Мониторинг качества данных в компании
Оглавление
Введение
. Теоретические аспекты управления качеством данных
.1 Определение понятия качества данных и анализ подходов к
его изучению
.2 Определение измерений и показателей качества данных
.3 Анализ подходов и способов мониторинга качества данных в
информационных системах
Выводы по первой главе
. Формирование требований к автоматизации процесса
мониторинга качества данных в компании ХХХ
.1 Анализ процесса мониторинга качества данных
.2 Обоснование необходимости автоматизации
.3 Формирование функциональных требований к системе
мониторинга консистентности данных
.4 Формирование нефункциональных требований к системе
мониторинга консистентности данных
.5 Документирование требований к системе мониторинга
консистентности данных
Выводы по второй главе
. Разработка и введение в эксплуатацию системы мониторинга
консистентности данных
.1 Написание скриптов проверок для системы мониторинга
.2 Анализ результатов внедрения системы мониторинга
консистентности данных в эксплуатацию
Заключение
Список литературы
Приложение 1 Техническое задание на создание системы
мониторинга консистентности данных
Приложение 2 SQL-скрипты проверок
Введение
мониторинг качество данные скрипт
Компания ХХХ является одним из самых узнаваемых онлайн-ритейлеров в сфере
моды и занимает лидирующие позиции среди интернет-магазинов одежды и обуви в
России и странах СНГ.
Число клиентов компании растет большими темпами, с ростом количества
заказов необходимо думать о производительности и отказоустойчивости сервисов,
искать новые возможности для автоматизации процессов, протекающих в компании.
Одной из особенностей компании ХХХ является ее ИТ-инфраструктура. На
данный момент в ИТ-департаменте более 300 сотрудников, работающих в двух
центрах разработки: Вильнюс (Литва) и Москва (Россия), где проектируются,
разрабатываются и внедряются ИТ-решения. В компании используется большое
количество систем собственной разработки: e-commerce
платформа, складская система, система управления доставкой, а также внедряются
такие системы, как ERP и BI-платформа.
Для принятия взвешенных управленческих решений в компании возникла
необходимость в объединении данных, находящихся на вышеперечисленных
источниках, и предоставлении этих данных пользователям в унифицированном виде.
Было принято решение о формировании департамента Business Intelligence, который на данный момент занимается
разработкой платформы для удовлетворения информационных потребностей
бизнес-пользователей. Платформа состоит из двух частей: хранилище данных (Oracle) и аналитическое приложение (SAP Business Objects).
Сбор данных в корпоративное хранилище происходит при помощи ETL-процессов (Extract, Transform, Load), обеспечивающих перенос данных с
систем-источников, а также их трансформацию в соответствии с заданными
правилами.
В ходе построения корпоративного хранилища данных аналитики и
разработчики столкнулись с проблемой несоответствия данных на различных
источниках. Причинами таких несоответствий зачастую были операторские ошибки
(опечатки при вводе, неправильно проведенная транзакция), потеря актуальности
данных одним из источников, технические сбои при передаче информации из одной
системы в другую и т.д. Разрешение этих проблем вручную практически невозможно,
однако имеются некоторые способы их автоматизации.
Для решения проблемы несоответствия данных руководством компании было
принято решение о создании автоматизированной системы, которая должна выявлять
несоответствия и ошибки в системах-источниках и уведомлять о них ответственные
лица. Такая система должна повысить качество данных, а значит и качество
предоставляемой отчетности, на основе которой руководство компании будет
способно принимать грамотные и оперативные стратегические и управленческие
решения.
Объектом исследования данной работы являются процессы мониторинга
качества данных информационных систем, функционирующих внутри компании, а
предметом исследования - средства автоматизации процессов мониторинга.
Целью работы является повышение качества предоставляемых данных путем
автоматизации процесса их мониторинга в системах-источниках. Эта цель подразумевает
выполнение ряда задач:
· Анализ и моделирование процесса мониторинга качества данных в
информационных системах;
· Формирование требований к системе мониторинга;
· Написание технического задания на разработку системы;
· Ввод в эксплуатацию системы мониторинга и получение первых
результатов ее применения.
Практическая значимость работы заключается в повышении качества и
достоверности предоставляемых отчетов департаментом Business Intelligence, что в свою очередь позволит иметь
более точное и полное представление об актуальном положении дел в компании,
оперативно реагировать на неожиданные ситуации.
1. Теоретические
аспекты управления качеством данных
Одной из основных проблем корпоративных аналитических систем и систем
бизнес-анализа является обеспечение качества данных, которые консолидируются
для анализа из различных систем-источников. Если не уделить достаточно внимания
этой проблеме, есть риск свести на нет преимущество самых современных
инструментов анализа и усилия специалистов, создающих аналитические решения.
Сами решения могут быть отдаленными от реальности и исказить реальное положение
дел в организации. При этом выработанные управленческие решения могут нанести
ущерб бизнесу. Именно поэтому необходимо производить мониторинг качества данных
и их преобразование на всех этапах аналитического процесса: от извлечения
данных из источников до их обработки в аналитических системах.
1.1
Определение понятия качества данных и анализ подходов к его изучению
Первые исследования вопросов качества, в частности, продуктового,
начались в 1950-х годах.
Первым и наиболее популярным определением качества данных является
определение Дж. Джурана [7]: данные имеют высокое качество, если они пригодны
для их предполагаемого использования в операциях, принятии решений и
планировании.
Еще одно определение было дано в 1996 году профессором информационных
технологий Массачусетского технологического института Ричардом Вонгом [1] и
формулировалось как «пригодность к использованию» («fitness for use») - степень, с которой данные подходили для
использования пользователям, или потребителям, данных.
Гораздо позже, в 2008 году, Генеральная администрация по надзору за
качеством [2] ввела общую формулировку понятия качества данных - степень, с
которой определенные характеристики данных удовлетворяют заявленным и
предполагаемым потребностям.
Многие исследователи в области качества данных предлагали разные
определения этому понятию, а также различные методы измерения качества данных.
Так, Ричард Вонг, профессор информационных технологий и основатель группы
Управления качеством данных в Школе Менеджмента при Массачусетском
технологическом институте, ввел термин «пригодность к использованию»,
подчеркивая важность точки зрения потребителя данных, который решает, подходят
ли они для дальнейшего использования и принесут ли они пользу. В то же время,
группой был разработан опрос, благодаря которому удалось определить и разбить
на группы важные с точки зрения потребителей данных характеристики:
. Внутренние характеристики включали точность, объективность и
достоверность;
. Контекстуальные характеристики подразумевали релевантность,
своевременность, полноту и соответствие;
. Репрезентативные характеристики состояли из интерпретируемости и
простоты понимания;
. Доступность и защищенность.
Национальный Институт Статистических Наук (США) в 2001 году опубликовал
доклад [4], в котором определил основные принципы качества данных:
. Данные - это продукт, со своими потребителями, для
которых они несут какую-либо пользу и имеют ценность;
. Как и любой другой продукт, данные имеют качество;
. Качество данных является многомерным понятием и включает в себя
внутренние, контекстуальные, репрезентативные характеристики, а также
характеристики доступа;
. Качество данных может быть измерено и улучшено, но технологий и
программных средств недостаточно;
. Понимание важности качества данных выражено не в полной мере.
Большинство организаций беспокоятся о своих данных и их качестве, но только
некоторые из них способны охарактеризовать влияние, которое оказывают некорректные
данные на бизнес и принимаемые решения, и еще меньше организаций внедряют
программное обеспечение для отслеживания показателей качества данных и их
последующей корректировки.
На тот момент существовало несколько существенных пробелов в изучении
качества данных. Во-первых, проверка качества данных должна проходить на
нескольких уровнях: на уровне записей в таблицах баз данных, на уровне одной
базы данных и на уровне совокупности интегрированных баз данных. Проверка
качества данных на низких уровнях агрегации, например, на уровне отдельных
записей, может быть осуществлена в рамках настроек таблиц, в которых эти записи
хранятся. Но как осуществлять проверку на более высоких уровнях агрегации - не
вполне очевидно. Во-вторых, для того, чтобы проводить подобные проверки,
необходима реализация определенных моделей и алгоритмов, которые, в свою
очередь, требуют автоматизации посредством программных средств и приложений.
Эти инструменты необходимы для измерения и совершенствования качества данных и
должны состоять из алгоритмов и средств визуализации.
Управление качеством данных может быть определено как
«качественно-ориентированный подход к управлению данными как активом». Это
подразумевает «применение концепции всеобщего управления качеством (TQM) для того, чтобы улучшить качество
данных и информации, включающее определение принципов качества данных, измерение
качества данных (его аудит и сертификация), анализ качества данных,
очистка и корректировка данных, а также дальнейшее совершенствование процессов
управления качеством данных» [8]. Чтобы сделать процесс управления качеством
данных более эффективным, он должен фокусироваться не только на корректировке
некачественных данных, но и стараться предотвращать проблемы на протяжении
всего жизненного цикла данных внутри организации для удовлетворения
информационных потребностей пользователей и заинтересованных сторон. Более
того, необходимо обеспечить эффективное взаимодействие между бизнес-единицами и
ИТ-инфраструктурой компании, чтобы учитывать как бизнес аспекты управления
данными, так и технические.
Согласно Л. Инглишу [9] издержки использования некачественных данных
могут быть классифицированы следующим образом:
· Затраты на ошибки и сбои в процессах, которые возникают в
результате того, что процессы протекают не должным образом из-за низкого
качества данных;
· Затраты на переделывание работы и устранение неполадок для
достижения желаемого уровня качества;
· Альтернативные издержки, связанные с упущенными выгодой и
возможностями.
Далее будут рассмотрены наиболее важные аспекты концепции качества
данных, а также некоторые подходы и методологии, используемые организациями для
оценки и улучшения качества данных.
Согласно DAMA [8], под
«управлением данными» («data management») чаще всего подразумевается:
. Бизнес-функция, в рамках которой разрабатываются стратегии,
планы и проекты по контролю, защите, поддержке и повышению ценности данных;
. Программное приложение по реализации и оценке эффективности
функций управления данными;
. Должностные лица, выполняющие функции управления данными.
На основе анализа научной и исследовательской литературы о качестве
данных, была сформирована Таблица 1, в которой представлена классификация
основных концепций, лежащих в основе управления данными.
Таблица
1
Концепции
и понятия управления данными
|
Концепция
|
Значение
|
|
Управление данными (Data Governance)
|
· Совокупность людей, процессов и технологий, позволяющая
организации использовать данные как ресурс предприятия [10] · Высокоуровневое планирование и
контроль управления данными, координирующее взаимодействие между бизнес- и
ИТ-подразделениями предприятия [11]
|
|
Управление качеством данных (Data Quality Management)
|
Применение концепции всеобщего управления качеством (TQM) для того, чтобы улучшить качество
данных и информации, включающее определение принципов качества данных,
измерение качества данных (его аудит и сертификация), анализ
качества данных, очистка и корректировка данных, а также дальнейшее
совершенствование процессов управления качеством данных [8]
|
|
Методология качества данных (Data Quality Methodology)
|
Набор принципов и методов, определяющих наиболее
рациональный процесс оценки и улучшения качества данных [12]
|
|
Методы обеспечения качества данных (Data Quality Techniques)
|
Могут быть ориентированы как на сами данные, так и на процессы,
связанные с этими данными. В первом случае это могут быть алгоритмы и
процессы, направленные на решение конкретных проблем, связанных с качеством
данных (удаление дубликатов или приведение данных к стандартному виду).
Процессно-ориентированные методики используются для анализа и реинжиниринга
процессов производства информации [12]
|
|
Инструменты обеспечения качества данных (Data Quality Tools)
|
Программные продукты, обеспечивающие удовлетворение
основных требований к качеству данных, в частности, реализующие
стандартизацию, очистку, мониторинг и корректировку данных [13]
|
|
Контроль качества данных (Data Quality Control)
|
Часть управления качеством данных которая отвечает за
контроль соответствия качества данных заявленным требованиям [14]
|
Данная работа будет сфокусирована на таких разделах управления качеством
данных как контроль качества данных (или мониторинг), а также методы и
инструменты обеспечения качества данных.
1.2
Определение измерений и показателей качества данных
Согласно предложенному выше определению, «данные имеют высокое качество,
если они пригодны для их предполагаемого использования в операциях, принятии
решений и планировании». Несмотря на широкое признание, это определение
нуждается в более глубокой спецификации, поскольку качество данных является
многомерной концепцией и вводится в действие при помощи измерений -
определенных характеристик данных, которые представляют ценность для конечных
потребителей этих данных. О них и пойдет речь в этом разделе.
Для того, чтобы систематизировать проблемы, связанные с данными, выделим
следующие уровни [15]:
. Технический уровень. Подразумевает нарушения, связанные
со структурой данных, их полнотой и целостностью, а также некорректными
форматами.
. Аналитический уровень. Включает факторы, которые мешают
корректному анализу данных, такие как аномальные значения, дубликаты,
противоречивые данные.
. Концептуальный уровень. Проблемы возникают в связи с тем,
стратегия сбора данных была изначально неверная. Данные не содержат полной
информации о бизнес-процессах и положении компании. Данных может быть мало - в
этом случае используются алгоритмы обогащения данных; иногда бывает, что данных
слишком много, а полезной является только часть из них - тогда используются
различные методы «очистки» данных.
На основе выделенных уровней качества данных была сформирована Таблица 2,
содержащая сравнительную характеристику этих уровней.
Таблица
2
Уровни
качества данных
|
Уровень
|
Факторы
|
Проявление
|
Место борьбы
|
|
Технический
|
· нарушения в структуре данных; · некорректное наименование таблиц
или полей; · некорректные
форматы данных; · нарушение
полноты и целостности; · противоречия
и дубликаты на уровне таблиц;
|
Мешают консолидированию и интегрированию данных в хранилище
данных и аналитические системы
|
ETL
|
|
Аналитический
|
· аномальные значения, опечатки; · шумы; · противоречия и дубликаты на уровне
записей;
|
Влияют на достоверность данных, искажают результаты
анализа.
|
Источники данных, ETL, аналитические системы
|
|
Концептуальный
|
Собранных данных недостаточно для анализа бизнес-процессов
|
Данных недостаточно для анализа
|
Разработка аналитических проектов
|
Для того, чтобы в полной мере оценить качество данных, необходимо
акцентировать внимание на всех трех уровнях.
В 2012 году международная Ассоциация Управления Данными сформировала
рабочую группу, которая должна была рассмотреть вопрос измерения качества
данных и предложить список параметров для оценки качества данных на основании
лучших практик. Рабочая группа выпустила статью [5], в которой определялись
шесть ключевых измерений для оценки. Организации должны оценивать состояние
своих данных, используя эти параметры, однако это совсем не обязательно
использовать все шесть из них. Некоторые параметры могут быть опущены за
необходимостью, остальные должны выбираться в зависимости от потребностей
бизнеса.
Таким образом, согласно исследованию рабочей группы, шестью ключевыми
параметрами для оценки качества данных являются полнота, уникальность,
своевременность, валидность («пригодность»), точность и консистентность
(согласованность).
. Полнота данных означает, что каждому атрибуту присваивается
определенное значение в наборе данных. Степень полноты данных может быть
вычислена путем подсчета отсутствующих (нулевых или пустых) значений атрибутов.
. Уникальность подразумевает, что ключевые поля записей в наборе
данных не могут быть записаны дважды.
. Своевременность - это свойство данных соответствовать нуждам
потребителей в нужный для них момент времени.
. Валидность означает, что данные соответствуют синтаксису (по
формату, типу, диапазону значений и тд). Определить степень пригодности данных
можно сравнив эти данные с документацией к ним.
. Точность - это степень, с которой данные корректно описывают
объект реального мира.
. Согласованность означает отсутствие различий между одними и теми
же данными, хранящихся на разных источниках. Два значения атрибута,
принадлежащие разным наборам данных, не должны противоречить друг другу.
В своем исследовании группа, изучавшая параметры оценки качества данных,
рекомендует организациям выбирать только те показатели, которые необходимо
отслеживать в контексте бизнеса и бизнес-требований. Каждая организация должна
определить для себя, в какой степени каждый показатель содействует улучшению
качества данных в рамках конкретной компании.
1.3 Анализ
подходов и способов мониторинга качества данных в информационных системах
Прежде чем приступать к анализу данных, необходимо провести комплекс
мероприятий, получивших название «очистка» данных, который основывается на
знаниях о характере данных и структуре источников, в которых они хранятся.
Однако прежде чем выполнять очистку данных, необходимо предварительно
провести ее оценку, для того чтобы выявить наиболее характерные проблемы и
степень их сложности, для того чтобы в дальнейшем выработать верную стратегию
их очистки. Вероятно, после подобной оценки будет принято решение отказаться от
очистки некоторых данных, ввиду того, что это слишком сложно, дорого и не
принесет никаких существенных результатов. Кроме того, некоторые методы очистки
могут только ухудшить ситуацию, а предварительная оценка уровня качества данных
позволит избежать подобных случаев.
Очень частой является ситуация, когда проекты по очистке данных
начинаются тогда, когда данные являются настолько некачественными, что их
анализ становится практически невозможным по каким-либо техническим причинам
или недостоверности получаемых результатов. Для того, чтобы избежать подобных
ситуаций, необходимо комплексно подходить к проблеме качества данных:
разрабатывать стратегию сбора и консолидации данных одновременно с их
мониторингом и оценкой качества, поиском причин, которые влияют на качество
данных и выработкой стратегии по их устранению.
В результате развития такого комплексного подхода к поддержанию качества
данных на должном уровне, появилась новая дисциплина - управление качеством
данных на предприятии. Развитие этой дисциплины можно обосновать тем фактом,
что многие организации потерпели неудачу из-за низкого качества данных и
невозможности принимать своевременные управленческие решения на их основе. Как
уже было сказано ранее, управление качеством данных стало частью общего
процесса управления качеством на предприятии TQM (Total Quality
Management).
Оценка качества данных может быть осуществлена тремя способами [15]:
1. Единовременная оценка качества. Проводится единоразово для
какого-то массива данных, после чего к нему применяется определенная стратегия
очистки, либо данные признаются качественными и остаются без изменений.
2. Мониторинг. Специальные программы поиска ошибок в данных непрерывно
сканируют поток данных, из различных источников.
3. Визуальная оценка. Используется в отдельных случаях, когда
специализированным программам не удалось повысить качество данных. Чаще всего
это способ используется во время предобработки данных, поступивших в аналитическую
систему: аналитик при помощи таблиц и графиков определяет аномальные значения в
данных, пропуски и прочие противоречия. Такой способ реально использовать
только в единичных случаях и с небольшим объемом данных.
В процессе разработки методики оценки качества данных в конкретной
организации необходимо определиться, где именно эта оценка будет происходить.
Возможны следующие варианты [15]:
1. В источниках данных выполняется поиск орфографических ошибок, пропущенных
значений, противоречий и дубликатов на уровне записей и таблиц. Преимуществом
этого варианта является то, что соответствующие методы очистки могут
применяться на этапе ETL-процессов,
а в хранилище данных поступят уже очищенные данные. Но тем не менее, качество
данных может вновь ухудшиться в результате объединения источников.
2. В процессе ETL выявляются проблемы в данных во время процесса их
переноса в хранилище данных, однако таким образом есть риск загрузить
информационную систему предприятия.
3. В аналитической системе оценка может производиться
аналитиком при помощи таблиц, графиков и диаграмм, а также на основе
статистических оценок.
Оценивать качество данных лучше всего на всех перечисленных выше этапах.
Так, в источниках удобно идентифицировать ошибки ввода данных; в процессе ETL можно проследить нарушения структуры
и полноты данных; в аналитической системе данные оцениваются с точки зрения их
пригодности для решения конкретной аналитической задачи.
Оценка качества данных, контроль ошибок и анализ проблем - обязательные
этапы любого проекта по бизнес-аналитике. Таким образом появилась необходимость
в облегчении выполнения этих этапов путем автоматических проверок, которые
должны осуществляться при помощи специальных инструментов. Эти инструменты
должны помочь выявить отклонения у объектов, атрибутов и отношений в хранилищах
данных и базах данных.
Основываясь на исследовании компании Gartner [16], рынок программного обеспечения по контролю и
мониторингу качества данных стремительно растет (Рисунок 1).
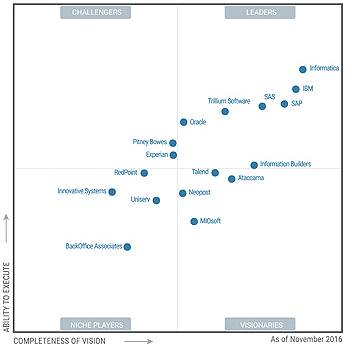
Рисунок 1 The Gartner 2016 Magic Quadrant for Data Quality
Tools
Выводы по
первой главе
В рамках Главы 1 были рассмотрены история исследования и определение
понятия качества данных. Так, качество данных - это степень, с которой
определенные характеристики данных удовлетворяют заявленным и предполагаемым
потребностям. Далее были рассмотрены концепции управления данными. В рамках
работы основное внимание будет уделено концепции мониторинга качества данных, а
также методам и инструментам контроля качества данных.
Для того, чтобы измерить качество данных, необходимо отслеживать
следующие показатели: полнота, уникальность, своевременность, валидность
(«пригодность»), точность и консистентность (согласованность). Также были рассмотрены
варианты измерения этих показателей.
2. Формирование
требований к автоматизации процесса мониторинга качества данных в компании ХХХ
ХХХ - крупная компания сектора e-commerce, осуществляющая онлайн-продажу и
доставку модной одежды, обуви, аксессуаров, косметики и парфюмерии. Стартовав в
2011 году, проект стал одним из ведущих игроков сферы интернет-торговли и занял
лидирующую позицию среди российских интернет-магазинов одежды и обуви.
Как уже было сказано ранее, компания имеет довольно развитую ИТ-инфраструктуру.
На данный момент в ИТ-департаменте более 300 сотрудников, работающих в двух
центрах разработки: Вильнюс (Литва) и Москва (Россия), где проектируются,
разрабатываются и внедряются ИТ-решения. В компании используется большое
количество систем собственной разработки: e-commerce
платформа, складская система, система управления доставкой, а также внедряет
такие решения, как учетная система и платформа Business Intelligence. Во всех этих системах ежедневно
фиксируются огромные массивы данных, которые при правильной обработке и
последующем анализе могут помочь найти новые стратегические возможности для
бизнеса.
Между информационными системами компании происходит постоянный обмен
данными. Например, когда заказ отменяется клиентом, эта информация поступает в
систему управления заказами, оттуда - в систему управления складом. В случае,
если произойдет какой-либо технический сбой, складская система не получит
вовремя информацию об отмене заказа, операторы начнут формировать заказ, в
котором уже нет нужды, в результате - потеря времени на лишние действия.
В случае возникновения каких-либо технических или операторских ошибок
возникает риск не только получить некорректные результаты при анализе этих
данных, но и снизить показатели результативности компании.
Аналитиками и разработчиками отдела бизнес-анализа в процессе непрерывной
работы с данными были обнаружены проблемы несоответствия одинаковых данных на
соответствующих источниках. В качестве основных причин таких несоответствий
можно выделить следующие:
. Человеческий фактор. Сотрудники компании непрерывно формируют
потоки «грязных», некачественных данных. Самые элементарные и незначительные
ошибки в вводе данных могут привести к большим искажениям информации о ходе
бизнеса. С одной стороны, процент подобных ошибок можно снизить, максимально
автоматизировав процессы и минимизировав ручной ввод информации в системы.
Также можно давать сотрудникам четкие инструкции по вводу данных. Однако все
эти меры не решат проблему кардинально.
. Технические сбои. Как уже было сказано ранее, компания ХХХ
отличается большим количеством информационных систем, которые ежедневно
фиксируют миллионы транзакций и совершают постоянный обмен данными друг с
другом. Периодически системы перегружаются, и такие перегрузки могут являться
причинами некоторых сбоев при передаче данных.
. Потеря актуальности данных одним из источников.
Так возникла необходимость в автоматизации процесса отслеживания таких
несоответствий и проектировании системы мониторинга.
Таким образом, целью построения системы мониторинга консистентности
данных является:
. Улучшить качество поступающих данных.
. Снизить число расхождений в данных между системами.
. Повысить качество и достоверность формируемой отчетности.
. Повысить бизнес-результаты компании за счет обеспечения
руководителей отчетностью, необходимой для принятия управленческих решений.
Для выявления узких мест в текущем процессе мониторинга качества данных
был проведен ряд интервью с аналитиками и разработчиками департамента
бизнес-анализа, которые курируют процессы оценки качества данных в компании.
По итогам был сформирован список требований к системе, описание процессов
мониторинга качества данных и написано техническое задание на разработку
системы.
2.1 Анализ
процесса мониторинга качества данных
На данный момент контроль качества данных осуществляется по пяти
показателям (полнота, уникальность, своевременность, валидность, точность) на
этапе сбора данных из систем, а также в процессе их консолидации и
преобразовании в процессе ETL.
На Рисунке 3 представлена обобщенная схема процесса ETL.
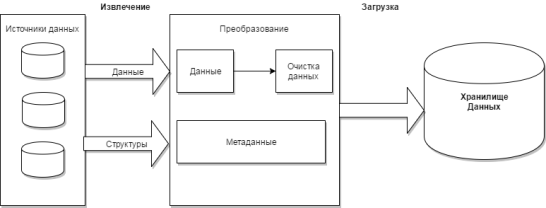
Рисунок
2 Схема ETL-процесса
На этапе извлечения данные запрашиваются из одного или нескольких
источников и подготавливаются к преобразованию. На этапе преобразования
производится преобразование форматов и кодировки данных, а также их обобщение и
очистка. На этапе загрузки - запись преобразованных данных в хранилище данных.
В рамках процесса ликвидируются ошибки, связанные с:
· корректностью форматов и представлений данных;
· уникальностью первичных ключей;
· полнотой и целостностью данных;
· соответствием некоторым аналитическим ограничениям и т.д.
Поиск и исправление ошибок происходит на уровнях: отдельной ячейки,
отдельной записи, отдельной таблицы и отдельной базы данных. В Таблице 3
представлена информация об исправляемых ошибках на каждом из перечисленных
уровней.
Таблица
3
Корректировка
ошибок
|
Уровень
|
Ошибки
|
|
Отдельная ячейка
|
· Орфографические ошибки или опечатки · Пропуски данных · Фиктивные значения (данные, не
имеющие смысла) · Логические
несоответствия (значение ячейки не соответствует смыслу поля)
|
|
Отдельная запись
|
Противоречивость данных в различных ячейках записи
|
|
Отдельная таблица
|
Дублирующие и противоречивые записи
|
|
Отдельная база данных
|
Нарушение целостности данных (различные объекты базы не
согласуются между собой)
|
В результате анализа процесса мониторинга качества данных в компании был
выявлен ряд недостатков. Во-первых, согласно оценке разработчиков хранилища
данных департамента бизнес-аналитики, полностью очистить данные удается очень
редко. Использование очень сложных алгоритмов очистки увеличивает время
переноса данных в хранилище до недопустимой величины. В связи с этим,
приходится обеспечивать компромисс между сложностью алгоритмов, затратами на
вычисление, временем очистки и результатами проверки.
2.2
Обоснование необходимости автоматизации
После анализа текущего процесса мониторинга качества данных в компании
ХХХ, было предложено внести в него ряд корректировок.
Согласно экспертной оценке ведущих разработчиков хранилища данных
департамента бизнес-анализа компании, интеграция процесса мониторинга
консистентности данных в процессы консолидации данных из систем-источников и
процессы ETL может стать причиной замедления этих
процессов. Для того, чтобы выявлять несоответствия, необходимо проводить сверки
между несколькими системами-источниками по множеству атрибутов, что может стать
причиной перегрузки процессов ETL и
консолидации данных.
Использование одного из готовых решений по контролю качества данных, представленных
на рынке информационных систем, также посчиталось нецелесообразным. Аналитиками
департамента бизнес-анализа была проведена оценка готовых средств и сделаны
следующие выводы. Довольно несложно измерить показатели таких параметров, как
полнота, уникальность, своевременность или валидность, которые являются
наиболее часто запрашиваемыми критериями качества данных. Существующие
программные приложения в основном направлены на отслеживание именно этих
показателей качества. Однако такой показатель, как консистентность (или
согласованность), который и является предметом исследования, такими
приложениями не измеряется. Он зависит от определенных ограничений и процессов,
характерных конкретной компании, поэтому реализация универсального решения
может оказаться сложной или даже невозможной.
В Таблице 4 представлена сравнительная характеристика сильных и слабых
сторон двух вариантов реализация процесса мониторинга качества данных - с
использованием специализированных инструментов и без их использования.
Таблица
4
Сравнение
вариантов реализации контроля качества данных
|
Сильные стороны решения
|
Слабые стороны решения
|
|
Реализация контроля качества данных без применения
специализированных инструментов
|
|
· уменьшение затрат на лицензии; · гибкость в организации процесса
разработки; · гибкость по
отношению к ИТ системам и форматам данных
|
· необходимость обучения специалистов специфике
разработанного решения; · затраты на документирование и поддержание документации в актуальном
состоянии
|
|
Реализация контроля качества данных с применением
специализированных инструментов
|
|
· снижение трудозатрат на разработку и реализацию; · наличие поддержки со стороны
поставщика
|
· увеличение затрат на лицензии; · жесткие условия относительно
реализации процесса разработки; · жесткие условия в отношении состава ИТ и форматов данных; · необходимость обучения персонала
|
Таким образом, в случае компании ХХХ целесообразно спроектировать
собственную систему мониторинга показателей несоответствия данных, обособленно
от процесса оценки качества данных во время процесса ETL. Это позволит усовершенствовать процесс мониторинга
качества данных в компании ХХХ, добавив контроль одного из ключевых
показателей.
Автоматизация процесса мониторинга несоответствий данных позволит
сократить количество расхождений одинаковых данных на разных источниках,
повысит качество этих данных, а также отчетности, которая строится на основании
этих данных, что позволит руководству компании принимать своевременные и
правильные управленческие решения и повысит показатели эффективности компании.
2.3
Формирование функциональных требований к системе мониторинга консистентности
данных
После проведения анализа процессов мониторинга качества данных в компании
ХХХ, в процессах был выявлен ряд недостатков: один из самых важных показателей
качества данных - консистентность - никак не отслеживается. В связи с этим было
принято решения об усовершенствовании процесса мониторинга качества данных
путем автоматизации процесса мониторинга консистентности данных. Одним из
важнейших этапов автоматизации процесса является формирование функциональных
требований к системе.
Для формирования требований пользователя к системе используются различные
методики, такие как методика Карла Вигерса, FURPS, FURPS+,
SWEBOK. При документировании требований, как
правило, используются корпоративные стандарты, основанные на ГОСТ 34.602-89
«Техническое задание на создание информационной системы» или сам стандарт.
Функциональные требования к разрабатываемой системе будут описаны по
методике FURPS+. Данная методика делит требования
на функциональные и нефункциональные. Название методики расшифровывается
следующим образом:
1. Functionality (Функциональность) - содержат основные функции системы,
такие как лицензирование, отчетность, безопасность, поддержка документооборота.
2. Usability (Удобство использования) - это субъективные требования
пользователей, например, эстетика интерфейса, стандарты оформления, справочная
информация в системе.
3. Reliability (Надежность) - это способность системы выполнять требуемые
функции в заданных режимах. Подразумевает такие характеристики, как допустимая
частота сбоев, предсказуемость поведения, точность вычислений и тд.
4. Performance (Производительность) - включает такие характеристики, как
скорость работы и время отклика, пропускная способность (число одновременно
работающих пользователей, количество пользовательских запросов, объем
запрашиваемых и передаваемых данных), скорость запуска и завершения работы
системы.
5. Supportability (Поддерживаемость) - требования к адаптируемости системы,
масштабированию, совместимости с другими системами.
Также в рассматриваемой методике к требованиям были добавлены
ограничения, которые должна иметь система.
. Ограничения проектирования. Ограничения, которые влияют на
проектные решения, такие как ограничения по технологиям, средствам разработки и
тд.
. Ограничения разработки. Задают стандарты написания программного
кода.
. Ограничения на интерфейсы - ограничения на взаимодействие с
другими системами.
Физические ограничения - ограничения на технические и аппаратные средства
системы.
Для формирования требований к системе необходимо построить модель
процесса, который она автоматизирует. Процесс мониторинга консистентности
данных должен быть осуществлен при помощи четырех модулей - система управления
проверками, ETL-средство, база данных системы
мониторинга и система визуализации(web-приложение) - следующим образом. Система управления проверками, согласно
расписанию проверок, запускает ETL-средство,
которое извлекает данные из заданных систем по заданному временному интервалу.
Далее извлеченные данные сохраняются в базе данных системы мониторинга. Система
управления проверками запускает скрипты проверок к базе данных, результат
проверки сохраняется в базе и передается системе управления проверками. Далее система
формирует excel- и html-файлы. Excel-файлы
рассылаются ответственным лицам, а html-файлы передаются в систему визуализации данных, которая представляет
собой web-приложение.
На Рисунке 3 представлена модель описанного процесса.
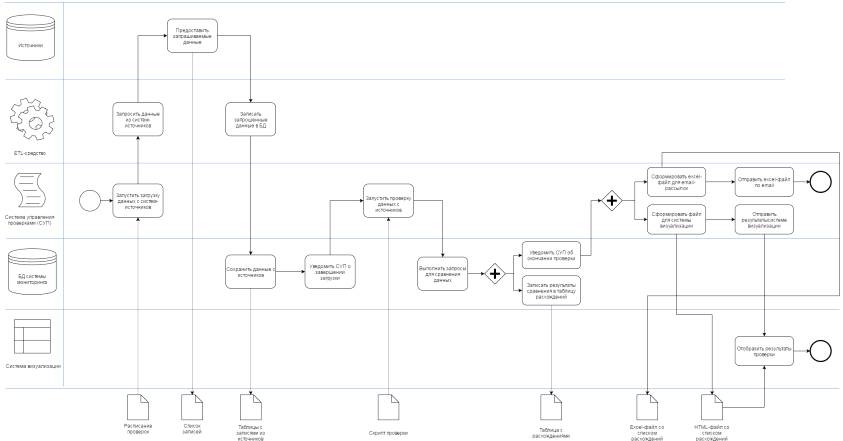
Рисунок
3 Модель процесса мониторинга консистентности данных
На основании построенной модели были выявлены требования к системе
мониторинга консистентности данных. В Таблице 5 представлен список операций,
которые должна выполнять система.
Таблица
5
Операции
системы мониторинга
|
Операция
|
Вход
|
Выход
|
Описание
|
|
Запустить загрузку данных с систем-источников
|
Расписание проверок
|
Список проверяемых источников
|
Crontab по установленному расписанию для
каждой проверки запускает java-скрипты
подсистемы управления проверками, которые в свою очередь запускают ETL-средство
|
|
Запросить данные из систем-источников
|
Список проверяемых источников, временной интервал проверки
|
Запрос к базе источника
|
ETL-средство получает от Python-приложения информацию о наименованиях
систем, из которых необходимо выгрузить данные, а также значение инкремента
для вычисления интервала выгрузки
|
|
Записать запрошенные данные в БД
|
Список записей
|
Таблица с записями в БД
|
ETL-средство передает данные с систем-источников в БД
системы мониторинга
|
|
Сохранить запрошенные данные в БД
|
Список записей
|
Таблица с записями в БД
|
БД системы мониторинга записывает данные из систем
источников в промежуточном слое
|
|
Запустить проверку данных с систем-источников
|
Название проверки
|
Запрос к базе системы мониторинга
|
Python-приложение запускает скрипты
проверки к БД системы мониторинга
|
|
Выполнить запросы проверки данных
|
Запрос к базе системы мониторинга
|
Список найденных расхождений
|
БД системы мониторинга выполняет скрипты, запущенные Python-приложением
|
|
Зафиксировать результаты сравнения в таблицу расхождений
|
Список найденных расхождений
|
Таблица со списком расхождений
|
БД системы мониторинга сохраняет результаты выполнения
запросов Python-приложения в таблицу расхождений
|
|
Сформировать excel-файл для email-рассылки
|
Таблица со списком расхождений
|
Excel-файл со списком расхождений
|
Python-приложение «забирает» результаты
проверки из таблицы расхождений в БД и создает excel-файл
|
|
Отправить excel-файл с результатами проверки
|
Excel-файл со списком расхождений
|
Email-нотификация
|
Python-приложение получает список email-адресов из специальной таблицы в
БД и запускает рассылку созданных excel-файлов
|
|
Сформировать html-файл для визуализации данных
|
Таблица со списком расхождений
|
HTML-файл со списком расхождений
|
Python-приложение «забирает» результаты
проверки из таблицы расхождений в БД и создает HTML-файл
|
|
Отправить результаты в систему визуализации
|
HTML-файл со списком расхождений
|
HTML-файл со списком расхождений
|
Python-приложение передает сформированные
HTML-файлы в подсистему отображения (web-приложение)
|
|
Отобразить результаты проверки
|
HTML-файл со списком расхождений
|
Графическая визуализация результатов проверки
|
Web-приложение на основании полученных html-файлов отображает результаты
проверки
|
Разрабатываемая система мониторинга консистентности данных должна
состоять из следующих подсистем:
подсистема сбора и преобразования данных;
подсистема управления проверками;
база данных системы мониторинга;
подсистема отображения результатов мониторинга.
Каждая система выполняет свою операцию. В Таблице 6 приведено разделение
операций по подсистемам.
Таблица
6
Подсистема
- Операция
|
Подсистема
|
Операция
|
|
Подсистема сбора и преобразования данных
|
· Запросить данные из систем-источников · Записать запрошенные данные в БД
|
|
Подсистема управления проверками
|
· Запустить загрузку данных с систем-источников · Запустить проверку данных с
систем-источников · Сформировать
excel-файл для email-рассылки · Отправить excel-файл
с результатами проверки · Сформировать html-файл
для визуализации данных · Отправить результаты в систему визуализации
|
|
База данных системы мониторинга
|
· Сохранить запрошенные данные в БД · Выполнить запросы проверки данных · Зафиксировать результаты сравнения
в таблицу расхождений
|
|
Подсистема отображения результатов мониторинга
|
· Отобразить результаты проверки
|
. Требования к подсистеме сбора и преобразования данных.
.1. Подсистема сбора и преобразования данных должна обеспечивать
возможность извлечения данных из систем-источников, использующих различные виды
баз данных (PostgreSQL, MySQL, Oracle
и тд.).
.2. Подсистема сбора и преобразования данных должна поддерживать
извлечение данных измененных или добавленных с момента последнего успешного
извлечения данных (инкрементальное извлечение данных).
.3. Подсистема сбора и преобразования данных должна обеспечивать
возможность отслеживания статуса ETL-процесса
с указанием количества элементов данных, извлеченных из систем-источников.
.4. Подсистема сбора и преобразования данных должна быть
оптимизирована для работы с большим количеством данных.
.5. Подсистема сбора должна отправлять отчет о работе подсистеме
управления проверками.
. Требования к подсистеме управления проверками
.1. Подсистема управления проверками должна запускать подсистему
сбора и преобразования данных с систем-источников согласно заранее
установленному расписанию проверок.
.2. Подсистема управления проверками должна запускать скрипты
проверок к базе данных системы мониторинга.
.3. Подсистема управления проверками должна формировать excel-файлы с результатами проверок.
.4. Подсистема управления проверками должна выполнять рассылку excel-файлов с результатами проверок
ответственным департаментам.
.5. Подсистема управления проверками должна формировать html-файлы с результатами проверок для
дальнейшей передачи их в подсистему отображения результатов мониторинга.
.6. Подсистема управления проверками должна передавать html-файлы с результатами проверок в
подсистему отображения результатов мониторинга.
. Требования к базе данных системы мониторинга.
.1. База данных системы мониторинга должна накапливать и хранить
информацию из различных источников, необходимую для решения задач мониторинга
консистентности данных.
.2. В рамках базы данных должны быть реализованы следующие разделы:
.2.1. Промежуточный раздел, в котором консолидируются данные с
систем-источников.
.2.2. Раздел служебных данных, в котором хранятся настроечные таблицы
для функционирования системы:
текущие значения инкрементов;
SQL-скрипты для реализации каждой из проверок;
cписки получателей результатов проверок и тд.
.2.3. Раздел результатов проверок, в котором содержатся найденные
расхождения. Должен включать как список с результатами по каждой проверке, так
и уникальный список расхождений.
.2.4. Раздел, содержащий таблицы, используемые средствами визуализации -
подсистемой отображения данных мониторинга.
. Требования к подсистеме отображения результатов мониторинга.
.1. Подсистема отображения данных мониторинга должна обеспечивать
пользователям доступ через WEB-браузер
без установки дополнительного программного обеспечения.
.2. Подсистема отображения данных мониторинга должна отображать
количество найденных за день расхождений по каждой из проверок, а также
количество исправленных расхождений.
.3. Подсистема отображения данных мониторинга должна обеспечивать
возможность использования различных динамических представлений информации,
такие как графики и диаграммы для более наглядного отображения результатов
мониторинга.
2.4
Формирование нефункциональных требований к системе мониторинга консистентности
данных
Согласно методологии формирования требований FURPS+, к нефункциональным требованиям относятся удобство
использования, надежность, производительность, поддерживаемость.
Требования к надежности и отказоустойчивости
1. Технические средства, обеспечивающие хранение информации в
системе мониторинга, должны использовать технологии, обеспечивающие повышенную
надежность хранения данных.
. При возникновении сбоев, включая аварийное отключение
электропитания, система мониторинга должна автоматически восстанавливать свою
работоспособность после устранения сбоев.
. Для каждого пользователя системы мониторинга должна быть
заведена собственная учетная запись (логин).
. Должна быть возможность блокирования пользователя системы
мониторинга с отключением всех текущих сессий.
Требования к сохранности информации при авариях
1. Система мониторинга должна сохранять свое функционирование при
корректном перезапуске виртуальной машины. Должна быть предусмотрена
возможность полного резервного копирования данных системы.
. Должна быть предусмотрена возможность восстановления данных,
содержащихся в системе, из резервной копии с последующей дозагрузкой актуальных
данных из систем-источников.
Требования к производительности
1. Данные системы мониторинга должны быть доступны пользователям
круглосуточно.
. Загрузка данных из внешних систем-источников должна
осуществляться ежедневно согласно расписанию.
. Должна обеспечиваться возможность единовременной работы до 100
пользователей.
Требования к масштабируемости
1. Должна существовать возможность увеличения объема данных,
содержащихся в БД информационной системы, увеличения производительности
загрузки и обработки данных.
. Должна существовать возможность добавления новых информационных
систем в качестве источников.
Требования к удобству использования
1. Информационные панели должны обеспечивать наблюдение за
состоянием проверок в режиме реального времени.
. Должна быть предусмотрена возможность фильтрации информационных
панелей по типам проверок в режиме реального времени.
2.5
Документирование требований к системе мониторинга консистентности данных
Следующим этапом работы стало формулирование технического задания на
создание системы мониторинга консистентности данных. Построение и оформление
технического задания будет происходить согласно ГОСТ 34.602-89 «Техническое
задание на создание автоматизированной системы».
ГОСТ 34.602-89 имеет следующие разделы:
. Общие сведения. Содержит наименование системы, информацию о
заказчике и разработчике системы, сроки начала и окончания работ, источники финансирования
и т.д.
. Назначение и цели создания системы. Указывается, для управления
какими процессами предназначена система, перечень объектов автоматизации;
приводятся значения технических, производственно-экономических и прочих
показателей, которые должны быть достигнуты в результате создания АИС.
. Характеристика объектов автоматизации. Приводятся краткие
сведения об области деятельности заказчика и сферы автоматизации.
. Требования к системе. Состоит из трех подразделов:
.1. Требования к системе в целом.
.1.1. Требования к структуре и функционированию системы;
.1.2. Требования к численности и квалификации персонала системы и режиму
его работы;
.1.3. Показатели назначения;
.1.4. Требования к надежности;
.1.5. Требования к эргономике и технической эстетике;
.1.6. Требования к эксплуатации, техническому обслуживанию, ремонту и
хранению компонентов системы;
.1.7. Требования к защите информации от несанкционированного доступа;
.1.8. Требования по сохранности информации при авариях;
.1.9. Требования к защите от влияния внешних воздействий;
.1.10. Дополнительные требования;
.1.11. Требования безопасности
.2. Требования к функциям, выполняемым системой. В этом разделе
приводят перечень функций и задач по каждой подсистеме, временной регламент по
реализации функций и требования к качеству реализации.
.3. Требования к видам обеспечения.
.3.1. Требования к математическому обеспечению;
.3.2. Требования к информационному обеспечению;
.3.3. Требования к лингвистическому обеспечению;
.3.4. Требования к программному обеспечению;
.3.6. Требования к метрологическому обеспечению;
.3.7. Требования к организационному обеспечению;
.3.8. Требования к методическому обеспечению.
. Состав и содержание работ по созданию системы. Данный раздел
содержит стадии и этапы работ по созданию системы, сроки их выполнения и т.д.
. Порядок контроля и приемки системы. В этом разделе указывают
виды, состав и объем испытаний системы, требования к приемке работ.
. Требования к составу и содержанию работ по подготовке объекта
автоматизации к вводу системы в действие. Приводится перечень основных
мероприятий, которые следует выполнить при подготовке объекта автоматизации к
вводу Системы в действие.
. Требования к документированию.
. Источники разработки.
В разработанном техническом задании будут включены следующие разделы:
. Общие сведения.
. Назначение и цели создания системы.
. Характеристика объектов автоматизации.
. Требования к
системе.. Требования к системе в целом.. Требования к структуре и
функционированию системы.. Требования к надежности.. Требования
безопасности.. Требования к функциям, выполняемым системой.. Требования к
информационному обеспечению;. Требования к лингвистическому обеспечению;. Требования
к программному обеспечению;. Требования к техническому обеспечению;
. Состав и содержание
работ по созданию системы.
. Порядок контроля и
приемки системы.
. Требования к составу
и содержанию работ по подготовке объекта автоматизации к вводу системы в
действие.
Задокументированное задание
находится в приложении (см. Приложение 1).
Выводы по
второй главе
В рамках второй главы были рассмотрены процессы мониторинга качества
данных в компании ХХХ. Контроль качества данных в компании происходил по пяти
показателям в рамках процесса ETL:
полнота, уникальность, своевременность, валидность, точность. Поиск
несоответствий в данных между различными источниками подразумевает контроль
показателя консистентности данных, который в компании не отслеживается. Таким
образом возникла предпосылка к автоматизации процесса консистентности данных.
Далее была построена модель процесса мониторинга консистентности данных в
компании ХХХ, описаны операции, которые необходимо выполнять системе
автоматизации процесса мониторинга. На основании модели были составлены и
задокументированы функциональные и нефункциональные требования к системе
мониторинга консистентности данных.
Далее было написано техническое задание на разработку системы
мониторинга, которое было передано разработчикам компании.
3. Разработка
и введение в эксплуатацию системы мониторинга консистентности данных
Следующим после формирования технического задания по ГОСТ 34.602-89
этапом стало написание SQL-скриптов
проверок, осуществляемых системой. Техническое задание и SQL-скрипты необходимо предоставить
программистам, тем самым передав систему мониторинга в разработку.
3.1 Написание
скриптов проверок для системы мониторинга
Как уже было сказано ранее, между информационными системами компании
происходит постоянный обмен данными. На Рисунке 4 представлена схема обменов
некоторых ключевых систем компании, а именно:
. Система управления доставкой. Объединяет информационные системы
транзитных складов, содержит информацию о статусах доставки заказов, клиентах,
курьерах и тд.
. Система планирования ресурсов (учетная система). Система
автоматизации планирования предприятием, охватывает такие области как
управление производством, финансами, продажами, маркетингом, взаимоотношениями
с клиентами.
. Система управления заказами. Содержит информацию о заказах,
контролирует и управляет статусами заказов, содержит всю информацию по
покупателям.
. Система управления складом. Содержит информацию о товарах:
прибытие, приемка, текущее местонахождение на складе, сборка по заказам,
отгрузка. Позволяет отслеживать текущий статус сборки заказа, наличие товара на
складе и прочее.
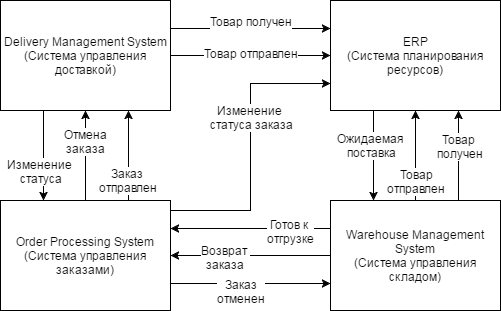
Рисунок
4 Схема обмена данными между информационными системами
В систему управления заказами (Order Processing System, OPS) в первую
очередь поступает заказ от клиента. Далее OPS передает данные о поступившем
заказе в Систему планирования ресурсами (Enterprise Resource Planning, ERP) и в
Систему управления складом (Warehouse Management System, WMS) для того, чтобы
склад начал формировать заказ. Дальнейшие изменения статусов заказов передаются
из OPS системы в ERP и WMS системы. Для склада очень критично знать, если
клиент решит отменить заказ, так как в случае если заказ будет отменен, а склад
продолжит его формирование, есть риск потери времени и, как результат, снижение
показателей работы склада. После того, как заказ сформирован, WMS отправляет
эту информацию в ERP систему и OPS, которая затем уведомляет систему
транзитного (промежуточного) склада - Delivery Management System, DMS, - чтобы
он ожидал прибытие заказа. После получения заказа с товарами транзитным
складом, DMS информирует об этом OPS и ERP, а также и обо всех последующих
изменениях в статусах доставки заказов. Заказ может быть также отменен и
вернуться на склад. О возвращении товара на склад WMS информирует OPS.
Выше представлены и описаны не все обмены данными между системами, а
только критичные с точки зрения бизнеса. Разрабатываемая система мониторинга
консистентности данных должна осуществлять следующие типы проверок (Таблица 7):
Таблица
7
Описание
обменов данными для проверок
|
Система-отправитель → система-получатель
|
Проверка
|
Описание
|
Регулярность
|
|
OPS → WMS
|
Отмененные заказы
|
Список отмененных заказов OPS сравнивается со списком отмененных заказов WMS за одинаковый промежуток времени
|
1 раз в час
|
|
WMS → OPS
|
Отгрузка заказа
|
Список отгруженных заказов WMS сравнивается со списком отгруженных заказов OPS за одинаковый промежуток времени
|
1 раз в час
|
|
WMS → OPS
|
Приемка возвратов
|
Список товаров, принятых WMS как «отменен покупателем», сравнивается со списком
таких товаров из OPS за
одинаковый промежуток времени
|
1 раз в день
|
|
OPS → DMS
|
Отмененные заказы
|
Список отмененных заказов OPS сравнивается со списком отмененных заказов DMS за одинаковый промежуток времени
|
1 раз в день
|
|
OPS → DMS
|
Заказ отправлен
|
Список заказов OPS со
статусом «отправлен со склада» сравнивается с таким же списком DMS за одинаковый промежуток времени
|
1 раз в день
|
|
DMS → OPS
|
Актуальный статус заказа
|
Список заказов и их статусов на транзитном складе в DMS сравнивается со списком заказов и
статусов по ним за один промежуток времени в OPS
|
1 раз в день
|
|
OPS → ERP
|
Статус заказа
|
Список заказов и их статусов в OPS сравнивается со списком заказов и статусов в ERP за один промежуток времени
|
1 раз в день
|
|
DMS → ERP
|
Товар прибыл на транзитный склад
|
Список товаров в DMS, прибывших на транзитный склад, сравнивается со списком товаров в ERP со статусом «прибыл на транзитный
склад»
|
1 раз в час
|
|
DMS → ERP
|
Товар отгружен из транзитного склада
|
Список товаров в DMS, отгруженных из транзитного склада на главный склад, сравнивается со
списком товаров в ERP со статусом
«отгружен из транзитного склада»
|
1 раз в час
|
|
WMS → ERP
|
Товар принят на складе
|
Список товаров в WMS, полученных во время приемки поставки на складе, сравнивается со
списком полученных товаров в ERP
|
1 раз в 4 часа
|
|
WMS → ERP
|
Товар отгружен со склада
|
Список товаров в WMS, отправленных со склада во время отгрузки заказов, сравнивается со
списком отгруженных товаров в ERP
|
1 раз в 4 часа
|
|
ERP → WMS
|
Товар ожидается к прибытию
|
Список товаров в ERP, которые ожидаются на складе, но еще туда не поступили. Сравнивается
со списком товаров в WMS,
которые находятся в статусе «в ожидании»
|
1 раз в 2 часа
|
В приложении (см. Приложение 2) находятся SQL-скрипты, реализующие эти проверки. Приложение
содержит скрипты только тех проверок, которые были готовы на момент передачи
технического задания в разработку.
3.2 Анализ
результатов внедрения системы мониторинга консистентности данных в эксплуатацию
После написания технического задания и передачи его команде
разработчиков, следуют этапы разработка информационный системы и ее ввод в
эксплуатацию. Эти этапы были осуществлены согласно п.5 «Состав и содержание
работ по созданию системы», п.6 «Порядок контроля и приемки Системы» и п.7
«Требования к составу и содержанию работ по подготовке объекта автоматизации к
вводу системы в действие» технического задания (см. Приложение 1).
В результате введения системы в эксплуатацию и ее функционирования в
течение некоторого времени были получены следующие результаты.
Во-первых, было обнаружено 3 070 036 расхождений в рамках проверки «WMS → OPS: Приемка возвратов». Эти расхождения приводили к
тому, что доход компании оценивался выше, чем он был на самом деле, а также
выплаты некоторым поставщикам товаров были больше, в результате чего компания
несла убытки. Поиск таких расхождений помог сохранить компании 8 518 млн
рублей. В рамках проверки «WMS →
OPS: Отгрузка товара» было найдено 378
расхождений, которые также являлись потенциальными потерями для компании, так
как учетная система не знала об отгруженных товарах, и, соответственно, не
знала, что должна «получить» за них деньги. Поиск таких расхождений помог
сберечь компании около 1 млн рублей. Таким образом, одним из важных результатов
автоматизации процесса мониторинга консистентности можно считать сбережение
бюджета компании.
Во-вторых, на начало функционирования системы было выявлено около 6 млн
расхождений. На текущий момент число этих расхождений варьируется около 40 000
и находится в процессе исправления. Снижение числа расхождений между информационными
системами является показателем повышения качества данных в компании ХХХ.
На сегодняшний момент проводится диагностика систем на предмет атрибутов,
расхождения в которых могут нарушить «чистоту» данных, разрабатываются и
дорабатываются алгоритмы проверок.
Заключение
В данной работе было рассмотрено усовершенствование процессов мониторинга
качества данных путем автоматизации процесса мониторинга консистентности
данных. Основным недостатком текущих процессов являлось отсутствие контроля
показателя консистентности, в то время как другие показатели - полнота,
уникальность, своевременность, валидность, точность - отслеживались.
В работе были изучены методы и инструменты оценки качества данных.
Некоторые концепции управления качеством данных были применены на практике для
разработки системы мониторинга консистентности данных в компании ХХХ.
После сбора необходимой информации об объекте автоматизации, был
проанализирован текущий процесс мониторинга качества данных, были обнаружены
его «узкие места» и предложено решение по их устранению. Так, для
усовершенствования этого процесса было предложено автоматизировать процесс
контроля консистентности данных посредством создания информационной системы.
На основании построенной модели процесса мониторинга консистентности
данных, были сформированы функциональные и нефункциональные требования к
информационной системе, разработано техническое задание на разработку этой
системы.
В рамках проекта необходимо было разработать SQL-скрипты проверок для информационных систем, которые
описаны в третьей главе данной работы. Также описан результат автоматизации
процессов, то, как разработка системы повлияла на результаты компании. В ходе
анализа результатов работы системы мониторинга выяснилось, что количество
расхождений в информационных системах компании сильно уменьшилось, а значит,
можно говорить о улучшении показателя консистентности данных и повышении
качества этих данных.
Список
литературы
1. Wang, R. Y., & Strong, D. M. (1996) Beyond
Accuracy: What Data Quality Means to Data Consumers. Journal of Management
Information Systems, 12(4): pp 5-33.
2. General Administration of Quality Supervision
(2008) Inspection and Quarantine of the People’s Republic of China. Quality
management systems-Fundamentals and vocabulary (GB/T19000-2008/ISO9000:2005),
Beijing.
. Alexander, J. E., & Tate, M. A. (1999)
Web wisdom: How to evaluate and create information on the web, Mahwah, NJ:
Erlbaum.
. Alan, F. K., Sanil, A. P., Sacks, J. (2001)
Workshop Report: Affiliates Workshop on Data Quality, North Carolina: NISS.
. Cao, J. J., Diao, X. C., Wang, T. (2010)
Research on Some Basic Problems in Data Quality Control. Microcomputer
Information, 09: pp 12-14.
6. Goasdoué V., Nugier S., Duquennoy
D., Laboisse B. (2007) An evaluation framework for Data Quality Tools, ICIQ.
. Juran, J. M. (1989). Juran on Leadership for
Quality: An Executive Handbook, NY: The Free Press.
. The Data Management Association (2008). The
DAMA Dictionary of Data Management. Bradley Beach, NJ: Technics Publications
LLC.
. English, L. (1999). Improving Data Warehouse
and Business Information Quality. Wiley & Sons.
. The Customer Data Integration Institute
(2006). Corporate Data Governance Best Practices - 2006-07 Scorecards for Data
Governance in the Global 5000.
. The Data Management Association (2008). The
DAMA Dictionary of Data Management. Bradley Beach, NJ: Technics Publications
LLC.
. Batini, C., Cappiello, C. Francalanci, C.
& Maurino, A. (2009). Methodologies for data quality assessment and
improvement. ACM Comput. Surv, 41 (3).
13. Gartner [Электронный ресурс]
Gartner Magic Quadrant for Data Quality Tools / Friedman T. & Bitterer, A.
(2009). URL:
<http://www.gartner.com/technology/media-products/reprints/dataflux/167657.html>.
. International
Standards Organization (2005). ISO 9000:2005 (E). Quality Management Systems:
Fundamentals and Vocabulary (3rd edition).
15. В.Н. Любицын (2012). Повышение качества данных в контексте современных аналитических технологий. Вестник ЮУргГУ, № 23.
. Gartner [Электронный ресурс]
2016 Magic Quadrant for Data Quality Tools, 23 November 2016. - URL:
<https://www.gartner.com/doc/3522717/magic-quadrant-data-quality-tools>.
17. ГОСТ 34.602-89
Техническое задание на создание автоматизированной системы.
Приложение 1 Техническое задание на создание системы мониторинга
консистентности данных
. Общие сведения
.1. Наименование системы
Полное наименование системы: Система мониторинга консистентности данных.
Краткое наименование системы: Система.
2. Назначение и цели создания системы
.1. Назначение системы
Система мониторинга консистентности данных предназначена для повышения
качества принимаемых управленческих решений сотрудниками компании.
Основным назначением Системы является автоматизация мониторинга
показателя консистентности качества данных.
2.2. Цели создания системы
Система создается с целью:
· улучшить качество поступающих данных;
· снизить число расхождений между информационными системами
компании;
· повысить качество и достоверность формируемой отчетности.
3. Характеристика объекта автоматизации
Объектом исследования при создании и внедрении системы является компания
ХХХ и департамент бизнес-анализа компании.
Предметом исследования являются процессы мониторинга качества данных в
компании ХХХ.
4. Требования к системе
.1. Требования к системе в целом
.1.1. Требования к структуре и функционированию систем
.1.1.1. Требования к структуре системы
Система должна иметь модульную структуру, что позволит разбить
разработку, настройку и внедрение на постепенно принимаемые к эксплуатации
наборы реализованных функций.
4.1.1.2. Перечень подсистем, их назначение и основные
характеристики
В состав системы должны входить следующие подсистемы:
. Подсистема сбора и преобразования данных, которая предназначена
для реализации процессов сбора данных из систем источников, приведения
указанных данных к виду, необходимому для наполнения подсистемы хранения
данных.
. Подсистема управления проверками, обеспечивающая поддержку
процессов запуска загрузки данных в систему, проверки данных на
консистентность, рассылки результатов.
. База данных, предназначенная для хранения информации о
проверках.
. Подсистема отображения результатов мониторинга, предназначенная
для формирования графической отчетности.
4.1.1.3. Требования к режимам функционирования системы
К функционированию системы предъявляются следующие требования:
круглосуточная работоспособность системы;
наличие обработки исключительных ситуаций;
защита информации от несанкционированного доступа;
обеспечение сохранности информации при авариях;
обеспечение хранения и распространения форм отчетности.
4.1.2. Требования к надежности
Надежность Системы определяется надежностью функциональных модулей,
общего программного обеспечения, комплексов технических и инженерных средств.
Подсистемы должны обеспечивать сохранение накопленной на момент отказа
или выхода из строя информации с последующим восстановлением функционирования
системы после проведения ремонтных и восстановительных работ.
4.1.3. Требования к безопасности
Защита от несанкционированного доступа должна происходить при помощи
разграничения полномочий и обеспечения безопасности хранения, предоставляемых
программным обеспечением СУБД и операционной системой, на которых функционирует
Система.
В Системе должно обеспечиваться разграничение прав доступа по следующим
уровням:
разграничение доступа к данным
разграничение возможностей работы с данными (просмотр,
редактирование)
В рамках Системы должны присутствовать функции администрирования:
настройка полномочий пользователей
ведение мониторинга ошибок Системы
ведение списка пользователей, имеющих доступ к системе
ведение списка всех действий пользователя
Для подсистемы отображения данных должна выполняться аутентификация
пользователей при попытке входа в систему с указанием логина и пароля.
4.2. Требования к функциям, выполняемым системой
.2.1. Требования к подсистеме сбора и преобразования данных
1. Подсистема сбора и преобразования данных должна обеспечивать
возможность извлечения данных из систем-источников, использующих различные виды
баз данных (PostgreSQL, MySQL, Oracle
и тд.).
2. Подсистема сбора и преобразования данных должна поддерживать
извлечение данных измененных или добавленных с момента последнего успешного
извлечения данных (инкрементальное извлечение данных).
3. Подсистема сбора и преобразования данных должна обеспечивать
возможность отслеживания статуса ETL-процесса
с указанием количества элементов данных, извлеченных из систем-источников.
4. Подсистема сбора и преобразования данных должна быть
оптимизирована для работы с большим количеством данных.
5. Подсистема сбора должна отправлять отчет о работе подсистеме
управления проверками.
.2.2. Требования к подсистеме управления проверками
1. Подсистема управления проверками должна запускать подсистему
сбора и преобразования данных с систем-источников согласно заранее
установленному расписанию проверок.
. Подсистема управления проверками должна запускать скрипты
проверок к базе данных системы мониторинга.
3. Подсистема управления проверками должна формировать excel-файлы с
результатами проверок.
. Подсистема управления проверками должна выполнять рассылку
excel-файлов с результатами проверок ответственным департаментам.
. Подсистема управления проверками должна формировать html-файлы с
результатами проверок для дальнейшей передачи их в подсистему отображения
результатов мониторинга.
. Подсистема управления проверками должна передавать html-файлы с
результатами проверок подсистему отображения результатов мониторинга.
.2.3. Требования к базе данных системы мониторинга
1. База данных системы мониторинга должна накапливать и хранить
информацию из различных источников, необходимую для решения задач мониторинга
консистентности данных.
2. В рамках базы данных должны быть реализованы следующие разделы:
a. Промежуточный раздел, в котором консолидируются данные с систем-источников.
b. Раздел служебных данных, в котором хранятся настроечные таблицы
для функционирования системы:
i. текущие значения инкрементов;
ii. SQL-скрипты для реализации каждой из проверок;
iii. cписки получателей результатов проверок и тд.. Раздел результатов
проверок, в котором содержатся найденные расхождения. Должен включать как
список с результатами по каждой проверке, так и уникальный список расхождений.
d. Раздел, содержащий таблицы, используемые средствами визуализации
- подсистемой отображения данных мониторинга.
.2.4. Требования к подсистеме отображения результатов
мониторинга
1. Подсистема отображения данных мониторинга должна обеспечивать
пользователям доступ через WEB-браузер без установки дополнительного
программного обеспечения.
2. Система должна поддерживать браузеры Internet Explorer, Safari,
Mozilla Firefox, Google Chrome.
. Подсистема отображения данных мониторинга должна отображать
количество найденных за день расхождений по каждой из проверок, а также
количество исправленных расхождений.
4. Подсистема отображения данных мониторинга должна обеспечивать
возможность использования различных динамических представлений информации,
такие как графики и диаграммы для более наглядного отображения результатов
мониторинга.
.3. Требования к видам обеспечения
.3.1. Требования к информационному обеспечению
Хранение данных в системе должно быть реализовано при помощи современных
реляционных или объектно-реляционных СУБД.
Доступ к данным должен быть предоставлен только авторизованным
пользователям с учетом их служебных полномочий, а также с учетом категории
запрашиваемой информации.
Структура базы данных должна быть организована рациональным способом,
исключающим единовременную полную выгрузку информации, содержащейся в базе
данных системы.
Технические средства, обеспечивающие хранение информации, должны
использовать современные технологии, позволяющие обеспечить повышенную
надежность хранения данных.
4.3.2. Требования к лингвистическому обеспечению
Система должна быть реализована с использованием языков программирования
высокого уровня, имеющих промышленные масштабы развития и сопровождения: SQL, Java, Python.
Запуск работы Системы должен быть реализован с использованием командной
оболочки UNIX (Shell).
Для реализации алгоритмов манипулирования данными в базе данных
необходимо использовать стандартный язык запроса к данным SQL и его процедурное
расширение PL/pgSQL.
При взаимодействии системы с web-приложением должен применяться язык HTML.
4.3.3. Требования к программному обеспечению
База данных Системы должна быть построена на базе СУБД PostgreSQL 9.5.2 (64-bit).
Управление проверками и взаимодействие web-приложения с базой данных должны осуществляться при
помощи Python 2.7.
Для построения графиков на основе проверок используется
JavaScript-библиотека d3.js.
4.3.4. Требования к техническому обеспечению
Под разрабатываемую Систему должны быть выделены сервера компании.
Сервер базы данных и сервер web-приложения должны быть развернуты на серверной платформе со следующими
характеристиками: CPU Intel Xeon Processor
E5-2650 v3, ОЗУ: 16 Гб, HDD:
500 Gb, тактовая частота процессора: 2,3 GHz.
5. Состав и содержание работ по созданию системы
Процесс создания Системы, согласно ГОСТ 34.601-90, представляет собой
совокупность упорядоченных во времени, взаимосвязанных, объединенных в стадии и
этапы работ, выполнение которых необходимо и достаточно для создания Системы,
соответствующей требованиям, описанным в предыдущих разделах данного документа.
В Таблице 1 приведено подробное поэтапное описание состава работ по созданию
системы.
Таблица
1
Состав работ по этапам
|
№ Этапа
|
Наименование этапа
|
Результаты выполнения работ
|
Срок
|
|
1
|
Уточнение требований
|
· Устав проекта · План-график проекта · Техническое задание на Систему по ГОСТ 34.602-89
|
3-5 дней
|
|
2
|
Разработка программного обеспечения Системы
|
Разработанное программное обеспечение подсистем Системы
|
10-14 дней
|
|
3
|
Ввод Системы в действие
|
· Протокол предварительных испытаний · Протокол приемочных испытаний
|
2-4 дней
|
5.1. Содержание работ первого этапа
.1.1. Устав проекта
Устав проекта является основным документом, регламентирующим проект, в
котором определяются:
состав проектной группы
сроки согласования проектных документов
политика информационной безопасности
5.1.2. Техническое задание
В ходе первого этапа должно быть проведено уточнение требований и
разработано техническое задание на следующие подсистемы:
подсистема сбора и преобразования данных;
подсистема управления проверками;
база данных системы мониторинга;
подсистема отображения результатов мониторинга.
5.2. Содержание работ второго этапа
На третьем этапе проводится разработка программного обеспечения Системы
согласно утверждённому техническому проекту, описаниям информационного и
программного обеспечения и другим документам первого этапа проекта.
С целью проведения испытаний Системы должен быть реализован
пользовательский интерфейс для проверки работоспособности web-приложения. К
дизайну и удобству использования данного пользовательского интерфейса
требований не предъявляется.
5.3. Содержание работ третьего этапа
На третьем этапе проводится ввод в действие Системы.
. Должны быть проведены предварительные испытания Системы по
утверждённой программе и методике испытаний.
В ходе предварительных испытаний должно быть проведено функциональное
тестирование Системы.
. Должна быть произведена отладка взаимодействия со смежными
системами.
. Должны быть проведены приемочные испытания Системы согласно п.6
«Порядок контроля и приемки Системы» настоящего документа.
6. Порядок контроля и приемки Системы
Результатом работ должна являться работоспособная Система и комплект
документации на Систему.
Испытания представляют собой процесс проверки выполнения заданных функций
системы, определения и проверки соответствия требованиям технического задания
характеристик Системы, выявления и устранения недостатков в действиях Системы,
в разработанной документации.
Система проходит следующие виды испытаний:
· предварительные испытания;
· приёмочные испытания.
Предусмотренные испытания проводятся аналитиками департамента
бизнес-анализа.
Результаты проведения каждого вида испытаний должны быть зафиксированы в
соответствующем протоколе со списком выявленных замечаний.
По завершении предварительных и приёмочных испытаний оформляются
соответствующие акты, содержащие вывод о соответствии Системы предъявляемым
требованиям.
Для проведения испытаний необходимо обеспечить программно-аппаратный
комплекс, характеристики которого соответствуют требованиям, указанным в
техническом задании к Системе.
Объем работ по каждому виду испытаний приведен в Таблице 2:
Таблица 2
Объем работ по видам испытаний
|
|
Вид испытания
|
Объем испытаний
|
|
1
|
Предварительные испытания
|
Функциональное тестирование Тестирование производительности
Тестирование интерфейса
|
|
2
|
Приемочные испытания
|
Функциональное тестирование Тестирование производительности
Тестирование совместимости
|
7. Требования к составу и содержанию работ по подготовке
объекта автоматизации к вводу системы в действие
Для создания необходимых условий функционирования Системы и гарантии ее
соответствия требованиям, описанным в настоящем техническом задании, необходимо
провести комплекс мероприятий.
В рамках технических мероприятий должна быть осуществлена закупка и
установка необходимого технического оборудования.
В рамках организационных мероприятий должен быть осуществлен доступ к
базам данных источников.
Также необходимо подготовить персонал, участвующий в эксплуатации
системы.
Приложение 2 SQL-скрипты проверок
В Таблице 1 представлены скрипты проверок. В колонке «Проверка» указано
наименование проверки в формате «Источник А → Источник Б «Наименование
проверки», в колонках «Запрос к источнику А», «Запрос к источнику Б» - sql-скрипты, выполняющие выгрузку данных
из систем-источников, в колонке «Запрос проверки» содержит sql-скрипт, сравнивающий данные с двух
систем.
Таблица 1
Скрипты проверок систем-источников
|
Проверка
|
Запрос к источнику А
|
Запрос к источнику Б
|
Запрос проверки
|
|
OPS → DMS «Отмененные заказы»
|
SELECT DISTINCT o.order_nr AS
ops_order_nr, o.created_at AS ops_order_created_dttm, o.shipping_method AS
ops_shipping_method, cr.cancel_reason AS ops_cancel_reason,
cr.user_login_created AS ops_cancel_user, cr.created AS ops_cancel_dttm,
d.cancelled_by AS ops_delaied_cancel_user, d.cancelled_at AS
ops_delaied_cancel_dttm, ${p_reconciliation_interval_id} AS
reconciliation_interval_id, ${p_reconciliation_id} AS reconciliation_id,
${p_database_code} AS database_code FROM ops_sales_order o INNER JOIN
ops_sales_order_item i ON i.fk_sales_order = o.id_sales_order INNER JOIN
ops_status_history_main h ON h.fk_sales_order_item = i.id_sales_order_item
LEFT JOIN ops_sales_order_cancel_reason cr ON cr.fk_sales_order =
o.id_sales_order LEFT JOIN ops_sales_order_delivery d ON d.fk_sales_order =
o.id_sales_order WHERE 1 = 1 AND h.fk_status_list_main = 4 -- Regular: AND (
cr.created BETWEEN ${p_min_date} AND ${p_max_date} OR d.cancelled_at BETWEEN
${p_min_date} AND ${p_max_date} ) AND o.created_at >= ${p_min_date} - INTERVAL
2 MONTH -- Recheck: OR o.order_nr = {order_nr}
|
select o.order_nr AS dms_order_nr,
o.delivery_status AS dms_delivery_status, o.order_registered_time AS
dms_order_registered_time, o.created_at AS dms_order_created_dttm,
o.updated_at AS dms_order_updated_dttm, ${p_reconciliation_interval_id} AS
reconciliation_interval_id, ${p_reconciliation_id} AS reconciliation_id,
${p_database_code} AS database_code FROM dms_view_orders o WHERE 1 = 1 AND
o.delivery_status = 'cancelled' AND o.is_deleted = 0 -- Regular: AND o.updated_at
BETWEEN ${p_min_date} - INTERVAL 2 HOUR AND ${p_max_date} + ${p_stepback} --
Recheck: OR o.order_nr = ${order_nr}
|
SELECT b.ops_order_nr AS order_nr,
b.ops_order_created_dttm, b.ops_shipping_method, b.ops_cancel_reason,
b.ops_cancel_user, b.ops_cancel_dttm, b.ops_delaied_cancel_user,
b.ops_delaied_cancel_dttm, b.reconciliation_interval_id, b.reconciliation_id,
b.database_code FROM source.sta_cancel_order_ops2dms_ops b LEFT JOIN
source.sta_cancel_order_ ops2dms _dms e ON e.dms_order_nr = b.ops_order_nr
WHERE e.dms_order_nr IS NULL
|
|
DMS → ERP «Товар прибыл на транзитный склад»
|
SELECT s.external_id AS
dms_shipment_external_id, s.created_at AS dms_shipment_created_at, s.sent_at
AS dms_shipment_sent_at, mt.name AS dms_shipment_movement_type, CASE WHEN
i.item_id IS NOT NULL THEN 1 END AS dms_item_exists,
${p_reconciliation_interval_id} AS reconciliation_interval_id,
${p_reconciliation_id} AS reconciliation_id, ${p_database_code} AS
database_code FROM dms_view_shipment s INNER JOIN
dms_view_goods_movement_type mt ON mt.id = s.goods_movement_type_id LEFT JOIN
dms_view_container_shipments c ON c.shipment_id = s.id LEFT JOIN
dms_view_container_shipment_items i ON i.container_shipment_id = c.id WHERE
s.direction = 'in' AND s.status = 3 AND COALESCE(c.type, 'none') <>
'missing' -- Regular: AND s.updated_at BETWEEN ${p_min_date} AND ${p_max_date}
-- Recheck: OR s.external_id = ${shipment_id}
|
SELECT gi.shipmentid AS
erp_shipment_id, gi.taglorryarrived AS erp_taglorryarrived,
gi.createddatetime AS erp_createddatetime, CASE WHEN gi.status = 0 THEN
'None' WHEN gi.status = 1 THEN 'Ready' WHEN gi.status = 2 THEN 'InProcess'
WHEN gi.status = 3 THEN 'Error' WHEN gi.status = 4 THEN 'Finished' WHEN
gi.status = 5 THEN 'Waiting' WHEN gi.status = 6 THEN 'Missed' WHEN gi.status
= 7 THEN 'Duplicate' WHEN gi.status = 8 THEN 'ErrorReprocess' END AS
erp_shipment_status, CASE WHEN gil.tagstate IS NOT NULL THEN 1 END AS
erp_item_exists, ${p_reconciliation_interval_id} AS
reconciliation_interval_id, ${p_reconciliation_id} AS reconciliation_id,
${p_database_code} AS database_code FROM erp_inventgoodsintable_lmd gi LEFT
JOIN erp_inventgoodsinline_lmd gil ON gil.sessionid_ = gi.sessionid_ AND
gil.dataareaid = 'lmd' AND gil.partition = 5637144576 WHERE gi.dataareaid =
'lmd' AND gi.partition = 5637144576 AND gi.destination <> 'БЫКОВО' AND
gi.status <> 7 -- Regular: AND COALESCE(gi.modifieddatetime,
gi.createddatetime) BETWEEN DATEADD(HOUR, -5, ${p_min_date}) AND
DATEADD(MINUTE, 60, ${p_max_date}) -- Recheck: OR gi.shipmentid =
${shipment_id}
|
WITH dms AS ( SELECT
e.dms_shipment_external_id, MAX(e.dms_shipment_created_at) AS
dms_shipment_created_at, MAX(e.dms_shipment_sent_at) AS dms_shipment_sent_at,
MAX(e.dms_shipment_movement_type) AS dms_shipment_movement_type,
COALESCE(SUM(e.dms_item_exists), 0) AS dms_item_qty,
MAX(e.reconciliation_interval_id) AS reconciliation_interval_id,
MAX(e.reconciliation_id) AS reconciliation_id, MAX(e.database_code) AS
database_code FROM source.sta_goods_in_dms2erp_dms e GROUP BY
e.dms_shipment_external_id ), erp AS ( SELECT a.erp_shipment_id,
MAX(a.erp_taglorryarrived) AS erp_taglorryarrived, MAX(a.erp_createddatetime)
AS erp_createddatetime, MAX(a.erp_shipment_status) AS erp_shipment_status,
COALESCE(SUM(a.erp_item_exists), 0) AS erp_item_qty FROM
source.sta_goods_in_dms2erp_erp a GROUP BY a.erp_shipment_id ) SELECT
e.dms_shipment_external_id AS shipment_id, e.dms_shipment_created_at,
e.dms_shipment_sent_at, e.dms_shipment_movement_type, e.dms_item_qty,
a.erp_taglorryarrived, a.erp_createddatetime, a.erp_shipment_status,
a.erp_item_qty, CASE WHEN e.dms_item_qty > COALESCE(a.erp_item_qty, 0) THEN
'Express > AXA' WHEN e.dms_item_qty < COALESCE(a.erp_item_qty, 0) THEN
'Express < AXA' END AS check_status, e.reconciliation_interval_id,
e.reconciliation_id, e.database_code FROM dms e LEFT JOIN erp a ON
a.erp_shipment_id = e.dms_shipment_external_id WHERE e.dms_item_qty <>
COALESCE(a.erp_item_qty, 0)
|
|
ERP → WMS «Товар ожидается к прибытию»
|
SELECT ib.modifieddatetime AS
erp_modified, ib.itembarcode AS erp_ean, CASE WHEN d.inventsizeid <>
''0000'' THEN ib.itemid + d.inventsizeid ELSE ib.itemid END AS erp_sku,
ROW_NUMBER() OVER (PARTITION BY ib.itembarcode ORDER BY ib.modifieddatetime
DESC) AS erp_rnum, ${p_reconciliation_interval_id} AS
reconciliation_interval_id, ${p_reconciliation_id} AS reconciliation_id,
${p_database_code} AS database_code FROM erp_inventitembarcode ib INNER JOIN
erp_inventdim d ON d.inventdimid = ib.inventdimid WHERE ib.dataareaid = 'lmd'
AND ib.partition = 5637144576 AND d.dataareaid = 'lmd' AND d.partition =
5637144576 AND ib.modifieddatetime >= '2015-01-01 00:00:00' -- Condition
for regular reconciliation: ib.modifieddatetime BETWEEN ${p_min_date} AND
${p_max_date}
|
SELECT id.created AS wms_created,
id.modified AS wms_modified, id.ean AS wms_ean, id.item_nr AS wms_sku
${p_reconciliation_interval_id} AS reconciliation_interval_id, ${p_reconciliation_id}
AS reconciliation_id, ${p_database_code} AS database_code FROM wms_itemdata
id WHERE id.modified >= to_date('01.01.2015', 'dd.mm.yyyy') -- Condition
for regular reconciliation: id.modified BETWEEN ${p_min_date} - INTERVAL '5
HOURS' AND ${p_max_date} + INTERVAL '75 MINUTES' -- Condition for recheck:
id.item_nr = ${p_sku}
|
SELECT
a.reconciliation_interval_id, a.reconciliation_id, a.database_code,
a.erp_modified, a.erp_ean, a.erp_sku, w.wms_created, w.wms_modified,
w.wms_ean, w.wms_sku FROM source.sta_product_info_erp a LEFT JOIN
source.sta_product_info_wms w ON w.wms_sku = a.erp_sku WHERE
COALESCE(a.erp_rnum, 1) = 1 AND (a.erp_ean <> w.wms_ean OR w.wms_ean IS
NULL)
|
|
OPS → DMS «Заказ отправлен»
|
SELECT soi.item_nr AS ops_item_nr,
soi.id_sales_order_item AS ops_item_id, soi.barcode AS ops_barcode, soi.sku
AS ops_sku, so.order_nr AS ops_order_nr, so.created_at AS ops_order_dttm,
so.shipping_method AS ops_shipping_method, slm.code AS ops_item_main_status,
soi.status_main_last_change AS ops_item_main_status_dttm, shm.created_at AS
ops_item_shipping_dttm, shm.inserted_at AS ops_shipping_status_dttm,
${p_reconciliation_interval_id} AS reconciliation_interval_id,
${p_reconciliation_id} AS reconciliation_id, ${p_database_code} AS
database_code FROM sales_order_item soi INNER JOIN sales_order so ON
so.id_sales_order = soi.fk_sales_order INNER JOIN status_list_main slm ON
slm.id_status_list_main = soi.fk_status_list_main INNER JOIN
status_history_main shm ON shm.fk_sales_order_item = soi.id_sales_order_item
WHERE shm.fk_status_list_main = 5 -- shipped -- Regular: AND shm.inserted_at
BETWEEN ${p_min_date} AND ${p_max_date} AND soi.updated_at >=
${p_min_date} -- Recheck: OR soi.item_nr = ${item_nr}
|
SELECT o.order_nr AS dms_order_nr,
i.item_guid AS dms_item_nr, i.barcode AS dms_barcode, i.sku AS dms_sku,
${p_reconciliation_interval_id} AS reconciliation_interval_id,
${p_reconciliation_id} AS reconciliation_id, ${p_database_code} AS
database_code FROM view_orders o INNER JOIN view_items i ON i.order_id = o.id
WHERE o.is_deleted = 0 AND i.is_deleted = 0 -- Regular: AND i.updated_at
BETWEEN ${p_min_date} - INTERVAL 2 HOUR AND ${p_max_date} + INTERVAL 2 HOUR
-- Recheck: OR i.item_guid = ${item_nr}
|
SELECT b.ops_item_nr AS item_nr,
b.ops_item_id, b.ops_barcode, b.ops_sku, b.ops_order_nr, b.ops_order_dttm,
b.ops_shipping_method, b.ops_item_main_status, b.ops_item_main_status_dttm,
b.ops_item_shipping_dttm, b.ops_shipping_status_dttm,
b.reconciliation_interval_id, b.reconciliation_id, b.database_code FROM
source.sta_order_sent_bob2dms_bob b LEFT JOIN
source.sta_order_sent_bob2dms_le e ON e.dms_item_nr = b.ops_item_nr WHERE
e.dms_item_nr IS NULL
|