Прогнозирование изменений валютного курса
Оглавление
Введение
Глава 1. Теоретические предпосылки исследования
1.1 Актуальность работы
1.2 Методические предпосылки исследования
1.3 Предмет, объект, цель и задачи исследования.
Глава 2. Основные подходы к решению поставленных задач
2.1 Семантический анализ текста
2.2 Лингвистический подход
2.3 Twitter API. Представление данных
2.4 Выбор селекторов
2.5 Наборы данных
2.6 Предобработка данных
2.7 N-грамы. Вектор признаков
2.8 Классификаторы
2.9 Этапы исследования
2.10 Язык анализа R
Глава 3. Результаты
Заключение
Список используемой литературы
Приложения
Введение
Forex является самым крупным и наиболее ликвидным
финансовым рынком, с ежедневным оборотов в, примерно, $1 трлн, что вызывает
серьезный интерес к этому сектору финансов и ясно дает понять, что по различным
причинам любой трейдер на Форекс хотел бы иметь точный прогноз обменного курса.
Но прогнозирования финансового рынка привлекает к себе большое внимание не
только трейдеров, но и представителей академических кругов, а также в бизнеса.
Но можно ли финансовый рынок в действительности предсказать?
На обменный курс влияет множество факторов и событий.
Какие-то факторы очень быстро отражаются на курсе национальной валюты, какие-то
медленно и не так заметно. Как правило, такие реакции, как изменения обменного
курса в целом может быть хорошо объяснено задним числом, но в течение коротких
периодов времени их затруднительно предсказать выше случайного уровня.
Условно эти факторы можно поделить на три категории:
· краткосрочные
· среднесрочные
· долгосрочные
Из психологических исследований известно, что эмоции, в
дополнение к информации, играют существенную роль в принятии решений человеком
[16], [18], [39]. Поведенческие финансы предоставляют еще одно доказательство
того, что финансовые решения значительно движимы эмоциями и настроением [19].
Таким образом, новости, настроение (сантимент) инвесторов, информационный шум -
это то, что принято считать стимуляторами краткосрочные колебаний курса. Обычно
они небольшие - всего несколько копеек в день вверх или вниз. Именно на таких
ежедневных колебаниях играют спекулянты на бирже. Но для этого нужно постоянно
отслеживать новостные ленты и очень быстро реагировать на появляющиеся в них
новости. Кроме того нужно хорошо понимать, какое влияние та или иная новость окажет
на рубль, а так же как ее воспримет большинство игроков на рынке. Иногда паника
населения, сметающего валюту из обменников, может очень сильно повлиять на курс
рубля и даже обрушить его на несколько процентов.
Большинство трейдеров используют традиционными методами
прогноза, как технический анализ в сочетанием фундаментальным. Множество
исследований по прогнозированию финансового рынка [1], [2], [3] основаны на
теории случайных блужданий и гипотезе эффективного рынка (efficient market hypotesis, EMH) [4]. В соответствии с EMH на финансовом рынке цены
в значительной степени обусловлены новой информацией, то есть новостями, а не
нынешними и прошлыми ценами. Так как новости непредсказуемы, цены на фондовом
рынке будут блуждать случайным образом и не могут быть предсказаны с более чем
50-процентной точностью [5].
Существует две проблемы с EMH. Во-первых,
многочисленные исследования показывают, что цены на финансовом рынке не
блуждают по случайному паттерну и в действительности могут быть предсказаны в
некоторой степени [5], [6], [7], [8], тем самым ставя под сомнение основные
допущения EMH. Во-вторых, последние исследования показывают, что новости может
быть и непредсказуемы, но для прогнозирования изменений различных экономических
и коммерческих показателей самые ранние индикаторы могут быть извлечены из
социальных медиа платформ (Facebook, блоги, Twitter и т.д.). На самом деле,
само существование таких платформ является вызовом для гипотезы эффективного
рынка, так как предлагают данные в режиме реального времени с возможной
предсказательным потенциалом для валютного и других рынков.
Данная работа основана на анализе данных, извлечённых из Twitter. Будучи глобальным и
чувствительным к небольшим изменениям в международной повестке дневных новостей
Twitter, кажется, соответствует
метафоре барометра кризиса и может быть преобразован в прогностическую модель
валютного курс. По-настоящему эффективный валютный рынок будет означать, что
обсуждения в Twitter не имеют прогностическое значение для валютных курсов. С одной
стороны, данные, почерпнутые из Twitter могут облегчить предсказание интересующих нас
переменных. С другой стороны, предсказательные возможности концепций,
упомянутых в Твиттере, будут меняться во времени и могут легко подвергаться
структурным сдвигам.
В данной работе проведена поведенческая аналитика данных Twitter путём семантического
анализа текста и выявления тональности сообщений. Было реализовано две системы:
одна система основана на лексическом подходе, вторая - на машинном обучении с
учителем. В работе приводиться писание подхода к извлечению данных, способы
представления тексов для обучения, различные алгоритмы классификации и метрики
оценки эффективности. Производиться сравнение работы алгоритмов машинного
обучения классификации сообщений из Twitter при представлении признаков как юинираммы и
биграмм.
валютный курс лексический подход
Глава
1. Теоретические предпосылки исследования
1.1
Актуальность работы
Самым крупным финансовым рынком в мире является валютный, но
он ненадёжный и переменчивый. Выявление степени зависимости между поведением
пользователей Twitter и изменением валютного курса, а также разработка системы анализа
данных, позволяющей предсказывать волатильность обменного курса может быть
использована в качестве вклада в процесс принятия инвестиционных решений.
Основным вкладом данной работы является применение поведенческой аналитики
данных Twitter к российском валютному рынку для пары USD/RUB. Исследование является
исключительным за счёт того, что подобный анализ не был проведен в таком
контексте, не смотря на то, что существует ряд работ по изучению влияния Twitter-настроений на изменения
на фондовом рынке и несколько работ, посвящённых другим валютным парам. Одним
из преимуществ изучения валютного рынка является то, что из-за его огромного
объема, возможность спекуляций с помощью дезинформации в Twitter, предполагается, будет
ниже, чем в анализе фондового рынка.
1.2
Методические предпосылки исследования
Несмотря на большое количество работ затрагивающих настроение
и фондовые рынки, данный момент существует очень ограниченное количество
исследований по изучению способности настроений в микроблогах прогнозировать
обменные курсы. Для того, чтобы самое лучшее из наших знаний существующая
литература по данной тематике ограничивается только две работы. Papaioannou и др. (2013) разработали
авторегрессию и модель искусственной нейронной сети для прогнозирования
ежедневного курса доллара к евро, охватывающие период 10 октября 2010 по 05
января 2011. Авторы собирают 20250 сообщения от Twitter и выберают те, которые
относятся обменному курсу USD/EUR. В соответствии с доказательствами,
представленными при некоторых предположениях модели, которые используют
информацию, предоставленную твиты может превзойти модель RW. Второй документ (Janetsko, 2014) собирает
сообщения Twitter с 1 января 2013 года по 27 сентября 2013 г. Автор развивает
модель ARIMA кормили с тенденциями настроения участников рынка, как
извлекается твиты с целью прогнозирования цены дня закрытия EUR / USD ставка. Он приходит к
выводу, что модель настроения на основе постоянно превосходит модель RW. Изучение существующей
литературы относительно краткосрочного прогнозирования валютных курсов приводит
к смешанным результатам, так как нет четкого консенсуса относительно
эффективности валютного рынка в ежедневной торговой горизонта (например, см Tabak и Лима (2009) и Краудер
(1994)).
При изучении исследований по прогностическому моделированию с
помощью данных из социальных медиа, были сформулированы три базовых требования:
Во-первых, все моделируемые области должны провоцировать интенсивные
общественные обсуждения на социальных медиа-платформах. На самом деле
приобретение этих данные может или не может быть тривиальным или дорогостоящим.
Однако ясно, что недостатка в данных, доступных для моделирования, не должно
быть. Во-вторых, для каждой области является принципиальным смоделировать
однозначную числовую меру, внешнею по отношению к Интернету, например, доходы,
биржевые ставки или результаты всеобщих выборов. Это требование подчеркивает, что
переменная, которую будут предсказывать, является неотъемлемой частью любой
установки прогнозирования. В-третьих, социальные медиа обычно генерируют
переизбыток данных. Twitter, например, является источником полумиллиарда текстовых сообщений
в день (Гоел, 2013). Популярность социальных медиа часто означает, что поиск
информации, которая облегчает выбранную задачу моделирования является сложным
испытанием. Таким образом, третьим требованием для успешного моделирования с
помощью данных социальных медиа является выбор информации с пояснительным или
прогнозным потенциалом. Например, Papaioannou и др. (2013) решает проблему выбора с
помощью функции поиска Архивариус API для твитов, которые использовали выражение
"buy EUR / USD".
Эти три требования, описанные выше, помогают сузить условия,
при которых Twitter может быть использован для моделирования обменного курса USD/RUB. Во-первых, Twitter представляет собой
глобальную платформу, на которой обмениваются новостями, мнениями,
комментариями в беспрецедентных масштабах. Часто этот тип информации
варьируется в зависимости от волатильности рынков, включая валютные рынки.
Во-вторых, USD/RUB обменный курс, очевидно, является численная мера, поддающейся
моделированию. Возможно что данные, добытые из Twitter выполняют третье
требование, т.е. возможно отборать информацию с пояснительным или предиктивным
потенциалом. Данный вопрос остаётся открытым, и заслуживает более подробного
обсуждения.
1.3 Предмет,
объект, цель и задачи исследования.
Целью данной работы является выявление, исследование и оценка
ценных особенностей и закономерностей в движения обменного курса Доллар США /
Российский рубль (USD/RUB) путем анализа соответствующих данных, полученных из Twitter с помощью анализа
настроений. Необходимо определить, могут ли сообщения, найденные в Twitter быть использованы в
качестве вклада в процесс принятия инвестиционных решений. Более конкретная
цель данной работы заключается в решении вопроса о том, какая система и в какой
степени может улучшить прогнозирование валютного курса EUR / USD. Таким образом был
определен объектом исследования является валютный рынок
Предметом исследования является изменение валютного рынка.
Для достижения цели необходимо решить следующие задачи:
. Сбор всех необходимых данных и их формальное описание
для дальнейшего анализа;
2. Выявление теоретических основ проблемы: подходов к
анализу тональности, модели представления текста, фунций весов,
классифицирующие алгоритмы. Выбрать то сочетание модели языка и весов, которое
даст наилучший показатель точности на данной выборке.
. Реализовать 3 метода анализа тональности:
) лингвистический метод, основанный на сравнении с готовым
тональным словарём;
) метод машинного обучения "с учителем",
использующий в качестве признаков юниграмы.
) метод машинного обучения, использующий биграммы.
4. Для подходов, основанных на машинном обучении,
сравнить результаты работы различных классифицирующих алгоритмов (наивный
Байесовский алгоритм, k-ближайших соседей, алгоритм "случайный
лес", метод опорных векторов). Выбрать алгоритм, дающий наибольший уровень
точности на конкретной обучающей выборке.
Глава 2.
Основные подходы к решению поставленных задач
2.1
Семантический анализ текста
Главной задачей sentiment analysis (анализа тональности)
является выявление эмоционального отношения (или мнения) автора высказывания к
некоторому объекту, выраженное в тексте.
Мнения бывают двух типов:
. непосредственное мнение;
2. сравнение.
Разрабатываемые системы основываются на анализе
непосредственных мнений. Таким мнением называется кортеж из пяти элементов (e, f, op, h, t), где:
(entity, feature) - объект тональности e (сущность, о которой высказывается автор) или
его свойства f
(атрибуты, части объекта);
orientation или polarity - тональная оценка (эмоциональная позиция
автора относительно упомянутой темы);
holder - субъект тональности (автор, то есть кому
принадлежит это мнение);
time - врем, когда было оставлено мнение.
Так как мнения извлекаются с помощью Twitter API не случайным образом, а
по определенным условиям, объект тональности известен. Twitter API также предоставляет
информацию об авторе и времени.
Примеры тональных оценок [4]:
· позитивная;
· негативная;
· нейтральная.
Под "нейтральной" подразумевается, что текст не
содержит эмоциональной окраски.
Существующая работа по анализу настроений могжет быть
классифицирована с различных точек зрения: по используемому методу,
представлению текста, уровню детализации анализа текста, виду рейтинга и т.д.
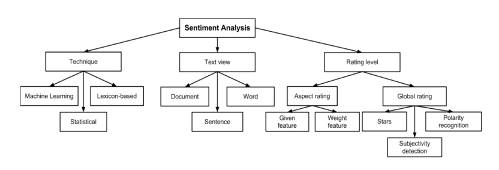
С точки зрения представления текста, определение настроение
осуществляется для всего документа (сообщения). Это может быть сделано с
помощью машинного обучения "с учителем”, "без учителя”, с помощью
подхода, основанного на лингвистических правилах, или на комбинации из этих
различных методов. В рамках исследования реализовываются два различных подхода:
лингвистический и машинное обучение "с учителем”.
2.2
Лингвистический подход
Подход основанный на лингвистике включает в себя вычисление
настроений для документа с использованием заранее подготовленного тонарного
словаря, содержащего слова, для которых уже отмечена тональность. Массив данных
для позитивных и негативных слов, выражающих мнение (тональных слов) взят у Linis Crowd - краудсорсинговом
веб-ресурсе для создания лингвистических инструментов.
Метод машинного обучения
Метод машинного обучения использует несколько алгоритмов
классификации для определения настроения путем обучения на известном наборе
данных с тональной размет. Подход машинного обучение с учителем требует в
качестве обучающей выборки набор тонально размеченных документов.
2.3 Twitter
API. Представление данных
Twitter, социальная сеть для ведения микроблога,
считается 9ым самым популярным сайтом в соответствии с рейтингом Alexa на состояние января 2015
года. Она имеет около 284 млн ежемесячно активных пользователей. Каждый день
публикуются порядка 500 миллионов твитов, большинство из которых находятся в
открытом доступе. Популярность Twitter среди академиков, ученых и исследователей
растет, за счёт простоты сбора данных на основе предопределенных
пользовательских параметров Twitter API, в отличие от других социальных медиа сайтов,
таких как Facebook, где извлечение данных является трудной задачей.
"Twitter Streaming API" - это возможность,
предоставляемая Twitter, которая позволяет любому извлекать максимум 1% выборку всех
данных. Morstatter считает, что для больших наборов данных или больших задач,
которые генерируют много трафика, 1% данных, по-видимому, 'верный' в полной
мере поток, с общим набором самых популярных ключевых слов и хэштегов [9].
Поскольку собранные сообщения за 12 месяцев
продолжительности имеет значительное количество твитов, ожидается, что общие
тенденции будут наблюдатся в этом образце, проведет в течение всего набора
данных.
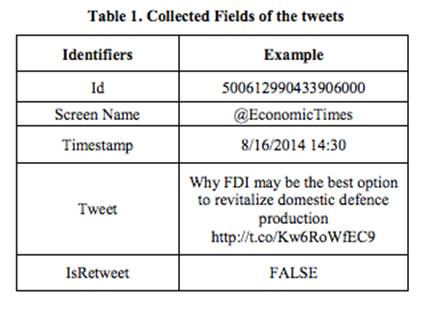
Text - Текст твита
Screen Name - отображаемое имя пользователя, разместившего
твит
ID - уникальный идентификатор твита
Retweet - "True", если твит был
процитирован другим пользователем
Другой пользователь еще 'False'
Retweet Count - Число раз это сообщение было процитировано
Favorited - был ли этот статус добавлен в избранное
Trunkated - усечен ли твит
Geo - возвращает 'NULL', если твит не имеет
геотега, в противном случае возвращает место, откуда он был написан.
Created - дата, в которую был размещен твит.
Многие из атрибутов возвращают значение "NULL", такие, как favorite, retweet, geo. Так что для каждого
твита были извлечены только следующие несколько атрибутов:
2.4 Выбор
селекторов
Доллар США и рубль упоминаются в большом количестве твитов,
которые, кажется, не имеют никакого отношения к обменному курсу USD/RUB, например, рекламные
объявления. И наоборот, есть большое количество твитов, которые не упоминают
доллар или рубль явно, но которые могут быть связаны с обменным курсом USD/RUB, например, упоминания о
данных по безработице в России или кризисной ситуации в стране. Даже при том,
что информация, найденная в Twitter часто бессмысленная или просто не связана с
валютным рынком, можно предположить, что значительное число сообщений,
передаваемых в Twitter содержат информацию, которая несёт определенную связь с валютным
рынком. В соответствии с этим предположением, на кону вопрос о том, какая
информация в Twitter имеет прогностический потенциал в отношении переменных валютного
рынка. Если этот тип информации доступен через Twitter, он должен быть
идентифицирован с использованием соответствующих селекторов. Что может быть
таким соответствующим селектором? Исследование, описанное в данной работе
руководствуется предположением, что в Twitter выбор переменных с помощью предиктивного
контента для обменного курса USD/RUB достижимо со ссылкой на понятия, используемые
при обсуждении последних политических тенденций. Это определяет фокус, и он
должен быть специфическими для работы в качестве селектора для твиты. В то же
время, такой акцент сам по себе не исключает, что данные, отобранные таким
образом, могут также отражать позитивное развитие событий в зоне евро. Это
верно до тех пор, как есть некоторые дискуссии по поводу кризиса евро на Twitter. В противном случае, не
существует дисперсия в данных и прогнозирование становится невозможным. Он
высказал предположение, что интенсивные обсуждения кризиса евро связаны с
медвежьей евро и бычий доллар США. И наоборот, если обсуждение любого кризиса в
зоне евро теряет импульс, например, из-за позитивных новостей из еврозоны, то
стоимость евро по отношению к доллару США можно ожидать, чтобы быть на подъеме.
Кроме того, предполагается, что такие дискуссии о кризисе евро не только
связаны с обменным курсом EUR / USD, но несет потенциал, чтобы предсказать это. Даже
при том, что информация, найденная на Twitter часто бессмысленными или просто не связаны с
валютных рынков, можно предположить, что значительное число сообщений,
передаваемых на Twitter содержат информацию, которая несут определенную связь с валютных
рынков. В соответствии с этим предположением, вопрос на кону которого обмен
информацией на Twitter имеет прогностическую потенциал в отношении переменных валютного
рынка. Если этот тип информации доступно на Twitter, он должен быть
идентифицирован с использованием соответствующих селекторов. Что может быть
такой, соответствующий селектор? Исследование, описанное в данной работе
руководствуется предположением, что на Twitter выбор переменных с
помощью предиктивного контента для обменного курса EUR / USD достижимо со ссылкой на
понятия, используемые при обсуждении кризиса евро. Это указание фокус, и он
должен быть специфическими для работы в качестве селектора для твиты. В то же
время, этот акцент делает само по себе не исключает, что данные, индуцированные
таким образом, могут также отражать позитивное развитие событий в зоне евро.
Это верно до тех пор, как есть некоторые дискуссии по поводу кризиса евро на Twitter. В противном случае, не
существует дисперсия в данных и прогнозирование становится невозможным. Он
высказал предположение, что интенсивные обсуждения кризиса евро связаны с
медвежьей евро и бычий доллар США. И наоборот, если обсуждение любого кризиса в
зоне евро теряет импульс, например, из-за позитивных новостей из еврозоны, то
стоимость евро по отношению к доллару США можно ожидать, чтобы быть на подъеме.
Кроме того, предполагается, что такие дискуссии о кризисе евро не только
связаны с обменным курсом EUR / USD, но несет потенциал, чтобы предсказать это.
2.5 Наборы
данных
В данной работе используются таких два основных набора
данных:
· Ежедневный курс USD/RUB, т.е. число российских
рублей за один доллар.
Данные были получены из Центрального банка РФ (www.tcmb.gov. tr), за период 6 марта 2016
года по 15 марта 2016 года.
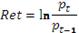 (1)
(1)
где pt - курс на начало дня.
Причина использования возвращаемое данные вместо данных о
ценах, чтобы определить направление движения валюты. Если возвращаемое значение
является положительным, то значение зависимой переменной определяется как 1, и
если возвращается отрицательное значение или оно равно 0, зависимая переменная
равна 0.
· Сообщения Twitter, собранные с помощью
таких ключевых слов, как "курс доллара", "рубль", "дол
руб", "нефть", "санкции", "кризис" которые
были опубликованы в период с 6 марта 2016 года по 15 марта 2016 года.
2.6
Предобработка данных
Набор данных, полученный с помощью Twitter API состоял из более чем 90
тысяч единиц. Такое число сообщений является избыточных.
Так как исходные данные являются необработанным текстом, была
проведена предварительная обработка для приведения документов к
нормализованному виду, пригодному для анализа.
. Удаление шума - Очистка данных от второстепенных
новостей, а также рекламных объявлений.. Из наборы данных были удалены все
сообщения пользователей, число постов которых было больше 20, так как было
предположено, что эти пользователи являются новостными агрегаторами, в которых
не отражается настроения самого автора.
b. Были удалены записи, в текстах которых содержаться
такие термины, как "официальный", "новости",
"вести", "eur to rub", "цена на нефть баррель" и др.
Такие сообщение также зачастую содержат именно информационные сообщения. Этот
шаги в данном исследовании являются своего рода упрощённым способом выявления и
избавление от сообщений, не содержащих субъективное высказывание.
2. На данном этапе, до токенизации, которая позволяет
избавиться от знаков препинания, были отобран набор документов, содержащих
эмоциональную окраску. Этот набор будет применятся в качестве тонального
корпуса для классификации методом машинного обучения. Определение тональности
осуществляется путём поиска в тексте пиктограмм, изображающий эмоции (таб.) Неоднозначные
документы, содержащие обе эмоции были исключены.
|
Тональность
|
Символы
|
|
Positive
|
:):]: - ) =): - D: ’): ’] =’)
|
|
Negative
|
D: D=: (: [>= (>= [: - [: - (= (: ’: \ =/
o. O O_o Oo
|
Выборка оказалась не многочисленной, из всего массива данных
были выявлены 344 тональных сообщения.
. Токенизация. Этот процесс разбивает текст документа
в последовательность лексем. Разбиение определяются путём удаления всех не
буквенных и не кириллических символов.
4. Stemming. Данный процесс определяет метод, который
используется, чтобы найти морфологическую базу слова. Для этих целей была
использована программа mystem, написанная Илья Сегалович и Виталий Титов [].
Она производит морфологический анализ текста на русском языке и умеет строить
гипотетические разборы для слов, не входящих в словарь.
2.7 N-грамы.
Вектор признаков
Метод N-грамм определяет последовательность из n элементов в наборе. Он
используется в различных областях обработки естественного языка и анализа
генетической последовательности. Модель N-грамм определяет способ
нахождения набора n-грамм слов из данного документа. Обычно используемые модели
включают юниграмм (n = 1), биграммы (n = 2) и триграмм (n = 3). Однако значение n может быть использована
и на более высоких уровнях граммов. Эта модель может быть лучше объяснена с
помощью следующего примера:
|
Текст
|
" Волк в овечьей шкуре"
|
|
Юниграмм
|
"Волк", "овечий", "шкура"
|
|
Биграмм
|
"Волк", "овечий",
"шкура", "овечий шкура”
|
|
Триграммы
|
"волк в шкуре", "лучший",
"лучшая политика".
|
Юниграммы представляет самую простую модель для подхода n-грамм. Она состоит из
всех отдельных слов, присутствующих в тексте. Модель биграмм определяет пару
смежных слов. Более высокий порядок могут быть сформированы аналогичным
образом, принимая во внимание смежные слова. Высокий порядок n-грамм являются более
эффективным способом в определении контекста, так как они обеспечивают лучшее
понимание позиции слова.
Один элемент базы анализируемых документов состоит из пары
вектора слов, который мы получили в результате предварительной обработки
сообщения и тональности этого сообщения. Так как компьютеру проще оперировать
числами, такой вектор слов представляется в виде вектора чисел: путём агрегации
из векторов слов всех документов составляется feature vector, а слова в векторах
заменяются на индексы этих слов в feature vector. Рассмотрим на примере
юниграм: имеются два предложения.
t1 = "Мне нравится бегать"
t2 = "Мне нравиться ходить пешком"
Составляем из него вектор признаков, и представляем каждое
предложение как вектора d1 и d2.
|
Вектор признаков fv
|
"мне"
|
"нравится"
|
"бегать"
|
"ходить"
|
"пешком"
|
|
t1
|
1
|
1
|
1
|
0
|
0
|
|
t2
|
1
|
1
|
0
|
1
|
1
|
d1 = {1, 1, 1, 0, 0}, d2 =
{1, 1, 0, 1, 1}
С помощью модели n-грамм, можно получить набор векторов, которые в
дальнейшем могут быть сравнены друг с другом, путем вычислений расстояний между
ними. Чем ближе векторы друг к другу - тем более они походят друг на друга.
2.8 Классификаторы
Наивный байесовский классификатор - вероятностная
методология классификации, которая относится к категории методов машинного
обучения "с учителем". Наивным он называется потому, что условная
вероятность каждой переменной не зависит от условных вероятностей других. После
извлечения среднего значения и дисперсии для каждого регрессора на известной
выборке данных, модель может классифицировать новые (не известные до этого
момента) документы, основываясь на теореме Байеса (1), в результате определяет
принадлежность.
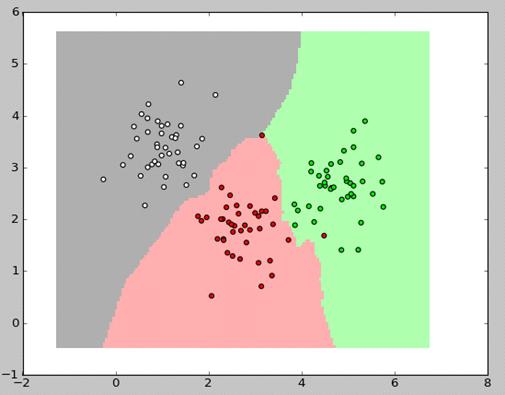
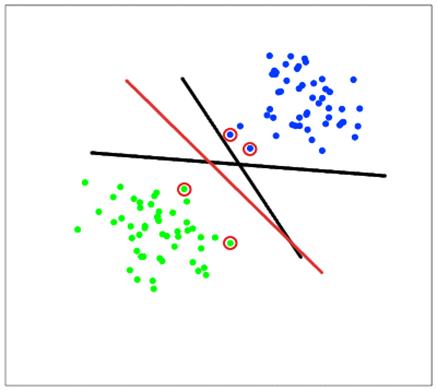
Алгоритм k-ближайших соседей (Knn). Основная идея Knn заключается в
определении принадлежности каждого экземпляра к классу большинства своих
ближайших соседей K в пространстве признаков. Пример классификации Knn
для двух классов изображен на рисунке 1.
Дерево решений. Дерево решений позволяет
перейти к содержащемуся в нем решению путем выполнения последовательности
проверок. Каждый внутренний узел в дереве соответствует проверке значения
одного из свойств, а ветви, исходящие из этого узла, обозначены возможными
значениями результатов проверки. Каждый листовой узел в дереве задает значение,
возвращаемое после достижения этого листа.
Метод опорных векторов представляет собой
бинарный метод классификации при машинном обучении "с учителем”. Основное
понятие которое стоит за методом заключается в том, чтобы найти линейный
разделитель для двух классов в пространстве признаков. Решение задачи
минимизации алгоритма сходится к линейному разделителю, который имеет большой
запас между этими двумя классами. Маржа между классами определяется набором
точек данных, называемых опорными векторами. Примером классификации
SVM с ядром RBF изображен на рисунке 2.
2.9 Этапы
исследования
Первый шаг: Сбор данных - на этом этапе данные, подлежащего
анализу, выявленных из Twitter, MySpace
Второй этап: Предварительная обработка - На данном этапе,
приобретенные данные очищается и подготовлены к подаче его в классификатор.
Третий этап: Подготовка данных - Ручной сбор данных
подготовлен Наиболее часто используемый метод краудсорсинга. Эти данные
являются топливо для классификатора; Это
будет подаваться в алгоритм для обучения цели.
Четвертый шаг: Классификация - это сердце всей техники. в
зависимости
по требованию SVM приложения или наивным Байеса развернут для
анализа.
Классификатор (после завершения обучения) готова к
развертыванию в режиме реального времени
твитов / текст для целей добычи настроения.
Пятый шаг: Результаты - результаты представлены на основе
типа представления
выбран т.е. диаграммы, графики и т.д. Настройка
производительности производится до момента выпуска
алгоритм.
2.10 Язык
анализа R
В данной работе в качестве инструментального средства была
выбрана система статистических вычислений R.
R применяется везде, где нужна работа с данными. Это не только
статистика в узком смысле слова, но и "первичный" анализ (графики,
таблицы сопряжённости), и продвинутое математическое моделирование. R без особых проблем может
использоваться и там, где сейчас принято использовать коммерческие программы
анализа уровня MatLab/Octave.
Глава 3.
Результаты
ЭТАП 1
На данном этапе был произведен лингвистический анализ
настроения, рассмотренный в главе 1. Все обработанные сообщения сортируются на
3 категории, определенные как POSITIVE, NEUTRAL и NEGATIVE. В зависимости от их настроения. В таблице 2
ниже показано содержание твитов в качестве примера.

Результате анализа было получено 1691 позитивных, 2239
негативных и 11488 нейтральных сообщений.
Выведем основные позитивные и негативные слова и их частоты.
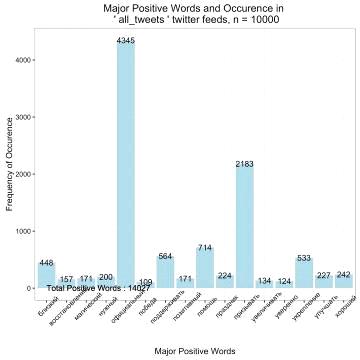
Рисунок. Динамика настроений для всех терминов
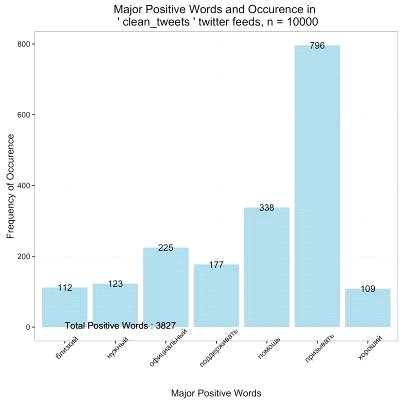
Рисунок. Динамика валютного курса
Наконец, для объединения со временным рядом, число
положительных, отрицательных и нейтральных настроений рассчитываются отдельно
для каждого дня. На рис. Представлена динамика изменения количества сообщений
различной тональности и их общего количества твитов. Если сравнить с динамикой
обменного курса того же периода, можно наблюдать схожую тенденцию в локальных
максимумах.
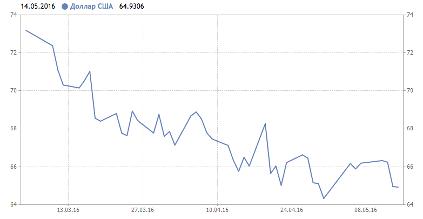

Рисунок. Облако слов для всех слов, встречающихся в выборке
Модель
Для анализа данных, добытых из твитера, мы будем использовать
бинарную зависимую переменную, логистическую модель. Эта логистическая
регрессионная модель выражается, как:
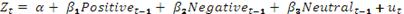 (2)
(2)

В модели используются настроения за предыдущий день от
прогнозируемой даты, так как ожидается задержка в воздействии данных Twitter на валютный курс.
Результаты логистической регрессии приведены в таблице 3.
Таблица 3. Результаты логистической регрессии
|
Переменная
|
Коэффициент
|
Prob.
|
|
C
|
2.2243
|
0.4062
|
|
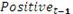
|
0.2377
|
0.3968
|
|
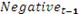
|
0.0360
|
0.7411
|
|
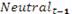
|
-0.0058
|
0.3590
|
|
Nagelkerke R2
|
0.367
|
Полученные результаты свидетельствуют о том, что настроение в Twitter влияет на обменный курс. Коэффициент при
переменной является положительным, а коэффициент на 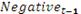 переменной T-1 является
отрицательным. Оба являются значимыми на уровне 1%. Коэффициент при переменной Neut_t-1
незначительна.
переменной T-1 является
отрицательным. Оба являются значимыми на уровне 1%. Коэффициент при переменной Neut_t-1
незначительна.
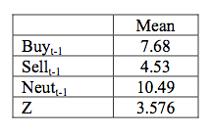
Для того, чтобы вычислить эффект увеличения на одну единицу в
переменных, используемых формул являются следующие:
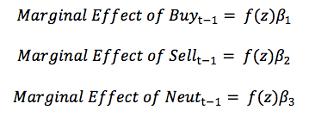
Величина f (x) равна 0,244. Высчитанный маржинальный эффекты можно найти
в таблице 5
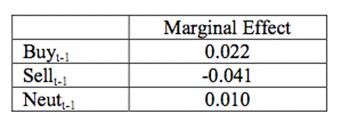
Эти результаты означают, что, когда число твитов находятся на их
средних значений, увеличение числа твитов, выражающих позитивные настроения в
предыдущий день 1% повышает вероятность увеличения обменного курса на 0,17%, а
также увеличение числа числа твитов, выражающих негативные настроения 1%
повышает вероятность снижения обменного курса на 0, 19%.
В таблице 6 приведена расчетная анализ уравнений для оценки логит.
P (Z = 1) ≤0.5 показывает число раз, что предсказанный вероятность
Z равна 1 меньше или равно 0,5; P (Z = 1) > 0,5
показывает число раз меньше, чем 0,5. Мы рассматриваем предсказание, как
правильно, когда либо P (Z = 1) ≤0.5 и Z = 0 или P (Z = 1) > 0,5 и Z = 1. С
помощью этого критерия модель правильно предсказывает 58% увеличения обменного
курса и 82% уменьшается. Эти результаты свидетельствуют о том, что модель
подходит разумно, даже если только переменные, используемые для объяснения
движения биржи являются количество твитов в предыдущий день.
Этап 2
|
Метод классификации
|
Accuracy
|
|
Stochastic Gradient Boosting
|
0.7842782
|
|
Метод опорных векторов
|
0.8219755
|
|
k-ближайших соседей
|
0.7944828
|
|
Наивный байесовский алгоритм
|
|
Случайный лес
|
0.8389831
|
|
Метод классификации
|
Accuracy
|
|
0.7842782
|
|
Support Vector Machines
with Linear Kernel
|
0.8219755
|
|
CART
|
0.7944828
|
|
Random Forest
|
0.9897721
|
Дальнейшая работа
Выбор твитов. Как описано выше, выбор 2-й шаг твитов
оказались успешными в иден - tifying ковариатами, что предсказали курс EUR / USD выше шанс уровне. Риск
ковариаты и СП Было установлено, что из-прогноза неоднократно модели случайных
блужданий и шума ковариата. Смысловое содержание этих слов говорит о том, что
говорить о риске на Twitter могут быть использованы для спрогнозирована обменный курс EUR / USD. Помимо значения риска и
SP результат обнадеживает в
том смысле, что эти понятия не являются недолговечным, как, например, имена
политиков, многие из которых играют роль в общественном обсуждении лишь на
относительно короткий промежуток времени.
Качество данных. Данные защищены от Twitter не является стандартным
в эконометрического анализа временных рядов. Что касается риска ковариатами и SP качество данных этих
данных была на уровне, необходимом для значимого анализа временных рядов, о чем
свидетельствует большинство диагностических тестов, проведенных. Остаточные
тесты, проведенные для этих ковариатами не дал никаких указаний, что остатки не
являются независимыми, что данные не на уровне стационарности или что данные не
является линейной. Соответствующие Q-Q участки показывают, что остатки разумно в соответствии с
нормальным распределением.
Настройки параметров. Соотношение между
числом возможных предсказаний и размера окна оценки (образец сплит) оказался
самым влиятельным параметром в данном исследовании. Для прогнозирующие эффекты
быть обнаружены большие окна оценки требовались которая сыграла важную роль в
снижении ошибки выборки дал шумные данные подсчетов твит. модель прогулка
оказалась недостаточной для защиты от случайных выводов. Для достижения этой
цели стало очевидным, что как тестовая модель, т.е. модель случайного блуждания
и исходные данные, т.е. шум ковариатой Rand должен был быть
использован. Что касается оценки соответствия модели, все 17 ковариаты
превзошла модель случайного блуждания, но только ковариата долг превзошла также
шум ковариантно съела. Когда речь идет о вне-образца прогнозирования, только
модели regARIMA, что превзошла соответствующую модель случайного блуждания и
ковариата Rand можно рассматривать как доказательство предварительного dictive эффекта выше случайного
уровня. Это оказалось верным для SP и риска в большинстве случаев (образец расколы)
рассмотренных.
Заключение
Основным практическим результатом работы стало построение
двух систем анализа настроений данных, извлеченных из твитер: системы,
основанной на сравнении с тональным словарём, и системы, базирующейся на
машинном обучении с учителем.
На результатах данных систем была проверена гипотеза о
предсказательном потенциале настроений пользователей Twitter. Было выявлено
корреляция между волатильностью валютного курса и количеством сообщений с
тональной разметкой.
Качество модели, использующей выборку, которая получилась в
результате работы системы машинного обучения показала лучшие результаты в
сравнени с другой системой.
Таким образом, можно сделать вывод, что сообщения Twitter могут повысить точность
прогноза. Однако, стоит открытым вопрос о выявлении концепций для извлечения
данных, которые будут меняться со временем. Очевидно, что требуются дальнейшие
исследования для изучения взаимосвязи между общественностью в социальных
каналах и валютных курсов.
Список
используемой литературы
1. Fama,
E.F. (1965) The Journal of Business 38, 34-105
2. Wysocki,
P. (1998), Cheap Talk on the Web: The Determinants of Postings on Stock Message
Boards. University of
Michigan Business School Working Paper 98025.
3. Tumarkin,
R. & Whitelaw, R. F. (2001), News or Noise? Internet Postings and Stock
Prices.
. Dewally,
M. (2003), Internet Investment Advice: Investing with a Rock of Salt. Financial Analysts Journal, 59 (4),
65-77.
5. Antweiler,
W. & Frank, M. (2004), Does Talk Matter? Evidence From a Broad Cross
Section of Stocks. Working
Paper, Universıty of Minnesota.
6. Gu,
B., Konana, P. & Liu, A. (2006), Identifying Information in Stock Message
Boards and Its Implications for Stock Market Efficiency. Workshop on Information Systems and
Economics, Los Angeles, CA.
7. Hawn,
Carleen. "Take two aspirin and tweet me in the morning: how Twitter,
Facebook, and other social media are reshaping health care." Health affairs 28.2 (2009): 361-368
8. Tayal,
D. & Komaragiri, S. (2009), Comparative Analysis of the Impact of Blogging
and Micro-blogging on Market Performance. International Journal, 1 (3), 176-182.
9. Asur,
S. & Huberman, B. (2010), Predicting The Future With Social Media. In Proceedings of
10. Sarasohn-Kahn,
Jane. The wisdom of patients: Health care meets online social media. Oakland, CA: California HealthCare
Foundation, 2008.
11. Culnan,
Mary J., Patrick J. McHugh, and Jesus I. Zubillaga. "How large US
companies can use Twitter and other social media to gain business value." MIS Quarterly Executive 9.4 (2010):
243-259.
12. Qualman,
Erik. Socialnomics: How social media transforms the way we live and do
business. John Wiley
& Sons, 2010.
13. Fama,
E. F. (1965) The Journal of Business 38, 34-105
. Jensen,
Michael C. "Some anomalous evidence regarding market efficiency." Journal of financial economics 6.2
(1978): 95-101.
15. Bollen,
Johan, Huina Mao, and XiaojunZeng. "Twitter mood predicts the stock
market." Journal of
Computational Science 2.1 (2011): 1-8.
16. Zhang,
Xue, HaukeFuehres, and Peter A. Gloor. "Predicting stock market indicators
through twitter "I hope it is not as bad as I fear”." Procedia-Social and Behavioral
Sciences 26 (2011): 55-62.
17. Morstatter,
Fred, et al. "Is the Sample Good Enough? Comparing Data from Twitter’s
Streaming API with Twitter’s Firehose." (2013).
18. Chung,
Jessica Elan, and EniMustafaraj. "Can collective sentiment expressed on
twitter predict political elections?." AAAI. 2011.
19. Tumasjan,
Andranik, et al. "Election forecasts with Twitter: How 140 characters
reflect the political landscape." Social Science Computer Review (2010): 0894439310386557.
20. Tumasjan,
Andranik, et al. "Predicting Elections with Twitter: What 140 Characters
Reveal about Political Sentiment." ICWSM 10 (2010): 178-185.
21. Conover,
M., Ratkiewicz, J., Francisco, M., Gonçalves, B., Menczer, F., &Flammini,
A. (2011, July). Political
polarization on twitter. In ICWSM.
22. Asur,
Sitaram, and Bernardo A. Huberman. "Predicting the future with social
media." In Web Intelligence and Intelligent Agent Technology (WI-IAT),
2010 IEEE/WIC/ACM International Conference on, vol.1, pp.492-499. IEEE, 2010.
23. Bollen,
Johan, Huina Mao, and XiaojunZeng. "Twitter mood predicts the stock
market." Journal of
Computational Science 2.1 (2011): 1-8.
24. Zhang,
Xue, HaukeFuehres, and Peter A. Gloor. "Predicting stock market indicators
through twitter "I hope it is not as bad as I fear”." Procedia-Social and Behavioral
Sciences 26 (2011): 55-62.
25. Chang,
Hsia Ching. "A new perspective on Twitter hash tag use: diffusion of
innovation theory." Proceedings of the American Society for Information
Science and Technology 47.1 (2010): 1-4.
. Cullum,
Brannon. "What makes a Twitter hashtag successful." Movements.org17 (2010).
27. Blaszka,
Matthew, Lauren M. Burch, Evan L. Frederick, Galen Clavio, Patrick Walsh, and
J. Sanderson. "# WorldSeries: An empirical examination of a Twitter
hashtag during a major sporting event." International Journal of Sport Communication 5, no.4
(2012): 435 - 453.
28. Chang,
Hsia-Ching, and HemalataIyer. "Trends in Twitter hash tag applications:
Design features for valueadded dimensions to future library catalogues. "Library Trends 61, no.1 (2012):
248-258.
29. Davidov,
Dmitry, Oren Tsur, and Ari Rappoport. "Enhanced sentiment learning using
twitter hashtags and smileys." Proceedings of the 23rd International
Conference on Computational Linguistics: Posters. Association for Computational
Linguistics, 2010.
30. Bradley,
M. M., and Lang, P. J. Affective Norms for EnglishWords (ANEW) Instruction
Manual and Affective Ratings. Technical Report C-1, The Center for Research
inPsychophysiology University of Florida, 2009.
. Nielsen,
Finn Årup. "A new ANEW: Evaluation of a
word list for sentiment analysis in microblogs." arXiv preprint arXiv:
1103.2903 (2011).
. Hansen,
Lars Kai, et al. "Good friends, bad news-affect and virality in twitter. "Future information technology.
Springer Berlin Heidelberg, 2011.34-43.
. Pavlopoulos,
Ioannis, and Ιωάννης Παυλόπουλος. "Aspect based sentiment
analysis." (2014).
34. Stuefer,
Marina. "Social Media Sentiment Analysis for Stock Price Behavior
Prediction. "
35. Zhang,
Xue, HaukeFuehres, and Peter A. Gloor. "Predicting stock market indicators
through twitter "I hope it is not as bad as I fear”." Procedia-Social and Behavioral
Sciences 26 (2011): 55-62.
36. Agarwal,
Apoorv, et al. "Sentiment analysis of twitter data." Proceedings of
the Workshop on Languages in Social Media. Association for Computational Linguistics, 2011.
. http://linis-crowd.org/
Приложения
Приложение 1.
Реализация лексического подхода для анализа настроений на языке R
#############################################################
# Sentiment Twitter Analysis based on lexical
approach
# author: Anna Sivakova
#############################################################
# Загружаем библиотеки, готовим обучающую выборку
#############
library
(twitteR)(ROAuth)(plyr)(dplyr)(stringr)(ggplot2)(RTextTools)
# загружаем словарь слов< - read. csv
("data. csv", fileEncoding = "UTF-8", header = T, sep
="; ")< - as. character (words$Words [words$average. rate==1])<
- as. character (words$Words [words$average. rate==-1])< - function
(sentence) {=gsub (' [[: punct:]] ','',sentence)=gsub (' [[: cntrl:]]
','',sentence)=gsub (' [[: digit:]] ','',sentence)=gsub ("^\\s+|\\s+$",
"", sentence)=gsub (' [^А-Яа-я0-9] ', '', sentence)=system
("/Users/Sivakova/r/dissertation/mystem - cl", intern = TRUE, input =
sentence)< - gsub (" [{}]", "", sentence)< - gsub
(" (\\| [^] +)", "", sentence)< - gsub ("\\?",
"", sentence)< - gsub ("\\s+", "",
sentence)< - str_split (sentence," ")< - unlist
(sentence)(wordss)
}< - function (searchterm)
{
#extact tweets and create storage file< -
read. csv (file=paste ('clean_tweets. csv'), fileEncoding =
"UTF-8")< - df [, order (names (df))]$created < - strftime
(df$created, '%Y-%m-%d')
#merge the last extraction with storage file and
remove duplicates< - read. csv (file=paste ('clean_tweets', '_stack. csv'),
fileEncoding = "UTF-8")
#tweets evaluation function. sentiment < -
function (sentences, pos. words, neg. words,. progress='none')
{(plyr)(stringr)< - laply (sentences, function
(sentence, pos. words, neg. words) {. matches < - match (sentence, pos.
words). matches < - match (sentence, neg. words). matches <-! is. na
(pos. matches). matches <-! is. na (neg. matches)< - sum (pos. matches) -
sum (neg. matches)(score)
}. df < - data. frame (score=scores, text =
sent)(scores. df)
}. words < - positive. words < -
negative< - stack$text < - as. factor (Dataset$text)< - length
(Dataset$text)< - txtProgressBar (min = 0, max = total, style = 3)< -
lapply (Dataset$text,function (x) clean (x))< - score. sentiment
(tweetclean, pos. words, neg. words,. progress='text')
#positive<-function (tweet) {. match=match
(tweet,pos. words). match=! is. na (pos. match). score=sum (pos. match)(pos.
score)
}. score < - lapply (tweetclean, function (x)
returnpscore (x))< - 0(i in 1: length (positive. score)) {< -
pcount+positive. score [[i]]
}< - function (tweets) {< - match
(t,positive)< - positive [pmatch]< - posw [! is. na (posw)](posw)
}< - NULL< - data. frame (matches)(t in
tweetclean) {< - c (poswords (t),pdatamart)
}(pdatamart,10)
#negative<-function (tweets) {. match=match
(tweets,neg. words). match=! is. na (neg. match). score=sum (neg. match)(neg.
score)
}. score < - lapply (tweetclean, function (x)
returnnscore (x))< - 0(i in 1: length (negative. score)) {< -
ncount+negative. score [[i]]
}< - function (tweets) {< - match
(tweets,negative)< - negative [nmatch]< - negw [! is. na (negw)](negw)
}< - NULL< - data. frame (matches)(t in
tweetclean) {< - c (negwords (t),ndatamart)
}(ndatamart,10)< - unlist (pdatamart)< -
unlist (ndatamart)< - data. frame (table (pwords))< - data. frame (table
(nwords))< - dpwords%>%mutate (pwords) %>%filter
(Freq>100)(dpwords,aes (pwords,Freq)) +geom_bar
(stat="identity",fill="lightblue") +theme_bw () +_text (aes
(pwords,Freq,label=Freq),size=4) +(x="Major Positive Words",
y="Frequency of Occurence",title=paste ("Major Positive Words
and Occurence in \n '",searchterm,"' twitter feeds, n
=","10000")) +_text (aes (1,5,label=paste ("Total Positive
Words: ",pcount)),size=4,hjust=0) +theme (axis. text. x=element_text (angle=45))(file<-paste
(searchterm, '_plot1. jpeg'))< - dnwords%>%mutate (nwords) %>%filter
(Freq>100)(dnwords,aes (nwords,Freq)) +geom_bar
(stat="identity",fill="lightblue") +theme_bw () +_text (aes
(nwords,Freq,label=Freq),size=4) +(x="Major Negative Words",
y="Frequency of Occurence",title=paste ("Major Negative Words
and Occurence in \n '",searchterm,"' twitter feeds, n
=","10000")) +_text (aes (1,5,label=paste ("Total Negative
Words: ",ncount)),size=4,hjust=0) +theme (axis. text. x=element_text
(angle=45))(file<-paste (searchterm, '_plot2. jpeg')). csv (scores,
file=paste (searchterm, '_scores. csv'), row. names=TRUE, fileEncoding =
"UTF-8") #save evaluation results
#total score calculation: positive / negative /
neutral< - read. csv ('all_tweets _scores. csv', fileEncoding =
"UTF-8") #save evaluation results< - scores$created < -
stack$created$created < - as. Date (stat$created)< - mutate (stat,
tweet=ifelse (stat$score > 0, 'positive', ifelse (stat$score < 0,
'negative', 'neutral'))). tweet < - group_by (stat, tweet, created). tweet
< - summarise (by. tweet, number=n ()). csv (by. tweet, file=paste
(searchterm, '_opin. csv'), row. names=TRUE, fileEncoding = "UTF-8")
#chart(by. tweet, aes (created, number)) +
geom_line (aes (group=tweet, color=tweet), size=2) +_point (aes (group=tweet,
color=tweet), size=4) +(text = element_text (size=18), axis. text. x =
element_text (angle=90, vjust=1)) +
#stat_summary (fun. y = 'sum', fun. ymin='sum',
fun. ymax='sum', colour = 'yellow', size=2, geom = 'line') +(searchterm)(file<-paste
(searchterm, '_plot. jpeg'))=Corpus (VectorSource (tweetclean))=tm_map
(tweetscorpus,removeWords,stopwords ("english"))("english")
[30: 50]
}< - function () {< - read. table
("EURUSD_160301_160322. txt", header = T, sep = ";",
fileEncoding = "UTF-8")< - as. data. frame. matrix
(qoutes)["RETURN"] < - NA(i in 2: nrow (qoutes)) {$RETURN [i] <
- log10 (qoutes$X. OPEN [i] /qoutes$X. OPEN [i-1])
}
#df$created < - strftime (df$created,
'%Y-%m-%d')(qoutes)
}< - function () {< - read. table
("EURUSD_160301_160322. txt", fileEncoding = "UTF-8")$X.
DATE. < - strftime (q$X. DATE., '%Y-%m-%d')< - read. csv ('allterms
_opin. csv', fileEncoding = "UTF-8")["positive"] < -
NA["negative"] < - NA["neutral"] < -
NA["Z"] < - NA(i in 2: nrow (q)) {(q$RETURN [i] <=0) {$Z [i]
< - 0
} else {$Z [i] < - 1
}<
- q$X. DATE. [i]< - 0(k<=nrow (score)) {(as. String (score$created [k])
== d) {(score$tweet [k] == "positive") {$positive [i] < -
score$number [k]< - k+1
} else
if (score$tweet [k] == "negative") {$negative [i] < - score$number
[k]< - k+1
}
else$neutral [i] < - score$number [k]< - k+1
} else
{k < - k+1}
}
}$Z
< - factor (reg$Z)< - glm (Z ~ positive + negative + neutral, data = q,
family = "binomial")('rms')b < - lrm (Z ~ positive + negative +
neutral, data = reg)(mod1b)(q)
}<
- function (searchterm) {_token < -
"2420922668-JMDEnynORwSXe539IqP0XFEa6J1JQDY2bcVLJeh"_token_secret
< - "1DDNxNdQJIwbrt6GyJx3BCTToPRCJ62oaOFupeWpzUb5W"_key < -
"eLIc0KRqRqcJzRlPHYis5WYjU"_secret < - "aGB7fWofOoagYEBysqKQKKhB4iqOfpfFGFoHgwoQJ62qyG04C2"_twitter_oauth
(api_key,api_secret,access_token,access_token_secret)< - searchTwitter
(searchterm, n=20, since = "2014-01-01")< - twListToDF (list)<
- df [, order (names (df))]$created < - strftime (df$created,
'%Y-%m-%d')(file. exists (paste (searchterm, '_stack. csv')) ==FALSE) write.
csv (df, file=paste (searchterm, '_stack. csv'), row. names=F, fileEncoding =
"UTF-8")
#merge
the last extraction with storage file and remove duplicates< - read. csv
(file=paste (searchterm, '_stack. csv'), fileEncoding = "UTF-8")<
- rbind (stack, df)< - subset (stack,! duplicated (stack$text)). csv (stack,
file=paste (searchterm, '_stack. csv'), row. names=F, fileEncoding =
"UTF-8")
#tweets evaluation function
}
Приложение 2.
Реализация системы анализа настроений сообщений, основанной на машинном
обучении.
# Загружаем библиотеки, готовим обучающую выборку
#############
library
(tm)(SnowballC)(e1071)(caret)(randomForest)("/Users/sivakova/R/dissertation")_tweets
< - read. csv ("positive_tweets. csv", fileEncoding =
"utf8", header = T, sep =",")< - rep (1, nrow
(pos_tweets))< - pos_tweets [,2]_tweets < - data. frame (text,
sentiment)_tweets < - read. csv ("negative_tweets. csv",
fileEncoding = "utf8", header = T, sep =",")< - rep (-1,
nrow (neg_tweets))< - neg_tweets [,2]_tweets < - data. frame (text,
sentiment)_tweets < - read. csv ("neut. csv", fileEncoding =
"utf8", header = T, sep ="; ")< - rep (0, nrow
(neut_tweets))< - neut_tweets [,2]_tweets < - data. frame (text,
sentiment)< - rbind (pos_tweets, neg_tweets, neut_tweets)
# Смотрим на данные
##########################################
# Проверяем размерность, инспектируем первое ревю
dim (training)
# Избавляемся от HTML тегов
cleanHTML < - function (x) {(gsub ("<.
*?
>", "", x))
}
# Оставляем только текст, убираем однобуквенные слова и слова
нулевой длины
onlyText < - function (x) {< - gsub
("'s", "", x) (gsub (" [^а-яА-Я]", "", x))
}
# Токенизируем
tokenize < - function (x) {< - tolower
(x)=system ("/Users/Sivakova/r/dissertation/mystem - cl", intern =
TRUE, input = x)< - gsub (" [{}]", "", x)< - gsub
(" (\\| [^] +)", "", x)< - gsub ("\\?",
"", x)< - gsub ("\\s+", "", x)< - unlist
(strsplit (x, split=" "))
}
# Создаем список стоп-слов
#stopWords < - stopwords ('ru')
# Обрабатываем все записи< - sapply (1: nrow
(training), function (x) {
# Прогресс-индикатор(x %% 1000 == 0) print (paste
(x, "reviews processed"))< - training [x,1]< - cleanHTML
(rw)< - onlyText (rw)< - tokenize (rw)< - rw [nchar (rw) >1]
#rw < - rw [! rw %in% stopWords] (rw, collapse=" ") # Снова
склеиваем в текст
})
# Строим "Мешок слов"
#######################################
train_vector < - VectorSource (rwsU) # Вектор
train_corpus < - Corpus (train_vector, #?
Корпус= list (language = "ru"))_bag < - DocumentTermMatrix (train_corpus,
# Спец. матрица документы/термины=list (weight=presence, stemming=F))
# train_bag < - removeSparseTerms (train_bag,
0.9982) # Убираем слишком редкие термины (train_bag)
# Смотрим на перечень наиболее распространенных терминов
hight_freq < - findFreqTerms (train_bag, 5,
Inf)(train_bag [1: 4, hight_freq [1: 10]])
# Из специальной матрицы формируем обучающий датафрейм
l < - train_bag$nrow_df < - data. frame
(inspect (train_bag [1: l,]))_df < - cbind (training$sentiment, train_df)
# Сокращенный датафрейм для статьи
# train_df < - data. frame (inspect (train_bag
[1: 1000,hight_freq]))
# train_df < - cbind (training$sentiment [1:
1000], train_df)(train_df) [1] < - "sentiment"< - names
(train_df) [-1] # Формируем словарь (для тестовой выборки)
# Убираем ненужное
# Выращиваем Случайный лес ##################################
t_start < - Sys. time (). seed (3113)
####################################################=
create_matrix (rws, language="russian",=FALSE, removeNumbers=F,
removePunctuation = F,=FALSE,)= create_container (mat, sentiment,=1: 260,
testSize=261: 323,virgin=FALSE)= train_models (container, algorithms=c (
"SVM",
"GLMNET",
"BAGGING",
"RF"
###########################= classify_models
(container, models)(as. numeric (as. numeric (sentiment [261: 323])), results
[,"FORESTS_LABEL"])_accuracy (as. numeric (as. numeric (sentiment
[261: 323])), results [,"FORESTS_LABEL"])(as. numeric (as. numeric
(sentiment [261: 323])), results [,"SVM_LABEL"])_accuracy (as.
numeric (as. numeric (sentiment [261: 323])), results [,"SVM_LABEL"])(as.
numeric (as. numeric (sentiment [261: 323])), results
[,"GLMNET_LABEL"])_accuracy (as. numeric (as. numeric (sentiment
[261: 323])), results [,"GLMNET_LABEL"])(as. numeric (as. numeric
(sentiment [261: 323])), results [,"BAGGING_LABEL"])_accuracy (as.
numeric (as. numeric (sentiment [261: 323])), results
[,"BAGGING_LABEL"])< - trainControl (method="cv",
number=5)
# train the LVQ model. seed (7)< - train (as.
factor (sentiment) ~., data=train_df, method="gbm",
trControl=control, verbose=FALSE)
# train the SVM model. seed (7)< - train (as.
factor (sentiment) ~., data=train_df, trControl= control,
method="nb")
#modelNb < - train (as. factor (sentiment) ~.,
data=train_df, method="awnb", trControl=control)< - train (as.
factor (sentiment) ~., data=train_df, method="rpart",=trainControl
(method="cv", number=10, savePredictions = TRUE))< - train (as.
factor (sentiment) ~., data=train_df,="svmLinear", trControl=control,
scale = FALSE)< - train (as. factor (sentiment) ~., data=train_df,="rf",=trainControl
(method="cv",number=5),=TRUE,=100,do. trace=10,allowParallel=TRUE)
# collect
resamples(modelGbm)(modelSvm)(modelKf)(modelNb)(forest)< - resamples
(modelGbm$results$Accuracy, modelSvm$results$Accuracy,
modelKf$results$Accuracy, forest$results$Accuracy)
# control < - trainControl
(method="repeatedcv", number=10, repeats=3)
#
# forest < - train (as. factor (sentiment) ~.,
data=train_df,
# method="rf",
# trControl=trainControl
(method="cv",number=5),
# prox=TRUE,
# ntree=100,# do. trace=10,# allowParallel=TRUE)
#
#
# set. seed (3113)
# modelextraTrees < - train (as. factor
(sentiment) ~., data=train_df, method="extraTrees",
# trControl=trainControl
(method="cv",number=5),
# prox=TRUE,
# ntree=100,# do. trace=10,# allowParallel=TRUE)
#
#
# # train the GBM model
# set. seed (3113)
# modelGbm < - train (as. factor (sentiment)
~., data=train_df, method="gbm",
# trControl=control, verbose=FALSE)
#
#
# # train the SVM model
# set. seed (3113)
# modelSvm < - train (as. factor (sentiment)
~., data=train_df,
# method="svmRadial",
trControl=control)
#
# # collect resamples
# results < - resamples (list (RF = forest,
TREE = modelextraTrees, GBM=modelGbm, SVM=modelSvm))
# summarize the distributions(results)
# boxplots of results(results)
# dot plots of results(results)_end < - Sys. time ()
# Смотрим на модель и на время обучения
t_end-t_start(forest)
# Загружаем и обрабатываем контрольную выборку
###############
testing < - read. csv ("test. csv",
fileEncoding = "utf8", header = T, sep ="; ")
# Проверяем размерность
dim (testing)
# Обрабатываем тестовые ревю
rws < - sapply (1: nrow (testing), function
(x) {(x %% 1000 == 0) print (paste (x, "tweet processed"))< -
testing [x,1]< - cleanHTML (rw)< - onlyText (rw)< - tokenize (rw)<
- rw [nchar (rw) >1]
#rw < - rw [! rw %in% stopWords] (rw, collapse=" ")
})
# Формируем вектор ревю, строим корпус, формируем матрицу
документы/термины ###
test_vector < - VectorSource (rws)_corpus <
- Corpus (test_vector,= list (language = "ru"))_bag < -
DocumentTermMatrix (test_corpus,=list (stemming=TRUE,= vocab))< - nrow
(test_bag)_df < - data. frame (inspect (test_bag [1: l,]))< - rep (0,
l)_df < - cbind (testing [1: l,1], sentiment, test_df []) (test_df) [1] < - "text"
# Прогнозируем сентимент ####################################
length (test_df [1,])_df [,2] < - predict
(modelGbm, newdata = test_df [,-2])(test_df [,2], testing [,2])[,2]_df [,2]
< - predict (forest, newdata = test_df [-1])
# Сохраняем результата в csv. csv (test_df [,1:
2], file="Submission. csv",=FALSE,. names=FALSE)
# Загружаем и обрабатываем все твиты
##########################
testing < - read. csv ("clean_tweets.
csv", fileEncoding = "utf8", header = T, sep =",")
# Проверяем размерность
dim (testing)
# Обрабатываем тестовые ревю
rws1 < - sapply (1: nrow (testing), function
(x) {(x %% 20 == 0) print (paste (x, "tweet processed"))< -
testing [x,2]< - tokenize (rw)< - rw [nchar (rw) >1]< - rw [! rw
%in% stopWords](rw, collapse=" ")
})< - testing [7,2]=system
("/Users/Sivakova/r/dissertation/mystem - cl", intern = TRUE, input =
rw)
# Формируем вектор ревю, строим корпус, формируем матрицу
документы/термины ###
test_vector < - VectorSource (rws)_corpus <
- Corpus (test_vector,= list (language = "ru"))_bag < -
DocumentTermMatrix (test_corpus,=list (stemming=TRUE,= vocab))< - nrow
(test_bag)_df < - data. frame (inspect (test_bag [1: l,]))< - rep (0,
l)_df < - cbind (testing [1: l,2], sentiment, test_df []) (test_df) [1] < - "text"
# Прогнозируем сентимент ###################################
length (test_df [1,])_df [,2] < - predict
(forest, newdata = test_df [,-2])(test_df [,2], testing [,2])[,2]_df [,2] <
- predict (forest, newdata = test_df [-1])
# Сохраняем результата в csv. csv (test_df [,1:
2], file="Submission. csv",=FALSE,. names=FALSE)