Алгоритм нахождения кластеров
Введение
Нахождение сообществ или кластеров является достаточно популярной темой
для изучения, широко обсуждаемой и изучаемой последние годы. Такой интерес
обусловлен возрастающим объемом данных, используемых при моделировании систем.
Методы анализа графов и алгоритмы поиска сообществ используются во многих
сферах, таких как: социология, биология, физика и информатика. Одним словом, в
тех областях, где информация может быть представлена в виде графа, в котором
вершины соответствуют неким объектам, а ребра - связям между этими объектами.
Например, в качестве объектов могут выступать интернет ресурсы, а связью между
ними будут пользователи, использующие эти ресурсы или url ссылки с одного
ресурса на другой. Особый интерес в последние годы представляет анализ моделей
социальных сетей. Описанная структуру можно отнести к типу графов, называемыми
социальными, они обладают неким набором свойств, специфичных только для такого
типа графов.
На данный момент существует множество алгоритмов нахождения сообществ на
графах, большинство из них будет описано в данной работе. Однако из-за роста
объема данных в моделях, с которыми работают алгоритмы, увеличивается и время
получения результатов. Именно поэтому возникает необходимость в модификации уже
известных алгоритмов и поиске новых.
Обзор
существующих методов кластеризации
На текущий момент разработано множество различных методов нахождения
сообществ в графах. В данной работе описаны только некоторые самые популярные
подходы и подробнее рассмотрю алгоритм Гирвана-Ньюмана и метод спектрального
анализа графов. Но перед тем, как приступить к описанию алгоритмов находения
сообществ необходимо пояснить, что же из себя эти самые сообщества
представляют.
Сообщество
Понятие сообщества (community) не имеет четкого определения. Мы условимся
называть сообществом множество вершин, для которых внутренних связей между
вершинами больше, чем внешних. Часто подразумевается, что сообщество состоит из
одной компоненты связности, которую нельзя разделить на более мелкие
компоненты. В данной работе мы будем рассматривать только такие разбиения
графов, при которых вершины будут относиться к одному и только одному
сообществy.
Однако существуют модели, в которых допускается принадлежность вершин к
нескольким разным сообществам, однако изучение алгоритмов нахождения
сообществах - задача, требующая других подходов и методов.
Условимся, что в рассматриваемых в работе методах каждая вершина графа
будет относиться ровно к одному сообществу после разбиения. Тогда, задачу
поиска сообществ можно описать как задачу поиска разбиения изначального
множества вершин, на непересекающиеся подмножества таким образом, чтобы некий
параметр графа был минимизирован.
Минимальное
сечение
Одним из самых первых подходов к нахождению сообществ в графах является
метод минимального сечения, а также его модификации. При использовании данного
метода сеть делится на заранее установленное количество кластеров, как правило
приблизительно одинакового размера. Основная идея метода заключается в
нахождении такого сечения, при котором количество ребер между вершинами из
разных кластеров сводится к минимуму.
Самым знаменитым алгоритмом из этого класса можно считать алгоритм
Кернигана-Лина, первоначально разработанный для оптимизации схем размещения
экектронных компонент на печатных платах. [1]
Однако для нахождения сообществ этот метод является не лучшим выбором,
так как не позволяет оценить, имеет ли сеть структуру сообществ и целесообразно
ли искать их. Помимо прочего метод требует, чтобы количество кластеров в сети
было задано заранее.
кластер
граф спектр модулярность
Иерархическая
кластеризация
В случаях, когда невозможно сразу определить структуру графа, количество
сообществ в нем или вообще их наличие можно прибегнуть к использованию
алгоритмов иерархической кластеризации. Алгоритмы, относящиеся к этому типу
также позволяют выделить графы, имеющие иерархическую структуру. Основная идея
алгоритмов из этого класса заключается в использовании меры схожести между
вершинами, такими как коэфициент Отиаи [2], коэфициент Жаккара [3] или
расстояние Хемминга [4] для матрицы смежности. На основании этих показателей
вершины графа распределяются по кластерам, а после алгоритм повторяется для
образовавшихся подграфов. Такой процесс называют процессом таксономии,
результатом которого является иерархическая древообразная структура. Такие
процессы нередко встречаются в области биологии при систематизации и
классификации живых организмов.
Можно выделить два типа алгоритмов, относящихся к алгоритмам
иерархической кластеризации: агломеративные или объединительные, в ходе которых
сообщества, состоящие из одной вершины, объединяются в более крупные, и
дивизивные или разделяющие, которые делят одно сообщество, включающее в себя
все вершины графа на более мелкие сообщества. Дивизивный подход изначально был
менее распространен, однако за последнее время его популярность стремительно
растет. Также такие методы можно разделить по количеству признаков схожести:
монотетические - использующие один признак и политетические - использующие
несколько различных признаков.
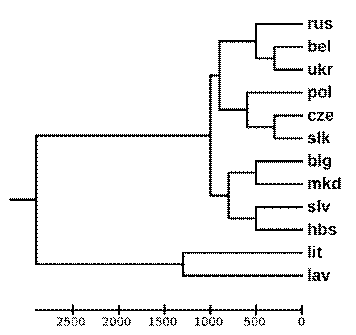
Результат работы алгоритма может быть наглядно представлен в виде
дендрограмы - дерева, построенного на основании матрицы мер схожести.
Дендрограмма в удобной форме иллюстрирует иерархическую структуру графа.
Частичная
кластеризация
Данный класс алгоритмов предполагает отображение вершин графа в
евклидовом пространстве, так чтобы расстояние между ними отражало некую меру
несходства между вершинами. Таким образом, вершины, соответствующие точкам,
находящимся ближе друг к другу, вероятнее будут находиться в одном кластере.
Часто меру несхожести или функцию схожести (cost function) выражают с
использованием центральной точки (centroid point), обнаруживаемой в каждом
кластере. Самые популярные алгоритмы частичной кластеризации:
· Mинимальная k-кластеризация. Необходимым критерием этого алгоритма
является нахождение такого разбиения, при котором наибольший диаметр
(максимальное расстояние между двумя точками из этого кластера) найденных
кластеров был минимально возможным.
· K-сумма. Имеет тот же принцип, что и минимальная k-кластеризация, только
вместо диаметра сообщества используется среднее расстояние между всеми парами
вершин в кластере.
· K-центр. Для каждого кластера находится центральная точка и разбиение
выбирается таким образом, чтобы минимизировать максимальное расстояние между
центральной точкой и другими точками в кластере, соответствующем этой точке.
· K-медиана. Тот же подход, что и в предыдущем методе, но вместо
максимального расстояния минимизируется среднее расстояний между центральной
точкой и остальными точками кластера.
· Метод k-средних. Наиболее популярный и часто используемый из методов
частичной кластеризации, описанный в 1950 г. математиками Гуго Штейнгаузом и
Стюартом Ллойдом [5][6]. Он схож с другими рассмотренными методами, но при
нахождении разбиения минимизируется суммарное квадратичное отклонение точек
кластеров от центров этих кластеров, равное
где k - число кластеров, 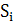 - найденные кластеры, i = 1,2, …, k и
- найденные кластеры, i = 1,2, …, k и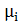 - центры масс векторов
- центры масс векторов 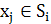 .
.
Метод
Гирвана-Ньюмана
Алгоритм, предложенный Гирваном и Ньюманом [7], относящийся к классу
алгоритмов деления. Идея метода состоит в том, чтобы последовательно убирать
связи между вершинами, предположительно находящимися в разных сообществах, до
тех пор, пока не образуется множество несвязных компонент изначального графа,
равное заданному числу кластеров. Выбор ребра, которое необходимо удалить
осуществляется, основываясь на идеи центральности по посредничеству (далее
центральность), предложенной Фриманом в 1977 г [8].
Центральность - характеристика, приписываемая каждому ребру в графе,
являющаяся неотрицательной величиной, численно равной количеству кратчайших
путей, проходящих через данное ребро. Если между вершинами n кратчайщих путей,
то каждый из путей учитывается с коэфициентом 1/n при подсчете модулярности.
Кратчайшим путем между двумя вершинами называется последовательность ребер,
соединяющая эти вершины и обладающая наименьшей суммой весов.
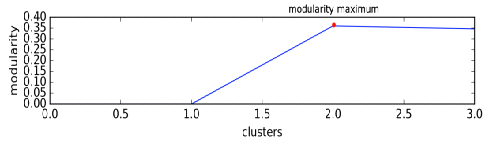
Для того, чтобы полученное данным алгоритмом разбиение являлось
оптимальным используется характеристика модулярности (см. модулярность). Как
только в процессе работы алгоритма изменяется количество компонент связности,
для полученного разбиения рассчитывается модулярность, при достижении максимума
модулярности работа алгоритма завершается.
В итоге алгоритм нахождения сообществ выглядит следующим образом:
1. Находится центральность для всех ребер в графе.
2. Ребро с наибольшим значением центральности удаляется.
. Центральность для всех ребер пересчитывается заново.
. При изменении количества компонент связности рассчитывается
модулярность текущего разбиения.
. Если модулярность начинает убывать, работа алгоритма завершается. В
качестве результата берется разбиение, соответствующее наибольшему показателю
модулярности.
К сожалению, данный метод имеет высокую сложность O(m^2n) и его
использование на графах с большим количеством вершин нецелесообразно. Однако
время работы алгоритма можно сильно сократить, если заранее знать количество
кластеров в оптимальном разбиении.
Спектральный
метод
Основная идея спектрального метода нахождения сообществ в графах
заключается в анализе собственных векторов и собственных значений матриц,
связанных с графом, таких, как матрица смежности или Лапласиан[9]. Множество
собственных значений таких матриц называют спектром графа.
Спектральная
теория графов возникла в 1950-60 годах. Кроме теоретических исследований графов
<https://ru.wikipedia.org/wiki/Теория_графов> о связи структурных и
спектральных свойств графов, другим источником стали исследования в кантовой
химии <https://ru.wikipedia.org/wiki/Квантовая_химия>. Монография 1980
года «Спектры графов» (Spectra of Graphs) Цветковича, Дооба и Сакса (Cvetković, Michael Doob, Sachs) [10] обобщила почти все
исследования в этой области, известные к тому моменту. В 1988 году вышло
обновлённое обозрение «Последние исследования в теории спектра графа» [11].
Третье издание книги «Спектры графов» (1995) содержит итоги дальнейших вкладов
в этой области [12].
В
данной работе производилось изучение спектрального метода с использованием
матрицы смежности, однако сейчас ведутся разработки методов определения
кластеров по спектру матриц, составленных различными способами, например,
нормированная матрица Лапласа [13] и Non-backtracking-матрица [14].
Другие методы
Помимо описанных алгоритмов существует так же множество других, имеющих в
основе совершенно разные методики. В данной работе мы не будем на них подробно
останавливаться, но все же приведем описание некоторых их них:
1. Fastgreedy - метод, основанный на жадной оптимизации функции модулярности. [15]
2. Multilevel - метод, основанный на многоуровневой оптимизации функции модулярности. [16]
. LabelPropogation - метод, основанный на присвоении меток к каждой вершине. Каждый раз выбирается метка с максимальной встречаемостью среди смежных вершин.
[17]
. Walktrap - подход, основанный на случайном блуждании. Использует идею о том,
что короткие случайные блуждания не приводят к выходу из текущего сообщества. [18]
. Infomap - метод случайного блуждания, основанный на понятии информаци- онных потоков
в сетях, кодирования и сжатия информации. [19]
Анализ и
сравнение выбранных методов
Анализируемые
модели графов.
Для тестирования и анализа реализованных алгоритмов были использованы два
готовых набора данных и два разных алгоритма генерации случайных графов.
Наборы данных
Фортунато и Кастеллиано
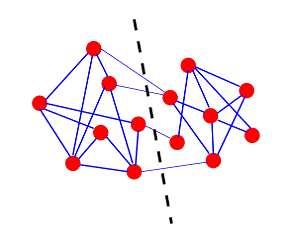
Данный граф был описан Фортунато и Кастеллиано в книге «Encyclopedia of
Complexity and Systems Science» [21]. Граф содержит 14 вершин и 25 ребер.
Оптимальное разбиение, содержащее два кластера изображено на рисунке.
Карате клуб
Захария
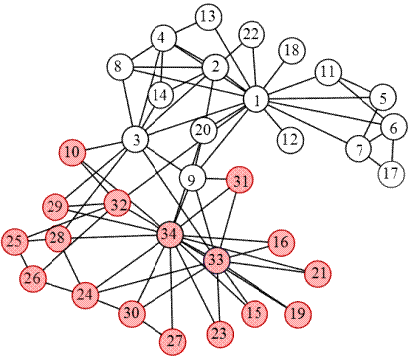
Данная социальная сеть изучалась Уэйном Захарием с 1970 по 1972 г.
Сеть содержит 34 вершины и 78 ребер и основана на реальных данных о
взаимодействии членов карате клуба внутри университетского клуба карате и вне
его. Этот набор данных является широко известным и часто используется для
демонстрации самой идеи нахождения сообществ графах и тестирования алгоритмов
нахождения кластеров.
В клубе произошла конфликтная ситуация между администратором и
инструктором, в результате которого половина участников вместе с инструктором
отделились от остальных и основали свой клуб, а некоторые и вовсе перестали
заниматься карате. На основании собранных данных Захарий точно определил, к
какой группе примкнет каждый член клуба, за исключением одного человека,
который вступил в клуб после начала конфликта.
На рисунке изображено разбиение, предложенное Захарием, полученное с
использованием алгоритма Форда-Фалкерсона [23].
Случайно
генерируемые графы
Помимо готовых наборов данных, работа алгоритма была исследована на
случайно генерируемых графах. В качестве моделей генерации были выбраны модель
Эрдеша - Реньи и ее модификация, позволяющая получить граф с выделенными
сообществами.
Модель Эрдеша
- Реньи
Модель Эрдеша-Реньи [24] является одной из основных моделей генерации
случайных графов. Она названа в честь Пола Эрдеша и Реньи, которые впервые
представили ее в 1959 году. Другая, схожая модель была введена независимо и
одновременно с моделью Эрдеша-Реньи Эдгаром Гилбертом [25]. В модели, описанной
Эрдешом и Реньи, ребро между каждой парой вершин существует с некой
вероятностью, заданной для всего графа.
В модели Гильберта каждое ребро имеет индивидуальную фиксированную
вероятность существования, независимо от других ребер.
Обе модели позволяют сгенерировать неориентированный случайный граф без
кратных ребер и петель. Для модели Эрдеша-Реньи среднее количество ребер равняется
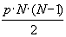
Важным достоинством этой модели является тот факт, что при количестве
вершин, стремящихся к бесконечности и вероятности большей 2ln(n)/n вероятность
того, что полученный граф будет связным стремится к 1.
Однако у модели имеется большой недостаток: полученные графы не имеют
четко выделенных сообществ.
Граф с
выраженной структурой сообществ
Для того, чтобы генерировать графы с сообществами, алгоритм Эрдеша-Реньи
был модифицирован следующим образом: Все вершины графа заранее распределяются
по заданному количеству кластеров, после соединяются ребрами с вероятностью p
для ребер между вершинами в одном сообществе и q - для ребер, соединяющих
вершины из разных сообществ. При достаточно малых q (< 0.1) и больших p (>
0.5) такой метод позволяет получить граф с различимой структурой сообществ.
Оптимизация
найденной структуры
Часто случается, что истинное разбиение сообщества не известно, что
характерно при исследовании реальных графов больших размеров. Тогда, чтобы
оценить качество полученных при помощи алгоритмов разбиений, используют некие
критерии качества. Одним из таких критериев является оценка модулярности
полученного разбиения.
Модулярность
Данная мера качества была предложена Гирваном и Ньюманом во время разработки
алгоритма кластеризации вершин графа [7]. Модулярность является скалярной
величиной, значение которой находится на отрезке [-1,1]. Высокое значение
модулярности означает, что найденное разбиение достаточно качественно и
количество ребер, лежащих внутри сообществ велико, а ребер вне сообществ мало.
Практика показывает, что сети, для которых существует разбиение с
модулярностью, лежащей в диапазоне от 0.3 до 1 имеют достаточно различимую
структуру с сообществами.
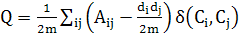
Где 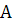 - Матрица смежности графа,
- Матрица смежности графа, 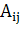 -
- 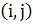 элемент матрицы,
элемент матрицы, 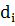 - степень вершины графа,
- степень вершины графа, 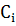 - метка вершины (номер сообщества, к
которому относится вершина),
- метка вершины (номер сообщества, к
которому относится вершина), 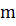 - общее количество ребер в графе.
- общее количество ребер в графе. 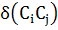 - дельта-функция, равная единице,
если
- дельта-функция, равная единице,
если 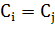 , иначе нулю.
, иначе нулю.
Связь между
количеством кластеров, модулярностью и спектром
Существует предположение, что количество отдельно стоящих собственных
значений в спектре совпадает с количеством кластеров в графе, соответствующем
этому спектру [26]. Пока это предположение не было доказано, но не раз находило
подтверждение на практике.
В ходе данной работы были собраны данные о модулярности разбиений и
спектре графов, основанных на наборах данных, описанных выше. В большенстве
случаев количество отдельно стоящих собственных векторов совпадало с
максимальным значением модулярности. Однако часто нельзя было однозначно судить
о количестве таких собственных значений, что характерно для графов, не имеющих
чётко выраженной структуры с сообществами.
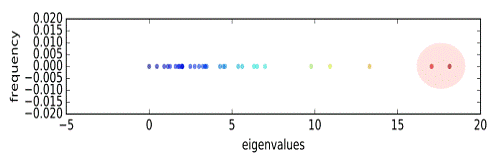
Тем не менее, если граф обладает такой структурой, спектральный анализ
позволяет заранее узнать количество сообществ в графе, а после использовать
алгоритмы, требующие этой информации, такие как алгоритм Гирвана-Ньюмана или k-means, не прибегая к методу максимизации модулярности.
Связь между
структурой графа и спектром
Для того, чтобы проиллюстрировать связь структуры графа и его спектра был
проведен небольшой эксперимент.
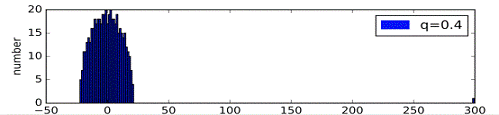
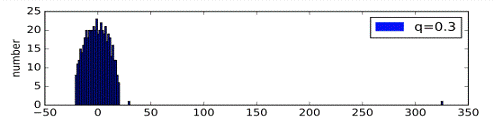
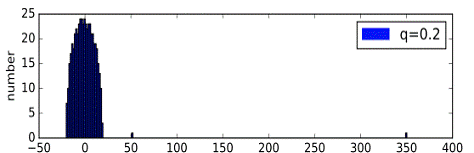
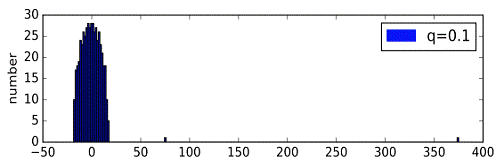
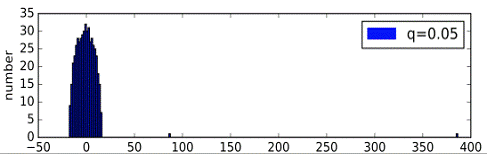
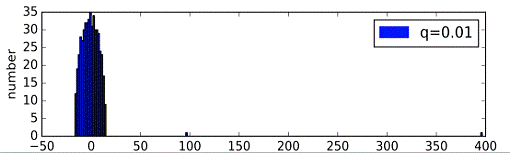
Были сгенерированы случайные графы, имеющие структуру с сообществами. При
генерации вероятность нахождения ребра между вершинами из одного кластера была
взята за p=0.4, а между вершинами из разных кластеров за q<0.4 и уменьшалась
для каждого последующего эксперимента. Количество точек в графах было взято за
V=500, а число кластеров за n=2. Конечно это частный случай, и на графах с
другими параметрами будет наблюдаться немного другая картина, однако общий
характер процесса будет схожим, за исключением разве что графов с малым
количеством вершин.
На графиках четко виден процесс постепенного отделения и удаления одного
собственного значения от основного массива собственных значений, при уменьшении
вероятности q.
Программная
реализация
Для программной реализации описанных алгоритмов поиска сообществ и
генерации графов, а также для их визуализации и составления статистики был
выбран язык программирования Python
и набор научных библиотек, таких как graph-tool, numpy, matplotlib и др.
Основной модуль graph-tool [27] является эффективным
инструментом для манипулирования графами и их статистического анализа. В
отличие от большинства других подобных модулей, обладающих схожей
функциональностью, большинство методов и структур данных в graph-tool реализованы на языке программирования C++, что даёт алгоритмам, написанным с
использованием этой библиотеки, высокую скорость работы.
Библиотека предоставляет широкий спектр разнообразных методов для работы
с графами, например, фильтрация вершин и рёбер, нахождение различных параметров
вершин и рёбер, кратчайших путей, составление матриц смежности, инцидентности и
Лапласиана, а также реализации наиболее популярных алгоритмов на графах.
Библиотека предоставляет возможности визуализации и отрисовки графов в
отдельном потоке с использованием пакетов Cairo, GTK+ и Graphviz. Так же несомненным плюсом является
подробная и понятная документация с множеством примеров.
Выводы
Был выявлен и наглядно продемонстрирован тот факт, что анализ спектра
графа позволяет заранее определить количество кластеров в нём, не прибегая к
оценке качества разбиений на основе модулярности, что позволяет значительно
сократить время работы многих алгоритмов, для оптимальной работы которых
необходимо вычислять количество кластеров.
Однако предложенный метод как было выяснено требует дальнейшей доработки
и формализации. Необходимо ввести некий критерий, позволяющий при анализе
спектра определить, является ли собственное значение, удалённое от других
таковым на самом деле или, нет. А также критерий, определяющий на основе
спектра, имеет ли граф структуру с сообществами.
Список источников
. Kernighan, B. W.; Lin, Shen (1970).
"An efficient heuristic procedure for partitioning graphs". Bell
System Technical Journal 49: 291-307.
. Cheetam A.H., Hazel J.E. Binary
(presence-absence) similarity coefficients // J. Paleontology, V. 43, № 5.
1969. P. 1130-1136.
3. Tan, Pang-Ning; Steinbach, Michael;
Kumar, Vipin (2005), Introduction to Data Mining, ISBN 0-321-32136-7.
. Hamming, Richard W. (1950),
"Error detecting and error correcting codes"
. Lloyd S. (1957). Least square
quantization in PCM’s. Bell Telephone Laboratories Paper.
. Steinhaus H. (1956). Sur la division
des corps materiels en parties. Bull. Acad. Polon. Sci., C1. III vol IV:
801-804.
. Girvan M. and Newman M. E. J.,
Community structure in social and biological networks, Proc. Natl. Acad. Sci.
USA 99, 7821-7826 (2002)
8.
Dragoš Cvetković, Peter Rowlinson, Slobodan Simić. Eigenspaces of Graphs. 1997. - ISBN
0-521-57352-1 <https://ru.wikipedia.org/wiki/%D0%A1%D0%BB%D1%83%D0%B6%D0%B5%D0%B1%D0%BD%D0%B0%D1%8F:%D0%98%D1%81%D1%82%D0%BE%D1%87%D0%BD%D0%B8%D0%BA%D0%B8_%D0%BA%D0%BD%D0%B8%D0%B3/0521573521>.
. Dragoš M. Cvetković, Michael Doob, Horst Sachs. Spectra of Graphs. -
1980.