Розробка клієнтського додатку для роботи з онлайн-агрегатором новин
ВСТУП
програмування мова
агрегатор
Актуальність теми. Сучасний етап
розвитку суспільства характеризується широким використанням інформаційних та
телекомунікаційних технологій в усіх сферах діяльності людини. Більшість людей
кожного дня читають новини з найрізноманітніших джерел: газети, журнали,
інтернет сайти, соціальні мережі та ін. Одним з таких джерел є
онлайн-агрегатори новин, які призначені для автоматичного збору актуальної для
вас інформації, та представлення її в одному місці.
Після появи Windows
10
та її універсальної програмної платформи (UWP)
пройшло ще зовсім не багато часу, а вона вже встигла зарекомендувати себе з
кращої сторони як серед користувачів, так і серед розробників програмного
забезпечення. Хоча популярність платформи дуже різко зростає, та на даний
момент для неї випустили не так багато додатків як для інших ОС. Клієнтських
додатків що працюють на даній платформі також було випущено не багато, а для
онлайн-агрегатора TheOldReader
- жодного.
Мета та завдання дослідження:
розробка клієнтського додатку для роботи з онлайн-агрегатором новин
універсальної програмної платформи Windows
(UWP).
Для досягнення мети необхідно
вирішити часткові завдання:
аналіз існуючих онлайн-агрегаторів,
додатків для них та;
аналіз універсальної програмної платформи
Microsoft
Windows;
аналіз мови програмування С#
та
систем управління базами даних;
розробка моделі даних для
використання в клієнтському додатку.
Об’єкт дослідження: принцип роботі
онлайн-агрегаторів новин.
Предмет дослідження: використання API
онлайн-агрегатора новин в клієнтському додатку для універсальної програмної
платформи Microsoft
Windows.
Практичне значення отриманих
результатів: розроблений додаток буде доступний для завантаження всім
користувачам операційної системи Windows
10 та Windows
10 Mobile, що дасть
змогу існуючим та новим користувачам сервісу TheOldReader,
зручно користуватися сервісом з будь-якого пристрою та постійно слідкувати за
новинами.
РОЗДІЛ 1. СИСТЕМИ
ОНЛАЙН-АГРЕГАТОРИ НОВИН ТА УНІВЕРСАЛЬНА ПРОГРАМНА ПЛАТФОРМА MICROSOFT WINDOWS
1.1 Онлайн-агрегатори
агрегатор - клієнтська програма або
веб-застосунок для автоматичного збору повідомлень із джерел, що експортують у
формати RSS або Atom, наприклад заголовків новин, блогів, подкастів та відео
блогів.
Агрегатори бувають двох типів -
веб-агрегатори (онлайн-агрегатори) і програмні, але завдання у них однакові -
робота з RSS та отримання поновлень.
Програмний агрегатор - це програма,
що встановлюється на комп'ютер для роботи з RSS. Така програма може бути
вбудована в браузер або поштовий клієнт, в операційну систему, або може бути
окремою програмою. Більшість сучасних браузерів (включно з Opera, Mozilla
Firefox, Maxthon та Internet Explorer) мають вбудовані інструменти збору RSS.
Серед інших популярних програм з підтримкою стрічок новин можна виділити
програвачі мультимедіа iTunes(агрегація подкастів) та Miro (можливість
отримання оновлень відеоблогів).
Онлайн-агрегатор - це агрегатор, що
міститься в Інтернеті. До такого агрегатора можна отримати доступ з будь-якого
комп'ютера, що під'єднаний до мережі Інтернет.
Принцип роботи арегаторів новин
Користувач вносить в
агрегатор адреси джерел, які його цікавлять, або вибирає з запропонаваних
агрегатором. Далі агрегатор самостійно, з заданим інтервалом або по запиту
користувача, перевіряє всі джерела на наявність оновленб та у випадку їх
наявності завантажуе їх в профіль користувача та повідомляє про його про це,
після чого користувач мае мождивість ознайомитися з ними.
Існуючі онлайн агрегатори
Найпопулярніші з
існуючих онлайн-агрегаторів це:
· TheOldReader
· Google
Reader
· Yandex.Лента
· Feedly
TheOldReader
"TheOldReader"
був запущений в якості хобі проекту Олени Булигіної, Дмитра Красноухова і
Антона Толчанова. У березні 2013 року, в сервісу було лише 10000 користувачів,
але після того як Google оголосила про закриття Google Reader він почав швидко
набирати популярність. До кінця квітня 2013 року проект нараховував вже 200000
користувачів. Тоді Антон Толчанов покинув проект.
У серпні 2013 року,
через місяць після закриття Google Reader, Олена Булигіна та Дмитро Красноухов,
боролися за збереження веб-сайту який працював в умовах великого припливу нових
користувачів. 29 липня команда TheOldReader заявила що вони набули 420000
зареєстрованих користувачів, та про те, що протягом одного дня на сервісі
реєструвалося 60000 нових користувачів. Того ж дня команда оголосила про свій
намір відмінити відкриту реєстрацію, зробивши його доступним тільки для
обмеженого числа людей. Тим не менш, через кілька днів, надійшло ще одне
оголошення, що веб-сайт буде залишатися відкритим для всіх бажаючих, за
підтримки неназваної "юридичної особи в Сполучених Штатах". У
листопаді 2013 року, команда заявила, що новий власник сервісу це Levee Labs.
Нова команда вклалася в
модернізацію обладнання та змінила хостинг-провайдера, реалізувала ряд нових
функцій забезпечивши безперебійне функціонування сервісу. Коли стало питання
монетизації, засновники сайту публічно відкинули можливість введення на сервіс
реклами.
Схоже нова команда
сервісу розділяє їх бачення, сервіс залишився безкоштовним для всіх бажаючих, з
можливістю купити "преміум Послуги" що були представлені у лютому
2014 року.
На сьогоднішній день
сервіс являється одним з найпопулярніших онлайн-агрегаторів новин у світі.
Feedly - агрегатор
новин, що розроблявся як альтернатива Google Reader.
В листопаді 2006 року
Едвін Ходаіакчиан став співзасновником DevHD. Компанія мала намір створити
платформу, яка використовує RSS-стрічки, онлайн-сховище та інтеграцію з
соціальними мережами для того, щоб показувати інформацію яка цікава
користувачам. Перша розробка DevHD, Streets, яка збирає оновлення з різних
онлайн-джерел стола основою майбутнього Feedly. Feedly, який був оптимізований
для стрічок RSS, вперше був випущений 15 червня 2008 року. Спочатку сервіс
називався Feeddo, та був представлений в вигляді "розширення" для
браузерів, але потім був переведений на веб-платформу, також були випущені
додатки для мобільних платформ.
березня 2013 року Feedly
заявив про 500 000 нових користувачів, які почали користуватися сервісом після
об'яви компанією Google про закриття Google Reader. 2 квітня 2013 року
кількість користувачів складала уже близько 3 мільйонів, а в кінці травня, того
ж року, уже 12 мільйонів.
Yandex.Лента
«Яндекс.Лента» -
RSS-агрегатор. Один із сервісів компанії Яндекс. Перший реліз відбувся 21 липня
2005 року в рамках проекту «Яндекс.Нано». В подальшому сервіс був об'єднаний з
сервісом «Яндек.Почта» під назвою «Підписки».
липня 2013 року сайт
lenta.yandex.ru був закритий (встановлено перенаправлення на «Підписки»), замість
нього був запущений «легкий» інтерфейс «Підписок» за адресою ll.yandex.ru.
Новий сервіс, зовні схожий на «Яндек.Ленту», відрізнявся урізаним функціоналом
та відсутність налаштувань.
лютого 2015 року проект
було переформатовано: з «Яндекс.Почти» його перенесли в «Яндекс.Новости», де
він отримав назву «Мои новости». При цьому функціональність була різко
скорочена: записи не відмічаються як прочитані, їх не можна згорнути, читати
записи можна тільки починаючи з останніх. Тоді ж була закрита сторінка ll.yandex.ru.reader
Google Reader -
веб-сервіс компанії Google, що надавав користувачам послуги RSS-агрегації. На
початку 2001 року інженер-програміст Chris Wetherell розпочав проект, який він
назвав "JavaCollect", що працював як новинний портал на основі веб-джерел.
Пізніше, працюючи в Google, він із маленькою командою почав схожий проект, що
був відкритий 7 жовтня 2005 року під назвою Google Reader. У вересні 2006 року
Google анонсував ре дизайн сервісу, що включав нові функції: кількість
непрочитаного, можливість "відмітити все як прочитане", нову систему
навігації, яку було засновано на концепції папок, та розширений вигляд, завдяки
якому користувачі отримали можливість переглядати декілька елементів одночасно.
Також після редизайну читачі отримали можливість поділяти цікави новини з
іншими людьми. У січні 2007 року Google додав до сервісу відео контент з
YouTube та Google Video. У вересні 2007 року маркетинговий менеджер продукту
Kevin Systrom (який пізніше заснував Instagram) оголосив, що Google Reader втратив
бета-статус, покинувши майданчик Google Labs.
Інтерфейс Google Reader
змінювався декілька разів, починаючи з ранньої версії, яку один з дизайнерів
Google порівняв із "річкою" новин, до наступних версій, що були
оптимізовані для широкого спектру пристроїв, від браузерів до відео-консолі
Wii. Наприкінці 2008 року Google Reader зазнав значного оновлення досвіду
користування та дизайну. Очолюваний дизайнером Google Jenna Bilotta, новий
дизайн відрізнявся легшим візуальним стилем, відкидною навігацією та переглядом
друзів, можливістю приховати кількість непрочитаного та пучками стрічок.
У 2013 році Google
Reader мав, серед інших, такі функції:
· головна
сторінка, що дозволяла читачеві окинути оком нові публікації;
· автоматичне
позначення публікацій такими, що вже прочитані, при прокручуванні елементів у
розширеному перегляді;
· поєднання
клавіш для основних функцій;
· два
режиму перегляду публікацій: розширений (заголовок та опис публікації) та
списком (тільки заголовок);
· імпорт
та експорт підписок у форматі OPML;
· пошук
серед всіх стрічок та серед всіх публікацій.
У березні 2013 року
Google заявив про закриття Google Reader, пославшись на падіння популярності
сервісу, 1 липня 2013 року. Починаючи з 2 липня 2013 року відвідувачам сервісу
надається сторінка про його закриття.
Існуючі додатки для сервісу
TheOldReader
На даний момент для
сервісу розроблено велику кількість додатків для різних платформ:
· Reeder
for iOS
· Feeddler
· Feeddler
Pro
· Readery
· Feedoo
· Add
My Feed
· The
Old Reader Extension for News+
· gReader
· gReader
Pro
· D7
Reader
· D7
Reader Pro
· The
Old Reader (unofficial, beta)
· Listener
Launcher
· Wizz
Widget
· NewsJet
· Daily
Feed
· FeedMePhone
· Old
Reader
· NewsSpot
· ThOR
· Gravity
(Beta Support)X
· Reeder
for Mac
· iRSS
· Vienna
3
· Liferea
· theoldreader-cli
· The
Old Reader Notifier
Та багато інших
додатків, розширень до браузерів та ін.
Однак після випуску
операційної системи Microsoft Windows та об’єднання магазинів додатків Windows
та Windows Phone в єдиний магазин, ще не існує жодного додатку для цього
сервісу, створеного на базі універсальної програмної платформи Microsoft
Windows.сервісу TheOldReader
Всі API
запити які робляться до сервісу мають мітити в header
запиту Auth Token.
Відповіді від сервера передаються у форматі json.
«з
електронного ресурсу [11]»
Запит для отримання Auth Token
Адреса для посилання:
Запит:
Приклад відповіді:
o SID=none
o LSID=none
o Auth=LyTEJPvTJiSPrCxLu46d
Використання Auth Token:
В заголовок кожного запиту до
сервера сервісу необхідно включати рядок авторизації - Authorization:
GoogleLogin auth=TOKEN
Після того як був отриманий Auth Token
всі запити до сервісу робляться за посиланням
Основні запити API:
· status?output=json
- повертає статус сервера
· user-info?output=json
- повертає інформацію про користувача
· tag/list?output=json
- повертає список тек з підписками
· rename-tag -
переіменовуе теку
· disable-tag -
видаляе теку
· unread-count?output=json
- повертае список оновлених новин
· subscription/quickadd?quickadd=blog.theoldreader.com
- створює нову підписку
· mark-all-as-read -
відмічає всі оновлення як прочитані
· stream/items/contents?output=json
- повертає повну новину
· subscription/list?output=json
- повертає список підписок
.2
Універсальна програмна платформа Windows
Додатки UWP - це рішення для
Windows, засновані на універсальній програмній платформі Windows (UWP), яка
була вперше представлена в Windows 8 як середовище виконання Windows. В основі
концепції додатків UWP лежить припущення про те, що користувачі хочуть мати
можливість працювати з додатками на всіх своїх пристроях, вибираючи для
виконання конкретної задачі найбільш зручний або продуктивніший пристрій.10
полегшує розробку додатків для UWP, пропонуючи всього один набір API, один
пакет додатку та один магазин для забезпечення роботи додатку на всіх пристроях
під управлінням Windows 10 - комп’ютері, планшеті, телефоні та на інших
пристроях. Простіше підтримувати декілька розмірів екранів та різних моделей
взаємодії - сенсорний дисплей, мишка та клавіатура, ігровий пристрій управління
або перо.
Особливості UWP
При розробці ви орієнтуєтесь на
сімейство пристроїв, а не на конкретну ОС. Сімейство пристроїв визначає
API-інтерфейси, характеристики системи та поведінка, очікуємі на пристроях
всередині сімейства. Воно також визначає набір пристроїв, на які може бути
встановлено додаток UWP.
Всі додатки UWP розповсюджуються в
вигляді пакетів AppX. Це гарантує надійність механізму встановлення та
забезпечує безпроблемне розгортання і оновлення ваших додатків.
Один магазин для всіх пристроїв.
Основні API універсальної платформи
для Windows (UWP) однакові для всіх сімейств пристроїв Windows. Якщо додаток
використовує лише основні API, воно буде працювати на будь-якому пристрої під
управлінням Windows 10.розширень додають спеціальні API для кожного сімейства
пристроїв. Якщо додаток призначений для конкретного сімейства пристроїв, його
можна реалізовувати за допомогою цих API. При цьому все одно можна мати лише
один пакет, що працює на всіх пристроях, відмітивши на яких пристроях має
працювати додаток перед викликом розширення API.
Елементи інтерфейсу користувача
використовують "ефективні пікселі", тому вони автоматично адаптуються
до числа пікселів на екрані пристрою. Крім того, вони чудово працюють з різними
методами вводу, такими як клавіатура, мишка, дотики, перо та ігрові пристрої
управління.
Додатки UWP можуть використовувати
живі плитки та екран блокування для виводу короткої та значимої в даному
контексті інформації.повідомлення пропонують увазі користуваяа важливі
оповіщення від додатків в потрібний момент.
В Центрі підтримки додтки можуть
відображати та упорядковувати оповіщення та зміст, очікуючих від користувача
будь яких дій.
Підтримуется використання фонової
роботи та тригеррів які дозволяють відновити роботу додатку в потрібних
користувачу момент.
Додатки UWP можуть використовувати
голосові функції та пристрої Bluetooth щоб допомогти користувачам взаємодіяти з
навколишнім світом.
Мови програмування UWP
Ви можете створювати додатки UWP на
тих мовах програмування, з якими знайомі краще за все, наприклад на C# або
Visual Basic з XAML, JavaScript з HTML або C++ з DirectX. Ви навіть можете
написати компоненти на одній мові, а використовувати їх в додатках написаних на
іншій мові.
Додатки UWP можуть використовувати
середовище виконання Windows, тобто є власний API, включений в ОС. Цей API
реалізований на C++ та підтримується в C#, Visual Basic, C++ та JavaScript
природнім для кожної мови способом.Visual Studio 2015 включає в себе шаблон
додатків UWP для кожної мови, який дозволяє створювати один проект для всіх
пристроїв.
З цього розділу зрозуміло, що TheOldReader
це одна з найпопулярніших альтернатив Google
Reader, для якої,
нажаль, ще не існує клієнтських додатків для нової версії найпопулярнішої
операційної системи у світі Windows
10.
Нова платформа Windows
10 та UWP
дозволяють створити один єдиний додаток для всіх пристроїв, що відкриває широкі
можливості для розробників програмного забезпечення, а єдиний магазин Windows
додає не аби якої зручності у доставці додатків до користувачів.
РОЗДІЛ 2. ОСОБЛИВОСТІ МОВИ
ПРОГРАМУВАННЯ C # ТА БАЗИ ДАНИХ
Створення та розвиток C#
C# (вимовляється «сі
шарп») у працях [20-25] - об'єктно-орієнтована мова програмування. Розроблено в 1998-2001
роках групою інженерів під керівництвом Андерса Хейлсберг в компанії Microsoft
як мова розробки додатків для платформи Microsoft .NET Framework і згодом був
стандартизований як ECMA-334 і ISO / IEC 23270.# відноситься до сім'ї мов з
C-подібним синтаксисом, з них його синтаксис найбільш близький до C ++ і Java.
Мова має статичну типізацію, підтримує поліморфізм, перевантаження операторів
(у тому числі операторів явного і неявного приведення типу), делегати,
атрибути, події, властивості, узагальнені типи і методи, ітератори, анонімні
функції з підтримкою замикань, LINQ, винятки, коментарі у форматі XML.
Перейнявши багато що від
своїх попередників - мов C ++, Pascal, Модула, Smalltalk і, особливо, Java - С
#, спираючись на практику їх використання, виключає деякі моделі, що зарекомендували
себе як проблематичні при розробці програмних систем, наприклад, C # на відміну
від C ++ не підтримує множинне спадкування класів (між тим допускається
множинне спадкування інтерфейсів).
Особливості мови
C # розроблявся як мова
програмування прикладного рівня для CLR і, як такий, залежить, насамперед, від
можливостей самої CLR. Це стосується, перш за все, системи типів C #, яка
відображає BCL. Присутність або відсутність тих чи інших виразних особливостей
мови диктується тим, чи може конкретна мовна особливість бути трансльований у
відповідні конструкції CLR. Так, з розвитком CLR від версії 1.1 до 2.0 значно
збагатився і сам C #; подібної взаємодії слід чекати і надалі (проте, ця
закономірність була порушена з виходом C # 3.0, що представляє собою розширення
мови, не спираються на розширення платформи .NET). CLR надає C #, як і всім
іншим .NET-орієнтованим мовам, багато можливостей, яких позбавлені «класичні»
мови програмування. Наприклад, збірка сміття не реалізована в самому C #, а
проводиться CLR для програм, написаних на C # точно так само, як це робиться
для програм на VB.NET, J # та ін.
Назва мови
Назва «Сі шарп» (від
англ. Sharp - дієз) походить від музичної нотації, де знак дієз означає
підвищення відповідного ноті звуку на півтон, що аналогічно назвою мови C ++,
де «++» позначає інкремент змінної. Назва також є грою з ланцюжком C → C
++ → C ++++ (C #), так як символ «#» можна скласти з 4х знаків «+».
Внаслідок технічних
обмежень на відображення (стандартні шрифти, браузери і т. Д.) І тієї
обставини, що знак дієз ♯ не представлені на стандартній клавіатурі, знак
номера # був обраний для представлення знака дієз при записі імені мови
програмування. Це Угода відображено в специфікації мови C # ECMA-334. Проте, на
практиці (наприклад, при розміщенні реклами та коробковому дизайні), Майкрософт
використовує призначений музичний знак.
Назви мов програмування
не прийнято перекладати, тому мова слід називати по-англійськи «Сі шарп».
Стандартизація
C # стандартизований в
ECMA (ECMA-334) [9] і ISO (ISO / IEC 23270). Відомо як мінімум про три
незалежних реалізаціях C #, що базуються на цій специфікації і знаходяться в
даний час на різних стадіях розробки:
- Mono,
розпочата компанією Ximian, продовжена її покупцем і наступником Novell, а
потім Xamarin.
- dotGNU
і Portable.NET, що розробляються Free Software Foundation.
- SharpDevelop.
Версії
Протягом розробки мови C
# було випущено декілька його версій:
Загальна інформація за
версіями
Версія 1.0
Проект C # був початий в
грудні 1998 і отримав кодову назву COOL (C-style Object Oriented Language).
Версія 1.0 була анонсована разом з платформою .NET в червні 2000 року, тоді ж
з'явилася і перша загальнодоступна бета-версія; C # 1.0 остаточно вийшов разом
з Microsoft Visual Studio .NET в лютому 2002 року.
Крім того, в C #
вирішено було перенести деякі можливості C ++, відсутні в Java: беззнакові
типи, перевантаження операторів (з деякими обмеженнями, на відміну від C ++),
передача параметрів в метод за посиланням, методи зі змінним числом параметрів,
оператор goto (з обмеженнями ). Також в C # залишили обмежену можливість роботи
з покажчиками - у місцях коду, спеціально позначених словом unsafe і при
вказівці спеціальної опції компілятору.
Версія 2.0
Проект специфікації C #
2.0 вперше був опублікований Microsoft у жовтні 2003 року; в 2004 році виходили
бета-версії (проект з кодовою назвою Whidbey), C # 2.0 остаточно вийшов 7
листопада 2005 разом з Visual Studio 2005 і .NET 2.0.
Нові можливості у версії
2.0
Часткові типи
(розділення реалізації класу більш ніж на один файл).
Узагальнені, або
параметризрвані типи (generics). На відміну від шаблонів C ++, вони підтримують
деякі додаткові можливості і працюють на рівні віртуальної машини. Разом з тим,
параметрами узагальненого типу не можуть бути вирази, вони не можуть бути
повністю або частково спеціалізовані, не підтримують шаблонних параметрів за
замовчуванням, від шаблонного параметра не можна успадковуватися, і т. Д. [13]
Нова форма ітератора, що
дозволяє створювати співпрограми за допомогою ключового слова yield, подібно
Python і Ruby.
Анонімні методи, що
забезпечують функціональність замикання.
Оператор '??': return
obj1 ?? obj2; означає (в нотації C # 1.0) return obj1! = null? obj1: obj2;.
Обнуляти ('nullable')
типи-значення (що позначаються знаком питання, наприклад, int? I = null;), що
представляють собою ті ж самі типи-значення, здатні приймати також значення
null. Такі типи дозволяють поліпшити взаємодію з базами даних через мову SQL.
Можливість створювати
збережені процедури, тригери і навіть типи даних на .Net мовах (у тому числі і
на C #).Підтримка 64-розрядних обчислень, що крім усього іншого, дозволяє
збільшити адресний простір і використовувати 64-розрядні примітивні типи даних.
Версія 3.0У червні 2004
року Андерс Гейлсберг вперше розповів на сайті Microsoft про плановані
розширеннях мови в C # 3.0. [14] У вересні 2005 року вийшли проект специфікації
C # 3.0 і бета-версія C # 3.0, що встановлюється у вигляді доповнення до
існуючих Visual Studio 2005 і. NET 2.0. Остаточно ця версія мови увійшла в Visual
Studio 2008 і .NET 3.5.
Нові можливості у версії
3.0
У C # 3.0 з'явилися
наступні радикальні додавання до мови:
ключові слова select,
from, where, що дозволяють робити запити з SQL, XML, колекцій і т. п. (запит,
інтегрований в мову, Language Integrated Query, або LINQ)
Ініціалізація об'єкта
разом з його властивостями:c = new Customer (); c.Name = "James";
c.Age = 30;
можна записати якc = new
Customer {Name = "James", Age = 30};
Лямбда-вирази:.Where
(delegate (Foo x) {return x.size> 10;});
тепер можна записати
як.Where (x => x.size> 10);
Дерева виразів:
лямбда-вирази тепер
можуть представлятися у вигляді структури даних, доступній для обходу під час
виконання, тим самим дозволяючи транслювати строго типізовані C # -виражені в
інші домени (наприклад, вирази SQL).
Висновок типів локальної
змінної: var x = "hello"; замість string x = "hello";
Безіменні типи: var x =
new {Name = "James"};
Методи-розширення -
додавання методу в існуючий клас за допомогою ключового слова this при першому
параметрі статичної функції.static class StringExtensions
{static int ToInt32
(this string val)
{Int32.Parse (val);
}
}
// ...s =
"10";x = s.ToInt32 ();
Автоматичні властивості:
компілятор згенерує закрите (private) поле і відповідні аксессор і мутатор для
коду видуstring Name {get; private set; }# 3.0 сумісний з C # 2.0 по
генеруємому MSIL-коду; поліпшення в мові - чисто синтаксичні і реалізуються на
етапі компіляції. Наприклад, багато хто з інтегрованих запитів LINQ можна
здійснити, використовуючи безіменні делегати в поєднанні з предикативними
методами над контейнерами зразок List.FindAll і List.RemoveAll.
Версія 4.0
Прев'ю C # 4.0 було
представлено в кінці 2008 року, разом з CTP-версією Visual Studio 2010.Basic
10.0 і C # 4.0 були випущені в квітні 2010 року, одночасно з випуском Visual
Studio 2010.
Нові можливості у версії
4.0
Можливість використання
пізнього зв'язування, для використання:
з мовами з динамічною
типізацією (Python, Ruby)
з COM-об'єктами
відбиття (reflection)
об'єктів із змінною
структурою (DOM). З'являється ключове слово dynamic.
Іменовані і опціональні
параметри
Нові можливості COM
interop
Коваріантність і
контраваріантним
Контракти в коді (Code
Contracts)
приклади:calc =
GetCalculator ();sum = calc.Add (10, 20); // Динамічний викликvoid SomeMethod
(int x, int y = 5, int z = 7); // Опциональниє параметри
Приклад «Hello, World!»
[Ред | правити вікі-текст]
Нижче представлений код
класичної програми «Hello world» на C # для консольного застосування:System;
Example
{Program
{void Main ()
{.WriteLine ("Hello
World!"); // Вивід заданого тексту в консоль.ReadKey (); // Очікування
натискання клавіші користувачем
}
}
}
і код цієї ж програми
для програми Windows Forms:
// Assembly: System.dll
// Assembly:
System.Drawing.dll
// Assembly:
System.Windows.Forms.dllSystem;System.Drawing;System.Windows.Forms;
WindowsForms
{class Program
{
[STAThread]static void
Main ()
{DemoForm (). ShowDialog
();
}
} class DemoForm: Form
{label = new Label ();
DemoForm ()
{.Text = "Hello
World!";.Controls.Add (label);.StartPosition = FormStartPosition.CenterScreen;.BackColor
= Color.White;.FormBorderStyle = FormBorderStyle.Fixed3D;
}
}
}
Поняття бази даних
Базу даних (БД) можна
визначити як уніфіковану сукупність даних, спільно використовувану різними
завданнями в рамках деякої єдиної автоматизованої інформаційної системи (ІС).
Теорія управління базами
даних як самостійна дисципліна почала розвиватися приблизно з початку 50-х
років двадцятого століття. За цей час в ній склалася певна система
фундаментальних понять. Наведемо деякі з них.
Предметною областю
прийнято називати частину реального світу, що підлягає вивченню з метою
організації управління в цій сфері і подальшої автоматизації процесу
управління. В рамках даної книги для нас в першу чергу представляють інтерес
предметні області, так чи інакше пов'язані зі сферою економіки і фінансів.
Атрибут - це
інформаційне відображення властивостей об'єкта. Кожен об'єкт характеризується
деяким набором атрибутів.
Ключовим елементом даних
називаються такий атрибут (або група атрибутів), який дозволяє визначити Значення
інших елементів-даних. Запис даних (англ, еквівалент запис) - це сукупність
значень пов'язаних елементів даних.
Первинний ключ - це
атрибут (або група атрибутів), який унікальним чином ідентифікують кожен
екземпляр об'єкта (запис). Вторинним ключем називається атрибут (або група
атрибутів), значення якого може повторюватися для декількох записів
(примірників об'єкта). Насамперед вторинні ключі використовуються в операціях
пошуку записів.
Процедури зберігання
даних в базі повинні підкорятися деяким загальним принципам, серед яких в першу
чергу слід виділити:
Про цілісність і
несуперечність даних, під якими розуміється як фізична схоронність даних, так і
запобігання невірного використання даних, підтримка допустимих поєднань їх
значень, захист від структурних спотворень і несанкціонованого доступу;
Про мінімальна
надмірність даних позначає, що будь-який елемент даних повинен зберігатися в
базі в єдиному вигляді, що дозволяє уникнути необхідності дублювання операцій,
вироблених з ним.
Програмне забезпечення,
яке здійснює операції над базами даних, отримало назву СУБД - система
управління базами даних. Очевидно, що його робота має бути організована таким
чином, щоб виконувалися перераховані принципи.
Моделі організації даних
Набір принципів, що
визначають організацію логічної структури зберігання даних в базі, отримав
назву моделі даних. Моделі баз даних визначаються трьома компонентами:
- Допустимою
організацією даних;
- Обмеженнями
цілісності;
- Безліччю
допустимих операцій.
У теорії систем
управління базами даних виділяють моделі чотирьох основних типів: ієрархічну,
мережеву, реляційну і об'єктно-реляційну.
Термінологічної основою
для ієрархічної та мережної моделей є поняття: атрибут, агрегат та запис. Під
атрибутом (елементом даних) розуміється найменша пойменована структурна одиниця
даних. Пойменоване безліч атрибутів може утворювати агрегат даних. У деяких
випадках окремо взятий агрегат може складатися з безлічі екземплярів однотипних
даних, або, як ще кажуть, бути множинним елементом. Нарешті, записом називають
складовою агрегат, який не входить до складу інших агрегатів. В ієрархічній
моделі всі записи, агрегати і атрибути бази даних утворюють ієрархічно
організований набір, тобто таку структуру, в якій всі елементи пов'язані
відносинами підпорядкованості, і при цьому будь-який елемент може підкорятися
тільки одному якомусь іншому елементу. Таку форму залежності зручно зображувати
за допомогою деревоподібного графа (схеми, що складається з точок і стрілок,
яка связна і не має циклів). Приклад ієрархічної структури бази даних наведено
на рис. 1.
Рис. 1. Схема
ієрархічної моделі даних
Типовим
представником сімейства баз даних, заснованих на ієрархічній моделі, є
Information Management System (IMS) фірми IBM, перша версія якої з'явилася в
1968 р
Концепція мережевої
моделі даних пов'язана з ім'ям Ч. Бахмана. Мережевий підхід до організації
даних є розширенням ієрархічного. В ієрархічних структурах запис-нащадок
повинна мати в точності одного предка; в мережевій структурі даних нащадок може
мати будь-яке число предків (рис.2).
Рис. 2. Схема
мережевої моделі даних
Мережева БД
складається з набору записів і набору зв'язків між цими записами, точніше, з
набору екземплярів записів заданих типів (з допустимого набору типів) і набору
екземплярів із заданого набору типів зв'язку. Прикладом системи управління
даними з мережевою організацією є Integrated Database Management System (IDMS)
компанії Cullinet Software Inc., розроблена в середині 70-х років. Вона
призначена для використання на "великих" обчислювальних машинах.
Архітектура системи заснована на пропозиціях Data Base Task Group (DBTG),
Conference on Data Systems Languages (CODASYL), організації, відповідальної за
визначення стандартів мови програмування Кобол.
Серед достоїнств систем
управління даними, заснованих на ієрархічній або мережевий моделях, можуть бути
названі їх компактність і, як правило, високу швидкодію, а серед недоліків -
неуніверсальність, високий ступінь залежності від конкретних даних.
Реляційна модель даних
Концепції реляційної
моделі вперше були сформульовані в роботах американського вченого Е. Ф. Кодда.
Звідки походить її друга назва - модель Кодда.
Рис.3. Схема
реляційної моделі даних
У реляційної моделі об'єкти і
взаємозв'язки між ними представляються за допомогою таблиць (рис. 7.3). Для її
формального визначення використовується фундаментальне поняття відносини.
Власне кажучи, термін "реляційна" походить від англійського relation
- відношення. Якщо задані довільні кінцеві безлічі D1, D2, ..., Dn, то
декартовим твором цих множин D1? D2? ...? Dn називають безліч всілякі наборів
виду (d1, d2 ..., dn), деD1, d2 D2, ..., dn Dn. Ставленням R визначеним на
множинах D1, D2, ..., Dn,, називається підмножина декартова твори Dl x D2x ...
х Dn. При цьому безлічі D1? D2? ...? Dn називаються доменами відносини, а
елементи декартова твори - кортежами відносини. Число я визначає ступінь
відносини, а кількість кортежів - його потужність. Поряд з поняттями домену та
кортежу при роботі з реляційними таблицями використовуються альтернативні ним
поняття поля і записи.
У реляційній базі даних кожна
таблиця повинна мати первинний ключ (ключовий елемент) - поле або комбінацію
полів, які єдиним чином ідентифікують кожен рядок в таблиці.
Важливою перевагою реляційної моделі
є те, що в її рамках дії над даними можуть бути зведені до операцій реляційної
алгебри, які виконуються над відносинами. Це такі операції, як об'єднання,
перетин, віднімання, декартовій твір, вибірка, проекція, з'єднання, ділення.
Найважливішою проблемою,
розв'язуваної при проектуванні баз даних, є створення такої їх структури, яка б
забезпечувала мінімальне дублювання інформації і спрощувала Процедури обробки
та оновлення даних. Код-будинок був запропонований деякий набір формальних
вимог універсального характеру до організації даних, які дозволяють ефективно
вирішувати перераховані завдання. Ці вимоги до стану таблиць даних отримали
назву нормальних форм. Спочатку були сформульовані три нормальні форми. Надалі
з'явилася нормальна форма Бойса-Кодда і нормальні форми більш високих порядків.
Однак вони не набули широкого поширення на практиці.
- Кажуть,
що ставлення знаходиться в першій нормальній формі, якщо всі його атрибути є
простими.
- Кажуть,
що ставлення знаходиться в другій нормальній формі, якщо воно задовольняє
вимогам першої нормальної форми і кожен не ключовий атрибут функціонально повно
залежить від ключа (однозначно визначається ним).
- Кажуть,
що ставлення знаходиться в третій нормальній формі, якщо воно задовольняє
вимогам другої нормальної форми і при цьому будь-який не ключовий атрибут
залежить від ключа нетранзитивно. Зауважимо, що транзитивної називається така
залежність, при якій який-небудь не ключовий атрибут залежить від іншого не
ключового атрибута, а той, у свою чергу, вже залежить від ключа.
Принциповим моментом є
те, що для приведення таблиць до стану, що задовольняє вимогам нормальних форм,
або, як ще кажуть, для нормалізації даних над ними, повинні бути здійснені
перераховані вище операції реляційної алгебри.
Основною перевагою
реляційної моделі є її простота. Саме завдяки їй вона покладена в основу
переважної більшості реально працюючих СУБД.
Мова SQL
У розробленій Коддом
реляційної моделі були визначені як вимоги до організації таблиць, що містять
дані, так і мова, що дозволяє працювати з ними. Згодом ця мова отримав назву
SQL (Structured Query Language - структурована мова запитів). SQL був вперше
реалізований фірмою I на початку 70-х років двадцятого століття під назвою
Structures English Query Language (SEQUEL). Він був орієнтований на управління
прототипом реляційної бази даних IBM-System R. Надалі SQL став стандартом de
facto мови роботи з реляційними базами даних. Цей його статус був вперше
зафіксований в 1986 році Американським національним інститутом стандартів
(ANSI). Іншими досить відомими стандартами SQL стали стандарти ANSI SQL-92 ISO
SQL-92, X / Open. У складі SQL можуть бути виділені наступні групи інструкцій:
- Мова
опису даних - DDL (Data Definition Language);
- Мова
маніпулювання даними - DML (Data Manipulation Language);
- Мова
управління транзакціями.
Інструкції DDL
призначені для створення, зміни та видалення об'єктів бази даних. Інструкції
мови визначення даних (DDL)
|
Інструкція
|
Призначення
|
|
CREATE
|
Створення нових об'єктів(таблиць,
полів, індексів)
|
|
DROP
|
Видалення об'єктів
|
|
ALTER
|
Зміна об'єктів
|
Наприклад, нам необхідно
створити таблицю, що містить дані по каталогу фірм, кожна фірма в якому
характеризується кодом, найменуванням, MCCTOJV розташування штаб-квартири,
розміром статутного фонду. Даної операції зі ответствует SQL-виразTABLE Фірми
КодФірми TEXT (5),
НазвФірми TEXT (30),
АдресФірми TEXT (40),
УстФонд (DOUBLE);
Відзначимо, що допустимі
імена полів створюваної таблиці і типи містяться в них даних можуть варіюватися
для різних версій і діалектів SQL Якщо нам знадобиться змінити структуру
таблиці Фірми - припустимо, додасть! до неї ще одну колонку з прізвищем
директора, то зробити це можна за допомогою SQL-інструкції:TABLE Фірми ADD
COLUMN Директор TEXT. (30);
а вираз, що дає Команду
на знищення таблиці, буде виглядати так:TABLE Фірми;
Інструкції DML дозволяють
вибирати дані з таблиць, а також додавати, видаляти і змінювати їх.
Інструкції мови
маніпулювання даними (DML)
|
Інструкція
|
Призначення
|
|
SELECT
|
Виконання запиту до бази даних з
метою відбору записів, що задовольняють заданим критеріям
|
|
INSERT
|
Додавання записів в таблиці бази
даних
|
|
UPDATE
|
Зміна значень окремих записів і
полів
|
|
DELETE
|
Видалення записів з бази даних
|
- команда на вибірку
записів з бази даних - є найбільш часто використовуваною SQL-інструкцією. Сфера
даних, якими вона маніпулює, визначається за допомогою спеціальних пропозицій.
Основні пропозиції мови
SQL
|
Інструкція
|
Призначення
|
|
FROM
|
|
WHERE
|
Специфицируются умови, яким
повинні задовольняти вибирані дані
|
|
GROUP BY
|
Визначає, що обрані записи повинні
бути згруповані
|
|
HAVING
|
Задає умова, якому повинна
задовольняти кожна група відібраних записів
|
|
ORDER BY
|
Специфицируются порядок сортування
записів
|
Прикладом найпростішого
застосування інструкції SELECT може служити команда на вибірку всіх даних з
таблиці Фірми:
* FROM Фірми;
Однак, взагалі кажучи,
дана інструкція являє собою досить потужний інструмент маніпуляції з вмістом
баз даних. Так, вираз
Int ([УстФонд] / 500) *
500 AS Діапазон,(КодФірми) AS ЧіслоФірмФірмиBY Int ([УстФонд] / 500) * 500;
задає команду на
виведення даних про розподіл значень статутних фондів фірм по інтервалах
довжиною 500 грошових одиниць (д. е.), тобто скільки фірм мають статутний фонд
менше 500 д. е., від 500 до 1000 д. е. і т. д . Третьою складовою частиною SQL
є мова управління транзакціями. Транзакція - це логічно завершена одиниця
роботи, яка містить одну або більше елементарних операцій обробки даних. Всі
дії, що становлять транзакцію, повинні або виконатися повністю, або повністю не
виконатися.
Інструкції мови управління
транзакціями
|
Інструкція
|
Призначення
|
|
COMMIT
|
Фіксація в базі даних всіх змін,
зроблених поточної транзакцією
|
|
SAVEPOINT
|
Установка точки збереження
(початку транзакції)
|
|
ROLLBACK
|
Відкат змін, зроблених з моменту
початку транзакції
|
У більшості СУБД
елементарні команди, складові тіло транзакції, виконуються над деякою буферної
копією даних, і лише якщо їх вдається успішно довести до кінця, відбувається
остаточне оновлення основної бази. Транзакція починається від точки збереження,
що задається інструкцією SAVEPOINT, і може бути завершена за командою COMMIT
або перервана по команді ROLLBACK (відкат). Також в сучасних системах
управління даними передбачені кошти автоматичного відкоту транзакцій при
виникненні системних збоїв. Таким чином, механізм управління транзакціями є
найважливішим інструментом підтримки цілісності даних.
Програмні системи управління базами
даних
Коротко зупинимося на
конкретних програмних продуктах, що відносяться до класу СУБД. На самому
загальному рівні всі СУБД можна розділити:
На професійні, або
промислові;
Персональні (настільні).
Професійні (промислові)
СУБД являють собою програмну основу для розробки автоматизованих систем
управління великими економічними об'єктами. На їх базі створюються комплекси
управління та обробки інформації великих підприємств, банків або навіть цілих
галузей. Першорядними умовами, яким повинні задовольняти професійні СУБД, є:
Можливість організації
спільної паралельної роботи великої кількості користувачів;
Масштабованість, тобто
можливість зростання системи пропорційно розширенню керованого об'єкта;
Переносимість на різні
апаратні і програмні платформи;
Стійкість по відношенню
до збоїв різного роду, в тому числі наявність багаторівневої системи
резервування збереженої інформації;
Забезпечення безпеки
збережених даних і розвиненою структурованої системи доступу до них.
Промислові СУБД до
справжнього моменту мають вже досить багату історію розвитку. Зокрема, можна
відзначити, що наприкінці 70-х - початку 80-х років в автоматизованих системах,
побудованих на базі великих обчислювальних машин, активно використовувалася
СУБД Adabas. В даний час характерними представниками професійних СУБД є такі
програмні продукти, як Oracle, DB2, Sybase, Informix, Ingres, Progress.
Основоположниками СУБД
Oracle стала група американських розробників (Ларрі Еллісбн, Роберт Майнер і
Едвард Оутс), які більше двадцяти років тому створили фірму Relational Software
Inc. і поставили перед собою завдання створити систему, на практиці реалізує
ідеї, викладені в роботах Е. Ф. Кодда І К. Дж. Дейта. Результатом їх діяльності
стала реалізація переносимої реляційної системи управління базами даних з
базовим мовою обробки SQL. У 1979 р замовникам була представлена версія Oracle
для міні-комп'ютерів PDP-11 фірми Digital Equipment Corporation відразу для
декількох операційних систем: RSX- 11, IAS, RSTS і UNIX. Трохи пізніше Oracle
був перенесений на комп'ютери VAX під управлінням VAX VMS. Значна частина коду
була написана на асемблері, і тому процес перенесення системи на нову платформу
вимагав значних зусиль. Основною відмінністю Oracle черговий, третій версії
було те, що вона була повністю написана на мові С. Таке рішення забезпечувало
переносимість системи на багато нові платформи, зокрема, на різні клони UNIX.
Другою важливою особливістю нової (1983 р) версії була підтримка концепції
транзакції. Приблизно в цей же час фірма отримала нове ім'я - Oracle
Corporation - і зайняла лідируюче місце на ринку виробників СУБД. Четверта
версія Oracle характеризувалася розширенням переліку підтримуваних платформ і
операційних систем. Oracle був перенесений як на великі ЕОМ фірми IBM
(мейнфрейми), так і на персональні комп'ютери, що працюють під управлінням MS
DOS. Саме в четвертій версії був зроблений важливий крок у розвитку технології
підтримки цілісності баз даних. Для багатокористувацьких систем було
запропоновано оригінальне рішення Oracle підтримки "несуперечності
читання". У п'ятій версії була вперше реалізована СУБД з архітектурою
"клієнт-сервер". Подальші версії СУБД Oracle були орієнтовані на
побудову великомасштабних систем обробки транзакцій, зміна методів реалізації
систем введення / виводу, буферизації, підсистем управління паралельним
доступом, резервування і відновлення. Також була реалізована підтримка
симетричних мультипроцесорних архітектур.
Проект і
експериментальний варіант СУБД Ingres були розроблені в університеті Берклі під
керівництвом одного з найбільш відомих у світі вчених і фахівців в області баз
даних Майкла Стоунбрейкера. З самого початку СУБД Ingres розроблялася як мобільна
система, що функціонує в середовищі ОС UNIX. Перша версія Ingres була
розрахована на 16-розрядні комп'ютери і працювала головним чином на машинах
серії PDP. Це була перша СУБД, поширювана безкоштовно для використання в
університетах. Згодом група Стоунбрейкера перенесла Ingres в середу ОС UNIX
BSD, яка також була розроблена в університеті Берклі. Сімейство СУБД Ingres з
університету Берклі прийнято називати університетської Ingres. На початку 80-х
була утворена компанія RTI (Relational Technology Inc.), яка розробила і стала
просувати комерційну версію СУБД Ingres. В даний час комерційна Ingres
підтримується, розвивається і продається компанією Computer Associates. Зараз
це одна з найбільш розвинених комерційних реляційних СУБД. В той же час, з
приводу університетської Ingres є багато високоякісних публікацій. Більш того,
університетську Ingres можна випробувати на практиці і навіть подивитися її
вихідні тексти.
Перераховані вище (для
СУБД Oracle) тенденції носять універсальний характер і визначають шляхи
розвитку інших програмних продуктів, що цілком пояснюється жорсткою
конкурентною ситуацією, що склалася на даному ринку.
Персональні системи
управління даними - це програмне забезпечення, орієнтоване на вирішення завдань
локального користувача або компактної групи користувачів і призначене для
використання на мікроЕОМ (персональному комп'ютері). Це пояснює і їх друга
назва - настільні. Визначальними характеристиками настільних систем є:
Відносна простота
експлуатації, що дозволяє створювати на їх основі працездатні додатки як
"просунутим" користувачам, так і тим, чия кваліфікація невисока;
Відносно обмежені вимоги
до апаратних ресурсів.
Історично першою серед
персональних СУБД, які отримали масове поширення, стала Dbase фірми Ashton-Tate
(згодом права на неї перейшли до фірми Borland, а з 1999 р дана програма
підтримується фірмою dBASE Inc.). Надалі серія реляційних персональних СУБД
поповнилася такими продуктами, як FoxBase / FoxPRO (Fox Software, надалі -
Microsoft), Clipper (Nantucket, потім - Computer Associates), R: base
(Microrim), Paradox (Borland, на даний момент правами володіє фірма Corel),
Access (Microsoft), Approach (Lotus).
Що завоювали широку
популярність в Росії системи Dbase, FoxPRO і Clipper працювали з таблицями
даних, які розміщувалися в файлах, що мали розширення * .dbf (термін dbf-формат
став загальноприйнятим). Згодом сімейство цих баз даних отримало інтегроване
найменування Xbase.
Незважаючи на неминучі
відмінності, що обумовлюють задумами розробників, всі перераховані системи в
ході своєї еволюції придбали ряд загальних конструктивних рис, серед яких,
насамперед, можуть бути названі:
Наявність візуального
інтерфейсу, що автоматизує процес створення засобів маніпуляції даними, -
екранних форм, шаблонів звітів, запитів і т. П .;
Наявність інструментів
створення об'єктів бази даних в режимі діалогу: Experts в Paradox, Wizards в
Access, Assistants в Approach;
Наявність розвиненого
інструментарію створення програмних розширень в рамках єдиного середовища СУБД:
мова розробки додатків PAL в Paradox, VBA (Visual Basic for Applications) в
Access, Lotus Script в Approach;
Вбудована підтримка
універсальних мов управління даними, наприклад SQL або QBE (Query By Example).
Серед СУБД, які, умовно
кажучи, займають проміжне положення між настільними і промисловими системами,
можуть бути названі SQLWindows / SQLBase фірми Centura (до 1996 р Gupta),
InterBase (Borland), нарешті, Microsoft SQL Server.
СУБД SQLite- полегшена
реляційна система керування базами даних. Втілена у вигляді бібліотеки, де
реалізовано багато зі стандарту SQL-92.. Сирцевий код SQLite поширюється як
суспільне надбання, тобто може використовуватися без обмежень та безоплатно з
будь-якою метою.
Особливістю SQLite є те,
що воно не використовує парадигму клієнт-сервер, тобто рушій SQLite не є
окремим процесом, з яким взаємодіє застосунок, а надає бібліотеку, з якою
програма компілюється і рушій стає складовою частиною програми. Таким чином, як
протокол обміну використовуються виклики функцій (API) бібліотеки SQLite. Такий
підхід зменшує накладні витрати, час відгуку і спрощує програму. SQLite
зберігає всю базу даних (включаючи визначення, таблиці, індекси і дані) в
єдиному стандартному файлі на тому комп'ютері, на якому виконується застосунок.
Простота реалізації досягається за рахунок того, що перед початком виконання
транзакції весь файл, що зберігає базу даних, блокується; ACID-функції
досягаються зокрема за рахунок створення файлу-журналу.
Кілька процесів або
нитей можуть одночасно без жодних проблем читати дані з однієї бази. Запис в
базу можна здійснити тільки в тому випадку, коли жодних інших запитів у цей час
не обслуговується; інакше спроба запису закінчується невдачею, і в програму
повертається код помилки. Іншим варіантом розвитку подій є автоматичне
повторення спроб запису протягом заданого інтервалу часу.
У комплекті постачання
йде також функціональна клієнтська частина у вигляді виконуваного файлу
sqlite3, за допомогою якого демонструється реалізація функцій основної
бібліотеки. Клієнтська частина працює з командного рядка, і дозволяє звертатися
до файлу БД на основі типових функцій ОС.
Завдяки архітектурі
рушія можливо використовувати SQlite як на вбудовуваних (embedded) системах,
так і на виділених машинах з гігабайтними масивами даних.
· транзакції
атомарні, послідовні, ізольовані, і міцні (ACID) навіть після збоїв системи і
збоїв живлення
· Встановлення
без конфігурації - не потребує ані установки, ані адміністрування
· Реалізує
значну частину стандарту SQL92
· База
даних зберігається в одному крос-платформовому файлі на диску
· Підтримка
терабайтних розмірів баз даних і гігабайтного розміру рядків і BLOBів
· Малий
розмір коду: менше ніж 350KB повністю налаштований, і менш 200KB з опущеними
додатковими функціями
· Швидший
за популярні рушії клієнт-серверних баз даних для найпоширеніших операцій
· Простий,
легкий у використанні API
· Написана
в ANSI C, включена прив'язка до TCL; доступні також прив'язки для десятків
інших мов
· Добре
прокоментований сирцевий код зі 100% тестовий покриттям гілок
· Доступний
як єдиний файл сирцевого коду на ANSI C, який можна легко вставити в інший
проект
· Автономність:
немає зовнішніх залежностей
· Крос-платформовість:
з коробки підтримується Unix (Linux і Mac OS X), OS/2, Windows (Win32 і WinCE).
Легко переноситься на інші системи
· Сирці
перебувають в суспільному надбанні
· Поставляється
з автономним клієнтом інтерфейсу командного рядка, який може бути використаний
для управління базами даних SQLite
На завершення розділу
необхідно зазначити, що в останні роки намітилася стійка тенденція до стирання
чітких граней між настільними і професійними системами баз даних. Останнє, в
першу чергу, пояснюється тим, що розробники в прагненні максимально розширити
потенційний ринок для своїх продуктів постійно розширюють набір їх
функціональних характеристик. А за допомогою SQLite можна використовувати всі переваги СУБД на будь яких пристроях,
від ПК до Телевізорів та телефонів.
РОЗДІЛ 3. ОПИС ПРОГРАМНОГО ПРОДУКТУ ТА АЛГОРИТМ ЙОГО СТВОРЕННЯ
Приклад JSON об’єкту
отриманого з сервера, що містить в собі один запис:
{
"direction":"ltr",
"id":"feed/5594de7cfea0e74d87000305",
"title":"Хабрахабр /
Все публикации",
"description":"",
"self":
{"href":"https://theoldreader.com/reader/api/0/stream/contents?output=json&xt=user/-/state/com.google/read&n=1&s=user/-/state/com.google/reading-list"},
"alternate":
{"href":"#"870132.files/image001.gif">
Рис. 3.2. Схема моделі локальної
бази даних
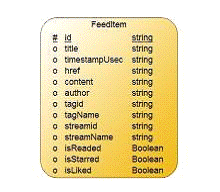
Процес оновлення та збереження даних
Враховуючи описане вище, оновлення
та збереження даних проходить у 3 етапи:
- Отримання списку
тегів (папок)
- Отримання підписок
для кожного тега
- Отримання записів
для кожної підписки
Справ в тому, що самі записи не
містять у собі інформації до якого тегу вони належать, також там не має
інформації про відмітки Starred,
Liked, що також треба
враховувати. Тому при отриманні записів з підписок ми рекурсивно записуємо в БД
записи та присвоюємо їм ідентифікатор тега та підписки, для того щоб в
подальшому користувач мав змогу фільтрації даних за цими параметрами.
Після цього з’являєтеся вся
необхідна інформація для збереження даних в локальну БД та відображення їх
користувачу.
Інструкція для
користувача
Перед використанням додатку
необхідно зареєструватися на сайті #"870132.files/image003.gif">
Рис. 3.3. Вікно вводу логіна та
пароля
Після авторизації додаток оновить
усі, існуючі в профілі, користувача підписки, та надалі буде автоматично
слідкувати за їх оновленням, а у разі появи нових записів повідомить про це
користувача за допомогою центру повідомлень Windows
10 та позначкою на плитці додатку.
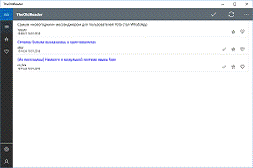
Рис. 3.4. Робоче вікно програми
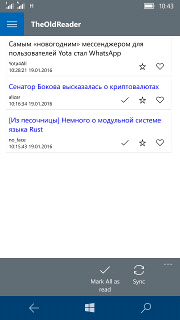
Рис. 3.5. Робоче вікно програми
на мобільному пристрої
Також у користувача є можливість
відмітити всі нові записи прочитаними, та оновити всі підписки вручну як видно
на рис. 2.
Панель зліва дозволяє перемикатися
між теками користувача (всі записи, обрані, улюблені). Натиснувши на кнопку з
трьома горизонтальними лініями зверху, панель розшириться та покаже підписи до
всіх кнопок що на ній знаходяться, див. рис. 3.
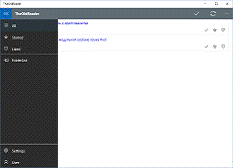
Рис. 3.6. Робоче вікно програми з
розгорнутою панеллю
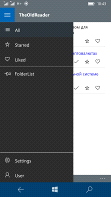
Рис. 3.7. Робоче вікно програми з
розгорнутою панеллю на мобільному пристрої
Натиснувши на новину вона
відкриється в головному вікні з повним її змістом і автоматично буде помічена
як прочитана, також з’являться кнопки для додавання цієї новини в улюблені або
в обрані записи за допомогою кнопок на верхній панелі, як показано на рис. 4.
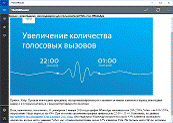
Рис. 3.8. Робоче вікно з контентом
новини

Рис. 3.9. Робоче вікно з контентом
новини на мобільному пристрої
Вихідний код програмного
продукту
Клас для роботи з API сервера:
using
System;System.Collections.Generic;System.IO;System.Linq;System.Net;System.Net.Http;System.Net.Http.Headers;System.Text;System.Threading.Tasks;Windows.UI.Popups;TheOldReader_WinX
{TheOldReader
{const String APIEndPoint =
"https://theoldreader.com/reader/api/0/";string _token;string token
{{ return _token; }{ _token =
"GoogleLogin auth=" + value; }
}async Task<bool> LogIn(string
user, string pwd)
{output = await Post("https://theoldreader.com/reader/api/0/accounts/ClientLogin",.Format("client=TheOldReaderWX&accountType=HOSTED_OR_GOOGLE&service=reader&Email={0}&Passwd={1}",
user, pwd));
{=
output.Substring(output.IndexOf("Auth=")).Replace("Auth=",
"");true;
}
{false;
}
}async Task<string>
Post(String URI, String _PostData)
{client = new
HttpClient();.DefaultRequestHeaders.TryAddWithoutValidation("Authorization:
", token);wcfResponse = await client.PostAsync(new Uri(URI), new
StringContent(_PostData, Encoding.UTF8, "application/x-www-form-urlencoded"));await
wcfResponse.Content.ReadAsStringAsync();
}async Task<string> Get(String
URI)
{client = new
HttpClient();.BaseAddress = new
Uri(URI);.DefaultRequestHeaders.TryAddWithoutValidation("Authorization:
", token);await client.GetStringAsync(URI);
}
#region Paramsasync
Task<string> getTagList()
{API =
"tag/list?output=json";URI = APIEndPoint + API;await Get(URI);
}async Task<string>
getSubscriptionList()
{API =
"subscription/list?output=json";URI = APIEndPoint + API;await Get(URI);
}async Task<string>
getUnreadCount()
{API =
"unread-count?output=json";URI = APIEndPoint + API;await Get(URI);
}async Task<string>
getUserInfo()
{API =
"user-info?output=json";URI = APIEndPoint + API;await Get(URI);
}async Task<string>
getMoreItemsForSubscription(String SubName, int ItemCount, String Continuation)
{URI =
String.Format("{0}stream/contents?output=json&n={2}&c={3}&s={1}",
APIEndPoint, SubName, ItemCount, Continuation);await Get(URI);
}async Task<string>
getItemsForSubscription(String SubName, int ItemCount)
{URI =
String.Format("{0}stream/contents?output=json&n={2}&s={1}",
APIEndPoint, SubName, ItemCount);await Get(URI);
}async Task<string>
getUnreadItemsForSubscription(String SubName, int ItemCount)
{URI =
String.Format("{0}stream/contents?output=json&xt=user/-/state/com.google/read&n={2}&s={1}",
APIEndPoint, SubName, ItemCount);await Get(URI);
}
{URI =
String.Format("{0}stream/contents?output=json&xt=user/-/state/com.google/read&n={2}&s={1}",
APIEndPoint, "user/-/state/com.google/reading-list", ItemCount);await
Get(URI);
}
//Получить все избранные записиasync
Task<string> getStarredItems()
{URI =
String.Format("{0}stream/contents?output=json&xt=user/-/state/com.google/read&n={2}&s={1}",
APIEndPoint, "user/-/state/com.google/starred", 1000);await Get(URI);
}
//Получить все понравившиеся
записиasync Task<string> getLikedItems()
{URI = String.Format("{0}stream/contents?output=json&xt=user/-/state/com.google/read&n={2}&s={1}",
APIEndPoint, "user/-/state/com.google/like", 1000);await Get(URI);
}
//Отметить запись прочитаннойasync
Task<string> markFeedItemRead(string ItemId, bool bRead)
{PostData = String.Format("{0}=user/-/state/com.google/read&i={1}",
bRead ? "a" : "r", ItemId);await Post(APIEndPoint +
"edit-tag", PostData);
}
//Отметить все прочитаннымиasync
Task<string> markAllItemsAsRead(string FeedId)
{PostData =
String.Format("s={0}", FeedId);await Post(APIEndPoint +
"mark-all-as-read", PostData);
}
//Отметить несколько записей
прочитаннымиasync Task<string> markFeedItemsRead(List<string>
ItemIds, bool Read)
{await
changeTagOfItems("user/-/state/com.google/read", ItemIds, Read);
}
//Отметить звездочкойasync
Task<string> starItem(string FeedId, bool Starred)
{szPostData =
String.Format("{0}={2}&i={1}", Starred ? "a" :
"r", FeedId, "user/-/state/com.google/starred");await
Post(APIEndPoint + "edit-tag", szPostData);
}
//Отметить звездочкой несколько
записейasync Task<string> starItems(List<string> FeedIds, bool
Starred)
{await
changeTagOfItems("user/-/state/com.google/starred", FeedIds,
Starred);
}
//Изменить тег нескольких
записейasync Task<string> changeTagOfItems(string TagName,
List<string> FeedIds, bool Add)
{(FeedIds != null &&
FeedIds.Count > 0)
{sb = new
StringBuilder();.AppendFormat("{0}={1}", Add ? "a" :
"r", TagName);
(String curItemId in
FeedIds).AppendFormat("&i={0}", curItemId);
PostData = sb.ToString();await
Post(APIEndPoint + "edit-tag", PostData);
}"";
}
//Переметить подписку в папкуasync
Task<string> moveSubscriptionToFolder(string feedId, string folderId)
{PostData =
"";(!String.IsNullOrEmpty(folderId) && folderId !=
"user/-/state/com.google/reading-list")=
String.Format("ac=edit&s={0}&a={1}", feedId, folderId);=
String.Format("ac=edit&s={0}&r={1}", feedId, folderId);await
Post(APIEndPoint + "subscription/edit", PostData);
}
//Подписатьсяasync
Task<string> addSubscription(string FeedUrl)
{PostData = "";await
Post(APIEndPoint + "subscription/quickadd?quickadd=" + FeedUrl,
PostData);
}
//Отписатьсяasync Task<string>
unsubscribe(string feedId)
{PostData =
String.Format("ac=unsubscribe&s={0}", feedId);await
Post(APIEndPoint + "subscription/edit", PostData);
}
#endregion
}
}
Отже даний додаток використовує
найновіші функції UWP,
його можна завантажити з магазина на ПК, телефон чи телевізор з Windows
10 і він буде виглядати та працювати на цих пристроях саме так як очікує того
користувач.
ВИСНОВКИ
У дипломній роботі вирішено
актуальну задачу, пов’язану з розробкою клієнтського
додатку для онлайн-агрегатора новин, на базі універсальної програмної платформи
Microsoft Windows (UWP).
На початку написання дипломної
роботи було переглянуто історію створення подібних додатків та існуючі сервіси
для агрегації новин. Отримано основну інформацію що до їх функціонування та
обрано сервіс для якого буде розроблятися додаток.
В процесі проектування програмного
забезпечення була обрана мова програмування С#
на базі UWP, створена структура моделі та
покрокові етапи розробки програми. UWP дозволяє розробляти один дизайн, один код для будь яких пристроїв
що працюють під управлінням сімейства операційних систем Windows 10. На мою думку у
даної платформи величезний потенціал, який розкривається перед розробниками
програмного забезпечення.
З розробленим додатком,
користувачам сервісу TheOldReader, стане простіше та зручніше слідкувати за оновленням улюблених
блогів, сайтів новин чи просто розважальних ресурсів, з будь якого пристрою, з
будь якого місця.
СПИСОК ВИКОРИСТАНИХ
ДЖЕРЕЛ
1. Рихтер Джеффри.
CLR via C#. Программирование на платформе Microsoft .NET Framework 4.5 на языке
C#. 4-е изд. / Джеффри Рихтер. - Питер, 2013. - 896 с.
. Стиллмен Э.
Изучаем C#. Включая C# .NET 4.0 и Visual Studio 2010. 2-е издание / Э. Стиллмен.,
Дж. Грин - O'Reilly, 2012. - 689 с.
. Троелсен Эндрю.
Язык программирования C# 2010 и платформа .NET 4 / Эндрю Троелсен. - Вильямс,
2010. - 1392 с.
. Фленов М. Библия
C#, 2-е издание / М. Фленов. - БХВ-Петербург, 2011. - 560 с.
. Шилдт Герберт. C#
4.0: Полное руководство / Герберт Шилдт. - Вильямс, 2011. - 1056 с.
. Агуров П. C#.
Сборник рецептов / П. Агуров. - БХВ-Петербург, 2007. - 432 с.
. Павловская Т.А.
C#. Программирование на языке высокого уровня: Учебник для вузов / Т.А.
Павловская. - Питер, 2009. - 432 с.
. Бьюли А. Изучаем
SQL / Алан Бьюли. - Символ-Плюс, 2007. - 312 с.
. Молинаро Энтони.
SQL. Сборник рецептов / Энтони Молинаро. - O'Reilly, 2009. - 672 с.
. Бураков П.В.
Введение в системы баз данных. Учебное пособие / П.В. Бураков., В.Ю. Петров. -
СПбГУ ИТМО, 2010. 129 с.