Побудова регресійної залежності хімічного складу і механічних властивостей сталі, оптимізація властивостей з використанням отриманої математичної моделі
Вступ
Математична модель - це наближений опис
якого-небудь класу явищ або об'єктів реального світу на мові математики.
Основна мета моделювання - дослідити ці об'єкти і передбачити результати
майбутніх спостережень. Математичне моделювання і пов'язаний з ним комп'ютерний
експеримент незамінні в тих випадках, коли натурний експеримент неможливий з
тих чи інших причин. Математична модель дозволяє одержати визначену інформацію
про процеси, що протікають в об’єкті, розрахувати характеристики об’єкту і дати
рекомендації з його оптимізації.
Основні етапи математичного моделювання
включають в себе:
А) Побудова моделі. На цьому етапі задається
деякий "нематематичний" об'єкт - конструкція, виробничий процес . При
цьому, як правило, чіткий опис ситуації неможливий. Спочатку виявляються
основні особливості явища і зв'язки між ними на якісному рівні. Потім знайдені
якісні залежності формулюються мовою математики, тобто будується математична
модель. Це найважча стадія моделювання.
Б) Розв’язання математичної задачі, до якої
приводить модель. На цьому етапі велика увага приділяється розробці алгоритмів
і чисельних методів рішення задачі на ЕОМ, за допомогою яких результат може
бути знайдений з необхідною точністю.
В) Інтерпретація отриманих результатів з
математичної моделі. Результати, виведені з моделі на мові математики,
інтерпретуються мовою, прийнятою в даній області.
Г) Перевірка адекватності моделі. На цьому етапі
з'ясовується, чи узгоджуються результати експерименту з теоретичними наслідками
з моделі в межах певної точності.
Д) Модифікація моделі. На цьому етапі
відбувається або ускладнення моделі, щоб вона була більш адекватною дійсності,
або її спрощення заради досягнення практично прийнятного рішення.
У даній курсовій роботі передбачається побудова
регресійної залежності хімічного складу і механічних властивостей сталі,
оптимізація властивостей з використанням отриманої математичної моделі.
Відповідно до індивідуального завдання необхідно виконати попередню обробку
даних; побудувати регресійну модель першого і другого порядку, перевірити їх
адекватність; перевірити значимість коефіцієнтів рівняння; дати рекомендації
щодо підвищення рівня властивостей; вибрати й обґрунтувати оптимальний вид
рівняння для визначення очікуваних значень властивостей.
. Попередня обробка результатів
Попередню обробку виконують для кожного фактора,
у даному випадку для C, Mn, Si, S, Al, Ti, T, 𝛹.
Для проведення попередньої обробки використовуємо програму
"Statistica".
Рекомендується наступний порядок проведення
попередньої обробки:
обчислення вибіркових характеристик;
перевірка на грубі випади;
перевірка закону розподілу;
перевірка незалежності факторів між собою
(кореляційний аналіз).
При обчисленні вибіркових характеристик
визначають:
а) вибіркове середнє - Хср
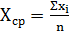 (1.1)
(1.1)
Де
хі - значення фактора в і-ом
досліді;- число дослідів.
б) мінімальне та максимальне
відхилення
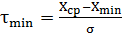 (1.2)
(1.2)
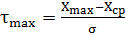 (1.3)
(1.3)
в) коефіцієнт варіації
= 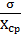 (1.4)
(1.4)
Коефіцієнт варіації характеризує
відносний розкид результатів, і значення Хср і COV використовують надалі у
аналізі.
Всі значення статичних характеристик
приведені у таблиці 1.1.
Таблиця 1.1 - Попередня статистична
обробка даних
|
Xср
|
ΔХ -95%
|
ΔХ +95%
|
Xmin
|
Xmax
|
S2
|
σ
|
cov, %
|
|
С
|
0.3720
|
0.3435
|
0.4005
|
0.3100
|
0.5500
|
0.006
|
0.07631
|
20.5
|
|
Mn
|
1.0793
|
1.0257
|
1.1329
|
0.8400
|
1.2400
|
0.021
|
0.14355
|
13.3
|
|
Si
|
0.4250
|
0.3849
|
0.4651
|
0.3200
|
0.5600
|
0.012
|
0.10747
|
25.3
|
|
S
|
0.0286
|
0.0280
|
0.0292
|
0.0260
|
0.0300
|
0.000
|
0.00152
|
5.3
|
|
Al
|
0.0205
|
0.0136
|
0.0274
|
0.0090
|
0.0600
|
0.000
|
0.01836
|
89.5
|
|
Ti
|
0.0917
|
0.0713
|
0.1120
|
0.0280
|
0.1800
|
0.003
|
0.05444
|
59.4
|
|
T
|
384.1667
|
364.0278
|
404.3056
|
300.000
|
500.0000
|
290.8764
|
53.93296
|
14
|
|
𝛹
|
28.7667
|
27.6414
|
29.8920
|
22.0000
|
35.0000
|
9.082
|
3.01357
|
10.5
|
Визначимо коефіцієнт варіації для
кожного фактору:
(C) = 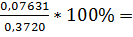 20,5%(Mn)
=
20,5%(Mn)
= 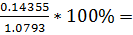 13.3%(Si)
=
13.3%(Si)
= 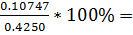 25.3%
25.3%
cov(S) = 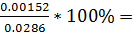 5.3%(Al)
=
5.3%(Al)
= 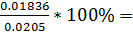 89.5%(Ti)
=
89.5%(Ti)
= 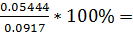 59.4%(T)
=
59.4%(T)
= 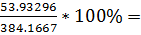 14%(𝛹)
=
14%(𝛹)
= 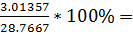 10.5%
10.5%
Перевірку вибірки на наявність
випадів можна здійснювати за різними методиками і вибір методу залежить від
числа дослідів. Найбільше поширений метод полягає в обчисленні критерію
відносного максимального відхилення і порівняння його з табличним значенням. У
цьому методі для максимального і мінімального значень вибірки обчислюють по
формулам (1.2) та (1.3).
Для невеликого числа дослідів
(n<25 ) знайдене значення t порівнюють
з табличним значенням критерію максимального відхилення С для обраного рівня
надійності Р і числа ступенів волі f=n.
Якщо С > t,
даний результат є випадом і відповідний результат можна виключити з вибірки.
Для більшого числа дослідів t
(в нашому випадку ми маємо 30 дослідів) можна порівнювати з критерієм Ст’юдента
tтабл для числа ступенів волі f=n і вважати результат випадом, якщо t
> t.
У нашому випадку для n=30 і f = 28
tтабл=2,045.
Визначимо нормоване відхилення по
мінімальному значенню за формулою (1.2):
τmin(C)=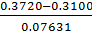 =0.812459
=0.812459
τmin(Mn)=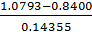 =1.667254
=1.667254
τmin(Si)=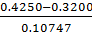 =0.977008
=0.977008
τmin(S)=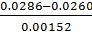 =1.707999
=1.707999
τmin(Al)=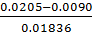 =0.626301
=0.626301
τmin(Ti)=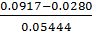 =1.169558
=1.169558
τmin(T)=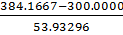 =1.560579
=1.560579
τmin(𝛹)=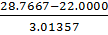 =2.245399
=2.245399
Визначимо нормоване відхилення по
максимальному значенню за формулою (1.3):
𝜏max(C)=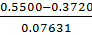 = 2.332544
= 2.332544
𝜏max(Mn)=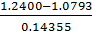 =1.119243
=1.119243
𝜏max(Si)=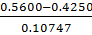 =1.256154
=1.256154
𝜏max(S)=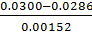 =0.919692
=0.919692
𝜏max(Al)=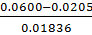 =2.0151207
=2.0151207
𝜏max(Ti)=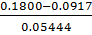 =1.622686
=1.622686
𝜏max(T)=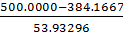 =2.147728
=2.147728
𝜏max(𝛹)=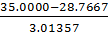 =2.068421
=2.068421
Обчислені дані приведені в таблиці
1.2
Таблиця 1.2 - Результати перевірки
вихідних даних на наявність випадів
|
Xmin
|
Xmax
|
τmin
|
τmax
|
cov,%
|
tтабл
|
Випади
|
|
C
|
0.3100
|
0.5500
|
0.812459
|
2.332544
|
20.5
|
2.045
|
0.5500
|
|
Mn
|
0.8400
|
1.2400
|
1.667254
|
1.119243
|
13.3
|
2.045
|
|
|
Si
|
0.3200
|
0.5600
|
0.977008
|
1.256154
|
25.3
|
2.045
|
|
|
S
|
0.0260
|
0.0300
|
1.707999
|
0.919692
|
5.3
|
2.045
|
|
|
Al
|
0.0090
|
0.0600
|
0.626301
|
2.151207
|
89.5
|
2.045
|
0.0600
|
|
Ti
|
0.0280
|
0.1800
|
1.169558
|
1.622686
|
59.4
|
2.045
|
|
|
T
|
300.0000
|
500.0000
|
1.560573
|
2.147728
|
14
|
2.045
|
500.0000
|
|
𝛹
|
22.0000
|
35.0000
|
2.245399
|
2.068421
|
10.5
|
2.045
|
22.0000
|
Оцінка виду
розподілу і можливості перетворення його до нормального може бути виконана за
різними критеріями (графічно - по виду кривої розподілу, по співвідношенню
коефіцієнтів асиметрії й ексцесу і за критерієм Пірсона - c2).
При виконанні цього етапу спочатку необхідно переглянути гістограму частотного
розподілу по кожному фактору. Для відповіді на питання про закон розподілу в
цьому випадку необхідно порівняти за критерієм Пірсона - c2
одержуваний розподіл результатів з теоретичним для даного закону.
Для цього необхідно
порівняти розрахований критерій Пірсона з табличним для обраної надійності Р і
числа ступенів волі f =n - 3. Якщо c2 таб л≥
c2експ,
дані розподілені за цим законом. Чим менше c2експ,
тим менше відхилення від теоретичного закону.
Регресійний аналіз
припускає, що результати експериментів розподілені по нормальному закону, тобто
у вибірці однаково часто зустрічаються результати більші і менші середнього
значення. При розробці регресійної моделі необхідно перевірити закон розподілу
значень факторів. Оцінку виду розподілу виконаємо за різними критеріями
(графічно - по виду кривої розподілу і за критерієм Пірсона - c2).
Спочатку переглянемо гістограми частотного розподілу по кожному фактору. Потім
порівняємо одержуваний розподіл результатів з теоретичним для даного закону.
Чим менше c2експ, тим менше відхилення від
теоретичного закону. В таблиці 1.3 приведені розраховані критерії Пірсона для
нормального розподілу. Закон розподілу вибирають по меншому c2.
Таблиця 1.3 -
Результати перевірки вихідних факторів на відповідність закону розподілу
|
Фактор
|
c2норм
|
c2равном
|
c2экспон
|
c2табл
|
З-н распределения
|
|
C
|
11,00735
|
48,13758
|
|
26,296
|
нормальный
|
|
|
|
|
24,996
|
|
|
Mn
|
10,12206
|
11,95152
|
|
16,919
|
нормальный
|
|
|
|
|
16,919
|
|
|
Si
|
21,30845
|
12,13333
|
|
23,685
|
равномерный
|
|
|
|
|
23,685
|
|
|
S
|
14,89586
|
20,37128
|
|
19,675
|
нормальный
|
|
|
|
|
21,026
|
|
|
Al
|
11,21607
|
|
5,70342
|
9,488
|
экспоненциальный
|
|
|
|
|
9,488
|
|
|
Ti
|
6,19798
|
9,14000
|
|
27,587
|
нормальный
|
|
|
|
|
27,587
|
|
|
T
|
1,707440
|
5,66667
|
|
19,675
|
нормальный
|
|
|
|
|
19,675
|
|
|
𝛹
|
2,13235
|
5038889
|
|
24,996
|
нормальный
|
|
|
|
|
24,996
|
|
На рисунку 1.1 приведені криві
розподілу факторів. Ми приймаємо, що всі ці закони розподілу нормальні, але
криві нагадують криві бімодального закону розподілу.
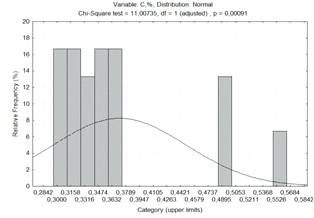
Рисунок 1.1 - Діаграма частотного
розподілу вмісту вуглецю
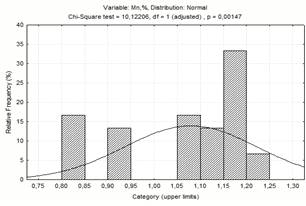
Рисунок 1.2 - Діаграма частотного
розподілу вмісту марганцю
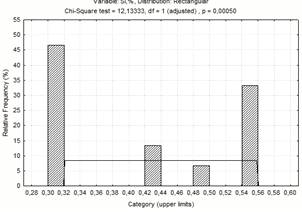
Рисунок 1.3 - Діаграма частотного
розподілу вмісту кремнію
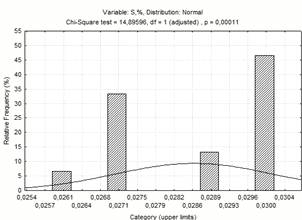
Рисунок 1.4 - Діаграма частотного
розподілу вмісту сірки
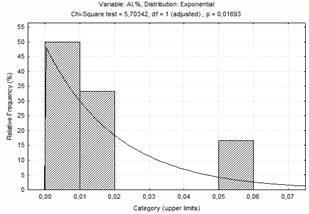
Рисунок 1.5 - Діаграма частотного
розподілу вмісту алюмінію
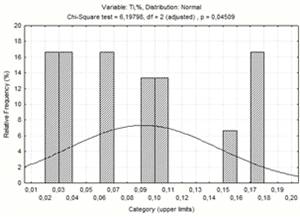
Рисунок 1.6 - Діаграма частотного
розподілу вмісту титану
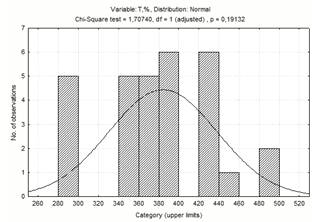
Рисунок 1.7 - Діаграма частотного
розподілу температури

Рисунок 1.8 - Діаграма частотного
розподілу відносного звуження
2. Кореляційний аналіз
Кореляційний аналіз на етапі
попередньої обробки застосовують для визначення ступеня зв’язку факторів між
собою і з властивістю. Оцінка коефіцієнтів у рівнянні регресії методом
найменших квадратів вимагає незалежність факторів. У матеріалознавстві фактори
досить часто зв’язані між собою (наприклад, спільне введення легуючих добавок у
сталь у виді феросплавів). Сильна кореляція між факторами може привести до
перекручених оцінок впливу факторів на властивість (за рахунок взаємної
позитивної кореляції не впливові фактори можуть бути оцінені як впливові,
негативна кореляція взаємно компенсує вплив факторів на властивість). Тому для
вирішення питання про включення того чи іншого фактора в модель необхідно
виконати аналіз даних за допомогою програми кореляційного аналізу. Кількісною
характеристикою ступеня зв’язку в методі кореляційного аналізу с коефіцієнт
парної кореляції r
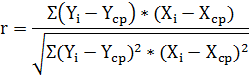
де r - коефіцієнт парної
кореляції;ср, xср - середні значення по відповідним перемінним.
Спочатку підготуємо таблицю
кореляційного аналізу, у яку в процесі обчислень занесемо значення коефіцієнтів
парної кореляції (таблиця 2.1). Значимі коефіцієнти позначимо *.
Таблиця 2.1 - Таблиця кореляційного
аналізу
|
C
|
Mn
|
Si
|
S
|
Al
|
Ti
|
T
|
𝛹
|
|
C
|
1.00
|
-0.05
|
0.15
|
-0.23
|
-0.17
|
0.52*
|
0.48*
|
-0.29
|
|
Mn
|
-0.05
|
1.00
|
0.61*
|
-0.57*
|
0.41*
|
0.38*
|
-0.13
|
0.11
|
|
Si
|
0.15
|
0.61*
|
1.00
|
-0.13
|
0.67*
|
0.39*
|
0.05
|
-0.12
|
|
S
|
-0.23
|
-0.57*
|
-0.13
|
1.00
|
-0.36*
|
-0.66*
|
0.06
|
-0.01
|
|
Al
|
-0.17
|
0.41*
|
0.67*
|
-0.36*
|
1.00
|
0.62*
|
-0.16
|
-0.09
|
|
Ti
|
0.52*
|
0.38*
|
0.39*
|
-0.66*
|
0.62*
|
1.00
|
0.15
|
-0.20
|
|
T
|
0.48*
|
-0.13
|
0.06
|
-0.16
|
0.15
|
1.00
|
0.37*
|
|
𝛹
|
-0.29
|
0.11
|
-0.12
|
-0.01
|
-0.09
|
-0.20
|
0.37*
|
1.00
|
Після розрахунку коефіцієнта парної
кореляції необхідно перевірити його статистичну значимість. Для цього по
таблиці критичних значень коефіцієнтів парної кореляції для обраного рівня
надійності Р=0,95 і числа ступенів волі f=30-2=28 знаходять значення
rтабл=0,30. Якщо |rрозр| ≥ rтабл, лінійний зв’язок між цими величинами є
статистично значимий. Значимість коефіцієнта парної кореляції можна також
перевірити по t - критерію Ст’юдента. Для цього обчислюють і порівнюють з
табличним значенням критерію Ст’юдента для обраної надійності Р=0,95 і числа
ступенів волі f=30-1=29. Маємо tтабл= 2,04.
Значення r лежать в
інтервалі -1...+1.Чим ближче r до ±1, тим сильніше ступінь лінійного зв'язку
між перемінними. Знак "-" (негативна кореляція) означає, що зі
збільшенням однієї перемінної інша буде зменшуватися. Знак "+" - зі
збільшенням однієї перемінної інша буде також зростати. При r = 1 між
перемінними існує функціональний зв'язок.
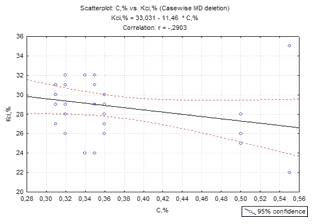
Рисунок 2.1 -
Графік зв’язку між вуглецем та відносного звуження
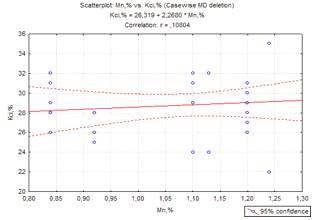
Рисунок 2.2 -
Графік зв’язку між марганцем та відносним звуженням
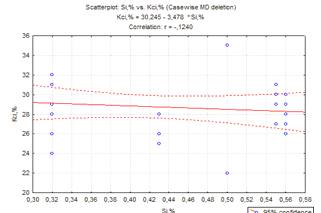
Рисунок 2.3 - Графік зв’язку між
кремнієм та відносним звуженням
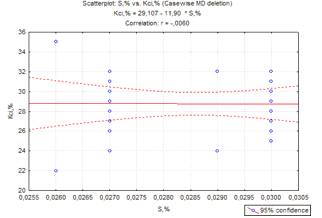
Рисунок 2.4 - Графік зв’язку між
сіркою та відносним звуженням
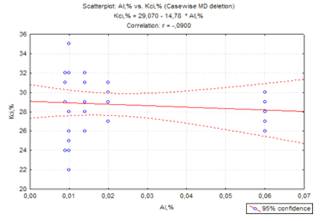
Рисунок 2.5 - Графік зв’язку між
алюмінієм та відносним звуженням
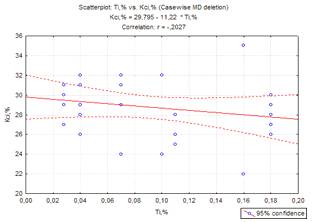
Рисунок 2.6 - Графік зв’язку між
титаном та відносним звуженням
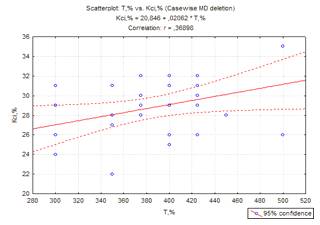
Рисунок 2.7 - Графік зв’язку між
температурою та відносним звуженням
Після перевірки
значимості за даними таблиці кореляційного аналізу будуємо граф кореляційних
зв'язків (рисунок 2.8). Для цього наносимо вершини графа - досліджувані фактори
і властивість, потім з’єднуємо відрізками ті вершини, між якими існує
статистично значимий зв'язок.
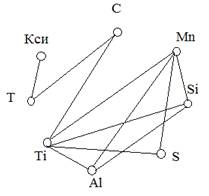
Рисунок 2.8 - Граф
кореляційних зв’язків
3. Розробка регресійної моделі
першого порядку
Розробку
регресійної моделі завжди починають з побудови лінійної моделі, що включає усі
фактори (крім виключених через взаємну кореляцію). Таку математичну модель
називають повною. Під повною регресійною моделлю першого порядку розуміють
залежність виду:
у= bo + b1x1 + b2x2
+ …… + bkxk ± ε
(2.1)
де к - число
факторів;
ε
- помилка пророкування моделі.
Задача регресійного
аналізу полягає в розрахунку за результатами експериментів значень коефіцієнтів
bi. Коефіцієнти розраховують на ЕОМ і одночасно зі значеннями коефіцієнтів
одержують ряд статистичних характеристик, що описують рівняння в цілому, а
також характеризують вплив факторів.
Статичні
характеристики, що описують рівняння в цілому:- залишкова сума квадратів;
ε - стандартне
відхилення моделі (інтервал відхилення від площини регресії,у якому з заданою
надійністю лежать експериментальні значення властивості);- коефіцієнт
детермінації, що показує, яка частина варіації властивості пояснюється моделлю
(0-100%);- коефіцієнт множинної кореляції,що показує ступінь зв’язку факторів
із властивістю. Його значення лежать в інтервалі 0-1,0;- критерій Фішеру
моделі;- критерій Ст’юдента моделі, що лежить від R;
залишки - різниця
експериментальних і розрахованих по рівнянню значень властивості.
Статичні
характеристики, зв’язані з факторами:
∆bi -
довірчий інтервал визначення і-го коефіцієнта;- коефіцієнт часткової кореляції.
Регресійний аналіз
проводять у визначеній послідовності:
1
перевірка адекватності моделі;
2
перевірка статистичної значимості
коефіцієнтів;
3
аналіз моделі і видача рекомендацій
з оптимізації властивості.
Адекватність моделі перевіряють по F
і t. Якщо Fpозр ≥ Fтабл, то модель є адекватною і її можна використовувати
для подальшого аналізу. При аналізі адекватності перевагу варто віддавати F-
критерію як більш чуттєвому.
Це означає, що, якщо модель
адекватна по t і неадекватна по F, модель варто вважати неадекватною. У нашому
випадку модель э адекватною, тому що 3.5595>2.6
Таблиця 3.1 - Модель першого порядку
при N = 30Summary for Dependent Variable:= 0 ,72875340 R2 = 0,53108151R2
=0,38188018 F(7,22) = 3,5595<01038 Std.Error of estimate: 2,3693
|
Beta
|
Std.Err.
|
Patrial cor.
|
B
|
Std.Err.
|
t (22)
|
p-level
|
|
Intercept
|
|
|
139.00
|
90.739
|
1.53189
|
0.139803
|
|
C
|
-3.83547
|
2.620490
|
-151.46
|
103.484
|
-1.46365
|
0.157433
|
|
Mn
|
-1.95888
|
1.781274
|
-41.12
|
37.395
|
-1.09971
|
0.283349
|
|
Si
|
3.10465
|
2.626484
|
87.06
|
73.649
|
1.18206
|
0.249802
|
|
S
|
-1.12001
|
0.817872
|
-2217.26
|
1619.128
|
-1.3642
|
0.184687
|
|
Al
|
-4.29518
|
3.399339
|
-704.93
|
557.906
|
-1.26353
|
0.219623
|
|
Ti
|
3.16689
|
2.636016
|
175.32
|
145.928
|
1.20139
|
0.242374
|
|
T
|
0.71229
|
0.169652
|
0.04
|
0.009
|
4.19851
|
0.000372
|
Рівняння повної моделі першого
порядку має вигляд:
𝛹
= 139,00 - 151,46C - 41.12Mn + 87.06Si - 2217.26S -704.93Al +175.32Ti+ 0.04T ±
2.3693
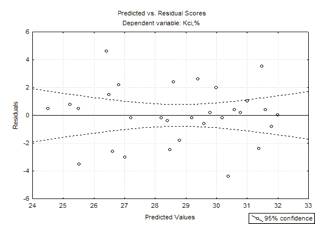
Рисунок 3.1 - Графік
експериментальних значень та залишків для початкової моделі
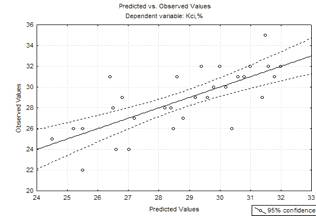
Рисунок 1.2 - Графік
експериментальних та отриманих значень для початкової моделі
Для підвищення якості і вiрогiдностi
розробленої моделi необхiдно проаналiзувати залишки - рiзницю мiж
експериментальними i розрахованими по моделi значеннями властивостi.
Значення залишкiв повиннi
задовольняти наступним вимогам:
- сума
залишків повинна дорівнювати нулю. За знаком і величиною відхилення суми від
нуля можна визначити розташування поверхні відгуку об'єкта щодо площини
регресії. Якщо сума залишків більше нуля, поверхня лежить вище площини
регресії, якщо менше нуля - то нижче. Це задовольняє визначити вид перетворення
для значень властивості;
- значення
𝛹ехсп - 𝛹розр повинні
корелювати між собою. Чим більше коефіцієнт парної кореляції між ними, тим
точніше модель відображає результати експерименту;
- значення
залишків повинні мати нормальний закон розподілу.
Далі з моделі першого порядку
виключили 12й дослід, отримали модель для 29 дослідів. Після чого статистичні
характеристики моделі підвищились:Summary for Dependent Variable:= 0,79661372
R2=0 ,63459342R2= 0,51279123 F(7,21)=5,2100<,00147 Std.Error of estimate:
2,1196
Потім видалили 7 дослід, отримали
модель для 28 дослідів. Статистичні характеристики моделі також
підвищились:Summary for Dependent Variable= 0,83521759 R2= 0,697588 42R2=
0,59174437 F(7,20)=6,5907<,00041 Std.Error of estimate: 1,9320
Далі видалили 9й дослід, отримали
модель для 27 дослідів. Статистичні характеристики моделі значно
підвищились:Summary for Dependent Variable=0 ,86101418 R2=0 ,74134542R2=0
,64605162 F(7,19)=7,7796<,00017 Std.Error of estimate: 1,8075
Після цього видалили 5й дослід,
отримали модель для 26 дослідів. Внаслідок послідовного виключення деяких
дослідів модель стала ще кращою, її статистичні характеристики значно
підвищилися. А саме вона має більший критерій Фішеру 10,074 >3.5595 і
коефіцієнт множинної кореляції 0,89254985>0.79661372.
Таблиця 3.2 - Статистичні
характеристики покращеної моделі першого порядку N=26Summary for Dependent
Variable:= 0,89254985 R2= 0,79664523R2=0 ,71756282 F(7,18)=10,074<,00004
Std.Error of estimate: 1,6462
|
Beta
|
Std.Err. of Beta
|
Patrial. Cor.
|
B
|
Std.Err. of B
|
t (18)
|
p-level
|
|
intercept
|
|
|
|
-13.4691
|
71.071
|
-0.189516
|
0.851809
|
|
C
|
0.085723
|
1.938752
|
0.010421
|
3.5087
|
79.354
|
0.044216
|
0.965219
|
|
Mn
|
0.856137
|
1.236334
|
0.161088
|
20.1562
|
29.107
|
0.692480
|
0.497473
|
|
Si
|
-0.917305
|
1.984998
|
-0.108282
|
-26.0696
|
56.413
|
-0.462119
|
0.649533
|
|
S
|
0.134078
|
0.616939
|
0.051157
|
272.3130
|
1253.010
|
0.21327
|
0.830398
|
|
Al
|
0.767979
|
2.688286
|
0.067182
|
121.6505
|
425.834
|
0.285676
|
0.778388
|
|
Ti
|
-0.547542
|
1.965603
|
-0.065517
|
-30.8925
|
110.900
|
-0.278562
|
0.783756
|
|
T
|
0.893194
|
0.118105
|
0.872135
|
0.0582
|
0.008
|
7.562685
|
0.000001
|
Після виключення деяких дослідів
повна модель першого порядку має вигляд:
𝛹
= -13.4691+3.5087C+20.1562Mn - 26.0696Si + 272.3130S + 121.6505Al - 30.8925 +
0.0582 ± 1.6462
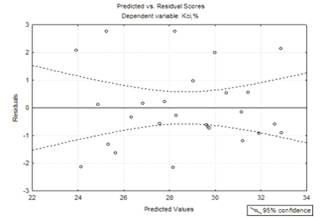
Рисунок 3.3 - Графік
експериментальних значень та залишків кінцевої моделі першого порядку
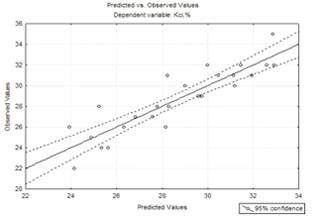
Рисунок 3.4 - Графік
експериментальних та отриманих значень для кінцевої моделі першого порядку
Проранжуємо фактори, розташувавши їх
у порядку зменшення ступеня впливу на властивість. Для цього побудуємо
гістограми ранжирування, на яких розташуємо фактори у порядку зменшення
коефіцієнтів у кодовому масштабі b, які
характеризують ступінь впливу фактора на властивість, і коефіцієнтів часткової
кореляції rxy, що характеризують ступінь зв’язку фактора та властивості і у
деякій мірі доповнюють коефіцієнти у кодовому масштабі. Гістограми ранжирування
представлені на рисунках 2.5 і 2.6.
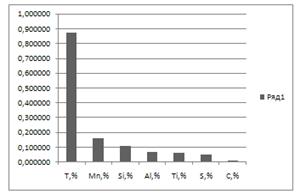
Рисунок 2.5 - Гістограма
ранжирування факторів за коефіцієнтом часткової кореляції для покращеної моделі
першого порядку.
. Розробка регресійної моделі
другого порядку
У матеріалознавстві
в більшості випадків більш точно результати експерименту описують нелінійні
моделі. Обмежимося неповною моделлю другого порядку.
Ефекти взаємодії
вибирають на пiдставi знань про об’єкт дослідження, з урахуванням графа
кореляційних зв'язків обираємо ефект взаємодії між та Т і С. При перемноженні
модель адекватна (Fрозр>Fтабл).
Таблиця 4.1 -
Статистичні характеристики вихідної моделі другого порядку
Regression Summary for Dependent
Variable:=0 ,77979743 R2=0 ,60808403R2=0 ,45878271 F(8,21)=4,0729<,00462
Std.Error of estimate: 2,2170
|
Beta
|
Std.Err. of Beta
|
Patrial. Cor.
|
B
|
Std.Err. of B
|
t (21)
|
p-level
|
|
intercept
|
|
|
|
172.38
|
86.483
|
1.99328
|
0.059383
|
|
C
|
-5.95304
|
2.664471
|
-0.438238
|
-235.09
|
105.221
|
-2.23423
|
0.036470
|
|
Mn
|
-1.94420
|
1.666803
|
-0.246669
|
-40.82
|
34.992
|
-1.16642
|
0.256520
|
|
Si
|
3.07456
|
2.457719
|
0.263350
|
86.21
|
68.916
|
1.25098
|
0.224700
|
|
S
|
-1.14674
|
0.765419
|
-0.310747
|
-2270.19
|
1515.287
|
-1.49819
|
0.148966
|
|
Al
|
-4.28549
|
3.180859
|
-0.282062
|
-703.34
|
522.049
|
-1.34728
|
0.192250
|
|
Ti
|
3.19717
|
2.466638
|
0.272169
|
176.99
|
136.552
|
1.29617
|
0.208983
|
|
T
|
-0.68426
|
0.705614
|
-0.207028
|
-0.04
|
0.039
|
-0.96973
|
0.343218
|
|
T-C
|
3.04375
|
1.498452
|
0.405232
|
0.20
|
0.099
|
2.03126
|
0.055077
|
Рівняння вихідної моделі другого
порядку має вигляд:
сталь регресійний
математичний випад
𝛹
= 172.38 - 235.09C - 40.82Mn + 86.21Si - 2270.19S - 703.34Al + 176.99Ti - 0.04T
+ 0.20T-C ± 2.2170
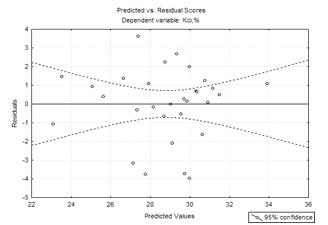
Рисунок 4.1 - Графік
експериментальних значень та залишків для вихідної моделі другого порядку
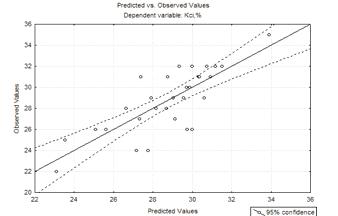
Рисунок 4.2 - Графік
експериментальних та отриманих значень для вихідної моделі другого порядку
При аналізі залишків був виключений
12й дослід, після чого статистичні характеристики почали збільшуватись. Модель з
29 дослідами має такі характеристики:Summary for Dependent Variable:=
0,82201429 R2=0,67570749R2= 0,54599048 F(8,20)=5,2091<,00130 Std.Error of
estimate: 2,0352
Далі виключили 7й дослід. Модель із
28 дослідами має такі статистичні характеристики:Summary for Dependent
Variable:= 0,86957487 R2= 0,75616045R2= 0,65349116 F(8,19)=7,3650<,00018
Std.Error of estimate: 1,7803
Потім виключили 9й дослід. Модель із
27 дослідами має такі характеристики:Summary for Dependent Variable:=
0,89935793 R2= 0,80884468R2= 0,72388676 F(8,18)=9,5205<,00004 Std.Error of
estimate: 1,5334
Після виключення 5го досліду
статистичні характеристики значно збільшилися, а саме вона має більший критерій
Фішеру 9,5205>4.0729 і коефіцієнт множинної кореляції 0.89935793> А саме
вона має більший критерій Фішеру 10,074 >3.5595 і коефіцієнт множинної
кореляції 0,892549 >0.796613.
Таблиця 4.2 - Статистичні
характеристики кінцевої моделі другого порядкуSummary for Dependent Variable:=
0,93016718 R2=0 ,86521098R2= 0,80178085 F(8,17)=13,640<,00001 Std.Error of
estimate: 1,2399
|
BetaStd.Err. of BetaPatrial. Cor.BStd.Err. of
Bt (18)p-level
|
|
|
|
|
|
|
|
|
intercept
|
|
|
|
147.43
|
51.7225
|
2.85045
|
0.011064
|
|
C
|
-6.60130
|
1.708096
|
-0.683875
|
-238.72
|
61.7681
|
-3.86471
|
0.001243
|
|
Mn
|
-1.19953
|
1.105409
|
-0.254518
|
-23.44
|
21.5997
|
-1.08514
|
0.293009
|
|
Si
|
1.88124
|
1.662377
|
0.264679
|
47.97
|
42.3917
|
1.13166
|
0.273490
|
|
S
|
-0.73287
|
0.518201
|
-0.324453
|
-1312.38
|
927.9625
|
-1.41426
|
0.175338
|
|
Al
|
-3.24226
|
2.219159
|
-0.334002
|
-467.54
|
320.0066
|
-1.46103
|
0.162244
|
|
Ti
|
2.52766
|
1.727797
|
0.334390
|
122.68
|
83.8575
|
0.161727
|
|
T
|
-1.56066
|
0.419969
|
-0.669495
|
-0.09
|
0.0246
|
-3.71613
|
0.001717
|
|
T-C
|
4.96393
|
0.932355
|
0.790634
|
0.32
|
0.0606
|
5.32407
|
0.000056
|
Оптимальна модель
другого порядку має наступний вигляд:
𝛹
= 147.43 - 238.72C - 23.44Mn + 47.97Si - 1312.38S - 767.54Al + 122.68Ti - 0.09T
+ 0.32T-C ± 1.2399
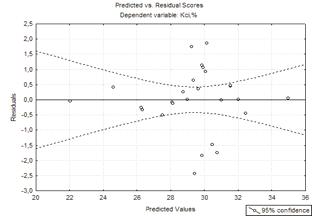
Рисунок 4.3 -
Залишки оптимальної моделі другого порядку після виключення дослідів
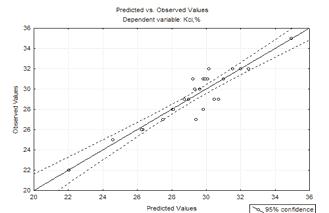
Рисунок 4.4 -
Залишки оптимальної моделі другого порядку після виключення дослідів
Визначимо
оптимальний вид рівняння для розрахунку очікуваного значення властивості.
Для цього
порівняємо статистичні характеристики, що описують рівняння в цілому.
Чим менше залишкова
сума квадратів, чим більше коефіцієнти детермінації, множинної кореляції і
критерій Фішеру, тим точніше модель описує результати експерименту. Для
порівняння статистичних характеристик складемо таблицю 4.3.
Таблиця 4.3 -
Порівняння статистичних характеристик моделей першого і другого порядків
|
Статистична характеристика
|
Модель першого порядку
|
Модель другого порядку
|
|
Коефіцієнт множинної кореляції R
|
0,89254985
|
0,93016718
|
|
Коефіцієнт детермінації R2
|
0,79664523
|
0 ,86521098
|
|
Критерій Фішеру F
|
10,074
|
13,640
|
|
ε
|
1,6462
|
1,2399
|
Виходячи з таблиці 4.3 можна зробити
висновок, що модель другого порядку набагато точніше описує результати
експерименту, так як вона має значно більші коефіцієнти детермінації та
множинної кореляції, а також помітно більший критерій Фішеру.
Тому для розрахунку очікуваного
значення властивості краще використовувати модель другого порядку.