Исследование и разработка алгоритмов распознавания лиц
Оглавление
Введение
Глава 1. Рассмотрение теоретических
аспектов
1.1 Обнаружение лица
1.2 Выравнивание лица
1.3 Вычисление и сравнение признаков
Глава 2. Методы и идеи,
использованные в реализации
Глава 3. Процесс исследования
Заключение.
Список литературы
Приложения
Введение
Современное состояние и актуальность темы
исследования. В современном мире для идентификации человека используются
биометрические методы. Биометрией называется совокупность способов и устройств
для идентификации человека, которые основаны на его уникальных физиологических
или поведенческих характеристиках.
К биометрическим методам относятся:
· дактилоскопия;
· аутентификация по радужной оболочке;
· идентификация по сетчатке глаза;
· распознавание по лицу;
· распознавание по голосу;
· распознавание по рукописному
почерку;
· распознавание по клавиатурному
почерку;
· термографическое наблюдение лицевых
артерий и вен;
· идентификация по венам руки и др.
В настоящее время наблюдается непреходящий
интерес к проблеме распознавания лиц. Распознавание лиц можно условно поделить
на 2 задачи: идентификация и верификация. Задача идентификации состоит в том,
чтобы сравнить захваченное лицо со всеми изображениями лиц, хранящимися в базе
данных. Цель верификации состоит в том, чтобы сравнить лицо человека с
фотографии кандидата, с лицом на эталонной фотографии, хранящейся в базе
данных.
Задача распознавания лиц актуальна как в области
интеллектуальных сред, так и в системах безопасности. Например, в этом году был
запущен онлайн-сервис распознавания лиц по фотографиям в интернете на основе
российской технологии, разработанной N-Tech.Lab.
Google также опубликовал научную работу о новой системе искусственного
интеллекта FaceNet, которая распознаёт лица людей с точностью 99,63% на
стандартном наборе данных LFW. Система исследователей из Facebook показала
результат около 97,5%. Среди продуктов с открытым исходным кодом можно выделить
OpenCV. Это библиотека
алгоритмов компьютерного зрения, обработки изображений и численных алгоритмов
общего назначения. Может свободно использоваться в академических и коммерческих
целях - распространяется в условиях лицензии BSD.
Распознавание человека по изображению лица имеет
ряд преимуществ по сравнению с другими методами идентификации человека:
) не требуется специальное или
дорогостоящее оборудование;
) не нужен физический контакт с
устройствами. Не надо ни к чему прикасаться или специально останавливаться и
ждать срабатывания системы. В большинстве случаев достаточно просто пройти мимо
или задержаться перед камерой на небольшое время.
К недостаткам распознавания человека по
изображению лица следует отнести:
) сама по себе такая система не
обеспечивает 100% надёжности идентификации. Там, где требуется высокая
надёжность, применяют комбинирование нескольких биометрических методов;
) распознавание лица неэффективно тогда,
когда значительные изменения, например, вследствие несчастного случая, делают
невозможным даже человеческую визуализацию;
) кроме того система может ошибаться
из-за ряда других факторов: признаков старения, мимики, освещения и угла
зрения.
В настоящее время активно используются несколько
десятков компьютерных методов распознавания лиц, вот некоторые из них:
· нейронные сети;
· метод главных компонент (собственных
лиц);
· локальные бинарные шаблоны;
· метод эластичных графов;
· метод, основанный на скрытых
марковских моделях;
· активные модели внешнего вида;
· активные модели формы.
В своей работе я рассматриваю распознавание лиц
людей с использованием локальных бинарных шаблонов (Local
Binary Patterns
- LBP). Оператор LBP
может быть использован для поиска объекта на изображении (например лица), а
также проверки этого объекта на принадлежность некоторому классу (верификация,
распознавание эмоций, пола по лицу).
Целью выпускной квалификационной работы является
исследование алгоритмов распознавания лиц для последующего написания своей
программы для распознавания лиц и внедрения данного решения в компанию. Было
принято решение разработки своего ПО именно потому, что на данный момент не
существует бесплатных, демонстрирующих хороший процент распознавания, систем
распознавания лиц.
Для достижения поставленной цели предусмотрено
решение следующих задач:
) Исследовать имеющиеся некоммерческие
продукты с открытым исходным кодом.
) Исследовать использующиеся в них
алгоритмы.
) На основе этих алгоритмов написать своё
собственное ПО.
) Интегрировать разработанное ПО для
распознавания лиц в Timebook.
Объектом исследования выпускной квалификационной
работы являются алгоритмы для распознавания лиц.
Предмет исследования - исследование алгоритмов
для распознавания лиц с целью написания ПО для пропускной системы предприятия.
Методы исследования. В качестве методов
исследований использовалось статистическое моделирование, компьютерная
обработка изображений и компьютерное зрение.
Глава 1.
Рассмотрение теоретических аспектов
Процесс распознавания лиц можно поделить на
несколько этапов:
. обнаружение лица на фотографии (face
detection);
. выравнивание лица (face
alignment);
. вычисление признаков (features
extraction);
. сравнение признаков (features
matching).
.1 Обнаружение лица
алгоритм
распознавание лицо
Задача обнаружения лица на изображении является
первым шагом в процессе решения задачи распознавания лиц.
Существующие алгоритмы для обнаружения лиц можно
разделить на четыре категории:
· распознавание с помощью шаблонов,
заданных разработчиком;
· эмпирический метод;
· метод характерных инвариантных
признаков;
· метод обнаружения по внешним
признакам, обучающиеся системы.
Эмпирический подход «базирующийся на знаниях
сверху-вниз» (knowledge based top-down methods) предполагает создание
алгоритма, который реализует набор правил, которым должен отвечать фрагмент
фотографии, для того чтобы считаться человеческим лицом. Данный набор правил -
это попытка формализовать эмпирические знания о том, как выглядит лицо на
изображении и чем руководствуется человек для принятия решения: видит он лицо
или не лицо.
Основные правила:
· центральная часть лица имеет
однородную яркость и цвет;
· у центральной и верхней частей лица
разная яркость;
· лицо содержит в себе нос, рот и два
симметрично расположенных глаза, резко отличающиеся по яркости относительно
остальной части лица.
Метод сильного уменьшения изображения
используется для того, чтобы сгладить помехи и уменьшить вычислительные
операции. На таком изображении проще обнаружить зону с равномерным
распределением яркости, а потом проверить наличие резко отличающихся по яркости
областей внутри. Именно эти области можно с разной долей вероятности определить
как лицо.
Метод построения гистограмм для того, чтобы
определить области изображения, где находится лицо, строит горизонтальную и
вертикальную гистограммы. А в областях-кандидатах происходит поиск черт лица.
Такой подход использовался в самом начале развития компьютерного зрения из-за
того, что он не был требовательным к вычислительной мощности процессора.
Методы, рассмотренные выше, имеют неплохие показатели по выявлению лиц на
изображении с несложным однородным фоном и легки в реализации. Позднее было
разработано множество похожих алгоритмов. Но все эти методы абсолютно
непригодны для обработки изображений, с большим количеством лиц или со сложным
фоном. Также данные методы очень чувствительны к повороту и наклону головы.
Методы характерных инвариантных признаков,
базирующиеся на знаниях снизу-вверх (Feature invariant approaches) являются
вторым семейством способов для обнаружения лиц. В этих методах проблема
рассматривается с другой стороны: нет попытки в явном виде формализовать
процессы, которые происходят в человеческом мозге. Сторонники этого подхода
пытаются выявить свойства и закономерности изображения лица неявно, найти
инвариантные особенности лица, независимо от положения или угла наклона.
Основные этапы алгоритмов этой группы методов:
· обнаружение на изображениях явных
признаков лица: рта, носа, глаз;
· обнаружение границы, формы, цвета,
текстуры, яркости лица;
· объединение всех найденных
признаков, затем их верификация.
Метод обнаружения лиц в сложных сценах
подразумевает поиск правильного геометрического расположения черт лица. Для
этих целей применяется Гауссовский фильтр со множеством различных ориентаций и
масштабов. Затем производится поиск соответствия найденных черт и их взаимного
положения случайным перебором.
Суть метода группировки признаков в
использовании второй производной Гауссовского фильтра для того, чтобы найти
интересующие области изображения. Затем при помощи порогового фильтра
группируются края вокруг каждой такой области. После этого применяется оценка
при помощи Байесовской сети для комбинирования выявленных признаков - таким
образом производится выборка черт лица.
Методы из этой группы имеют возможность
распознавать лицо в различных положениях. Но при небольшом перекрытии лица
другими объектами, засветке или возникновении шумов процент распознавания резко
падает. Значительное влияние оказывает сложный фон изображения. Основа
рассмотренных подходов - эмпирика. Она является одновременно и сильной, и
слабой стороной. Большая изменчивость объекта распознавания, зависимость от
условий съемки и освещения позволяют отнести детектирование лиц на изображениях
к задачам высокой сложности. Использование эмпирических правил позволяет
построить некую модель изображения лица и свести данную задачу к выполнению
нескольких относительно простых проверок. Но несмотря на разумную посылку -
попытаться применить успешно функционирующий инструмент для распознавания -
человеческое зрение, методы из первой категории пока очень далеки по
эффективности от своего прообраза, потому что исследователи, которые избрали
этот путь, сталкиваются с большим количеством трудностей. Во-первых, процессы,
которые происходят в человеческом мозгу во время распознавания образов,
достаточно плохо изучены, и набор эмпирических знаний о лице человека,
доступных исследователям на сознательном уровне, не исчерпывает инструментарий,
который использует мозг подсознательно. Во-вторых, достаточно трудно эффективно
перевести неформальный человеческий опыт и знания в набор формальных правил,
потому что жесткие рамки правил приведут к тому, что в некоторых случаях лица
не будут обнаружены, и, наоборот, а слишком общие правила приведут к большому
числу случаев ложного обнаружения.
Распознавание с помощью шаблонов, заданных
разработчиком (Template Matching Methods). Шаблоны задают некий стандартный
образ изображения лица, например, с помощью описания свойств отдельных частей
лица и их возможного взаимного положения. Детектирование лица с помощью шаблона
состоит в проверке каждой области изображения на соответствие заданному
шаблону.
Особенности данного подхода:
· два вида шаблонов:
o деформируемые;
o недеформируемые;
· шаблоны запрограммированы заранее;
· для нахождения лица на изображении
используется корреляция.
Метод обнаружения лица при помощи трехмерных
форм использует шаблон в виде пар отношений яркостей в двух областях. Для обнаружения
лица необходимо пройти всё изображение на сравнение с заданным шаблоном. Делать
это надо с различным масштабом.
Модели распределения опорных точек являются
статистическими моделями, которые представляют объекты, форма которых может
измениться. Полезная особенность метода - это способность выделить форму
переменных объектов в пределах обучающего набора с небольшим количеством
параметров формы. Данная точная и компактная параметризация может быть
использована для разработки эффективных систем классификации.
Достоинствами распознавания с помощью шаблонов
являются относительная простота реализации и хорошие результаты на изображениях
с не очень сложным фоном. Главный недостаток - это необходимость калибровки
шаблона вблизи с изображением лица. А большая трудоёмкость вычисления шаблонов
для различных ракурсов и поворотов лица ставят под вопрос целесообразность их
использования.
Методы обнаружения лица по внешним признакам
(методы при которых необходимо провести этап обучения системы, путём обработки
тестовых изображений). Изображению или фрагменту изображения ставится в
соответствие некий вычисленный вектор признаков, использующийся для
классификации изображения на два класса - лицо/не лицо. Обычно поиск лица на
изображении с помощью методов, которые основаны на построении математической
модели изображения лица, заключается в том, чтобы перебрать все прямоугольные
фрагменты изображения всех размеров и проверить каждый фрагмент на наличие
лица. Но из-за того, что схема полного перебора имеет такие недостатки, как
избыточность и большая вычислительная сложность, авторы применяют разнообразные
методы уменьшения количества рассматриваемых фрагментов.
Главные принципы методов:
· Схоластика. То есть каждое
изображение сканируется окном и представляется некими векторами ценности.
· Блочная структура. Изображение
разбивается на пересекающиеся или непересекающиеся участки различных масштабов
и производится оценка с помощью алгоритмов оценки весов векторов.
Для того, чтобы обучить алгоритмы требуется
набор вручную подготовленных изображений с лицами и без лиц.
Стоит также отметить, что самая важная задача -
это выделить сильные классификаторы, так как они будут являться наиболее
приоритетными для проверки выявленных признаков на изображении. Количество
более слабых классификаторов стоит уменьшать за счёт их похожести друг на
друга, а также удаления классификаторов, которые возникли за счёт шумовых
выбросов.
Основные методики выполнения данных задач:
· Искусственные нейронные сети;
· Метод главных
компонент;
· Метод факторного анализа;
· Линейный дискриминантный анализ;
· Метод опорных
векторов;
· Наивный Байесовский классификатор;
· Скрытые Марковские модели;
· Метод распределения;
· Разреженная
сеть
окон;
· Активные
модели;
· Метод Виолы-Джонса и др.
Рассмотрим особенности некоторых из них. Сегодня
метод искусственных нейронных сетей является самым распространенным способом
для решения задач распознавания лиц. Искусственная нейронная сеть - это
математическая модель, которая представляет собой систему соединённых и взаимодействующих
между собой нейронов. Нейронные сети не программируются в привычном смысле
этого слова, они обучаются. Технически обучение заключается в нахождении
коэффициентов связей (синапсов) между нейронами.
Метод опорных векторов применяется для того,
чтобы уменьшить размерность пространства признаков, не приводя при этом к
существенной потере информативности обучающего набора объектов. Применение
метода главных компонент к набору векторов линейного пространства, позволяет
перейти к такому базису пространства, что дисперсия набора будет направлена
вдоль нескольких первых осей базиса, которые называются главными осями.
Натянутое на полученные таким образом главные оси подпространство является
оптимальным среди всех пространств в том смысле, что наилучшим образом
описывает обучающий набор. Это набор алгоритмов похожий на алгоритмы вида
«обучение с учителем», которые используются для классификации и регрессионного
анализа. Этот метод принадлежит к семейству линейных классификаторов. В основе
метода опорных векторов лежит линейное разделение классов.
Сегодня самым перспективным в плане высокой
производительности, малой частоты ложных срабатываний и высоким процентом
верных обнаружений лиц является метод Виолы-Джонса.
Главные принципы, на которых основан метод:
· изображения используются в
интегральном представлении, это позволяет быстро найти лицо;
· используются признаки Хаара, с
помощью этих признаков происходит поиск лица и его черт;
· используется бустинг для выбора
наиболее подходящих признаков для искомого объекта на изображении;
· используется классификатор, который
даёт ответ: лицо/не лицо;
· используются каскады признаков Хаара
для быстрого отбрасывания окон, где лицо не найдено.
Классификаторы обучаются очень медленно, но лица
обнаруживаются очень быстро. Алгоритм демонстрирует хорошую работу, если
искомый объект находится на изображении под небольшим углом, примерно до 30
градусов. При большем угле наклона процент обнаружений намного ниже. К
сожалению, это не позволяет в стандартной реализации обнаруживать повернутое
лицо человека под углом больше 30 градусов, что в значительной степени
затрудняет или делает невозможным использование данного алгоритма в современных
системах обнаружения лиц.
Задача обнаружения лица человека на цифровом
изображении выглядит следующим образом. Имеется изображение, на котором есть
лицо. Оно представлено двумерной матрицей пикселов, в которой каждый пиксель
имеет значение от 0 до 255 включительно, если изображение является чёрно-белым,
от 0 до 2553, если изображение цветное. Алгоритм должен определить лица и
пометить их - поиск осуществляется в активной области изображения
прямоугольными признаками, с помощью которых и описывается найденное лицо.
Проще говоря, используется подход на основе сканирующего окна. Изображение сканируется
окном поиска, а затем к каждому положению применяется классификатор.
Для того, чтобы производить какие-либо действия
с данными, используется интегральное представление изображений в методе
Виолы-Джонса. Интегральное представление позволяет быстро рассчитать суммарную
яркость произвольной прямоугольной области на изображении, причём какого бы
размера данная область не была, время расчёта константно.
Интегральное представление изображения - это
матрица, совпадающая по размерам с исходным изображением. В каждом её элементе
хранится сумма яркостей всех пикселей, которые находятся выше и левее данного
элемента. В стандартном методе Виолы - Джонса используются прямоугольные
признаки, которые называются Хаароподобными вейвлетами. Для их вычисления
используется понятие интегрального изображения, которое было рассмотрено выше.
Признаки Хаара дают точечное значение перепада яркости по оси X и Y
соответственно.
Алгоритм сканирования окна с признаками выглядит
следующим образом. Имеется исследуемое изображение, окно сканирования и
используемые признаки выбраны. Затем окно сканирования начинает последовательно
передвигаться по изображению с шагом в 1 ячейку окна. Сканирование производится
последовательно для разных масштабов, причём масштабируется не само изображение,
а сканирующее окно. Все найденные признаки попадают к классификатору, который
решает - найдено лицо или нет.
Вычислять все признаки на персональных
маломощных компьютерах просто нереально. Поэтому классификатор должен
реагировать только на нужное подмножество признаков. Следовательно,
классификатор нужно научить нахождению лиц по определённому подмножеству. Это
можно сделать, обучая вычислительную машину автоматически.
В контексте алгоритма, имеется множество
изображений, разделённых на классы. Задано несколько изображений, для которых
известно, к какому классу они относятся, например, класс «фронтальное положение
носа». Эти несколько изображений - обучающая выборка. Классовая принадлежность
остальных изображений не известна. Требуется построить алгоритм, способный
классифицировать произвольный объект из исходного множества. Для решения этой
проблемы существует технология бустинга. Бустинг - это комплекс методов,
которые способствуют повышению точности аналитических моделей. Модель, которая
допускает небольшое количество ошибок классификации, называется «сильной».
«Слабая» же не позволяет надёжно классифицировать и делает в работе много
ошибок.
Алгоритм бустинга для поиска лиц:
. Определение слабых классификаторов по
прямоугольным признакам;
. Для каждого перемещения сканирующего
окна вычисляется прямоугольный признак на каждом примере;
. Выбирается самый подходящий порог для
каждого признака;
. Отбираются лучшие признаки и лучший
порог;
. Перевзвешивается выборка.
Каскадная модель сильных классификаторов - это
дерево принятия решений, в котором каждый узел построен таким образом, чтобы
обнаруживать все интересующие образы и отклонять регионы, которые не являются
образами. Узлы дерева размещены таким образом, что чем узел ближе к корню
дерева, тем из меньшего количества примитивов он состоит и, следовательно,
требует меньше времени на принятие решения. Этот вид каскадной модели идеально
подходит для обработки изображений, на которых количество детектируемых образов
не велико. В данном случае метод может быстрее решить, что данный регион не
содержит образ, и перейти к следующему.
В том случае, если на вход системе подаётся
цветное изображение, то можно в значительной мере увеличить скорость работы
алгоритма, если предварительно обработать изображение при помощи цветового
кодирования. Цветовое кодирование также помогает сократить число ложных
срабатываний.
Сегодня алгоритм Виолы-Джонса является самым
популярным благодаря высокой точности срабатывания и высокой скорости работы.
.2 Выравнивание лица
После того, как лицо будет найдено на
изображении (будут получены координаты верхнего левого угла, длина и ширина
прямоугольника с лицом), необходимо подвергнуть изображения предобработке. С
целью снижения уровня шума можно использовать разнообразные фильтры (медианный,
гауссовский и пр.). Кроме того, необходимо провести процедуру нормализации
изображения, т.е. кадрировать, масштабировать и довернуть до горизонтального
положения линии, соединяющей центры глаз. Хотя в данной работе теоретическому
материалу о предобработке уделено мало внимания, следует отметить, что качество
работы системы существенным образом зависит от предобработки входных
изображений. В ходе выполнения работы было отмечено, что отсутствие этапа
фильтрации приводит к снижению вероятности правильной верификации.
.3 Вычисление и сравнение признаков
Заключительным этапом является вычисление
признаков и сравнение их совокупностей между собой. Ниже представлено описание
самых популярных алгоритмов.
Метод гибкого сравнения на графах (Elastic graph
matching).
Суть метода состоит в том, чтобы сопоставить
эластичные графы, описывающие изображения лиц. Лица представляются в виде
графов со взвешенными ребрами и вершинами. На этапе распознавания эталонный
граф остаётся неизменным, а другой подвергается деформации с целью наилучшей
подгонки к эталонному. В системах распознавания, основанных на данном методе,
графы могут представлять собой прямоугольную решетку или структуру,
образованную антропометрическими точками лица.
В вершинах графа вычисляются значения признаков,
обычно с помощью комплексных значений фильтров Габора или с помощью Габоровских
вейвлет, которые вычисляются в определённой локальной области вершины графа
посредством свертки значений яркости пикселов с Габоровскими фильрами.
Ребра графа взвешиваются расстояниями между
смежными вершинами. Расстояние между двумя графами вычисляется с помощью
некоторой ценовой функции деформации, которая учитывает различие между
значениями признаков, вычисленными в вершинах, и степень деформации ребер
графа.
Граф деформируется путем смещения каждой его
вершины на некоторое расстояние в определённых направлениях относительно её
исходного положения и выбора позиции вершины, при которой различие между
значениями признаков в вершинах деформируемого графа и соответствующих вершинах
эталонного графа будет минимальным. Данная операция выполняется для каждой из
вершин графа до тех пор, пока не будет достигнуто наименьшее суммарное различие
между признаками эталонного и деформируемого графов. Значение ценовой функции
деформации при таком положении деформируемого графа - это мера различия между
эталонным графом и входным изображением лица. Эта процедура деформации должна
выполняться для всех эталонных лиц, которые имеются в базе данных системы. В
результате работы данной системы распознавания мы получим эталон с наилучшим
значением ценовой функции деформации.
В некоторых источниках указывается 95-97%-ная
эффективность распознавания даже при различной мимике на фотографиях и повороте
лица до 15 градусов. Однако разработчики подобных систем заявляют о том, что
для работы системы требуются большие вычислительные мощности.
Нейронные сети.
В наши дни существует около десятка
разновидностей нейронных сетей. Самой популярной разновидностью являться сеть,
в основе которой лежит многослойный перцептрон. Она позволяет классифицировать
входное изображение в соответствии с предварительным её обучением.
Нейронные сети обучаются на наборе обучающих
примеров. Суть обучения сводится к тому, чтобы настроить веса межнейронных
связей в процессе решения задачи оптимизации с использованием метода
градиентного спуска. В процессе обучения нейронной сети происходит
автоматическое извлечение, определение важности и построение взаимосвязей между
ключевыми признаками. Предполагается, что обученная нейронная сеть сможет
применить полученный во время обучения опыт на неизвестные образы за счет
способностей к обобщению.
Самые лучшие результаты в распознавании лиц
продемонстрировала Convolutional Neural Network или сверточная нейронная сеть,
которая является логическим развитием архитектур когнитрона и неокогнитрона.
Успех был достигнут за счёт учета двумерности изображения, в отличие от
многослойного перцептрона.
Сверточную нейронная сеть отличают от других
локальные рецепторные поля, которые обеспечивают двумерную связность нейронов,
общие веса, которые обеспечивают обнаружение некоторых черт в любом месте
изображения, и иерархическая организация с так называемым пространственным
сэмплингом. Благодаря данным нововведениям свёрточная нейронная сеть
обеспечивает некоторую устойчивость к масштабированию, смене ракурса,
поворотам, смещению и некоторым другим искажениям.
Тестирование данной нейронной сети на базе
данных ORL (содержит изображения лиц с небольшими изменениями масштаба,
освещения, пространственными поворотами, эмоциями) показало 96%-ную точность
распознавания.
Свёрточные нейронные сети стали популярными
благодаря разработке DeepFace, которую позднее приобрёл Facebook. Информация об
особенностях архитектуры не разглашается.
Недостатком нейронных сетей в первую очередь
является их скорость обучения. Например, добавление нового эталонного лица в БД
потребует полного переобучения сети на всем наборе. Данная процедура, в
зависимости от объёма выборки, может занять от 1 часа вплоть до нескольких
дней. Также существует несколько проблем математического характера, которые
связаны с обучением. Например, выбор оптимального шага оптимизации, попадание в
локальный оптимум, переобучение, трудно формализуемый этап выбора архитектуры
сети (характер связей, количество слоев, нейронов) и т.д. Принимая во внимание
все вышесказанное, можно заключить, что нейронная сеть - это «черный ящик»
результатами работы, трудными в интерпретации.
Скрытые Марковские модели (СММ, HMM).
СММ используют статистические свойства сигналов
и учитывают их пространственные характеристики. Элементы модели: начальная
вероятность состояний, множество наблюдаемых состояний, множество скрытых
состояний, матрица переходных вероятностей. Каждому элементу соответствует своя
Марковская модель. Во время распознавания объекта проверяются сгенерированные
Марковские модели и ищется наибольшая из наблюдаемых вероятность того, что
последовательность наблюдений для объекта сгенерирована соответствующей
моделью.
По состоянию на сегодня не существует
коммерческого продукта с использованием НММ для распознавания лиц.
Метод главных
компонент
или
Principal Component Analysis (PCA).
Первоначально PCA
начал использоваться в статистике в целях снижения пространства признаков без
значимой потери информации. В задаче распознавания лиц его используют главным
образом для того, чтобы представить лицо как вектор малой размерности, который
затем сравнивается с эталонными векторами из базы.
Главной целью РСА является значительное
уменьшение размерности пространства признаков так, чтобы оно как можно лучше
описывало «типичные» образы, принадлежащие множеству лиц. Используя этот метод
можно обнаружить различную изменчивость в обучающей выборке и описать эту
изменчивость в базисе нескольких ортогональных векторов (собственных векторов
или Eigenface).
Набор собственных векторов, который был получен
один раз на обучающей выборке, используется для кодирования остальных
изображений лиц, которые можно представить взвешенной комбинацией собственных
векторов. При использовании ограниченного количества собственных векторов можно
получить сжатую аппроксимацию входному изображению лица, которую впоследствии
можно хранить в БД, как вектор коэффициентов, который служит одновременно
ключом поиска в БД.
Суть РСА сводится к следующему. Сначала весь
обучающий набор лиц преобразуется в общую матрицу данных, где каждая строка -
это один экземпляр изображения лица. Все лица обучающего набора должны быть
одной размерности и желательно с нормированной гистограммой.
Следующий шаг - это нормировка данных и
приведение строк к 0-му среднему и 1-й дисперсии, затем вычисляется
ковариационная матрица. Для полученной матрицы определяются собственные
значения и соответствующие им собственные вектора, они же собственные лица.
Затем производится сортировка собственных лиц в порядке убывания собственных
значений и оставляются только первые k векторов.
РСА хорошо зарекомендовал себя в приложениях.
Однако, тогда, когда на изображении лица имеются значительные изменения в
выражении лица или освещённости, эффективность метода значительно падает. Это
происходит из-за того, что метод главных компонент выбирает подпространство с
целью максимальной аппроксимации входного набора данных, а не с целью
выполнения дискриминации между классами лиц.
Для решения этой проблемы было предложено
решение с использованием линейного дискриминанта Фишера (Fisherface).
Были проведены эксперименты в условиях сильного
нижнего и бокового затенения изображений лиц, в которых Fisherface показал
95%-ную эффективность по сравнению с 53%-ной у Eigenface.
Active Appearance Models (AAM) и
Active Shape Models (ASM).
Активные модели внешнего вида - это
статистические модели изображений, которые с помощью разных деформаций могут
быть подогнаны под реальное изображение. Этот тип моделей в двумерном варианте
предложил Тим Кутс и Крис Тейлор в 1998 году. Изначально ААМ применялись для
того, чтобы оценить параметры изображений лиц.
ААМ содержит два типа параметров: параметры
формы и параметры внешнего вида. Перед использованием модель обучают на
множестве заранее размеченных изображений (размечают вручную). Каждая метка
имеет свой номер и определяет характерную точку, которую модель находит во
время адаптации к новому изображению.
Процедура обучения активных моделей внешнего
вида начинается с нормализации форм на размеченных изображениях для того, чтобы
компенсировать различия в наклоне, смещении и масштабе. Для этих целей
применяется Прокрустов анализ.
Активные модели внешнего вида состоят из набора
параметров, одни из которых представляют форму лица, а другие задают его
текстуру. При решении задачи обнаружения лица на фотографии выполняется поиск
параметров, таких как форма, текстура и расположение, которые представляют
синтезируемое изображение, наиболее близкое к наблюдаемому. По степени близости
активных моделей внешнего вида подгоняемому изображению принимается решение о
наличии либо отсутствии лица.
Суть метода Active Shape Models заключается в
учете статистических связей между расположением антропометрических точек. На
каждом изображении из обучающей выборки эксперт размечает расположение
антропометрических точек. На каждом изображении точки нумеруются в одинаковом
порядке.
Для того, чтобы привести координаты на всех
изображениях к единой системе, обычно выполняется прокрустов анализ. В
результате данного анализа все точки на изображении приводятся к одному
масштабу и центрируются. Затем для всего набора образов высчитывается матрица
ковариации и средняя форма. На основе ковариационной матрицы вычисляются
собственные вектора, которые сортируются в порядке убывания соответствующих им
собственных значений.
Локализации Active Shape модели на новом
изображении, не входящем в обучающую выборку, осуществляется в процессе решения
оптимизационной задачи.
Всё же основной целью AAM и ASM является не
распознавание лиц, а локализация лица и антропометрических точек на фотографии
для дальнейшей обработки.
Локальный бинарный шаблон (ЛБШ, Local
Binary Pattern,
LBP).
LBP - это
определенный вид признака, который используется для классификации или
верификации в компьютерном зрении и представляет собой простой оператор. ЛБШ в
первый раз были предложены в 1996 году для анализа текстуры полутоновых
изображений. При этом дальнейшие исследования показали, что локальные бинарные
шаблоны индифферентны к небольшим поворотам изображения и изменениям в условиях
освещения.Binary Pattern - это описание окрестности пикселя изображения в
бинарном представлении. Базовый оператор LBP,
применяемый к пикселю на изображении, использует восемь пикселей окрестности.
Пиксели, значение интенсивности которых больше или равно значению интенсивности
центрального пикселя, принимают значение - 1, остальные принимают значение - 0.
Таким образом, результат применения базового оператора LBP
к пикселю изображения - восьмиразрядный двоичный код, описывающий окрестность
данного пикселя.
Использование круговой окрестности и билинейной
интерполяции значений интенсивностей пикселей позволяет построить ЛБШ с
произвольным радиусом и количеством точек.
Некоторые двоичные коды несут в себе больше
информации, чем другие. ЛБШ называется равномерным, если он содержит три или
менее серий «0» и «1» (например, 00000000, 001110000 и 11100001). Равномерные
локальные бинарные шаблоны определяют только важные локальные особенности
изображения, например, пятна, концы линий, углы и грани. А также ЛБШ существенно
экономят память.
Применяя оператор LBP
к каждому пикселю, можно построить гистограмму, в которой каждому равномерному
коду LBP
соответствует отдельный столбец. В добавок к этим столбцам есть ещё один
столбец, содержащий информацию обо всех неравномерных шаблонах.
Изображения лиц можно рассматривать как набор
всевозможных локальных особенностей, хорошо описываемых с помощью ЛБШ. Однако
гистограмма, которая была построена для всего изображения в целом, кодирует
лишь наличие тех или иных локальных особенностей, но при этом не имеет
абсолютно никакой информации об расположении этих особенностей на изображении.
Для того, чтобы учесть такого рода информацию, изображение разбивается на
прямоугольные подобласти, для каждой из которых вычисляется своя гистограмма LBP.
Затем эти гистограммы конкатенируются и получается общая гистограмма, которая
учитывает локальные и глобальные особенности изображения.
При данном подходе для достижения лучших
результатов можно изменять параметры оператора LBP
и число разбиений изображения на прямоугольные подобласти.
Глава 2. Методы и идеи, использованные в
реализации.
Для написания приложения был изучен рынок
бесплатных продуктов с открытым исходным кодом. Наиболее оптимальным решением
стало использование библиотеки OpenCV,
ввиду её активной поддержки разработчиками и широких возможностей по обработке
изображений. Финальная версия приложения состоит из модуля для сбора статистики
и из модуля распознавания.
Модуль распознавания написан на C++
с использованием библиотеки OpenCV.
В его реализации использовалось:
· каскады Хаара для поиска лиц и глаз
(носа);
· методы обработки изображений из
библиотеки OpenCV;
· Локальные Бинарные Шаблоны для
вычисления и сравнения признаков.
В качестве входных данных использовались
аргументы командной строки (путь к первому изображению, путь ко второму
изображению). На выходе мы получали некую дистанцию. Чем меньше эта дистанция,
тем больше «похожесть» изображений. Для сборки проекта использовался cmake.
Модуль статистики написан на Java.
На вход принимает 3 аргумента: путь к модулю распознавания, путь к выборке с
фотографиями, путь к файлу для записи детализированной статистики. Данная
программа запускает модуль распознавания, сравнивая каждую фотографию с каждой
из тестовой выборки. В итоге мы получаем csv-файл
с развёрнутой статистикой и общую статистику.
Строка в csv-файле
имеет вид:
label1;label2;filename1;filename2;confidence
где label1
и label2 - это условные
группы людей (1 человек - 1 группа); filename1
и filename2 - пути
сравниваемых файлов; confidence
- дистанция, полученная в результате сравнения (рисунок 2.1).

Рисунок 2.1. Пример с тремя строками из файла с
развёрнутой статистикой (открыт и форматирован в LibreOffice
Calc)
В общей статистике есть 4 числа:
· средняя дистанция при сравнении
«своих» фотографий;
· средняя дистанция при сравнении
«чужих» фотографий;
· среднеквадратичное отклонение при
сравнении «своих» фотографий;
· среднеквадратичное отклонение при
сравнении «чужих» фотографий.
Под «своими» фотографиями понимаются фотографии
одного и того же человека. Под «чужими» фотографиями - фотографии разных людей.
Описание финального алгоритма.
Финальную версию алгоритма работы модуля
распознавания можно разделить на следующие части:
· Конвертация изображения из RGB-пространства
в чёрно-белое.
· Выравнивание гистограммы
чёрно-белого изображения.
· Обнаружение лица.
· Обнаружение пары глаз.
· Нахождение центра глаз и
выравнивание их по горизонтальной линии.
· Кадрирование согласно коэффициентам.
· Применение медианного и Гауссовского
фильтров.
· Извлечение и сравнение признаков с
помощью ЛБШ.
Изображение конвертировалось в чёрно-белое в
первую очередь для возможности использования ЛБШ (работает только с
одноканальными изображениями). Выравнивание гистограммы применялось для
выравнивания яркости и повышения контрастности изображения, что положительно
сказалось на результатах распознавания. Обнаружение лица на изображении
осуществлялось посредством использования каскадного классификатора Хаара,
обученного на фронтальных лицах (готовое решение от OpenCV).
Лиц на фотографии может быть больше одного, поэтому выбирается самое большое.
Для поиска глаз также использовались каскады Хаара, но обученные на глазах
(также готовое решение от OpenCV).
Глаза искались не на всём изображении, а только в области лица. Но несмотря на
это алгоритм всё равно ошибался и мог найти более 2 глаз на лице. В связи с
этим было принято решение считать за глаза только самые большие 2 глаза. За
центр глаза было принято считать точку пересечения прямых, проходящих через
середины параллельных сторон квадрата, возвращаемого в результате обнаружения
глаза. Выравнивание по глазам производилось таким образом, чтобы прямая,
проведённая через центры глаз, была параллельна оси абсцисс. В процессе
исследования было выявлено, что неплохих результатов распознавания можно
достичь, если кадрировать лицо так, как показано на рисунке 2.2. Для уменьшения
уровня шума использовались медианный и Гауссовский фильтры со значением радиуса
окна фильтрации равным 3 пикселям. Последним шагом в распознавании является
применение локальных бинарных шаблонов. Хороших результатов удалось добиться с
числом точек окрестности в шаблоне ЛБШ равным 8, радиусом равным 2 и с числом
разбиений изображения: 6 × 6.
При тестировании использовалось 12 изображений
(3 человека, 4 фотографии каждого) из набора «Aberdeen»
библиотеки «Psychological Image Collection at Stirling (PICS)». На всех
фотографиях изображены фронтальные лица; фотографии имеют разное освещение плюс
небольшие отклонения в мимике и положении лиц; фотографии каждого отдельно
взятого человека сделаны примерно в одно и то же время, вследствие чего у
каждого отдельно взятого человека одна и та же причёска на всех фотографиях.
Эту выборку можно назвать почти «идеальной». На этой выборке финальный вариант
распознавателя показал 100% результат.
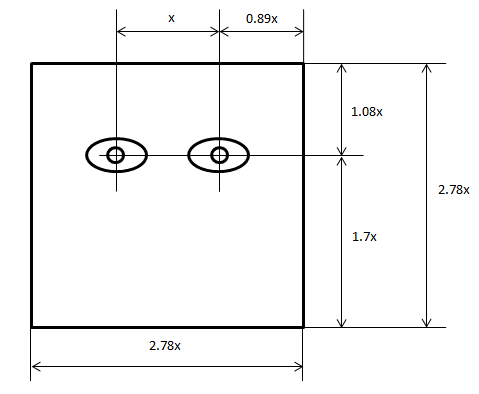
Рисунок 2.2. Параметры кадрирования лица на
изображении
Глава 3. Процесс исследования
Процесс исследования представлял из себя
итеративный набор экспериментов.
Каждый эксперимент состоял из 4 фаз:
· Размышление.
· Реализация.
· Запуск.
· Анализ результатов.
В первой фазе исследовался теоретический
материал (чтение научных статей, описания алгоритмов), обдумывался, в
результате чего позже рождалась какая-либо идея. Во второй фазе эта идея
реализовывалась в коде. Затем производился поиск ошибок в коде посредством
тестирования. По завершении тестирования запускалась программа сбора
статистики. Программа сбора статистики запускала модуль распознавания для пар
фотографий из тестовой выборки. Каждая фотография сравнивалась с каждой 1 раз,
но не сама с собой. После этого общая статистика записывалась в отдельный Excel-файл,
где каждая строка - это отдельный эксперимент. Имея несколько результатов
экспериментов можно было выбрать лучший и исходя из этого выбирать дальнейшее
направление для исследования. Чем меньше отношение среднего среди «своих»
фотографий к среднему среди «чужих», тем лучше. Файл с подробной статистикой
сортировался в порядке возрастания дистанции. Идеальным результатом считалось,
если максимальная дистанция сравнения фотографий одного и того же человека
меньше, чем минимальная дистанция сравнения фотографий разных людей (и чем
больше разница, тем лучше). Содержимое этого файла, сгенерированного финальной
версией программы, запущенной на тестовой выборке, содержится в приложении 2.
В ходе всего исследования было проведено более
20 исследований, из них 14 являлись наиболее значимыми и были задокументированы
(приложение 1). Последний эксперимент показал наилучшие результаты и был выбран
финальным. Отношение средних с результатом округления составило 0.276;
максимальная дистанция у «своих» фотографий составила 23.77425, а минимальная у
«чужих» - 34.00935.
На основе результатов работы финальной версии
была создана процентная метрика (график 3.1). В первую очередь это было сделано
для сравнения с «эталонной» коммерческой системой распознавания, разработанной
компанией VisionLabs,
которая возвращает результат сравнения в виде процента уверенности. Для
сравнения была использована новая расширенная выборка фотографий «MUCT». Оттуда
были взяты фотографии 10 людей, 3 фотографии каждого. Стратегия сравнения такая
же: «каждый с каждым» (таблица 3.1).
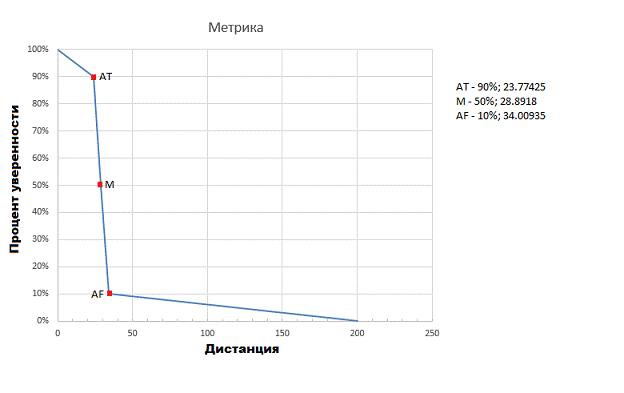
График 3.1. Перевод дистанции в проценты
Таблица 3.1. Результаты работы распознавателей
на расширенной выборке
|
Свои
|
Чужие
|
|
Среднее
|
σ
|
Среднее
|
σ
|
|
Собственная
разработка
|
79.897354%
|
26.323261%
|
9.564245%
|
9.374744%
|
|
VisionLabs
|
99.0138%
|
3.1629694%
|
6.1211834%
|
15.611576%
|
Для выявления процента ошибочных определений
было принято, что, если дистанция при сравнении 2 изображений больше, чем
28.8918 (среднее арифметическое от максимальной дистанции у «своих» фотографий
- 23.77425 и минимальной у «чужих» - 34.00935), то на изображениях разные люди,
если меньше или равна, то на изображениях один и тот же человек. Так как VisionLabs
возвращает процент уверенности, где 100% - это точно один и тот же человек, 0%
- точно разные, серединой было принято считать 50% (таблица 3.2). Использовалась
расширенная выборка.
Таблица 3.2. Количество ошибок при распознавании
на расширенной выборке (435 сравнений)
|
False positive
|
False negative
|
Всего
|
|
Собственная
разработка
|
6/435
|
4/435
|
10/435 (~2.3%)
|
|
VisionLabs
|
20/435
|
0/435
|
20/435 (~4.6%)
|
Так как процент ошибок меньше, чем у VisionLabs,
было принято решение внедрить данную разработку в пропускную систему
предприятия.
Заключение
В ходе исследования в качестве программной базы
для разработки была выбрана библиотека OpenCV.
Во время проведения экспериментов было выявлено,
что на точность распознавания сильно влияет качество предобработки изображения,
а именно:
· выравнивание по уровню глаз;
· кадрирование;
· использование фильтров;
· выравнивание яркости и повышение
контрастности.
Также было выяснено, что использование
каскадного классификатора Хаара является хорошим способом для поиска лиц на
изображении, но не лучшим способом для поиска глаз. Локальные бинарные шаблоны
наиболее эффективны с числом точек окрестности - 8, радиусом - 2 и с числом
разбиений изображения - 6 × 6. Но
при не фронтальном положении лица на фотографии точность распознавания заметно
падает. В итоге, после всех манипуляций, связанных с предобработкой фотографий,
и подбором параметров для ЛБШ, точность распознавания на расширенной тестовой
выборке оказалась выше, чем у коммерческого аналога. Дальнейшим шагом для
достижения главной цели является интеграция данного программного решения в
систему распознавания лиц компании Timebook.
Шаги по улучшению. Финальная версия программы
имеет несколько «узких» мест, желательных к устранению. Не всегда корректно
определяются глаза (не определяет пару, либо определяет больше, чем 2 глаза).
Для решения этой проблемы в дальнейшем возможен отказ от каскадов Хаара и
использование альтернатив, к примеру, flandmark.
Результат распознавания сильно зависит от положения лица, так как используется
ЛБШ для выявления и сравнения признаков. Возможное решение этой проблемы -
использование другого алгоритма, например, так популярных сегодня, нейронных
сетей.
Приложение 1
Общая статистика экспериментов
|
Свои
|
Чужие
|
Отношение*
|
|
Среднее
|
σ
|
Среднее
|
σ
|
|
|
Эксперимент
1
|
24.412867
|
8.865932
|
40.494236
|
10.066717
|
0.602873
|
|
Эксперимент
2
|
23.679071
|
8.847048
|
41.14884
|
9.27761
|
0.575449
|
|
Эксперимент
3
|
31.219543
|
7.8973794
|
60.17528
|
8.19984
|
0.51881
|
|
Эксперимент
4
|
31.806816
|
7.8281226
|
59.939724
|
8.882614
|
0.530647
|
|
Эксперимент
5
|
52.95416
|
36.936806
|
86.11484
|
28.615545
|
0.614925
|
|
Эксперимент
6
|
35.83384
|
11.417789
|
73.51707
|
12.095636
|
0.487422
|
|
Эксперимент
7
|
63.631996
|
52.24717
|
136.93749
|
58.7277
|
0.464679
|
|
Эксперимент
8
|
48.609398
|
33.39628
|
109.300026
|
38.113407
|
0.444734
|
|
Эксперимент
9
|
42.02643
|
29.43545
|
95.088932
|
50.04269
|
0.44197
|
|
Эксперимент
10
|
17.993512
|
5.1304098
|
45.593776
|
6.7266456
|
0.394648
|
|
Эксперимент
11
|
19.161852
|
6.0499115
|
45.35268
|
9.456951
|
0.422508
|
|
Эксперимент
12
|
21.343697
|
9.658336
|
58.285706
|
13.159464
|
0.366191
|
|
Эксперимент
13
|
14.063918
|
5.889904
|
47.32205
|
14.01314
|
0.297196
|
13.641985
|
5.6808805
|
49.436707
|
15.187509
|
0.275948
|
* отношение среднего по своим к среднему по
чужим (чем меньше, тем лучше).
|
equalizeHist()
|
Масштабирование
|
Выравнивание
|
Кадрирование
|
ЛБШ
|
Обрезание
фотографии после обнаружения лица
|
Фильтры
|
|
Эксперимент
1
|
нет
|
нет
|
нет
|
нет
|
1,
8, 8х8
|
да
|
нет
|
|
Эксперимент
2
|
да
|
нет
|
нет
|
нет
|
1,
8, 8х8
|
да
|
нет
|
|
Эксперимент
3
|
да
|
200х200
|
нет
|
нет
|
1,
8, 8х8
|
да
|
нет
|
|
Эксперимент
4
|
нет
|
200х200
|
нет
|
нет
|
1,
8, 8х8
|
да
|
нет
|
|
Эксперимент
5
|
да
|
200х200
|
По
носу
|
нет
|
1,
8, 8х8
|
да
|
нет
|
|
Эксперимент
6
|
да
|
200х200
|
По
глазам
|
нет
|
1,
8, 8х8
|
да
|
нет
|
|
Эксперимент
7
|
да
|
200х200
|
По
глазам
|
0.55,
0.38
|
1,
8, 8х8
|
да
|
нет
|
|
Эксперимент
8
|
да
|
200х200
|
По
глазам
|
0.55,
0.38
|
2,
8, 6х6
|
да
|
нет
|
|
Эксперимент
9
|
да
|
нет
|
По
глазам (улучшенное)
|
0.55,
0.38
|
2,
8, 6х6
|
да
|
нет
|
|
Эксперимент
10
|
да
|
нет
|
По
глазам (улучшенное)
|
0.55,
0.38
|
2,
8, 6х6
|
нет
|
нет
|
|
Эксперимент
11
|
да
|
200х200
|
По
глазам (улучшенное)
|
0.55,
0.38
|
2,
8, 6х6
|
нет
|
нет
|
|
Эксперимент
12
|
да
|
нет
|
По
глазам (улучшенное)
|
0.55,
0.38
|
2,
8, 6х6
|
нет
|
Медианный,
Гауссовский
|
|
Эксперимент
13
|
да
|
нет
|
По
глазам (улучшенное)
|
0.89,
1.08
|
2,
8, 6х6
|
нет
|
|
|
Эксперимент
14
|
да
|
нет
|
По
глазам (улучшенное)
|
0.89,
1.08
|
2,
8, 6х6
|
нет
|
Медианный,
Гауссовский
|
Описание названия колонок:
· equalizeHist()
- вызов данного метода из библиотеки OpenCV
перед обнаружением лица. Данный метод выравнивает яркость и нормализует
контрастность изображения.
· Масштабирование - масштабирует
вырезанное лицо до указанного разрешения.
· Выравнивание - выравнивает
изображение. Используется 4 варианта:
o Нет выравнивания
o По носу (середина носа - середина
изображения после предобработки)
o По глазам (выравнивание до
горизонтального положения линии, соединяющей центры глаз)
o По глазам (улучшенное) (то же самое,
что и по глазам, только с некоторыми улучшениями)
· Кадрирование - кадрирование
изображения по коэффициентам. Коэффициент расстояния между центрами глаз - 1.
Первое число - это коэффициент расстояния от левого края изображения до центра
глаза, который слева. Второе число - это коэффициент расстояния от верхнего
края изображения до горизонтальной линии, соединяющей центры глаз.
· ЛБШ - параметры для ЛБШ. Первое
число - радиус, второе - количество точек окрестности, третье - число разбиений
изображения.
· Обрезание фотографии после
обнаружения лица. «да» - фотография обрезается сразу после обнаружения лица,
«нет» - фотография обрезается только после выравнивания и кадрирования.
· Фильтры - использование фильтров для
уменьшения шумов после выравнивания и кадрирования изображения.
Приложение 2. Подробная статистика финального
эксперимента
Отсортировано в порядке возрастания дистанции.
Тестовая выборка
|
3
|
3
|
/home/mihail/diploma/aberdeen_shortened/3/alister2.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister1.jpg
|
5.9136295
|
|
1
|
1
|
/home/mihail/diploma/aberdeen_shortened/1/adrian2.jpg
|
/home/mihail/diploma/aberdeen_shortened/1/adrian1.jpg
|
6.146455
|
|
3
|
3
|
/home/mihail/diploma/aberdeen_shortened/3/alister3.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister1.jpg
|
7.275235
|
|
2
|
2
|
/home/mihail/diploma/aberdeen_shortened/2/alison2.jpg
|
/home/mihail/diploma/aberdeen_shortened/2/alison1.jpg
|
7.441855
|
|
3
|
3
|
/home/mihail/diploma/aberdeen_shortened/3/alister3.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister2.jpg
|
8.99225
|
|
1
|
1
|
/home/mihail/diploma/aberdeen_shortened/1/adrian2.jpg
|
/home/mihail/diploma/aberdeen_shortened/1/adrian3.jpg
|
9.22398
|
|
2
|
2
|
/home/mihail/diploma/aberdeen_shortened/2/alison3.jpg
|
/home/mihail/diploma/aberdeen_shortened/2/alison2.jpg
|
9.956369
|
|
1
|
1
|
/home/mihail/diploma/aberdeen_shortened/1/adrian3.jpg
|
/home/mihail/diploma/aberdeen_shortened/1/adrian1.jpg
|
10.03125
|
|
2
|
2
|
/home/mihail/diploma/aberdeen_shortened/2/alison3.jpg
|
/home/mihail/diploma/aberdeen_shortened/2/alison1.jpg
|
10.66945
|
|
2
|
2
|
/home/mihail/diploma/aberdeen_shortened/2/alison4.jpg
|
/home/mihail/diploma/aberdeen_shortened/2/alison3.jpg
|
14.8844
|
|
1
|
1
|
/home/mihail/diploma/aberdeen_shortened/1/adrian3.jpg
|
/home/mihail/diploma/aberdeen_shortened/1/adrian4.jpg
|
15.2464
|
|
3
|
3
|
/home/mihail/diploma/aberdeen_shortened/3/alister3.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister4.jpg
|
17.435001
|
|
1
|
1
|
/home/mihail/diploma/aberdeen_shortened/1/adrian2.jpg
|
/home/mihail/diploma/aberdeen_shortened/1/adrian4.jpg
|
18.8511
|
|
1
|
1
|
/home/mihail/diploma/aberdeen_shortened/1/adrian1.jpg
|
/home/mihail/diploma/aberdeen_shortened/1/adrian4.jpg
|
18.9893
|
|
2
|
2
|
/home/mihail/diploma/aberdeen_shortened/2/alison4.jpg
|
/home/mihail/diploma/aberdeen_shortened/2/alison1.jpg
|
19.153801
|
|
2
|
2
|
/home/mihail/diploma/aberdeen_shortened/2/alison4.jpg
|
/home/mihail/diploma/aberdeen_shortened/2/alison2.jpg
|
20.5807
|
|
3
|
3
|
/home/mihail/diploma/aberdeen_shortened/3/alister1.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister4.jpg
|
20.9903
|
|
3
|
3
|
/home/mihail/diploma/aberdeen_shortened/3/alister2.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister4.jpg
|
23.77425
|
|
2
|
1
|
/home/mihail/diploma/aberdeen_shortened/2/alison3.jpg
|
/home/mihail/diploma/aberdeen_shortened/1/adrian3.jpg
|
34.00935
|
|
2
|
1
|
/home/mihail/diploma/aberdeen_shortened/2/alison2.jpg
|
/home/mihail/diploma/aberdeen_shortened/1/adrian1.jpg
|
35.81765
|
|
2
|
1
|
/home/mihail/diploma/aberdeen_shortened/2/alison1.jpg
|
/home/mihail/diploma/aberdeen_shortened/1/adrian1.jpg
|
35.927803
|
|
1
|
3
|
/home/mihail/diploma/aberdeen_shortened/1/adrian4.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister4.jpg
|
35.96275
|
|
2
|
1
|
/home/mihail/diploma/aberdeen_shortened/2/alison2.jpg
|
/home/mihail/diploma/aberdeen_shortened/1/adrian3.jpg
|
36.15985
|
|
2
|
1
|
/home/mihail/diploma/aberdeen_shortened/2/alison3.jpg
|
/home/mihail/diploma/aberdeen_shortened/1/adrian1.jpg
|
36.2037
|
|
2
|
1
|
/home/mihail/diploma/aberdeen_shortened/2/alison4.jpg
|
/home/mihail/diploma/aberdeen_shortened/1/adrian4.jpg
|
36.24445
|
|
1
|
3
|
/home/mihail/diploma/aberdeen_shortened/1/adrian1.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister1.jpg
|
37.15775
|
|
2
|
1
|
/home/mihail/diploma/aberdeen_shortened/2/alison2.jpg
|
/home/mihail/diploma/aberdeen_shortened/1/adrian2.jpg
|
37.72155
|
|
2
|
1
|
/home/mihail/diploma/aberdeen_shortened/2/alison3.jpg
|
/home/mihail/diploma/aberdeen_shortened/1/adrian2.jpg
|
38.0915
|
|
2
|
1
|
/home/mihail/diploma/aberdeen_shortened/2/alison1.jpg
|
/home/mihail/diploma/aberdeen_shortened/1/adrian3.jpg
|
38.5365
|
|
2
|
1
|
/home/mihail/diploma/aberdeen_shortened/2/alison1.jpg
|
/home/mihail/diploma/aberdeen_shortened/1/adrian2.jpg
|
39.11535
|
|
1
|
3
|
/home/mihail/diploma/aberdeen_shortened/1/adrian1.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister3.jpg
|
40.1183
|
|
2
|
3
|
/home/mihail/diploma/aberdeen_shortened/2/alison4.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister4.jpg
|
40.83395
|
|
2
|
1
|
/home/mihail/diploma/aberdeen_shortened/2/alison4.jpg
|
/home/mihail/diploma/aberdeen_shortened/1/adrian3.jpg
|
41.35815
|
|
2
|
1
|
/home/mihail/diploma/aberdeen_shortened/2/alison3.jpg
|
/home/mihail/diploma/aberdeen_shortened/1/adrian4.jpg
|
41.78735
|
|
1
|
3
|
/home/mihail/diploma/aberdeen_shortened/1/adrian2.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister1.jpg
|
43.3433
|
|
1
|
3
|
/home/mihail/diploma/aberdeen_shortened/1/adrian3.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister3.jpg
|
44.0983
|
|
2
|
1
|
/home/mihail/diploma/aberdeen_shortened/2/alison2.jpg
|
/home/mihail/diploma/aberdeen_shortened/1/adrian4.jpg
|
44.43485
|
|
2
|
3
|
/home/mihail/diploma/aberdeen_shortened/2/alison1.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister3.jpg
|
44.441948
|
|
2
|
1
|
/home/mihail/diploma/aberdeen_shortened/2/alison4.jpg
|
/home/mihail/diploma/aberdeen_shortened/1/adrian1.jpg
|
44.454002
|
|
1
|
3
|
/home/mihail/diploma/aberdeen_shortened/1/adrian3.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister1.jpg
|
44.59
|
|
2
|
3
|
/home/mihail/diploma/aberdeen_shortened/2/alison3.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister4.jpg
|
44.612198
|
|
1
|
3
|
/home/mihail/diploma/aberdeen_shortened/1/adrian2.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister3.jpg
|
44.6786
|
|
1
|
3
|
/home/mihail/diploma/aberdeen_shortened/3/alister4.jpg
|
44.779503
|
|
2
|
3
|
/home/mihail/diploma/aberdeen_shortened/2/alison1.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister4.jpg
|
44.849403
|
|
2
|
1
|
/home/mihail/diploma/aberdeen_shortened/2/alison1.jpg
|
/home/mihail/diploma/aberdeen_shortened/1/adrian4.jpg
|
45.0011
|
|
1
|
3
|
/home/mihail/diploma/aberdeen_shortened/1/adrian2.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister4.jpg
|
45.02565
|
|
1
|
3
|
/home/mihail/diploma/aberdeen_shortened/1/adrian3.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister4.jpg
|
45.1193
|
|
2
|
3
|
/home/mihail/diploma/aberdeen_shortened/2/alison2.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister3.jpg
|
46.9468
|
|
2
|
1
|
/home/mihail/diploma/aberdeen_shortened/2/alison4.jpg
|
/home/mihail/diploma/aberdeen_shortened/1/adrian2.jpg
|
47.414352
|
|
2
|
3
|
/home/mihail/diploma/aberdeen_shortened/2/alison3.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister3.jpg
|
48.490402
|
|
2
|
3
|
/home/mihail/diploma/aberdeen_shortened/2/alison1.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister1.jpg
|
48.67815
|
|
1
|
3
|
/home/mihail/diploma/aberdeen_shortened/1/adrian4.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister3.jpg
|
49.0149
|
|
2
|
3
|
/home/mihail/diploma/aberdeen_shortened/2/alison4.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister3.jpg
|
50.16235
|
|
2
|
3
|
/home/mihail/diploma/aberdeen_shortened/2/alison2.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister1.jpg
|
51.45775
|
|
1
|
3
|
/home/mihail/diploma/aberdeen_shortened/1/adrian4.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister1.jpg
|
51.60845
|
|
2
|
3
|
/home/mihail/diploma/aberdeen_shortened/2/alison2.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister4.jpg
|
51.834396
|
|
2
|
3
|
/home/mihail/diploma/aberdeen_shortened/2/alison4.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister1.jpg
|
55.97485
|
|
2
|
3
|
/home/mihail/diploma/aberdeen_shortened/2/alison3.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister1.jpg
|
56.7955
|
|
2
|
3
|
/home/mihail/diploma/aberdeen_shortened/2/alison4.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister2.jpg
|
61.69295
|
|
2
|
3
|
/home/mihail/diploma/aberdeen_shortened/2/alison1.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister2.jpg
|
63.181152
|
|
2
|
3
|
/home/mihail/diploma/aberdeen_shortened/2/alison2.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister2.jpg
|
70.920105
|
|
2
|
3
|
/home/mihail/diploma/aberdeen_shortened/2/alison3.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister2.jpg
|
73.107
|
|
1
|
3
|
/home/mihail/diploma/aberdeen_shortened/1/adrian4.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister2.jpg
|
75.7419
|
|
1
|
3
|
/home/mihail/diploma/aberdeen_shortened/1/adrian1.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister2.jpg
|
90.403595
|
|
1
|
3
|
/home/mihail/diploma/aberdeen_shortened/1/adrian2.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister2.jpg
|
93.04085
|
|
1
|
3
|
/home/mihail/diploma/aberdeen_shortened/1/adrian3.jpg
|
/home/mihail/diploma/aberdeen_shortened/3/alister2.jpg
|
102.02286
|
Приложение
3. Листинг
face_recognizer.cpp
#include
"opencv2/core/core.hpp"
#include
"opencv2/contrib/contrib.hpp"
#include
"opencv2/opencv.hpp"
#include <cctype>
#include <iostream>
#include <iterator>
#include <stdio.h>
#include <dirent.h>
#include <unistd.h>
#include <fstream>
#include <cerrno>
#include <sstream>
#include <math.h>
#include <algorithm> //
std::sortnamespace cv;namespace std;cascadeName =
"/usr/share/opencv/haarcascades/haarcascade_frontalface_alt.xml";detectAndCut(Mat
&img, CascadeClassifier& cascade, bool normalize = true)
{<Rect> faces;(normalize)
{(img, img, COLOR_BGR2GRAY);(img, img, img.size(), 0, 0, INTER_LINEAR);(img,
img);
}.detectMultiScale(img, faces,
.1, 2, 0
|CASCADE_FIND_BIGGEST_OBJECT
//|CASCADE_DO_ROUGH_SEARCH
|CASCADE_SCALE_IMAGE
,(30,
30));(vector<Rect>::const_iterator r = faces.begin(); r != faces.end();
r++)
{*r;
}"No faces were found";
}void fill_vectors(Mat&
etalon_image, Mat& candidate_image, vector<Mat>& images,
vector<int>& labels) {.push_back(etalon_image);.push_back(0);.push_back(candidate_image);.push_back(0);
}Sort {operator() (Rect i, Rect j)
{(i.height > j.height);
}
} mySort;<Rect>
getTheBiggestEyes(vector<Rect> eyes) {(eyes.size() <= 2) {eyes;
}<Rect>
realEyes;(eyes.begin(), eyes.end(), mySort);(int i = 0; i < 2; i++)
{.push_back(eyes.at(i));
}realEyes;
}alignByEyes(Mat image, Rect face) {
// preparationsmallImgROI =
image(face);char *cascade_eye =
"/usr/share/opencv/haarcascades/haarcascade_eye.xml";eyesClassifier;<Rect>
eyes;(!eyesClassifier.load(cascade_eye))
{<< "ERROR: Could not
load classifier cascade" << endl;(-1);
}.detectMultiScale(smallImgROI,
eyes,
.2, 3, 0
//|CASCADE_FIND_BIGGEST_OBJECT
//|CASCADE_DO_ROUGH_SEARCH
//|CASCADE_SCALE_IMAGE
,(15, 15));=
getTheBiggestEyes(eyes);
//
for(vector<Rect>::const_iterator r = eyes.begin(); r != eyes.end(); r++)
{
// CvPoint p1 = { face.x + r->x,
face.y + r->y };
// CvPoint p2 = { face.x + r->x +
r->width, face.y + r->y + r->height };
// rectangle(image, p1, p2,
CV_RGB(0, 255, 0), 1, 4, 0);
// printf(" %d %d %d %d\n",
face.x + r->x, face.y + r->y, r->width, r->height);
// }(eyes.size() == 2) {xHalfEye[2],
yHalfEye[2];i = 0;(vector<Rect>::const_iterator r = eyes.begin(); r !=
eyes.end(); r++, i++) {[i] = face.x + r->x + r->width / 2;[i] = face.y +
r->y + r->height / 2;
}
// rotationrotateAngle =
atan((double)(yHalfEye[0] - yHalfEye[1]) / (double)(xHalfEye[0] - xHalfEye[1]))
* 180 / M_PI;f pc(image.cols/2.,
image.rows/2.);r = getRotationMatrix2D(pc, rotateAngle, 1.0);(image, image, r,
image.size());cascade;(!cascade.load(cascadeName)) {<< "ERROR: Could
not load classifier cascade" << endl;(-1);
}{= detectAndCut(image, cascade,
false);
} catch (char const* msg) {<<
msg << endl;(-1);
}=
image(face);.detectMultiScale(smallImgROI, eyes,
.2, 3, 0
//|CASCADE_FIND_BIGGEST_OBJECT
//|CASCADE_DO_ROUGH_SEARCH
//|CASCADE_SCALE_IMAGE
,(15, 15));=
getTheBiggestEyes(eyes);
//
for(vector<Rect>::const_iterator r = eyes.begin(); r != eyes.end(); r++)
{
// CvPoint p1 = { face.x + r->x,
face.y + r->y };
// CvPoint p2 = { face.x + r->x +
r->width, face.y + r->y + r->height };
// rectangle(image, p1, p2,
CV_RGB(0, 255, 0), 1, 4, 0);
// printf(" %d %d %d
%d\n", r->x, r->y, r->width, r->height);
// }(eyes.size() == 2) {xHalfEye[2],
yHalfEye[2];i = 0;(vector<Rect>::const_iterator r = eyes.begin(); r !=
eyes.end(); r++, i++) {[i] = face.x + r->x + r->width / 2;[i] = face.y +
r->y + r->height / 2;
}
//
croppingcurrentBetweenPupilsDistance = abs(xHalfEye[0] -
xHalfEye[1]);currentLeftEyeX = xHalfEye[0] < xHalfEye[1] ? xHalfEye[0] :
xHalfEye[1];myROI;.x = currentLeftEyeX - 0.89 *
currentBetweenPupilsDistance;.width = 2.78 * currentBetweenPupilsDistance;.y =
yHalfEye[0] - 0.39 * myROI.width;.height = myROI.width;= image(myROI);
//resize(image, image, Size(200,
200));
}
}image;
}main(int argc, const char *argv[])
{(argc != 3) {<< "usage: " << argv[0] << "
<etalon_path> <candidate_path>" << endl;(1);
}etalon = string(argv[1]);candidate
= string(argv[2]);cascade;(!cascade.load(cascadeName))
{<< "ERROR: Could not
load classifier cascade" << endl;-1;
}etalon_image,
candidate_image;etalonFace, candidateFace;_image = imread(etalon, 1);{=
detectAndCut(etalon_image, cascade);
} catch (char const* msg) {<<
msg << endl;-1;
}_image = alignByEyes(etalon_image,
etalonFace);_image = imread(candidate, 1);{= detectAndCut(candidate_image,
cascade);
} catch (char const* msg) {<<
msg << endl;-1;
}_image =
alignByEyes(candidate_image, candidateFace);medianBlurFilterIntensity =
3;gaussianBlurFilterIntensity = medianBlurFilterIntensity;(etalon_image,
etalon_image, medianBlurFilterIntensity);(candidate_image, candidate_image,
medianBlurFilterIntensity);(etalon_image, etalon_image,
Size(gaussianBlurFilterIntensity, gaussianBlurFilterIntensity),
0);(candidate_image, candidate_image, Size(gaussianBlurFilterIntensity,
gaussianBlurFilterIntensity), 0);
//
namedWindow("named_window");
// imshow("named_window",
etalon_image);
// waitKey();
// imshow("named_window",
candidate_image);
// waitKey();<Mat>
images;<int> labels;_vectors(etalon_image, candidate_image, images,
labels);(images.size() <= 1) {error_message = "This demo needs at least
2 images to work. Please add more images to your data
set!";_Error(CV_StsError, error_message);
}testSample = images[images.size() -
1];.pop_back();.pop_back();<FaceRecognizer> model = createLBPHFaceRecognizer(2,
8, 6, 6); // try call with params: 2, 8, 6, 6>train(images,
labels);predictedLabel = model->predict(testSample);confidence =
0.0;>predict(testSample, predictedLabel, confidence);<< confidence
<< endl;0;
}
Calculator.java
import java.util.ArrayList;class
Calculator {float xAverageTheirs, standardDeviationTheirs, xAverageStrangers,
standardDeviationStrangers;ArrayList<ArrayList<String>>
source;Calculator(ArrayList<ArrayList<String>> source) {.source =
source;
}void calculate(int group)
{sumTheirs = 0, sumStrangers = 0;quantityTheirs = 0, quantityStrangers =
0;(ArrayList<String> row : source) {(row.get(0).equals(row.get(1))) {+=
Float.parseFloat(row.get(group));++;
} else {+=
Float.parseFloat(row.get(group));++;
}
}= sumTheirs / quantityTheirs;=
sumStrangers / quantityStrangers;numeratorTheirs = 0, numeratorStrangers =
0;(ArrayList<String> row : source) {(row.get(0).equals(row.get(1)))
{xMinusXAvg = Float.parseFloat(row.get(group)) - xAverageTheirs;+= xMinusXAvg *
xMinusXAvg;
} else {xMinusXAvg =
Float.parseFloat(row.get(group)) - xAverageStrangers;+= xMinusXAvg *
xMinusXAvg;
}
}= (float)Math.sqrt(numeratorTheirs
/ quantityTheirs);= (float)Math.sqrt(numeratorStrangers / quantityStrangers);
}float getXAverageTheirs()
{xAverageTheirs;
}float getStandardDeviationTheirs()
{standardDeviationTheirs;
}float getXAverageStrangers()
{xAverageStrangers;
}float
getStandardDeviationStrangers() {standardDeviationStrangers;
}
}
Client.java
public class Client
{static String interimStatisticsFilePath
= null;static String folderWithPhotos = null;static String executableFilename =
null;static void main (String args[])
{= args[0];= args[1];= args[2];r =
new Recognizer();.recognize();
// r.recognizeShuffle();s = new
Statistics();.gather();
}
}
IMatcher.java
public interface IMatcher
{static float NO_FACE_ETALON =
-1;static float NO_FACE_CANDIDATE = -2;static float INTERNAL_ERROR = -3;static
float NO_SUCH_FILE = -4;float compare(String etalon, String candidate) throws
Exception;
}
OpenCVMatcher.java
import
java.io.BufferedReader;java.io.InputStreamReader;class OpenCVMatcher implements
IMatcher
{String etalon, candidate;float
extractAndMatch() throws Exception {p;command = null;result = null;{=
Client.executableFilename + " " + etalon + " " + candidate;=
Runtime.getRuntime().exec(command);line = "";errors = new
BufferedReader(new InputStreamReader(p.getErrorStream()));output = new
BufferedReader(new InputStreamReader(p.getInputStream()));((line =
output.readLine()) != null) {= line;
}((errors.readLine()) != null)
{}.waitFor();
} catch (Exception e) {e;
}{Float.parseFloat(result);
} catch (NumberFormatException e)
{-1;
}
}float compare(String etalon, String
candidate) throws Exception
{.etalon = etalon;.candidate =
candidate;extractAndMatch();
}
}
Parser.java
import
java.io.BufferedReader;java.io.FileInputStream;java.io.InputStream;java.io.InputStreamReader;java.nio.charset.Charset;java.util.ArrayList;java.util.regex.Matcher;java.util.regex.Pattern;class
Parser {static ArrayList<ArrayList<String>> parse(String filepath,
int[] groups) throws Exception {line;(fis = new FileInputStream(filepath);isr =
new InputStreamReader(fis, Charset.forName("UTF-8"));br = new
BufferedReader(isr);
) {<ArrayList<String>>
results = new ArrayList<ArrayList<String>>();pattern =
Pattern.compile("^(.+);(.+);(.+);(.+);(.+)$",
Pattern.MULTILINE);((line = br.readLine()) != null) {m = null;=
pattern.matcher(line);.find();<String> temp = new ArrayList<String>();(int
group : groups) {.add(m.group(group));
}.add(temp);
}results;
}
}
}
Percentager.java
public class Percentager
{static void main (String args[])
{etalonFilename =
"/home/mihail/diploma/aberdeen_face_database/amellanby15.jpg";candidateFilename
= "/home/mihail/diploma/aberdeen_face_database/andrew7.jpg";.executableFilename
= "/home/mihail/workspace/binary/face_recognizer";opencvMatcher = new
OpenCVMatcher();resultOpenCV = 0, resultOpenCV1 = 0, resultOpenCV2 = 0;{=
opencvMatcher.compare(etalonFilename, candidateFilename);= opencvMatcher.compare(candidateFilename,
etalonFilename);= (resultOpenCV1 + resultOpenCV2) / 2;
} catch (Exception e) {
// TODO Auto-generated catch
block.out.println(e.getMessage());
}
//System.out.println("Confidence:
" + getPercentFromDistance(resultOpenCV) + "%");.out.println("These
people are identical: " + getAnswerFromDistance(resultOpenCV));
}static String
getAnswerFromDistance(float resultOpenCV) {(resultOpenCV <
20)"true";if (resultOpenCV >= 26)"false";"not
sure";
}static int
getPercentFromDistance(float resultOpenCV) {
//distance
thresholdsabsolutelyTrueThreshold = 13;trueThreshold = 46;notSureThreshold =
177;falseThreshold = 501;
//percent
thresholdsabsolutelyTruePercent = 99;truePercent = 70;notSurePercent =
30;falsePercent = 0;
//stepsabsolutelyTrueStep = 1d /
absolutelyTrueThreshold;trueStep = 29d / (trueThreshold -
absolutelyTrueThreshold);notSureStep = 40d / (notSureThreshold -
trueThreshold);falseStep = 30d / (falseThreshold - notSureThreshold);
//logicconfidencePercent =
0;(resultOpenCV > notSureThreshold) {= falsePercent + ((falseThreshold -
resultOpenCV) * falseStep);
} else if (resultOpenCV >
trueThreshold) {= notSurePercent + ((notSureThreshold - resultOpenCV) *
notSureStep);
} else if (resultOpenCV >
absolutelyTrueThreshold) {= truePercent + ((trueThreshold - resultOpenCV) *
trueStep);
} else {= absolutelyTruePercent +
((absolutelyTrueThreshold - resultOpenCV) * absolutelyTrueStep);
}(int)confidencePercent;
}
}
PhotosContainer.java
public class PhotosContainer
{int label;String filename;PhotosContainer(int
label, String filename)
{.label = label;.filename =
filename;
}int getLabel()
{label;
}String getFilename()
{filename;
}
}
Recognizer.java
import
java.io.File;java.io.PrintWriter;java.util.ArrayList;java.util.Iterator;java.util.List;java.util.Random;class
Recognizer {<PhotosContainer> photoNames = new
ArrayList<PhotosContainer>();void listFilesForFolder(final File folder)
{(final File fileEntry : folder.listFiles()) {(fileEntry.isDirectory())
{(fileEntry);
} else {.add(new
PhotosContainer(Integer.parseInt(folder.getName()),.folderWithPhotos + '/' +
folder.getName() + '/' + fileEntry.getName()));
}
}
}void recognizeShuffle() {File
folder = new File(Client.folderWithPhotos);{(folder);
} catch (Exception e)
{.getMessage();
}
}void compare(File folder) throws
Exception {[] pathsList = folder.listFiles();rand = new Random();(int i = 0; i
< 5; i++) {randFolder = pathsList[rand.nextInt(pathsList.length)];[]
fileList = randFolder.listFiles();randEtalonFile = fileList[rand.nextInt(fileList.length)];randCandidateFile
=
fileList[rand.nextInt(fileList.length)];(randEtalonFile.getName().equals(randCandidateFile.getName()))
{= fileList[rand.nextInt(fileList.length)];
}opencvMatcher = new
OpenCVMatcher();resultOpenCV1 = opencvMatcher.compare(randEtalonFile.getAbsolutePath(),
randCandidateFile.getAbsolutePath());resultOpenCV2 =
opencvMatcher.compare(randCandidateFile.getAbsolutePath(),
randEtalonFile.getAbsolutePath());resultOpenCV = (resultOpenCV1 +
resultOpenCV2) / 2;.out.println(randEtalonFile.getAbsolutePath() + " and
" + randCandidateFile.getAbsolutePath()
+ " are identical: " +
getAnswerFromDistance(resultOpenCV) + " (distance = " + resultOpenCV
+ ")");
}(int i = 0; i < 5; i++)
{randEtalonFolder = pathsList[rand.nextInt(pathsList.length)];[] fileList =
randEtalonFolder.listFiles();randEtalonFile =
fileList[rand.nextInt(fileList.length)];randCandidateFolder =
pathsList[rand.nextInt(pathsList.length)];=
randCandidateFolder.listFiles();randCandidateFile =
fileList[rand.nextInt(fileList.length)];(randEtalonFile.getName().equals(randCandidateFile.getName()))
{= fileList[rand.nextInt(fileList.length)];
}opencvMatcher = new
OpenCVMatcher();resultOpenCV1 =
opencvMatcher.compare(randEtalonFile.getAbsolutePath(),
randCandidateFile.getAbsolutePath());resultOpenCV2 =
opencvMatcher.compare(randCandidateFile.getAbsolutePath(),
randEtalonFile.getAbsolutePath());resultOpenCV = (resultOpenCV1 +
resultOpenCV2) / 2;.out.println(randEtalonFile.getAbsolutePath() + " and
" + randCandidateFile.getAbsolutePath()
+ " are identical: " +
getAnswerFromDistance(resultOpenCV) + " (distance = " + resultOpenCV
+ ")");
}
}static String
getAnswerFromDistance(float resultOpenCV) {(resultOpenCV == -1) {"no faces
were found";
} else if (resultOpenCV <
28)"true";if (resultOpenCV >= 28)"false";"not
sure";
}void recognize() {(PrintWriter
writer = new PrintWriter(Client.interimStatisticsFilePath, "UTF-8"))
{File folder = new File(Client.folderWithPhotos);(folder);count =
(photoNames.size() * photoNames.size() - photoNames.size()) / 2;i =
0;(Iterator<PhotosContainer> iterator = photoNames.iterator();
iterator.hasNext();) {etalon = iterator.next();(PhotosContainer candidate :
photoNames) {(!etalon.getFilename().equals(candidate.getFilename())) {
//
System.out.println(etalon.getLabel() + ";" + candidate.getLabel() +
";" + etalon.getFilename() +
// ";" +
candidate.getFilename());opencvMatcher = new OpenCVMatcher();resultOpenCV1 =
opencvMatcher.compare(etalon.getFilename(),
candidate.getFilename());resultOpenCV2 = opencvMatcher.compare(candidate.getFilename(),
etalon.getFilename());resultOpenCV = (resultOpenCV1 + resultOpenCV2) / 2;
// IMatcher openbrMatcher = new
OpenBRMatcher();
// float resultOpenBR =
openbrMatcher.compare(etalon.getFilename(), candidate.getFilename());
//
System.out.println(etalon.getLabel() + ";" + candidate.getLabel() +
";" + etalon.getFilename() +
// ";" +
candidate.getFilename() + ";" +
resultOpenCV);.println(etalon.getLabel() + ";" + candidate.getLabel()
+ ";" + etalon.getFilename() +
";" + candidate.getFilename()
+ ";" + resultOpenCV);++; System.out.println(((float)i/count*100) +
"%");
}
}.remove();
}
/* Exceptions processing */
} catch (Exception e) {
//some exception
message.printStackTrace();
}
}
}
Statistics.java
import java.util.ArrayList;class
Statistics {void gather() {[]groupsToResult = {1, 2,
5};<ArrayList<String>> results = null;{=
Parser.parse(Client.interimStatisticsFilePath, groupsToResult);
} catch (Exception e)
{.out.println("Parser fucked up");
}calculator = new
Calculator(results);.calculate(2);.out.println(calculator.getXAverageTheirs() +
" - " + calculator.getXAverageStrangers() + "; "
+
calculator.getStandardDeviationTheirs() + " - " +
calculator.getStandardDeviationStrangers());
// calculator.calculate(3);
//
System.out.println(calculator.getXAverageTheirs() + " - " +
calculator.getXAverageStrangers() + "; "
// +
calculator.getStandardDeviationTheirs() + " - " +
calculator.getStandardDeviationStrangers());
// calculator.calculate(4);
// System.out.println(calculator.getXAverageTheirs()
+ " - " + calculator.getXAverageStrangers() + "; "
// +
calculator.getStandardDeviationTheirs() + " - " +
calculator.getStandardDeviationStrangers());
}
}
Time.java
public class Time {static long
SECOND = 1000;static long MINUTE = 60 * Time.SECOND;static long HOUR = 60 *
Time.MINUTE;
}
VisionLabsMatcher.javastatic
java.nio.file.StandardCopyOption.REPLACE_EXISTING;java.io.BufferedReader;java.io.File;java.io.FileReader;java.io.IOException;java.io.InputStreamReader;java.nio.file.Files;java.nio.file.Path;java.nio.file.Paths;java.util.regex.Matcher;java.util.regex.Pattern;class
VisionLabsMatcher implements IMatcher
{final String pathToEtalonTemp =
"C:/temp/etalon_temp";final String pathToCandidateTemp =
"C:/temp/candidate_temp";final String pathToEtalonKeys =
"C:/temp/etalon_keys";final String pathToCandidateKeys =
"C:/temp/candidate_keys";final String pathToReport =
"C:/temp/report.csv";final static String HASP_FEATURE_EXPIRED =
"HASP_FEATURE_EXPIRED";final static String NO_FACES_FOUND =
"NoFacesFound";float extractAndMatch() throws Exception {p;command =
null;{=
VisionLabsMatcher.class.getProtectionDomain().getCodeSource().getLocation().getPath()
+ "/../Extractor -S " +
pathToEtalonTemp + " -D " + pathToEtalonKeys + " -Dt DPM -St CNN
-Ft VGG";= Runtime.getRuntime().exec(command);line = "";errors =
new BufferedReader(new InputStreamReader(p.getErrorStream()));output = new
BufferedReader(new InputStreamReader(p.getInputStream()));((output.readLine())
!= null) {}((line = errors.readLine()) != null)
{(line.contains(HASP_FEATURE_EXPIRED)) {new Exception(HASP_FEATURE_EXPIRED);
} else if
(line.contains(NO_FACES_FOUND)) {NO_FACE_ETALON;
} else {INTERNAL_ERROR;
}
}.waitFor();=
VisionLabsMatcher.class.getProtectionDomain().getCodeSource().getLocation().getPath()
+ "/../Extractor -S " +
pathToCandidateTemp + " -D " + pathToCandidateKeys + " -Dt DPM
-St CNN -Ft VGG";= Runtime.getRuntime().exec(command);= new
BufferedReader(new InputStreamReader(p.getErrorStream()));= new BufferedReader(new
InputStreamReader(p.getInputStream()));((output.readLine()) != null) {}((line =
errors.readLine()) != null) {NO_FACE_CANDIDATE;
}.waitFor();=
VisionLabsMatcher.class.getProtectionDomain().getCodeSource().getLocation().getPath()
+ "/../Matcher2 -T " +
pathToEtalonKeys + " -C " + pathToCandidateKeys + " -D " +
pathToReport + " -M 1 -St CNN";= Runtime.getRuntime().exec(command);=
new BufferedReader(new InputStreamReader(p.getErrorStream()));= new
BufferedReader(new InputStreamReader(p.getInputStream()));((output.readLine())
!= null) {}((line = errors.readLine()) != null) {INTERNAL_ERROR;
}.waitFor();
} catch (Exception e) {e;
}parseResult();
}float parseResult() {pattern =
Pattern.compile("^(.+); (.+); (.+); (.+)$",.MULTILINE);reader =
null;{= new BufferedReader(new FileReader(pathToReport));line = null;m =
null;((line = reader.readLine()) != null) {{= pattern.matcher(line);.find();
} catch (Exception e)
{INTERNAL_ERROR;
}Float.parseFloat(m.group(4));
}
} catch (Exception e) {INTERNAL_ERROR;
} finally {{.close();
} catch (IOException e) {
}
}(float) -1;
}float compare (String etalon,
String candidate) throws Exception
{result =
NO_SUCH_FILE;(prepare(etalon, candidate)) {= extractAndMatch();
}boolean prepare(String etalon, String
candidate) {etalonTemp = new File(pathToEtalonTemp);.mkdir();candidateTemp =
new File(pathToCandidateTemp);.mkdir();etalonKeys = new
File(pathToEtalonKeys);.mkdir();candidateKeys = new
File(pathToCandidateKeys);.mkdir();sourceEtalon = new File(etalon);sourceCandidate
= new File(candidate);etalonTempPath = Paths.get(pathToEtalonTemp +
"/etalon.jpg");candidateTempPath = Paths.get(pathToCandidateTemp +
"/candidate.jpg");{.copy(sourceEtalon.toPath(), etalonTempPath,
REPLACE_EXISTING);.copy(sourceCandidate.toPath(), candidateTempPath,
REPLACE_EXISTING);
} catch (IOException e) {false;
}true;
}
}
Список литературы
) International
Journal of Computer Vision 57(2), 137 - 154, 2004.
) Journal
of Signal and Information Processing, 173 - 175, 2013.
) IJCSNS
International Journal of Computer Science and Network Security, Vol.10 No.6,
2010.
) M.
Turk and A. Pentland, “Eigenfaces for Recognition”, Journal of Cognitive
Neuroscience, Vol.3, No.1, 71 - 86, 1991.
) International
Journal of Advanced Technology in Engineering and Science Vol.1, Issue No.12,
2013.
) Jigar
M. Pandya, Devang Rathod, Jigna J. Jadav, “A Survey of Face Recognition
approach”, International Journal of Engineering Research and Applications
(IJERA) ISSN: 2248-9622 Vol.3, Issue 1, 632, 2013.
) Jyoti
S. Bedre, Shubhangi Sapkal, “Comparative Study of Face Recognition Techniques:
A Review”, Emerging Trends in Computer Science and Information Technology -
2012 (ETCSIT2012) Proceedings published in International Journal of Computer
Applications (IJCA), 2012.
) Mohammed
Javed, Bhaskar Gupta, “Performance Comparison of Various Face Detection
Techniques”, International Journal of Scientific Research Engineering &
Technology (IJSRET) Vol.2 Issue No.1, 19 - 27, 2013.
) J.
R. Beveridge, P. J. Phillips, G. H. Givens, B. A. Draper, M. N. Teli, and D. S.
Bolme, “When high-quality face images match poorly”, Proceedings, Ninth
International Conference on Automatic Face and Gesture Recognition, 2011.
) O.
Barkan, J. Weill, L. Wolf, and H. Aronowitz. “Fast high dimensional vector
multiplication face recognition”, ICCV, 2013.
) T.
Berg and P. N. Belhumeur. “Tom-vs-pete classifiers and identity-preserving
alignment for face verification”, BMVC, 2012.
) G.
B. Huang, M. A. Mattar, H. Lee, and E. G. Learned-Miller. “Learning to align
from scratch”, NIPS, 773 - 781, 2012.
) Y.
Taigman and L. Wolf. “Leveraging billions of faces to overcome performance
barriers in unconstrained face recognition”, 2011.
14) Голубев
М. Н. “Использование информации о цвете в алгоритме выделения лиц на базе
бустинга”, Сб. науч. труд. 13-й
всерос.
науч.-техн.
конф.
“Нейроинформатика
- 2011”, М, 2011. Ч.
3. С.
55 - 62.
) Unsang
Park, “Face Recognition: face in video, age invariance, and facial marks”,
Michigan State University, 2009.
) T.
Ahonen, A. Hadid and M. Pietikainen, “Face description with Local Binary
Patterns”, Application to Face Recognition. Machine Vision Group, University of
Oulu, Finland, 2006.
) T.
Ahonen, A. Hadid, M. Pietikainen and T. Maenpaa. “Face recognition based on the
appearance of local regions”, Proceedings of the 17th International Conference
on Pattern Recognition, 2004.
) R.
Gottumukkal and V.K. Asari, “An Improved Face Recognition Technique Based on
Modular PCA Approach”, Pattern Recognition Letters, Vol.25, 429 - 436, 2004.
) T.
Ojala, M. Pietikainen and D. Harwood, “A comparative study of texture measures
with classification based on feature distributions”, Pattern Recognition
Vol.29, 1996.
) M.
Turk and A. Pentland, “Eigenfaces for recognition”, Cognitive Neuroscience, 72
- 86, 1991.
) M.
Kirby and L. Sirovich, “Application of the Karhunen-Loeve procedure for the
characterization of human faces”, IEEE Transactions on Pattern Analysis and
Machine Intelligence, 103 - 108, 1990.
) W.
Zhao, R. Chellappa, P. J. Phillips, and A. Rosenfeld, “Face recognition: A
literature survey”, ACM Computing Surveys (CSUR), 399 - 458, 2003.
) S.
Z. Li and A. K. Jain, “Handbook of Face Recognition”, Springer-Verlag,
Secaucus, NJ, 2005.
) W.
Zhao and R. Chellappa “Robust face recognition using symmetric shape
from-shading”, Technical Report, Center for Automation Research, University of
Maryland, 1999.
) T.
Chen, Y. Wotao, S. Z. Xiang, D. Comaniciu, and T. S. Huang, “Total variation
models for variable lighting face recognition”, IEEE Transactions on Pattern
Analysis and Machine Intelligence, 1519 - 1524, 2006.
) M.
Grudin, “On internal representation in face recognition systems”, Pattern
Recognition, 1161 - 1177, 2000.
) P.
A. Viola and M. J. Jones, “Robust real-time face detection”, International
Journal of Computer Vision, 137 - 154, 2004.