Алгоритм, эвристически строящий оптимальный граф для задачи децентрализованного поиска
Содержание
Введение
1. Задача об оптимальном графе для децентрализованного поиска
1.1 Формулировка
1.1.1 Жадный алгоритм
1.1.2 Модель Клайнберга
1.1.3 Математическая модель
1.2 Алгоритмы решения
1.2.1 Алгоритм локального поиска
1.2.2 Табу алгоритм
1.2.3 Метод ветвей и границ
1.3 Дополнения к алгоритмам
1.3.1 Выбор между одинаковыми соседями
1.3.2 Стартовый граф
2. Программная реализация
3. Результаты
Вывод
Список литературы
Приложение
Введение
Термин тесный мир (the small world) известен с 60х годов 20 века [1]. Множество
математических моделей было предложено для объяснения, как тесный мир возникает
в реальных сетях [5][6]. Некоторые из этих моделей были использованы для
построения P2P сетей с логарифмической сложностью поиска, например
распределенная хэш-таблица (Distributed Hash Table). Системы описанные в работах [2] и
[3] основаны на модели Клайнберга [4]. Эта модель основана на том, что вершины
графа имеют координаты в D
мерном пространстве. Поиск в этой модели осуществляется с помощью жадного алгоритма,
где старт начинается в произвольной вершине, и переход осуществляется,
основываясь только на локальной информации - информации о соседях. При
построении графа по модели Клайнберга жадный алгоритм в среднем делает 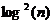 шагов.
шагов.
С развитием технологий и увеличением количества
информации, ее хранение и обработка стала трудоемкой. Вначале вся информация
могла храниться в одном месте (сервере), и клиенты имели доступ с серверу и
могли получать необходимую информацию. Потом информация начала храниться на
разных компьютерах, но к ним доступ имел только сервер, поэтому все равно все
запросы проходили через него. Такой поиск использует центр поиска. Позже
произошел отказ от какого-то специального компьютера, который должен быть
центром, и возникли одноранговые компьютерные сети (p2p - peer to peer).
В одноранговых сетях все элементы являются
равноправными, и поиск может начинаться с любого элемента и проходить через
любые элементы. Пример одноранговой сети можно увидеть на рисунке 1, а пример
сети с сервером на рисунке 2.
|
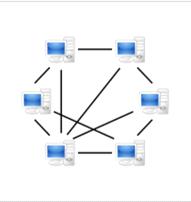 Рисунок 1 - Одноранговая сеть Рисунок 1 - Одноранговая сеть
|
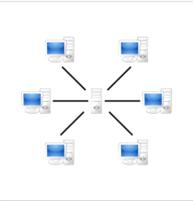 Рисунок 2 - Клиент-серверная сеть Рисунок 2 - Клиент-серверная сеть
|
Так как для поиска в одноранговой сети нет центра,
который знает где находится информация. Для того, чтобы избежать необходимости
хранения огромного количества информации, каждый узел одноранговой сети хранит
информацию только о своих соседях, т.е. о тех узлах, с которыми он соединен.
Поэтому для передачи или поиска необходимой информации в общем случае
используется так называемы алгоритм broadcast. Этот алгоритм начинается с
одного узла, потом передает информацию всем его соседям, и в каждом узле снова
передает всем его соседям. Поэтому, если сеть связанная, то поиск точно сможет
предоставить необходимую информацию.
В сети присутствует некоторое количество машин, при
этом каждая может связаться с любой из других. Каждая из этих машин может
посылать запросы другим машинам на предоставление каких-либо ресурсов в
пределах этой сети и, таким образом, выступать в роли клиента. Будучи сервером,
каждая машина должна быть способной обрабатывать запросы от других машин в
сети, отсылать то, что было запрошено. Каждая машина также должна выполнять
некоторые вспомогательные и административные функции (например, хранить список
других известных машин-«соседей» и поддерживать его актуальность).
Одноранговые сети используются для построения
файлообменных сетей, сетей распределенных вычислений, финансовых сетей и др.
Пользователи файлообменной сети выкладывают какие-либо
файлы в общую (англ. share - делиться) директорию, содержимое которой доступно
для скачивания другим пользователям. Какой-нибудь другой пользователь сети
посылает запрос на поиск какого-либо файла. Программа ищет у клиентов сети
файлы, соответствующие запросу, и показывает результат. После этого
пользователь может скачать файлы у найденных источников. В современных
файлообменных сетях информация загружается сразу с нескольких источников. Её
целостность проверяется по контрольным суммам.
Такие сети позволяют в сравнительно короткие сроки
выполнять поистине огромный объём вычислений, который даже на суперкомпьютерах
потребовал бы, в зависимости от сложности задачи, многих лет и даже столетий
работы. Такая производительность достигается благодаря тому, что некоторая
глобальная задача разбивается на большое количество блоков, которые одновременно
выполняются сотнями тысяч компьютеров, принимающими участие в проекте.
1. Задача об оптимальном графе для
децентрализованного поиска
.1 Формулировка
Целью данной работы было проанализировать построенные
оптимальные структуры и характер роста целевой функции.
1.1.1 Жадный алгоритм
В задаче о децентрализованном поиске дан граф 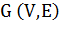 невзвешенный и неориентированный.
Также дана функция расстояния
невзвешенный и неориентированный.
Также дана функция расстояния 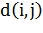 , которая может вычислять расстояние между любыми двумя
вершинами графа
, которая может вычислять расстояние между любыми двумя
вершинами графа  .
.
Определим соседей вершины 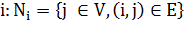 . Тогда жадный поиск в графе будет
происходить следующим образом.
. Тогда жадный поиск в графе будет
происходить следующим образом.
GreedyWalk( ,
,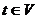 )//
)//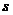 -начальная вершина,
-начальная вершина, 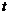 - искомая вершина
- искомая вершина
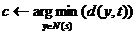
2 if 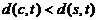 then
then
return GreedyWalk( ,
, )
)
else
return
Жадному алгоритму на вход подается две вершины -
начальная и финальная. Он рассматривает все вершины из соседей начальной,
рассчитывает расстояние от них до финальной вершины и переходит в ту, от
которой минимальное расстояние. После этого такие же операции проводит с
текущей вершины. Все это продолжается до тех пор пока мы не придем в вершину,
расстояние от которой до финальной вершины будет минимально среди всех ее
соседей.
Такой алгоритм в общем случае не дает точной гарантии
нахождения финальной вершины от любой. См. рисунок 3.

Если использовать в качестве функции расстояния
Евклидово расстояние на плоскости. И запустить жадный алгоритм с начальной
точкой 1 и финальной точкой 4, то алгоритм после рассмотрения соседей вершины
1, перейдет в вершину 2, как самую ближайшую. И в итоге не сможет найти вершину
4, так как из вершины 2 некуда двигаться.
Для того, чтобы избежать такой ситуации исходный граф
должен иметь определенную структуру, такая структура может быть построена с
помощью разбиения Вороного. Диаграмма Вороного конечного множества точек S на
плоскости представляет такое разбиение плоскости, при котором каждая область
этого разбиения образует множество точек, более близких к одному из элементов
множества S, чем к любому другому элементу множества.
Рассмотрим пример набора точек на плоскости с
Евклидовым расстоянием.
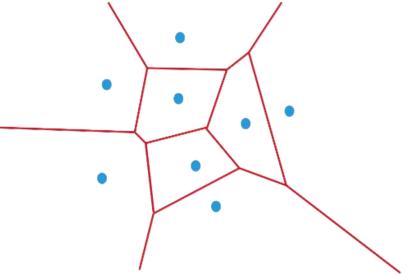
Рисунок 4 - разбиение Вороного
На рисунке 4 можно заметить, что любая точка, попавшая
в какую-либо область, всегда будет ближе к точке, породившей эту область, чем к
любой другой.
После того, как алгоритм разбил плоскость с помощью
разбиения Вороного, соединяем ребрами те вершины, которые имеют общую границу.
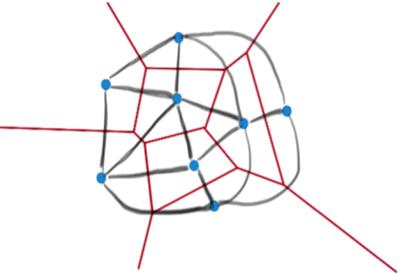
Рисунок 5 - граф после соединения
вершин
После построения всех необходимых ребер, получаем
граф, в котором жадный алгоритм всегда найдет нужную вершину, начиная с любой.
Такой граф называется графом Делоне.
При запуске жадного поиска от какой-либо вершины, мы
какое-то количество раз вызываем функцию подсчета расстояний от одной вершины
до другой. Назовем сложностью поиска одной вершины от другой количество вызовов
функции подсчета расстояния. Рассмотрим пример поиска вершины 15, от вершины 1
на графе с рисунков 6 - 13.
|
 Рисунок 6 - начало поиска Рисунок 6 - начало поиска
|
 Рисунок 7 - первый шаг Рисунок 7 - первый шаг
|
|
 Рисунок 8- выбор после первого шага Рисунок 8- выбор после первого шага
|
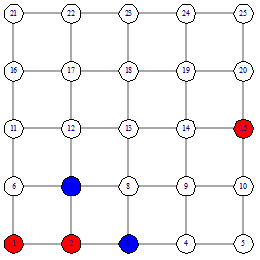 Рисунок 9 - второй шаг Рисунок 9 - второй шаг
|
|
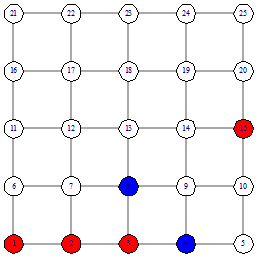 Рисунок 10 - третий шаг Рисунок 10 - третий шаг
|
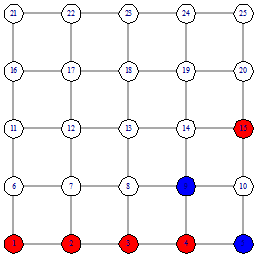 Рисунок 11 - четвертый шаг Рисунок 11 - четвертый шаг
|
|
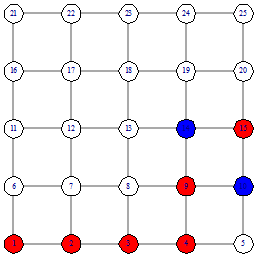 Рисунок 12- пятый шаг Рисунок 12- пятый шаг
|
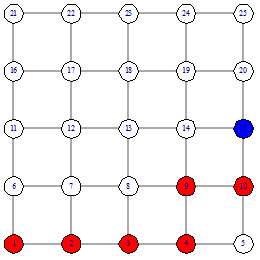 Рисунок 13 - шестой шаг Рисунок 13 - шестой шаг
|
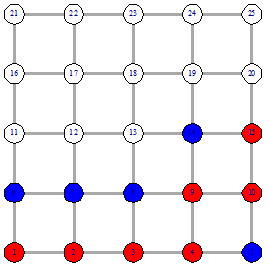
Рисунок 14 - итоговый путь
Поиск начинается с подсчета расстояния от начальной
вершины до финальной 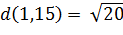 . Потом мы рассматриваем соседей начальной вершины 1 - это
вершины 2 и 6 и считаем расстояния от них
. Потом мы рассматриваем соседей начальной вершины 1 - это
вершины 2 и 6 и считаем расстояния от них 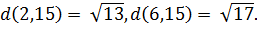 Так как наименьшее расстояние у
вершины 2, то идем в вершину 2 (рисунок 8). Следующим шагом рассматриваем
соседей вершины 2. Продолжаем до тех пор, пока не дойдем до вершины 15. В этом
поиске мы столкнулись с неопределенностью на шаге номер 3 (рисунок 10).
Расстояние от 4 и от 8 вершины одинаково. Возникает вопрос - какую вершину
выбирать. На этот вопрос мы ответим при описании нашего алгоритма.
Так как наименьшее расстояние у
вершины 2, то идем в вершину 2 (рисунок 8). Следующим шагом рассматриваем
соседей вершины 2. Продолжаем до тех пор, пока не дойдем до вершины 15. В этом
поиске мы столкнулись с неопределенностью на шаге номер 3 (рисунок 10).
Расстояние от 4 и от 8 вершины одинаково. Возникает вопрос - какую вершину
выбирать. На этот вопрос мы ответим при описании нашего алгоритма.
После того, как мы нашли финальную вершину, надо
посчитать сложность поиска. Сложность поиска равна 12. На рисунке 14 красными
вершинами отмечен путь жадного алгоритма, который включает в себя 7 вершин, и 5
синих вершин, которые не входят в жадный путь, но при этом использовались
жадным алгоритмом, поэтому они вносят свой вес в сложность алгоритма.
.1.2 Модель Клайнберга
В своем подходе Клайнберг рассматривает точки на
плоскости, которые представляют собой сетку размера 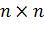 . Тогда для того, чтобы жадный
алгоритм мог найти необходимые вершины, начиная с любой, начальный граф должен
иметь вид сетки, где каждая вершина соединена с вершиной слева, справа, сверху
и снизу. Пример такого графа можно увидеть на рисунке 15.
. Тогда для того, чтобы жадный
алгоритм мог найти необходимые вершины, начиная с любой, начальный граф должен
иметь вид сетки, где каждая вершина соединена с вершиной слева, справа, сверху
и снизу. Пример такого графа можно увидеть на рисунке 15.
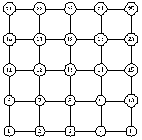
Рисунок 15 - пример графа сетки
При такой структуре графа жадный поиск выполняется за 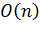 , где
, где 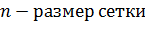 . В нашем примере
. В нашем примере 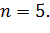
Поэтому Клайнберг решил проверить, а нельзя ли немного
изменить структура графа и при этом ускорить поиск. Оказалось, что можно. В
своей модели он в существующую структуру сетку добавляет дополнительные ребра
следующим образом:
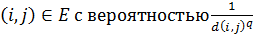 (1)
(1)
В формуле (1) 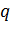 - коэффициент кластеризации. Такой
способ добавления ребер позволяет ускорить жадный поиск в среднем до
- коэффициент кластеризации. Такой
способ добавления ребер позволяет ускорить жадный поиск в среднем до 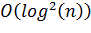 .
.
Иногда в формуле (1) вместо коэффициента кластеризации
используется просто вводимый пользователем параметр, и в зависимости от него
граф может менять свой вид.
Например, при большом q, вероятность уменьшается с
увеличением расстояния. Если же q мало, то вероятность длинных ребер
возрастает.
.1.3 Математическая модель
В нашем подходе мы хотим понять как выглядят
оптимальные структуры. Также проанализировать характер роста целевой функции.
Дополнительно интересно нельзя ли выполнять поиск быстрее, чем в модели
Клайнберга и как будет выглядеть граф в этом случае. Для этого мы построили
математическую модель, которая описывает поставленную оптимизационную задачу.
Переменные:
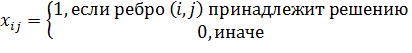 (2)
(2)
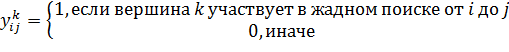 (3)
(3)
Целевая функция:
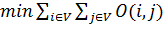 (4)
(4)
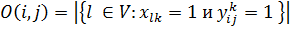 (5)
(5)
Ограничения:
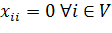 (6)
(6)
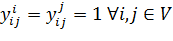 (7)
(7)
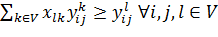 (8)
(8)
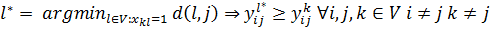 (9)
(9)
Целевая функция (4) представляет собой сумму
сложностей всех жадных поисков от каждой вершины до каждой. Сложность в
математической форме записана в (5) есть мощность множества вершин, которые
являются соседями вершин, находящихся в пути жадного алгоритма.
Ограничения (6) и (7) являются тривиальными, первое
запрещает петли в графе, второе говорит, что начальная и финальная вершина
обязательно должны быть в пути жадного алгоритма.
Ограничение (8) нужно для сохранения целостности пути.
Оно описывает, что если вершина 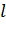 находится в пути жадного алгоритма, то хотя бы один из ее
соседей тоже должен будет там находиться. По сути для всех вершин, кроме
начальной и финальной, таких соседей будет 2 - вершина, из которой пришли, и
вершина, в которую уйдем.
находится в пути жадного алгоритма, то хотя бы один из ее
соседей тоже должен будет там находиться. По сути для всех вершин, кроме
начальной и финальной, таких соседей будет 2 - вершина, из которой пришли, и
вершина, в которую уйдем.
Последнее ограничение (9) описывает выбор следующей
вершины в пути по принципу жадного алгоритма. Т.е. если вершина 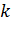 находится в пути, то среди ее
соседей обязательно найдется вершина
находится в пути, то среди ее
соседей обязательно найдется вершина 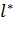 , расстояние от которой будет
наименьшее среди всех соседей , и эта вершина будет в пути.
, расстояние от которой будет
наименьшее среди всех соседей , и эта вершина будет в пути.
Получившаяся модель является нелинейной 0-1 моделью.
1.2 Алгоритмы решения
.2.1 Алгоритм локального поиска
Для решения оптимизационной задачи сначала был
разработан алгоритм локального поиска. Алгоритм начинал работу с графа-сетки, а
потом производил локально оптимальные действия на каждом шагу, до тех пор пока
не достигнет локального минимума.
На каждом шагу алгоритм рассматривал действия, которые
могли в себя включать добавление ребра, удаление ребра или добавление одного и
удаление другого.
Так как при больших значениях числа вершин в графе,
количество действий на каждый шаг возрастает, а подсчет сложности жадного
алгоритма затратен по времени, то были рассмотрены только симметричные решения.
Поэтому если рассмотреть граф 4х4 (рис. 16) то, красным отмечены вершины,
которые рассматриваются при выборе вершин для начала ребер для удаления или
добавления, а пунктирные линии представляют собой линии симметрии. На рисунке
17 нарисованы примеры симметричных ребер это ребра 5-15, 8-14, 2-12 и 3-9.
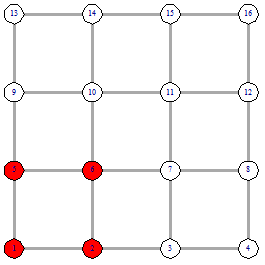
Рисунок 16 - Вершины для выбора
начала ребер
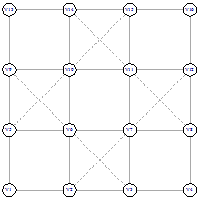
Рисунок 17 - Симметричные ребра
Принцип построения таких ребер описан ниже:
. У нас есть одно ребро с началом в вершине 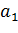 , а концом в вершине
, а концом в вершине 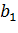 .
.
. Для построения симметричного ребра считаем
его начало и конец
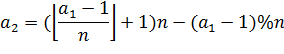
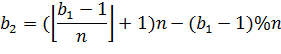
. Далее считаем третье ребро
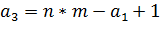
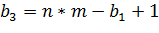
. Последнее ребро
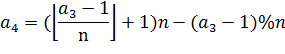
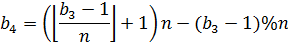
В примере на рисунке 17 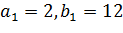 , тогда
, тогда 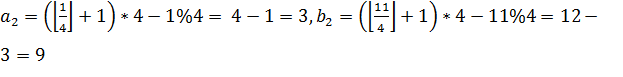 , получается ребро 3-9.
, получается ребро 3-9.
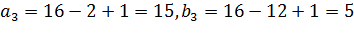 , получаем ребро 5-15. И последнее
ребро
, получаем ребро 5-15. И последнее
ребро 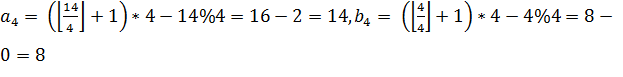 8-14. Таким образом при добавлении
или удалении ребра a-b, происходит удаление или добавление от 0 до 3х
симметричных ему ребер.
8-14. Таким образом при добавлении
или удалении ребра a-b, происходит удаление или добавление от 0 до 3х
симметричных ему ребер.
При использовании этого предположения количество
вариантов изменения решения на каждом шаге заметно сокращается, поэтому
локальный поиск приходит к локально оптимальному решению значительно быстрее.
Ниже представлен псевдокод этого алгоритма:
LocMin(G) //G - граф
. action* = -1
. O* = O(G)
. for action in actions
. O = calculate O for action
. if O < O*
. O* = O
. action* = action
. if action* == -1
. return G
. else
11. do action* for G
. return LocMin(G)
.2.2 Табу алгоритм
После изучения результатов, полученных при запуске
алгоритма локального поиска, был имплементирован табу алгоритм для получения
более лучшего решения. Для изменения алгоритма были добавлены новые входные
параметры, такие как количество шагов алгоритма, на которое действие помещается
в табу лист, и количество раз, когда алгоритм доходит до локального минимума
без улучшений подряд. Второй параметр был введен для того, чтобы можно было
закончить работу алгоритма.
Этот алгоритм отличается от предыдущего тем, что при
достижении локального минимума он не останавливается, а делает действие,
которое меньше всего ухудшает целевую функцию, затем заносит действие обратное
сделанному в табу лист и продолжает работу. Тем самым мы можем сдвинуться с
локального минимума и перейти в другой локальный минимум. Как показали
результаты этот подход работает лучше предыдущего.
Однако из-за того, что количество действий на каждом
шаге все еще очень большое даже после введения симметричности добавления и
удаления ребер, было введено изменение в работу алгоритма. Теперь он ищет не
самое оптимальное действие на каждом шаге, а первое действие, которое улучшает
целевую функцию. Псевдокод работы этого алгоритма представлен ниже:
Tabu(G) //G - граф
. check tabu list
. action* = -1
. O* = O(G)
. for action in actions
. O = calculate O for action
. if O < O*
. O* = O
. action* = action
. break
. if action* == -1
. if O* ≥ min_O
. fails++
. if fails == number_of_fails
. return G
. else
. fails = 0
. min_O = Inf
. tabu_action = -1
. for action in G
. O = calculate O for action
. if O < min_O
. min_O = O
. tabu_action = action
. do tabu_action
25. add reverse tabu_action to
tabu list for number_of_tabu steps
26. return Tabu(G)
. else
28. do action for G
. return Tabu(G)
В этом алгоритме на первом шаге идет проверка табу
листа, во-первых, на уменьшение для каждого элемента количество шагов в табу
листе, во-вторых, удаление тех элементов, счетчик которых достиг нуля.
Так же изменения произошли в первом цикле. Во-первых,
выбирается не самое оптимальное действие, как говорилось ранее, а первое
действие, которое приносит улучшение. Во-вторых, при выборе действия
проверяется не лежит ли оно в табу, тем самым это помогает нам не возвращаться
обратно в тот же локальный минимум. Однако если действие, которое лежит в табу
листе, все же улучшает решение до такого, что оно лучше самого лучшего
известного, то это действие совершается и удаляется из табу списка.
Небольшие отличия от предыдущего алгоритма есть в
моменте после нахождения локального минимума. Во-первых, идет проверка улучшили
мы или нет текущее оптимальное, если да, то алгоритм сохраняет новое
оптимальное, обнуляет количество неудач (fails) и продолжает работу. Если же
алгоритм не нашел решение лучшее, чем текущее оптимальное, то количество неудач
увеличивается на 1, сравнивается с глобальным параметром. Если количество
неудач сравнялось с фиксированным числом, то алгоритм останавливается. Если
алгоритм не остановлен, то программа находит действие, которое приводит к
наименьшему ухудшению целевой функции. Делает его и добавляет обратное действие
в табу список на определенное количество шагов.
1.2.3 Метод ветвей и границ
После получения результатов работы второго алгоритма,
нужно было проверить предположение о существовании оптимального решения,
которое содержит в себе только симметричные ребра. Так как и первый и второй
алгоритм являются эвристическими, т.е. не дают гарантии нахождения глобально
оптимального решения, то для проверки этой гипотезы был придуман метод ветвей и
границ, который является точным алгоритмом, т.е. находит глобально оптимальное
решение.
В этом методе уже рассматривались все возможные
действия, без симметричности. На рисунке 18 можно увидеть начало дерева для
графа 4х4.
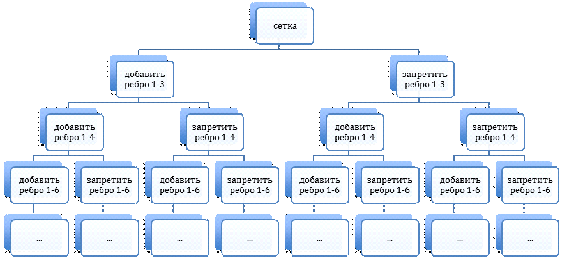
Рисунок 18 - Ветвление в методе
ветвей и границ
Таким образом это дерево представляет собой все
возможные варианты существующих графов. Для того, чтобы не рассматривать все
решения, используют границы. На каждом шаге идет подсчет нижней границы для
определения наименьшего возможного значения целевой функции для текущего
релаксированного графа.
Рассмотрим алгоритм подсчета нижней границы для
релаксированной задачи с матрицей смежности (таблица 1)
Таблица 1 - Матрица смежности
|
0
|
1
|
1
|
-1
|
-1
|
1
|
|
1
|
0
|
0
|
1
|
0
|
0
|
|
1
|
0
|
0
|
1
|
1
|
0
|
|
-1
|
1
|
1
|
0
|
0
|
1
|
|
-1
|
0
|
1
|
0
|
0
|
1
|
|
1
|
0
|
0
|
1
|
1
|
0
|
В таблице выше представлена матрица смежности графа с
шестью вершинами, где 1 означает, что ребро есть; 0 означает, что ребра нет, но
может быть проведено; -1 означает, что этого ребра не может быть в графе, построенном
далее.
При вычислении нижней границы для такой матрицы
смежности алгоритм выполняет жадный поиск от каждой вершины до каждой. Но когда
алгоритм рассматривает соседей вершины, то он рассматривает не только те
вершины, с которыми она соединена, но и те вершины, с которыми она может быть
соединена (те, где 0 в матрице), при этом игнорирует вершины, с которыми нет
возможности соединиться (где -1 в матрице). Однако при подсчета сложности
поиска от одной вершины до другой в сумму целевой функции входят только те
вершины, до которых есть ребро. Например, если мы рассмотрим вторую вершину у
нее 2 соседа (1 и 4) и 3 возможных соседа (3,5 и 6). При поиске от нее алгоритм
рассмотрит все 5 вершин и выберет ту, которая ближе к финальной точке, но при
этом в целевую функцию внесет только 2 единицы.
1.3 Дополнения к алгоритмам
.3.1 Выбор между одинаковыми соседями
При проведении жадного поиска от одной вершины до
другой может появится случай, когда у алгоритма будет несколько вершин с
одинаковым расстоянием до финальной точки. Возникает вопрос, какую вершину
выбрать для продолжения пути. В нашем алгоритме есть входной параметр, который
отвечает за способ выбора одной вершины из множества одинаковых.
Эта переменная может принимать три значения:
· 0 - выбираем вершину с наименьшей
степенью. Таким образом она внесет наименьший вклад в целевую функцию, что
улучшит решение.
· 1 - выбираем вершину с наибольшей
степенью. Хоть она и внесет в целевую функцию максимально возможный вклад, но
при этом из нее можно будет рассмотреть наибольшее количество вершин для
дальнейшего пути, что может сократить поиск.
· 2 - выбираем случайную вершину.
Рассмотрим на примере, как изменится значение
сложности жадного поиска.
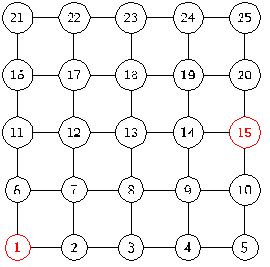
Рисунок 19 - начало поиска
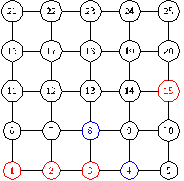
Рисунок 20 - выбор следующей вершины
На рисунке 20 видим, что расстояние от вершины 4 до
вершины 15 равно расстоянию от вершины 8 до 15, таким образом мы используем
входной параметр для определения следующей вершины. Если он равен 0, то
выбирается вершина 4, так как она имеет степень 3 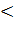 4 - степени вершины 8. Если он равен
1, то выбирается вершина 8. Если он равен 2, то с вероятностью 0.5 выбирается
вершина 4, с вероятностью 0.5 выбирается вершина 8.
4 - степени вершины 8. Если он равен
1, то выбирается вершина 8. Если он равен 2, то с вероятностью 0.5 выбирается
вершина 4, с вероятностью 0.5 выбирается вершина 8.
Различный выбор будет влиять на путь и значение
целевой функции. На следующих рисунках показано, как выглядит пути в каждом из
двух случаев.
|
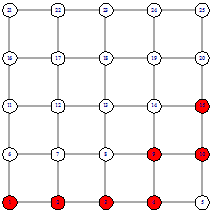 Рисунок 21 - Выбор 0 Рисунок 21 - Выбор 0
|
 Рисунок 22 - Выбор 1 Рисунок 22 - Выбор 1
|
Теперь можно посчитать сложность поиска от вершины 1
до вершины 15. В первом случае сложность равна 12, во втором случае - 13.
.3.2 Стартовый граф
После тестирования локального и табу алгоритма на
различных входных графах-сетка было принято решение начинать не с пустого графа
и стараться добавить в него ребра, а начинать с полного графа и удалять ребра.
Так как чаще всего оптимальное решение предполагает добавление небольшого
количества ребер к графу-сетке, то если алгоритм начинает с полного графа, то
время работы увеличивается в несколько раз. Но результаты показывают, что
иногда, начиная с полного графа вместо сетки, можно прийти к наиболее лучшему
решению.
1.3.3 Функции расстояний
Для выбора функции вычисления расстояний между вершинами,
наш алгоритм использует входной параметр. Если параметр равен 1, то 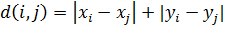 . Если параметр равен 2, то
. Если параметр равен 2, то 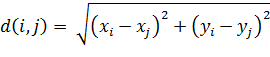 . Если параметр равен INFINITY, то
. Если параметр равен INFINITY, то 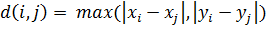 . Также можно ввести любое
положительное число p, тогда
. Также можно ввести любое
положительное число p, тогда 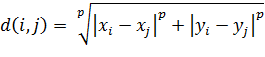 .
.
2. Программная реализация
Для реализации алгоритмов был выбран язык С++, так как
он обладает быстротой выполнения и поддерживает объектно-ориентированное
программирование.
Граф представляет собой класс, который содержит в себе
все необходимые данные, такие как на рисунке 23.

Рисунок 23 - Переменные класса Graph
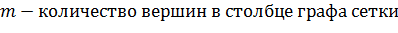
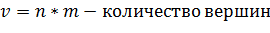
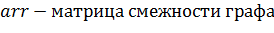
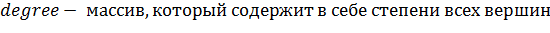
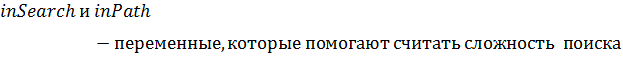
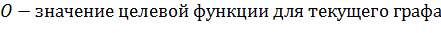
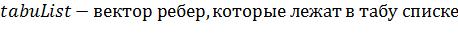
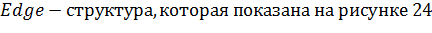

Рисунок 24 - структура Edge
представляет собой структуру данных, которая содержит
в себе начало ребра (start), конец ребра (finish), количество шагов алгоритма,
на которое это ребро помещается в табу список (tabuSteps) и действие, которое
запрещено делать (tabuAction).
Также алгоритм принимает на вход файл конфигурации,
который содержит в себе параметры для алгоритмов. Эти параметры отвечают за
количество fails в табу алгоритме, количество табу шагов, на которое ребро
помещается в табу список и способ перехода к следующему шагу алгоритма (в
локальном и табу алгоритме). Способ перехода либо выбираем самое лучшее
действие из всех локальных переходов, либо первое действие, который уменьшает
нашу целевую функцию.
3. Результаты
Результаты табу алгоритма всегда лучше результатов
алгоритма локального поиска, поэтому в результатах будут показаны только
решения, которые были получены с помощью табу алгоритма.
Были проведены тесты на графах 4х4, 5х5, 6х6, 7х7 с
различными параметрами для выбора между одинаковыми вершинами и с началом как
от графа-сетки, так и от полного графа с использованием различных расстояний.
Названия рисунков представляют собой расстояние, переменная выбора вершины и
значение целевой функции.
4х4 (стартовый граф - граф-сетка)
|
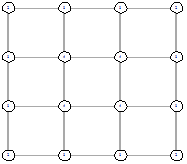 Рисунок 25 - L1, 0, 1728 Рисунок 25 - L1, 0, 1728
|
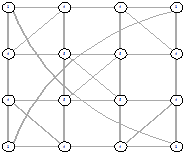 Рисунок 26 - L1, 1, 1828 Рисунок 26 - L1, 1, 1828
|
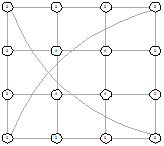 Рисунок 27 - L1, 2, 1782 Рисунок 27 - L1, 2, 1782
|
|
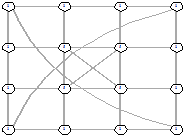 Рисунок 28 - L2, 0, 1800 Рисунок 28 - L2, 0, 1800
|
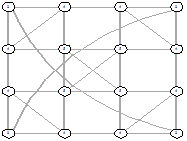 Рисунок 29 - L2, 1, 1820 Рисунок 29 - L2, 1, 1820
|
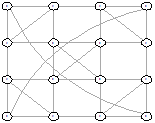 Рисунок 30 - L2, 2, 1814 Рисунок 30 - L2, 2, 1814
|
|
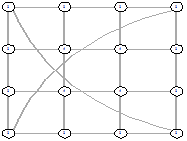 Рисунок 31 - LI, 0, 1816 Рисунок 31 - LI, 0, 1816
|
Рисунок 32 - LI, 1, 1872
|
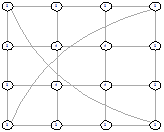 Рисунок 33 - LI, 2, 1846 Рисунок 33 - LI, 2, 1846
|
4х4 (стартовый граф - полный граф)
|
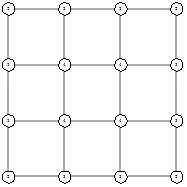 Рисунок 34 - L1, 0, 1728 Рисунок 34 - L1, 0, 1728
|
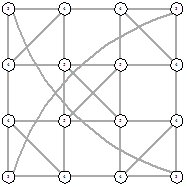 Рисунок 35 - L1, 1, 1828 Рисунок 35 - L1, 1, 1828
|
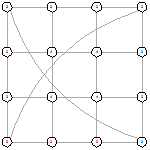 Рисунок 36 - L1, 2, 1782 Рисунок 36 - L1, 2, 1782
|
|
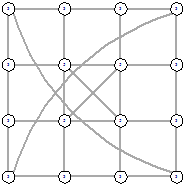 Рисунок 37 - L2, 0, 1800 Рисунок 37 - L2, 0, 1800
|
Рисунок 38 - L2, 1, 1820
|
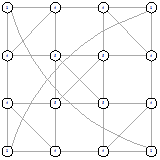 Рисунок 39 - L2, 2, 1814 Рисунок 39 - L2, 2, 1814
|
|
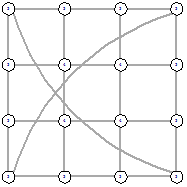 Рисунок 40 - LI, 0, 1816 Рисунок 40 - LI, 0, 1816
|
Рисунок 41 - LI, 1, 1872
|
Рисунок 42 - LI, 2, 1846
|
Можно заметить, что результаты алгоритма не отличаются
не зависимо от стартового графа, поэтому можно предполагать, что мы нашли глобальный
минимум. Рассмотрим результаты для графа 5х5.
5х5 (стартовый граф - граф-сетка)
|
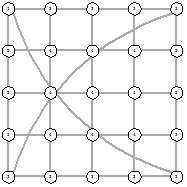 Рисунок 43 - L1, 0, 5429 Рисунок 43 - L1, 0, 5429
|
 Рисунок 44 - L1, 1, 5729 Рисунок 44 - L1, 1, 5729
|
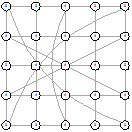 Рисунок 45 - L1, 2, 5556 Рисунок 45 - L1, 2, 5556
|
|
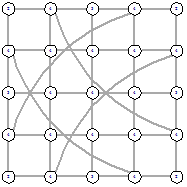 Рисунок 46 - L2, 0, 5613 Рисунок 46 - L2, 0, 5613
|
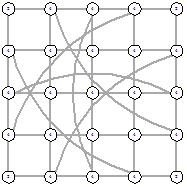 Рисунок 47 - L2, 1, 5697 Рисунок 47 - L2, 1, 5697
|
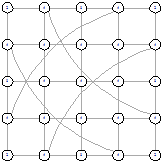 Рисунок 48 - L2, 2, 5683 Рисунок 48 - L2, 2, 5683
|
|
Рисунок 49 - LI, 0, 5643
|
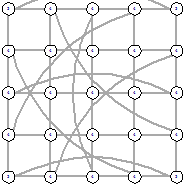 Рисунок 50 - L2, 1, 5733 Рисунок 50 - L2, 1, 5733
|
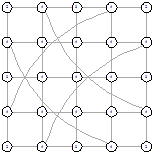 Рисунок 51 - L2, 2, 5710 Рисунок 51 - L2, 2, 5710
|
5х5 (стартовый граф - полный граф)
|
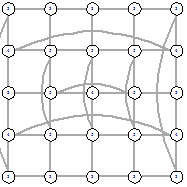 Рисунок 52 - L1, 0, 5373 Рисунок 52 - L1, 0, 5373
|
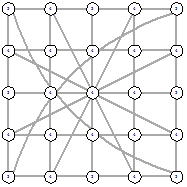 Рисунок 53 - L1, 1, 5685 Рисунок 53 - L1, 1, 5685
|
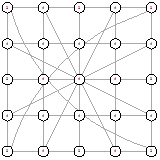 Рисунок 54 - L1, 2, 5563 Рисунок 54 - L1, 2, 5563
|
|
Рисунок 55 - L2, 0, 5593
|
 Рисунок 56 - L2, 1, 5633 Рисунок 56 - L2, 1, 5633
|
 Рисунок 57 - L2, 2, 5650 Рисунок 57 - L2, 2, 5650
|
|
Рисунок 58 - LI, 0, 5619
|
Рисунок 59 - L2, 1, 5726
|
Рисунок 60 - L2, 2, 5705
|
В этом же примере можно заметить, что алгоритм может
давать разные решения при разном начальном графе. Далее будут приведены
оптимальный графы размером 6х6 и 7х7 по одному для каждой функции расстояний.
6х6
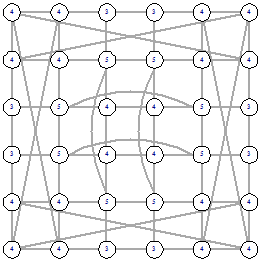
Рисунок 61 - L1, 0, 13356 c полного
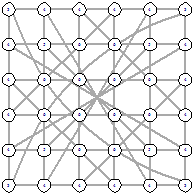
Рисунок 62 - L2, 2, 13452 с полного
Рисунок 63 - LI, 0, 13882 и с полного
и с сетки
7х7
Рисунок 64 - L1, 0, 28177 с полного
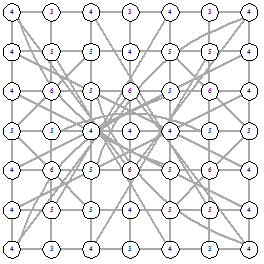
Рисунок 65 - L2, 0, 29095 с полного
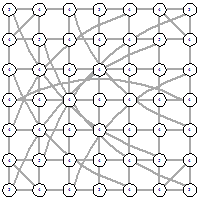
Рисунок 66 - LI, 0, 29498 с полного
Для метода ветвей и границ на вход были поданы матрицы
меньших размеров, так как этот алгоритм ищет точное оптимально решение и это
занимает много времени. Тесты проводились на этом алгоритме, чтобы проверить
корректность предположения, что среди всех оптимальных решений обязательно найдется
хотя бы одно, которое содержит в себе только симметричные ребра.
|
 Рисунок 67 - оптимальный граф 2х3 Рисунок 67 - оптимальный граф 2х3
|
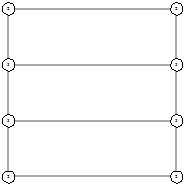 Рисунок 68 - оптимальный граф для 2х4 Рисунок 68 - оптимальный граф для 2х4
|
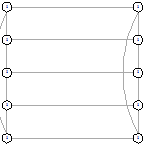 Рисунок 69 - оптимальный граф для 2х6 Рисунок 69 - оптимальный граф для 2х6
|
|
 Рисунок 70 - ОГ 1х4 Рисунок 70 - ОГ 1х4
|
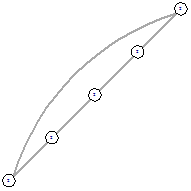 Рисунок 71 - ОГ 1х5 Рисунок 71 - ОГ 1х5
|
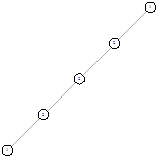 Рисунок 72 - ОГ 1х5 Рисунок 72 - ОГ 1х5
|
|
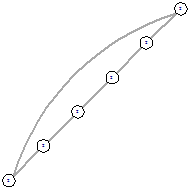 Рисунок 73 - ОГ 1х6 Рисунок 73 - ОГ 1х6
|
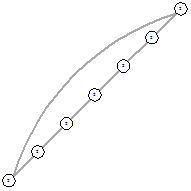 Рисунок 74 - ОГ 1х7 Рисунок 74 - ОГ 1х7
|
 Рисунок 75 - ОГ 1х8 Рисунок 75 - ОГ 1х8
|
|
 Рисунок 76 - ОГ 1х9 Рисунок 76 - ОГ 1х9
|
 Рисунок 77 - ОГ 1х10 Рисунок 77 - ОГ 1х10
|
|
|
 Рисунок 78 - ОГ 1х11 Рисунок 78 - ОГ 1х11
|
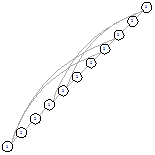 Рисунок 79 - ОГ 1х11 Рисунок 79 - ОГ 1х11
|
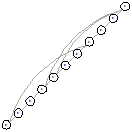 Рисунок 80 - ОГ 1х11 Рисунок 80 - ОГ 1х11
|
Можно заметить, что для графов 2х3, 2х4 и 2х5
получившиеся оптимальные графы являются симметричными, однако для 1х11 уже
возникает несимметричное решение. При этом симметричное все же присутствует.
Однако не всегда так. Рассмотрим следующие результаты для 3х4.
|
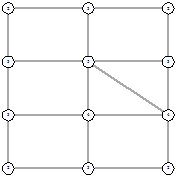 Рисунок 81 - ОГ 3х4 Рисунок 81 - ОГ 3х4
|
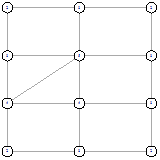 Рисунок 82 - ОГ 3х4 Рисунок 82 - ОГ 3х4
|
|
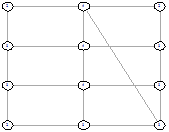 Рисунок 83 - ОГ 3х4 Рисунок 83 - ОГ 3х4
|
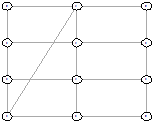 Рисунок 84 - ОГ 3х4 Рисунок 84 - ОГ 3х4
|
Получившиеся решения не симметричны, однако для
каждого несимметричного есть симметричное ему другое несимметричное решение.
Таким образом гипотеза, что всегда есть симметричное решение не подтвердилась,
поэтому нужно либо отказываться от симметричности и перебирать все ребра, либо
находить такой способ, чтобы при жадный поиск строил симметричные пути.
Также табу алгоритм был запущен на графах с 1х4 до
1х42 и с 2х2 до 2х25, по результатам работы были построены графики зависимости
сложности поиска от количества вершин. Результаты приведены на следующих
рисунках.
|
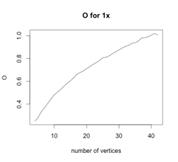 Рисунок 85 - Сложность поиска от количества вершин
для 1х Рисунок 85 - Сложность поиска от количества вершин
для 1х
|
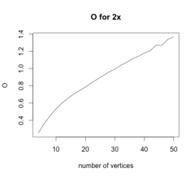 Рисунок 86 - Сложность поиска от количества вершин
для 2х Рисунок 86 - Сложность поиска от количества вершин
для 2х
|
Для того, чтобы понять какая зависимость представлена
на графике, то построим зависимость сложности от квадрата логарифма количества
вершин.
|
 Рисунок 87 - Сложность от квадрата логарифма
количества вершин для 1х Рисунок 87 - Сложность от квадрата логарифма
количества вершин для 1х
|
 Рисунок 88 - Сложность от квадрата логарифма
количества вершин для 2х Рисунок 88 - Сложность от квадрата логарифма
количества вершин для 2х
|
Можно заметить, что сложность поиска для таких графов
будет 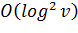 .
.
Построим зависимость сложности от количества вершин
для графов 2х2, 3х3, 4х4, 5х5, 6х6, 7х7, 8х8, 9х9.
|
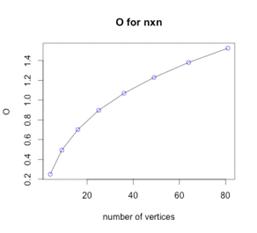 Рисунок 89 - Сложность поиска от количества вершин
для nxn Рисунок 89 - Сложность поиска от количества вершин
для nxn
|
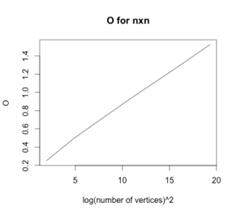 Рисунок 90 - Сложность поиска от квадрата логарифма
количества вершин для nxn Рисунок 90 - Сложность поиска от квадрата логарифма
количества вершин для nxn
|
Можно заметить, что тут также присутствует сложность
поиска .
граф алгоритм локальный
стартовый
Вывод
В результате работы был предложен алгоритм, который
эвристически строит оптимальный граф для задачи децентрализованного поиска.
Предполагалось, что алгоритм построит решения, на которых поиск будет работать
быстрее, чем у Клайнберга, однако такого не произошло. Сложность поиска
остается одинаковой. Также был предложен алгоритм, который находит точные
решения для поставленной задачи на малых размерах. Предполагалось, что алгоритм
подтвердит наличие оптимальных решений с только симметричными ребрами, однако
алгоритм дал отрицательный результат. В будущем предполагается построить
алгоритм, который будет строить оптимальный граф для поиска с возможностью
ошибки, т.е. не находить иногда необходимую вершину (задача аппроксимированного
поиска ближайшего соседа). Возможно на такой задаче сложность поиска удастся
уменьшить.
Список литературы
1. Milgram, Stanley. "The small world
problem." Psychology today 2, no. 1 (1967): 60-67.
. Maymounkov, Petar, and David Mazieres.
"Kademlia: A peer-to-peer information system based on the xor
metric." In Peer-to-Peer Systems, pp. 53-65. Springer Berlin Heidelberg,
2002.
. Beaumont, Olivier, Anne-Marie Kermarrec, Loris
Marchal, and Etienne Riviere. "VoroNet: A scalable object network based on
Voronoi tessellations." In Parallel and Distributed Processing Symposium,
2007. IPDPS 2007. IEEE International, pp. 1-10. IEEE, 2007.
. Kleinberg, Jon. "The small-world phenomenon: An
algorithmic perspective." In Proceedings of the thirty-second annual ACM
symposium on Theory of computing, pp. 163-170. ACM, 2000.
. Watts, Duncan J., and Steven H. Strogatz.
"Collective dynamics of ‘small-world’networks." nature 393, no. 6684
(1998): 440-442.
6. Bollobás,
Béla, and Oliver Riordan. "The diameter of a scale-free random graph." Combinatorica 24,
no. 1 (2004): 5-34.
Приложение
#include "Graph.h"
#include <math.h>
#include <algorithm>
#include <fstream>
#include <iostream>
#include <sys/stat.h>
#include
<random>TYPE;TYPE_V;::vector <Graph> bestest;counter;namespace
std;::Graph(int n, int m, bool flag)
{>v = n*m;= new int*[v];= new
int[v];= new bool[v];= new bool[v];(int i = 0; i < v; i++){[i] = new
int[v];[i] = 0;[i] = false;[i] = false;
}(int i = 0; i < v; i++){(int j =
0; j < v; j++){[i][j] = 0;
}
}(i - 1 >= (i / n)*n){[i - 1][i] =
1;[i][i - 1] = 1;
}(i + n < v){[i + n][i] = 1;[i][i
+ n] = 1;
}(i - n >= 0){[i - n][i] = 1;[i][i
- n] = 1;
}
}(flag == true){(int i = 0; i < v;
i++){(int j = 0; j < v; j++){(i != j && arr[i][j] == 0)[i][j] = 2;
}
}
}
(int i = 0; i < v; i++){(int j =
0; j < v; j++){(arr[i][j] != 0)[i] += 1;
}
}>n = n;>m = m;
}::Graph(const Graph& g){= g.n;=
g.m;= g.v;= new int*[v];= new int[v];= new bool[v];= new bool[v];(int i = 0; i
< v; i++){[i] = new int[v];[i] = g.getDegree()[i];[i] = false;[i] = false;
}(int i = 0; i < v; i++){(int j =
0; j < v; j++){[i][j] = g.getArr()[i][j];
}
}(int i = 0; i <
g.getStrict().size(); i++){.push_back(g.getStrict()[i]);
}= g.getO();
}::Graph(string nfile){file(nfile);a,
b;>> a >> b;>n = a;>m = b;>v = a*b;>arr = new
int*[v];>degree = new int[v];>inSearch = new bool[v];>inPath = new
bool[v];(int i = 0; i < this->v; i++){>arr[i] = new
int[v];>degree[i] = 0;>inSearch[i] = false;>inPath[i] = false;
}(int i = 0; i < this->v;
i++){(int j = 0; j < this->v; j++){>> this->arr[i][j];
}
}(int i = 0; i < this->v;
i++){(int j = 0; j < this->v; j++){>degree[i] += this->arr[i][j];
}
}
}Graph::addToStrict(Edge
ed){.push_back(ed);
}Graph::canDoAction(int iAdd, int
jAdd, int iDelete, int jDelete, double best) {a1 = (iAdd / n + 1)*n - 1 -
iAdd%n;b1 = (jAdd / n + 1)*n - 1 - jAdd%n;a2 = n*m - 1 - iAdd;b2 = n*m - 1 -
jAdd;a3 = (a2 / n + 1)*n - 1 - a2%n;b3 = (b2 / n + 1)*n - 1 - b2%n;ad1 =
(iDelete / n + 1)*n - 1 - iDelete%n;bd1 = (jDelete / n + 1)*n - 1 -
jDelete%n;ad2 = n*m - 1 - iDelete;bd2 = n*m - 1 - jDelete;ad3 = (a2 / n + 1)*n
- 1 - a2%n;bd3 = (b2 / n + 1)*n - 1 - b2%n;oldO = O;flag = 0;(int index = 0;
index < strict.size(); index++){(((iAdd == strict.at(index).start &&
jAdd == strict.at(index).finish) || (a1 == strict.at(index).start && b1
== strict.at(index).finish) || (a2 == strict.at(index).start && b2 ==
strict.at(index).finish) || (a3 == strict.at(index).start && b3 ==
strict.at(index).finish)) && strict.at(index).action == true){++;
}(((iDelete == strict.at(index).start
&& jDelete == strict.at(index).finish) || (ad1 == strict.at(index).start
&& bd1 == strict.at(index).finish) || (ad2 == strict.at(index).start
&& bd2 == strict.at(index).finish) || (ad3 == strict.at(index).start
&& bd3 == strict.at(index).finish)) && strict.at(index).action ==
false){++;
}
}(flag == 0){true;
}(iAdd != -1){>addSymEdges(iAdd,
jAdd);
}(iDelete !=
-1){>deleteSymEdges(iDelete, jDelete);
}();(O < best){(iAdd !=
-1){>deleteSymEdges(iAdd, jAdd);
}(iDelete !=
-1){>addSymEdges(iDelete, jDelete);
}(oldO);true;
}(iAdd !=
-1){>deleteSymEdges(iAdd, jAdd);
}(iDelete !=
-1){>addSymEdges(iDelete, jDelete);
}(oldO);false;
}Graph::canDoActionInTabu(int iAdd,
int jAdd, int iDelete, int jDelete) {a1 = (iAdd / n + 1)*n - 1 - iAdd%n;b1 =
(jAdd / n + 1)*n - 1 - jAdd%n;a2 = n*m - 1 - iAdd;b2 = n*m - 1 - jAdd;a3 = (a2 /
n + 1)*n - 1 - a2%n;b3 = (b2 / n + 1)*n - 1 - b2%n;ad1 = (iDelete / n + 1)*n -
1 - iDelete%n;bd1 = (jDelete / n + 1)*n - 1 - jDelete%n;ad2 = n*m - 1 -
iDelete;bd2 = n*m - 1 - jDelete;ad3 = (a2 / n + 1)*n - 1 - a2%n;bd3 = (b2 / n +
1)*n - 1 - b2%n;oldO = O;flag = 0;(int index = 0; index < strict.size();
index++){(((iAdd == strict.at(index).start && jAdd ==
strict.at(index).finish) || (a1 == strict.at(index).start && b1 ==
strict.at(index).finish) || (a2 == strict.at(index).start && b2 ==
strict.at(index).finish) || (a3 == strict.at(index).start && b3 ==
strict.at(index).finish)) && strict.at(index).action == true){++;
}(((iDelete == strict.at(index).start
&& jDelete == strict.at(index).finish) || (ad1 ==
strict.at(index).start && bd1 == strict.at(index).finish) || (ad2 ==
strict.at(index).start && bd2 == strict.at(index).finish) || (ad3 ==
strict.at(index).start && bd3 == strict.at(index).finish)) &&
strict.at(index).action == false){++;
}
}(flag == 0){true;
}false;
}Graph::addSymEdges(int a, int
b){count = 0;(a >= 0 && b >= 0 && a < v && b
< v){(arr[a][b] == 0){[a][b] = 2;[b][a] = 2;[a]++;[b]++;++;a1 = (a / n +
1)*n - 1 - a%n;b1 = (b / n + 1)*n - 1 - b%n;(arr[a1][b1] == 0){[a1][b1] =
2;[b1][a1] = 2;[a1]++;[b1]++;++;
}a2 = n*m - 1 - a;b2 = n*m - 1 -
b;(arr[a2][b2] == 0){[a2][b2] = 2;[b2][a2] = 2;[a2]++;[b2]++;++;
}a3 = (a2 / n + 1)*n - 1 - a2%n;b3 =
(b2 / n + 1)*n - 1 - b2%n;(arr[a3][b3] == 0){[a3][b3] = 2;[b3][a3] =
2;[a3]++;[b3]++;++;
}count;
}
}0;
}Graph::deleteSymEdges(int a, int
b){count = 0;(a >= 0 && b >= 0 && a < v && b
< v){(arr[a][b] == 2){[a][b] = 0;[b][a] = 0;[a]--;[b]--;++;a1 = (a / n +
1)*n - 1 - a%n;b1 = (b / n + 1)*n - 1 - b%n;(arr[a1][b1] == 2){[a1][b1] =
0;[b1][a1] = 0;[a1]--;[b1]--;++;
}a2 = n*m - 1 - a;b2 = n*m - 1 -
b;(arr[a2][b2] == 2){[a2][b2] = 0;[b2][a2] = 0;[a2]--;[b2]--;++;
}a3 = (a2 / n + 1)*n - 1 - a2%n;b3 =
(b2 / n + 1)*n - 1 - b2%n;(arr[a3][b3] == 2){[a3][b3] = 0;[b3][a3] =
0;[a3]--;[b3]--;++;
}count;
}
}0;
}Graph::Distance(int a, int b){x_a =
a%n;y_a = a / n;x_b = b%n;y_b = b / n;(TYPE == -1){d = max(abs(x_a - x_b),
abs(y_a - y_b));d;
}{d = pow(abs(x_a - x_b), TYPE) +
pow(abs(y_a - y_b), TYPE);pow(d, 1 / (double)TYPE);
}
}Graph::FindPath(int a, int b){[a] =
true;(a == b){[a] = true;;
}[a] = true;t = 0;* paths = new
double[degree[a]];* indexes = new int[degree[a]];(int i = 0; i < v;
i++){(arr[a][i] > 0){[i] = true;[t] = Distance(i, b);[t] = i;++;(t ==
degree[a]);
}
}minI = 0;minV = paths[0];(int i = 1;
i < degree[a]; i++){(paths[i] < minV && inPath[indexes[i]] ==
false){= paths[i];= i;
}{(TYPE_V){0:(paths[i] == minV
&& inPath[indexes[i]] == false){(degree[indexes[i]] <
degree[indexes[minI]]){= paths[i];= i;
}
};1:(paths[i] == minV &&
inPath[indexes[i]] == false){(degree[indexes[i]] > degree[indexes[minI]]){=
paths[i];= i;
}
};2:(paths[i] == minV &&
inPath[indexes[i]] == false){(rand()%2 == 0){= paths[i];= i;
}
};
}
}
}(indexes[minI], b);[] paths;[]
indexes;;
}Graph::calculateO(){* sum = new
int[v];(int i = 0; i < v; i++){[i] = 0;(int j = 0; j < v; j++){(int t =
0; t < v; t++){[t] = false;
}(i, j);count = 0;(int t = 0; t <
v; t++){[i] += inSearch[t];+= inSearch[t];[t] = false;
}
//cout << "For v = "
<< i << " serch to " << j << " = "
<< count << endl;
}
}s = 0.0;(int i = 0; i < v; i++){
//cout<<"i =
"<< i << " sum = " << sum[i] << endl;+=
sum[i];
}[] sum;= s;s;
}Graph::calculateApproxO(){sum =
0.0;number = 20;t = 0;(number != t){i = rand()%v;j = rand()%v;(int t = 0; t
< v; t++){[t] = false;
}(i, j);(int t = 0; t < v; t++){+=
inSearch[t];[t] = false;
}++;
}= (sum/number)*(v*v);sum;
}Graph::setO(double O){>O = O;
}Graph::save(std::string dir,
std::string name){::cout << "Start SAVE" <<
std::endl;file;
//dir = "/"+dir;
//std::cout << dir <<
endl;(dir.c_str(), 0777);// << endl;.open(dir + "/" + name);(int
i = 0; i < v; i++){(int j = 0; j < v; j++){(arr[i][j] != -1)<<
arr[i][j] << " ";<< 0 << " ";
}<< endl;
}.close();::cout <<
"Finish SAVE" << std::endl;
}& Graph::operator=(const Graph
&g){(int i = 0; i < v; i++){[i] = g.getDegree()[i];[i] = false;
}(int i = 0; i < v; i++){(int j =
0; j < v; j++){[i][j] = g.getArr()[i][j];
}
}.clear();(int i = 0; i <
g.getStrict().size(); i++){.push_back(g.getStrict()[i]);
}= g.getO();*this;
}Graph::CheckStrict(){(int i = 0; i
< strict.size(); i++){[i].numberOfSteps--;
}(int i = strict.size() - 1; i >=
0; i--){(strict[i].numberOfSteps == 0){.erase(strict.begin() + i);
}
}
}Graph::RealTabuStep(int
number_for_add, int number_for_delete){bestKnown(*this);fails = 0;flag =
false;(number_for_add + number_for_delete > 0){();<Graph> graphs;**
edges_add = new int*[number_for_add];** edges_delete = new
int*[number_for_delete];(int i = 0; i < number_for_add; i++)_add[i] = new
int[2];(int i = 0; i < number_for_delete; i++)_delete[i] = new int[2];c_add
= 0;c_delete = 0;(int i = 0; i < v; i++){((i < (n*m / 2)) && (i
<= (n/ 2 + i / n))){(int j = i + 1; j < v; j++){(arr[i][j] ==
0){_add[c_add][0] = i;_add[c_add][1] = j;_add++;
}(arr[i][j] ==
2){_delete[c_delete][0] = i;_delete[c_delete][1] = j;_delete++;
}
}
}
}min = INFINITY;minI = 0;(int i = 0;
i <= c_delete; i++){.push_back(Graph(*this));(i !=
c_delete){.at(graphs.size() - 1).deleteSymEdges(edges_delete[i][0],
edges_delete[i][1]);(cfg.takeFirstGood == true && flag ==
false){.at(graphs.size() - 1).calculateO();
//graphs.at(graphs.size() -
1).calculateApproxO();(graphs.at(graphs.size() - 1).getO() < O){minII =
(graphs.size() - 1) + i*(c_add + 1);a = minII % (c_add + 1);b = minII / (c_add
+ 1);iAdd = -1, jAdd = -1, iDelete = -1, jDelete = -1;(a != 0){= edges_add[a -
1][0];= edges_add[a - 1][1];
}(b != c_delete){=
edges_delete[b][0];= edges_delete[b][1];
}(canDoAction(iAdd, jAdd, iDelete,
jDelete, bestKnown.getO()) == true){= graphs.at(graphs.size() - 1).getO();=
(graphs.size() - 1) + i*(c_add + 1);;
}
}
}
}(min < O &&
cfg.takeFirstGood == true){;
}index = graphs.size() - 1;(int j =
0; j < c_add; j++){.push_back(Graph(graphs.at(index)));.at(graphs.size() -
1).addSymEdges(edges_add[j][0], edges_add[j][1]);(cfg.takeFirstGood == true
&& flag == false){.at(graphs.size() - 1).calculateO();
//graphs.at(graphs.size() -
1).calculateApproxO();(graphs.at(graphs.size() - 1).getO() < O){minII =
graphs.size() - 1 + i*(c_add + 1);a = minII % (c_add + 1);b = minII / (c_add +
1);iAdd = -1, jAdd = -1, iDelete = -1, jDelete = -1;(a != 0){= edges_add[a -
1][0];= edges_add[a - 1][1];
}(b != c_delete){=
edges_delete[b][0];= edges_delete[b][1];
}(canDoAction(iAdd, jAdd, iDelete,
jDelete, bestKnown.getO()) == true){= graphs.at(graphs.size() - 1).getO();=
graphs.size() - 1 + i*(c_add + 1);;
}
}
}
}
/*if (cfg.takeFirstGood == false ||
flag == true){::parallel_for(size_t(0), size_t(graphs.size()), [&](size_t
ind1){.at(ind1).calculateO();
});(flag == false){(int ind = 0; ind
< graphs.size(); ind++){(graphs.at(ind).getO() < min){minII = ind +
i*(c_add + 1);a = minII % (c_add + 1);b = minII / (c_add + 1);iAdd = -1, jAdd =
-1, iDelete = -1, jDelete = -1;(a != 0){= edges_add[a - 1][0];= edges_add[a -
1][1];
}(b != c_delete){=
edges_delete[b][0];= edges_delete[b][1];
}(canDoAction(iAdd, jAdd, iDelete,
jDelete, bestKnown.getO()) == true){= graphs.at(ind).getO();= ind + i*(c_add +
1);
}
}
}
}{(int ind = 0; ind <
graphs.size(); ind++){(graphs.at(ind).getO() < min && ((ind +
i*(c_add + 1)) != (c_add + c_delete)) && O <
graphs.at(ind).getO()){minII = ind + i*(c_add + 1);a = minII % (c_add + 1);b =
minII / (c_add + 1);iAdd = -1, jAdd = -1, iDelete = -1, jDelete = -1;(a != 0){=
edges_add[a - 1][0];= edges_add[a - 1][1];
}(b != c_delete){=
edges_delete[b][0];= edges_delete[b][1];
}(canDoActionInTabu(iAdd, jAdd,
iDelete, jDelete) == true){= graphs.at(ind).getO();= ind + i*(c_add + 1);
}
}
}
}
}*/(min < O &&
cfg.takeFirstGood == true){;
}
//cout << "step "
<< i << "/" << c_delete << endl;.clear();
}
//cout << "FLAG ="
<< flag << endl;(flag == true){a = minI % (c_add + 1);b = minI /
(c_add + 1);(a != 0){t = addSymEdges(edges_add[a - 1][0], edges_add[a - 1][1]);
//cout << "ADD TABU -
" << edges_add[a - 1][0] << "-" << edges_add[a
- 1][1] << endl;ed;.start = edges_add[a - 1][0];.finish = edges_add[a - 1][1];.action
= false;.numberOfSteps = cfg.numberOfTabuStep;(ed);_for_delete += t;_for_add -=
t;
}(b != c_delete){t =
deleteSymEdges(edges_delete[b][0], edges_delete[b][1]);
//cout << "DELETE TABU -
" << edges_delete[b][0] << "-" <<
edges_delete[b][1] << endl;ed;.start = edges_delete[b][0];.finish =
edges_delete[b][1];.action = true;.numberOfSteps =
cfg.numberOfTabuStep;(ed);_for_delete -= t;_for_add += t;
}= false;();
//calculateApproxO();
//cout << "Current opt =
" << O << endl;(int i = 0; i < c_add; i++)edges_add[i];[]
edges_add;(int i = 0; i < c_delete; i++)edges_delete[i];[] edges_delete;
}{(min == INFINITY){();
//calculateApproxO();= true;(O <
bestKnown.getO()){= (*this);
//cout << "Best was found
at " << fails << " step!" << endl;= 0;
}{++;
}(int i = 0; i < c_add;
i++)edges_add[i];(int i = 0; i < c_delete; i++)edges_delete[i];[]
edges_add;[] edges_delete;.clear();
//cout << "Current opt =
" << O << " Current number of fails = " <<
fails << endl;(fails == cfg.numberOfFails){
//cout << "FINISH
ALL" << endl;
//bestKnown.save("Dir_" +
to_string(bestKnown.getO()) + to_string(n) + "_" + to_string(m),
"Out_RT_START_FROM_EMPTY.txt");
(*this) = bestKnown;;
}
}{= false;a = minI % (c_add + 1);b =
minI / (c_add + 1);(a != 0){t = addSymEdges(edges_add[a - 1][0], edges_add[a -
1][1]);
//cout << "ADD - "
<< edges_add[a - 1][0] << "-" << edges_add[a -
1][1] << endl;(edges_add[a - 1][0], edges_add[a - 1][1],
true);_for_delete += t;_for_add -= t;
}(b != c_delete){t =
deleteSymEdges(edges_delete[b][0], edges_delete[b][1]);
//cout << "DELETE - "
<< edges_delete[b][0] << "-" << edges_delete[b][1]
<< endl;(edges_delete[b][0], edges_delete[b][1], false);_for_delete -=
t;_for_add += t;
}(min);
//cout << "Current opt =
" << O << endl;(int i = 0; i < c_add; i++)edges_add[i];[]
edges_add;(int i = 0; i < c_delete; i++)edges_delete[i];[] edges_delete;
}
}.clear();
}
}Graph::deleteIfExist(int a, int b,
bool flag){(int i = 0; i < strict.size(); i++){(strict[i].start == a
&& strict[i].finish == b && strict[i].action ==
flag){.erase(strict.begin() + i);;
}
}
}Graph::Algorithm(std::string config,
int number_of_edges_add, int number_of_edges_delete, bool
flag){file(config);(!file){<< "Error opening file! We will use
standart configuration!" << endl;
}{trash;>> trash;>>
trash;>> cfg.numberOfFails;>> trash;>> trash;>>
cfg.numberOfTabuStep;>> trash;>> trash;>> cfg.takeFirstGood;
}n_of_ed =
number_of_edges_add;number_of_adds = number_of_edges_delete;_of_ed =
number_of_edges_add;_of_adds = number_of_edges_delete;
//cout << "Start tabu"
<< endl;(n_of_ed, number_of_adds);
//cout << "Finish
tabu" << endl;<< "BEST = " << getO() <<
endl;(TYPE == -1){(flag == false){("new_Dir_" + to_string(n) +
"_" + to_string(m), "Out_RT_START_FROM_EMPTY_" + to_string((int)getO())
+ "WITH_L INFINITY_AND_TYPE_V_"+to_string(TYPE_V)+".txt");
}{("new_Dir_" +
to_string(n) + "_" + to_string(m),
"Out_RT_START_FROM_FULL_" + to_string((int)getO()) + "WITH_L
INFINITY_AND_TYPE_V_"+to_string(TYPE_V)+".txt");
}
}{(flag ==
false){("new_Dir_" + to_string(n) + "_" + to_string(m),
"Out_RT_START_FROM_EMPTY_" + to_string((int)getO()) + "WITH_L
" +
to_string(TYPE)+"_AND_TYPE_V_"+to_string(TYPE_V)+".txt");
}{("new_Dir_" +
to_string(n) + "_" + to_string(m),
"Out_RT_START_FROM_FULL_" + to_string((int)getO()) + "WITH_L
" + to_string(TYPE)+"_AND_TYPE_V_"+to_string(TYPE_V)+".txt");
}
}.close();
}Graph::FindPathWithEdges(int a, int
b){[a] = true;(a == b){[a] = true;;
}[a] = true;t = 0;* paths = new
double[degree[a]];* indexes = new int[degree[a]];(int i = 0; i < v;
i++){(arr[a][i] > 0){[i] = true;[t] = Distance(i, b);[t] = i;++;(t ==
degree[a]);
}
}minI = 0;minV = paths[0];(int i = 1;
i < degree[a]; i++){(paths[i] < minV && inPath[indexes[i]] ==
false){= paths[i];= i;
}{(TYPE_V){0:(paths[i] == minV
&& inPath[indexes[i]] == false){(degree[indexes[i]] <
degree[indexes[minI]]){= paths[i];= i;
}
};1:(paths[i] == minV &&
inPath[indexes[i]] == false){(degree[indexes[i]] > degree[indexes[minI]]){=
paths[i];= i;
}
};2:(paths[i] == minV &&
inPath[indexes[i]] == false){(rand()%2 == 0){= paths[i];= i;
}
};
}
}
}[a][indexes[minI]] += 1;c =
indexes[minI];[] paths;[] indexes;(c, b);;
}Graph::calculateOwithEdges(){* sum =
new int[v];(int i = 0; i < v; i++){[i] = 0;(int j = 0; j < v; j++){(int t
= 0; t < v; t++){[t] = false;
}(i, j);count = 0;(int t = 0; t <
v; t++){[i] += inSearch[t];+= inSearch[t];[t] = false;
}
//cout << "For v = "
<< i << " serch to " << j << " = "
<< count << endl;
}
}s = 0.0;(int i = 0; i < v; i++){
//cout<<"i =
"<< i << " sum = " << sum[i] << endl;+=
sum[i];
}[] sum;= s;s;
}Graph::generateNewEdges(){s = 0;(int
i = 0; i < v; i++)+= degree[i];p = (v*(v-1)/2-s/2)/2;::random_device rd; //
only used once to initialise (seed) engine::mt19937 rng(rd()); // random-number
engine used (Mersenne-Twister in this case)::uniform_int_distribution<int>
uni(0,p); // guaranteed unbiasednum = uni(rng);(num > 0){i = rand()%v;j =
rand()%v;(arr[i][j] != 0){= rand()%v;= rand()%v;
}t = addSymEdges(i, j);-= t;
}
}Graph::AlgorithmWithDeleteEdges(){=
new int*[v];(int i = 0; i < v; i++) {[i] = new int[v];
}();t_o = this->O;best(*this);p =
0;(true){(int i = 0; i < v; i++){(int j = 0; j < v; j++){[i][j] = 0;
}
}();(this->O >= t_o &&
p != 0){best;
}{_o = this->O;= *this;
}++;<< "Bla = "
<< this->O << endl;(int i = 0; i < v; i++){(int j = 0; j <
v; j++){<< edges[i][j] << " ";
}<< endl;
}<< endl;(int i = 0; i < v;
i++){(int j = 0; j < v; j++){<< edges[i][j] << " ";
}<< endl;
}<< endl;min = INFINITY;(int i
= 0; i < v; i++) {(int j = i; j < v; j++){(edges[i][j] != 0 &&
arr[i][j] == 2){(min > edges[i][j])= edges[i][j];
}
}
}(int i = 0; i < v; i++) {(int j =
0; j < v; j++){(edges[i][j] == min && arr[i][j] == 2){(i, j);
}
}
}
}
}
//babGraph::addEdge(int a, int b){(a
>= 0 && b >= 0 && a < v && b <
v){(arr[a][b] == 0){[a][b] = 2;[b][a] = 2;[a]++;[b]++;
}
}
}Graph::strictEdge(int a, int b){(a
>= 0 && b >= 0 && a < v && b <
v){(arr[a][b] == 0){[a][b] = -1;[b][a] = -1;
}
}
}Graph::unstrictEdge(int a, int b){(a
>= 0 && b >= 0 && a < v && b <
v){(arr[a][b] == -1){[a][b] = 0;[b][a] = 0;
}
}
}Graph::deleteEdge(int a, int b){(a
>= 0 && b >= 0 && a < v && b <
v){(arr[a][b] == 2){[a][b] = 0;[b][a] = 0;[a]--;[b]--;
}
}
}Graph::FindPathForBound(int a, int
b){[a] = true;(a == b){[a] = true;;
}[a] = true;t = 0;* paths = new
double[v];* indexes = new int[v];(int i = 0; i < v; i++){(arr[a][i] !=
-1){(arr[a][i] > 0)[i] = true;[t] = Distance(i, b);[t] = i;++;
}{[t] = INFINITY;[t] = i;++;
}
}minI = 0;minV = paths[0];(int i = 1;
i < v; i++){(paths[i] < minV && inPath[indexes[i]] == false){=
paths[i];= i;
}{(TYPE_V){0:(paths[i] == minV
&& inPath[indexes[i]] == false){(degree[indexes[i]] <
degree[indexes[minI]]){= paths[i];= i;
}
};1:(paths[i] == minV &&
inPath[indexes[i]] == false){(degree[indexes[i]] > degree[indexes[minI]]){=
paths[i];= i;
}
};2:(paths[i] == minV &&
inPath[indexes[i]] == false){(rand()%2 == 0){= paths[i];= i;
}
};
}
}
}next_vertix = indexes[minI];[]
paths;[] indexes;(next_vertix, b);;
}Graph::LowBound(){* sum = new
int[v];(int i = 0; i < v; i++){[i] = 0;(int j = 0; j < v; j++){(i,
j);(int t = 0; t < v; t++){[i] += inSearch[t];[t] = false;[t] = false;
}
}
}s = 0;(int i = 0; i < v; i++){+=
sum[i];
}[] sum;
//O = s / v;s;
}Graph::BranchAndBoundAddOne(Graph*
bestBB, int step, double* bestO){lb = LowBound();
// for (int c = 0; c < step-1;
c++){
// cout << "\t";
// }
// cout << "LB = "
<< lb << endl;(lb > (*bestO)){;
}
// if (step == 0){
// calculateO();
// if (O <= *bestO){
//
// if (O < *bestO){
// bestest.clear();
// }
// (*bestBB) = (*this);
// (*bestO) = O;
// bestest.push_back(*bestBB);
//
//
// }
// }start = -1;finish = -1;(int i =
0; i < v; i++){(int j = i + 1; j < v; j++){
//if ((i <= n*m / 2) && (i
<= n/ 2 + i / n)){(arr[i][j] == 0){= i;= j;;
}
}(start == -1);
}(start == -1){();
/*if(O ==
869){>save("Dir_For_BaB_" + to_string(n) + "_" +
to_string(m), "Out_" +
to_string(int(bestBB->getO()))+"_" + to_string(counter) +
".txt");++;
}*/
//calculateO();
// for (int c = 0; c < step; c++){
// cout << "\t";
// }
// cout << "Current O =
" << O << endl;(O <= *bestO){(O < *bestO){
//cout << "OOOOOO = "
<< O << " BO = "<< bestO << endl;.clear();
}
(*bestBB) = (*this);
(*bestO) = O;.push_back(*bestBB);
//if(O == 869){
//
bestBB->save("Dir_For_BaB_" + to_string(n) + "_" +
to_string(m), "Out_" +
to_string(int(bestBB->getO()))+"_" + to_string(bestest.size()) +
".txt");
//}
//bestBB->save("Dir_" +
to_string(n) + "_" + to_string(m), "Out_" +
to_string(int(bestBB->getO()))+".txt");
//cout << "Best O = "
<< bestBB->getO() << endl;
};
}
// for (int c = 0; c < step; c++){
// cout << "\t";
// }
// cout << "Best O =
" << bestBB->getO() << endl;
// for (int c = 0; c < step; c++){
// cout << "\t";
// }
// cout << "ADD - "
<< start << " " << finish << endl;(start,
finish);(bestBB, step + 1, bestO);
// for (int c = 0; c < step; c++){
// cout << "\t";
// }
// cout << "STRICT -
" << start << " " << finish <<
endl;(start, finish);(start, finish);(bestBB, step + 1, bestO);(start, finish);
//return bestO;
}::~Graph()
{[] degree;(int i = 0; i < v;
i++)arr[i];[] arr;[] inSearch;[] inPath;.clear();
}