Кореляційний аналіз
ЗМІСТ
ВСТУП
. ПОСТАНОВКА ЗАДАЧІ
.1 КОРЕЛЯЦІЙНИЙ АНАЛІЗ
.2 РЕГРЕСІЙНИЙ АНАЛІЗ
. АЛГОРИТМ РІШЕННЯ ЗАДАЧІ
. ОПИС АЛГОРИТМУ РІШЕННЯ ЗАДАЧІ
. ХАРАКТЕРИСТИКА ДАНИХ І ЇХ УМОВНІ ПОЗНАЧКИ
. ПРОГРАМА РІШЕННЯ ЗАДАЧІ
. ОПИС ПРОГРАМИ
. РІШЕННЯ ЗАДАЧІ У ПАКЕТІ EXCEL
. ГРАФIЧНИЙ АНАЛIЗ
ВИСНОВОК
СПИСОК ВИКОРИСТАНОЇ ЛІТЕРАТУРИ
ДОДАТОК 1. РЕЗУЛЬТАТИ РОБОТИ ПРОГРАМИ
ДОДАТОК 2. РЕЗУЛЬТАТИ РІШЕННЯ ЗАДАЧІ З ВІДОБРАЖЕННЯМ
РОЗРАХУНКІВ ФОРМУЛ В ПАКЕТІ EXCEL
ВСТУП
Припустимо, що приладом з випадковими помилками нескінченно
велике число разів виміряна точна величина. Отримана в результаті такого
експерименту безліч величин називається генеральною сукупністю.
Дослідник при постановці дослідів робить кінцеве, звичайно
невелике, число замірів. Їх можна розглядати, як випадкову вибірку з
гіпотетичної генеральної сукупності. Завдання обробки зводиться до визначення
за даними вибірки показників, що оцінюють параметри генеральної сукупності.
Розподіл величин у сукупності може бути різним. В інженерних
експериментах у більшості випадків можна вважати, що розподіл підпорядковується
нормальному закону. Для нормального розподілу характерна симетричність -
позитивні і негативні помилки зустрічаються однаково часто. Нормальний розподіл
характеризується двома параметрами:
генеральним середнім (математичним очікуванням);
- генеральним середнім квадратичним відхиленням.
Математичне очікування виступає, як найбільш ймовірне
значення вимірюваної величини. Дисперсія ж є чисельною характеристикою ступеня
розсіювання. Звичайно проводиться двадцять п’ять дослідів, і потім визначаються оцінки для математичного очікування і
середньоквадратичного відхилення. Оцінкою для математичного очікування є
вибіркове середнє М, а для визначення оцінки генерального середньоквадратичного
відхилення спочатку знаходиться дисперсія вибірки D.
1. ПОСТАНОВКА
ЗАДАЧІ
1.1 КОРЕЛЯЦІЙНИЙ
АНАЛІЗ
Кореляційний аналіз є одним з широко поширених методів оцінки
статистичних зв’язків. Він відповідає на
питання: чи впливає вхідна величина на
вихідну і яка ступінь зв’язку між величинами? Ступінь зв’язку оцінюється
коефіцієнтом кореляції. Коефіцієнт кореляції між випадковими величинами за
абсолютною величиною не перевищує 1. Чим ближче значення R до 1, тим тісніше лінійний зв’язок
між Х і У. якщо оцінюється вплив на вихідну величину однієї вхідної величини,
то визначається коефіцієнт парної кореляції. В кореляційному аналізі виходять з
того, що як вхідні, так і вихідні величини є однаковими.
Оцінкою коефіцієнта парної кореляції є величина:
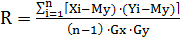 ,
,
де
і - порядковий номер експерименту;
n - кількість експериментів;
Mx, My - математичне очікування для змінних Х
і Y відповідно;
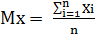 ,
, 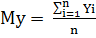 ,
,
Gx, Gy - середньоквадратичне відхилення для
змінних Х і Y відповідно;
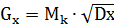 ,
, 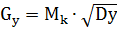 ,
,
Dx, Dy - дисперсія для змінних X i Y відповідно;
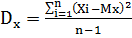 ,
, 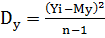 ,
,
k - коефіцієнт, що визначається по таблиці 1, у залежності від числа ступенів
свободи f=n-1
Таблиця 1 - Значення коефіцієнта Mk
|
f
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
60
|
|
Mk
|
1,253
|
1,128
|
1,085
|
1,064
|
1,051
|
1,042
|
1,036
|
1,032
|
1,028
|
1,025
|
1,004
|
- коефіцієнт варіації для змінної X;
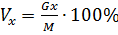 .
.
Перевірка значимості коефіцієнта кореляції здійснюється за
виразом:
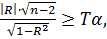
де
 - табличне значення критерію Стьюдента для f=n-2 i відповідного
рівня значимості, величина якого наведена в таблиці 2.
- табличне значення критерію Стьюдента для f=n-2 i відповідного
рівня значимості, величина якого наведена в таблиці 2.
Таблиця 2- Значення критерію Стьюдента для рівня значимості 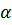 = 0,05
= 0,05
|
f
|
1
|
2
|
4
|
5
|
6
|
8
|
10
|
20
|
30
|
60
|
|
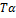
|
12,71
|
4,303
|
3,182
|
2,775
|
2,571
|
2,447
|
2,305
|
2,228
|
2,086
|
2,042
|
2,00
|
1.2 РЕГРЕСІЙНИЙ
АНАЛІЗ
Метою регресійного аналізу є встановлення аналітичної
залежності між вихідною і вхідної величинами. У загальному випадку залежність
між величинами може бути представлена у вигляді таблиці, графічно і аналітично.
Перший спосіб полегшує визначення вихідної величини для наведених у таблиці
значень вхідних; графічний - створює наочність представлення. Аналітична
залежність дозволяє досліджувати функцію методом математичного аналізу, тобто
визначити значення максимуму, мінімуму, точок перегину і т.д. Дана залежність є
найбільш універсальною.
Завдання отримання аналітичної залежності включає три етапи:
вибір рівняння регресії, визначення коефіцієнтів рівняння, перевірка
відповідності встановленої залежності експериментальному матеріалу.
Перший етап.
З’ясувати вид функції можна або з теоретичних міркувань, або
аналізуючи розташування точок (xn, yn) на координатній площині. На практиці зазвичай використовують наступні
залежності:
. лінійна y=ax+b ;
2. параболічна y=ax2+bx+c ;
. логарифмічна y=alnx+b ;
. степенева y=axb ;
. експоненціальна y=beax .
Другий етап.
Найбільш достовірні значення коефіцієнтів виходять при
використанні для їх визначення методу найменших квадратів. Сутність зводиться
до того, що коефіцієнти шукаються такими, щоб сума квадратів відхилень
експериментальних значень функції від значень, обчислених за емпіричною
формулою, виявилося мінімальною.
Наприклад, для експоненцiальної залежностi
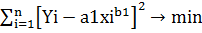 ,
,
Де
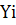 - фактичне значення функції для
- фактичне значення функції для 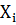 ;
;
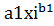 - розрахункове значення функції.
- розрахункове значення функції.
Для визначення коефіцієнтів рівняння необхідно вирішити
систему рівнянь для конкретної залежності.
Для логарифмічної залежності система рівнянь має вигляд:
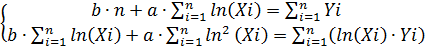
Степенева ті експоненціальна залежності перетворюються в
лінійні наступним чином:
) якщо в степеневій залежності виду lg(y) = b lg(x) + lg(a) застосувати заміну: Y1=lg(y); A=lg(a), X1=lg(x), то отримаємо рівняння виду: Y1=bXi+A.
lg(x) + lg(a) застосувати заміну: Y1=lg(y); A=lg(a), X1=lg(x), то отримаємо рівняння виду: Y1=bXi+A.
Тоді для степеневої залежності система рівнянь має вигляд:
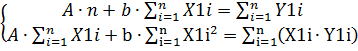
) якщо в експоненціальній залежності виду ln(y) = ax+ln(b) застосувати заміну: Y1=ln(y), B=ln(b), то отримаємо рівняння виду: Y1=aX+B.
Тоді для експоненціальної залежності система нормальних
рівнянь має вигляд:
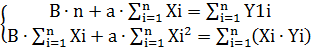
Обробка степеневої і експоненціальної залежностей відбувається
аналогічно лінійній з урахуванням проведених замін. Після розрахунку
коефіцієнтів регресійної моделі необхідно обчислити дійсні коефіцієнти,
використовуючи перетворення:
для степеневої залежності a=10A;
-для експоненційної залежності b=eB.
2. АЛГОРИТМ
РІШЕННЯ ЗАДАЧІ






3. ОПИС
АЛГОРИТМУ РІШЕННЯ ЗАДАЧІ
Блок 1 - початок процесу обробки даних.
Блок 2 - введення початкових даних; кількість дослідів N.
Блок 3, 4 - організація циклу для введення елементів масиву X, Y.
Блок 5-7 - організація циклу для накопичення суми елементів масиву X.
Блок 8 - розрахунок математичного очікування для змінної X.
Блок 9-11 - організація циклу для накопичення суми SDx.
Блок 12 - розрахунок дисперсії для змінної Х.
Блок 13 - присвоєння коефіцієнту Mk значення з таблиці 1.
Блок 14 - розрахунок середнього квадратичного відхилення для
змінної X.
Блок 15 - розрахунок коефіцієнта варіації для змінної Х.
Блок 16-18 - організація циклу для накопичення суми елементів
масиву Y.
Блок 19 - розрахунок математичного очікування для змінної Y.
Блок 20-22 - накопичення суми SDy.
Блок 23 - розрахунок дисперсії для змінної Y.
Блок 24 - розрахунок середнього квадратичного відхилення для
змінної Y.
Блок 28 - розрахунок оцінки коефіцієнта парної кореляції.
Блок 29 - виведення статистичних показників: математичного
очікування, дисперсії, середньоквадратичного відхилення, коефіцієнту варіації,
оцінки коефіцієнта парної кореляції.
Блок 30 - присвоєння коефіцієнту T значення з таблиці 2.
значення з таблиці 2.
Блок 31-33 - перевірка умови і виведення відповідного
повідомлення.
Блок 34-36 - накопичення сум для ступеневої залежності.
Блок 37 - обчислення показників.
Блок 38, 39 - розрахунок коефіцієнтів для ступеневої
залежності.
Блок 40-42 - накопичення сум для експоненційної залежності.
Блок 43 - обчислення визначників.
Блок 44, 45 - розрахунок коефіцієнтів для експоненціальної
залежності.
Блок 46-48 - накопичення сум для логарифмічної залежності.
Блок 49 - обчислення визначників.
Блок 50 - розрахунок коефіцієнтів для логарифмічної
залежності.
Блок 51 - виведення коефіцієнтів для ступеневої,
експоненційної та логарифмічної залежностей.
Блок 52-54 - організація циклу для розрахунку значень, обчислених за емпіричними
формулами.
Блок 55-58 - визначення і виведення мінімального значення
Блок 59-63 - визначення виду залежності та виведення
відповідного повідомлення.
Блок 64 - кінець обробки даних.
4. ХАРАКТЕРИСТИКА
ДАНИХ І ЇХ УМОВНІ ПОЗНАЧКИ
|
№ п/п
|
Назва величини
|
Позначення в алгоритмі
|
Позначення в програмі
|
Тип величини
|
|
1
|
Кількість дослідів
|
N
|
N
|
Integer
|
|
2
|
Експериментальні дані
|
X(), Y()
|
X(), Y()
|
Масив
|
|
3
|
Допоміжні змінні
|
i
|
I
|
Integer
|
|
4
|
Математичне очіування для Х і Y
|
Mx, My
|
Mx, My
|
Real
|
|
5
|
Дисперсія для змінних Х і Y
|
Dx, Dy
|
Dx, Dy
|
Real
|
|
6
|
Допоміжні змінні
|
SDx, SDy, S1, S2, S3, S4, SR
|
SDx, SDy, S1, S2, S3, S4, SR
|
Real
|
|
7
|
Середнє квадратичне відхилення для змінних X i Y
|
Gx, Gy
|
Gx, Gy
|
Real
|
|
8
|
Коефіцієнт варіації для змінної Х
|
Vx
|
Vx
|
Real
|
|
9
|
Коефіцієнт парної кореляції
|
R
|
R
|
Real
|
|
10
|
Константи
|
T , Mk , Mk
|
Real
|
|
11
|
Визначники
|
∆, ∆1, ∆2, ∆3
|
∆, ∆1, ∆2, ∆3
|
Real
|
|
12
|
Коефіцієнти ступеневої залежності
|
A1, B1
|
A1, B1
|
Real
|
|
13
|
Коефіцієнти експоненційної залежності
|
A2, B2
|
A2, B2
|
Real
|
|
14
|
Коефіцієнти логарифмічної залежності
|
A3, B3
|
A3, B3
|
Real
|
|
15
|
Допоміжний масив
|
m()
|
m()
|
Масив
|
|
16
|
Мінімальна сума квадратів
відхилень експериментальних значень
|
min
|
min
|
Real
|
5. ПРОГРАМА
РІШЕННЯ ЗАДАЧІ
kursovaya;x,y,m:
array[1..15] of real;,n:integer; nmin,min, S1, S2, S3, S4, A1, A2, A3, B1, B2,
B3, d, d1, d2, Mx, My, Dx, Dy, SDx,SDy, Gx, Gy, Vx, SR, R, S, Mk,
Ta:real;('vvod n');(n);('vvod mas x');i:=1 to n do('vvod
x[',i,']=');(x[i]);;('vvod mas y');i:=1 to n do('vvod
y[',i,']=');(y[i]);;:=0;i:=1 to n do:=S+x[i];:=S/n;:=0;i:=1 to n
do:=SDx+sqr(x[i]-Mx);:=SDx/(n-1);:=1.025;:=Mk*sqrt(Dx);:=(Gx/Mx)*100;:=0;i:=1
to n do:=S+y[i];:=S2/n;i:=1 to n do:=Sdy+sqr(y[i]-My);:=Sdy/(n-1);:=Mk*sqrt(Dy);:=0;i:=1
to n
do:=SR*((x[i])-Mx)*(y[i]-My);:=SR/(n-1)*Gx*Gy;('Mx=',Mx:5:3,'Gx=',Gx:5:3,'Dx=',Dx:5:3,'Vx=',Vx:5:3,'R=',R:5:3);:=2.228;(abs(R))*sqrt(n-2)/sqrt(1-sqrt(R))>Ta
then('коефіцієнт кореляції
задовільнює умові ')(''коефіцієнт кореляції не задовільнює умові ');:=0; S2:=0; S3:=0; S4:=0;i:=1 to n
do:=S1+ln(x[i])/ln(10);:=S2+ln(y[i])/ln(10);:=S3+sqr(ln(x[i])/ln(10));:=S4+(ln(x[i])/ln(10))*(ln(y[i])/ln(10));:=N*S3-S1*S1;:=S2*S3-S1*S4;:=N*S4-S2*S1;:=d1/d;:=d2/d;:=exp(A1*ln(10));:=0;
S2:=0; S3:=0; S4:=0;i:=1 to n
do:=S1+x[i];:=S2+ln(y[i]);:=S3+sqr(x[i]);:=S4+(X[i]*ln(y[i]));:=N*S3-S1*S1;:=S2*S3-S1*S4;:=N*S4-S2*S1;:=d1/d;:=d2/d;:=exp(B2);:=0;
S2:=0; S3:=0; S4:=0;i:=1 to n
do:=S1+ln(x[i]);:=S2+y[i];:=S3+x[i];:=S4+ln(x[i])*y[i];:=N*S3-S1*S1;:=S2*S3-S1*S4;:=N*S4-S2*S1;:=d2/d;:=d1/d;('Коефіцієнти ступеневої
залежності: a1=',a1:5:3, '
b1=',b1:5:3);('Коефіцієнти
експоненційної залежності:
a2=',a2:5:3, ' b2=',b2:5:3);('Коефіцієнти
логарифмічної залежності:
a3=',a3:5:3, ' b3=',b3:5:3);[1]:=0;m[2]:=0;m[3]:=0;i:= 1 to n
do[1]:=m[1]+sqr(y[i]-(A1*exp(B1*ln(x[i]))));[2]:=m[2]+sqr(y[i]-(B2*exp(A2*x[i])));[3]:=m[3]+sqr(y[i]-(A3*ln(x[i])+B3));;:=m[1];:=1;i
:=2 to n dom[i]<min then:=m[i];:=i;;;nmin=2 then('експоненційна залежність')nmin=3 then('логарифмічна залежність')('ступенева залежність');.
6. ОПИС
ПРОГРАМИ
коефіцієнт кореляція залежність логарифмічний
У даній роботі для рішення завдання використовується програма
Pascal. Програма починається з
заголовка Program kursovaya;
Після заголовка іде розділ оголошення змінних Var, наприклад :
Var: i, n: integer; nmin,min, S1, S2, S3, S4, A1, A2,
A3, B1, B2, B3, d, d1, d2, Mx, My, Dx, Dy, SDx,SDy, Gx, Gy, Vx, SR, R, S, Mk,
Ta:real; x,y,m:mas1;
У роботі використовуються такі типи даних: цілий - (integer), дійсний - (real), масиви - (array).
Розділ операторів полягає в операторні дужки : begin .. end.
Для введення вихідних даних використовується оператор read і оператор writeln для виведення пояснювального тексту,
наприклад:
writeln (‘ввод
n’); read (n);
Для введення елементів масиву використовується оператор циклу
з відомим числом повторень for i оператор
read, наприклад:
for i:= 1 to n do read (y[i]);
Для перевірки логічних умов використовується умовний оператор
if… then…else, наприклад:
if abs(r)*sqrt(n-2)/sqrt(1-sqr(R))>=Ta then('Коефіцієнт задовольняє умові ')('Коефіцієнт не задовольняє умові ');
Для виведення результатів на екран використовується оператор writeln, наприклад:
writeln (‘R= ‘, R:7:3);
де в апострофах полягає пояснювальний текст, перша цифра в
шаблоні виведення змінної позначає загальну кількість позицій для виведення
числа, а друга цифра - кількість символів у дробовій частині.
Програма завершується оператором end з крапкою.
7. РІШЕННЯ
ЗАДАЧІ У ПАКЕТІ EXCEL
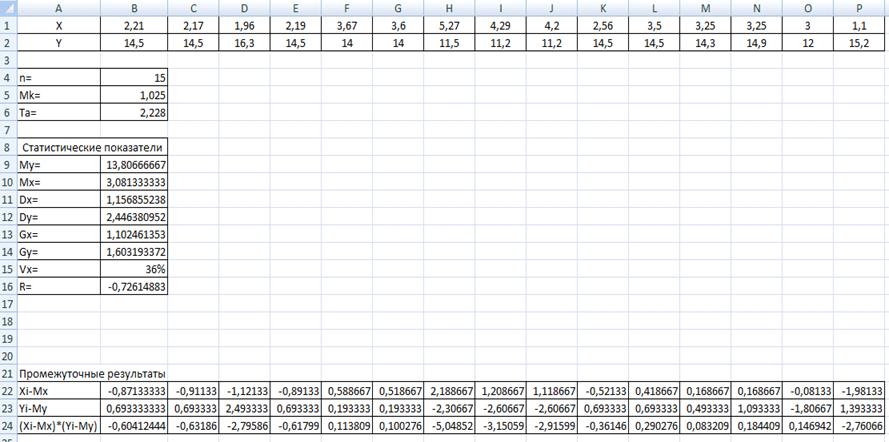
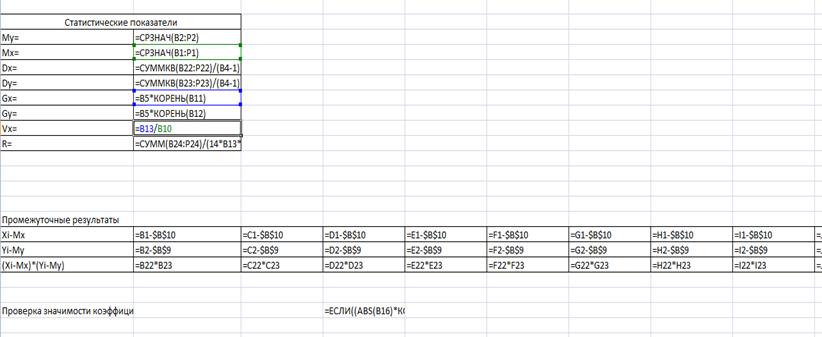
Рис. 1- Розрахунок статистичних показників на робочому листі
1
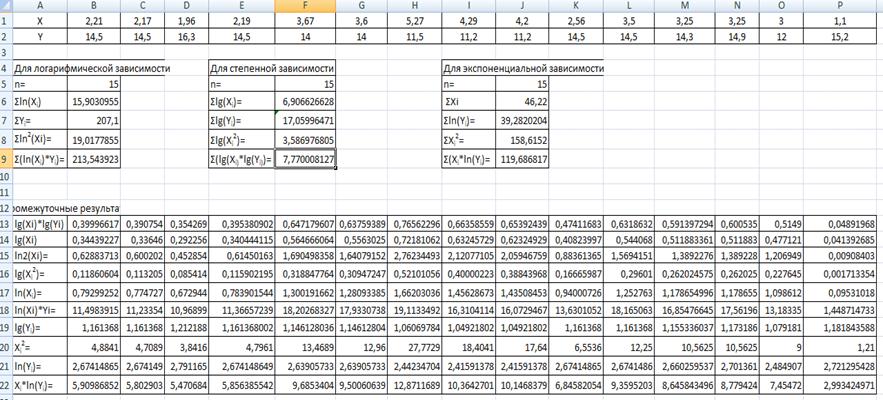
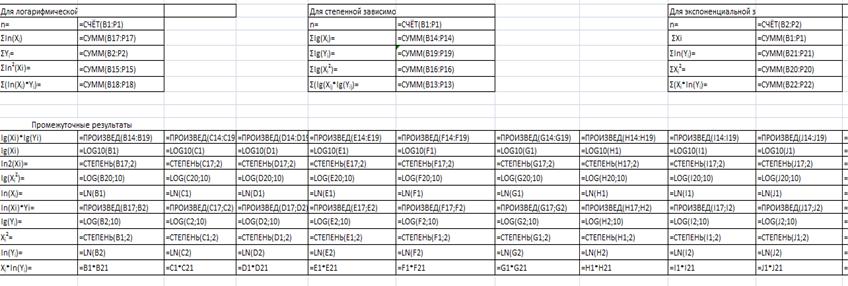
Рис. 2-
Розрахунок допоміжних
сум на робочому листі 2
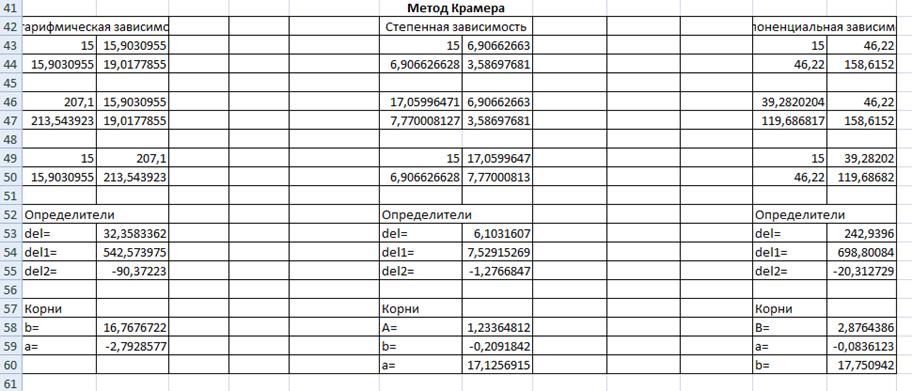
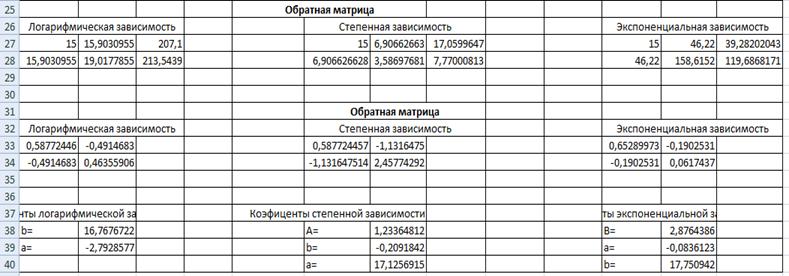
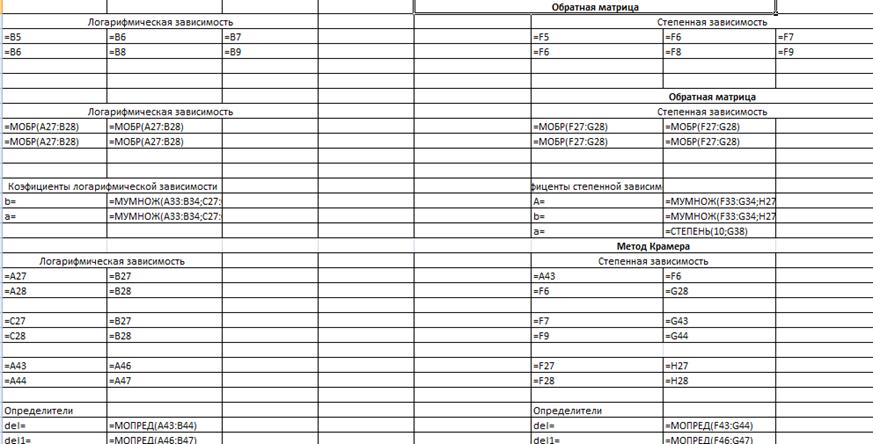
Рис3-Розрахунок коефіцієнтів методом Крамера, та методом
зворотної матриці на робочому листі 3
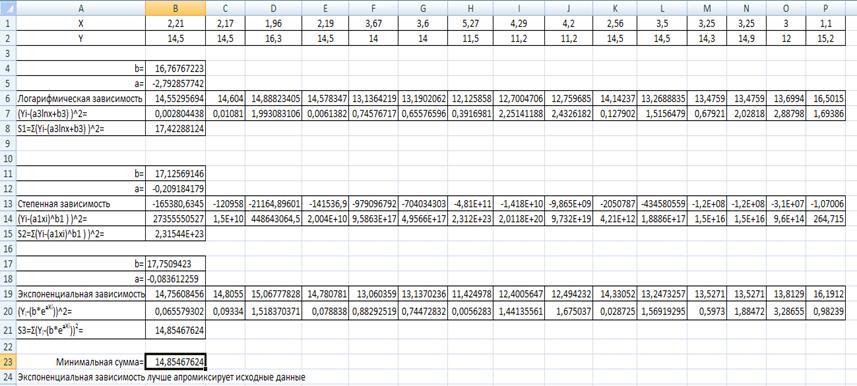
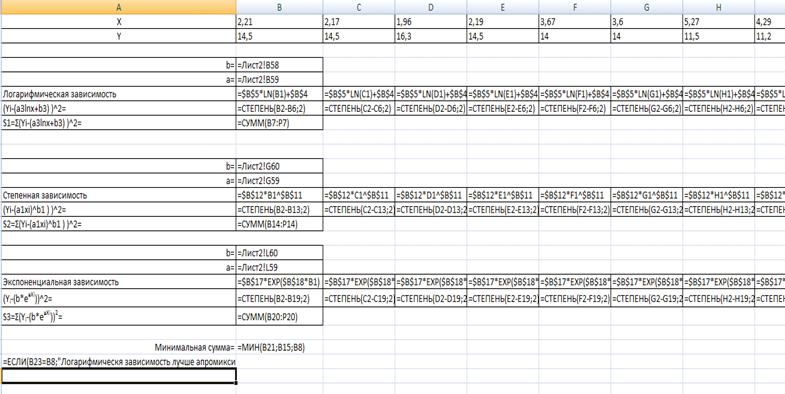
Рис. 4
- Оцінка погрішності
методу найменших квадратів на робочому листі 4
8.
ГРАФIЧНИЙ АНАЛIЗ
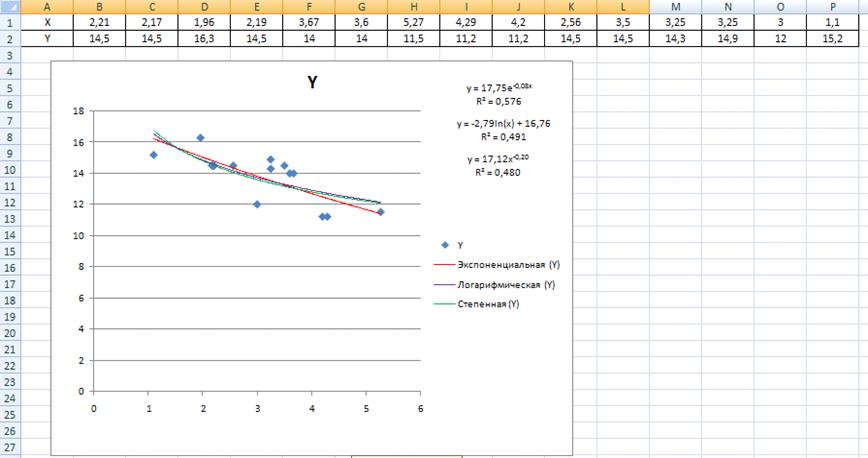
Рис. 5 Побудова графіку на робочому листі 4
За даними в таблиці, було побудовано графік, нанесені лінії
тренду та рівняння залежностей: експоненціальної,
логарифмічної, ступеневої.
Рівняння експоненціальної залежності  ;
;
Рівняння логарифмічної залежності 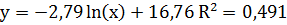
Рівняння ступеневої залежності 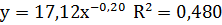
За рівняннями встановлено, що експоненціальна залежність
краще апроксимує дані, так як значення R найбільш наближається до одиниці.
ВИСНОВОК
У результаті курсової роботи було проведено кореляційний
аналіз і знайдені статистичні показники - R=-0,73, Mx=3,081; Dx=1,16; Gx=1,102; Vx=36% Даний коефіцієнт показує, яка
ступінь зв'язку між величинами. Отриманий коефіцієнт задовольняє умові, що було
з'ясовано при обробці даних в програмі Паскаль і абсолютно збігається з
результатом, отриманим в пакеті Excel.
У результаті курсової роботи були отримані коефіцієнти для
трьох залежностей:
- Для логарифмiчної залежності: a= -2,79; b=16,77;
- Для ступеневої залежності: a=1,02; b=28,51;
Для експоненційної залежності: a=
-0,08; b=17,75;
У результаті курсової при обробці експериментальних даних було з'ясовано, що параболічна залежність краще
апроксимує вихідні дані.
Курсова робота виконувалася на основі знань, отриманих при вивченні курсу
«Обчислювальна математика і програмування». Для виконання роботи було використано програми: Microsoft Word, Microsoft Excel, Pascal ABC, що закріпило отримані
знання.
СПИСОК
ВИКОРИСТАНОЇ ЛІТЕРАТУРИ
1. Методическое пособие к выполнению лабораторных работ в среде
программирования TURBO PASCAL(для
студентов направления подготовки «химическая технология»)/сост.: Л.А.
Лазебная.- Донецк: ДонНТУ, 2012. - 95 с.
. Методическое пособие к выполнению лабораторных работ в текстовом
редакторе WORD /сост.: Л.А. Лазебная, И.Ю. Анохин. - Донецк: ДонНТУ, 2012. - 82
с.
. Методическое пособие к выполнению лабораторных работ по теме
«решение математических задач средствами Excel»/сост.: Л.А. Лазебная, С. В.
Масло.- Донецк: ДонНТУ, 2006. - 37 с.
ДОДАТОК 1.
РЕЗУЛЬТАТИ РОБОТИ ПРОГРАМИ
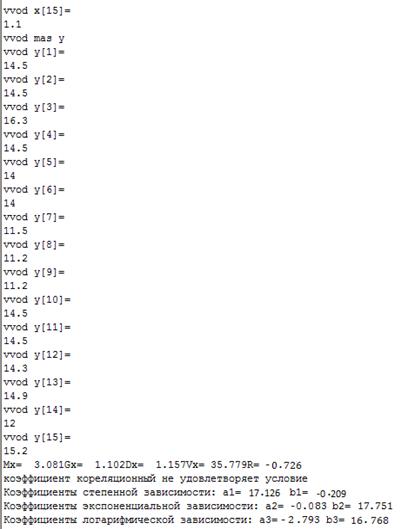
ДОДАТОК 2.
РЕЗУЛЬТАТИ РІШЕННЯ ЗАДАЧІ З ВІДОБРАЖЕННЯМ РОЗРАХУНКІВ ФОРМУЛ В ПАКЕТІ EXCEL