Обучение с подкреплением
Оглавление
Введение
Теоретическая часть
Описание игры Snake
Q-Learning
SARSA (State-Action-Reward-State-Action)
Аппроксимация Q значения с помощью нейронной сети
Постановка задачи
Описание Экспериментов
Заключение
Список литературы
Введение
В наши дни машинное обучение набирает огромную популярность.
Его возможности применяют для широкого спектра задач, от решений по улучшению
сервиса для клиентов, до предсказания разного рода катастроф. Отдельно стоит
упомянуть такие бурно развивающиеся направления, как робототехника и
искусственный интеллект. Большая часть нынешних исследований направлена на
создание и совершенствования искусственного интеллекта, который, в свою
очередь, применятся в робототехнике.
Использование алгоритмов машинного обучения для компьютерных
игр также набирает огромную популярность, так как любая видеоигра является
отличным тестовым полигоном для алгоритмов, использующихся при создании моделей
искусственного интеллекта. Многие известные корпорации такие как Google и Microsoft тестируют и улучшают
свои модели ИИ на компьютерных играх.
Не имея никакого представления о игре, может ли искусственный
интеллект научится эффективно играть в нее? В настоящей работе рассматривается
проблема создания искусственного интеллекта для динамической среды о которой
обучаемый агент ничего не знает. В качестве динамической среды, выступает
компьютерная игра Snake, в которой игроку, управляя змейкой, необходимо собрать как можно
больше яблок, избегая препятствий (в качестве препятствия выступает и само тело
змейки):
Для создания ИИ используется обучение с подкреплением. Идея такого
подхода берет свое начало в психологии и изучает то, как некоторый
"агент" должен действовать в рамках определенной среды, чтобы
максимизировать некий "выигрыш". Такие алгоритмы пытаются найти
стратегию действий агента, определяя пару состояние окружения - действе,
которые необходимо предпринять для получения выгоды.
Для обучения агентов, которые ничего не знают о среде, существует
два наиболее популярных алгоритма Q-learning и SARSA [1], которые успешно применялись для компьютерной игры Mario [2], где для обучения агента авторы
ограничили область видимости, чтобы уменьшить количество данных среды. SARSA и Q-approximation успешно применялись в робототехнике, на
примере робота, который ищет свет в фиксированном лабиринте [3].
В настоящем исследовании алгоритмы обучения с подкреплением будут
применяться для обучения агента в постоянно изменяющейся среде, что усложняет
задачу.
Цель и задачи исследования - исследование техник обучения с подкреплением в динамической
среде (компьютерная игра Snake) с
экспериментальным сравнением алгоритмов.
Структура работы: структура работы обусловлена целью и задачами исследования. Работа
состоит из введения, семи глав, заключения и списка литературы.
Как и было сказано во введении, основой целью данной работы
является исследование обучения с подкреплением в динамической игре - Snake.
Теоретическая
часть
В данной работе будут применятся алгоритмы обучения с
подкреплением, где агент действует в неизвестном окружении, пытаясь
максимизировать выигрыш. Сама среда, в которой действует агент, обычно
формулируется как марковский процесс принятия решений с конечным множеством
состояний.
Обучение с подкреплением относится к типу обучения без
учителя, так как пары "входные данные-ответ" не предоставляются во
время обучения, агент сам накапливает знания и исследует неизученные области,
опираясь на предыдущий опыт.
Простейшая модель обучения с подкреплением состоит из:
1) Множество состояний среды S;
2) Множество действий A;
) Набор правил для состояний;
) Правила, которым подчиняется агент.
В произвольный момент времени t агент характеризуется
некоторым состоянием st из множества S и множеством возможных
действий A
(st), выбрав одно из
доступных действий, агент переходит в следующее состояние st+1 и получает некоторую
награду rt. Взаимодействуя таким образом с окружением, агент вырабатывает
стратегию  , которая максимизирует величину R=r0+. +rn или величину:
, которая максимизирует величину R=r0+. +rn или величину:
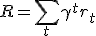
Где 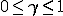 discount-factor, который показывает, насколько важно будущее
поощрение.
discount-factor, который показывает, насколько важно будущее
поощрение.
Можно сделать вывод, что обучение с подкреплением хорошо
подходит для решения задач, связанных с выбором между долгосрочной и
краткосрочной выгодой.
Описание игры
Snake
Snake - популярная компьютерная игра, возникшая в
середине 70-х годов.
Как правило, игрок управляет длинным тонким объектом,
напоминающим змею, который ползает по плоскости (ограниченной стенками),
собирая еду (яблоки) и избегая столкновения с границами игрового поля и с
собственным телом. Также на поле могут существовать дополнительные препятствия.
Каждый раз, когда змея съедает яблоко, ее длина увеличивается, что постепенно
усложняет игру. Игрок управляет направлением головы змеи (влево, вправо, вверх,
вниз), а тело змеи движется следом, причем игрок не может остановить движение.
Каждый раз, когда змейка съедает яблоко, новое яблоко появляется в случайном не
занятом месте игрового поля.

В настоящей работе будет использоваться игра, реализованная
на языке Python. Для тестирования алгоритмов, будет использовано 2 версии:
1) Обычная, без дополнительных препятствий, игровое поле
20х20 клеток:
2) Более сложная реализация, где во время игры
появляются препятствия в виде точек, размер поля 40х40:
Q-Learning
Q-обучение - один из методов обучения с подкреплением, где на
основе получаемого вознаграждения, агент формируют функцию полезности Q, которая в дальнейшем
позволяет выбирать подходящую стратегию, основываясь на предыдущем опыте.
Сама функция полезности выглядит следующим образом:
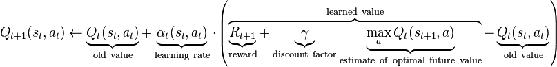
Где: st - состояние среды в момент времени t
at - действие, совершенное в момент времени t
αt - параметр, отвечающий за
то, как сильно агент будет учитывать новый опыт, причем 0<α≤1 (чем больше α, тем сильнее изменяется
функция полезности после каждого действия)
γ - discount factor, который отвечает за то,
как сильно агент будет принимать во внимание будущую награду при обновлении
функции полезности
Rt+1 - поощрение при совершении действия at в состоянии st
Алгоритм Q-Learning (псевдокод):

SARSA
(State-Action-Reward-State-Action)
Алгоритм SARSA берет за основу концепцию Q-обучения, однако шаг Update (обновление ценности)
происходит по-другому.
Обновление функции полезности зависит от текущего состояния
агента S1,
действия, которое выберет агент А1, награды R за это действие,
следующего состояние S2, в котором окажется агент и следующего действия, которое он
предпримет. Получается такая схема (st, at, rt, st+1, at+1), что и образует
аббревиатуру SARSA.
Формула значения Q выглядит следующим образом:
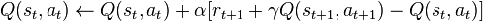
Где переменные означают то же, что и в классическом Q-learning
Аппроксимация
Q значения с помощью нейронной сети
Зачастую, количество состояний настолько большое, что
классические алгоритмы не справляются с такой большой нагрузкой, или показывают
не очень хорошие результаты.
Для того, чтобы решить эту проблему, можно использовать
нейронную сеть для аппроксимации значения функции Q. В нашем исследовании,
будет использоваться такая схема:
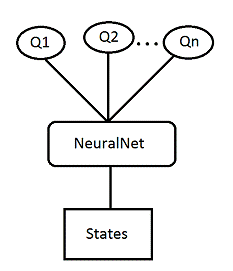
Где на вход подается состояние среды, а на выходе получаем
значения функции Q для каждого из возможных действий.
Алгоритм обучения c помощью нейронной сети:
1) Пока игра не закончена:
2) Запустить нейронную сеть
3) Выбрать действие, соответствующее наибольшему
значению функции Q, если максимальных элементов несколько, равновероятно выбрать
одно из действий
) Совершить действие, выбранное в (3), перейти в
состояние s’
и получить поощрение rt+1
) Запустить нейронную сеть, используя в качестве
входного параметра s’. Сохранить максимальное значение функции Q (maxQ)
6) Так как нейронная сеть, в нашем случае, имеет три
выхода (для каждого действия LEFT, RIGHT,STRAIGHT), нам необходимо обновить только то значение в
выходном векторе, которые агент совершил, причем обновить следующим образом: reward + gamma*maxQ, где (0<=gamma<=1)
Обучается нейронная сеть методом обратного распространения
ошибки.
Например, если вначале алгоритма выходной вектор выглядел
так:
То после одной итерации он будет выглядеть так:
(0.1,0.15,12,0.4)
И использоваться как требуемое выходное значение сети.
В данном исследовании используется нейронная сеть с 5-ю
входными нейронами (область видимости змейки + положение яблока), одним скрытым
слоем (7 нейронов) и тремя выходными нейронами.
Постановка
задачи
Как было сказано во введении, основная цель данной работы -
исследование различных техник обучения с подкреплением в динамической среде, а
именно, в компьютерной игре Snake.
Видеоигра Snake является отличным тестовым полигоном для
тестирования алгоритмов машинного обучения.
Компоненты игры:
1) поле, размеры которого задаются пользователем (в
данном случае 20х20);
2) яблоко, которое появляется в случайном незанятом
месте игрового поля;
) змейки, которая может двигаться по игровому полю.
Во время игры змейка не может пересекать свое тело и
препятствия, находящиеся на игровом поле, в случае нарушения данного правила,
игра начинается заново. Если змейка достигла яблока, ее размер увеличивается на
1 и к итоговому счету также прибавляется единица. Новое яблоко появляется в
случайной незанятой клетке
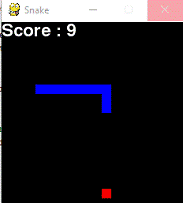
Для применения алгоритмов Q-learning и SARSA, была заложен следующая
логика:
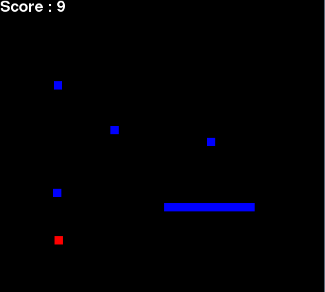
) змейка видит все, что происходит вокруг головы
(желтая область) и знает координаты яблока (красный квадрат):
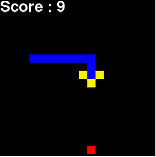
) агент (змейка) не знает, что яблоко нужно съесть;
Состояние среды представляет из себя массив из пяти
элементов, значение каждого элемента равно 0, 1 или - 1.
Первые три элемента представляют область видимости змейки,
где:
· 0 - в
соответствующем секторе ничего нет
· 1 - в данном
квадрате находится фрукт
· 1 -
препятствие
Оставшиеся два элемента показывают положение фрукта на
игровом поле.
Обучение агента происходит следующим образом:
· При достижении яблока дается награда 500
· При смерти (столкновение с препятствием
или телом змейки) награда равна - 100
· При действиях, когда ничего из
вышеперечисленного не происходит, награда равна - 10
· Обычное Q - обучение с параметрами
gamma= 0.9 и alpha =0.8
Множество значений Q представляет из себя словарь, где каждому
состоянию поставлено в соответствии значение полезности для каждого из
возможных действий, например:
(-1, 1, 0, 3,4): {'STRAIGHT': - 84.29095559716063, 'LEFT': - 99.12, 'RIGHT': 1033.1638760268927}
В данном случае, змейка повернет направо.
Описание
Экспериментов
Для начала, испытаем алгоритмы на самой простой реализации, где
агент действует на поле размеров 20х20 без дополнительных препятствий.
В результате, как видно на скриншотах, в первые 20-30 секунд
обучения, все алгоритмы показывали результат, при котором, змейка не двигалась
к цели и принимала случайные решения:
Q-learning:
После 1-3-х минут обучения, средний счет был около 2-х а
максимальный доходил до пяти.
Чтобы добиться удовлетворительных результатов, понадобилось
всего 10-15 минут обучения, когда средний счет был около 10, а максимальный
доходил до 16.
За 30 минут обучения, средний счет был равен 12, а
максимальный доходил до 19.
SARSA:
Далее был применен метод SARSA, условия эксперимента
остались аналогичными.
В первые секунды обучения, змейка также не двигалась к цели.
После трех минут обучения средний счет составил 2 ед, с максимальным счетом
равным 6.
За 15 минут удалось добиться среднего счета 8 и максимального
счета 18.
При 30 минутах обучения средний счет равен 13, а максимальный
счет 21.
Q-value approximation:
Далее был применен метод аппроксимации значения Q.
В отличии от первых двух алгоритмов, удовлетворительных
результатов удалось добить только к 15-й минуте обучения со средним счетом 10 и
максимальным 22.
Сравнив три алгоритма на простой реализации, можно сделать вывод,
что что алгоритм SARSA показывает лучшие результаты, но требует большего обучения. Q-learning же хорошо себя
показывает, когда время обучение не очень большое, около 20 минут, метод
аппроксимации тоже показывает хорошие результаты, но требует еще большего
обучения, чем SARSA.
Теперь попробуем алгоритмы на более сложной реализации: поле
40х40 и дополнительные препятствия.
Так как реализация более сложная, увеличим время тренировки
до двух часов или ~3300 игровых эпизодов.
Q-learning:
Алгоритм хорошо себя показал, счет для каждой игры виден на
графике:
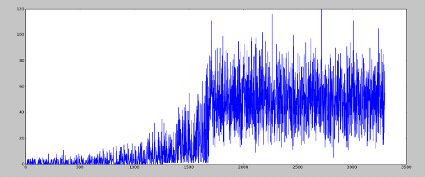
Как видно на рисунке, примерно после 1700 игры результаты
значительно улучшаются.
Теперь посмотрим средние значения за каждые 100 игр:
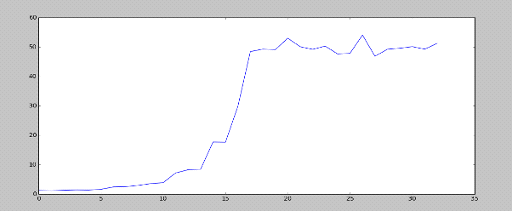
После ~ 2000 игровых эпизодов, обучение сильно замедлилось и
средний счет практически перестает расти.
SARSA: алгоритм хорошо себя
показывает
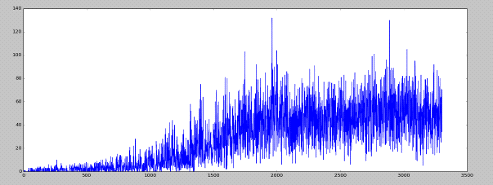
Как видно на рисунке, счет плавно растет от игры к игре
Посмотрим средние значения за каждые 100 игр:
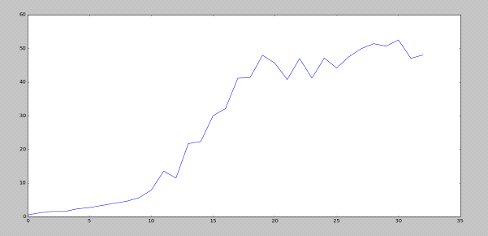
После ~2500 игровых эпизодов, обучение значительно
замедлилось и средний счет перестал расти.
Сравним алгоритмы Q-learning и SARSA:
На рисунке изображены графики средних значений счета за
каждые 100 эпизодов, зеленым цветом SARSA, синим - Q-learning
обучение компьютерная игра алгоритм
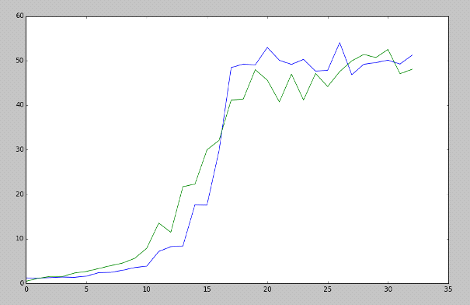
Как видно на графике, оба алгоритма показывают примерно
одинаковые результаты. Однако SARSA растет плавнее и заканчивает расти немного
позже, чем Q-learning. Можно сделать вывод,
что при обучении агентов на относительно малом числе эпизодов (до 1500) лучше
использовать SARSA, однако при длительном обучении (более 3000 эпизодов) оба
алгоритма показываю себя одинаково хорошо.
Neural-network Q-value approximation:
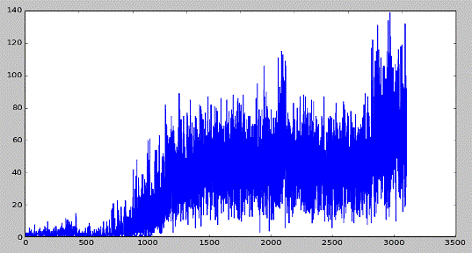
Посмотрим средние значения за каждые 100 игр:
После ~1700 Игровых эпизодов, обучение значительно
замедляется, но продолжает расти
Теперь, сравним алгоритм аппроксимации Q-значения c SARSA и Q-learning (которые показали
примерно одинаковые результаты):
Зеленым цветом - Q-value approximation
Красным цветом - SARSA
Синим цветом - Q-leaning
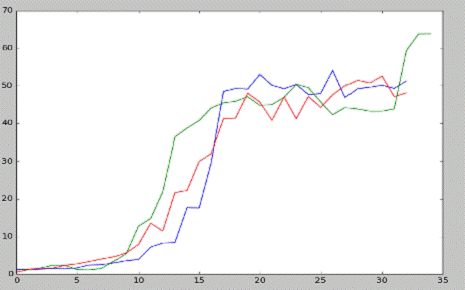
Как видно на сравнительном графике, алгоритм аппроксимации Q-значения работает хуже
остальных, когда число игровых эпизодов меньше 1000, начиная с тысячи до двух,
алгоритм показывает значительно лучшие результаты. В конечном итоге, после
~3000 эпизодов обучения все три алгоритма показали примерно одинаковый
результат.
Однако стоит заметить, что алгоритм аппроксимации Q-значения работает
значительно быстрее по времени, за два часа удалось провести около 4000 0
игровых эпизодов, когда Q-learning и SARSA успели провести только 3000.
В итоге, можно сделать вывод, что для задач, где число
состояний среды мало или требуется провести мало количество тренировочных
эпизодов, лучше использовать Q-learning и SARSA, если же окружение большое и агента приходится
обучать на больших данных, то предпочтительнее использовать аппроксимацию Q-значения.
Заключение
В данной работе было рассмотрено применение алгоритмов
обучения с подкреплением в динамической среде, а именно - компьютерной игре Snake. Алгоритмы были
протестированы на ряде тестовых примеров. Эксперименты показали, что обучение с
подкреплением отлично подходит для применения в областях, где требуется обучить
агента действовать в постоянно изменяющейся среде.
В дальнейшем планируется рассмотреть другие техники обучения
без учителя для разного рода задач.
Список
литературы
[1] Sutton, Richard S.; Barto, Andrew G. "Reinforcement
Learning: An Introduction” (1998)
[2] Yizheng Liao, Kun Yi, Zhe Yang: Reinforcement Learning to Play
Mario, CS229.
[3] Bing-Qiang Huang, Gung-Yi Cao, Min Guo: Reinforcement Learning
Neural Network to the problem of autonomous mobile robot obstacle avoidance,
18-21, (2005).
[4] Michiel R., Marco W.: Reinforcement Learning in the Game of
Othello: Learning Against a Fixed Opponent and Learning from Self-Play
[5] M. Wiering and M. van Ottelo: Reinforcement Learning:
State-of-the-art. (2012)
[6] Imran Ghory: Reinforcement learning in board games.
[7] Yngvi B., Vignir H., Ársæll J. and Einar
J. ”Efficient use of reinforcement learning in a computer game”