Изучение взаимосвязей социально-экономических явлений и процессов на примере рынка автомобилей в Москве и Московской области за 2014 год (марка автомобиля Suzuki Liana)
МИНИСТЕРСТВО
ОБРАЗОВАНИЯ МОСКОВСКОЙ ОБЛАСТИ
Государственное
образовательное учреждение высшего профессионального образования
МОСКОВСКИЙ
ГОСУДАРСТВЕННЫЙ ОБЛАСТНОЙ УНИВЕРСИТЕТ (МГОУ)
Кафедра
«Прикладная математика и информатика»
КУРСОВАЯ
РАБОТА
по
дисциплине «Теория статистики»
тема:
Изучение взаимосвязей социально-экономических явлений и процессов на примере
рынка автомобилей в Москве и Московской области за 2014 год (марка автомобиля Suzuki
Liana)
Научный руководитель:
старший преподаватель Жигирева Е.Г.
(ученая степень, ученое звание, фамилия,
инициалы)
Москва
Оглавление
Введение
1. Исходные данные
2. Аналитические группировки
. Многомерная группировка
. Интервальный вариационный
ряд
. Критерий Пирсона
. Определение доверительного
интервала и оптимального объема выборки
. Корреляционно-регрессионный
анализ
Заключение
Список литературы
Введение
наблюдение
вариационный ряд
В наше время проведение выборочных
статистических наблюдений является особо актуальным, поскольку всё больше и
больше факторов влияют на стоимость тех или иных товаров и услуг.
Цель курсовой работы получить представление об
изучаемом объекте, установить взаимосвязи и зависимости различных сторон
изучаемого явления, определить влияние факторов на результативный признак. В нашем
случае мы будем определять зависимость цены машины Suzuki
Liana от времени её
эксплуатации и пробега.
Задачи курсовой работы:
. Используя сайт auto.ru,
провести выборочное наблюдение 50 предлагаемых на продажу автомобилей марки Suzuki
Liana.
. Для выявления зависимости
результативного признака Y
(цена) от признаков-факторов X
(время эксплуатации) и X
(пробег) провести аналитические группировки автомобилей.
. На основании данных статистического
наблюдения, применяя метод многомерной средней, выделить три группы
автомобилей.
. Исследовать статистическое
распределение Y с помощью
интервального вариационного ряда.
· построить интервальный ряд;
· построить графическое изображение
(гистограмму и кумуляту);
· вычислить показатели центра
(среднюю, моду и медиану), вариации (дисперсию, среднее квадратическое
отклонение и коэффициент вариации) и формы (коэффициенты асимметрии и эксцесса)
. Провести проверку с помощью критерия
согласия 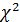 Пирсона,
соответствие эмпирических распределений нормальному распределению на уровне
значимости
Пирсона,
соответствие эмпирических распределений нормальному распределению на уровне
значимости 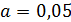 .
.
. На основании данных выборочного
наблюдения определить доверительный интервал, в котором заключена средняя цена
продаваемых машин, гарантируя результат с вероятностью 0,9 и 0,95.
. На основании данных выборочного
наблюдения:
· составить уравнение множественной
регрессии результативного признака 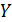 ,
обосновав систему факторов, включённых в модель;
,
обосновав систему факторов, включённых в модель;
· определить множественный коэффициент
корреляции и частные коэффициенты корреляции;
· сопоставить роль признаков-факторов 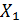 и
и
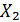 в
формировании результативного признака
в
формировании результативного признака 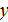 , вычислив
коэффициенты эластичности.
, вычислив
коэффициенты эластичности.
Объектом исследования является выборка 50 машин
марки Suzuki
Liana.
1. Исходные данные
С помощью сайта Авто.ру составим сводную таблицу
автомобилей, в которую будут включены данные по 50 автомобилям Suzuki
Liana: цена, время
эксплуатации и пробег.
Табл. 1.1
|
№
автомобиля
|
Цена,
тыс. рублей (Y)
|
Время
эксплуатации, лет (Х1)
|
Пробег,
тыс. км (Х2)
|
|
1
|
165
|
10
|
170
|
|
2
|
170
|
11
|
124
|
|
3
|
195
|
10
|
189
|
|
4
|
195
|
7
|
87
|
|
5
|
203
|
8
|
150
|
|
6
|
205
|
11
|
124
|
|
7
|
210
|
11
|
210
|
|
8
|
216
|
9
|
93
|
|
9
|
218
|
8
|
148
|
|
10
|
220
|
10
|
112
|
|
11
|
225
|
10
|
95
|
|
12
|
230
|
10
|
101
|
|
13
|
230
|
9
|
202
|
|
14
|
235
|
8
|
91
|
|
15
|
237
|
10
|
117
|
|
16
|
239
|
7
|
101
|
|
17
|
245
|
9
|
144
|
|
18
|
248
|
10
|
138
|
|
19
|
250
|
8
|
160
|
|
20
|
255
|
7
|
90
|
|
21
|
260
|
9
|
117
|
|
22
|
265
|
7
|
93
|
|
23
|
265
|
9
|
181
|
|
24
|
267
|
8
|
104
|
|
25
|
267
|
8
|
71
|
|
26
|
270
|
9
|
138
|
|
27
|
270
|
10
|
119
|
|
28
|
270
|
7
|
98
|
|
29
|
275
|
7
|
111
|
|
30
|
278
|
7
|
112
|
|
31
|
280
|
8
|
93
|
|
32
|
285
|
8
|
108
|
|
33
|
292
|
6
|
84
|
|
34
|
295
|
6
|
80
|
|
35
|
296
|
6
|
81
|
|
36
|
300
|
9
|
115
|
|
37
|
305
|
9
|
85
|
|
38
|
310
|
7
|
96
|
|
39
|
315
|
7
|
115
|
|
40
|
317
|
6
|
74
|
|
41
|
320
|
7
|
78
|
|
42
|
328
|
6
|
128
|
|
43
|
340
|
8
|
83
|
|
44
|
345
|
7
|
73
|
|
45
|
347
|
7
|
112
|
|
46
|
350
|
7
|
150
|
|
47
|
350
|
8
|
134
|
|
48
|
360
|
7
|
173
|
|
49
|
364
|
7
|
70
|
|
50
|
389
|
6
|
76
|
|
Итого
|
13566
|
406
|
5798
|
. Аналитические группировки
С целью выявления зависимости результативного
признака Y от признаков
факторов X1 и X2
проведём аналитические группировки продаваемых автомобилей по времени
эксплуатации и пробегу.
Аналитическая группировка - группировка,
выявляющая взаимосвязи между изучаемыми явлениями и их признаками.
Аналитические группировки используются для исследования взаимных связей,
существующих между показателями, характеризующими рассматриваемую совокупность
данных.
Количество интервалов группировки вычисляется по
формуле Стерджесса:
= 1 + 3,322lgn (2.1)
= 1 + 3,322lg50 = 6,64, где n
- объём выборки.
Округлим 6,64 до целого, получим число
интервалов, равное 7.
Ширина интервалов вычисляется по формуле:
h = (xmax
- xmin)/m,
(2.2)
где m
- количество интервалов
h1 = (11 - 6)/7 =
5/7 - сократим количество интервалов до 6
h2 = (210 - 70)/7 = 20
Табл. 2.1
Аналитическая группировка по времени
эксплуатации автомобиля
|
Группы
автомобилей по времени эксплуатации
|
Средняя
цена, тыс. руб.
|
|
6
|
319,50
|
|
7
|
299,20
|
|
8
|
269,50
|
|
9
|
261,38
|
|
10
|
223,75
|
|
11
|
195,00
|
|
Итого
|
|
По результатам данной аналитической группировки
можно сделать вывод: цена автомобиля снижается с увеличением времени его
эксплуатации.
Табл. 2.2
Аналитическая группировка по пробегу автомобиля
|
Группы
автомобилей по пробегу
|
Средняя
цена, тыс. руб.
|
|
70
- 90
|
306,15
|
|
90
- 110
|
256,55
|
|
110
- 130
|
268,08
|
|
130
- 150
|
269,14
|
|
150
- 170
|
207,50
|
|
170
- 190
|
273,33
|
|
190
- 210
|
220,00
|
|
Итого
|
|
Из результатов аналитической группировки видно:
в целом цена автомобиля снижается при увеличении его пробега, но данное влияние
не столь однозначно, как в случае влияния времени эксплуатации.
. Многомерная группировка
На основании данных статистического наблюдения,
применяя метод многомерной средней, выделим три типа автомобилей.
В случае сложной группировки комбинация двух
признаков ещё позволяет сохранить обозримость статистической таблицы, но
комбинация трех и более признаков дает неудовлетворительный результат. Число
подгрупп сильно возрастает, и в них становится не- возможной равномерность
статистических единиц. Сохранить сложность описания групп и преодолеть
недостатки комбинационной группировки позволяет метод многомерных группировок,
или метод многомерной классификации. Простейший вариант многомерной
классификации - метод многомерной средней.
Цель многомерной группировки: выявить
усредненное влияние признаков-факторов (времени эксплуатации и пробега) на
результат.
Нормированный уровень признака вычисляется по
формуле:
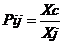 ; (3.1)
; (3.1)
где Xс
- средняя величина исследуемого признака, Xj
-j-й элемент
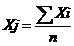 ; (3.2)
; (3.2)
где ΣXi
- сумма значений признака для всех элементов совокупности
Многомерное среднее находим по формуле:
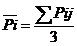 ; (3.3)
; (3.3)
Табл. 3.1
|
№
|
Нормированные
уровни признаков
|
многомерная
средняя
|
|
автомобиля
|
Q
|
P1
|
P2
|
(P1+P2)/2
|
|
1
|
0,61
|
1,23
|
1,47
|
1,35
|
|
2
|
0,63
|
1,35
|
1,07
|
1,21
|
|
3
|
0,72
|
1,23
|
1,63
|
1,43
|
|
4
|
0,72
|
0,86
|
0,75
|
0,81
|
|
5
|
0,75
|
0,99
|
1,29
|
1,14
|
|
6
|
0,76
|
1,35
|
1,21
|
|
7
|
0,77
|
1,35
|
1,81
|
1,58
|
|
8
|
0,80
|
1,11
|
0,80
|
0,96
|
|
9
|
0,80
|
0,99
|
1,28
|
1,14
|
|
10
|
0,81
|
1,23
|
0,97
|
1,10
|
|
11
|
0,83
|
1,23
|
0,82
|
1,03
|
|
12
|
0,85
|
1,23
|
0,87
|
1,05
|
|
13
|
0,85
|
1,11
|
1,74
|
1,43
|
|
14
|
0,87
|
0,99
|
0,78
|
0,89
|
|
15
|
0,87
|
1,23
|
1,01
|
1,12
|
|
16
|
0,88
|
0,86
|
0,87
|
0,87
|
|
17
|
0,90
|
1,11
|
1,24
|
1,18
|
|
18
|
0,91
|
1,23
|
1,19
|
1,21
|
|
19
|
0,92
|
0,99
|
1,38
|
1,19
|
|
20
|
0,94
|
0,86
|
0,78
|
0,82
|
|
21
|
0,96
|
1,11
|
1,01
|
1,06
|
|
22
|
0,98
|
0,86
|
0,80
|
0,83
|
|
23
|
0,98
|
1,11
|
1,56
|
1,34
|
|
24
|
0,98
|
0,99
|
0,90
|
0,95
|
|
25
|
0,98
|
0,99
|
0,61
|
0,80
|
|
26
|
1,00
|
1,11
|
1,19
|
1,15
|
|
27
|
1,00
|
1,23
|
1,03
|
1,13
|
|
28
|
1,00
|
0,86
|
0,85
|
0,86
|
|
29
|
1,01
|
0,86
|
0,96
|
0,91
|
|
30
|
1,02
|
0,86
|
0,97
|
0,92
|
|
31
|
1,03
|
0,99
|
0,80
|
0,90
|
|
32
|
1,05
|
0,99
|
0,93
|
0,96
|
|
33
|
1,08
|
0,74
|
0,72
|
0,73
|
|
34
|
1,09
|
0,74
|
0,69
|
0,72
|
|
35
|
1,09
|
0,74
|
0,70
|
0,72
|
|
36
|
1,11
|
1,11
|
0,99
|
1,05
|
|
37
|
1,12
|
1,11
|
0,73
|
0,92
|
|
38
|
1,14
|
0,86
|
0,83
|
0,85
|
|
39
|
1,16
|
0,86
|
0,99
|
0,93
|
|
40
|
1,17
|
0,74
|
0,64
|
0,69
|
|
41
|
1,18
|
0,86
|
0,67
|
0,77
|
|
42
|
1,21
|
0,74
|
1,10
|
0,92
|
|
43
|
1,25
|
0,99
|
0,72
|
0,86
|
|
44
|
1,27
|
0,86
|
0,63
|
0,75
|
|
45
|
1,28
|
0,86
|
0,97
|
0,92
|
|
46
|
1,29
|
0,86
|
1,29
|
1,08
|
|
47
|
1,29
|
0,99
|
1,16
|
1,08
|
|
48
|
1,33
|
0,86
|
1,49
|
1,18
|
|
49
|
1,34
|
0,86
|
0,6
|
0,73
|
|
итого
|
50
|
50
|
50
|
50
|
|
среднее
значение признаков
|
1,00
|
1,00
|
1,00
|
1,00
|
Распределим автомобили на три типа, для этого
вычислим ширину интервала по формуле:
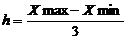 = (1,58 - 0,69)/3
= 0,3
= (1,58 - 0,69)/3
= 0,3
Табл. 3.2
|
Группы
автомобилей по многомерной средней
|
Средняя
цена, тыс. руб.
|
|
0,69
- 0,99
|
292,22
|
|
0,99
- 1,29
|
256,16
|
|
1,29
- 1,59
|
217,50
|
|
Итого
|
50
|
Вывод: Многомерный анализ показывает усреднённое
влияние времени эксплуатации и пробега на цену автомобиля. Здесь, как и в
аналитических группировках, прослеживается обратная зависимость между
результативным признаком (цена) и факторными (пробег и время эксплуатации).
4. Интервальный вариационный ряд
Исследовать статистическое распределение
результативного признака Y
с помощью интервального вариационного ряда, для чего:
-построить интервальный ряд;
дать его графическое изображение (гистограмма и
кумулята);
вычислить показатели центра (среднюю, моду и
медиану), вариации (дисперсию, среднее квадратическое отклонение и коэффициент
вариации) и формы (коэффициенты ассиметрии и эксцесса).
Интервальным вариационным рядом называют
упорядоченную совокупность интервалов варьирования значений случайной величины
с соответствующими частотами или относительными частотами попаданий в каждый из
них значений величины.
Для построения интервального вариационного ряда
нужно определить: количество интервалов по формуле Стерджесса: 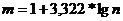 =
1 + 3,322lg50 = 6,64, где n
- количество автомобилей, участвующих в исследовании. Как и в аналитических
группировках, количество интервалов будет равняться 7.
=
1 + 3,322lg50 = 6,64, где n
- количество автомобилей, участвующих в исследовании. Как и в аналитических
группировках, количество интервалов будет равняться 7.
Ширину интервалов определяется по формуле:
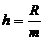
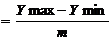 (4.1)
(4.1)
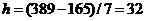 (тыс. рублей)
(тыс. рублей)
где m
- количество интервалов,
R - размах вариации,
равен разнице между максимальным и минимальным значением признака.
Табл. 4.1
|
Интервалы
цен, тыс. рублей, Yi
|
Количество
автомобилей, ni
|
niнак
|
|
165
- 197
|
4
|
4
|
|
197
- 229
|
7
|
11
|
|
229
- 261
|
9
|
20
|
|
261
- 293
|
14
|
34
|
|
293
- 325
|
7
|
41
|
|
325
- 357
|
6
|
47
|
|
357
- 389
|
3
|
50
|
|
Итого
|
50
|
|
Гистограмма (см. рис. 1) - это диаграмма,
построенная в столбиковой форме, в которой величина показателя изображается
графически в виде столбика.
Кумулята (см. рис. 2) - это графическое
изображение статистического ряда накопленных данных, полученной информации
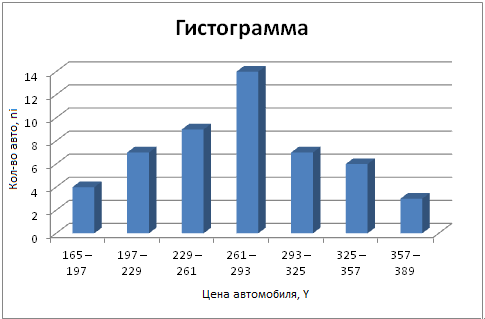
Рис. 4.1. Гистограмма
Показатели центра. Средняя арифметическая - одна
из наиболее распространённых мер центральной тенденции.
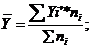 (4.2)
(4.2)
Y`i - середина
соответствующего интервала
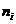 - частота
соответствующего интервала
- частота
соответствующего интервала
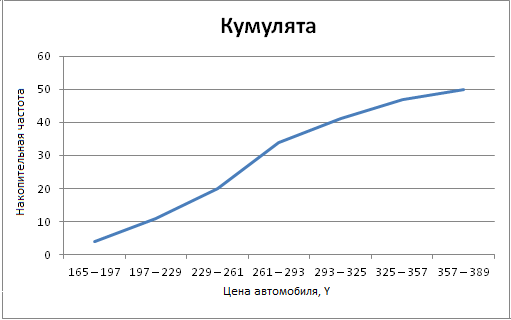
Рис. 4.2. Кумулята
Табл. 4.2
|
интервалы
цен Yi
|
кол-во
авто ni
|
Y`i
|
Y`ini
|
|
165
- 197
|
4
|
181
|
724
|
|
197
- 229
|
7
|
213
|
1491
|
|
229
- 261
|
9
|
245
|
2205
|
|
261
- 293
|
14
|
277
|
3878
|
|
293
- 325
|
7
|
309
|
2163
|
|
325
- 357
|
6
|
341
|
2046
|
|
357
- 389
|
3
|
373
|
1119
|
|
итого
|
50
|
|
13626
|
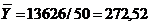 (тыс. рублей)
(тыс. рублей)
Мода - это значение признака, наиболее часто
встречающееся в изучаемой совокупности.
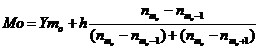 (4.3)
(4.3)
где
Ymо - нижняя
граница модального интервала
h - интервальный шаг
(величина модального интервала)
nмо, мо+1, мо-1 -
частоты модального, предмодального и послемодального интервала 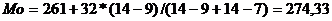 (тыс.
рублей)
(тыс.
рублей)
Медиана - это значение варьирующего признака,
которое делит ряд распределения на две равные части по объёму частот или
частостей.
Определим медианный интервал. Разделим 50 на 2,
получим 25. Накопительное 25 находится между 20 и 34, берём наибольшее число -
34. Таким образом, медианный интервал - это 261 - 293.
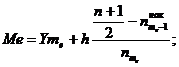 (4.4)
(4.4)
где
YMe - нижняя
граница медианного интервала
h - величина
медианного интервала
nMе-1нак -
накопленная частота предмедианного интервала
nме - частота
медианного интервала
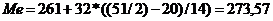 (тыс. рублей)
(тыс. рублей)
Вывод: так как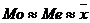 ,
можно предположить, что распределение данного признака близко к симметричному,
но требуется дальнейшее исследование.
,
можно предположить, что распределение данного признака близко к симметричному,
но требуется дальнейшее исследование.
Показатели вариации. Дисперсия - мера разброса
величины, то есть её отклонения от математического ожидания.
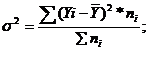 (4.5)
(4.5)
где Yi’
- середина соответствующего интервала;
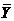 - среднее;
- среднее;
ni -
количество автомобилей в соответствующем интервале
Табл. 4.3
|
Интервалы
цен Yi
|
кол-во
авто ni
|
Y`i -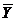
|
(Y`i -)2
|
(Y`i -)2ni
|
|
165
- 197
|
4
|
181
|
-91,52
|
8375,91
|
33503
|
|
197
- 229
|
7
|
213
|
-59,52
|
3542,63
|
24798
|
|
229
- 261
|
9
|
245
|
-27,52
|
757,35
|
6816
|
|
261
- 293
|
14
|
277
|
6,48
|
42,00
|
588
|
|
293
- 325
|
7
|
309
|
38,48
|
1480,71
|
10365
|
|
325
- 357
|
6
|
341
|
70,48
|
4967,43
|
29805
|
|
357
- 389
|
3
|
373
|
104,48
|
10916,07
|
32748
|
|
Итого
|
50
|
|
|
|
138623
|
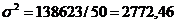 (тыс. рублей)2
(тыс. рублей)2
Среднее квадратическое отклонение показывает, на
сколько в среднем отклоняются конкретные варианты признака от среднего
значения.
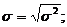 (4.6)
(4.6)
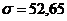 (тыс. рублей)
(тыс. рублей)
Коэффициент вариации - это процентное отношение
СКО к средней величине признака.
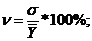 (4.7)
(4.7)
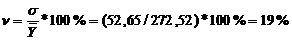
где  -
среднее квадратическое отклонение;
-
среднее квадратическое отклонение;
- среднее
Так как 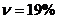 ,
что меньше 33%, то можно считать данную совокупность однородной.
,
что меньше 33%, то можно считать данную совокупность однородной.
Проверим распределение на нормальность,
используя правило «трёх сигм»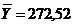 (тыс. рублей),
(тыс. рублей), 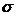 =
52,65 (тыс. руб.)
=
52,65 (тыс. руб.)
Находим интервалы по среднему квадратическому
отклонению (±1; ±2;±3),
в таблице приведены полученные результаты
Табл. 4.4.
Результаты по правилу «трёх сигм»
|
Интервал
по СКО
|
кол-во
авто, шт.
|
Эмпирическое
распределение, %
|
Нормальное
распределение, %
|
|
209,87
- 335,17
|
37
|
74
|
68,3
|
|
147,22
- 397,82
|
50
|
100
|
95,44
|
|
84,57
- 460,47
|
50
|
100
|
99,72
|
Сравнив эмпирическое распределение с нормальным,
можно сделать вывод, что эмпирическое распределение близко к нормальному, но не
совпадает с ним.
Табл. 4.5
Показатели формы распределения признака
|
Интервалы
цен Yi
|
кол-во
авто ni
|
Y`i
|
Y`i -
|
(Y`i -)3
|
(Y`i -)3ni
|
(Y`i -)4
|
(Y`i -)4ni
|
|
165
- 197
|
4
|
181
|
-91,52
|
-766563
|
-3066253
|
70155875
|
280623500
|
|
197
- 229
|
7
|
213
|
-59,52
|
-210857
|
-1476002
|
12550230,2
|
87851611
|
|
229
- 261
|
9
|
245
|
-27,52
|
-20842,3
|
-187581
|
573579,628
|
5162216,7
|
|
261
- 293
|
14
|
277
|
6,48
|
272,0978
|
3809,369
|
1763,19369
|
24684,712
|
|
293
- 325
|
7
|
309
|
38,48
|
56977,74
|
398844,2
|
2192503,29
|
15347523
|
|
325
- 357
|
6
|
341
|
70,48
|
350104,5
|
2100627
|
24675364,8
|
148052189
|
|
357
- 389
|
3
|
373
|
104,48
|
1140511
|
3421533
|
119160593
|
357481779
|
|
Итого
|
50
|
|
|
|
1194978
|
|
894543503
|
Коэффициент асимметрии - величина,
характеризующая асимметрию распределения данной случайной величины
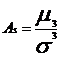 (4.8)
(4.8)
где 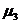
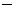 центральный момент
3-го порядка;
центральный момент
3-го порядка;
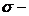 среднее
квадратическое отклонение.
среднее
квадратическое отклонение.
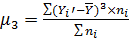 (4.9)
(4.9)
где Yi’
- середина соответствующего интервала;
- среднее;
ni -
количество автомобилей в соответствующем интервале
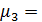 1194978
1194978
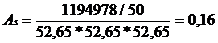
Вывод: так как коэффициент асимметрии
положительный, то в выборке присутствует правосторонняя асимметрия, а это
значит, что в распределении преобладают дешевые машины. Асимметрия
незначительна, так как ее значение меньше 0,25.
Коэффициент эксцесса - показатель,
характеризующий степень остроты пика распределения случайной величины.
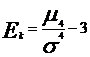 (4.10)
(4.10)
где 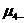 центральный
момент 4-го порядка;
центральный
момент 4-го порядка;
среднее
квадратическое отклонение.
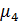 =
= 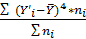 (4.11)
(4.11)
где Yi’
- середина соответствующего интервала;
- среднее;
ni - количество
автомобилей в соответствующем интервале
= 894543503
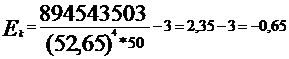
Вывод: коэффициент эксцесса меньше 0,
распределение имеет сглаженную вершину.
. Критерий Пирсона
Цель: сравнить распределение цен на автомобили с
нормальным распределением и доказать, что их отличие статистически незначимо.
Нормальное распределение играет особую роль в
статистике. Разнообразные статистические данные с хорошей степенью точности
можно считать реализациями случайной величины, имеющей нормальное
распределение. Можно предполагать нормальное распределение у случайной
величины, если на её отклонение от некоторого фиксированного значения влияет
множество различных факторов, причем влияние каждого из них вносит малый вклад
в это отклонение, а их действия почти независимы.
Сформулируем две гипотезы:
Н0 - Эмпирическое распределение цен на
автомобили статистически незначимо отличается от нормального.
H1 - Эмпирическое
распределение цен на автомобили статистически значимо отличается от
нормального.
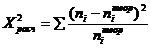 (5.1)
(5.1)
где ni
- количество автомобилей в соответствующем интервале,
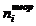 - теоретическое
количество автомобилей в соответствующем интервале
- теоретическое
количество автомобилей в соответствующем интервале
Произведем вспомогательные расчеты:
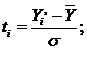 (5.2)
(5.2)
где Yi’
- середина соответствующего интервала;
- среднее;
- среднее
квадратическое отклонение.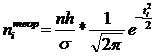 (5.3)
(5.3)
где n
- количество автомобилей в исследуемой совокупности;
h - ширина ценового
интервала;
- среднее
квадратическое отклонение;
ti - расчётный
коэффициент t для
соответствующего интервала.
Табл. 5.1
|
интервалы
цен Yi
|
кол-во
авто ni
|
Y`i
|
Y`i -
|
ti
|
niтеор
|
(ni
- niтеор)2/niтеор
|
|
165
- 197
|
4
|
181
|
-91,52
|
-1,74
|
2,67
|
0,66
|
|
197
- 229
|
7
|
213
|
-59,52
|
-1,13
|
6,40
|
0,06
|
|
229
- 261
|
9
|
245
|
-27,52
|
-0,52
|
10,59
|
0,24
|
|
261
- 293
|
14
|
277
|
6,48
|
0,12
|
12,03
|
0,32
|
|
293
- 325
|
7
|
309
|
38,48
|
0,73
|
9,29
|
0,56
|
|
325
- 357
|
6
|
341
|
70,48
|
1,34
|
4,94
|
0,23
|
|
357
- 389
|
3
|
373
|
104,48
|
1,98
|
1,71
|
0,97
|
|
итого
|
50
|
|
|
|
47,63
|
3,04
|
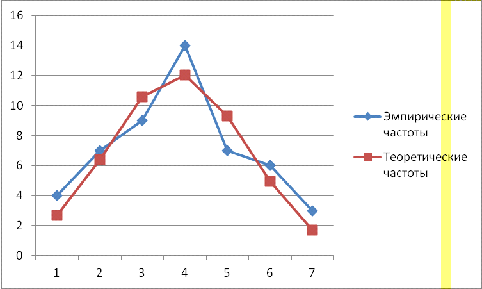
Рис. 5.1 Сравнение эмпирических и теоретических
частот
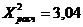
Определим 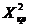 с
помощью таблицы критических значений
с
помощью таблицы критических значений 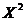 .=
m - r - 1 = 7 - 2 - 1 = 4 (т.к. закон нормальный, то r = 2)
.=
m - r - 1 = 7 - 2 - 1 = 4 (т.к. закон нормальный, то r = 2)
(0,05; 4) = 9,488
Теоретическое распределение больше
эмпирического, следовательно, мы принимаем Н0.
Вывод: Эмпирическое распределение цен на
автомобили статистически незначимо отличается от теоретического.
. Определение доверительного интервала и
оптимального объёма выборки
Выборочным называется несплошное наблюдение, при
котором признаки регистрируются у отдельных единиц изучаемой статистической
совокупности, отобранных с использованием специальных методов, а полученные в
процессе обследования результаты с определенным уровнем вероятности
распространяются на всю исходную совокупность.
Данная выборка является повторной
собственно-случайной.
Цель: Определить в каком интервале колеблется
цена на автомобиль Suzuki
Liana в генеральной
совокупности.
. Определить среднюю ошибку выборки. При
повторном отборе попавшая в выборку единица подвергается обследованию, т.е.
регистрации значений ее признаков, возвращается в генеральную совокупность и
наравне с другими единицами участвует в дальнейшей процедуре отбора
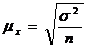 (6.1)
(6.1)
где
2 - дисперсия
n - объём выборки;
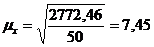
. Определить предельную ошибку выборки.
Предельная ошибка выборки связана с заданным уровнем вероятности.
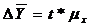 (6.2)
(6.2)
где, t
- коэффициент доверия, зависящий от вероятности гамма (γ),
с
которой определяется предельная ошибка;
μх - стандартная
ошибка выборки;
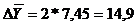
. Построить доверительный интервал
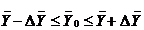 (6.3)
(6.3)
где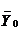 -
середина доверительного интервала;
-
середина доверительного интервала;
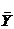 - средняя цена;
- средняя цена;
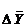 - предельная ошибка
выборки.
- предельная ошибка
выборки.
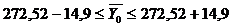
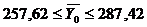
Вывод: На основании проведенного выборочного
обследования с вероятностью 0,954 можно заключить, что средняя цена на
автомобиль Suzuki
Liana лежит в пределах
интервала от 257,62 до 287,42 тыс. рублей.
Определение оптимального объема выборки.
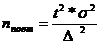 (6.4)
(6.4)
где t
- коэффициент доверия
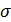 - среднее
квадратическое отклонение
- среднее
квадратическое отклонение
∆ - предельная ошибка выборки
При Δ
= 10 тыс. руб. и вероятностью 0,95 t=2
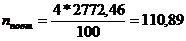
Вывод: Необходимая численность выборки для
определения средней цены продаваемых автомобилей равна 111.
Корреляционно-регрессионный анализ. Цель: на
основании данных выборочного наблюдения:
-составить уравнение множественной регрессии
результативного признака Y,
обосновав систему факторов, включенных в модель.
сопоставить роль признаков-факторов Х1 и Х2 в
формировании результативного признака Y,
вычислив коэффициенты эластичности.
провести корреляционный анализ.
Составим уравнение множественной регрессии
результативного признака.
Изучение связи между тремя и более связанными
между собой признаками носит название множественной регрессии.
Используем метод приведения параллельных данных,
которое позволит установить наличие связи и получить представление о ее
характере.
Данные приведены в расчетной таблице:
Табл. 7.1
|
№
|
X1*Y
|
X2*Y
|
X1*X2
|
X1-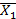
|
(X1-)2
|
X2-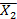
|
(X2-)2
|
Y-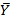
|
(Y- )2
|
|
1
|
1650
|
28050
|
1700
|
1,88
|
3,5344
|
54,04
|
2920,322
|
-106,32
|
11303,94
|
|
2
|
1870
|
21080
|
1364
|
2,88
|
8,2944
|
8,04
|
64,6416
|
-101,32
|
10265,74
|
|
3
|
1950
|
36855
|
1890
|
1,88
|
3,5344
|
73,04
|
5334,842
|
-76,32
|
5824,742
|
|
4
|
1365
|
16965
|
609
|
-1,12
|
1,2544
|
-28,96
|
838,6816
|
-76,32
|
5824,742
|
|
5
|
1624
|
30450
|
-0,12
|
0,0144
|
34,04
|
1158,722
|
-68,32
|
4667,622
|
|
6
|
2255
|
25420
|
1364
|
2,88
|
8,2944
|
8,04
|
64,6416
|
-66,32
|
4398,342
|
|
7
|
2310
|
44100
|
2310
|
2,88
|
8,2944
|
94,04
|
8843,522
|
-61,32
|
3760,142
|
|
8
|
1944
|
20088
|
837
|
0,88
|
0,7744
|
-22,96
|
527,1616
|
-55,32
|
3060,302
|
|
9
|
1744
|
32264
|
1184
|
-0,12
|
0,0144
|
32,04
|
1026,562
|
-53,32
|
2843,022
|
|
100
|
2200
|
24640
|
1120
|
1,88
|
3,5344
|
-3,96
|
15,6816
|
-51,32
|
2633,742
|
|
11
|
2250
|
21375
|
950
|
1,88
|
3,5344
|
-20,96
|
439,3216
|
-46,32
|
2145,542
|
|
12
|
2300
|
23230
|
1010
|
1,88
|
3,5344
|
-14,96
|
223,8016
|
-41,32
|
1707,342
|
|
13
|
2070
|
46460
|
1818
|
0,88
|
0,7744
|
86,04
|
7402,882
|
-41,32
|
1707,342
|
|
14
|
1880
|
21385
|
728
|
-0,12
|
0,0144
|
-24,96
|
623,0016
|
-36,32
|
1319,142
|
|
15
|
2370
|
27729
|
1170
|
1,88
|
3,5344
|
1,04
|
1,0816
|
-34,32
|
1177,862
|
|
16
|
1673
|
24139
|
707
|
-1,12
|
1,2544
|
-14,96
|
223,8016
|
-32,32
|
1044,582
|
|
17
|
2205
|
35280
|
1296
|
0,88
|
0,7744
|
28,04
|
786,2416
|
-26,32
|
692,7424
|
|
18
|
2480
|
34224
|
1380
|
1,88
|
3,5344
|
22,04
|
485,7616
|
-23,32
|
543,8224
|
|
19
|
2000
|
40000
|
1280
|
-0,12
|
0,0144
|
44,04
|
1939,522
|
-21,32
|
454,5424
|
|
20
|
1785
|
22950
|
630
|
-1,12
|
1,2544
|
-25,96
|
673,9216
|
-16,32
|
266,3424
|
|
21
|
2340
|
30420
|
1053
|
0,88
|
0,7744
|
1,04
|
1,0816
|
-11,32
|
128,1424
|
|
22
|
1855
|
24645
|
651
|
-1,12
|
1,2544
|
-22,96
|
527,1616
|
-6,32
|
39,9424
|
|
23
|
2385
|
47965
|
1629
|
0,88
|
0,7744
|
65,04
|
4230,202
|
-6,32
|
39,9424
|
|
24
|
2136
|
27768
|
832
|
-0,12
|
0,0144
|
-11,96
|
143,0416
|
-4,32
|
18,6624
|
|
25
|
2136
|
18957
|
568
|
-0,12
|
0,0144
|
-44,96
|
2021,402
|
-4,32
|
18,6624
|
|
26
|
2430
|
37260
|
1242
|
0,88
|
0,7744
|
22,04
|
485,7616
|
-1,32
|
1,7424
|
|
27
|
2700
|
32130
|
1190
|
1,88
|
3,5344
|
3,04
|
9,2416
|
-1,32
|
1,7424
|
|
28
|
1890
|
26460
|
686
|
-1,12
|
1,2544
|
-17,96
|
322,5616
|
-1,32
|
1,7424
|
|
29
|
1925
|
30525
|
777
|
-1,12
|
1,2544
|
-4,96
|
24,6016
|
3,68
|
13,5424
|
|
30
|
1946
|
31136
|
784
|
-1,12
|
1,2544
|
-3,96
|
15,6816
|
6,68
|
44,6224
|
|
31
|
2240
|
26040
|
744
|
-0,12
|
0,0144
|
-22,96
|
527,1616
|
8,68
|
75,3424
|
|
32
|
2280
|
30780
|
864
|
-0,12
|
0,0144
|
-7,96
|
63,3616
|
13,68
|
187,1424
|
|
33
|
1752
|
24528
|
504
|
-2,12
|
4,4944
|
-31,96
|
1021,442
|
20,68
|
427,6624
|
|
34
|
1770
|
23600
|
480
|
-2,12
|
4,4944
|
-35,96
|
1293,122
|
23,68
|
560,7424
|
|
35
|
1776
|
23976
|
486
|
-2,12
|
4,4944
|
-34,96
|
1222,202
|
24,68
|
609,1024
|
|
36
|
2700
|
34500
|
1035
|
0,88
|
0,7744
|
-0,96
|
0,9216
|
28,68
|
822,5424
|
|
37
|
2745
|
25925
|
765
|
0,88
|
0,7744
|
-30,96
|
958,5216
|
33,68
|
1134,342
|
|
38
|
2170
|
29760
|
672
|
-1,12
|
1,2544
|
-19,96
|
398,4016
|
38,68
|
1496,142
|
|
39
|
2205
|
36225
|
805
|
-1,12
|
1,2544
|
-0,96
|
0,9216
|
43,68
|
1907,942
|
|
40
|
1902
|
23458
|
444
|
4,4944
|
-41,96
|
1760,642
|
45,68
|
2086,662
|
|
41
|
2240
|
24960
|
546
|
-1,12
|
1,2544
|
-37,96
|
1440,962
|
48,68
|
2369,742
|
|
42
|
1968
|
41984
|
768
|
-2,12
|
4,4944
|
12,04
|
144,9616
|
56,68
|
3212,622
|
|
43
|
2720
|
28220
|
664
|
-0,12
|
0,0144
|
-32,96
|
1086,362
|
68,68
|
4716,942
|
|
44
|
2415
|
25185
|
511
|
-1,12
|
1,2544
|
-42,96
|
1845,562
|
73,68
|
5428,742
|
|
45
|
2429
|
38864
|
784
|
-1,12
|
1,2544
|
-3,96
|
15,6816
|
75,68
|
5727,462
|
|
46
|
2450
|
52500
|
1050
|
-1,12
|
1,2544
|
34,04
|
1158,722
|
78,68
|
6190,542
|
|
47
|
2800
|
46900
|
1072
|
-0,12
|
0,0144
|
18,04
|
325,4416
|
78,68
|
6190,542
|
|
48
|
2520
|
62280
|
1211
|
-1,12
|
1,2544
|
57,04
|
3253,562
|
88,68
|
7864,142
|
|
49
|
2548
|
25480
|
490
|
-1,12
|
1,2544
|
-45,96
|
2112,322
|
92,68
|
8589,582
|
|
50
|
2334
|
29564
|
456
|
-2,12
|
4,4944
|
-39,96
|
1596,802
|
117,68
|
13848,58
|
|
Сумма
|
107362
|
1538769
|
48310
|
|
105,28
|
|
61601,92
|
|
139396,88
|
|
Среднее
|
2152,64
|
30773,58
|
966,2
|
|
|
|
|
|
|
Множественная модель регрессии строится при
условии неколлинеарности факторов. Проверим факторы на коллинеарность с помощью
линейного коэффициента корреляции, который определяет тесноту и направление
связи при линейной зависимости:
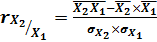 (7.1)
(7.1)
Также найдем 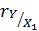 и
и
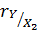 :
:
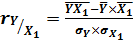 (7.2)
(7.2)
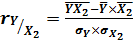 (7.3)
(7.3)
Результативный показатель - цена Y.
Факторные признаки:
Время эксплуатации X1,
пробег X2.
σY=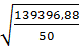 = 52,8
= 52,8
σX1=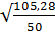 = 1,45
= 1,45
σX2=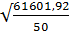 = 35,1
= 35,1
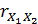 = (966,2 -
(8,12*115,96)) / (1,45*35,1) ≈ 0,48
= (966,2 -
(8,12*115,96)) / (1,45*35,1) ≈ 0,48
Связь между пробегом (X2)
и временем эксплуатации (X1)
умеренная прямая. 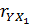 = (2152,64 -
(271,32*8,12))/(52,8*1,45) ≈ -0,66
= (2152,64 -
(271,32*8,12))/(52,8*1,45) ≈ -0,66
Связь между результативным признаком Y
(цена) и Х1 (время эксплуатации) обратная заметная. 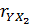 =
(30773,58 - (271,32*115,96))/52,8*35,1) ≈ -0,37
=
(30773,58 - (271,32*115,96))/52,8*35,1) ≈ -0,37
Связь между результативным признаком Y
(цена) и Х2 (пробег) обратная умеренная.
Так как rX1/X2 <
0,7, то X1 и X2
- неколлинеарные, множественную модель можно построить, а также вычислить
коэффициент множественной корреляции.
<
0,7, то X1 и X2
- неколлинеарные, множественную модель можно построить, а также вычислить
коэффициент множественной корреляции.
Множественная модель регрессии. Регрессионный
анализ помогает определить форму связи и показывает насколько изменится
результат, если фактор изменится на единицу.
Множественная модель регрессии описывается
уравнением:
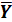 =
=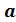 0
+ 𝑎1X1
+ 𝑎2X2
(7.4)
0
+ 𝑎1X1
+ 𝑎2X2
(7.4)
где
а0 -показывает усредненное влияние неучтенных
факторов на признак результат;
а1- коэффициент регрессии, который показывает на
сколько в среднем изменится значение результативного признака при изменении 1
единицы факторного признака X1.
a2- коэффициент
регрессии, который показывает на сколько в среднем изменится значение
результативного признака при изменении 1 единицы факторного признака X2.
Найдем параметры уравнения регрессии с помощью
системы нормальных уравнений:
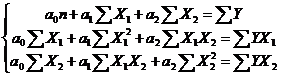 (7.5)
(7.5)
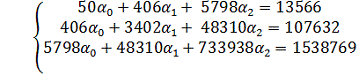
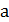 0 = 468,19
0 = 468,19
1 = -22,75
2 = -0,1
Множественная модель имеет вид: 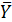 =
468,19 - 22,75X1 - 0,1X2
=
468,19 - 22,75X1 - 0,1X2
Вывод: неучтенные факторы сильно влияют на
результат. При увеличении времени эксплуатации автомобиля на 1 год цена
уменьшается на 22,75 тысяч рублей, а при увеличении пробега на 1 тыс. км цена уменьшается
на 0,1 тысячу рублей.
Проверим адекватность выбранной модели
регрессии.
Гипотезы:
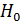 : коэффициент
регрессии незначим, модель регрессии выбрана неверно;
: коэффициент
регрессии незначим, модель регрессии выбрана неверно;
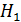 : коэффициент
регрессии значим, модель регрессии адекватна
: коэффициент
регрессии значим, модель регрессии адекватна
Для доказательства адекватности модели
необходимо найти ошибку аппроксимации.
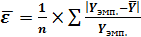 (7.6)
(7.6)
Табл. 7.3
Расчетные данные для нахождения ошибки
аппроксимации
|
№
n. n.
|
Цена
тыс. руб., Y
|
Время
эксплуатации лет, X1
|
Пробег,
тыс. км (Х2)
|
Y ̅
|
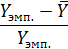
|
|
1
|
165
|
10
|
170
|
223,69
|
0,3557
|
|
2
|
170
|
11
|
124
|
205,54
|
0,20906
|
|
3
|
195
|
10
|
189
|
221,79
|
0,13738
|
|
4
|
195
|
7
|
87
|
300,24
|
0,53969
|
|
5
|
203
|
8
|
150
|
271,19
|
0,33591
|
|
6
|
205
|
11
|
124
|
205,54
|
0,00263
|
|
7
|
210
|
11
|
210
|
196,94
|
0,06219
|
|
8
|
216
|
9
|
93
|
254,14
|
0,17657
|
|
9
|
218
|
8
|
148
|
271,39
|
0,24491
|
|
10
|
220
|
10
|
112
|
229,49
|
0,04314
|
|
11
|
225
|
10
|
95
|
231,19
|
0,02751
|
|
12
|
230
|
10
|
101
|
230,59
|
0,00257
|
|
13
|
230
|
9
|
202
|
243,24
|
0,05757
|
|
14
|
235
|
8
|
91
|
277,09
|
0,17911
|
|
15
|
237
|
10
|
117
|
228,99
|
0,033797
|
|
16
|
239
|
7
|
101
|
298,84
|
0,25038
|
|
17
|
245
|
9
|
144
|
249,04
|
0,01649
|
|
18
|
248
|
10
|
138
|
226,89
|
0,085121
|
|
19
|
250
|
8
|
160
|
270,19
|
0,08076
|
|
20
|
255
|
7
|
90
|
299,94
|
0,17624
|
|
21
|
260
|
9
|
117
|
251,74
|
0,031769
|
|
22
|
265
|
7
|
93
|
299,64
|
0,13072
|
|
23
|
265
|
9
|
181
|
245,34
|
0,074189
|
|
24
|
267
|
8
|
104
|
275,79
|
0,03292
|
|
25
|
267
|
8
|
71
|
279,09
|
0,04528
|
|
26
|
270
|
9
|
138
|
249,64
|
0,075407
|
|
27
|
270
|
10
|
119
|
228,79
|
0,15263
|
|
28
|
270
|
7
|
98
|
299,14
|
0,10793
|
|
29
|
275
|
7
|
111
|
297,84
|
0,08305
|
|
30
|
278
|
7
|
112
|
297,74
|
0,07101
|
|
31
|
280
|
8
|
93
|
276,89
|
0,011107
|
|
32
|
285
|
8
|
275,39
|
0,033719
|
|
33
|
292
|
6
|
84
|
323,29
|
0,10716
|
|
34
|
295
|
6
|
80
|
323,69
|
0,09725
|
|
35
|
296
|
6
|
81
|
323,59
|
0,09321
|
|
36
|
300
|
9
|
115
|
251,94
|
0,1602
|
|
37
|
305
|
9
|
85
|
254,94
|
0,164131
|
|
38
|
310
|
7
|
96
|
299,34
|
0,034387
|
|
39
|
315
|
7
|
115
|
297,44
|
0,055746
|
|
40
|
317
|
6
|
74
|
324,29
|
0,023
|
|
41
|
320
|
7
|
78
|
223,69
|
0,300969
|
|
42
|
328
|
6
|
128
|
205,54
|
0,373354
|
|
43
|
340
|
8
|
83
|
221,79
|
0,347676
|
|
44
|
345
|
7
|
73
|
300,24
|
0,129739
|
|
45
|
347
|
7
|
112
|
271,19
|
0,218473
|
|
46
|
350
|
7
|
150
|
205,54
|
0,412743
|
|
47
|
350
|
8
|
134
|
196,94
|
0,437314
|
|
48
|
360
|
7
|
173
|
254,14
|
0,294056
|
|
49
|
364
|
7
|
70
|
271,39
|
0,254423
|
|
50
|
389
|
6
|
76
|
229,49
|
0,410051
|
|
Сумма
|
13566
|
406
|
5798
|
|
7,380341
|
|
Среднее
арифм.
|
271,32
|
8,12
|
115,96
|
|
|
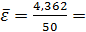 0,147 или 14,7%
0,147 или 14,7%
Вывод: модель регрессии можно считать
адекватной, так как ошибка аппроксимации равна 14,7%, что не превышает 12-15%.
По форме модель является двухфакторной, линейной, прямой.
Корреляция
Определим множественный коэффициент корреляции,
который характеризует тесноту и направление связи между коррелируемыми
признаками.
R = 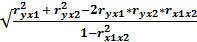 (7.7)
(7.7)
Множественный коэффициент корреляции равен:
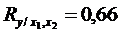
Таким образом, множественный коэффициент
корреляции показывает заметную связь между элементами выборки.
Определим значимость множественного коэффициента
корреляции.
Сформулируем 2 гипотезы:
H0 - корреляционная
связь между исследуемыми признаками статистически значимо не отличается от 0.
Н1 - корреляционная связь между исследуемыми
признаками статистически значимо отличается от 0.
Проверим корреляционную связь на статистическую
значимость, используя t-критерий
Стьюдента.
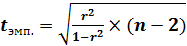 (7.8)
(7.8)
где
r - линейный
коэффициент корреляции
n- объем
статистической совокупности
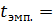 6,09
6,09
Определим степень свободы:= n
- k - 1= 48
По таблице Стьюдента tтеор. =
3,460 (α = 0,001, v = 48).
,09 >3,46
Вывод: подтверждается альтернативная гипотеза H1,
так как 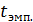 >
tтеор. Следовательно, коэффициент корреляции статистически значим.
>
tтеор. Следовательно, коэффициент корреляции статистически значим.
Коэффициенты эластичности
Определение роли признаков-факторов Х1 и Х2 в
формировании результативного признака Y,
с помощью вычисления коэффициентов эластичности. Коэффициент эластичности
показывает, на сколько процентов изменится Y при изменении соответствующего Хi
на 1%.
Коэффициент эластичности показывает, на сколько
процентов изменится значение Y
при изменении значения фактора на 1 %.
Коэффициент эластичности вычисляется по формуле:
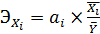 (7.9)
(7.9)
где
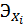 - коэффицинт
эластичности;
- коэффицинт
эластичности;
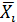 - среднее значение
соответствующего факторного признака;
- среднее значение
соответствующего факторного признака;
-среднее значение
результативного признака;
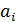 - коэффициент
регрессии при соответствующем факторном признаке.
- коэффициент
регрессии при соответствующем факторном признаке.
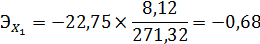
Вывод: при увеличении времени эксплуатации
автомобиля на 1% его цена уменьшится в среднем на 68%
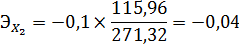
Вывод: при увеличении пробега автомобиля на 1%
его цена уменьшится в среднем на 4%
Заключение
По итогам данной курсовой работы можно сделать
следующие выводы.
Аналитические группировки автомобилей по времени
эксплуатации и пробегу показали: цена автомобиля неизменно падает при повышении
времени эксплуатации и имеет менее сильную тенденцию к падению при увеличении
пробега.
Многомерный анализ показывает усреднённое
влияние времени эксплуатации и пробега на цену автомобиля. Здесь, как и в
аналитических группировках, прослеживается обратная зависимость между
результативным признаком (цена) и факторными (пробег и время эксплуатации).
Исследование статистического распределения
результативного признака Y
с помощью построения показало, что распределение является однородным,
асимметричным с правосторонней асимметрией и со сглаженной вершиной.
Проверка распределения с помощью правила «трёх
сигм» и критерия Пирсона на соответствие статистического распределения
результативного признака Y
нормальному закону распределения на уровне значимости α
= 0,05 показала,
что распределение соответствует нормальному закону.
Определение необходимого объёма выборки
показало, что выборка в случае увеличения её с 50 до 111 автомобилей была бы
наиболее репрезентативной.
Уравнение регрессии показало, что цена
автомобиля сильно зависит от неучтённых факторов.
Множественный коэффициент корреляции показал
умеренную зависимость результативного признака Y
и признаков-факторов X1
и X2 друг от друга.
Коэффициенты эластичности показали в процентах,
как меняется цена при изменении каждого из факторов на 1%.
Таким образом, цель исследования была
достигнута, задачи - выполнены.
Список литературы
1. http://moscow.auto.ru/cars/suzuki/liana/all/
Продажа Suzuki
Liana. Дата обращения к
странице: 3 октября 2014 года.
2. http://studopedia.ru/3_187786_statisticheskaya-svodka-i-gruppirovka.html
Студопедия. Студенческая энциклопедия. Статистическая сводка и группировка.
Дата обращения к странице - 10 октября 2014 года.
. Статистика.
Конспект лекций для студентов заочного отделения / Ю.М. Протасов. - М. :
Флинта, 2012. - 152 с. - С.32
. http://umk.portal.kemsu.ru/uch-mathematics/papers/posobie/t4-2.htm
К.Е. Афанасьев, С.В. Стуколов, А.В. Демидов, В.В. Малышенко. Многомерные
вычислительные системы и параллельное программирование. Учебно-методический
комплекс. Дата обращения к странице - 20 октября 2014 года.
. http://dic.academic.ru/dic.nsf/econ_dict/4562
Академик. Экономический словарь. Дата обращения к странице: 1 ноября 2014 года.
. http://jur.vslovar.org.ru/7791.html
Визуальный словарь. Дата обращения к странице: 1 ноября 2014 года.
. http://studopedia.net/1_13308_pokazateli-tsentra-raspredeleniya-i-strukturnie-harakteristiki-variatsionnogo-ryada.html.
Показатели центра распределения и структурные характеристики вариационного
ряда. Дата обращения к странице: 5 ноября.
. http://ru.wikipedia.org/wiki/Дисперсия_случайной_величины
Дата обращения к странице - 10 ноября 2014 года.
. http://www.exponenta.ru/educat/systemat/shelomovsky/lab/lab04.asp
Образовательный математический сайт. Дата обращения к странице: 15 ноября 2014
года.
. Статистика:
Учеб. пособие/Под. Ред. проф. М.Р. Ефимовой. М.: ИНФРА-М, 2006. - 336 с. - С.
177
. http://www.grandars.ru/student/vysshaya-matematika/ekonometricheskaya-model.html
Энциклопедия экономиста. Дата обращения к странице - 20 ноября 2014 года