Программирование на языке С#
Оглавление
Введение
. Особенности и преимущества языка C#
.1 Общее описание языка
.2 Сравнение C# с другими языками
программирования
.3 Использование языка
. Проектирование вычислительной
системы транспортной логистики
.1 Логистика
.2 Транспортные задачи
.3 Основные понятия и ограничения
.4 Алгоритмы поиска маршрутов в
графе
. Разработка вычислительной системы
транспортной логистики на языке C#
.1 Выбор среды разработки
.2 Визуализация транспортной сети
.3 Редактирование транспортной сети
.4 Задание условий поиска
.5 Пример работы алгоритма
Заключение
Список используемых источников и
литературы
Введение
язык транспортный логистика маршрут
Программирование - одновременно наука и
искусство создания компьютерных программ и\или программного обеспечения с помощью
языков программирования. Программирование сочетает в себе элементы искусства,
фундаментальных наук (прежде всего информатика и математика). Цель
программирования состоит в том, чтобы создать программу, которая показывает
определенное желательное поведение в ответ на действия пользователя либо
автономно - независимо от пользователя.
Программирование включает в себя:
· Анализ
· Проектирование - разработка
комплекса алгоритмов
· Кодирование и компиляцию - написание
исходного текста программы и преобразование его в исполнимый код с помощью
компилятора
· Тестирование и отладку - выявление и
устранение ошибок в программах
· Испытания и сдачу программ
· Сопровождение
Большая часть работы программистов связана с
написанием исходного кода, тестированием и отладкой программ на одном из языков
программирования. Исходные тексты и исполняемые файлы программ являются
объектами авторского права и являются интеллектуальной собственностью их
авторов и правообладателей.
Язык программирования - формальная знаковая
система, предназначенная для записи компьютерных программ. Язык
программирования определяет набор лексических, синтаксических и семантических
правил, задающих внешний вид программы и действия, которые выполнит исполнитель
(компьютер) под ее управлением.
Со времени создания первых программируемых машин
человечество придумало более двух с половиной тысяч языков программирования.
Каждый год их число пополняется новыми. Некоторыми языками умеет пользоваться
только небольшое число их собственных разработчиков, другие становятся известны
миллионам людей. Профессиональные программисты иногда применяют в своей работе
более десятка разнообразных языков программирования.
Теоретическую основу языков программирования
составляют алгоритмические языки. В настоящее время для ЭВМ разработано
значительное количество языков программирования. Они отличаются друг от друга
различными свойствами, а значит, и областью применения.
· Паскаль Самоучитель программирования
· Ассемблер Леонтьев
· С++
· BASIC
· Delphi
· С#
Язык программирования С# был создан в конце
1990-х годов и стал частью общей .NET-стратегии Microsoft. Впервые он увидел
свет в качестве α-версии в
середине 2000 года. Главным архитектором С# был Андерс Хейлсберг (Anders
Hejlsberg) - один из ведущих специалистов в области языков программирования,
получивший признание во всем мире.
В рамках данной дипломной работы основными
задачами будут являться: проектирование и разработка вычислительной системы для
решения транспортной задачи, поиска кратчайшего пути в транспортной сети, состоящей
из нескольких графов, где каждый граф может представлять собой отдельный вид
транспорта. В среде разработки C#,
выделение лучших сторон, особенностей данного языка программирования высокого
уровня, для наиболее оптимального решения данной задачи.
В настоящее время задачи транспортной логистики
представляют несомненный интерес, как с точки зрения практического
программирования, так и с точки зрения теоретической.
Это связано с несколькими причинами.
Причина первая состоит в том, что в настоящее
время компьютерная техника имеется в наличии практически в любой организации и
естественным желанием этой организации является её использование "на сто
процентов", в частности и для оптимизации транспортных расходов.
Вторая причина состоит в том, что, не смотря на
то, что задача поиска кратчайшего пути в графе на текущий момент уже является
классической, её различные реализации могут значительным образом отличаться как
с точки зрения интерфейса и удобства использования, так и с точки зрения
скорости работы.
Третья причина состоит в том, что классические
постановки задачи, связанные с поиском кратчайшего пути, подробно описанные в
ряде трудов (6) (7) (16) (24) (26), решают лишь общую задачу. И, если имеются
некоторые априорные данные о предмете исследования или наложены дополнительные
ограничения, всегда может быть построена некоторая модификация уже известного
алгоритма, обладающая лучшими характеристиками как с точки зрения использования
оперативной памяти, так и с точки зрения скорости работы.
1. Особенности и преимущества языка C#
.1 Общее описание языка
Последнее время С и С++ являются наиболее
используемыми языками для разработки коммерческих и бизнес приложений. Эти
языки устраивают многих разработчиков, но в действительности не обеспечивают
должной продуктивности разработки. К примеру, процесс написания приложения на
С++ зачастую занимает значительно больше времени, чем разработка эквивалентного
приложения, скажем, на Visual Basic. Сейчас существуют языки, увеличивающие
продуктивность разработки за счет потери в гибкости, которая так привычна и
необходима программистам на С/С++. Подобные решения являются весьма неудобными
для разработчиков и зачастую предлагают значительно меньшие возможности. Эти
языки также не ориентированы на взаимодействие с появляющимися сегодня
системами и очень часто они не соответствуют существующей практике
программирования для Web. Многие разработчики хотели бы использовать
современный язык, который позволял бы писать, читать и сопровождать программы с
простотой Visual Basic и в то же время давал мощь и гибкость C++, обеспечивал
доступ ко всем функциональным возможностям системы, взаимодействовал бы с
существующими программами и легко работал с возникающими Web стандартами.
Учитывая все подобные пожелания, Microsoft
разработала новый язык - C#. В него входит много полезных особенностей -
простота, объектная ориентированность, типовая защищенность, "сборка
мусора", поддержка совместимости версий и многое другое. Данные
возможности позволяют быстро и легко разрабатывать приложения, особенно COM+
приложения и Web сервисы. При создании C#, его авторы учитывали достижения
многих других языков программирования: C++, C, Java, SmallTalk, Delphi, Visual
Basic и т.д. Надо заметить что по причине того, что C# разрабатывался с чистого
листа, у его авторов была возможность (которой они явно воспользовались),
оставить в прошлом все неудобные и неприятные особенности (существующие, как
правило, для обратной совместимости), любого из предшествующих ему языков. В
результате получился действительно простой, удобный и современный язык, по
мощности не уступающий С++, но существенно повышающий продуктивность
разработок.
Очень часто можно проследить такую связь - чем
более язык защищен и устойчив к ошибкам, тем меньше производительность
программ, написанных на нем. К примеру рассмотрим две крайности - очевидно это
Assembler и Java. В первом случае вы можете добиться фантастической быстроты
своей программы, но вам придется очень долго заставлять ее работать правильно
не на вашем компьютере. В случае же с Java - вы получаете защищенность,
независимость от платформы, но, к сожалению, скорость вашей программы вряд ли
совместима со сложившимся представлением о скорости, например, какого-либо
отдельного клиентского приложения (конечно существуют оговорки - JIT компиляция
и прочее). Рассмотрим C++ с этой точки зрения - на мой взгляд соотношение в
скорости и защищенности близко к желаемому результату, но на основе
собственного опыта программирования я могу с уверенностью сказать, что
практически всегда лучше понести незначительную потерю в производительности
программы и приобрести такую удобную особенность, как "сборка
мусора", которая не только освобождает вас от утомительной обязанности
управлять памятью вручную, но и помогает избежать вам многих потенциальных
ошибок в вашем приложении. В действительности скоро "сборка мусора",
да и любые другие шаги к устранению потенциальных ошибок стану отличительными
чертами современного языка. В C#, как в несомненно современном языке, также
существуют характерные особенности для обхода возможных ошибок. Например,
помимо упомянутой выше "сборки мусора", там все переменные
автоматически инициализируются средой и обладают типовой защищенностью, что
позволяет избежать неопределенных ситуаций в случае, если программист забудет
инициализировать переменную в объекте или попытается произвести недопустимое
преобразование типов. Также в C# были предприняты меры для исключения ошибок
при обновлении программного обеспечения. Изменение кода, в такой ситуации,
может непредсказуемо изменить суть самой программы. Чтобы помочь разработчикам
бороться с этой проблемой C# включает в себя поддержку совместимости версий
(vesioning). В частности, в отличии от C++ и Java, если метод класса был
изменен, это должно быть специально оговорено. Это позволяет обойти ошибки в
коде и обеспечить гибкую совместимость версий. Также новой особенностью
является native поддержка интерфейсов и наследования интерфейсов. Данные
возможности позволяют разрабатывать сложные системы и развивать их со временем.
В C# была унифицирована система типов, теперь вы
можете рассматривать каждый тип как объект. Несмотря на то, используете вы
класс, структуру, массив или встроенный тип, вы можете обращаться к нему как к
объекту. Объекты собраны в пространства имен (namespaces), которые позволяют
программно обращаться к чему-либо. Это значит что вместо списка включаемых
файлов заголовков в своей программе вы должны написать какие пространства имен,
для доступа к объектам и классам внутри них, вы хотите использовать. В C#
выражение using позволяет вам не писать каждый раз название пространства имен,
когда вы используете класс из него. Например, пространство имен System содержит
несколько классов, в том числе и Console. И вы можете писать либо название
пространства имен перед каждым обращением к классу, либо использовать using как
это было показано в примере выше.
Важной и отличительной от С++ особенностью C#
является его простота. К примеру, всегда ли вы помните, когда пишите на С++,
где нужно использовать "->", где "::", а где
"."? Даже если нет, то компилятор всегда поправляет вас в случае
ошибки. Это говорит лишь о том, что в действительности можно обойтись только
одним оператором, а компилятор сам будет распознавать его значение. Так в C#,
оператор"->" используется очень ограничено (в unsafe блоках, о
которых речь пойдет ниже), оператор "::" вообще не существует.
Практически всегда вы используете только оператор "." и вам больше не
нужно стоять перед выбором.
Еще один пример. При написании программ на C/С++
вам приходилось думать не только о типах данных, но и о их размере в конкретной
реализации. В C# все упрощено - теперь символ Unicode называется просто char (а
не wchar_t, как в С++) и 64-битное целое теперь - long (а не __int64). Также в
C# нет знаковых и беззнаковых символьных типов.
В C#, также как и в Visual Basic после каждого
выражения case в блоке switch подразумевается break. И более не будет
происходить странных вещей если вы забыли поставить этот break. Однако если вы
действительно хотите чтобы после одного выражения case программа перешла к
следующему вы можете переписать свою программу с использованием, например,
оператора goto.
Многим программистам (на тот момент, наверное,
будущим программистам) было не так легко во время изучения C++ полностью
освоиться с механизмом ссылок и указателей. В C# (кто-то сейчас вспомнит о
Java) нет указателей. В действительности нетривиальность указателей
соответствовала их полезности. Например, порой, трудно себе представить
программирование без указателей на функции. В соответствии с этим в C# присутствуют
Delegates - как прямой аналог указателя на функцию, но их отличает типовая
защищенность, безопасность и полное соответствие концепциям
объектно-ориентированного программирования.
Хотелось бы подчеркнуть современное удобство C#.
Когда вы начнете работу с C#, а, надеюсь, это произойдет как можно скорее, вы
увидите, что довольно большое значение в нем имеют пространства имен. Уже
сейчас, на основе первого примера, вы можете судить об этом - ведь все файлы
заголовков заменены именно пространством имен. Так в C#, помимо просто
выражения using, предоставляется еще одна очень удобная возможность -
использование дополнительного имени (alias) пространства имен или класса.
Современность C# проявляется и в новых шагах к
облегчению процесса отладки программы. Традиционым средством для отладки
программ на стадии разработки в C++ является маркировка обширных частей кода
директивами #ifdef и т.д. В C#, используя атрибуты, ориентированные на условные
слова, вы можете куда быстрее писать отлаживаемый код.
В наше время, когда усиливается связь между
миром коммерции и миром разработки программного обеспечения, и корпорации
тратят много усилий на планирование бизнеса, ощущается необходимость в
соответствии абстрактных бизнес процессов их программным реализациям. К сожалению,
большинство языков реально не имеют прямого пути для связи бизнес логики и
кода. Например, сегодня многие программисты комментируют свои программы для
объяснения того, какие классы реализуют какой-либо абстрактный бизнес объект.
C# позволяет использовать типизированные, расширяемые метаданные, которые могут
быть прикреплены к объекту. Архитектурой проекта могут определяться локальные
атрибуты, которые будут связанны с любыми элементами языка - классами,
интерфейсами и т.д. Разработчик может программно проверить атрибуты какого-либо
элемента. Это существенно упрощает работу, к примеру, вместо того чтобы писать
автоматизированный инструмент, который будет проверять каждый класс или
интерфейс, на то, является ли он действительно частью абстрактного бизнес объекта,
можно просто воспользоваться сообщениями основанными на определенных в объекте
локальных атрибутах.
1.2 Сравнение C# с другими языками
программирования
#, являясь последним из широко распространенных
языков программирования, должен впитать в себя весь имеющийся опыт и вобрать
лучшие стороны существующих языков программирования, при этом являясь
специально созданным для работы в .NET. Сама архитектура .NET продиктовала ему
(как и многим другим языкам, на которых можно писать под .NET) объектно-ориентированную
направленность. Конечно, это не является правилом, возможно создание
компиляторов даже функциональных языков по .NET, на эту тему существуют
специальные работы.
Свой синтаксис C# во многом унаследовал от C++ и
Java. Разработчики, имеющие опыт написания приложений на этих языках, найдут в
C# много знакомых черт. Но вместе с тем он является во многом новаторским -
аттрибуты, делегаты и события, прекрасно вписанные в общую идеологию языка,
прочно заняли место в сердцах .NET - разработчиков. Их введение позволило
применять принципиально новые приемы программирования.
Конечно, излюбленным объектом для сравнения с C#
у мировой коммьюнити является Java. Также разработанный для работы в
виртуальной среде выполнения, имеющей объектно-ориентированную архитектуру и
сборщик мусора, осноыванный на механизме ссылок. При сравнении с этим языком
сразу выделаются такие особенности, как возможность объявлять несколько классов
в одном файле, из чего следует синтаксическая поддержка иерархической системы
пространств имен. Из реализации ООП-концепций сходство в механизме наследования
и реализации (и в Java и в C# возможно единичное наследование, но множественная
реализация интерфейсов, в отличие от C++). Но в Java отсутствуют свойства и
индексаторы (а также делегаты и события, но они отсутствуют еще много где).
Также есть возможность перечисления контейнеров.
Из вещей, включенных в спецификацию языка, но не
являющихся чисто "программистскими" необходимо отметить возможность
использование комментариев в формате XML. Если комментарии отвечают специально
описанной стркутуре, компилятор по ним может сгенерировать единый XML-файл
документации.
Но C# внес и свои уникальные черты, которые уже
были упомянуты - это события, индексаторы, аттрибуты и делагаты. Все эти
элементы будут обсуждены в следующих частях, сейчас лишь отмечу, что они
предоставляют собой очень полезные возможности, которые не останутся
невостребованными.
1.3 Использование языка
В этой части будут рассмотрены более
практические аспекты использования C#. Компиляция, отладка и тому подобные
вопросы. Начнем с компиляции:
Переходя к более подробному знакомству с C#,
традиционно рассмотрим программу "Hello, world": using System;
class Hello{void Main()
{.WriteLine("hello, world");
}
}
Поместите эту
программу
в
файл
hello.cs и скомпилируйте
ее
командой
csc hello.cs
Так выглядит вызов компилятора в простейшем
случае. Далее мы приведем полный список параметров компилятора. При вызове
компилятора убедитесь, что у вас прописан путь csc.exe - C Sharp Compiler
В результате вы получите файл hello.exe,
запустив который, вы увидите надпись "hello, world".
Метод Main - это точка входа в программу. С него
начинается выполнение (те, кто знаком с C++ или Java) понимают, о чем идет
речь. Этот метод обязательно должен быть статическим. Далее в нашем примере
используется метод WriteLine из класса System.Console. Этот метод отправляет
строку на стандартный вывод.
Вы можете также создавать библиотеки классов -
dll-сборки, которые могут использоваться другими приложениями. Для этого нужно
указать /target:library в опциях компилятора
Если компилятор обнаружит ошибки в программе, он
выдаст соответствующее сообщение и остановит процесс компиляции. Также он может
выдать предупреждения - если он обнаружит код, который, строго говоря, правильный,
но имеет подозрения на ошибку. К таким предупреждениям стоит прислушиваться.
Вообще, компилятор C# имеет множество
возможностей, узнать о которых можно из слеующей таблицы. В ней описаны все
опции командной строки компилятора CSC:
Выходные файлы/out:<file> Имя выходного
файла (если не указано - производное от имени первого исходного файла)
/target:exe Скомпилировать консольный
запускаемый файл (по умолчанию) (Краткая форма: /t:exe)
/target:winexe Скомпилировать запускаемый файл
Windows (Краткая форма: /t:winexe)
/target:library Скомпилировать в библиотеку DLL
(Краткая форма: /t:library)
/target:module Скомпилировать модуль, который
может быть добавлен в другую конструкцию (Краткая форма: /t:module)
* Примечание: Модуль и библиотека имеют
одинаковые расширения (DLL), но несмотря на это, они представляют из себя
разные вещи. Библиотека - это классическая библиотека DLL. Модуль - это файл
откомпилированный без создания конструкции (assembly). В дальнейшем вы можете
добавить модуль в любую другую конструкцию при компиляции (с помощью опции
/addmodule). /nooutput[+|-] Только проверять ошибки в коде; не создавать
запускаемый файл
/define:<список символов> Определяет
директивы препроцессора (Краткая форма: /d)
Написание csc /define:mark1 MyApp.cs равносильно
наличию в файле строки
#define mark1
/doc:<file> Создать XML файл документации
Входные файлы/recurse:<маска> Включить все
файлы, удовлетворяющие маске.
/main:<тип> Обозначить класс, содержащий
точку входа в программу (все остальные будут игнорироваться) (Краткая форма:
/m)
/reference:<список файлов> Включить
метаданные из указанных файлов конструкций (Краткая форма: /r)
* Примечание: все данные, помеченные как public,
из указаных файлов конструкций будут включены в данную конструкцию. Если файл
не содержит объявления конструкции, то метаданные из него могут быть включены с
помощью /addmodule./addmodule:<список файлов> Включить указанные модули в
сборку
Ресурсы/win32res:<file> Добавляет файл
ресурсов Win32(.res) в выходной файл
/win32icon:<file> Добавляет иконку в
выходной файл
/resource:<resinfo> Включает .NET ресурс
(Краткая форма: /res)
* Примечание: resinfo являет собой следующую
последовательность: filename[,identifier[,mimetype]], где filename - имя файла
ресурса, identifier - логическое имя ресурса (используется для его загрузки),
mimetype - медиа тип ресурса (обычно отсутствует).
/linkresource:<resinfo> Создает ссылку на ресурсный файл в данной сборке
(не включая его в выходной файл)(Краткая форма: /linkres)
Создание кода/debug[+|-] Создавать информацию
отладки.
/debug:{full|pdbonly} Указание типа отладки
('full' - по умолчанию, позволяет прикреплять отладчик к запускаемой программе)
/optimize[+|-] Запускать оптимизацию (Краткая
форма: /o)
/incremental[+|-] Запускать компиляцию только
измененных частей кода(Краткая форма: /incr)
Ошибки и предупреждения /warnaserror[+|-]
Относиться к предупреждениям, как к ошибкам
/warn:<n> Установить уровень
предупреждений (0-4) (Краткая форма: /w)
/nowarn:<список предупреждений> Исключить
указанные предупреждения
* Примечание: список предупреждений -
последовательность их номеров num1[,num2[...]]
Язык/checked[+|-] Выполнять проверки на
переполнения и опустошения
/unsafe[+|-] Допускать unsafe код (unsafe код -
небезопасный код, он будет обсужден в дополнительных главах)
Разное@<file> Прочтение команд и опций
компилятора из файла
/help Показывает информацию о использовании
(Краткая форма: /?)
/nologo Не показывать копирайт при компиляции
Дополнительно/baseaddress:<address>
Базовый адрес для создаваемой библиотеки
/bugreport:<file> Создавать файл отчета об
ошибках
/codepage:<n> Указать таблицу символов,
для использования во время открытия исходного текста
/fullpaths Компилятор будет указывать полные
имена файлов
/nostdlib[+|-] Не допускать включения
стандартной библиотеки (mscorlib.dll). В этой библиотеке хранятся все основные
классы .NET Framework.
2. Проектирование вычислительной системы
транспортной логистики
.1 Логистика
Логистика - стратегическое управление
(менеджмент) материальными потоками в процессе закупки, снабжения, перевозки и
хранения материалов, деталей и готового инвентаря (техники и проч.). Понятие
включает в себя также управление соответствующими потоками информации, а также
финансовыми потоками.
Логистика направлена на оптимизацию издержек и
рационализацию процесса производства, сбыта и сопутствующего сервиса как в
рамках одного предприятия, так и для группы предприятий. В зависимости от
специфики деятельности компании применяются различные логистические системы.
Понятие логистики включает в себя множество
поддисциплин: закупочная, транспортная, складская, производственная,
информационная логистика и другие [19].
В рамках данной дипломной работы будет
рассматриваться транспортная логистика.
Транспортная логистика
Транспортная логистика - это система по организации
доставки, а именно по перемещению каких-либо материальных предметов, веществ и
пр. из одной точки в другую по оптимальному маршруту. Одно из основополагающих
направлений науки об управлении информационными и материальными потоками в
процессе движения товаров.
Оптимальным считается маршрут, по которому
возможно доставить логистический объект, в кратчайшие сроки (или
предусмотренные сроки) с минимальными затратами, а также с минимальным вредом
для объекта доставки.
Вредом для объекта доставки считается негативное
воздействие на логистический объект как со стороны внешних факторов (условия
перевозки), так и со стороны временного фактора при доставке объектов,
подпадающих под данную категорию.
Перечислим основные задачи, которые стоят перед
транспортной логистикой [20]:
. Выбор типа транспортного средства.
. Выбор вида транспортного средства.
. Совместное планирование транспортных процессов
со складскими и производственными операциями.
. Совместное планирование транспортных процессов
на различных видах транспорта.
. Обеспечение технологического единства
транспортно-складского процесса.
. Определение рациональных маршрутов поставки.
Все они (кроме подзадач связанных со складскими
операциями) будут затронуты в данном исследовании.
Подходы к решению задачи
Исследование операций - дисциплина, занимающаяся
разработкой и применением методов нахождения оптимальных решений на основе
математического моделирования, статистического моделирования и различных
эвристических подходов в различных областях человеческой деятельности. Иногда
используется название математические методы исследования операций.
Когда мы говорим об оптимальности решения всегда
необходимо определять набор признаков, по которым данное решение будет
предпочтительнее других. В свою очередь цель исследования операций -
предварительное количественное обоснование оптимальных решений.
Характерная особенность исследования операций -
системный подход к поставленной проблеме и анализ. Системный подход является
главным методологическим принципом исследования операций. Он заключается в
следующем. Любая задача, которая решается, должна рассматриваться с точки
зрения влияния на критерии функционирования системы в целом. Для исследования
операций характерно то, что при решении каждой проблемы могут возникать новые
задачи. Важной особенностью исследования операций есть стремление найти
оптимальное решение поставленной задачи (принцип "оптимальности").
Однако на практике такое решение найти невозможно по таким причинам [2] [23]:
. отсутствие методов, дающих возможность найти
глобально оптимальное решение задачи
. ограниченность существующих ресурсов (к
примеру, ограниченность машинного времени ЭВМ), что делает невозможным
реализацию точных методов оптимизации.
В таких случаях ограничиваются поиском не
оптимальных, а достаточно хороших, с точки зрения практики, решений. Приходится
искать компромисс между эффективностью решений и затратами на их поиск.
Исследование операций дает инструмент для поиска таких компромиссов.
.2 Транспортные задачи
Задача коммивояжёра
Одной из самых известных задач транспортной
логистики является задача коммивояжёра.
Задача заключается в отыскании самого выгодного
маршрута, проходящего через указанные города хотя бы по одному разу с
последующим возвратом в исходный город. В условиях задачи указываются критерий
выгодности маршрута (кратчайший, самый дешёвый, совокупный критерий и т.п.) и
соответствующие матрицы расстояний, стоимости и т.п. Как правило, указывается,
что маршрут должен проходить через каждый город только один раз - в таком случае
выбор осуществляется среди гамильтоновых циклов.
Существует несколько частных случаев общей
постановки задачи, в частности, геометрическая задача коммивояжёра (также
называемая планарной или евклидовой, когда матрица расстояний отражает
расстояния между точками на плоскости), треугольная задача коммивояжёра (когда
на матрице стоимостей выполняется неравенство треугольника), симметричная и
асимметричная задачи коммивояжёра. Также существует обобщение задачи, так
называемая обобщённая задача коммивояжёра.
Общая постановка задачи, впрочем, как и
большинство её частных случаев, относится к классу NP-сложных задач [11] [13].

Перечислим основные методы решения этой задачи:
полный лексический перебор
случайный перебор жадные алгоритмыметод
ближайшего соседа
o метод включения ближайшего города o метод
самого дешёвого включения
метод минимального остовного дерева
Все эффективные (сокращающие полный перебор)
методы решения задачи коммивояжёра - методы эвристические. В большинстве
эвристических методов находится не самый эффективный маршрут, а приближённое
решение. Зачастую востребованы так называемые any-time алгоритмы, то есть постепенно
улучшающие некоторое текущее приближенное решение.
Существует также постановки, в которых задача
коммивояжера становится NP-полной. Обычно такие постановки выглядят следующим
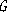
образом: существует ли на заданном графе такой
обход, что его стоимость не превышает. Часто на ней проводят обкатку новых
подходов к эвристическому сокращению полного перебора.
На практике применяются различные модификации
более эффективных методов: метод ветвей и границ и метод генетических алгоритмов,
а также алгоритм муравьиной колонии.сложные задачи
В теории алгоритмов классом NP1 называют множество алгоритмов,
время работы которых существенно зависит от размера входных данных. В то же
время, если предоставить алгоритму некоторые дополнительные сведения (так
называемых свидетелей решения), то он сможет достаточно быстро (за время, не
превосходящее многочлена от размера данных) решить задачу. Многие задачи на
графах относят к классу NP-полных задач [7].
Транспортная задача
Транспортная задача (Задача Монжа-Канторовича) -
задача об оптимальном плане перевозок продукта из пунктов отправления в пункты
потребления. Разработка и применение оптимальных схем грузовых потоков
позволяют снизить затраты на перевозки. Транспортная задача является по теории
сложности вычислений NP-сложной.
Когда суммарный объем предложений (грузов,
имеющихся в пунктах отправления) не равен общему объему спроса на товары
(грузы), запрашиваемые пунктами потребления, транспортная задача называется
несбалансированной.
.3 Основные понятия и ограничения
В математической теории графов и информатике
граф - это совокупность объектов со связями между ними.
Объекты представляются как вершины, или узлы
графа, а связи - как дуги, или рёбра. Для разных областей применения виды
графов могут различаться направленностью, ограничениями на количество связей и
дополнительными данными о вершинах или рёбрах [16].
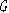
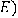
Граф или неориентированный граф - это
упорядоченная пара для которой выполнены следующие условия:
это множество вершин или узлов,
это множество пар (в случае неориентированного
графа - неупорядоченных) вершин, называемых рёбрами.
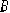
Будем считать, что в рамках решаемой задачи
будут рассматриваться только неориентированные графы, т.е. если между двумя
вершинами ( и ) существует ребро, то путь от вершины к вершине будет
иметь такую же стоимость что и путь от вершины к вершине . Это ограничение не
является жёстким и может быть легко обойдено на уровне алгоритмов работы с
графом.
Граф не должен содержать кратных рёбер. Будем
считать, что пару вершин всегда связывает только единственное ребро. Это
ограничение также не является жёстким.
Граф не должен содержать петель, т.к. петля не
имеет смысла с точки зрения транспортной сети.
Граф не должен содержать изолированных вершин,
т.к из вершины всегда должно выходить хотя бы одно ребро.
Граф не обязательно должен быть связным, т.к.
поиск может осуществляться только внутри обособленной области связности.
Граф является взвешенным, т.е. каждое ребро
имеет определённый вес. В качестве весовых коэффициентов будут использоваться
целые неотрицательные числа. Вещественные числа не являются удобными в связи с
тем, что вещественные числа в машинном представлении всегда хранятся с потерей
точности, что затрудняет выполнение операции сравнения и приводит к
необходимости заведения специальной константы, определяющей точность
вычислений. Допускается наличие ребра, имеющего нулевой вес, в том случае если
некоторая вершина одновременно принадлежит нескольким графам. В этом случае,
обыгрывается ситуация в которой некоторая узловая точка одновременно
принадлежит нескольким транспортным системам и смена вида транспорта отнимает
нулевое количество ресурсов.
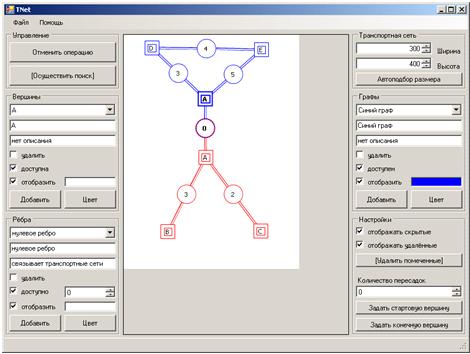
Рисунок 1 Пример случая ребра нулевой длины
.4 Алгоритмы поиска маршрутов в графе
Базовой операцией в любом графовом алгоритме
является полный и систематический обход графа. Целью обхода - посетить каждую
вершину и каждое ребро ровно один раз в строго определенном порядке. Существует
два основных алгоритма обхода:
поиск в ширину (breadth-first
search - BFS);
поиск в глубину (depth-first
search - DFS).
Для определенных задач нет никакой разницы,
какой из них вы будете использовать, но в некоторых случаях выбор становится
жизненно важным.
Обе процедуры обхода графа используют одну
фундаментальную идею, а именно: мы должны помечать вершины, которые уже видели,
чтобы не пытаться посетить их снова. Иначе мы можем зациклиться и никогда не
выйти из алгоритма. BFS и DFS различаются только порядком, в котором они
рассматривают вершины.
Поиск в ширину
Поиск в ширину следует использовать в том
случае, если
. нам не важен порядок, в котором мы обходим
вершины и ребра графа, то есть нас устроит любой,
. нам нужно найти кратчайший путь в невзвешенном
графе.

Поиск в ширину выполняется в следующем порядке:
началу обхода приписывается метка 0, смежным с ней вершинам - метка 1. Затем
поочередно рассматривается окружение всех вершин с метками 1, и каждой из
входящих в эти окружения вершин приписываем метку 2 и т.д.
Если исходный граф связный, то поиск в ширину
пометит все его вершины. Дуги вида порождают
остовный бесконтурный орграф, содержащий в качестве своей части остовное
ордерево, называемое поисковым деревом.
Легко увидеть, что с помощью поиска в ширину
можно также занумеровать вершины, нумеруя вначале вершины с меткой 1, затем с
меткой 2 и т.д.
Этот алгоритм имеет несколько большие требования
по использованию памяти т.к. все пути ищутся параллельно. Кроме того, как уже
было сказано выше, он не лучшим образом подходит для работы с взешенными
графами. К тому же, этот алгоритм не даёт возможностей использования эвристик,
которые могут значительным образом сократить перебор.
Алгоритм Дейкстры
Для поиска кратчайшего пути в реберно-взвешенных
графах или графах со взвешенными вершинами предпочтительно использовать
алгоритм Дейкстры.

Для заданной вершины он находит
кратчайший путь от до всех остальных вершин, включая желаемую вершину.
Основная идея весьма схожа с алгоритмом Прима.
На каждой итерации мы собираемся добавлять ровно одну вершину к дереву

вершин, для которых мы знаем кратчайший путь до
. Точно так же как и в алгоритме Прима, мы будем отслеживать для всех вершин
лучший путь, известный на данный момент, и добавлять их в порядке увеличения
стоимости.
Разница между алгоритмами Прима и Дейкстры в
том, как они оценивают желательность каждой вершины, не входящей в дерево. В
задаче нахождения минимального остовного дерева все, что нас интересует, - это
вес следующего потенциального ребра дерева. Для нахождения кратчайшего пути нам
нужно выбрать вершину, ближайшую (в смысле наименьшего путевого расстояния) к
началу. Получаем функцию от веса нового ребра и от расстояния от начала смежной
вершины дерева.
Если бы транспортная сеть ограничивалась одним
графом, то алгоритм Дейкстры являлся бы одним из лучших выборов для поиска
оптимального пути. Но, сама идея алгоритма при учёте количества пересадок может
привести к тому, что некоторые потенциально достижимые вершины никогда не будут
достигнуты, т.к. алгоритм "израсходует" все допустимые пересадки,
стремясь сделать путь максимально дешёвым. В первую очередь это связано с тем,
что поиск осуществляется не только для целевой вершины, но и для всех вершин
входящих в транспортную сеть.
Алгоритм Беллмана-Форда
Алгоритм Беллмана-Форда - алгоритм поиска
кратчайшего пути во взвешенном графе. В отличие от алгоритма Дейкстры, алгоритм
Беллмана-Форда допускает рёбра с отрицательным весом. Предложен независимо
Ричардом Беллманом и Лестером Фордом.
Для реализации этого алгоритма чаще всего
используются принципы динамического программирования. Он имеет несомненное
преимущество перед алгоритмом Дейкстры т.к. позволяет ограничивать поиск не
только стоимостью пути, но и количеством рёбер входящих в этот путь.
Но он не позволяет формализовать и
алгоритмизировать ограничения на количество пересадок, т.к. в нём, как и в
алгоритме Дейкстры путь ищется не только до заданной вершины, но и для всех
остальных.
Основные недостатки этого алгоритма для решения
поставленной задачи аналогичны недостаткам алгоритма Дейкстры. Кроме того, этот
алгоритм более требовательный в плане использования оперативной памяти.
Выводы
Ни один из представленных классических
алгоритмов в явном виде не позволяет решать поставленную задачу. Наиболее
подходящим был признан поиск в глубину. Модифицированный алгоритм будет
строиться на его основе.
3. Разработка вычислительной системы
транспортной логистики на языке C#
.1 Выбор среды разработки
Для реализации программного комплекса
использовался язык высокого уровня C# и среда разработки MS Visual Studio 2008.
Этот выбор обусловлен исходя из следующих критериев [5] [9] [15] [17] [22]:
. Среда разработки и язык позволяют быстро и
качественно создавать пользовательский интерфейс высокого уровня, используя
дизайнер форм, сводя к минимуму труд программиста. В качестве альтернативы
могла быть рассмотрена среда разработки Code Gear 2009, но MS Visual Studio
2008 явно обладает рядом преимуществ т.к. является естественной платформой для
разработки под Windows.
. Язык C# так же обладает рядом преимуществ по
сравнению с Object Pascal, т.к. является более новым и более развитым языком.
. В нём на очень высоком уровне реализованы
механизмы безопасности кода.
. Ещё одним несомненным плюсом является наличие
русскоязычной развитой справочной системы, что значительно упрощает процесс
программирования.
. Ещё одной альтернативным языком могла бы быть
JAVA, но для её работы требуется устанавливать собственный Framework, в то
время как Framework необходимый для работы программ написанных с использованием
C# уже присутствует на уровне операционной системы.
. Ещё одним преимуществом является возможность
использовать как управляемый, так и неуправляемый код, как ручное, так и
автоматизированное управление памятью. Основные конкурентыи Object Pascal не
позволяют одновременно использовать обе эти модели.
. Ещё одним преимуществом может рассматриваться
использование байт-кода, что обеспечивает высокую скорость работы и более
полное использование аппаратных возможностей ПК.
В качестве альтернативы не рассматривались среды
веб-разработки, т.к. должно было быть получено однопользовательское приложение
не предполагающие наличие и использование веб-сервера и скриптовых языков.
.2 Визуализация транспортной сети
Рассмотрим алгоритм визуализации транспортной сети.
В функцию передаются два флага, которые
позволяют временно скрывать части транспортной сети помеченные как невидимые и
как удалённые.
Для отрисовки графических примитивов
используется антиалайзинг, что снижает ступенчатость линий, соединяющих
элементы транспортной сети.
Для текста, антиалайзинг был отключен, т.к.
использовался шрифт небольшого размера, а сглаживание снижало лёгкость его
чтения.
Текущие объекты (вершины и рёбра) отрисовываются
с использованием полужирного начертания линий и шрифтов.
Перейдём непосредственно к алгоритму.
Сначала отрисовывались рёбра, т.к. вершины их
перекрывают и визуально находятся на один уровень выше.
Каждое ребро определяется парой вершин, вершины
имеют координаты. Они и определяют расположение ребра. Контуры ребра
отрисовываются
цветом графа. Внутреннее заполнение может быть выбрано индивидуально для
каждого из рёбер.
В середине ребра рисуется кружочек, в который
вписывается числовое значение, характеризующее вес ребра.
Т.к. ребро может соединять два графа и каждый из
этих двух графов может иметь собственный цвет, то половина ребра будет иметь
контур одного цвета, а вторая полвина будет иметь контур другого цвета.
Кружочек в этом случае рисуется пунктирным с чередованием двух цветов.
Предусмотрена система обозначений в виде
суффиксов веса: Ч - ребро недоступно;
° - ребро помечено как невидимое; † - ребро
помечено для удаления.
После того, как отрисованы рёбра, начинается
визуализация вершин.
Контуры вершины имеют цвет графа, внутренняя
заливка может быть установлена индивидуально для каждой вершины.
Для вершин предусмотрена та же система
обозначений, что и для рёбер. Кроме этого предусмотрено ещё два возможных
суффикса.
" - вершина является стартовой; " -
вершина является конечной.
.3 Редактирование транспортной сети
Добавление элементов
При добавлении нового графа в конец списка
добавляется ещё одни элемент, и он становится текущим, после чего пользователь
может задать имя графа, описание, цвет и прочие характеристики. Все вершины
добавляются в левый верхний угол транспортной сети, откуда они могут быть
перемещены на требуемое место. Вершины добавляются в текущий граф. Добавление
ребра осуществляется в два этапа. При нажатии на кнопку "Добавить"
текущая вершина считается стартовой, и пользователь переходит в режим добавления
ребра, в котором он дважды должен кликнуть на вершине конечной. Предусмотрен
запрет на создание петель и дублирующихся рёбер.
Удаление элементов
Удаление элементов связано с рядом сложностей.
Во-первых, для хранения объектов используется списочная структура и её
реорганизация может потребовать достаточно большого времени. Поэтому выбрана
стратегия, согласно которой элементы помечаются на удаление, а само удаление
откладывается до прямого требования пользователя. Во-вторых, удаление элементов
может потребовать удаление зависимых элементов. В связи с этим предусмотрены
следующие правила:
если граф помечен на удаление, все рёбра и
вершины в него входящие так же помечаются на удаление;
если вершина помечена на удаление, все рёбра ей
инцидентные также помечаются на удаление;
Реализация этих правил осуществляется при помощи
свойств, которые меняют признак пометки на удаление не только для заданного
пользователем объекта, но и для всех с ним связных .
Редактирование элементов
Пользователь может менять все характеристики
элементов. При этом на признак доступности элемента и признак невидимости
распространяются те же правила что и на признак пометки на удаление.
А все элементы управления на форме имеют
соответствующие обработчики событий, которые при изменении значений сразу
фиксируют их.
Для хранения данных использовался формат XML.
Этот открытый формат имеет явные преимущества, т.к. является стандартом. Таким
образом, транспортная сеть в этом формате потенциально может использоваться и в
других приложениях. Для сохранения в вышеуказанный формат использовались
принципы сериализации и десериализации.
Т.к. рабочая структура данных не может быть
использована для сериализации в текстовый формат (сериализации возможна только
в бинарный формат данных), была разработана более простая промежуточная схема
хранения данных не на основе списков, а на основе массивов.
Использовались стандартные диалоги открытия и
сохранения файлов.
3.4 Задание условий поиска
Условия поиска задаются при помощи компонента
numericUpDown.
Поиск маршрутов
В этом разделе будет представлено 4 реализации
алгоритма поиска оптимального маршрута удовлетворяющего ограничениям связанным
с невозможностью превышения количества пересадок.
Листинг предложенных алгоритмов представлены в
приложении.
Все представленные алгоритмы обладают похожей
секцией инициализации:
Перед осуществлением непосредственного поиска
выполняются следующие действия.
. Выполняется проверка того, что пользователь
указал стартовую и конечную вершины. Эта предварительная проверка позволяет не
запускать алгоритм поиска в том случае, если для его работы недостаточно
исходных данных.
. Проверяется заблокированность стартовой и
конечной вершин. Эта предварительная проверка позволяет не запускать алгоритм
поиска в том случае, если в связи имеющимися ограничениями путь в принципе не
может существовать.
. Все вершины, которые ранее были помечены как
часть пути, должны потерять эту отметку.
. Все рёбра, которые ранее были помечены как
часть пути, должны потерять эту отметку.
. Создаётся стек для хранения вершин входящих в
оптимальный путь. Создаётся стек для хранения рёбер входящих в оптимальный
путь. По идее этот стек является избыточным, т.к. рёбра могут быть
восстановлены из последовательности вершин, но его наличие позволяет получить к
рёбрам непосредственный доступ без дополнительных затрат на их поиск.
Использование стека для хранения обусловлено тем фактом, что для поиска в
глубину эта структура данных является более удобной и естественной.
. Начальная стоимость оптимального пути
принимается за максимальное целое число. Подобное допущение возможно в силу
того, что транспортная сеть является конечной и в качестве весовых
коэффициентов рёбер используются целые положительные числа.
. Создаётся стек для хранения вершин, входящих в
текущий путь. Создаётся стек для хранения рёбер, входящих в текущий путь.
. Вес текущего пути принимается за ноль.
. Количество сделанных пересадок принимается за
ноль. После осуществления поиска оптимального маршрута выполняются действия
необходимые для его визуализации.
. Делается проверка того, изменила ли значение
переменная, в которой должен храниться вес оптимального пути. Перед запуском
алгоритма поиска маршрута эта переменная имела значение равное максимальному
целому числу. Если переменная не изменила значение, делается вывод о том, что
при заданных условиях ни один путь между начальной и конечной вершинами не
может быть найден, и пользователю выводится соответствующее сообщение.
. Из стека извлекаются все рёбра вошедшие в
оптимальный маршрут.. Каждое ребро, извлечённое из стека, помечается как часть
оптимального маршрута. Для каждого ребра, извлечённого из стека, определяются
образующие его вершины и так же помечаются как часть оптимального маршрута.
. Осуществляется отрисовка транспортной сети с
отмеченным на ней маршрутом.
Поиск в глубину (рекурсивная версия)
Перейдём к самому алгоритму поиска. Данная
версия алгоритма поиска в глубину была реализована с использованием рекурсии,
т.к. рекурсия является очень естественным приёмом при работе с графами.
Учитывая тот факт, что использование рекурсии может приводить к замедлению
работы алгоритма в следующем параграфе будет рассмотрена версия алгоритма
поиска вглубину без использования рекурсии. Основная идея алгоритма состоит в
следующем.
В функцию передаётся 4 параметра:
. Вершина, в которой мы сейчас находимся (из
какой вершины пришли).
. Вершина, в которую мы хотим пойти.
. Ребро, по которому мы хотим пойти.
. Вершина, в которую мы хотим попасть.
Функция содержит избыточные данные (например,
зная текущую и следующую вершину мы легко можем восстановить ребро по которому
мы хотим пойти), но это упрощает реализацию алгоритма, т.к. не требует
организации дополнительного поиска в графовой структуре данных.
Стеки вершин и рёбер, а также стоимости текущего
и оптимального пути задаются при помощи глобальных переменных.
При первом запуске алгоритма, мы не находимся ни
в одной из вершин, поэтому первый параметр функции принимает значение минус
единица. Аналогичная ситуация складывается с третьим параметром. В связи с тем,
что мы попадаем в стартовую вершину не через какое-либо из существующих рёбер,
то этот параметр так же равняется минус единице. Второй параметр соответствует
стартовой вершине. Четвёртый параметр соответствует той вершине, в которую мы
хотим попасть.
Перейдём к штатному режиму работы алгоритма.
В-первую очередь проверяется "А можно ли
идти в эту вершину?". Идти нельзя если:
мы уже были в этой вершине (если пренебречь
этим условием, то возможно образование циклов, а т.к. веса рёбер у нас всегда
положительные, то путь, в котором есть цикл, никогда не сможет стать
оптимальным);
вершина заблокирована; ребро заблокировано.
Если нельзя, то функция досрочно прекращает свою
работу. Во-вторых, проверяется "А нужно ли идти в эту вершину?". Идти
не нужно если:
если мы получим путь более тяжёлый, чем текущий
оптимальный (эта эвристика позволяет нам не рассматривать полностью все пути и
сокращать перебор, отсекая ненужные ветви, в том случае, если заведомо
известно, что маршрут с текущим префиксом не сможет быть оптимальным); если мы
получим количество пересадок, большее, чем заложено в ограничении (это основное
отличие классического алгоритма поиска в глубину от рассматриваемого при
решении поставленной задачи). Если не нужно, то функция досрочно прекращает
свою работу. После этих проверок вершина, которая подходит по всем параметрам,
добавляется в стек вершин, в котором хранится текущий путь.
Затем пересчитываются показатели.
увеличивается вес текущего пути (соответственно
на вес ребра по которому был сделан очередной шаг алгоритма поиска в глубину);
при необходимости увеличивается количество пересадок. Делается проверка "А
не достигли ли мы заданной вершины?". Если вершина достигнута, то делается
проверка на то, а не является ли текущий путь более оптимальным (в смысле
суммарного веса), по сравнению с текущим кандидатом на оптимальность. Если
текущий путь лучше, то он записывается на место оптимального.
Далее осуществляется шаг рекурсии. Для всех
рёбер, выходящих из текущей вершины, делается рекурсивный вызов, тем самым
обеспечивается полный перебор, который и требуется для решения поставленной
задачи.
При нормальном завершении работы функции
необходима реализация корректного возврата из рекурсии, т.е. должны быть
пересчитаны показатели:
уменьшается вес текущего пути (т.к. мы движемся
обратно по маршруту); при необходимости уменьшается количество пересадок. И,
наконец, из стека извлекается текущая вершина.
Поиск в глубину (нерекурсивная версия)
Нерекурсивная версия этого алгоритма может иметь
выигрыш по скорости работы в связи с тем что:
Каждый вызов рекурсивной функции приводит к
тому, что происходит надстраивание программного стека, сохраняется точка
возврата, создаётся окружение для запуска функции, выделяется память под
локальные переменные и т.д.увеличиваются требования по памяти
o увеличиваются требования по количеству
выполняемых инструкций.
Кроме того, алгоритм уже имеет в своём составе
стек, в котором хранится текущий путь. В принципе, при использовании
рекурсивной версии поиска в глубину есть возможность избежать необходимости
хранения пройденного пути в стеке, т.к. этот путь может быть восстановлен при
обратном ходе рекурсии. Кроме того, современные процессоры и компиляторы имеют
ряд механизмов, оптимизирующих рекурсивные вызовы таким образом, что накладные
расходы будут практически не заметны. Но, учитывая, что в данном случае
решается не классическая задача поиска в глубину, этот подход может вызвать ряд
проблем.
В нерекурсивную функцию поиска в глубину
передаётся только два параметра: стартовая вершина, и вершина в которую мы
хотим попасть.
Рассмотрим сам алгоритм.
. Осуществляется проверка того, не является ли
стартовая вершина совпадающей с финальной вершиной. Если это так, то
осуществляется досрочный выход из функции поиска маршрута. При этом ни одно
ребро не может быть помечено как часть оптимального пути т.к. согласно принятым
выше ограничениям в графе не могут присутствовать петли. Поэтому только одна
вершина добавляется в список вершин, входящих в оптимальный путь.
. Для каждой вершины заводится вспомогательный
массив, в котором хранится порядковый номер ребра, которое было выбрано перед
переходом в следующую вершину. В рекурсивной версии алгоритма не было
необходимости в этой переменной, т.к. эта информация сохранялась перед
рекурсивным вызовом в локальной переменной. Элементы этого вспомогательного
массива инициализируются значением минус единица, т.к. ни одно ребро ещё не
было выбрано.
. В стек складывается текущая вершина, с которой
начинается поиск.
. Поиск продолжается до тех пор, пока не будут
просмотрены все возможные маршруты. Учитывая специфику алгоритма поиска
(которая будет рассмотрена ниже) при возврате назад, все посещённые ранее
вершины постепенно извлекаются из стека. Поэтому условием завершения поиска
является извлечение из стека последней вершины (т.е. когда он становится
пустым). В рекурсивной версии мы имеем почти аналогичное условие, только там
пустым становится стек рекурсивных вызовов.
. Верхняя вершина стека является текущей.
Осуществляется проверка того, а не дошли ли мы до финальной вершины.. Если мы
дошли до финальной вершины, то необходимо выполнить уже стандартную проверку
того, а не является ли найденный путь более лёгким по сравнению с текущим
кандидатом на оптимальный маршрут. Если это действительно так, то текущий путь
запоминается как оптимальный и его вес так же запоминается. Далее нам
необходимо сделать шаг назад, что бы мы могли проверить альтернативные пути,
исходящие из предыдущей вершины. Для этого нам необходимо просмотреть ребро,
находящееся на вершине стека рёбер, и узнать из какой вершины мы пришли. Смысла
дальнейшего передвижения из финальной вершины по графу нет, поэтому далее
делается шаг назад:. из стека вершин текущего маршрута извлекается верхняя
вершина;. из стека рёбер текущего маршрута извлекается верхнее ребро;. вес
текущего маршрута уменьшается на вес извлечённого ребра;. если возврат назад на
один шаг связан с пересадкой, то текущее количество сделанных пересадок
уменьшается на единицу.. В том случае, если мы ещё не дошли до финальной
вершины нам необходимо просмотреть все рёбра, по которым может быть
осуществлено движение из текущей вершины. При этом отсекаются пути, которые
приводят нас в вершины, которые уже хранятся в текущем пути. Это делается в
силу того, что маршрут, содержащий цикл никогда не может претендовать на статус
оптимального в плане суммарного веса посещённых рёбер. Так же не
рассматриваются заблокированные рёбра и рёбра, которые приводят в
заблокированные вершины. В силу ограничений на максимальное количество
пересадок не рассматриваются рёбра, которые приводят к превышению заданного количества.
Для первого ребра, прошедшего вышеуказанную проверку, выполняется следующий
набор действий:. вершина, в которую попадает ребро, добавляется в стек вершин и
становится текущей;. ребро добавляется в стек, в котором хранится текущий
маршрут;. на этом цикл завершается, т.к. делается шаг в следующую вершину, но
для вершины, из которой делается шаг, запоминается на каком ребре была сделана
остановка, с тем, чтобы по возвращению в эту вершину, продолжить перебор
возможных маршрутов.. После того, как все рёбра, выходящие из текущей вершины,
проверены, делается шаг назад. Для этого. из стека вершин текущего маршрута
извлекается верхняя вершина;. из стека рёбер текущего маршрута извлекается
верхнее ребро;. вес текущего маршрута уменьшается на вес извлечённого ребра;.
если возврат назад на один шаг связан с пересадкой, то текущее количество
сделанных пересадок уменьшается на единицу; v. и так как мы ушли из текущей
вершины, счётчик просмотренных из неё рёбер обнуляется, т.е. принимает значение
минус единица. Очевидно, что этот алгоритм является самым эффективным в плане
использования оперативной памяти, т.к. мы храним только один текущий путь.
Рассмотрим вопрос, связанный со скоростью работы. Все представленные в этой
работе алгоритмы основаны на полном переборе. Во всех алгоритмах используются
одинаковые эвристики, позволяющие отсекать заведомо неоптимальные ветви.
Следовательно, с этой точки зрения ускорение возможно по следующим
направлениям:
. отказаться от рекурсии (что и было сделано в
рамках данного алгоритма);
. использование избыточных данных, позволяющих
хранить уже рассчитанные значения (что и было сделано во всех предложенных
алгоритмах);
. использование многопоточных алгоритмов,
рассчитанных на выполнение на многоядерных процессорах (что и будет сделано в
следующих разделах).
Поиск в ширину (однопоточная версия)
Функция поиска в ширину является более
требовательной в плане использования оперативной памяти, т.к. ней все пути
рассматриваются параллельно. Особенно эта проблема становится актуальной в графах
с большим количеством связей. Поэтому однопоточная версия этого алгоритма не
желательна для использования и приводится в силу того, что на её основе будет
строиться многопоточная версия.
Алгоритму на вход подаётся два параметра, номер
стартовой вершины и номер конечной вершины. Перед запуском алгоритма
осуществляется проверка на то, не совпадают ли стартовая и конечная вершина. В
случае совпадения производится досрочный выход из функции подобно тому, как это
делалось в предыдущем алгоритме.
Как и раньше текущий путь будет размещаться в
структуре данных типа стек. Туда помещается стартовая вершина.
В классической версии поиска в ширину
используется структура данных типа очередь. Однако мы не можем использовать
только очередь, т.к. нам важен не только обход графа в заданном порядке, нам
необходимо иметь возможность хранения всего пройденного пути и сравнения его с
оптимальным. Именно в силу этого условия будет использована не просто очередь,
а очередь стеков (в каждом стеке будет храниться один из потенциальных путей).
На самом деле будет использовать 4 очереди.
В первой очереди будут храниться стеки вершин
потенциальных маршрутов. Во второй очереди будут храниться стеки рёбер
потенциальных маршрутов. В третьей очереди будут храниться веса потенциальных
маршрутов. И в четвёртой очереди будут храниться количества пересадок сделанных
на текущий момент для каждого из потенциальных маршрутов. По мере достижения
финальной вершины, маршруты будут удаляться из очередей. Поэтому условием
окончания работы алгоритма будет тот факт, что одна из очередей будет пуста.
Пусть это будет очередь вершин. Основной цикл до опустения очереди вершин будет
выглядеть следующим образом:
. Из начала очереди маршрутов из вершин
извлекается маршрут и делается текущим.
. Из начала очереди маршрутов из рёбер
извлекается маршрут и делается текущим.
. Из начала очереди весов извлекается вес
текущего маршрута. 4. Из начала очереди количества пересадок извлекается
текущее количество пересадок.
. Извлекаем с вершины стека вершин текущего
маршрута вершину и делаем её текущей.
. Если текущая вершина совпадает с финальной
вершиной, то осуществляется проверка того, а не является ли текущий путь более
лёгким, по сравнению с текущим, считающимся оптимальным маршрутом. И если это
так, то он записывается на его место и его вес также запоминается.
.
Если же текущая вершина не является финальной, то нам необходимо сформировать
все возможные направления движения из неё исходящие. Для этого просматриваются
все рёбра, которые выходят из текущей вершины. Не рассматриваются рёбра,
которые приводят к возникновению циклов, т.е. приводят к вершинам уже
находящимся в текущем пути. Так же не рассматриваются заблокированные рёбра и
рёбра, приводящие в заблокированные вершины. Не рассматриваются рёбра, имеющие
такой вес, которые будучи сложенным с текущим весом, будет превышать вес
текущего оптимального маршрута. Не рассматриваются рёбра, которые ведут к
превышению максимально возможного количества пересадок. После того, как
подходящие ребра найдены, для каждого из них осуществляется следующая
последовательность действий:. в стек вершин добавляется конечная вершина
ребра;. в стек рёбер добавляется ребро;. пересчитывается текущий вес за счёт
прибавления веса ребра, по которому осуществляется переход;. пересчитывается текущее
количество пересадок, в соответствии с ребром по которому осуществляется
переход;. копия стека вершин помещается в конец очереди стеков вершин;. копия
стека рёбер помещается в конец очереди стеков рёбер; g. вес текущего пути
помещается в конец очереди весов; h. количество пересадок текущего пути
помещается в конец очереди количества пересадок;. делается шаг назад путём
извлечения вершины из стека текущих вершин и извлечением ребра из стека текущих
рёбер, также пересчитывается текущий вес путём вычитания веса удалённого ребра
и пересчитывается количество сделанных пересадок в сторону уменьшения.
Поиск
в ширину (многопоточная версия)
Этот
метод является улучшенной версией поиска в ширину. Он сохраняет тот же самый
принцип обхода графа, но позволяет одновременно просматривать сразу несколько
потенциальных маршрутов. Распараллеливание поиска в глубину невозможно в силу
специфики порядка обхода вершин. В данной версии алгоритма не осуществляется
ограничение на максимальное количество одновременно работающих потоков, и при
необходимости, может быть осуществлено за счёт использования механизма пула
потоков. В силу многопоточности для запуска алгоритма используются
дополнительные построения.
.
Заводится глобальная переменная, в которой хранится текущее количество активных
потоков. Каждый поток при запуске увеличивает её значение и уменьшает перед
завершением.
.
Заводится вспомогательная структура данных хранящая в себе полный набор
параметров необходимых для алгоритма. Это делается в силу того, что
функции-делегату представляющей собой тело потока может быть передан только
один параметр типа object. В состав структуры входят следующие поля:. текущая
вершина; b. конечная вершина; c. текущий вес;. текущее количество пересадок;.
стек вершин, входящих в текущий путь; f. стек рёбер, входящих в текущий путь.
После
запуска потока для осуществления поиска в ширину главный поток, отвечающий за
работу формы должен дождаться завершения всех вспомогательных потоков. Для
этого он ждёт завершения первого созданного потока, а затем ждёт пока
переменная, в которой хранится текущее количество активных потоков, не станет
равной нулю. Отдельное ожидание завершения первого порождённого потока
необходимо в силу того, что он может не успеть инициализироваться и
инкрементировать значение переменной, в которой хранится текущее количество
активных потоков.
Рассмотрим
сам алгоритм:
.
Увеличивается количество активных потоков.
.
В локальный стек вершин помещается текущая вершина.
.
Если текущая вершина совпадает с финальной вершиной, то необходимо проверить,
не является ли текущий путь лучшим по сравнению с кандидатом на оптимальность.
Однако, подобная проверка может быть осуществлена только в рамках критической
секции, которая помогает избежать потенциальных конфликтов с параллельными
потоками. И, если текущий путь лучше оно копируется в качестве оптимального и
его вес запоминается (эти два действия так же должны осуществляться в рамках
критической секции).
.
Если же мы ещё не дошли до финальной вершины. Перебираются все рёбра исходящие
из текущей вершины. Не рассматриваются рёбра, которые приводят к возникновению
циклов, т.е. приводят к вершинам уже находящимся в текущем пути. Так же не
рассматриваются заблокированные рёбра и рёбра, приводящие в заблокированные
вершины. Не рассматриваются рёбра, имеющие такой вес, которые будучи сложенным
с текущим весом, будет превышать вес текущего оптимального маршрута. После
того, как подходящие ребра найдены, для каждого из них осуществляется следующая
последовательность действий:. формируется копия текущего стека вершин; b.
формируется копия текущего стека рёбер;. формируется копия веса текущего пути;.
формируется копия количества пересадок на текущем пути;. в копию стека вершин
помещается конец ребра, по которому мы хотим идти;. в копию сетка рёбер помещается
рёбро, по которому мы хотим идти;. копия веса текущего пути увеличивается на
вес ребра, по которому мы хотим пойти;. копия количества пересадок на текущем
пути если ребро ведёт в другую транспортную сеть;. и вместо того чтобы
помещать это всё в конец очереди, как это делалось в классическом поиске в
ширину создаётся ещё один поток с только что сформированным набором параметров.
.
После того как все возможные пути из текущей вершины перебраны и
соответствующие потоки стартовали, поток уничтожается, уменьшая количество
запущенных потоков на единицу.
3.5 Пример работы алгоритма
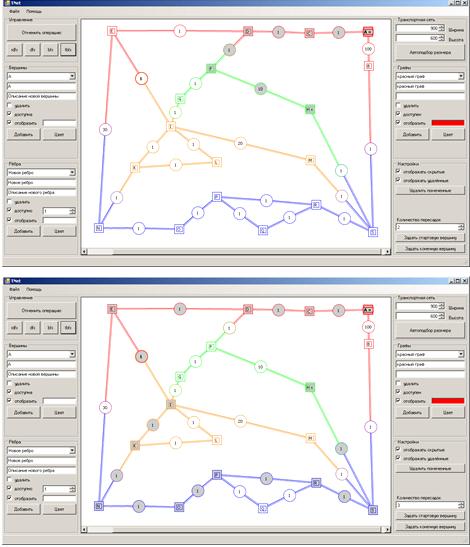
Рассмотрим небольшой пример. Пусть необходимо
найти путь из вершины A в вершину H. При двух разрешённых пересадках
оптимальный путь (представленный на верхнем рисунке) состоит из четырёх рёбер и
имеет вес равный 13. При трёх разрешённых пересадках оптимальный путь
(представленный на нижнем рисунке) состоит из одиннадцати рёбер и имеет вес
равный 11. Подобный результат обеспечивают все разработанные алгоритмы.
Заключение
В ходе дипломной работы была спроектирована и
разработана вычислительная система для решения задач транспортной логистики. В
результате проведённого исследования было разработано четыре модифицированных
алгоритма поиска оптимального маршрута в транспортной сети с возможностью
задания широкого спектра дополнительных условий и ограничений.
В результате проведённого анализа наиболее
заслуживающими внимания с точки зрения практического использования были
признаны: нерекурсивный поиск в глубину и многопоточный поиск ширину. Первый из
них менее требователен к оперативной памяти и ориентирован на исполнение в
системах, базирующихся на процессоре с одним ядром. Второй имеет большие
требования к оперативной памяти, но за счёт использования многопоточности может
быть более быстродействующим в системах, базирующихся на многоядерных
процессорах.
Так же была разработана собственная модель для
внутреннего представления транспортной сети.
В качестве среды разработки был выбран пакет
Visual Studio 2008. Реализация велась с использованием языка программирования
высокого уровня C#. Для хранения транспортной сети использовались принципы
сериализации объектов и формат XML. Были выявлены отличительные особенности и положительные
стороны данной среды программирования.
На основе разработанного модифицированного
алгоритма и модели внутреннего представления данных был создан программный
комплекс, обладающий следующими возможностями:
. Создание, модификация, загрузка, сохранение
транспортной сети.
. Визуализация транспортной сети с возможностью
с возможностью временного сокрытия отдельных её частей.
. Задание условий поиска и критериев
оптимальности поиска маршрута.
. Осуществление поиска маршрутов с учётом
заданных ограничений.
Одним из дальнейших направлений развития данной
дипломной работы может быть более подробное исследование многопоточной версии
алгоритма поиска в ширину и определения такого максимального количества
работающих параллельных потоков, которое бы обеспечивало и высокую скорость
работы и не допускало бы пробуксовки.
Список используемых источников и литературы
1. Задачи по программированию. /
С.А. Абрамов, Г.Г. Гнездилова, Е.Н. Капустина, М.И. Селюн. - Москва: Наука,
1988. - 234 с.
. Вентцель, С.Е. Исследование
операций: задачи, принципы, методология. / С.Е. Вентцель. - Москва. : Наука,
1980. - 304 с.
. Вирт, Н. Алгоритмы и структуры
данных. / Н. Вирт. - Москва: Мир, 1989. - 340 с.
. Демидович, Е.М.
Основы
алгоритмизации и программирования. Язык СИ. / Е.М. Демидович. - Мосвка:
"Бестпринт" 2003. - 403 с.
. Дейтл, Х. C#. / Х. Дейтл. - Санкт
Петербург. : БХВ-Петербург, 2006.- 542 с.
. Лекции по теории графов. / В.А.
Емеличев, О.И. Мельников, В.И. Сарванов, Р.И. Тышкевич. - Москва: Наука, 1990.
- 674 с.
. Кормен, М.Т. Часть VI. Алгоритмы
для работы с графами // Алгоритмы: построение и анализ. - Москва:
"Вильямс", 2006. - 345 с.
. Кнут, Д.Э. Искусство
программирования, том 3. Сортировка и поиск, 2-е изд. / Д.Э. Кнут. - Москва.:
ООО "И.Д. Вильямс", 2007. - 832с.
. Культин, Н.Б. Microsoft Visual C#
в задачах и примерах. / Н.Б. Культин. - Санкт Петербург: БХВ-Петербург, 2009. -
289 с.
. Лахатин, А.С. Языки
программирования. Учеб. пособие. / А.С. Лахатин, Л.Ю. Искакова. - Екатеринбург,
1998. - 548 с.: ил.
. Левитин, А.В. Алгоритмы: введение
в разработку и анализ. / А.В. Левитин. - Москва : "Вильямс", 2006. -
430 с.
. Меньшиков, Ф. Олимпиадные задачи
по программированию. / Ф. Меньшиков. - Санкт Петербург. : "Питер",
2006. - 386 с.
. Мудров, В.И. Задача о
коммивояжере. / В.И. Мудров. - Москва: "Знание", 1969. - 254 с.
Муртаф, Б. Современное линейное
программирование. / Б. Муртаф. - Москва: Мир, 1984. - 630 с.
. C# 2005 и платформа .NET 3.0 для
профессионалов. / К. Нейгл, Б. Ивьен, Д. Глинн и др. - Москва: ООО "И.Д.
Вильямс", 2008. - 765 с.
. Оре, О. Теория графов. / О. Оре. -
Москва: Наука, 1968. - 380 с.
. Павловская, Т.А. C#.
Программирование на языке высокого уровня. / Т.А. Павловская. - Санкт
Петербург: "Питер", 2007. - 544 с.
. Поляков, А. Программирование на
языке Си. / А. Поляков. - Москва: Наука,. 2012. - 460 с.
. Сербин, Д.В. Основы логистики. /
Д.В. Сербин. - Таганрог: ТРТУ, 2004. - 420 с.
. Сток, Р.Д. Стратегическое
управление логистикой. / Р.Д. Сток. - Москва: Инфра-М, 2005. - 512 с.
. Стивен, С. Олимпиадные задачи по
программированию. / С. Стивен, М.А. Скиена. - Москва: ИД Кудиц-образ, 2005. -
340 с.
. Стэкер, М.А. Разработка клиентских
Windows-приложений на платформе Microsoft .NET Framework. / М.А. Стэкер, С.Д.
Стэйн, Т. Нортроп. - Санкт Петербург: "Питер", 2008. - 580 с.
. Таха, Х.А. Введение в исследование
операций. / Х.А. Таха. - Москва: "Вильямс", 2007. - 374 с.
. Уилсон, Р. Введение в теорию
графов. Пер с англ. / Р. Уилсон. - Москва: Мир, 1977. - 286 с.
. Уэйт, М. Язык С. Руководство для
начинающих. / М. Уэйт, С. Прага, Д. Мартин. - Москва: Мир, 1995. - 521с.: ил.
. Харари, Ф. Теория графов /
Ф.Харари. - Москва: Мир, 1973. - 420 с.
. Богатырев, А. Язык
программирования С [Электронный ресурс] / А. Богатырев.- электр. дан. - Режим
доступа: http://www.refby.com. - Загл. с экрана.
. программное Обеспечение и Интернет
ресурсы: http://lib.mexmat.ru/
Приложение
Функция отрисовки транспортной сети
public void Draw(bool showInvisible,
bool showDeleted) {
//отрисовать граф
//перо для отрисовкиdcPen = new Pen(Color.Black,
1); //кисть для отрисовки
Brush dcBrush = new
SolidBrush(Color.White);
//если необходимо изменить размер компонента
перед отрисовкой
if (this.pb.Width != this.width ||
this.pb.Height != this.height) {.pb.Width = this.width; this.pb.Height =
this.height;.pb.Image = new Bitmap(this.width, this.height); this.dc =
Graphics.FromImage(this.pb.Image);
}
//отрисовка
ведѐтся
в
высоком
качестве.SmoothingMode
= System.Drawing.Drawing2D.SmoothingMode.HighQuality; dc.TextRenderingHint =
System.Drawing.Text.TextRenderingHint.SingleBitPerPixel;
//заливаем
всю
картинку
белым
цветом
this.dc.FillRectangle(dcBrush, 0, 0, this.width, this.height);
//перед тем как отрисовывать вершины, нужно
отрисовать рѐбра for (int i = 0; i < aEdge.Count; i++)
{
//отрисовываем только видимые и не помеченные
как удалѐнные рѐбра
if ((aEdge[i].Visible == true ||
(aEdge[i].Visible == false && showInvisible == true)) &&
(aEdge[i].Deleted == false || (aEdge[i].Deleted == true && showDeleted
== true)))
{x1 = aVertex[aEdge[i].srcVertex].X;
int y1 = aVertex[aEdge[i].srcVertex].Y; int x2 =
aVertex[aEdge[i].destVertex].X; int y2 = aVertex[aEdge[i].destVertex].Y; int xm
= (x1 + x2) / 2;
int ym = (y1 + y2) / 2;
//цвет исходящий от первой вершины dcPen.Width =
4;
dcPen.Color =
aGraph[aVertex[aEdge[i].srcVertex].iGraph].Color; dc.DrawLine(dcPen, x1, y1,
xm, ym);.Color = aGraph[aVertex[aEdge[i].destVertex].iGraph].Color;
dc.DrawLine(dcPen, x2, y2, xm, ym);.Width = 2;.Color = aEdge[i].Color;
dc.DrawLine(dcPen, x1, y1, x2, y2);
((SolidBrush)dcBrush).Color =
aEdge[i].Color;suffix = ""; string prefix =
"";(aEdge[i].Enabled == false) suffix += "Ч";
if (aEdge[i].Visible == false) suffix += "°"; if (aEdge[i].Deleted ==
true) suffix += "†";(aEdge[i].IsPartOfPath == true) {
//suffix += " ="; //prefix
= "= ";
((SolidBrush)dcBrush).Color =
Color.FromArgb(200, 200, 200); }(aEdge[i].Selected == true) {
dcPen.Width = 2;
//рисуем кружочек за который можно таскать ребро
dc.FillEllipse(dcBrush, xm - rSize,
ym - rSize, 2 * rSize, 2 * rSize);.Color =
aGraph[aVertex[aEdge[i].srcVertex].iGraph].Color; dcPen.DashStyle =
System.Drawing.Drawing2D.DashStyle.Dot; dcPen.DashOffset =
0;.DrawEllipse(dcPen, xm - rSize, ym - rSize, 2 * rSize, 2 * rSize);.Color =
aGraph[aVertex[aEdge[i].destVertex].iGraph].Color; dcPen.DashOffset =
1;.DrawEllipse(dcPen, xm - rSize, ym - rSize, 2 * rSize, 2 * rSize);.DashStyle
= System.Drawing.Drawing2D.DashStyle.Solid;
//надпись на ребре int x = xm;
int y = ym;textSize =
TextRenderer.MeasureText(prefix + aEdge[i].Weight.ToString() + suffix,
textFontBold);-= textSize.Width / 2; y -= textSize.Height / 2;textRect = new
Rectangle(x, y, textSize.Width, textSize.Height);.DrawText(this.dc, prefix +
aEdge[i].Weight.ToString() + suffix, textFontBold, textRect, Color.Black);
} else {.Width = 1;
//рисуем
кружочек
за
который
можно
таскать
ребро
dc.FillEllipse(dcBrush, xm - rSize, ym - rSize, 2 * rSize, 2 * rSize);.Color =
aGraph[aVertex[aEdge[i].srcVertex].iGraph].Color; dcPen.DashStyle =
System.Drawing.Drawing2D.DashStyle.Dot; dcPen.DashOffset =
0;.DrawEllipse(dcPen, xm - rSize, ym - rSize, 2 * rSize, 2 * rSize);.Color =
aGraph[aVertex[aEdge[i].destVertex].iGraph].Color; dcPen.DashOffset =
1;.DrawEllipse(dcPen, xm - rSize, ym - rSize, 2 * rSize, 2 * rSize);.DashStyle
= System.Drawing.Drawing2D.DashStyle.Solid;
//надпись на ребре int x = xm;
int y = ym;textSize =
TextRenderer.MeasureText(prefix + aEdge[i].Weight.ToString() + suffix,
textFontNormal);-= textSize.Width / 2; y -= textSize.Height / 2;textRect = new
Rectangle(x, y, textSize.Width, textSize.Height);.DrawText(this.dc, prefix +
aEdge[i].Weight.ToString() + suffix, textFontNormal, textRect, Color.Black);
} }
}
//теперь необходимо отрисовать вершины for
(int i
= 0; i < aVertex.Count;
i++) {
//отрисовываем только видимые и не помеченные
как удалѐнные вершины
if ((aVertex[i].Visible == true ||
(aVertex[i].Visible == false && showInvisible == true))
&& (aVertex[i].Deleted ==
false || (aVertex[i].Deleted == true && showDeleted == true)))
{
//цвет
границы.Color
= aGraph[aVertex[i].iGraph].Color; //цвет
заполнения
((SolidBrush)dcBrush).Color =
aVertex[i].Color;suffix = "";(aVertex[i].Enabled == false) suffix +=
"Ч";
if (aVertex[i].Visible == false) suffix += "°"; if
(aVertex[i].Deleted == true) suffix += "†";(aVertex[i].IsStart ==
true) suffix += " ""; if (aVertex[i].IsFinish == true) suffix +=
" "";(aVertex[i].IsPartOfPath == true) {
((SolidBrush)dcBrush).Color =
Color.FromArgb(200, 200, 200); }(aVertex[i].Selected == true) {.Width = 2;
* dSize);
* dSize););
//рисуем квадратик за который можно таскать
вершину
dc.FillRectangle(dcBrush,
aVertex[i].X - dSize, aVertex[i].Y - dSize, 2 * dSize,.DrawRectangle(dcPen,
aVertex[i].X - dSize, aVertex[i].Y - dSize, 2 * dSize, 2
//надпись
на
вершине
int x = aVertex[i].X; int y = aVertex[i].Y;textSize =
TextRenderer.MeasureText(aVertex[i].Title + suffix,-= textSize.Width / 2; y -=
textSize.Height / 2;textRect = new Rectangle(x, y, textSize.Width,
textSize.Height); dc.FillRectangle(dcBrush, textRect);.DrawRectangle(dcPen,
textRect);.DrawText(this.dc, aVertex[i].Title + suffix, textFontBold, textRect,
Color.Black);
} else {.Width = 1;
* dSize);
* dSize);
//рисуем квадратик за который можно таскать
вершину
dc.FillRectangle(dcBrush,
aVertex[i].X - dSize, aVertex[i].Y - dSize, 2 * dSize,.DrawRectangle(dcPen,
aVertex[i].X - dSize, aVertex[i].Y - dSize, 2 * dSize, 2
//надпись
на
вершине
int x = aVertex[i].X; int y = aVertex[i].Y;textSize =
TextRenderer.MeasureText(aVertex[i].Title + suffix, textFontNormal);-=
textSize.Width / 2; y -= textSize.Height / 2;textRect = new Rectangle(x, y,
textSize.Width, textSize.Height); dc.FillRectangle(dcBrush,
textRect);.DrawRectangle(dcPen, textRect);.DrawText(this.dc, aVertex[i].Title +
suffix, textFontNormal, textRect, Color.Black);
} }
}
//обновляем
картинку
т.к.
перерисовали
this.pb.Refresh();
}
Свойство, реализующее признак видимости графа
new public bool Visible
{{base.Visible; }{.Visible = value;
//наследовать свойство видимости всем
принадлежащим графу вершинам for
(int i
= 0; i < this.iVertex.Count;
i++)
{.aVertex[this.iVertex[i]].Visible =
value; }
} }
Свойство, реализующее признак видимости вершины
new
public bool
Visible {
get {base.Visible; }{.Visible =
value;
//наследовать свойство видимости смежным рѐбрам
for (int
i = 0; i
< this.iEdge.Count;
i++)
{.aEdge[this.iEdge[i]].Visible =
value; }
} }
Свойство базового класса, реализующее свойство
видимости
public bool Visible {{this.visible;
}
set {.visible = value; }
}
Функции для сохранения/загрузки транспортной
сети
private void menuItemСохранить_Click(object
sender, EventArgs e) {(saveFileDialogTN.ShowDialog() == DialogResult.OK) {
//экземпляр xmlSer класса XmlSerializer нужен
для сериализацииxmlSer = new
XmlSerializer(typeof(TransportNetworkSerialization)); //имя файла в который
будет сохраняться результат сериализации
//string fileName =
System.Environment.CurrentDirectory + "\\tst.xml"; string fileName =
saveFileDialogTN.FileName;
//поток fileStream для создания XML-файла
FileStream fileStream = new FileStream(fileName,
FileMode.Create);tns = new TransportNetworkSerialization();
tn.PreSerialize(tns);
//сериализация
xmlSer.Serialize(fileStream, tns); //закрываем
поток
fileStream.Close();
} }void menuItemЗагрузить_Click(object
sender, EventArgs e) {(openFileDialogTN.ShowDialog() == DialogResult.OK) {
//экземпляр xmlSer класса XmlSerializer нужен
для десериализацииxmlSer = new
XmlSerializer(typeof(TransportNetworkSerialization)); //имя файла из которого
будет осуществляться десериализации
//string fileName = System.Environment.CurrentDirectory
+ "\\tst.xml"; string fileName = openFileDialogTN.FileName;
//поток fileStream для чтения XML-файла
FileStream fileStream = new
FileStream(fileName, FileMode.Open);tns = new TransportNetworkSerialization();
//десериализация=
(TransportNetworkSerialization)xmlSer.Deserialize(fileStream); //закрываем
поток
fileStream.Close();
//теперь нужно развернуть транспортную сеть
//нужно очистить все списки tn.aEdge.Clear();
tn.aVertex.Clear(); tn.aGraph.Clear();
//и визуальные списки тоже необходимо очистить
comboBoxEdge.Items.Clear(); comboBoxVertex.Items.Clear();
comboBoxGraph.Items.Clear();
//и поля ввода тоже необходимо очистить
textBoxGraphTitle.Text = ""; textBoxGraphDescription.Text =
""; checkBoxGraphDeleted.Checked = false; checkBoxGraphEnabled.Checked
= true; checkBoxGraphVisible.Checked = true; panelGraph.BackColor =
Color.Black;
textBoxVertexTitle.Text =
""; textBoxVertexDescription.Text = "";
checkBoxVertexDeleted.Checked = false; checkBoxVertexEnabled.Checked = true;
checkBoxVertexVisible.Checked = true; panelVertex.BackColor = Color.White;.Text
= ""; textBoxEdgeDescription.Text = ""; checkBoxEdgeDeleted.Checked
= false; checkBoxEdgeEnabled.Checked = true; checkBoxEdgeVisible.Checked =
true; panelEdge.BackColor = Color.White; numericUpDownEdge.Value = 0;
//а теперь в списки нужно добавлять значения
//сначала
будем
добавлять
графы(int
i = 0; i < tns.aGraph.Length; i++) {_Click(sender, e);
textBoxGraphTitle.Text = tns.aGraph[i].title;.Text = tns.aGraph[i].description;
checkBoxGraphDeleted.Checked = tns.aGraph[i].deleted;
checkBoxGraphEnabled.Checked = tns.aGraph[i].enabled;
checkBoxGraphVisible.Checked = tns.aGraph[i].visible;.BackColor =
Color.FromArgb(tns.aGraph[i].colorR, tns.aGraph[i].colorG,
tns.aGraph[i].colorB);.aGraph[i].Color = panelGraph.BackColor; }
//теперь необходимо добавить вершины
for (int i = 0; i <
tns.aVertex.Length; i++) {.SelectedIndex = tns.aVertex[i].iGraph;
buttonVertexAdd_Click(sender, e); textBoxVertexTitle.Text =
tns.aVertex[i].title;.Text = tns.aVertex[i].description;
checkBoxVertexDeleted.Checked = tns.aVertex[i].deleted;
checkBoxVertexEnabled.Checked = tns.aVertex[i].enabled; checkBoxVertexVisible.Checked
= tns.aVertex[i].visible;.BackColor = Color.FromArgb(tns.aVertex[i].colorR,
tns.aVertex[i].colorG, tns.aVertex[i].colorB);.aVertex[i].Color =
panelVertex.BackColor; tn.aVertex[i].X = tns.aVertex[i].x; tn.aVertex[i].Y =
tns.aVertex[i].y;
}
//и, наконец необходимо добавить рѐбра(int
i = 0; i < tns.aEdge.Length; i++) {
if
(tn.AddEdge(tns.aEdge[i].srcvertex, tns.aEdge[i].destvertex) == true) {
//его
имя
записываем
в
список
comboBoxEdge.Items.Add(tn.aEdge[tn.aEdge.Count - 1].Title); //и
оно
становится
текущим.SelectedIndex
= tn.aEdge.Count - 1; }.Text = tns.aEdge[i].title; textBoxEdgeDescription.Text
= tns.aEdge[i].description; checkBoxEdgeDeleted.Checked = tns.aEdge[i].deleted;
checkBoxEdgeEnabled.Checked = tns.aEdge[i].enabled; checkBoxEdgeVisible.Checked
= tns.aEdge[i].visible;.BackColor = Color.FromArgb(tns.aEdge[i].colorR,
tns.aEdge[i].colorG, tns.aEdge[i].colorB);.aEdge[i].Color =
panelEdge.BackColor; numericUpDownEdge.Value = tns.aEdge[i].weight;
}
//сначала
устанавливаем
ширину
и
высоту
транспортной
сети
this.numericUpDownWidth.Value = tns.width; this.numericUpDownHeight.Value =
tns.height;
} }void
PreSerialize(TransportNetworkSerialization tns) {
//подготовить данные для сериализации
//сначала подготовить графы
tns.aGraph = new GraphSerialization[this.aGraph.Count];
for (int i = 0; i < tns.aGraph.Length; i++)
{.aGraph[i] = new
GraphSerialization(); tns.aGraph[i].colorR = this.aGraph[i].Color.R;
tns.aGraph[i].colorG = this.aGraph[i].Color.G; tns.aGraph[i].colorB =
this.aGraph[i].Color.B; tns.aGraph[i].deleted = this.aGraph[i].Deleted;
tns.aGraph[i].description = this.aGraph[i].Description; tns.aGraph[i].enabled =
this.aGraph[i].Enabled; tns.aGraph[i].selected = this.aGraph[i].Selected;
tns.aGraph[i].title = this.aGraph[i].Title; tns.aGraph[i].visible =
this.aGraph[i].Visible;
}
//потом
подготовить
вершины.aVertex
= new VertexSerialization[this.aVertex.Count]; for (int i = 0; i <
tns.aVertex.Length; i++)
{.aVertex[i] = new
VertexSerialization(); tns.aVertex[i].colorR = this.aVertex[i].Color.R; tns.aVertex[i].colorG
= this.aVertex[i].Color.G; tns.aVertex[i].colorB = this.aVertex[i].Color.B;
tns.aVertex[i].deleted = this.aVertex[i].Deleted; tns.aVertex[i].description =
this.aVertex[i].Description; tns.aVertex[i].enabled = this.aVertex[i].Enabled;
tns.aVertex[i].selected = this.aVertex[i].Selected; tns.aVertex[i].title =
this.aVertex[i].Title; tns.aVertex[i].visible = this.aVertex[i].Visible;
tns.aVertex[i].x = this.aVertex[i].X;.aVertex[i].y = this.aVertex[i].Y;
tns.aVertex[i].iGraph = this.aVertex[i].iGraph;
}
//и,
наконец
подготовить
рѐбра.aEdge
= new EdgeSerialization[this.aEdge.Count]; for (int i = 0; i <
tns.aEdge.Length; i++)
{.aEdge[i] = new
EdgeSerialization(); tns.aEdge[i].colorR = this.aEdge[i].Color.R;
tns.aEdge[i].colorG = this.aEdge[i].Color.G; tns.aEdge[i].colorB =
this.aEdge[i].Color.B; tns.aEdge[i].deleted = this.aEdge[i].Deleted;
tns.aEdge[i].description = this.aEdge[i].Description; tns.aEdge[i].enabled =
this.aEdge[i].Enabled;.aEdge[i].selected = this.aEdge[i].Selected;
tns.aEdge[i].title = this.aEdge[i].Title; tns.aEdge[i].visible =
this.aEdge[i].Visible; tns.aEdge[i].srcvertex = this.aEdge[i].srcVertex;
tns.aEdge[i].destvertex = this.aEdge[i].destVertex; tns.aEdge[i].weight =
this.aEdge[i].Weight;
}
//и не забыть сохранить ширину и высоту
транспортной сети tns.width = this.Width;.height = this.Height; }
Функции для осуществления поиска в глубину
//многопоточный поиск в ширину public void
tbfs(object p)
{_count++;t =
(ptbfs)p;.current_pathV.Push(t.start);v;= t.current_pathV.Peek();
//увеличиваем количество запущенных потоков
//в стеке лежит путь, а путь мы начинаем с
стартовой вершины
//номер текущей вершины //узнаѐм номер
текущей вершины(v == t.finish) {
//если дошли до финальной вершины lock (locker)
{(t.current_weight < best_weight)
{_weight = t.current_weight;_path = new Stack<int>(t.current_pathV);
best_pathE = new Stack<int>(t.current_pathE);
} }
//если дошли до финальной вершины }{
//если же мы не дошли ещѐ до финальной
вершины
//идти из этой вершины во все остальные по
очереди foreach (int iE in tn.aVertex[v].iEdge)
{
int vv; //один
из вариантов, куда можно пойти if (tn.aEdge[iE].srcVertex == v)
vv = tn.aEdge[iE].destVertex; else=
tn.aEdge[iE].srcVertex;
if (t.current_pathV.Contains(vv) == true) //туда
идти нельзя, мы там уже были continue; //и
дальше можно эту вершину не обсчитывать
if (tn.aVertex[vv].Enabled == false)
continue;
//в неѐ идти нельзя, она заблокированная
//и дальше можно эту вершину не обсчитывать
if (tn.aEdge[iE].Enabled == false)//по этому
ребру идти нельзя, оно заблокированное continue; //и
дальше можно эту вершину не обсчитыватьw = tn.aEdge[iE].Weight; //вес
того ребра по которому мы можем пойти lock (locker)
{(t.current_weight + w >
best_weight)//есть более
лѐгкие
пути
continue; //и
дальше можно эту вершину не обсчитывать }
int tr; //нужна
ли пересадка для попадания в следующую //она нужна если вершины принадлежат
разным транспортным сетям
if (tn.aVertex[v].iGraph !=
tn.aVertex[vv].iGraph) tr = 1;= 0;(t.current_transfer + tr >
numericUpDownTransfer.Value) //есть
более
короткие
пути
continue; //и
дальше можно эту вершину не обсчитывать
ptbfs tt = new
ptbfs();.current_pathV = new Stack<int>(t.current_pathV);
tt.current_pathE = new Stack<int>(t.current_pathE);
//идти
в
эту
вершину
//tt.current_pathV.Push(vv); tt.current_pathE.Push(iE); //идти
в
эту
вершину
//пересчитать
показатели.current_transfer
= t.current_transfer + tr; tt.current_weight = t.current_weight + w; //пересчитать
показатели.start
= vv; tt.finish = t.finish;
//положить в стек вершину //положить в стек
ребро
//увеличим количество пересадок //увеличим
стоимость пути
Thread ttt = new Thread(tbfs); //создали
поток ttt.Start(tt); //пустили поток с параметом
}
//если же мы не дошли ещѐ до финальной
вершины }
thread_count--; //не
забыть уменьшить текущее количество потоков }
//поиск
в
ширинуvoid
bfs(int s, int finish) {
//отдельно нужно рассмотреть случай если
стартовая вершина совпадает с финальной if (s == finish)
{ //конечно
это редкий случай, но тем не менее best_path.Push(s);
return; }
current_path.Push(s); //в стеке лежит путь, а
путь мы начинаем с стартовой вершины
//очередь стеков вершин, а в каждом стеке лежит
путь Queue<Stack<int>> qV = new Queue<Stack<int>>();
qV.Enqueue(new Stack<int>(current_path));
//очередь стеков рѐбер, а в каждом стеке
лежит путь Queue<Stack<int>> qE = new
Queue<Stack<int>>(); qE.Enqueue(new
Stack<int>(current_pathE));
//положили в очередь текущий путь
//положили в очередь текущий путь
Queue<int> qW = new
Queue<int>(); qW.Enqueue(0);<int> qT = new Queue<int>();
qT.Enqueue(0);
//очередь весов для каждого пути //положили в
очередь текущий нулевой вес
//очередь количества пересадок для каждого пути
//положили в очередь текущее нулевое количество пересадок
while (qV.Count != 0) //пока мы
не просмотрим все возможные пути {
current_path = new
Stack<int>(qV.Dequeue()); //достаѐм из стека текущий путь вершин
current_pathE = new Stack<int>(qE.Dequeue()); //достаѐм из
стека текущий путь рѐбер current_weight = qW.Dequeue(); //узнаѐм
его вес
current_transfer = qT.Dequeue(); //узнаѐм
сколько пересадок было на этом пути
int v;= current_path.Peek();(v ==
finish) {
//если
дошли
до
финальной
вершины
if (current_weight < best_weight) {_weight = current_weight;_path = new
Stack<int>(current_path); best_pathE = new
Stack<int>(current_pathE);
}
//если дошли до финальной вершины }{
//если же мы не дошли ещѐ до финальной
вершины
//номер текущей вершины //узнаѐм номер
текущей вершины
//идти из этой вершины во все остальные по
очереди foreach (int iE in tn.aVertex[v].iEdge)
{
int vv; //один
из вариантов, куда можно пойти if (tn.aEdge[iE].srcVertex == v)
vv = tn.aEdge[iE].destVertex; else=
tn.aEdge[iE].srcVertex;
if (current_path.Contains(vv) == true) //туда
идти нельзя, мы там уже были continue; //и
дальше можно эту вершину не обсчитывать(tn.aVertex[vv].Enabled == false) //в неѐ
идти нельзя, она заблокированная continue; //и
дальше можно эту вершину не обсчитывать
//по этому ребру идти нельзя, оно
заблокированное if (tn.aEdge[iE].Enabled == false)
continue; //и
дальше можно эту вершину не обсчитывать
int w = tn.aEdge[iE].Weight; //вес
того ребра по которому мы можем пойти if (current_weight + w > best_weight)
//есть более лѐгкие пути
continue; //и
дальше можно эту вершину не обсчитывать
int t; //нужна
ли пересадка для попадания в следующую //она нужна если вершины принадлежат
разным транспортным сетям
if (tn.aVertex[v].iGraph !=
tn.aVertex[vv].iGraph) t = 1;
else= 0;
//есть более короткие пути
if (current_transfer + t >
numericUpDownTransfer.Value)
continue; //и
дальше можно эту вершину не обсчитывать
//идти в эту вершину current_path.Push(vv);
current_pathE.Push(iE); //идти в эту вершину
//пересчитать показатели current_transfer += t;
current_weight += w; //пересчитать показатели
//положить в стек вершину //положить в стек
ребро
//увеличим количество пересадок //увеличим
стоимость пути
//генерируем для очереди очередное направление
движения qV.Enqueue(new Stack<int>(current_path));
//генерируем для очереди очередное направление
движения qE.Enqueue(new Stack<int>(current_pathE));
//генерируем для очереди очередное направление
движения qW.Enqueue(current_weight);
//генерируем для очереди очередное направление
движения qT.Enqueue(current_transfer);
//вернуться
current_path.Pop(); current_pathE.Pop(); //вернуться
//достать из стека вершину //достать из стека
ребро
//вернуться и пересчитать показатели
current_transfer -= t; //уменьшим
количество пересадок current_weight -= w; //уменьшим
стоимость пути //вернуться и персчитать показатели
}
//если же мы не дошли ещѐ до финальной
вершины }
} }
//нерекурсивный
поиск
в
глубину
private void dfs(int s, int finish) {
//отдельно нужно рассмотреть случай если
стартовая вершина совпадает с финальной if (s == finish)
{ //конечно
это редкий случай, но тем не менее best_path.Push(s);
return; }
int v; //номер
текущей вершины
//в этом всмпомогательном массиве мы будем
помнить индекс ребра по которому ходили из этой вершины в последний раз
int[] d = new int[tn.aVertex.Count];
//ни из одной вершины никуда ещѐ не ходили
for (int i = 0; i <
tn.aVertex.Count; i++) d[i] = -1;_path.Push(s);(current_path.Count != 0)
{= current_path.Peek();
//в стеке лежит путь, а путь мы начинаем с
стартовой вершины //пока мы не просмотрим все возможные пути
//узнаѐм номер текущей вершины
if (v
== finish) {
//если
дошли
до
финальной
вершины
if (current_weight < best_weight) {_weight = current_weight;_path = new
Stack<int>(current_path); best_pathE = new
Stack<int>(current_pathE);
}
//если дошли
int e; //по
какому ребру дошли до финальной вершины //узнаѐм его по вершине стека,
т.к. в стеке что-то точно есть
e = current_pathE.Peek();
int v1 = tn.aEdge[e].srcVertex; //начало
ребра по которому пришли int v2 = tn.aEdge[e].destVertex; //конец
ребра по которому пришли
int t; //нужна
ли была пересадка для попадания в эту вершину //она нужна если вершины
принадлежат разным транспортным сетям
if (tn.aVertex[v1].iGraph !=
tn.aVertex[v2].iGraph) t = 1;
else= 0;
int w = tn.aEdge[e].Weight; //вес ребра по
которому мы пришли в финальную вершины
//пересчитать показатели
//уменьшить количество пересадок, т.к. мы
собираемся делать шаг назад current_transfer -= t;
//уменьшить вес текущего пути, т.к. мы
собираемся делать шаг назад current_weight -= w;
//пересчитать показатели
//выйти из этой вершины current_path.Pop(); current_pathE.Pop();
//выйти из этой вершины
//делаем шаг назад //делаем шаг назад
//и так как мы из этой вершины ушли, то счѐтчик
рѐбер для неѐ обнуляется d[v] = -1;
//если дошли до финальной вершины }{
//если же мы не дошли ещѐ до финальной
вершины
d[v]++; //ищем
дальше по списку куда можно пойти while (d[v] < tn.aVertex[v].iEdge.Count)
{
int vv; //в
эту вершину есть ребро из текущей
int e = tn.aVertex[v].iEdge[d[v]]; //вот как раз
это ребро и идѐт из текущей if (tn.aEdge[e].srcVertex == v)
vv = tn.aEdge[e].destVertex; else=
tn.aEdge[e].srcVertex;
if (current_path.Contains(vv) == true)//туда
идти нельзя, мы там уже были {
d[v]++; //ищем
дальше по списку куда можно пойти continue; //и
дальше можно эту вершину не обсчитывать
}(tn.aVertex[vv].Enabled == false) {
d[v]++; continue;
}
//в неѐ идти нельзя, она заблокированная
//ищем дальше по списку куда можно пойти //и
дальше можно эту вершину не обсчитывать
//по этому ребру идти нельзя, оно
заблокированное if (tn.aEdge[e].Enabled == false)
{
d[v]++; //ищем
дальше по списку куда можно пойти continue; //и
дальше можно эту вершину не обсчитывать
}
int w = tn.aEdge[e].Weight; //вес
того ребра по которому мы можем пойти if (current_weight + w > best_weight)
//есть более лѐгкие пути
{
d[v]++; //ищем
дальше по списку куда можно пойти continue; //и
дальше можно эту вершину не обсчитывать
}
int t; //нужна
ли пересадка для попадания в следующую //она нужна если вершины принадлежат
разным транспортным сетям
if (tn.aVertex[v].iGraph !=
tn.aVertex[vv].iGraph) t = 1;
else= 0;
//есть более короткие пути
if (current_transfer + t >
numericUpDownTransfer.Value) {
d[v]++; //ищем
дальше по списку куда можно пойти continue; //и
дальше можно эту вершину не обсчитывать
}
//идти в эту вершину current_path.Push(vv);
current_pathE.Push(e); //идти в эту вершину
//пересчитать показатели current_transfer += t;
current_weight += w; //пересчитать показатели
//положить в стек вершину //положить в стек
ребро
//увеличим количество пересадок //увеличим
стоимость пути
//и так как мы пошли в вершину, то у нас теперь
другая текущая и цикл нужно кончать
break; }(v == current_path.Peek())
{(v == s) current_path.Pop(); if (v == s) break;
//если из вершины идти дальше некуда
//делаем последний шаг назад //именно последний
шаг назад
int e; //по
какому ребру дошли до этой вершины //узнаѐм его по вершине стека, т.к. в
стеке что-то точно есть
e = current_pathE.Peek();
int v1 = tn.aEdge[e].srcVertex; //начало
ребра по которому пришли int v2 = tn.aEdge[e].destVertex; //конец
ребра по которому пришли
int t; //нужна ли была пересадка для попадания в
эту вершину //она нужна если вершины принадлежат разным транспортным сетям
if (tn.aVertex[v1].iGraph !=
tn.aVertex[v2].iGraph) t = 1;
else= 0;
int w = tn.aEdge[e].Weight; //вес ребра
по которому мы пришли в эту вершины //пересчитать показатели
//уменьшить количество пересадок, т.к. мы
собираемся делать шаг назад current_transfer -= t;
//уменьшить вес текущего пути, т.к. мы
собираемся делать шаг назад current_weight -= w;
//пересчитать показатели
//выйти из этой вершины
current_path.Pop(); //делаем шаг назад
current_pathE.Pop(); //делаем шаг назад //выйти из этой вершины
//и так как мы из этой вершины ушли, то счѐтчик
рѐбер для неѐ обнуляется d[v] = -1;
}
//если же мы не дошли ещѐ до финальной
вершины }
} }
//рекурсивный
поиск
в
глубинуvoid
rdfs(int s, int v, int e, int finish) {
//можно ли идти в эту вершину
if (current_path.Contains(v) ==
true) return; if (tn.aVertex[v].Enabled == false) return; if (e != -1)
if (tn.aEdge[e].Enabled == false) return;
//можно ли идти в эту вершину
//нужно ли идти в эту вершину int w;
if (e != -1)= tn.aEdge[e].Weight;
else= 0;(current_weight + w > best_weight) return;
//мы в ней уже были //в неѐ идти нельзя
//по этому ребру идти нельзя
//вес того ребра, по которому идѐм
//есть более лѐгкие пути
int t; //нужна ли пересадка if (e != -1)
{
if (tn.aVertex[s].iGraph
!= tn.aVertex[v].iGraph)
t = 1;
else
t = 0; }
else
t = 0;
if (current_transfer
+ t > numericUpDownTransfer.Value)
//есть
более
короткие
пути
return;
//нужно ли идти в эту вершину
//идти в эту вершину current_path.Push(v);
if (e != -1) current_pathE.Push(e);
//идти
в
эту
вершину
//пересчитать показатели current_transfer += t;
current_weight += w; //пересчитать показатели
//если
дошли(v
== finish) {(current_weight < best_weight) {_weight = current_weight;_path =
new Stack<int>(current_path); best_pathE = new
Stack<int>(current_pathE);
} }
//если дошли
//идти из этой вершины во все остальные по
очереди foreach (int iE in tn.aVertex[v].iEdge)
{
int vv; //один
из вариантов, куда можно пойти if (tn.aEdge[iE].srcVertex == v)
vv = tn.aEdge[iE].destVertex; else=
tn.aEdge[iE].srcVertex;(v, vv, iE, finish); }
//идти из этой вершины во все остальные по
очереди
//пересчитать показатели current_transfer -= t;
current_weight -= w; //пересчитать показатели
}
Функция поиска оптимального пути
private void
buttonSearch_Click(object sender, EventArgs e) {
int start=-1; //стартовая вершина int
finish=-1; //конечная вершина
//ищем стартовую и конечную вершину
for (int i = 0; i <
tn.aVertex.Count; i++) {(tn.aVertex[i].IsStart == true) start = i; if
(tn.aVertex[i].IsFinish == true) finish = i;
}
//если хотя бы одну не нашли(start == -1 ||
finish == -1) {
//ошибка.Show("Не указана начальная или
конечная вершина!", "Ошибка", MessageBoxButtons.OK,
MessageBoxIcon.Error);
//и
выходим
return;
}(tn.aVertex[start].Enabled == false
|| tn.aVertex[finish].Enabled == false) {
//ошибка.Show("Начальная
или
конечная
вершина
заблокированы!",
"Ошибка",
MessageBoxButtons.OK, MessageBoxIcon.Error);
//и выходим return;
}
//нужно снять отметку с старого пути
for (int i = 0; i <
tn.aEdge.Count; i++) {.aEdge[i].IsPartOfPath = false; }
//нужно снять отметку с старого пути
for (int i = 0; i <
tn.aVertex.Count; i++) {.aVertex[i].IsPartOfPath = false; }_path.Clear();
best_pathE.Clear(); best_weight = int.MaxValue;_path.Clear();
current_pathE.Clear(); current_weight = 0; current_transfer = 0;
rdfs(-1, start, -1, finish);
//если не нашли путь
if (best_weight == int.MaxValue) {
//ошибка.Show("Путь
до
конечной
вершины
не
может
быть
найден!",
"Ошибка",
MessageBoxButtons.OK, MessageBoxIcon.Error);
//и выходим return;
}
//теперь нужно пометить путь while
(best_pathE.Count != 0) {i =
best_pathE.Pop();.aEdge[i].IsPartOfPath =
true;.aVertex[tn.aEdge[i].srcVertex].IsPartOfPath = true;
tn.aVertex[tn.aEdge[i].destVertex].IsPartOfPath = true;
}
//отрисовать.Draw(checkBoxShowInvisible.Checked,
checkBoxShowDeleted.Checked);
}