Распределенные системы баз данных
ФЕДЕРАЛЬНОЕ Государственное
АВТОНОМНОЕ образовательное учреждение высшего профессионального образования
БЕЛГОРОДСКИЙ ГОСУДАРСТВЕННЫЙ
НАЦИОНАЛЬНЫЙ ИССЛЕДОВАТЕЛЬСКИЙ УНИВЕРСИТЕТ
(НИУ "БелГУ")
Институт инженерных технологий и
естественных наук
факультет информационных технологий и
прикладной математики
кафедра информационных систем
управления
Курсовая работа
Тема работы:
Распределенные системы баз данных
БЕЛГОРОД 2015
Содержание
Введение
1. Теоретическое описание баз данных
1.1 Определение и характеристики распределенных систем баз данных
1.2 Однородные и неоднородные базы данных
1.3 Дифференциальные файлы
2. Распределение баз данных
2.1 Архитектура распределенных СУБД
2.2 Стратегии распределения данных
2.3 Распределение сетевого справочника данных
2.4 Основы проектирования распределенной базы данных
Заключение
Список использованных источников
Введение
Актуальность исследования. В настоящее время,
имеются проблемы, которые связаны с продуктивным распределением и
систематизированием больших потоков информации. Для устранения таких проблем
требуется внедрение распределенных систем баз данных. В частности
распределенная обработка информации является самой результативной для
оптимизации использования ресурсов и упрощения работы пользователя.
По большей части пользователь запрашивает только ту
информацию, которая необходима ему на данный момент. Для этого наиболее
эффективно перемещать определенную долю базы данных как можно ближе к
пользователю. Таким образом, формируется регионально распределенная база
данных. Создание такой базы предоставляет множество преимуществ, таких как
снижение времени отклика системы, повышение надежности хранения данных,
уменьшение затрат на оборудование.
Распределенные базы данных позволяют работать удаленным
пользователям с огромным количеством информации в наиболее удобной для них
форме. Ведущей причиной создания систем, которые используют базы данных,
является готовность объединения всех обрабатываемых на предприятии данных в
единое целое и обеспечения контролируемого к ним доступа. Формирование
распределенных баз данных дает возможность разработать общедоступные данные,
поддерживаемые любым из существующих подразделений предприятия, обеспечив их
хранение именно в тех местах, где они требуются [8]. Данный прием повышает
возможность одновременного потребления информации, при этом увеличивая
продуктивность доступа к нужным данным и обеспечивая большие возможности по
управлению сложных многоуровневых и многозвенных объектов и процессов.
Именно распределенная система баз данных осуществляет
обеспечение средствами слияния локальных баз данных, находящихся в определенных
узлах вычислительной сети, с тем, чтобы пользователь, который работает в
каком-то узле сети, располагал доступом ко всем существующим базам данных как к
единой базе данных.
Объектом исследования являются распределенные
базы данных.
Предметом исследования является изучение видов
распределенных баз данных, а также процессы их функционирования.
Цель работы состоит в исследовании и анализе
распределенных баз данных, а также распределенных систем баз данных.
Основываясь на поставленной цели, можно выделить следующие задачи
исследования:
. определить понятия распределенных баз данных и
системы управления базой данных;
2. проанализировать реализацию систем распределенных баз
данных;
. изучить основы проектирования распределенных баз
данных.
Структура исследования. Данная работа состоит из
введения, 2 глав, 7 параграфов, заключения и списка литературы. Основное
содержание работы изложено на _____ страницах. Список литературы состоит из 22
источников.
1.
Теоретическое описание баз данных
1.1
Определение и характеристики распределенных систем баз данных
База данных представляет собой определенную структуру,
которая необходима для хранения каких-либо данных. В настоящее время требуется
хранение не только данных, но и глобальной информации.
Распределенная база данных - это база данных, включающая в
себя части из некоторого количества информационных баз данных, которые
расположены на разных узлах сети компьютеров и при этом регулируемые разными
системами управления баз данных [9]. Для обычных пользователей и прикладных
программ данная база данных является всего лишь локальной базой данных. При
этом под распределенной базой подразумевается только метод ее образования, без
описания наружного облика.
В своих трудах о классических распределенных базах данных К.
Дейт зафиксировал двенадцать свойств:
. Локальная автономия - регулирование данными на каждом узле
системы осуществляется ограниченно. База данных, которая расположена на одном
из узлов, представляется неотделимым компонентом распределенной системы. Ввиду
того, что распределенная система параллельно представляет собой часть единых
данных, при этом работающая как настоящая локальная база данных, она
управляется локально и является независимой от остальных узлов системы.
. Независимость узлов - каждый узел системы равноправен и
независим от другого, а базы внутри этих узлов представляются равноправными
производителями данных в единое для них пространство данных. База данных на любом
из узлов сети является самодостаточной, так как включает в себя полный словарь
данных и при этом она ограждена от неутвержденного доступа.
распределенная база поток информация
3. Непрерывные операции - предоставляют постоянный и
непрекращающийся доступ данным, который осуществляется в пределах одной базы и
не обуславливается расположением или локальными операциями.
. Прозрачность расположения - гарантирует абсолютную явность
размещения всех данных. Пользователь, который обращается к базе данных, может и
не знать действительного расположения данных в узлах данной системы. Любая
операция, которая осуществляется над данными, не предусматривает знания об их
расположении.
. Прозрачная фрагментация - дает возможность расположить
данные распределено, но при этом они будут представлять собой общую
совокупность. Выделяется два вида фрагментации: горизонтальная и вертикальная.
Горизонтальная фрагментация определяет размещение строк одной таблицы в разных
узлах, то есть строки одной таблицы находятся в ряде эквивалентных ей, а
вертикальная - размещает столбцы одной таблицы в некоторое количество узлов.
. Прозрачное тиражирование - с помощью средств, которых не
сидит пользователь системы (внутрисистемными), осуществлять перемещение
различных модификаций между базами данных.
7. Обработка распределенных запросов - имеются альтернативные
пересылки данных, которые дают возможность осуществить необходимый запрос.
8. Обработка распределенных транзакций - выполнимость
операций, таких как insert, update, delete, для обновления распределенной базы данных. При выполнении этих
операций применяется двухфазный протокол фиксации транзакций, благодаря чему не
уничтожается единство и сбалансированность данных распределенной базы. Протокол
обеспечивает гармоничное изменение данных на ряде узлов в пределах
распределенной транзакции.
. Независимость от оборудования - распределенная система не
требует использовать определенную модель компьютера.
. Независимость от операционных систем - возможно
использование любой операционной системы.
. Прозрачность сети - доступ к данным распределенной базы
реализуется по сети. Многообразие поддерживаемых системой управления базой
данных сетевых протоколов не ограничивается системой с распределенными базами
данных, то есть возможно использование различных сетевых протоколов.
. Независимость от баз данных - возможно совмещение систем
управления базами данных разных производителей, а также можно применять
различные модели операций поиска и обновления баз данных [5].
Сущность всех этих свойств состоит в том, чтобы пользователь
не ощущал особых различий между распределенной и централизованной базой данных.
Распределенные системы управления баз данных выполняют
процессы реализации с распределенными базами данных. Распределенная система
управления баз данных (РаСУБД) является совокупностью программ, которые
необходимы для управления распределенной базой данных. Именно она делает
информацию для пользователей "прозрачной". Таким образом,
распределенная база данных включает в себя несколько частей, размещающихся на определенном
количестве компьютеров, которые расположены в сети. Благодаря этому к
распределенной базе данных осуществляется параллельный доступ некоторого
количества пользователей [9]. Задача обеспечения "прозрачности"
заключается в том, чтобы распределенная система внешне вела себя так же, как и
централизованная. Данное распределение данных дает возможность, к примеру,
держать в одном узле сети данные, неоднократно использующиеся в этом узле.
Такой подход способствует ускорению работы с данными и позволяет
функционировать с оставшимися данными базы данных, даже если для доступа к ним
необходимо потратить определенное количество времени на передачу данных по
сети.
Главной целью системы распределенных баз данных считается
предоставление контролируемого доступа и независящего обращения к данным,
распределенным в сети ЭВМ [19]. Под контролируемым доступом понимается степень
сохранности, которая требуется для обеспечения надлежащей защиты, при этом к
системе обращаются пользователи только с санкционированным доступом.
Объективность обращения, или расчленяемость, дает возможность пользователям
обращаться к данным через разные вычислительные средства.
Система управления распределенными базами данных выделяет
специальные средства для объединения локальных баз данных, расположенных в
некоторых узлах компьютерной сети, для обеспечения пользователю доступа ко всем
базам данных как к единой [1]. При этом должны быть обеспечены легкость
эксплуатации системы и допустимость независимого функционирования даже при
административных потребностях или при каком-либо повреждении целостности сети.
Для клиентских приложений распределенная база данных
предстает в виде определенной совокупности. Все части данных имеют право
располагаться более чем на одном компьютере, которые будут объединяться с
помощью линий связи. При этом каждая честь базы данных будет функционировать
под управлением обособленной системой управления. Работа пользователя с
распределенной базой данных осуществляется благодаря приложениям. Они в свою
очередь могут разделяться на те, которым необходимо непосредственный доступа к
данным, расположенным на других узлах (локальные приложения), и на те, которым
нужен аналогичный доступ (глобальные приложения) [11]. В РаСУБД обязательно
необходимо наличие как минимум одного глобального приложения. Именно поэтому
каждая РаСУБД обязана иметь последующие специфики:
) комплект логически связанных делимых данных;
2) хранимые данные разбиты на некое число фрагментов;
) среди фрагментов может существовать организованная
репликация данных;
) фрагменты и их высказывания распределены по разным
узлам;
) узлы должны объединяться сетевыми соединениями;
) работа с данными на любом узле осуществляется
локальной СУБД.
Система управления базой данных на любом узле может
реализовывать автономную работу локальных приложений.
1.2
Однородные и неоднородные базы данных
Зачастую функционирование распределенных систем
осуществляется благодаря объединению различных аппаратных и программных
средств. Именно поэтому необходимо использовать однородные или неоднородные,
вычислительные системы. Для начала нужно выявить связь между сетевой и
локальной системами управления базами данных. При использовании однородных
систем управления базами данных не обнаруживается никаких проблем, связанных с
моделью данных, языком запросов или какими-либо пользовательскими средствами.
Все это совпадает с тем, что реализуется локальной системой управления базой
данных. Но также следует определиться, нужно ли работать всем пользователям с
сетевой системой управления базы данных или пользователям, запрашивающим
данные, которые содержатся в локальном узле, нужно напрямую сотрудничать с
локальной системой управления. При использовании однородной базы данных
возможности, которые даются пользователям сетевой системой управления, должны
быть равносильны [20].
При поддержании распределенной базы данных неоднородных
систем управления возникает намного больше проблем. Если база данных
образовалась из нескольких независящих ранее друг от друга баз данных, тогда
применяется неоднородная система управления базами данных. В данном случае для
исполнителя очень важно добиться прозрачности доступа, но это не значит лишь
осуществления доступа к удаленным системам управления базами данных и их базам
данных. Это означает то, что пользователю неведомо размещение данных или для
выполнения своей работы ему не нужны эти сведения. При использовании
неоднородной системы управления базой данных так происходит только в том
случае, если локальная система управления, тоже является "прозрачной"
и пользователю не требуется быть в курсе того, какой локальной системой
управления выполняется запрос. Осуществляется это существенно различными путями
[8]. Первый путь заключается в предоставлении возможности пользователю
применять на каждом узле пользовательский интерфейс, который обеспечивается
локальной системой управления базой данных. В этом случае, схему, которая
имеется в наличии, необходимо расширить, для включения данных из других узлов.
Выбрав этот путь, пользователи работают так, как будто удаленные данные существуют
в данной локальной базе данных.
Вся сложность состоит в том, чтобы программное обеспечение
сетевой системы управления базой данных во всех узлах давало возможность
использовать данные из какого-либо другого узла вне зависимости различных
факторов. Когда количество разных локальных систем управления базой данных
становится больше, то увеличивается и количество различных преобразований схем.
Все намного легче, если применять комплексный
пользовательский интерфейс для всей сети и стандартизированные внутренние формы
реализации запроса. Это помогает решить проблему преобразования схем. В этом
случае пользователи, которым требуются данные из удаленных узлов, применяют
единый интерфейс. Интерфейс может отличаться от того, который используется в
любой локальной системе управления базой данных. Обязана существовать лишь одна
общая схема сетевой базы данных.
В сущности, однородные распределенные системы баз данных
заключают в себе лишь один продукт системы управления с единственным языком баз
данных SQL. Такие системы управления базами данных являются очень
взаимосвязанными системами, так как у них есть внутренние средства поиска
данных и средства обработки запросов. Данные средства отлажены для получения
большей результативности и пропускной способности.
Неоднородные распределенные системы баз данных представляют
собой противоположный вариант однородной системы. Неоднородные системы могут
заключать в своем составе как минимум два абсолютно различных продукта управления
данными. К примеру, системы управления базой данных могут иметь одного
исполнителя, но работать на совершенно разных платформах.
Однородные распределенные системы баз данных в основном
реализуются способом "сверху вниз", неоднородные - наоборот "снизу
вверх", чтобы была возможность для образовать единую среду управления над
уже существующими информационными ресурсами [22].
Формирование распределенных баз данных методом "сверху
вниз" реализуется почти так же, как и проектирование централизованных баз данных.
В совершенстве проектирование происходит благодаря формальной методологии,
которая включает в себя организацию концептуальной модели базы данных, ее
отображение в логической модели данных и создание с настройкой специфических
для определенной системы управления базой данных структур.
Однако проектирование распределенной базы данных методом
"сверху вниз" предполагает то, что ее объекты не будут направлены в
одно место, а будут распределяться по нескольким вычислительным системам. Если
узлы однородных систем распределенных баз данных применяют единый тип системы
управления базой данных, то узлы неоднородных система имеют возможность
использовать разные виды систем управления.
Намного легче формировать и сопровождать однородные системы
распределенных баз данных, если к ранее имеющейся распределенной системе
добавлять новые узлы, тем самым увеличивая продуктивность этой системы, так как
идет параллельной обработки информации [7; 15]. А неоднородные системы
зарождаются тогда, когда узлы, которые используют свои собственные системы с
базами данных, постепенно объединяются в распределенную систему. В таких
системах для осуществления сотрудничества между разными видами системами
управления базами данных необходимо обеспечить преобразование передаваемых
сообщений, при этом любой узел обязан иметь возможность осуществлять запросы на
языке используемой системы управления.
1.3
Дифференциальные файлы
Все изменения базы данных постепенно собираются в специальном
файле изменений, который именуется дифференциальным файлом. Его главная идея
заключается в том, что основной файл базы данных остается неизменным при любых
ее изменениях.
При обновлении базы данных со значительным объемом хранимых в
ней данных, самым простым и дешевым методом является скапливание различных изменений,
которые происходят за определенный промежуток времени, и в дальнейшем их
переносе в абсолютно новую версию базы данных. Наиболее затратный способ,
который базируется на стоимости хранения, времени поддержания и общей сложности
системы, представляет собой изменение базы данных при исполнении каждой
транзакции обновления.
Кроме двух перечисленных методов, возможно применение
дифференциального файла, выполняющего сбор и распознавание предстоящих
изменений записей. Для реализации операции выборки необходимо заблаговременно
обратиться к дифференциальному файлу, который является наиболее результативным
средством для доступа к самому последнему состоянию базы данных. Подобным
образом, за счет повышения времени доступа возможно уменьшение расходов, которые
идут на обновление базы дынных [19]. В том случае, когда дифференциальный файл
приобретает внушительные размеры, происходит преобразование, в ходе которого
все изменения, хранимые в дифференциальном файле, регистрируются базой данных.
Таким образом, возникает новое поколение базы данных, а в дифференциальный
файл, который к этому моменты является пустым, вновь записываются различные
изменения.
Для каждого приложения и его версии имеются разные
представления о дифференциальном файле. Относительно распределенных систем баз
данных существует три варианта дифференциального файла. Дифференциальная
структура для ленточных систем создана для исключения записей, которые не
меняются в течении последовательной пакетной обработки обновлений. При этом
файл с данными делится на одинаково упорядоченные подфайлы. Подфайлы
представляют собой общность записей, в которых может осуществляться лишь
чтение, при этом они хранятся на одной ленте, а небольшая совокупность
изменяемых записей хранится на совершенно отдельной "ленте изменений"
[9; 24]. Когда данные из файла обновляются, происходит слияние двух лент и при
этом образуется новая измененная лента. Доступные только для чтения записи
ленты никогда на нее не записываются. Именно поэтому после модификации половины
всех записей желательно осуществлять преобразование файла с данными.
В файловой системе с прямым доступом для обработки изменений
требуется применять принцип дифференциального файла. В таком случае система
обращается к записям с помощью уникального идентификатора, а каждая ссылка на
данные осуществляется через индекс базы данных, который адресует все записи.
Если главный файл данных уже существует, то он больше не изменяется. Все записи
базы данных, которые создаются в последующем, направляются к индексу и
сохраняются в совершенно другой части переполнения. Любые изменения записей
данных характеризуются как записи добавления. Происходит создание новой копии
записи и обновление ее индекса, чтобы в дальнейшем получать указания на область
переполнения. Предыдущая запись не удаляется, а поддерживается как старый
образ, на который указывает новая запись. Этот образ указывает на то, что
созданная запись из-за всевозможных обновлений увеличивается в объеме, не
нарушая при этом размещение соседних записей.
Система с аналогичной структурой была создана для возможности
восстановления базы данных, если вдруг произойдет отключение электрического
питания. В подобной ситуации любые запросы будут проходить через системный
индекс и все преобразования начнут выделяться в специальный файл изменений,
который будет носить название Modfile. Все записи, с которыми начнут происходить
видоизменения, будут указывать на свой старый образ. Если же произойдет
отключение электропитания, то вся информация из журнала транзакций вместе с
информацией из файла Modfile станет применяться для удаления незаконченных
обновлений [9].
Каждый раз при обновлении записи с помощью любого из
вышеописанных способов, устройство поиска информации, которая до этого была
связана только с главным файлом, преображается, указывая на только что
созданную копию записи, охраняющуюся в дифференциальном файле. Доступ к
текущему значению идентифицированной записи реализуется только при помощи
единого устройства поиска - системного индекса, не зависимо от расположения
записи в главном или дифференциальном файле.
Так как у любой записи базы данных есть собственный
идентификатор, то поиск вначале осуществляется в дифференциальном файле. Если в
файле запись не обнаруживается, то выборка происходит в главном файле. Имеется
в виду именно то, что каждый файл может обладать своим собственным устройством
поиска. Индекс главного файла всегда остается неизменным и если произошел
какой-либо сбой, то он легко восстанавливается, так как имеет свою копию.
Изменяемая часть индекса переносится в меньший и легко восстановимый индекс
дифференциального файла.
Для защиты главного файла и устройства его поиска от
различных видоизменений, мы вынуждены осуществлять дополнительные затраты в
виде поиска в дифференциальном файле при любом запросе к записи. При таком
подходе два файла размещаются на различных устройствах, а доступ к ним
происходит с помощью независимых каналов. А так как поиск реализуется
параллельно, пользователи системы не ощущают дополнительной задержки [3]. Но в
том случае, когда мы не можем применить параллельный поиск нужно ждать
увеличения среднего времени выборки на время произвольного доступа к вторичной
памяти. При этом дополнительное время доступа может быть не очень большим, а
это в свою очередь сильно уменьшает производительность системы.
Если же достаточно большое увеличение времени доступа
непозволительно, то следует использовать видоизмененную стратегию поиска,
которая применяет предпоисковый фильтрующий алгоритм для уменьшения
нежелательных обращений к дифференциальному файлу.
Существует некоторое количество преимуществ дифференциальной
организации базы данных. Пять из них связаны с целостностью базы данных, так
как при применении дифференциального файла уменьшается не только стоимость
копирования и восстановления, но и сводится к минимуму возможность неисправимых
потерь данных. Другие три преимущества связаны с эксплуатацией. Одновременно
дифференциальный файл может повышать доступность данных и снижать затраты
памяти со стоимостью выборки [3; 17].
. Снижение стоимости создания дампа базы данных. При
перезапуске происходит восстановление состояния базы данных, которое
существовало в какой-то момент времени. Далее осуществляется добавление в базу
данных накопившегося результата обработки всех транзакций обновления, которые
выполнялись с самого последнего копирования базы данных. Благодаря частому
копированию осуществляется быстрое восстановление базы данных, но также из-за
этого возможны крупные системные издержки. Время, которое необходимо для
копирования, пропорционально объему копируемых данных, из-за чего использование
дифференциального файла может сильно уменьшить стоимость восстановления большой
базы данных, в частности, при части записей, которые изменены с момента
последнего копирования, очень мала.
2. Возможность создания дампа приращениями. Для
осуществления полного восстановления базы данных нужно добавлять записи
дифференциального файла, которые были сформированы уже после последнего
копирования базы данных, к текущему состоянию новой копии файла. При каждом
дампировании приращениями можно сохранять текущее состояние двоичного вектора
дифференциального файла и индекс поиска.
. Возможность дампирования и реорганизации параллельно
с обновлением. Благодаря формированию дампа дифференциального файла заметно
уменьшается время, в течение которого нельзя осуществлять запросы на
обновление. После завершения формирования дампа все хранящиеся в нем записи
переходят в основной дифференциальный файл. Поэтому параллельно с эксплуатацией
можно проводить реорганизацию. Замена старого дифференциального файла на новый
осуществляется после завершения реорганизации.
. Ускорение восстановления после потери данных. С
помощью отката неправильно обработанной или частично не завершенной транзакции
можно быстро восстанавливать систему.
. Снижение риска безвозвратной потери данных.
Дифференциальный файл сосредотачивает все изменения на небольшом физическом
пространстве и предоставляет такие вероятные преимущества как минимизацию
критической незащищенности области, размещение критической области становится возможным
на более надежном устройстве, дублирование небольшой критической области для
достижения наивысшей надежности.
. Эффективная поддержка "файла памяти".
Почти все системы, для избегания масштабных издержек, которые связаны с выбором
применяемых программных средств, накапливают изменения для пакетной обработки
после окончания.
. Упрощение разработки программного обеспечения. В
системе с дифференциальным файлом основной файл данных и связанный с ним индекс
не подвергаются действию обновлений, что в свою очередь позволяет применять
имеющиеся средства для разработки нового программного обеспечения.
. Снижение стоимости хранения базы данных в будущем.
Снижение стоимости, которое обеспечивается применением дифференциального файла,
сильно расширяет возможные сферы применения автоматизированных информационных
систем.
2.
Распределение баз данных
2.1
Архитектура распределенных СУБД
В текущем быстро изменяющемся компьютерном мире существуют,
по меньшей мере, три базисных идеологии: клиент-сервер, Web и распределенные
объекты (DCOM, CORBA). Каждое из этих направлений в свою очередь имеет
достаточное множество решений и стандартов от различных производителей.
"Клиент-сервер" - это вид распределенной системы,
имеющей сервер, который выполняет запросы клиента, при этом сервер и клиент
взаимодействуют друг с другом, используя тот или иной протокол. Клиент
представляет собой программу, использующую, а под сервером программа
подразумевается программа, которая обслуживает запросы клиентов на получение
определенных ресурсов. Данное определение содержит в себе почти все возможные
программные технологии, в которых принимают участие как минимум две программы,
при этом функции между ними распределены неравномерно [5].
Для распределения обязанностей между сервером и клиентом при
осуществлении запросов к базам данных имеется два подхода. Ели применять
технологию файлового сервера, то когда клиент осуществляет запрос, сервер в
ответ передает ему нужные для запроса файлы. А уже затем клиент оставляет
необходимую для себя информацию. В данном случае почти все работу осуществляет
только клиент. Через каналы связи идет значительный поток данных, большинство
из этих данных в конечном итоге не появятся в ответе на запрос.
В технологии "клиент-сервер" сервер выполняет
сортировку данных для ответа на запрос, а до клиента уже доходит лишь только
результат, то есть он получает только те данные, которые он запрашивал (рис 1).
В процессе работы с файл-серверной технологией ответственность за сохранность и
целостность базы данных полностью ложится на программу и сетевую операционную
систему. Обработка всех данных осуществляется на рабочих местах, при этом
сервер применяется только как разделяемый накопитель. Все пользователи напрямую
пользуются информацией и вносят нужные изменения в файлы данных и в индексные
файлы [22].
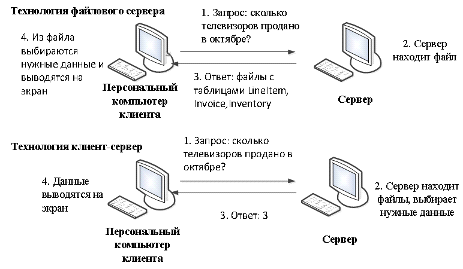
Рис. 1. Сравнение технологий файлового сервера и
"клиент-сервера".
При достаточно большом объеме данных и работе в
многопользовательском режиме значительно уменьшается быстродействие, поскольку,
чем больше пользователей, тем выше требования к разделению данных. Также может
обнаружиться повреждение баз данных. К примеру, в момент записи в файле может
произойти сбой сети или неисправность питания. При данных условиях компьютер
прекращает работу и база данных повреждается, а индексный файл оказывается
разрушенным. После схожих сбоев следует проводить индексацию, которая
продолжается до нескольких часов [16].
Клиент-серверная дает возможность избежать подобных проблем,
поскольку вся работа с базой данных осуществляется на сервере, не идет по
проводам и никак не связана со сбоями на рабочих станциях. Любое запрашиваемое
действие на добавление в файл перехватывается сервером. Изменения в файл
записываются лишь после получения сервером сообщения, о том, что исправления
файла завершены. Благодаря этому невозможно повреждение индексных файлов, а
также значительно увеличивается быстродействие системы.
Помимо высокого быстродействия и надежности, архитектура
"клиент-сервер" предоставляет большое количество преимуществ и в
области технического обеспечения. В первую очередь, сервер совершенствует
реализацию функций обработки данных, что освобождает от необходимости
оптимизации рабочих станций. Рабочая станция может иметь не очень быстрый
процессор, и все же, сервер предоставит возможность быстро получать результаты
обработки запроса. Во-вторых, поскольку рабочими станциями не обрабатываются
все переходные данные, сильно снижается нагрузка на сеть. Появляется
вероятность ведения журнала операций, которой сам регистрирует любые транзакции
что, в свой черед, помогает быстро восстанавливать системы при аппаратных сбоях
[17].
Существует двухуровневая и трехуровневая модель архитектуры
"клиент-сервер" (рис. 2). Данная модель является самой универсальной,
так как она схожа со схемой разработки локальных баз данных. Большинство систем
"клиент-сервер", которые используются на сегодняшнем рынке,
развивались из уже имевшихся локальных приложений базы данных, хранящих на
сервере собственные данные в файле. Перенос систем происходит для увеличения
продуктивности работы, защищенности, также надежности базы данных [3].
Рис. 2. Двухуровневая модель "клиент-сервер".
К преимуществам модели относится:
) во многих случаях дает возможность разделить функции
вычислительной системы между некоторым количеством независящих друг от друга
компьютеров. Благодаря этому упрощается работа вычислительной системы. К
примеру, замена, ремонт, модификация или перемещение сервера ни каким образом
не касаются клиентов. Вся информация хранится на сервере, который защищён
намного лучше, чем большинство клиентов. На сервере намного легче осуществлять
контроль полномочий для разрешения доступа к данным только тех клиентов,
которые обладают подходящими правами доступа;
2) дает возможность объединять различных клиентов.
Зачастую оперировать ресурсами одного сервера могут клиенты с различными
аппаратными платформами, ОС и т.п. [8].
К недостаткам модели относится:
) неисправность сервера может нарушить
работоспособность всей вычислительной сети;
2) требуется высококвалифицированный специалист
(системный администратор), который будет поддерживать работу системы;
) высокая стоимость оборудования [21].
Данные этой модели все время размещены на сервере, в то время
как а клиентские приложения - на собственном компьютере.
Одной из версий модели "клиент-сервер" служит
трехуровневая архитектура клиент-сервер. В ней все функции преобразования
данных располагаются на одном или более отделенных друг от друга серверов. Это
дает возможность разделять функции хранения, обработки и представления данных
для наиболее результативного применения всех возможностей серверов и клиентов.
К преимуществам модели относится:
) масштабируемость;
2) конфигурируемость - уровни обособлены друг от друга,
что в свою очередь дает возможность (при верном развертывании архитектуры)
быстро и с помощью простых средств переконфигурировать систему при появлении
сбоев или при плановой работе на одном из уровней;
) высокая безопасность;
) высокая надёжность;
) низкие требования к скорости канала (сети) между
терминалами и сервером приложений;
) низкие требования к производительности и техническим
характеристикам терминалов, из-за снижения цены. Терминалом может быть не
только компьютер, но и сотовый телефон [21].
Также имеются и некоторые другие недостатки архитектуры. Если
трехуровневую архитектуру сравнивать c клиент-серверной или файл-серверной то
мы можем увидеть такие ее недостатки как:
) сложность создания приложений;
2) возникновение затруднений при разворачивании и
администрировании системы;
) высокие требования к производительности серверов
приложений, что в свою очередь ведет в повышению стоимости серверного
оборудования;
) значительные запросы к к скорости канала между
сервером базы данных и серверами приложений.
В трехуровневой модели "клиент-сервер" (рис.3)
клиент представляет собой только пользовательский интерфейс к данным, в то
время как сами данные размещаются на удаленном сервере. Клиентское приложение
производит запросы, чтобы добыть доступ к данным или изменить их, используя
сервер. В случае если клиент, сервер и бизнес-правила рассредоточены на разных
компьютерах, разработчику следует оптимизировать доступ к данным и осуществлять
их целостность по всей системе.
Рис. 3. Трехуровневая модель "клиент-сервер".
Технология клиент-сервер позволяет взаимодействовать
компьютерам в локальной сети так, чтобы один компьютер (сервер) отдавал
собственные ресурсы другому компьютеру (клиенту). Именно поэтому имеется
разделение сетей на одноранговые и серверные [1].
В одноранговой архитектуре сети не существует выделенных
серверов и все рабочие станции имеют право исполнять функции клиента и сервера.
При этом рабочая станция отдают некоторое количество своих ресурсов в общее
распоряжение для всех существующих рабочих станций сети. Зачастую одноранговые
сети строятся на базе идентичных по мощности компьютерах. В своей эксплуатации
и настройке одноранговые сети очень легкие. Но если сеть состоит из малого
количества компьютеров и главной для нее функцией является только обмен
информацией среди рабочих станций, то одноранговая архитектура является самым
лучшим решением [7].
Существование распределенных данных и допустимость изменения
своих серверных ресурсов каждой рабочей станцией затрудняет обеспечение
надежной защиты информации от неутвержденного доступа. Это относится к
недостаткам одноранговых сетей. Из-за этого разработчики уделяют большое
внимание вопросам защиты информации. Также к недостаткам одноранговых сетей
относится их довольно низкая работоспособность. Это происходит в следствие
того, что полностью все сетевые ресурсы находятся на рабочих станциях, которые
синхронно реализуют функции клиентов и серверов.
В серверных сетях происходит организованное распределение
функций среди всех компьютеров, одни из них все время являются клиентами, а
другие - серверами. Так как каждая компьютерная сети осуществляет свои услуги,
то все серверы делятся на несколько типов: сетевой сервер, файловый сервер,
сервер печати, почтовый сервер и др. Сетевой сервер - это специализированный
компьютер, ориентированный только на осуществление основного объема
вычислительных работ и функций по управлению компьютерной сетью. Этот сервер
состоит из ядра сетевой операционной системы и именно под ее управлением
реализуется вся работа локальной сети. Такой сетевой организации присуще
быстродействие и большой объем памяти. Функции всех рабочих станций заключаются
в вводе и выводе информации, а также в обмене этой информации с сетевым
сервером [19].
Главной функция файлового сервера состоит в хранении,
управлении и передачи файлов данных. Файловый сервер не обрабатывает и не
изменяет сохраняемые и передаваемые им файлы. Возможно, что сервер не будет
знать, является ли файл текстовым или графическим. В общем случае на файловом
сервере наличие клавиатуры и монитора не является обязательным. Всевозможные
изменения в файлах данных происходят на клиентских рабочих станциях. Поэтому
клиентам нужно считывают файлы данных из файлового сервера, при этом ни
реализуют нужные изменения в данных и затем возвращают их обратно в файловый
сервер. Данный тип организации наиболее благоприятен, если с единой базой
данных работает множество пользователей. В пределах большой сети возможно
одновременное использование нескольких файловых серверов.
Сервер печати (принт-сервер) является печатающим устройством,
которое имеет доступ и подключается к передающей среде благодаря сетевому
адаптеру. Данное сетевое печатающее устройство самостоятельно и его работа не
зависит от других сетевых устройств. Сервер печати обслуживает заявки на печать
от всех серверов и рабочих станций [12]. В виде серверов печати употребляются
специальные высокопроизводительные принтеры. При большой интенсивности обмена
данными с глобальными сетями в рамках локальных сетей обособляются почтовые
серверы, благодаря которым обрабатываются сообщения электронной почты. Для
эффективного взаимодействия с сетью Internet могут использоваться Web-серверы.
2.2 Стратегии
распределения данных
Выбор стратегии распределения данных в узлах сети компьютера
опреляется в зависимости от количества узлов, в которых хранятся данные, а
также от наличия дублированной информации. Архитектура системы и ее программное
обеспечение устанавливают возможные стратегии управления базой данных. В ходе
формирования базы данных определяются характерные черты реализуемой стратегий
распределения данных.
Есть четыре разновидности стратегии распределения данных:
. Централизация (существует единственная копия базы
данных, которая размещается в одном узле),
2. Расчленение (существует единственная копия базы
данных и непересекающиеся подмножество, которые размещены на разных узлах),
. Смешанная (существует некоторое количество копий
подмножеств базы данных, во всех узлах может находиться любая часть базы
данных) [21].
Система управления распределенными базами данных, допускающая
лишь централизованное распределение, представляет собой самую простую, а
система, в которой возможно смешанное распределение данных я является самой
сложной. По сравнению с централизованной стратегией, стратегии расчленения и
дублирования представляют собой намного более сложные [4; 17]. Стратегия
расчленения предусматривает существование только единственной копии базы
данных, в этом случае нужно точно знать, какие фрагменты базы данных
расположены во всех узлах. Стратегия дублирования рассчитывает существование во
всех узлах целой копии базы данных и все эти копии должны обслуживаться
слаженно для гарантии их полноты и целостности.
Смешанная стратегия соединяет в себе проблемы двух предыдущих
стратегий распределения, но при этом она имеет гибкость и преимущества этих
стратегий. Система управления распределенными базами данных требует постоянного
контроля как над преобразованиями состояний копий всех подмножеств базы данных,
так и над расположением каждой копии.
Главным достоинством централизованной базы данных (рис.4)
является простота. Поскольку все операции реализуются под контролем одного
единственного узла, то существующие проблемы и действия полностью понятны.
Из-за того, что все данные размещаются в единственном узле, существует
вторичная память, которая в данном узле уменьшает размер базы данных. Любой
запрос на выборку и обновление данных идет в центральный узел сети вместе со
всеми сопровождающимися затратами на стоимость связи и временную задержку. При
этом может случиться так, что при возникновении каких-либо ошибок в связи, база
данных будет недоступна для удаленных пользователей и полностью выйдет из строя
при отказе центрального сервера.
Рис. 4. Стратегия централизации распределения данных
Если все данные распределяются, основываясь на стратегии
расчленения, то база данных располагается почти на всех узлах сети и невозможно
наличие копий отдельных фрагментов базы данных. База данных делится на
некоторое количество непересекающиеся подмножеств (логические фрагменты) и
каждая логическая часть располагается на отдельном узле. Объем базы данных
ограничивается объемом вторичной памяти, которая присутствует во всей сети, а
не только в одном узле [4]. Результативность стратегии расчленения повышается
вместе с уровнем локализации ссылок, то есть вместе с большим количеством
запросов, которые организует пользователь в базе данных локальных
информационных систем (рис. 5).
Рис. 5. Стратегия расчленения распределения данных
Достоинства такой стратегии распределения состоят в
увеличении объема базы данных; из-за того, что многие запросы удовлетворяется
локальными базами, уменьшается время ответа; увеличении доступности и
надежности; в сравнении с централизованным распределением снижаются затраты для
запросов на выборку и обновление; при выходе из строя одного из серверов
система остаются частично работоспособной.
К недостаткам метода относится то, что некоторые удаленные
запросы или транзакции могут запрашивать доступ ко всем серверам, что в свою
очередь, повышает время ожидания и стоимость; требуется иметь сведения о
распределении данных в БД. Тем не менее, простота и надежность заметно
повышаются. Разделение базы данных больше всего подходит в том случае, если
локальные и глобальные сети ЭВМ используются совместно [15].
Если же данные распределяются, основываясь на стратегии
дублирования (рис. 6), то во всех узлах сети находится целая копия базы данных,
таким образом в каждом узле, где есть данные, имеется целая база данных.
Главное достоинство данной стратегии состоит в большой безопасности,
доступности и результативности выборки. Недостатками стратегии дублирования
являются неестественно большие требования к объему внешней памяти, а также
сложности с корректировкой баз данных, поскольку нужна синхронизация для
взаимодействия копий. Основным достоинствам стратегии дублирования является то,
что каждый запрос реализуется локально, в следствие чего, организуется быстрый
доступ.
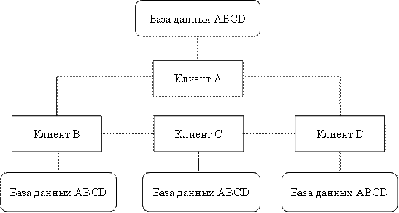
Рис. 6. Стратегия дублирования распределения данных
Смешанная стратегия распределения данных (рис.7) соединяет
подходы, которые связаны с расчленением и дублированием данных для приобретения
достоинств, которыми они обладают. Данная стратегия разделяет базы данных на
логические фрагменты, как это делается в стратегии расчленения, но вдобавок к
этому позволяет иметь любое количество физических копий каждого фрагмента,
которые называются хранимыми фрагментами.
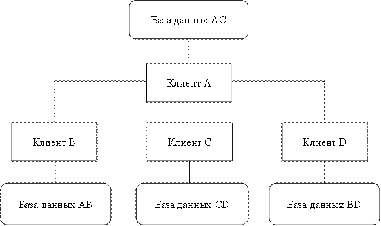
Рис. 7. Стратегия смешанного распределения данных
Ключевое достоинство данной системы состоит в гибкости,
благодаря которой устанавливается компромисс между объемом памяти, которая
необходима в целом и для каждого узла в отдельности. Именно эта гибкость
реализует надежность и производительность всей работы. В данной стратегии
довольно легко осуществляется параллельная обработка, а именно обслуживание
распределенного запроса или транзакции. Главным недостатком стратегии
дублирования является проблема взаимозависимости факторов, которые влияют на
продуктивность системы, ее надежность, увеличиваются требования к памяти.
2.3
Распределение сетевого справочника данных
В соответствии с применением базой данных одного из возможных
видов стратегий (централизованная, расчлененная, дублированная или смешанная),
которые непосредственно ею используются, сетевой справочник размещается на
узлах сети. Для того чтобы выбрать наиболее целесообразную стратегию,
необходимо сначала выбрать правильное сочетание стратегий распределения данных,
которые применяются сетевой системой управления базой данных, и разрешениями
касательно требований, как самих пользователей, так и приложений к системам баз
данных. Поэтому основная стратегия распределения оказывается в распоряжении
сетевой системы управления базой данных, а значит, ее действия следует
оценивать до определения именно сетевой систему управления. Но некоторые из действий
о распределении данных не могут действовать и на распределения справочника. К
примеру, если справочник имеет некоторое количество копий, то необходимо в
дальнейшем производить согласование его последующих версий [10; 17].
В теории возможно применение любой стратегии распределения
справочника при этом она не будет зависеть от стратегии распределения данных.
Но в действительности применяется только несколько сочетаний. Если вместе
использовать централизованную и смешанную стратегии при распределении сетевого
справочника будет происходить потеря большинства преимуществ, которыми обладает
смешанная стратегия распределения данных. При выборе стратегии распределения
важно учитывать то, что многие параметры сетевого справочника и самой базы
данных, которая управляет этим справочником, будут сильно различаться, например
отношение количества обновлений к количеству выборок (изменчивость). К
преимуществам расчлененного и дублированного справочника относится то, что при
выполнении пользователем любого запроса будут осуществляться запросы на выборку
из самого справочника. Если же применять смешанную стратегию, то необходимо,
чтобы существовал справочник справочника, для осуществления нахождения системой
управления базой данных нужные фрагменты справочника. В системе SDD-1 такой справочник
называется указателем справочника и дублируется в каждом узле. В целом сетевой
справочник представляет собой часть сетевой системы управления базой данных и
вовсе не рассматривается как отдельный объект. Для правильного и целесообразного
выбора стратегии распределения справочника необходимо принимать во внимание
стратегии распределения данных и цели функционирования базы данных [9].
Формирование сетевого справочника может потребоваться уже при
реализации базы данник, но в данном случае может возникнуть огромное количество
пределов по сравнению с ограничениями на этапе формирования базы данных.
Некоторые системы управления базами требуют такое же размещение сетевого
справочника, как и при размещении данных. Поэтому возможно деление сетевого
справочника на некоторое количество логических фрагментов, а далее эти
фрагменты размещаются на узлах сети, возможно с применением избыточности. Но в
случае, если сетевой справочник обрабатывается подобно базе данных, устройства
поддержания базы данных, вместе с параллельным управлением и безопасностью
используются для поддержания справочника [7]. При этом крайне важно учитывать
надежность, и параметры производительности.
Главная функция сетевого справочника данных заключается в
создании связи между именем объекта и их размещением в системе распределенных
данных. Имеется два подхода для разрешения данной проблемы, а именно применение
полного имени доступа или функции каталогизации. Когда применяется полное имя
для доступа, связь происходит за счет включения поля, который указывает на
расположение распределенных данных непосредственно в имени каталога файла, а
это в свою очередь дает явное указание размещения. Функция каталогизации
осуществляет распределение разделенных систем данных, поддержку внутренних
связей, благодаря чему пользователю не обязательно знать расположение файлов.
2.4 Основы
проектирования распределенной базы данных
Существует множество довольно известных методов построения
программного обеспечения для проектирования баз данных. К примеру, для этого
можно использовать нисходящее проектирование, которое всецело подходит для
структуры базы данных. На исходной вступительной стадии концептуальная модель,
которая предоставляет для использования все возможные элементы данных и
координацию конкретной области, постепенно формируется в
системно-ориентированную структуру базы данных. Процесс развития проектирования
очень сильно структурирован, что в свою очередь хорошо сказывается на конечном
результате. Любой этап процесса проектирования обязательно завершается хорошо
определенным результатом. А в том случае, если вдруг конечный результат не
удовлетворяет изначально запрошенных требований или каким-то системным
ограничениям возможно итеративное повторение предыдущих этапов. Но кроме этого
при необходимости можно накладывать дополнительные требования [18]. Благодаря
этому проектировщик может в дальнейшем модифицировать проектные решения на
любом предыдущем этапе. В действительности при реализации затраты на само
проектирование сильно увеличиваются. При этом любые проектные решения заново
анализируются после того, как отдельные решения уже были осуществлены. Именно
поэтому использование итерации наиболее продуктивно на тех этапах, которые
предшествуют этапу реализации. Все же применение итераций может сильно снизить
итоговую стоимость реализации базы данных, но это применение одновременно с
этим затрудняет достижение одной из самых главных целей при проектировании -
воспроизводимости. Однако на сегодня итерация представляет собой самое нужное,
важное и полезное средство. Итерацию можно использовать на всех этапах процесса
проектирования. Также при процессе проектирования базы данных возможно
применение многошаговой методологии экспертной оценки проекта или проектной
экспертизы, которая содержит в себе такие методы, как сквозной структурный
контроль базы данных и прикладное программное обеспечение [18; 21]. Когда
системы баз данных применяют стратегию, которая подходит для универсальных
информационных систем, то очень эффективно применение проектной экспертизы.
Главная и единственная цель экспертизы заключается в обнаружении ошибок при
системном проектирования и их исправлении на самых ранних стадиях жизненного
цикла, для снижения затрат, которые идут на разработку системы.
Проектная экспертиза осуществляется как минимум четыре раза
за весь жизненного цикла проектирования:
) после оценки требований и проектирования
информационной структуры, то есть после концептуального проектирования;
2) после четко разработанного проектирования системы;
) после эксплуатации системы и ее исполнения;
) после начала эксплуатации, в то время как в систему
вложена полная информация насчет эксплуатационных характеристик.
Средства для проектирования и оценочные критерии
Все этапы, сопровождающие процесс проектирования, определяются
уникальной подборкой методов проектирования и критериями для оценки
всевозможных решений. Невзирая на то, что все методы процесса проектирования
имеют либо процедурный, либо эмпирический, либо исследовательский характер,
каждый из этих методов может быть выполнен подобно программе. Таким образом,
все эти методы превращаются в инструментальное средство проектирования, которое
почти зависит от выбранного стиля проектирования.
Оценочные критерии в виде средств проектирования как таковые
нужны, чтобы из всевозможных структур базы данных выбрать подходящую. Почти все
значительные проблемы при проектировании базы данных происходят из-за неверного
представления о том, что представляет собой проектирование базы данных. В наши
дни и в ближайшее будущее нечеткость выбора оценочных критериев будет самым
слабым местом при проектировании баз данных [16].
В основном большинство трудностей, которые связаны с
определение критериев выбора всевозможных решений, обуславливаются двумя
причинами. Первая причина состоит в том, что можно создать огромное количество
разнообразных структур баз данных, которые бы удовлетворяли одинаковой
совокупности системных требований. Критерии выбора обязаны давать возможность
для дифференциации всех возможных альтернатив. Вторая причина заключается в
том, что всевозможные варианты почти невозможно оценить, поскольку на каждый
критерий уходит неопределенное количество времени.
Средства описания
На каждом этапе проектирования все спецификации требований и
структуры баз данных представляются как простая модель или набор соединенных
между собой моделей, которые понятны итоговому пользователю данных, прикладному
программисту и системным.
В методологии проектирования имеется три главных раздела
описательных средств. К первому разделу относится язык описания данных ЯОД,
который входит в состав системы управления базой данных. Этот язык применяется
для характеристики итогового результата в процессе проектирования реализации.
Второй раздел несет в себе описание первоначальной
информации. На сегодняшний день всевозможные средства, которые необходимы для
сбора и анализа информации, сходны в одном, а именно в том, что они
организовывают форматы для спецификации информации типа ISP и UP. Кроме этого
они реализуют основные проверки совместимости данных [14].
Третий раздел описательных средств необходим для
представления результатов промежуточных этапов. Он является промежуточным между
ЯОД и описанием первоначальной информации.
Любые средства проектирования и оценочные критерии
используются на каждом этапе разработки. Применение количественных критериев
(время ответа на запрос, затраты на обновление, стоимость памяти, время на
формирование, стоимость преобразования) содействует формированию противоречивых
критериев относительно друг друга [19]. Одновременно с этим имеется огромное
множество критериев оптимальности, которые являются неизмеримыми свойствами,
при этом они почти не выражаются в количественном выражении или как целевая
функция.
Качественными критериями оценки базы данных являются
гибкость, приспосабливаемость, доступность для новых пользователей,
сочетаемость с другими системами, допустимость преобразования для применения в
другой вычислительной среде, шанс воссоздания, возможность разделения и
увеличение структуры.
В распределенных системах баз данных логически не дробимая
база данных может расчленяться и размещаться во всей сети для увеличения
работоспособности системы. Расчленение и размещение базы данных без бдительного
централизованного планирования зачастую создает беспорядок и несовместимость
при применении базы данных [18].
Существует 6 главных этапов проектирования распределенной
базы данных:
) формулирование и анализ требований;
2) концептуальное проектирование;
) проектирование реализации;
) расчленение базы данных;
) размещение базы данных;
) физическое проектирование.
На этапе формулирования и анализе требований определяются
цели предприятия и уникальные требования к базе данных, которые могут вытекать
из целей или быть высказаны самим управляющим персоналом предприятия. Все
данные требования заносятся в документацию, чтобы ей могли воспользоваться
итоговый пользователь и проектировщик базы данных. Своеобразные цели и
требования, которые предъявляются к базе данных, нужно установить на наиболее
высшем уровне предприятия. Все необходимые требования, которые были собраны и
задокументированы, обязательно должны нести в себе ограничения, гарантирующие
безопасность, надежность, уровень достигнутой технологии, а кроме этого еще и
политические и бюрократические рамки [6; 8; 19].
Этап концептуального проектирования состоит из описания и
синтеза различных информационных запросов пользователей в исходный проект баз
данных. На данном этапе реализуется высокоуровневое отображение данных
запросов. Хорошим примером такого представления является диаграмма "сущность-связь".
Эта диаграмма состоит из определенного набора сущностей, представляющего или
моделирующего некое множество сведений, которое специфицировано в требованиях.
Связи, существующие между сущностями, представляют функциональные аспекты
информации, которые представлены сущностями.
Имеется небольшое количество подходов для построения диаграмм
типа "сущность-связь". Единым для всех типов подходов является набор
из четырех главных проектных решений или шагов:
) определение сущностей;
2) определение атрибутов сущностей;
) идентификации ключевых атрибута сущностей;
) определение связей между сущностями.
По завершению создания первоначальной информационной
структуры идет ее уточнение и совершенствование. Основная задача этапа
проектирования реализации заключается в формировании системно-ориентированной
схемы с применением в виде первоначальных данных результатов концептуального
проектирования и запросов обработки (UР-информации).
Первоначально исследуется содержание запросов обработки
данных. Формат локальных информационных структур, которые подлежат обработке,
отвечают формату первоначальной структуры, которая получается на этапе
концептуального проектирования. Затем первоначальная структура имеет
возможность объединиться со всеми локальными структурами в совершенно новую
информационную структуру. После этого уже формируются предварительные типы
записей. Но при этом важно учитывать знания, которые были получены при
пересмотре и объединении разных информационных структур, и связи обрабатываемых
данных с характеристики типов записей, которые допускает данная система
управления базой данных [19].
Логическая структура базы данных (схема), которая построена
данным образом, может оцениваться количественно благодаря таким параметрам, как
количество обращении к логическим записям, объем обрабатываемых в каждом
приложении данных, общий объем хранимых данных.
Этап расчленения базы данных непосредственно взаимосвязан с
разделением глобальной базы данных и объединении разнообразных приложений,
которые основываются на модели. Существует три типа выходных данных этапа
расчленения, а именно совокупность расчлененных частей базы данных (разделов),
размер каждого раздела, модели и частоты использования приложений. На данном
этапе проектирования первоначальная глобальная база данных расчленяется на
множество подфайлов, содержащих в себе в точности все сведения, которые были в
глобальной базе данных. Каждый подфайл в расчлененной базе данных представляет
собой неделимую единицу размещения данных. Далее осуществляется анализ того, как
приложения базы данных потребляют возможные разделы базы данных. Взаимосвязь
между разделом базы данных и приложениями устанавливается сигнатурой типа
приложения, сигнатурой узла сети, которая формирует приложение, частотой
применения приложения и моделью приложения [20].