Браузерное расширение для визуализации грамматики
Введение
Изучение иностранных языков - важная задача в
современном мире. Сегодняшняя экономика приобретает все более глобальный
характер, и все более частой становится необходимость общения с людьми из
других стран и культур. Знание иностранных языков открывает новые возможности
карьерного роста, позволяя работать в компаниях, ведущих бизнес в нескольких
странах мира, или работающих с иностранными клиентами; позволяет проще
путешествовать по миру и общаться с людьми за рубежом. Многие люди так же
изучают иностранный язык как хобби.
Изучение нового языка это, в то же время,
достаточно непростая задача, требующая много времени и усилий. Для достижения
прогресса необходимы регулярные занятия, включающие в себя как изучение
грамматических правил языка, так и новых слов, т.е пополнение словарного
запаса. Многим людям, желающим выучить иностранный язык, сложно регулярно
выделять время на занятия с педагогом или в языковых школах.
Развитие технологий помогает в решении данной
проблемы. Онлайн-обучение становится все более и более популярным. В настоящее
время в свободном доступе появляется все больше материалов для изучения
иностранных языков, разрабатывается множество мобильных приложений, платформ и
веб-сайтов, помогающих людям изучать язык в свободное время.
Одним из типов программ, облегчающих изучение,
чтение текстов и доступ к информации на иностранных языках, являются браузерные
расширения. Браузерное расширение - это дополнительное программное обеспечение,
расширяющее функционал программы браузера, с помощью которой пользователь
просматривает страницы в сети Интернет.
Браузерное расширение, имея доступ к страницам,
просматриваемым пользователем и их содержимому, позволяет различным образом
использовать время, которое пользователь тратит на просмотр веб-сайтов для
изучения языка и в то же время помочь пользователю понять информацию,
представленную на иностранном языке путем, например, предоставления переводов и
словарных значений непонятных слов и фраз.
В рамках данной работы разрабатывается
браузерное расширение, предоставляющее информацию, такую как перевод, словарные
значения и аудио для выделенного на произвольной странице сети Интернет
английского слова и хранящее историю переведенных слов. Так же данное
расширение предоставляет пользователю возможность добавить слова, показавшиеся
ему незнакомыми или сложными, в специально разработанное мобильное приложение
для изучения иностранных языков, использующее различные методики, позволяющие
эффективным образом расширять словарный запас.
Разрабатываемое браузерное расширение
представляет собой не отдельный программный продукт, с помощью которого
возможно полноценное изучение языка, а программу, дополняющую данное мобильное
приложение в качестве альтернативного источника списка изучаемых слов, попутно
облегчая понимание информации на английском языке на просматриваемых страницах.
Предполагается, что данное расширение улучшит впечатление от продукта
(мобильного приложения) и увеличит пользу от его использования, предоставляя
пользователю возможность персонализации изучаемого контента.
Также разрабатываемое расширение предполагает
собой платформу, базу для разработки и тестирования нового функционала,
облегчающего пользователям изучение иностранных языков. Примером такого
функционала служит возможность автоматического выделения наиболее важных слов
на текущей странице, принимая во внимание историю просмотренных пользователем
страниц, которая так же будет разработана в рамках данной работы.
Анализ существующих решений
В настоящее время существует множество
браузерных расширений, различным образом использующие возможности доступа к
просматриваемым пользователем страницам в целях изучения иностранных языков или
облегчения понимания информации, представленной на иностранном языке. Далее
будет рассмотрено несколько программных продуктов, некоторые из которых так же
предоставляют возможность дальнейшего изучения выбранных слов в
специализированных сервисах или мобильных приложениях.[1] - одна из популярных
онлайн-платформ для изучения английского языка. Одним из продуктов, предоставляемых
платформой является браузерное расширение “ЛеоПереводчик”, доступное для Chrome
и Safari (рис. 1). [2].
Рис 1. Основной интерфейс браузерного расширения
“ЛеоПереводчик”.
Расширение предоставляет следующие возможности:
Перевод слова на странице по двойному клику на
него (рис. 2).
Перевод не только слов, но и выражений, содержащих
выделенное слово.
Добавление слов в личный словарь, слова из
которого в последующем используются в других продуктах платформы в качестве
изучаемых слов.
Рис 2. Перевод слова на странице по двойному
клику.
Данное браузерное расширение практически
полностью повторяет функционал, разрабатываемый в рамках данной работы.
Особенность данного расширения в том, что оно не представляет собой продукт для
изучения языка, а лишь является одним из инструментов онлайн-платформы.
Интерфейс для изучающих английский язык как
иностранный
Расширение [3] разработано в рамках работы над
интерфейсом, помогающим студентам, изучающим английский язык как иностранный,
легче читать тексты на английском языке(рис. 3).

Рис. 3. Пример информации, предоставляемой
расширением.
В целом, данная программа является типичным
примером расширения, предоставляющего дополнительную информацию, помогающую
пользователю понять значение того или иного слова на странице. Его особенность
заключается в том, что оно предлагает синонимы и определения к выбранному
слову, учитывая контекст, в котором оно расположено.
Данное браузерное расширение [4] работает в
браузере Firefox и представляет собой программу, изменяющую содержимое страницы
в целях изучения пользователем иностранного языка в то время, как он
просматривает необходимый ему контент (рис. 4).

Рис. 4. Страница с измененным расширением
содержимым.
Расширение основано на идее пополнять словарный
запас изучаемого иностранного языка во время чтения страниц на родном языке,
таким образом делая изучение незаметным и более простым из-за контекста на
родном языке. Во время чтения страниц на английском языке происходит замена
некоторых слов их переводом, оставляя большинство текста на английском,
предоставляя контекст для угадывания значения замененных слов.
Пользователь так же может пройти тест с
несколькими вариантами ответа по значениям переведенных слов (рис. 5) чтобы
получить немедленную оценку, угадан ли перевод, или нет, что, согласно авторам
приложения, мотивирует пользователей тратить больше время на изучение слов, что
ведет к более легкому их запоминанию.

Рис.5. Тест по значениям переведенных слов.
Данный подход к изучению был протестирован
авторами на тестовой группе пользователей. Несмотря на то, что пользователи
сочли данное расширение приятным и интересным методом пополнения словарного
запаса, авторы расширения не уверены в том, насколько данный метод влияет на
эффективность изучения в долгосрочной перспективе.
Браузерное расширение для визуализации
грамматики
Приложение [5] направлено на предоставление
визуализации грамматики выделенного предложения для того, чтобы предоставить
возможность студентам, начинающим изучать иностранный язык понять предложение
без знания грамматики языка и одновременно, изучать грамматику (рис. 6).

Рис.6. Визуалиация грамматики по клику на
предложение на иностранном языке.
Автором так же было проведено исследование, в
рамках которого было выявлено, что данное расширение действительно помогает
пользователем лучше понять предложение, и многие пользователи так же оценили
то, насколько интересен и приятен опыт изучения структуры предложений с помощью
ее визуализации.
Существует множество браузерных расширений,
функционал которых связан с изучением иностранных языков, которые не были
рассмотрены выше, но функционал большинства из них схож с функционалом одного
из представленных в данном обзоре приложений.
Необходимость разработки нового расширения с
нуля обусловлена тем, что ни одно существующее решение в данный момент не
предоставляет открытый исходный код, что не позволяет модифицировать их для
решения поставленных задач. Также данный анализ показывает то, что с помощью
подобного рода браузерных расширений можно сделать изучение языка и пополнение
словарного запаса интересным, увлекательным, занимающим меньшее время, и
показывает дальнейшие возможные направления развития функционала
разрабатываемого в рамках данной работы расширения.
Выбор методов решения поставленных задач
Браузерные расширения представляют собой
программы, улучшающие или расширяющие возможности браузера дополнительным
функционалом. Так как браузер это программа, запускающаяся на компьютере
пользователя, браузерное расширение так же запускается локально на компьютере
клиента. Для облегчения решения поставленных задач в разработке браузерного
расширения в рамках данной работы применяется архитектура “клиент-сервер”.
Модель “клиент-сервер” (рис. 7) - распределенная
структура организации приложений, распределяющая задачи или нагрузку между
поставщиками услуг, называемыми серверами, и заказчиками услуг, называемыми
клиентами. Программный код клиентов и серверов выполняется, чаще всего, на
различном оборудовании и взаимодействуют с помощью компьютерных сетей, но так
же возможен запуск и серверов, и клиентов в рамках одной системы.

Рис.7. Диаграмма клиент-серверной архитектуры.
[36]
Хост, на котором расположен сервер, запускает
одну или несколько серверных программ, которые предоставляют свои ресурсы
клиентам. Клиент, в свою очередь, не делится своими ресурами, а запрашивает
данные (например, базы данных, файлы) или сервисную функцию (работа с
электронной почтой, обмен сообщениями, просмотр веб-страниц) сервера.
Клиенты и серверы общаются между собой с помощью
модели обмена сообщениями запрос-ответ: клиент посылает серверу запрос, а
сервер возвращает ответ. Как правило, сервер представляет собой некую
абстракцию для клиента, т.е клиент не знает, как именно сервер обрабатывает тот
или иной запрос и доставляет ответ. Клиенту необходимо только лишь знать
протокол обмена сообщениями. Для формализации обмена данными, и организации
слоя абстракции между сервером и клиентом сервер может реализовать API
(application programming interface, интерфейс программирования приложений),
представляющий собой набор методов и функций, доступных клиенту, а так же
описание входных и выходных данных.
К преимуществам клиент-серверной архитектуры
относят централизацию вычислений, что снижает требования к клиентским
компьютерам, отсутствие дублирования кода, хранение данных на сервере и
возможность организации контроля полномочий, разрешая доступ к данным клиентам
с соответствующими правами доступа, а так же возможность легкого
модифицирования серверного кода в любое время, что позволяет добавлять и
изменять функционал не требуя обновления программ на компьютерах пользователей.
Недостатками архитектуры считается органичение доступа к функциям и данным при
неработоспособности сервера, а так же относительно высокая стоимость
обслуживания подобных систем и оборудования.
Необходимость использования клиент-серверной
архитектуры в разрабатываемом браузерном расширении обусловлена, в первую
очередь, необходимостью хранения пользовательских данных (истории переведенных
слов) и восстановления их при установке расширения на другом компьютере, а так
же необходимостью выполнения сложных вычислений, которые бы заняли относительно
большое время на компьютерах клиентов, учитывая так же ограниченную среду
выполнения программного кода в браузерном расширении. Таким образом,
предполагается реализация программы-клиента, представляющей собой собственно
расширение для браузера, и программы-сервера, предоставляющая API для клиента.
Программа-клиент
Клиентская программа представляет собой
расширение для веб-браузера - программы, используемой пользователем для доступа
к веб-страницам. Клиент реализует пользовательский интерфейс, хранение
локальной информации на компьютере пользователя, а так же обмен сообщениями с
серверной программой.
Программа-клиент реализует следующий функционал:
Реализует авторизацию пользователя с клиентской
стороны (получение авторизационных токенов Facebook, обмен авторизационных
данных с сервером, отображение статуса авторизации).
Отображает историю переведенных и добавленных на
изучение слов.
Предоставляет по двойному клику по слову на
странице его перевод, аудио и дополнительную информацию о нем, добавляя при
этом слово в историю просмотренных слов, и предлагая добавить его на изучение в
мобильное приложение.
По запросу пользователя подсвечивает важные
слова на текущей странице, определенные согласно специальному алгоритму
сервером.
Выбор браузера для реализации расширения
Браузерное расширение - программа, определенным
образом расширяющая или изменяющая функционал и, возможно, интерфейс
веб-браузера. Реализация подобного рода программ возможна в большинстве
современных браузеров, среди которых:
Internet Explorer (с
1999 г.)(с
2004 г.)(с
2009 г.)Chrome
(с
2010 г.)(с
2010 г.)Edge
(c 2016 г.)
Несмотря на то, что в большинстве случаев
разработка расширений ведется с использованием общего стека технологий (HTML,
JavaScript, CSS), синтаксис и методы разработки, архитектура, и API могут
значительно различаться в различных браузерах до такой степени, что расширение,
разработанное для одного браузера, фактически не работает в другом.
В рамках данной работы предполагается создание
расширения, не являющегося готовым продуктом, хоть и представляющего пользу, а
своего рода платформой для разработки и тестирования нового функционала, что, в
свою очередь, ведет к созданию готового продукта.
Учитывая это, а так же сложность разработки и
поддержки расширений для нескольких браузеров по причинам, описанным выше,
целесообразно выбрать один браузер для первоначальной реализации требуемого
функционала.
Таким браузером был выбран Google Chrome,
являющийся самым популярным браузером на апрель 2016 г. (табл. 1) [7], что позволяет
представить продукт как можно большему числу пользователей при реализации
расширения для одной программы-браузера.
Таблица 1
Распределение рынка браузеров, 2016 г.
|
2016
|
Chrome
|
IE
|
Firefox
|
Safari
|
Opera
|
|
April
|
70.4 %
|
5.8 %
|
17.5 %
|
3.7 %
|
1.3 %
|
|
March
|
69.9 %
|
6.1 %
|
17.8 %
|
3.6 %
|
1.3 %
|
|
February
|
69.0 %
|
6.2 %
|
18.6 %
|
3.7 %
|
1.3 %
|
|
January
|
68.4 %
|
6.2 %
|
18.8 %
|
3.7 %
|
1.4 %
|
Веб-браузер Google Chrome так же предоставляет
один из наиболее широких API для доступа к содержимому страниц, истории
посещенных пользователем страниц, и для модификации пользовательского
интерфейса браузера.
Выбор архитектуры реализации расширения
Браузерные расширения, как было сказано выше,
представляют собой программу, реализованную на стеке технологий
HTML/CSS/JavaScript. Особенности архитектуры, предлагаемой браузерами для
разработки расширений, является необходимость использования одного HTML файла,
реализующего весь пользовательский интерфейс и всю логику его поведения.
Таким образом, единственным способом организации
архитектуры расширения является так называемое одностраничное веб-приложение
(single page application, SPA). Одностраничное приложение предполагает
реализацию интерфейса пользователя на единственной странице и обновление данных
без ее перезагрузки по мере необходимости или в качестве реакции на действия
пользователя (рис. 8).
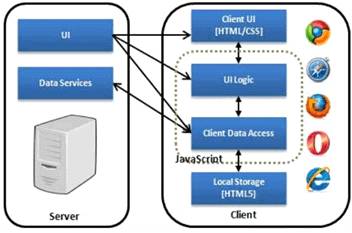
Рис. 8. Схема архитектуры одностраничного
веб-приложения.
Взаимодействие с одностраничным приложением
часто включает в себя взаимодействие с серверной программой, предоставляющей
новые данные для отображения, чем и будет в том числе являться разрабатываемая
в рамках данной работы серверная программа. Для реализации одностраничного
приложения на стороне клиента используются различного рода вспомогательные библиотеки
(фреймворки), которые будут рассмотрены далее.
Программа-сервер
Серверная программа представляет собой набор
функций и методов, формирующий API для предоставления данных клиенту и
обслуживания запросов, поступивших от клиента. API сервера релизует следующий
функционал:
Авторизация пользователей через Facebook.
Сохранение и получение истории переведенных
слов.
Предоставление перевода и дополнительной
информации о выделенном на странице слове.
Лемматизация слов.
Хранение истории посещенных страниц и реализация
алгоритма, выделяющего на ее основе важные слова на текущей странице.
Предоставляет доступ к словам, добавленным на
изучение через расширение мобильному приложению для изучения иностранных слов.
Выбор аппаратной архитектуры для серверной
программы
Для того, чтобы запустить разработанную
серверную программу, необходимо наличие соответствующего аппаратного
обеспечения (одного или нескольких компьютеров - серверов). Данные компьютеры
должны обладать значительной мощностью для запуска программ, выполняющих
сложные вычисления, а так же для одновременного обслуживания большого
количества запросов от клиентов. Так же, немаловажен быстрый и стабильный
доступ к данным компьютерам через Интернет с резервированием каналов, чтобы
минимизировать вероятность неработоспособности системы в целом из-за отказа
серверной части. Организация такого рода аппаратного обеспечения стоит
значительных денежных и временных ресурсов.
В настоящее время все большую популярность
приобретают облачные сервисы. Суть подобных сервисов в предоставлении
повсеместного и удобного доступа к пулу общих конфигурируемых вычислительных
ресурсов (сети, сервера, хранилища данных, приложения и сервисы). Данные
сервисы могут быть предоставлены и освобождены оперативно и с использованием
минимальных эксплуатационных затрат.
Основными преимуществами облачных сервисов
считаются:
Эластичность и расширяемость - возможность в
любой момент перераспределить, расширить или сузить вычислительные ресурсы.
Стоимость - большинство компаний,
предоставляющих облачные сервисы, заявляют о значительном снижении стоимости
вычислительных ресурсов.
Легкость в обслуживании - доступ к
администрированию облачных вычислительных ресурсов возможен в любой момент из
любого места через Интернет
Надежность и безопасность - как правило,
вычислительные ресурсы в облачных сервисах дублируются в различных локациях, и
большинство провайдеров уделяет большое внимание вопросам безопасности доступа
к ним.
Набор сервисов, предоставляемых провайдерами
облачных сервисов, организуется в стек следующего вида: “инфраструктура как
сервис” (infrastructure-as-a-service, IaaS), “платформа как сервис”
(platform-as-a-service, PaaS), “программное обеспечение как сервис”
(software-as-a-service, SaaS) (рис. 9).
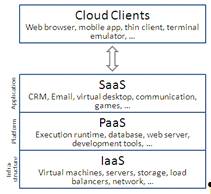
Рис. 9. Стек облачных сервисов.
Модель “инфраструктура как сервис” представляет
собой доступ к вычислительным ресурсам реального или виртуального компьютера и
соответствующему сетевому окружению.
Модель “платформа как сервис” предоставляет
доступ к различным окружениям для разработки: веб-серверам, базам данных,
средствам для разработки и тестирования. Здесь вся
информационно-технологическая инфраструктура, включающая в себя вычислительные
сети, серверы, системы хранения, т.е фактически ресурсы, предоставляемые в
рамках модели “инфраструктура как сервис”, целиком и полностью управляется
провайдером.
Модель “программное обеспечение как сервис”
предоставляет пользователям доступ кразличного рода програмному обеспечению,
размещенному в облаке. Программное обеспечение полностью обслуживается
провайдером, что исключает затраты с установкой, обновлением и поддержкой
программного обеспечения для клиентов.
Для запуска разработанной в рамках данной работы
программы-сервера будет использован один из сервисов, реализующих модель
“платформа как сервис” (PaaS). Таким образом будет исключена необходимость
установки и поддержки аппаратного обеспечения, что будет полностью
контролироваться провайдером облачных сервисов, что приведет к уменьшению
сроков разработки системы, уменьшению стоимости ее разработки и обслуживания, а
так же сделает ее легко расширяемой и устойчивой к варьирующимся нагрузкам.
Выбор программной архитектуры для серверной
программы
Важное значение для разрабатываемого браузерного
расширение имеет организация программной архитектуры серверной части. Здесь
будет рассмотрено два способа организации методов разрабатываемого API: как
монолитное приложение (monolithic application) и как набор сервисов называемый
микросервисами (microservices), приобретаемый все большую популярность в
настоящее время (рис. 10).
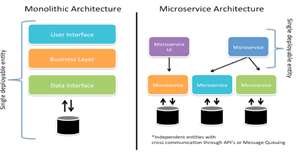
Рис. 10. Монолитная и микросервисная
архитектура. [28]
В основе монолитного подхода лежит идея, что
приложение представляет собой единое целое, содержит в себе весь необходимый
функционал, не зависит от других приложений. Монолитное приложение отвечает не
за конкретную задачу, а реализует все задачи, требуемые от системы, в рамках
одного приложения. Разрабатываемые в рамках данного подхода приложения, при
отстутствии грамотной организации кода и модульности, могут стать слишком
сложны для разработки, поддержки и масштабирования.
Микросервисы, в свою очередь, представляют собой
набор небольших, независимых друг от друга процессов, общающихся между собой.
Такие сервисы похожи на небольшие блоки из которых строится модульная система.
Преимуществами данного подхода являются:
Легкость замены и модификации сервиса, т.к от
программного кода конкретного сервиса не зависит работоспособность ни одного
другого.
Возможность реализации различных сервисов с
использованием различных технологий (языков программирования, баз данных, и
т.д.).
Легкость развертывания получившейся системы, т.к
при изменении функционала одного из сервисов не требуется развертывание
приложения целиком.
Архитектура микросервисов так же критикуется по
ряду причин, включащих в себя дополнительные сложности, возникающие при
организации такой инфраструктуры, т.к требуется организация обмена данными
между микросервисами и дополнительные расходы на грамотную организацию развертывания
такой системы.
Серверное приложение, разрабатываемое в рамках
данной работы, будет организовано по принципу микросервисов, т.к объем задач,
которые должно решать данное приложение, невелик, и задачи практически не
связаны между собой.
Теоретические основы построения системы
Одна из основных задач разрабатываемого
браузерного расширения - предоставление пользователю перевода выделенного на
странице слова и дополнительной информации о нем. Так же дополнительным
функционалом, предоставляемым расширением, является возможность выделить на
текущей странице слова, являющиеся характерными для данной странице, чтобы
помочь пользователю легче понять содержимое страницы на иностранном языке, а
так же подсказать ему слова для изучения, которые наиболее ему необходимы.
Перевод слов
Для получения перевода выделенных на странице
слов, информации о части речи слова и его словарных значениях, аудио и прочей
информации используются два основных источника. Для большинства слов источником
информации является словарь, используемый в мобильном приложении для изучения
иностранных слов, дополнением которого и является разрабатываемое расширение.
Словарь (Collins, 2015) включает в себя более 100 000 слов на английском языке,
их словарные значения и аудио, что обеспечивает возможность предоставления
хороших данных для большинства переводимых слов.
Для слов, перевода которых не найдено в базе
мобильного приложения, используется API переводчика Google Translate [10].
Переводчик так же предоставляет перевод слов и словарные значения для них, но
лимит запросов в день достаточно сильно ограничен, что, помимо лучшего качества
данных и аудио в словаре Collins, и обуславливает необходимость использования
альтернативного Google Translate источника данных.
Лемматизация слов
Большая часть слов, встречающихся в текстах на
веб-страницах, не находится в нормальной форме. Для того, чтобы обеспечить
поиск перевода выделенного слова и дополнительной информации о нем, адекватную
передачу слов на изучение в мобильное приложение, а так же для хранения истории
встречающихся слов для алгоритма, выделяющего важные слова на странице
используется процесс приведения слова к нормальной форме, называющийся
лемматизацией.
Для лемматизации используется библиотека для
работы с естественными языками Natural Language Toolkit (NLTK) [47], написанная
на языке Python. Данная библиотека предоставляет широкий набор средств для
работы с различными корпусами текстов и лексическими ресурсами и для работы с
текстовой информацией на естественном языке.
По умолчанию данная библиотека использует для
лемматизации слов на английском языке лексическую базу данных WordNet [29],
имеющую в своем составе морфологический процессор morphy [30], который в рамках
WordNet используется для поиска нормальной формы слова для переданной строки,
что позволяет осуществлять поиск по WordNet, хранящей слова в нормальной
формах, по поисковым запросам, содержащим слова не находящиеся в нормальной
форме.
Выделение характерных слов на странице
Разрабатываемое в рамках данной работы браузерное
расширение, как было сказано выше, помимо предоставления базовых функций, таких
как предоставление перевода, словарных значений, аудио и дополнительной
информации о слове, выделенном на странице, а так же хранения истории
просмотренных и добавленных на изучение слов, предполагает реализацию платформы
для добавления дополнительного функционала, использующего возможности бразура
для различного рода улучшения процессов пополнения словарного запаса и изучения
иностранных языков.
В рамках данной работы, помимо реализации самой
платформы и базового функционала расширения, в качестве примера подобного рода
дополнительного функционала реализуется возможность автоматического выделения
важных слов на странице учитывая историю просмотренных страниц пользователя. В качестве
алгоритма для выделения таких слов используется алгоритм, использующий оценку
важности слова по мере TF-IDF.
Мера TF-IDF (англ. TF - term frequency, частота
слова; IDF - inverse document frequency, обратная частота документа) -
статистическая мера, позволяющая оценить важность слова в контексте документа,
который является частью коллекции документов. Важность слова повышается
пропорционально числу потребления данного слова в рассмариваемом документе, но
компенсируется частотой употребления слова в других документах коллекции.
Вес слова по TF-IDF подсчитывается по двум
метрикам: (Term Frequency - частота слова) представляет собой меру, оценивающую
частоту встречаемости слова в документе. Так как документы различаются по
объему, возможно такое, что слово будет встречаться в длинных документах чаще,
чем в коротких. Поэтому, для нормализации, часто количество раз, которое слово
встретилось в документе, делится на общее количество слов в документе.
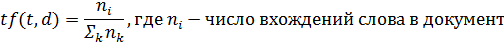
IDF (Inverse Document Frequency - обратная
частота документа) характеризует важность рассматриваемого слова. Учет IDF
уменьшает вес слов, часто встречающихся в других документах коллекции, тем
самым уменьшается вес общеупотребительных слов.
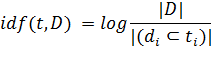
где |D| - количество документов в
коллекции, а в знаменателе - количество документов, в которых встречается
рассматриваемое слово.
Мера TF-IDF является произведением двух
сомножителей: в результате большой вес получат слова, которые редко
употребляются в документах коллекции, но часто употребляются в текущем
документе.
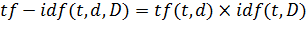
В разрабатываемом расширении коллекцией
документов, по которым происходит расчет метрики IDF, будет являться история
страниц, просмотренных пользователем. Тем самым, использование TF-IDF позволит
автоматически выделять на текущей странице слова, важные в контексте текущего
документа, не являющиеся общеупотребительными, а так же в большой степени
являющиеся для пользователя новыми, т.е словами, которые редко встречаются ему
при просмотре веб-страниц, что должно помочь пониманию содержимого
просматриваемой странице на иностранном языке.
Выбор программных и инструментальных средств для
решения поставленных задач
Для решения поставленных задач в первую очередь
необходимо сделать выбор используемого для реализации серверной программы
облачного сервиса, предоставляющего услуги по модели Platform-as-a-Service
(PaaS). Далее, исходя из сделанного выбора, выбираются конкретные сервисы
выбранной платформы, которые будут использоваться в разработке, языки
программирования, на которых будет написан программный код серверной и
клиентской части, а так же система управления базами данных (СУБД). Для
реализации клиентской части необходимо выбрать программную платформу
(фреймворк), позволяющий реализовать одностраничное веб-приложение (single page
web-application).
Выбор облачного сервиса
В настоящее время, в связи с популярностью
подхода Platform-as-a-Service, существует множество провайдеров облачных
сервисов, предоставляющих услуги по подобной модели. Далее будут рассмотрены
преимущества и недостатки нескольких наиболее популярных провайдеров.App Engine
[13] - облачный сервис, предоставляющий услуги Platform-as-a-Service для
создания распределенных веб-приложений на языках Java, Python, PHP и Go. Среда
Java, запускаемая сервисом, поддерживает так же другие языки, работающие на JRE
(Java Runtime Environment). Сервис предоставляет SDK для каждого из четырех
основных поддерживаемых языков, а так же плагин для среды разработки
Eclipse.App Engine предоставляет поддерживаемую инфраструктуру и среду для
разработки, гарантируя возможность легкого масштабирования, но только, если
приложение соответствует ограничениям платформы. Хранилище данных, предоставляемое
сервисом, представляет собой NoSQL базу данных типа “ключ-значение”. Сервис
использует модель “песочницы”, изолируя выполняемые процессы, тем самым
предотвращая возможность влияния на их выполнение извне.
Стоимость услуг, оказываемых сервисом,
определяется по времени их использования: $0.05/час за вычислительные ресурсы,
$0.18/GB за хранение данных, $0.12/GB за доступ к ним.
Облачный сервис Heroku [14] предоставляет
возможность создания абстрактных вычислительных контейнеров, называющиеся Dyno,
которые представляют собой виртуальный Unix-подобный контейнер, выполняющий
процессы в изолированной среде. Такие контейнеры делятся на два типа:
отвечающие на HTTP запросы (web dynos) и отвечающие на запросы на выполнение
различного рода задач, находящихся в очереди (worker dynos).
Платформа поддерживает выполнение программного
кода, написанного на языках Ruby, Python, Java, Scala, Closure и Node.js. Так
же как сервисы платформы Heroku доступны различные сторонние приложения.
Стоимость услуг зависит от количества и размеров
запущенных контейнеров ($0.05/час-$0.10/час), размера используемой базы данных
и подключенных сторонних приложений.
Платформа Windows Azure Services [15] является
своего рода “гибридом” Platform-as-a-Service и Infrastructure-as-a-Service,
предоставляя как PaaS сервисы, такие как среда выполения программ, базы данных,
очереди сообщений и прочие, как и IaaS услуги (виртуальные машины, объектные
хранилища). Это позволяет использовать по мере необходимости как те, так и
другие сервисы в рамках реализации одного приложения.
Сервис поддерживает разработку приложений с
помощью .NET, Node.js, PHP, Python, Java и
Ruby. Для
разработки и развертывания приложений доступны возможности Visual Studio. В
качестве хранилища данных сервис предлагает как SQL, так и NoSQL базы данных.
Стоимость оказываемых услуг так же зависит от
времени использования вычислительных ресурсов: цены начинаются от $0.02/час
(768MB RAM и 1 виртуальное ядро) и могут достигать $0.64/час за среду с 14GB
RAM и 8 виртуальными ядрами.
Платформа Amazon Web Services (AWS) [16] так же
предоставляет как сервисы IaaS, так и сервисы PaaS. AWS представляет собой
безопасную платформу облачных сервисов, которая предоставляет вычислительные
мощности, доступ к хранилищам, базам данных, услугам доставки контента и другим
функциональным возможностям.
К преимуществам сервиса относятся большой набор
предоставляемых PaaS сервисов, широкое географическое присутствие сервисов,
благодаря которому достигается минимальная задержка при их использовании и низкая
стоимость услуг.
Стоимость оказываемых услуг определяется
различным образом в рамках каждого сервиса, поэтому для удобства расчета
стоимости работы и поддержки разработанного приложения используется специальный
калькулятор. Так же новым пользователям предоставляется некоторое количество
ресурсов бесплатно для начала работы.
Все рассмотренные выше платформы предоставляют
достаточно широкий набор сервисов для реализации всех поставленных задач. Для
реализации серверной программы для разрабатываемого браузерного расширения в
рамках данной работы была выбрана платформа облачных сервисов Amazon Web
Services.
Данная платформа обладает наиболее широким
выбором PaaS сервисов что позволяет наиболее гибким образом выбрать решение для
поставленной задачи. В то же время AWS предоставлет так же сервисы по модели
IaaS, что позволяет, при необходимости, смешивать эти два подхода. Так же
важно, что данная платформа используется для организации серверной части в
мобильном приложении, дополнением которого будет являться разрабатываемое
расширение, и для минимизации затрат на последующую поддержку имеет смысл
использовать те же сервисы.
Выбор языков программирования
Для реализации поставленных задач необходимо
выбрать языки программирования, с помощью которых будет реализована серверная и
клиентская части.
Клиентская часть, представляющая собой
браузерное расширение, реализуется с помощью стека технологий
HTML/CSS/JavaScript, т.е языком программирования, на котором будет реализовано
расширение, является язык JavaScript. Соответственно, интерфейс расширения
реализован на HTML/CSS.
Для реализации серверной части будет использован
сервис Amazon Web Services - Lambda [17]. AWS Lambda позволяет запускать
программный код без выделения серверов и управления ими, оплачивая только фактическое
время вычисления. Данный сервис поддерживает языки программирования Node.js,
Java и Python.
Серверная часть разрабатываемого расширения
будет реализована на языке программирования Node.js, представляющий собой
реализацию языка JavaScript для серверного использования. Выбор одного и того
же языка программирования для реализации обоих частей расширения сократит
затраты на последующую поддержку и разработку.
Тем не менее, часть разрабатываемого функционала
серверной части (лемматизация) будет реализована на языке Python так же с
ипользованием AWS Lambda, так как Python обладает обширной базой библиотек,
предназначенных для работы с натуральными языками.
Выбор системы управления базами данных
Для реализации требуемого функционала, а именно
хранения истории слов, переведенных пользователем, с возможностью их
восстановления, а так же для хранения истории просмотренных пользователем
страниц для использования их в качестве корпуса документов для использования в
алгоритме выделения важных слов на просматриваемой странице, необходимо
использование какого-либо хранилища данных как на сервере, так и на клиенте.
Платформа Amazon Web Services предлагает широкий
выбор баз данных в рамках модели Platform-as-a-Service. Реляционные базы данных
представлены сервисом Amazon RDS, предлагающим на выбор ядра БД MySQL, Oracle,
SQL Server, PostgreSQL и Amazon Aurora. AWS RDS обеспечивает возможность
масштабирования вычислительных ресурсов и хранилища, использования нескольких
зон доступности и реплик чтения, и ряд других возможностей.база данных
реализуется сервисом Amazon DynamoDB. Данный сервис обладает высоким
быстродействием, эффективной масштабируемостью и низкой стоимостью.
Так как разрабатываемая система представляет
собой в том числе основу для последующих экспериментов с функционалом, т.е
структура базы данных может изменяться для реализации нового функционала, в
качестве серверного хранилища данных принято решение использовать NoSQL базу
данных, т.е сервис Amazon DynamoDB. Так же данный сервис используется в мобильном
приложении, что, опять-таки, уменьшит стоимость затрат на последующую поддержку
системы.
В качестве клиентского хранилища данных
используется HTML Local Storage [34] (локальное хранилище), позволяющее
сохранять данные локально в браузере пользователя, представляющее собой базу
данных вида «ключ-значение». Данное хранилище поддерживается всеми популярными
браузерами, включая браузер GoogleChrome.
Выбор single page application фреймворка
Разрабатываемое браузерное расширение, как было
сказано выше, является, по сути, одностраничным веб-приложением (single page
web application, SPA), то есть, все изменения данных в интерфейсе требуется
осуществлять без перезагрузки страницы. Несмотря на то, что объем логики,
требующей реализации для работы расширения не слишком велик, и возможна
реализация такой логики без использования вспомогательных библиотек на чистом
JavaScript, использование легкого SPA фреймворка значительно облегчит и ускорит
разработку и последующую поддержку приложения. Далее будут кратко рассмотрены
несколько наиболее популярных библиотек для организации одностраничных
веб-приложений..js [21] является минималистичным MVC фреймворком, на котором
основано множество популярных высоконагруженных веб-приложений, таких как
Twitter, Pinterest и Hulu.
Одним из основных преимуществ данного фреймворка
являются его легкость (минифицированная и сжатая библиотека имеет размер 6.3KB
и зависит всего от одной библиотеки - Underscore.js). Так же важным
преимуществом является гибкость - в отличие от многих других фреймворков,
Backbone.js оставляет выбор многих компонентов, таких как шаблонизатор, на
усмотрение разработчика, что позволяет выбирать компоненты, наиболее подходящие
для решения конкретной задачи.
Данные преимущества позволяют наилучшим образом
использовать данную библиотеку для решения относительно простых задач
построения одностраничных веб-приложений, где приоритетна скорость рендеринга
страницы, либо для реализации виджета, являющегося частью традиционного
веб-приложения.
Минималистичность данной библиотеки так же
иногда относят к ее недостаткам, так как возможность использования различных
компонентов и плагинов может усложнять разработку для новичков, не знакомых со
всеми особенностями фреймворка. Недостатками так же считаются необходимость
написания чрезмерного количества шаблонного кода для работы данной библиотеки,
и отсутствие поддержки рендеринга страницы на стороне сервера, что может
помешать поисковым ботам индексировать содержимое страницы.[19] - библиотека
для организации веб-приложений, поддерживаемая компанией Google и являющаяся
одной из наиболее часто используемых JavaScript MV* библиотек.
Основной особенностью данного фреймворка
является организация двустороннего связывания данных, что представляет собой
состояние, когда данные привязаны к сооветствующему HTML-элементу в шаблоне, и
этот элемент имеет возможность как показывать, так и обновлять эти данные. То
есть, данные могут обновляться как со стороны модели, так и со стороны шаблона,
что позволяет значительным образом сократить количество кода, необходимого для
реализации динамических страниц. Так же возможностями библиотеки является
наличие и возможность создания - дополнительных HTML-элементов с определяемым
поведением и легкое встраивание зависимостей.
Двустороннее связывание данных иногда относят к
недостаткам данного фреймворка, так как в некоторых ситуациях такая возможность
усложняет отладку и тестирование кода, а так же негативным образом влияет на
скорость работы приложения, особенно при наличии большого объема отображаемой
информации. Так же, как и в случае с Backbone.js, отсутствует возможность
рендеринга страницы на стороне сервера.
Фреймворк Ember.js [20], созданный в 2011 году,
является библиотекой, разрабатываемой открытым сообществом программистов.
Несмотря на относительно большой размер исходного кода (~95KB), большой объем
функционала уже включен в библиотеку, не требуя подключения сторонних
компонентов.
К преимуществам фреймворка относят минимальную
необходимость конфигурации при разработке приложений - пропагандируется принцип
“соглашение над конфигурацией” (“convention over configuration”), что сокращает
время разработки и количество написанного программного года. Так же библиотека
содержит широкий набор стандартных компонентов, что избавляет разработчиков от
необходимости заново решать известные задачи, позволяя сфокусироваться на
реализации нового функционала.
Подход “соглашение над конфигурацией” в
некоторых ситуациях является недостатком фреймворка, так как при соблюдении
такого принципа разработчики оказываются ограничены в конфигурации приложения
рамками, обозначенными библиотекой. Так же при таком подходе генерируется
значительное количество кода, что при разработке объемных приложений может
привести к излишним сложностям. Так же библиотека на текущий момент поддерживает
возможность двустороннего связывания данных, от которой разработчики обещают в
скором времени отказаться..js [18] - библиотека, выпущенная Facebook в 2013
году, которая развивается крайне быстро на текущий момент, в том числе из-за
использования подходов, не типичных для других фреймворков для организации
веб-приложений. В то время как библиотеки, рассмотренные выше, представляют
собой фактически MVC-фреймворки, React.js представляет собой скорее часть,
отвечающую за вид, в то время как реализация остальной части архитектуры
остается на выбор разработчика, для которой Facebook предлагает решение под
названием Flux. [37]
Данный фреймворк считается одним из наиболее
быстрых решений для разработки веб-приложений. Так же к преимуществам относят
легкость освоения библиотеки, компонентный подход к организации интерфейса и
наличие рендеринга страниц на стороне сервера. С помощью данного фреймворка так
же возможно создание мобильных приложений (React Native [22]).
Основным недостатком является отсутствие
шаблонов и компонентов для генерации интерфейса, что означает, что большая
часть HTML кода не может быть вынесена отдельно от программного кода на языке
JavaScript.
Для реализации расширения, реализуемого в рамках
данной работы, была выбрана библиотека AngularJS. Так как основной задачей, для
упрощения реализации которой было решено использовать фреймворк, является
обновление данных в интерфейсе расширения, двустороннее связывание данных
оказывается крайне полезной возможностью, в несколько раз сокращающей количество
написанного кода и времени на его поддержку и разработку новых функций. Так же
немаловажна возможность создания собственных html-директив, полезная для
реализации различных элементов интерфейса.
Структура разрабатываемого програмного
обеспечения
Разрабатываемая система реализует архитектуру
“клиент-сервер”, где клиентом является браузерное расширение, а сервером -
программный код, запущенный на сервисах, предоставляемыми облачной платформой
Amazon Web Services реализующий API, используемое клиентом.
Клиент представляет из себя одностраничное
веб-приложение, запускаемое как расширение браузера Google Chrome и
разрабатываемое с использованием фреймворков AngularJS и jQuery для доступа к
DOM-модели просматриваемого документа. Интерфейс приложения реализован с
помощью HTML/CSS, язык программирования - JavaScript.
Серверная часть представляет собой набор
микросервисов, написанных на языке Node.JS. Для запуска программного кода
микросервисов и хранения данных используются облачные сервисы Amazon Web
Services.
Общение и обмен данными между сервером и
клиентом происходит с помощью API, предоставляемого сервером. Таким образом,
общая структура разрабатываемого приложения показана на рис. 11:

Рис. 11. Общая структура разрабатываемого
приложения.
Далее будет подробнее описана структура каждого
из компонентов разрабатываемой программы.
Структура браузерного расширения (клиента)
Архитектура браузерных расширений, предлагаемая
для реализации браузером Google Chrome, состоит из компонентов [23], показанных
на рис. 12:
Файла-манифеста (manifest.json) описывающего
возможности, настройки, права доступа расширения;
Фоновой страницы расширения (background page),
работающей постоянно, пока расширение активно;
Скрипта содержимого страниц (content script),
исполняемого в контексте текущей страницы, просматриваемой пользователем;
Интерфейса расширения, показывающегося по кнопке
в верхнем баре браузера (browser action).
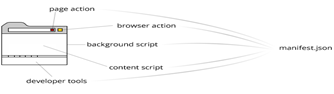
Рис. 12. Общая структура расширений браузера
Google Chrome. [38]
Скрипт содержимого страниц (content script)
будет использован для того, чтобы определять слово, выделенное пользователем на
текущей странице, показывать всплывающее окно с переводом слова и
дополнительной информацией о нем, и предлагать добавлять слово на изучение в
мобильное приложение. Так же content script используется для выделения важных
слов на странице, полученных с сервера с помощью алгоритма, использующего меру
TF-IDF.
Интерфейс расширения (browser action)
представляет собой всплывающее окно, в котором доступна информация о
просмотренных пользователем словах и о словах, добавленным им на изучение, а
так же возможность пройти авторизацию через Facebook.
Так как скрипт содержимого страниц выполняется в
контексте, отличном от скриптов интерфейса расширения, необходимо звено,
связывающее между собой эти два компонента. Таким компонентом является фоновая
страница, осуществляющая обмен данными между скриптом содержимого страниц и
скриптом интерфейса расширения, а так же осуществляющее все общение с серверным
API по запросам этих двух компонентов. Для осуществления такого рода
коммуникации между компонентами используется API обмена сообщениями браузера
Google Chrome (Message Passing) [24]. Общение с сервером происходит с помощью API,
распространяемой сервисом AWS Lambda, представляющей собой удобную в разработке
надстройку над HTTP запросами, осуществляющими вызов серверных функций.
Содержимое файла-манифеста, описывающего
конфигурацию расширения, будет подробно описано в следующем разделе. Общая
структура разрабатываемого браузерного расширения показана на рис. 13:
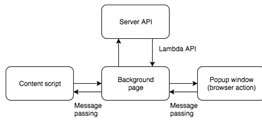
Рис. 13. Общая структура разрабатываемого
браузерного расширения.
Структура серверного API
Серверная программа представляет из себя набор
микросервисов, каждый из которых является функцией, загруженой и запускаемой в
среде облачного сервиса AWS Lambda. Вызов данных функций производится с помощью
API, предоставляемого облачным сервисом.
Серверная часть отвечает за выполнение следующих
функций:
Перевод и предоставление дополнительной
информации о слове;
Добавление слова на изучение;
Хранение и просмотр истории слов, добавленных на
изучение;
Хранение статистики по встречаемости слов в
истории просматриваемых пользователем страниц для оценки важности слова в
контексте текущего документа;
Выполнение алгоритма, выявляющего важные слова в
контексте текущего документа.
Таким образом, для реализации вышеописанного
функционала необходимо создание следующих микросервисов:- отвечает за перевод
слова.- добавляет слово на изучение и сохраняет в истории.- возвращает историю
слов, добавленных на изучение.- получает на вход набор URL из истории
просмотренных страниц пользователя, получат слова, встречаемые на данных
страницах и обновляет статистику встречаемости слов.- возвращает важные слова
для конкретной страницы.
Для организации работы механизма авторизации
необходимо так же использование двух дополнительных микросервисов:- возвращает
token провайдера профилей разработчика для последующей передачи в AWS Cognito;-
получает token провайдера разработчика от предыдущего микросервиса,
обменивается данными с AWS Cognito и возвращает ID профиля пользователя
(identity id) и token, использующийся клиентом для подписи всех запросов к
сервисам AWS.
Все микросервисы принимают на вход и возвращают
данные в формате JSON. Далее будут описаны форматы входных и выходных данных
каждой из функций.: входные данные показаны в табл. 2, выходные - в табл. 3;
стуктура объектов Wordи Term, использующихся в описании данных показана в табл.
3 и табл. 4 соответственно; пример выходных данных функции в формате
JSONпоказан на рис. 14.
Таблица 2
Входные данные функции TranslateWord
|
Параметр
|
Тип данных
|
Обязателен
|
По-умолчанию
|
|
Word
|
String
|
Да
|
|
Таблица 3
Выходные данные функции TranslateWord
|
Параметр
|
Тип данных
|
Обязателен
|
По-умолчанию
|
|
Words
|
Array[Word]
|
Да
|
|
Таблица 4
Структура объекта Word
|
Параметр
|
Тип данных
|
Обязателен
|
По-умолчанию
|
|
ForeignWord
|
String
|
Да
|
|
|
NativeWord
|
String
|
Да
|
|
|
PartOfSpeechId
|
String
|
Да
|
|
|
Terms
|
Array[Term]
|
Да
|
|
Таблица 5
Структура объекта Term
|
Параметр
|
Тип данных
|
Обязателен
|
По-умолчанию
|
|
Word
|
String
|
Да
|
|
|
Order
|
Number
|
Да
|
|
|
PartOfSpeechId
|
String
|
Да
|
|

Рис.14. Пример данных, возвращаемых
функциейTranslateWord.
: входные данные показаны в табл. 6, в случае
успеха возвращает null.
Таблица 6
Входные данные функции AddWord
|
Параметр
|
Тип данных
|
Обязателен
|
По-умолчанию
|
|
Word
|
Word
|
Да
|
|
: входные параметры отсутствуют, формат выходных
данных указан в табл. 7.
Таблица 7
Выходные данные функции TranslateWord
|
Параметр
|
Тип данных
|
Обязателен
|
По-умолчанию
|
|
Words
|
Array[Word]
|
Да
|
|
TeachTfIdf: формат входных данных указан в табл.
8, в случае успеха возвращает null.
Таблица 8
Входные данные функции TeachTfIdf
|
Параметр
|
Тип данных
|
Обязателен
|
По-умолчанию
|
|
Urls
|
Array[String]
|
Да
|
|
|
IdentityId
|
String
|
Да
|
|
: формат входных данных указан в табл. 9,
выходных - в табл. 10; структура объекта WeighedWordуказана в табл. 11, пример
выходных данных функции приведен на рис. 15.
Таблица 9
Входные данные функции GetImportantWords
|
Параметр
|
Тип данных
|
Обязателен
|
По-умолчанию
|
|
Url
|
String
|
Да
|
|
|
Limit
|
Number
|
Нет
|
10
|
Таблица 10
Выходные данные функции GetImportantWords
|
Параметр
|
Тип данных
|
Обязателен
|
По-умолчанию
|
|
Words
|
Array[WeightedWord]
|
Да
|
|
Таблица 11
Структура объекта WeighedWord
|
Параметр
|
Тип данных
|
Обязателен
|
По-умолчанию
|
|
Word
|
String
|
Да
|
|
|
Tf
|
Number
|
|
|
Idf
|
Number
|
Да
|
|
|
TfIdf
|
Number
|
Да
|
|

Рис.15. Пример данных, возвращаемых функцией
GetImportantWords.
: входные данные показаны в табл. 12, выходные -
в табл. 13, коды ошибок, возвращаемых функцией показаны в табл. 14.
Таблица 12
Входные данные функции GetDeveloperIdentityToken
|
Параметр
|
Тип данных
|
Обязателен
|
По-умолчанию
|
|
Identifier
|
String
|
Да
|
|
|
AccountType
|
String
|
Да
|
|
|
Token
|
String
|
Да
|
|
Таблица 13
Выходные данные функции
GetDeveloperIdentityToken
|
Параметр
|
Тип данных
|
Обязателен
|
По-умолчанию
|
|
Token
|
String
|
Да
|
|
Таблица 14
Коды ошибок функции GetDeveloperIdentityToken
|
Код ошибки
|
Описание
|
|
WRONG_SOCIAL_NETWORK_TOKEN
|
Переданный токен Facebook
неверен.
|
|
UNEXPECTED_NETWORK_RESPONSE
|
Ответ от Facebook не соответствует
ожидаемому.
|
.: формат входных данных указан в табл. 15,
выходных данных - в табл. 16
Таблица 15
Входные данные функции GetIdentityInfo
|
р
|
Тип данных
|
Обязателен
|
По-умолчанию
|
|
AuthToken
|
String
|
Да
|
|
Таблица 16
Выходные данные функции
GetDeveloperIdentityToken
|
Параметр
|
Тип данных
|
Обязателен
|
По-умолчанию
|
|
IdentityId
|
String
|
Да
|
|
|
Token
|
String
|
Да
|
|
Для всех разрабатываемых функций характерен
общий набор возвращаемых ошибок, указанный в табл. 17.
Таблица 17
Набор ошибок, возвращаемых всеми функциями
|
Код ошибки
|
Описание
|
|
NO_REQUIRED_PARAMETER
|
Один из обязательных параметров
не был передан функции.
|
|
PARAMETER_WRONG_TYPE
|
Один из параметров имеет не тот
тип, что указан в спецификации.
|
|
PARAMETER_WRONG_VALUE
|
Один из параметров имеет значение,
не разрешенное спецификацией для данного параметра.
|
Структура хранения данных
браузерный расширение слово данные
Для хранения данных на сервере используется
NoSQL база данных Amazon DynamoDB. Коллекция данных в DynamoDB представлена
таблицей, хранящей некоторое количество записей. Запись состоит из одного или
нескольких аттрибутов. Каждая запись должна иметь уникальный первичный ключ,
который представляется с помощью одного из двух вариантов: [25]Key (hash key) -
является значением, от которого СУБД берет хеш-функцию, определяющую раздел
памяти, в котором хранится запись. В таблице не может быть двух записей с
одинаковыми partition key.Key и Sort Key (range key) - является композитным
первичным ключом, состоящим из Partition Key, описанного выше, и Sort Key,
используемого для сортировки записей, имеющих одинаковый Partition Key.
Несколько записей в таблице при использовании такого варианта первичного ключа
могут иметь одинаковые значения Partition Key, но обязательно должны иметь
разные Sort Key, т.е значение композитного первичного ключа так же должно быть
уникально.
Для хранения данных, требующихся для реализации
требуемого функционала были выделены следующие таблицы:- хранит информацию об
истории добавленных на изучение слов, структура таблицы показана в табл. 18.
Таблица 18
Структура таблицы ExtensionWordsAdded
|
Название аттрибута
|
Тип данных
|
|
|
IdentityId
|
String
|
Partition Key
|
|
ForeignWord
|
String
|
Sort Key
|
|
CreatedAt
|
Number
|
Timestamp (ms)
|
|
Data
|
JSON Object (String)
|
|
В качестве Partition Key в данной таблице
выступает IdentityId, являющийся уникальным идентификатором пользователя в
системе AWS Cognito, использующейся для авторизации. Имея идентификатор
пользователя и выбрав все записи в таблице по Partition Key, можно получить
коллекцию слов, добавленных данным конкретным пользователем. Для обеспечения
уникальности первичного ключа, в качестве Sort Key выступает иностранное слово.
Остальная информация о переведенном слове хранится в поле Data как JSON объект
той же структуры Word, которая возвращается серверным API при переводе слова,
переведенный в строку.- хранит информацию о том, сколько раз в истории
просмотренных страниц пользователя встретилось то или иное слово для алгоритма,
оценивающего важность слова в контексте просматриваемого документа используя
меру TF-IDF.
Для расчета метрики IDF для конкретного слова
небходимо знать общее количество документов в коллекции документов, и
количество документов в данной коллекции, в которых встретилось рассматриваемое
слово. Для оптимизации расчета данной метрики было решено организовать таблицу,
которая хранит все слова, встречающиеся в истории просмотренных пользователем
страниц, и каждому слову сопоставляет количество документов, в которых
встретилось это слово.
Таблица 19
Структура таблицы ExtensionWordsOccurences
|
Название аттрибута
|
Тип данных
|
|
|
IdentityId
|
String
|
Partition Key
|
|
Occurences
|
JSON Object (String)
|
|
В качестве Partition Key так же выступает
IdentityId, что позволяет имея идентификатор пользователя выбрать из таблицы
историю встреченных слов. Статистика по словам хранится как JSON объект,
представленный в таблице строкой, как показано на рис. 16:

Рис. 16. Структура объекта, хранящего историю
встречаемости слов.
В ключе TotalDocuments хранится общее количество
документов, по которым собрана статистика. В объекте по ключу Occurences
доступна собственно статистика по встречаемости слов в рассмотренных
документах, где ключом выступает слово, а значением - количество документов, в
которых встретилось данное слово. Таким образом, получив из базы данных данную
информацию, становится возможным расчет IDF для конкретного слова, в то время
как метрика TF рассчитывается без использования каких-либо исторических данных.
Для хранения данных на клиенте
используется локальное хранилище браузера вида «ключ-значение», структура
данных показана в табл. 20.
Таблица 20
Структура данных, хранящихся в локальном
хранилище браузера
|
Название аттрибута
|
Тип данных
|
|
authDeveloperIdentityToken
|
String
|
|
authFacebookUserInfo
|
JSON Object (String)
|
|
addedWords
|
JSON Object (String)
|
|
viewedWords
|
JSON Object (String)
|
В ключе authDeveloperIdentityToken хранится
токен, полученный от сервера после авторизации пользователя, и использующися в
механизме авторизации при перезагрузке расширения. Информация об авторизованном
пользователе (имя и IDFacebook) доступна в ключе auth
FacebookUserInfo.Информация о добавленных и просмотренных словах хранится как
объект JSON, преобразованный в строку (так как localStorage поддерживает
значения только строкового типа), и доступна в ключах addedWordsи viewedWords соответственно.
Структура используемого механизма авторизации
Для авторизации пользователей в разрабатываемом
браузерном расширении используется сервис AWS Cognito, предоставляющий систему
организации прав доступа ко всем сервисам облачной платформы Amazon Web
Services, включая используемые в рамках данной работы сервисы Lambda и
DynamoDB.
Механизм, используемый для авторизации
пользователь, не разрабатывается в рамках данной работы, так как используется
существующая модель, разработанная для авторизации пользователей в мобильном
приложении. Так как одной из функциональных задач расширения является
возможность добавления слов на изучение в мобильном приложении, важно
использование одного и того же механизма аутентификации, чтобы идентификаторы
для одних и тех же пользователей совпадали на разных платформах. Таким образом
появляется возможность получения по идентификатору пользователя добавленных
через расширение слов в приложении.
Далее будет кратко рассмотрен используемый
механизм авторизации в целях понимания того, каким образом данный механизм
должен быть реализован в браузерном расширении.поддерживает два типа доступа:
авторизованный и неавторизованный. [26] В обоих случаях пользователю выдается
уникальный идентификатор, называемый Identity ID. При инициализации SDK Cognito
каждый пользователь получает неавторизованный доступ к сервисам AWS, получить
авторизованный доступ можно, пройдя механизм аутентификации. Именно в ходе
процесса аутентификации Identity ID авторизованного пользователя в Cognito
получает привязку к данным, с помощью которых пользователь проходит авторизацию
(например, аккаунту в социальной сети или связке логин/пароль). Таким образом,
в дальнейшем при авторизации в Cognito с помощью одних и тех же данных
пользователь получает один и тот же Identity ID, что дает возможность
использовать этот идентификатор для хранения пользовательской информации,
например, истории добавленных слов.Cognito поддерживает авторизацию с помощью
встроенных обработчиков популярных социальных сетей и сервисов авторизации
(Google+, Facebook, Amazon, Twitter), так и предоставляет возможность
реализации собственного обработчика регистрации и авторизации пользователей
(developer authenticated identities), в случае, если разработчик желает
реализовать механизм аутентификации на своем сервере, что полезно в случае,
если требуется поддержка соцсети, не поддерживаемой Cognito, или авторизация с
помощью логина и пароля.
В случае использования встроенных обработчиков,
схема получения авторизованного доступа и IdentityId в Cognito выглядит как на
рис. 17 [27]:
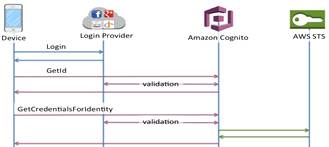
Рис. 17. Схема авторизации с помощью встроенного
провайдера.
Клиент инициирует процедуру авторизации с
поддерживаемой соцсетью и получает авторизационный токен, который после этого
отдается SDK Cognito, и дальнейшее получение и обновление токена для доступа к
сервисам AWS остается вне зоны ответственности разработчика. В данном случае
Cognito занимается так же проверкой токена соцсети и отвечает за выдачу
одинакового IdentityId одним и тем же пользователям соцсети.
При использовании механизма авторизации, не
поддерживаемого Cognito, а реализованного разработчиком (developer
authenticated identities), схема авторизации указана на рис. 18:
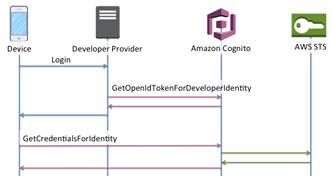
Рис. 18. Схема авторизации с помощью провайдера
разработчика.
В данном случае за авторизацию (проверку данных,
введенных (логин и пароль) или переданных (токен соцсети) пользователем и
соотношение их с определенным аккаунтом) отвечает сервер разработчика, который,
после проверки, так же должен произвести следующий шаг, который в предыдущей
схеме осуществлялся автоматически SDK Cognito - получение OpenID токена от
Cognito.
Так как в мобильном приложении необходима
поддержка одновременной авторизации с использованием нескольких провайдеров,
включая те, что не поддерживаются AWS Cognito, и авторизация с помощью
логина/пароля, используется механизм авторизации с помощью провайдера
разработчика.
Учитывая эти требования, вышеописанная схема
усложняется дополнительным шагом - функцией GetDeveloperIdentityToken, которая
принимает от пользователя авторизацонные данные, соотносит их по email-адресу с
определенным акаунтом на сервере, и возвращает токен, который используется для
авторизации с помощью провайдера разработчика - функции GetIdentityInfo по
схеме.
Таким образом, финальная используемая схема
аутентификации пользователя для получения авторизованного доступа к сервисам
AWS через AWS Cognito выглядит следующим образом (рис. 19):
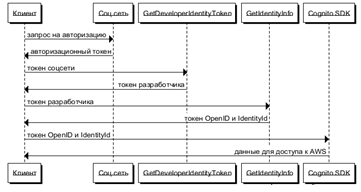
Рис. 19. Используемая схема авторизации.
Разработка программного обеспечения
Серверная часть
Серверная программа была разработана на языке
Node.JS с использованием сервиса AWS Lambda. В рамках данной работы было
разработано 5 “функций”, каждая из которых представляет собой фактически класс
с набором методов. Функции никак не связаны и не общаются между собой.
Каждая функция выполняет некоторый набор
действий, общий для каждой из функций (рис. 20). Так как часть действий
выполняется асинхронно, для того, чтобы гарантировать последовательность
выполнения используется библиотека async [39]. Для общения с используемой базой
данных DynamoDB используется модуль aws-sdk [40], предоставляющий SDK для
доступа к сервисам Amazon AWS.

Рис. 20. Диаграмма активностей функции.
Происходит инициализация библиотек,
использующихся функцией.
С помощью модуля input-resolver [41]происходит
проверка формата и целостности данных, поступивших на вход функции (рис. 21).
При несоответствии спецификации возвращается ошибка.

Рис. 21. Пример конфигурации модуля
input-resolver.
Происходит получение identityId (идентификатора
пользователя, вызвавшего функцию) из параметров, переданных либо на вход
функции, либо автоматически через SDK AWS Lambda (рис. 22).
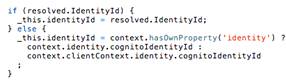
Рис. 22. Получение идентификатора пользователя.
Выполняются заявленные конкретной функцией
задачи
Возвращается результат, либо отправляется
ошибка.
Далее будут рассмотрены процессы, выполняемые
каждой из функций для достижения поставленных перед ней задач.
Сохранение слов в истории добавленных на
изучение слов происходит функцией AddWord. Единственной задачей функции
является получение слова от клиента и добавление его в таблицу
ExtensionWordsAdded. Для общения с базой данных используется класс docClient
SDK Amazon DynamoDB (рис. 23).
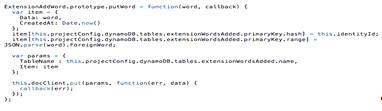
Рис. 23. Создание записи в таблице на примере
добавления слова.
Получение истории добавленных на изучение слов
обеспечивается функцией GetAddedWords. Данная функция по полученному
идентификатору пользователя выбирает все записи из таблицы, хранящей историю
добавленных слов, и возвращает данные клиенту (рис. 24).
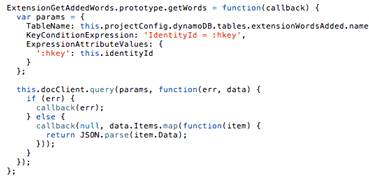
Рис. 24. Получение записей из таблицы по
идентификатору пользователя.
За обработку истории просмотренных страниц
пользователя и пополнение статистики о встреченных словах отвечает функция
TeachTfIdf. Алгоритм функции выглядит следующим образом:
Получение статистики о встреченных словах из
таблицы ExtensionWordsOccurences;
Для каждой страницы, поступившей на вход -
получение английских слов со страницы, подсчет и обновление статистики;
Запись обновленной статистики в таблицу.
Важные слова для конкретной страницы возвращает
функция GetImportantWords, которая действует так:
Получает статистику о встреченных словах из базы
данных;
Получает английские слова из переданной
страницы;
Подсчитывает значение меры tf-idf для каждого из
слов (рис. 25);
Сортирует полученные данные по значению tf-idf
по убыванию и возвращает N наиболее важных слов (по умолчанию N=10, либо
указывается параметром Limit функции).
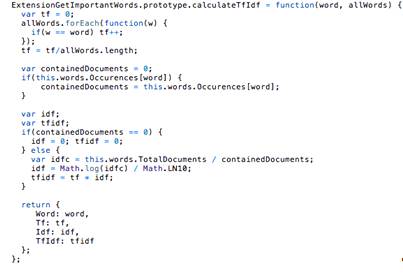
Рис. 25. Подсчет меры tf-idf для слова.
Получение английских слов со страницы функциями
TeachTfIdf и GetImportantWords происходит набором методов, вынесенных в общую
библиотеку используемых методов lib.js, которые осуществляют получение
html-содержимого страницы с помощью модуля request [42], получение слов cо
страницы с помощью модуля cheerio [43] и их лемматизацию (рис. 26).

Рис. 26. Диаграмма активностей модуля,
получающего слова со страницы.
Для осуществления лемматизации слов была создана
отдельная функция LemmatizeWord(рис. 27), написанная на языке Python и
используящая библиотеку Natural Language Toolkit (NLTK) [47].

Рис. 27. Лемматизация слова.
Перевод и предоставление дополнительной
информации о слове производится функцией TranslateWord. Для получения
информации о слове в первую очередь происходит обращение ко внутренней базе
данных, при отсутствии слова в ней - обращение к API переводчика Google
Translate. После получения данных о слове производится фильтрация словарных
значений, содержащих нецензурные фразы и слова используя словарь таких
выражений.
Клиентская часть
Исходный код браузерного расширения, как было
описано выше, делится на три компонента: browser action, content script и
background window. Для облегчения организации процесса разработки используются
два компонента: gulp [44] как система, позволяющая автоматизировать процессы
сборки и тестирования расширения, и bower [45] как модуль, отвечающий за
установку и подключение зависимостей (пакетный менеджер).
Интерфейс расширения
За отображение интерфейса, показывающего историю
добавленных и просмотренных слов, а так же реализующего механизм авторизации,
отвечает компонент browser action, исходный код которого находится в файле
popup,js, а шаблон интерфейса - в файле popup.html. Логика работы данного
интерфейса реализуется с помощью Angular.JS: происходит создание модуля
wordsApp и контроллера PopupController, который реализует следующие методы:-
отвечает за авторизацию через Facebook. Данный метод создает новую вкладку, в
которой открывается страница подтверждения доступа к приложению и, при
необходимости, авторизации.- возвращает статус слова (просмотрен/добавлен)
путем проверки наличия слова в localStorage хранилищах добавленных и
просмотренных слов. Данный метод используется для отображения или скрытия
кнопки “Учить слово” для слов, уже добавленных на изучение.- очищает историю
просмотренных слов путем очистки соответствующего localStorage хранилища.-
добавляет слово на изучение.
Интерфейс просмотренных слов использует функцию
двухстороннего связывания данных AngularJS. Отображение добавленных и
просмотренных слов происходит с помощью директивы ng-repeat, которая отображает
html элемент, к которому применена эта директива, для каждого элемента
коллекции данных, переданных директиве в качестве параметра (рис. 28).

Рис. 28. Отображение добавленых слов с помощью
ng-repeat.
Доступ к добавленным и просмотренным словам,
хранящимся в localStorage браузера, осуществляется с помощью инжекции сервиса
$storage, предоставляемого библиотекой ngStorage [35]. Данная библиотека
обеспечивает двухстороннее связывание данных так же для хранилища localStorage.
Отображение или скрытие определенных частей
интерфейса согласно какому-либо условию происходит с помощью директивы ng-show,
принимающей в качестве параметра выражение или функцию, возвращающую true для
показа элемента, и false для скрытия (рис. 29).

Рис. 29. Отображение различных данных в
зависимости от статуса авторизации и пример использования директивы ng-click.
Отображение данных поля, находящегося в зоне
видимости контроллера, осуществляется в html шаблоне с помощью синтаксиса
{{variable}}, где variable - переменная, которую нужно отобразить.
Таким образом в шаблоне popup.html
отрисовывается две вкладки, переключающиеся с помощью ng-show по значению
переменной showAdded (true - показывается вкладка с добавленными словами, false
- c просмотренными). В каждой вкладке для каждого слова, хранящегося в
соответствующем хранилище в localStorage отрисовывается шаблон слова с помощью
ng-repeat. Вызов методов clearHistory, fbLogin и addWord происходит по клику
пользователя на соответствующую ссылку с помощью директивы ng-click, параметром
которой является метод контроллера, который необходимо вызвать (рис. 29).
Скрипт содержимого страницы
За работу всплывающего окна, появляющегося по
двойному клику по слове на просматриваемой страницей отвечает скрипт
contentscript.js. Интерфейс всплывающего окна отображается по шаблону,
содержащемуся в файле context.html.
В первую очередь, данным скриптом создается
новый элемент в теле просматриваемой страницей, в которую подгружается шаблон
интерфейса всплывающего окна (рис. 30).

Рис. 30. Создание нового элемента в теле
документа.
Отслеживание двойного клика по слову происходит
с помощью библиотеки jQuery. После получения информации о подобном событии
осуществляется получение выделенного на странице слова, позиционирование
всплывающего окна согласно позиции выделенного слова, передача информации о
слове в контроллер AngularJS, отвечающий за отображение информации в окне, и
собственно отображение окна (смена стиля элемента с display=none на
display=block) (рис. 31).
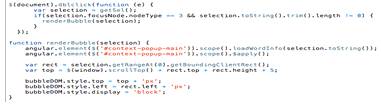
Рис. 31. Отображение окна по двойному клику.
Логика работы интерфейса всплывающего окна так
же реализуется с помощью AngularJS: создается модуль contentPopupApp с
контроллером PopupController, реализующим следующие методы:- добавляет слово на
изучение- вызывается извне контроллера по двойному клику на слово, получая
выделенное на странице слова, далее подгружает информацию на слове, сохраняя ее
в поле word, по которому отображает данные шаблон context.html.- заменяет
основной перевод слова по клику на одно из словарных значений в всплывающем
окне.
Так как скрипт содержимого страниц выполняется
вне контекста браузерного расширения, а в контексте просматриваемой страницы
(иначе у скрипта не было бы доступа к содержимому страницы), прямой связи с
остальными частями приложения у него нет. Для решения этой проблемы
используется API Message Passing [24] браузера Google Chrome, позволяющего
передавать сообщения и получать ответы на них от других частей расширения.
Данный API используют методы контроллера addWord и loadWordInfo (рис. 32), для
реализации функционала которых требуется вызов методов скрипта фоновой
страницы, отвечающего за общение с серверной частью и хранилищем данных.
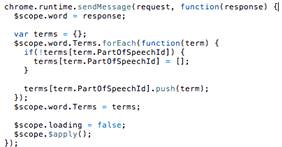
Рис. 32. Отправка запроса на перевод слова
скрипту фоновой страницы.
Так же API Message Passing используется в
скрипте содержимого страницы для того, чтобы получать сообщение о необходимости
подсветить важные слова на странице от скрипта фоновой страницы. Для подсветки
слов используется плагин jQuery под названием highlight [32] (рис. 33).

Рис. 33. Подсветка слов на странице
Протокол и формат сообщений, которыми
обмениваются части расширения с помощью Message Passing API будет описан далее.
Для обеспечения дополнительной безопасности,
например, предотвращения XSS атак, AngularJS работает в режиме, называемом
Script Contextual Escaping (SCE). [31] Данный режим предполагает, что в
некоторых контекстах привязка данных должна сопровождаться явным указанием на
то, что используемое значение безопасно в данном контексте. В скриптах
содержимого страницы и интерфейса расширения такого указания требует привязка
URL аудиофайла к HTML5 элементу, осуществляющему проигрывание аудио.
Для удобства привязки URL аудиофайлов, учитывая
эту особенность, был использован механизм AngularJS, называемый фильтрами.
Фильтры позволяют форматировать значение привязываемого выражения в шаблонах,
контроллерах и сервисах. Был разработан фильтр, который явно указывает SCE, что
URL аудио безопасен для привязки в данном контексте (рис. 34).

Рис. 34. Фильтр URL аудио и его использование в
HTML шаблоне.
Скрипт фоновой страницы
Скрипт фоновой страницы, запускающийся в фоне
при установке расширения, является своего рода связующим звеном между
компонентами системы, отвечает за общение с серверным API, за доступ к
хранилищу данных браузера и за получение корректных авторизационных данных.
Скрипт фоновой страницы содержится в файле background.js.
Исходный код скрипта поделен на 4 “сервиса” -
класса, отвечающих за различные задачи, стоящие перед данным компонентом. Схема
связей между этими классами показана на рис. 35.- отвечает за вызов серверных
методов AWS Lambda;- отвечает за различные функции, связанные со списками
слов;- отвечает за задачи по авторизации пользователя;- занимается задачами,
связанными с отображением важных слов на странице.
Рис. 35. Диаграмма классов, их публичных методов
и связей между ними.
Скрипт фоновой страницы так же отслеживает три
вида событий, происходящих в ходе работы браузера:- отслеживает сообщения,
присылаемыми скрипту другими компонентами расширения (интерфейсом и скриптом
содержимого страницы) и при необходимости, отправляет ответ;- используется в
авторизации для инициализации процесса: слушатель вызывает процесс авторизации
при появлении у одной из вкладок ссылки вида ...facebook.com/connect/login_success.html,
что свидетельствует об успешном получении кода авторизации от социальной сети
Facebook;- отслеживает событие клика по пункту “подсветить важные слова”
контекстного меню на просматриваемой странице и вызывает соответствующий метод
сервиса importantSvc.
С помощью API Message Passing скриптом фоновой
страницы отслеживаются сообщения следующей структуры JSON: в ключе intent
содержится требуемое действие, в ключе word - слово, с которым требуется
произвести это действие. Далее следует перечисление типов действий,
отслеживаемых скриптом:- принимает от скрипта содержимого страницы слово,
получает от сервера перевод слова и дополнительные данные, добавляет слово в
список просмотренных вызывая метод сервиса wordSvc и отправляет данные обратно
в скрипт содержимого страницы для отображения;- вызывает соответствующий метод
сервиса wordSvc, добавляя слово в список добавленных на изучение слов.
Доступ к истории просмотренных пользователем
страниц сервисом importantSvc для отправки этой истории для дальнейшей
обработки на сервер осуществляется с помощью API History [46] браузера Google
Chrome. Метод chrome.history.search, принимая на вход текстовую строку для
поиска по истории (в нашем случае - пустую строку для получения всей истории),
возвращает страницы, просмотренные пользователем (рис. 36).

Рис. 36.Получение истории просмотренных страниц
и отправка их на сервер.
Одним из основных процессов, осуществляемых
скриптом фоновой страницы, является процесс авторизации. За организацию
процесса авторизации отвечает сервис authSvc. При получении кода пользователя
от Facebook сервис получает токен пользователя от Facebook, получает токен
разработчика от getDeveloperIdentityToken и сохраняет его в localStorage для
дальнейшего использования.
Так как AWS Cognito не сохраняет данные
пользователя при перезапуске расширения, необходимо каждый раз проводить
инициализацию. Для этого токен, сохраненный на предыдущем шаге, отправляется
функции getIdentityInfo, чтобы получить IdentityId и OpenId токен Cognito.
Далее эти данные передаются SDK Cognito путем установки объекта
AWS.config.credentials, после чего вызывается метод refresh этого объекта для
получения соответствующих прав доступа (рис. 37). [33]
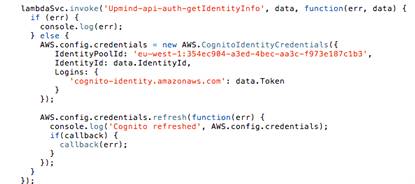
Рис. 37. Получение данных от getIdentityInfo и
передача данных Cognito.
При вызове данного процесса в момент первичной
авторизации пользователя, по завершению процесса происходит вызов метода
teachTfIdf сервиса importantSvc для передачи истории просмотренных страниц
пользователя на сервер, а так же метода getAddedWords сервиса wordSvc для
получения с сервера истории просмотренных пользователем слов.
Общая схема процесса авторизации организованного
на клиенте выглядит следующим образом (рис. 38):
Рис. 38. Общая схема процесса авторизации.
Тестирование разработанного программного
обеспечения
Функционал разработанного браузерного расширения
был протестирован вручную по следующим сценариям:
Просмотр перевода и дополнительной информации о
слове по двойному клику на слово (рис. 39);
Рис. 39. Просмотр информации о слове на
странице.
Добавление слова на изучение;
Проверка наличия добавленного слова в списках
просмотренных и добавленных слов (рис. 40);
Рис. 40. История просмотренных слов.
Авторизация пользователя через Facebook (рис.
41);
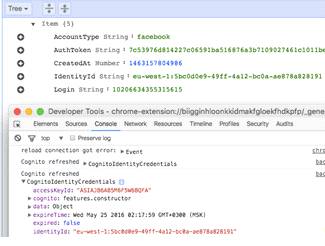
Рис. 41. Совпадение идентификатора
авторизованного пользователя в расширении с идентификатором этого же
пользователя в базе данных.
Восстановление истории просмотренных
пользователем слов;
Подсветка важных слов на странице (рис. 42).

Рис. 42. Подсветка важных слов на странице
По результатам ручного тестирования приложение
показало полную и корректную работоспособность всего заявленного функционала.
Заключение
Целью данной работы являлось создание приложения
в форме расширения браузера GoogleChrome, предоставляющего перевод и
дополнительную информацию о словах, выделенных пользователем на странице,
хранящего историю просмотренных слов, а так же возможность добавить слово на
изучение в мобильное приложение для изучения иностранных слов.
Также разработанное браузерное расширение должно
стать основой для реализации экспериментального функционала, улучшающего
пользовательский опыт изучения языка. Одним из примеров такого функционала,
который был реализован в данной работе, является выделение важных и новых для
пользователя слов на странице с использованием специальных алгоритмов.
В ходе реализации поставленных задач были
изучены способы организации распределенных приложений, проанализированы
возможности для запуска серверного функционала с помощью облачных сервисов,
изучены способы выделения ключевых слов на странице и лемматизации слов,
проработана архитектура клиентской и серверной частей, а так же структура
хранилища данных.
В результате работы была разработана система,
представляющая из себя расширение для браузера GoogleChrome (клиент),
предоставляющее перевод слов на странице, просмотр истории слов и подсветку
важных слов на странице, и серверную часть, хранящую историю слов пользователя
и выполняющую запросы клиента на получение данной истории и на выделение важных
слов на странице. Данная система полностью удовлетворяет поставленным перед ней
требованиям.
В качестве направлений дальнейшей работы можно
выделить следующие:
Увеличение скорости работы системы;
Покрытие системы автоматическим тестированием
для улучшения стабильности работы;
Улучшение качества перевода слов и
предоставляемого контента;
Усовершенствование алгоритма выделения важных
слов на странице путем улучшения качества собираемого по истории просмотренных
страниц пользователя референсного корпуса, а так же использования и совмещения
других метрик странности слова;
Реализация нового функционала, предоставляющего
новые возможности для изучения иностранных языков и интеграции с мобильным
расширением.
Список использованной литературы
Lingualeo
- английский язык онлайн. URL: <https://lingualeo.com/ru/browserapps>
(дата обращения 20.05.2016)
Лео-переводчик.
URL: <https://lingualeo.com/ru/browserapps> (дата обращения 18.05.2016)
Azab, M., Hokamp, C., Mihalcea, R.
Using Word Semantics To Assist English as a Second Language Learners. //
Proceedings of NAACL-HLT. 2015. С. 116-120
Trusty, A., Truong,
K. N. Augmenting the web for second language vocabulary learning. //
Proceedings of the SIGCHI Conference on Human Factors in Computing Systems.
2014. С. 3179-3188
Kovacs, G.
Multimedia for language learning.Massachusetts Institute of Technology, 2013
Client/Server Architecture. URL: <https://docs.oracle.com/cd/A57673_01/DOC/server/doc/SCN73/ch20.htm>
(датаобращения14.05.2016)M, Powell J. Single Page Web Applications. Manning
publications, 2013.
Cloud Computing. URL:
<https://en.wikipedia.org/wiki/Cloud_computing> (дата обращения
15.05.2016)
Monolithic Architecture pattern.
URL: <#"896481.files/image046.jpg">
Рис. 43. Листинг файла manifest.json (часть 1)

Рис. 40. Рис.
44. Листинг
файла
manifest.json (часть
2).
Приложение 2. Листинги файлов с
исходным кодом, реализующим браузерное расширение

Рис. 45. Листинг файла background.js (часть 1).

Рис. 46. Листинг файла background.js (часть 2).

Рис.
47. Листинг файла background.js (часть 3).
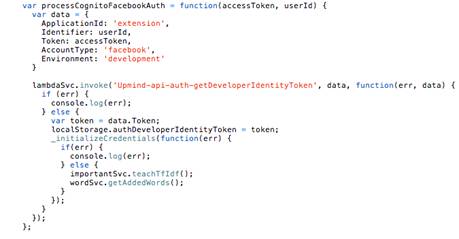
Рис. 48. Листинг файла background.js (часть 4).

Рис. 49. Листинг файла background.js (часть 5).

Рис. 50. Листинг файла background.js (часть 6).

Рис. 51. Листинг файла background.js (часть 7).

Рис. 52. Листинг файла background.js (часть 8).

Рис. 53. Листинг файла contenscript.js (часть
1).

Рис. 54. Листинг файла contenscript.js (часть
2).

Рис. 55. Листинг файла popup.js.
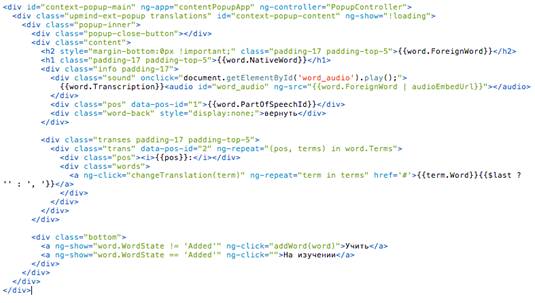
Рис. 56. Листинг файлаcontext.html.

Рис. 57. Листинг файлаpopup.html (часть 1).
Рис. 58. Листинг файлаpopup.html (часть 2).


Рис. 59. Листинг файлаmain.css (часть 1).

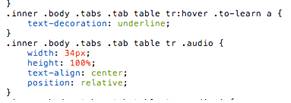
Рис. 60. Листинг файлаmain.css (часть 2).

Рис. 61. Листинг файлаmain.css (часть 3).
Приложение 3. Листинги файлов с
исходным кодом, реализующим серверную часть

Рис. 62. Листинг функцииaddWord (часть 1).

Рис. 63. Листинг функции addWord (часть 2).

Рис. 64. Листинг функции get Added Words (часть
1).

Рис. 65. Листинг функции get AddedWords (часть
2).
Рис. 66. Листинг функции
get
ImportantWords
(часть 1).

Рис. 67. Листинг
функции
get Important Words (часть
2).

Рис. 68. Листинг функции teach TfIdf (часть 1).

Рис. 69. Листинг функции teach TfIdf (часть 2).
Рис. 70. Листинг функции teach TfIdf (часть 3).