Программа обнаружения и выделения текста
Введение
Распознавание текста на изображениях - это очень важная задача, имеющая
множество практических приложений: индексирование фотографий и видео, мобильное
распознавание текста, навигация роботов и многие другие.
Сегодня цифровая камера есть почти в каждом телефоне, смартфоне и
планшете. На сервис хостинга видеозаписей YouTube, согласно их официальной
статистике[29] ежесекундно загружается 72 часа видео, количество же фотографий
в интернете и вовсе сложно сосчитать. Необходимо найти способ эффективно управлять
этими мультимедиа ресурсами и анализировать их содержимое. Текст, содержащий
высокоуровневую смысловую информацию, очень хорошо подходит для решения этой
задачи. Например, текст на изображениях в интернете может соотноситься с
содержимым веб страниц. Текст на обложках книг и журналов зачастую необходим
для их индексации, так две книги с одинаковым оформлением, но разными
заглавиями будут внешне неотличимы, если не известен текст на обложках.

Рисунок 1.1. Демонстрация работы приложения “Word Lens”
Заголовки новостей обычно содержат информацию о том где, когда и с кем
произошло событие, описываемое в репортаже. Субтитры к спортивным видео могут
содержать информацию о счете и спортсменах. Кроме того, в отличие от другой
информации, которую можно получить из изображения, текст создается людьми,
поэтому он может напрямую определять содержимое безо всяких вычислений.
Нас окружает очень большое количество текстовой информации, такой как
таблички, знаки, вывески. К сожалению, не все и не всегда могут ей
воспользоваться. Например, слабовидящим может быть полезно устройство, читающее
для них вслух. И даже у здоровых людей при въезде в другую страну могут
возникнуть проблемы из-за языкового барьера. Для последних создаются программы,
которые могут переводить текст с фотографий на язык, указанный пользователем.
Например, приложение Word Lens, пример работы которого приведен на рис. 1.1.
Навигация при помощи GPS или ГЛОНАСС достаточно удобна, но не всегда
доступна. Внутри некоторых помещений, где нет сигнала от спутника, её
использовать невозможно. А в случае, например, атомной бомбардировки воздух
ионизируется, и радиосвязь перестает быть доступной. Поэтому роботам для
полноценного ориентирования необходимо использовать визуальную информацию. Как
уже было сказано ранее, текст может быть очень полезен. Номера домов, таблички
на кабинетах, схемы, планы и маршрутные карты - все это может быть
использовано, но только, если робот сможет распознать текст на них.
Помимо этого существует множество приложений, в которых необходимо
автоматически распознавать текст на изображении: сканирование автомобильных
номеров при автоматической фиксации нарушений или нанесение на карту различных
организаций, используя панорамные снимки улиц.
А в некоторых случаях, выделение текста имеет значение само по себе.
Например, момент появления заголовка в видеозаписи новостей может фиксировать
начало нового сюжета, что может использоваться при автоматическом реферировании
видео. Или, может быть, необходимо просто привлечь внимание пользователя к
какому-то тексту.
К. Юнг и соавторы в работе [15] дали определение интегрированной системы
получения текстовой информации из изображений (рис. 1.2), состоящей из четырех
этапов:
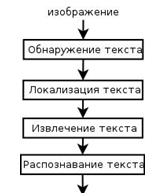
Рисунок 1.2 Архитектура интегрированной системы получения текстовой
информации из изображений
. Обнаружение. На этом этапе определяется, есть ли на изображении текст
или нет.
2. Локализация. На втором этапе определяется местоположение текста.
Обычно результатом работы этого этапа является описывающий прямоугольник, в
котором содержится текст.
. Извлечение. Выделенные текстовые области очищаются от всего
постороннего, убирается фон. Текст группируется на слова и символы.
. Распознавание. На последнем этапе происходит непосредственно
само преобразование графической информации в текст.
Из всех этапов обнаружение и локализация текста, наиболее критичны для
общей производительности системы. Кроме того, эти два этапа можно рассматривать
совместно. Ведь если текст обнаружен, то известно его местоположение.
В последние годы было предложено значительное количество методов для
решения этих задач, но быстрое и точное выделение текста на фотографиях до сих
пор остается достаточно сложной проблемой из-за большого разнообразия шрифтов,
размеров, цветов, способов ориентирования в пространстве. Часто эту проблему
усугубляют изменения освещения, сложный фон, препятствия, искажения изображения
и потеря качества при сжатии.
В 2003, 2005 и 2011 годах в рамках конференции ICDAR были проведены
соревнования на лучший алгоритм автоматического выделения и распознавания
текста. Результаты, продемонстрированные там, ясно показывают, что проблема не
решена до конца. Так результат победителя 2011 года [22], Кима Чугуун: полнота
62,47% и точность 82.98%.
Полнота и точность - величины характеризующие качество работы алгоритмов
поиска и классификации. В рамках данной предметной области точность - отношение
площади выделенных текстовых областей к общей площади выделенных областей.
Полнота - отношение площади выделенных текстовых областей к общей площади
текстовых областей.
В этой работе, была поставлена задача, исследовать некоторые из
существующих на сегодняшний день методов обнаружения и выделения текста, и на
их основе построить систему обнаружения и выделения текста на изображениях.
1.Обзор
источников
текст изображение интегрированный
Существующие на данный момент методы выделения текста можно условно
разделить на две группы: методы, основанные на анализе регионов и методы,
основанные на анализе компонент связности. Методы, на основе анализа регионов
выполняют текстурный анализ фрагментов изображения. Для каждого фрагмента,
региона, генерируется вектор значений, состоящий из численных оценок различных
текстурных свойств. Этот вектор подается на вход классификатору, который
оценивает степень “текстовости” региона. Затем, соседние текстовые регионы
объединяются для получения блоков текста. Из-за того, что текстурные признаки
текстовых областей отличаются от признаков нетекстовых областей, то такие
методы могут обнаруживать текст даже на достаточно зашумленных изображениях.
Методы, на основе анализа компонент связности разделяют все изображение на
отдельные компоненты по какому-либо признаку, например, по цвету. Нетекстовые
компоненты отбрасываются при помощи эвристик или классификаторов. Так как
количество сегментов-кандидатов относительно мало, данные методы имеют меньшую
вычислительную сложность, чем методы, основанные на анализе регионов, а
выделенные текстовые компоненты могут напрямую использоваться для
распознавания.
Хотя существующие подходы заявляют о впечатляющих результатах, все еще
существует ряд проблем. Методы, на основе анализа регионов работают
относительно медленно, и их производительность чувствительна к расположению
текста. Напротив, методы на основе анализа компонент связности не могут точно
сегментировать текст без информации о расположении и масштабе текста. Более
того, существует множество нетекстовых компонент, которые легко спутать с
текстовыми, при индивидуальном анализе. Например, колесо автомобиля можно
принять за букву “О”. Стоит отметить, что некоторые работы предлагают смешанные
подходы, в которых используются методы на основе анализа и регионов и компонент
связности.
1.1 Методы, основанные на анализе регионов
В своей работе Адам Коатс и соавторы [7] предложили интересный подход,
основанный на обучении без учителя для получения признаков. Разработанная ими
система состоит из трёх этапов:
. Применяется алгоритм обучения без учителя для получения набора
рассчитанных признаков из фрагментов изображений, полученных из обучающего
множества.
2. Уменьшается количество признаков путем использования
пространственного объединения [2].
. Обучается классификатор для выделения текста.
На первом этапе системы они собирают коллекцию фрагментов изображений 8
на 8 пикселей в градациях серого. Все фрагменты предварительно обрабатывают.
Для этого сначала нормализуют значения интенсивности и градиента каждого
фрагмента, вычитая из значений этих величин в каждой точке их математическое
ожидание и умножая полученную разность на среднеквадратичное отклонение. Потом
применяют забеливание [14] [18] на основе анализа нулевых компонент.
Забеливание используется для предварительной обработки вектора признаков. Оно
нормирует значения векторов таким образом, что коэффициенты вариации отдельных
величин становятся равны.
Затем, из нормализованных и забеленных данных, при помощи алгоритма
К-средних, получают набор признаков.
Пространственное объединение применяется для сокращения количества
информации представляющей каждый фрагмент изображения. Авторы статьи используют
квадратные фрагменты стороной 32 пикселя. Для каждой области 8 на 8 пикселей в
этом фрагменте рассчитывается вектор признаков. Далее используется усредняющее
объединение, то есть просто рассчитывается новый вектор как среднее
арифметическое всех векторов, описывающих восьмипиксельные области. Если этого
не сделать, то количество информации возрастет многократно.
В качестве классификатора используется метод опорных векторов [26]. Свое
обучающее множество Коатс и его коллеги строят на основе обучающего набора
данных ICDAR 2003 [23], получая из него фрагменты 32 на 32 пикселя. Для
определения, является ли фрагмент текстом или нет, используется уже готовая
разметка исходного набора. Общий размер полученного множества составил 60000
фрагментов.
При детектировании используется метод скользящего окна. Вычисляется
вектор признаков для каждого тридцатидвухпиксельного фрагмента изображения.
Данные вычисления проводятся несколько раз, для разного масштаба изображения,
для того чтобы детектировать текст разного размера. Затем каждому пикселю
исходного изображения ставится в соответствие максимальный результат
классификатора, полученный для всех фрагментов его содержащих, при разных
масштабах. Полученные значения бинаризуются с некоторым порогом и в результате
получается маска указывающая наличие текста на изображении. Варьируя порог
бинаризации, можно получать различные значения точности и полноты. Точность
рассчитывается как отношения количества правильно маркированных пикселей к
общему числу маркированных пикселей. Полнота - как отношение количества
правильно маркированных пикселей к общему числу пикселей, которые следовало
маркировать.
Этот подход показывает далеко не самые высокие результаты (точность 61% при
полноте 69%), но он интересен тем, что не использует каких-то логически
обоснованных признаков, а получает их сам.
Система, описанная в работе [6], является очень хорошим примером системы
основанной на анализе регионов. Ее создатели решили использовать не абстрактные
признаки, такие как собственные числа, рассчитанные для фрагмента изображения
(такой признак использовался в [7]), или вейвлеты Хаара. Вместо этого они
искали более информативные признаки, а именно такие, которые будут давать
схожие результаты для различных текстовых регионов.
Первый набор признаков основан на наблюдении за поведением производных по
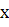 и
и 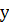 в пределах текстового региона.
Авторы выбрали из обучающего множества все текстовые области, растянули или
сжали их до фиксированного размера, и посчитали для них значения производных.
Средние величины производных формируют определенный шаблон.
в пределах текстового региона.
Авторы выбрали из обучающего множества все текстовые области, растянули или
сжали их до фиксированного размера, и посчитали для них значения производных.
Средние величины производных формируют определенный шаблон.
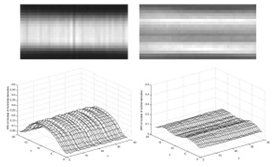
Рисунок 1.3. Наверху: математические ожидания значений производных по (слева) и по (справа). Внизу: их дисперсия.
Из рисунка 1.3 видно, что значения производных на заднем фоне (выше и
ниже текста) достаточно низкие. Производная по имеет большие значения в центральной
области, где и находится непосредственно текст. А производная по принимает большие значения на
границе текста и фона, а в центральной части она мала. Также дисперсия
производной по имеет большие значения в центре, из-за того, что символы
имеют разнообразную форму и размер. А у производной по значения дисперсии отличаются слабо.
Исходя из данного наблюдения, рассчитываются признаки в различных
областях фрагмента изображения (сверху, снизу, в центре). Границы областей
взяты из анализа рисунка 1.1. Следующей группой признаков являются признаки,
основанные на гистограммах интенсивности, направления и модуля градиента. В
искусственных изображениях часто бывает резкая граница между текстом и фоном,
поэтому можно легко разделить их по наличию двух пиков на гистограмме. В
реальных изображениях, которые рассматриваются в этой работе, границы, как
правило, смазаны, и гистограмма имеет только один пик. Поэтому используются
кроме уже перечисленных гистограмм еще и совмещенные гистограммы интенсивности
и градиента.
Третьей группой признаков являются признаки, основанные на выделении
границ, такие как количество граней, их размеры.
По заявлению авторов их алгоритм детектирует 97% текста на изображениях(
точность детектирования не называется). Из-за выбора первых признаков, алгоритм
не детектирует негоризонтальный текст и, по заявлению авторов, плохо работает с
одиночными символами.
Надежда Рубцова и ее коллеги в работе [19] представили интегрированную
систему для распознавания текста, реализующую все этапы подобной системы: от
обнаружения до распознавания. Главная идея их работы состоит в интеграции
отдельных этапов и использовании результатов одних этапов на других.
Для выделения текста они используют следующий подход: как и во всех
остальных работах, использующих анализ регионов, происходит построение пирамиды
изображений с различными масштабами. Далее, каждое изображение разбивается на
фрагменты размером 20 на 20 пикселей, которые называют нодами. Первый этап
называется анализом нод. На данном этапе, похожие ноды объединяются в более
крупные формации - регионы. Для определения степени схожести используется
несколько признаков. Первый из них это гистограмма интенсивности из десяти
интервалов.
Кроме того ноды характеризуются гранями. Гранью, в терминологии данной работы,
является переходная область, выделенная высокими значениями градиента, между
областями с разной интенсивностью. Авторы используют грани, как локальную
характеристику, и не рассчитывают их для всего изображения, так как значения
градиента могут сильно отличаться между его различными областями. Этот
локальный анализ состоит в разделении всех величин градиента на существенные и
не существенные, при помощи EM-алгоритма [1] [8]. Области, которым
соответствуют существенные величины градиента, помечаются на маске локальных
граней. На этой маске указаны широкие области перехода и игнорируются узкие,
однопиксельные, грани.
Третий признак, характеризующий ноды, рассчитывается на основе
преобразования ширины штриха [9]. Рассчитывается преобразование для изображения
в каждом из масштабов, штрихи шириной более пяти пикселей при этом
отбрасываются. Далее, чтобы заполнить незначительные пустоты на стыках
фрагментов символов оставшихся после преобразования или убрать случайный шумы,
результат преобразования складывается с результатом детектора границ Кэнни [5]
и размывается. Так как после размытия маска перестает быть бинарной, то
полученный результат называют уже содержимым ширины штриха. Характеристикой
нода является сумма значений содержимого: если оно находится ниже определенного
порога, то это значит, что фрагмент изображения в ноде однороден и не будет
сливаться с другими нодами.
После объединения соседних схожих нод в регионы наступает этап анализа
регионов. Регионы классифицируются на текстовые и нетекстовые, при помощи
классификатора, на основе метода опорных векторов [25] [26]. Для классификации
используются семь признаков, почти все из которых основаны на построении, так
называемой, ЕМ-модели. Авторы предлагают при помощи EM-алгоритма разложить
распределение интенсивности в небольшой области вокруг граней, в пределах
региона на два класса: ”текст” и ”фон”. А в качестве признаков использовать
разницу между математическими ожиданиями полученных распределений: отношению
между количеством пикселей региона относящихся к одной из моделей к общему
количеству пикселей и отношению разницы бинаризованного EM-моделью региона и
маски локальных граней, от всех нод входящих в регион к бинаризованному
региону. Также продемонстрирована попытка смоделировать то же распределение интенсивности,
только одним распределением, и отношение ошибок показывает, на сколько точнее
модель при помощи одного распределения чем при помощи двух распределений.
Признаки Тамуры [27], отношение размера областей перехода к размеру региона и
сам размер региона являются единственными признаками не основанными на
ЕМ-модели. Полученный классификатор обучался на наборе данных ICDAR 2003.
Далее следует дополнительная обработка регионов и распознавание текста,
но это выходит за рамки данной работы.
В самой работе приведены только результаты работы всей системы и не
вполне ясно насколько хорошо работает выделение текста. Несмотря на это, в ней
используются интересные признаки, которые можно использовать в дальнейшем.
1.2 Методы, основанные на анализе компонент связности
В работе [9] Б. Эпштейна, Э. Офека и Е. Векслера представлен способ
выделения независимых компонент на основе оператора ширины штриха. Оператор
ширины штриха - это оператор, ставящий в соответствие каждому пикселю исходного
изображений ширину штриха, к которому он наиболее вероятно относится. Сначала,
выделяются грани при помощи оператора Собеля. Затем, начиная от точки на
выделенной грани, в сторону увеличения градиента, для светлого текста на темном
фоне, или уменьшения, для темного на светлом, помечаются все пиксели до
следующей грани. Для всех помеченных пикселей, указывается ширина их штриха,
равная их количеству. Если пиксель был помечен ранее, то значение его ширины
штриха меняется только на меньшее.
Соседние пиксели, значения ширины штриха для которых отличаются не более
чем в три раза, группируются вместе, формируя компоненты связности. Далее ко
всем отдельным компонентам применяются правила, которые позволяют отбросить те
из них, которые скорее всего не являются буквами. Все пороговые параметры для
правил получены из набора данных ICDAR 2003. Авторы делают умозаключение, что
дисперсия ширины штриха в пределах одной компоненты не должна быть слишком
большой. Отношение высоты к ширине должно находится в пределах от 0:1 до 10,
также отношение диаметра компоненты к медиане ширины штриха должно быть меньше
чем 10. Это правило позволяет отфильтровать слишком длинные и узкие компоненты.
Так же, отфильтровываются слишком большие или слишком малые компоненты, то есть
те, которые не входят в диапазон от 10 до 300 пикселей. И, в заключение, чтобы
не учитывать рамки вокруг текста, удаляются из рассмотрения те компоненты,
прямоугольник описывающий которых, содержит более двух других компонент.
Далее, прошедшие фильтрацию компоненты группируются в строки. На этом
этапе компоненты дополнительно отфильтровываются. Так, например, не
рассматриваются отдельные компоненты. Текст внутри одной строки должен иметь
примерно одинаковые ширину штриха, расстояние между символами, размер символов.
Также сравнивается средний цвет соседних символов.
Результаты, заявленные в статье, достаточно высоки: точность 71% при
полноте 60%. Так же этот алгоритм относительно быстрый, в 15 раз быстрее
ближайшего аналога. Правда неизвестно, как и на каких машинах тестировалась его
производительность. Еще благодаря тому, что компоненты связности уже выделены,
то не требуется дополнительное извлечение текста. Из недостатков следует
отметить то, что при фильтрации отбрасываются все отдельно стоящие символы и
негоризонтальные строки, что сильно снижает полноту.
В работе [13] представлен интересный метод выделения текста, в основе
которого лежит бинаризация исходного изображения. Из исходного изображения
получается изображение в оттенках серого (монохромное), называемое в работе 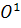 , и инвертированное монохромное,
, и инвертированное монохромное,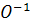 . Далее, при помощи адаптивной
бинаризации, вычисляются два бинаризованных изображения,
. Далее, при помощи адаптивной
бинаризации, вычисляются два бинаризованных изображения, 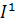 и
и 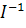 соответственно. Из этих двух
выбирают одно, которое содержит текстовую информацию. Для этого оба
бинаризованных изображения разбиваются на компоненты связности и эти компоненты
проверяют на текстовость. То изображение, в котором больше компонент похожих на
символы, считается содержащим текстовую информацию. Из него убирают компоненты
не прошедшие проверку. Для фильтрации регионов используют такие признаки как
размер компоненты, расстояние между соседними компонентами по горизонтали.
Кроме признаков, используются проверки, такие как имеют ли компоненты схожую
высоту и принадлежат ли они одной строке.
соответственно. Из этих двух
выбирают одно, которое содержит текстовую информацию. Для этого оба
бинаризованных изображения разбиваются на компоненты связности и эти компоненты
проверяют на текстовость. То изображение, в котором больше компонент похожих на
символы, считается содержащим текстовую информацию. Из него убирают компоненты
не прошедшие проверку. Для фильтрации регионов используют такие признаки как
размер компоненты, расстояние между соседними компонентами по горизонтали.
Кроме признаков, используются проверки, такие как имеют ли компоненты схожую
высоту и принадлежат ли они одной строке.
По заявлению разработчиков им удалось выделить “почти все” текстовые
области в наборе данных ICDAR 2003. Несмотря на это, недостатки данного метода
видны из самого его описания. Как и все методы, на основе анализа компонент
связности, данный отфильтровывает одиночные символы, кроме того, разработчиками
установлены искусственные ограничения на количество символов в строке: от 3 до
100. Как и в большинстве методов, невозможно выделить рукописный текст, текст
со сливающимися символами, из-за того что он будет выделятся как одна
компонента и отбрасываться при фильтрации.
1.3 Гибридные методы
Гибридные методы представляют собой попытку объединить в себе анализ
независимых компонент и анализ регионов для выделения текста. Так в работе [17]
предложена система, состоящая из трех этапов.
На первом этапе, предварительной обработки, используется анализ регионов
для поиска областей, которые могут содержать текст. В качестве признака,
используется гистограмма направленных градиентов, а в качестве классификатора -
каскадный классификатор WaldBoost [24]. Следует отметить, что целью этого этапа
является не точное выделение текста, а определение вероятности того, что в
данной области может быть текстом. Для этого, для каждого фрагмента
изображения, не зависимо от того принят он или отклонен, выходные значения
классификатора переводятся в апостериорную вероятность, используя метод
калибровки классификатора. Апостериорная вероятность установки значения 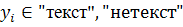 , зависящего от результата работы
классификатора
, зависящего от результата работы
классификатора 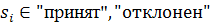 , на стадии
, на стадии 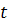 , может быть получена с использованием формулы Байеса:
, может быть получена с использованием формулы Байеса:
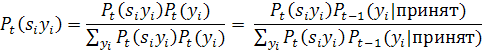
Все вероятности 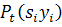 рассчитываются заранее, на этапе обучения. Таким образом,
строятся карты вероятностей для каждого изображения в пирамиде, затем они
проецируются на исходное изображение и получается карта вероятностей для
исходного изображения. Эта карта используется для того, чтобы провести
адаптивную бинаризацию по адаптированному алгоритму Ниблака. Новое значение
интенсивности вычисляется по формуле:
рассчитываются заранее, на этапе обучения. Таким образом,
строятся карты вероятностей для каждого изображения в пирамиде, затем они
проецируются на исходное изображение и получается карта вероятностей для
исходного изображения. Эта карта используется для того, чтобы провести
адаптивную бинаризацию по адаптированному алгоритму Ниблака. Новое значение
интенсивности вычисляется по формуле:
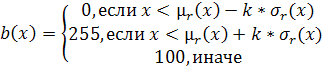
где 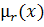 и
и 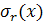 - значения математического ожидания и дисперсии для значений
интенсивности внутри круга радиуса
- значения математического ожидания и дисперсии для значений
интенсивности внутри круга радиуса 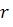 вокруг пикселя
вокруг пикселя 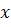 . Сглаживающий коэффициент
. Сглаживающий коэффициент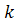 подобран эмпирическим путем.
Значение радиуса
подобран эмпирическим путем.
Значение радиуса 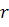 рассчитываетсяна основе значения вероятности текста из
полученной карты вероятностей. Дальше следует переход к анализу независимых
компонент. Для этого выделяются компоненты со значениями интенсивности 0 или
255, а те, чьи значения интенсивности равны 100 - не рассматриваются.
рассчитываетсяна основе значения вероятности текста из
полученной карты вероятностей. Дальше следует переход к анализу независимых
компонент. Для этого выделяются компоненты со значениями интенсивности 0 или
255, а те, чьи значения интенсивности равны 100 - не рассматриваются.
Для анализа компонент используется модель условных случайных полей (CRF,
conditional random field) со следующими признаками:
· Признаки отдельных компонент:
o Нормализованные ширина и высота;
o Отношение ширины к высоте;
o Отношение количества пикселей принадлежащих компоненте к
количеству пикселей принадлежащих минимальному описывающему прямоугольнику;
o Среднее значение вероятности того что пиксели внутри
компоненты являются частью текста. Для этого признака используется карта
вероятностей, полученная на этапе анализа регионов;
o Среднее значение градиента на границе компоненты.
· Признаки пары компонент, вычисляемые для пар соседних
независимых компонент:
o Отношения между минимальными и максимальными шириной и
высотой двух компонент. Текстовые компоненты обычно не отличаются слишком
сильно друг от друга по размерам;
o Расстояние между центрами компонент;
o Перекрытие рассчитывается как отношение между площадью
пересечения компонент с площадями самих компонент;
o Модуль разности средних значений интенсивности компонент.
Уже из анализа самих признаков видно, что данный подход позволяет
находить строки любой формы, но отфильтровывает отдельностоящие символы.
Результаты же тестирования описанной системы на наборе данных ICDAR 2003:
точность 67:4%, полнота 69:7%. По скорости этот метод сильно превосходит
методы, основанные на анализе регионов, но уступает методам на основе анализа
компонент.
Метод, предложенный в статье [16], использует обратный порядок. Сначала
выделяются компоненты связности из бинаризованного изображения. Из них строится
дерево компонент, в каждой вершине которого находится компонента связности,
если одна из компонент лежит в другой, то она становится ее поддеревом. Это
дерево обходится в ширину и каждая из его вершин проверяется на текстовость с
использованием методов на основе анализа регионов. Для этого используется
трехступенчатый каскадный классификатор. В каждом каскаде используется только
один признак. В первом - размер.
Слишком мелкие компоненты, которые невозможно распознать, даже если они
являются символами, и слишком крупные компоненты, занимающие более половины
изображения, отбрасываются. Стоит отметить, что система, описанная в статье,
рассчитана на выделение текста в видео потоке, и ее авторы считают, что на
других кадрах слишком крупный текст может быть показан с другого расстояния в
более читаемом виде. Во втором каскаде - энергия границы. Для этого
рассчитываются значения градиента из исходного изображения вдоль границы
компоненты, а затем считается энергия полученных значений по формуле:
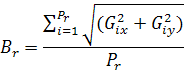
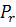 - количество пикселей вдоль границы, а
- количество пикселей вдоль границы, а 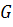 - значения градиента, полученные с
использованием оператора Собеля. Этот признак показывает контраст между
регионом и фоном. В третьем каскаде используется самый затратный по
вычислительной мощности признак, названный авторами текстурностью. Для этого
рассчитываются собственные числа для интенсивностей внутри, описывающий области
вокруг компоненты. Их среднее значение используется в качестве признака.
Высокие значения текстурности соответствуют высоким изменениям частот в
пределах региона.
- значения градиента, полученные с
использованием оператора Собеля. Этот признак показывает контраст между
регионом и фоном. В третьем каскаде используется самый затратный по
вычислительной мощности признак, названный авторами текстурностью. Для этого
рассчитываются собственные числа для интенсивностей внутри, описывающий области
вокруг компоненты. Их среднее значение используется в качестве признака.
Высокие значения текстурности соответствуют высоким изменениям частот в
пределах региона.
Затем все отфильтрованные компоненты-символы объединяются в текст. Для
этого используются только расстояния между компонентами и отношение их
размеров. На этом, последнем, шаге не учитывается их положение, что позволяет
выделять строки любой длины: единственное, что отфильтровывается -
отдельностоящие символы. Численных результатов в работе не приводится, но не
следует ожидать, что они будут очень высокими, так как даже сами разработчики
указывают на то, что выделение проводится довольно грубо, чтобы увеличить
количество кадров в секунду.
2.Выбор средств разработки
.1 Выбор библиотеки
При разработке сложных приложений для работы с изображениями крайне важно
правильно выбрать библиотеку, которая позволяет выполнять все необходимые
задачи. В настоящее время существует всего несколько альтернатив: OpenCV, SimpleCV, Intel Integrated Perfomance Primitives,
Java Advanced Images API, Python Imaging Library.
OpenCV - библиотека с открытым исходным кодом, распространяемая под
лицензией BSD. В этой библиотеке реализованы функции компьютерного зрения,
обработки изображений, машинного обучения и математических алгоритмов.
Библиотека написана на C++, но может быть использована в проектах на языках
Java, Python, Ruby, Matlab и других. Существуют реализации библиотеки для
различных операционных систем, в том числе и для Android. Однако, для некоторых
задач библиотека может быть слишком универсальной и включать в себя много
лишнего.
Intel Integrated Perfomance Primitives - коммерческая библиотека
разработанная компанией Intel.
Реализует множество математических функций, функций обработки сигналов и изображений.
Библиотека очень высоко оптимизирована и использует все расширенные наборы
инструкций современных процессоров, как Intel так и AMD. Работает под
операционными системами Linux, Windows и Max OS. Из недостатков следует
отметить высокую стоимость: 199$ за однопользовательскую лицензию.- библиотека
является попыткой сделать компьютерное зрение доступным людям без специальной
подготовки. Все реализованные функции максимально упрощены, чтобы не вводить
пользователя в смущение. Реализована на Python и предназначена для работы с
ним. Так как проект еще молодой, то его документация не слишком полная и
состоит в основном из примеров использования тех или иных функций.
Java Advanced Images API - библиотека является частью Java SE. Она содержит лишь несколько основных функций для работы с изображениями,
какие-то более или менее сложные функции (поворот изображения, например)
приходится писать самостоятельно.Imaging Library - библиотека распространяется
в двух версиях: свободной и проприетарной. Под свободной лицензией выпускаются
старые проприеритарные версии. Как видно из названия может использоваться
только в проектах на языке Python. У библиотеки почти полностью отсутствует
документация, в расчете на то, что люди будут покупать коммерческую поддержку.
Функции реализовано мало и они рассчитаны в первую очередь на дизайнерскую
обработку изображений и практически отсутствуют возможности для их анализа.
Среди всех рассмотренных альтернатив, было решено, что наиболее
подходящей, в условиях моей задачи, является библиотека OpenCV. В ней
реализовано множество функций, в том числе и для машинного обучения. У нее
имеется достаточно подробная документация. Библиотека распространяется под
свободной лицензией, что позволяет бесплатно использовать ее, в том числе и в
коммерческих приложениях. Кроме того, следует отметить разнообразие платформ и
языков программирования, которые работают с данной библиотекой.
2.2 Выбор языка программирования
Список альтернатив определяется возможностями выбранной библиотеки. Так
как библиотека написана на C++, то и ее интерфейс в первую очередь предназначен
для работы с C++, но также существует полная поддержка интерфейсов для языков
Java и Python. Интерфейсы для других языков реализованы частично или не
стабильно, поэтому рассмотрены только уже перечисленные четыре языка.
Главным критерием для выбора языка программирования является скорость
работы и объем потребляемой памяти программами, написанными на том или ином
языке, так как количество данных, которые предстоит обработать, достаточно велико.
Для сравнения использовался сервис The Computer Language Benchmarks Game.
Данный сервис позволяет сравнивать скорость программ, количество потребляемой
памяти и даже объем кода у аналогичных программ на различных языках
программирования.
Для сравнения, используются одиннадцать различных тестов, с исходными
кодами можно ознакомится на веб-сайте проекта. Так же можно выбрать платформу
для тестирования приложения: одноядерный или четырехядерный процессор и 32х или
64х битная система.
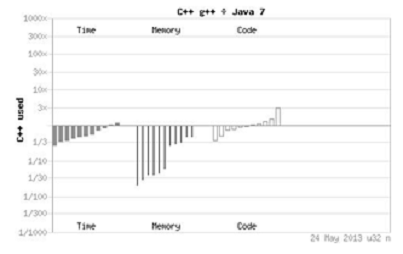
Рисунок 2.1. Сравнение производительности программ на языках C++ и Java.
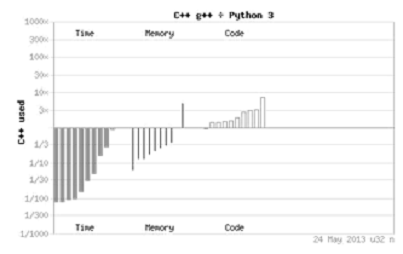
Рисунок 2.2. Сравнение производительности программ на языках C++ и
Python.
Из графика 2.1 видно, программы написанные на языке С++, выполняются
быстрее до трех раз, а памяти занимают более чем в тридцать раз меньше. Преимущество
С++ над Python (см. рис. 2.2) еще более очевидно. Конечно в обоих случаях
программы на С++ проигрывают по такому показателю как количество строк кода.
Это значит что процесс разработки идет дольше.
Из недостатков языка С++ следует отметить то, что в нем отсутствуют
сборщики мусора и другие инструменты, которые делают разработку на Java и
Python более удобной и безопасной, хотя при этом и замедляют выполнение
программ. Но с не удобствами можно мириться, а для контроля утечек памяти
существуют специальные инструменты.
3.Разработка классификатора
.1 Выбор классификатора
Существует множество различных классификаторов. В библиотеке OpenCV
реализованы следующие:
Нормальный байесовский классификатор
Эта простая модель подразумевает, что вектора признаков из каждого класса
имеют нормальное распределение, и распределены независимо. Поэтому
распределение всех данных можно представить как смесь гауссианов, по одной
компоненте на класс. Используя обучающее множество, алгоритм получает вектор
математических ожиданий и матрицы ковариации для каждого класса, а затем
использует их для предсказания.
Достоинством метода является то, что не требуется много данных для
обучения. Но требуется выполнения условия независимости переменных, хотя и при
зависимых он может работать успешно.
Алгоритмы на основе метода опорных векторов.
Основная идея метода опорных векторов - перевод исходных векторов в
пространство более высокой размерности и поиск разделяющей гиперплоскости с
максимальным зазором в этом пространстве. Две параллельных гиперплоскости
строятся по обеим сторонам гиперплоскости, разделяющей наши классы. Оптимальным
решением считается то, которое максимизирует расстояние от разделяющей
гиперплоскости, до ближайших векторов признаков из обоих классов (в случае двух
классов). Ближайшие к гиперплоскости вектора называются опорными векторами, это
значит, что положение остальных векторов не влияет на гиперплоскость.
Деревья принятия решений
Это бинарные деревья, которые могут использоваться для классификации или
для регрессии. При решении задач классификации, каждая листовая вершина
помечается меткой класса, несколько вершин могут иметь одну метку. При решении
задач регрессии в листовые вершины помещаются константы, поэтому задача
регрессии сводится к выбору константы. А во всех остальных вершинах находятся
пороговые значения, полученные в результате обучения классификатора, и номер
переменной в векторе признаков, значение которой должно проверяться в этой
вершине. Начиная из корня, и до достижения листовой вершины, классификатор
выбирает левое поддерево, если значение признака меньше порога, или правое,
если значение больше порога.
Бустинг
Бустинг это мощный подход к машинному обучению, который позволяет
объединять несколько слабых классификаторов в один мощный. Даже если каждый из
составляющих классификаторов работает чуть лучше чем генератор случайных чисел,
то результирующий может быть сравним по точности работы с методом опорных
векторов или с нейронными сетями.
Самым популярным слабым классификатором, использующимся в бустинге,
является дерево принятия решений. Можно использовать даже деревья, в которых
есть только одна не листовая вершина, так называемые пеньки. Реализация
бустинга в библиотеке OpenCV не позволяет выполнять многоклассовую
классификацию, но этого и не требуется в моей работе.
Градиентные усиленные деревья
Эта модель представляет собой набор деревьев принятия решений. Каждое
следующее дерево уточняет результат предыдущего и уменьшает общую ошибку. Она
позволяет решать задачи классификации, в том числе и многоклассовой, и
регрессионного анализа.
Случайные деревья
Алгоритм позволяет решать задачи классификации и регрессионного анализа.
Случайные деревья - это сборка деревьев принятия решений, в терминологии
авторов метода лес. Классификация работает следующим образом: классификатору на
вход приходит вектор признаков, он классифицируется всеми деревьями, а
результат выбирается путем голосования.
Все деревья обучаются на одних и тех же признаках, но на разных наборах
данных. Эти наборы генерируются из исходного случайным образом, так чтобы в
каждом из полученных наборов было одинаковое количество векторов. В каждом узле
обучаемого дерева переменные, по которым будет происходить разделение
выбираются из некоторого их подмножества, определяемого для каждого узла случайным
образом.
Нейронные сети
В библиотеке OpenCV есть реализация такой разновидности нейронных сетей,
как многослойные перцептроны. Они состоят из входного, выходного и одного или
нескольких промежуточных слоев. Каждый слой включает в себя один или несколько
нейронов, напрямую связанных с нейронами из предыдущего и следующего слоя. Все
нейроны внутри перцептрона одинаковы. Каждый из них имеет несколько входных
связей, принимающих выходные значения с нейронов предыдущего слоя, и выходных
связей, передающих результат на следующий слой. Все входные значения умножаются
на определенные весовые коэффициенты, индивидуальные для каждого нейрона, и
суммируются. Сумма преобразуется при помощи активирующей функции, которая тоже
может отличаться для разных нейронов, но определяется программистом. Обучение
сводится к определению весовых коэффициентов.
Алгоритмы бустинга, такие как дискретный AdaBoost, вещественный AdaBoost,
LogitBoost, Gentle AdaBoost, используются в задачах распознавания образов,
потому что они слабо подвержены переобучению, по сравнению с другими
алгоритмами машинного обучения. Кроме того использование бустинга позволяет
легко использовать вектора признаков большой размерности.
Все алгоритмы бустинга близки по своей структуре, поэтому в дальнейшем
будет рассмотрен вещественный AdaBoost, который, согласно результатам,
приведенным в статье [11] является лучшим из всех алгоритмов бустинга для
двуклассовой классификации.
3.2 Вещественный AdaBoost
Классификатор вещественный AdaBoost [21] является обобщением дискретного
AdaBoost [20]. Рассмотрим оба классификатора.
Пусть мы имеем обучающее множество 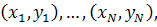 , где
, где 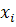 - вектор признаков,а
- вектор признаков,а 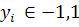 - метка класса. Тогда классификатор:
- метка класса. Тогда классификатор:
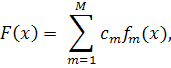
где 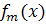 - слабый классификатор, возвращающий значения из множества
-1,1, а
- слабый классификатор, возвращающий значения из множества
-1,1, а 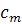 - константы. Результат работы
классификатора определяется как знак функции
- константы. Результат работы
классификатора определяется как знак функции 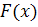 :
:
Процедура AdaBoost обучает слабые классификаторы на взвешенном обучающем
множестве, увеличивая веса тех элементов, которые были неверно
классифицированы. Это делается для последовательности взвешенных значений, а
затем итоговый классификатор представляется как линейная комбинация
классификаторов, полученных на каждом из шагов. Ниже представлен подробный
алгоритм Descrite AdaBoost:
. Задаются начальные веса 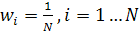
2. Для каждого 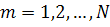
a. Обучить классификатор 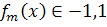 используя взвешенной обучающее
множество.
используя взвешенной обучающее
множество.
b. Подсчитать ошибку классификации
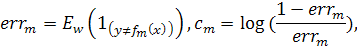
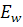 - представляет собой математическое ожидание, вычисленное
для взвешенного обучающего множества, а
- представляет собой математическое ожидание, вычисленное
для взвешенного обучающего множества, а 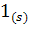 - идентификатор множества. Обновить
веса
- идентификатор множества. Обновить
веса
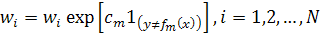
и нормализовать их, так чтобы
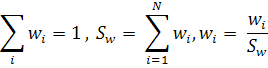
На каждой итерации увеличиваются веса неверно классифицированных векторов
на значение, определяемое взвешенной ошибкой классификации.
Результат: 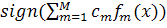
Обобщением дискретного AdaBoost стал вещественный AdaBoost, использующий
предикторы возвращающие значение вероятности принадлежности к классу. Множество
значений слабого классификатора находится уже в области вещественных чисел.
Знак 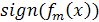 определяет класс, а
определяет класс, а 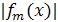 вероятность. Ниже представлен
алгоритм вещественного AdaBoost:
вероятность. Ниже представлен
алгоритм вещественного AdaBoost:
1. Задаются начальные веса 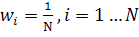
2. Для каждого
a. Обучается классификатор, возвращающий вероятность принадлежности
к классу, используя обучающее множества с весами 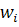 :
:
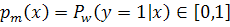
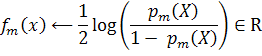
b. Обновить веса
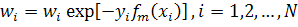
и нормализовать их, так чтобы
. Результат: 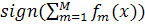
Для уменьшения времени вычислений для подобных моделей без существенной
потери в точности используется техника обрезания. По ходу выполнения алгоритма
и роста количества деревьев большое количество примеров из обучающего множества
начинают классифицироваться корректно все с возрастающей вероятностью.
Следовательно, вес таких примеров уменьшается.
Примеры с малым весом дают соответственно малый вклад в обучение слабых
классификаторов. Поэтому такие примеры могут быть удалены при обучении, без
большого вреда для результатов обучения слабого классификатора. Для этого может
быть задано пороговое значение для обрезания обучающего множества. Надо
заметить, что эта процедура повторяется индивидуально для каждого слабого
классификатора, и обрезанные на одной стадии примеры могут быть использованы
при обучении на следующих стадиях.
3.3 Деревья решений
В реализации алгоритмов бустинга в библиотеке OpenCV в качестве слабых
классификаторов используются деревья принятия решений.
Дерево принятия решений - это бинарное дерево (дерево, у которого каждая
не листовая вершина имеет две дочерних). Оно может быть использовано, как для
задач классификации, так и для регрессии.
Классификация с использованием деревьев осуществляется следующим образом.
Процедура предсказания начинается с корневой вершины. Из каждой нелистовой
вершины процедура предсказания идет налево или направо, в зависимости от
значения определенной переменной из вектора признаков, чей индекс хранится в
текущем узле. Для этого значение переменной сравнивается с пороговым значением
хранящимся в узле. Если значение меньше порога, то процедура идет налево, иначе
- направо.
В каждом узле используется пара индекс переменной, порог. Эта пара
называется разбиением. Когда достигается листовой узел, значение хранящееся в
нем используется как результат работы классификатора.
Деревья строятся рекурсивно, начиная с корневого узла. Все обучающее
множество используется для разбиения корня. В каждом узле лучшее разбиение
выбирается при помощи какого-то критерия. В машинном обучении для классификации
используется критерий чистоты Джини, который показывает как часто случайно
выбранный элемент из множества будет неверно классифицирован, если он будет
классифицирован случайным образом в соответствии с распределением меток в
подмножестве. Он может быть рассчитан как произведение суммы вероятностей
каждого элемента быть выбранным на вероятность неверной классификации этого
элемента.
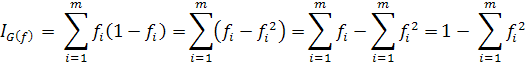
А для задач регрессии, численного предсказания, используется в качестве
критерия сумма квадратов ошибок.
Все данные разделяются в соответствии с выбранным разбиением на два
подмножества, которые используются для обучения левого и правого поддеревьев.
На каждом шаге рекурсивная процедура может остановится в одном из следующих
случаев:
· Достигнута максимальная глубина дерева.
· Мощность обучающего множества в узле меньше заданного порога,
и не является представительной.
· Все примеры в узле принадлежат одному множеству или, в случае
регрессии, вариация между ними мала.
· Лучшее выбранное разделение не дает заметного выигрыша в
сравнении со случайным выбором.
3.4 Признаки для классификации
Из рассмотренных ранее работ мной были отобраны следующие:
Среднеквадратичное отклонение интенсивности. Текст, как правило,
выделяется на фоне. Если значения интенсивности варьируется очень слабо в
пределах фрагмента изображения, то скорее всего этот фрагмент не содержит
текста.
Среднеквадратичное отклонение градиента показывает разброс значений
градиента в пределах фрагмента. Как и предыдущий признак может отфильтровывать
сплошные области, но требует дополнительного расчета значений градиента.
Энтропия вычисляемая для значений интенсивности так же используется в
качестве признака. Величина рассчитывается по формуле:
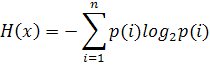
Статистики производной по X. Этот признак использует наблюдения описанные
в статье [6], заключающиеся в разных значениях производной в разных областях
фрагмента изображения, содержащего текст (см. рис. 1.3).
Сначала рассчитываются производные по Х, с использованием оператора
Собеля. Затем для каждой области, представленной на рисунке 3.1(a),
рассчитываются значения математического ожидания и среднеквадратичного
отклонения значений производной в этой области. В итоге получается шесть
значений.
Рисунок 3.1. Шаблоны областей для расчета статистик производных: (a) -
производной по X; (b) - производной по Y.
Статистики производной по Y. Эти статистики рассчитываются идентично
предыдущим, только используются области представленные на рисунке 3.1(b).
Получается десять значений.
Гистограмма значений градиента. В той же работе было описано
использование в качестве признаков значений гистограмм градиента. Перед
вычислением значения признаков исходный фрагмент изображения всегда
масштабируется до размера 20 на 20 пикселей, в результате чего отпадает
необходимость в нормировании значений гистограммы. Значения разбиваются на
двадцать равных интервалов, в результате чего этот признак дает нам двадцать
значений.
Гистограмма значений интенсивности. Таким же образом рассчитывается
гистограмма значений интенсивности. Значения разбиваются также на двадцать
интервалов.
Гистограмма интенсивности-градиента. Это гистограмма построенная по двум
значениям. Все величины входящие в один интервал гистограммы интенсивности
разбиваются на интервалы по значению градиента. Разбиение в обоих случаях
происходит по двадцати интервалам. В общей сложности в результате получается
четыреста значений.
Гистограмма ширин штриха. Идея, лежащая в его основе, состоит в том, что
в текстовых областях ширины штрихов распределены не так как в нетекстовых. Для
вычислений используется реализация преобразования ширины штриха представленная
в работе [9]. Перед вычислением, изображение сжимается до размера 20 на 20 пикселей,
для увеличения скорости работы, потому что преобразование является затратной по
времени операцией. Все значения распределяются, как и в других признаках,
использующих гистограммы, на двадцать интервалов.
Вес текста. Этот признак заимствован из работы [19]. Он представляет
собой отношение количества текстовых пикселей к общему количеству пикселей
фрагмента изображения. Разделение пикселей происходит на основе построения, так
называемой EM-модели.модель - это смесь двух гауссианов, представляющая распределение
значений интенсивности на фрагменте изображения. В модели решено использовать
два гауссиана, исходя из свойства самой задачи: должен отслеживаться контраст
между передним планом (символами) и задним планом (фоном), допускающий
читабельность текста. Для получения значений гауссовых распределений
используется EM-алгоритм. Если брать для обучения значения интенсивности со
всего фрагмента изображения, тогда преобладающий фон (его, как правило, гораздо
больше текста) будет сильно влиять на результаты обучения. Поэтому выбираются
значения только из областей перехода. Для этого сначала рассчитывается градиент
фрагмента, затем он бинаризуется. Пороговое значение вычисляется как 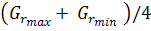 , где
, где 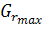 и
и 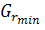 - максимальное и минимальное значения
градиента соответственно. Получается, таким образом, маска областей перехода.
- максимальное и минимальное значения
градиента соответственно. Получается, таким образом, маска областей перехода.
Значение самого признака вычисляется по формуле:
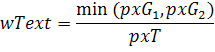
где 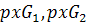 - количество пикселей принадлежащих одной или второй
гауссовой составляющей EM-модели, из них выбирается меньшее значение, исходя из
предположения, что текста меньше чем фона;
- количество пикселей принадлежащих одной или второй
гауссовой составляющей EM-модели, из них выбирается меньшее значение, исходя из
предположения, что текста меньше чем фона; 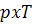 - общее количество пикселей
фрагмента изображения.
- общее количество пикселей
фрагмента изображения.
Разделенность гауссианов. Этот признак как и предыдущий основан на
EM-модели. Он показывает на сколько разделены математические ожидания
гауссианов. Если они практически сливаются друг с другом, то и текст с фоном не
различимы. Вычисляется по формуле:
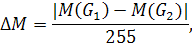
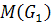 - математическое ожидание гауссиана, 255 - максимальная
разница интенсивностей в восьмибитном изображении.
- математическое ожидание гауссиана, 255 - максимальная
разница интенсивностей в восьмибитном изображении.
Из-за того, что построение EM-модели весьма затратно по времени, и даже
сжатие изображения не сильно ускоряет процесс, то последние два признака
вычисляются вместе и выступают как один признак с двумя значениями.
Представленные выше признаки были протестированы на коллекции изображений ICDAR
2011. Для каждого из признаков обучался классификатор и затем проверялся на
всех изображениях тестового набора. Далее, полученные результаты для каждого из
признаков были сравнены с результатами, полученными случайной маркировкой
фрагментов без использования классификатора. Так получилось, что четыре
признака из десяти показали результаты не лучше чем генератор случайных чисел.
Поэтому в дальнейшем было решено использовать только:
· среднеквадратичное отклонение градиента;
· статистики по обеим производным;
· гистограмма градиента;
· гистограмма ширин штриха;
· признаки, основанные на EM-модели.
При разделении признаков по каскадам будем отталкиваться от скорости
работы признаков. Самым быстрым из отобранных является гистограмма значений
градиента, поэтому она будет использовать на первом этапе. На втором этапе -
гистограмма ширин штриха и среднеквадратичное отклонение градиента. Статистики
по производным и признаки на основе EM-модели будут использоваться на последнем
третьем этапе. Таким образом, получается каскад из трех классификаторов.
3.5 Каскадный классификатор Виолы и Джонса
В работе [28] П. Виола и М. Джонс представили интересный подход к
построению классификаторов, который они использовали для поиска лиц на
изображении. Их идея заключается в построении каскада из нескольких
классификаторов, на каждом шаге которого будут постепенно отбрасываться
отдельные фрагменты.
Давно известно, что чем сложнее функция классификации, тем она точнее, но
тем меньше ее способность к обобщению. Если главный фактор - это уменьшение
ошибки, то минимизация структурных рисков предоставляет формальный метод для
выбора классификатора с правильным балансом сложности и порождаемой ошибки.
Другое важное ограничение - сложность вычислений. Так как время
вычислений и ошибка - совершенно разные вещи, то теоретически невозможно
выбрать оптимальный баланс. Тем не менее для многих функций классификации время
вычислений напрямую зависит от структурной сложности. В таких случаях
сокращение временных затрат напрямую зависит от уменьшения сложности.
Но эта прямая аналогия не работает в задачах, в которых баланс между
метками сильно смещен в сторону какого-либо класса. Например, при выделении
текста на тысячи фрагментов без текста приходится всего несколько текстовых.
Как ни странно, но в таких задачах можно хороших результатов при достаточно
высоком проценте правильно классифицированных фрагментов и весьма быстрой
классификации. Ключевой момент, который следует осознать, состоит в том, что
хоть и невозможно построить простой классификатор с очень низким процентом
ошибок, но в некоторых случаях можно построить классификатор, который
практически никогда не будет неверно классифицировать текстовые области.
Например, удалось получить очень быстрый классификатор, верно определяющий все
текстовые области, но при этом в 90% случаев ошибающийся на нетекстовых
областях. Такой детектор может использоваться для предварительной фильтрации:
если фрагмент помечен как “не текст”, то он сразу отбрасывается, а если
фрагмент помечен как “текст”, то требуется дополнительная классификация. Из
последовательности подобных классификаторов, каждый следующий сложнее,
медленнее и точнее предыдущего, и строится каскад классификаторов. Увеличение
количества стадий приводит к увеличению точности, так в своей работе Виола и
Джонс использовали каскад из 38 стадий. В качестве классификаторов авторы
использовали асимметричный AdaBoost.
Обычный AdaBoost на каждом шаге пытается минимизировать общую ошибку, но
нам требуется минимизировать количество неверно классифицированных текстовых
областей. Идея заключается в том, чтобы изменить баланс весов данных в пользу
имеющих положительные метки. Но для этого нельзя просто изменить баланс на
первом шаге, потому что AdaBoost изменит веса и уже второй слабый классификатор
будет симметричен. Поэтому авторы предлагают кроме изменения начального баланса
изменить классическую формулу AdaBoost на:
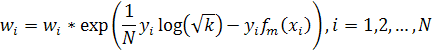
где, k - коэффициент предпочтения положительных меток над отрицательными.
3.6 Реализация AdaBoost в библиотеке OpenCV
Реализация метода AdaBoost представлена в библиотеке OpenCV в виде класса
CvBoost. Объявление конструктора этого класса представлено в листинге 3.1.
Листинг 3.1: Конструктор класса CvBoost
CvBoost :: CvBoost (Mat& trainData,tflag,Mat&
responses,Mat& varIdx,Mat& sampleIdx,Mat& varType,Mat&
missingDataMask = Mat(),params = CvBoostParams(),
Параметры:
· trainData - матрица, содержащая обучающее
множество.
· tflag - указывает на то, что представляют собой векторы
признаков: столбцы (tflag = CV_COL_SAMPLE) или строки (tflag = CV_ROW_SAMPLE)
матрицы trainData.
· varIdx - вектор-маска, позволяющий при обучении пропускать
какие-либо признаки. По умолчанию задан пустой матрицей, следовательно, используется
весь вектор признаков.
· sampleIdx - то же что и varIdx для векторов. Позволяет
обучиться не на всем множестве, а лишь не некоторых векторах. По умолчанию
используются все множество.
· varType - вектор хранящий множество типов признаков. Каждый признак
может быть либо категорийным (CV_VAR_CATEGORICAL), либо численным
(CV_VAR_ORDERED, или то же самое CV_VAR_NUMERICAL). От этого зависит принцип
построения разбиения в узлах деревьев. Количество элементов в векторе на
единицу больше числа признаков. Последний элемент вектора означает тип
выходного значения классификатора. Если вектор не задан, то все данные
считаются категорийными.
· missingDataMask - матрица того же размера что и trainData,
ненулевые элементы которой обозначают отсутствующую информацию. По умолчанию
используются все данные.
· CvBoostParams - параметры обучения. Про них будет подробнее
сказано ниже.
Листинг 3.2: Конструктор класса CvBoostParams.
CvBoostParams (
int
boost_type,weak_count,weight_trim_rate,max_depth,use_surrogates,float priors,
На листинге 3.2 представлен конструктор класса CvBoostParams,
описывающего параметры обучения классификатора.
· boost_type - определяет тип классификатора. Библиотека OpenCV
позволяет выбирать из четырех алгоритмов бустинга:
– CvBoost::DISCRETE - дискретный AdaBoost;
– CvBoost::REAL - вещественный AdaBoost;
– CvBoost::LOGIT - LogitBoost;
– CvBoost::GENTLE - гладкий AdaBoost.
· weak_count - определяет количество слабых классификаторов.
· weight_trim_rate - устанавливает порог обрезания. Принимает
значения на отрезке [0; 1]. Вектора с весами меньшими или равными
1-weight_trim_rate не участвуют в обучении следующего слабого классификатора.
При установке параметра в 0 обрезание не используется.
· max_depth - определяет максимальную высоту деревьев-классификаторов.
· use_surrogates - флаг, указывающий на разрешение
использования суррогатных разбиений. Суррогатные разбиения используются при
работе с отсутствующими данными.
· priors - ссылка на массив из переменных типа float, которые
определяют предпочтение одного из классов. Например, при значениях 1, 10 второй
класс предпочтительнее первого в 10 раз. Если параметр не задан (priors = 0),
то веса будут рассчитываться по обычной схеме.
При использовании конструктора по умолчанию, устанавливаются следующие
параметры:
· boost_type=CvBoost::REAL;
· weak_count = 100;
· weight_trim_rate = 0.95;
· max_depth = 1;
· use_surrogates = true;
· priors = 0;
Листинг 3.3: Метод predict класса CvBoost.
float CvBoost :: predict (cv :: Mat& sample ,cv ::
Mat& missing=Mat ( ) ,cv :: Range& slice =Range : : all( ) ,rawMode =
false ,returnSum = false
)
)
Для классификации вызывается метод predict (см. листинг 3.3).
Единственный обязательный параметр этого метода - вектор признаков sample,
который и будет классифицироваться. Назначение остальных:
· missing - вектор, отмечающий отсутствующие данные, аналогичен
по принципу действия параметру missingDataMask конструктора класса. По
умолчанию все данные считаются присутствующими и используются для
классификации.
· slice позволяет выбирать множество слабых классификаторов,
используемых для классификации. По умолчанию используются все классификаторы.
· rawMode - недокументированный параметр, должен быть
установлен в 0.
· returnSum - флаг, указывающий на формат возвращаемого
значения. Если установлен в 0, то будет возвращаться метка класса (-1 или 1),
иначе сумма значений классификаторов.
Заключение
Разработанная система обучалась и тестировалась на наборах данных ICDAR
2011. Тестирование осуществлялось по методике, описанной в работе [7]. Все
фрагменты прошедшие классификацию и помеченные как текст, составляли маску. В
качестве истинных значений использовалась разметка набора данных. Далее
рассчитывалась полнота и точность по следующим формулам:
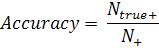
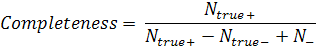
где 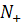 - количество пикселей классифицированных как текст;
- количество пикселей классифицированных как текст;
 - количество пикселей классифицированных как не текст;
- количество пикселей классифицированных как не текст;
 - количество текстовых пикселей классифицированных как
текст;
- количество текстовых пикселей классифицированных как
текст;
 - количество нетекстовых пикселей классифицированных как не
текст.
- количество нетекстовых пикселей классифицированных как не
текст.

Рисунок 4.1. Изображение, на котором получен лучший результат.
Результаты работы классификатора на сегодняшний день составляют: точность
- 29%, полнота - 88%. На рисунке 4.1 представлено изображение, на котором
классификатор показал лучший результат. Данное изображение отличается
достаточно хорошим контрастом между текстом и фоном, слабо размыто и легко
читаемо.
На рисунке 4.2 - изображение, на котором классификатор показал худшие
результаты. Текст на этом изображении почти полностью сливается с фоном, а
камни, которые выделялись в качестве текста, выглядят гораздо лучше.

Рисунок 4.2 Изображение, на котором получен худший результат
Конечно, результаты далеки от совершенства, но самое главное, в том, что
в процессе работы был поднят значительный научный пласт знаний, а так же
изучены различные подходы к решению проблемы выделения текста, рассмотрены
несколько алгоритмов классификации и сделана попытка реализовать классификатор.
Стоит отметить, что полученные знания имеют довольно обширное применение, что
доказывается актуальностью работы и разнообразием прикладных областей.
В дальнейшем планируется совершенствовать результаты, добавляя различные
признаки и используя гибридные подходы, с дополнительным анализом компонент
связности. Кроме этого, в перспективе, есть планы начать работу над выделением
текста в видеопотоке и слежения за ним.
Список
использованных источников
1. Borman
Sean. The Expectation Maximization Algorithm A short tutorial. Retrieved April
27, 2014, from http://www.seanborman.com/publications.
. Boureau,
Y.L. & Bach, F. & LeCun, Y. (2010). Learning mid-level features for
recognition. Computer Vision and Pattern Recognition (CVPR), 2010 IEEE
Conference, 2559-2566.
. Breiman
Leo. Random forests - random features: Tech. Rep.,1999. September.
. Breiman
L. & Friedman J. H. & Olshen R. A.. Classification and regression
trees.Wadsworth Publishing Company, 1984.
. Canny
John. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal.
Mach. Intell. 1986. Т. 8, № 6. С. 679-698.
. Chen
Xiangrong & Yuille Alan L. Detecting and reading text in natural scenes.
Proceedings of the 2004 IEEE computer society conference on Computer vision and
pattern recognition, 2004, 366-373.
. Coates,
A. & Carpenter, B. & Satheesh, S. (2011). Text Detection and Character
Recognition in Scene Images with Unsupervised Feature Learning. Document
Analysis and Recognition, ICDAR 2011 International Conference, 440-445.
. Dempster
A. P. & Laird N. M. & Rubin D. B. (1997) Maximum likelihood from
incomplete data via the EM algorithm. Journal of the Royal Statistical Society:
Series B. 1977. Т. 39. С. 1-38.
. Epshtein,
B. & Eyal, O. & Yonatan,W. (2013). Detecting Text in Natural Scenes
with Stroke Width Transform. Retrieved April 27, 2014, from
http://www.math.tau.ac.il/~turkel/imagepapers/text_detection.pdf
. Friedman
Jerome. Greedy Function Approximation: A Gradient Boosting Machine. Annals of
Statistics. 2000. Т. 29. С. 1189-1232.
. Friedman
Jerome & Hastie Trevor & Tibshirani Robert. Additive Logistic
Regression: a Statistical View of Boosting.Annals of Statistics. 1998. Т. 28.
с. 2000.
. Fukunaga
Keinosuke. Introduction to statistical pattern recognition. Computer Science
and Scientific Computing. Second изд. Academic Press, 1990.
. Gatos
Basilios & Pratikakis Ioannis & Perantonis Stavros. Towards Text
Recognition in Natural Scene Images.
. Hyvarinen,
A. & Oja, E. (2000). Independent component analysis: algorithms and
applications. Neural Networks Oxford, 13(4-5), 411- 430.
. Jung,
K. & Kim, K. & Jain Anil, K. (2004). Text information extraction in
images and video: a survey. Pattern Recognition, 37(5), 977-997.
. Merino
Carlos & Mirmehdi Majid. A framework towards real-time detection and
tracking of text. Second International Workshop on Camera-Based Document
Analysis and Recognition (CBDAR 2007). 2007. September. С. 10-17.
. Pan
Yi-Feng & Hou Xinwen & Liu Cheng-Lin. A Hybrid Approach to Detect and
Localize Texts in Natural Scene Images. Trans. Img. Proc. Piscataway, NJ, USA,
2011. Т. 20, № 3.. 800-813.
. Picard
Rosalind, W. (2010). Decorrelating and then Whitening data. Retrieved April 27,
2014, from http://courses.media.mit.edu/2010fall/mas622j/whiten.pdf
. Roubtsova
Nadejda S. & Wijnhoven Rob G. J. & de With Peter H. N. Integrated text
detection and recognition in natural images, 2012.
. Schapire
Robert E. & Freund Yoav, Experiments with a New Boosting Algorithm.
ICML,Lorenza Saitta. Morgan Kaufmann, 1996. С. 148- 156.
. Shahab
Asif & Shafait Faisal & Dengel Andreas. ICDAR 2011 Robust Reading
Competition Challenge 2: Reading Text in Scene Images. ICDAR. IEEE, 2011. С.
1491-1496.
. Simon
M. Lucas & Alex Panaretos & Luis Sosa. ICDAR 2003 Robust Reading
Competitions, ICDAR. IEEE Computer Society, 2003, 682-687.
. Sochman
J.& Matas J. WaldBoost - learning for time constrained sequential
detection. Computer Vision and Pattern Recognition, 2005. CVPR 2005. IEEE
Computer Society Conference on. Т. 2. 2005. С. 150-156
. Vapnik
Vladimir N. The Nature of Statistical Learning Theory. Springer, 1995.
. Vorontsov
K.V. Support vector machine lections. Retrieved April 27, 2014, from:
http://www.ccas.ru/voron/download/SVM.pdf
. Tamura
H. & Mori S. & Yamawaki T. Texture features corresponding to visual
perception. IEEE Transactions on Systems, Man and Cybernetics. 1978. Т. 8, № 6.
. Viola
Paul & Jones Michael. Fast and Robust Classification using Asymmetric
AdaBoost and a Detector Cascade. Advances in Neural Information Processing
System 14. MIT Press, 2001. С. 1311-1318.
. YouTube
Press (2014). YouTube Official Statistics. Retrieved April 1, 2014, from
http://www.youtube.com/yt/press/statistics.htm