Проблематика прогнозирования спроса
Содержание
Введение
Глава 1. Проблематика прогнозирования спроса
.1 Теоретическая модель
.2 Построение модели спроса
.2.1 Основные этапы построения модели спроса
.2.2 Принципы и методы построения линейных, нелинейных
моделей спроса
.3 Применение эконометрических моделей на практике
.3.1 Моделирование экономики на основе эконометрической
модели LAM
.3.2 Оценивание ценовой функции для картин
Глава 2. Эконометрическое моделирование спроса на автомобили
в России
.1 Сбор статистических данных
.2 Анализ эконометрической модели
.2.1 Проверка значимости коэффициентов модели
.2.2 Проверка автокорреляции
.2.3 Проверка на наличие гетероскедастичности
.2.4 Проверка качества модели
.3 Программное обеспечение для анализа модели
.3.1 Статистические пакеты для анализа данных
.3.2 Пакет SPSS
Глава 3. Построенные эконометрические модели спроса на
зарубежные и отечественные автомобили в России
.1 Анализ парных корреляций
.2 Модель общего спроса на автомобили в России
.2.1 Построение модели
.2.2 Ретроспективный прогноз
.2.3 Качественные выводы из построенной модели
.3 Модель спроса на отечественных автомобилей
.3.1 Построение модели
.3.2 Ретроспективный прогноз
.3.3 Качественные выводы из построенной модели
.4 Модель спроса на зарубежных автомобилей
.4.1 Построение модели
.4.2 Ретроспективный прогноз
.4.3 Качественные выводы из построенной модели
Заключение
Литература
Приложения
Введение
Анализ объема и динамики продаж - один из основных этапов в управлении
продажами. Выявление зависимостей спроса на товар и его прогнозирование
помогает в принятии ответственных стратегических решений, планировании
деятельности и организации работы отделов продаж.
Современная экономическая теория, как на микро, так и на макро уровне
стремительно развивается. Постоянно усложняющиеся экономические процессы
привели к необходимости создания и совершенствования особых методов изучения и
анализа. При этом широкое распространение получило использование моделирования
и количественного анализа. На базе последних выделилось и сформировалось одно
из направлений экономических исследований - эконометрика.
Эконометрия - наука, изучающая количественные взаимосвязи экономических
объектов и процессов при помощи математических и статистических методов и
моделей. Основная задача эконометрии - построение количественно определенных
экономико-математических моделей, разработка методов определения их параметров
по статистическим данным и анализ их свойств. Наиболее часто используемым
математическим аппаратом решения задач данного класса служат методы
корреляционно-регрессионного анализа.
Эконометрическое моделирование составляет основу математического описания
экономического развития любой сферы хозяйственной деятельности. Наибольшую
актуальность оно приобретает в момент развития рыночных отношений, поскольку
функционирование компаний с учетом конкурентной среды так или иначе оценивается
как работа в условиях неопределенности, которая предполагает присутствие
различного рода возмущений, которые непосредственно влияют на объясняемые
переменные. Построение прогноза на базовой методологии эконометрической модели,
конечно, не исключит ошибки результирующих параметров модели, но определенно
уменьшит их количественное значение.
Целью настоящей работы является построение эконометрической модели
динамики продаж зарубежных и отечественных автомобилей на основе собранных
статистических данных для прогнозирования спроса в России.
Исходя из поставленной цели определен следующий круг задач:
1) Проанализировать общие принципы построения эконометрической модели;
2) Определить факторы, влияющие на уровень спроса на отечественные и
зарубежные автомобили в России, собрать статистические данные по ним;
3) Построить эконометрическую модель спроса на автомобили в России;
4) Провести ретроспективный прогноз на основании построенной модели.
Объект исследования - рынок продаж автомобилей в России.
Предмет исследования - исследование спроса на отечественные и зарубежные
марки автомобилей в России.
Глава 1.
Проблематика прогнозирования спроса
.1
Теоретическая модель
Если обобщить теоретическую модель, описывающую взаимосвязи между
явлениями или закономерности их развития, то можно записать следующее
соотношение:
y = ¦(a,x) + e
В указанном соотношении ¦(a,x) - это функционал, соответствующий
виду и структуре взаимосвязей. Величина у называется результативным признаком
или объясняющей (зависимой) переменной, она характеризует уровень исследуемого
явления. Величина x = (x1, x2, .., xn)
представляет собой вектор значений независимых (объясняющих) переменных xi.
Величина α=(α0, α1, α2, ..., αn) составляет вектор произвольных констант, которые
называются параметрами модели, а ε - ошибка модели.
Ошибка модели ε рассматривается как случайная величина и
характеризует различие реального значения объясняющей переменной y от
вычисленного в соответствии с указанным соотношением при определенных условиях
(конкретных значениях независимых переменных факторов xi).
Для расчета числового значения параметров α0,α1,α2,...,αn используется заранее собранный массив наблюдений
относящийся к изучаемому процессу и рассматриваемым факторам. В одном
наблюдении присутствует множество значений (yt,x1t,x2t,...,xnt).
Индекс t характеризует отдельное наблюдению.
Зависимую переменную y часто называют эндогенной (внутренней) переменной
модели, отображая той факт, что значения зависимой переменной определяется
только значениями независимых переменных xi.
Объясняющие переменные (предикаторы) x1,x2,...,xn
называют экзогенными (внешними) переменными. Термин "внешний"
сообщает о том, что значения предикаторов xi являются заданными, так
как определяются вне исследуемой модели.
По типу взаимосвязи факторов с зависимой переменной y модели разделяются
на линейные и нелинейные. По характеристикам своих параметров модели можно
разделить на две категории: модели с постоянной и переменной структурой. К
специфичному виду модели можно отнести системы взаимосвязанных эконометрических
уравнений, включающих несколько уравнений общего вида теоретической модели.
В общем случае алгоритм создания модели можно разбить на несколько шагов:
) Aнализ особых свойств исследуемых явлений и процессов, описание
наиболее подходящих классов моделей для их обоснования;
) Оценка выбранного типа эконометрической модели с учетом исходных
данных, выражающих значения предикаторов в определенные моменты времени;
) Проверка качества полученной модели и обоснования целесообразности ее
применения в ходе дальнейшего эконометрического исследования;
) В случае принятия решения о нецелесообразности использования созданной
эконометрической модели необходимо вернуться к предыдущему этапу работы и
попытаться построить другой вариант модели, который будет более точнее
описывать изучаемые явления и процессы.
.2
Построение модели спроса
.2.1
Основные этапы построения модели спроса
1) Постановочный этап
На данном этапе производится определения итоговых целей строящейся
модели, отбор задействованных факторов, анализ их влияния. Главными цели:
оценка состояния и анализ изменения экономического объекта, прогнозирование
основных экономических показателей объекта, сценарный анализ, применение полученных
результатов для планирования управления.
) Априорный этап
На втором этапе оценивается сущность исследуемого объекта, идет
систематизация имеющихся данных.
) Этап параметризации
На этапе параметризации определяется общий вид модели, типы взаимосвязей,
их состав. Главная цель этапа - определить тип функции f(x).
) Информационный этап
Производится анализ и сбор статистических данных.
) Этап идентификации
На этапе идентификации модели осуществляется основная часть исследований.
Проводится эконометрическая оценка модели и ее параметров.
) Этап верификации
При верификации модели идет оценка адекватности модели, проводится анализ
точности полученных значений. Проверяется смоделированный процесс на
соответствие с реальным, высчитывается ошибка прогноза.
.2.2 Принципы
и методы построения линейных, нелинейных моделей спроса
Каждый раз анализируя предложения и спрос появляется необходимость
сделать некоторый прогноз. Для корректного прогнозирования важно построить
качественную модель, с помощью которой возможно будет сделать прогноз.
При создании линейной модели спроса или предложения зачастую учитываются
не только сами значения показателей, важно уделить внимание влияющим на спрос
факторам. Например, на спрос напрямую влияет уровень доходов населения, период
(сезонность), ставки процентов в банке и многие другие факторы. Так и на
предложение могут повлиять высокие цены на ресурсы, новые дорогостоящие
технологии, налоги и многое другое.
Разберем в первую очередь наиболее часто применяющуюся модель для
описания спроса и других различных экономических показателей.
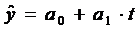
где а0 и а1 - расчетные параметры, t - временной фактор, относительно
которого изменяется спрос и предложение;.
Указанная выше модель называется трендовой моделью экономической
динамики. Другими словами - кривая роста для экономических процессов. Главной
целью данной модели является прогнозирование изучаемого процесса на исследуемый
период времени.
На данный момент существует большое количество типов кривых роста для
экономических процессов. В приоритетном порядке в экономике применяются
полиномиальные, экспоненциальные и S-образные кривые роста. Указанная выше модель относится к типу
полиномиальной кривой роста. Наиболее простые кривые роста могут принимать
схожий вид:
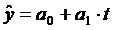 (полином первой степени)
(полином первой степени)
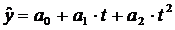 (полином второй степени)
(полином второй степени)
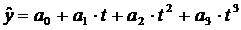 (полином третьей степени)
(полином третьей степени)
где а1 - линейный прирост, а2 - ускорение роста, а3
- изменение ускорения роста.
Для вычисления параметров модели применяется метод наименьших квадратов.
Также можно записать уравнения в матричной форме. Опишем вычисление параметров
с помощью метода МНК.
Полином первой степени:
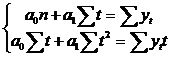
Полином второй степени:
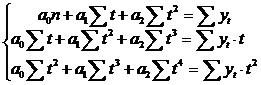
Полином третьей степени:
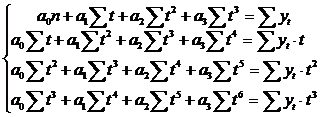
Подобным образом можно рассчитать все параметры для полиномиальных
моделей.
Для корректного выбора кривой роста для дальнейшего моделирования и
прогнозирования нужно учитывать специфику каждого вида кривых. Но на практике
получается так, что используется модель, анализ которой дает наилучшие
результаты. Оценка качества модели осуществляется относительно случайной
величине et. Параметры модели можно записать в
следующем виде:
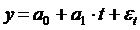 ,
,
где 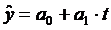
кривая роста (полиномиальная или другая), а et - случайная величина. Существует две
причины возникновения случайной величины:
. Прогнозирование экономического показателя на основе временного ряда
базируется на экстраполяции (анализ будущих значений на основании изменения
прошедших) и относится к одномерным методам прогнозирования. Обычно в таких
случаях исследуемых показатель зависит от множества факторов, четко определить
которые достаточно проблематично. Исходя из этого модель является упрощением
действительности, поэтому отклонения и возникают.
2. Возникновение неких препятствий при измерении данных (наличие
ошибок измерений), а также возникновение ошибки при округлении расчетных
значений.
Процесс вычисления данного показателя во временном ряде соотносят не с
фактором, а с течением времени, что отражается в создании одномерных временных
рядов.
Помимо полиномиальных кривых роста широко распространенным способом
моделирования тенденции временного ряда является создание аналитической
нелинейной функции, объясняющую зависимость ряда от времени. Так как
зависимость от времени может быть различна, для представления модели
используются разнообразные виды функций. В создании эконометрических моделей
спроса и предложения зачастую применяют экспоненциальный тренд:
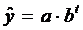 .
.
Нужно выявить подходящую из рассмотренных модель, которая наиболее
качественно описывает исследуемый параметр, другими словами определить тип
тенденции.
Вариантов для определения вида тенденции несколько. Среди известных
способов наиболее распространены: качественный анализ исследуемого процесса,
построение графика и его визуальный анализ, вычисление некоторых показателей
динамики. В подобных случаях возможно рассмотреть коэффициент автокорреляции
уровней ряда. Если рассчитать коэффициент автокорреляции по уровням ряда
(исходным и преобразованным), тип тенденции можно определить путем их
сравнения. Если тенденция временного ряда определена как линейная, его соседние
значения yt и yt-1 коррелированы между собой. В такой
ситуации коэффициент автокорреляции первого порядка для значений начального
ряда должен быть высоким. Если для временного ряда наблюдается нелинейная
тенденция, то коэффициент автокорреляции первого порядка по логарифмам значений
начального ряда будет выше, чем соответствующий коэффициент, вычисленный по
значениям ряда. Чем сильнее будут различаться величины коэффициентов, тем более
явно будет прослеживаться нелинейная тенденция в исследуемом временном ряде.
Существует и другой случай - степенная модель, имеющая вид:
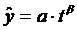
Рассмотрим анализ параметров модели в нелинейных трендах. Каждый из них
может быть рассчитан с помощью метода МНК, если нелинейную модель привести к
линейному виду. В таком случае экспоненциальный тренд примет следующий вид:
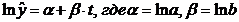 .
.
Отсюда вычислим a и b:
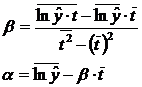
Параметры а и b вычисляются
обратным способом.
В случае степенной модели:
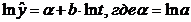 .
.
Для получения параметров a и b необходимо решить систему нормальных
уравнений:
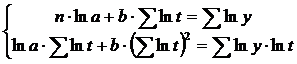
Взаимосвязь спроса от времени не всегда четко выражена. Наилучший способ
для анализа подобных явлений использовать модель множественной регрессии, в
которой исследуемый фактор будет зависеть от набора переменных. На практике
подобные модели используются чаще, так как позволяют оценить исследуемое
значение при изменении влияющих на него факторов.
Рассмотрим пример спроса на картофель (переменная y), который зависит от уровня
заработной платы (х1), время года (х2), территориальной
расположенности (х3), количества сбережений населения (х4),
показателя динамики инфляции (х5). Для некоторых независимых
переменных можно сопоставить количественные значения. В таком случае строится
модель многофакторной регрессии:
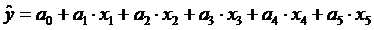 .
.
Подобная модель будет четко отображать ситуации, при возможных изменениях
различных факторов.
При вычислении параметров модели применяют метод МНК или используют
матричную запись.
В матрице Х хранятся значения факторов, в матрице Y - зависимые переменные, в матрице А - коэффициенты регрессии.
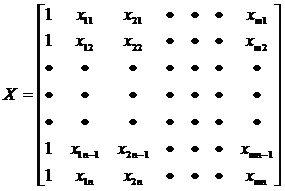 ;
; 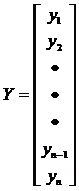 ;
; 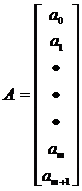
В данной случае уравнение множественной регрессии будет иметь вид:
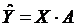 .
.
С помощью стандартных преобразований над матрицей получим выражение
матрицы А:
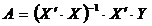 ,
,
где X’ - транспонированная матрица Х.
Среди моделей в теории спроса и предложения встречаются не только
линейные и нелинейные. Большинство экономистов выявляют различные связи
предложения и спроса. Можно привести пример системы совместных уравнений -
модель кейнсианского типа:
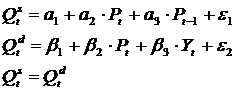
где 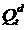 - спрос на товар;
- спрос на товар;
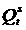 - предложение на товар;
- предложение на товар;
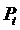 - цена товара;
- цена товара;
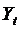 - доход;
- доход;
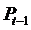 - цена товара в предыдущий период;
- цена товара в предыдущий период;
t -
момент времени.
Как правило, система совместных уравнений состоит из эндогенных и
экзогенных переменных.
В нашем случае эндогенные переменные обозначены как Q. Это объясняемые переменные, их
количество должно соответствовать количеству уравнений в системе.
Все остальное относится к экзогенным переменным. Это объясняющие
переменные, которые влияют на эндогенные переменные, но сами от них не зависят.
Структура подобной модели отражает уровень влияния любого фактора на
значение зависимой переменной. Корректируя уровень цен на товары и доходы, есть
возможность прогнозировать величины спроса и потребления.
При оценке возможностей спроса часто используются однофакторные функции.
Соответственно, кривую спроса можно описать следующим соотношением
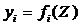 ,
,
где Z - доход. Такие функции называются
кривыми Энгеля. Формы подобных кривых могут различаться для различных видов
товаров. Функция будет иметь линейный вид в случаях пропорционально
возрастающего спроса и дохода. Подобный вид имеет спрос на фрукты и одежду,
пример кривой представлен на рисунке 1.1.
В случаях роста спроса относительно высокими темпами по сравнению с
доходом, кривая примет более выпуклый вид (рис. 1.2). Такая ситуация
наблюдается с дорогостоящим товаром.
В обратном случае, когда темп роста спроса замедляется с определенного
момента, кривая Энгеля примет вогнутый вид (рис. 1.3). Подобная ситуация
характерна для товаров первой необходимости.
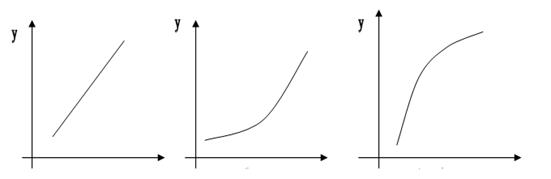
Рисунки 1.1-1.3. Кривые спроса
Помимо перечисленных, для исследования спроса на товары применяются и
другие функции (например, S-образные).
Зачастую, для построение модели используются специфичные данные конкретной
области, поэтому модели очень индивидуальны.
1.3 Применение
эконометрических моделей на практике
Существует три классификации задач, для решения которых применяются
эконометрические модели:
) отличие по конечным целям;
) отличие по уровню иерархии;
) отличие по области исследования.
По конечным прикладным целям различают две основные задачи:
прогнозирование экономических показателей, описывающих состояние и
уровень развития исследуемой системы;
сценарный анализ: оценка состояния системы при возможных изменения ее
параметров.
По иерархии задачи подразделяются последующим уровням:
макроуровень (страна);
мезоуровень (области, отрасли, монополии);
микроуровень (семья, компании, магазин).
Области исследования экономической системы:
рынок;
инвестиционная, финансовая, социальная политики;
ценообразование;
распределительные отношения;
спрос и потребление;
комплекс проблем.
.3.1
Моделирование экономики на основе эконометрической модели LAM
Первоначально модель LAM (Long-run Adjustment Model) разработали для моделирования и прогнозирования
экономик стран восточной Европы в переходный период. Первые версии модели были
использованы 1993 году для моделирования процесса приватизации в Польше и
Чехословакии. Следующая версия модели применялась для прогнозирования основных
макроэкономических показателей Венгрии, Польши, Литвы, Эстонии, Словакии,
Чехии, Румынии. Во второй версии модели LAM-2 не учитывались уравнения, описывающие
характеристику потребления и инвестиций. Это было основным недостатком модели,
который был устранен в новой версии LAM-3. Помимо исправления недочета предыдущей модели, для LAM-3 был доработан механизм коррекции
ошибок: линейный заменен на билинейный.
Принцип и назначение модели:
) Модель LAM-3 считается
малой моделью, целью которой является анализ и краткосрочный (квартальный)
прогноз основных макроэкономических показателей: ВВП, импорт, экспорт, индекс
потребительских цен, показатели доходов и потребления, инвестиций,
средне-душевой доход и занятость населения, уровень безработицы, спрос на
деньги и другие.
2) Модель легка в управлении и достаточна проста в сопровождении.
Есть возможность быстрого доступа к корректировке модели при появлении новых
данных.
) Структура модели для различных национальных экономик не
изменяется, отличается только входными параметрами. Сама модель состоит из 25
уравнений: четыре из них описывают долгосрочные зависимости, двадцать одно -
краткосрочные.
4) Основу модели LAM-3
составляет билинейный вектор авторегрессии
(Bilinear Vector AutoRegressive model- BiVAR).
В статье "О моделировании экономик России и Беларуси на основе эконометрической
модели LAM-3" с помощью универсальной
методологии построены эконометрические модели LAM-Rus и LAM-Bel для квартального прогнозирования динамики основных
макроэкономических показателей для экономики России и Беларуси соответственно.
Также модель позволяет количественно измерить различные сценарии экономической
политики. Анализ качества модели на основе полученных оценок показал
практическую значимость модели. Вычисленные в статье показатели позволяют
разработать план дальнейших действий для эконометрических исследований.
.3.2
Оценивание ценовой функции для картин
Важность рынок произведений искусства с экономической точки зрения
является общепризнанным фактом. Для инвесторов, которые нацелены на извлечения
максимальной выгоды из своих активов, предметы искусства - лишь финансовый
инструмент. В кризисный период цены на стандартные активы падают. Но цены на
произведения искусства не подвергаются таким изменениям ввиду самостоятельности
актива, что соответствует низкой корреляции с другими активами.
Хотя рынок по продаже произведений искусства появился в семнадцатом веке,
его анализ и исследование стали проводиться относительно недавно.
В статье "Оценивание гедонистической ценовой функции для картин
Клода Моне" оценивается гедонистическая регрессионная модель зависимости
цены от набора факторов (характеристик работы), построенная на основе 296
случаях продажи картин мастера по всему миру с апреля 1997 года по декабрь 2009
года. Для объясняющих переменных были выбраны материал основы, техника исполнения,
размер полотна, наличие даты и подписи, аукционный дом продажи, наличие
упоминаний о работе, опыт мастера к моменту написания картины, порядок лота.
Регрессии получилась значимой для 76% вариации цен. Рассчитанные коэффициенты
модели позволяют оценить стоимость работ, определять случаи продажи по
"завышенной" цене. В ходе построения модели была подтверждена
гипотеза о том, что написанные маслом картины самые дорогие. Гипотеза об
отсутствии влияния кризиса на цену, напротив, была опровергнута.
Глава 2.
Эконометрическое моделирование спроса на автомобили в России
.1 Сбор
статистических данных
Для прогнозирования спроса на автомобили выделены доминантные факторы,
описанные в таблице 2.1.
Таблица 2.1. Доминантные факторы спроса на автомобили
|
Фактор
|
Обозначение
|
|
Средневзвешенная процентная
ставка по кредитам, предоставленными кредитными организациями физическим
лицам на срок свыше 1 года, %
|
Credite_rate
|
|
Бивалютная корзина, руб
|
Currency_basket
|
|
Розничная цена на бензин
АИ-95, руб/л
|
Cosoline_price
|
|
Среднедушевой доход,
руб/месяц
|
Average income
|
|
Численность населения
|
Population
|
|
Динамика инфляции, %
|
Inflation_dynamic
|
В таблице 2.2 описаны марки автомобилей, по которым были собраны данные
по продажам. Статистика продаж содержится в приложении 4.
Таблица 2.2. Список марок автомобилей, проданных в России с января 2007
года
|
Отечественные автомобили
|
Зарубежные автомобили
|
|
Vortex, ГАЗ комм., ГАЗ
легк., ЗАЗ, Иж, Лада, Ока, ТагАЗ, УАЗ.
|
Acura, Alfa Romeo, Audi,
BAW, BMW, Brilliance, BYD, Cadillac, Changan, Chery, Chevrolet, Chrysler,
Citroen, Daewoo, Datsun, Dodge, Dongfeng, FIAT, Ford, Foton, Geely, Great
Wall, Hafei, Haima, Honda, Hummer, Hyundai, Infiniti, Iran Khodro, Isuzu,
Iveco, JAC, Jaguar, Jeep, Kia, Land Rover, Lexus, Lifan, Luxgen, Mazda,
Mercedes-Benz, Mercedes-Benz комм., Mini, Mitsubishi, Nissan, Opel, Peugeot,
Porsche, Renault, SAAB, SEAT, Skoda, smart, SsangYong, Subaru, Suzuki,
Toyota, Volkswagen, Volkswagen комм., Volvo, Богдан.
|
В таблице 2.3 описаны зависимые переменные:
Таблица 2.3. Прогнозируемые переменные
|
Описание переменной
|
Обозначение
|
|
Общие продажи автомобилей
|
Sold_out
|
|
Продажи отечественных марок
авто
|
Russian_cars
|
|
Продажи зарубежных
автомобилей
|
Foreign_cars
|
Статистические данные собраны из следующих источников:
Таблица 2.4. Источники статистических данных
|
Фактор
|
Источник
|
|
Population,
Average income
|
Федеральная служба
государственной статистики
|
|
Sold_out, Russian_cars, Foreign_cars
|
Association of
European Businesses (AEB)
|
|
Credite_rate, Currency_basket
|
Статистика Центрального
банка Российской Федерации
|
|
Cosoline_price
|
Котировки Яндекс (данные
предоставлены: Петрол Плюс Регион)
|
|
Inflation_dynamic
|
Уровень-инфляции.рф
(основаны на индексах потреб. цен, взятых у ФСГС)
|
Для построения модели спроса использовалась линейная регрессионная модель
зависимости показателей продаж от объясняющих переменных. Модель построена на
основании 90 наблюдений: данные по каждому месяцу, начиная с января 2007 года
(приложение 4).
.2 Анализ
эконометрической модели
.2.1
Проверка значимости коэффициентов модели
Чтобы оценить значимость того или иного коэффициента линейной регрессии,
используется t-критерий Стьюдента.
) Для проверки значимости выдвигается гипотеза H0 о статистической
незначимости коэффициента уравнения регрессии;
2) Производится вычисление значение t-критерия фактического (tфакт)
и с помощью таблицы t-распределения
Стьюдента определяется табличное (критическое) значение t-критерия (tтабл);
) Далее необходимо проверить условие | tфакт | ≤
tтабл. Если условие выполняется, то нулевая гипотеза H0 подтверждается,
коэффициент уравнения регрессии статистически незначим (коэффициент
недостоверен, равен нулю). Если | tфакт | > tтабл, то
гипотеза H0 опровергается, статистическая значимость коэффициента признается.
Формулы для вычисления величин tb,факт, ta,факт:
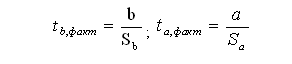
где Sa и Sb - стандартные ошибки коэффициентов
регрессии, которые вычисляются по формулам:
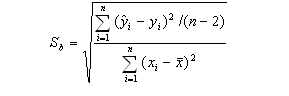
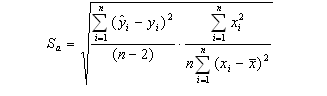
где ŷi - вычисленные значения зависимой переменной, i
- фактические значения объясняемой переменной, - объем выборки, i -
фактические значения предикатора,
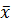 -
средняя величина фактических значений предикаторов.
-
средняя величина фактических значений предикаторов.
2.2.2
Проверка автокорреляции
Для тестирования автокорреляции первого порядка элементов исследуемой
последовательности используется статистический критерий, известный как критерий
Дарбина-Уотсона (или DW-критерий).
Критерий назван в честь Джеффри Уотсона и Джеймса
Дарбина. Вычисляется критерий Дарбина-Уотсона по следующей формуле:
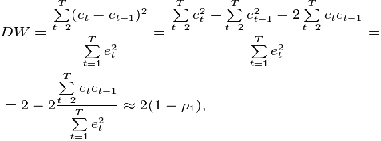
где 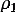 - коэффициент автокорреляции первого порядка.
- коэффициент автокорреляции первого порядка.
Принято считать, что в модели регрессии
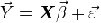
ошибки распределены как
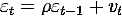 ,
,
где 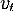 специфировано, как белый шум
специфировано, как белый шум 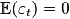 ,
,
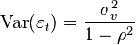 ,
,
а 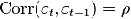 ,
,
где 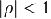 .
.
В случае наличия положительной автокорреляции 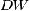 стремится к нулю, при ее отсутствии
стремится к нулю, при ее отсутствии 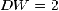 ;, а при отрицательной - критерий
стремится к 4:
;, а при отрицательной - критерий
стремится к 4:
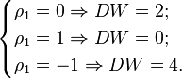
Применение критерия Дарбина-Уотсона на практике
реализуется при сопоставлении величины DW с тобличными значениями dL
и dU для заданного числа наблюдений n,
числа независимых переменных модели k и уровня значимости α.
1. Если DW < dL, то гипотеза о независимости случайных отклонений
отвергается (равносильно наличию положительная автокорреляция);
2. Если DW > dU, то гипотеза не отвергается;
. Если dL < DW < dU, то оснований для принятия решений
недостаточно.
В тех случаях, когда DW превышает 2, с dL и
dU необходимо сравнивать выражение (4 -
DW), а не сам коэффициент DW.
.2.3
Проверка на наличие гетероскедастичности
Один из статистических критериев для проверки наличия
гетероскедастичности (то есть непостоянной дисперсии) случайных ошибок модели
линейной регрессии - Критерий Бройша-Пагана. Применяется, если есть основания
полагать, что дисперсия ошибок 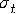 может зависеть от некоторой совокупности наблюдаемых
переменных:
может зависеть от некоторой совокупности наблюдаемых
переменных:
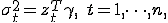 , где
, где 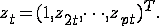 .
.
Проверяемая гипотеза сформулирована следующим образом:
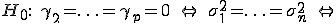 остатки гомоскедастичны;
остатки гомоскедастичны;
Альтернативная гипотеза:
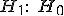 неверна (остатки гетероскедастичны).
неверна (остатки гетероскедастичны).
Процедуру вычисления статистики можно описать
следующими шагами.
1) Начальная модель
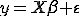
оценивается стандартным методом наименьших квадратов
(МНК), определяются остатки 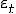 .
.
2) Предположив гомоскедастичность модели, дисперсия ее
ошибки вычисляется как
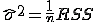 .
.
) Вычисляются стандартизированные остатки 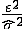 .
.
4) Производится построение дополнительной регрессия
квадратов стандартизированных ошибок на начальные значения предикаторов:
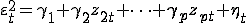 .
.
) 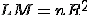 ,
,
где 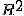 - коэффициент детерминации построенной на предыдущем этапе
регрессии.
- коэффициент детерминации построенной на предыдущем этапе
регрессии.
Если статистика критерия имеет распределение
хи-квадрат с 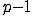 степенями свободы, то гипотеза о гомоскедастичности остатков
подтверждается.
степенями свободы, то гипотеза о гомоскедастичности остатков
подтверждается.
.2.4
Проверка качества модели
Проверка адекватности модели или, другими словами, тестирование
значимости объясняющей переменной X проводится по критерию Фишера. Другими словами, проверяется, значимо ли
влияние предикатора X влияет на значение объясняемой переменной Y.
Используя суммы квадратов отклонений, вычислим F-критерий Фишера по
формуле:
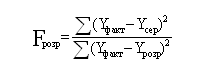
При учете степеней свободы расчетная формула для вычисления критерия
Фишера выглядит следующим образом:
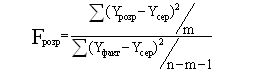
где m, (n-m-1) - число степеней свободы числителя и знаменателя
зависимости соответственно; n - количество наблюдений; m - количество
предикаторов.
Тестирование значимости переменной X по критерию Фишера состоит из
следующих этапов:
. Формулируем нулевую гипотезу H: β1=0;
2. Принимаем вероятность ошибки (уровень значимости) α
(5%);
3. Производим вычисления F-отношения;
. Из таблицы F-распределения Фишера определяем величину
F-критическое при заданном уровне значимости (или ошибки) и по степеням свободы
f1 и f2;
. Если Fфакт < Fтабл то гипотезу о
незначимости предикатора отклоняем с 5%-ным риском ошибиться, где Fтабл
- значение F при 5%-ном риске ошибки.
Значение Fтабл определяют по специальным таблицам в
зависимости от степеней свободы f1 и f2:
=(n-m-1), f2=(n-1).
Если неравенство Fфакт > Fтабл справедливо, то
можно сделать заключение об адекватности построенной модели, следовательно
линейная связь между предикатором и объясняемой переменной допустима.
Итоговое оценочное значение качества модели отражается в коэффициент
детерминации R². Если регрессия является парной, коэффициент детерминации
будет совпадать с квадратом коэффициента корреляции:
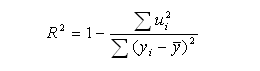
где u²i
- разница между исходным значением Y и предсказанным значением с помощью
построенной модели.
Коэффициент детерминации определяет долю разброса объясняемой переменной,
которая определяется регрессией Y на X; дробное отношение определяет
составляющую часть разброса объясняемой переменной, которая не определяется
регрессией.
Для общего случая корректным является соотношение 0≤R²≤1.
Чем ближе коэффициент
детерминации к единице, тем сильнее линейная связь между X и Y. Чем связь
слабее, тем R² ближе к нулю.
Средняя ошибка аппроксимации - еще одно средство оценки уравнения
регрессии является.
Фактические значения результативного признака отличаются от
теоретических, вычисленных по уравнению регрессии, т.е. y и yx. Чем
меньше эта разность, тем теснее теоретические значения к эмпирическим данным,
качество модели лучше.
Средняя ошибка аппроксимации рассчитывается по следующей формуле:
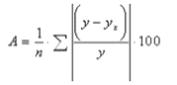
Для качественно построенных моделей, величина этого показателя не должно
превышать 10%.
.3
Программное обеспечение для анализа модели
.3.1
Статистические пакеты для анализа данных
В связи с ростом потребности статистического анализа данных практически
во всех сферах деятельность, а особенно в научной, рынок программного
обеспечения для статистической обработки данных стремительно развивался. В
течение последних 20 лет компьютерные программы, способные статистически анализировать
большие объемы данных для прогнозирования событий, оценки вероятных альтернатив
выбора, выявления закономерностей, сделали большой шаг в своем развитии.
Постоянно ведутся работы по совершенствованию программ в части сокращения
времени работы с данными, повышения качества представления отчетов с
результатами, модернизации интерфейса, актуализации справочной информации,
добавления новых статистических методов, процедур и прочего.
Рынок программного обеспечения развивается
стремительными темпами. Задачи по обработке данных разнообразны, для их решения
применяются разноплановые типы статистических процедур анализа для получения
ответов на вопросы по всем областям деятельности. Все это вызвало появление
большого разнообразия статистических пакетов. На текущий момент на рынке можно
встретить порядка тысячи статистических пакетов (компьютерных программ) для
обработки данных.
Для рынка ПО для статистического анализа данных
характерна высокая конкуренция, зачастую происходит объединение или поглощение
компаний по разработке программ. К примеру, один из лидеров на рынке компания
SPSS Inc. поглотила компанию SYSTAT Software Inc в 1994 году, а в 1996 году - BMDP Statistical Software Inc. За счет данных "покупок"
компания повысила качество своих продуктов. Приобретение SYSTAT позволило оптимизировать процедуру
обработки и анализа данных, а поглощение BMDP Software - улучшить графические
инструментарий SPSS. В 2009 году
компанию IBM Inc. поглотила компанию SPSS Inc.
Пользователю каждый раз необходимо выбирать оптимальный
и подходящий для него статистический пакет, исходя из поставленного круга
задач. Ни для кого не секрет, что оптимальным является вариант, комбинирующий в
себе высокий уровень работы, нужные функциональные возможности и умеренную
цену. При
выборе важно обратить внимание на следующие характеристики:
· соответствие параметрам поставленных задач;
· объем данных для статистического анализа;
· квалификация пользователя в области статистики (уровень
знаний);
· соответствие компьютерного оборудования пользователя.
По функциональности программы для статистического
анализа можно разделить на 3 основные группы.
1. Универсальные пакеты, или пакеты общего
назначения (например, Minitab, STATISTICA, STATA, S-PLUS, STATGRAPHICS, Stadia,
SYSTAT, SPSS).
Данные программы не заточены под определенную
предметную область, их можно применять для анализа данных в различных областях
деятельности. В основном в этих программах используется простой интерфейс и
предложен широкий спектр статистических методов и процедур. Как правило, с
подобными статистическими пакетами работают начинающие пользователи, обладающие
начальным уровнем знаний в статистике, или же опытные пользователи, которые
находятся на начальном этапе работы и с набором статистических методов еще не
определились. Возможность использовать широкий спектр статистических методов
для пробного анализа различных типов данных делает данный пакет многопрофильным
и универсальным. Практические все универсальные пакеты имеют ряд схожих друг с
другом встроенных статистических процедур.
Каждый универсальный статистический пакет должен
соответствовать следующему перечню требований:
o иметь достаточно широкий перечень встроенных стандартных
методов и процедур для статистического анализа.;
o быть понятным для "новичка" в освоении интерфейса и
применении различных методов анализа;
o быть способным обрабатывать большие базами данных и
соответствовать высоким требованиям к хранению данных;
o иметь стандартизированный вид представления данных для их
последующего использования в других пакетах анализа и базах данных;
o иметь в наличии широкий выбор в графическом представлении
данных и результатов анализа;
o иметь некую базу знаний, или справочную систему, в которой
пользователь сможет найти ответы на свои вопросы по использованию пакета; иметь
документационное.
2. Профессиональные пакеты (например, BMDP, SAS).
Основное отличие профессиональных пакетов от
универсальных в том, что первые позволяют обрабатывать гораздо больший объем
данных, имеют более узкоспециализированные методы, есть возможность для
создания своей системы для обработки данных. Зачастую, такие пакеты сложны для
начинающих пользователей. Для профессионалов, наоборот, подобные пакеты
предоставляют дополнительный широкий круг возможностей для более подробного
анализа данных, исходя из своих потребностей к построенным моделям. Конечно,
такие возможности добавляют к себестоимости, и профессиональные пакеты являются
более дорогостоящи. Ценовой фактор препятствует широкому распространению
использования профессиональных статистических пакетов в различных областях
деятельности.
3. Специализированные пакеты (например, DATASCOPE,
BioStat, MESOSAUR).
Существуют некоторые области деятельности, исследуемые
данные которых специфичны и отличны от других, требуют применения
соответствующих специфических методов, которых нет в универсальных пакетах.
Специализированные пакеты предназначены для проведения
анализа данных отдельно взятой предметной области с применением узкого круга
специализированных статистических процедур. Подобные пакеты используют
высококвалифицированные специалисты соответствующей предметной области.
Приведем примеры существующих специализированных пакетов:
· BioStat - нацелен на анализ данных в области биологии
и медицины.
· MESOSAUR - отечественный
статистический пакет, используется при анализе одномерных и многомерных
временных рядов и построении регрессионных моделей.
· DATASCOPE - российский статистический
пакет, используется при анализе многомерных данных.
В случаях необходимости систематического решения для
конкретной области или решения с использованием ограниченного набора сложных
статистических методов, следует использовать соответствующий специализированный
пакет.
Преобладающее количество существующих на рынке
статистических пакетов имеют гибкую модульную структуру, которую можно изменять
и дополнять за счет установки дополнительных плагинов (модулей), представленных
для покупки или свободного скачивания в Интернете. Данная способность
способствует адаптации пакета к требованиям конкретного пользователя.
Перечень минимальных требований, которым должен
соответствовать каждый статистический пакет:
· модульность;
· ассистирование при выборе способа обработки данных;
· использование простого проблемно-ориентированного языка для
формулировки задания пользователя;
· автоматическая организация процесса обработки данных;
· ведение банка данных пользователя и составление отчета о
результатах проделанного анализа;
· диалоговый режим работы пользователя с пакетом;
· совместимость с другим программным обеспечением.
Как правило, постоянно ведется поддержка существующих
статистических пакетов. Каждая последующая версия приобретает новые возможности
для анализа (добавление новых методов), не теряя при этом старый функционал.
Новые версии зачастую остаются с начальным названием, меняется лишь порядковый
номер версии. Распространенные пакеты поддерживают мультиязычность.
Каждая команда разработчиков рекламирует свой
статистический пакет, как самый наилучший для анализа данных. При широком
выборе зачастую сложно выбрать правильный пакет. В любом случае, статистический
пакет лишь инструмент в руках аналитика. Если специалист не компетентен в
конкретной области, то никакой совершенный пакет не поможет ему проделать
качественный анализ. С другой стороны, неверно выбранный пакет может сильно
затруднить процесс работы даже высококвалифицированного специалиста.
Таблица 2.1. Статистические пакеты
|
Универсальные пакеты или
пакеты общего назначения
|
Профессиональные пакеты
|
Специализированные
пакеты
|
|
SPSS, STATA,
STATISTICA, Stadia, STATGRAPHICS, Minitab
|
SAS
|
BioStat
|
Ниже приведен минимальный набор статистических
методов, который включены в каждый наиболее известный программный продукт,
предназначенный для статистической обработки данных и относящихся к упомянутым
ранее трем основным группам программ (таб. 2.1).
· описательная статистика (базовые статистические методы,
проверка нормальности распределения данных);
· дисперсионный анализ;
· кластерный анализ;
· непараметрическая статистика (анализ таблиц сопряженности,
непараметрические сравнения, дисперсионный анализ);
· контроль качества;
· обработка данных (сортировка, трансформация данных, отбор);
· дискриминантный анализ;
· регрессионный анализ;
· факторный анализ.
.3.2 Пакет
SPSS
Statistical Package for the Social Sciences (далее пакет SРSS) - один из универсальных статистических пакетов, который был
разработан компанией SРSS Inc. Первая версия продукта была представлена еще в 1968
году. В 2009 году, после поглощения компанией IBM, название пакета включает в
свое название аббревиатуру IBM (IBM SPSS Statistics).
Команда разработчиков статистического данного пакета
считает, что их программный продукт занимает одну из лидирующих позиций среди
существующих по части решения вопросов при анализе данных в академической,
правительственной и бизнессфере.РSS относится к типу многомодульной программы.
В стартовом пакете идет SPSS Base (базовый
модуль), который предоставляет возможность управлять данными и содержит
основные методы статистического анализа, перечисленные в предыдущей главе.
Чтобы проделать более широкий и глубокий анализ данных, дополнительно
потребуется установить модули пакета. Для 19 версии пакета IBM SPSS Statistics существует шестнадцать
дополнительных модулей. Например, модуль Advanced Statistics позволяет
проводить глубокий анализ взаимосвязей, процедуры, которые способны учитывать
свойства данных. Также в модуле присутствуют мощные инструменты для создания
моделей. Подобной возможности в базовом модуле нет. Среди разработанных модулей
есть модуль Direct Marketing, с помощью которого маркетологи могут
самостоятельно проводить основные виды анализа. Модуль Bootstrapping
предоставляет специалистам возможность тестировать модель на устойчивость.
Модуль Data Entry облегчает процедуру создания анкет и заполнения результатов,
автоматизируя его.
Достоинства SPSS:
· мощный аппарат статистического анализа;
· пакет относится к универсальным (возможность использовать
широкий спектр статистических методов для анализа различных типов данных в
разных областях деятельности);
· большой ряд статистических и графических процедур и методов
(свыше 50 типов диаграмм) для анализа данных исоздания отчетов;
· понятный для пользователя интерфейс, высокая
производительность;
· открытый доступ для свободного скачивания пробной версии
программного продукта на официальном сайте, поддержка мультиязычности;
· совместимость с ОС Windows, Mac, Linux;
· наличие достаточного количества справочной информации,
литературы по работе с пакетом.
Недостатки SPSS:
· для хорошей работы пакета необходима высокая производительная
мощность компьютера;
· в сравнении с аналогичными статистическими пакетами
относительно высокая стоимость.
В последнюю на данный момент версию пакета добавлены
следующие возможности:
· возможность импортировать данные из SAS и MS Excel;
· возможность экспортировать результаты в MS Office, PDF;
сохранение результатов в формате HTML;
· способность обрабатывать несколько наборов данных
одновременно;
· возможность создания диаграммы для переменных с несколькими
ответами;
· возможность создания диаграммы с двумя осями ординат;
· модернизированный редактор синтаксиса для самостоятельного
написания скриптов (поддержка автозавершения, цветовое кодирование команд);
· с помощью Data Preparation осуществляется быстрая подготовка
данных к анализу, что способствует облегчению процедуры ручного анализа данных,
выявляя, объясняя и исправляя недочеты. С помощью указанной функции подготовки
данных возможно построить различные отчеты по существующим данным.
На рисунке 2.1 отображено окно редактора данных SPSS.
В нижней части окна по центру расположены две вкладки: Данные и Переменные,
позволяющие переключаться с режима просмотра/редактирования значений переменных
в режим просмотра/редактирования их характеристик.
Рисунок 2.1. Окно редактора данных SPSS
Результаты статистического анализа приводятся в
диалоговом окне под названием Вывод (рис. 2.2).
Рисунок 2.2. Окно вывода SPSS
В качестве основного программного обеспечения, используемого в течение
практической работы, выступает статистический пакет SPSS.
SPSS
обеспечивает достаточный инструментарий обработки данных, позволяет выполнять
регрессионный анализ и строить прогностические модели. С помощью этого
программного средства можно очень быстро выявить наличие статистической
зависимости в анализируемых данных и затем, используя полученные взаимосвязи,
сделать прогноз изучаемых показателей.
Глава 3.
Построенные эконометрические модели спроса на зарубежные и отечественные
автомобили в России
В построении модели спроса использованы количественные переменные:
) Credite_rate - средневзвешанная процентная ставка по кредитам,
предоставленными кредитными организациями физическим лицам на срок свыше 1
года, %
) Currency_basket - бивалютная корзина, руб
) Cosoline_price -розничная цена на бензин АИ-95, руб/л
) Average income - среднедушевой доход, руб/месяц 5) Population -
численность населения
) Inflation_dynamic - динамика инфляции, %
Для наблюдения сезонности продаж в процессе построения модели будут добавлены
11 номинальных переменных: February, March, April, May, June, July, August,
September, October, November, December. Фиктивная переменная принимает значение
1 в соответствующем названию периоду наблюдения, во всех остальных случаях - 0.
Также в модель будут добавлены две фиктивные переменные: Crisis и After_crisis.
Переменная Crisis будет равна 1, если на момент
наблюдения в стране будет финансовый кризис. After_crisis
равна 1, если кризис закончился и начался послекризисный период. Во всех
остальных случаях значения этих переменных принимают значение 0. В работе
период кризиса напрямую отражает падение фондового рынка.
.1 Анализ
парных корреляций
Так как для построения модели используются переменные с количественными
шкалами, используем коэффициент корреляции Пирсона. Высоким коэффициент
корреляции принимаем при значении коэффициента большем 0.75.
Таблица 3.1. Парные корреляции независимых переменных
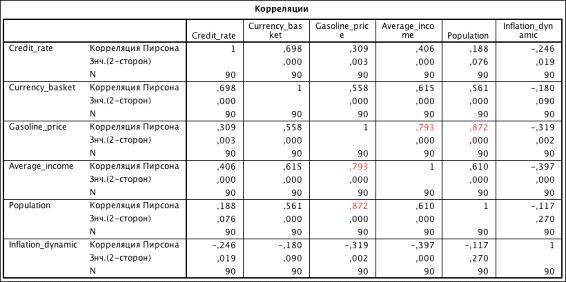
Из таблицы 3.1 видно, что следующие переменные имеют наивысший
коэффициент корреляции: Population и Gasoline_price. В значениях данных
переменных наблюдается тендеция увеличения, можем сделать вывод о наличии
временной зависимости. Избавимся от нее, убрав тренд из переменных
Gasoline_price и Population. Разберем процедуру избавления от тренда на примере
переменной Gasoline_price. Представим зависимость розничной цены на бензин y от времени t в виде линейной модели первого порядка:
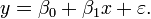
β0 и β1 - параметры модели, а ε - ошибка, распределение которой
подчиняется нормальному закону с нулевым средним значением и постоянным
отклонением σ2.
Построим линейную регрессию, где зависимой переменной будет
Gasoline_price, независимой - Time
(ряд натуральных чисел от 1 до 90, соответствующий номеру наблюдения).
Таким образом мы можем записать:
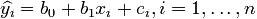
Где 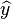 означает предсказанное моделью значение y при данном x,
b0 и b1 - выборочные оценки параметров
модели, а
означает предсказанное моделью значение y при данном x,
b0 и b1 - выборочные оценки параметров
модели, а
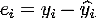
значения ошибок аппроксимации.
Убрав из уравнения b1xi, мы избавимся от явления тренда для переменной Gasoline_price. Рассчитаем новую переменную Gasoline_price_cor,
как значение y без b1xi. Проделаем аналогичную процедуру для
Population, получим скорректированную переменную Population_cor. Вновь построим
таблицу парных корреляций для проверки зависимости переменных друг от друга.
Таблица 3.2. Парные корреляции независимых переменных
Из таблицы 3.2 видно, что убрав тренд из переменных Gasoline_price и Population, избавились от корреляционной
зависимости. Все коэффициенты меньше 0.75 - можно использовать переменные для
построения модели прогноза уровня продаж.
При построении моделей спроса вместо переменных
Gasoline_price и Population будут использоваться скорректированные переменные
Gasoline_price_cor и
Population_cor соответственно.
.2 Модель
общего спроса на автомобили в России
.2.1
Построение модели
Зависимая переменная: Sold_out - общее кол-во продаж автомобилей в
России за период
Отбор переменных
Рисунок 3.1.Блок-схема метода Forward Selection
Методом прямого отбора (рис. 3.1) определим переменные, которые будут
использованы при построении модели. Фактор, который сильнее всего коррелирован
с результирующим признаком, имеет больший приоритет на включение в модель.
Таблица 3.3.Корреляция входных переменных с результирующим признаком
|
Credit_rate
|
Currency_basket
|
Gasoline_price_cor
|
Average_income
|
Population_cor
|
Inflatiom_dynamic
|
|
Sold_out
|
-0,359
|
-0,213
|
0,604
|
0,404
|
0,163
|
-0,179
|
Из таблицы 3.3 видно, наибольшая тесная связь с зависимой переменной
наблюдается у показателя Gasoline_price_cor. Следуя алгоритму метода прямого отбора эту
переменную в первую очередь следует проверить на включение в модель. Вычислим
оценки значений результирующего признака, которые получим из модели, включающую
в себя одну переменную Gasoline_price_cor. Результаты сведены в таблицу:
Таблица 3.4.Расчетные данные для проверки переменной на включение в
модель
|
№
|
Gasoline_proce_cor (X)
|
Sold_out (Y)
|
Pred_Sold (Ŷ)
|
Yср
|
(Ŷ - Yср)^2
|
(Y - Ŷ)^2
|
|
1
|
20,01
|
117256
|
217657,7922
|
202988,1444
|
215198566,2
|
10080519883
|
|
2
|
20,9
|
130675
|
237946,7571
|
202988,1444
|
1222104599
|
11507229871
|
|
3
|
20,76
|
179057
|
234682,7005
|
202988,1444
|
1004544885
|
3094218558
|
|
4
|
20,52
|
201867
|
229380,4017
|
202988,1444
|
696551243,6
|
756987273,7
|
|
5
|
20,48
|
204478
|
228381,0587
|
202988,1444
|
644800095,9
|
571356216,6
|
|
6
|
20,59
|
199013
|
230778,7862
|
202988,1444
|
772319767
|
1009065170
|
|
7
|
20,85
|
211110
|
236800,0553
|
202988,1444
|
1143245318
|
659978943,4
|
|
8
|
21,15
|
218150
|
243500,7386
|
202988,1444
|
1641270286
|
642659948,1
|
|
…
|
…
|
…
|
…
|
…
|
…
|
…
|
|
90
|
20,65
|
199398
|
232213,6789
|
202988,1444
|
854131866,6
|
1076868784
|
|
|
|
|
Итого
|
89323437298
|
1,55132E+11
|
Исходя из данных таблицы 3.4 расcчитаем величину частного F-критерия,
соответствующую Gasoline_price_cor.
MSE = SSE/df = 1,55132E+11/88 = 1762859429real =
SSR / MSE = 89323437298 / 1762859429 = 50,66963131
По таблице значений F-критерия Фишера (Приложение 2)на уровне значимости
α = 0,05 найдем
граничное значение для Freal (при количестве степеней свободы d1 = 1 и d2 =
88).
Ftable = 3.95
Freal > Ftable
Рассчитанное значение F-критерия существенно превышает пороговое значение
Ftable, что указывает на необходимость
включения переменной X2 в регрессионную модель (при этом вероятность того, что
решение о включении окажется неправильным, составляет α
= 0,05).
В таблице 3.5 отображены рассчитанные значения F-критерия для остальных независимых переменных в порядке
убывания их корреляционной зависимости от объясняющей переменной
Таблица 3.5. Рассчетные значения F-критериев для каждой переменной
|
Переменная
|
Freal
|
Ftable
|
|
Gasoline_price_cor
|
50,67
|
3.95
|
|
Average_income_cor
|
17,189
|
3.95
|
|
Credit_rate
|
13,058
|
3.95
|
|
Currency_basket
|
4,184
|
3.95
|
|
Inflation_dynamic
|
2,918
|
3.95
|
В ходе метода прямого отбора мы отобрали все объясняющие переменные, за
исключением Infation_dynamic и Population_cor, так как их Freal < Ftable. Использовав метод обратного отбора,
можно было сократить количество итераций алгоритма.
Выявление зависимости спроса от сезона
Построим модель линейной регрессии, где зависящей переменной будет Sold_out, а объясняющими - отобранные переменные, а также
переменные, отвечающие за сезонность. Согласно t-таблице (Приложение 1), коэффициент для нашей модели будет
значимым, если модуль его значения t будет больше 1,98. Вероятность того, что решение о включении окажется
неправильным, составляет α = 0,05.
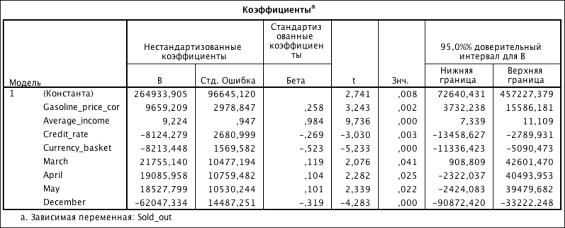
Таблица 3.6. Коэффициенты модели (R2 = 0.770)
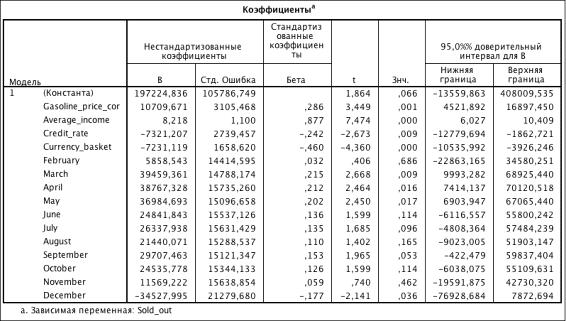
Исключим из модели фиктивные переменные, которые незначимы: February,
June, July, August, September, October, November. Построим новую модель.
Таблица 3.7. Коэффициенты модели (R2 = 0.762)
Проверка значимости квадратичной формы переменных
Для проверки функциональности количественных переменных будем поочередно
включать их квадратичное значение в модель, проверять значимость.
) Включаем Credit_rate_sqr:
Таблица 3.8. Коэффициенты модели (R2 = 0.757)
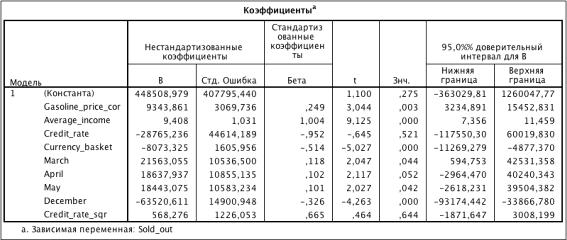
Из таблицы 3.8: Credit_rate_sqr незначим.
) Включаем Currency_basket _sqr:
Таблица 3.9. Коэффициенты модели (R2 = 0.731)
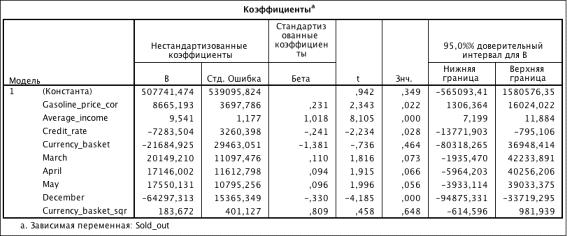
Из таблицы 3.9: Currency_basket_sqr незначим.
) Включаем Gasoline_price_cor _sqr:
Таблица
3.10. Коэффициенты модели (R2 = 0.736)
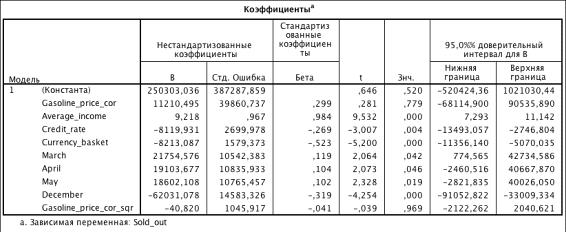
Из таблицы 3.10: Gasoline_price_cor _sqr незначим.
4) Включаем Average_income _sqr2 (значение Average_income в квадрате
и поделенное на 1000000):
Таблица 3.11. Коэффициенты модели (R2 = 0.786)
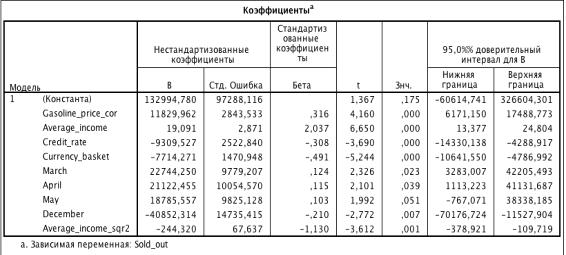
Из таблицы 3.1: Average_income _sqr значим.
Квадратичную форму переменной можно использовать только в том случае,
когда сама переменная также входит в состав модели. По итогам проверки
переменных в модели на квадратичную зависимость добавили новый предикатор Average_income_sqr2.
Влияние кризиса на продажи
Добавим в модель две новые фиктивные переменные: Crisis и After_crisis. Переменные отражают период
финансового кризиса в стране. Соответственно, если в момент конкретного
наблюдения в стране был кризис - значение Crisis равно 1, в после кризисный период - значение After_crisis равно 1. Во всех остальных случаях - 0.
Таблица 3.12. Коэффициенты модели (R2 = 0.812)
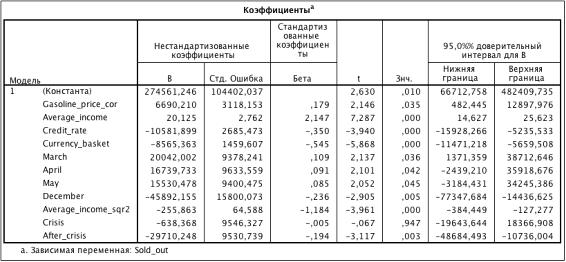
Из таблицы 3.12: Crisis
незначим, исключаем из модели:
Таблица 3.13. Коэффициенты модели (R2 = 0.810)
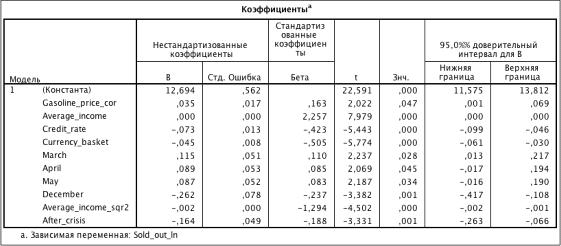
Исходя из результатов таблицы 3.13 все переменные значимы.
Проверка логорифмической зависимости
Построим линейную регрессию отобранных переменных от ln(Sold_out):
Таблица 3.14. Коэффициенты модели (R2 = 0.820)
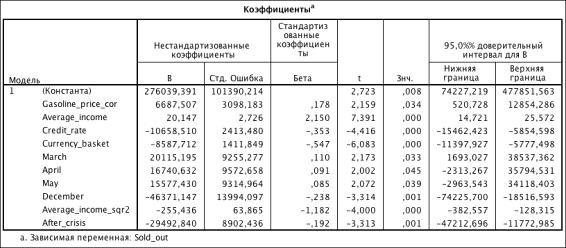
Результат оценки модели (таблица 3.14) с зависящей переменной, выраженной
натуральным логарифмом Sold_out, показал лучшее значение
коэффициента детерминации R2.
Проверка на гетероскедастичность
Количество степеней свободы p = 11
Критерий Бройша-Пагана LW =
24,21
LW
имеет распределение 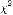 с 10 степенями свободы (Приложение 3) при уровне значимости α
= 0,01, следовательно
гипотеза о гомоскедастичности остатков подтверждается.
с 10 степенями свободы (Приложение 3) при уровне значимости α
= 0,01, следовательно
гипотеза о гомоскедастичности остатков подтверждается.
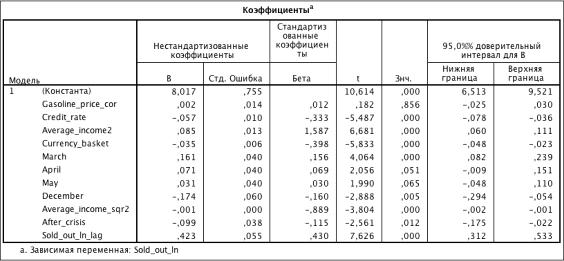
Проверка на автокорреляцию
Для проверки модели на наличие автокорреляции использовался критерий
Дарбина-Уотсона, подсчет производился автоматически системой SPSS. Для построенной модели DW = 0,463. Значение критерия меньше
табличного dL, что говорит о наличии положительной
автокорреляции, необходимо в модель к предикторам добавлять лаговое значение
зависимой переменной (Sold_out_ln_lag).
Таблица 3.15. Коэффициенты модели (R2 = 0.895)
.2.2
Ретроспективный прогноз
На основе 90 наблюдений была построена модель и применена к 9
наблюдениям. Рассчитанные прогнозные значения сведены в таблицу 3.26.
Средняя ошибка прогноза рассчитана по следующей формуле, где реальное
значение продаж, прогнозное значение продаж, n - количество наблюдений.
Таблица 3.16. Ошибка прогноза
|
Период
|
Реальное значение продаж
|
Прогнозное значение
продаж
|
Ошибка прогноза
|
|
JUL 2014
|
180767
|
194822
|
7,77%
|
|
AUG 2014
|
172016
|
161080
|
6,36%
|
|
SEP 2014
|
197233
|
212856
|
7,92%
|
|
OCT 2014
|
211365
|
199283
|
5,72%
|
|
NOV 2014
|
229439
|
195346
|
14,86%
|
|
DEC 2014
|
270653
|
298539
|
10,30%
|
|
JAN 2015
|
115561
|
96853
|
16,19%
|
|
FEB 2015
|
128333
|
114071
|
11,11%
|
|
MAR 2015
|
139850
|
127655
|
8,72%
|
|
|
|
MPE=
|
9,88%
|
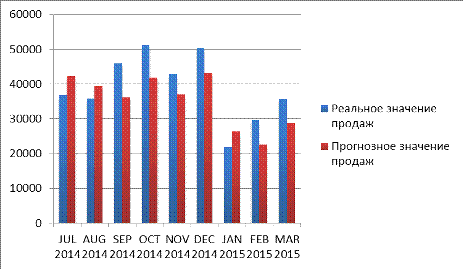
Диаграмма 3.1. Сравнение реального уровня продаж с прогнозным значением
.2.3
Качественные выводы из построенной модели
Модель спроса:
Sold_out_ln = 8.017 - 0.057Credit_rate - 0.035Currency_basket
+ 0.002Gasoline_price_cor + 0.085Average_income2 + 0.161March + 0.071April +
0.058May - 0.174December - 0.001Average_income_sqr2 - 0.099After_crisis +
0.423Sold_out_ln_lag
Выводы:
1) В ходе построения модели была исключена количесвтенная переменная Inflution_dynamic, следовательно динамика инфляции в стране не влияет
на спрос в нашей стране.
2) Отрицательные коэффициенты перед переменными Credit_rate и Currency_basket свидетельствуют о снижении спроса
при повышении процентной ставки по кредитам и увеличении стоимости бивалютной корзины.
) Положительная зависимость продаж от цены на бензин объясняется
желанием приобрести новый автомобиль, которые будет более экономичным по части
расхода топлива.
) Положительный коэффициент перед Average_income2
и отрицательный перед Average_income_sqr2 говорит о том, что при росте денежного дохода до
определенного уровня спрос растет, но после его преодоления - падает. Это
означает, что денежные средства идут, например, на покупку недвижимости.
) Положительные коэффициенты перед March, April
и May говорят о набольших значениях продаж
весной, все хотят новый автомобиль к летнему сезону. Особенно пик продаж наблюдается в
марте.
) Отрицательный коэффициент перед December означает снижение спроса в конце
года, описывая поведение покупателей: в январе следующего года автомобиль,
произведенный в предыдущем месяце будет считаться прошлогодним, следовательно и
стоимость его будет ниже.
) Существование положительной зависимости от послекризисного
периода объясняется возможным появлением дополнительных денежных средств, по
сравнению с предшествующим периодом.
) Наличие лагового значения переменной характеризует зависимость
спроса от продаж в предыдущий период: коэффициент положительный - зависимость
положительная.
) Средняя ошибка прогноза модели составила 9.88%, что допускает
использования данной модели на практике.
.3 Модель
спроса на отечественных автомобилей
.3.1
Построение модели
Зависимая переменная: Russian_cars - общее кол-во продаж отечественных
автомобилей в России за период.
Отбор переменных
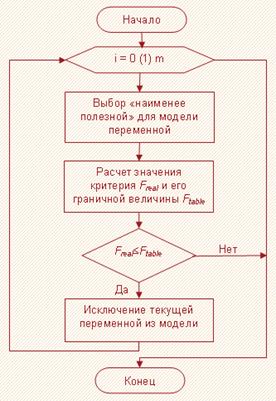
Рисунок 3.2. Блок-схема метода Backward Elimination
Методом обратного отбора (рис. 3.2) определим качественные переменные для
включения в модель.
Таблица 3.17. Корреляция входных переменных с результирующим признаком
|
Credit_rate
|
Currency_basket
|
Gasoline_price_cor
|
Average_incom
|
Population_cor
|
Inflatiom_dynamic
|
|
Russian_cars
|
-0,611
|
-0,607
|
0,39
|
-0,062
|
-0,093
|
-0,082
|
В первую очередь рассчитаем значение F-критерия для Average_income, затем для Inflation_dynamic и
так далее.
Таблица 3.18. Рассчетные значения F-критериев для каждой переменной
|
Переменная
|
Freal
|
Ftable
|
|
Average_income
|
0,345
|
3.95
|
|
Inflation_dynamic
|
0,602
|
3.95
|
|
Population_cor
|
0,762
|
3.95
|
|
Gasoline_price_cor
|
15,803
|
3.95
|
Переменные Average_incom, Inflation_dynamic и Population_cor исключаем из модели, так как их Freal < Ftable .
Проверка зависимости спроса от сезона
Построим модель линейной регрессии, где зависящей переменной будет Russian_cars, объясняющими - отобранные переменные, а также
переменные, отвечающие за сезонность. Допустимый уровень t-статистики остается на аналогичном
предыдущим построениям уровне - 1,98. Вероятность того, что решение о включении
окажется неправильным, составляет α = 0,05.
Таблица 3.19. Коэффициенты модели (R2 = 0.692)
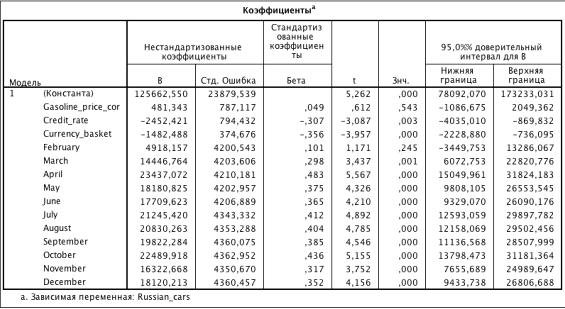
Исключим из модели фиктивную переменную, которые незначима: February. Под
исключение также попадает одна количественная переменная - Gasoline_price_cor.
Построим новую модель:
Таблица 3.20. Коэффициенты модели (R2 = 0.685)
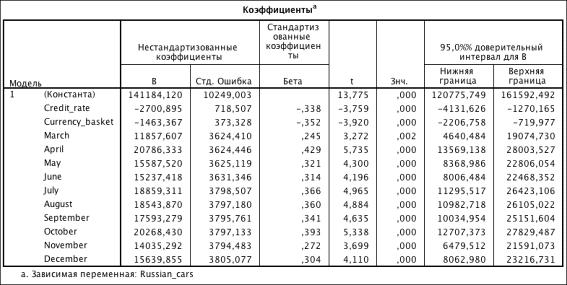
Проверка значимости квадратичной формы переменных
При проверке системы не функциональность никаких зависимостей от
квадратичных форм переменных выявлено не было
Влияние кризиса на продажи
Таблица 3.21. Коэффициенты модели (R2 = 0.738)
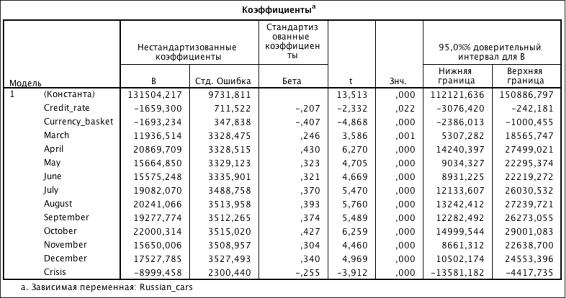
Проверка логорифмической зависимости
Таблица 3.22. Коэффициенты модели (R2 = 0.732)
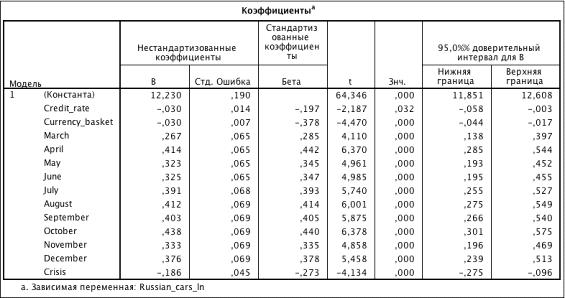
Результат оценки модели с зависящей переменной, выраженной натуральным
логарифмом Russian_cars, показал значение коэффициента детерминации R2 хуже.
Проверка на гетероскедастичность
Количество степеней свободы p = 13
Критерий Бройша-Пагана LW =
21,3
LW
имеет в распределение с 12 степенями свободы (Приложение 3) при уровне значимости α
= 0,05, следовательно
гипотеза о гомоскедастичности остатков подтверждается, гетероскедастичность
отсутствует.
DW =
0,671. Значение критерия меньше табличного dL, что говорит о наличии положительной
автокорреляции, необходимо в модель к предикаторам добавлять лаговое значение
зависимой переменной (Russian_cars_lag).
Таблица 3.23. Коэффициенты модели (R2 = 0.830)
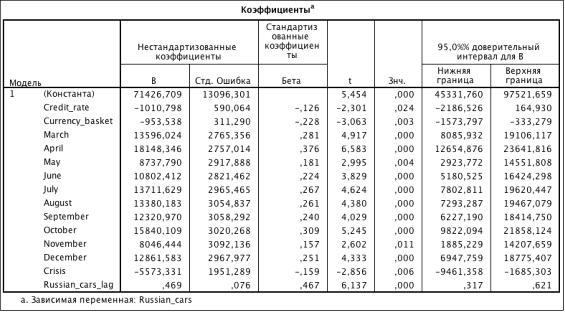
.3.2
Ретроспективный прогноз
эконометрический спрос моделирование автокорреляция
Таблица 3.24. Ошибка прогноза
|
Период
|
Реальное значение продаж
|
Прогнозное значение
продаж
|
Ошибка прогноза
|
|
JUL 2014
|
36892
|
42312
|
14,69%
|
|
AUG 2014
|
35776
|
39387
|
10,09%
|
|
SEP 2014
|
45900
|
36209
|
21,11%
|
|
OCT 2014
|
51198
|
41826
|
18,31%
|
|
NOV 2014
|
42790
|
37010
|
13,51%
|
|
DEC 2014
|
50452
|
43252
|
14,27%
|
|
JAN 2015
|
21843
|
26349
|
20,63%
|
|
FEB 2015
|
29626
|
22606
|
23,69%
|
|
MAR 2015
|
35599
|
28737
|
19,28%
|
|
|
|
MPE=
|
17,29%
|
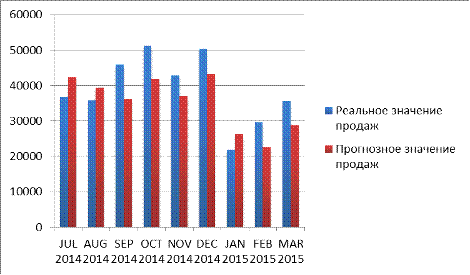
Диаграмма 3.2. Сравнение реального уровня продаж с прогнозным значением
Средняя ошибка прогноза составила 17.29%, применять данную модель на
практике нельзя, мала прогнозная точность.
.3.3
Качественные выводы из построенной модели
Модель спроса:
Russian_cars = 71426.709-1010.798 * Credit_rate - 953.538 *
Currency_basket + 13596.024 * March + 18148.46 * April+ 8737.790 * May + 10.802
* June + 13711.629 * July + 13380.183 * August + 12320.970 * September +
15840.109 * October + 8046.444 * November - 12861.583 * December - 5573.331 *
Crisis+0.469 * Russian_cars_lag
1) В ходе построения модели были исключены следующие количесвтенные
переменные: Inflution_dynamic, Population, Average_income и Gasoline_price. Динамика инфляции в стране,
численность населения, уровень среднедушевого дохода и цена на топливо
незначительно влияют на спрос отечественных автомобилей.
2) Отрицательный коэффициент перед переменными Credit_rate и Currency_basket свидетельствуют о снижении спроса
при повышении процентной ставки по кредитам и увеличении стоимости бивалютной
корзины.
) В модели остались практически все переменные для анализа
сезонности продаж. Свидетельствует об относительно ровном распределении продаж
в течение года. Пик продаж наблюдается в апреле.
) Отрицательный коэффициент перед December означает снижение спроса в конце
года, описывая поведение покупателей: в январе следующего года автомобиль,
произведенный в предыдущем месяце будет считаться прошлогодним, следовательно и
стоимость его будет ниже.
) Отрицательные коэффициенты перед переменной Crisis говорит о снижение спроса на момент
кризиса.
) Наличие лагового значения переменной характеризует зависимость
спроса от продаж в предыдущий период: коэффициент положительный - зависимость
положительная.
.4 Модель
спроса на зарубежных автомобилей
.4.1
Построение модели
Зависимая переменная: Foreign_cars - общее кол-во продаж зарубежных
автомобилей в России за период.
Отбор переменных
Методом обратного отбора (рис. 3.2) определим качественные переменные для
включения в модель.
Таблица 3.25.Корреляция входных переменных с результирующим признаком
|
Credit_rate
|
Currency_basket
|
Gasoline_price_cor
|
Inflation_dynamic
|
Average_income
|
Population_cor
|
|
Foreign_cars
|
-0,239
|
-0,063
|
0,606
|
-0,19
|
0,509
|
0,227
|
В первую очередь рассчитаем значение F-критерия для Currency_basket, затем для Inflation_dynamic и
так далее.
Таблица 3.26. Рассчетные значения F-критериев для каждой переменной
|
Переменная
|
Freal
|
Ftable
|
|
Currency_basket
|
0,353
|
3.95
|
|
Inflation_dynamic
|
3,309
|
3.95
|
|
Population_cor
|
4,797
|
3.95
|
Переменные Currency_basket и Inflation_dynamic исключаем из модели, так
как их Freal < Ftable .
Выявление зависимости спроса от сезона
Построим модель линейной регрессии, где зависящей переменной будет Russian_cars, объясняющими - отобранные переменные, а также
переменные, отвечающие за сезонность. Допустимый уровень t-статистики остается на аналогичном
предыдущим построениям уровне - 1,98. Вероятность того, что решение о включении
окажется неправильным, составляет α = 0,05.
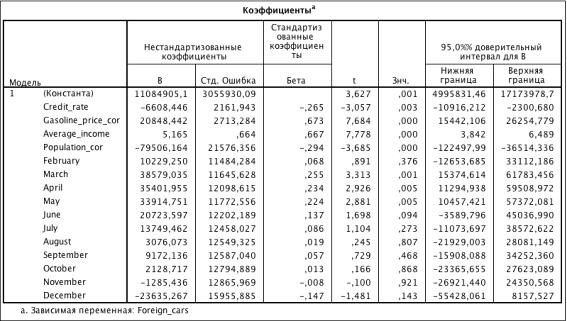
Таблица 3.27. Коэффициенты модели (R2 = 0.781)
Исключим из модели фиктивные переменные, которые существенно незначимы:
February, June, July, August, September, October, November. Построим новую
модель.
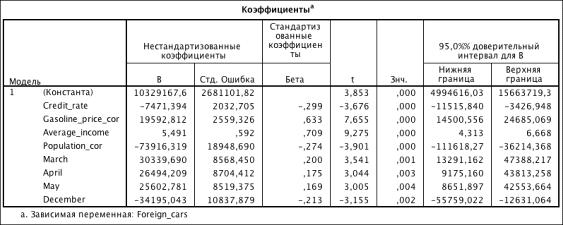
Таблица 3.28. Коэффициенты модели (R2 = 0.764)
Проверка значимости квадратичной формы переменных
Проверка показала аналогичную ситуацию, как и при построении модели общих
продаж: добавилась новая переменная Average_income_sqr2.
Таблица 3.29. Коэффициенты модели (R2 = 0.786)
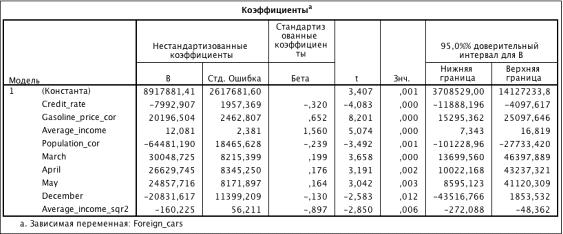
Влияние кризиса на продажи
Таблица 3.30. Коэффициенты модели (R2 = 0.828)
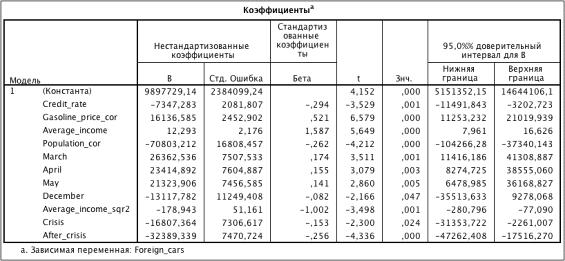
Проверка логарифмической зависимости
Таблица 3.31. Коэффициенты модели (R2 = 0.829)
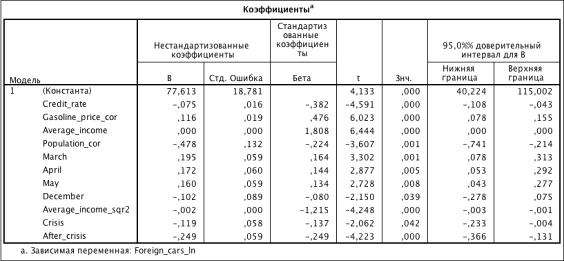
Результат оценки модели с зависящей переменной, выраженной натуральным
логарифмом Foreign_cars, показал значение коэффициента детерминации R2 лучше.
Проверка на гетероскедастичность
Количество степеней свободы p = 11
Критерий Бройша-Пагана LW =
21,24
LW
имеет распределение с 10 степенями свободы (Приложение 3) при уровне значимости α
= 0,05, следовательно
гипотеза о гомоскедастичности остатков подтверждается.
Проверка на автокорреляцию
DW =
0,448. Значение критерия меньше табличного dL, что говорит о наличии положительной
автокорреляции, необходимо в модель к предикаторам добавлять лаговое значение
зависимой переменной Foreign_cars_ln _lag).
Таблица 3.32. Коэффициенты модели (R2 = 0.856)
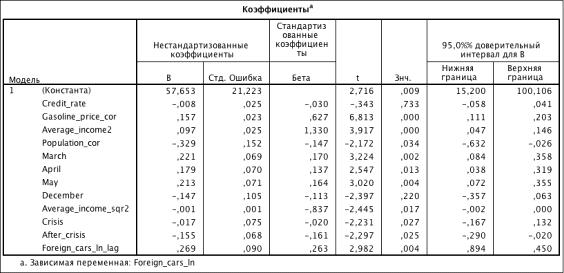
.4.2
Ретроспективный прогноз
Таблица 3.33. Ошибка прогноза
|
Период
|
Реальное значение продаж
|
Прогнозное значение
продаж
|
Ошибка прогноза
|
|
JUL 2014
|
143875
|
142556
|
0,92%
|
|
AUG 2014
|
136240
|
146116
|
7,25%
|
|
SEP 2014
|
151333
|
149494
|
1,22%
|
|
OCT 2014
|
160167
|
158441
|
1,08%
|
|
NOV 2014
|
186649
|
173344
|
7,13%
|
|
DEC 2014
|
220201
|
190003
|
13,71%
|
|
JAN 2015
|
93718
|
81944
|
12,56%
|
|
FEB 2015
|
98707
|
93685
|
5,09%
|
|
MAR 2015
|
104251
|
125398
|
20,28%
|
|
|
|
MPE=
|
7,69%
|
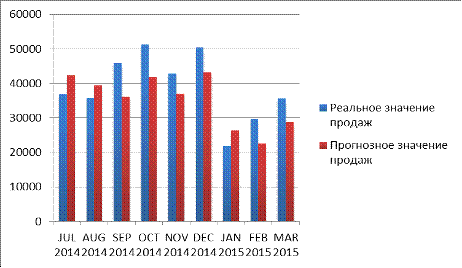
Диаграмма 3.3. Сравнение реального уровня продаж с прогнозным значением
Средняя ошибка прогноза составила 7.69%, модель можно применять на
практике.
.4.3
Качественные выводы из построенной модели
Модель спроса:
Foreign_cars_ln = 57.653 - 0.008 * Credit_rate + 0.157 *
Gasolin_price_cor + 0.097 * Average_income2 - 0.001 * Average_income_sqr2 -
0.329 * Population_cor + 0.221 * March + 0.179 * April + 0.213 * May - 0.147 *
December - 0.017 * Crisis - 0.175 * After_crisis + 0.269 * Foreign_cars_lag
Выводы:
1) В ходе построения модели были исключены количесвтенные переменные Inflution_dynamic и Currency_basket, следовательно динамика инфляции в
стране и курс валюты не влияет на спрос.
2) Отрицательный коэффициент перед переменной Credit_rate свидетельствуют о снижении спроса при повышении
процентной ставки по кредитам.
) Положительная зависимость продаж от цены на бензин объясняется
желанием приобрести новый автомобиль, которые будет более экономичным по части
расхода топлива.
) Отрицательный коэффициент перед Population характеризует снижение уровня продаж
при увеличении численности населения. Это объясняется перенасыщение
автомобилей, возможно увеличивается спрос на вторичном рынке.
) Положительный коэффициент перед Average_income2
и отрицательный перед Average_income_sqr2 говорит о том, что при росте денежного дохода до
определенного уровня спрос растет, но после его преодоления - падает. Это
означает, что денежные средства идут, например, на покупку недвижимости.
) Положительные коэффициенты перед March, April
и May говорят о набольших значениях продаж
весной, все хотят новый автомобиль к летнему сезону. Особенно пик продаж наблюдается в
марте.
) Отрицательный коэффициент перед December означает снижение спроса в конце
года, описывая поведение покупателей: в январе следующего года автомобиль,
произведенный в предыдущем месяце будет считаться прошлогодним, следовательно и
стоимость его будет ниже.
) Отрицательные коэффициенты перед переменными Crisis и After_crisis
говорят о снижение спроса на момент кризиса и в период после него.
) Наличие лагового значения переменной характеризует зависимость
спроса от продаж в предыдущий период: коэффициент положительный - зависимость
положительная.
Заключение
В практической части работы проведено исследование и прогнозирование
уровня продаж автомобилей в России. Среди факторов, влияющих на спрос, были
выделены следующие показатели:
) Среднедушевой доход;
2) Процентная ставка по кредиту;
) Величина бивалютной корзины;
) Розничная цена на бензин;
) Динамика инфляции;
) Численность населения;
) Период продажи (месяц);
) Кризисный период.
Первые шесть факторов выражены через количественные переменные. За
седьмой и восьмой отвечали специальные фиктивные переменные.
Исследование проводилось на 90 ежемесячных наблюдениях за период с января
2007 года по июнь 2014 года. Среди статистических пакетов для работы с данными
был выбран IBM SPSS Statistics. Данный пакет относится к универсальной группе,
что характеризует наличие широкого круга статистических методов. Интерфейс
понятен для пользователя, имеется широкий выбор справочной литературы.
Построены три модели спроса:
) Модель общего спроса на новые автомобили в России;
2) Модель спроса на автомобили парок отечественного производителя;
) Модель спроса на зарубежные автомобили в России.
Модели общего спроса и спроса на зарубежные автомобили оказались
значимыми для 90% вариаций показателя продаж, на отечественные - для 83%. При
анализе моделей подтвердились следующие гипотезы: рост процентной ставки по кредиту
и стоимости бивалютной корзины отрицательно влияют на уровень продаж, весной
наблюдается пик продаж. Также, наблюдения показали, что спрос растет при
увеличении дохода лишь до определенного уровня, после чего падает. Такая
ситуация объясняется возможным инвестированием денежных средств, например, в
недвижимость. Гипотеза о уменьшении спроса при увеличении стоимости бензина
была опровергнута. Обратная взаимосвязь цены на бензин и уровня продаж
объясняется потребностью в более экономичных (в плане расхода топлива) новых
автомобилях.
Полученные модели были применены к данным за период с июля 2014 по март
2015, сделав тем самым ретроспективный прогноз. Модели общего спроса и спроса
на автомобили показали хороший результат: средняя ошибка прогноза составила
менее 10%, средняя ошибка для модели спроса на отечественные автомобили
составила 17,29%. Улучшение последней модели возможно за счет добавления
дополнительных объясняющих переменных, которые не были учтены. Основное
препятствие к такому расширению модели заключается в отсутствии соответствующих
данных для всех наблюдений.
Литература
1. Магнус Я.Р., Катышев П.К., Пересецкий А.А.
Эконометрика. Начальный курс: Учеб. - 5-е изд., испр. - М.: Дело, 2001.
2. Айвазян С.А., Методы эконометрики: учебник- М.: Магистр:
ИНФРА-М, 2010.
. Вербик Марно Путеводитель по современной
эконометрике. - М.: Научная книга, 2008.
. Эконометрика: Учебник / Под ред. И.И. Елисеевой. -
М.: Финансы и статистика, 2002.
. Харемза В.В., Харин Ю.С., Макарова С.Б. Прикладная
эконометрика "О моделировании экономик России и Беларуси на основе
эконометрической модели LAM-3"
3-е изд., 2006.
. Ратникова Т.А., Сергеева Е.С. Прикладная
эконометрика "Оценивание гедонистической ценовой функции для картин Клода
Моне" 4-е изд., 2010.
. Бабешко Л.О. Основы эконометрического моделирования:
Учеб. Пособие. - М.: КомКнига, 2006.
. Бокс Дж., Дженкинс Г. Анализ временных рядов. Выпуск
1: Прогноз и управление. - М. Мир, 1974.
. Дрейпер Н., Смит Г. Прикладной регрессионный анализ.
Множественная регрессия - М.: Диалектика, 2007.
. Практикум по эконометрике: Учеб. пособие / И.И.
Елисеева, С.В. Курдышева, Н.М. Гордеенко и др.; Под ред. И.И. Елисеевой. - М.:
Финансы и статистика, 2002.
. Экономико-математические методы и прикладные модели:
Учеб. пособие для вузов / В.В. Федосеев, А.Н. Гармаш, Д.М. Дайитбегов и др.;
Под ред В.В. Федосеева. - М.: ЮНИТИ, 2002.
. Орлова И.В. Экономико-математические методы и
модели. Практикум: Учеб. пособие для вузов. - М.: Финстатинформ, 2000.
. Орлов А.И. Устойчивость в социально-экономических
моделях. - М.: Наука, 2001.
. Плошко Б.Г., Елисеева И.И. История статистики:
Учебное пособие. - М.: Финансы и статистика, 2000.
. Практикум по эконометрике: Учеб. пособие / Под ред.
И.И. Елисеевой. - М.: Финансы и статистика, 2001.
. Смоляк С.А., Титаренко Б.П. Устойчивые методы
оценивания: Статистическая обработка неоднородных совокупностей. - М.:
Статистика, 2000.
. Экономико-математические методы и прикладные модели:
Учеб. пособие для вузов / В.В. Федосеев, А.Н. Гармаш, Д.М. Дайитбегов, И.В. Орлова,
А. Половников. - М.: ЮНИТИ, 2000.
. Эконометрика: Учебник / Под ред. И.И. Елисеевой. -
М.: Финансы и статистика, 2001.
19. www.gks.ru - Федеральный сайт государственной
статистики.
20. www.intuit.ru - Курс "Введение в программную
среду и их разработку", Лекция 11 "Статистическая обработка
данных".
21. www.aebrus.ru - Association of European
Businesses/
22. www.cbr.ru - Федеральный сайт ЦБ РФ
Приложение
1
Критические значения коэффициента Стьюдента (t-критерия) для различной
доверительной вероятности p
|
df
|
Р
|
df
|
Р
|
df
|
Р
|
|
|
0,10
|
0,05
|
0,01
|
0,001
|
|
0,10
|
0,05
|
0,01
|
0,001
|
|
0,10
|
0,05
|
0,01
|
0,001
|
|
1
|
6,314
|
12,70
|
63,65
|
636,61
|
31
|
1,696
|
2,040
|
2,744
|
3,633
|
61
|
1,670
|
2,000
|
2,659
|
3,457
|
|
2
|
2,920
|
4,303
|
9,925
|
31,602
|
32
|
1,694
|
2,037
|
2,738
|
3,622
|
62
|
1,670
|
1,999
|
2,657
|
3,454
|
|
3
|
2,353
|
3,182
|
5,841
|
12,923
|
33
|
1,692
|
2,035
|
2,733
|
3,611
|
63
|
1,669
|
1,998
|
2,656
|
3,452
|
|
4
|
2,132
|
2,776
|
4,604
|
8,610
|
34
|
1,691
|
2,032
|
2,728
|
3,601
|
64
|
1,669
|
1,998
|
2,655
|
3,449
|
|
5
|
2,015
|
2,571
|
4,032
|
6,869
|
35
|
1,690
|
2,030
|
2,724
|
3,591
|
65
|
1,669
|
1,997
|
2,654
|
3,447
|
|
6
|
1,943
|
2,447
|
3,707
|
5,959
|
36
|
1,688
|
2,028
|
2,719
|
3,582
|
66
|
1,668
|
1,997
|
2,652
|
3,444
|
|
7
|
1,895
|
2,365
|
3,499
|
5,408
|
37
|
1,687
|
2,026
|
2,715
|
3,574
|
67
|
1,668
|
1,996
|
2,651
|
3,442
|
|
8
|
1,860
|
2,306
|
3,355
|
5,041
|
38
|
1,686
|
2,024
|
2,712
|
68
|
1,668
|
1,995
|
2,650
|
3,439
|
|
9
|
1,833
|
2,262
|
3,250
|
4,781
|
39
|
1,685
|
2,023
|
2,708
|
3,558
|
69
|
1,667
|
1,995
|
2,649
|
3,437
|
|
10
|
1,812
|
2,228
|
3,169
|
4,587
|
40
|
1,684
|
2,021
|
2,704
|
3,551
|
70
|
1,667
|
1,994
|
2,648
|
3,435
|
|
11
|
1,796
|
2,201
|
3,106
|
4,437
|
41
|
1,683
|
2,020
|
2,701
|
3,544
|
71
|
1,667
|
1,994
|
2,647
|
3,433
|
|
12
|
1,782
|
2,179
|
3,055
|
4,318
|
42
|
1,682
|
2,018
|
2,698
|
3,538
|
72
|
1,666
|
1,993
|
2,646
|
3,431
|
|
13
|
1,771
|
2,160
|
3,012
|
4,221
|
43
|
1,681
|
2,017
|
2,695
|
3,532
|
73
|
1,666
|
1,993
|
2,645
|
3,429
|
|
14
|
1,761
|
2,145
|
2,977
|
4,140
|
44
|
1,680
|
2,015
|
2,692
|
3,526
|
74
|
1,666
|
1,993
|
2,644
|
3,427
|
|
15
|
1,753
|
2,131
|
2,947
|
4,073
|
45
|
1,679
|
2,014
|
2,690
|
3,520
|
75
|
1,665
|
1,992
|
2,643
|
3,425
|
|
16
|
1,746
|
2,120
|
2,921
|
4,015
|
46
|
1,679
|
2,013
|
2,687
|
3,515
|
76
|
1,665
|
1,992
|
2,642
|
3,423
|
|
17
|
1,740
|
2,110
|
2,898
|
3,965
|
47
|
1,678
|
2,012
|
2,685
|
3,510
|
78
|
1,665
|
1,991
|
2,640
|
3,420
|
|
18
|
1,734
|
2,101
|
2,878
|
3,922
|
48
|
1,677
|
2,011
|
2,682
|
3,505
|
79
|
1,664
|
1,990
|
2,639
|
3,418
|
|
19
|
1,729
|
2,093
|
2,861
|
3,883
|
49
|
1,677
|
2,010
|
2,680
|
3,500
|
80
|
1,664
|
1,990
|
2,639
|
3,416
|
|
20
|
1,725
|
2,086
|
2,845
|
3,850
|
50
|
1,676
|
2,009
|
2,678
|
3,496
|
90
|
1,662
|
1,987
|
2,632
|
3,402
|
|
21
|
1,721
|
2,080
|
2,831
|
3,819
|
51
|
1,675
|
2,008
|
2,676
|
3,492
|
100
|
1,660
|
1,984
|
2,626
|
3,390
|
|
22
|
1,717
|
2,074
|
2,819
|
3,792
|
52
|
1,675
|
2,007
|
2,674
|
3,488
|
110
|
1,659
|
1,982
|
2,621
|
3,381
|
|
23
|
1,714
|
2,069
|
2,807
|
3,768
|
53
|
1,674
|
2,006
|
2,672
|
3,484
|
120
|
1,658
|
1,980
|
2,617
|
3,373
|
|
24
|
1,711
|
2,064
|
2,797
|
3,745
|
54
|
1,674
|
2,005
|
2,670
|
3,480
|
130
|
1,657
|
1,978
|
2,614
|
3,367
|
|
25
|
1,708
|
2,060
|
2,787
|
3,725
|
55
|
1,673
|
2,004
|
2,668
|
3,476
|
140
|
1,656
|
1,977
|
2,611
|
3,361
|
|
26
|
1,706
|
2,056
|
2,779
|
3,707
|
56
|
1,673
|
2,003
|
2,667
|
3,473
|
150
|
1,655
|
1,976
|
2,609
|
3,357
|
|
27
|
1,703
|
2,052
|
2,771
|
3,690
|
57
|
1,672
|
2,002
|
2,665
|
3,470
|
200
|
1,653
|
1,972
|
2,601
|
3,340
|
|
28
|
1,701
|
2,049
|
2,763
|
3,674
|
58
|
1,672
|
2,002
|
2,663
|
3,466
|
250
|
1,651
|
1,969
|
2,596
|
3,330
|
|
29
|
1,699
|
2,045
|
2,756
|
3,659
|
59
|
1,671
|
2,001
|
2,662
|
3,463
|
300
|
1,650
|
1,968
|
2,592
|
3,323
|
|
30
|
1,697
|
2,042
|
2,750
|
3,646
|
60
|
1,671
|
2,000
|
2,660
|
3,460
|
350
|
1,649
|
1,967
|
2,590
|
3,319
|
Приложение 2
Таблица значений F-критерия
Фишера при уровне значимости 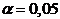
|
|
1
|
2
|
3
|
4
|
5
|
6
|
8
|
12
|
24
|
|
|
1
|
161,5
|
215,7
|
224,6
|
230,2
|
233,9
|
238,9
|
243,9
|
249,0
|
254,3
|
|
2
|
18,51
|
19,00
|
19,16
|
19,25
|
19,30
|
19,33
|
19,37
|
19,41
|
19,45
|
19,50
|
|
3
|
10,13
|
9,55
|
9,28
|
9,12
|
9,01
|
8,94
|
8,84
|
8,74
|
8,64
|
8,53
|
|
4
|
7,71
|
6,94
|
6,59
|
6,39
|
6,26
|
6,16
|
6,04
|
5,91
|
5,77
|
5,63
|
|
5
|
6,61
|
5,79
|
5,41
|
5,19
|
5,05
|
4,95
|
4,82
|
4,68
|
4,53
|
4,36
|
|
6
|
5,99
|
5,14
|
4,76
|
4,53
|
4,39
|
4,28
|
4,15
|
4,00
|
3,84
|
3,67
|
|
7
|
5,59
|
4,74
|
4,35
|
4,12
|
3,97
|
3,87
|
3,73
|
3,57
|
3,41
|
3,23
|
|
8
|
5,32
|
4,46
|
4,07
|
3,84
|
3,69
|
3,58
|
3,44
|
3,28
|
3,12
|
2,93
|
|
9
|
5,12
|
4,26
|
3,86
|
3,63
|
3,48
|
3,37
|
3,23
|
3,07
|
2,90
|
2,71
|
|
10
|
4,96
|
4,10
|
3,71
|
3,48
|
3,33
|
3,22
|
3,07
|
2,91
|
2,74
|
2,54
|
|
11
|
4,84
|
3,98
|
3,59
|
3,36
|
3,20
|
3,09
|
2,95
|
2,79
|
2,61
|
2,40
|
|
12
|
4,75
|
3,88
|
3,49
|
3,26
|
3,11
|
3,00
|
2,85
|
2,69
|
2,50
|
2,30
|
|
13
|
4,67
|
3,80
|
3,41
|
3,18
|
3,02
|
2,92
|
2,77
|
2,60
|
2,42
|
2,21
|
|
14
|
4,60
|
3,74
|
3,34
|
3,11
|
2,96
|
2,85
|
2,70
|
2,53
|
2,35
|
2,13
|
|
15
|
4,54
|
3,68
|
3,29
|
3,06
|
2,90
|
2,79
|
2,64
|
2,48
|
2,29
|
2,07
|
|
16
|
4,49
|
3,63
|
3,24
|
3,01
|
2,85
|
2,74
|
2,59
|
2,42
|
2,24
|
2,01
|
|
17
|
4,45
|
3,59
|
3,20
|
2,96
|
2,81
|
2,70
|
2,55
|
2,38
|
2,19
|
1,96
|
|
18
|
4,41
|
3,55
|
3,16
|
2,93
|
2,77
|
2,66
|
2,51
|
2,34
|
2,15
|
1,92
|
|
19
|
4,38
|
3,52
|
3,13
|
2,90
|
2,74
|
2,63
|
2,48
|
2,31
|
2,11
|
1,88
|
|
20
|
4,35
|
3,49
|
3,10
|
2,87
|
2,71
|
2,60
|
2,45
|
2,28
|
2,08
|
1,84
|
|
21
|
4,32
|
3,47
|
3,07
|
2,84
|
2,68
|
2,57
|
2,42
|
2,25
|
2,05
|
1,81
|
|
22
|
4,30
|
3,44
|
3,05
|
2,82
|
2,66
|
2,55
|
2,40
|
2,23
|
2,03
|
1,78
|
|
23
|
4,28
|
3,42
|
3,03
|
2,80
|
2,64
|
2,53
|
2,38
|
2,20
|
2,00
|
1,76
|
|
24
|
4,26
|
3,40
|
3,01
|
2,78
|
2,62
|
2,51
|
2,36
|
2,18
|
1,98
|
1,73
|
|
25
|
4,24
|
3,38
|
2,99
|
2,76
|
2,60
|
2,49
|
2,34
|
2,16
|
1,96
|
1,71
|
|
26
|
4,22
|
3,37
|
2,98
|
2,74
|
2,59
|
2,47
|
2,32
|
2,15
|
1,95
|
1,69
|
|
27
|
4,21
|
3,35
|
2,96
|
2,73
|
2,57
|
2,46
|
2,30
|
2,13
|
1,93
|
1,67
|
|
28
|
4,20
|
3,34
|
2,95
|
2,71
|
2,56
|
2,44
|
2,29
|
2,12
|
1,91
|
1,65
|
|
29
|
4,18
|
3,33
|
2,93
|
2,70
|
2,54
|
2,43
|
2,28
|
2,10
|
1,90
|
1,64
|
|
30
|
4,17
|
3,32
|
2,92
|
2,69
|
2,53
|
2,42
|
2,27
|
2,09
|
1,89
|
1,62
|
|
35
|
4,12
|
3,26
|
2,87
|
2,64
|
2,48
|
2,37
|
2,22
|
2,04
|
1,83
|
1,57
|
|
40
|
4,08
|
3,23
|
2,84
|
2,61
|
2,45
|
2,34
|
2,18
|
2,00
|
1,79
|
1,51
|
|
45
|
3,21
|
2,81
|
2,58
|
2,42
|
2,31
|
2,15
|
1,97
|
1,76
|
1,48
|
|
50
|
4,03
|
3,18
|
2,79
|
2,56
|
2,40
|
2,29
|
2,13
|
1,95
|
1,74
|
1,44
|
|
60
|
4,00
|
3,15
|
2,76
|
2,52
|
2,37
|
2,25
|
2,10
|
1,92
|
1,70
|
1,39
|
|
70
|
3,98
|
3,13
|
2,74
|
2,50
|
2,35
|
2,23
|
2,07
|
1,89
|
1,67
|
1,35
|
|
80
|
3,96
|
3,11
|
2,72
|
2,49
|
2,33
|
2,21
|
2,06
|
1,88
|
1,65
|
1,31
|
|
90
|
3,95
|
3,10
|
2,71
|
2,47
|
2,32
|
2,20
|
2,04
|
1,86
|
1,64
|
1,28
|
|
100
|
3,94
|
3,09
|
2,70
|
2,46
|
2,30
|
2,19
|
2,03
|
1,85
|
1,63
|
1,26
|
|
125
|
3,92
|
3,07
|
2,68
|
2,44
|
2,29
|
2,17
|
2,01
|
1,83
|
1,60
|
1,21
|
|
150
|
3,90
|
3,06
|
2,66
|
2,43
|
2,27
|
2,16
|
2,00
|
1,82
|
1,59
|
1,18
|
|
200
|
3,89
|
3,04
|
2,65
|
2,42
|
2,26
|
2,14
|
1,98
|
1,80
|
1,57
|
1,14
|
|
300
|
3,87
|
3,03
|
2,64
|
2,41
|
2,25
|
2,13
|
1,97
|
1,79
|
1,55
|
1,10
|
|
400
|
3,86
|
3,02
|
2,63
|
2,40
|
2,24
|
2,12
|
1,96
|
1,78
|
1,54
|
1,07
|
|
500
|
3,86
|
3,01
|
2,62
|
2,39
|
2,23
|
2,11
|
1,96
|
1,77
|
1,54
|
1,06
|
|
1000
|
3,85
|
3,00
|
2,61
|
2,38
|
2,22
|
2,10
|
1,95
|
1,76
|
1,53
|
1,03
|
|
|
3,84
|
2,99
|
2,60
|
2,37
|
2,21
|
2,09
|
1,94
|
1,75
|
1,52
|
1
|
Приложение 3
Таблица распределения χ2 для различной доверительной вероятности α
|
 
|
0,99
|
0,98
|
0,95
|
0,90
|
0,80
|
0,70
|
0,50
|
0,30
|
0,20
|
0,10
|
0,05
|
0,02
|
0,01
|
0,001
|
|
1
|
0,000
|
0,001
|
0,004
|
0,016
|
0,064
|
0,148
|
0,455
|
1,074
|
1,642
|
2,71
|
3,84
|
5,41
|
6,64
|
10,83
|
|
2
|
0,020
|
0,040
|
0,103
|
0,211
|
0,446
|
0,713
|
1,386
|
2,41
|
3,22
|
4,60
|
5,99
|
7,82
|
9,21
|
13,82
|
|
3
|
0,115
|
0,185
|
0,352
|
0,584
|
1,005
|
1,424
|
2,37
|
3,66
|
4,64
|
6,25
|
7,82
|
9,84
|
11,34
|
16,27
|
|
4
|
0,297
|
0,429
|
0,711
|
1,064
|
1,649
|
2,20
|
3,36
|
4,88
|
5,99
|
7,78
|
9,49
|
11,67
|
13,28
|
18,46
|
|
5
|
0,554
|
0,752
|
1,145
|
1,610
|
2,34
|
3,00
|
4,35
|
6,06
|
7,29
|
9,24
|
11,07
|
13,39
|
15,09
|
20,5
|
|
6
|
0,872
|
1,134
|
1,635
|
2,20
|
3,07
|
3,83
|
5,35
|
7,23
|
8,56
|
10,64
|
12,59
|
15,03
|
16,81
|
22,5
|
|
7
|
1,239
|
1,564
|
2,17
|
2,83
|
3,82
|
4,67
|
6,35
|
838
|
9,80
|
12,02
|
14,07
|
16,62
|
18,48
|
24,3
|
|
8
|
1,646
|
2,03
|
2,73
|
3,49
|
4,59
|
5,53
|
7,34
|
9,52
|
11,03
|
13,36
|
15,51
|
18,17
|
20,1
|
26,1
|
|
9
|
2,09
|
2,53
|
3,32
|
4,17
|
5,38
|
6,39
|
8,34
|
10,66
|
12,24
|
14,68
|
16,92
|
19,68
|
21,7
|
27,9
|
|
10
|
2,56
|
3,06
|
3,94
|
4,86
|
6,18
|
7,27
|
9,34
|
11,78
|
13,44
|
15,99
|
18,31
|
21,2
|
23,2
|
29,6
|
|
11
|
3,05
|
3,61
|
4,58
|
5,58
|
6,99
|
8,15
|
10,34
|
12,90
|
14,63
|
17,28
|
19,68
|
22,6
|
24,7
|
31,3
|
|
12
|
3,57
|
4,18
|
5,23
|
6,30
|
9,03
|
11,34
|
14,01
|
15,81
|
18,55
|
21,0
|
24,1
|
26,2
|
32,9
|
|
13
|
4,11
|
4,76
|
5,89
|
7,04
|
8,63
|
0,93
|
12,34
|
15,12
|
16,98
|
19,81
|
22,4
|
25,5
|
27,7
|
34,6
|
|
14
|
4,66
|
5,37
|
6,57
|
7,79
|
9,47
|
10,82
|
13,34
|
16,22
|
18,15
|
21,1
|
23,7
|
26,9
|
29,1
|
36,1
|
|
15
|
5,23
|
5,98
|
7,26
|
8,55
|
10,31
|
11,72
|
14,34
|
17,32
|
19,31
|
22,3
|
25,0
|
28,3
|
30,6
|
37,7
|
|
16
|
5,81
|
6,61
|
7,96
|
9,31
|
11,15
|
12,62
|
15,34
|
18,42
|
20,5
|
23,5
|
26,3
|
29,6
|
32,0
|
39,3
|
|
17
|
6,41
|
7,26
|
8,67
|
10,08
|
12,00
|
13,53
|
16 34
|
19,51
|
21,6
|
24,8
|
27,6
|
31,0
|
33,4
|
40,8
|
|
18
|
7,02
|
7,91
|
9,39
|
10,86
|
12,86
|
14,44
|
17,34
|
20,6
|
22,8
|
26,0
|
28,9
|
32,3
|
34,8
|
42,3
|
|
19
|
7,63
|
8,57
|
10,11
|
11,65
|
13,72
|
15,35
|
18,34
|
21,7
|
23,9
|
27,2
|
30,1
|
33,7
|
36,2
|
43,8
|
|
20
|
8,26
|
9,24
|
10,85
|
12,44
|
14,58
|
16,27
|
19,34
|
22,8
|
25,0
|
28,4
|
31,4
|
35,0
|
37,6
|
45,3
|
|
21
|
8,90
|
9,92
|
11,59
|
13,24
|
15,44
|
17,18
|
20,3
|
23,9
|
26,2
|
29,6
|
32,7
|
36,3
|
38,9
|
46,8
|
|
22
|
9,54
|
10,60
|
12,34
|
14,04
|
16,31
|
18,10
|
21,3
|
24,0
|
27,3
|
30,8
|
33,9
|
37,7
|
40,3
|
48,3
|
|
23
|
10,20
|
11,29
|
13,09
|
14,85
|
17,19
|
19,02
|
22,3
|
26,0
|
28,4
|
32,0
|
35,2
|
39,0
|
41,6
|
49,7
|
|
24
|
10,86
|
11,99
|
13,85
|
15,66
|
18,06
|
19,94
|
23,3
|
27,1
|
29,6
|
33,2
|
36,4
|
40,3
|
43,0
|
51,2
|
|
25
|
11,52
|
12,70
|
14,61
|
16,47
|
18,94
|
20,9
|
24,3
|
23,2
|
30,7
|
34,4
|
37,7
|
41,7
|
44,3
|
52,6
|
|
26
|
2,20
|
13,41
|
15,38
|
17,29
|
19,82
|
21,8
|
25,3
|
29,2
|
31,8
|
35,6
|
38,9
|
42,9
|
45,6
|
54,1
|
|
27
|
12,88
|
14,12
|
16,15
|
18,11
|
20,7
|
22,7
|
26,3
|
30,3
|
32,9
|
36,7
|
40,1
|
44,1
|
47,0
|
55,5
|
|
28
|
13,56
|
14,85
|
16,93
|
18,94
|
21,6
|
23,6
|
27,3
|
31,4
|
34,0
|
37,9
|
41,3
|
45,4
|
48,3
|
56,9
|
|
29
|
14,26
|
15,57
|
17,71
|
19,77
|
22,5
|
24,6
|
28,3
|
32,5
|
35,1
|
39,1
|
42,6
|
46,7
|
49,6
|
58,3
|
|
30
|
14,95
|
16,31
|
18,19
|
20,6
|
23,4
|
25,5
|
29,3
|
33,5
|
36,2
|
40,3
|
43,8
|
48,0
|
50,9
|
59,7
|
Приложение 4
Статистические данные
|
№
|
Год
|
Квартал
|
Месяц
|
Ставка по кредитам,%
|
Бивалютная корзина, руб
|
РЦ на бензин, руб/л
|
Инфляция, %
|
Среднедушевой доход,
руб/месяц
|
Общие продажи автомобилей
|
Продажи зарубежных авто
|
Продажи отечествен. авто
|
Численность населения
|
|
1
|
2007
|
1
|
1
|
15,7
|
29,67306
|
20,15
|
1,68
|
8347,32
|
117256
|
72845
|
44411
|
142,8
|
|
2
|
2007
|
1
|
2
|
15,7
|
29,86859
|
21,19
|
1,11
|
10313,03
|
130675
|
90270
|
40405
|
142,8
|
|
3
|
2007
|
1
|
3
|
15,6
|
29,9159
|
21,19
|
0,59
|
11130,02
|
179057
|
126007
|
53050
|
142,8
|
|
4
|
2007
|
2
|
4
|
15,5
|
29,91245
|
21,1
|
0,57
|
11665,35
|
201867
|
140852
|
61015
|
142,8
|
|
5
|
2007
|
2
|
5
|
29,91271
|
21,2
|
0,63
|
11738,87
|
204478
|
137970
|
66508
|
142,8
|
|
6
|
2007
|
2
|
6
|
15,1
|
29,899
|
21,45
|
0,95
|
12395,18
|
199013
|
136831
|
62182
|
142,8
|
|
7
|
2007
|
3
|
7
|
15
|
29,81084
|
21,86
|
0,87
|
12528,69
|
211110
|
139316
|
71794
|
142,8
|
|
8
|
2007
|
3
|
8
|
14,6
|
29,7973
|
22,3
|
0,09
|
12617,10
|
218150
|
140018
|
78132
|
142,8
|
|
9
|
2007
|
3
|
9
|
14,8
|
29,75509
|
22,15
|
0,79
|
12843,32
|
205658
|
144108
|
61550
|
142,8
|
|
10
|
2007
|
4
|
10
|
14,8
|
29,61971
|
21,88
|
1,64
|
13071,10
|
229804
|
151137
|
78667
|
142,8
|
|
11
|
2007
|
4
|
11
|
14,7
|
29,61592
|
21,27
|
1,23
|
14115,56
|
222537
|
157142
|
65395
|
142,8
|
|
12
|
2007
|
4
|
12
|
15
|
29,61835
|
21,43
|
1,13
|
19625,86
|
242537
|
174007
|
68530
|
142,8
|
|
13
|
2008
|
1
|
1
|
15,2
|
29,67782
|
21,52
|
2,31
|
10425,80
|
174488
|
113303
|
61185
|
142,8
|
|
14
|
2008
|
1
|
2
|
15,1
|
29,74544
|
21,7
|
1,2
|
12901,60
|
220953
|
156077
|
64876
|
142,8
|
|
15
|
2008
|
1
|
3
|
15,2
|
29,62434
|
21,89
|
1,2
|
13311,50
|
258033
|
184819
|
73214
|
142,8
|
|
16
|
2008
|
2
|
4
|
15,3
|
29,61066
|
22,54
|
1,42
|
14745,00
|
292662
|
200269
|
92393
|
142,8
|
|
17
|
2008
|
2
|
5
|
15,5
|
29,65655
|
23,23
|
1,35
|
14344,90
|
283554
|
199733
|
83821
|
142,8
|
|
18
|
2008
|
2
|
6
|
15,6
|
29,51
|
24,01
|
0,97
|
15159,30
|
273909
|
201979
|
71930
|
142,8
|
|
19
|
2008
|
3
|
7
|
15,8
|
29,42013
|
24,81
|
0,51
|
15635,80
|
275090
|
199076
|
76014
|
142,8
|
|
20
|
2008
|
3
|
8
|
16
|
29,5997
|
25,14
|
0,36
|
16011,10
|
244274
|
175449
|
68825
|
142,8
|
|
21
|
2008
|
3
|
9
|
16,1
|
30,25538
|
25,02
|
0,8
|
15090,90
|
249918
|
179465
|
70453
|
142,8
|
|
22
|
2008
|
4
|
10
|
16,6
|
30,37231
|
24,95
|
0,91
|
15240,90
|
243719
|
169052
|
74667
|
142,8
|
|
23
|
2008
|
4
|
11
|
17,7
|
30,67904
|
24,25
|
0,83
|
15513,00
|
201243
|
136512
|
64731
|
142,8
|
|
24
|
2008
|
4
|
12
|
18,1
|
32,58015
|
22,84
|
0,69
|
19959,50
|
212359
|
159661
|
52698
|
142,8
|
|
25
|
2009
|
1
|
1
|
19,4
|
37,15372
|
21,92
|
2,37
|
11254,10
|
118054
|
82960
|
35094
|
142,7
|
|
26
|
2009
|
1
|
2
|
19,8
|
40,30411
|
21,22
|
1,65
|
15077,90
|
134926
|
99391
|
35535
|
142,7
|
|
27
|
2009
|
1
|
3
|
20,2
|
39,42265
|
20,6
|
1,31
|
15863,50
|
136914
|
98041
|
38873
|
142,7
|
|
28
|
2009
|
2
|
4
|
20,2
|
38,39669
|
20,08
|
0,69
|
17028,50
|
136343
|
93019
|
43324
|
142,7
|
|
29
|
2009
|
2
|
5
|
20,1
|
37,20951
|
18,77
|
0,57
|
16583,70
|
120387
|
83563
|
36824
|
142,7
|
|
30
|
2009
|
2
|
6
|
20,5
|
36,67074
|
20,37
|
0,6
|
17291,40
|
120767
|
81881
|
38886
|
142,7
|
|
31
|
2009
|
3
|
7
|
20,2
|
37,28956
|
21,82
|
0,63
|
17187,30
|
117264
|
74123
|
43141
|
142,7
|
|
32
|
2009
|
3
|
8
|
37,70004
|
22,7
|
0
|
16236,70
|
111514
|
71912
|
39602
|
142,7
|
|
33
|
2009
|
3
|
9
|
20,1
|
37,16315
|
23,4
|
-0,03
|
16767,80
|
119640
|
79249
|
40391
|
142,7
|
|
34
|
2009
|
4
|
10
|
19,8
|
35,84349
|
23,5
|
0
|
17716,00
|
116676
|
77274
|
39402
|
142,7
|
|
35
|
2009
|
4
|
11
|
19,7
|
35,30141
|
23,5
|
0,29
|
17323,40
|
105300
|
71802
|
33498
|
142,7
|
|
36
|
2009
|
4
|
12
|
19,2
|
36,2037
|
23,39
|
0,41
|
24460,50
|
128132
|
86159
|
41973
|
142,7
|
|
37
|
2010
|
1
|
1
|
20,3
|
35,56952
|
23,09
|
1,64
|
13699,00
|
74114
|
50031
|
24083
|
142,8
|
|
38
|
2010
|
1
|
2
|
19,2
|
35,17493
|
22,91
|
0,86
|
17052,80
|
92130
|
64875
|
27255
|
142,8
|
|
39
|
2010
|
1
|
3
|
18,8
|
34,31618
|
22,7
|
0,63
|
17687,40
|
126761
|
83019
|
43742
|
142,8
|
|
40
|
2010
|
2
|
4
|
18,5
|
33,70965
|
23,14
|
0,29
|
19116,20
|
165554
|
100218
|
65336
|
142,8
|
|
41
|
2010
|
2
|
5
|
18,5
|
33,95777
|
23,53
|
0,5
|
17900,40
|
158980
|
101033
|
57947
|
142,8
|
|
42
|
2010
|
2
|
6
|
18,1
|
34,29493
|
23,94
|
0,39
|
19053,40
|
175989
|
110762
|
65227
|
142,8
|
|
43
|
2010
|
3
|
7
|
18
|
34,4558
|
24,04
|
0,36
|
18985,10
|
177192
|
110459
|
66733
|
142,8
|
|
44
|
2010
|
3
|
8
|
17,9
|
34,33911
|
24,31
|
0,55
|
18137,20
|
169775
|
109820
|
59955
|
142,8
|
|
45
|
2010
|
3
|
9
|
18
|
34,98837
|
24,49
|
0,84
|
18526,10
|
186731
|
121529
|
65202
|
142,8
|
|
46
|
2010
|
4
|
10
|
18
|
35,61605
|
24,55
|
0,5
|
19609,60
|
189278
|
120848
|
68430
|
142,8
|
|
47
|
2010
|
4
|
11
|
17,7
|
36,09066
|
24,82
|
0,81
|
19585,30
|
189732
|
123326
|
66406
|
142,8
|
|
48
|
2010
|
4
|
12
|
16,7
|
35,32371
|
25,07
|
1,08
|
28173,20
|
204588
|
134387
|
70201
|
142,8
|
|
49
|
2011
|
1
|
1
|
17,5
|
34,59543
|
25,48
|
2,37
|
15108,80
|
128270
|
82593
|
45677
|
142,9
|
|
50
|
2011
|
1
|
2
|
17,5
|
34,13134
|
25,76
|
0,78
|
18909,10
|
166158
|
116664
|
49494
|
142,9
|
|
51
|
2011
|
1
|
3
|
17,6
|
33,56455
|
25,44
|
0,62
|
19113,90
|
223843
|
160119
|
63724
|
142,9
|
|
52
|
2011
|
2
|
4
|
17,4
|
33,69482
|
25,52
|
0,43
|
20872,00
|
235815
|
164325
|
71490
|
142,9
|
|
53
|
2011
|
2
|
5
|
17,2
|
33,3713
|
26,35
|
0,48
|
19101,70
|
235455
|
168852
|
66603
|
142,9
|
|
54
|
2011
|
2
|
6
|
17,1
|
33,51141
|
26,94
|
0,23
|
21278,90
|
246783
|
173484
|
73299
|
142,9
|
|
55
|
2011
|
3
|
7
|
17,3
|
33,3101
|
27,17
|
-0,01
|
21207,50
|
224858
|
157731
|
67127
|
142,9
|
|
56
|
2011
|
3
|
8
|
17,1
|
34,35833
|
27,66
|
-0,24
|
19953,10
|
224810
|
155870
|
68940
|
142,9
|
|
57
|
2011
|
3
|
9
|
17
|
35,80259
|
27,83
|
-0,04
|
20376,20
|
235707
|
168116
|
67591
|
142,9
|
|
58
|
2011
|
4
|
10
|
17
|
36,57828
|
28,12
|
0,48
|
20727,10
|
240904
|
174055
|
66849
|
142,9
|
|
59
|
2011
|
4
|
11
|
35,79206
|
28,26
|
0,42
|
21309,90
|
239563
|
181385
|
58178
|
142,9
|
|
60
|
2011
|
4
|
12
|
17,1
|
35,99251
|
28,33
|
0,44
|
31568,00
|
251682
|
189746
|
61936
|
142,9
|
|
61
|
2012
|
1
|
1
|
17,7
|
35,30355
|
28,3
|
0,5
|
15963,40
|
154446
|
117184
|
37262
|
143
|
|
62
|
2012
|
1
|
2
|
17,8
|
34,20401
|
28,26
|
0,37
|
20258,10
|
207304
|
159120
|
48184
|
143
|
|
63
|
2012
|
1
|
3
|
18,1
|
33,58691
|
28,29
|
0,58
|
20690,80
|
253100
|
195470
|
57630
|
143
|
|
64
|
2012
|
2
|
4
|
18,5
|
33,68649
|
28,4
|
0,31
|
22190,20
|
266597
|
200779
|
65818
|
143
|
|
65
|
2012
|
2
|
5
|
18,6
|
34,69095
|
28,75
|
0,52
|
21140,10
|
261461
|
200972
|
60489
|
143
|
|
66
|
2012
|
2
|
6
|
18,4
|
36,62899
|
28,96
|
0,89
|
23960,20
|
272599
|
211537
|
61062
|
143
|
|
67
|
2012
|
3
|
7
|
19
|
35,89642
|
28,99
|
1,23
|
22875,60
|
255926
|
194325
|
61601
|
143
|
|
68
|
2012
|
3
|
8
|
19,1
|
35,38304
|
29,03
|
0,1
|
23239,00
|
259051
|
191723
|
67328
|
143
|
|
69
|
2012
|
3
|
9
|
19,6
|
35,5433
|
29,26
|
0,55
|
23230,70
|
259962
|
194159
|
65803
|
143
|
|
70
|
2012
|
4
|
10
|
19,7
|
35,26594
|
29,93
|
0,46
|
23178,40
|
254020
|
188231
|
65789
|
143
|
|
71
|
2012
|
4
|
11
|
19,9
|
35,4013
|
30,34
|
0,34
|
24886,80
|
240577
|
179526
|
61051
|
143
|
|
72
|
2012
|
4
|
12
|
19,7
|
35,04646
|
30,4
|
0,54
|
35364,00
|
253579
|
193431
|
60148
|
143
|
|
73
|
2013
|
1
|
1
|
20,8
|
34,74866
|
30,46
|
0,97
|
17588,40
|
162077
|
124552
|
37525
|
143,3
|
|
74
|
2013
|
1
|
2
|
20,5
|
34,75854
|
30,68
|
0,56
|
23128,90
|
210663
|
162698
|
47965
|
143,3
|
|
75
|
2013
|
1
|
3
|
20,4
|
34,91116
|
30,82
|
0,34
|
24542,90
|
244225
|
191686
|
52539
|
143,3
|
|
76
|
2013
|
2
|
4
|
20,2
|
35,59357
|
30,91
|
0,51
|
26009,40
|
245333
|
188326
|
57007
|
143,3
|
|
77
|
2013
|
2
|
5
|
20,1
|
35,46199
|
30,88
|
0,66
|
22796,50
|
229670
|
179695
|
49975
|
143,3
|
|
78
|
2013
|
2
|
6
|
19,3
|
36,9364
|
30,85
|
0,42
|
26213,10
|
241355
|
191203
|
50152
|
143,3
|
|
79
|
2013
|
3
|
7
|
19,3
|
37,27327
|
30,83
|
0,82
|
25716,20
|
234567
|
184690
|
49877
|
143,3
|
|
80
|
2013
|
3
|
8
|
18,7
|
37,94988
|
31,37
|
0,14
|
25757,40
|
231915
|
180633
|
51282
|
143,3
|
|
81
|
2013
|
3
|
9
|
18,6
|
37,49837
|
32,02
|
0,21
|
24803,10
|
246895
|
194575
|
52320
|
143,3
|
|
82
|
2013
|
4
|
10
|
17,9
|
37,34103
|
32,55
|
0,57
|
25958,10
|
234481
|
184628
|
49853
|
143,3
|
|
83
|
2013
|
4
|
11
|
17,8
|
37,81337
|
32,68
|
0,56
|
26876,80
|
232009
|
183487
|
48522
|
143,3
|
|
84
|
2013
|
4
|
12
|
17,5
|
38,35827
|
32,63
|
0,51
|
38712,00
|
264257
|
210774
|
53483
|
143,3
|
|
85
|
2014
|
1
|
1
|
18,31
|
39,30782
|
32,51
|
0,59
|
18682,70
|
152662
|
123135
|
29527
|
143,7
|
|
86
|
2014
|
1
|
2
|
41,03212
|
32,49
|
0,7
|
24890,20
|
206526
|
167826
|
38700
|
143,7
|
|
87
|
2014
|
1
|
3
|
17,78
|
42,42333
|
32,76
|
1,02
|
24464,00
|
243332
|
196307
|
47025
|
143,7
|
|
88
|
2014
|
2
|
4
|
17,74
|
41,77559
|
32,25
|
0,9
|
28335,00
|
226526
|
178737
|
47789
|
143,7
|
|
89
|
2014
|
2
|
5
|
17,67
|
40,6853
|
33,42
|
0,9
|
26084,00
|
201487
|
158245
|
43242
|
143,7
|
|
90
|
2014
|
2
|
6
|
17,53
|
40,03563
|
33,62
|
0,62
|
27567,40
|
199398
|
159357
|
40041
|
143,7
|
|
91
|
2014
|
3
|
7
|
17,53
|
40,18003
|
33,87
|
0,49
|
28143,80
|
180767
|
143875
|
36892
|
143,7
|
|
92
|
2014
|
3
|
8
|
17,39
|
41,49881
|
34,56
|
0,24
|
28581,20
|
172016
|
136240
|
35776
|
143,7
|
|
93
|
2014
|
3
|
9
|
17,66
|
42,88614
|
35,1
|
0,65
|
26937,20
|
197233
|
151333
|
45900
|
143,7
|
|
94
|
2014
|
4
|
10
|
17,6
|
45,72924
|
35,47
|
0,82
|
27846,30
|
211365
|
160167
|
51198
|
143,7
|
|
95
|
2014
|
4
|
11
|
17,72
|
51,37721
|
35,74
|
1,28
|
28943,20
|
229439
|
186649
|
42790
|
143,7
|
|
96
|
2014
|
4
|
12
|
17,37
|
61,61731
|
35,61
|
2,62
|
41073,40
|
270653
|
220201
|
50452
|
143,7
|
|
97
|
2015
|
1
|
1
|
19,46
|
69,73618
|
35,41
|
3,85
|
13833,20
|
115561
|
93718
|
21843
|
144,1
|
|
98
|
2015
|
1
|
2
|
19,21
|
68,46774
|
35,17
|
2,22
|
27666,30
|
128333
|
98707
|
29626
|
144,1
|
|
99
|
2015
|
1
|
3
|
18,68
|
62,63551
|
35,17
|
1,21
|
27251,30
|
139850
|
104251
|
35599
|
144,1
|