Изучение пунктуации на примерах корпуса школьных текстов
ОГЛАВЛЕНИЕ
ВВЕДЕНИЕ
Глава
1. Корпус текстов школьников
.1
Корпус текстов школьников в контексте корпусной лингвистики
.2
содержание корпуса текстов школьников
.3
Пополнение корпуса текстов школьников
Глава
2. Пунктуационный разметчик Интерробанг
.1
Техническое описание программы Интерробанг
.2
Язык разметки TEI для кодировки пунктуации
.3
Описание интерфейса. Работа в программе Интерробанг
Глава
3. Пунктуационная разметка текстов школьников. Классификация пунктуационных
ошибок
Глава
4. Обработка корпуса с помощью программы интерробанг и анализ полученных данных
4.1
Статистический анализ данных
.2
Анализ данных разметки и статистической обработки
4.2.1
Оформление заголовков
.2.2
Удаленные знаки препинания
.2.3
Парность знаков
4.2.4
Пробелы
.2.5
Абзацное членение
.2.6
Разделительные знаки
.2.7
Выделительные знаки
.2.8
Другие пунктуационные случаи
.2.9
Лишние знаки неясной этиологии
ЗАКЛЮЧЕНИЕ
СПИСОК
ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ И ЛИТЕРАТУРЫ
ПРИЛОЖЕНИЯ
ВВЕДЕНИЕ
Направление корпусной лингвистики, которая занимается сбором,
обработкой и анализом текстовых данных, активно развивается сегодня по всему
миру. Увеличивается число национальных корпусов (собрание текстов в электронной
форме, представляющих определенный язык во всем многообразии жанров, стилей,
территориальных и социальных вариантов), возникают новые форматы и типы
корпусов: корпусы текстов одного писателя, корпусы синонимов, мультимедийные
корпусы, представляющие данные сразу нескольких языковых и
экстралингвистических уровней речи, корпусы эмоционально окрашенной речи и т.д.
Корпусные данные исследуются и используются для решения
различных прикладных задач - от создания словарей до интеллектуальных
диалоговых систем. Но на фоне многообразия данных, современных методов и
алгоритмов обработки данных и их представления, до сих пор остаются области, не
вполне охваченные исследователями, например, речь современных подростков.
Дискуссия о целесообразности создании корпуса ученических
текстов, представляющих родную речь, ведется уже почти на протяжении целого десятилетия.
За последние годы, наконец, сформировалось понимание того, что в условиях
высокой технической оснащенности образовательных учреждений собирать школьный
дискурс (сочинения, изложения, диктанты, пересказы, устные доклады и т.п.)
перестало быть затруднительным, а практика корпусного анализа текстов дает
ощутимый результат в развитии обучающих систем (В.А. Плунгян, 2005; О.Н.
Камшилова, 2011; О.Э. Садовникова, 2013; Е.В. Рахилина, 2015).
Возможности корпусных технологий уже давно оценили и взяли на
вооружение вузовские преподаватели: они используют их для того, чтобы оценить,
какие ошибки учащиеся допускают чаще и с какими стоит и нужно специально
работать, создают на базе корпусов специальные тренажеры для повышения уровня
грамотности учащихся. Пример успешной работы с корпусными для создания
тренировочных упражнений (О.Н. Камшилова и др., 2008).
Несмотря на положительный опыт учителей иностранного языка и
давно прозвучавшее предложение лингвистов использовать актуальные корпусные
данные (Н.Р. Добрушина, 2005; Н.Р. Добрушина, А.И. Левинзон, 2006), методисты,
сталкивающиеся с вопросом, чем наполнить учебники и задачники по русскому
языку, до сих пор не проявили интереса к текстам школьников.
Как правило, в случае отбора текстов для анализа и тренировки
языкового навыка переиздают хорошо известные пособия; по традиции выбирают
тексты из классической литературы, к сожалению, часто тяжелые, морально
устаревшие, неблизкие и непонятные современному школьнику; либо тексты
конструируются искусственно, и их неестественность вызывает у ребенка реакцию
отторжения и нежелания изучать родной язык. Между тем материал для создания
тренажеров под рукой - написанные учащимися тексты, в которых допущены типичные
орфографические, пунктуационные и речевые ошибки.
У учеников и родителей часто возникает ложное ощущение, что
учителей мало заботит, какие ошибки допускают школьники, где «больное место» у
конкретного ребенка, в каких случаях ошибаются почти все учащиеся, и какую
помощь им оказать. На самом деле учителю-русисту, ведущему в нескольких классах
с большим количеством детей, сложно заметить, что усваивается школьниками, а
какие правила и навыки так и не удалось закрепить. У него до сих пор не было
инструмента и достаточной статистической информации, которые позволили бы представить
полную картину ученических проблем исправиться с ними.
Кроме того, мониторинг корпусных данных, возможно, позволит
учителю видеть, какие случаи не стоит исправлять в детских текстах. Язык
меняется, и, хотя справочниками это еще не зафиксировано, на самом деле речь
часто идет уже не об ошибке, а о языковой норме (достаточно вспомнить пример с
предлогом «про» в значении «о»).
Именно такие соображения наводят на мысль о необходимости
смены подхода к созданию справочного материала по русскому языку.
Корпус школьных текстов с размеченными ошибками может быть
использован и в практических целях: для создания учебных тренажеров и как
готовая база примеров и статистических данных для создания спелчекеров -
современных систем проверки правописания. Разработчики таких программ на данный
момент применяют данные, полученные преимущественно из справочной литературы и
корпусов с текстами, написанными грамотно и проверенными корректорами
(Орфограммка, Орфус, Литера5 и др.). Только некоторые спелчекеры (Орфограммка)
обрабатывают данные об ошибках пользователей для улучшения процедуры проверки.
Особый интерес для авторов спелчекеров представляют данные о пунктуационных
ошибках - в связи с нехваткой данных ни одна из существующих систем проверки на
сегодняшний день не может обеспечить качественной проверки пунктуации.
В рамках настоящей магистерской работы мы поставили цель
изучить пунктуацию на примерах из собранного нами Корпуса школьных текстах.
Анализ пунктуации и особенно пунктуационных ошибок представляет для нас
исследовательский интерес как с теоретической точки зрения, так и с
практической. С одной стороны, мы рассчитываем получить данные, позволяющие под
иным углом взглянуть на методику изучения пунктуационных правил, с другой, мы
видим одной из задач после наполнения корпуса и сбора статистических данных
создание школьного спелчекера - программы, которая автоматически будет
исправлять ошибки в загруженных текстах и выставлять оценки.
Глава
1. Корпус текстов школьников
Корпус текстов школьников (КТШ) - совокупность текстов,
написанных подростками на уроках русского языка и словесности и в рамках
домашних заданий по этим предметам. Тексты корпуса могут использоваться для
лингвистических исследований регламентированной письменной речи, для разработки
учебно-методических материалов.
Тексты собирались в ходе эксперимента, проводившегося в
2014-2015 гг. на базе школы 179 г. Москвы. В течение учебного года учащимся
нескольких 7-х и 8-х классов школы предлагалось сдавать на проверку тексты,
написанные в рамках курса словесности и русского языка, в удобном им формате -
рукописном или напечатанном.
Учащиеся быстро оценили преимущества текстов, сданных на
проверку в электронном виде: работа над ошибками - редактирование текста,
включающее переписывание текста, по мнению учащихся, была менее трудоемким
занятием в том случае, если текст был написан не от руки, а напечатан.
Глава представлена тремя разделами. В первом разделе речь
пойдет о Корпусе школьных текстов в контексте корпусной лингвистики в целом: о
предмете корпусной лингвистики, об истории вопроса, о предназначении корпусов,
о корпусах подростковой речи и Корпусе текстов школьников как материале для
социолингвистических и лингвистических исследований. Во втором разделе будет
рассказано о технологии сбора текстов для КТШ. В третьем - о проблемах, с
которыми мы столкнулись при наполнении Корпуса.
1.1
Корпус текстов школьников в контексте корпусной лингвистики
Корпусная лингвистика, возникшая во второй половине XX - одно из самых молодых
направлений в науке и в то же время весьма популярное среди
ученых-исследователей всего мира. Корпусная лингвистика позволяет изучать
письменную и устную речь, предлагая для исследований большое количество данных,
удобных для полуавтоматической и автоматической обработки, по результатам
которой строятся и проверяются сложные лингвистические, исторические,
социологические и др. гипотезы.
Объектом изучения корпусной лингвистики являются собранные в
большом количестве тексты и записи звучащей речи на определенном языке или
нескольких языках. Задача лингвиста не только собрать речевые данные, но и
обработать их, исходя из целей и задач собираемого корпуса, а также
анализируемых языковых уровней. В результате такой обработки исследователь
получает разметку корпуса, т.е. не только текст как последовательность
словоформ или лемм и знаков препинания, но и дополнительную информацию о тексте
в целом (метатекстовая разметка: автор текста, жанр, врем создания и т.д.) и
информацию о различных единицах текста (разметка, включающая леммы, теги с морфологической
или семантической характеристикой слова, выделение синтагм, синтаксическую
разметку предложений и т.д.). Аннотированные и размеченные тексты, т.е.
материал, подготовленный для заключительного этапа исследовательской работы,
анализа языковых фактов, - это и есть корпус.
В большинстве случаев современные корпусные данные
формируются и обрабатываются с помощью специальных программ - утилит для сбора
данных, программы, очищающие от избыточных данных и форматирующие, программы
для разметки, программы для статистической обработки, программы, формирующие
гипотезы, и, конечно, комплексные решения (WordSmith Tools, AntConc и др.).
Основное внимание в корпусной лингвистике долгое время было
приковано к созданию содержащих метаразметку и грамматические пометы
национальных корпусов, корпусов языков с большим числом носителей -
английского, чешского, хорватского, венгерского, итальянского, русского,
японского и т.п. Основой для таких корпусов в большинстве случаев служила
классическая литература. Впоследствии такие корпуса пополнялись
публицистическими произведениями и научными текстами, сегодня в них находится
место интернет-дискурсу, устной речи и созданию мультимедийному контенту (в
корпусах аудио и видеозаписи сопровождаются письменной расшифровкой и разметкой
жестового сопровождения).
В конце XX-начале XXI вв. наметилась тенденция к созданию параллельных
корпусов для двух или нескольких
языков (English-Norwegian Parallel Corpus). Такие корпуса часто содержат
мататекстовую, грамматическую и эрратологическую разметку, т.е. информацию об
ошибках при переводе. Параллельные корпуса в значительной степени изменили
подход в методике преподавания иностранных языков.
В наше время с целью сохранения мирового наследия активно
создаются корпуса языков малых народов, например, электронный корпус текстов на
языках малочисленных народов Сибири (на материалах ненецкого, телеутского,
шорского и эвенкийского языков); корпуса древних текстов (например, Helsinki
Corpus - корпус древне- и среднеанглийских текстов с 8 по 17 вв.) и текстов на
языках, которые находятся под угрозой исчезновения (например, Сorpus of Chipaya
texts).
На фоне повышенного интереса к концепции использования
интернета как огромного корпуса, предназначенного для машинной обработки, и к
разработкам по переводу текстового контента в онтологии знаний (В.Д. Соловьев и
др., 2006) широкое распространение получили тематические корпуса (медицинские,
юридические, экономические и др.).
В последние десятилетия интерес корпусной лингвистики
прикован, в том числе и в России, к глубокому, многоаспектному изучению родного
языка.
Работа ведется сразу по нескольким направлениям.
Изучается детская (дошкольная) речи (например, CHILDES Corus: содержит
транскрибированную речь детей 20 национальностей, речь детей с нормальным
развитием и с афазией или аутизмом) и речь билингвов и мультилинговов
(например, Корпус устной речи русско-болгарских билингвов). На данных,
полученных в этой области, строятся модели порождения речи.
Изучается наследуемый язык (например, Эритажный корпус,
являющийся частью проекта «Корпуса и коллекции интерферированных вариантов
русского языка»). После публикаций Кембриджского университета о подкорпусе CIC Cambridge Learner
Corpus, который позволяет отслеживать наиболее частое употребление узуальных
конструкций и типичных ошибок в академической речи, а потому используется при
составлении учебников и тренажеров по английскому языку, повсеместно стали в
университетах стали разворачиваться корпуса академической речи. Наконец,
обозначился интерес к речи школьника.
Именно последнему направлению будет посвящено данное
исследование.
На сегодняшний день известны два корпуса подростковой речи - SCOSE (создавался
исследователям из Саарского университета (Germany), содержит речь
подростков из Лондона и пригородов, около 12,000 словоупотреблений) и COLT (собран исследователями
из Бергенского Университета; разработан на базе спонтанной устной речи детей в
возрасте от 13 до 17 лет из разных пригородов Лондона; включает в себя около 5
000 000 слов; записи сопровождаются метаразметкой, сообщающей возраст, пол,
социальный статус говорящего).
В первую очередь интерес такие корпуса вызывают у
социолингвистов, изучающих сленг современных подростков (например, A.B. Stenström, G. Andersen и др., 2012; E.M.D Drange. и др., 2014).
В данном исследовании ставится другая цель. КТШ собирается и
обрабатывается таким образом, чтобы посмотреть на тексты школьников с
эрратологической точки зрения: изучается, какие ошибки чаще всего допускают
современные подростки в регламентированной учебным процессом речи - в
сочинениях, изложениях, диктантах и других формах школьного языкового дискурса.
1.2
Содержание корпуса текстов школьников
Корпус текстов школьников - пополняемая база ученических
текстов.
Ученические тексты, включенные в КТШ, - это тексты,
написанные от руки (затем набранные на компьютере волонтерами) или
напечатанные, авторами которых являются учащиеся 7-9 классов, т.е. подростки
12-15 лет. Все тексты? включенные в базу, переведены в текстовый формат (.txt) txt c кодировкой utf-8 и рассортированы по
папкам: 7б1-2014, 8е-2013, 8е-2014, 9е-2014, неразобранное-2014. В настоящее
время (июнь 2015г.) таких файлов 238 (приблизительно 100 000
словоупотреблений). Ожидают форматирования и сортировки 123 текста -
преимущественно домашние сочинения семиклассников, написанные в почтовых
редакторах; набора и форматирования - 220 рукописных текстов шестиклассников и
семиклассников, написанных на уроке (не диктанты).
Во всех папках с отформатированными работами, кроме тех,
которые содержат в своем название слово «неразобранные», содержатся тексты в
формате .txt (имеют названия на кириллице) и их аннотированные и размеченные
дубли в формате .ieb (имеют названия на латинице). На данный момент в корпусной базе
126 файлов в формате .ieb. (47 448 словоупотреблений).
Каждый такой файл аннотирован в программе Интерробанг с
помощью метаразметки на языке TEI (#"862958.files/image001.jpg">
Рис. 1. Главное рабочее окно программы Интерробанг
· Меню «Сервис» с двумя пунктами: «Статистика» -
выводит статистическую информацию об ошибках, отмеченных проверяющим в открытом
файле, и «Дамп» - открывает окно с TEI-разметкой открытого
файла.
· Меню «Справка» -
выводит справку по графическим обозначениям причин постановки/удаления знака
препинания.
Под меню расположена панель инструментов с кнопками основных
операций:
 - кнопка «Открыть»
- кнопка «Открыть»
 - кнопка «Импорт»
- кнопка «Импорт»
 - кнопка «Печать»
- кнопка «Печать»
 - кнопка «Сохранить»
- кнопка «Сохранить»
 - кнопка «Статистика»
- кнопка «Статистика»
 - кнопка «Справка»
- кнопка «Справка»
При загрузке файла с помощью кнопок «Открыть» или
«Импортировать» в основной части окна появится пригодный для правки текст с
выделенными программой знаками препинания. Все эти знаки препинания будут
обозначены синим цветом (например,  ), а в TEI-формате им будут присвоены теги с
соответствующими значениями.
), а в TEI-формате им будут присвоены теги с
соответствующими значениями.
Система распознает:
".": "dot",
"!": "exclamation",
"?": "question",
",": "comma",
";": "semicolon",
":": "colon",
" - ":
"dash","\u2013": "dash","\u2014":
"dash",
"-": "hyphen",
"(": "open_parenthesis",
")": "close_parenthesis",
"[": "open_bracket",
"]": "close_bracket",
"{": "open_curly",
"}": "close_curly",
"...": "ellipsis",
"?!.": "qex_ellipsis",
"/": "slash",
"?!": "interrobang",
'"': "quote",
и различные типы кавычек:
u"\u00AB":
"left_angle_quote","\u00BB":
"right_angle_quote","\u201C":
"left_quote","\u201D":
"right_quote","\u201E": "low_quote","\u201F":
"high_quote","\u2033": "prime_qoute",
u"\u2036":
"reversed_prime_quote".
Правка осуществляется с клавиатуры компьютера.
Каждому знаку препинания можно приписать при помощи
специальных значков в поле «Разметка» (внизу справа) причину постановки или
удаления знака (рис. 2).
Рис. 2 Поле «Разметка» с объяснительными значками
О соответствии объяснительных значков правилам и типам ошибок
можно прочесть в конце Главы 3.
При исправлении фон знака препинания меняется с синего на
красный. Если знак удаляется (это действие осуществляется с помощью стандартных
средств компьютерной клавиатуры), знак препинания зачеркивается и ему
присваивается соответствующий TEI-тег исправления. Если понятно, с каким правилом
связана ошибка, выбирается соответствующий значок в поле «Разметка» основного
окна (справа внизу), а знаку препинания в .ieb-файле присваивается
коррелирующий с выбранным значком TEI-тег.
Если знак добавляется, он автоматически оформляется нижним
подчеркиванием, а проверяющим из набора значков в поле «Разметка» выбирается
один или несколько символов, объясняющих причину постановки знака. В этом
случае знаку препинания будет присвоен тег пунктуационной правки с одним или
несколькими значениями.
Если один знак исправляется на другой или другие, то
неправильный знак зачеркивается, а для новых выбирается значок, указывающий на
причину замены, а в TEI-разметке появляется соответствующие теги внесенных исправлений.
Справа в главном окне находится специальное поле для ввода
атрибутов текста - «Свойства» (см. рис. 3): автор; класс; тип текста -
сочинение, изложение, диктант, другое; название текста; формат -
печатный/рукописный; степень доверия - высокая/низкая; проверяющий.
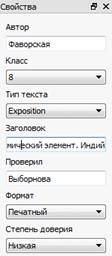
Рис. 3. Поле «Свойства» для ввода значений основных атрибутов
текста
Значения свойств будут сохранены в метатегах TEI-размтеки.
Данные о тексте можно вводить в любой момент, даже при
повторном открытии документа, так же как и осуществлять пунктуационную правку.
После внесения исправлений и данных о тексте документ
сохраняется.
Если интересна статистика об ошибках без вывода на печать,
нажимается кнопка «Статистика», которая вызывает появление окна, где
последовательно сообщается, в каких знаках ошибся писавший текст и сколько на каждое
правило было сделано ошибок (см. рис. 4).
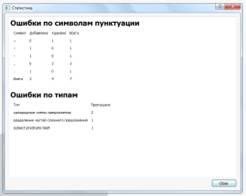
Рис. 4. Окно с выводом статистической информации о пунктуации
в тексте
Если интересует TEI - разметка текста, достаточно нажать выбрать в
«Сервисе» пункт «Дамп», чтобы вызвать программное окно (Shell, Python) с результатом TEI-обработки (см. рис. 5 и
6).

Рис. 5. TEI-разметка: метатеги

Рис. 6. TEI-разметка: теги
Глава
3. Пунктуационная разметка текстов школьников. Классификация пунктуационных
ошибок
Пунктуационная разметка в нашем
исследовании определена следующими задачами:
обозначить все встречающиеся в текстах
школьников знаки препинания;
отметить все случаи, в которых учащийся
допустил пунктуационную ошибку;
осуществить проверку текста учащегося
таким образом, чтобы, получив проверенную работу, ученик не только понимал, где
он ошибся в пунктуации, но и почему знаки препинания должны были быть
поставлены иначе в каждом в конкретном случае.
провести статистический анализ
пунктуационных ошибок в школьных текстах.
Для решения этих задач нам предстояло
решить, как и по какому принципу собирать, обрабатывать и считать
пунктуационные данные.
Сначала был сформирован список того, что
мы считаем знаками препинания: "." (точка), "!"
(восклицательный знак), "?" (вопросительный знак), ","
(запятая), ";"(точка с запятой), ":" (двоеточие), " -
" (тире), "-" (дефис: включили в группу пунктуационных знаков,
так как с помощью дефисов выделяются одиночные приложения после определяемого
слова), "/"(слэш), кавычки, открывающие скобки, закрывающие скобки,
комбинированные знаки - "..." (многоточие), "?!." ,
"?!".
Затем предстояло определить, какие типы
ошибок будут учитываться при заметке. При составлении классификации ошибок мы
опирались на то, что расчленение письменного текста происходит по трем
основаниям, определяющим принципы современной русской пунктуации:
формально-грамматическому (с учетом
синтаксического строения предложения и его компонентов),
смысловому (отражение содержательной
значимости речи),
интонационному (распределение пауз,
логических и смысловых акцентов, передача эмоциональных нюансов речи) (Правила
русской орфографии и пунктуации, 2009).
Большая часть пунктуационных правил все же
привязана к синтаксическому строению предложения, а именно, это
знаки конца предложения;
знаки, разделяющие части сложного
предложения;
знаки, указывающие на синтаксическую
однородность;
знаки, выделяющие группы слов с четко
фиксируемым местом расположения (Т.В. Базжина, Т.Ю. Крючкова. Русская
пунктуация, 2015).
Именно эти знаки препинания составляют
необходимый пунктуационный минимум, который обязателен в школьной программе и,
следовательно, применим при исправлении школьных текстов в программе
Интерробанг.
Поскольку смысловые оттенки речи могут
быть разнообразными, то и знаки, ориентированные на их передачу, допускают
вариантность в соответствии с возможностью разного осмысления тех или иных
конструкций (Правила русской орфографии и пунктуации, 2009). Наша программа не
предполагает вариативности. Если вариант ученика допустим, проверяющий по
своему усмотрению либо не исправляет его (предусмотрен вариант обозначения
знака как авторского), или исправляет на тот, который ближе всего к правилам
первого основания, т.е. к норме.
Согласно третьему основанию в программе
обрабатываются случаи выделения междометий и конца предложений.
Для удобства школьников и проверяющих при
создании типологии ошибок также было решено опираться на самые общие причины
постановки/отсутствия знаков препинания, применяемые в школе, и, следовательно,
причины ошибок. После нескольких встреч с практикующими преподавателями и
обсуждений возможного набора правил, таких позиций было выделено 16. Вслед за
[Т.В. Базжина, Т.Ю. Крючкова. Русская пунктуация, 2015], все правила были
изначально разделены на две группы - правила, связанные с разделительной
функцией, и правила, связанные с выделительной функцией. Затем выделилась также
третья группа, куда попали случаи, которые невозможно отнести ни к одной из
двух указанных выше групп.
По совету старшего преподавателя
филологического факультета Казанского государственного университета и учителя
Лицея при КГУ Афанасьевой Т.В. всем правилам были присвоены легко
запоминающиеся объяснительные значки. Практика использования подобных значков
уже имела место в школе до создания КТШ и хорошо себя зарекомендовала в
заданиях, когда детей просят в собственном тексте разметить с помощью
объяснительных значков логику расстановки знаков препинания. Такие задания
связаны с тем, что на уроке преподаватель обычно не успевает адекватно оценить,
усвоил ли ученик правило. Кроме того, используя объяснительные значки, ученики
повторяют правила. О том, что использование системы объяснительных значков дает
положительные результаты и дети успешно осваивают пунктуационную логику,
свидетельствуют высокие баллы, которые получают школьники, знакомые с этой
системой, на экзаменах по русскому языку при ответах на вопросы по синтаксису и
пунктуации.
В системе Интерробанг используется
следующий набор объяснительных значков, соответствующий правилам и типам
пунктуационных ошибок:
Разделительные знаки препинания:
 - разделение частей сложного предложения / clauses
- разделение частей сложного предложения / clauses
 - однородные части / homogeneous clauses
- однородные части / homogeneous clauses
 - однородные члены предложения / homogeneous
- однородные члены предложения / homogeneous
 - обобщающее слово при однородных членах предложения / homogeneous generalization
- обобщающее слово при однородных членах предложения / homogeneous generalization
Выделительные знаки препинания:
 - обращение / allocution
- обращение / allocution
 - вводные и вставные конструкции / expletive
- вводные и вставные конструкции / expletive
 - уточнение, примыкание, присоединение / specifier
- уточнение, примыкание, присоединение / specifier
 - обособленное дополнение / dangling object
- обособленное дополнение / dangling object
 - сравнительный оборот / similie
- сравнительный оборот / similie
 - обособленное обстоятельство / dangling adverbial
- обособленное обстоятельство / dangling adverbial
 - обособленное определение / dangling attribute
- обособленное определение / dangling attribute
 - приложение / apposition
- приложение / apposition
Другое:
 - тире между подлежащим и сказуемым / subject-predicate dash
- тире между подлежащим и сказуемым / subject-predicate dash
 - эллиптическое тире / blank dash
- эллиптическое тире / blank dash
 - кавычки / quotes
- кавычки / quotes
 - авторская пунктуация / author mark
- авторская пунктуация / author mark
Глава
4. Обработка корпуса с помощью программы интерробанг и анализ полученных данных
Корпус школьных текстов был обработан с помощью программы
Интерробанг - автоматически выделены знаки препинания (и сходные с ними
символы). Затем в программе в ручном режиме исправлены ошибки и во всех
допустимых случаях добавленным и удаленным знакам препинания были присвоены
объяснительные значки (в TEI-разметке соответствующие значкам значения тегов)
- иконки, привязанные к различным пунктуационным правилам и типам ошибок. Затем
была произведен статистический анализ данных разметки и собраны примеры по
типам ошибок.
В процессе разметки формировалось представление о видах
пунктуационных ошибок и того, что принято считать пунктуационными огрехами,
делались предположения о частотности тех или иных пунктуационных случаев вообще
и некоторых типов ошибок в частности, поднимались вопросы происхождения ошибок,
формировалась база интересных случаев. В результате разметки и таких наблюдений
программа разметки КШТ несколько раз менялась, в первую очередь изменения
коснулись набора объяснительных значков и списка метатегов.
В разделе 4.1 представлены результаты статистической
обработки.
В разделе 4.2 приведен анализ данных разметки и
статистической обработки.
4.1
Статистический анализ данных
Подсчет статистики ошибок в разметчике Интерробанг
осуществляется по TEI-тегам choice при помощи программы stats.py. Знаки, которые попали в
тег sic учитываются как удаленные, а те, которые попали в тег cor, - как
добавленные проверяющим. Распределение осуществляется на основе значений
атрибута subtype тега pc для объяснительных значков и значений атрибута pc для знаков препинания.
Таким образом, статистика учитывает количество
недостающих/избыточных знаков (см. рис. 1) и причины постановки/удаления знака
препинания (см. рис. 2).
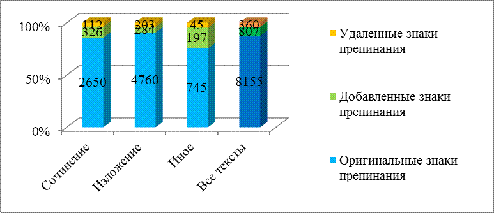
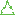
Рис. 1. Распределение удаленных и добавленных знаков
препинания в текстах разного типа
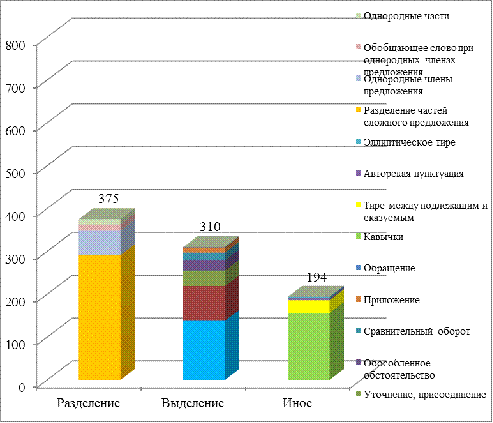
Рис. 2. Распределение по типу ошибок
Согласно полученным данным, КТШ в настоящий момент содержит
1168 аннотированных знаков (см. рис. 3), более половины из которых - запятые
(630 знаков).
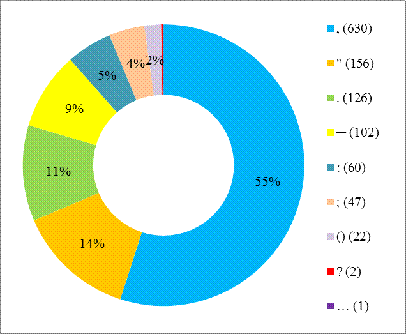
Рис. 3. Частота исправлений знаков препинания
Самый редкий знак в базе ошибок (1 случай) - многоточие.
Такие двойные знаки, как "?!" и "?!." не только не
удалялись и не добавлялись при проверке, но и не использовались в ученических
текстах ни разу.
На данный момент ни разу не производилось никаких операций с
такими знаками, как "!", фигурные и квадратные скобки, слеш и дефис
для обособления одиночных приложений.
Знак, который чаще всего, 462 раза (см. рис. 2), приходилось
добавлять проверяющим, - запятая. Также часто учащиеся пропускали кавычки - 156
раз - так как этот знак парный, следовательно, речь идет о 78 случаях. 75 раз
было добавлено тире. Точку в конце предложения пришлось поставить 42 раза.
Самым удаляемым знаком в корпусе также была запятая (168
раз). На втором месте по количеству удалений была точка (84 раза), которую
учащиеся часто ставили между частями сложноподчиненного предложения. 42 раза
проверяющие убрали ";". Удивительно, что второй по количеству ошибок
знак препинания, кавычки, ни разу не был удален - все случаи употребления были
уместны.
Согласно данным о количестве использования объяснительных
значков, проверяющему была понятна причина ошибки, сделанной учащимся, в 879
случаях, т.е. в корпусе зафиксировано более 250 ошибок неясной этиологии.
Ошибки в разделительных знаках препинания отмечены в 375
случаях, несколько меньше, 310 случаев, ошибок выделения, притом что правил,
связанных с обособлением в два раза больше, чем причин для разделения. На
остальные 4 объяснительных случая (тире между подлежащим и сказуемым и
эллиптическое, употребление кавычек и авторские знаки) приходится суммарно 194
значка, из которых большинство связаны с «забытыми» кавычками (см. рис 2).
Чаще всего ошибки связаны с неправильным разделением частей
сложного предложения - 303 случая, из которых 12 на неправильное разделение
однородных частей. Большое количество ошибок школьники допускают при
обособлении второстепенных членов - 171 пример, из них чаще всего ошибки касались
обособления определений 93 случая, где 12 примеров касаются обособления особого
типа определений - приложения. На третьем месте по частоте ошибок -
использование кавычек (156 значков). Следующая группа - ошибки на знаки
препинания при словах, грамматически не связанных с членами предложения:
учащиеся ошиблись в 139 случаях, большинство из которых связано с неумением
отличать вводные слова от не вводных и только один с обособлением обращения. 72
ошибки допущено школьниками по теме «Однородные члены предложения», причем 15
ошибок связано с использованием обобщающих слов. Учащиеся не всегда справляются
с темой «Тире между подлежащим и сказуемым» - 30 примеров на нее. Наконец 5 и 3
случаев приходится на авторские знаки и эллиптическое тире соответственно.
В корпусе пока не зафиксировано ни одного примера
неправильного обособления дополнений, т.е. оборотов со значением включения,
исключения или замещения.
Также было проведено сравнение количества ошибок в
оригинальных работах учащихся (сочинениях) и работах реферативного характера
(изложениях) (см. рис. 3, 4, 5).
Одинаково много ошибок было сделано при использовании
запятой. В изложении серьезно больше, чем в сочинении, было допущено ошибок на
постановку ";" - в 14 раз. Также в изложениях в 2-3 раза было больше
ошибок на использование скобок, тире и точки (см. рис. 4), однако
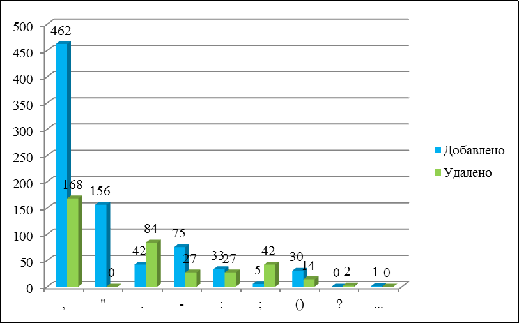
Рис. 4 Распределение ошибок в знаках препинания в изложения и
сочинениях
Такое распределение не показательно, так как объем изложений
превышает объем сочинений в 2,5 раза (см. рис. 3, 5):
изложения (28956 слов, 4760 знаков препинания);
сочинения (13008 слов, 2650 знаков препинания).
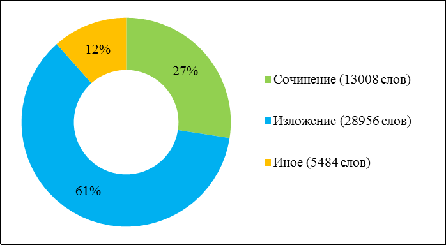
Рис. 5. Объем в Корпусе текстов разных типов
В сочинениях было допущено в три раза больше, чем в
изложении, ошибок на постановку кавычек (см. рис. 6).
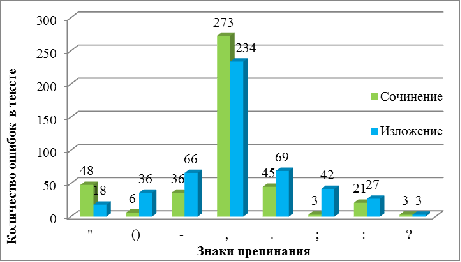
Рис. 6. Распределение ошибок в знаках препинания в сочинениях
и изложениях
При анализе типа ошибок выяснилось, что как в сочинениях, так
и в изложениях много ошибок допускается при разделении частей и при выделении
вводных конструкций (см. рис. 7). Отмечено практически одинаковое значительное
количество ошибок на однородные члены предложения в обоих типах текстов. При
этом в изложении также превалируют ошибки на выделение определений и постановку
тире между подлежащим и сказуемым, а в сочинениях на выделение обстоятельств и
уточняющих и пояснительных конструкций.
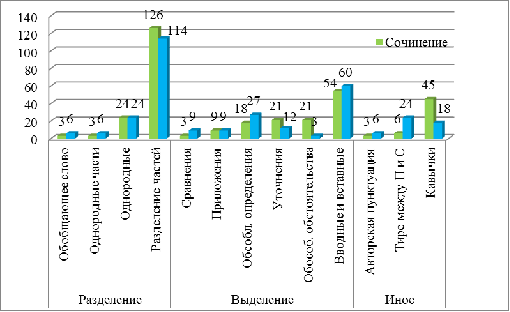
Рис. 7. Распределение по типу ошибок в текстах разного типа
Несмотря на то, что еще рано говорить о сколько-нибудь
серьезных выводах, данные, полученные в результате статистического анализа,
позволяют нам строить гипотезы, которые мы сможем проверить после пополнения
корпуса до более значительных размеров.
интерробанг пунктуационный корпусный текст
4.2 Анализ данных разметки и статистической
обработки
В ходе проверки текстов КТШ при помощи программы Интерробанг
были изучены примеры пунктуационных трудностей у современных школьников, в
некоторых случаях были предложены гипотезы для объяснения причины ошибки и ее
устранения (они будут изложены в соответствующих разделах).
Поиск примеров осуществлялся с помощью программы find.py, которая по файлам КТШ
выбирает абзацы текста, содержащие знаки препинания и/или объяснительные значки
(пример в ПриложенииБыл произведен поочередный сбор примеров для всех
размеченных ненулевых объяснений (по результатам статистической обработки в
корпусе не найдено ни одного случая ошибки на обособление дополнений), т.е.
поиск по следующим значениям:
· авторская пунктуация,
· вводные и вставные конструкции,
· кавычки,
· обобщающее слово при однородных членах
предложения,
· обособленное обстоятельство,
· обособленное определение,
· обращение,
· однородные части,
· однородные члены предложения,
· приложение,
· разделение частей сложного предложения,
· сравнительный оборот,
· тире между подлежащим и сказуемым,
· уточнение, присоединение,
· эллиптическое тире.
.2.1
Оформление заголовков
Членение
заголовка на значимые части
Приведем примеры оформления заголовков, сделанных школьниками
к своим текстам:
Елизавета Грингауз Рецензия
Рацеева Ольга 7б1 буква и
БукваФ 7б Чекалов Павел
Аннотация к реферату Тест Тьюринга Бубнов
Алексеева Ирина Империя обмана Стива Джобса
Алексеева Ира.Кобальт
Очевидно, что несоблюдение правильного членения может легко
привести к неправильному семантическому осмыслению таких заголовков, например,
сложно понять, где заканчивается фамилия и начинается класс; являются ли
сочетания цифр и букв обозначением класса или частью названия текста;
невозможно отличить заголовок от информации о типе и жанре текста и т.д.
В следующей версии Интерробанга мы хотим предусмотреть
специальное обозначение для ошибок на членение частей заголовка.
Опираясь на рекомендации, изложенные в изданиях по
редакционно-издательскому делу, следует провести разъяснительную работу со
школьными методистами и учителями русского языка о необходимости обучения детей
правильному оформлению заголовки.
Точка
в конце заголовка
Начиная с 30-х годов XX века закрепилось
правило: «Точка в конце заголовка, состоящего из одного предложения, не
ставится» [Правила русской орфографии и пунктуации, 2009]. В заголовках
из знаков конца предложения могут употребляться знаки вопросительный,
восклицательный и многоточие.
Несмотря на то, что на занятиях правило об оформлении
заголовка без точки регулярно проговаривается, во многих работах (20%) учащиеся
в конце заголовков ставят точку. Особенно это касается рукописных текстов (15
работ), но и в напечатанных работах (8 работ) такая ошибка тоже встретилась.
Стремление школьников поставить точку в конце заголовка может быть тем, что в
начальной школе у них был выработан навык постановки точки в указанной позиции:
«Справочная книга редактора и корректора»: «Точку в заголовке, вынесенном в отдельную
строку, опускают, за исключением изданий для начинающих читать детей (напр., в
букваре), чтобы не мешать закреплению стереотипа: в конце предложения надо
ставить точку». [А.Э. Мильчина, 1985. с. 24]
Меньшее количество ошибок на данное правило в печатных
работах можно объяснить тем, что школьники регулярно читают современную учебную
литературу, подвергшуюся профессиональной корректуре. Можно предположить, что
выработанный в младших классах навык в рукописных текстах ставить точку
вытесняется (особенно у детей с развитой визуальной памятью) неосознаваемым, но
запоминаемым отсутствием точки после заголовка в печатных текстах.
В дальнейшем хочется проверить данную гипотезу, подкрепив или
опровергнув ее большим количеством корпусных примеров.
.2.2
Удаленные знаки препинания
Первоначально при создании программы предполагалось, что
система будет учитывать объяснение только поставленных проверяющим знаков
препинания, однако в процессе обработки стало понятно, что причину удаления
знака более чем в половине случаев также можно определить.
Знаки препинания, которые были удалены без объяснения причин:
· те, что противоречат общему принципу русской
пунктуации - знаки препинания отсутствуют в устойчивых выражениях
· алогичные знаки - логика ребенка и причина
постановки знака непонятны;
· авторские, интонирующие знаки, если они
противоречат логике основных правил.
Знаки препинания, удаленные с указанием правила, которое
необходимо разобрать с учащимся, чтобы избегать аналогичных ошибок в будущем:
1. знаки препинания между подлежащим и сказуемым,
2. знаки препинания при неоднородных членах предложения
(тема «однородных члены»)
. знаки препинания при повторяющихся союзах (тема
«однородные клены»
. для выделения одиночных деепричастий, утративших
глагольное значение
. для выделения сравнительных конструкций, ставших
цельными выражениями
. между однородными частями, связанными союзом и (для
этого случая даже отдельно был введен значок, сообщающий о том, что мы имеем
дело с однородными частями сложного предложения. Этот значок до сих пор
ставился только в случае удаления части).
. в устойчивых конструкциях с подчинительным союзами
. в придаточных частях сложного предложениях, имеющих
подчинительный союз или союзное слово, но начинающихся с других слов;
. знаки препинания при бессоюзной связи (случаи замены
знака)
4.2.3
Парность знаков
В процессе обработки материалов также было замечено, что
знаки препинания в Корпусе делятся на
одиночные: ("."(точка), "!"
(восклицательный знак), "?" (вопросительный знак),
";"(точка с запятой), ":" (двоеточие), "-"
(дефис), "..." (многоточие), "?!." и "?!";
одиночные или парные в зависимости от контекста и положения в
предложении выделяемых конструкций.
Могут быть изначально разделяющими знаками, не ставятся в
начале предложения, если с них начинается оборот и если они поглощаются знаками
конца предложения или части сложного предложения: "," (запятая),
" - " (тире).
В (слэш) - в нашем корпусе встретился случай одиночного слэша
("/"), использованного не в качестве пунктуационного(км/ч).
парные знаки, в случае с которыми при наличии открывающего
знака обязательно должен быть закрывающий: открывающим кавычкам соответствуют
закрывающие, например, у открывающего знака "«"будет
закрывающий"»".
На данный момент о парности знаков можно говорить только по
результатам наблюдений и преподавательского опыта, в дальнейшем этот параметр
планируется включить в разметку для получения новых статистических данных, для
создания полуавтоматической разметки и проверки работ, а также же для создания
автоматической системы оценивания работ учащихся (в традиционной системе
оценивания одиночные знаки дают одну ошибку, но и парные знаки также дают одну
ошибку).
4.2.4 Пробелы
При разметке текстов мы столкнулись еще с одной особенностью
печатных школьных текстов: в половине из них не соблюдаются типографические
рекомендации по расстановке пробелов.
А продавец не знает ,что делать.
И вот зашел другой посетитель и говорит : "Я -
лингвист.О чем идет спор?"
(Мельников А., 7б1, Сочинение о букве ять)
Реферат Кирилла Шмелькова посвящен актуальной теме-
зарождение вселенной, а именно концепции Большого взрыва.
(Грингауз Е., 8е, Рецензия на реферат Шмелькова К.)
Как мы видим, пробелы могут быть пропущены, поставлены лишние
или они поставлены в тех позициях, где их не могло быть вовсе.
Неправильная расстановка пробелов может даже привести к такой
ситуации, когда на месте дефиса (орфографический знак) оказывается тире, т.е.
знак препинания:
Его используют для гамма - облучения при
анкологическихонкологических заболеваниях.
(Алексеева Ира, 8е, Кобальт)
Европейская типографическая практика предлагает следующие
правила постановки тире (небольшие отличия в разных странах касаются пробелов
при выделительном тире):
. В тексте обычно не допускается наличие двух и более
пробелов подряд, поскольку это даёт искажённое представление о количестве
знаков, которое бывает важно при типографских расчётов объёмов.
2. Пробел ставится после запятой, точки (в том числе и
обозначающей сокращения и инициалы), точки с запятой, двоеточия,
вопросительного и восклицательного знака, многоточия (кроме многоточий,
начинающих предложение).
. Пробел может не ставиться, если тире идёт сразу
после точки или запятой.
. Пробел не ставится перед запятой, точкой, точкой с
запятой, двоеточием, вопросительным и восклицательным знаками, многоточием
(кроме многоточия, стоящего в начале предложения); после многоточия, стоящего в
начале предложения; с внутренней стороны скобок и кавычек; с обеих сторон
дефиса (за исключением односторонних дефисов, то есть случаев вроде «одно- и двухэтажный»)
и апострофа.
Мы считаем, что в следующей версии Интерробанга необходимо
внести добавить разметку для исправления ошибок, связанных с постановкой
пробелов, а школьникам, как и в случае с оформлением заголовков, рассказать о
типографических приемах, делающих текст удобным для прочтения и пригодным для
машинной обработки.
4.2.5
Абзацное членение
Во многих тестах, включенных в базу КТШ, отсутствует абзацный
отступ в начале нового абзаца, как того требует в машинописном тексте ГОСТ
29.115-88: абзацный отступ должен равняться 3 или 5 пробелам и быть одинаковым
для всего текста.
Стоит отметить, что, несмотря на то, что в книгоиздательском
деле действительно принято выделять абзацы отступом, в интернет-пространстве
тексты книг также часто оформлены без соблюдения требования абзацного отступа.

Рис. 1. Пример текста без абзацных отступов
Нам кажется, что в данном случае имеет смысл говорить о
тенденции к отказу от обязательного абзацного оступа в печатном тексте.
4.2.6
Разделительные знаки
Разделение
частей сложного предложения
Как следует из данных, приведенных в предыдущем разделе
(4.1), ошибки, связанные с неправильным членением предложения на части,
составляют основной процент ошибок в нашем корпусе.
Такой результат ожидаем, так как к ошибкам на «части»
относится сразу несколько распространенных случаев:
. постановка точки в конце предложения
Добывается путём окислительного обжига киновари.
(Гажеев С., 8.е, Реферат о ртути)
Отсутствие точки в конце предложения, которая должна бы
обозначать окончание мысли,- очень частая ошибка в ученических текстах,
особенно печатных.
. разделение частей в сложносочиненной конструкции - самая
редкая из всех ошибок на разделение части, которая может иметь разную природу:
неправильный выбор знака:
Сейчас иногда в научных и рекламных целях употребляют
стилизованные под древность шрифты с таким Н-образным начертанием буквы И;,
однако их применение чаще сбивает с толку, чем помогает, особенно если шрифт
используется для выделения отдельных слов, а то и букв.
(Рацеева О., 7б1, Сочинение о букве и)
неумение выделить или увидеть грамматическую основу:
Ртуть является восемьдесятым элементом в таблице Менделеева,
и имеет относительную атомную массу - двести целых пятьдесят девять сотых.
(Гажеев С., 8.е, Реферат о ртути)
постановка лишней запятой между однородными частями:
Таким образом, мы видим, что Луна образовалась в результате
столкновения гигантского метеорита с Землёй. И теперь Луна является
неизменным спутником Земли, оказывающим постоянное воздействие на неё.
(Жук Т., 8е, реферат по статье «Теория гигантского
столкновения»)
разделение частей сложноподчиненной конструкции.
Здесь имеет смысл говорить о трех случаях:
когда запятая пропущена между частями;
когда не хватает двух запятых, обособляющих часть внутри
другой части и;
когда запятая поставлена не в том месте.
В древних государствах, чтобы покрасить стекло или фарфор,
требовалось выделить из вещества краску.
А в средневековой Саксонии при плавлении некого вида руды
выделялся ядовитый газ, который, рудокопы признали шалостью гнома
Кобольда.
(Алексеева И., 8е, Реферат о кобальте)
знаки препинания на стыке сочинительного и подчинительного
союзов - случай редкий, но зато представленный не только в корпусе, но и во
всех учебных пособиях и современных контрольно-измерительных материалах.
А, если не повезет,
То кто-то быстро умрёт.
(Рудак Георгий, 7б1, Сочинение «От жажды умираю надручьем»)
разделение частей при бессоюзии: здесь возможны два типа
ошибок: в первом случае пропущен знак препинания между частями (крайне редко);
во втором - использован неверный знак.
Но L не только буква, на и цифра,: в Римской Империи
ею обозначали число пятьдесят.
(Бубнов Е., 8е, Сочинение о лямбде)
Действительно, причин для постановки «запятой части» много,
однако мы ввели только два объяснительных значка:
- разделение частей сложного предложения/ clauses
- однородные части/ homogeneous clauses
Второй значок ставится преимущественно в случае лишней
запятой при однородных частях, чтобы приучить учащихся к мысли, что свойство
однородности характерно не только для членов предложения, но и для частей
сложного предложения. Мы не стали вводить значки для различения всех случаев,
чтобы не перегружать систему значков, во-первых, а во-вторых, практика
использования значков на уроках показала, что для того, чтобы научить детей ставить
знаки препинания между частями необходимо в первую очередь научить их видеть
разные грамматические основы.
Пунктуация
при однородных членах предложения
Для этой темы было создано два значка:
- однородные члены предложения/ homogeneous
- обобщающее слово при однородных членах предложения/ homogeneous generalization
Первый используется при разделяющих "," и
";" и при удалении знака препинания, если члены предложения, между
которыми он поставлен, являются неоднородными или их связывает одиночный
сочинительный союз.
Они выделили этот инертный газ методом исключения,
после того, как кислород, азот, и все более тяжелые компоненты
воздух[а] были превращены в жидкость.
(Шахов В.,8е, Реферат о неоне)
Второй значок указывает то, что поставленные проверяющим
":" или " - " свидетельствуют о наличии в предложении
обобщающих слов.
Корпусные исследования, а также разбор в классе работ,
размеченных с помощью программы Интерробанг, подтвердили правильность решения о
том, что двух объяснительных значков для ошибок, связанных с однородными
членами предложения, достаточно,при этом необходимость введения в систему
первого значка не вызывала сомнений, а второй значок помог учащимся и учителям
быстро сориентироваться, какое правило следует повторить или пройти:
":" и " - " при обобщающих словах или же ":" и
" - " при бессоюзной связи между частями сложного предложения.
4.2.7 Выделительные знаки
Обособление
определений и приложений
За несколько лет до появления корпуса в своей
преподавательской практике мы использовали только значок пояснения запятых и
тире при обособленных определениях, выраженных прилагательными, причастиями или
соответствующими оборотами, и при обособлении несогласованных определений.
Вторичное ядерное топливо - ядерное топливо, не сущуствующие
в природе.
(Черных И., 8е, Реферат об уране)
Эта теория, получившая название гипотезы гигантского
столкновения, объясняет низкую плотность лунного вещества.
(Жук Т., 8е, реферат по статье «Теория гигантского
столкновения»)
Приложения - определения, выраженные существительными в той
же падежной форме, что и определяемое слово, обозначались значком для
обособленных определений, то не маркировались никак. Дети не переставали путать
несогласованные определения и приложения. Поэтому появился самостоятельный
значок
- приложение/ apposition, который позволил ученику, кода он
расставляет значки в диктанте, показать, что он различает эти две темы, а
учителю, использующему Интерробанг, понять, с какой темой нужно помочь
разобраться школьнику.
Дело в том, что в игре Half Life(период полураспада) лямбда -
это логотип части исследовательского центра Black Mesa, Комплекса
"Лямбда", в последствии стала символом сопротивления альянсу, а также
напоминает руку, держащую монтировку, - самое известное оружие в игре.
(Фоминский Л., 8е, Сочинение о лямбде)
Для выделения приложений при создании программы мы решили
считать дефис знаком препинания. Однако на данный момент в корпусе не
встретилось ни одного такого случая использования дефиса. Большинство дефисов -
это орфографические дефисы, присоединяющие частицы (например, -таки) ,
постфиксы (то, либо, нибудь) и префикс кое-.
Мы не хотим отказываться от идеи выделения пунктуационного
дефиса при приложениях, так как это значимое правило в одной из основных тем
школьной программы, кроме того, в ближайшем будущем база КТШ должна пополниться
диктантами, в том числе со случаями выделения одиночных приложений. С другой
стороны, мы видим необходимость и возможность автоматически исключить в
следующей версии основную часть орфографических дефисов из пунктуационной
разметки.
Колобродить - значит возиться, производить беспокойство, шум,
суету, бесцельно шататься, слоняться, Беспокойно блуждать, рассеиваться, не
сосредоточиваясь на каком-нибудь предмете.
(Чижиков А., 7б1, Сочинение с глаголом «колобродить» )
Обособление
дополнений
На данный момент в корпусе не зафиксировано ни одного случая
ошибки на обособление дополнений. При этом в корпусе встретилось четыре примера
использования оборотов с предлогом «кроме» (в значении «за исключением») и два
с «за исключением».
Кроме комнаты буквы Ё, в новой мультимедийной экспозиции
имеются виртуальный «Город букв» и игровая комната.
(Чижиков Артем, 7б1, Сочинение о букве ё)
Конечно, проблемы остаются: мы не можем объяснить саму
первопричину возникновения Вселенной , но более правдоподобной теории на сей
счёт на данный момент просто нету ,кроме, конечно, высказывания ("Бог
создал мир").
(Шмельков К., 8е, Реферат на тему «Большой взрыв»)
Не ожидала от «Ёлок» ничего, кроме очередной эксплуатации
новогодней темы.
(Суд И., 8е-2014, Рецензия на новогодний фильм)
Кроме того, участники подготовили к отправке на электронную
почту администрации президента видео с поздравлениями и пожеланиями от самих
себя.
(Доспехов Д., 8е-2014, Репортаж о праздновании нового года)
Жаль, что наш современный алфавит не может похвастаться такой
красивой буквой, за исключением, пожалуй, буквы Я, которая является дальней
родственницей большого Юса!
(Врублевская О., 8е, Сочинение о букве я )
За исключением протона и электрона, все эти частицы очень
скоро распадаются на другие элементарные частицы.
(Фаворская О., 8е, Реферат на тему «Темная материя»)
Выборка, касающаяся обособленных дополнений, для нашего Корпуса
пока слишком мала, чтобы можно было утверждать, что учащиеся всегда обособляют
такие конструкции.
Обособление
обстоятельств и уточняющих и присоединительных конструкций
Первоначально создано два объяснительных значка - оба для
обособления обстоятельств:
- уточнение, примыкание, присоединение/ specifier
- обособленное обстоятельство/ dangling adverbial
Первый значок использовался для того, чтобы показать, что
некоторые существительные с предлогами, требуют обособления в связи с тем, что
передают обстоятельственное значение причины или уступки.
Несмотря на разницу в возрасте, этих фильмов явно лучше вышел
пираты силиконовый долины.
(Слепов Ф., 8е, Сравнительная рецензия по фильмам о Стиве
Джобсе)
Второй значок относился к случаям уточняющих обстоятельств,
которые, как мы предположили в ходе докорпусных наблюдений, нередко встречаются
в детских текстах - значительно чаще, чем уточняющие определения.
В прошлом, 2014 году, на чемпионате мира во Франции, в
Париже, он стал чемпионом мира.
(Кулдошин А., 7б1, Интервью с интересным человеком)
В нашей системе не было специального значка для случаев
присоединения, поэтому по принципу сходства пунктуационного выделения для всех
уточняющих оборотов и присоединительных конструкции был использован значок,
который использовался ранее только уточняющих обстоятельств.
[…]мне надо по колобродить, и не чуть-чуть.
Ртуть плавится при температуре плюс восемнадцать градусов по
цельсию., То есть при комнатной температуре.
(Гажеев С., 8е, Реферат по теме «Ртуть»)
А с моей точки зрения, с точки зрения обывателя, фильм
запутанный и неинтересный, так что смотреть его стоит только заинтерисованным в
продукции "apple".
(Алексеева И., 8е, Сравнительная рецензия по фильмам о Стиве
Джобсе)
Обособление
сравнений
Большинство примеров, которым был присвоен значок
(сравнительный оборот/ similie), касаются правила об обособлении сравнительных оборотов, в том
числе это многочисленные случаи, когда оборот, начинающийся со сравнительного
союза «как», не является сравнительным, а «как» задает отношения
тождественности или имеет значение «в качестве».
L - двенадцатая буква латинского алфавита, заимствованная в
Кириллицу как «Л», используется во многих науках, как сокращение в
биологии имени Карла Линнея - одного из первых биологических систематиков.
(Бубнов Е., 8е, Сочинение о букве Л)
Выделение
нечленов предложения
Вводным и вставным конструкциям был присвоен общий значок
(вводные и вставные конструкции/ expletive), так как между ними много общего с точки зрения
синтаксиса и в школе обычно вводные и вставные конструкции проходятся в одном
блоке.
Нынешнее кириллическое Н, в свою очередь,
выглядело как прописное греческое или латинское N.
(Рацеева О., 7б1, Сочинение о букве и)
По сходной причине этим же значком мы договорились отмечать
случаи отсутствия в школьных текстах запятых при междометиях. Однако ни одного
случая использования междометий в КТШ пока не засвидетельствовано.
Самым редким объяснительным значком (единичный случай
использования) в нашем корпусе на данный момент является
- обращение/ allocution,
когда за обращение учащимся ошибочно было принято местоимение ты, следующее за
основным обращением.
Шестиклассник, ты, ступаешь на сложный путь
изобретателя в Е классах.
(Галимов С., 9е, Сочинение «Обращение к младшим ешкам»)
4.2.8
Другие пунктуационные случаи
- этот
знак, связанный с традиционным школьным правилом о постановке тире между
подлежащим и сказуемым, мы применяли в двух случаях: если ученик не ставил в
нужной позиции тире или если вместо тире между подлежащим и сказуемым
оказывались другие знаки, как правило, это была ",".
Основное отличие в строение - это отсутствие у Луны
раскаленного ядра.
(Жук Т., 8е, реферат по статье «Теория гигантского
столкновения»)
- эллиптическое тире/ blank dash: в
нашем пока небольшом Корпусе встречаются единичные случаи пропуска тире в
неполном предложении.
Неон используется для создания неоновых вывесок, а в жидком
виде - как охладитель в криогенных установках.
(Шахов В., 8е, Реферат о неоне)
В первой версии программы Интерробанг мы упустили из виду
такой значимый знак препинания, как кавычки. Однако при разметке мы столкнулись
с большим количеством случаев, когда в ученических текстах не доставало
кавычек, поэтому мы не только ввели этот знак препинания в общую систему, но и
решили создать для него специальный значок (кавычки/ quotes), указывающий на кавычки
при прямой речи,
при цитатах,
для выделения «чужих» слов,
при необычно употребляемых слов.

(Мельников А., 7б1, Сочинение о букве ять)
В итоге в 126 текстов проверяющие добавили 156 кавычек, т.е.
в 78 пунктуационных случаях учащимися были пропущены кавычки. В связи с таким
высоким числом случаев неоправданного пропуска кавычек мы решили предположить,
что правила на использование кавычек являются либо сложными для усвоения, либо
в программе средней школы на изучение данной темы отводится слишком мало
времени, потому что эти правила вынесены в программу старшей школы. Эти
гипотезы предполагается проверить после пополнения корпуса текстами
старшеклассников.
Те знаки, которые согласно школьным учебникам не считаются
правильными, однако, учитывая смысловой и интонационный принципы пунктуации,
могут быть поставлены, проверяющие относили к авторским и присваивали им
объяснительный значок
- авторская пунктуация/ author mark.
В некоторых случаях проверяющие предлагают заменить
ученический знак препинания на тот, который признается школьной системой.
По поводу парного выступления.: Это наш дебют в данной
дисциплине.
(Кулдошин А., 7б1, Интервью с интересным человеком)
Что такое радий? Радий - это химический элемент, излучающий радиацию,
и в связи с этим очень интересный.
(Заиченко С., 8е, Реферат на тему «Радий»)
Вплоть до конца 18 века химики считали известь простым телом.
В 1789 году А. Лавуазье предположил, что известь, барит и другие вещества ,
- сложные.
(Трофимова М., 8е, Реферат на тему «Кальций»)
4.2.9
Лишние знаки неясной этиологии
Весьма интересной частью нашего исследования КТШ в будущем
могут стать многочисленные примеры, в которых учащимися поставлены лишние знаки
препинания, для которых проверяющий зачастую затрудняется определить, к какому
правилу их отнести или вовсе не может найти объяснения.
Приливная теория утверждает, что от Земли из за очень
быстрого вращения вокруг своей оси оторвался кусок и из него, на орбите
сформировалась Луна.
(Жук Т., 8е, реферат по статье «Теория гигантского
столкновения»)
В данном тексте ,изложена информация о теории Большого
Взрыва.
В нём рассказывается , на чём основана данная теория и без
какой теории , она была бы неверна .
О превосходстве теории Большого Взрыва ,над другими
теориями образования вселенной и фактах, подтверждающих её .
(Шмельков К., 8е, аннотация к статье «Большой взрыв»)
Неон открыли в июле 1898 года, английские химики
Уильям Рамзай и Морис Траверс.
(Шахов В., 8е, Реферат о неоне)
Фильм «Ёлки»- типичный фильм на новогоднюю тему, и, как
иногда водится, там представлены практически все социальные слои населения-от
президента, до вора и гастрбайтера, которые встречают Новый Год в
разных часовых поясах.
(Суд И., 8е-2014, Новогодняя рецензия на фильм)
ЗАКЛЮЧЕНИЕ
Методы обучения русскому языку в условиях активного развития
компьютерных и образовательных технологий нуждаются в динамичных изменениях.
Ценным материалом для корректировки образовательных стандартов могут стать
корпусные данные, полученные при обработке текстов самих школьников.
В рамках настоящей магистерской работы была поставлена цель
собрать Корпус школьных текстов, аккумулирующий примеры подростковой речи,
регламентированной учебными задачами на уроках русского языка и словесности, и
изучить пунктуацию в накопленном материале.
Сбор материала для Корпуса школьных текстов осуществлялся
двумя способами: во-первых, корпус пополнялся за счет рукописных работ
учащихся, переведенных в электронный формат, во-вторых, текстами, набранными
подростками на компьютере.
Вторая группа текстов собиралась экспериментально. С
разрешения директора школы 179, в которой проводился эксперимент, учащимся было
предложено по желанию сдавать письменные творческие домашние задания и работы
реферативного характера в рукописном (традиционный подход) или в электронном
виде.
База корпуса продолжает активно пополняться оригинальными
печатными работами и электронными версиями рукописных текстов. В новом учебном
году планируется увеличивать объем корпуса, в том числе за счет диктантов и
образцов устной регламентируемой речи (видеозаписями с письменной расшифровкой
устных выступлений школьников).
Тексты в Корпусе группируются по классам, годам написания,
типу текса и формата, поверяются и оцениваются. Таким образом, Корпус - это
инструмент методической работы учителя, позволяющий отслеживать развитие
учебных навыков у школьников. Кроме того, корпус школьных тексов может быть
использован для социологических и лингвистических исследований, для изучения
различных проявлений узуальной речи школьников.
В рамках настоящего исследования проводилось изучение
пунктуации текстов Корпуса, в первую очередь эрратологического аспекта этой
темы, т.е. анализировались пунктуационные ошибки, допускаемые школьниками
среднего подросткового возраста.
Для обработки пунктуационного содержания текстов на основе
современных справочников и учебников была разработана собственная типология
ошибок и система пунктуационной разметки с использованием объяснительных
значков. Эта классификация и система значков легли в основу создания
программы-разметчика Интерробанг, которую использовали при проверке ученических
работ, содержащихся в Корпусе.
С помощью программы Интерробанг в полуавтоматическом режиме
было осуществлено аннотирование каждого текста Корпуса (кем написан, тип и
форма текста и т.д.), автоматически произведена предварительная разметка
существующих в текстах знаков препинания, в режиме ручной разметки закодированы
внесенные проверяющим исправления, автоматически собрана база примеров всех
типов ошибок и выполнен статистический анализ размеченных данных.
Полученные примеры и статистические показатели были
проанализированы и описаны.
Результаты исследования могут быть использованы для уточнения
правил и содержания образовательного стандарта по русскому языку в школе
(учебных программ, контрольно-измерительных материалов и т.д.).
Изучение пунктуации на материале школьных текстов также имеет
большое практическое значение. Собранная база примеров с пунктуационными
ошибками позволит сделать учебные тренажеры, а результаты статистической
обработки предполагается использовать для создания пунктуационного спелчекера -
системы автоматической проверки пунктуационной грамотности.
Кроме того, в процессе работы над данной магистерской было
замечено, что школьникам необходимо прививать культуру печатного письма, причем
не только в контексте коммуникации в социальных сетях, которой посвящено ряд
исследовательских работ, но и оформления учебных текстов.
Обозначенные перспективы использования материалов Корпуса
школьных текстов, программы Интерробанг и результатов данной работы
свидетельствуют о том, что, несмотря, на то, что в рамках настоящей
магистерской работы все поставленные цели были достигнуты, исследования в
области изучения корпусных данных школьного речи будут продолжены.
На данный момент на сайте
www.compling.ru/interrobang в открытом доступе находится версия 1.0. программы
Интеробанг. В планах автора обновление программы до версии 1.1. с модулем
автоматического оценивания пунктуационной грамотности текста в зависимости от
года обучения, также автор ставит перед собой задачу в ближайшее время
разместить на указанном ресурсе собранный и размеченный Корпус текстов
школьников.
СПИСОК
ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ И ЛИТЕРАТУРЫ
1. В.А.
Плунгян. Зачем мы делаем национальный корпус русского языка? // Отечественные
записки. №2(23) - М., 2005.
2. Камшилова
О.Н. Анализ ошибок в корпусе ученических текстов: исследовательский и
технологический аспект // Материалы Международной конференции «Корпусная
лингвистика - 2011», 27-29 июня 2011, Санкт-Петербург - СПб., 2011. CC. 175-180.
. О.Э.
Садовникова. Прямое и косвенное использование корпусов в зарубежной
лингводидактике // Magister Dixit, №4, 2013.
. Е.В.
Рахилина. О языковой интерференции и лингвистических корпусах русского языка //
Русский мир, 2015
. Камшилова
О.Н., Колина М.В., Николаева Е.А. Разработка корпуса текстов петербургских
школьников: задачи и перспективы // Прикладная лингвистика в науке и
образовании, СПб., 2008.
. Н.Р.
Добрушина. Как использовать Национальный корпус русского языка в образовании?
// Национальный корпус русского языка: 2003-2005. Результаты и перспективы, М.,
2005.
. Н.Р.
Добрушина А.И. Левинзон. Информационные технологии в гуманитарном образовании:
Национальный корпус русского языка // Вопросы образования, №4, 2006.
. А.В.
Кучуганов, Г.В. Лапинская. Распознавание рукописных текстов // Материалы
международной научной конференции Ижевск, 13-17 июля 2006 г.
9. Корпус
речи школьников СПБ. [Электронный ресурс] - [Санкт-Петербург, 2009-2012]
. Орфограммка.
Веб-сервис проверки правописания [Электронный ресурс] / ООО «Орфограмматика» -
[2013]
. В.Д.
Соловьев, Б.В. Добров, В.В. Иванов, Н.В. Лукашевич. Онтологии и тезаурусы.
Учебное пособие - Казань, Москва, 2006.
. О.Г.
Горина. Использование технологий корпусной лингвистики для развития лексических
навыков студентов-регионоведов в профессионально-ориентированном общении на
английском языке [Диссертация на соискание ученой степени к.п.н.] - М., 2014.
13. A.B. Stenström, G. Andersen,
I.K. Hasund. Trends in Teenage Talk: Corpus compilation, analysis and findings.
- John Benjamins Publishing, 2002.
. Drange E.M.D., Hasund I.K., Stenström A.B. "Your mum!" Teenagers’ swearing
by mother in English, Spanish and Norwegian // International Journal of Corpus
Linguistics. - 2014. // Т. 19, №1. - С. 29-59.
15. I.M. Palacios Martínez. The Language
of British Teenagers. A Preliminary Study of its Main Grammatical Features. //
Journal of the Spanish Association of Anglo-American Studies. 33.1, 2011
. Т.В
Базжина., Т.Ю. Крючкова. Русская пунктуация. Пособие-справочник. - М.: Форум,
2015.
17. Правила
русской орфографии и пунктуации. Полный академический справочник / Под ред. В.В.
Лопатина. - М: Эксмо, 2009.
. А.Э.
Мильчин, Л.К. Чельцова. Справочник издателя и автора. Редакционно-издательское
оформление издание. 2-е изд., испр. и доп. - М.: ОЛМА-Пресс, 2003.
19. А.
Einsohn. The
Copyeditor's Handbook: A Guide for Book Publishing and Corporate -
Communications University of California Press, 2005.
20. Д.Э.
Розенталь. Справочник по правописанию и литературной правке. 16-е изд. - М.:
2012.
. Н.С.
Валгина., В.Н. Светлышева. Орфография и пунктуация: Справочник.-М.: Издатель
Булатникова И.C., ООО «Большая Медведица», 2002.
22. А. Einsohn. The Copyeditor's Handbook: A Guide for
Book Publishing and Corporate - Communications University of California Press,
2005.
23. Справочник
по TEI: Text Encoding Initiative. [Электронный ресурс]
24. Справочники
по Python. [Электронный ресурс]
. Справочник
по PyQt4. [Электронный ресурс]
ПРИЛОЖЕНИЕ 1
Хранение файлов Корпуса текстов школьников
ПРИЛОЖЕНИЕ 2
Образец осуществленной разметки в Рабочем окне
программы Интерробанг
ПРИЛОЖЕНИЕ 3
Образец напечатанного размеченного документа

ПРИЛОЖЕНИЕ 4
Образец TEI-разметки документа
<?xml version="1.0"?>
<tei
xmlns="http://www.tei-c.org/ns/1.0">
<teiHeader>
<fileDesc>
<titleStmt>
<author>Алексеева</author>
<title>Рецензия-сравнение</title>
<respStmt>Выборнова</respStmt>
<authgrade>8</authgrade>
<format>typed</format>
<confidence>high</confidence>
</titleStmt>
</fileDesc>
</teiHeader>
<text>
<front>
<divGen type="Another"/>
</front>
<body>
<p>Алексеева Ирина <choice>
<sic/>
<cor>
<pc
subtype="quotes">"</pc>
</cor>
</choice>Империя обмана Стива Джобса<choice>
<sic/>
<cor>
<pc
subtype="quotes">"</pc>
</cor>
</choice>
</p>
<p/>
<p>В этой статье я хочу сравнить два
фильма<pc>,</pc>
рассказывающие</p>
<p>об одном и том же событии<pc>,</pc> но
имеющие длинный
список отличий<pc>:</pc> <choice>
<sic/>
<cor>
<pc
subtype="quotes">"</pc>
</cor>
</choice>Империя соблазна<choice>
<sic/>
<cor>
<pc
subtype="quotes">"</pc>
</cor>
</choice> и <choice>
<sic/>
<cor>
<pc
subtype="quotes">"</pc>
</cor>
</choice>Пираты силиконовой долины<choice>
<sic/>
<cor>
<pc>"</pc>
</cor>
</choice>
<pc>.</pc> <choice>
<sic/>
<cor>
<pc subtype="quotes">"</pc>
</cor>
</choice>Империя соблазна<choice>
<sic/>
<cor>
<pc
subtype="quotes">"</pc>
</cor>
</choice> рассказывает о полной жизни Стива
Джобса<choice>
<sic/>
<cor>
<pc
subtype="homogeneous_generalization">,</pc>
</cor>
</choice> всех ее мелких моментах<pc>,</pc>
а в фильме <choice>
<sic/>
<cor>
<pc
subtype="quotes">"</pc>
</cor>
</choice>Пираты силиконовой долины<choice>
<sic/>
<cor>
<pc
subtype="quotes">"</pc>
</cor>
</choice> подробно отснят и рассмотрен момент кражи
идеи Стива
Джобса Биллом Гейтсом<pc>.</pc> Если оценивать
два этих
фильма<pc>,</pc> то можно увидеть
полный<choice>
<sic/>
<cor>
<pc
subtype="homogeneous">,</pc>
</cor>
</choice> красивый сюжет и отлельный фрагмент из жизни
Стива
Джобса<pc>.</pc> <choice>
<sic/>
<cor>
<pc
subtype="quotes">"</pc>
</cor>
</choice>Империя соблазна<choice>
<sic/>
<cor>
<pc
subtype="quotes">"</pc>
</cor>
</choice> снята позже<choice>
<sic/>
<cor>
<pc
subtype="similie">,</pc>
</cor>
</choice> чем <choice>
<sic/>
<cor>
<pc subtype="quotes">"</pc>
</cor>
</choice>Пираты силиконовой долины<choice>
<sic/>
<cor>
<pc
subtype="quotes">"</pc>
</cor>
</choice>
<choice>
<sic/>
<cor>
<pc
subtype="similie">,</pc>
</cor>
</choice> и сделана лучше<pc>,</pc> сюжет
более красочный и
развервернутый<pc>,</pc> качество и графика
лучше<pc>.</pc> Если
описовать кратко<choice>
<sic/>
<cor>
<pc
subtype="clauses">,</pc>
</cor>
</choice> то <choice>
<sic/>
<cor>
<pc
subtype="quotes">"</pc>
</cor>
</choice>Империя соблазна<choice>
<sic/>
<cor>
<pc
subtype="quotes">"</pc>
</cor>
</choice> о том<pc>,</pc> как Стив Джобс
работал над компьтерами и
создавал apple о его карьерном росте и несносном
характере<pc>,</pc>
о том<choice>
<sic/>
<cor>
<pc
subtype="clauses">,</pc>
</cor>
</choice> как <choice>
<sic/>
<cor>
<pc
subtype="quotes">"</pc>
</cor>
</choice>apple<choice>
<sic/>
<cor>
<pc
subtype="quotes">"</pc>
</cor>
</choice> пришел в упадок и как
возродился<pc>.</pc> А фильм
<choice>
<sic/>
<cor>
<pc
subtype="quotes">"</pc>
</cor>
</choice>Пираты силиконовой долины<choice>
<sic/>
<cor>
<pc
subtype="quotes">"</pc>
</cor>
</choice> рассказывает <pc>(</pc>а
настоящее название <choice>
<sic/>
<cor>
<pc>"</pc>
</cor>
</choice>Пираты кремниевой долины<choice>
<sic/>
<cor>
<pc
subtype="quotes">"</pc>
</cor>
</choice>
<pc>,</pc> а переводчики просто
ошиблись<pc>)</pc> о конкретном
моменте жизни Стива Джобса<choice>
<sic/>
<cor>
<pc
subtype="clauses">,</pc>
</cor>
</choice> о том<pc>,</pc> как Билл Гейтс
украл главную продукцию
<choice>
<sic/>
<cor>
<pc
subtype="quotes">"</pc>
</cor>
</choice>apple<choice>
<sic/>
<cor>
<pc
subtype="quotes">"</pc>
</cor>
</choice>
<pc>.</pc>
</p>
<p>Я советую посмотреть оба фильма для полного
погружения в жизнь
гениального Стива Джобса<pc>.</pc> С точки зрения
предпринимателей и</p>
<p>компьютерщиков<choice>
<sic/>
<cor>
<pc
subtype="expletive">,</pc>
</cor>
</choice> фильм получился жизненный и автор успешно
воссоздал
образ Стива Джобса<pc>.</pc> А с моей точки
зрения<pc>,</pc> с
точки зрения обывателя<choice>
<sic/>
<cor>
<pc
subtype="specifier">,</pc>
</cor>
</choice> фильм запутанный и неинтересный<choice>
<sic/>
<cor>
<pc
subtype="clauses">,</pc>
</cor>
</choice> так что смотреть его стоит только
заинтересованным в
продукции <choice>
<sic/>
<cor>
<pc
subtype="quotes">"</pc>
</cor>
</choice>apple<choice>
<sic/>
<cor>
<pc
subtype="quotes">"</pc>
</cor>
</choice>
<pc>.</pc>
</p>
</body>
</text>
</tei>