Разработка математической модели, позволяющей прогнозировать расходы на перевозки в зависимости от увеличения грузооборота
Оглавление
Введение
1. Расчет параметров
уравнений линейной и нелинейной парной регрессии
1.1 Расчет параметров
линейной парной регрессии
1.2 Расчет параметров
степенной парной регрессии
1.3 Расчет параметров
показательной парной регрессии
2. Дисперсионный анализ
линейной и степенной функции регрессии
3. Оценка тесноты связи
расходов на перевозки и грузооборота с помощью показателей корреляции и
детерминации
4. Оценка ошибки
аппроксимации уравнений регрессии
5. Сравнительная оценка силы
связи грузооборота с расходами на перевозки с помощью среднего коэффициента
эластичности
6. Оценка статистической
надежности результатов линейного регрессионного моделирования
7. Расчет прогнозного
значения расходов на перевозки по линейной модели при увеличении грузооборота
8. Реализация решенных задач
на компьютере
8.1 Реализация процедуры
«ЛИНЕЙН»
8.2 Реализация процедуры
«Анализ данных»
8.3 Реализация процедуры
«ТРЕНД»
Выводы
Введение
В управлении хозяйственными процессами наибольшее значение имеют, прежде
всего, экономико-математические модели, часто объединяемые в системы моделей.
Экономико-математическая модель (ЭММ) - это математическое описание
экономического объекта или процесса с целью их исследования и управления ими.
Это математическая запись решаемой экономической задачи.
Экономико-математические модели применяются для решения большого числа
практических задач. В основу ЭММ положены уравнения регрессии.
Регрессия - величина, выражающая зависимость среднего значения случайной
величины у от значений случайной величины х.
Уравнение регрессии выражает среднюю величину одного признака как функцию
другого.
В настоящей курсовой работе стоит задача обосновать математическую модель
расходов на перевозки в зависимости от грузооборота. Исходными данными для ее
расчета являются реальные значения расходов на перевозки и грузооборота (всего
17 железных дорог). Для обоснования модели в курсовой работе рассматриваются
линейные и нелинейные парные функции регрессии. В работе на основе полученных
функций регрессии выполнен выбор математической модели, позволяющей
прогнозировать расходы на перевозки в зависимости от увеличения грузооборота.
1. Расчет
параметров уравнений линейной и нелинейной парной регрессии
регрессия корреляция
математический
1.1 Расчет
параметров линейной парной регрессии
Парная линейная регрессия имеет вид:
ŷx = a + b · x,
где ŷx - результативный
признак, характеризующий расходы на перевозки;
x -
фактор (грузооборот);
a, b - параметры, подлежащие определению.
Построение уравнения регрессии сводится к оценке ее параметров. Для
оценки параметров регрессии используется метод наименьших квадратов. Он
позволяет получить такие оценки параметров, при которых сумма квадратов
отклонений фактических значений результативного признака (расходов на
перевозки) y от теоретических ŷx будет минимальной. В этом случае для определения параметров a и b линейной регрессии необходимо решить следующую систему
уравнений:
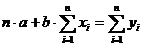
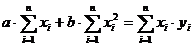
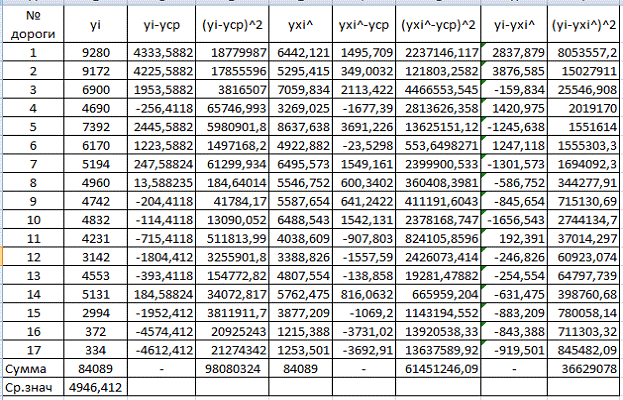
На основании исходных данных выполнены расчеты сумм приведенной системы
уравнений, теоретических значений функции регрессии, а также разности функции
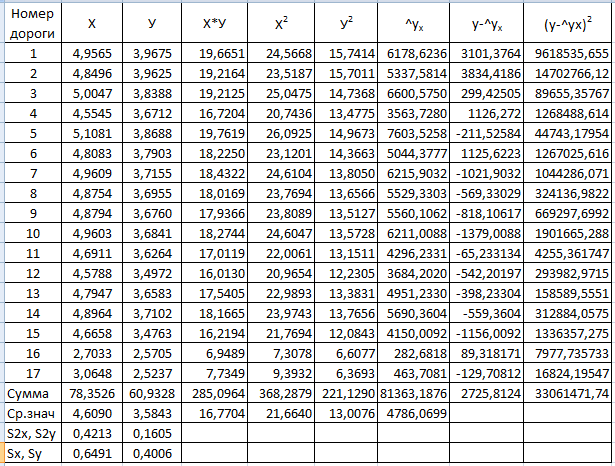
регрессии и опытных значений, которые представлены в табл. 1.1.
Таблица 1.1
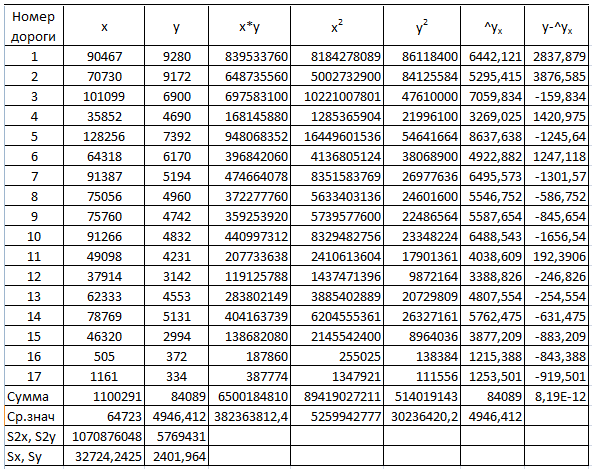
С учетом обозначений при n = 17
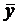 = (y1 + y2 + … + y17)/17;
= (y1 + y2 + … + y17)/17; 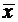 = (x1 + x2 + … + x17)/17;
= (x1 + x2 + … + x17)/17;
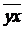 = (y1x1 + y2x2 + … + y17 x17)/17;
= (y1x1 + y2x2 + … + y17 x17)/17;
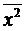 = (x12 + x22 + … + x17)/17; Sx2 =
= (x12 + x22 + … + x17)/17; Sx2 = 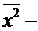
 2.
2.
Значения параметров линейной регрессии вычисляются по формулам:
b = (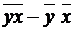 ) / ( 2) =
) / ( 2) =
= (382363812,4 - 4946,412 × 64723) / (32724,242)2 = 0,058;
a = - b 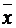 = 4946,412 - 0,058 × 64723 =1186,047.
= 4946,412 - 0,058 × 64723 =1186,047.
Тогда уравнение регрессии, являющееся линейной моделью расходов на
перевозки в зависимости от грузооборота, примет вид:
ŷx = 1186,047+0,058 · x .
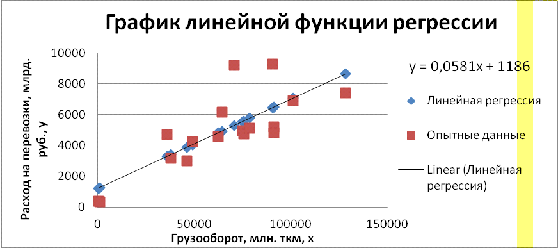
Рис. 1.1 «График линейной функции регрессии»
.2 Расчет
параметров степенной парной регрессии
Степенная парная регрессия относится к нелинейным регрессиям по
оцениваемым параметрам. Однако она считается внутренне линейной, так как
логарифмирование ее приводит к линейному виду. Таким образом, построению
степенной модели
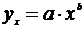
предшествует процедура линеаризации переменных. Линеаризация позволяет
использовать для определения параметров функции регрессии метод наименьших
квадратов. При этом оценки параметров будут вычислены по алгоритму, изложенному
в 1.1.
для этой цели проведем логарифмирование обеих частей уравнения:
lg ŷ = lg a + b lg x.
Ŷ = lg ŷ; X = lg x; A = lg a . Тогда уравнение примет вид:
Ŷ = A + b X.
Как отмечалось, для расчета параметров А и b используются соотношения метода наименьших квадратов,
поскольку в новых переменных Y и X соотношение стало линейным, а
следовательно, оценки параметров будут состоятельными, несмещенными и эффективными.
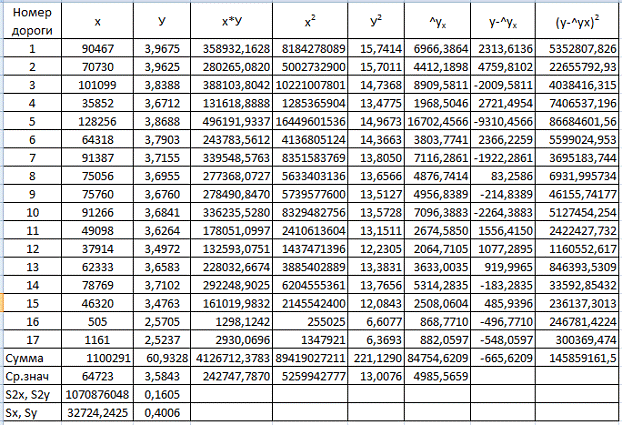
Весь предварительный расчет параметров степенной функции регрессии
аналогично линейной сведен в табл. 1.2.
Таблица 1.2
Тогда
b = ( -
-
 )/Sx2 = (16,7704 - 4,609 · 3,5843) / 0,4213 =0,5945;= - b · = 3,5843 - 0,5945 · 4,609 = 0,844.
)/Sx2 = (16,7704 - 4,609 · 3,5843) / 0,4213 =0,5945;= - b · = 3,5843 - 0,5945 · 4,609 = 0,844.
Таким образом, степенное уравнение регрессии с учетом логарифмических
переменных будет иметь вид: Ŷ = 0,844 + 0,594 · X.
Выполнив его потенцирование, получим: x = 6,9841 · x
0,5945
Подставляя в последнее уравнение фактические значения x, получаем теоретическое значение ŷx. Эти значения приведены в табл. 1.2.
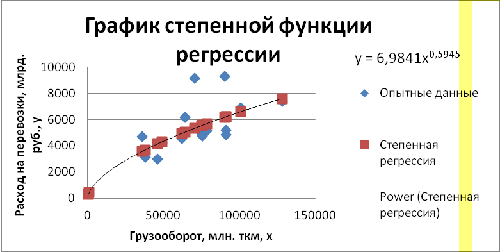
Рис. 1.2 «График степенной функции регрессии»
.3 Расчет
параметров показательной парной регрессии
Поскольку показательная функция относится к классу нелинейных по
оцениваемым параметрам, то построению функции парной показательной регрессии
ŷx = a·bx
предшествует, как и в случае степенной функции регрессии, процедура
линеаризации переменных с помощью логарифмирования обеих частей функции
регрессии. После логарифмирования получим следующее выражение:
lg ŷх = lg a + x lg b.
Введя обозначения переменных и констант
Ŷ = lg ŷх, A = lg a, B = lg b,
Ŷ = A + B x.
Для определения параметров все вычисления сведены в табл. 1.3.
Таблица 1.3
C
учетом табличных данных значения параметров линейной регрессии составят:
B =  / Sx2 = (242747,787- 3,584 × 64723) / (32724,24)2 = 1,0049;
/ Sx2 = (242747,787- 3,584 × 64723) / (32724,24)2 = 1,0049;
A =  - B
- B 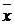 = 3,584 - 1,0049 × 64723 = 2,933.
= 3,584 - 1,0049 × 64723 = 2,933.
Таким образом, получено уравнение
Ŷ = 2,933 + 1,0049x,
или после потенцирования
ŷx = 858,68 ∙ (1,00002) x.
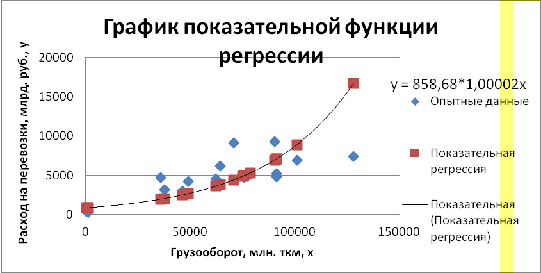
Рис. 1.3 «График показательной функции регрессии»
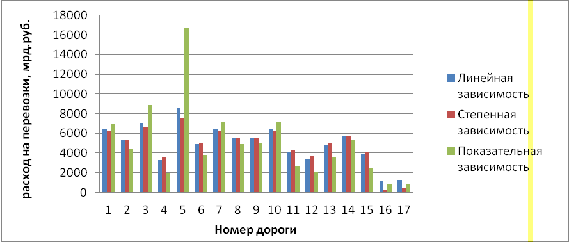
Рис. 1.4 «Теоретические значения расходов на перевозки»
Рис.1. 5 «Графики функций регрессии»
2.
Дисперсионный анализ линейной и степенной функции регрессии
Центральное место в дисперсионном анализе занимает разложение общей суммы
квадратов отклонения результирующего показателя y от его среднего значения 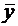 на две части, а именно на
объясненную (факторную) и остаточную:
на две части, а именно на
объясненную (факторную) и остаточную:
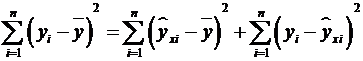 , (*)
, (*)
где 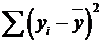 - общая сумма квадратов отклонений;
- общая сумма квадратов отклонений;
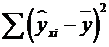 - объясненная (факторная) сумма квадратов;
- объясненная (факторная) сумма квадратов;
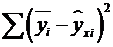 - остаточная сумма квадратов.
- остаточная сумма квадратов.
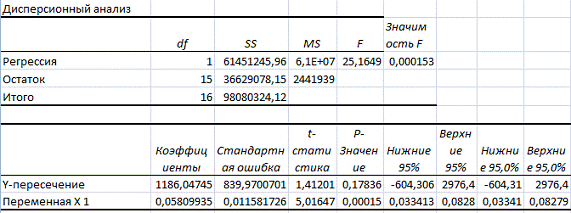
Результаты расчетов сведены в табл. 2.1.
На основании выполненных расчетов имеем:
=61451246,09+36629078.
Равенство (*) выполняется.
Если коэффициент b
увеличить в 1,1 раза, то измененное уравнение линейной регрессии будет иметь
вид: ŷx = 1186,047+0,0638*x. и приведенное
выше соотношение (*) выполняться не будет.
Таблица 2.1.
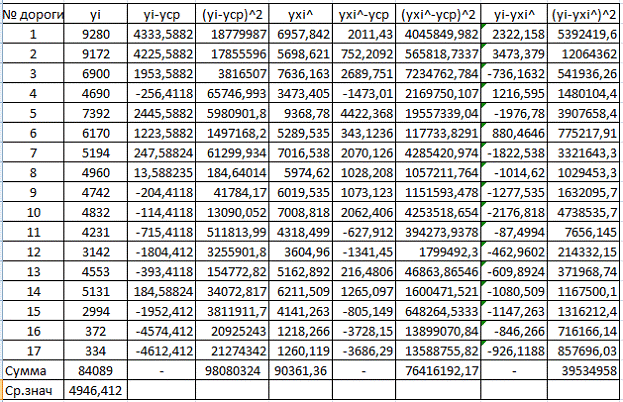
≠ 76416192,17+39534958,
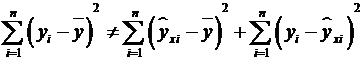 .
.
Дисперсионный анализ для степенной функции сведен в табл. 2.3.
Таблица 2.3
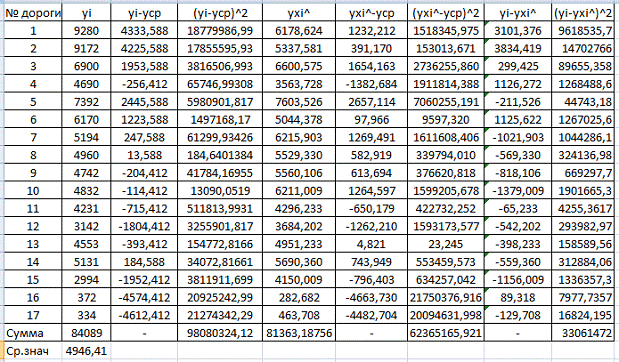
На основании выполненных расчетов имеем:
98080324,12 ≠ 62365165,921+33061472,
Это говорит о том, что равенство (*) выполняться не будет.
 .
.
3. Оценка
тесноты связи расходов на перевозки и грузооборота с помощью показателей
корреляции и детерминации
Уравнение регрессии всегда дополняется показателем тесноты связи. При
использовании линейной регрессии в качестве такого показателя выступает
линейный коэффициент корреляции rxy.
Существуют различные формы записи линейного коэффициента корреляции. Наиболее
часто встречаются следующие:
rxy = b (Sx / Sy) = Mxy /(Sx / Sy) =
(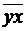 -
-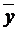
 )/ SxSy.
)/ SxSy.
Как известно, линейный коэффициент корреляции находится в пределах -1 ≤
rxy ≤ 1. Если коэффициент регрессии
b > 0, то 0 ≤ rxy ≤ 1, и наоборот, при b < 0 -1 ≤ rxy ≤ 0.
Используя первое выражение для rxy, рассчитаем линейный коэффициент парной корреляции:
rxy = b (Sx/Sy) = 0,058∙
(32724,24/2401,963953) =0,791.
Значение коэффициента корреляции показывает, что связь прямая, то есть с
увеличением грузооборота расходы на перевозки увеличиваются.
Так же учитывая, что значение коэффициента корреляции находится в
промежутке от 0,8 до 1,0, следовательно, связь сильная, т.е. расходы на
перевозки зависят в большей степени от грузооборота, нежели от других факторов.
Для оценки качества подбора линейной функции необходимо определить
квадрат линейного коэффициента rxy2,
который называется коэффициентом детерминации линейной функции регрессии. Он
характеризует долю дисперсии (разброса) расходов на перевозки ŷx, объясняемую зависимостью грузооборота
x, в общей дисперсии, возникающей за
счет влияния множества факторов, не учтенных функцией регрессии.
Соответственно величина 1 - rxy2 характеризует долю дисперсии расходов на перевозки y, вызванную влиянием остальных не
учтенных в математической модели факторов.
Определим коэффициент детерминации: rxy2 = (0,791)2 = 0,626.
Следовательно, изменение расходов на перевозки на 63% объясняется
изменением грузооборота. Величина данного показателя находится в пределах 0 ≤
Rxy ≤ 1, при этом, чем она ближе к
1, тем теснее связь между расходами на перевозки и грузооборотом, тем более
надежное уравнение регрессии.
Расчеты показателей степени связи между расходами на перевозки и
грузооборотом при степенной модели показывают, что она немного хуже линейной
модели (pxy = 0,78; R2 = 0,61).
Расчеты показателей степени связи между пассажирооборотом и длиной дороги
при степенной модели показывают, что индекс корреляции не лежит в пределах от 0
до 1, следовательно он не показателен.
4. Оценка
ошибки аппроксимации уравнений регрессии
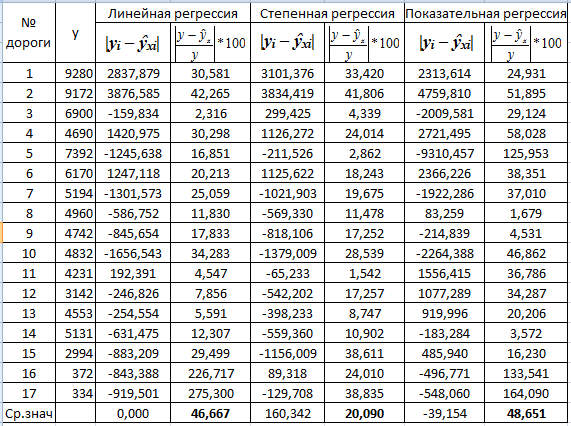
Из графиков и приведенных в таблицах расчетных данных следует, что
фактическое значение расходов на перевозки y отличается от теоретического значения ŷx, рассчитанных по одному из уравнений
регрессии. Очевидно, чем меньше это отличие, тем ближе опытные данные к
теоретическим значениям и тем лучше качество модели.
Величина, представляющая собой разность опытного и теоретического
результативного признака (y - ŷx) для каждого опыта представляет
собой ошибку аппроксимации функции, связывающей расходы на перевозки и
грузооборот. В данном случае число таких опытов равно 17. Для оценки каждого
опыта используются не сами разности, а абсолютные значения разностей опытного и
теоретического результативных признаков, отнесенные к опытному признаку и выраженные
в процентах, то есть:
Аi = |(yi - ŷxi) / yi | ∙ 100% .
Оценка качества всей функции регрессии может быть осуществлена как
средняя ошибка аппроксимации - средняя арифметическая Аi:
А = (А1 + А2 + … + А17 ) / 17.
Найдем величину средней ошибки аппроксимации линейной функции связи между
расходами на перевозки и грузооборотом: А = 275,3 / 17 = 46,6 %.
Аналогично получим среднюю ошибку аппроксимации для степенной функции: А
= 38,8 / 17 = 20,09% и для показательной функции: А = 164,09 / 17 = 48,6%.
Таблица 4.1
Их анализ показывает, что ошибка аппроксимации находится в допустимых для
практического использования пределах, с теоретической точки зрения может быть
продолжен поиск более качественной функции регрессии.
5. Сравнительная
оценка силы связи грузооборота с расходами на перевозки с помощью среднего
коэффициента эластичности
Средний коэффициент эластичности Э показывает, на сколько процентов в
среднем изменятся расходы на перевозки ŷx от своей средней величины при изменении грузооборота x на 1% от своего среднего значения.
Для произвольной величины x он
может быть вычислен по следующей формуле:
Э = yx' (x)·  / ŷx.
/ ŷx.
С учетом приведенной формулы средний коэффициент эластичности Э для линейной
функции регрессии ŷx =
1186,047+0,058 · x
примет следующий вид:
 = ŷx' (x) · / ŷx= b · / (a + b) .
= ŷx' (x) · / ŷx= b · / (a + b) .
Средний
коэффициент эластичности для степенной функции:
= b, он
составляет: 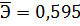 .
.
Средний
коэффициент эластичности для показательной функции:
В таблицах 5.1, 5.2, 5.3 вычислены коэффициенты эластичности для
линейной, степенной и показательной функций регрессии соответственно:
Таблица 5.1
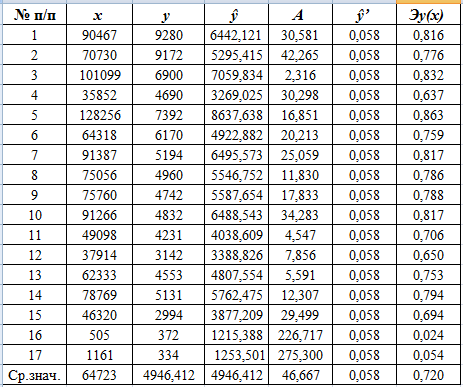
Таблица 5.2
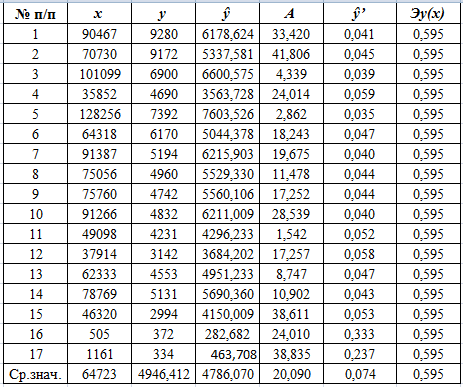
Таблица 5.3
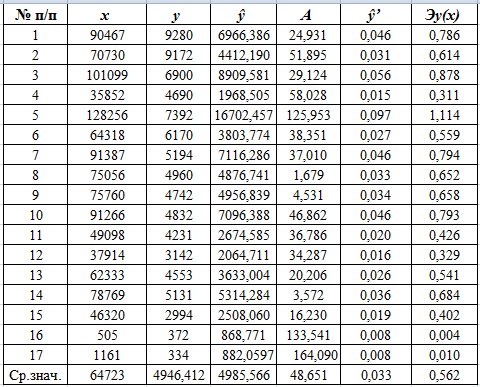
Анализ разработанных математических моделей показывает, что увеличение на
1% грузооборота, например, Московской железной дороги (№2), приводит к
увеличению на 0,776; 0,595; 0,614% расходов на перевозки. При этом по линейной
модели это увеличение составляет 0,78%, по степенной функции регрессии - 0,59%,
по показательной функции регрессии - 0,78%.
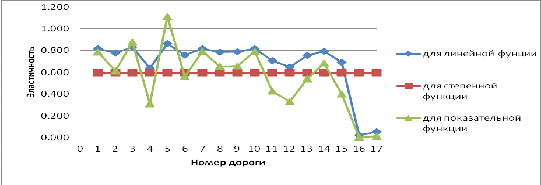
Рис. 5.1 «Значения коэффициентов эластичности линий линейной, степенной и
показательной функций регрессии»
6. Оценка
статистической надежности результатов линейного регрессионного моделирования
Оценку статистической надежности уравнения регрессии в целом будем
производить с помощью F-критерия
Фишера. При этом примем нулевую гипотезу H0, что коэффициент регрессии b равен нулю. В таком случае фактор x не оказывает влияния на результат y, то есть грузооборот не оказывает влияния на расходы на
перевозки. Альтернативная гипотеза H1 будет состоять в статистической надежности линейного регрессионного
моделирования. Для установления истинной значимости линейной модели необходимо
выполнить сравнение факторного Fфакт
и критического (табличного) Fтабл
значений F-критерия Фишера. Факторный F-критерий Фишера вычисляется по
формуле:
Fфакт
= Sфакт2 / Sост2,
где Sфакт2 - факторная выборочная
дисперсия, вычисленная на одну степень свободы по соотношению:
Sфакт2
= ((ŷx1 - )2 + (ŷx2 - )2 + ...+ (ŷx17 - )2) / 1;
Sост2
- остаточная выборочная дисперсия, вычисленная на одну степень свободы по
соотношению:
Sост2
= ( (y1 - ŷx1)2 + (y2 - ŷx2)2 + ...+ (y17 - ŷx17)2
)/ n - 2.
Если нулевая гипотеза справедлива, то факторная и остаточная выборочные
дисперсии не отличаются друг от друга. Для опровержения нулевой гипотезы H0 необходимо, чтобы факторная
дисперсия превышала остаточную дисперсию в несколько раз. Табличное Fтабл значение F-критерия Фишера - это максимальная
величина критерия (отношения дисперсий) под влиянием случайных факторов при
данных степенях свободы и уровне значимости α, который примем равным 0,05.
Если Fтабл < Fфакт , то нулевая гипотеза о случайной природе коэффициента
регрессии, а следовательно, и оцениваемой модели отвергается и признается их
статистическая значимость и надежность. Если Fтабл > Fфакт,
то нулевая гипотеза не отклоняется и признается статистическая незначимость и
ненадежность уравнения регрессии.
По таблице значений F-критерия
Фишера при уровне значимости α = 0,05 и степенях свободы k1 = 1, k2 = 15 получаем Fтабл = 4,54. Выполнив расчет, получим Fфакт = 2441938,544 / 61451245,963 = 25,16.
Полученные значения F-критерия
Фишера указывают, что Fтабл
< Fфакт, поэтому необходимо отвергнуть
нулевую гипотезу о случайной природе коэффициента регрессии.
7. Расчет
прогнозного значения расходов на перевозки по линейной модели при увеличении
грузооборота
Полученное уравнение линейной регрессии позволяет использовать его для
прогноза. Согласно заданию на курсовую работу, следует рассчитать прогнозное
значение расходов на перевозки, если прогнозное значение грузооборота железной
дороги увеличится на 10% от среднего значения всех дорог. При этом установить
доверительный интервал прогноза для уровня значимости, равного 0,05.
Если прогнозное значение грузооборота составит:
= 1,1 · = 1,1 ·64723 = 71195,3 млн.ткм
то прогнозное точечное значение расходов на перевозки можно вычислить по
соотношению:
ŷx = 1186+0,058· xр = 1186+0,058 · 71195,3 =
=5322,45 млрд.руб.
Для определения доверительного интервала прогноза расходов на перевозки
необходимо вычислить ошибку прогноза по формуле:
ŷp = Sост · (1 + 1 / 17 + ( xp - )2/( (x1 - )2 + (x2 - )2 + ... + (x17 -- )2))1/2 = 1562,67· (1 + 1/17 +
(71195,3 -64723)2 /18204892818)1/2 = 0,0006
Предельная ошибка прогноза, которая с вероятностью 0,95 не будет
превышена, составит:
∆ŷp = tтабл · mŷp =2,131 · 0,0006 = 0,0012.
Здесь tтабл - табличное значение t-статистки Стьюдента для числа степеней свободы n - 2 = 15 и уровне значимости 0,05
равное tтабл = 2,131.
Тогда предельные значения доверительного интервала прогноза расходов на
перевозки при прогнозируемом увеличении грузооборота на 10% можно вычислить по
формулам:
ŷxp min = ŷxp - ∆ŷp
=5322,45 - 0,0012=5322,4470 млрд.руб.;
ŷxp max = ŷxp + ∆ŷp =
5322,45 + 0,0012=5322,4494 млрд.руб.
Выполненный прогнозный расчет по линейной регрессионной модели показал,
что с вероятностью 0,95 она достаточно точна. Выполненный прогноз расходов на
перевозки является надежным и находится в пределах от 5322,4470 млрд.руб. до
5322,4494 млрд.руб.
8. Реализация
решенных задач на компьютере
Определение линейной функции регрессии выполним с помощью ППП Excel.
.1 Реализация
процедуры «ЛИНЕЙН»
Статистическая функция ЛИНЕЙН позволяет вычислить параметры линейной
регрессии:
ŷx = a + b · x .
Вся регрессионная статистика будет выводиться по схеме:
|
Значение коэффициента b
|
значение коэффициента а
|
|
Среднеквадратическое
отклонение b
|
среднеквадратическое
отклонение а
|
|
коэффициент детерминации
|
среднеквадратическое
отклонение y
|
|
F-статистика
|
число степеней свободы
|
|
регрессионная сумма
квадратов
|
остаточная сумма квадратов
|
Алгоритм вычисления регрессионной статистики включает следующие этапы:
) подготовку исходных данных;
) выделение области пустых ячеек 5 ´ 2 для вывода результатов
регрессионной статистики;
) активизацию Мастера функций одним из способов:
а) в главном меню выбрать ВСТАВКА/ФУНКЦИЯ;
в) на панели СТАНДАРТНАЯ щелкнуть по кнопке ВСТАВКА ФУНКЦИИ;
) в окне КАТЕГОРИЯ выбрать СТАТИСТИЧЕСКИЕ, в окне ФУНКЦИЯ - ЛИНЕЙН; затем
щелкнуть по кнопке ОК;
) заполнить аргументы функции;
) в левой верхней ячейке выделенной области появится первый элемент
итоговой таблицы. Для раскрытия всей таблицы необходимо нажать на клавишу F2, затем нажать комбинацию клавишей CTRL + SHIFT + ENTER.
Ниже приводятся результаты регрессионной линейной математической модели
расходов на перевозки в зависимости от грузооборота 17 дорог по статистическим
данным Рф.
|
Значение коэффициента b
0,058099351
|
Значение коэффициента a
1186,047451
|
|
Среднеквадратическое
отклонение b 0,011581726
|
Среднеквадратическое
отклонение а 839,9700701
|
|
Коэффициент детерминации
0,626539997
|
Среднеквадратическое отклонение
y 1562,670325
|
|
F-статистика 25,1649437
|
Число степеней свободы 15
|
|
Регрессионная сумма
квадратов 61451245,96
|
Остаточная сумма квадратов
36629078,15
|
.2 Реализация
процедуры «Анализ данных»
Для активизации надстройки «Пакет анализа» необходимо открыть меню
«Сервис» и щелкнуть по строке «Надстройки…». В открывшемся меню следует
отметить строку «Пакет анализа» и подтвердить выбор кнопкой «ОК».
Инструмент анализа «Регрессия» пакета анализа данных Excel позволяет по введенным
статистическим данным получить значения выборочных коэффициентов корреляции и
детерминации, стандартного отклонения; разложения общей суммы квадратов на
объясненную и остаточную, расчетное значение 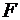 -статистики и уровень значимости на
котором расчетная -статистика равняется соответствующей табличной величине;
значения регрессионных параметров, их стандартные ошибки, и
-статистики и уровень значимости на
котором расчетная -статистика равняется соответствующей табличной величине;
значения регрессионных параметров, их стандартные ошибки, и 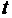 -статистики; таблицу теоретических
значений и величины их отклонений от опытных данных; график статистических
данных с линией регрессии и график остатков; и другие статистические оценки.
-статистики; таблицу теоретических
значений и величины их отклонений от опытных данных; график статистических
данных с линией регрессии и график остатков; и другие статистические оценки.
Вызов опции «Регрессия» осуществляется через надстройку «Анализ данных…»
меню «Сервис».
Вызов надстройки «Анализ данных…» приведет к появлению списка инструментов
анализа. В этом списке необходимо выбрать «Регрессия» и подтвердить выбор
нажатием кнопки «ОК».
Интерфейс инструмента анализа «Регрессия» представляет собой диалоговое
окно, в верхней части которого следует ввести статистические данные результирующей
переменной в поле «Входной интервал Y» и данные фактора в поле «Входной
интервал X». При необходимости построения
уравнения регрессии вида 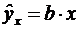 нужно задать параметр «Константа-ноль». Параметр «Уровень
надежности» в процентах определяет величину доверительной вероятности
нужно задать параметр «Константа-ноль». Параметр «Уровень
надежности» в процентах определяет величину доверительной вероятности  . В качестве выходного интервала
удобно задать адрес ячейки непосредственно рядом с таблицей исходных данных.
Рекомендует активизировать параметры «Остатки» (таблица теоретических значений
результирующего показателя и соответствующие значения остатков), «График
остатков» (график отклонений теоретических значений результирующего показателя
от его опытных значений) и «График подбора» (график статистических данных с соответствующими
теоретическими величинами, вычисленными по уравнению регрессии).
. В качестве выходного интервала
удобно задать адрес ячейки непосредственно рядом с таблицей исходных данных.
Рекомендует активизировать параметры «Остатки» (таблица теоретических значений
результирующего показателя и соответствующие значения остатков), «График
остатков» (график отклонений теоретических значений результирующего показателя
от его опытных значений) и «График подбора» (график статистических данных с соответствующими
теоретическими величинами, вычисленными по уравнению регрессии).
После подтверждения настроек нажатием кнопки «ОК» итоги регрессионного
анализа высветятся в заданной области.
Ниже приведены пояснения к итогам расчетов инструмента анализа «Регрессия».
. Регрессионная статистика:
Множественный R - выборочный коэффициент корреляции;квадрат - выборочный
коэффициент детерминации;
Нормированный R-квадрат - выборочный скорректированный на объем выборки
коэффициент детерминации;
Стандартная ошибка - стандартная ошибка результирующей переменной;
Наблюдения - объем выборки.
. Дисперсионный анализ:
Регрессия - строка таблицы, соответствующая объясненной сумме квадратов
отклонений;
Остаток - строка таблицы, соответствующая остаточной сумме квадратов
отклонений;
Итого - строка таблицы, соответствующая общей сумме квадратов отклонений;
df -
столбец значений числа степеней свободы;
SS -
столбец значений сумм квадратов отклонений;- столбец значений сумм квадратов
отклонений отнесенных к числу степеней свободы;
F -
расчетное значение -статистики;
Значимость F - значение
уровня статистической значимости, при котором табличное значение -статистики с числом степеней свободы
1 и  будет равно расчетной -статистике (если это значение меньше
заданного уровня значимости, то есть основание отвергнуть гипотезу о
статистической ненадежности уравнения регрессии).пересечение - строка таблицы
соответствующая свободному регрессионному коэффициенту;
будет равно расчетной -статистике (если это значение меньше
заданного уровня значимости, то есть основание отвергнуть гипотезу о
статистической ненадежности уравнения регрессии).пересечение - строка таблицы
соответствующая свободному регрессионному коэффициенту;
Переменная X1 - строка таблицы соответствующая регрессионному
коэффициенту при переменной ;
Коэффициенты - столбец значений регрессионных параметров;
Стандартная ошибка - столбец значений выборочных среднеквадратичных
отклонений регрессионных параметров;статистика - столбец расчетных значений -статистик регрессионных параметров;
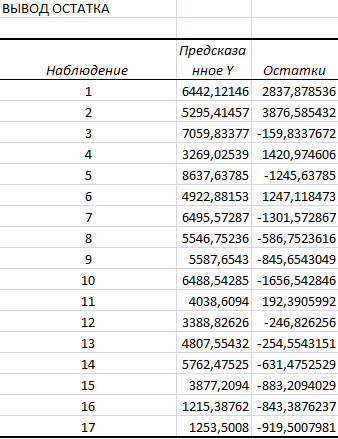
. Вывод остатков:
Наблюдения - номера наблюдений по порядку;
Предсказанное Y - теоретические значения результирующего показателя,
соответствующие опытным величинам;
Остатки - отклонения (разность) теоретических значений результирующего
показателя и соответствующих опытных значений.

.3 Реализация
процедуры «ТРЕНД»
Построению линий регрессии и получению регрессионных зависимостей в Excel
с помощью процедуры «ТРЕНД» предшествует создание точечных графиков исходных
данных. Построение точечных графиков начинается с вызова мастера диаграммы, в
окне которого на вкладке «Стандартные» выбирается тип «Точечная» и вид
позволяющий сравнивать пары значений.
Построение графика заключается в добавлении нового ряда статистических
данных. Для этого на вкладке «Ряд» «Мастера диаграммы» необходимо нажать кнопку
«Добавить». Добавление нового ряда данных требует ввода его имени и значений
фактора и результирующего показателя соответственно в поля «Значения X» и
«Значения Y».
На построенном графике следует щелкнуть правой кнопкой «мыши» по одной из
точек графика и в появившемся меню выбрать «Добавить линию тренда». На вкладке
«Тип» окна «Линия тренда» выбирается вид построения линии тренда «Линейная».
Изменить название и использовать возможность отображения уравнения на диаграмме
можно на вкладке «Параметры».
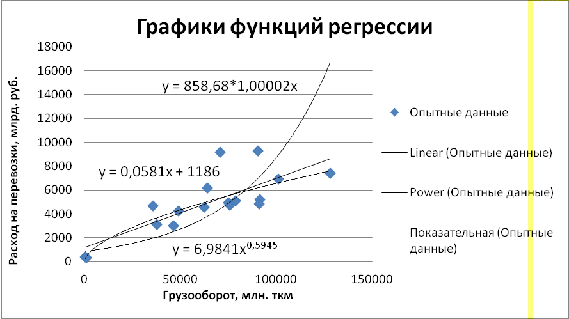
Рис.8.1 «Линии тренда»
Выводы
1. В настоящей курсовой работе решена задача разработки
математической модели расходов на перевозки в зависимости от грузооборота.
Исходными данными для ее расчета явились реальные значения расходов на
перевозки и грузооборота 17 железных дорог, расположенных на территории РФ. Для
выбора и обоснования модели в курсовой работе рассмотрены линейная, степенная и
показательная математические модели.
2. Выполнена оценка тесноты связи расходов на перевозки и
грузооборота с помощью показателей корреляции и детерминации. Сравнение
показателей степени связи между расходами на перевозки и грузооборотом
показывают, что для практических целей целесообразно использовать линейную
модель, она несколько лучше степенной, поскольку обладает высоким коэффициентов
корреляции и детерминации. Индекс корреляции в показательной модели не лежит в
пределах от 0 до 1, следовательно, он не показателен.
3. Проведена оценка качества уравнения регрессии с помощью ошибки
аппроксимации. Анализ ошибки аппроксимации функций регрессии показывает, что
она находится в допустимых для практического использования пределах, но с
теоретической точки зрения необходим поиск более качественной функции
регрессии. Из трех моделей можно выделить степенную, так как она имеет
минимальную ошибку аппроксимации, по сравнению с другими моделями:
- для линейной функции: А = 46 %
- для степенной функции: А = 20 %
для показательной функции: А = 48 %.
4. Осуществлена сравнительная оценка силы связи фактора
(грузооборот) с результатом (расход на перевозки) с помощью среднего
коэффициента эластичности. Анализ разработанных математических моделей
показывает, что увеличение на 1% грузооборота, например, Московской железной
дороги (№2), приводит к увеличению на 0,776; 0,595; 0,614% расходов на
перевозки. При этом по линейной модели это увеличение составляет 0,78%, по
степенной функции регрессии - 0,59%, по показательной функции регрессии -
0,61%.
5. Полученные значения F-критерия Фишера при анализе качества линейного уравнения регрессии
указывают, что Fтабл < Fфакт (4,54 < 25,16), значит
необходимо отвергнуть нулевую гипотезу о случайной природе коэффициента
регрессии и оцениваемой модели, а также принять альтернативную гипотезу о
статистической надежности линейного уравнения регрессии.
6. Выполненный прогнозный расчет по линейной регрессионной модели
показал, что при достаточной надежности (вероятность 0,95) модель точна:
ŷxp = 5322,45 млрд.руб.;
ŷxp min =5322,4470 млрд.руб.; ŷxp max =5322,4494 млрд.руб.
7. Сравнение результатов расчетов, выполненных на основе пакета
прикладных программ Excel и согласно
разработанным в курсовой работе алгоритмам (в соответствии с изученными методами
в дисциплине «Эконометрика»), показало высокую степень их совпадения.
Таким образом, цель курсовой работы, которая заключалась в освоении и
отработке навыков использования основных эконометрических моделей,
алгоритмизации и программирования в процессе решения прикладной задачи
статистического анализа расходов на железнодорожные перевозки от грузооборота
была достигнута.