Разработка алгоритмов анализа длинных последовательностей, создаваемых системами имитационного моделирования
ВЫПУСКНАЯ
КВАЛИФИКАЦИОННАЯ РАБОТА
Разработка алгоритмов
анализа длинных последовательностей, создаваемых системами имитационного
моделирования
Введение
программа моделирование имитационный пользователь
В данной работе рассматриваются задачи анализа строк,
создаваемых системами имитационного моделирования. В качестве задач были
рассмотрены - вычисление редакционного расстояния, нахождение наибольшей общей
подстроки, нахождение периода. Поскольку имитационное моделирование позволяет
воссоздавать процессы, происходящие в различных областях: от бизнес-процессов
до информационной безопасности, алгоритмы решения задач анализа строк,
создаваемых при моделировании, позволяют анализировать довольно разные данные
без изменений в коде программы.
Для каждой задачи рассмотрены различные варианты ее решения,
эффективность того или иного алгоритма, в конце будет описан алгоритм,
выбранный для реализации на языках программирования Pascal и C. Выбор алгоритма основывается на затратах
памяти, так как сеанс моделирования порождает строки, характеризующиеся большим
объемом данных - в каждой строке не менее 1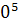 элементов.
элементов.
1.
Общая информация
1.1 Имитационное моделирование
Имитационное моделирование является одним из самых мощных
инструментов анализа при разработке сложных систем и анализе процессов их
функционирования. Имитационное моделирование как метод научного исследования
предполагает использование компьютерных технологий для имитации различных
процессов или операций - моделирования. Результаты определяются случайным
характером процессов. На основе этих данных можно получить устойчивую
статистику [4].
Имитационное моделирование позволяет моделировать поведение
системы во времени. Его используют, когда:
. Дорого или невозможно экспериментировать на реальном
объекте.
. Невозможно построить аналитическую модель: в системе
есть время, причинные связи, последствие, нелинейности, стохастические
(случайные) переменные.
. необходимо сымитировать поведение системы во времени
[4].
Области применения:
- Бизнес-процессы
- Бизнес-симуляция
- Боевые действия
- Динамика населения
- Дорожное движение
- ИТ-инфраструктура
- Математическое
моделирование исторических процессов
- Логистика
- Пешеходная динамика
- Производство
- Рынок и конкуренция
- Сервисные центры
- Цепочки поставок
- Уличное движение
- Управление проектами
- Экономика здравоохранения
- Экосистема
- Информационная
безопасность
- Релейная защита [5]
1.2 Основные определения
Последовательность - упорядоченный набор элементов [1].
Алфавит - конечное непустое множество, описывающее природу
элементов строки. Члены этого множества называются буквами [1]. В данной работе
алфавит состоит из целых положительных чисел.
Строковая последовательность (строка для краткости) - частный
случай строки, удовлетворяющий следующим правилам:
. Каждый элемент последовательности имеет уникальную
метку
. Каждый элемент с некоторой меткой x (за исключением не более
одного элемента, который называется самый левый элемент) имеет единственный
предшествующий элемент с меткой p(x).
. Каждый элемент с некоторой меткой x (за исключением не более
одного элемента, который называется самый правый элемент) имеет единственный
последующий элемент с меткой s(x).
. Для любого элемента с меткой x, который не является
самым левым, выполняется равенство x=s (p(x)).
. Для любого элемента с меткой x, который не является
самым правым, выполняется равенство x=p (s(x)).
6. Для двух различных элементов с метками x и y существует
такое целое положительное число k, что x=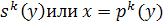 [1].
[1].
В данной работе строковая подпоследовательность,
удовлетворяющая правилам 1-6, трактуется как одномерный массив. Произвольную
строку x
на алфавите A
в виде массива можно задать следующим образом - x: array [1..n] of A [1].
Строка x длины n и строка y длины m равны в том случае, если:
1. n=m
2. x[i]=y[i], 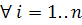 [1]
[1]
Строка α является подстрокой β, если β=γαδ.
α называется префиксом
β, если β=αγ. [3]
α называется суффиксом
β, если β=γα. [3]
α называется бордером
β, если α одновременно является и
суффиксом и префиксом β [3].
Число p называется периодом строки α (n=|α|) если 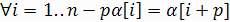 . Кратность - количество повторений периода [3].
. Кратность - количество повторений периода [3].
2. Алгоритмы анализа длинных
подпоследовательностей, создаваемых системами имитационного моделирования
.1 Расстояние между строками
Постановка задачи. Для данных строк 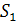 и
и 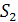 , где ||, || > 0, и
метрики d, задающей расстояния между строками, вычислить d(,
, где ||, || > 0, и
метрики d, задающей расстояния между строками, вычислить d(,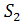 ) [6].
) [6].
Расстояние Хемминга [Hamming, 1982].
Расстоянием Хемминга между двумя строками является число позиций,
в которых не совпадают элементы сравниваемых строк. Если строки одинаковой
длины и разрешена только операция замены, стоимость которой равна единице, то
минимальная цена преобразования будет равна числу позиций, в которых не
совпадают элементы [2].
Расстоянием Левенштейна [Levenshtein distance] называется минимальное количество
операций вставки или удаления одного символа, замены одного символа на другой,
необходимых для преобразования одной строки в другую [2].
Алгоритм Вагнера-Фишера [Wagner-Fischer]
Для нахождения редакционного расстояния был использован алгоритм
Вагнера-Фишера с небольшим изменением. Алгоритм Вагнера - Фишера вычисляет
редакционное расстояние, основываясь на наблюдении, что если мы зарезервируем
матрицу для хранения редакционных расстояний между всеми префиксами первой
строки и всеми префиксами второй, то мы можем посчитать все значения в матрице,
«потоково» заполняя матрицу. В итоге расстоянием между двумя полными строками
будет значение, которое будет посчитано последним [2]. Чтобы вычислить
редакционное расстояние (расстояние Левенштейна) необходимо вычислить матрицу D. Определим возможные операции, которые могут быть
использованы для преобразования одной строки в другую:
§ с (a, b) - цена замены
символа a на символ b
§ с (ε, b) - цена вставки символа b
§ с (a, ε) - цена удаления символа a
и цену этих операций:
§ с (a, а) = 0
§ с (a, b) = 1 при a≠b
§ с (ε, b) = 1
§ с (a, ε) = 1 [2]
Будем считать, что все c неотрицательны, а так же
действует правило треугольника: если 2 последовательные операции можно заменить
одной, то общая цена не ухудшается [2].
Пусть и - две строки (длиной M и N соответственно) над некоторым
алфавитом, тогда расстояние Левенштейна d(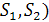 можно подсчитать по следующей формуле:
можно подсчитать по следующей формуле: 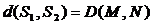 , где
, где 
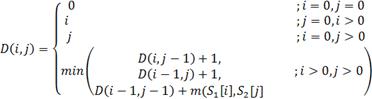
где m (a, b) равно нулю, если a=b и единице в противном случае min
(a, b, c) возвращает наименьший из аргументов. Шаг по i представляет собой
удаление из первой строки, по j - вставку в первую строку, а шаг по i и j символизирует
замену символа или отсутствие изменений [2].
Очевидно, справедливы следующие
утверждения:
- 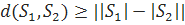
- 
- d(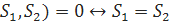 [2]
[2]
Доказательство
Рассмотрим формулу более подробно.
Очевидно, что расстояние Левенштейна между двумя пустыми строками будет равно
нулю. Так же очевидно то, что чтобы получить пустую строку из строки длиной i,
нужно совершить i операций удаления, а чтобы получить строку длиной j из
пустой, нужно произвести j операций вставки.
Теперь рассмотрим нетривиальный случай,
когда обе строки являются не пустым.
Заметим, что в оптимальной
последовательности операций, их можно произвольно менять местами. Рассмотрим
две последовательные операции:
· Две замены одного и того
же символа - не оптимально (если мы заменили x на y, потом y на z, выгоднее
было сразу заменить x на z).
· Две замены разных
символов можно менять местами
· Два стирания или две
вставки можно менять местами
· Вставка символа с его
последующим стиранием - не оптимально (можно их обе отменить)
· Стирание и вставку разных
символов можно менять местами
· Вставка символа с его
последующей заменой - не оптимально (излишняя замена)
· Вставка символа и замена
другого символа меняются местами
· Замена символа с его
последующим стиранием - не оптимально (излишняя замена)
· Стирание символа и замена
другого символа меняются местами [2]
Пусть 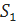 кончается на символ «a»,
кончается на символ «a», 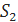 кончается на символ «b». Есть три варианта:
кончается на символ «b». Есть три варианта:
. Символ «а», на который кончается , в какой-то момент был стёрт. Сделаем это стирание первой
операцией. Тогда мы стёрли символ «a», после чего превратили первые i-1 символов в (на что потребовалось D (i-1, j) операций), значит, всего
потребовалось D (i-1, j) +1 операций
. Символ «b», на который кончается , в какой-то момент был добавлен. Сделаем это добавление последней
операцией. Мы превратили в первые j-1 символов , после чего добавили «b». Аналогично предыдущему случаю,
потребовалось D (i, j-1)+1
операций.
. Оба предыдущих утверждения неверны. Если мы добавляли
символы справа от финального «a», то, чтобы сделать последним символом «b», мы
должны были или в какой-то момент добавить его (но тогда утверждение 2 было бы
верно), либо заменить на него один из этих добавленных символов (что тоже
невозможно, потому что добавление символа с его последующей заменой не
оптимально). Значит, символов справа от финального «a» мы не добавляли. Самого
финального «a» мы не стирали, поскольку утверждение 1 неверно. Значит,
единственный способ изменения последнего символа - его замена. Заменять его 2
или больше раз не оптимально. Значит,
1. Если a=b, мы последний символ не
меняли. Поскольку мы его также не стирали и не приписывали ничего справа от
него, он не влиял на наши действия, и, значит, мы выполнили D (i-1, j-1)
операций.
2. Если a≠b, мы последний
символ меняли один раз. Сделаем эту замену первой. В дальнейшем, аналогично
предыдущему случаю, мы должны выполнить D (i-1, j-1) операций, значит, всего
потребуется D (i-1, j-1)+1 операций.
Для примера возьмем строки 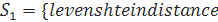 } и
} и 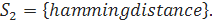 Заполненный массив стоимостей для данных строк будет выглядеть
следующим образом (Рисунок 1):
Заполненный массив стоимостей для данных строк будет выглядеть
следующим образом (Рисунок 1):
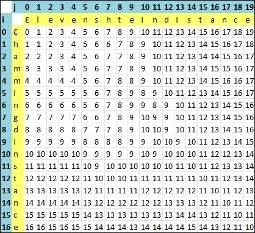
Рисунок 1 - Заполненный массив стоимостей для строк } и 
Минимальная стоимость преобразования находится в ячейке D [m, n], где m - длина строки
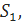 n - длина строки
.
n - длина строки
.
Алгоритм в выше описанном виде требует O (m*n)
операций и такие же емкостные затраты. Последнее являлось стимулом к изменению
алгоритма, так как для нахождения расстояния Левенштейна для строк длинной в 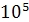 потребуется около38 гигабайт памяти в Pascal и в С. Поскольку для вычисления следующей строки матрицы D требуется только предыдущая, было решено использовать
массив, содержащий предыдущую строку, из которой вычисляется текущая, и,
собственно, текущая строка. После модернизации алгоритм выглядит следующим
образом:
потребуется около38 гигабайт памяти в Pascal и в С. Поскольку для вычисления следующей строки матрицы D требуется только предыдущая, было решено использовать
массив, содержащий предыдущую строку, из которой вычисляется текущая, и,
собственно, текущая строка. После модернизации алгоритм выглядит следующим
образом:
1. На первом шаге заполняем первую строку матрицы по
формуле
. Счетчик строк равен 0
. На основе первой строки, используя формулу,
заполняем вторую строку
. Увеличиваем счетчик строк на 1
. Если он равен длине второй полной строки, то
расстояние Левенштейна равно последнему элементу матрицы D, если нет, то переходим
на следующий шаг
. Сдвигаем значения второй строки матрицы в первую D [0, j]=D [1,
j]
. Переходим к шагу 2
После изменения классического алгоритма временная сложность O (m*n) при памяти O (min(n, m)).
После модернизации будет происходить следующее:
) Заполняем первые 2 строки, счетчик строк равен 1 (Рисунок
2).

Рисунок 2 - Массив стоимостей на первом шаге
) Поскольку 1≠16 сдвигаем значения из второй строки в
первую и вычисляем новые значения второй строки, счетчик строк увеличиваем на 1
(Рисунок 3):

Рисунок 3 - Массив стоимостей на втором шаге
) 2≠16, снова сдвигаем значения, вычисляем новые и
увеличиваем счетчик строк (Рисунок 4):

Рисунок 4 - Массив стоимостей на 3 шаге
4) 3≠16, сдвигаем строки, вычисляем значения 2 строки,
увеличиваем счетчик строк (Рисунок 5):

Рисунок 5 - Массив стоимостей на 4 шаге
) 4≠16, сдвигаем строки, вычисляем новые значения,
увеличиваем счетчик строк (Рисунок 6):

Рисунок 6 - Массив стоимостей на 5 шаге
) 5≠16, сдвигаем строки, вычисляем новые значения,
увеличиваем счетчик строк (Рисунок 7):

Рисунок 7 - Массив стоимостей на 6 шаге
) 6≠16, сдвигаем строки, вычисляем новые значения,
увеличиваем счетчик строк (Рисунок 8):

Рисунок 8 - Массив стоимостей на 7 шаге
8) 7≠16, сдвигаем строки, вычисляем новые значения,
увеличиваем счетчик строк (Рисунок 9):

Рисунок 9 - Массив стоимостей на 8 шаге
) 8≠16, сдвигаем строки, вычисляем новые значения,
увеличиваем счетчик строк (Рисунок 10):

Рисунок 10 - Массив стоимостей на 9 шаге
) 9≠16, сдвигаем строки, вычисляем новые значения,
увеличиваем счетчик строк (Рисунок 11):

Рисунок 11 - Массив стоимостей на 10 шаге
) 10≠16, сдвигаем строки, вычисляем новые значения,
увеличиваем счетчик строк (Рисунок 12):

Рисунок 12 - Массив стоимостей на 11 шаге
12) 11≠16, сдвигаем строки, вычисляем новые значения,
увеличиваем счетчик строк (Рисунок 13):

Рисунок 13 - Массив стоимостей на 12 шаге
) 12≠16, сдвигаем строки, вычисляем новые значения,
увеличиваем счетчик строк (Рисунок 14):

Рисунок 14 - Массив стоимостей на 13 шаге
) 13≠16, сдвигаем строки, вычисляем новые значения,
увеличиваем счетчик строк (Рисунок 15):

Рисунок 15 - Массив стоимостей на 14 шаге
) 14≠16, сдвигаем строки, вычисляем новые значения,
увеличиваем счетчик строк (Рисунок 16):

Рисунок 16 - Массив стоимостей на 15 шаге
16) 15≠16, сдвигаем строки, вычисляем новые значения,
увеличиваем счетчик строк (Рисунок 17):

Рисунок 17 - Массив стоимостей на 16 шаге
=16, расстояние Левенштейна вычислено.
Так же редакционное расстояние может быть вычислено и с
помощью алгоритма нахождения наибольшей общей подпоследовательности - алгоритма
Хиршберга (подробно описан далее). Временная и емкостная сложность этого
алгоритма идентичны соответствующим сложностям измененного алгоритма
Вагнера-Фишера. Модернизированный алгоритм Вагнера-Фишера был выбран поскольку
он более прост в реализации, а так же алгоритм Хиршберга был реализован для
поиска LCS.
2.2 Вычисление наибольшей общей
подпоследовательности
Постановка задачи. Для данных строк и (||, || > 0)
найти |LCS(,)|, где LCS(,) - самая
длинная общая подпоследовательность (longest common subsequence)
и [6].
Подпоследовательность последовательности X получается в результате удаления нескольких элементов (не
обязательно соседних) из последовательности X. Имея две подпоследовательности X и Y, наибольшая общая подпоследовательность
определяется как самая длинная последовательность, являющаяся
подпоследовательностью как , так и . Например, для последовательностей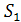 ={1, 3, 6, 2, 1, 1, 8} и ={1, 6, 2, 8, 9} LCS будет равна
{1, 6, 2, 8}. Следует отметить, что наибольших общих подпоследовательностей,
может быть несколько. [2]
={1, 3, 6, 2, 1, 1, 8} и ={1, 6, 2, 8, 9} LCS будет равна
{1, 6, 2, 8}. Следует отметить, что наибольших общих подпоследовательностей,
может быть несколько. [2]
Существуют множество различных подходов к решению данной задачи,
были рассмотрены следующие: полный перебор, алгоритм Нидлмана-Вунша, алгоритм Ханта-Шуманского,
алгоритм Хишберга.
Полный перебор
При полном переборе может быть осуществлен различными
способами: можно перебирать варианты подпоследовательности, варианты
вычеркивания из данных подпоследовательностей и т.д. Но какой бы подход не был
использован, время работы программы будет экспонентой от длины строки.
Алгоритм Нидлмана-Вунша [Needleman-Wunsch]
Данный подход заключается в поэтапном заполнении матрицы, где
строки являются элементами а столбцы элементы . При заполнении действуют два правила:
. Если элемент  =
= , то в ячейке (i, j) записывается значение ячейки (i-1, j-1) с добавлением единицы.
, то в ячейке (i, j) записывается значение ячейки (i-1, j-1) с добавлением единицы.
. Если элемент ≠, то в ячейку (i, j) записывается максимум из значений (i-1, j) и (i, j-1) [7].
Заполнение происходит в двойном цикле по i и j с увеличением значений
на 1, таким образом, на каждой итерации нужные на этом шаге значения ячеек уже
вычислены. После того, как произойдет полное заполнение матрицы, соединив
ячейки, в которых происходило увеличение значений, мы получим искомую НОП.
Соединять при этом нужно двигаясь от максимальных индексов к минимальным, если
в ячейке увеличивалось значение, то добавляем соответствующий элемент к LCS, если нет, то двигаемся
вверх или влево в зависимости от того где находится большее значение в матрице
[7] (Рисунок 18, 19).
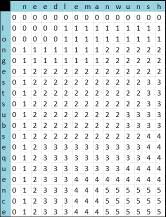
Рисунок 18 - Заполненная матрица похожести для строк 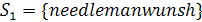 и
и 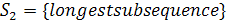

Рисунок 19 - Выделение LCS
Временная сложность алгоритма - O (m*n), по
памяти O (m*n). Очевидно, что для работы с большими
объемами данных он не подходит, так будет требоваться много памяти.
Алгоритм Ханта-Шиманского [Hunt, Szymanski]
Метод выделения LCS для двух
входных строк и Ханта и Шиманского эквивалентен нахождению максимального
монотонно возрастающего пути в графе, состоящего из точек (i, j), таких,
что 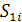 =
= 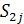 . На рисунке
20 иллюстрируется LCS (longestsunsequense, needlemanwunsh)=neeun, определенная с помощью «наибольшей» строго убывающей и
непрерывной ломаной линии, проходящей через узлы сетки, представляющие
совпадения = [1].
. На рисунке
20 иллюстрируется LCS (longestsunsequense, needlemanwunsh)=neeun, определенная с помощью «наибольшей» строго убывающей и
непрерывной ломаной линии, проходящей через узлы сетки, представляющие
совпадения = [1].
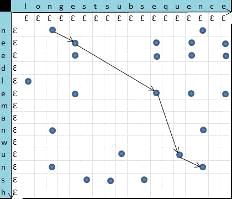
Рисунок 20 - LCS,
определенная с помощью «наибольшей» строго убывающей и непрерывной ломаной
линии
Ключевым в методе является массив значений. Установим некоторые
свойства массива j, которые будут использованы в данном
алгоритме [1].
Лемма 1. Для всех целых i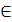 1..
1..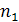 и h
и h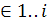 выполняются нервенства:
выполняются нервенства:
[i − 1, h − 1] + 1 ≤ j [i, h] ≤ j [i −
1, h]. [1]
Доказательство тривиально при i = 1, поэтому будем считать, что i
> 1.
Заметим, что если элемент j [i−1, h] определен, то также
определены j [i − 1, h − 1] и j [i, h]. Если подстроки [1..i − 1] и [1..j [i − 1, h]] имеют LCS длиной h, тогда (по определению
массива j) подстроки [1..i] и [1..j [i − 1, h]] имеют общую подпоследовательность длиной
не менее h. Отсюда следует, что j [i, h] ≤ j [i − 1, h] [1].
Далее, поскольку элемент j [i, h] определен, подстроки [1..i] и [1..j [i, h]] имеют общую подпоследовательность длиной h. Удалив
самые правые буквы из этих подстрок, можно уменьшить длину общей
подпоследовательности не более, чем на единицу. Поэтому подстроки [1..i − 1] и [1..j [i, h] − 1] имеют общую подпоследовательность и,
следовательно, LCS длиной не менее h−1. Это означает, что j [i − 1,
h − 1] ≤ j [i, h]. Что и требовалось доказать [1].
Лемма 2. Для всех целых i∈1..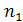 и h∈1..|LCS( [1..i],)| значение j [i, h] вычисляется по следующему правилу:[i, h]
равняется наименьшему целому
и h∈1..|LCS( [1..i],)| значение j [i, h] вычисляется по следующему правилу:[i, h]
равняется наименьшему целому 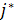 ∈ j [i − 1, h − 1] + 1..j [i −
1, h], такому, что [i] = [] (если такое существует); j [i, h] = j [i − 1, h], если такого не существует [1].
∈ j [i − 1, h − 1] + 1..j [i −
1, h], такому, что [i] = [] (если такое существует); j [i, h] = j [i − 1, h], если такого не существует [1].
Доказательство. Сначала рассмотрим, как более простой, второй
вариант вычисления j [i, h], когда такого не существует. Поскольку j [i, h] определяет наименьший префикс
строки , то самым правым элементом в LCS для подстрок [1..i] и [1..j [i, h]] будет буква [j [i, h]]. Вследствие леммы 1 j [i, h] ∈j [i − 1, h − 1] + 1..j [i −
1, h]. Но по нашему предположению не существует из этого интервала, такого, что [] = [i], поэтому [i] ≠ [j [i, h]]. Следовательно, та же самая LCS будет общей
подпоследовательностью и для подстрок [1..i − 1] и [1..j [i, h]] - в таком случае j [i, h] ≥ j [i − 1,
h]. Вследствие леммы 1 справедливо также обратное неравенство. Отсюда делаем
заключение, что j [i, h] = j [i − 1, h] [1].
Теперь предполагаем, что существует наименьшее целое из интервала j [i − 1, h − 1] + 1..j [i − 1, h], такое, что [i] = []. Из этого предположения вытекает, что подстроки [1..i] и [1..] имеют общую подпоследовательность, состоящую из LCS( [1..i−1], [1..j [i−1, h−1]]) длиной h−1 и буквы x 2 []. Отсюда заключаем, что j [i, h] не превышает 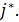 Теперь покажем, что j [i, h] не меньше . Предположим, что имеет место строгое неравенство j [i, h] < . Тогда, вследствие леммы 1, j [i − 1, h − 1] <j
[i, h] < . Поскольку - это наименьшее целое из интервала j [i − 1, h −1]+1..j
[i − 1, h], такое, что [i] = [], то отсюда заключаем, что [i] ≠ [j [i, h]]. Так как по условию |LCS( [1..i], [1..j [i, h]])| = h, поэтому подстроки [1..i − 1] и [1..j [i, h]] также имеют общую подпоследовательность длиной h.
Следовательно, j [i − 1, h] ≤ j [i, h + 1], а лемма 1 уточняет, что
j [i−1, h] = j [i, h+1]. Но это невозможно, поскольку, как мы видели, j
[i, h + 1] < < j [i − 1, h]. Это противоречие и доказывает, что j [i,
h] не меньше . Имея также доказанным утверждение, что j [i, h] не превышает , делаем вывод, что j [i, h] = . Теорема доказана [1].
Теперь покажем, что j [i, h] не меньше . Предположим, что имеет место строгое неравенство j [i, h] < . Тогда, вследствие леммы 1, j [i − 1, h − 1] <j
[i, h] < . Поскольку - это наименьшее целое из интервала j [i − 1, h −1]+1..j
[i − 1, h], такое, что [i] = [], то отсюда заключаем, что [i] ≠ [j [i, h]]. Так как по условию |LCS( [1..i], [1..j [i, h]])| = h, поэтому подстроки [1..i − 1] и [1..j [i, h]] также имеют общую подпоследовательность длиной h.
Следовательно, j [i − 1, h] ≤ j [i, h + 1], а лемма 1 уточняет, что
j [i−1, h] = j [i, h+1]. Но это невозможно, поскольку, как мы видели, j
[i, h + 1] < < j [i − 1, h]. Это противоречие и доказывает, что j [i,
h] не меньше . Имея также доказанным утверждение, что j [i, h] не превышает , делаем вывод, что j [i, h] = . Теорема доказана [1].
Этот алгоритм можно описать в виде последовательности таких шагов.
Шаг 1. Вычисление массива MATCHLIST
Из леммы 2 следует, что для вычисления значений j [i+1, 0..n-1] на основе значений j [i, 0..n-1] надо для каждого значения i ∈ 1.. знать такую позицию j в
строке , для которой [i] = [j]. Эту информацию в подходящей форме будем
получать из массива MATCHLIST, в котором каждая позиция i является указателем на список значений j, таких, что [i] = [j]. Для дальнейших вычислений на шаге 3
желательно, чтобы эти значения j были
упорядочены в убывающем порядке [1].
Шаг 2. Начальное задание значений массива 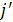
Полагаем [0] ← 0 и для всех h∈1.. полагаем [h] ← +1 (тем самым показываем, что элементы [h] не определены). [1]
Шаг 3. Вычисление значений j [i, h] на основе значений j [i−1, h], i = 1,2,…,. Эти вычисления выполняются путем замены значений в предыдущем
массиве j [0..], соответствующем номеру i −
1, на аналогичные значения, соответствующие номеру i. Напомним (лемма 2), что j [i, h] = j [i −
1, h] (тогда значение [h] не изменяется) только в том случае, если
не существует номера из интервала j [i − 1, h − 1] + 1..j [i − 1, h], такого, что [i] = []. Поэтому для текущего значения i и для каждого значения ∈MATCHLIST[i] по значениям
массива надо найти такое значение 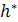 , что [ − 1] + 1 ≤ ≤ []. Тогда, согласно лемме 2,
, что [ − 1] + 1 ≤ ≤ []. Тогда, согласно лемме 2,  [] ← . Каждое такое присвоение, которое изменяет значение [], соответствует одной из r точек сетки (как показано на рисунке выше), где [i] = []. Это присвоение можно интерпретировать как создание конечного
узла (листа) (i, , LINK[ − 1]) на синтаксическом дереве, где LINK[
[] ← . Каждое такое присвоение, которое изменяет значение [], соответствует одной из r точек сетки (как показано на рисунке выше), где [i] = []. Это присвоение можно интерпретировать как создание конечного
узла (листа) (i, , LINK[ − 1]) на синтаксическом дереве, где LINK[ − 1] - указатель на узел, созданный ранее при присвоении для
[ − 1]. (Для
− 1] - указатель на узел, созданный ранее при присвоении для
[ − 1]. (Для  = 1 полагаем, что LINK[ − 1] = NULL.) Когда
лист создан, указатель на него хранится в LINK[]. После обработки всех i ∈ 1..n 1 наибольшее значение h, такое, что [h] < + 1, равняется длине LCS(, ), а LINK[h]
указывает путь длиной h по дереву от
листа до корня. Этот путь и определяет LCS. [1]
= 1 полагаем, что LINK[ − 1] = NULL.) Когда
лист создан, указатель на него хранится в LINK[]. После обработки всех i ∈ 1..n 1 наибольшее значение h, такое, что [h] < + 1, равняется длине LCS(, ), а LINK[h]
указывает путь длиной h по дереву от
листа до корня. Этот путь и определяет LCS. [1]
Шаг 4. Запись LCS (x 1, x 2) в обратном
порядке.
На дереве находится первый узел, который соответствует наибольшему
значению h, такому, что [h] < + 1. Затем записывается путь от этого узла до корня дерева - это
и будет LCS(, ), записанная в обратном порядке.
Пример работы алгоритма Ханта-Шуманского.
={longestsubsequence}
={needlemanwunsh}
Заполненный массив MATCHLIST
(Рисунок 21):

Рисунок 21 - Значения массива MATCHLIST
Значения элементов массива после i-й итерации следующие (Рисунок 22):
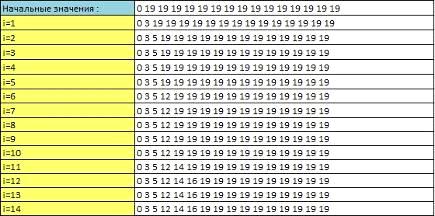
Рисунок 22
Время работы этого алгоритма равно O((r + n) log n), где n - длина
большей последовательности, а r - количество совпадений, в худшем случае при r
= n*n, мы получаем время работы хуже, чем в предыдущем варианте решения.
Требования по памяти остаются порядка O (r+n).
Алгоритм Хиршберга [Hirschberg]
Хиршберг предложил алгоритм непосредственного вычисления LCS(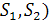 за время порядка O (n*m) без явного
вычисления массива стоимостей. Он так же показал, что этот алгоритм требует
память объемом только O (min(m, n) [2]. Для реализации был выбран этот алгоритм.
за время порядка O (n*m) без явного
вычисления массива стоимостей. Он так же показал, что этот алгоритм требует
память объемом только O (min(m, n) [2]. Для реализации был выбран этот алгоритм.
Теорема 1. 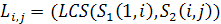 (1) [10].
(1) [10].
Обозначим длину LCS для
суффиксов (i+1, m) и (j+1, n) как 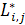 =|LCS((i+1, m),(j+1, n))| (2), где: - первая строка; n - длина первой
строки; - вторая строка; m - длина второй
строки [10].
=|LCS((i+1, m),(j+1, n))| (2), где: - первая строка; n - длина первой
строки; - вторая строка; m - длина второй
строки [10].
Для 0<j<m значения 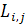 являются длинами LCS префикса (1, i) и различных префиксов . Аналогично, значения являются длинами LCS обращенного
суффикса
являются длинами LCS префикса (1, i) и различных префиксов . Аналогично, значения являются длинами LCS обращенного
суффикса 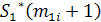 и различных префиксов обращенной строки
и различных префиксов обращенной строки 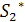 [10].
[10].
Определим 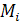 формулой:
формулой:  , тогда
, тогда 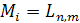 для 0< i <n [10].
для 0< i <n [10].
Доказательство: пусть 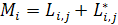 для j=
для j=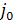 .
. 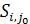 - произвольная LCS((i, j),(i,),
- произвольная LCS((i, j),(i,), 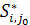 - произвольная LCS((i+1, n),(
- произвольная LCS((i+1, n),(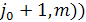 , тогда с=
, тогда с=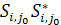 является общей подпоследовательностью и , ее длина равна M. Таким
образом,
является общей подпоследовательностью и , ее длина равна M. Таким
образом, 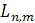 ≥(3) [10].
≥(3) [10].
Пусть 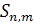 - произвольная LCS(,), тогда является подпоследовательностью , равной S1
- произвольная LCS(,), тогда является подпоследовательностью , равной S1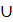 S2, где S1 - подпоследовательность (1, i), а S2 - подпоследовательность (i+1, n). Таким образом, существует значение
S2, где S1 - подпоследовательность (1, i), а S2 - подпоследовательность (i+1, n). Таким образом, существует значение 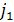 , такое, что S2 является
подпоследовательностью (1,), а S2 - подпоследовательностью (
, такое, что S2 является
подпоследовательностью (1,), а S2 - подпоследовательностью (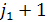 , m) [10].
, m) [10].
Длины S1 и S2 удовлетворяют следующим условиям:
|S1|≤|LCS((1, i),(1,))| ≤ согласно (1).
|S2|≤|LCS((i+1, n),(+1, m))| ≤ согласно (2)
Таким образом: 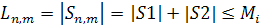 (4)
(4)
Из неравенств (3) и (4) получаем 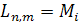 . Что и требовалось доказать [10].
. Что и требовалось доказать [10].
Алгоритм:
1) Сначала необходимо проверить не тривиальный ли
случай. Если хотя бы одна из строк пуста, то в качестве результата возвращается
пустая строка. Если хотя бы одна из строк односимвольная, то проверяется,
содержится ли этот символ в другой строке. Если содержится, то в качестве
результата возвращается этот символ, в противном случае - пустая строка [10].
) Если случай нетривиальный, первая строка делится
пополам, после чего ищутся длина наибольшей общей подпоследовательности ее
первой половины и префиксов второй строки различной длины и длина LCS ее второй половины и
суффиксов второй строки различной длины [10].
) По теореме 1 ищется первая позиция во второй строке
К такая, что LCS первой половины первой строки и первых К символов второй строки в
соединении с LCS второй половины первой строки и последних m-K (m - длина второй строки)
символов второй строки равна требуемой LCS первой и второй строк.
) Найденное К используется для решения двух подзадач,
для которых так же вычисляются шаги 1-4 [10].
) В конечном итоге все подзадачи сводятся к тривиальным
и их результаты объединяются [10].
Вычисление длины LCS.
Так как длина LCS любой строки
и пустой строки равна 0, значения границ массива инициализируются нулями. В
позиции (i, j), если 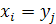 , мы получаем новую LCS, присоединяя
этот символ к текущей LCS префиксов x (1, i-1) и y (1, j-1), то есть L (i, j)=L (i-1, j-1)+1. Иначе
длина текущей LCS просто равна максимальному из предыдущих
значений. [10]
, мы получаем новую LCS, присоединяя
этот символ к текущей LCS префиксов x (1, i-1) и y (1, j-1), то есть L (i, j)=L (i-1, j-1)+1. Иначе
длина текущей LCS просто равна максимальному из предыдущих
значений. [10]
Так как для расчетов нам нужна только предпоследняя строка, можно
сократить расходы памяти, храня только текущую и предыдущую строки. [10]
Эта задача решается для двух половин первой строки.
1. Заполняем вторую строку 0 (Рисунок 23).

Рисунок 23 - Состояние массива на 1 шаге
. Сдвигаем строку вверх (Рисунок 24).

Рисунок 24 - Состояние массива на 2 шаге
Изначально после сдвига в первой строке будут 0, затем другие
числа.
. Рассчитываем текущую строку.
4. Пока не достигнем длины первой строки (первая строка в
данном случае одна из половин  ) повторяем шаги 2-3 [10].
) повторяем шаги 2-3 [10].
После решения двух задач (для каждой половины ) получим два вектора  .
.  ) и будет длиной LCS для строк и
) и будет длиной LCS для строк и 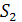 [10].
[10].
2.3 Вычисление длины периода и количество
повторений периода (кратность)
Постановка задачи. Для данной строки , || = n > 0,
найти самую длинную подстроку, встречающуюся в больше одного раза. Самая длинная повторяющаяся подстрока - это
самая длинная из строк максимальной длины x, такая, что = uxvxw для
некоторых строк u, v и w, где |u|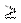 0, |v|0 и |w| 0 [6]. Если
же существует несколько периодов максимальной длины, то выбрать период с
максимальной кратностью.
0, |v|0 и |w| 0 [6]. Если
же существует несколько периодов максимальной длины, то выбрать период с
максимальной кратностью.
Алгоритм Крочемора [Crochemore]
Основная идея алгоритма Крочемора: выполнение декомпозиции
подпоследовательностей на каждом уровне ℓ только относительно
последовательностей, которые на этом уровне являются малыми [1].
На уровне ℓ≥ 2 разбиение множества позиций строки
на отдельные непересекающиеся множества (последовательности) - это декомпозиция
разбиения на уровне ℓ − 1 [1].
В декомпозиции последовательности 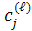 на подпоследовательности (
на подпоследовательности (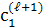 ,
, 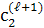 , …,
, …, 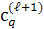 ) (q ≥1) назовем одну подпоследовательность с самым большим
количеством элементов большой, а остальные q - 1 подпоследовательностей -
малыми. Для уровня ℓ = 1 каждая последовательность малая [1].
) (q ≥1) назовем одну подпоследовательность с самым большим
количеством элементов большой, а остальные q - 1 подпоследовательностей -
малыми. Для уровня ℓ = 1 каждая последовательность малая [1].
Основная сложность в реализации этого алгоритма заключается в
структурах данных, обеспечивающих время выполнения алгоритма за O (n log n) [1].
Структуры необходимые для обеспечения работы алгоритма за O (n log n),
классифицированные в соответствии с их основными функциями:
. Запись текущей последовательности для каждой позиции в строке x.
- Массив SEQ [ℓ..n]: SEQ[i] содержит
индекс текущей последовательности, которой принадлежит i-я позиция в строке x.
- Массив SEQLIST [1..2n]: SEQLIST[j] -
указатели на двусвязный список позиций, принадлежащих последовательности с
индексом j и расположенных в порядке их возрастания.
- Массив SEQSIZE [1..2n]: SEQSIZE[j] равно
количеству позиций в последовательности с индексом j, т.е. количеству позиций в
списке, на который указывает элемент SEQLIST[j].
- Стек INDEXSTACK: стек неиспользованных
индексов последовательностей, инициализированный для размещения индексов 1,2,…,
2n [1].
Всякий раз, когда необходимо сформировать новую
последовательность или на уровне 1, или в качестве части декомпозиции
существующей последовательности, из стека INDEXSTACK извлекается индекс
последовательности. Если последовательность становится пустой в результате ее
декомпозиции на подпоследовательности, индекс последовательности возвращается в
стек INDEXSTACK. Всякий раз, когда к последовательности с индексом j
добавляется позиция i, выполняются операторы присваивания SEQ[i] ← j; SEQSIZE[j] ← SEQSIZE[j] + 1, а номер i
добавляется в конец списка SEQLIST[j]. Если i-я позиция удаляется из
последовательности с индексом j в результате его вхождения в
подпоследовательность с индексом j, выполняется присваивание SEQSIZE[i] ←SEQSIZE[j]
− 1, а i-я позиция удаляется из списка SEQLIST[i].
. Управление малыми последовательностями.
- Очередь SMALL: очередь индексов j малых
последовательностей, организованная таким образом, что (для ℓ > 1) все
имеющиеся в ней малые последовательности являются подпоследовательностями одной
и той же последовательности предыдущего уровня.
- Очередь QUEUE: очередь пар (i, j), где i -
позиция в малой последовательности с индексом j, которая должна использоваться
для декомпозиции текущего уровня; для каждого j позиции i располагаются в
возрастающем порядке.
- Массив LASTSMALL [1..2n]: LASTSMALL[ ] = j > 0 тогда и только тогда, когда j - это индекс малой
последовательности, использованной последней по времени для декомпозиции
последовательности с индексом [1].
] = j > 0 тогда и только тогда, когда j - это индекс малой
последовательности, использованной последней по времени для декомпозиции
последовательности с индексом [1].
Для ℓ = 1 очередь SMALL содержит все индексы, которые
первоначально вычисляются в соответствии с каждым символом строки x; для ℓ
> 1 очередь SMALL создается повторно путем просмотра подпоследовательностей,
тех последовательностей, для которых была выполнена декомпозиция на уровне ℓ,
и добавлением к очереди SMALL всех подпоследовательностей, кроме единственной
«большой» подпоследовательности (см. описание массивов SPLIT и SUBSEQ в
следующем пункте). Для каждого элемента j в очереди SPLIT эти действия можно
выполнить за один просмотр списка, на который указывает элемент SUBSEQ[j].
Таким образом, очередь SMALL модифицируется за время, пропорциональное
количеству имеющихся в ней элементов [1].
Очередь QUEUE создается в начале обработки для каждого уровня ℓ
> 1 путем удаления элементов из очереди SMALL. Для каждой последовательности
j, обнаруженной в очереди SMALL, извлекаются найденные в списке SEQLIST[j]
позиции i > 1, а элементы (i, j) добавляются к очереди QUEUE. Основная
обработка каждого из уровней ℓ > 1 выполняется после того, как из
очереди QUEUE один за другим удаляются элементы (i, j). Для каждой удаленной
позиции I последовательность = SEQ [i−1] является той последовательностью, которая будет
подвергнута декомпозиции. Следовательно, если LASTSMALL[] ≠j, то последовательность была последней по времени подвергнута декомпозиции относительно
некоторого другого класса, поэтому необходим новый индекс последовательности.
Соответственно с этим устанавливаем LASTSMALL[] ← j, извлекаем из стека INDEXSTACK следующий номер
последовательности и добавляем его к списку, на который указывает SUBSEQ[ [1].
[1].
. Организация подпоследовательностей.
- Массив SPLITFLAG [1..2n]: SPLITFLAG[j] = 1 тогда и только
тогда, когда последовательность с индексом j будет подвергнута
декомпозиции на текущем уровне (с использованием последовательностей, которые
хранятся в очереди SMALL).
- Список SPLIT: список
последовательностей j, которые будут подвергнуты декомпозиции на текущем уровне (т.е.
для которых SPLITFLAG[j]
= 1).
- Массив SUBSEQ [1..2n]: при декомпозиции
последовательности j на текущем уровне SUBSEQ[j] указывает на список индексов подпоследовательностей
последовательности j, первым элементом в этом списке будет сам индекс j [1].
Все эти структуры данных инициализируются для каждого уровня ℓ
> 1 одновременно с формированием из очереди SMALL очереди QUEUE. В
частности, когда (i, j) добавляется к очереди QUEUE, известно, что i будет
использоваться для декомпозиции последовательности , в которой имеется позиция i − 1 ( = SEQ [i − 1]). Поэтому, если SPLITFLAG[] = 0, то в это время хранится в SPLIT - списке последовательностей,
которые подлежат декомпозиции на уровне ℓ, в то время как выполняются
следующие присваивания:
SPLITFLAG[] ← 1; SUBSEQ[] ← < >; LASTSMALL[] ← 0. [1]
По завершении обработки каждого уровня ℓ (ℓ > 1)
последовательности j удаляются один за другим из списка SPLIT: если SEQSIZE[j] = 0, то эта последовательность уже пуста
и поэтому ее индекс больше не требуется. Поэтому j помещается в стек INDEXSTACK и
удаляется из списка, на который указывает SUBSEQ[j]. [1]
. Вычисление кратных строк.
· Массив GAP [ℓ..n]: элемент GAP[i]
равен положительной разности между i-й позицией в строке x и следующей большей
позицией в той же самой последовательности на текущем уровне; если нет большей
позиции, то GAP[i] = ∞.
· Массив GAPLIST [ℓ..n]: GAPLIST[g]
указывает на двусвязный список i-x позиций, для которых GAP[i] = g.
Для ℓ = 1 массивы GAP и GAPLIST инициализируются
непосредствен - но путем обработки каждого списка, на который указывает SEQLIST[j],
где j = 1,2,…,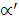 , вычисляя GAP[i] для каждой i-й позиции в списке SEQLIST[j],
затем добавляя i-ю позицию к списку, на который указывает GAPLIST [GAP[i]] [1].
, вычисляя GAP[i] для каждой i-й позиции в списке SEQLIST[j],
затем добавляя i-ю позицию к списку, на который указывает GAPLIST [GAP[i]] [1].
При ℓ > 1 массивы GAP и GAPLIST обновляются при удалении
элемента (i, j) из очереди QUEUE, что приводит к декомпозиции
последовательности = SEQ [i−1], при которой позиция i−1 в SEQLIST[] будет перемещена в конец SEQLIST[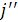 ]. Поскольку списки, на которые указывают и SEQLIST и GAPLIST,
двусвязные, повторное вычисление элементов массива GAP, необходимое из-за
удаления позиции i − 1 из одного списка и ее вставки в другой список,
можно выполнить непосредственно [1].
]. Поскольку списки, на которые указывают и SEQLIST и GAPLIST,
двусвязные, повторное вычисление элементов массива GAP, необходимое из-за
удаления позиции i − 1 из одного списка и ее вставки в другой список,
можно выполнить непосредственно [1].
Мы видим, что, после создания последовательностей для уровня ℓ,
каждый элемент в GAPLIST[ℓ] описывает две идентичные подстроки строки x
длиной ℓ, первые буквы которых находятся друг от друга на расстоянии ℓ,
другими словами, имеем квадрат этой подстроки.
Для этого алгоритма обязательна упорядоченность алгоритма.
Временная сложность - O (n log n), емкостная - O(n).
Алгоритм Мейна-Лоренца [Main, Lorentz]
Для реализации был выбран алгоритм Мейна-Лоренца, поскольку
он работает с неупорядоченным алфавитом, но все равно выполняется за время
порядка O(nlogn),
а так же не требует реализации большого количества сложных структур данных. Это
алгоритм типа «разделяй и властвуй», который вычисляет все квадраты подстрок,
следовательно, все кратные строки в строковой последовательности x = x [ℓ..n],
распределяя их на три различных класса.
· Класс С1 - класс квадратов w 2, которые начинаются и заканчиваются
в подстроке x [1..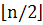 ], т.е.
], т.е. 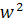 = x [i..i + 2|w| − 1], где i + 2|w| − 1 ≤.
= x [i..i + 2|w| − 1], где i + 2|w| − 1 ≤.
· Класс С2 - класс квадратов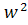 , которые начинаются и заканчиваются в подстроке x[ + 1..n], т.е. = x [i..i + 2|w| − 1], где i >
, которые начинаются и заканчиваются в подстроке x[ + 1..n], т.е. = x [i..i + 2|w| − 1], где i >
· Класс С3 - класс квадратов , которые начинаются в подстроке x [1..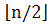 ] и заканчиваются в подстроке x[+1..n], т.е. здесь = x [i..i+2|w|−1], где 1 ≤ i ≤ и < i + 2|w| − 1 ≤ n.
] и заканчиваются в подстроке x[+1..n], т.е. здесь = x [i..i+2|w|−1], где 1 ≤ i ≤ и < i + 2|w| − 1 ≤ n.
Обозначим u = [1..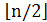 ] и v = x[
] и v = x[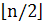 +1..n]. Основная идея алгоритма Мейна-Лоренца заключается в
вычислении квадратов подстрок в строке x = uv на основе эффективного вычисления
новых квадратов класса C3 [1].
+1..n]. Основная идея алгоритма Мейна-Лоренца заключается в
вычислении квадратов подстрок в строке x = uv на основе эффективного вычисления
новых квадратов класса C3 [1].
Для описания процедуры C3 (u, v) (ищет квадраты класса С3) вначале
отметим, что новые квадраты 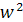 в строке uv могут быть двух видов:
в строке uv могут быть двух видов:
· правый квадрат, когда второе вхождение w в
строку uv полностью находится в подстроке v;
· левый квадрат, когда в подстроке u имеется
непустой префикс второго вхождения w [1].
Например, подстроки u = aba и v = ba порождают правый квадрат = (ba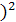 и левый квадрат = (ab [1].
и левый квадрат = (ab [1].
Процедура C3 реализуется как комбинация процессов вычисления
правых и левых квадратов. Пусть u = u [ℓ..] и v = v [ℓ..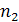 ]. Чтобы в uv найти все правые квадраты, необходимо вычислить два
массива. Массивы можно кратко определить следующим
образом:
]. Чтобы в uv найти все правые квадраты, необходимо вычислить два
массива. Массивы можно кратко определить следующим
образом:
· Массив LP [2..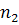 + 1]: для каждой позиции i = 2,3,…, строки v LP[i]=lcp (v[i..], v), при этом для i = + 1 принимаем, что LP[i] = 0.
+ 1]: для каждой позиции i = 2,3,…, строки v LP[i]=lcp (v[i..], v), при этом для i = + 1 принимаем, что LP[i] = 0.
· Массив LS [1..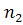 ]: для каждой позиции i =
1,2,…, строки v LS[i]=lcs (v[1..i], u) [1].
]: для каждой позиции i =
1,2,…, строки v LS[i]=lcs (v[1..i], u) [1].
Например, для строки v = abaababa массив LP [2..9] =
01303010. Если u=abaab, тогда LS [1..8] = 02005020. Приближенно можно сказать,
что массив LP рекуррентно определяет максимальные длины префиксов v внутри
самой v, а массив LS определяет вхождения суффиксов u максимальной длины в
строку v
[1].
Лемма 1. Пусть u [1..] и v [1..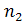 ] - произвольные непустые строки и пусть p ≤ и I ∈ p..2p−1 - положительные целые числа. В uv имеется квадрат длиной 2p, заканчивающийся на i-й позиции строки v, тогда и
только тогда, когда: 2p − LS[p] ≤i ≤p + LP [p + 1] [1].
] - произвольные непустые строки и пусть p ≤ и I ∈ p..2p−1 - положительные целые числа. В uv имеется квадрат длиной 2p, заканчивающийся на i-й позиции строки v, тогда и
только тогда, когда: 2p − LS[p] ≤i ≤p + LP [p + 1] [1].
Доказательство. В строке uv для
любого квадрата w 2 длиной 2p, заканчивающегося на i-й
позиции, первое вхождение w должно
начинаться с буквы u[ −2p + i + 1], а второе вхождение - с буквы v [i − p + 1]. Поэтому такой квадрат имеет «право на существование» тогда
и только тогда, когда: u[ − 2p + i + 1..] v [1..i − p] = v [i − p + 1..i]; т.е. только тогда, когда:
· u[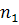 − 2p + i + 1..
− 2p + i + 1..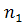 ] = v
[i − p + 1..p] и
] = v
[i − p + 1..p] и
· v [1..i − p] = v [p + 1..i].
Отметим, что если i = p, вследствие чего квадрат формируется из суффикса w строки u и префикса w строки v, второе условие сводится
к утверждению, что ε = ε, и поэтому становится ненужным. [1]
Первое условие, которое говорит о том, что строка v [i−p+1..p] длиной 2p−I является суффиксом
строки u,
выполняется только тогда, когда LS[p] ≥ 2p −i, т.е. только в случае выполнения неравенства 2p − LS[p]? i. Второе условие
эквивалентно неравенству i ≤ p + LP [p + 1], что и завершает доказательство [1].
Правый квадрат возможен только для тех значений p и i, которые
удовлетворяют условиям леммы 1. Кроме того, для каждого допустимого значения p ∈ 1.. соответствующие допустимые значения величины i могут находиться только в интервале 2p − LS[p]..p + LP [p + 1].
Для вычисления левых квадратов нужны аналогичные массивы:
· Массив L [2..]: для каждой позиции i =
2,3,…, строки u L [i]= lcp (u[i..], v).
[2..]: для каждой позиции i =
2,3,…, строки u L [i]= lcp (u[i..], v).
· Массив L [1.. − 1]: для каждой позиции i = 1,2,…, − 1 строки u
[1.. − 1]: для каждой позиции i = 1,2,…, − 1 строки u
L [i] = lcs (u[ℓ..i], u) [1].
[i] = lcs (u[ℓ..i], u) [1].
Временная сложность алгоритма - O (n log n),
емкостная - O(n) [1].
3. Описание программы
3.1 Средства, используемые в разработке
Microsoft Visual Studio
Visual Studio - это полный набор инструментов и служб для
разработки приложений для настольных компьютеров, Интернета, мобильных
устройств и облачных систем. Visual Studio позволяет создавать как консольные приложения,
так и приложения с графическим интерфейсом. Основными языками Visual Studio являются Visual C#, Visual Basic и C++. [11]Visual Studio
объединяет в себе огромное количество функций, позволяющих осуществлять
разработки для Windows всех версий, в том числе и 8, Интернета, SharePoint,
различных мобильных устройств и облачных технологий. Visual Studio включает в
себя редактор исходного кода с поддержкой технологии IntelliSense и
возможностью рефакторинга кода. Встроенный отладчик может работать как отладчик
уровня исходного кода, так и как отладчик машинного уровня. Остальные
встраиваемые инструменты включают в себя редактор форм для упрощения создания
графического интерфейса приложения, веб-редактор, дизайнер классов и дизайнер
схемы базы данных. Visual Studio позволяет создавать и подключать сторонние
дополнения (плагины) для расширения функциональности практически на каждом
уровне [11].
Плюсом Microsoft Visual Studio для разработки на С
является наличие стандартной утилиты анализа кода Code Analysis. Эта утилита позволяет
быстро отыскивать «слабые» места в коде. Например, использование не безопасных
функций, утечки памяти, выход за границы массива.
В этой работе для создания проекта используется Visual Studio Professional 2013.
В качестве языка разработки используется C.
PascalABC.NET
PascalABC.NET - это среда разработки,
поддерживающая язык Pascal нового поколения, включающий классический Pascal, большинство
возможностей языка Delphi, а также ряд собственных расширений. Он реализован на
платформе Microsoft.NET и содержит все современные языковые средства: классы,
перегрузку операций, интерфейсы, обработку исключений, обобщенные классы и
подпрограммы, сборку мусора, лямбда-выражения, средства параллельного
программирования [8]..NET является мультипарадигменным языком: на нем можно
программировать в структурном, объектно-ориентированном и функциональном стилях
[8]..NET - это также простая и мощная интегрированная среда разработки,
поддерживающая технологию IntelliSense, содержащая средства автоформатирования,
встроенный отладчик и встроенный дизайнер форм [8].
Самое большое преимущество среды
разработки PascalABC.NET перед другими является наличие удобного режима
отладки. В этом режиме пользователю доступны следующие средства отладки:
возможность задания точек останова программы, пошаговое выполнение кода
программы со входом в подпрограмму и без входа в подпрограмму, а так же
просмотр текущих значений глобальных и локальных переменных.
Динамическое программирование
Динамическое программирование - метод
решения сложных задач путем их разбиения на более простые. Основная идея:
основная задача разбивается на меньшие отдельные задачи (подзадачи), они
решаются, после чего необходимо объединить решения подзадач в одно общее
решение. Часто многие из этих подзадач одинаковы. Подход метода заключается в
решении каждой подзадачи один раз. Это приводит к сокращению вычислений. Этот
подход полезен в случаях, когда число повторяющихся подзадач экспоненциально
велико [9].
Оптимальная подструктура в динамическом
программировании означает, что оптимальное решение подзадач меньшего размера
может быть использовано для решения исходной задачи. В общем случае мы можем
решить задачу, в которой присутствует оптимальная подструктура, проделывая
следующие три шага:
1. Разбиение задачи на подзадачи
меньшего размера.
2. Нахождение оптимального решения
подзадач рекурсивно, проделывая такой же трех шаговый алгоритм.
. Использование полученного решения
подзадач для конструирования решения исходной задачи [9].
Перекрывающиеся подзадачи в динамическом
программировании означают подзадачи, которые используются для решения
некоторого количества задач (не одной) большего размера (то есть мы несколько
раз проделываем одно и то же), динамическое программирование пользуется
следующими свойствами задачи:
· перекрывающиеся
подзадачи;
· оптимальная подструктура;
· возможность запоминания
решения часто встречающихся подзадач [9].
Динамическое программирование бывает двух
видов:
· нисходящее динамическое
программирование: задача разбивается на подзадачи меньшего размера, они
решаются и затем комбинируются для решения исходной задачи. Используется
запоминание для решений часто встречающихся подзадач.
· восходящее динамическое
программирование: все подзадачи, которые впоследствии понадобятся для решения
исходной задачи, просчитываются заранее и затем используются для построения
решения исходной задачи. Этот способ лучше нисходящего программирования в
смысле размера необходимого стека и количества вызова функций, но иногда бывает
нелегко заранее выяснить, решение каких подзадач нам потребуется в дальнейшем
[9].
.2
Структура программы
Структура программы на языке Pascal
Структуры данных:
IntArray = array of
longint - массив целых чисел.= array of
array of longint - массив массивов целых чисел.
Функции и процедуры:
function Min (X: integer; Y: integer) - функция возвращающая
минимальное значение из пары чисел X и Y.
function Max (X: integer; Y: integer) - функция возвращающая
максимальное значение из пары чисел X и Y.
function SubString (STR: IntArray; SubSTR: IntArray; FirstIndex: longint) - поиск индекса первого
вхождения подмассива SubSTR в массив STR с элемента FirstIndex.
procedure ReadFromFile
(file1: text; path: string; var S: IntArray) - процедура считывающая значения массива из файла. На вход подается
переменная текстового файла file1, путь к файлу path, массив S, который будет
заполняться.
procedure InitSEQ() - процедура,
инициализирующая подпоследовательность. Изначально заполняет LCS -1, то есть LCS пуста.
procedure LCS_LENGTH (M: integer; N: integer; X: IntArray; Y: IntArray; var LL: IntArray) - Процедура,
вычисляющая вектор, равный последней строке матрицы LCS. Входные параметры: X -
первая строка, Y - вторая строка, LL - массив, в который будет помещен
результат.
procedure FindMaxPeriod (STR: IntArray) - процедура, которая
находит период максимальной длины. На вход подается массив STR, в котором содержится
строка для которой необходимо произвести поиск.
procedure LCS (M:
integer; N: integer; X: IntArray; Y: IntArray; var C: IntArray) - процедура, которая
вычисляет LCS. На вход подаются: длина первой строки M; длина второй строки N; массив X, содержащий первую
строку; массив Y, содержащий вторую строку; массив C, в который будет
записываться LCS.
function EditDinst (D: IntMatrix; X: IntArray; Y: IntArray; i, j: longint) - функция, заполняющая
массив стоимостей. На вход функция получает: массив стоимостей D; массив X, содержащий первую
строку; массив Y, содержащий вторую строку; текущий элемент i в массиве X; текущий элемент j в массиве Y.
function Levenshtein (X: IntArray; Y: IntArray; l1: longint; l2: longint) - функция, вычисляющая
расстояние Левенштейна. Входные параметры: массив X, содержащий первую
строку; массив Y, содержащий вторую строку; длина первой строки l1; длина второй строки l2.PrintLCS() - выводит
результат вычислений LCS.PrintEditDinst() - выводит результат вычислений
расстояния Левенштейна.PrintLCSToFile() - записывает в файл результат
вычислений LCS.PrintEditDinstToFile() - записывает результат вычисления
редакционного расстояния.
Структура программы на языке C
Функции и процедуры:
int Min (int X, int Y) - возвращает
минимальное значение из пары чисел X и Y.
int Max (int X, int Y) - возвращает
максимальное значение из пары чисел X и Y.
long int subString (int str[], long int strSize, int subStr[], long int subStrSize, long int firstIndex) - поиск индекса первого
вхождения подмассива subStr[], длинной subStrSize, в массив str[], длинной strSize, с элемента firstIndex.
int * lcsLength (long int m, long int n, int X[], int Y[], int LL[]) - вычисление вектора,
который равен последней строке матрицы LCS. Входные параметры: X[]
- первая строка; Y[] - вторая строка; LL[] - массив, в который будет помещен
результат; m
- длина первой строки; n - длина второй строки.
int * lcs (long int m,
long int n, int X[], int Y[], int C[]) - вычисляет LCS. Входные параметры: длина
первой строки m;
длина второй строки n; массив X[], содержащий первую строку; массив Y[], содержащий вторую
строку; массив C[], в который будет записываться LCS.
long int editDinst (long int D[], long int n, int X[], int Y[], long int i, long int j) - заполнение массива
стоимостей D[].
n - длина второй строки; X[] - первая строка; Y[] - вторая строка; i - текущий элемент в
массиве X;
j - текущий элемент в
массиве Y.
long int levenshtein (int
X[], int Y[], long int l1, long int l2) - вычисление расстояния Левенштейна. X[] - первая строка; Y[] - вторая строка; l1 - длина первой строки; l2 - длина второй строки.
void findMaxPeriod (int str[], long int length) - нахождение периода
максимальной длины. Входные параметры: str[] - строка, в которой
необходимо найти период максимальной длины; length - длина
строки.printLCSToFile (int C[]) - запись результата вычисления LCS в файл.
void printEDToFile (long int editDinstance) - запись результата
вычисления расстояния Левенштейна в файл.
Программа StringGenerator создана для генерации тестовых данных.
Так как основная программа решает три задачи: нахождение расстояния Левенштейна
двух строк, нахождение наибольшей общей подпоследовательности и нахождение
максимального периода максимальной кратности (не меньше 2), то к тестовым
данным были предъявлены следующие условия:
- Первая строка должна генерироваться с
указанными параметрами периодичности и длины.
- Вторая строка должна получаться путем
изменения указанного числа элементов первой строки.
Эти два условия позволяют создать тестовые данные
одновременно для всех трех решаемых задач, так как:
- Заранее заданные параметры периодичности
позволяют оценивать правильность определения наличия периода в строке (при этом
стоит учитывать, что, например, период длины 3 кратности 4 будет определяться
программой как период длины 6 кратности 2, и это правильно, так как программа
ищет максимальный период).
- Получение второй строки путем изменения
первой позволяет определять правильность нахождения расстояния Левенштейна и
наибольшей общей подпоследовательности.
При запуске программы пользователю предлагается ввести
параметры для генерации первой строки:
) Длина периода.
) Кратность периода.
) Смещение периода (указывается, чтобы период
начинался не с начала строки).
) Длина строки.
Во время ввода проверяется корректность вводимых данных,
отсеиваются отрицательные значения и значения длины, меньшие минимально
возможного (Смещение + Длина периода * Кратность периода).
После окончания процесса генерации первой строки данные
записываются в файл «S1.txt», а пользователю, для генерации второй строки, предлагается
ввести количество отличий второй строки от первой.
После ввода указанное количество случайных элементов второй
строки заменяется новыми, при этом проверяется, чтобы несколько раз не был
изменен один и тот же элемент, а так же, что генератор случайных чисел выдал
новое случайное число, не равное уже существующему элементу. Данные проверки
гарантируют, что вторая строка будет иметь то количество отличий, которое
указал пользователь. После окончания процесса генерации второй строки данные
записываются в файл «S2.txt» и программа заканчивает свою работу.
3.4 Инструкция пользователю
Программа StringGenerator создает строки с заданными
характеристиками. В ней можно задать: длину строки, длину периода, кратность
периода, смещение периода, количество отличий второй строки от первой.
Результат работы записывается в текстовый файл S1 или файлы S1и S2. При запуске
пользователю будет предложено ввести длину периода, затем кратность, смещение
периода относительно начала строки, длину строки и количество отличий второй
строки от первой (Рисунок 25).
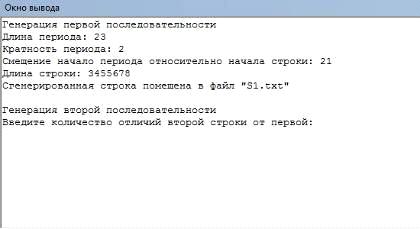
Рисунок 25 - Диалоговое меню программы StringGenerator
Все алгоритмы анализа строк реализованы в основной программе.
Программа имеет реализацию на 2 языках программирования: С и Pascal. Программа на С написана
с использованием стандарта С-99. При запуске пользователю будет предложено
выбрать конкретный алгоритм для выполнения или вычислить все.
Диалоговое меню программы на языке С (Рисунок 26):
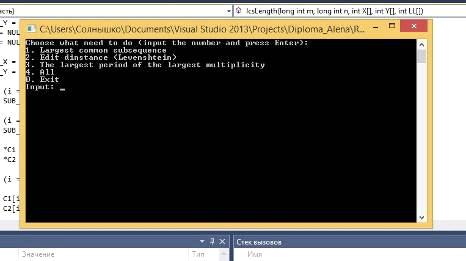
Рисунок 26 - Диалоговое меню программы на языке С
Диалоговое меню программы на языке Pascal (Рисунок 27):
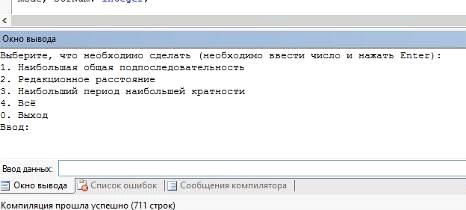
Рисунок 27 - диалоговое меню программы на языке Pascal
Необходимо ввести число от 1 до 4 для выполнения определенной
задачи или задач:
. При вводе 1 будет вычислена LCS.
. При вводе 2 будет вычислено расстояние Левенштейна.
. При вводе 3 будет найден период максимальной длины и
его кратность, так дополнительно необходимо указать для какой строки необходимо
выполнить поиск: необходимо ввести 1 для поиска в первой строке, 2 для поиска
во второй.
. При вводе 4 будет вычислено расстояние Левенштейна,
найдена LCS и наибольший период и его кратность. Так же необходимо уточнение
в какой из строк следует искать период: вводится 1 для поиска в 1 строке, 2 для
поиска во второй.
Данные на вход программе должны подаваться в виде файлов,
содержащих пары чисел (Statei, si), где si - момент системного
времени, в который произошло i-е событие в модели, Statei - состояние системы в
этот момент (целое положительное число). Рекомендуется, чтобы каждая пара чисел
находилась в новой строке. Файлы должны называться S1.txt и S2.txt для первой и
второй строки соответственно.
После завершения работы программы результаты будут помещены в
файл или файлы. Результат нахождения:) редакционного расстояния будет
находиться в файле EditDinst.txt (Рисунок 28).
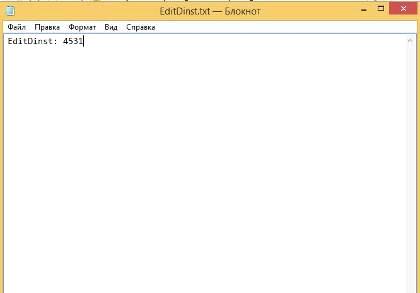
Рисунок 28 - Результат вычисления расстояния Левенштейна)
наибольшей общей подпоследовательности в файле LCS.txt (Рисунок 29).
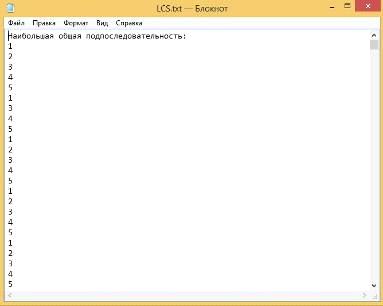
Рисунок 29 - Результат вычисления LCS
) максимального периода максимальной кратности в файле
Period.txt (Рисунок 30).
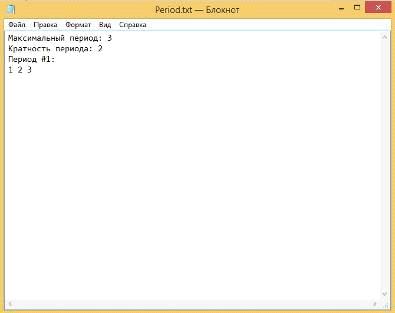
Рисунок 30 - результат вычисления периодической структуры
При новом запуске программы все старые файлы решений будут
удалены.
3.5 Примеры работы программы
Примеры работы программы будут приведены на строках
небольшого размера (40-80 символов) для наглядности и возможности оценки
корректности вычислений.
Вычисление расстояния Левенштейна.
) Строки совпадают.
Первая строка (Рисунок 31):
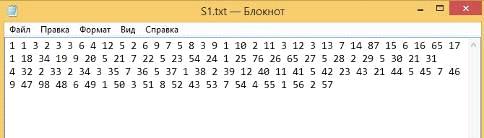
Рисунок 31 - первая строка
Вторая строка (Рисунок 32):
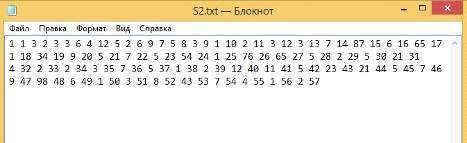
Рисунок 32 - вторая строка
Результат вычислений (Рисунок 33):
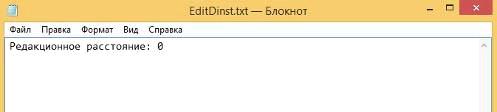
Рисунок 33 - результат вычисления расстояния Левенштейна
) Строки абсолютно разные.
Первая строка (Рисунок 34):
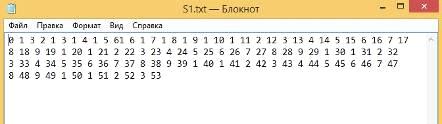
Рисунок 34 - первая строка
Вторая строка (Рисунок 35):
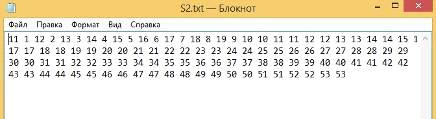
Рисунок 35 - вторая строка
Результат вычислений (Рисунок 36):
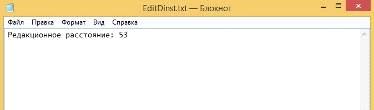
Рисунок 36 - результат вычисления расстояния Левенштейна
) Строки частично разные, длина строк совпадает.
Первая строка (Рисунок 37):

Рисунок 37 - первая строка
Вторая строка (Рисунок 38):
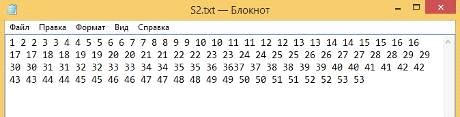
Рисунок 38 - вторая строка
Результат вычислений (Рисунок 39):
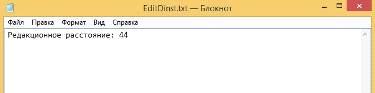
Рисунок 39 - Результат вычисления расстояния Левенштейна
Строки частично разные, длина строка разная.
Первая строка (Рисунок 40):
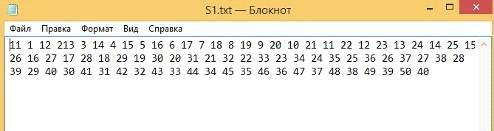
Рисунок 40 - Первая строка
Вторая строка (Рисунок 41):
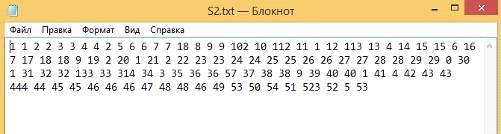
Рисунок 41 - Вторая строка
Результат вычислений (Рисунок 42):
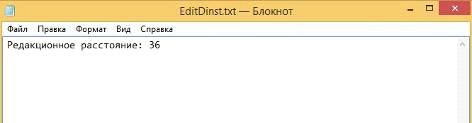
Рисунок 42 - Результат вычисления расстояния Левенштейна
Нахождение наибольшей общей подпоследовательности.
1) Строки совпадают.
Первая строка (Рисунок 43):
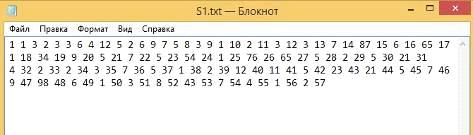
Рисунок 43 - Первая строка
Вторая строка (Рисунок 44):

Рисунок 44 - Вторая строка
Результат вычислений (Рисунок 45):

Рисунок 45 - Результат вычисления LCS
) Строки абсолютно разные.
Первая строка (Рисунок 46):
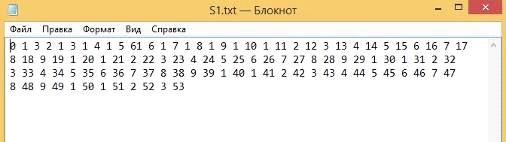
Рисунок 46 - Первая строка
Вторая строка (Рисунок 47):
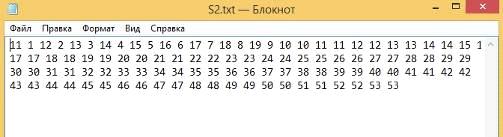
Рисунок 47 - Вторая строка
Результат вычислений (Рисунок 48):
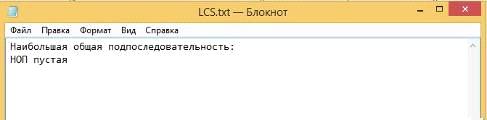
Рисунок 48 - Результат вычисления LCS
) Строки частично разные, длина строк совпадает.
Первая строка (Рисунок 49):
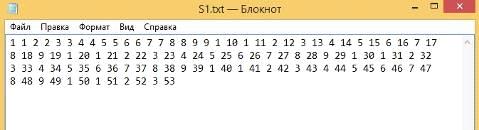
Рисунок 49 - Первая строка
Вторая строка (Рисунок 50):
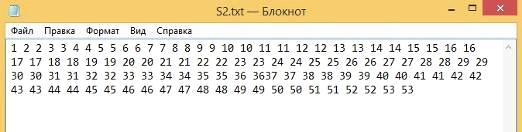
Рисунок 50 - Вторая строка
Результат вычислений (Рисунок 51):
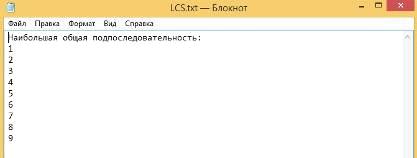
Рисунок 51 - Результат вычисления LCS
) Строки частично разные, длина строк разная.
Первая строка (Рисунок 52):
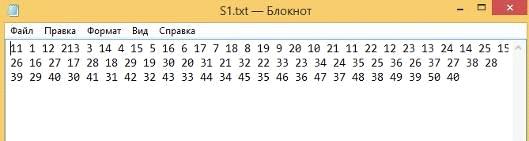
Рисунок 52 - Первая строка
Вторая строка (Рисунок 53):
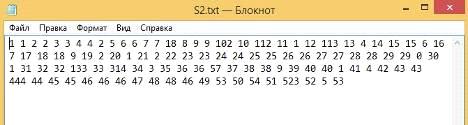
Рисунок 53 - Вторая строка
Результат вычислений (Рисунок 54):
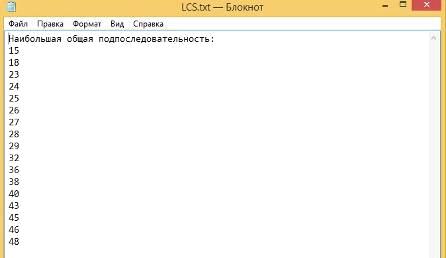
Рисунок 54 - Результат вычисления LCS
Нахождения периода максимальной кратности.
1) Период кратности более 2 не встречается в строке
Строка (Рисунок 55):
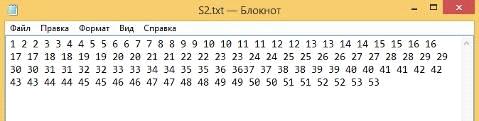
Рисунок 55 - Первая строка
Результат вычислений (Рисунок 56):
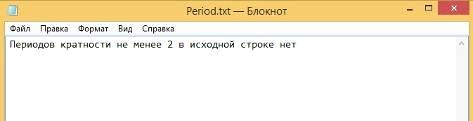
Рисунок 56 - Результат вычисления периодической структуры
) В строке только один максимальный период
Строка (Рисунок 57):

Рисунок 57 - Строка, в которой необходимо найти период максимальной
длины
Результат вычислений (Рисунок 58):

Рисунок 58 - Результат вычисления периодической структуры
) В строке несколько периодов максимальной длины
Строка (Рисунок 59):

Рисунок 59 - Строка, в которой необходимо найти период
максимальной длины
Результат вычислений (Рисунок 60):
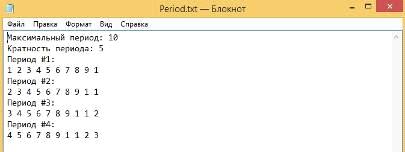
Рисунок 60 - Результат вычисления периодической структуры
Заключение
В ходе работы были рассмотрены различные алгоритмы решения
каждой из задач. Был проведен сравнительный анализ этих алгоритмов. Для каждой
из задач был реализован один алгоритм, менее требовательный к памяти. Программа
была реализована на 2 языках программирования: Pascal и C.
Так же была разработана программа, генерирующая строки с
заданными параметрами. Генерация строк с различными параметрами необходима для
качественного тестирования. Тестирование на строках длиной более 105
показало удовлетворительные результаты. Результат вычислений записывается в
файл, что позволяет хранить результаты продолжительное время и использовать в
других программах.
Список использованных источников
1. Смит
Б. Методы и алгоритмы вычислений на строках. - М.: ООО «И.Д. Вильямс», 2006.
2. The String-to-String Correction Problem / Robert A.
Wagner, Michael J. Fischer - Journal of the ACM Volume 21 Issue 1, Jan. 1974,
Pages 168-173
. http://neerc.ifmo.ru/wiki/index.php? title=Основные_определения,_связанные_со_строками
4. Строгалев В.П., Толкачева И.О. Имитационное моделирование.
- МГТУ им. Баумана, 2008.
5. Толстуев
Ю.И., Планковский С.И. Моделирование и симуляция логических систем. Курс
лекций. Харьковский авиационный институт. 2009.
6. Baeza-Yates R.A. (1989b) «String searching algorithms
revisited,» Lecture Notes in Computer Science, Vol. 382, p. 75-96.
. http://habrahabr.ru/post/142825/
. http://ru.wikipedia.org/wiki/PascalABC.NET
9. Беллман
Р. Динамическое программирование. - М.: Изд-во иностранной литературы, 1960.
10. String Search / Graham A Stephen - October 1992.
. http://ru.wikipedia.org/wiki/Visual_Studio
Приложение
Код
основной программы на языке Pascal
type= array of longint;= array of array of
longint;
: text;, S2: IntArray; // Строки, Length2:
longint; // Длины строк: IntArray; //
НОП и всп. массив, strNum: integer;
// Поиск минимального значения
function Min (X: integer; Y: integer): integer;X
< Y then Min:= X Min:= Y;
end;
// Поиск максимального значения
function Max (X: integer; Y: integer): integer;
beginX > Y then Max:= X Max:= Y;
end;
// Поиск подстроки в строке
function SubString (STR: IntArray; SubSTR:
IntArray; FirstIndex: longint): longint;, j, LastIndex: longint;
isFind: boolean;:= -1; // Изначально вхождение не найдено
LastIndex:= Length(STR) - Length(SubSTR);
(FirstIndex <= LastIndex) Theni:= FirstIndex
to LastIndex do
:= true;
j:= 0 to SubSTR. Length - 1 do(SubSTR[j] <>
STR [i + j]) then isFind:= false;
(isFind) then:= i;
break;;;
;
// Процедура, считывающая значения массива из файла
procedure ReadFromFile (file1: text; path:
string; var S: IntArray);A: integer;: char;: longint;: longint;
(file1, path);(file1);
:= 0;
(not eof(file1)) do // Придется полностью просматривать файл// т.к. FileSize работает некорретно(c = ' ')
do(file1, c);
(file1, c);
:= (ord(c) - 48);(file1, c);
(c <> ' ') do:= A * 10 + (ord(c) -
48);(file1, c);;
(Length);(file1, c);
(eof(file1)) then break;
(file1, c);(c <> #13) do(file1, c);
(file1, c);;
(file1);(S, Length); // Выделяем память под массив
i:= 0;
(not eof(file1)) do // Придется полностью просматривать
файл// т.к. FileSize работает некорретно
while (c = ' ') do(file1, c);
(file1, c);
:= (ord(c) - 48);(file1, c);
(c <> ' ') do:= A * 10 + (ord(c) -
48);(file1, c);;
[i]:= A;
(file1, c);(eof(file1)) then break;
(file1, c);
(c <> #13) do
read (file1, c);
(file1, c); // Сам символ перевода каретки
INC(i);;
(file1);
end;
// Процедура, инициализирующая подпоследовательность
// Изначально заполняет НОП -1-ми, т.е. НОП - пуста
procedure InitSEQ();j: longint;
:= Length(S1);:= Length(S2);
if (Length1 < Length2) then // Длина C - минимум из M и N
(приходится// брать с запасом, т.к. пока мы не знаем
SetLength (SEQ, Length1); // длину НОПj:= 0 to
Length1 - 1 do
SEQ[j]:= -1; // -1 показывает конец НОП,// изначально НОП
пуста
SetLength (SEQ, Length2);j:= 0 to Length2 - 1 do
SEQ[j]:= -1;;
;
// Процедура, вычисляющая вектор, равный последней строке
матрицы НОП
// Входные параметры: X - первая строка, Y - вторая строка,
LL - массив,
// в который будет помещен результатLCS_LENGTH (M:
integer; N: integer; X: IntArray; Y: IntArray; var LL: IntArray);
var, j: longint; // Итерационные счетчики: IntMatrix; //
Двумерный массив, хранящий i-ю и (i-1) - ю строки матрицы НОП
(H, 2); // Устанавливаем размер открытого массива H
SetLength (H[0], N + 1);(H[1], N + 1);
for i:= 0 to N do // Инициализируем 2-ю строку массива H
H [1, i]:= 0;
i:= 0 to M - 1 do // Вычисляем H
j:= 0 to N do // Сдвигаем вторую строку вверх[0, j]:= H [1,
j];
j:= 0 to N - 1 do // Само вычисление(X[i] = Y[j])
then H [1, j + 1]:= H [0, j] + 1H [1, j + 1]:= Max (H[1, j], H [0, j + 1]);
end;
j:= 0 to N do // Копируем результат в выходной вектор[j]:= H
[1, j];
;
// Нахождение максимального периода максимальной кратности
procedure FindMaxPeriod (STR: IntArray);:
IntMatrix; // Матрица подстрок текущей длины
MaxCurrMult: IntArray; // Массив максимальных кратностей для
подстрок текущей длины
PeriodLength, offset, index, prev_index, i, j:
longint;, CurrMult: longint;: boolean;:= Length(STR) div 2;
MaxMult:= 1;
(PeriodLength > 0) do // Начинаем с подстрок большей
длины. Если находим период с кратностью >1, то закончили
begin
SetLength (SubSTR, Length(STR));
SetLength (MaxCurrMult, Length(STR));:= 0;
while ((Length(STR) - (offset + 2 * PeriodLength)) + 1 >
0) do // Если в строке осталось меньше элементов, чем в подстроке, то берем
след.
begin
(SubSTR[offset], PeriodLength);:= 0;:=
1;[offset]:= 1;
i:= 0 to PeriodLength - 1 do[offset, i]:= STR [i
+ offset];
_index:= SubString (STR, SubSTR[offset], 0);
while (index <> -1) do // Поочередно ищем вхождения,
определяя, период это или нет.
begin:= SubString (STR, SubSTR[offset],
prev_index + 1);
if (index = prev_index + PeriodLength)
then(CurrMult);(CurrMult > MaxCurrMult[offset]) then MaxCurrMult[offset]:=
CurrMult;CurrMult:= 1;
_index:= index;;
(MaxCurrMult[offset] > MaxMult) then MaxMult:=
MaxCurrMult[offset];
(offset);;
(MaxMult > 1) then break;
(PeriodLength);;
(output, 'Period.txt');
rewrite(output);
(MaxMult < 2) then('Периодов кратности не менее 2 в
исходной строке нет')
else('Максимальный период: ', Length (SubSTR[0]));
writeln ('Кратность периода: ', MaxMult);
j:= 0;offset:= 0 to Length(STR) do:= false;
(MaxCurrMult[offset] = MaxMult) theni:= 0 to
offset - 1 do(SubString (SubSTR[i], SubSTR[offset], 0) <> -1) then
AlreadyWas:= true;
(AlreadyWas) then continue;
(j);
writeln ('Период #', j, ':');
for i:= 0 to Length (SubSTR[offset]) - 1
do(SubSTR[offset, i], ' ');
();
;;(output);;;;;;(output);;;
// Процедура, вычисляющая НОПLCS (M:
integer; N: integer; X: IntArray; Y: IntArray; var C: IntArray);
var, j, k: longint; // Итерационные счетчики, L2: IntArray;
// Последнии строки матрицы H
SUB_X, SUB_Y: IntArray; // Подстроки
C1, C2: IntArray;: boolean; // Флаг непустой
подпоследовательности
Found: boolean; // Флаг нахождения y_index
x_index: longint; // Индекс деления строки X_index: longint;
// Индекс деления строки Y_i: longint; // переменная, для индекса последнего
элемента SUB_X_max: longint; // максимальная L1j + L2n-j
:= 0; // Инициализация для цикла While
SetLength (L1, N + 1);(L2, N + 1);:= false;
((M = 0) or (N = 0)) then // Тривиальный случай[0]:= -1if (M
= 1) then
((notEmpty <> true) and (i < N)) do(X[0]
= Y[i]) then:= true;(i);;
if (notEmpty = true) then C[0]:= X[0] // Если НОП не пуста,
присваиваем ед. возможное значениеC[0]:= -1; // Иначе - код ошибки
else if (N = 1) then
((notEmpty <> true) and (i < M)) do(Y[0]
= X[i]) then:= true;(i);;
if (notEmpty = true) then C[0]:= Y[0] // Если НОП не пуста,
присваиваем ед. возможное значениеC[0]:= -1; // Иначе - код ошибки
begin // Начинается рассм. нетривиального случая_index:= M
div 2; // Делим X напополам
SetLength (SUB_X, x_index);(SUB_Y, N);
i:= 0 to x_index - 1 do // Заполняем подматрицы_X[i]:= X[i];
i:= 0 to N - 1 do_Y[i]:= Y[i];
_LENGTH (x_index, N, SUB_X, SUB_Y, L1); // Вычисляем L1
(SUB_X, M - x_index); // Меняем длину «подмассива» X
last_i:= High (SUB_X); // Получаем индекс последнего эл-та
SUB_X
for i:= 0 to last_i do // Заполняем подматрицы_X[i]:= X [M -
i - 1];
i:= 0 to N - 1 do_Y[i]:= Y [N - i - 1];
LCS_LENGTH (M - x_index, N, SUB_X, SUB_Y, L2); //
Вычисляем L2
_max:= 0;
i:= 0 to N do // Находим Max (L1j +
L2n-j)(lcs_max < L1 [i] + L2 [N - i]) then_max:= L1 [i] + L2 [N - i];
(lcs_max = 0) then exit; // Если lcs пуста, выходим.
:= 0;:= false;
((Found = false) and (i <= N)) do // Находим
y_index(lcs_max = L1 [i] + L2 [N - i]) then_index:= i;:= true;(i);;
(SUB_X, x_index);(SUB_Y, y_index);
i:= 0 to x_index - 1 do // Заполняем подматрицы_X[i]:= X[i];
for i:= 0 to y_index - 1 do_Y[i]:= Y[i];
(C1, lcs_max);(C2, lcs_max);
:= High(C1);
i:= 0 to j do[i]:= -1;[i]:= -1;;
(x_index, y_index, SUB_X, SUB_Y, C1);
(SUB_X, M - x_index);(SUB_Y, N - y_index);
_i:= High (SUB_X);
j:= 0 to last_i do // Заполняем подматрицы_X[j]:= X
[x_index + j];
_i:= High (SUB_Y);
j:= 0 to last_i do_Y[j]:= Y [y_index + j];
(M - x_index, N - y_index, SUB_X, SUB_Y, C2);
k:= 0;:= Length(C1);
((k < j) and (C1 [k] <> -1)) do // Объединяем С1 и
С2 в С
begin[k]:= C1 [k];(k);;
:= k;:= 0;:= Length(C2);((k < j) and (C2 [k]
<> -1)) do[i+k]:= C2 [k];(k);;
;;
// Заполнение матрицы расстоянийEditDinst (D:
IntMatrix; X: IntArray; Y: IntArray; i, j: longint): longint;, prev, m:
longint;
:= D [1, j - 1] + 1;
prev:= D [0, j] + 1;
(res > prev) then res:= prev;
X [i - 1] = Y [j - 1] then m:= 0m:= 1;
:= D [0, j - 1] + m;
(res > prev) then res:= prev;
:= res;
end;
// Функция вычисляющая расстояние Левенштейна
function Levenshtein (X: IntArray; Y: IntArray;
l1: longint; l2: longint): longint;i, j: longint;: IntMatrix;
(D, 2);(D[0], l2 + 1);(D[1], l2 + 1);
i:= 0 to l2 do // Заполняем первую строку[0, i]:= i;
for i:= 1 to l1 do
begin
[1, 0]:= i; // Первый элемент в строке
for j:= 1 to l2 do[1, j]:= EditDinst (D, X, Y, i,
j);
j:= 0 to l2 do[0, j]:= D [1, j];
;
:= D [1, l2];
;
// Процедура, выводящая на печать результаты
// вычислений
procedure PrintLCS();i: longint;
begin
('Первая строка:');
for i:= 0 to Length1 - 1 do(S1 [i], ' ');
writeln();('Вторая строка:');
for i:= 0 to Length2 - 1 do(S2 [i], ' ');
writeln();('Наибольшая общая подпоследовательность: ');
i:= 0;
(SEQ[0] = -1) then('НОП пустая')((i <=
High(SEQ)) and (SEQ[i] <> -1)) do(SEQ[i], ' ');(i);;
;
PrintEditDinst();();('Редакционное расстояние: ',
Levenshtein (S1, S2, Length1, Length2));
end;
// Процедура, осуществляющая вывод результатов в файл
begin(output, 'LCS.txt'); // Файл OUTPUT определен в System и
указывает устройство вывода
// => просто и элегантно перенаправляем вывод в
файл(output); //
('Наибольшая общая подпоследовательность: ');
i:= 0;
(SEQ[0] = -1) then('НОП пустая')((i <=
High(SEQ)) and (SEQ[i] <> -1)) do(SEQ[i]);(i);;
(output);
;
PrintEditDinstToFile();(output,
'EditDinst.txt');(output);
('Редакционное расстояние: ', Levenshtein (S1, S2, Length1,
Length2));(output);;
(file1, 'EditDinst.txt');(file1);(file1,
'LCS.txt');(file1);(file1, 'Period.txt');
erase(file1);:= -1;
('Выберите, что необходимо сделать (необходимо ввести число и
нажать Enter): ');('1. Наибольшая общая подпоследовательность');('2.
Редакционное расстояние');('3. Наибольший период наибольшей кратности');('4.
Всё');('0.
Выход');((mode
<> 1) and (mode <> 2) and (mode <> 3) and (mode <> 4)
and (mode <> 0)) do('Ввод: ');(mode);;:= -1;;(file1, 'S1.txt',
S1);Length(S1) = 0 then('Файл S1.txt пуст');;;;('Данные в файле S1.txt представлены в неверном формате.');
writeln ('Представьте данные в правильном формате и удалите
пустые строки');
exit;;;
(file1, 'S2.txt', S2);Length(S2) = 0 then('Файл S2.txt пуст');;;;('Данные в файле S2.txt представлены в неверном формате.');
writeln ('Представьте данные в правильном формате и удалите
пустые строки');;;;
(); // Инициализируется матрица и определяются Length1 и
Length2
mode of
: begin('Работа программы прервана пользователем');;;
: begin('Результаты будут помещены в файл LCS.txt');('Дождитесь
окончания работы программы…');
LCS (Length1, Length2, S1, S2, SEQ);();;
: begin('Результаты будут помещены в файл
EditDinst.txt');
writeln ('Дождитесь окончания работы программы…');();;
: begin('В какой строке искать период? (введите число и
нажмите Enter)');('1. Первая строка');('2. Строка');
write ('Ввод: ');((strNum <> 1) and (strNum
<> 2)) do(strNum);:= 0;
end;('Результаты будут помещены в файл
Period.txt');('Дождитесь окончания работы программы…');
if (strNum = 1) then(S1)(S2);;
: begin('В какой строке искать период? (введите число и нажмите
Enter)');('1. Первая строка');('2. Строка');
write ('Ввод: ');((strNum <> 1) and (strNum
<> 2)) do(strNum);:= 0;;('Результаты будут помещены в файлы LCS.txt,
EditDinst.txt и Period.txt');
writeln ('Дождитесь окончания работы программы…');
if (strNum = 1) then(S1)(S2);(Length1, Length2,
S1, S2, SEQ);();();;;(Output);
except;('Работа программы окончена.');.
Код
основной программы на языке C
#include <stdio.h>
#include <stdbool.h>
#include <stdlib.h>
// Вычисление минимального значения
int Min (int X, int Y)
{(X < Y)X;
return Y;
}
// Вычисление максимального значения
int Max (int X, int Y)
{(X > Y)X;
return Y;
}
// Поиск подстроки в строке
long int subString (int str[], long int strSize,
int subStr[], long int subStrSize, long int firstIndex)
{
_Bool isFind;lastIndex = strSize - subStrSize;
(firstIndex <= lastIndex) {(long int i =
firstIndex; i <= lastIndex; i++)
{= true;
(long int j = 0; j < subStrSize;
j++)(subStr[j]!= str [i + j])= false;
(isFind == true) return i;
}
}
return -1;
}
// Процедура, вычисляющая вектор, равный последней строке
матрицы НОП
int * lcsLength (long int m, long int n, int X[],
int Y[], int LL[]) {
int **H = (long int **) malloc (2 * sizeof (long
int *));int i = 0, j = 0;
(i = 0; i < 2; i++)[i] = (long int *)
malloc((n + 1) * sizeof (long int));
for (i = 0; i <= n; i++) // Инициализируем вторую строку
H[1] [i] = 0;
(i = 0; i < m; i++) // Вычисляем Н
{(j = 0; j <= n; j++) // Сдвигаем вторую строку вверх
H[0] [j] = H[1] [j];
(j = 0; j < n; j++)
{(X[i] == Y[j])[1] [j + 1] = H[0] [j] + 1;
{(H[1] [j] > H[0] [j + 1])[1] [j + 1] = H[1]
[j];[1] [j + 1] = H[0] [j + 1];
}
}
}
for (j = 0; j <= n; j++)[j] = H[1] [j];
(i = 0; i < 2; i++) // Освобождаем память(H[i]);
(H);= NULL;
LL;
}
// Вычисление LCS* lcs (long int m,
long int n, int X[], int Y[], int C[]) {
long int i = 0, j = 0; // Инициализация для цикла While
int *L1 = (int *) malloc((n + 1) * sizeof(int));*L2
= (int *) malloc((n + 1) * sizeof(int));
(i = 0; i <= n; i++)
{[i] = 0;[i] = 0;
}
_Bool notEmpty = false;
((m == 0) | (n == 0)) // Тривиальный случай
{[0] = -1;C;
}if (m == 1)
{= 0;((notEmpty!= true) & (i < n))
{(X[0] == Y[i])= true;
i++;
}
(notEmpty == true) // Если НОП не пуста, присваиваем ед.
возможное значение[0] = X[0];[0] = -1; // Иначе - код ошибки
//C = NULL;C;
}if (n == 1)
{= 0;((notEmpty!= true) & (i < m))
{(Y[0] == X[i])= true;
i++;
}(notEmpty == true) // Если НОП не пуста, присваиваем ед.
возможное значение[0] = Y[0];[0] = -1; // Иначе - код ошибки
//C = NULL;C;
}// Начинается рассм. нетривиального случая
{int x_index = m / 2; // делим X напополам
*SUB_X = (int *) malloc((x_index)*
sizeof(int));*SUB_Y = (int *) malloc((n)* sizeof(int));
(i = 0; i < x_index; i++) // заполняем подматрицы_X[i] = X[i];
(i = 0; i < n; i++)_Y[i] = Y[i];
= lcsLength (x_index, n, SUB_X, SUB_Y, L1); // Вычисяем L1
(SUB_X);(SUB_Y);
_X = (int *) malloc((m - x_index)*
sizeof(int));_Y = (int *) malloc((n)* sizeof(int));
long int last_i = m - x_index;
(i = 0; i < last_i; i++) // заполняем подматрицы_X[i] = X [m -
i - 1];
(i = 0; i < n; i++)_Y[i] = Y [n - i - 1];
= lcsLength (m - x_index, n, SUB_X, SUB_Y, L2);
// Вычисляем L2
int lcs_max = 0;
(i = 0; i <= n; i++)_max = Max (lcs_max, L1
[i] + L2 [n - i]);
if (lcs_max == 0) return C; // Если lcs пуста, выходим.
i = 0;
_Bool found = false;int y_index;
((found == false) & (i <= n)) // находим y_index
{(lcs_max == L1 [i] + L2 [n - i])
{_index = i;= true;
}
++;
}
(SUB_X); // Освобождаем память(SUB_Y);(L1);(L2);
_X = (int *) malloc((x_index)* sizeof(int));_Y =
(int *) malloc((y_index)* sizeof(int));
(i = 0; i < x_index; i++) // Заполняем матрицы_X[i] = X[i];
(i = 0; i < y_index; i++)_Y[i] = Y[i];
*C1 = (int *) malloc((lcs_max + 1)*
sizeof(int));*C2 = (int *) malloc((lcs_max + 1)* sizeof(int));
(i = 0; i <= lcs_max; i++)
{[i] = -1;[i] = -1;
}
= lcs (x_index, y_index, SUB_X, SUB_Y, C1);
(SUB_X); // Освобождаем память(SUB_Y);
SUB_X = (int *) malloc((m - x_index)* sizeof(int));_Y
= (int *) malloc((n - y_index)* sizeof(int));
_i = m - x_index;
(j = 0; j < last_i; j++)_X[j] = X [x_index +
j];
_i = n - y_index;
(j = 0; j < last_i; j++)_Y[j] = Y [y_index +
j];
= lcs (m - x_index, n - y_index, SUB_X, SUB_Y,
C2);
int k = 0;
((k < m - x_index) && (C1 [k]!= -1))
{[k] = C1 [k];++;
}
int k_1 = k;= 0;
((k < n - y_index) && (C2 [k]!= -1))
{[k_1 + k] = C2 [k];++;
}
//C [k_1 + k] = -1;
(C1); // не забываем освобождать память
free(C2);(SUB_X);(SUB_Y);
C;
}
}
// Заполнение матрицы расстоянийint editDinst
(long int D[], long int n, int X[], int Y[], long int i, long int j) {m;int res
= D [1 * n + j - 1] + 1;int prev = D [0 * n + j] + 1;
(res > prev)= prev;
(X [i - 1] == Y [j - 1])= 0;m = 1;
= D [0 * n + j - 1] + m;
(res > prev) = prev;
return res;
}
// Вычисление расстояния Левенштейна
long int levenshtein (int X[], int Y[], long int
l1, long int l2) {
int i = 0, j = 0;int *D = (long int *) malloc (2
* (l2 + 1) * sizeof (long int));
(i = 0; i <= l2; i++)[i] = i;
(i = 1; i <= l1; i++)
{[1 * (l2 + 1)] = i;(j = 1; j <= l2; j++)[1 *
(l2 + 1) + j] = editDinst (D, l2, X, Y, i, j);
(j = 0; j <= l2; j++)[0 * (l2 + 1) + j] = D [1
* (l2 + 1) + j];
}
int res = D [1 * (l2 + 1) + l2];
free(D); // освобождаем память= NULL;
return res;
}
// Вычисление максимального периодаfindMaxPeriod (int str[], long int length) {int periodLength
= length / 2;int maxMult = 1;int i = 0, j = 0;int index;int prev_index;int
currMult;int offset;int size;*subStr = NULL;int *maxCurrMult = NULL;
while (periodLength > 0) // Начинаем с подстрок большей
длины. Если находим период с кратностью >1, то закончили
{= ((length - (2 * periodLength)) + 1) *
periodLength;= (int *) malloc (size * sizeof(int));
(i = 0; i < size; i++)[i] = -1;
= (long int *) malloc (length * sizeof (long
int));= 0;
((length - (offset + 2 * (periodLength)) + 1)
> 0)
{= 0;= 1;[offset] = 1;
(i = 0; i < periodLength; i++)[periodLength *
offset + i] = str [i + offset];
_index = subString (str, length, &subStr
[periodLength * offset], periodLength, 0);
(index!= -1)
{= subString (str, length, &subStr
[periodLength * offset], periodLength, prev_index + 1);
(index == prev_index + periodLength)
{++;(currMult > maxCurrMult[offset])[offset] = currMult;
}= 1;
_index = index;
}
(maxCurrMult[offset] > maxMult)= maxCurrMult[offset];
++;
}(maxMult > 1);
(periodLength > 1) {(subStr);(maxCurrMult);
}= NULL;= NULL;-;
}
*file;
((file = fopen («Period.txt», «w»))!= NULL) {
((maxMult < 2) || (subStr == NULL))(file,
«There is no periods of multiplicity 2 in the initial string\n»);
{(file, «Maximum period:%d\n»,
periodLength);(file, «Multiplicity:%d\n», maxMult);= 0;
_Bool alreadyWas;int offset;(offset = 0; offset
< size; offset++)
{= false;
(maxCurrMult[offset] == maxMult)
{(i = 0; i < offset; i++)(subString
(&subStr[i * length], periodLength, &subStr [offset * length],
periodLength, 0)!= -1)= true;
(alreadyWas) continue;
++;(file, «Period #%d:\n», j);
(i = 0; i < periodLength; i++)(file, «%d»,
subStr [offset * periodLength + i]);
(file, «\n»);
}
}
}(file);
}
(subStr);(maxCurrMult);= NULL;= NULL;
}
printLCSToFile (int C[]) {int i;*file1;((file1 =
fopen («LCS.txt», «w»))!= NULL) {(file1, «LCS:\n»);= 0;(C[i] > 0)
{(file1, «%d\n», C[i]);++;
}(file1);
}
}
printEDToFile (long int editDinstance) {*file;
((file = fopen («EditDinst.txt», «w»))!= NULL)
{(file, «EditDinst:%d», editDinstance);(file);
}
}
main() {int i;A = -1, B = -1;
*file1;int length1 = 0;int length2 =
0;*S1;*S2;strNum;
(«LCS.txt»);(«EditDinst.txt»);
remove («Period.txt»);
// Читаем из первого файла
if ((file1 = fopen («S1.txt», «r»)) == NULL)
{(«File \ «S1.txt\» not Exist\n»);EXIT_FAILURE;
}
{
(fscanf (file1, «%d % d», &A, &B)!= EOF)
{((A < 0) || (B < 0))
{(«Data in file \ «S1.txt\» is
incorrect\n»);EXIT_FAILURE;
}++;
}(length1 == 0) {(«File \ «S1.txt\» is
empty\n»);EXIT_FAILURE;
}
S1 = (int *) malloc (length1 * sizeof(int));
= 0;(file1);= fopen («S1.txt», «r»);
(fscanf (file1, «%d % d», &A, &B)!= EOF)
{[i] = A;++;
}
(file1);
}
// Читаем из второго файла= -1, B = -1;
if ((file1 = fopen («S2.txt», «r»)) == NULL)
{(«File \ «S2.txt\» not Exist\n»);EXIT_FAILURE;
}
{
(fscanf (file1, «%d % d», &A, &B)!= EOF)
{((A < 0) || (B < 0))
{(«Data in file \ «S2.txt\» is
incorrect\n»);EXIT_FAILURE;
}++;
}
(length2 == 0) {(«File \ «S2.txt\» is
empty\n»);EXIT_FAILURE;
}
= (int *) malloc (length2 * sizeof(int));
= 0;(file1);= fopen («S2.txt», «r»);
(fscanf (file1, «%d % d», &A, &B)!= EOF)
{[i] = A;++;
}
(file1);
}
int editDinstance;int size = Max (length1,
length2);
*C = (int *) malloc (size * sizeof(int));
(int i = 0; i < size; i++)[i] = -1;
(«Choose what need to do (input the number and
press Enter):\n»);(«1. Largest common subsequence\n»);(«2. Edit dinstance
(Levenshtein)\n»);(«3. The largest period of the largest multiplicity\n»);(«4.
All\n»);(«0. Exit\n»);
choice;err;
{(«Input:»);= getchar();((err = getchar())!=
'\n') choice = '9';(stdin);
} while (! strchr («12340», choice));
(choice)
{'0':(«Program aborted by
user.\n»);EXIT_FAILURE;;'1':(«The results will be placed in file \
«LCS.txt\"\n»);(«Please, wait until the end of work.\n»);= lcs (length1,
length2, S1, S2, C);(C);;'2':(«The results will be placed in file \
«EditDinst.txt\"\n»);(«Please, wait until the end of work.\n»);=
levenshtein (S1, S2, length1, length2);(editDinstance);;'3':(«Choose string to
find period\n»);(«1. First string\n»);(«2. Second string\n»);
{(«Input:»);= getchar();((err = getchar())!=
'\n') choice = '9';(stdin);
} while (! strchr («12», strNum));(«The results
will be placed in file \ «Period.txt\"\n»);(«Please, wait until the end of
work.\n»);(strNum == '1')(S1, length1);(S2, length2);;'4':(«Choose string to
find period\n»);(«1. First string\n»);(«2. Second string\n»);
{(«Input:»);= getchar();((err = getchar())!=
'\n') choice = '9';(stdin);
} while (! strchr («12», strNum));(«The results
will be placed in files \ «LCS.txt\», \ «EditDinst.txt\» and \
«Period.txt\"\n»);(«Please, wait until the end of work.\n»);(strNum ==
'1')(S1, length1);(S2, length2);= lcs (length1, length2, S1, S2, C);(C);=
levenshtein (S1, S2, length1, length2);(editDinstance);;:;
}
(«Program is complete
successfully.\n»);(C);(S1);(S2);
return 0;
}
Код
программы, генерирующей строки с заданными характеристиками
var, periodLength, periodMult,
generated:longint;, globalIndex, i, j, differs, changeIndex: longint;, str,
changesIndexes: array of integer;: boolean;: text;
:= 0;
writeln ('Генерация первой последовательности');
('Длина периода: ');
readln(periodLength);(periodLength > -1);
(periodLength > 0) then
begin('Кратность периода: ');(periodMult);(periodMult >
0);('Смещение начало периода относительно начала строки: ');
readln(offset);(offset > -1);:= 0;:= 0;;
('Длина строки: ');(strLength);((offset + periodLength *
periodMult) > strLength) then
writeln ('Указанная длина строки меньше, чем (Смещение +
Длина периода * Кратность) = ', offset + periodLength * periodMult)
until (offset + periodLength * periodMult <=
strLength);
if (strLength < 1) then('Введенные параметры соответствуют
пустой строке, генерация прервана.');
EXIT;;
(period, periodLength);(str, strLength);
;
i:= 0 to periodLength - 1 do[i]:= random(1000);
:= 0;
(globalIndex < offset) do[globalIndex]:=
random(1000);(globalIndex);;
j:= 1 to periodMult doi:= 0 to periodLength - 1
do[globalIndex]:= period[i];(globalIndex);;
(globalIndex < strLength) do[globalIndex]:=
random(1000);(globalIndex);;
(output, 'S1.txt');(output);
i:= 0 to strLength - 2 do(str[i], ' ', i);
(str[strLength - 1], ' ', strLength - 1);
close(output);
('Сгенерированная строка помещена в файл «S1.txt» ');
();('Генерация второй последовательности');('Введите количество
отличий второй строки от первой: ');
readln(differs);
(changesIndexes, strLength);
i:= 0 to strLength - 1 do[i]:= 0;
:= 0;
(i < differs) do:= false;:= random (strLength
- 1);
(changesIndexes[changeIndex] = 0) then:=
random(1000);
(generated <> str[changeIndex])
then[changeIndex]:= random(1000);(generated <>
str[changeIndex]);(i);[changeIndex]:= 1;;
(output, 'S2.txt');(output);
i:= 0 to strLength - 2 do(str[i], ' ', i);
(str[strLength - 1], ' ', strLength - 1);
close(output);
('Сгенерированная строка помещена в файл «S2.txt» ');