Разработка программного обеспечения системы синтеза парадигм слов английского языка
Введение
Выявление формальных структур естественного
языка (ЕЯ), формализация языка в целом, построение конструктивной теории и
компьютерной модели языка являются приоритетными направлениями информатики на
протяжении последних десятилетий. Системы информационного поиска, диалоговые
системы, инструментальные средства для машинного перевода и автореферирования,
рубрикаторы и модули проверки правописания, так или иначе, проводят анализ
ЕЯ-текстов. Таким образом, область применения систем автоматической обработки
текстов (АОТ) достаточно разнообразна, а в виду большого роста объемов
текстовой информации и сложной ее структурированности, анализ ЕЯ-текстов
представляет собой очень актуальную проблему.
Достижения последних лет в области современной
логики, искусственного интеллекта и компьютерной лингвистики создали новые
предпосылки для исследований природы морфологических, синтаксических,
семантических и словообразовательных связей в ЕЯ и построения его
функциональной модели.
Компонента системы, реализующая формальную
лингвистическую модель и способная осуществлять полный лингвистический анализ
ЕЯ-текста, называется лингвистическим процессором (ЛП). Независимо от языка со
стороны своего внутреннего устройства ЛП представляет собой многоуровневый
преобразователь. В нем различаются три уровня представления текста -
морфологический, синтаксический и семантический. Каждый из уровней
обслуживается соответствующим компонентом модели - массивом правил и
определенным словарем.
На современном этапе развития информационных технологий
морфологический компонент стал неотъемлемой частью интеллектуальных АОТ-систем.
Все экспериментальные исследования в области машинной морфологии невозможны без
машинного грамматического словаря. Использование словаря позволяет осуществить
более полный анализ словоформы (т.е. оперировать большим числом грамматических
признаков) и повысить его точность. Основные трудности, с которыми сталкиваются
разработчики АОТ-систем следующие.
. Отсутствие единого общепринятого формата и
структуры словаря. Это приводит к тому, что алгоритмы всех компонент ЛП
автоматически становятся словарнозависимыми и каждый алгоритм разрабатывается
под определенный формат словаря.
. Отсутствие полных словарей. Объёмы данных, с
которыми имеет дело лингвистика, очень большие, кроме того лексика языка
непрерывно. Для каждой предметной области существует своя терминология,
включить которую в общий словарь невозможно.
. Отсутствие средств автоматизированной
лингвистической обработки словарей, она ведется в основном вручную, сопряжена с
большими трудозатратами и появлением большого числа ошибок, которые трудно
обнаруживаются. Поэтому создание больших по объему словарей - многолетний
процесс.
Данная работа посвящена разработке программных
средств синтеза парадигм слов английского языка для создания базы данных
английских словоформ с полной морфологической информацией.
Актуальность данной задачи обусловлена
необходимостью разработки средств АОТ, позволяющих быстро и эффективно
обрабатывать неструктурированную текстовую информацию.
Объектом исследования являются лексемы
английского языка.
Предмет исследования - модели словоизменения в
английском языке.
Методы, использованные при написании работы -
методы прикладного морфологического анализа.
Постановка задачи
Отдел распознавания речи Института проблем
искусственного интеллекта (ИПИИ) уже более 15 лет ведет работы, связанные с
обработкой ЕЯ-текстов. Данным отделом разработаны библиотеки словоизменения
слов русского языка, библиотека лемматизации и декларативного морфологического
анализа; создано несколько версий экспериментальных систем синтаксического
анализа и синтаксического корректора предложений. Данные средства обработки
естественно-языковых текстов широко используются как при разработке систем
распознавания речи, так и при разработке систем понимания ЕЯ-текстов.
В настоящее время специалистами отдела ведутся
работы в рамках международного проекта «Исследование и разработка программного
обеспечения понимания неструктурированной текстовой информации на русском и
английском языках на базе создания методов компьютерного полного
лингвистического анализа». В связи с этим возникает необходимость адаптировать
имеющиеся средства морфологической обработки, которые ориентированы на русский
язык, для анализа англоязычных текстов.
Целью курсовой работы является разработка
программного обеспечения (ПО) системы синтеза парадигм слов английского языка и
создание с его помощью базы данных английских словоформ, содержащей полную
морфологическую информацию каждой словоформы.
Разрабатываемый программный продукт (ПП) должен
обладать следующими возможностями:
создание, загрузка, редактирование и сохранение
словаря начальных форм слов английского языка в файле формата txt;
очистка, загрузка и сохранение базы английских
словоформ;
модификация базы английских словоформ;
получение парадигмы с указанием МИ каждой
словоформы по введенной пользователем лемме, содержащейся в словаре начальных
форм.
Для достижения указанной цели курсовой работы
ставятся и решаются следующие задачи:
) обзор методов машинной морфологии;
) проектирование и разработка ПО синтеза
парадигм слов английского языка;
) создание базы данных начальных форм английских
слов с грамматической информацией, необходимой для генерации базы данных
словоформ;
) формализация правил словоизменения английских
слов и разработка соответствующих алгоритмов;
) автоматическая генерация базы данных
английских словоформ с полной морфологической информацией, на основе
реализованных алгоритмов словоизменения, использующая базу данных начальных
форм английских слов;
) тестирование системы.
Проектирование системы синтеза парадигм слов
английского языка должно содержать:
описание функциональных возможностей
разрабатываемого ПО;
описание формата входных-выходных данных.
Разработка ПО синтеза парадигм слов английского
языка должна быть основана на результатах проектирования системы и включать
обоснование выбора средств программной реализации и описание алгоритмов
словообразования английского языка, структур данных, классов, функций
программного комплекса.
Тестирование и анализ результатов необходимы для
выявления ошибок в структуре алгоритма или его программной реализации,
структуре входных и внутренних данных, а также для ликвидации конфликтных
ситуаций с другим ПО.
1. Обзор методов машинной морфологии
Как уже было сказано выше, морфологическая
компонента является важнейшей в современных интеллектуальных системах, где
требуется распознавание и синтез речи, автоматизированный перевод с одного
языка на другой, понимание и генерирование ЕЯ-текста.
Эта компонента включает в себя морфологический
анализ и синтез словоформ. В ходе морфологического анализа проводится
соотнесение входной словоформы к одной из основ, хранящихся в словаре, т.е.
решается задача распознавания, а также определение его грамматических
параметров, т.е. выделение конкретной словоформы с данной основой.
Представление словоформы в виде совокупности основы и грамматических параметров
требуется для проведения синтаксического анализа с целью распознавания
словосочетаний и типа входной фразы. Морфологический синтез решает обратную
задачу, а именно, преобразует совокупность кода основы и грамматических
параметров в буквенную последовательность соответствующую синтезируемой
словоформе. При этом из класса словоформ, определяемого данной основой,
формируется словоформа, определяемая данными грамматическими параметрами. Эта
процедура является конечным этапом при генерировании ЕЯ-фраз.
Методы машинной морфологии могут быть
реализованы декларативными и процедурными способами.
.1 Декларативные методы машинной морфологии
Для методов декларативной ориентации характерно
наличие полного словаря всех возможных словоформ для каждого слова. При этом
каждая словоформа снабжается полной и однозначной морфологической информацией
(МИ), куда входят как постоянные, так и переменные морфологические параметры.
Задача морфологического анализа в этом случае сводится к поиску нужной
словоформы в словаре и копированию МИ, соответствующей найденной словоформе, в
программу. Работа морфологического синтеза состоит в считывании из словаря по
основе и набору МИ соответствующей словоформы этой основы.
Существует несколько классификаций основных
видов алгоритмов морфологического анализа-синтеза: со словарем основ; методом
логического умножения; без словарей; со словарем словоформ [1].
Морфологический анализ со словарем основ
является наиболее распространенным способом анализа. Для его проведения
требуется словарь основ слов и ряд вспомогательных таблиц. Основа - это
неизменяемая часть слова, которая выражает его лексическое значение, то есть соотнесённость
звуковой оболочки слова с соответствующими предметами или явлениями объективной
действительности. Применительно к русскому языку основа - это часть слова без
окончания. В английском языке основа слова, как правило, полностью совпадает с
самим словом.
Если слово имеет несколько вариантов основ, то
словарь, как правило, содержит все варианты. Обычно в этом случае один из
вариантов основы помечается как основной, а другие варианты содержат ссылку на
него. Это необходимо для дальнейшего семантического анализа, чтобы устранить
различные смысловые трактовки для одного и того же слова. Дополнительные
таблицы содержат, как правило, список возможных вариантов изменяемых частей
слов (в русском языке - окончаний) с соответствующим им значением грамматических
признаков.
В общем случае производится поиск всего слова в
словаре словоформ, если слово не найдено, от него отделяется последняя буква и
производится повторный поиск. Так продолжается до тех пор, пока основа не будет
найдена либо пока не останется букв. В случае удачного поиска из словаря
извлекаются варианты частей речи, соответствующих этой основе. Затем
производится поиск в таблице изменяемых частей слова. При этом пропускаются
варианты соответствующие частям речи, к которым данная основа не может относиться.
Таким образом, определяются грамматические признаки разбираемой словоформы.
В основу метода морфологического анализа методом
логического умножения положены положения формальной морфологии. Вводится
понятие словарной функции - функции, определенной на словоформах, и
сопоставляющей им некоторую информацию (последовательность нулей и единиц).
На предварительном этапе строится таблица, в
которой каждой возможной букве изменяемой части (с учетом позиции в этой самой
изменяемой части) ставится в соответствие вектор нулей и единиц. Каждая из
позиций такого вектора соответствует определенной комбинации грамматических
признаков. Единица означает, что данная буква в данной позиции может
соответствовать этой комбинации грамматических признаков, ноль - что не может.
На первом этапе этот метод также предполагает
членение словоформы на основу и изменяемую часть. Далее по предварительно
созданной таблице векторов каждой букве изменяемой части подбирается вектор.
Далее над векторами производится операция логического умножения. Таким образом
определяется возможная (возможные) комбинация (-ии) грамматических признаков.
Морфологический анализ без словарей [2]
проводится без использования словарей лишь с использованием таблицы аффиксов,
списка слов-исключений и списка служебных неизменяемых слов (например, союзов,
междометий, предлогов). Этот способ используется достаточно редко.
Также малооправданным, согласно работе Чесебиева
И.А. [1], представляется морфологический анализ со словарем словоформ,
подразумевающий наличие словаря, содержащего список все возможных словоформ с
соответствующими им грамматическими признаками. Кроме значительного роста
словаря возникает еще одна проблема: в случае отсутствия словоформы в словаре
система не имеет возможности оперировать этим словом.
.2 Процедурные методы машинной морфологии
При процедурном способе формирование словоформ
осуществляется с помощью таблиц аффиксов, расклассифицированных по частям речи.
Основными частями речи для синтеза являются существительное, прилагательное и
глагол (глагольные формы). Наиболее сложно осуществляется синтез глагольных
форм.
Процедурные методы в сравнении с декларативными
требуют больших временных затрат на обработку одного слова, но объем
используемых словарей позволяет загружать словари целиком в оперативную память.
Кроме того, такие словари значительно легче создавать, поскольку постоянные
параметры каждого слова вводятся однократно, вместе с его основой. Существенным
недостатком процедурных методов является отсутствие универсальности. Другими
словами, существует большое количество слов, которые нельзя представить в виде
суммы неизменной основы и аффикса. Например, для английских лексем
существительное «man», которое имеет во множественном числе форму «men»,
множество неправильных глаголов и т. д.
Существует два подхода к решению задачи
процедурными методами.
Первый подход предполагает наличие словаря основ
и словаря аффиксов. Для слова выполняется процедура поиска в словаре основ. При
этом ищутся все основы, с которых может начинаться анализируемое слово. Если
очередная основа удовлетворяет этому условию, то из словаря аффиксов
извлекается строка, содержащая все возможные аффиксы для данной основы. Каждый
аффикс из этой строки поочередно присоединяется к основе, и результат
сравнивается с анализируемым словом. В случае их точного совпадения формируется
очередная запись в список результатов поиска: по порядковому номеру аффикса в
строке аффиксов определяется переменная МИ (например, для существительного -
число и падеж), а по словарной информации данной основы - постоянная МИ.
Если в результате такого поиска не найдено ни
одного успешного варианта, то проводится поиск среди исключений. Исключения
присутствуют в словаре основ наряду с обычными основами. И те, и другие имеют в
словаре информацию о постоянных морфологических признаках и о номере строки
допустимых аффиксов.
Разница между исключениями и обычными основами
состоит в том, что, во-первых, строка с неизменной частью слова у исключений
пустая, и, во-вторых, номер строки аффиксов для исключений относится не к файлу
аффиксов, а к отдельному файлу исключений. Структура этого файла точно такая
же, но в него внесены целые словоформы, а не их окончания. Таким образом, при
поиске среди исключений приходится просматривать все словоформы всех присутствующих
в словаре исключений. Это занимает много времени, поэтому поиск среди
исключений проводится только в том случае, когда не найдено ни одного варианта
среди обычных основ. Сам анализ проводится точно так же. Если некоторая
словоформа некоторого исключения точно совпадает с анализируемым словом, то по
номеру словоформы определяются переменные морфологические параметры слова, а по
словарной информации самого исключения - постоянные параметры слова. В случае,
когда все этапы поиска дали отрицательный результат (не найдено ни одного
варианта), пользователю выдается запрос на ввод новой основы в словарь.
Второй подход предполагает наличие словаря
начальных форм и грамматической информации, необходимой для словоизменения
(как-то, часть речи, род и т.д.), а также программной реализации правил
словообразования. Для слов русского языка такой словарь давно разработан [3] и
успешно используется при разработке морфологических парсеров. Подход состоит в
том, что слово последовательно причисляется к каждой из частей речи.
Последовательно выбираются окончания для этой части речи. В случае, если
окончание одной из косвенных форм совпадает с концовкой слова, совпадающая
часть отбрасывается, производятся чередования в основе, если слово
соответствует шаблону чередования, и к полученной основе добавляется окончание
леммы. При построении леммы запоминается промежуточная информация.
Для русского языка, как и для большинства
синтетических языков, задача лексико-грамматического разбора решается довольно
просто и почти стопроцентной точностью, благодаря их развитой морфологии. В
аналитических языках, например английском, где широко представлена лексическая
многозначность, простой алгоритм, сопоставляющий каждому слову в тексте
наиболее вероятный для данного слова морфологический класс, дает лишь около 90%
точности.
Анализ показал, что наиболее распространенным
методом морфологического анализа-синтеза является декларативный, что
объясняется простотой его алгоритма и удобством кодирования. Поэтому в рамках
данной работы будем использовать именно этот подход.
.3 Способы представления морфологической
информации
Один из вопросов, требующих особого
рассмотрения, - способ представления МИ. Задание МИ должно быть компактно,
позволять быстро и просто извлекать отдельные морфологические характеристики
слова (например, только род или только часть речи).
Обычно постоянная и переменная МИ хранятся в
виде строк текста. Иногда ее представляют в виде фрейма, в котором для хранения
каждой из характеристик отведено отдельное поле. Для конкретной словоформы
заполняются не все поля, а только те которые для нее характерны. В первом и во
втором случае сталкиваемся с резервированием лишнего места и необходимостью
использования сложных процедур интерпретации.
Третий способ хранения МИ - в виде битовых полей.
Он сочетает в себе удобства обработки и экономное хранение МИ, поэтому более
предпочтителен. Рассмотрим способ задания МИ с помощью битовых полей,
реализованный в модуле декларативного морфологического анализа слов русского
языка РДМА_ИПИИ, разработанного в Институте проблем искусственного интеллекта
(ИПИИ).
Данная система использует алгоритмы быстрого
поиска строк в большом массиве строк и рассчитана на количество словоформ
словаря, содержащего 100 тыс. начальных форм, что приближенно равно 2 млн. Для
реализации проекта были разработаны средства быстрого поиска строковых величин
[4].
Ряд систем морфологического анализа позволяют
пользователю пополнять словарь. В данной системе предполагается, что
пользователь не должен пополнять словарь, т.к. он может являться источником
ошибок. Словарь заполняется единожды (процесс может быть растянут во времени)
разработчиком, и многократно используется конечным пользователем.
Модуль в явном виде хранит все данные в
древовидной структуре, извлечение отдельных морфологических характеристик слова
производится единообразно, невозможна неверная интерпретация МИ. Перечень
обозначений морфологических характеристик приведен в приложении А (таблица
А.1). Для извлечения МИ используются маски категорий МИ (приложение А, таблица
А.2). Определение значения одной из категорий, например рода, происходит путём
применения операции побитового «и» значения морфологической информации и маски
категорий. Если словоформе категория не присуща, то результат операции
побитового «и» её морфологической информации и маски этой категории будет равен
0. Например, для определения значения категории «род» словоформы с
морфологической информацией MI необходимо выполнить операцию MI & rod_mask,
в результате получим одно из значений: _Masculine, _Feminine, _Neuter или 0.
Для решения поставленной задачи были
адаптированы функции быстрого поиска и эффективного хранения строковых величин
этого модуля для слов английского языка, поэтому остановимся на описании
библиотеки РДМА_ИПИИ более подробно. В комплект ее поставки входят следующие
файлы:.h- заголовочный файл с описанием экспортируемых функций и используемых
типов;
UkrDeclareLemma.dll,
UkrDeclareLemma.lib - файлы библиотеки;
tab.dat, tree.dat, connect.dat - файлы,
содержащие данные словарной базы.
Интерфейс библиотеки позволяет выполнять
действия по следующим направлениям:
модификация словарной базы;
получение информации о словоформах;
получение информации о словарной базе;
служебные функции.
2. Обоснование выбора программных и технических
средств реализации
.1 Выбор языка программирования
Выбор языка программирования определяет
разнообразие возможностей, которые программист может реализовать в приложении,
а также то, насколько быстро он это сделает.
Си++ (англ. C++) - компилируемый строго
типизированный язык программирования общего назначения. Поддерживает разные
парадигмы программирования: процедурную, обобщённую, функциональную; наибольшее
внимание уделено поддержке объектно-ориентированного программирования (ООП).
Концепция ООП вносит в арсенал разработчика
новое средство - классы. Классы наряду с объектами составляют краеугольный
камень многих современных языков высокого уровня. Под классом подразумевается
некая сущность, которая задает некоторое общее поведение для объектов. Таким
образом, любой объект может принадлежать или не принадлежать определенному
классу, то есть обладать или не обладать поведением, которое данный класс
подразумевает. Помимо этого ООП дает подход к следующим важным свойствам классов.
Абстракция данных
<#"809154.files/image001.gif">
Рисунок 3.1 - Функциональная схема
взаимодействия модулей системы синтеза парадигм слов английского языка
Пояснения к рисунку 3.1._lem.txt - файл в
формате txt, содержащий начальные формы слов и грамматическую информацию в виде
последовательности символов, необходимую для порождения парадигм (создается
пользователем);_par.dat - файл, созданный консольным приложением и содержащий
парадигмы лемм из файла Engl_lem.txt с МИ каждой словофомы;- строковая
величина, лемма, введенная пользователем, для которой необходимо получить
парадигму;_F - строковая величина, словоформа, входящая в парадигму Lemma;-
битовое число, задающее МИ словоформы W_F;- логическая переменная, принимающая
значение 1, если W_F является леммой, 0 - иначе;- парадигма слова Lemma в виде
списка словоформ с МИ для каждой словоформы.
Для обеспечения требуемых функциональных
возможностей была разработана архитектура системы синтеза парадигм слов
английского языка, содержащая 3 взаимосвязанных модуля.
Консольное приложение необходимо для обеспечения
работы системы в режиме наполнения словарной базы. Оно отвечает за загрузку
файла «Engl_lem» в формате txt со словарем начальных форм английских слов, а
также по алгоритмам словоизменения генерирует парадигмы всех лемм из словаря с
сохранением результата в текстовый файл «Engl_par». При этом каждой словоформе
приписывается ее МИ, пользователь может редактировать оба файла, не нарушая
формат входных и выходных данных.
Полученный в результате работы консольного
приложения файл с парадигмами в режиме наполнения поступает на вход приложения
TABLE, которое предназначено для приведения этого файла в формат, требуемый
библиотекой РДМА_ИПИИ. Из приложения TABLE в режиме наполнения вызываются
функции библиотеки РДМА_ИПИИ, обеспечивающие очистку, загрузку и сохранение
словарной базы, а также и ее модификацию (добавление/удаление словоформы).
В результате наполнения базы словоформ с помощью
библиотеки РДМА_ИПИИ формируются файлы tab.dat, tree.dat, connect.dat,
содержащие данные словарной базы. В базе данных словоформ, построенной таким
образом, в режиме поиска парадигмы по лемме, введенной пользователем в поле
ввода приложения TABLE, ищется ее парадигма и выводится пользователю в виде
списка словоформ с их МИ в специальное поле.
.2 Формат входных и выходных данных
Входными данными для функционирования
разработанного программного обеспечения автоматической генерации английских
словоформ является словарь начальных форм, загружающийся из текстового файла
«Engl_lem.txt», в котором к настоящему моменту содержится более 8 000 записей.
Для его создания использовался словарь синонимов английского языка The Oxford
Thesaurus Dictionary of Synonyms [5].
Словарь начальных форм заполнялся вручную. В
словаре после исходной формы каждого слова следуют идентификаторы (основной и
дополнительный), разделенные пробелами, которые задают МИ о данном слове.
Основной состоит из буквенного символа, указывающего на принадлежность слова к
определенной части речи (n - существительное, adj - прилагательное, adv -
наречие, v - глагол, pron - местоимение, conj - союз, perp - предлог).
Дополнительный (может отсутствовать в записи) содержит следующую информацию:
// - означает наличие параллельной словоформы
(сравнительной или превосходной степени для прилагательных) наряду с той,
которая характерна для данного типа словоизменения. После этой метки следует
цифра, указывающая на степень сравнения (0 - сравнительная степень, 1 -
превосходная), которой соответствует параллельная словоформа. Сама параллельная
форма следует сразу после числа. Например, old adj //0elder1eldest. машинный морфология словоформа база
* - указывает на наличие простой формы
сравнительной и превосходной степени прилагательного. Если эта метка
отсутствует, то от прилагательного можно построить степени сравнения только с
помощью сложных форм.
! - означает неправильный глагол. После этой
метки следует цифра, указывающая на простую форму глагола (1 - Past Indefinite,
2 - Participle II), соответствующая форма глагола следует сразу после числа.
Например, begin v !1began2begun.
По сути, идентификаторы, принадлежащие каждой
словарной единице, определяют алгоритм изменения слова.
Ко входным данным также можно отнести строку
символов, вводимую пользователем в качестве леммы, для которой необходимо
получить парадигму.
Выходными данными системы морфологического
синтеза парадигм английских слов является:
. Массив строк, представляющий собой полную
словоизменительную парадигму слова, введенного пользователем, с указанием
соответствующий МИ. Парадигма выводится на экран в диалоговое окно приложения
TABLE в специальное поле. Например, выходная информация для леммы «round»
(«круг» - существительное, «круглый» - прилагательное, «округлять» - глагол,
«кругом» - наречие и «вокруг» - предлог) имеет вид:НаречиеПрилагательноеСрав.
с. ПрилагательноеПрев. с. ПрилагательноеСуществительное ’s Притяж. пад. Ед. ч.
Существительное Мн. ч. Существительное’ Притяж. пад. Мн.
ч.СуществительноеГлагол ИнфинитивГлагол Прош. неопр. действ. залога Глагол
прич. прош. вр.Глагол прич. наст. вр.Глагол наст. вр. 3 л. Ед. ч.Предлог
. Массив строк в тестовом файле «Engl_par.txt»,
полученном в результате работы консольного приложения и содержащего список
парадигм. Каждая строка содержит следующую информацию (разделенную табуляцией):
_F - словоформа, входящая в парадигму;- принимающая значение 1, если W_F
является леммой, 0 - иначе;- битовое число, задающее МИ словоформы W_F
. База данных словоформ английского языка,
полученная для лемм, которые содержатся в словаре начальных форм. Эта база
состоит из трех файлов: tab.dat, tree.dat, connect.dat, полученных в результате
работы библиотеки РДМА_ИПИИ, описание формата которых разработчики библиотеки
не предоставляют.
4. Разработка программного обеспечения синтеза
парадигм слов английского языка
.1 Формализация правил словообразования
английского языка
Способ представления МИ английских словоформ в
рамках данной работы был выбран в виде битовых полей. Перечень обозначений
морфологических характеристик приведен в приложении А (таблица А.3). По
аналогии с процедурами, реализованными в библиотеке РДМА_ИПИИ для извлечения МИ
используются маски категорий МИ (приложение А, таблица А.4).
Для существительных нам необходимо сгенерировать
словоформы множественного числа, а также притяжательного падежа.
Образование множественного числа английских
существительных описывается следующей системой правил.
Правило 1 (основное).. В общем случае английское
существительное можно поставить во множественное число, прибавив к нему
окончание -s. Например, shoe - shoes; hen - hens; bat - bats.
Правило 2. Если существительное оканчивается на
свистящий или шипящий звук, то есть на буквы -s, -ss, -x, -sh, -ch, то для него
форма множественного числа образуется при помощи окончания -es. Например,
bass - basses; match - matches; leash - leashes; box - boxes.
Правило 3. Если
существительное оканчивается на букву -y, перед которой стоит согласная, то во
множественном числе -y меняется на -i и к слову прибавляется окончание -es.
Например, lobby - lobbies; sky - skies.
Примечание. Если перед буквой -y стоит гласная,
то множественное число образуется по общему правилу при помощи окончания -s, а
буква -y остается без изменений. Например, bay - bays; day - days; way - ways.
Правило 4. К существительным, заканчивающимся на
-o прибавляется окончание -es. Например, potato - potatoes; tomato - tomatoes;
hero - heroes.
Исключения из правила 4: bamboos, embryos,
folios, kangaroos, radios, studios, zoos, Eskimos, Filipines, kilos, photos,
pros, pianos, concertos, dynamos, solos, tangos, tobaccos.
Правило 5. Если существительное оканчивается на
буквы -f или -fe, то во множественном числе они меняются на -v- и прибавляется
окончание -es. Например, thief -thieves;
wolf - wolves; half - halves; wife - wives.
Исключения из
правила
5: proofs, chiefs, safes, cliffs, gulfs, reefs.
У некоторых существительных при образовании
множественного числа происходит изменение в основе. Все такие случаи сведены в
таблицу 4.1.
Таблица 4.1 - Исключения при образовании
множественного числа английских существительных
|
Единственное
число
|
Множественное
число
|
|
foot
(нога, ступня)
|
feet
|
|
tooth
(зуб)
|
teeth
|
|
man
(мужчина, человек)
|
men
|
|
woman
(женщина)
|
women
|
|
mouse
(мышь)
|
mice
|
|
goose
(гусь)
|
geese
|
|
louse
(вошь)
|
lice
|
|
child
(ребенок)
|
children
|
|
ox
(бык, вол)
|
oxen
|
|
basis
|
bases
|
|
crisis
|
crises
|
|
phenomenon
|
phenomena
|
|
stimulus
|
|
formula
|
formulas/formulae
|
|
datum
|
data
|
|
index
|
indices
|
|
bureau
|
bureaux
|
|
focus
|
focuses/foci
|
Исходя из перечисленных правил, приведем
алгоритм образования множественного числа английских существительных.
Алгоритм образования множественного числа
английских существительных
Входные данные- строка (лемма существительного)
Выходные данные- строка (словоформа -
существительное str во множественном числе)
Промежуточные переменные- целое, длина строки
str= {b, c, d, f, g, h, j, r, l, m, n, p, q, r, s, t, v, w, x, z} множество
элементов символьного типа (множество согласных английского алфавита);_Rule4 =
{bamboo, embryo, folio, kangaroo, radio, studio, zoo, Eskimo, Filipine, kilo,
photo, pro, piano, concerto, dynamo, solo, tango, tobacco} множество элементов
строкового типа (множество слов-исключений из правила 4)_Rule5 = {proof, chief,
safe, cliff, gulf, reef} множество элементов строкового типа (множество
слов-исключений из правила 5)
начало
Инициализация= str;
если (str[l]==’s’) или (str[l]==’x’) или
((str[l]==’h’) и ((str[l-1]==’s’) или
(str[l-1]==’c’)))
то
.1 res = res + ‘es’
.2 выход из алгоритма
если (str[l]==’y’) и (str[l-1] принадлежит
множеству Consonant)
то
.1 res [l] =’i’
.2 res = res + ‘es’
3.3 выход из алгоритма
если (str[l]==’o’) и (str не принадлежит
множеству Exeption_Rule4)
то
.1 res = res + ‘es’
.2 выход из алгоритма
если (str[l]==’f’) и (str не принадлежит
множеству Exeption_Rule5)
то
.1 res [l] =’v’
.2 res = res + ‘es’
5.3 выход из алгоритма
если (str[l-1]==’f’) и (str[l]==’e’) и (str не
принадлежит множеству Exeption_Rule5)
то
.1 res [l-1] =’v’
.2 res = res + ‘s’
6.3 выход из алгоритма
res = res + ‘s’
Результат res
конец
Правило образования притяжательного падежа. Если
существительное не оканчивается на -s, то для него форма притяжательного падежа
образуется при помощи окончания -'s. В ином случае - добавлением апострофа в
конец слова. Например, today’s newspaper; mile’s distance; pupils’ work; cars’
color.
Алгоритм образования множественного числа английских
существительных
Входные данные- строка (лемма существительного)
Выходные данные- строка (словоформа -
существительное str в притяжательном падеже)
Промежуточные переменные- целое, длина строки
str
начало
Инициализация= str;
если (str[l]==’s’)
то res = res + ‘’s’
иначе res = res +
‘’’
3 Результат res
конец
В отличие от русского языка, в английском
прилагательные не изменяются по числам, родам и падежам, не имеют кратких форм.
Прилагательные могут изменяться лишь по степеням сравнения. В английском языке,
как и в русском, прилагательные (качественные) образуют две степени сравнения:
сравнительную и превосходную. Положительной степенью прилагательных называется
их основная форма, не выражающая степени сравнения.
Так же, как и в русском языке, прилагательные
образуют степени сравнения либо аналитически (сложные формы) - с помощью
дополнительных слов more (более), less (менее) и most (наиболее, самый), least
(наименее); либо синтетически - посредством изменения самого прилагательного с
помощью суффиксов -er и -est (простые формы). И так же, как и в русском языке,
аналитическая форма сравнительной степени может быть образована от любого
прилагательного, а синтетическая - от одних прилагательных может быть
образована, а от других - нет.
При этом соблюдаются следующие правила.
Правило 1 (основное). Односложные (т.е.
состоящие из одного слога) прилагательные и двусложные прилагательные,
оканчивающиеся на -y, -er, -ow, -le, образуют сравнительную степень при помощи
суффикса -er, превосходную степень - при помощи суффикса -est.
Правило 2. В односложных прилагательных,
оканчивающихся на одну согласную с предшествующим кратким гласным звуком,
конечная согласная буква удваивается (чтобы сохранить закрытость слога).
Например, big - bigger - biggest; thin - thinner - thinnest.
Правило 3. Если прилагательное оканчивается на
-y с предшествующей согласной, то -y меняется на -i. Например, busy - busier -
busiest; happy - happier - happiest
Примечание. Если перед -y стоит гласная, то -y
остается без изменения. Например, grey - greyer - greyest.
Правило 4. Конечная гласная -e (немое e) перед
суффиксами -er, -est опускается. Например, white - whiter - whitest.
Некоторые прилагательные в
английском языке <#"809154.files/image002.gif">
|
 - класс,
реализованный в модуле TABLE - класс,
реализованный в модуле TABLE
|
|
|
 -
стандартный класс библиотеки C++ -
стандартный класс библиотеки C++
|
|
|
- класс,
реализованный в консольном приложении
|
|
|
- класс
библиотеки РДМА_ИПИИ
|
|
|
|
- ссылка на класс, который
используется в данном классе
Рисунок 4.1 - Схема организации классов ПО
системы синтеза парадигм слов английского языка
Класс CTableDlg содержит в себе реализацию
главного окна программы, пользовательский интерфейс и обработчики событий от
элементов управления. В таблице 4.4 приведен список основных методов класса.
Таблица 4.4 - Список основных методов класса
CTableDlg
|
Метод
|
Описание
|
|
void
CTableDlg::OnCreate_Tree()
|
Добавляет
к дереву по строке элементы парадигмы начиная с 0
|
|
void
CTableDlg::OnAddTree()
|
Добавляет
к существующей таблице данные из текстового файла
|
|
void
CTableDlg::OnSave_Tree()
|
Сохраняет
дерево
|
|
void
CTableDlg::OnLoad_Tree()
|
Загружает
дерево
|
|
void
CTableDlg::OnLemma_Find()
|
Поиск
леммы слова в дереве
|
|
void
CTableDlg::OnFind_Paradigm()
|
Поиск
парадигмы слова в дереве
|
|
void
CTableDlg::OnDel()
|
Удаление
из существующей таблицы данных, из текстового файла
|
|
void
CTableDlg::OnCancel()
|
Выход
|
Класс english_paradigm предназначен для
формирования файла парадигм английского языка. Входными данными является файл
со словарем начальных форм английских слов с метками для их словоизменения. В
результате работы методов этого класса (см. табл. 4.5) на выходе консольного
приложения создается файл в формате, требуемом библиотекой РДМА_ИПИИ, для
добавления полученных словоформ в дерево.
Таблица 4.5 - Список основных методов класса
english_paradigm
|
Метод
|
Описание
|
|
bool Noun_paradigm(char *str)
|
Формирование
парадигм существительных
|
|
bool Verb_paradigm(char *str)
|
Формирование
парадигм глаголов
|
|
bool Adj_paradigm(char *str)
|
Формирование
парадигм прилагательных
|
Класс CTable2 принадлежит библиотеке РДМА_ИПИИ,
разработанной отделом распознавания речи ИПИИ. В таблице 4.6 приведены функции
очистки, загрузки, модификации и сохранения словарной базы, реализованные в
этом классе.
Таблица 4.6 - Список основных методов класса
CTable2
|
Метод
|
Описание
|
|
Функции
очистки, загрузки и сохранения словарной базы (в случае успешного завершения
возвращают нулевое значение)
|
|
|
void
Release()
|
очищает
словарную базу
|
|
UINT
LoadMem(char * Path).
|
загружает
в память дерево строк, сокращенную таблицу парадигм, таблицу связи дерева и
сокращенной таблицы парадигм, а также индексы к ним
|
|
UINT
LoadDisk(char * Path)
|
загружает
таблицу связи дерева и сокращенной таблицы парадигм, а также индексы в память
и устанавливает флажок, указывающий на то, что остальные данные читаются с
диска. При этом переменная Path указывает путь к папке, хранящей файлы
словарной базы: tab.dat, tree.dat, connect.dat.
|
|
UINT SaveMem(char * Path) - функция
|
сохраняет
в папку по указанному пути Path данные словарной базы, хранимые в памяти.
|
|
UINT
SaveDisk(char * Path)
|
сохраняет
в папку по указанному пути Path данные словарной базы, частично хранимые в
памяти, а частично на диске
|
|
Функции
модификации словарной базы
|
|
|
UINT InsertRows (MyChar*
wrdBud,MyChar* wrdUd,UINT LemmaNum,UINT MI,BOOL InsertRows);
|
функция
добавления словоформы в словарную базу. Параметры: wrdBud - строка написания
словоформы без ударения, wrdUd - строка написания словоформы с учётом
ударения, LemmaNum - номер в словарной базе леммы данной словоформы, MI -
число, в котором с помощью набора битовых полей закодирована морфологическая
информация о словоформе. При добавлении словоформы, которая является
собственной леммой, в поле LemmaNum должен фигурировать номер записи в
таблице словоформ, в которую будет помещена эта добавляемая словоформа. Для
получения этого значения вызывают вспомогательную функцию UINT
GetNextLemNum().
|
|
Метод
|
Описание
|
|
UINT DeleteRow (UINT Index,BOOL f)
|
функция
удаляет словоформы из словарной базы. Параметры: Index - номер словоформы в
базе.
|
|
Функции
получения информации о словоформах
|
|
|
UINT FindLemma(MyChar *word,
CStringArray& Lemma,CUIntArray &ResLemm,CUIntArray &MI)
|
Находит
леммы для строки word. Результаты выполнения функции: Lemma - массив
написаний леммы для словоформ, чьё написание совпадает со строкой word,
ResLemm - массив номеров лемм в словарной базе (необходим для установления
принадлежности словоформы конкретной парадигме), MI - массив значений
морфологической информации словоформ с указанным написанием.
|
|
void TranslateMI(UINT Mi,
char*str)
|
записывает
в строку str текстовую расшифровку числового значения морфологической
информации.
|
|
UINT FindParadigm(MyChar *word,
CStringArray& ParadigmBud,CStringArray& ParadigmUd,CUIntArray
&MI,CUIntArray &TabNums,CUIntArray &LemmNums)
|
находит
парадигмы, содержащие словоформы с написанием word. Результаты выполнения
функции: ParadigmBud (ParadigmUd) - массив написаний словоформ найденных
парадигм без учёта ударения (с учётом ударения), MI - массив значений
морфологической информации этих словоформ, LemmNums - массив номеров лемм в
словарной базе (необходим для установления принадлежности словоформы
конкретной парадигме).
|
|
UINT
GetWordNum (char* word)
|
возвращает
уникальный номер написания словоформы в базе. Возвращаемое значение - 0, если
база не содержит словоформы с написанием word, или положительное число -
идентификатор строки word в базе.
|
|
UINT GetWord (UINT treeNum, char*
str, int &buff_Size)
|
возвращает
написание словоформы, которое имеет в базе идентификатор treeNum.
Передаваемые параметры: treeNum - идентификатор искомой строки; str - буффер
для искомой строки; buff_Size - размер буфера для искомой строки.
Возвращаемое значение: 0 - при успешном завершении функции, при этом str -
содержит искомую строку; положительное число - в случае ошибки, когда
параметр treeNum превышает значение наибольшего идентификатора строки в базе;
-1 - в случае ошибки, когда размер буфера buff_Size меньше или равен длине
искомой строки, при этом в параметр buff_Size функция записывает нужный
размер буфера; -2 - в случае ошибки, когда база не содержит ни одной строки.
|
|
Метод
|
Описание
|
|
Функции
получения информации о словарной базе
|
|
|
UINT
GetTreeSize()
|
позволяет
определить количество строковых величин, хранимых в дереве строк.
|
|
UINT
GetRowsCount()
|
|
void
Evaluate(char *FilePath)
|
функция
сохраняет в файл по указанному пути информацию о затратах памяти на хранение
различных структур данных словарной базы.
|
|
Служебные
функции
|
|
|
ReleasestringArr(
vector<string>* &ParadigmUd)
|
используются
для очистки заполняемых функциями библиотеки переменных-указателей на
vector<string> и vector<unsigned int>, соответственно.
|
|
ReleaseCUIntArr( vector
<unsigned int>*& TabNums)
|
|
Вызов функций класса CTable2 происходит в
методах класса CTableDlg, фрагменты листинга, содержащего обращения к функцям
библиотеки РДМА_ИПИИ, приведены в приложении Б.
5. Анализ результатов функционирования системы
Комплексное тестирование необходимо для поисков
несоответствия системы ее исходным целям. На стадии тестирования были проверены
все «исключительные» ситуации, которые могут возникнуть при дальнейшем
использовании данного программного продукта, будь то попытка открыть файл
неверного формата, попытки синтеза парадигмы для леммы без указания или
некорректного указания грамматической информации для словобразования и т.д. В
основе обработки «исключительных» ситуаций, было предприняты следующие меры:
неверные шаги пользователей будут сопровождаться появлением модальных
диалоговых окон с информацией об ошибках пользователя или отключением соответствующих
элементов управления. Ниже приведено более детальное описание тестирования.
Для запуска консольного приложения необходимо
запустить исполняемый файл english_paradigm.exe. Для его корректной работы
необходим размеченный словарь начальных форм слов английского языка, хранящийся
в файле Engl_lem.txt в той же директории, что и english_paradigm.exe, формат
разметки приведен в описании формата входных данных (пункт 3.2). Возможны
следующие исключительные ситуации:
) файл Engl_lem.txt не найден;
) в файле словаря есть некорректно введенные
записи (например, неверно введен буквенный символ, стоящий после слова,
указывающий на его принадлежность к определенной части речи).
В первом случае система выдаст сообщение об
ошибке (рис. 5.1), во втором -некорректные записи не обрабатываются, но
предусмотрен их вывод файл Erorr.txt.
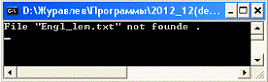
Рисунок 5.1 - Сообщение системы в случае
отсутствия словаря начальных форм
Если файл Engl_lem.txt не содержит ошибок, то
консольное приложение строит парадигмы слов словаря начальных форм, формирует
файл Engl_par.dat в текущей директории и автоматически закрывается.
Для формирования базы данных словоформ в виде
цифрового дерева, хранящего строковые величины, необходимо запустить
исполняемый файл table.exe. Откроется диалоговое окно приложения TABLE (рис.
В.1), содержащее поле ввода и кнопки «Создать/Добавить», «Загрузить»,
«Сохранить», «Найти парадигму» и «Выход».
В режиме наполнения на основе парадигм,
считываемых из файла Engl_par.dat, создается дерево строк, сокращенная таблица
парадигм, таблица связи дерева и сокращенной таблицы парадигм, которые хранятся
в подкаталоге «Tree» в файлах tab.dat, tree.dat, connect.dat соответственно.
Исключительная ситуация возможна при отсутствии Engl_par.dat, т.е. если
консольное приложение не отработало. В этом случае по нажатии на кнопку
«Создать/Добавить» появляется сообщение об
ошибке (рис. 5.2);
«Загрузить» загружается последняя сохраненная в
файлах tab.dat, tree.dat, connect.dat база словоформ;
«Сохранить» сохраняется пустое дерево строк;
«Найти парадигму» появляется сообщение об ошибке
(рис. 5.3).
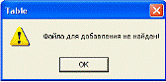
Рисунок 5.2 - Сообщение системы об отсутствии
файла Engl_par.dat, содержащего парадигмы слов английского языка
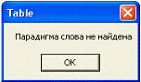
Рисунок 5.3 - Сообщение системы в случае
отсутствия леммы в словаре начальных форм
Если файл Engl_par.dat сформирован, то на его
основе можно создать базу словоформ в виде дерева с помощью кнопки
«Создать/Добавить», чтобы ее сохранить, необходимо нажать кнопку «Сохранить».
Созданную базу словоформ можно также добавить в предварительно загруженное
дерево с помощью той же кнопки «Добавить». Для чего необходимо выполнить
последовательность команд «Загрузить»-« Создать/Добавить»-«Сохранить».
В режиме поиска парадигмы, в который система
переходит по нажатии на кнопку «Найти парадигму», возможны следующие
исключительные ситуации:
) нет базы словоформ;
) нет введенной леммы в базе словоформ;
В обоих случаях система выдаст сообщение об
ошибке (рис. 5.3).
Если парадигма успешно найдена, то в поле вывода
появится список всех словоформ, образующих эту парадигму, с соответствующей МИ
(рис. В.2).
Выводы
В результате выполнения курсовой работы был
сделан достаточно полный обзор методов машинной морфологии и способов
представления МИ, сформулирована постановка задачи, спроектирована и программно
реализована система синтеза парадигм слов английского языка, проведено
комплексное тестирование результатов ее работы, что необходимо для выявления
ошибок в структуре алгоритмов программы, структуре входных и внутренних данных,
а также для ликвидации конфликтных ситуаций с другим программным обеспечением.
Это позволило сделать следующие выводы.
Морфологический компонент - неотъемлемая частью
интеллектуальных АОТ-систем. Морфологический анализ/синтез неосуществим без
машинного грамматического словаря, его использование позволяет проводить полный
анализ словоформы, оперируя большим числом грамматических признаков, и повысить
его точность. В связи с этим актуальность выбранной темы не вызывает сомнений.
Наиболее оптимальный способ представления МИ,
сочетающий в себе удобства обработки и экономное хранение, - в виде битовых
полей. Этот способ задания МИ реализован в модуле декларативного
морфологического анализа слов русского языка РДМА_ИПИИ. Модуль снабжен
средствами быстрого поиска строковых величин в большом массиве строк. В связи с
этим для создания и хранения базы словоформ английского языка, а также быстрого
поиска парадигм в созданной базе использовались функции библиотеки РДМА_ИПИИ.
Разработанное в результате выполнения курсовой
работы ПО состоит из трех модулей. Помимо библиотеки РДМА_ИПИИ в систему
входят: консольное приложение, позволяющее загрузить словарь начальных форм
английских слов, содержащий грамматическую информацию, необходимую для
словоизменения, и выполняющее синтез парадигм лемм этого словаря; приложение
TABLE, предназначенное для адаптации под английский язык функций хранения базы
словоформ и быстрого поиска парадигм в ней, реализованных в библиотеке
РДМА_ИПИИ. ПО, имеющее такую архитектуру, обеспечивает следующие возможности:
чтение и загрузка файла начальных форм английских слов; очистка, загрузка,
модификация и сохранение базы английских словоформ; получение парадигмы с
указанием МИ каждой словоформы по введенной пользователем лемме.
Тестирование ПО система синтеза парадигм
английского языка не выявило несоответствие системы ее исходным целям, ошибок в
структуре алгоритма программы, структуре входных и внутренних данных, а также
конфликтных ситуаций с другим ПО.
Разработанный программный продукт может
использоваться при создании средств морфологической обработки интеллектуальных
систем понимания и автоматического анализа текстов на английском языке. Кроме
того, созданную базу данных английских словоформ можно использовать для точной
оценки морфологической информации словоформы в задачах поверхностного
семантико-синтаксического анализа.
Список ссылок
1.
Чесебиев И.А. Понимание и синтез текста компьютером. [Электронный ресурс]. URL
: http//yabs. yandex.ru/ /resourse/bb/dif
.
Ножов И.М. Процессор автоматизированного морфологического анализа без словаря.
Деревья и корреляция. //Диалог’2000. Труды конференции - Протвино, 2000. Т.2.
С. 284-290.
3.
А. А. Зализняк. Грамматический словарь русского языка. Словоизменение.
<#"809154.files/image008.gif">
Рисунок В.1 - Главное окно приложения Table.exe
Для создания дерева словоформ на основе
парадигм, сохраненных в файле Engl_par.dat, необходимо нажать кнопку
«Создать/Добавить». Созданное дерево хранится в кэше до закрытия программы. При
желании его можно сохранить на диск нажатием на кнопку «Сохранить». При этом
дерево автоматически сохраняется в файлах tab.dat, tree.dat, connect.dat,
которые находятся в подкаталоге «Tree» и изначально являются пустыми.
Для модификации словаря словоформ (в случае
изменения словаря начальных форм Engl_lem.txt путем добавления/удаления записей
и перезапуска консольного приложения), необходимо загрузить существующее дерево
с помощью кнопки «Загрузить», после чего нажатием на кнопку «Создать/Добавить»
в загруженное дерево добавляются парадигмы из обновленного файла Engl_par.dat.
Полученный результат сохраняется на диск нажатием на кнопку «Сохранить».
Поиск парадигмы осуществляется в загруженном
дереве, в случае его отсутствия - в кэше. Для чего пользователю в поле ввода
необходимо ввести лемму и нажать на кнопку «Найти парадигму». В случае
успешного поиска парадигма выводится в поле вывода в виде списка словоформ с
соответствующей МИ (рис. В.2). Если лемма отсутствует в базе начальных форм, то
появляется сообщение об ошибке.
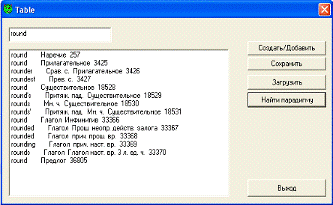
Рисунок В.2 - Успешное завершение поиска
парадигмы для леммы «round»