот метод основан на нелинейной связи между исходными и нормализуемыми
данными. Необходимо выбрать некий массив данных, назвать его нормализированным
и по нему построить функцию нормализации. Все остальные данные нормализовать в
соответствии с этой функцией [5].
.2 Квадратная матрица расстояний
От прямоугольной вещественной матрицы можно перейти к матрице расстояний
между регионами. Это будет квадратная матрица размера 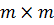 . Расстояние можно вычислить по одной
из нижеперечисленных метрик.
. Расстояние можно вычислить по одной
из нижеперечисленных метрик.
Рассмотрим самые распространённые метрики:
) Евклидово расстояние
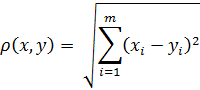
Самая распространённая метрика - представляет собой геометрическое
расстояние в многомерном пространстве.
) Метрика Минковского
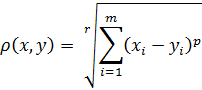
Так называемое степенное расстояние. В данном случае r отвечает за взвешивание больших
разностей расстояний, а р - за взвешивание разностей по координатам. Отметим,
что при r,p=2 совпадает с расстоянием Евклида.
) Манхэттэнская метрика
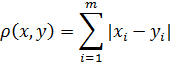
Также называется метрикой городских кварталов. Считается как средняя
разность по координатам. Обычно приводит к результатом, схожим с Евклидовым
расстоянием, но имеет преимущество для выборок с большими значениями выбросов.
) Косинусное сходство
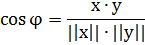
Эта мера эффективна для разреженных векторов, поскольку при подсчете
учитываются только ненулевые значения. Данный метод может быть применен, если
исходную вещественную матрицу преобразовать (отсечь данные по некоторому
порогу) и сделать более разреженной.
) Расстояние Хэмминга
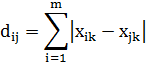
Является частным случаем метрики Минковского и применяется для бинарных
векторов. Для того чтобы применить это расстояние при подсчете матрицы
расстояний в данной задачи необходимо изначальную вещественнозначную матрицу
привести к бинарной (с помощью введения некоторого порога).
3.3 Граф близости
Граф близости размера 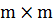 выводится из матрицы расстояний по некоторому порогу или по
степени вершин. Так как матрица расстояний не разрежена, то можно рассмотреть
некие пороги, например, топ-5 элементов в каждой строчке (для каждого кода
классификатора) или топ-5 по столбцам (для каждого региона). Таким образом
можно получить разреженную матрицу, которая позволит нагляднее визуализировать
результаты.
выводится из матрицы расстояний по некоторому порогу или по
степени вершин. Так как матрица расстояний не разрежена, то можно рассмотреть
некие пороги, например, топ-5 элементов в каждой строчке (для каждого кода
классификатора) или топ-5 по столбцам (для каждого региона). Таким образом
можно получить разреженную матрицу, которая позволит нагляднее визуализировать
результаты.
Вышеописанные модели универсальны в рамках рассматриваемой задачи.
Во-первых, они могут быть применены к данным не только за 2015, но и за
любой период.
Во-вторых, используя разные срезы и различные пороги можно перейти к
аналогичным матрицам, а значит, применить данную модель многократно в
зависимости от различных ситуаций.
В данном разделе описаны три математические модели. Из вещественнозначной
прямоугольной матрицы можно получить квадратную матрицу расстояний. В качестве
меры расстояния могут быть использованы метрики, описанные выше. Из матрицы
расстояний можно получить разреженный граф близости путем введения определенных
порогов и(или) ограничений.
4. Вычислительные эксперименты
.1. Выбросы
Итак, определим нетипичные регионы, отличающиеся своим «поведением» от
остальных.
Отнормируем вещественнозначную матрицу по регионам. Далее, для каждого
классификатора определим 25- и 75- процентиль, с помощью которых будет
образован интервал по статистике Тьюки. Значения, не вошедшие в этот интервал,
отмечены на Рис. 4.5 значениями 1. Далее для каждого региона просуммируем все
значения полученной матрицы в соответствующей строке и получим число отклонений
(нетипичных поведения) от типичного поведения в том или ином классификаторе.
Выделим первые 7 субъектов, показавшие наибольшее число отклонений.
Ими являются:
Москва (отклонения в 22 классификаторах),
Приморский край (11),
Республика Саха (Якутия) (10),
Красноярский край (10),
Республика Татарстан (9),
Алтайский край (9).
Стоит отметить, что данный рисунок очень наглядно отражает информацию о
выбросах в регионах, так как иллюстрирует непосредственно те коды
классификаторов ( 1 ), в которых
произошло отклонения для того или иного региона. Также отметим, что
Оренбургская область проявила себя тоже весьма подозрительно, так как для ее
показателей не встретилось ни одного выброса среди всех кодов классификаторов.
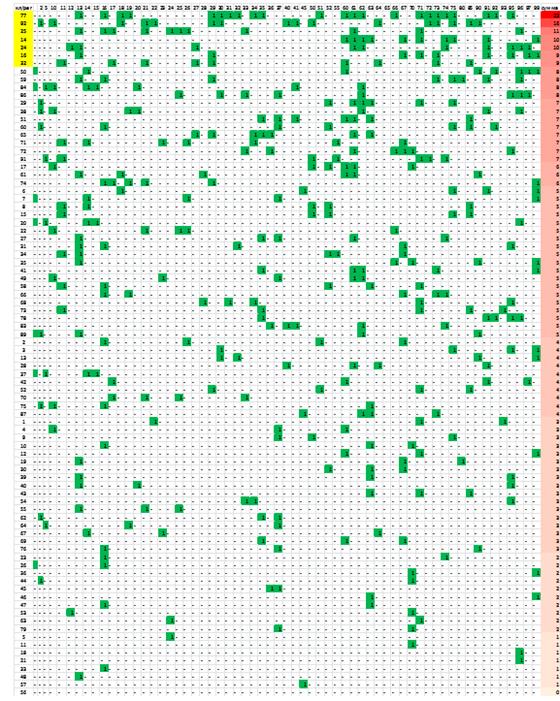
Рис. 4.1. Нахождение выбросов с помощью статистики Тьюки
алгоритм кластеризация файл матрица
Найдем выбросы вторым способом. Сделаем это с помощью матрицы расстояний 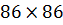 , посчитанной сначала по Евклидовой
метрике (
, посчитанной сначала по Евклидовой
метрике (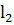 ), а потом с помощью Манхэттенского
расстояния (
), а потом с помощью Манхэттенского
расстояния (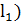 из отнормированной по регионам вещественнозначной матрицы.
Естественно, что эта матрица расстояний симметрична относительно главной
диагонали, а на этой диагонали стоят 0.
из отнормированной по регионам вещественнозначной матрицы.
Естественно, что эта матрица расстояний симметрична относительно главной
диагонали, а на этой диагонали стоят 0.
Из матрицы расстояний для каждого региона выберем минимальное расстояние
(до другого региона). Теперь рассмотрим самые максимальные из этих минимальных
расстояний.
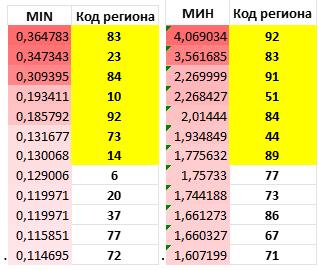
Рис. 4.2. Минимальные расстояния для регионов в матрице расстояний с
Евклидовой (слева) и Манхэттенской (справа) метриками
Теперь необходимо проанализировать полученные результаты. Как и
ожидалось, каждый метод определил разный набор субъектов РФ, претендующих на
право называться «выбросами». Отметим, что среди всех наборов присутствует
Севастополь (92 регион). Его мы точно отнесем к выбросам.
Практическим путем было выявлено, что нетипичными являются в среднем
около 8 регионов (в среднем такое число регионов ведет себя нетипичным образом
на различных тестах данного набора). Поэтому сформируем список выбросов,
включив в него топ-3 первых регионов из каждого метода.
Таким образом получаем, что выбросами - субъектами, ведущими себя
нетипично по сравнению с остальными объектами, являются:
Краснодарский край (23 регион);
Приморский край (25);
Москва (77);
Ненецкий автономный округ (83);
Таймырский Долгано-Ненецкий район (84);
Республика Крым (91);
Севастополь (92).
Данные регионы будут исключены из набора при кластеризации данных. Таким
образом, первую задачу - выявление выбросов - можно считать решеной и перейти к
определению кластеров.
.2 Кластеры
После удаления выбросов можно разбить оставшиеся объекты на кластеры.
Для начала создадим граф близости. Для этого из матрицы евклидовых
расстояний оставим 5 ближайших расстояний от каждой вершины до каждой. Выделим
центральные компоненты и получим следующий граф (рис. 4.3). Центральные
компоненты отражают влияние региона на все остальные. Чем больше вершина, тем
больше ее центральная компонента.
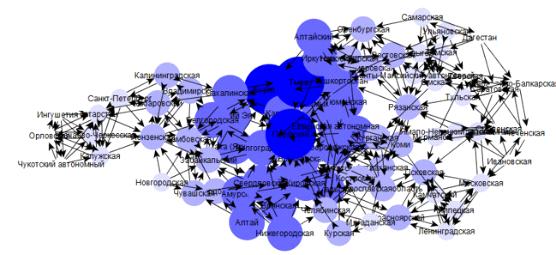
Рис 4.3. Граф близости по топ-5 вершин для Евклидового расстояния
Немного изменим масштаб, чтобы отчетливее были видны компоненты.
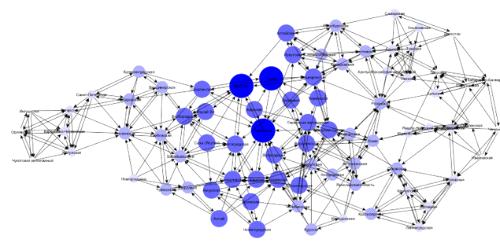
Рис 4.4. Граф близости по топ-5 вершин для Евклидового расстояния (другой
масштаб)
В данном случае особо выделяются Пермский край, Бурятия и Тыва.
Построив дендограмму и определив, что число кластеров = 5 представляется
оптимальным, отобразим регионы, объединенные в кластеры по алгоритму k-means.

Рис. 4.5. Распределение регионов по группам
Можно заметить явное сходство рис. 4.6 и 4.8, так как 4.8 - это примерное
вертикальное разбиение 4.6 и 4.7.
Таким образом, получено разбиение регионов на группы с нормировкой по
региону с расчетом евклидового расстояния.
Заключение
В ходе работы был рассмотрен большой набор открытых данных, состоящий из
примерно 39000 файлов и содержащий информацию о госзакупках, проводимых в
соответствии с ФЗ № 44. После обработки и отчистки данных посчитана вполне
обозримая матрица , элементы которой - общая стоимость договоров (контрактов),
заключенных в каждом из 86 регионов для каждого из 62 представленных классов
классификатора. Описаны теоретические подходы к выделению выбросов и разбиению
объектов на кластеры с различными способами нормировки данных и с
использованием различных метрик для подсчета меры близости (расстояния).
Построены математические модели, позволяющие проанализировать выборку с помощью
вещественнозначной матрицы расстояний, прямоугольных матрицы расстояния и графа
близости. Эти модели использованы для нахождения выбросов и разбиения
оставшихся субъектов РФ на похожие группы.
Завершает работу экспериментальная часть, в которой выделяется 7
субъектов РФ, поведение которых существенно отличается от остальной выборки. В
число этих субъектов входят Севастополь и Крым, присоединившиеся лишь в марте
2014 года. Естественно, что судьба этих регионов складывается нетипичным по
сравнению с остальными субъектами путем. Также в число нетипичных субъектов
входят Москва (политический центр страны), Красноярский и Приморский края,
Ненецкий автономный округ (самый малонаселенный субъект РФ) и Таймырский
Долгано-Ненецкий район (самый большой по площади район). После исключения
вышеописанных регионов из дальнейшего анализа была проведена кластеризация, в
ходе которой оставшиеся субъекты были разбиты на 5 групп, одна из которых
включает все субъекты, являющиеся центральными компонентами графа близости,
т.е. эта группа самая значимая среди остальных. Стоит отметить, что построенные
математические модели применимы для неоднократного использования в различных
ситуациях в рамках анализа данных о госзакупках.
Список используемой литературы
[1] Федеральный закон от 05.04.2013 N 44-ФЗ (ред. от
05.04.2016) "О контрактной системе в сфере закупок товаров, работ, услуг
для обеспечения государственных и муниципальных нужд".
[2] Общероссийский классификатор продукции по видам
экономической деятельности ОК 034-2007 (КПЕС 2002).
[3] Бериков, В. С. Всероссийский конкурсный отбор
обзорно-аналитических статей по приоритетному направлению
«Информационно-телекоммуникационные системы». - 2008. - 26 с.
[4] Низаметдинов, Ш.У. Анализ данных: учебное пособие / Ш.У.
Низаметдинов, В.П. Румянцев. - М. МИФИ, 2012. - 288с.
[5] Bolstad, B.M.
A comparison of normalization methods for high density oligonucleotide array
data based on variance and bias / B.M. Bolstad
<http://bioinformatics.oxfordjournals.org/search?author1=B.M.+Bolstad&sortspec=date&submit=Submit>
et al. // Bioinformatics, 2003, vol. 19, no. 2, pp. 185-193.
[6] Grubbs, F. E.
Procedures for detecting outlying observations in sample / F. E. Grubbs //
Technometrics, 1969, vol. 11, no. 1, pp. 1-21. doi
<https://en.wikipedia.org/wiki/Digital_object_identifier>:
10.1080/00401706.1969.10490657 <https://dx.doi.org/10.1080%2F00401706.1969.10490657>.
[7] Martin, E. A
density-based algorithm for discovering clusters in large spatial databases
with noise / E. Martin et al. // Proceedings of the Second International
Conference on Knowledge Discovery and Data Mining (KDD-96), pp. 226-231.
[8] Ripley, Brian
D. Robust statistics <http://www.stats.ox.ac.uk/pub/StatMeth/Robust.pdf>.
/ Brain D. Ripley // M.Sc. in Applied Statistics MT2004, 2004, pp. 1-11.
[9] Zimek, A. A
survey on unsupervised outlier detection in high-dimensional numerical data /
A. Zimek, E. Schubert, H.-P. Kriegel // Statistical Analysis and Data Mining,
2012, vol. 5, no. 5, pp. 363-387. doi
<https://en.wikipedia.org/wiki/Digital_object_identifier>:10.1002/sam.11161
<https://dx.doi.org/10.1002%2Fsam.11161>.
[10] Бегтин И. Открытые
данные - это возможность понять, как устроено наше государство [Электронный
ресурс] // polit.ru - электронное СМИ. 2015. 11 декабря.
[11] Бегтин И. Открытые
данные против коррупции: в чем Россия перегнала Запад [Электронный ресурс] // РБК
- электронное СМИ. 2016. 27 января. (дата обращения: 20.05.2016).
[12] Информационная
открытость. Открытые данные [Электронный ресурс] // ar.gov.ru - портал
административной реформы.
[13] CSV файлы для хакатона
[Электронный ресурс] // 2015. 7 ноября.
Приложение 1
Описание полей файлов
) Уникальный реестровый номер контракта regNum. Длина этого номера
фиксирована и всегда равна 19 символов от 0 до 9.
) Дата заключения контракта signDate. Имеет формат ГГГГ-ММ-ДД
ЧЧ:ММ:СС.
3) Price - цена контракта (руб.).
) Fz - номер федерального закона, по которому был заключен
контракт.
Напомним, что все контракты в этих файлах заключены в рамках
государственных закупок, проводимых в соответствии с федеральным законом ФЗ №
44. Поэтому в данных файлах Fz
всегда 44.
) Код региона РФ regionCode
- это число от 1 до 92, которое соответствует полному названию региона.
) Название заказчика госконтракта customer_name. Описывается
строкой - полное наименование заказчика.
) ИНН заказчика госконтракта customer_inn. Состоит из 10 символов
от 0 до 9.
) КПП заказчика госконтракта customer_kpp. Также состоит из 10 символов от 0 до 9.
) Название поставщика госконтракта supplier_name. Описывается
строкой - полное наименование поставщика.
) ИНН поставщика госконтракта supplier_inn. Состоит из 10
символов от 0 до 9.
) КПП поставщика госконтракта supplier_kpp. Также состоит из 10 символов от 0 до 9.
) Код единицы измерения OKEI_code. Отражает количество купленных
единиц товара / услуги.
) Название единицы измерения OKEI_name. Например, ШТ, КГ, Т, ЧЕЛ
и т.д.
) Код ОКПД предмета закупки OKPD/OKDP_code. Для каждого файла
уникален и совпадает с именем файла.
) Цена (руб.) предмета контракта product_sum.
) Цена (руб.) за 1 единицу измерения продукции product_price.
) Число единиц продукции в контракте product_quantity.
) Link - ссылка на запись контракта в clearspending.ru.