Создание классификатора, основанного на нейронной сети и способного определять качество вина
Введение
Когда-то вино было товаром роскоши, доступное лишь небольшой доле
населения. Но благодаря развитию технологий производства и росту благосостояния
среднестатистического жителя мира, каждый человек может купить бутылка вина и
насладиться его вкусом.
Каждый производитель вина сталкивается с необходимостью его оценки и
сертификации. Сертификации позволяет гарантировать, что вино соответствует
стандартам и является безопасным для употребления продуктом. Оценка вина
позволяет определить его качество с точки зрения человеком, то есть насколько
хорош его вкус, запах и т. д. Ее результаты могут быть использованы для
улучшения процесса производства, для распределения вин по брендам и определения
их цены. Оценка иногда является частью процесса сертификации.
Существует два основных метода, которые используются при сертификации
вина. Первый из них основывается на физико-химическом анализе. При этом
проверяются, в частности, такие параметры, как цвет вина, наличие примесей,
количество содержащегося алкоголя, сахаров и различных кислот. Вторым методом
является сенсорный анализ. Он основан на использование в качестве оценочного
прибора специально обученного человека - дегустатора. В процессе работы,
дегустатор должен определить качество вина основываясь на своих знаниях и
используя свои органы чувств.
Зависимость между физико-химическими свойствами вина и результатом
дегустации является крайне сложной и запутанной, и в настоящее время она до
конца не определена. Из этого следует, что с помощью физико-химического анализа
сложно дать ответ на вопрос, насколько хорошо будет вино с точки зрения
покупателя, и, следовательно, нельзя отнести вино к определенному бренду. С
другой стороны, дегустатор определяет качество вина исходя из своих
субъективных понятий о «хорошем» и «плохом» винах. Это приводит к тому, что
вино, выигравшее некоторый конкурс, может не получить никаких наград в другом
соревновании, а оценки разных дегустаторов, данные одному и тому же вину, могут
сильно различаться. Подобные происшествия подрывают доверие к существующей
системе оценивания вин, от чего могут пострадать как производители, которые не
смогут разделить свою продукцию по уровню качества и, соответственно, цене. Так
и потребители, которые потеряют возможность выбирать вино по качеству, и, по сути,
будут приобретать «кота в мешке». Следовательно, в сфере производства
винно-водочной продукции существует потребность в исследовании возможности
создания некоторого классификатора, который бы мог определять качество вина по
его химическому составу, руководствуясь лишь математическими алгоритмами.
Развитие информационных технологий привело к созданию ряда методов
анализа данных. Подобные методы позволяют осуществлять поиск взаимосвязей между
различными наборами данных. Как правило, работа идет с большими и сложными
наборами информации, обработка которых требует больших вычислительных ресурсов.
Появление данных методов дало толчок к развитию исследований в области создания
классификаторов. В качестве примера можно привести работу 2007 года, в которой,
используя вероятностную нейронную сеть, исследователи смогли с точностью в
94.77% правильно классифицировать год производства вина и место расположения
виноградника [8]. В этой работе в качестве информации о вине использовались
результаты хроматографии. В 2001 году нейронные сети использовались для
определения трех сенсорных характеристик вина, произведенного в Калифорнии,
основываясь на информации об уровне зрелости винограда и результатах
химического анализа [12].
В данной работе исследуется возможность создания классификатора,
основанного на нейронной сети и способного определять качество вина. В качестве
данных для анализа используется информация о составе вин и оценках данных им
дегустаторами. Набор данных охватывает вина, созданные в Португалии в провинции
Минью с мая 2004 по февраль 2007 годов. Данные были предоставлены
исследователями Paulo Cortez, Antonio Cerdeira, Fernando Almeida, Telmo Matos, Jose Reis в их статье «Modeling wine preferences by data mining from physicochemical properties» [9]. В ходе выполнения работы
необходимо выполнить следующие пункты:
· Рассмотреть существующие математические методы классификации,
и сравнить их с нейронными сетями применительно к данной задаче;
· Рассмотреть различные нейросетевые парадигмы, и оценить их с
точки зрения задачи классификации;
· Построить математическую модель классификатора для решения
данной задачи, реализовать и обучить его;
· Произвести анализ результатов.
В данной работе в первой главе рассматриваются различные методы решения
задачи классификации, и оценивается их применимость к задаче классификации
винно-водочных изделий. Во второй главе анализируются различные нейросетевые
парадигмы, методы обучения нейронных сетей, возникающие при этом проблемы и
пути их решения. В третьей главе описано построение классификатора с учетом
особенностей решаемой задачи. В четвертой главе приведено описание программной
реализации классификатора, его функциональные возможности и результаты
обучения. В пятой главе содержится анализ результатов тестирования классификатора.
1.
Задача классификации
Задача классификации заключается в определении, какому классу принадлежат
наблюдаемые объекты, основываясь на некотором предварительно известном наборе
пар, состоящих из описания объекта и класса, которому этот объект принадлежит.
Описание объекта представляет собой набор измеренных характеристик.
Математическая
постановка задачи выглядит следующим образом: есть множество непересекающихся
классов 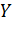 и
множество описаний объектов
и
множество описаний объектов 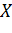 . Есть
неизвестная зависимость между множествами
. Есть
неизвестная зависимость между множествами 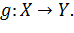 Есть
также некоторый известный набор пар
Есть
также некоторый известный набор пар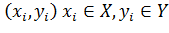 , такой,
что
, такой,
что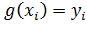 .
Требуется на основе этого набора найти функцию, способную классифицировать
любой объект из X.
.
Требуется на основе этого набора найти функцию, способную классифицировать
любой объект из X.
Существует
множество различных методов классификации объектов. Выбор метода для решения
поставленной задачи необходимо осуществлять исходя из особенностей предметной
области.
1.1 Метод опорных векторов
Для
решения задач классификации в 1963 году В. Вапник и А. Червоненкис предложили
метод, названный ими методом опорных векторов. Метод основан на поиске
гиперплоскости в пространстве признаков, оптимально разделяющей объекты на
классы. Набор признаков, характеризующий один определенный объект, называется
вектором. Допустим, мы имеем набор пар 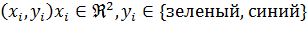 ,
изображенный на рисункеРис. 1.
,
изображенный на рисункеРис. 1.
Рис.
1. Пример разделяющей гиперплоскости
Гиперплоскостью в некотором пространстве называется подпространство с
размерностью, меньшей на 1, чем размерность самого пространства. Тогда в
двумерном пространстве гиперплоскостью будет прямая. Можно построить несколько
прямых, разделяющих два класса, как показано на рисунке. Идея метода заключается
в том, что для решения задачи классификации лучше всего выбрать такую
гиперплоскость (а в данном случае - прямую), чтобы расстояние от нее до
ближайших элементов классов было максимально. Пример подобной оптимально
разделяющей гиперплоскости можно увидеть на рисункеРис. 1. Это прямая,
нарисованная красным цветом. Вектора, которые расположены ближе всего к
разделяющей гиперплоскости, называют опорными векторами. На рисунке они
отмечены с помощью кругов [11].
Не всегда наборы векторов являются линейно-разделимыми. На рисунке Рис. 2
показан пример, в котором невозможно найти прямую линию, которая бы разделяла
два класса. В таком случае, можно использовать преобразование, которое бы
переводило вектора в пространство большей размерности. Тогда, согласно теореме
Ковера, после такого преобразования, с высокой долей вероятности можно получить
линейно-разделенные классы [1].
Рис.
2. Пример линейно-неразделимых классов
1.2 Нейронные сети
Нейронная сеть представляет собой математическую модель биологической
нейронной сети. Она состоит из множества простых устройств - нейронов,
соединенных между собой. Каждый нейрон принимает сигнал, преобразует его, и
затем посылает преобразованный сигнал другим нейронам.
Отличительной особенностью нейронных сетей является то, что они обучаются
для решения некоторой определенной задачи. С математической точки зрения, в
ходе обучения происходит задание коэффициентов связей между нейронами.
Нейронная сеть способна в процессе обучения находить сложные взаимосвязи между
элементами входных и выходных данных. Также, нейронные сети способны к
обобщению, то есть выдавать правильный ответ на данных, которые не участвовали
в обучение.
1.3
Байесовский классификатор
Это набор вероятностных методов классификации. Они основаны на теории,
что если известны плотности распределения классов, то можно в явном виде
выписать алгоритм классификации. Причем, при использовании этого алгоритма,
вероятность ошибки будет минимальна. Принцип действия байесовского классификатора
состоит из следующих шагов:
Вычислить для объекта функция правдоподобия каждого класса;
Вычислить апостериорные вероятности;
Отнести объект к тому класса, апостериорная вероятность которого
оказалась самой высокой.
Если при решении задачи неизвестны плотности распределения классов, то их
необходимо вычислить по обучающей выборке. Есть множество методов
восстановления плотности распределения, и, вследствие этого, существует
множество различные байесовских алгоритмов. Если предположить, что признаки,
описывающие объект, являются независимыми, то можно упростить построение
классификатора. Но, так как на практике, признаки редко бывают независимыми,
это приведет к уменьшению точности классификации объектов [7].
1.4 Выводы
по разделу
Рассмотрим описанные в данном разделе методы решения задачи классификации
с точки зрения их применимости к решению задач классификации винно-водочных
изделий. Исходные данные обладают следующими характеристиками:
· Они разбиты на две группы: белые вина и красные вина. Неизвестно,
насколько важен тип вина при определении уровня качества;
· Имеется довольно большая выборка примеров, в сумме около 6
тыс.;
· Каждый объект характеризуется 11 параметрами, что означает,
что размерность пространства признаков невелика;
· Данные представлены в числовом виде.
Метод опорных векторов обладает большой вычислительной сложностью, и для
его использования желательно иметь большее пространство признаков, чем имеется
в данной задаче.
Изначально отсутствует статистическая информация об исходных данных, что
затрудняет использование байесовского классификатора.
Нейронные сети способны к решению задач классификации, наборы данных в
которых являются линейно-неразделимыми. К тому же, нейронные сети показали
способность к аппроксимации произвольной функции с любой желаемой точностью
[2]. Вследствие этого, использование нейронных сетей для решения данной задачи
является предпочтительным вариантом.
2.
Искусственные нейронные сети
Сразу после своего рождения человек не обладает никакой информацией об окружающем
мире. Но он способен получить ее с помощью своих органов чувств, таких как
зрительная система или слуховой аппарат. Получая сигналы о мире, человек
реагирует на них некоторым образом. Его реакция способна вызвать изменения в
поступающих сигналах, что, в свою очередь, вызовет другую реакцию. Некоторые
сигналы могут быть однозначно распознаны как негативные, например боль, другие
же будут восприниматься как позитивные - приятный запах или чувство сытости.
Обладая от природы способностью к сопоставлению своих действий и последующего
результата, человек вырабатывает алгоритмы поведения для минимизации негативных
сигналов и оптимизации позитивных. Подобная способность к самообучению является
крайне интересной, так как ее понимание позволит решить множество задач,
например, создавать алгоритмы обработки информации, которые автоматически
подстраиваются под вводимые данные с целью улучшения результата. Человек
обладает такой возможностью благодаря его мозгу - биологической нейронной сети
огромных масштабов.
Интерес представляет не только способность к самообучению, но и то, какие
алгоритмы созданы человеческим мозгом для решения ряда ежедневных задач, такие
как распознавание образов (человек способен с высокой точностью отличать людей
друг от друга или принятие решений, особенно в условиях недостатка информации).
Для таких задач существуют различные математические методы их решения, но
зачастую они проигрывают человеку в скорости работы и точности. Следовательно,
можно предположить, что достаточно точная модель человеческого мозга покажет
сходную эффективность в таких задачах. Также, исследование модели, успешно
справляющейся с некоторым классом задач, позволит больше понять как о самой
проблематике задачи, и ее способах решения, так и об алгоритмах человеческого
мышления.
Искусственная нейронная сеть, как следует из названия, представляет собой
попытку построить такую модель. Понятие нейронных сетей включает в себя широкий
класс объектов, различия между которыми могут быть довольно велики, но все они
строятся на основе следующих принципов:
· информация в нейронной сети обрабатывается с помощью
множества однотипных элементов. Такой элемент называется “нейрон”;
· каждый нейрон обладает входом, выходом, и некоторой функцией,
преобразующей вход в выход. Данная функция называется функцией активации
нейрона;
· выход любого нейрона может быть связан с входом одного или
нескольких нейронов. Такая связь называется “синаптической”;
· синаптическая связь при передаче сигнала некоторым образом
преобразует его. Обычно каждой синаптической связи в соответствие проставляется
некоторое число, и при передаче сигнала он просто перемножается с этим числом;
· в случае если к входу одного нейрона присоединено несколько
синаптических связей, то приходящие по ним сигналы некоторым образом
преобразуются перед подачей в нейрон. Обычно они просто суммируются.
Искусственные нейронные сети, также как и биологические, обладают
свойством отказоустойчивости, которое состоит из двух частей. Во-первых,
нейронная сеть способна к обработке и распознаванию сигналов, отличающихся от
тех, что ранее в нее поступали. Например, когда человек видит новую для себя
модель автомобиля, он понимает, что это именно автомобиль, а не что-то другое.
Такой вывод он способен сделать благодаря тому, что новый автомобиль похож,
хоть и не полностью, на те, что он уже видел. Во-вторых, если по некоторой
причине происходит повреждение нейронной сети, то она часто оказывается
способной продолжить свою работу, пусть и зачастую с ухудшением качества
результата [4].
Благодаря своим особенностям, нейронные сети нашли применение во многих
областях, таких как:
· Авиационно-космическая отрасль: автопилоты, тренажеры для
пилотов, детекторы неисправностей для различных подсистем самолета;
· Автомобильные системы автоматического управления;
· Банковская сфера: системы для оценки кредитоспособности
клиентов, для автоматического определения использования краденых карт по
особенностям совершенных транзакций;
· Армия: системы обнаружения, ведения цели, распознавание цели
по радарному отклику;
· Электроника: нелинейное моделирование, компьютерное зрение,
распознавание и синтезирование речи.
2.1 Структура
нейрона
Мозг человека состоит из миллионов базовых элементов - нейронов. С точки
зрения моделирования работы мозга, каждый нейрон можно разделить на три части:
дендрит, аксон, и тело нейрона. Дендриты представляют собой длинные сети,
задача которых заключается в распространении электрических сигналов к телу
нейрона. Тело, в свою очередь, каким-то образом обрабатывает полученный сигнал
и выдает ответ с помощью аксона, который распространяет его вдоль себя. Нейроны
работают не независимо друг от друга, дендриты каждого нейрона соединены с
аксонами других нейронов. Таким образом, в биологическом мозге происходит
распространение сигналов от одного нейрона к другим. На рисунке Рис. 3
изображена схематическая схема нейрона.

Рис.
3. Схема биологического нейрона
Часть структуры головного мозга закладывается при рождении и сохраняется
в неизменном виде в течение всей жизни человека. Другие части мозга способны
изменяться со временем. В ходе подобных изменений происходит изменение
структуры связей между нейронами. Новые связи появляются, а старые исчезают.
Какие-то связи усиливаются, в результате чего сигнал от одного нейрона до
другого доходит почти в неизмененном виде. Другие связи могут ослабеть, и
сигнал будет доходить плохо. Наиболее активно процесс формирования и изменения
связей между нейронами происходит в начале жизни [6].
При создании искусственной нейронной сети происходит моделирование двух
особенностей настоящей нейронной сети:
· В основе сети лежит использование простых базовых компонентов
- нейронов;
· Нейроны соединяются друг с другом, и структура этих
соединений определяется задачами, возложенными на сеть.
Несмотря на то, что скорость работы биологических нейронов и скорость
распространения электрических сигналов по нервным волокнам между нейронами на
несколько порядков меньше скорости, с которой могут функционировать электронные
схемы, человеческий мозг способен справляться с объемными и вычислительно
сложными задачами за крайне короткий промежуток времени. Подобная
производительность возможна за счет того, что структура мозга представляет
собой параллельную систему. В такой системе все нейроны работают одновременно.
Для того, чтобы некоторый нейрон был способен произвести вычисления и
определить свое состояние в следующий момент времени, ему необходима информация
о текущем состояние только тех нейронов, которые расположены рядом с ним и к
которым он подсоединен с помощью дендритов.
Искусственные нейронные сети также обладают способностью к параллельной
обработке сигналов. И хотя для исследования и конструирования нейронной сети
обычно используются программы, работающие на обычных компьютерах с последовательной
системой выполнения команд, после завершения проектирования сети ее можно
реализовать физически, получив преимущества параллельной обработки [6].
Рассмотрим структуру отдельного нейрона - базового компонента нейронной
сети. Она представлена на рисунке Рис. 4.
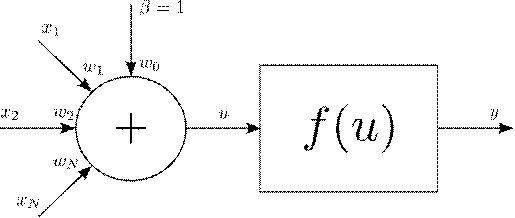
Рис.
4. Структура нейрона
Символами
 обозначены
входные значения нейронов. Это могут быть как выходные значения других
нейронов, так и входные данные.
обозначены
входные значения нейронов. Это могут быть как выходные значения других
нейронов, так и входные данные. 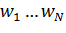 -
весовые коэффициенты синаптических связей. Каждое входное значение умножается
на соответствующий коэффициент. Затем, как следует из схемы, перемноженные
значения суммируются. К полученному результату добавляется смещение
-
весовые коэффициенты синаптических связей. Каждое входное значение умножается
на соответствующий коэффициент. Затем, как следует из схемы, перемноженные
значения суммируются. К полученному результату добавляется смещение 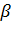 . На
рисунке, для упрощения структуры нейрона, представляется
как синаптическая связь с весовым коэффициентом
. На
рисунке, для упрощения структуры нейрона, представляется
как синаптическая связь с весовым коэффициентом 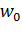 ,
соединенная с выходом “виртуального” нейрона, вход которого ни с чем не связан,
а выходное значение всегда равно 1. Полученная сумма
,
соединенная с выходом “виртуального” нейрона, вход которого ни с чем не связан,
а выходное значение всегда равно 1. Полученная сумма 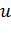 подается
на вход функции активации
подается
на вход функции активации 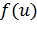 ,
результат работы которой и будет выходным значением нейрона.
,
результат работы которой и будет выходным значением нейрона.
Смещение
является важным понятием нейронной сети. Биологический нейрон реагирует на
раздражитель, только если величина воздействия превышает некоторый определенный
порог. Для имитации подобного поведения в искусственную нейронную сеть и
введено понятие смещения. Для примера, допустим, что функцией активации нейрона
является функция Хэвисайда, которая определяется следующим образом:
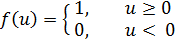 (1)
(1)
Рассмотрим
входной параметр 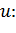
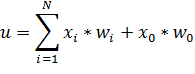 (2)
(2)
Причем
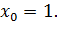 Тогда
при заданных весовых коэффициентах и входных значениях, выход нейрона можно
регулировать путем изменения величины смещения, а именно коэффициента .
Тогда
при заданных весовых коэффициентах и входных значениях, выход нейрона можно
регулировать путем изменения величины смещения, а именно коэффициента .
Как
правило, конкретная функция активации выбирается исследователем в зависимости
от особенностей исследуемой проблемы, а значения весов подбираются в ходе
настройки сети под конкретную задачу. Подобная настройка зовется процессом
обучения нейронной сети.
2.2 Структура
слоя нейронной сети
Для решения многих задач одного нейрона недостаточно. В таких случаях
может потребоваться использование группы нейронов, работающих параллельно.
Подобная группа нейронов называется слоем нейронной сети. Пример сети из одного
слоя приведен на рисункеРис. 5.
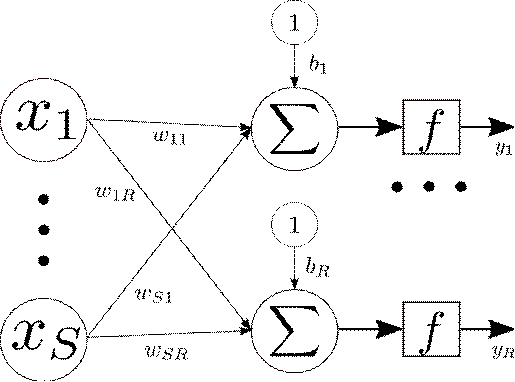
Рис.
5. Однослойная сеть
В
данной сети содержится R нейронов с одинаковой активационной функцией. В
качестве входа в сеть выступает вектор размерности S, выходом
является вектор размерности R. Каждый вход сети связан с каждым нейроном с помощью
синаптической связи с весом 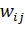 , где i -
номер входа, j - номер нейрона. Также у каждого нейрона есть
смещение, представленное в виде нейрона с выходом, равным 1, и соответствующим
весом связи, равным
, где i -
номер входа, j - номер нейрона. Также у каждого нейрона есть
смещение, представленное в виде нейрона с выходом, равным 1, и соответствующим
весом связи, равным 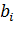 .
.
В
случае, если необходимо задать слой сети, в котором часть нейронов обладает
одной активационной функцией, а часть - другой, можно взять две сети, подобных
той, что изображена на рисунке Рис. 5, и скомбинировать их в одну. Тогда обе
сети будут иметь одни и те же входы, и каждая сеть будет генерировать часть
выходного вектора.
2.3 Нейросетевые
парадигмы
2.3.1 Персептрон
Персептрон - это одна из первых моделей нейронной сети. Несколько
возможных типов персептронов были предложены в 1957 г. Ф. Розенблаттом [4].
Описанный им персептрон предназначен для классификации линейно-разделимых
сигналов. Изначально предполагалось, что персептрон будет реализован аппаратно,
а не в качестве программы для компьютера, и позже был создан один из первых
нейрокомпьютеров, который использовался для распознавания изображений,
считывавшихся с набора фотосенсоров. Изначально персептрон состоял из трех
слоев: сенсорный, ассоциативный и реагирующий (выходной), но позже был создан
ряд модификаций. Схема оригинального персептрона с указанием слоев приведена на
рисунке Рис. 6. Он был сформирован как приблизительная модель сетчатки [4].
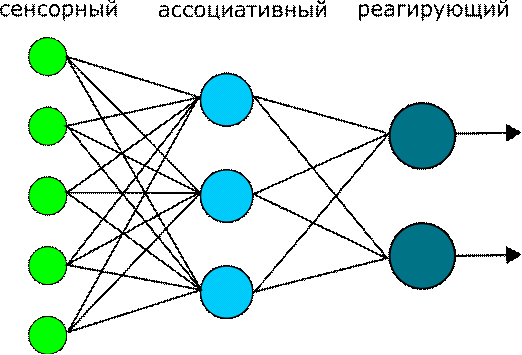
Рис.
6. Схема оригинального персептрона
В ходе итеративного обучения персептрона возможно, если выполнен ряд
предположений, достигнуть таких значений весов, что нейронная сеть будет
выдавать точный ответ для любого использованного в ходе обучения примера.
Конечно, одним из таких предположений является предположение о существовании
подобных весов.
Одной из интересных реализаций персептрона является вариант с
использованием бинарных значений активации для сенсорного и ассоциативного
слоев и значениями активации их множества {-1, 0, 1} для реагирующего слоя.
Веса, соединяющие сенсорный и ассоциативный слой, принимают значение -1, 0 или
1, фиксированы, и задаются случайным образом.
Функцией активации ассоциативного слоя является индикаторная функция с
некоторым фиксированным порогом, определяемая выражением (3).
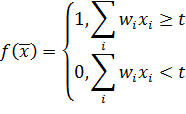 (3)
(3)
Где,
соответственно, 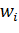 -
значение веса, соединяющего i-й вход с нейроном,
-
значение веса, соединяющего i-й вход с нейроном, 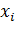 - это i-й
компонент входного вектора,
- это i-й
компонент входного вектора, 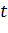 -
некоторое фиксированное пороговое значение. Таким образом, выходной вектор
ассоциативного слоя состоит из единиц и нулей. Активационная функция нейрона из
реагирующего слоя описывается следующей формулой:
-
некоторое фиксированное пороговое значение. Таким образом, выходной вектор
ассоциативного слоя состоит из единиц и нулей. Активационная функция нейрона из
реагирующего слоя описывается следующей формулой:
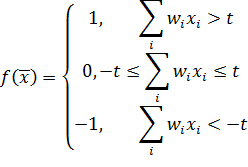 (4)
(4)
В ходе тренировки персептрона происходит изменение только весов,
соединяющих ассоциативный и выходной слои, остальные веса являются
фиксированными. Сама процедура тренировки выглядит следующим образом:
. Пропустить через сеть пример;
. Рассчитать значения ошибок между компонентами выходного и
ожидаемого векторов;
. Если сеть выдала ошибочный ответ, то на основании значения
ошибки произвести изменение весов;
. Повторять пункты 1-3 до достижения необходимого результата.
Рассмотри этапы тренировки более подробно. На первом этапе исследователь
получает от сети выходной вектор. При рассмотрении разницы между ним и
ожидаемым выходом, имеет значение только знак ошибки. То есть, нет никакой
разницы между следующими двумя случаями:
· Сеть вернула в i-м
компоненте выходного вектора 1, а ожидалось -1;
· Сеть вернула в i-м
компоненте выходного вектора 0, а ожидалось -1.
В обоих случаях знак ошибки одинаков, и определяет направление, в котором
в ходе корректировки должны изменяться весовые коэффициенты. Затем, на втором
этапе, значения весов корректируются по формуле (5):
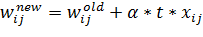 (5)
(5)
где
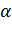 - это
скорость обучения, и она задается исследователем,
- это
скорость обучения, и она задается исследователем, 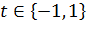 -
определяется знаком ошибки,
-
определяется знаком ошибки, 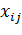 -
величина сигнала, прошедшего по соответствующей синаптической связи. Стоит
заметить, что будут скорректированы только те веса, по которым прошел ненулевой
сигнал, так как только такие веса внесли свою долю в величину ошибки. Если сеть
выдала на тестовый пример правильный ответ, то веса не корректируются.
-
величина сигнала, прошедшего по соответствующей синаптической связи. Стоит
заметить, что будут скорректированы только те веса, по которым прошел ненулевой
сигнал, так как только такие веса внесли свою долю в величину ошибки. Если сеть
выдала на тестовый пример правильный ответ, то веса не корректируются.
Обучение продолжается до тех пор, пока персептрон не перестанет совершать
ошибки. Согласно теореме о сходимости обучения персептрона, если существует
такой набор значений весов синаптических связей, который позволит персептрону
выдавать верный результат на все обучающие примеры, то такой набор будет
найден, и, более того, это произойдет за конечное число шагов [4].
Так как результатом работы нейрона в ассоциативном слое является 0 или 1,
и веса между сенсорным слоем и ассоциативным не меняются в ходе обучения, то
при построении классификатора можно упростить сеть, если вектор признаков
объекта уже является бинарным. Тогда входной слой может играть роль
ассоциативного слоя. Пример структуры сети для решения задачи об определении
принадлежности объектов к одному классу приведен на рисункеРис. 7.
Хотя после своего появления в 1960-х годах, персептроны привлекли много
внимания, и на них возлагались большие надежды, дальнейшее изучение показало,
что набор проблем, который можно решить с их помощью, является крайне
ограниченным. В то время, как персептрон успешно решал одни задачи, решение
других, которые казались на первый взгляд ничуть не сложнее, оказалось для него
невозможным.
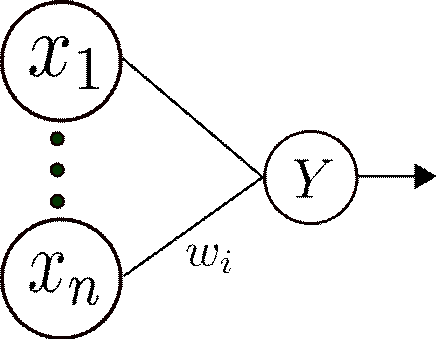
Рис.
7. Простейший классификатор на основе персептрона
Классическим примером является проблема реализации с помощью персептрона
функции “исключающего или”, известная как проблема отделимости [13]. Это
является следствием того, что однослойный персептрон способен решать задачу
классификации только для линейно-разделенных наборов признаков.
Столкнувшись с проблемой линейно-неразделенных данных, в некоторых
случаях можно попытаться преобразовать входные данные. Целью является
нахождение такой функции, чтобы преобразованные величины были
линейно-разделенными. В таком случае, задав соответствующие ассоциативные
элементы, можно построить персептрон для решения данной задачи. Но,
соответственно возникает вопрос, как выбрать необходимое преобразование. Ответ
на этот вопрос не всегда возможно получить, и зависит он от конкретной задачи
[2].
Однако то, что связи между входным слоем и ассоциативным фиксированы, и
не могут быть адаптированы в ходе обучения под конкретную задачу, представляет
собой большую проблему. Вследствие этого, при увеличении размерности входных
данных, необходимое число нейронов, занимающихся предварительным
преобразованием, и сложность соответствующих функций, растет крайне быстро.
Минский и Паперт в своей книге “Персептроны” (1969) рассматривают разные
структуры персептрона, в зависимости от использовавшегося в них преобразования
входных данных. И в каждом случае они находят примеры проблем, которые не могут
быть решены персептроном приведенной структуры [2].
Из рассмотренных ограничений персептрона следует, что необходимо
сконструировать сеть с адаптивными весами между входным и ассоциативным слоями.
Это приводит нас к рассмотрению многослойных сетей.
2.3.2 Многослойные
сети прямого распространения
Одним из самых распространенных типов нейронных сетей являются
многослойные сети. В основе структуры данного типа сетей лежит понятие слоя,
рассмотренное ранее. Причем входы нейронов слоя связаны с выходами нейронов
одного или нескольких других слоев.
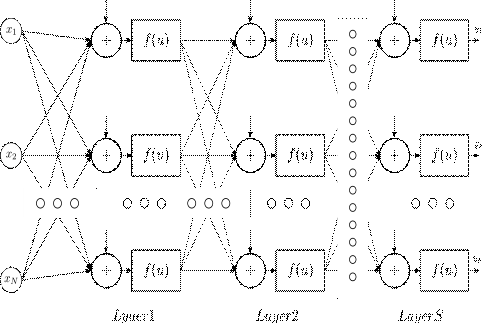
Рис.
8. Многослойная нейронная сеть
Набор “виртуальных” нейронов, с помощью которых в нейронную сеть подаются
входные данные, называют входным слоем. Слой нейронов, чьи выходы считаются
выходом сети, называется выходным слоем. Остальные слои нейронной сети имеют
название скрытых слоев. В различной литературе входной слой может участвовать
или не участвовать в подсчете общего количества слоев нейронной сети. Здесь и
далее, входной слой не будет учитываться при указании количества слоев сети.
На
рисункеРис. 8 указан пример двухслойной сети, у которой выход первого,
скрытого, слоя соединен с входом второго, выходного, слоя. Для обозначения
весов связей между выходами и входами нейронами двух слоев удобно использовать
матрицы. Пусть вход слоя соединен с выходом слоя с i нейронами, а в
самом слое содержится j нейронов. Тогда связь между слоями будет описывать
матрица 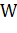 размера
размера 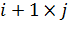 ,
составленная из коэффициентов , равных
весу при синаптической связи, соединяющей выход i-го нейрона
предыдущего слоя, с входом j-го нейрона описываемого слоя. При этом величины
,
составленная из коэффициентов , равных
весу при синаптической связи, соединяющей выход i-го нейрона
предыдущего слоя, с входом j-го нейрона описываемого слоя. При этом величины 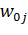 используют
для описания смещения j-го нейрона. Если теперь задать вектор входных
значений X размера j+1, в котором
используют
для описания смещения j-го нейрона. Если теперь задать вектор входных
значений X размера j+1, в котором 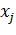 описывает
входное значение j-го нейрона, а
описывает
входное значение j-го нейрона, а 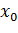 служит
для описания смещения и поэтому равен 1, то можно получить вектор
служит
для описания смещения и поэтому равен 1, то можно получить вектор 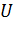 ,
составленный из значений активации нейронов.
,
составленный из значений активации нейронов.
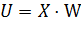 (6)
(6)
Если
соответствующим образом определить функцию активации 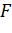 ,
принимающую на вход вектор U, то получим формулу (7) для выхода слоя в матричной
форме.
,
принимающую на вход вектор U, то получим формулу (7) для выхода слоя в матричной
форме.
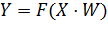 (7)
(7)
Многослойные сети прямого распространения, обучаемые методом обратного
распространения ошибки, как правило, успешно решают задачи классификации и
аппроксимации функции с любой, заранее заданной, точностью [6].
2.3.3 Сеть
радиально-базисных функций
В 1988 году Брумхед и Лоу представили архитектуру нейронной сети,
основанной на использование радиально-базисных функций в качестве функций
активации. Радиально-базисные функции - это класс функций, значение которых
зависит от расстояния от центральной точки и монотонно возрастает или убывает
при увеличении этого расстояния.
Одной из самых распространенных функций из этого класса является функция
Гаусса:
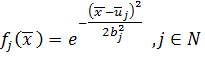 (8)
(8)
Эта
формула определяет выход j-го нейрона в сети из N нейронов,
когда на вход сети подается пример, описываемый вектором 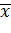 .
. 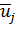 описывает
центр для j-го нейрона,
описывает
центр для j-го нейрона, 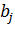 -
параметр, контролирующий гладкость функции.
-
параметр, контролирующий гладкость функции.
Радиально-базисные
функции могут быть использованы в сетях самого широкого класса, но, говоря о RBF-сетях,
обычно подразумевают сеть определенной архитектуры. Данная сеть имеет один
скрытый слой с нелинейной функцией активации, и выходной слой с линейной
функцией активации. Схема данной сети приведена на рисунке Рис. 9.
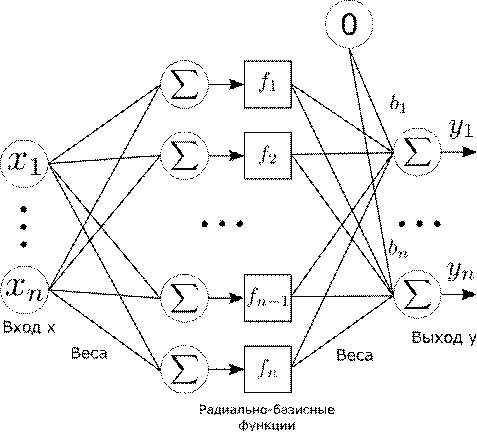
Рис.
9. Сеть радиально-базисных функций
Выходом такой сети является линейная комбинация значений выходов скрытого
слоя.
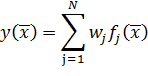 (9)
(9)
Радиально-базисные сети позволяют достигнуть глобального минимума при
оптимизации квадратичной функции ошибки [3]:
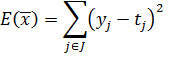 (10)
(10)
Радиально-базисные сети оказались весьма эффективны в решении задачи
точной интерполяции функции в многомерном пространстве. Данная интерполяция
названа точной в том смысле, что при подаче в сеть входного вектора данных из
обучающего набора, сеть должна возвращать в точности ожидаемый результат.
2.4 Обучение
нейронной сети
Важным свойством нейронных сетей является их способность к обучению.
Основываясь на данных, полученных из окружающей среды, нейронная сеть способна
изменить себя с целью повышения своей эффективности.
В контексте искусственных нейронных сетей, под обучением можно понимать
как настройку весовых коэффициентов сети, так и изменение ее структуры с целью
повышения эффективности поставленной задачи. Возможность сети самой искать
связи между предоставляемыми входными данными и выходными целями делает их
более привлекательными по сравнению с системами, в которых правила решения
задачи задаются вручную.
Обучение сети является итеративным процессом. В ходе одной итерации сети
выполняются следующие пункты:
. Получение информации из внешней среды посредством стимулов;
. Изменение параметров или структуры сети;
. Реакция сети на внешние стимулы теперь отличается от того, что
было раньше;
Существует множество различных алгоритмов обучения нейронных сетей, и
каждый алгоритм требует выполнения определенных условий насчет структуры
нейронной сети. Так же, в зависимости от исследуемой проблемы, одни алгоритмы
обучения могут показать лучший результат, чем другие [1].
Различные алгоритмы обучения можно условно разделить на две группы:
обучение с учителем и обучение без учителя.
В
случае обучения с учителем подразумевается наличие некоторой известной
информации об окружающей среде, а именно наличие некоторой выборки, состоящей
из пар вида 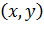 , где
, где 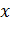 - это
единичный набор входных данных, а
- это
единичный набор входных данных, а 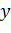 -
информация, описывающая, как сеть должна реагировать на введенные данные.
Возможны разные варианты того, что из себя представляет .
-
информация, описывающая, как сеть должна реагировать на введенные данные.
Возможны разные варианты того, что из себя представляет .
В
одном случае, представляет
собой описание ожидаемого выхода нейронной сети. Тогда пара называется
примером. Многие алгоритмы обучения в этом случае используют некоторую оценку
разности между требуемым и полученным ответами нейронной сети. Эта оценка
используется для определения того, насколько сильно необходимо изменить
структуру сети. Часто пытаются достигнуть того, чтобы за один процесс
корректировки весов для обрабатываемого в данный момент примера уменьшить
величину ошибку до нуля или близко к нему [10].
В
другом случае, исследователю для некоторого набора входных данных известна лишь
некоторая процедура, сообщающая, является ли ответ нейронной сети правильным
или нет. Главным отличием является то, что невозможно оценить, насколько далеко
от правильного ответа находится ответ нейронной сети.
Есть
возможность, что в результате обучения, сеть просто приспособится к вводимым в
ней примерам, и, получив на вход пример, не использовавшийся в ходе обучения,
выдаст неадекватный результат. Чтобы избежать этого, для самого обучения
используется только часть всех доступных примеров. Неиспользованная часть
примеров применяется для оценки качества получившейся нейронной сети.
В
случае если набора примеров нет, а известны только входные данные, можно
использовать обучение без учителя. В данном случае, нейронная сеть должна
выдавать для каждого примера некоторое “наилучшее значение”, величина которого
определяется конкретным алгоритмом обучения. В качестве примера можно
рассмотреть задачу кластеризации точек на плоскости. Она показана на
рисункеРис. 10.
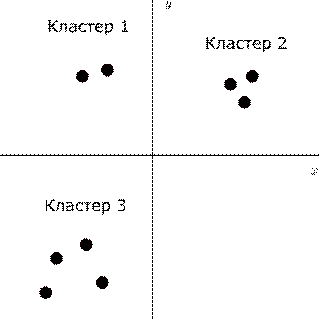
Рис.
10. Задача кластеризации
Для решения данной задачи, необходимо обучить сеть таким образом, что бы
она выдавала одинаковый ответ для точек, входящих в один и тот же кластер.
Изначально, исследователю недоступна информация о том, какая точку какому
кластеру соответствует. В общем случае количество кластеров также неизвестно.
Следовательно, в процессе обучения, сеть должна сама неким образом
модифицировать свою структуру для решения поставленной задачи. Обычно стараются
достигнуть того, чтобы на наборы входных данных, расположенных достаточно
близко друг к другу, сеть выдавала одинаковый ответ [10].
В ходе обучения, с учителем или без, исследователю необходимо определить,
каким образом он будет модифицировать значения весов синаптических связей. К
решению этого вопроса есть два основных похода: детерминированный и
стохастический [1].
В детерминированном подходе величины, на которые будут изменены веса,
определяются с помощью детерминированного алгоритма. Обычно это алгоритм,
основанный на анализе текущей структуры сети и ее параметров, и на разнице
между ожидаемой реакцией сети на некие данные и реальной.
При использовании стохастического подхода корректировка весов
производится случайным образом. То есть, исследователь пропускает через сеть
некоторый набор входных данных и сравнивает выход сети с желаемым. Если разница
слишком велика, то веса связей изменяются случайным образом, затем этот же
набор данных снова пропускается через сеть. Если величина ошибки уменьшилась,
то новые значения весов сохраняются, иначе отбрасываются.
В ходе обучения сети с учителем может возникнуть проблема переобучения.
Переобученная сеть будет способна давать точный ответ при вводе в нее примеров,
использовавшихся при обучении. Но при попытке использовать сеть на новых данных
будет получен неадекватный результат. Одним из признаков переобученной сети
являются слишком большие весовые коэффициенты. Для того чтобы избежать этого,
можно разделить набор примеров для тренировки на две части, и тренировать сеть
только на одной части. Другую часть использовать при этом для проверки степени
качества работы сети, и останавливать обучение в случае роста величины ошибки
[7].
2.4.1 Алгоритм
обучения Хэба
Дональ О. Хэбб в 1949 году предложил алгоритм изменения весовых
коэффициентов при синаптических связях, основанный на следующем правиле: “Если
аксон в клетке А близок к передаче возбуждения клетке Б, и постоянно и
неоднократно принимает участие в процессе возбуждения клетки Б, то в одной или
обеих клетках происходит некоторый процесс роста или метаболических изменений,
в результате чего эффективность клетки А в процессе возбуждения клетки Б
повышается”. Данный алгоритм может быть использован в сетях с различной
конфигурацией.
Правило Хэбба говорит, что если два нейрона, связанных синаптической
связью, активируются одновременно, то связь между ними усиливается. В
математическом виде изменение веса можно записать следующим образом:
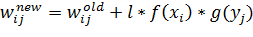 (11)
(11)
где,
соответственно, 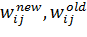 - новое
и старое значение веса при связи, соединяющей i-й элемент
входного вектора и j-й нейрон,
- новое
и старое значение веса при связи, соединяющей i-й элемент
входного вектора и j-й нейрон, 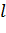 -
некоторая константа, задающая скорость изменения весов (или, другими словами,
скорость обучения),
-
некоторая константа, задающая скорость изменения весов (или, другими словами,
скорость обучения), 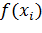 -
некоторая функция от i-го значения входного вектора,
-
некоторая функция от i-го значения входного вектора, 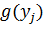 -
некоторая функция от выходного значения j-го вектора.
Можно заметить, что в формуле (11) нигде не присутствует значение целевого
вектора. Это позволяет использовать этот метод для обучения без учителя, когда
даны лишь входные вектора, а целевые неизвестны. Функции
-
некоторая функция от выходного значения j-го вектора.
Можно заметить, что в формуле (11) нигде не присутствует значение целевого
вектора. Это позволяет использовать этот метод для обучения без учителя, когда
даны лишь входные вектора, а целевые неизвестны. Функции  , а также
константа
, а также
константа 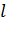 подбираются
самим исследователем.
подбираются
самим исследователем.
Модифицируем
метод Хэбба для случая наличия пар, состоящих из входного вектора и желаемого
результата. Рассмотрим однослойную сеть прямого распространения с функцией
активации первого слоя 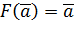 . Пусть
вектор описывает
вход сети,
. Пусть
вектор описывает
вход сети, 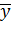 описывает
реальный выход сети, желаемый выход описывает вектор
описывает
реальный выход сети, желаемый выход описывает вектор 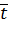 , а -
матрица весовых коэффициентов. Тогда выход одного нейрона будет описываться
следующей формулой:
, а -
матрица весовых коэффициентов. Тогда выход одного нейрона будет описываться
следующей формулой:
 (12)
(12)
классификация нейронный сеть обучение
где
N - размерность вектора , j -
индекс нейрона. Если известны целевые вектора, то можно модифицировать алгоритм
Хэбба. Примем 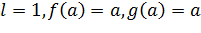 . Тогда
формула для вычисления изменения весов примет следующий вид:
. Тогда
формула для вычисления изменения весов примет следующий вид:
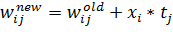 (13)
(13)
Если изначально значения матрицы весов равны нулю, то после обучения на n примерах мы получим следующие веса:
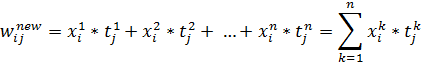 (14)
(14)
Предположим, что входные векторы ортонормированны, то есть:
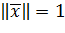 (15)
(15)
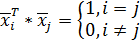 (16)
(16)
Проведем
обучение сети и подадим на вход один из участвовавших в обучении входных
векторов 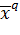 , q -
номер примера. Получим следующую формулу, описывающую элемент выходного вектора
сети:
, q -
номер примера. Получим следующую формулу, описывающую элемент выходного вектора
сети:
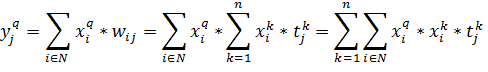 (17)
(17)
Так
как 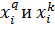 это
элементы ортогональных векторов
это
элементы ортогональных векторов 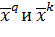 , то:
, то:
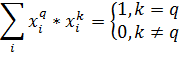 (18)
(18)
Тогда в качестве выходного значения получим:
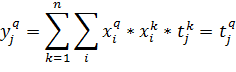 (19)
(19)
То есть выход сети в точности равен целевому значению. Рассмотрим случай,
когда входные вектора не являются ортогональными, а только нормированными.
Тогда результат работы сети будет выглядеть следующим образом:
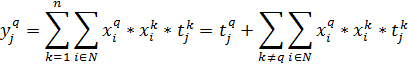 (20)
(20)
То есть сеть будет выдавать результат с ошибкой равной последнему
слагаемому.
2.4.2 Метод
наименьшей квадратичной ошибки
В 1960 году Бернард Уидроу и Мартин Хоф представили нейронную сеть ADALINE, а также алгоритм ее обучения,
названный ими LMS (Least Mean Square) - алгоритм. Это итеративный алгоритм обучения
нейронной сети. Он известен также как дельта-правило или алгоритм обучения
Уидроу - Хофа [4].
В ходе работы, данный алгоритм пытается уменьшить величину ошибки между
реальным и ожидаемым выходами сети. На каждой итерации обрабатывается один
тренировочный набор данных, после чего следует оценка ошибки и попытка ее
уменьшения путем корректировки весовых коэффициентов.
Структура сети ADALINE
похожа на структуру однослойного персептрона, за исключением функции активации.
Здесь используется линейная функция активации. Схема сети представлена на
рисунке Рис. 11. Она содержит в себе один слой из S нейронов. Размерность входного вектора равна R.
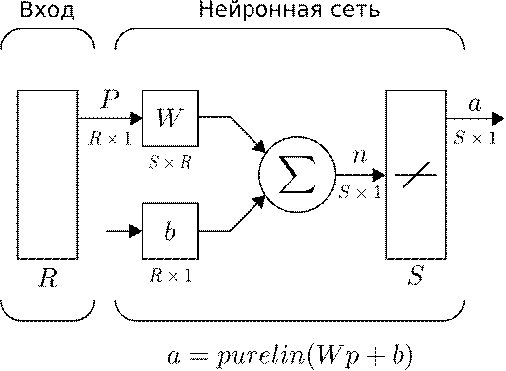
Рис.
11 Нейронная сеть ADALINE
Алгоритм
LMS является одним из алгоритмов обучения с учителем, и
требует наличия набора пар 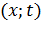 ,
сотоящих из вектора входных данных и вектора, описывающего ожидаемый выход
сеть. Для оценки разницы между ожидаемым и реальным выходами сети используется
сумма квадратов отклонений
,
сотоящих из вектора входных данных и вектора, описывающего ожидаемый выход
сеть. Для оценки разницы между ожидаемым и реальным выходами сети используется
сумма квадратов отклонений 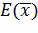 .
.
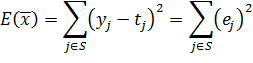 (21)
(21)
где,
соответственно 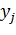 -
реальный выход j-го нейрона сети, а
-
реальный выход j-го нейрона сети, а 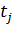 -
ожидаемый выход j-го нейрона.
-
ожидаемый выход j-го нейрона.
Тогда, учитывая, каким образом нейронная сеть преобразовывает входные
данные в выходные, можно записать:
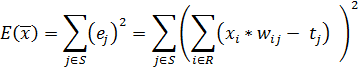 (22)
(22)
Градиент функции показывает направление ее наибольшего роста.
Следовательно, двигаясь в обратную сторону, можно производить минимизацию
функции ошибки. Тогда, на каждой итерации алгоритма обучения для уменьшения
величины ошибки можно производить корректировку весов по следующей формуле:
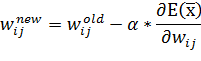 (23)
(23)
Коэффициент
задает
скорость изменения весовых коэффициентов. Выразим формулу для частной
производной:
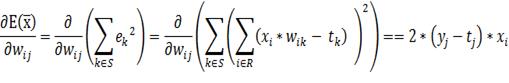 (24)
(24)
Коэффициент
подбирается
экспериментально или выбирается исследователем исходя из каких-то соображений
относительно специфики конкретной задачи. Можно лишь сказать, что если слишком
мало, то обучение будет идти слишком медленно. При достаточно большой скорости
изменения коэффициентов, в ходе обучения есть вероятность в результате одного
изменения “перепрыгивать" через минимум. К тому же, как показывает
практика, метод LMS требует значительного времени для обучения нейронной
сети.
Так
как функция ошибки является квадратичной функцией от элементов входного
вектора, то можно показать, что наличие одного уникального решения задачи
обучения при решении определенной задачи полностью зависит от характеристик
входных данных [6].
Таким
образом, процесс обучения выглядит следующим образом:
1. Для каждого примера из обучающей выборки:
а) Пропустить через нейронную сеть пример из обучающего набора;
б) Для примера вычислить функцию квадратичной ошибки и
скорректировать веса.
. Повторять пункт 1 необходимо до тех пор, пока не будут выполнены
условия для завершения обучения. Таким условием может стать уменьшение среднего
значения квадратичной ошибки или превышение количества итераций некоторого
заранее заданного числа.
Формулы, используемые для изменения весовых коэффициентов при
синаптических связях между входным слоем и выходным, имеют следующий вид:
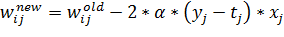 (25)
(25)
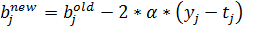 (26)
(26)
В дальнейшем, на основе этого метода был создан метод обратного
распространения ошибки, который можно использовать для нейронной сети прямого
распространения с произвольным числом слоев и с произвольными функциями
активации, при условии, что они являются непрерывными и дифференцируемыми.
2.4.3 Алгоритм
обратного распространения ошибки
Это метод поиска минимума функции ошибки, производимый в пространстве
весовых коэффициентов синаптических связей, и основанный на градиентном спуске.
В качестве результата процесса обучения выступает набор весовых коэффициентов,
минимизирующий функцию ошибки.
Алгоритм позволяет тренировать многослойные сети прямого распространения.
Он включат в себя три фазы:
1) Провести через сеть обучающий пример.
Это фаза прямого распространения;
2) Вычислить значение ошибки между
полученным выходом сети и ожидаемым, и на ее основе вычислить значения ошибок
для каждого предыдущего слоя, вплоть до входного. Эта фаза обратного распространения
ошибки;
3) Произвести единовременную
корректировку всех весов, основываясь на их текущем значении, значении ошибки,
соответствующей рассматриваемому нейрону и активационному значению нейрона.
Обучение с помощью алгоритма обратного распространения ошибки может
потребовать значительных вычислительных средств и времени, но получившаяся в
итоге сеть работает крайне быстро. Для реализации и использования уже обученной
сети необходима только первая фаза алгоритма.
Так же, как и в методе наименьшей квадратичной ошибки, необходимо
рассчитать производную функции ошибки, только теперь уже для произвольной
функции активации. Функция ошибки для сети с J выходами задается аналогичным способом:
(27)
где
-
реальный выход j-го нейрона сети, -
ожидаемый выход j-го нейрона. Пусть -
функция активации нейронов в выходном слое, тогда значение j-го
выходного нейрона будет определяться следующим способом:
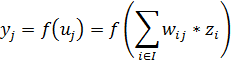 (28)
(28)
- веса
при связях, соединяющие i-й нейрон предыдущего слоя и j-й нейрон
выходного слоя, 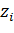 -
выходное значение i - го нейрона предыдущего слоя, I -
число нейронов в предыдущем слое. Найдем производную функции ошибки вдоль
синаптической связи :
-
выходное значение i - го нейрона предыдущего слоя, I -
число нейронов в предыдущем слое. Найдем производную функции ошибки вдоль
синаптической связи :
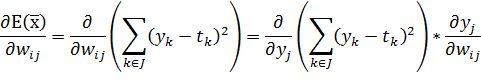 (29)
(29)
Подобное
преобразование возможно, так как 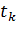 не
зависит от .
Рассмотрим первый множитель:
не
зависит от .
Рассмотрим первый множитель:
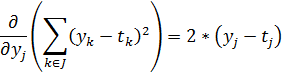 (30)
(30)
Учтем,
как выражается через
активационную функцию, и рассмотрим второй множитель:
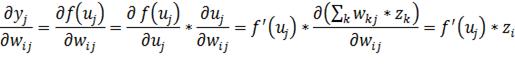 (31)
(31)
Конечный вид производной:
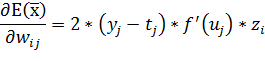 (32)
(32)
Легко видеть, что если выход сети равен ожидаемому значению, то значение
производной функции ошибки обращается в ноль.
На
основе производной вычисляется величина изменения веса в ходе
обучения:
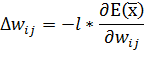 (33)
(33)
В
ходе первой фазы алгоритма, набор данных из
обучающей выборки пропускается через сеть. Последовательно обходится каждый
слой сети, начиная с входного слоя и заканчивая выходным. Каждый нейрон
вычисляет свой вход и выход, и распространяет его дальше по синаптическим
связям.
На
втором шаге, на основе вектора ,
полученного из сети, и целевого вектора ,
соответствующего входным данным, для каждого нейрона выходного слоя вычисляется
значение ошибки 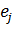 . Эти
значения используются для распространения ошибки на все нейроны предыдущего
слоя (последнего из скрытых слоев) и для изменения весов связей между скрытым
слоем и выходным слоем. Затем для каждого предыдущего слоя рассчитываются
значения
. Эти
значения используются для распространения ошибки на все нейроны предыдущего
слоя (последнего из скрытых слоев) и для изменения весов связей между скрытым
слоем и выходным слоем. Затем для каждого предыдущего слоя рассчитываются
значения 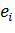 для
соответствующих нейронов. Слои обходятся в порядке, обратном порядку обхода в
первой фазе алгоритма.
для
соответствующих нейронов. Слои обходятся в порядке, обратном порядку обхода в
первой фазе алгоритма.
Рассмотрим
произвольный скрытый слой с функцией активации 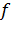 . Пусть в
нем находится I нейронов, а в следующем слое находится
. Пусть в
нем находится I нейронов, а в следующем слое находится  неронов.
Рассмотрим i-й нейрон. Он связан со всеми нейронами следующего
слоя, и для каждого из них уже подсчитано соответствующее значение ошибки . Также,
в ходе фазы прямого распространения было вычислено значение входа нейрона
неронов.
Рассмотрим i-й нейрон. Он связан со всеми нейронами следующего
слоя, и для каждого из них уже подсчитано соответствующее значение ошибки . Также,
в ходе фазы прямого распространения было вычислено значение входа нейрона 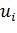 . Тогда
для i-го нейрона значение будет
рассчитываться по следующей формуле:
. Тогда
для i-го нейрона значение будет
рассчитываться по следующей формуле:
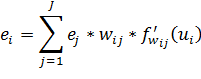 (34)
(34)
Нет необходимости считать значения ошибок для входного слоя, но веса,
связывающие входной слой и скрытый, также будут модифицированы на следующем
шаге алгоритма.
После
того, как значения ошибок для всех нейронов всех слоев вычислены, можно
приступать к корректировке весовых коэффициентов. Значение веса ,
соответствующее синаптической связи, соединяющей i-й нейрон
скрытого слоя с j-м нейроном следующего слоя, изменяется по следующей
формуле:
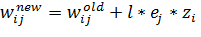 (35)
(35)
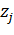 - это
значение сигнала, которое было передано по синаптической связи между i-м
нейроном скрытого слоя и j-м нейроном выходного слоя, или, другими словами,
выходное значение i-го нейрона, -
скорость обучения, она задает скорость изменения весов. Для связей, соединяющих
входной слой с первым скрытым слоем, формула примет следующий вид:
- это
значение сигнала, которое было передано по синаптической связи между i-м
нейроном скрытого слоя и j-м нейроном выходного слоя, или, другими словами,
выходное значение i-го нейрона, -
скорость обучения, она задает скорость изменения весов. Для связей, соединяющих
входной слой с первым скрытым слоем, формула примет следующий вид:
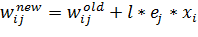 (36)
(36)
где
- это i-й
компонент входного вектора .
Обучение нейронной сети с помощью алгоритма обратного распространения
ошибки является вычислительно сложной задачей. Несмотря на распространение
высокоскоростных вычислительных систем, обучение сети может занять несколько
часов или дней. По этой причине, необходимо рассмотреть некоторые модификации
исходного алгоритма, позволяющие увеличить скорость обучения.
Все возможные способы ускорения алгоритма можно разбить на две категории.
В первую категорию входят эвристические алгоритмы, основанные на некоторых
предположениях относительно метода обучения. Во второй группе находятся
алгоритмы численной оптимизации скорости обучения.
2.4.3.1 Метод
моментов
Одним из способов увеличения скорости обучения, является использование
для модификации весов значения не только текущего градиента ошибки, но и
предыдущего. В некоторых случаях это позволяет получить значительное уменьшение
времени, затрачиваемого на тренировку.
Другое преимущество этого метода можно обнаружить, если в наборе примеров
для тренировки есть несколько примеров, которые значительно отличаются от
основной массы данных. В таком случае можно предположить, что они являются
ошибочными. Такие данные могут появляться, например, вследствие наложения шума.
Если не использовать данную модификацию алгоритма, то для того, чтобы избежать
деструктивного влияния на сеть этих примеров, исследователь может установить
низкую скорость обучения, но это замедлит весь процесс обучения [4].
Рассмотрим, как изменятся формулы для расчета величины изменения весов.
Для начала, необходимо сохранить значения весов, которые использовались для
одного или нескольких предыдущих тренировочных примеров. Тогда, для случая
использования только одного предыдущего значения весов, формула будет выглядеть
следующим образом:
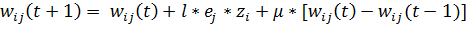 (37)
(37)
Где,
соответственно, 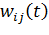 -
значение веса на t-м шаге, -
скорость обучения,
-
значение веса на t-м шаге, -
скорость обучения, 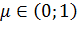 -
заданная исследователем константа.
-
заданная исследователем константа.
В
случае если несколько подряд идущих тренировочных примеров требуют изменения
весов в одном направлении, то метод моментов позволяет менять веса на большую
величину, даже при небольшой заданной скорости обучения. Следовательно, это
делает возможным установку небольшой скорости обучения, что позволит избежать
резкого изменения весов сети при встрече с примером, который вызовет большое
значение ошибки.
Дополнительным
плюсом данной модификации метода является то, что изменения весов идут не в
направлении градиента, а в направлении комбинации текущего и нескольких
предыдущих градиентов. Это снижает вероятность того, что в результате обучения
будет, достигнут локальный, а не глобальный минимум.
Недостатком
этого метода является то, что в некоторых случаях изменение весов может
производиться в направление увеличения значения ошибки. Также, величина скорости
обучения в любом случае будет задавать максимальную величину, на которую могут
быть изменены веса за один раз [4].
2.4.3.2
Пакетное обновление весов
В некоторых случаях выгодным является пакетное обновление весов. В этой
модификации алгоритма веса обновляются не сразу. Вместо этого, находится
среднее значение величины изменения весов для нескольких наборов данных,
которое и используется для изменения весов.
К сожалению, подобная схема обновления весов иногда приводит к увеличению
шанса оказаться в локальном минимуме функции ошибки [4].
2.4.3.3 Адаптивная
скорость обучения
Так как одним из главных факторов, от которых зависит время, необходимое
для обучения нейронной сети, является коэффициент скорости обучения, то интерес
представляют алгоритмы, позволяющие изменять его по ходу обучения. Одним из
наиболее развиваемых методов является дельта-бар-дельта алгоритм.
В
основе этого метода лежит идея позволить каждому весовому коэффициенту иметь
собственную скорость обучения, а также использование эвристических правил для
изменения этой скорости в ходе обучения сети:
· если для несколько подряд идущих тренировочных образцов
изменение веса при некоторой синаптической связи происходит в одну и ту же
сторону, то скорость обучения, соответствующая этой связи, увеличивается;
· если изменение веса происходит каждый раз в другую сторону,
то соответствующий коэффициент уменьшается.
Как показывает практика, применение подобной модификации алгоритма
обратного распространения ошибки, как правило, приводит к увеличению скорости
обучения [4]. Этот алгоритм, в ходе своей работы, будет изменять веса на
большие величины, если значение минимума функции ошибки находится далеко от
текущего положения. При приближении к минимуму, величина, на которую будут
изменяться веса в ходе обучения, будет уменьшаться [14].
Обновления весов между двумя слоями на шаге t+1 проходят по следующей формуле:
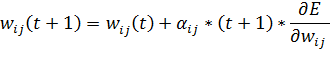 (38)
(38)
Формула
отличается от стандартной, используемой в оригинальном методе обратного
распространения ошибки, только коэффициентом скорости обучения. Как видно из
формулы, перед обновлением весов необходимо получить значение коэффициента 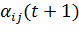 .
.
В
ходе обучения, для каждой синаптической связи подсчитывается значение
производной вдоль нее:
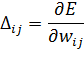 (39)
(39)
Для
определения нового коэффициента обучения необходимо знание 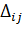 на
текущем и предыдущем шагах обучения.
на
текущем и предыдущем шагах обучения.
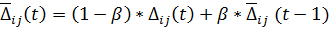 (40)
(40)
Значение
параметра определяется
исследователем исходя из его собственных соображений. Определение значения
скорости обучения происходит по следующей формуле:
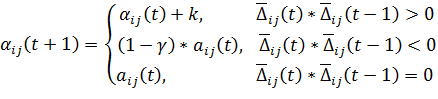 (41)
(41)
Величины
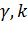 должны
быть заданы исследователем.
должны
быть заданы исследователем.
2.4.4 Методы
задания начальных значений весов
От того, как будут заданы начальные значения весов, зависит, с какой
скоростью будет обучаться сеть, и достигнет ли она глобального минимума функции
ошибки, или только локального.
Величина, на которую будут обновлены веса при обучении алгоритмом
обратного распространения ошибки, зависит как от значения самой функции
активации, вычисленного для данного входа нейрона, так и значения производной
функции активации в данной точке. Следовательно, значения весов должны
выбираться, исходя из свойств функции активации и свойств ее производной. Например,
если выбрать слишком большие веса, то в случае использования сигмоиды в
качестве функции активации, ее значение постоянно будет близко к единице, а
значение производной - к нулю. Если же выбрать слишком маленькие начальные
веса, то величина входного сигнала для скрытого или выходного слоя может
оказаться слишком маленькой, что может сильно замедлить обучение [4].
Во
многих случаях для задания начальных весов достаточно использовать случайные
значения из симметричного относительно нуля интервала, например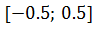 , или
другого, подходящего под конкретную задачу.
, или
другого, подходящего под конкретную задачу.
2.5
Кодирование классов
При использовании нейронных сетей для решения задачи классификации,
необходимо решить, каким образом представить классы в понятном для сети виде.
Один из возможных решений является нумерация классов в некотором порядке и
кодирование каждого класса в виде вектора, элементы которого задаются формулой
(42).
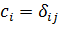 (42)
(42)
Где
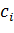 - i-й
элемент вектора, j - номер класса,
- i-й
элемент вектора, j - номер класса, 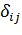 - символ
Кронекера [2].
- символ
Кронекера [2].
2.6 Выводы
по разделу
Рассмотрены описанные в данном разделе нейросетевые парадигмы с точки
зрения их применимости к решению задач классификации винно-водочных изделий.
Так как нет оснований делать предположение о линейной разделимости
классов, следовательно, стоит отказаться от использования однослойного
персептрона. Тогда для построения классификатора необходимо использовать
многослойный персептрон, радиально-базисную сеть или метод опорных векторов.
Радиально-базисная сеть способна классифицировать образы с точностью,
равной точности многослойного персептрона, но часто это требует большего
количества элементов [1].
Рассматриваемая задача содержит достаточно большого количества доступных
примеров, что является необходимым требованием для успешного решения задачи
классификации с помощью многослойного персептрона, обучаемого алгоритмом
обратного распространения ошибки [1].
Основываясь на приведенных особенностях применения различных методов, в
данной работе для решения задачи классификации было решено использовать
многослойный персептрон, обучаемый методом обратного распространения ошибки.
Также будут рассмотрены модификации метода обучения, позволяющие улучшить
качество полученной в результате сети.
3.
Построение классификатора
3.1 Постановка
задачи
Исходный набор данных содержит 4898 примеров для белых вин и 1599
примеров для красных вин. Каждый пример состоит из 11 атрибутов и номера
класса. Атрибуты характеризуют следующие химические параметры вина:
. Летучая кислотность;
. Активная кислотность;
. Содержание лимонной кислоты;
. Остаточный сахар;
. Хлориды;
. Количество свободной двуокиси серы;
. Общее количество двуокиси серы;
. Плотность;
. Общая кислотность;
. Количество сульфатов;
. Содержание алкоголя.
Целевым параметром является численно выраженное качество вина, которое
для известных примеров принимает значение от 3 до 9 включительно.
Необходимо разработать нейросетевой классификатор, позволяющий по набору
входных признаков определить класс качества вина.
3.2 Нормировка
данных
Большое значение некоторой переменной входного вектора не означает, что
она оказывает такое же большое влияние на определение результата.
Следовательно,
необходимо привести все данные к некоторому единому знаменателю. Для каждого
признака из входного вектора ,
независимо от других признаков, вычисляется среднее значение и значение
стандартного отклонения:
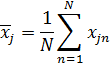
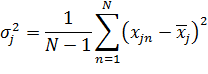 (43)
(43)
где
j - номер признака, 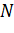 - общее
число примеров. Затем выполняется следующее линейное преобразование:
- общее
число примеров. Затем выполняется следующее линейное преобразование:
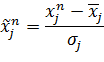 (44)
(44)
У преобразованных признаков значение математического ожидания равно 0, а
значение стандартного отклонения равно 1. В таблице Таблица 1 показаны
характеристики исходных данных.
Таблица
1
Характеристики
исходных данных
|
Признак, №
|
Максимальное значение
|
Минимальное значение
|
Математическое ожидание
|
Стандартное отклонение
|
|
1
|
15.9
|
3.8
|
7.2153
|
1.2964
|
|
2
|
1.58
|
0.08
|
0.33967
|
0.16464
|
|
3
|
1.66
|
0.0
|
0.31863
|
0.14532
|
|
4
|
65.8
|
0.6
|
5.4432
|
4.7578
|
|
5
|
0.611
|
0.009
|
0.056034
|
0.035034
|
|
6
|
289.0
|
1.0
|
30.525
|
17.749
|
|
7
|
440.0
|
6.0
|
115.74
|
56.522
|
|
8
|
1.039
|
0.98711
|
0.9947
|
0.0029987
|
|
9
|
4.01
|
2.72
|
3.2185
|
0.16079
|
|
10
|
2.0
|
0.22
|
0.53127
|
0.14881
|
|
11
|
14.9
|
8.0
|
10.492
|
1.1927
|
Так как это линейное преобразование, то оно могло бы быть проведено
первым слоем сети прямого распространения, но тогда возникает вопрос о том,
какие изначальные значения весов необходимо использовать, чтобы учесть разность
в порядках значений разных признаков. При использовании нормализованных данных,
для всех весов можно задать начальное значение порядка единицы.
В таблице Таблица 2 показаны характеристики преобразованных данных. У
всех признаков стандартное отклонение равно 1, а математическое ожидание равно
0.
Таблица
2
Характеристики
преобразованных данных
|
Признак, №
|
Минимальное значение
|
|
1
|
6.6989
|
-2.6344,
|
|
2
|
7.5338
|
-1.5772,
|
|
3
|
9.2306
|
-2.1927,
|
|
4
|
12.686
|
-1.018,
|
|
5
|
15.841
|
-1.3425,
|
|
6
|
14.562
|
-1.6635,
|
|
7
|
5.7368
|
-1.9416,
|
|
8
|
14.768
|
-2.53,
|
|
9
|
4.9227
|
-3.1004,
|
|
10
|
9.8701
|
-2.0918,
|
|
11
|
3.6959
|
-2.0892
|
3.3 Кодирование
классов
Целевой параметр качества для элементов выборки меняется от 3 до 9, то
есть в выборке отсутствует информация о винах со значением качества ниже 3 или
выше 9. Поэтому было принято решение задать 7 классов. Класс под номером 1
будет соответствовать значению качества равному 3, а класс с номером 7 будет
соответствовать значению качества равному 9. Для кодирования будем использовать
способ задания класса в виде вектора с 1 на позиции с номером класса, и с 0 на
остальных позициях.
3.4 Топология
сети
В данной работе для решения поставленной задачи используется полносвязная
сеть прямого распространения, которая обучается с использованием алгоритма
обратного распространения ошибки. Число слоев и количество нейронов, а также
параметры обучения, подбирается экспериментально. При этом следует учитывать
ряд зависимостей между этими параметрами и процессом обучения.
Во-первых, увеличение количества слоев или нейронов замедляет процесс
обучения. Это происходит вследствие роста объема необходимых вычислений. При
этом увеличение числа слоев или нейронов необязательно приведет к улучшению
качества полученной нейронной сети. Более того, в результате возможно
переобучение сети и ее неспособность к прохождению тестирования.
Во-вторых, выбор параметров для алгоритма обучения требует определенной
осторожности. Слишком маленький коэффициент обучения может привести к
экстремально низкой скорости обучения, в то время как большое значение
коэффициента может ограничить возможность минимизации значения функции ошибки.
В данной работе качестве функции активации во всех слоях используется
сигмоидальная функция, определяемая следующим образом.
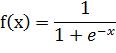 (45)
(45)
Эта функция принимает значения от 0 до 1. Ее график приведен на рисунке
Рис. 12.
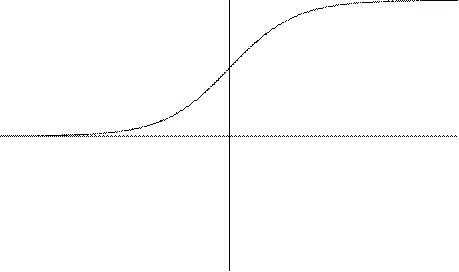
Рис.
12. График функции сигмоиды
3.5 Начальное
состояние нейронной сети
Метод начальной инициализации весов является одним из важнейших факторов,
влияющих на скорость обучения многослойной сети [5]. При определении способа
задания весов следует учитывать, что от величин весов зависит величина
аргумента функции активации. Если веса будут слишком большими или слишком
маленькими, то аргумент попадет в зоны затухания функции, производная в которых
имеет крайне маленькое значение. Это приведет к сильному падению скорости
обучения нейронной сети.
Из требования полной связности нейронной сети следует, что значения весов
при синаптических связях должны быть отличны от нуля. Если значение некоторого
веса равно 0, то этот вес не будет никак влиять на результат работы сети при ее
использовании. Так же он не будет изменяться при обучении с использованием алгоритма
обратного распространения ошибки.
Дополнительным условием является то, что начальные значения весовых
коэффициентов не должны влиять на возможности сети сходимости к минимуму в ходе
обучения.
Исходя
из этих соображений, и учитывая максимальные и минимальные величины,
встречающиеся в наборах исходных данных, в данной работе было принято решение
инициализировать весовые коэффициенты случайными значениями из множества [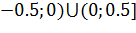 .
.
4.
Реализация классификатора
4.1 Структура
программного обеспечения
Для реализации приложения был выбран язык программирования С++ в версии
стандарта от 2011 года, а также следующие программные средства:
· Библиотека классов Boost;
· Среда программирования QtCreator;
· Система автоматизированной сборки приложений из исходного
кода CMake;
· Распределенная систем управления версиями исходного кода
программного обеспечения Mercurial.
Приложение способно функционировать в операционной системе GNU/Linux. Компиляция исходных кодов производилась компилятором
Clang версии 3.6. При разработке был
разработан ряд классов. Исходный код программного обеспечения приведен в
приложение А.
Класс ProgramOption используется для разбора параметров
командной строки. В ходе своей работы, он производит перевод параметров в
удобный для использования внутренний формат данных. При этом производится
проверка, что различные параметры совместимы друг с другом, не противоречат
один другому, и принимают значения из допустимого диапазона. В случае если по
каким-то причинам набор аргументов не может быть правильно разобран, то
выводится поясняющее сообщение. Также этот класс ответственен за вывод справки.
Классы
layer_t и net_t служат для реализации модели искусственной нейронной
сети. Класс layer_t содержит в себе данные, необходимые для описания
единичного слоя сети, а именно матрица весов между нейронами этого и
предыдущего слоя, и входные и выходные вектора. Также этот класс содержит в
себе информацию, которую необходимо сохранять для каждого слоя сети в ходе
обучения. Эта информация включает в себя вектор аргументов функции активации,
вектор значений величин ошибок. При использовании модификации алгоритма
обратного распространения ошибок с адаптивным изменением скорости обучения, в
объекте класса layer_t также сохраняется матрица значений скоростей обучений
для весов и значений  ,
полученных на предыдущем шаге обучения. Для упрощения реализации модели
нейронной сети и алгоритма обучения, величина смещения задается с помощью
виртуального нейрона, чей выход всегда равен 1. При этом, настоящее значение
смещения сохраняется как вес синаптической связи между этим нейроном и
некоторым нейроном слоя. Вследствие этого, матрица весов имеет дополнительную
строку под индексом 0, которая относится к весам, приходящим от виртуального
нейрона. Также, нулевые элементы входного и выходного векторов всегда равны 1.
,
полученных на предыдущем шаге обучения. Для упрощения реализации модели
нейронной сети и алгоритма обучения, величина смещения задается с помощью
виртуального нейрона, чей выход всегда равен 1. При этом, настоящее значение
смещения сохраняется как вес синаптической связи между этим нейроном и
некоторым нейроном слоя. Вследствие этого, матрица весов имеет дополнительную
строку под индексом 0, которая относится к весам, приходящим от виртуального
нейрона. Также, нулевые элементы входного и выходного векторов всегда равны 1.
Класс
net_t содержит в себе массив нейронной сети и информацию о
размерности векторов входа и выхода. Этот класс ответственен за создание
необходимого количества объектов класса layer_t.
При этом он настраивает их таким образом, чтобы вектор входа некоторого слоя
был выходом предыдущего. Это позволяет убрать лишнее дублирование в памяти одних
и тех же данных, а так же уменьшить количество производимых в ходе работы
программы операций копирования данных. Этот класс ответственен за инициализацию
весовых коэффициентов сети. Также он позволяет осуществлять загрузку сети из
файла и запись ее в файл для дальнейшего использования.
Обучение
нейронной сети осуществляется с помощью класса ffbp_train.
Он предоставляет ряд методов для настройки параметров процесса обучения, таких
как количество эпох, в течение которых будет производиться обучение сети, или
скорость обучения. В программе реализован как обычный алгоритм обучения методом
обратного распространения ошибки, так и его модификация, использующая
адаптивное изменение скорости обучения, которая задается отдельно для каждого
веса при синаптической связи. Выбор, какой алгоритм будет использован,
осуществляется исходя из заданных параметров.
Также
в программе реализован алгоритм борьбы с попаданием в локальный минимум функции
ошибки в процессе обучения. Состояние сети запоминается в конце каждой эпохи обучения.
Если после нескольких эпох ошибка валидации не уменьшается, то происходит откат
процесса обучения. При откате состояние сети и параметров обучения
восстанавливается на момент за несколько эпох до нахождения наилучшей сети.
Также увеличивается коэффициент, отвечающий за скорость обучения сети. В случае
использования метода адаптивного изменения весов, увеличиваются все величины
скоростей обучения. Так как величина изменения весов в ходе обучения зависит от
скорости обучения, то есть вероятность, что после изменения этого параметра, в
ходе последующего обучения сеть выйдет из локального минимума. Конечно, это
возможно только при условии, что она в нем находится на данной эпохе.
Данные,
которые будут использованы для обучения нейронной сети, должны быть записаны в
файлах определенного формата, а путь к ним передан программе при запуске.
Входные и целевые выходные вектора описываются в разных файлах, при этом i-й
входной вектор будет сопоставлен с i-м выходным вектором. В каждом
файле каждый вектор данных записывается на отдельной строке, элементы вектора
разделяются символом ‘;’. Первая строка, при чтении пропускается, так как
обычно в нее записываются наименования величин, лежащих во входных векторах.
Пустые строки игнорируются. Чтение файлов реализовано в функции import_csv.
Задание
параметров работы приложения производится путем передачи соответствующих
аргументов при запуске программы. Следующие аргументы являются обязательными:
· --data_file,-d - параметр, задающий файл, содержащий набор входных векторов
· --target_file,-t - параметр, задающий файл, содержащий набор выходных
векторов
· --train - произвести тренировку сети. Этот параметр может
быть заменен параметром --test
· --test - произвести
тестирование сети, при этом также должен быть указан путь к файлу с уже
обученной нейронной сетью.
Следующие параметры могут быть переданы программе при необходимости:
· --help,-h - вывести справочную информацию о
программе
· --epoches,-e
число - задать число эпох, в ходе которых будет производиться обучение. Число
должно быть неотрицательным.
· --validation
число - этот параметр позволяет задать долю примеров, которая будет
использована для проведения валидации в ходе обучения нейронной сети. Число
должно находиться в диапазоне 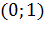
· --learn_rate,-r
число - задать скорость обучения. Число должно быть неотрицательным.
· --shuffle,-s -
перемешать примеры случайным образом перед началом обучения.
· --layers,-l
набор чисел - этот параметр позволяет задать количество и размерности скрытых
слоев сети. При использовании этого параметра необходимо указать набор чисел,
записанных через пробел. Число скрытых слоев будет равно количеству указанных
чисел, а сами числа задают число нейронов в соответствующем слое.
· --save путь
к файлу - этот параметр задает путь к файлу, в который будет сохранена
искусственная нейронная сеть после завершения обучения.
· --load путь
к файлу - указывает файл, из которого должна быть загружена нейронная сеть при
запуске приложения.
· --adaptive_learn
число1 число2 число3 - задает использование метода адаптивной скорости
обучения. Три числа задают параметры 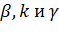 соответственно.
соответственно.
· --clone -
передача этого параметра включает использование алгоритма борьбы с попадание в
локальный минимум.
При использовании опции --test,
все опции, относящиеся к обучению новой сети, будут проигнорированы. Для
задания числа и размерности скрытых слоев, соответствующую опцию можно указать
несколько раз, при этом будут учитываться все переданные числа. Размерность
выходного слоя рассчитывается автоматически по размерности выходного вектора,
полученной из файла, переданного с опцией target_file.
4.2 Результаты
обучения нейронной сети
Для
обучения выборка была разделена на тренировочную, валидационную и тестовую
часть в соотношение 0.7, 0.15, 0.15. Использовался режим адаптивной скорости
обучения с параметрами 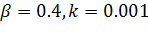 .
Параметр
.
Параметр 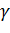 принимал
значения 0.05. Сеть обучается 1000 эпох, после нахождения минимума
валидационной ошибки происходит откат на 50 эпох, скорости обучения весов при
этом увеличиваются на 5 и 10.
принимал
значения 0.05. Сеть обучается 1000 эпох, после нахождения минимума
валидационной ошибки происходит откат на 50 эпох, скорости обучения весов при
этом увеличиваются на 5 и 10.
Тестируются
нейронной сети с количеством скрытых слоев от 0 до 2 включительно. Количество
нейронов в каждом слое последовательно увеличивается от 10 до 100 с шагом в 10.
При
обучении сети без скрытого слоя на тестовой выборке была получена
среднеквадратичная ошибка равная 0.3064935. При этом точно указан класс для 50%
тестовых образцов, с погрешностью  класс -
для 93.9% тестовых образцов. Данные о классификации образцов в ходе
тестирования нейронной сети приведены в таблице Таблица 3.
класс -
для 93.9% тестовых образцов. Данные о классификации образцов в ходе
тестирования нейронной сети приведены в таблице Таблица 3.
Таблица
3
Результаты
тестирования сети без скрытого слоя
|
Целевой класс
|
0
|
0
|
2
|
3
|
0
|
0
|
0
|
|
0
|
1
|
23
|
11
|
0
|
0
|
0
|
|
0
|
0
|
148
|
115
|
1
|
0
|
0
|
|
0
|
1
|
79
|
231
|
20
|
0
|
0
|
|
0
|
0
|
8
|
108
|
22
|
0
|
0
|
|
0
|
0
|
0
|
18
|
7
|
0
|
0
|
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
|
Точность, %
|
0
|
3
|
56
|
70
|
16
|
0
|
0
|
|
Выданный сетью класс
|
При
обучении сети с одним скрытым слоем наилучшие результаты были получены при
количестве нейронов в слое равном 40. В этой сети величина средней квадратичной
ошибки на тестовых примерах равна 0.2896. При этом точно указан класс для 57%
тестовых образцов, с погрешностью класс -
для 94.6% тестовых образцов. Данные о классификации образцов в ходе
тестирования нейронной сети приведены в таблице Таблица 4.
Таблица
4
Результаты
тестирования сети с одним скрытым слоем
|
Целевой класс
|
0
|
0
|
2
|
3
|
0
|
0
|
0
|
|
0
|
1
|
23
|
11
|
0
|
0
|
0
|
|
0
|
2
|
186
|
71
|
5
|
0
|
0
|
|
0
|
1
|
85
|
220
|
24
|
1
|
0
|
|
0
|
0
|
6
|
85
|
46
|
1
|
0
|
|
0
|
0
|
0
|
13
|
11
|
1
|
0
|
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
|
Точность, %
|
0
|
3
|
70
|
66
|
33
|
4
|
0
|
|
Выданный сетью класс
|
При
обучении сети с двумя скрытыми слоями наилучшие результаты были получены при
количестве нейронов в слоях равном 50 в первом скрытом и 40 во втором скрытом
слое. В этой сети величина средней квадратичной ошибки на тестовых примерах
равна 0.278. При этом точно указан класс для 58% тестовых образцов, с
погрешностью класс -
для 95.6% тестовых образцов. Данные о классификации образцов в ходе тестирования
нейронной сети приведены в таблице Таблица 5.
Таблица
5
Результаты
тестирования сети с двумя скрытыми слоями
|
Целевой класс
|
0
|
0
|
4
|
1
|
0
|
0
|
0
|
|
0
|
0
|
28
|
6
|
1
|
0
|
0
|
|
1
|
0
|
174
|
87
|
2
|
0
|
0
|
|
0
|
0
|
71
|
238
|
22
|
0
|
0
|
|
0
|
0
|
3
|
82
|
53
|
0
|
0
|
|
0
|
0
|
1
|
15
|
9
|
0
|
0
|
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
|
Точность, %
|
0
|
0
|
66
|
72
|
38
|
0
|
0
|
|
Выданный сетью класс
|
На рисунке Рис. 13 показан график изменения валидационной ошибки сети при
обучении для сетей, показавших наилучший результат в ходе тестирования. На нем
показано, что сеть с одним скрытым слоем в ходе обучения достигла наименьшей
ошибки валидации. Несмотря на это, при тестировании сеть с двумя скрытыми
слоями показала лучший результат.
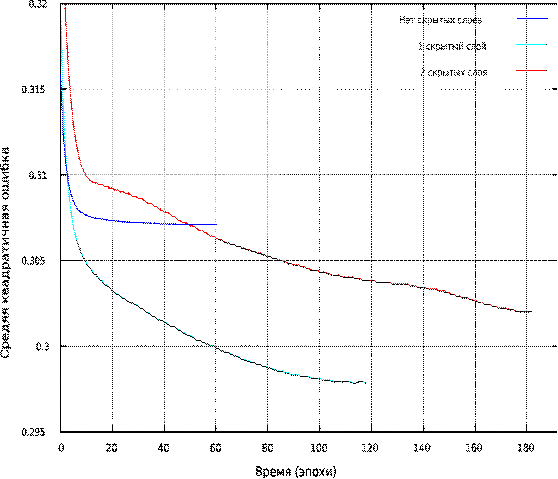
Рис.
13. График изменения валидационной ошибки в ходе обучения
5.
Анализ результатов
После
обучения была получена нейронная сеть, способная в 58% процентах случаях точно
классифицировать входной образ, и в 95.6% классифицировать с точностью класс.
На графикеРис. 13 показано, что скорость обучения нейронной сети без скрытых
слоев на определенном этапе резко падает до 0, в то время как наличие одного
или двух скрытых слоев позволяет производить обучение дальше.
Добавление
в сеть скрытого слоя привело к увеличению качества распознавания объектов
обученной сетью. Следовательно, можно предположить, что в данной задаче классы
являются линейно-неразделимыми.
Тестирование
показала низкую, от 0% до 4%, точность классификации объектов, принадлежащим к
крайним двум слева и двум справа классам. Возможно, это является следствием
небольшого количества примеров, принадлежащих этим классам. Точность
определения 5 класса изменяется от 16% до 38% в зависимости от количества
скрытых слоев в сети. При этом, точность классификации объектов, принадлежащим
классам 3 и 4, принимает значение от 56% до 72%.
Добавление
второго скрытого слоя в сеть не дало сильного улучшения точности классификации,
но сильно уменьшило скорость обучения сети.
Заключение
Была рассмотрена задача построения нейросетевого классификатора,
позволяющего по химическому составу определить качество вина.
Изучены различные математические модели классификаторов, в том числе
нейронные сети и машины опорных векторов. Каждая модель оценена с точки зрения
ее применимости к решению поставленной задачи. В результате решено строить
классификатор на основе нейронной сети.
Рассмотрены теоретические основы нейронных сетей. При этом приведены
описания различных нейросетевых парадигм, которые могут быть использованы для
решения задачи классификации. Вследствие невозможности утверждать, что классы в
задаче являются линейно-разделимыми, принято решение отказаться от
использования однослойных сетей. Выбор между сетью радиально-базисных функций и
многослойным персептроном сделан в пользу последнего из-за меньшей
вычислительной сложности при сравнимом результате.
На основе многослойной сети прямого распространения, обучаемой с помощью
алгоритма обратного распространения, построен классификатор. Методы
предварительной обработки данных и кодирования классов выбраны с учетом
особенной поставленной задачи. Задана топология сети и метод начальной
инициализации параметров. Определена структура классификатора, и его
функциональные возможности. Классификатор реализован на языке программирования
С++.
Полученные результаты обучения нейронной сети показывают, что после
обучения сеть оказалась способной производить классификацию винно-водочной
продукции. По результатам тестирования, классификатор показал наличие
принципиальной возможности определения качества винно-водочной продукции с
помощью классификатора, построенного на основе многослойной нейронной сети
прямого распространения, и обученной модифицированным алгоритмом обратного
распространения. Но точность этой классификации на данном этапе исследования
остается недостаточной для реального применения на производственном
предприятии. Требуются дополнительные исследования, направленные на повышение
точности распознавание качества вин.
Для дальнейшего исследования в области применимости нейронных сетей для
классификации вин, возможно рассмотреть RBF-сети. В данной работе использовалась сеть с
сигмоидной функцией активации. Возможно, ее изменение поможет улучшить
точность. Также представляет интерес использование кластерных нейронных сетей и
изучение зависимости между полученными сетью кластерами и классами вин,
заданными в исходных данных. Другим направлением дальнейших исследований может
быть попытка уменьшить размерность данных, например, с помощью метода главных
компонент.
Список
использованных источников
1. Хайкин
С. Нейронные сети - М. : Издательский дом «Вильямс», 2006 - 1104 с.
2. Bishop
C. M. Neural network for pattern recognition - New York: Oxford University
Press, 1995 - 482 pp.
. Broomnhead
D. S. and Lowe D. Radial Basis Functions, Multi-Variable Functional
Interpolation and Adaptive Nctworks - London, 1988 URL:
http://www.dtic.mil/cgi-bin/GetTRDoc?AD=ADA196234 (дата обращения 14.04.2015)
. Fausett
L. Fundamentals of neural network - New Jersey: Prentice-Hall, 1994 - XVII pp.
+492 pp.
. G.
Thimm, E. Fiesler High Order and Multilayer Perceptron Initialization // IEEE
Transactions on Neural Networks. 1996, №94-07
. Hagan
M. T., Demuth H. B., Beale M. Neural network design - USA: PWS Publishing
Company, 1996 - 733 pp.
. Hastie
T., Tibshirani R., Friedman J. The Elements of Statistical Learning - Springer
Verlag, 2009 - 764 pp.
. N.
H. Beltran, M. A. Duarte-Mermoud, M. A. Bustos, S. A. Salah, E. A. Loyola, A.
I. Pena-Neira, J. W. Jalocha. Feature extraction and classification of Chilean
wines // Journal of Food Engineering. 2006, Т. 75 вып. 1, с. 1-10
. Paulo
Cortez, Antonio Cerdeira, Fernando Almeida, Telmo Matos, Jose Reis. Modeling
wine preferences by data mining from physicochemical properties - Portugal,
University of Minho, 2008
. Rojas
R. Neural Networks. A Systematic Introduction - Berlin: Springer, 1996 - 509
pp.
. S.
R. Gunn. Support Vector Machines for Classification and Regression - University
of Southampton, 1998
. S.
Vlassides, J. Ferrier, and D. Block. Using Historical Data for Bioprocess
Optimization: Modeling Wine Characteristics Using Artificial Neural Networks
and Archived Process Information // Biotechnology and Bioengineering. 2001,
№73(1), c. 55-68
. Tim
Jones M. Al Application Programming - Massachusetts: CHARLES RIVER MEDIA, INC,
2003 - 311pp.
14. Yann LeCun,
Leon Bottou, Genevieve B. Orr, Klaus-Robert Muller. Efficient BackProp. URL:
<http://yann.lecun.com/exdb/publis/pdf/lecun-98b.pdf> (дата обращения 22.05.2015)