Применение технологии 'Nvidia CUDA' для неграфических вычислений
Министерство образования и науки
Российской Федерации
Федеральное государственное бюджетное
образовательное учреждение высшего профессионального образования
«Пермский национальный
исследовательский политехнический университет»
Березниковский филиал
КУРСОВАЯ РАБОТА
по дисциплине «ЭВМ и периферийные
устройства»
«Применение технологии «NVIDIA CUDA»
для неграфических вычислений»
Выполнил:
студент группы ИВТ-13д ______________ Хузиахметова А.Д.
Проверил:
канд.техн.наук, доцент_____________ Плехов П.В.
Березники 2015
Реферат
Результатом работы будут являться две программы, выполняющие вычисления
на графическом процессоре и две программы выполняющие расчёты на центральном
процессоре. При использовании как графического так и центрального процессоров,
алгоритмы и численные методы проведения расчётов в соответствующих программах,
одинаковы.
Пояснительная записка включает в себя сравнение центрального и
графического процессоров, описание их ключевых особенностей и различий,
сведения о технологии NVIDIACUDAи расширении языка C, а
так же примеры использования этой технологии в сравнении с вычислениями на
центральном процессоре и исходный код этих примеров.
Работа содержит 3 таблицы, 7 рисунков, 4 приложений состоит из 28 страниц
и ссылается на 6 источников.
Ключевы еслова: ALU, C, CUDA, CPU, GPU,
MIMD, NVIDIA, SIMD, SIMT,
SSE2, SSE3, TESLA, блок, графический, исполнительный,
память, параллельные вычисления, поток, процессор, центральный, ядро.
Оглавление
Реферат
Оглавление
Обозначения и сокращения
Введение
. Сравнение центрального и графического процессора в
параллельных расчётах
. Параллельное программирование на GPU
.1 Общие принципы работы GPU-ускорителей
.2 Типы памяти
.3 Расширения языка C для работы с CUDA
. Пример применения технологии CUDA для неграфических
вычислений
.1 Вычисление интеграла
.2 Сложение векторов
.3 Технические характеристики ПК применяемого для
вычислений
Заключение
Список литературы
Приложение А
Приложение Б
Приложение В
Приложение Г
Обозначения и сокращения
- арифметико -логическое устройство.
C -
язык программирования.
CUDA -
ComputeUnifiedDeviceArchitectureпрограммно-аппаратная архитектура параллельных
вычислений.
CPU-
Центральный процессор.- графический процессор.MultipleInstructionstream,
MultipleDatastream - Множественный поток команд, множественный поток данных.
NVIDIA-
американская компания, один из крупнейших разработчиков графических ускорителей
и процессоров.singleinstruction, multipledata- одиночный поток команд,
множественный поток данных- принцип компьютерных вычислений, позволяющий
обеспечить параллелизм на уровне данных.
SIMT - Singleinstruction, multiplethread - однаинструкция, множествопотоков.- Streaming SIMD
Extensions 2, потоковое SIMD-расширениепроцессора (Single Instruction,
Multiple Data, Однаинструкция - множестводанных) наборинструкций, разработанный Intel ивпервыепредставленныйвпроцессорахсерии Pentium 4. SSE2 расширяет набор инструкций SSE с
целью полностью вытеснить MMX. Набор SSE2 добавил 144 новые команды к SSE, в
котором было только 70 команд.- третья SIMD-расширения Intel, потомок SSE, SSE2
и MMX.
TESLA
- название семейства вычислительных систем NVIDIA на основе графических
процессоров с архитектурой CUDA.
Введение
Устройства для превращения персональных компьютеров в маленькие
суперкомпьютеры известны довольно давно. Ещё в 80-х годах прошлого века на
рынке предлагались так называемые транспьютеры, которые вставлялись в
распространенные тогда слоты расширения ISA. Первое время их производительность
в соответствующих задачах впечатляла, но затем рост быстродействия
универсальных процессоров ускорился, они усилили свои позиции в параллельных
вычислениях, и смысла в транспьютерах не осталось. Хотя подобные устройства
существуют и сейчас - это разнообразные специализированные ускорители. Но зачастую
сфера их применения узка и особого распространения такие ускорители не
получили.
Но в последнее время эстафета параллельных вычислений перешла к массовому
рынку, так или иначе связанному с трёхмерными играми. Универсальные устройства
с многоядерными процессорами для параллельных векторных вычислений,
используемых в 3D-графике, достигают высокой пиковой производительности,
которая универсальным процессорам не под силу.
Для ускорения расчетов в последние годы активно применяются возможности
современных графических карт, реализующие массово-параллельные вычисления
общего назначения на мощных графических процессорах. Примером данной технологии
является программно-аппаратная архитектура CUDA (от англ.
ComputeUnifiedDeviceArchitecture), разработанная компанией Nvidia. CUDA
реализует аппаратный параллелизм, базируясь на принципах вычислений SIMD (от
англ. SingleInstructionMultipleData), т.е. позволяет применять одни и те же
команды параллельно к множеству данных[1].
.
Сравнение центрального и графического
процессора в параллельных расчётах
Рост частот универсальных процессоров упёрся в физические ограничения и
высокое энергопотребление, и увеличение их производительности всё чаще
происходит за счёт размещения нескольких ядер в одном чипе. Продаваемые сейчас
процессоры содержат лишь до четырёх ядер (дальнейший рост не будет быстрым) и
они предназначены для обычных приложений, используют MIMD - множественный поток
команд и данных. Каждое ядро работает отдельно от остальных, исполняя разные
инструкции для разных процессов.
Специализированные векторные возможности (SSE2 и SSE3(Streaming SIMD
Extensions, потоковое SIMD-расширение процессора)) для четырехкомпонентных
(одинарная точность вычислений с плавающей точкой) и двухкомпонентных (двойная nточность) векторов появились в
универсальных процессорах из-за возросших требований графических приложений, в
первую очередь. Именно поэтому для определённых задач применение GPU выгоднее,
ведь они изначально сделаны для них.
Например, в видеочипах NVIDIA основной блок - это мультипроцессор с
восемью - десятью ядрами и сотнями ALU(арифметико - логическое устройство) в
целом, несколькими тысячами регистров и небольшим количеством разделяемой общей
памяти. Кроме того, видеокарта содержит быструю глобальную память с доступом к
ней всех мультипроцессоров, локальную память в каждом мультипроцессоре, а также
специальную память для констант.
Эти несколько ядер мультипроцессора в GPU(графический процессор) являются
SIMD (одиночный поток команд, множество потоков данных) ядрами. И эти ядра исполняют
одни и те же инструкции одновременно, такой стиль программирования является
обычным для графических алгоритмов и многих научных задач, но требует
специфического программирования. Зато такой подход позволяет увеличить
количество исполнительных блоков за счёт их упрощения.
Основные различия между архитектурами CPU(центральный процессор) и GPU:
. Ядра CPUсозданы для исполнения одного потока последовательных
инструкций с максимальной производительностью
. GPU проектируются для быстрого исполнения большого
числапараллельно выполняемых потоков инструкций.
. Универсальные процессоры оптимизированы для достижения высокой
производительности единственного потока команд, обрабатывающего и целые числа и
числа с плавающей точкой. При этом доступ к памяти случайный.
. Разработчики CPU стараются добиться выполнения как можно
большего числа инструкций параллельно, для увеличения производительности. Для
этого, начиная с процессоров IntelPentium, появилось суперскалярное выполнение,
обеспечивающеевыполнение двух инструкций за такт, а PentiumPro отличился
внеочереднымвыполнением инструкций. Но у параллельного выполнения
последовательного потокаинструкций есть определённые базовые ограничения и
увеличением количестваисполнительных блоков кратного увеличения скорости не добиться.
. У видеочипов работа простая и распараллеленная изначально.
Видеочип принимает на входе группу полигонов, проводит все необходимые
операции, и на выходе выдаёт пиксели. Обработка полигонов и пикселей
независима, их можно обрабатывать параллельно, отдельно друг от друга. Поэтому,
из-за изначально параллельной организации работы в GPU используется большое
количество исполнительных блоков, которые легко загрузить, в отличие от
последовательного потока инструкций для CPU. Кроме того, современные GPU также
могут исполнять больше одной инструкции за такт (dualissue). Так, архитектура
Tesla в некоторых условиях запускает на исполнение операции MAD+MUL или MAD+SFU
одновременно.
. GPU отличается от CPU ещё и по принципам доступа к памяти. В GPU
он связанный и легко предсказуемый - если из памяти читается пиксель текстуры,
то через некоторое время придёт время и для соседних пиксель. Да и при записи
то же - пиксель записывается во фреймбуфер, и через несколько тактов будет
записываться расположенный рядом с ним. Поэтому организация памяти отличается
от той, что используется в CPU. Видеочипу, в отличие от универсальных
процессоров, просто не нужна кэш-память большого размера, а для текстур
требуются лишь несколько (до 128-256 в нынешних GPU) килобайт.
. Работа с памятью у GPU и CPU несколько отличается. Так, не все
центральные процессоры имеют встроенные контроллеры памяти, а у всех GPU обычно
есть по несколько контроллеров, вплоть до восьми 64-битных каналов в чипе
NVIDIA GT200. Кроме того, на видеокартах применяется более быстрая память, и в
результате видеочипам доступна в разы большая пропускная способность памяти,
что также весьма важно для параллельных расчётов, оперирующих с огромными
потоками данных.
. В универсальных процессорах большие количества транзисторов и
площадь чипа идут на буферы команд, аппаратное предсказание ветвления и
огромные объёмы чиповой кэш - памяти. Все эти аппаратные блоки нужны для
ускорения исполнения немногочисленных потоков команд. Видеочипы тратят
транзисторы на массивы исполнительных блоков, управляющие потоками блоки,
разделяемую память небольшого объёма и контроллеры памяти на несколько каналов.
Вышеперечисленное не ускоряет выполнение отдельных потоков, оно позволяет чипу
обрабатывать нескольких тысяч потоков, одновременно исполняющихся чипом и
требующих высокой пропускной способности памяти.
. Универсальные центральные процессоры используют кэш - память для
увеличения производительности за счёт снижения задержек доступа к памяти, а GPU
используют кэш или общую память для увеличения полосы пропускания. CPU снижают
задержки доступа к памяти при помощи кэш-памяти большого размера, а также
предсказания ветвлений кода. Эти аппаратные части занимают большую часть
площади чипа и потребляют много энергии. Видеочипы обходят проблему задержек
доступа к памяти при помощи одновременного исполнения тысяч потоков - в то
время, когда один из потоков ожидает данных из памяти, видеочип может выполнять
вычисления другого потока без ожидания и задержек.
. Есть множество различий и в поддержке многопоточности. CPU
исполняет 1-2 потока вычислений на одно процессорное ядро, а видеочипы могут
поддерживать до 1024 потоков на каждый мультипроцессор, которых в чипе
несколько штук. И если переключение с одного потока на другой для CPU стоит
сотни тактов, то GPU переключает несколько потоков за один такт.
. Кроме того, центральные процессоры используют SIMD блоки для
векторных вычислений, а видеочипы применяют SIMT (одна инструкция и несколько
потоков) для скалярной обработки потоков. SIMT не требует, чтобы разработчик
преобразовывал данные в векторы, и допускает произвольные ветвления в потоках.
Можно сказать, что в отличие от современных универсальных CPU,
видеочипыпредназначены для параллельных вычислений с большим количеством
арифметическихопераций. Значительно большее число транзисторов GPU работает по
прямомуназначению - обработке массивов данных, а не управляет исполнением
(flowcontrol)немногочисленных последовательных вычислительных потоков[2]. Схема
того, сколько места в CPU и GPU занимает разнообразная логика показано на
рисунке 1.
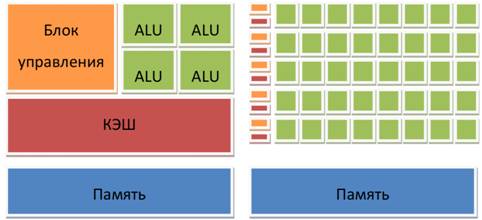
Рис.
1Устройство CPU и GPU.
2.
Параллельное программирование на GPU
процессор компьютер вычисление cuda
В настоящее время высокопроизводительные вычисления являются необходимым
составляющим звеном во многих видах человеческой деятельности: научных
исследованиях, промышленном производстве, образовании. Уровень развития
вычислительной техники и методов математического моделирования позволяет
выполнять симуляцию и анализ природных и технологических процессов, что
обеспечивает эффективное решение научных и производственных задач, предоставляя
промышленному производству конкурентное преимущество, а исследователям -
лидирующие позиции в современной науке. Спектр применения суперкомпьютерных
технологий чрезвычайно широк: авиа-, судо- и машиностроение, строительство,
нефтегазодобывающая промышленность, моделирование физических, химических и
климатических процессов, медицина, биотехнологии и многое другое.
Современные суперкомпьютеры обеспечивают выполнение до 1016 операций с
плавающей точкой в секунду (10 Петафлоп) при запусках тестов Linpack (но
существуют другие подходы к оценке их производительности) [3]. Достаточно ли
подобной вычислительной мощности для решения современных задач? Конечно, любая
имеющаяся производительность будет полностью потреблена пользователями, но даже
грубая оценка необходимых объемов вычислений показывает, что для решения многих
задач требования к производительности отличаются на порядки от возможностей
существующих ресурсов, например:
· моделирование номинальных и переходных режимов работы
ядерного реактора: для расчета процессов в реакторной установке требуется
порядка 100 часов на машине производительностью 1 Эфлопс [4];
· проектирование и разработка изделий в авиастроении: при
использовании метода прямого численного моделирования требуется использовать
сетку размером 1016 элементов и выполнять не менее 106 шагов моделирования по
времени [4];
· квантово-химические расчеты малых систем для одного состояния
методом связанных кластеров (CoupledClusterSinglesandDoubles, CCSD) для системы
из нескольких десятков (~50) атомов требуется порядка 1014 операций; при
решении оптимизационных задач требуется выполнение расчетов для десятков тысяч
состояний (при большом количестве измерений - миллионов).
Однако перенос расчетов на гетерогенные вычислительные устройства,
содержащие GPU узлы, позволяет существенно ускорить расчет. Графический
процессор изначально создавался как многоядерная структура, в которой
количество ядер может достигать сотен, а современные CPU содержат несколько
ядер (на большинстве современных систем от 2 до 6, по состоянию на 2012 г.).
Чтобы понять, какие преимущества приносит перенос расчётов на GPU, приведём
усреднённые цифры, полученные исследователями по всему миру. В среднем, при
переносе вычислений на GPU, во многих задачах достигается ускорение в 5-30 раз
по сравнению с быстрыми универсальными процессорами [5]. Самые большие цифры
(порядка 100-кратного ускорения и даже более!) достигаются на коде, который не
очень хорошо подходит для расчётов при помощи блоков SSE, но вполне удобен для
GPU. Рассмотрим здесь некоторые примеры ускорений при использовании
синтетического кода на GPU против SSE-векторизованного кода на CPU (по данным
NVIDIA):
· флуоресцентная микроскопия: в 12 раз по сравнению с расчетом
на CPU (12x);
· электростатика (прямое и многоуровневое суммирование Кулона):
40-120x и 7x.
Результатынаучныхрасчётов с применениемGPUв сравнении с CPU,показан на
рисунке 2.
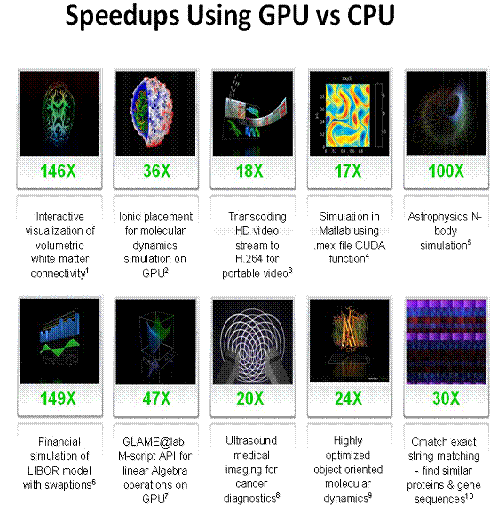
Рис.
2Примеры использования GPU-ускорителей в научных исследованиях и полученные
ускорения по сравнению с CPU.
2.1 Общие принципы работы GPU-ускорителей
Технология CUDA - это программно-аппаратная вычислительная архитектура
NVIDIA, основанная на расширении языка Си, которая даёт возможность организации
доступа к набору инструкций графического ускорителя и управления его памятью
при организации параллельных вычислений. CUDA помогает реализовывать алгоритмы,
выполнимые на графических процессорах видеоускорителейGeForce восьмого
поколения и старше (серии GeForce 8, GeForce 9, GeForce 200), а также Quadro и
Tesla.
Графический процессор представляется в виде набора независимых
мультипроцессоров (multiprocessors). Каждый мультипроцессор состоит из
нескольких CUDA-ядер (CUDA cores), нескольких модулей для вычисления
математических функций (SFU), конвейера, а также разделяемой памяти
(sharedmemory) и, кэша (для определенных видов памяти).
Графический процессор основан на так называемой архитектуре SIMT
(SingleInstruction, MultipleThread). Технология CUDA позволяет определять
специальные функции - ядра (kernels), которые выполняются параллельно на CPU в
виде множества различных потоков (threads). Таким образом, ядро является
аналогом потоковой функции. Каждый поток исполняется на одном CUDA-ядре,
используя собственный стек инструкций и локальную память.
Отдельные потоки группируются в блоки потоков (threadblock) одинакового
размера, при этом каждый блок потоков выполняется на отдельном
мультипроцессоре. Количество потоков в блоке ограничено (максимальные значения
для конкретных устройств могут быть найдены в [6] или получены во время
выполнения при помощи функций CUDA API). Потоки внутри блока потоков могут эффективно
взаимодействовать между собой с помощью общих данных в разделяемой памяти и
синхронизации. Кроме того, потоки могут взаимодействовать при помощи глобальной
памяти и атомарных операций.
На аппаратном уровне потоки блока группируются в так называемые варпы
(warps) по 32 элемента (на всех текущих устройствах), внутри которых все потоки
параллельно выполняют одинаковые инструкции (по принципу SIMD). Важным моментом
является то, что потоки фактически выполняют одну и ту же команды, но каждая со
своими данными. Поэтому если внутри варпа происходит ветвление (например в
результате выполнения оператора if), то все нити варпа выполняют все
возникающие при этом ветви. По этой причине операции ветвления могут негативно
сказываться на производительности - различные пути не могут выполняться
параллельно (в тоже время потоки одного варпа, выполняющие один путь, работают
параллельно).
В свою очередь, блоки потоков объединяются в решетки блоков потоков
(gridofthreadblocks). Следует отметить, что взаимодействие потоков из разных
блоков во время работы ядра затруднено: отсутствуют явные инструкции
синхронизации, взаимодействие возможно через глобальную память и использованием
атомарных функций (другим вариантом является разбиение ядра на несколько ядер
без внутреннего взаимодействия между потоками разных блоков).Пример иерархии
потоков приведен на рисунке 3.
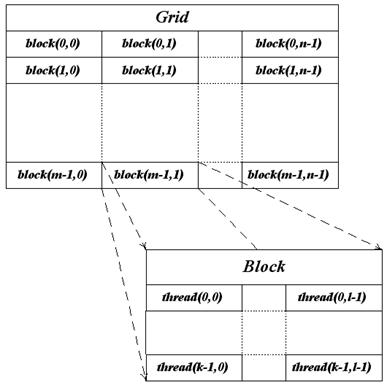
Рис.3Иерархия
потоков CUDA
Каждый
поток внутри блока потоков имеет свои координаты (одно-, двух- или трехмерные),
которые доступны через встроенную переменную threadIdx. В свою очередь,
координаты блока потоков (одно-, двух- или трехмерные) внутри решетки
определяются встроенной переменной blockIdx. Данные встроенные переменные
являются структурами с полями .x, .y, .z.
2.2
Типы памяти
Кроме иерархии потоков существует также несколько различных типов памяти.
Быстродействие приложения очень сильно зависит от скорости работы с памятью.
Именно поэтому в традиционных CPU большую часть кристалла занимают различные
кэши, предназначенные для ускорения работы с памятью (в то время как для GPU
основную часть кристалла занимают ALU).
В CUDA для GPU существует несколько различных типов памяти, доступных
нитям, сильно различающихся между собой (таблица 1).
Таблица
1
Типы
памяти в CUDA
|
Тип памяти
|
Доступ
|
Уровень выделения
|
Скорость работы
|
|
регистры (registers)
|
R/W
|
per-thread
|
высокая (onchip)
|
|
local
|
R/W
|
per-thread
|
низкая (DRAM)
|
|
shared
|
R/W
|
per-block
|
высокая (on-chip)
|
|
global
|
R/W
|
per-grid
|
низкая(DRAM)
|
|
constant
|
R/O
|
per-grid
|
высокая(on chip L1 cache)
|
|
texture
|
R/O
|
per-grid
|
высокая(on chip L1 cache)
|
Глобальная память - самый большой объём памяти, доступный для всех
мультипроцессоров на видеочипе, размер составляет от 256 мегабайт до 1.5
гигабайт на текущих решениях (и до 4 Гбайт на Tesla). Обладает высокой
пропускной способностью, более 100 гигабайт/с для топовых решений NVIDIA, но
очень большими задержками в несколько сот тактов. Не кэшируется, поддерживает
обобщённые инструкции load и store, и обычные указатели на память.
Локальная память - это небольшой объём памяти, к которому имеет доступ
только один потоковый процессор. Она относительно медленная - такая же, как и
глобальная.
Разделяемая память - это 16-килобайтный (в видеочипах нынешней
архитектуры) блок памяти с общим доступом для всех потоковых процессоров в
мультипроцессоре. Эта память весьма быстрая, такая же, как регистры. Она
обеспечивает взаимодействие потоков, управляется разработчиком напрямую и имеет
низкие задержки. Преимущества разделяемой памяти: использование в виде
управляемого программистом кэша первого уровня, снижение задержек при доступе
исполнительных блоков (ALU) к данным, сокращение количества обращений к
глобальной памяти.
Память констант - область памяти объемом 64 килобайта (то же - для
нынешних GPU), доступная только для чтения всеми мультипроцессорами. Она
кэшируется по 8 килобайт на каждый мультипроцессор. Довольно медленная -
задержка в несколько сот тактов при отсутствии нужных данных в кэше.
Текстурная память - блок памяти, доступный для чтения всеми
мультипроцессорами. Выборка данных осуществляется при помощи текстурных блоков
видеочипа, поэтому предоставляются возможности линейной интерполяции данных без
дополнительных затрат. Кэшируется по 8 килобайт на каждый мультипроцессор.
Медленная, как глобальная - сотни тактов задержки при отсутствии данных в кэше.
Естественно, что глобальная, локальная, текстурная и память констант -
это физически одна и та же память, известная как локальная видеопамять
видеокарты. Их отличия в различных алгоритмах кэширования и моделях доступа.
При этом центральный процессор (CPU) имеет R/W доступ только к глобальной,
константной и текстурной памяти (находящейся в DRAM GPU) и только через функции
копирования памяти между CPU и GPU (предоставляемые CUDA API).
2.3
Расширения языка C для работы с CUDA
Программы для CUDA (соответствующие файлы обычно имеют расширение .cu)
пишутся на «расширенном» С и компилируются при помощи команды nvcc.
Вводимые в CUDA расширения языкаС состоят из
· спецификаторов функций, показывающих, где будет выполняться функция
и откуда она может быть вызвана;
· спецификаторы переменных, задающие тип памяти, используемый
для данной переменных;
· директива, служащая для запуска ядра, задающая как данные,
так и иерархию потоков;
· встроенные переменные, содержащие информацию о текущем
потоке;
· runtime, включающий в себя дополнительные типы данных
Таблица
2
Спецификаторы
функций в CUDA
|
Спецификатор
|
Выполняется на
|
Может вызываться из
|
|
__device__
|
device
|
device
|
|
__global__
|
device
|
host
|
|
__host__
|
host
|
При этом спецификаторы __host__ и __device__ могут быть использованы
вместе (это значит, что соответствующая функция может выполняться как на GPU,
так и на CPU - соответствующий код для обеих платформ будет автоматически
сгенерирован компилятором). Спецификаторы __global__ и __host__ не могут быть
использованы вместе.
Спецификатор __global__ обозначает ядро и соответствующая функция должна
возвращать значение типа void.
На функции, выполняемые на GPU(__device__ и __global__) накладываются
следующие ограничения:
· нельзя брать их адрес (за исключением __global__ функций);
· не поддерживается рекурсия;
· не поддерживаются static-переменные внутри функции;
· не поддерживается переменное число входных аргументов.
Для задания размещения в памяти GPU переменных используются следующие спецификаторы
- __device__,__constant__ и __shared__. На их использование также накладывается
ряд ограничений:
· эти спецификаторы не могут быть применены к полям структуры
(struct или union);
· соответствующие переменные могут использоваться только в пределах
одного файла, их нельзя объявлять как extern;
· запись в переменные типа __constant__ может осуществляться
только CPU при помощи специальных функций;
· __shared__ переменные не могут инициализироваться при
объявлении.
В язык добавлены следующие специальные переменные
· gridDim - размер grid'а (имеет тип dim3);
· blockDim - размер блока (имеет тип dim3);
· blockIdx - индекс текущего блока в grid'е (имеет тип uint3);
· threadIdx - индекс текущей нити в блоке (имеет тип uint3);
· warpSize - размер warp'а (имеет тип int).
В язык добавляются 1, 2, 3, 4-мерные вектора из базовых типов - char1,
char2, char3, char4, uchar1, uchar2, uchar3, uchar4, short1, short2, short3,
short4, ushort1, ushort2, ushort3, ushort4, int1,int2, int3, int4, uint1,
uint2, uint3, uint4, long1, long2, long3, long4, ulong1, ulong2, ulong3,
ulong4, float1, float2, float3, float2, и double2.
Обращение к компонентам вектора идет по именам - x, y, z и w. Для
создания значений-векторов заданного типа служит конструкция вида
make_<typeName>.
Не поддерживаются векторные покомпонентные операции, т.е. нельзя просто
сложить два вектора при помощи оператора "+" - это необходимо явно
делать для каждой компоненты.
Также для задания размерности служит тип dim3, основанный на типе uint3,
но обладающий нормальным конструктором, инициализирующим все не заданные
компоненты единицами.
Для запуска ядра на GPU используется следующая конструкция:
kernelName<<<Dg,Db,Ns,S>>> ( args )
Здесь kernelName это имя (адрес) соответствующей __global__ функции, Dg - переменная (или значение) типа dim3, задающая размерность и размер grid'a (в блоках), Db -
переменная (или значение) типа dim3,
задающая размерность и размер блока (в нитях), Ns - переменная (или значение) типа size_t,
задающая дополнительный объем shared-памяти,
которая должна быть динамически выделена (к уже статически выделенной shared-памяти), S - переменная (или значение) типа cudaStream_t задает поток (CUDAstream), в котором должен произойти вызов, по умолчанию используется поток 0.
Через args обозначены аргументы вызова функции kernelName.
Также в языкС добавлена функция __syncthreads, осуществляющая синхронизацию всех
нитей блока. Управление из нее будет возвращено только тогда, когда все нити
данного блока вызовут эту функцию. Т.е. когда весь код, идущий перед этим
вызовом, уже выполнен (и, значит, на его результаты можно смело рассчитывать).
Эта функция очень удобная для организации бесконфликтной работы сshared-памятью.
Также CUDA поддерживает все математические
функции из стандартной библиотекиС, однако с точки зрения быстродействия лучше
использовать их float-аналоги (а
не double) - например sinf. Кроме этого CUDA предоставляет дополнительный набор математических
функций (__sinf, __powf и т.д.) обеспечивающие более низкую точность, но
заметно более высокое быстродействие чем sinf, powf и
т.п.
3.
Пример применения технологии CUDAдля
неграфических вычислений
3.1 Вычисление интеграла
Для оценки скорости вычисления на CPU и GPU, вычислим интеграл методом
прямоугольников на отрезке от 0 до 1 с числом шагов = 10000000, по формуле:
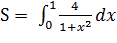
Для расчёта на CPUиспользован
язык C, исходный код программы см.
Приложение А. Результат работы программы показан на рисунке 4.
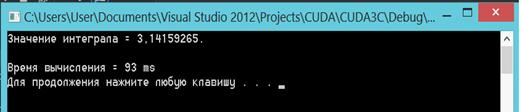
Рис.
4Время и результат вычисления интеграла методом прямоугольников на CPU.
Для
расчёта на GPUс применением CUDAбудут
использованы: аналогичная формула, численные методы и тоже число шагов,
расширение языка CдляCUDA. Исходный код программы см. Приложение Б.Результат
работы программы показан на рисунке 5.

Рис.
5Время и результат вычисления интеграла методом прямоугольников на GPU. С
применением технологии CUDA.
Из
полученных результатов видно, что время, затраченное на расчёты с применением технологииCUDA
меньше ( в данном случаи примерно на 40%). При многократном повторении
расчётов, средний выигрыш в скорости остьаётся примерно на таком же уровне.
Чтобы
подтвердить преимущество использования GPU для неграфических вычислений, далее
будет приведён пример сложения векторов.
3.2 Сложение векторов
Для подтверждения преимущества проведения неграфических вычислений на
GPUс применением технологии CUDA,
выполним сложение векторов.
Для проверки скорости вычислений на CPU и GPU, будут использованы программы,
производящие идентичные вычисления.
Пример расчёта на CPUвыполнен
с использованием язык C,
исходный код программы см. Приложение В. Результат работы программы показан на
рисунке 6.
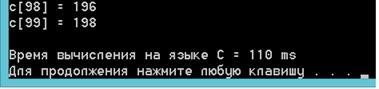
Рис.
6Время и результат сложения векторов на CPU.
Для
расчёта на GPU с применением CUDAбудут
использованы: аналогичныйалгоритм и методы, расширение языка CдляCUDA.
Исходный код программы см. Приложение Г.Результат работы программы показан на
рисунке 7.
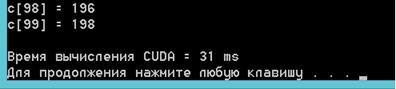
Рис.
7 Время и результат сложения векторов на GPUс применением CUDA
Из
полученных данных видно, что скорость вычисления (в данном случаи сложение
векторов) на GPUс использованием CUDAвыше,
чем на CPU. Прирост скорости составляет 354%, то есть скорость
сложения векторов по одинаковому алгоритму на GPUс использованием CUDAвыше,
чем на CPU в 3,5 раза.
3.3 Технические характеристики ПК применяемого для вычислений
Для выполнения всех приведённых примеров (вычисление интеграла, сложение
векторов), применялся ПК, основные характеристики которого приведены в таблице
3. Скоростивычислений на GPUиCPU будут отличаться, в зависимости от
их характеристик.
Таблица
3
Основные
технические характеристики ПК
|
Компонент
|
Характеристики
|
|
Процессор (CPU)
|
I5 - 4200M 2,5 - 3,1 ГГц, 2 ядра, 4
потока
|
|
Оперативная память (RAM)
|
DDR3 8 ГБ
|
|
Графический контроллер
|
NVIDIA GeForce
GT 740M 2 ГБDDR3
|
Заключение
Использование GPUи технологии CUDA для неграфических вычислений
является эффективным решением для увеличения скорости самих вычислений, и как
следствие уменьшения временных и материальных затрат.
Увеличение скорости вычислений наблюдается даже при использовании
мобильных графических контроллеров, что видно в примерах вычисления интеграла и
сложения векторов. Применение более мощных GPU будет эффективным при проведении сложных расчётов.
Для научных и технических вычислений общего назначения могут быть
использованы вычислительных систем NVIDIATesla, на основе графических
процессоров с архитектурой CUDA. Tesla не может полностью заменить обычный
универсальный процессор, но позволяет использовать вычислительный ресурс
множества своих ядер для решения определенного круга ресурсоёмких задач (вести
параллельную обработку данных).В отличие от видеоускорителей, не имеет средств
вывода изображения на дисплей. Являясь своего рода сопроцессором, Tesla может
использоваться для создания вычислительных систем на базе персональных
компьютеров, а также в составе серверов и вычислительных кластеров.
Преимуществом гетерогенных вычислительных систем с Tesla является большая
энергоэффективность и меньшая стоимость, как недостаток можно рассматривать
меньшую универсальность.
Применение GPU будет
эффективным и целесообразным для проведения сложных расчётов, а также позволяет
получить их результаты за приемлемое время.
Список литературы
1. Д.
Сандерс Технология CUDA в примерах. Введение в программирование графических
процессов / Д. Сандерс, Э. Кэндрот-М.: ДМК Пресс, 2011. -232 с.
. NVIDIA
CUDA - неграфические вычисления на графических процессорах [Электронный ресурс]
- режим доступа:http://www.ixbt.com/video3/cuda-1.shtml
3. TOP50
суперкомпьютеров [Электронный ресурс] - режим
доступа:<http://top50.supercomputers.ru>
. Эксафлопные
технологии. Концепция по развитию технологии высокопроизводительных вычислений
на базе суперэвм эксафлопного класса (2012-2020 гг.) [Электронный ресурс] -
режим доступа: http://filearchive.cnews.ru/doc/2012/03/esk_tex.pdf
. А.В. БоресковОсновы
работы с технологией CUDA. / А.В. Боресков, А.А. Харламов-М.: "ДМК
Пресс", 2010
. NVIDIA CUDA 4.0
Programming Guide. [Электронный ресурс] - режим
доступа:<http://developer.download.nvidia.com/compute/DevZone/docs/html/C/doc/CUDA_C_Programming_Guide.pdf>
Приложение А
Вычисление интеграла на CPU
#include "stdio.h"
#include <locale.h>main() {(LC_ALL,
"Russian");Time1, Time2, Delay1;= 10000000;= GetTickCount();left =
0.0;right = 1.0;step = (right-left)/numSteps;sum = 0;(double x = left +
0.5*step; x < right; x += step)+= 4.0/(1.0 + x*x);("Значениеинтеграла =
%0.8f.\n", sum/numSteps);= GetTickCount();= Time2 -
Time1;("\nВремявычисления = %d ms\n", Delay1);("pause");
return
0;
}
Приложение Б
Вычисление интеграла на GPU с
использованием CUDA
#include <stdio.h>
#include <locale.h>
#include <stdlib.h>
#include <cuda_runtime.h>
#include "device_launch_parameters.h"
#include "windows.h"
#if __DEVICE_EMULATION__(void){(stderr,
"Режимэмуляции\n");true;
}
#else(void) {;(&deviceCount);(deviceCount == 0) {("УстройстваCUDAнеобнаружены\n");false;
}(intdev = 0; dev<deviceCount; dev++) {;(&deviceProp,
dev);(dev == 0) {(deviceProp.major == 9999 &&deviceProp.minor == 9999)
{("Устройства CUDA не обнаружены\n");
return false;
} else if (deviceCount == 1) {("Найдено 1 CUDA устройство\n");
} else {
printf("Найдено
%dCUDA устройств \n", deviceCount);
}
}
}true;
}
#endif
__global__ void calc(double *a, int n) {= blockIdx.x *
blockDim.x + threadIdx.x;= a[idx];(idx< n){[idx] = 4.0 /(1.0 + val*val);
}
}main(intargc, char* argv[]) {(LC_ALL,
"Russian");(!InitCUDA()) {("pause");0;
}, Time2, Delay1; *a_h; // указатель на область памяти
хоста
double
*a_d; // указатель на область памяти устройства
constintnumSteps = 10000000; // количество разбиений
a_h = (double *)malloc(sizeof(double)*numSteps); // выделение памяти на хосте обычным способом
cudaMalloc((void **) &a_d, sizeof(double)*numSteps); // выделение памяти на устройстве
intblockSize = 192;blocks = numSteps / blockSize + (numSteps
% blockSize == 0 ? 0:1);left = 0.0;right = 1.0;step = (right-left)/numSteps;i =
0;(double x = left + 0.5*step; x < right; x += step) {_h[i] = x;++;
}(a_d, a_h, sizeof(double)*numSteps,
cudaMemcpyHostToDevice);= GetTickCount();<<< blocks,
blockSize>>> (a_d, numSteps);(a_h, a_d, sizeof(double)*numSteps,
cudaMemcpyDeviceToHost); // передаемданныеобратнонахостsum = 0.0;(int i = 0; i
<numSteps; i++) {+= a_h[i];
}= GetTickCount();= Time2 - Time1;("Значениеинтеграла
%0.7f\n", sum / numSteps);("\nВремявычисления = %d ms\n",
Delay1);("pause");(a_h);(a_d);EXIT_SUCCESS;
}
Приложение В
Сложение векторов на CPU
#include "stdio.h"
#include "windows.h"
#include <locale.h>
#define SIZE 1024(int *a, int *b, int *c, int n) {i;(i = 0; i
< n; ++i)[i] = a[i] + b[i];
}main() {(LC_ALL, "Russian");Time1, Time2,
Delay1;*a, *b, *c;= GetTickCount();= (int *)malloc(SIZE*sizeof(int));= (int
*)malloc(SIZE*sizeof(int));= (int *)malloc(SIZE*sizeof(int));(int i = 0; i <
SIZE; ++i) {[i] = i;[i] = i;[i] = 0;
}(a, b, c, SIZE);(int i = 0; i < 100; ++i)("c[%d] =
%d\n", i, c[i]);= GetTickCount();(a);(b);(c);= Time2 - Time1;("\nВремя вычисления на языке C = %dms\n", Delay1);
system("pause");
return
0;
}
Приложение Г
Сложение векторов на GPU с
использованием CUDA
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "stdio.h"
#include "windows.h"
#include <locale.h>
#define SIZE 1024
__global__ void VectorAdd(int *a, int *b, int *c, int n) {i =
threadIdx.x;
//for(i = 0; i < n; ++i)(i < n)[i] = a[i] + b[i];
}main() {(LC_ALL, "Russian");Time1, Time2,
Delay1;*a, *b, *c;*d_a, *d_b, *d_c;= (int *)malloc(SIZE*sizeof(int));= (int
*)malloc(SIZE*sizeof(int));= (int *)malloc(SIZE*sizeof(int));(&d_a,
SIZE*sizeof(int));(&d_b, SIZE*sizeof(int));(&d_c, SIZE*sizeof(int));=
GetTickCount();(int i = 0; i < SIZE; ++i) {[i] = i;[i] = i;[i] = 0;
}(d_a, a, SIZE*sizeof(int), cudaMemcpyHostToDevice);(d_b, b,
SIZE*sizeof(int), cudaMemcpyHostToDevice);(d_c, c, SIZE*sizeof(int),
cudaMemcpyHostToDevice);<<<1, SIZE>>>(d_a, d_b, d_c,
SIZE);(c, d_c, SIZE*sizeof(int), cudaMemcpyDeviceToHost);(int i = 0; i <
100; ++i)("c[%d] = %d\n", i, c[i]);= GetTickCount();= Time2 -
Time1;(a);(b);(c);(d_a);(d_b);(d_c);("\nВремявычисления CUDA = %d ms\n",
Delay1);("pause");0;
}