|
M
|
M
|
M
|
I
|
R
|
M
|
R
|
D
|
|
C
|
O
|
N
|
N
|
E
|
C
|
T
|
|
|
C
|
O
|
N
|
E
|
H
|
E
|
A
|
D
|
Найти только расстояние Левенштейна - более
простая задача, чем найти ещё и редакционное предписание.
Расстояние Левенштейна -
минимальное количество действий, необходимых для преобразования одного слова в
другое. В приведенном примере расстояние Левенштейна равно 4.
Преобразовать одно слово в другое можно различными
способами, количество действий также может быть разным. При вычислении
расстояния Левенштейна следует выбирать минимальное количество действий.
Существуют обобщения понятия «Расстояние
Левенштейна», при которых операции имеют разные цены.
Цены операций могут зависеть от вида операции
(вставка, удаление, замена) и/или от участвующих в ней символов, отражая разную
вероятность мутаций в биологии, разную вероятность разных ошибок при вводе
текста и т.д. В общем случае:
· w(a,
b)
- цена замены символа a на символ b
· w(ε,
b)
- цена вставки символа b
· w(a,
ε)
- цена удаления символа a
Необходимо найти последовательность замен,
минимизирующую суммарную цену. Расстояние Левенштейна является частным случаем
этой задачи при
· w(a, а) = 0
· w(a, b) = 1 при a≠b
· w(ε, b) = 1
· w(a, ε) = 1
Как частный случай, так и задачу для
произвольных w, решает алгоритм Вагнера - Фишера. Если к списку разрешённых
операций добавить транспозицию (два соседних символа меняются местами),
получается расстояние Дамерау - Левенштейна. Для неё также существует алгоритм,
требующий O(MN) операций. Дамерау показал, что 80% ошибок при наборе текста
человеком являются транспозициями.
Пусть S1 и S2
- две строки (длиной M и N
соответственно)
над некоторым алфавитом, тогда редакционное расстояние (расстояние Левенштейна)
d(S1,
S2) можно подсчитать по следующей рекуррентной формуле
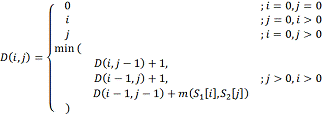
где функция m(a,b) равна
нулю, если a=b и единице в противном случае; min(a,b,c)
возвращает наименьший из аргументов.
Здесь шаг по i символизирует удаление (D)
из первой строки, по j - вставку (I) в первую строку, а шаг по обоим
индексам символизирует замену символа (R) или отсутствие изменений (M).
Очевидно, справедливы следующие утверждения:
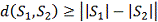
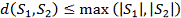
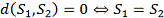
Рассмотрим формулу более подробно. Очевидно, что
редакционное расстояние между двумя пустыми строками равно нулю. Так же
очевидно то, что чтобы получить пустую строку из строки длиной i, нужно
совершить i операций удаления, а чтобы получить строку длиной j из
пустой, нужно произвести j операций вставки.
Осталось рассмотреть нетривиальный случай, когда
обе строки непусты.
Для начала заметим, что в оптимальной
последовательности операций, их можно произвольно менять местами. В самом деле,
рассмотрим две последовательные операции:
· Две замены одного и того же символа
-
неоптимально (если мы заменили x
на y, потом y
на z, выгоднее было
сразу заменить x на z).
· Две замены разных символов можно
менять местами
· Два стирания или две вставки можно
менять местами
· Вставка символа с его последующим
стиранием - неоптимально
(можно их обе отменить)
· Стирание и вставку разных символов
можно менять местами
· Вставка символа с его последующей
заменой
-
неоптимально (излишняя замена)
· Вставка символа и замена другого
символа меняются местами
· Замена символа с его последующим
стиранием - неоптимально
(излишняя замена)
· Стирание символа и замена другого
символа меняются местами
Пусть S1 кончается на символ
«a», S2 кончается на символ «b». Есть три варианта:
1. Символ «а», на который кончается S1,
в какой-то момент был стёрт. Сделаем это стирание первой операцией. Тогда мы
стёрли символ «a», после чего
превратили первые (i - 1) символов S1 в S2
(на что потребовалось D(i - 1, j) операций), значит, всего
потребовалось D(i - 1, j)+1 операций.
2. Символ «b»,
на который кончается S2, в какой-то момент был добавлен.
Сделаем это добавление последней операцией. Мы превратили S1
в первые (j - 1) символов S2, после чего добавили «b».
Аналогично предыдущему случаю, потребовалось D(i, j - 1)+1
операций.
. Оба предыдущих утверждения неверны.
Если мы добавляли символы справа от финального «a»,
то, чтобы сделать последним символом «b»,
мы должны были или в какой-то момент добавить его (но тогда утверждение 2 было
бы верно), либо заменить на него один из этих добавленных символов (что тоже
невозможно, потому что добавление символа с его последующей заменой
неоптимально). Значит, символов справа от финального «a»
мы не добавляли. Самого финального «a»
мы не стирали, поскольку утверждение 1 неверно. Значит, единственный способ
изменения последнего символа - его
замена. Заменять его 2 или больше раз неоптимально. Значит,
1. Если a=b, мы последний символ не
меняли. Поскольку мы его также не стирали и не приписывали ничего справа от
него, он не влиял на наши действия, и, значит, мы выполнили D(i -
1, j - 1) операций.
2. Если a≠b, мы последний
символ меняли один раз. Сделаем эту замену первой. В дальнейшем, аналогично
предыдущему случаю, мы должны выполнить D(i - 1, j - 1) операций,
значит, всего потребуется D(i - 1, j - 1)+1 операций.
.4.1 Алгоритм
Вагнера - Фишера
Для нахождения кратчайшего расстояния необходимо
вычислить матрицу D, используя выше приведённую формулу. Её можно вычислять как
по строкам, так и по столбцам. Псевдокод алгоритма:
для всех i от 0 до M
для всех j от 0 до N
вычислить D(i, j)
вернуть D(M,N)
Или в более развёрнутом виде, и при произвольных
ценах замен, вставок и удалений:
D(0,0) = 0
для всех j от 1 до N(0,j) = D(0,j-1) + цена
вставки символа S2[j]
для всех i от 1 до M(i,0) = D(i-1,0) + цена
удаления символа S1[i]
для всех j от 1 до N(i,j) = min((i-1, j) + цена
удаления символа S1[i],(i, j-1) + цена вставки символа S2[j],(i-1, j-1) + цена
замены символа S1[i] на символ S2[j]
)
вернуть D(M,N)
(Напоминаем, что элементы строк нумеруются с первого,
а не с нулевого.)
Для восстановления редакционного предписания
требуется вычислить матрицу D, после чего идти из правого нижнего угла (M,N) в
левый верхний, на каждом шаге ища минимальное из трёх значений:
· если минимально (D(i-1,
j)
+ цена удаления символа S1[i]),
добавляем удаление символа S1[i]
и идём в (i-1, j)
· если минимально (D(i,
j-1)
+ цена вставки символа S2[j]),
добавляем вставку символа S2[j]
и идём в (i, j-1)
· если минимально (D(i-1,
j-1)
+ цена замены символа S1[i]
на символ S2[j]),
добавляем замену S1[i]
на S2[j]
(если они не равны; иначе ничего не добавляем), после чего идём в (i-1,
j-1)
Здесь (i, j) - клетка матрицы, в которой мы
находимся на данном шаге. Если минимальны два из трёх значений (или равны все
три), это означает, что есть 2 или 3 равноценных редакционных предписания.
Этот алгоритм называется алгоритмом Вагнера-
Фишера. Он предложен Р. Вагнером (R. A. Wagner) и М. Фишером (M. J. Fischer) в
1974 году[38].
3.5 Наибольшая
общая последовательность (longest common subsequence, LCS)
Задача нахождения наибольшей общей
подпоследовательности (longest common subsequence, LCS) - задача поиска
последовательности, которая является подпоследовательностью нескольких
последовательностей (обычно двух). Часто задача определяется как поиск всех
наибольших подпоследовательностей. Это классическая задача информатики, которая
имеет приложения, в частности, в задаче сравнения текстовых файлов (утилита
diff), в том числе для поиска плагиата.
Подпоследовательность можно получить из
некоторой конечной последовательности, если удалить из последней некоторое множество
её элементов (возможно пустое). Например, BCDB является подпоследовательностью
последовательности ABCDBAB. Будем говорить, что последовательность Z является
общей подпоследовательностью последовательностей X и Y, если Z является
подпоследовательностью как X, так и Y. Требуется для двух последовательностей X
и Y найти общую подпоследовательность наибольшей длины. Заметим, что LCS
может быть несколько.
3.6 Вычисление
хеш-функции
В программе в качестве хеш-функции используется
Циклический избыточный код (CRC-32).
Алгоритм реализации CRC-32
взят из известной библиотеки #"787347.files/image015.gif">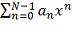 , последовательность коэффициентов
которого представляет собой исходную последовательность. Например,
последовательность битов 1011010 соответствует многочлену:
, последовательность коэффициентов
которого представляет собой исходную последовательность. Например,
последовательность битов 1011010 соответствует многочлену:
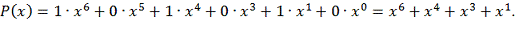
Количество различных многочленов
степени меньшей N равно 2N, что
совпадает с числом всех двоичных последовательностей длины N.
Значение контрольной суммы в
алгоритме с порождающим многочленом G(x) степени N
определяется как битовая последовательность длины N,
представляющая многочлен R(x),
получившийся в остатке при делении многочлена P(x),
представляющего входной поток бит, на многочлен G(x):
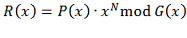
где
R(x) -
многочлен, представляющий значение CRC.
P(x) -
многочлен, коэффициенты которого представляют входные данные.
G(x) -
порождающий многочлен.
N - степень
порождающего многочлена.
При делении с остатком исходного
многочлена на порождающий полином G(x) степени N можно получить 2N
различных остатков от деления. G(x) всегда является неприводимым многочленом.
Обычно его подбирают в соответствии с требованиями к хеш-функции в контексте
каждого конкретного применения.
Тем не менее, существует множество
стандартизированных образующих многочленов, обладающих хорошими математическими
и корреляционными свойствами (минимальное число коллизий, простота вычисления).
.6.1 Параметры
вычисление хеш-функции: полином-генератор, разрядность и стартовое слово
В качестве примера рассмотрим схему формирования
контрольной суммы CRC-8. Порождающий многочлен g(x) = x8+x5+x4+1. Говоря о
формировании контрольной суммы CRC, в первую очередь нужно упомянуть о
полиноме-генераторе.
Другим параметром конкретного алгоритма
вычисления контрольной суммы является размер слова, или суммарное количество
регистров - информационных ячеек, используемых для вычисления численного
значения хеш-функции. При этом обязательно учитывается то, что размер слова и
степень образующего контрольную сумму полинома совпадают. На практике более
всего распространены 8, 16 и 32 - битовые слова, что является следствием
особенностей архитектуры современной вычислительной техники.
И последний параметр, важный при описании
определенной методики - начальные состояния регистров (стартовое слово). Это
последняя из трех значимых характеристик; зная их в совокупности, мы можем
восстановить алгоритм вычисления CRC.
.6.2 Популярные и
стандартизованные полиномы
В то время, как циклические избыточные коды
являются частью стандартов, у этого термина не существует общепринятого
определения - трактовки различных авторов нередко противоречат друг другу.
Этот парадокс касается и выбора
многочлена-генератора: зачастую стандартизованные полиномы не являются самыми
эффективными в плане статистических свойств соответствующего им check
reduntancy code.
При этом многие широко используемые полиномы не
являются наиболее эффективными из всех возможных. В 1993-2004 годах группа
учёных занималась исследованием порождающих многочленов разрядности до 16, 24 и
32 бит, и нашла полиномы, дающие лучшую, нежели стандартизированные многочлены,
производительность в смысле кодового расстояния. Один из результатов этого
исследования уже нашёл своё применение в протоколе iSCSI.
Самый популярный и рекомендуемый IEEE полином
для CRC-32 используется в Ethernet, FDDI; также этот многочлен является генератором
кода Хемминга. Использование другого полинома - CRC-32C - позволяет достичь
такой же производительности при длине исходного сообщения от 58 бит до 131
кбит, а в некоторых диапазонах длины входного сообщения могут быть даже выше -
поэтому в наши дни он тоже пользуется популярностью. К примеру, стандарт ITU-T
G.hn использует CRC-32C с целью обнаружения ошибок в полезной нагрузке.
В Википедии
(#"787347.files/image018.gif">
Рисунок 7 Пример работы программы Turnitin tool
Механизм работы программы следующий: документ
разбивается на фрагменты, которые сравниваются с содержимым базы данных при
помощи статистического алгоритма. Поиск плагиата происходит на базе сравнения
исходного текста с миллионами страниц контента в Интернете и внутренних баз
данных.
В базе хранятся произведения классиков, учебные
и научные работы. В случае обнаружения текстовых совпадений система выдает
предупреждение. Архив постоянно пополняется работами, которые были
предоставлены на экспертизу по поводу плагиата. Интересно отметить следующий
юридический казус: архивирование и дальнейшее использование учебных работ в
системе антиплагиата само по себе не соответствует европейским правовым нормам
об охране авторских прав, поэтому многие европейские университеты, являющиеся
клиентами Turnitin, требуют от студентов письменного согласия с тем, что их
работы будут сохранены в соответствующих электронных архивах.работает с
большинством европейских языков, в том числе с английским, испанским, немецким,
французским, итальянским. Программа является платной. Обычно лицензию покупает
университет.
Plagiarism-Finder 1.0.9
(#"787347.files/image019.gif">
Рисунок 8 Интерфейс программы Plagiarism-Finder
Длительность анализа зависит от требуемой
точности, мощности ПК и качества канала выхода в Интернет. Анализ курсовой,
содержащей 35 страниц (20 тыс. слов, 125 тыс. знаков), с широкополосным
доступом DSL займет примерно 2 мин (выборочный контроль), 6 мин понадобится для
так называемого среднего контроля (используется по умолчанию) и 40 мин - для
проведения тщательной проверки. Документ должен быть представлен в цифровой
форме. Plagiarism-Finder импортирует документы в форматах PDF (Acrobat Reader),
DOC (Microsoft Word), HTML, TXT (Plain Text) или RTF (Rich TextFormat).
Практически любой текстовый процессор позволяет представить документ в одном из
данных форматов. При этом пользователь ПК может даже не иметь программы
Microsoft Word. Программа ищет похожие тексты и выдает ссылки, однако вывод о
том, плагиат это или нет, рекомендуется делать при визуальном сравнении текстов
экспертом.
.3 Обзор программ
поиска плагиата в произвольных текстах
Обзор программ поиска плагиата в произвольных
текстах[17]:
Advego
Plagiatus
-
программа для проверки текста на уникальность, осуществляет поиск в internet
частичных или полных копий текста документа. Программа показывает степень
уникальности текста в процентном соотношении, так же указывает источники не
уникального текста, позволяет проверять текст на уникальность указанного URL.
Программа требует установки на компьютер.
Praide
unique
content
analyzer
- программа для проверки уникальности контента. Требует установки. Параметры
разбора позволяют изменять количество слов и фрагментах, количество слов
перекрытия.
Double
Content
Finder
- небольшая программа проверки текста на уникальность.
CopyCatch Gold
(#"787347.files/image020.gif">
Рисунок 9 Интерфейс CopyChecker
Investigator предназначена для поиска плагиата в
издательском бизнесе. Она сравнивает новую работу автора с его предыдущими
публикациями, а также осуществляет контроль дублирования внешних публикаций.
5
ОПИСАНИЕ ИСПОЛЬЗУЕМЫХ МЕТОДОВ ПОИСКА ПЛАГИАТА В ИСХОДНЫХ КОДАХ И ПРОИЗВОЛЬНЫХ
ТЕКСТАХ
5.1 Общая схема
поиска
Основная идея поиска плагиата в работе - это
использование взаимодополняющих методов поиска, применяемых как к произвольным
текстам, так и только для исходных кодов.
.1.1 Cхема
поиска для исходных кодов
Процесс выделения основных характеристик - это
введение представления, то есть из модели, с большим количеством избыточной
информации, переходим в более компактную модель, где незначимая информация
удалена (нормализация). Обычно в процессе нормализации все слова разделяются
только одним пробелом, и все буквы приводятся к единому регистру (см. пример
1).
Выбирая разные представления, выбираются
характеристики, которые для данного случая являются основными и оставляют их.
После этого вводим функцию близости (метрику), чтобы определить, какие
характеристики из оставшихся являются более, а какие менее значимы. То, какие
характеристики являются основными - это вопрос подхода, вопрос понимания
плагиата. Метрики должны представлять такие характеристики, которые достаточно
трудно изменить, пытаясь замаскировать копию. Должны быть устойчивы к
незначительным изменениям исходного кода. Должно быть возможно просто
сравнивать, используя эти метрики. И должны быть достаточно общими (чтобы быть
применимыми к достаточно широкому ряду языков программирования).
5.1.2 Основной
структурный метод для анализа исходных кодов
Если представить две программы в виде строк
токенов, то одним из критериев сходства строк считается длина их наибольшей
общей последовательности. Сравнение проводится следующим образом. Первый
оператор одной последовательности токенов (из базы сданных работ) сравнивается
с последним оператором другой последовательности (проверяемого кода). Если
операторы одинаковы, то счетчик совпадений увеличивается на единицу. Далее
первая последовательность сдвигается и снова происходит поэлементное сравнение
(рисунок 10).

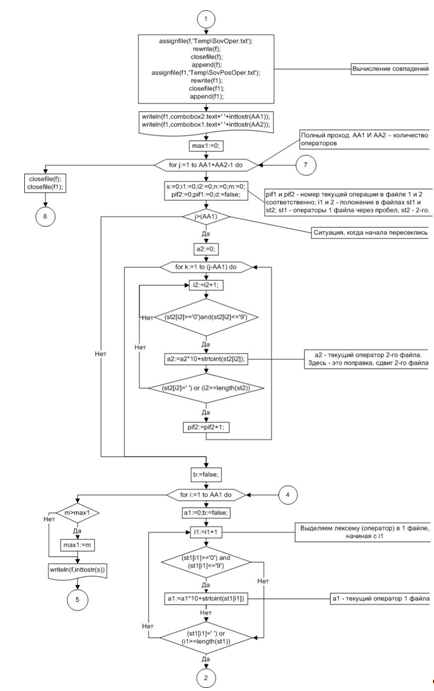
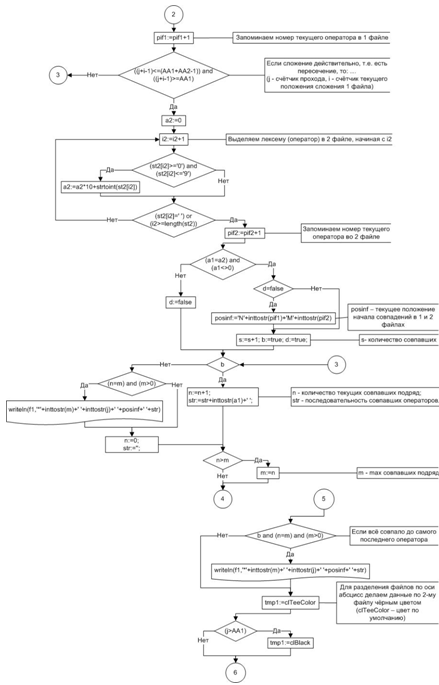
Рисунок 10 Первый этап поиска одинаковой
последовательности операторов
Этот процесс продолжается до тех пор, пока не
будет сравнен первый оператор второй последовательности с последним оператором
первой (рисунок 11).
Рисунок 11 Второй этап поиска одинаковой
последовательности операторов
Для каждой итерации запоминается счетчик
совпадений и длина непрерывного участка совпавших операторов, другими словами
длина списанного фрагмента кода программы.
Полученная информация изображается в виде
гистограммы для каждого файла в базе сданных работ, на абсциссе которой
откладывается величина смещения одной последовательности операторов
относительно другой, а на ординате - количество совпадений операторов при таком
смещении (рисунок 12).
Рисунок 12 Гистограмма результатов поиска
одинаковой последовательности операторов
Пик, наблюдаемый на рисунке, возник из-за того,
что в этих программах встречаются одинаковые фрагменты. Для «основных» пиков на
графике выводится на экран код проверяемой программы и уже сданной работы из
базы с выделенными фрагментами, соответствующими пику. Признать такое
заимствование плагиатом или нет, решает преподаватель, основываясь на величине
фрагмента, его роли в программе, схожести стиля программирования.
5.1.2.1 Достоинства и
недостатки
Основными достоинствами является большая
устойчивость алгоритма к самым распространенным среди студентов способам
сокрытия плагиата - добавлению комментариев, переименование переменных,
процедур и функций, добавлению/удалению некоторых операторов. Другим важным
достоинством данного метода является возможность применения данного метода к
очень широкому кругу языков программирования, ведь метод рассматривает
программу только как последовательность номеров операторов в базе языка
программирования. Так же применение именно этого метода позволяет
восстанавливать совпадающие участки кода исследуемых программ, что дает
возможность преподавателю убедиться в том, что работа списана.
Недостатки - возможность совпадения
токенизированного представления программ, но отсутствия совпадения в исходных
кодах программ, правда, вероятность этого крайне мала. Второй недостаток -
нелинейная зависимость времени обработки, от длины программы, однако программа
предназначена для анализа студенческих работ, которые редко бывают большого
объема.
.1.3 Дополнительный
атрибутный метод для исходных текстов
В связи с тем, что некоторые лабораторные классы
нашего института не могут похвастаться высокопроизводительными персональными
компьютерами, было принято решение добавить менее требовательный к ресурсам
метод.
Как и в первом методе, программы представляются
в виде строк токенов. Далее анализируются частоты появления операторов
программе. Частота определяется как количество появлений конкретного оператора,
деленное на количество появлений всех операторов. Частоты отображаются в виде
гистограммы. На абсциссе отложены порядковые номера операторов, а на ординате -
частоты появлений этих операторов (рисунок 13). Идея такого способа
идентификации плагиата опубликована в работе [10].
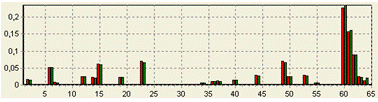
Рисунок 13 Диаграмма частотного анализа
операторов
По такой гистограмме можно судить о количестве
циклов, условных операторов и арифметических операций в каждой из программ.
Например, пики, наблюдаемые в районе 60-63 соответствуют арифметическим
операторам “:=”, “+” и “-” соответственно. Очевидно, что в обоих кодах
используется большое количество таких операторов и частоты их появления
примерно равны.
При маскировке нелегально заимствованного
фрагмента злоумышленник может изменить некоторые операторы и добавить новые, но
в целом изменения, вероятно, будут малы, и ожидается, что распределение частот
останется практически тем же. Конечно, близкие значения частот во фрагментах
различных программ еще не являются доказательством факта заимствования, но зато
дают повод это подозревать.
5.1.3.1 Достоинства и
недостатки
Основными достоинствами метода является высокая
скорость вычислений частот, что позволяет практически мгновенно в
автоматическом режиме отобрать «подозрительные» работы, а затем в режиме один
против одного проверить их с помощью основного структурного метода. Возможность
сравнения количества определенных операторов, например операторов присваивания.
Недостатки - возможность совпадения
токенизированного представления программ, но отсутствия совпадения в исходных
кодах программ. Второй недостаток - небольшая устойчивость алгоритма к
изменениям операторов в небольших текстах программ.
.2.1 Cхема
поиска для произвольных текстов (в том числе и программ)
Для анализа заимствованных фрагментов в исходных
кодах программ предлагается использовать методы шинглов и дистанции Левенштейна
и Дамерау для анализа произвольных текстов, и в том числе программ.
Пользователь может выбрать либо произвольный текст, либо загрузить исходный
текст программ из базы данных. После этого могут применяться методы сравнения
текстов на наличие одинаковых фрагментов (метод нахождения дистанции
Левенштейна и наибольшей общей подпоследовательности (longest
common
subsequence,
LCS)
либо вычисление «похожести» текстов в процентах с помощью метода шинглов.
Модуль, в котором
реализована эта схема, рассмотрен в главе 8.
6
ПРОГРАММНАЯ РЕАЛИЗАЦИЯ МОДУЛЯ ПОИСКА ПЛАГИАТА МЕТОДАМИ АНАЛИЗА ИСХОДНЫХ КОДОВ
ПРОГРАММ
.1 Интерфейс модуля
поиска плагиата в исходных кодах программ
.1.1 Главное окно
модуля поиска плагиата методами анализа исходных кодов
Программа реализована на языке программирования
- Delphi. В верхней части
диалогового окна (рисунок 14) находятся кнопки для вызова функций добавления
файла в базу, добавления языка в базу, удаления из базы файла/языка и компонент
для выбора текущего языка.
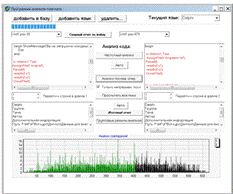
Рисунок 14 Главное окно модуля поиска плагиата в
исходных кодах программ
В средней части окна находятся кнопки основных
функций для анализа кода программ. Кнопка «Частотный анализ» позволяет сравнить
частоты появления операторов двух выбранных файлов (слева анализируемый файл,
справа - выбранный файл из базы). Ниже расположена кнопка «Авто» для режима
один против всех (сравнение файла, выбранного слева со всеми файлами в базе).
Кнопки (появляются после выбора режима «Авто») «<<» и «>>»
позволяют осуществлять навигацию по файлам в базе, выстроенным по возрастанию
вероятности плагиата. Стоит напомнить, что тексты программ, написанные одним м
тем же автором, даже при полном совпадении не считаются плагиатом, поэтому в
автоматическом режиме поиска все работы автора выбранного текста программы, принудительно
получают значение вероятности плагиата 1%, чтобы облегчить работу
преподавателя. В любом из режимов можно просмотреть информацию о выбранных
файлах, нажав соответствующую кнопку.
Кнопка «Анализ посл. опер.» позволяет выполнить
анализ совпадений последовательностей операторов выбранных текстов программ.
Если отмечено «Только непрерывн. посл.», то производится анализ только
максимальной последовательности операторов, иначе учитываются все, в том числе
и случайные совпадения этих последовательностей. Кнопка «Просчитать все пики»
позволяет переходить от максимальной последовательности совпадений к любой
другой, вывести соответствующие ей участки программ и сохранить отчет. Так же
как и для частотного анализа, для анализа последовательности операторов
предусмотрен автоматический режим.
В процесс доработки модуля была добавлена важная
возможность: после выполнения анализа последовательности операторов
показывается красным цветом наиболее длинный совпадающий участок исходного кода
(рисунок 14).
Результаты анализа кода программы выводится в
виде графика на стандартном компоненте Chart
(для частотного анализа на двух) и относительная оценка вероятности плагиата на
компонент ProgressBar.
Для целей диплома бакалавра были добавлены
кнопки «Сводный анализ», «Итоговый отчет» и «Групповые режимы анализа». При
нажатии кнопки «Групповые режимы анализа» открывается соответствующее новое
окно (рисунок 15).
6.1.2 Окно групповых режимов анализа
Окно групповых режимов анализа (рисунок 15)
используется при выполнении анализа одного файла сразу с несколькими файлами
(группой при пакетном режиме) или всех файлов со всеми файлами (при полном
анализе). Выделено четыре подраздела в этом окне:
· «Выполнить» для
осуществления операций анализа
· «Показать»
для показа отчетов и анализа результатов
· «Служебные действия»
для выполнения вспомогательных операций удаления отчетов
· «Настроить критерии плагиата»
для задания пороговых значений методов, при превышении которых выносится
заключение о возможности плагиата
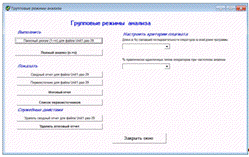
Рисунок 15 Окно групповых режимов анализа
.2 Взаимодействие
модуля поиска плагиата методами анализа исходных кодов
.2.1 Взаимодействие
модуля с архивом работ и базой языков (добавление файла в базу)
Взаимодействие модуля с архивом работ и базой
языков (добавление файла в базу) показано на рисунке 16.
) Копирование исследуемого кода в архив
работ студентов.
) Создание файла описания исследуемого файла.
) Добавление имени файла в список файлов этого
языка.
) Нормализация исследуемого кода.
) Составление файла последовательности
операторов исследуемой работы из нормализованного кода по базе операторов
языка.
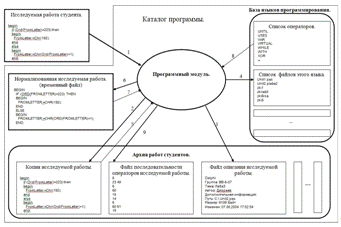
Рисунок 16 Взаимодействие модуля с архивом работ
и базой языков
.2.2 Взаимодействие
модуля с архивом работ и базой языков (частотный анализ, автоматический
частотный анализ)
Взаимодействие программы с архивом работ и базой
языков (частотный анализ, автоматический частотный анализ) показано на рисунке
17:
) По файлу операторов исследуемой работы составление
последовательности частот появления операторов.
) Для всех файлов данного языка, кроме работ
этого же автора, вычисление частот появления операторов и их сравнение.
) Составление временного файла результатов
сравнения частот появления операторов.
) По запросам преподавателя восстановление
исходных кодов для файлов с максимальным процентом совпадения частот появления
операторов.
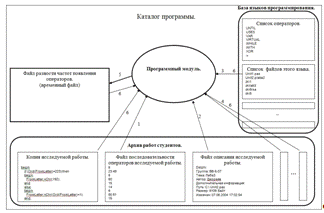
Рисунок 17 Взаимодействие модуля с архивом работ
и базой языков
.2.3 Взаимодействие
модуля с архивом работ и базой языков (автоматический анализ
последовательностей операторов)
1) По файлам операторов для всех файлов данного
языка, кроме работ автора исследуемой работы, вычисление максимальной длины
последовательности совпадающих операторов.
) Составление временного файла, содержащего
проценты отношений максимальной длины совпадений к количеству операторов
исследуемого файла.
) По запросам преподавателя восстановление
исходных кодов файлов по полученному временному файлу.
.2.4. Взаимодействие
модуля с архивом работ и базой языков (анализ последовательностей операторов,
просчет всех пиков)
1) По файлам операторов двух выбранных файлов
данного языка, вычисление последовательностей совпадающих операторов и запись
их в файл цепочек совпавших операторов.
) Сортировка строчек в этом файле в порядке
убывания.
) По запросам преподавателя восстановление
исходных кодов файлов с выделением строк, соответствующих пикам (цепочкам
совпадений), по полученному временному файлу.
) Создание отчета и сохранение его в файл.
6.2.5
Взаимодействие модуля с архивом работ и базой языков (удаление файла/языка из
базы)
1) Если выбран файл для удаления, то из базы
работ удаляется сам файл с исходным кодом, файл описания, файл
последовательности операторов, а списка файлов этого языка удаляется его имя.
) При удалении языка из базы, по списку файлов
этого языка удаляются все файлы, файлы с их описанием и последовательностью
операторов.
) Удаляется файл операторов этого языка, список
файлов и из файла известных языков стирается имя этого файла.
.2.6 Взаимодействие
модуля с базой языков (добавление языка в базу)
Взаимодействие модуля с базой языков (добавление
языка в базу) показано на рисунке 18:
) Нормализация файла с операторами языка.
) Занесение списка операторов в базу языков
программирования.
) Создание файла для списка файлов этого языка.
) Добавление названия нового языка в файл
известных языков.
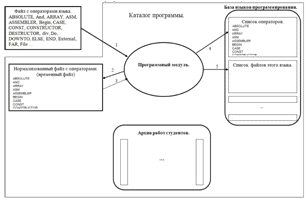
Рисунок 18 Взаимодействие модуля с базой языков
6.2.7 Пакетный
режим анализа (1->n)
При пакетном режиме анализа (режим сравнения
программ 1->n) - режим, при
котором текст одной из программ (в левом окне) автоматически (без участия
пользователя) сравнивается двумя методами (частотным анализом и анализом
последовательности операторов) с каждой из программ в списке (файле Batch.txt)
и последующей автоматической записью этого сравнения в сводный отчет.
.2.8 Полный анализ
(n->n)
При полном анализе (режим сравнения n->n)
- режим, при котором текст каждой из программ в базе данных (файле списка
файлов для данного языка, например, DelphiF.txt)
сравнивается двумя методами (частотным анализом и анализом последовательности
операторов) с каждой из программ в базе данных (файле списка файлов для данного
языка, например, DelphiF.txt)
и последующей автоматической записью этого сравнения в итоговый отчет.
.2.9 Поиск
первоисточника и списка первоисточников
При наличии сводного отчета для файла, в котором
есть подозрительные с точки зрения наличия плагиата файлы (то есть, обнаружены
файлы с похожим кодом) правомерно поставить вопрос о том, кто у кого списывал.
Для решения этой задачи и введена возможность поиска первоисточника - исходного
текста, с которого предположительно списывались другие программы.
.2.10 Некоторые
особенности модуля
Как было описано выше, при добавлении нового
текста программы в базу, для него создается сразу три файла: непосредственно
копия оригинала, файл последовательности операторов (из которого образуется
впоследствии строка токенов) и файл описания. Важно заметить, что файл описания
(см. пример 3) является одним из ключевых, в нем храниться информация о языке
программирования, на котором написан код, теме, учебной группе, фамилии автора,
о пути к оригиналу файла и дате его последних изменений. При заполнении этих
полей, следует обратить особое внимание на правильность фамилии автора, для
исключения поиска плагиата среди работ одного и того же студента. Дата и время
последних изменений в файле позволит предположить, кто является плагиатором.
Для повышения надежности и скорости работы
программы на медленных ПК, следует исключать из добавляемых файлов стандартные
части, свойственные данному языку программирования, а так же из базы операторов
языка программирования те оператоы, которые обычно используются в качестве
разделителей (например, в C++
обычно разделяют текст программы с помощью «////////////////////////»).
6.3 Описание
отчетов по анализу плагиата
.3.1 Критерии
автоматического заключения о наличии плагиата при пакетном и полном анализе
Ввиду того, что при пакетном и полном анализе
человек не включен в процесс принятия решения о наличии плагиата, предложены
следующие эмпирические критерии:
. Для частотного анализа сравнивается число
типов операторов в двух файлах. Вычисляются два числа: число типов операторов,
которые по частоте вхождения полностью совпали, и число типов операторов,
разница в частоте вхождения которых отличается не более, чем на 1%. Второе
число введено для того, чтобы иметь возможность учитывать практически
идентичные, но не полностью совпадающие частоты вхождения типов операторов.
Вывод о наличии плагиата по частоте операторов делается в том случае, если хотя
бы для одного из сравниваемых файлов процент одинаковых со вторым файлом типов
операторов превосходит выбранное пользователем значение (по умолчанию 70%). Эта
доля выбирается пользователем в окне групповых режимов анализа и может иметь
следующие значения (в процентах): 30,40,50,60,70,80,90. Если эта доля не
выбрана, то предполагается критерий - 70%. То есть устанавливается, что если в
двух сравниваемых программах доля практически идентичных по количеству
вхождений типов операторов превышает 70% от общего числа типов операторов в
одной из программ, то делается вывод о наличии плагиата.
. Для анализа последовательности совпавших типов
операторов критерий заключения о наличии плагиата устанавливается исходя из
доли длины совпавшей последовательности экземпляров операторов к числу
экземпляров операторов в программе. Эта доля выбирается пользователем в окне
групповых режимов анализа и может иметь следующие значения (в процентах):
10,20,30,40,50. Если эта доля не выбрана, то предполагается критерий - 50%. То
есть устанавливается, что если в двух сравниваемых программах совпадающая
последовательность экземпляров операторов превышает половину программы.
.3.2 Алгоритм
поиска первоисточника для файла или списка первоисточников при полном анализе
Алгоритм поиска такого файла достаточно прост. В
сводном отчете просматриваются все файлы с признаками плагиата по обоим
критериям (по частотному анализу и по анализу последовательности операторов) и
ищется файл с наиболее ранней датой создания (с учетом времени суток). Если
подозрительных файлов в сводном отчете нет, то сам изучаемый файл является
первоисточником. Пример результата такого поиска показан на рисунке 19.
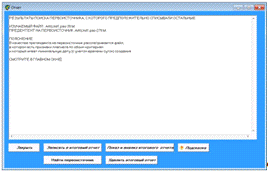
Рисунок 19 Окно результата поиска первоисточника
для 1 файла
Аналогичным образом получается список
первоисточников при полном анализе: просматриваются сводные отчеты для всех
файлов (рисунок 20): в полученном отчете в каждой строке первое имя - изучаемый
файл, второе имя - первоисточник. В списке для каждого из файлов полного
анализа приведен соответствующий первоисточник.
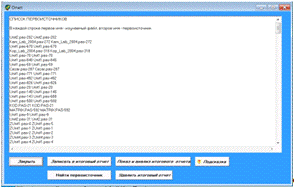
Рисунок 20 Окно результата поиска
первоисточников при полном анализе
6.3.3 Сводный отчет
Сводный отчет для каждого файла содержит
подробную информацию о сравнении этого файла с другими файлами по обоим
критериям анализа с детализацией года написания программ: один и тот же год,
предыдущие годы или без учета года написания.
Сводный отчет (или сразу множество сводных
отчетов) формируется тремя способами:
· Вручную в результате сравнения двух программ
(1->1) двумя методами (частотным анализом и анализом последовательности
операторов) и последующей записи этого сравнения в сводный отчет;
· Автоматически в результате
применения пакетного режима сравнения программ (1->n), при котором текст
одной из программ (в левом окне) сравнивается двумя методами (частотным
анализом и анализом последовательности операторов) с каждой из программ в
списке (файле Batch.txt) и последующей автоматической записью этого сравнения в
сводный отчет;
· Автоматически в результате
применения режима полного анализа программ (n->n), при котором текст каждой
из программ (в файле списка файлов для данного языка, например, DelphiF.txt)
сравнивается двумя методами (частотным анализом и анализом последовательности
операторов) с каждой из программ в списке (файле списка файлов для данного
языка, например, DelphiF.txt) и последующей автоматической записью этого сравнения
в сводный отчет.
Сводный отчет имеет следующую структуру:
ПОЛНОЕ ИМЯ ФАЙЛА и ГОД ЕГО НАПИСАНИЯ
КРИТЕРИИ ПЛАГИАТА:
Доля длины (в %) совпавшей
последовательности операторов ко всей длине программы -> <значение>%
% практически идентичных типов операторов
при частотном анализе -> <значение>%
<список файлов с детализацией
>
КОЛИЧЕСТВО СОПОСТАВЛЕНЫХ ФАЙЛОВ =
ПОДОЗРИТЕЛЬНЫЕ ФАЙЛЫ:
<список файлов >
ФАЙЛЫ БЕЗ УЧЕТА ГОДОВ:
ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО ЧАСТОТЕ =
ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО СОВПАДЕНИЮ =
ВСЕГО ПОДОЗРЕНИЙ ОДНОВРЕМЕННО ПО ОБОИМ КРИТЕРИЯМ
ПЛАГИАТА =
ОДИНАКОВЫЙ ГОД:
ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО ЧАСТОТЕ =
ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО СОВПАДЕНИЮ =
ВСЕГО ПОДОЗРЕНИЙ ОДНОВРЕМЕННО ПО ОБОИМ КРИТЕРИЯМ
ПЛАГИАТА =
ПЛАГИАТ ВЗЯТ ИЗ ПРЕДЫДУЩИХ ГОДОВ:
ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО ЧАСТОТЕ =
ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО СОВПАДЕНИЮ =
ВСЕГО ПОДОЗРЕНИЙ ОДНОВРЕМЕННО ПО ОБОИМ КРИТЕРИЯМ
ПЛАГИАТА =
Данные в сводном отчете структурированы
следующим образом:
1. Полный детализированный список файлов (<список
файлов с детализацией >), с которыми выполнялось сравнение.
2. ПОДОЗРИТЕЛЬНЫЕ ФАЙЛЫ. В этом разделе
приводится список файлов (<список файлов с детализацией подозрения на
плагиат>), в которых обнаружена возможность плагиата.
. БЕЗ УЧЕТА ГОДОВ. Резюме по подозрительным
файлам без учета годов из написания.
. ОДИНАКОВЫЙ ГОД. Резюме по
подозрительным файлам, которые написаны в один год. Проверяется возможность
плагиата на одном году обучения.
5. ПЛАГИАТ ВЗЯТ ИЗ ПРЕДЫДУЩИХ ГОДОВ. Резюме
по подозрительным файлам, которые написаны в предыдущие годы по сравнению с
годом написания исследуемой программы. Проверяется возможность плагиата, при
котором студенты воспользовались трудами предыдущих курсов обучения.
Каждая строка <Список файлов с
детализацией> имеет структуру, в которой сведены сведении по результатам
частотного анализа и анализа последовательности операторов.
Сведения по результатам частотного анализа:
· Имя файла, год написания
· Группа. Если поле не заполнено, то
пишется 'ГРПНЗВСТ '
· Автор. Если поле не заполнено, то
пишется 'АВТОРНЗВСТ '
· Число экземпляров операторов в 1
файле
· Число экземпляров операторов во 2
файле
· Число типов операторов в 1 файле
· Число типов операторов в 2 файле
· Число типов операторов с равной
долей вхождений в обоих файлах
· % типов операторов совпадают для 1
файла
· % типов операторов совпадают для 2
файла
· Число типов операторов с равной
долей вхождений в обоих файлах
· % типов операторов удовлетворяют
условию (разница в доле <1%) для 1 файла
· % типов операторов удовлетворяют
условию (разница в доле <1%) для 2 файла
· Признак того, что плагиат есть (1)
или нет (0) по критерию частоты операторов
Сведения по результатам анализа
последовательности операторов:
· Имя файла, год написания
· Группа. Если поле не заполнено, то
пишется 'ГРПНЗВСТ '
· Автор. Если поле не заполнено, то
пишется 'АВТОРНЗВСТ '
· Число экземпляров операторов в 1
файле
· Число экземпляров операторов во 2
файле
· Длина максимального совпадения
последовательных экземпляров операторов в файлах
· Процент от числа всех экземпляров
операторов в 1 файле
· Процент от числа всех экземпляров
операторов в 2 файле
· Признак того, что плагиат есть (1)
или нет (0) по критерию анализа последовательности операторов
Фрагмент сводного отчета по реальной базе данных
работ студентов:
СВОДНЫЙ ОТЧЕТ ПО ФАЙЛУ Arh\Unit1.pas-39.txt ГОД
2007
КРИТЕРИИ ПЛАГИАТА:
Доля длины (в %) совпавшей последовательности
операторов ко всей длине программы -> 50% (по умолчанию)
% практически идентичных типов операторов при
частотном анализе -> 70% (по умолчанию)
\Unit2.pas-202.txt 2004 _ВВ-5-00 Комодин 405 19
34 13 0 0,00 0,00 0 2,94 7,69 0 Arh\Unit2.pas-202.txt 2004 _ВВ-5-00 Комодин 405
19 8 1,9753 42,1053 0\Kam_Lab_2004.pas-272.txt 2004 _ВВ-5-00 Комодин 405 99 34
23 0 0,00 0,00 0 14,71 21,74 0 Arh\Kam_Lab_2004.pas-272.txt 2004 _ВВ-5-00
Комодин 405 99 11 2,7160 11,1111 0\Unit1.pas-670.txt 2004 _ВВ-5-00 Капанин 405
218 34 29 0 0,00 0,00 0 23,53 27,59 0 Arh\Unit1.pas-670.txt 2004 _ВВ-5-00
Капанин 405 218 11 2,7160 5,0459 0\Kop_Lab_2004.pas-318.txt 2004 _ВВ-5-00
Капанин 405 126 34 26 0 0,00 0,00 0 23,53 30,77 0 Arh\Kop_Lab_2004.pas-318.txt
2004 _ВВ-5-00 Капанин 405 126 17 4,1975 13,4921 0\Unit1.pas-70.txt 2004
_ВВ-5-01 АВТОРНЗВСТ 405 131 34 26 0 0,00 0,00 0 26,47 34,62 0
Arh\Unit1.pas-70.txt 2004 _ВВ-5-01 АВТОРНЗВСТ 405 131 11 2,7160 8,3969
0\Unit1.pas-840.txt 2004 ГРПНЗВСТ АВТОРНЗВСТ 405 218 34 29 0 0,00 0,00 0 23,53
27,59 0 Arh\Unit1.pas-840.txt 2004 ГРПНЗВСТ АВТОРНЗВСТ 405 218 11 2,7160 5,0459
0\Unit1.pas-59.txt 2004 _ВВ-5-01 АВТОРНЗВСТ 405 156 34 27 0 0,00 0,00 0 29,41
37,04 0 Arh\Unit1.pas-59.txt 2004 _ВВ-5-01 АВТОРНЗВСТ 405 156 13 3,2099 8,3333
0\Cezar.pas-287.txt 2004 _ВВ-61-00 Якушина 405 111 34 15 0 0,00 0,00 0 11,76
26,67 0 Arh\Cezar.pas-287.txt 2004 _ВВ-61-00 Якушина 405 111 5 1,2346 4,5045 0
…
КОЛИЧЕСТВО СОПОСТАВЛЕНЫХ ФАЙЛОВ = 282
ПОДОЗРИТЕЛЬНЫЕ ФАЙЛЫ:\Unit2.pas-670.txt 2007
ПЛАГИАТ_ПО_СОВПАДЕНИЮ\Unit3.pas-318.txt 2007
ПЛАГИАТ_ПО_СОВПАДЕНИЮ\Unit4.pas-161.txt 2007
ПЛАГИАТ_ПО_СОВПАДЕНИЮ\Unit5.pas-371.txt 2007
ПЛАГИАТ_ПО_СОВПАДЕНИЮ\Unit2.pas-327.txt 2007
ПЛАГИАТ_ПО_СОВПАДЕНИЮ\Unit3.pas-696.txt 2007
ПЛАГИАТ_ПО_СОВПАДЕНИЮ\Unit4.pas-843.txt 2007
ПЛАГИАТ_ПО_СОВПАДЕНИЮ\Unit5.pas-717.txt 2007
ПЛАГИАТ_ПО_СОВПАДЕНИЮ\Unit2.pas-246.txt 2007
ПЛАГИАТ_ПО_СОВПАДЕНИЮ\Unit3.pas-824.txt 2007 ПЛАГИАТ_ПО_СОВПАДЕНИЮ\Unit4.pas-278.txt
2007 ПЛАГИАТ_ПО_СОВПАДЕНИЮ\Unit5.pas-481.txt 2007
ПЛАГИАТ_ПО_СОВПАДЕНИЮ\Unit2.pas-680.txt 2004
ПЛАГИАТ_ПО_СОВПАДЕНИЮ\Unit1.pas-279.txt 2007 ПЛАГИАТ_ПО_ЧАСТОТЕ_ОПЕРАТОРОВ
ПЛАГИАТ_ПО_СОВПАДЕНИЮ\Unit1.pas-805.txt 2007 ПЛАГИАТ_ПО_ЧАСТОТЕ_ОПЕРАТОРОВ\Unit1.pas-818.txt
2007 ПЛАГИАТ_ПО_ЧАСТОТЕ_ОПЕРАТОРОВ\Unit1.pas-141.txt 2007
ПЛАГИАТ_ПО_ЧАСТОТЕ_ОПЕРАТОРОВ ПЛАГИАТ_ПО_СОВПАДЕНИЮ\Unit1.pas-713.txt 2007
ПЛАГИАТ_ПО_ЧАСТОТЕ_ОПЕРАТОРОВ\Unit1.pas-979.txt 2007
ПЛАГИАТ_ПО_ЧАСТОТЕ_ОПЕРАТОРОВ\Unit1.pas-154.txt 2007
ПЛАГИАТ_ПО_ЧАСТОТЕ_ОПЕРАТОРОВ
БЕЗ УЧЕТА ГОДОВ:
ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО ЧАСТОТЕ = 12
ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО СОВПАДЕНИЮ = 16
ВСЕГО ПОДОЗРЕНИЙ ОДНОВРЕМЕННО ПО ОБОИМ КРИТЕРИЯМ
ПЛАГИАТА = 3
ОДИНАКОВЫЙ ГОД:
ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО ЧАСТОТЕ = 9
ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО СОВПАДЕНИЮ = 15
ВСЕГО ПОДОЗРЕНИЙ ОДНОВРЕМЕННО ПО ОБОИМ КРИТЕРИЯМ
ПЛАГИАТА = 3
ПЛАГИАТ ВЗЯТ ИЗ ПРЕДЫДУЩИХ ГОДОВ:
ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО ЧАСТОТЕ = 3
ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО СОВПАДЕНИЮ = 1
ВСЕГО ПОДОЗРЕНИЙ ОДНОВРЕМЕННО ПО ОБОИМ КРИТЕРИЯМ
ПЛАГИАТА = 0
.3.4 Итоговый отчет
Итоговый отчет формируется тремя способами:
· Вручную путем записи в любой момент времени
резюме (одной строкой) по текущему сводному отчету для выбранного файла в
итоговый отчет;
· Автоматически в результате
применения пакетного режима (1->n) путем записи в итоговый отчет после
окончания анализа всего пакета резюме (одной строкой) по полученному сводному
отчету для выбранного файла;
· Автоматически в результате
применения режима полного анализа программ (n->n), путем записи в итоговый
отчет после окончания полного анализа для каждого из файлов резюме (одной
строкой) по полученному сводному отчету.
Описание структуры итогового отчета:
Итоговый отчет содержит список обобщенных
результатов сравнения каждого файла с другими файлами по обоим критериям
анализа с детализацией года написания программ: один и тот же год, предыдущие
годы или без учета года написания.
В итоговом отчете приводится список
проанализированных файлов, для каждого из которых указывается:
· имя файла и год написания;
· число подозрительных файлов по
частоте операторов по всем годам;
· число подозрительных файлов по
совпадению операторов по всем годам;
· число подозрительных файлов по обоим
критериям по всем годам;
(ЭТА ИНФОРМАЦИЯ ДЛЯ АНАЛИЗА ОБЩЕЙ КАРТИНЫ
ПЛАГИАТА БЕЗ УЧЕТА ГОДОВ)
· число подозрительных файлов по частоте
операторов по этому же году;
· число подозрительных файлов по
совпадению операторов по этому же году;
· число подозрительных файлов по обоим
критериям по этому же году;
(ЭТА ИНФОРМАЦИЯ ДЛЯ АНАЛИЗА КАРТИНЫ ПЛАГИАТА НА
ОДНОМ ГОДУ ОБУЧЕНИЯ)
· число подозрительных файлов по частоте
операторов по предыдущим годам;
· число подозрительных файлов по
совпадению операторов по предыдущим годам;
· число подозрительных файлов по обоим
критериям по предыдущим годам;
(ЭТА ИНФОРМАЦИЯ ДЛЯ АНАЛИЗА КАРТИНЫ ПЛАГИАТА,
КОГДА СПИСЫВАЮТ С ПРЕДЫДУЩИХ ЛЕТ)
· суммарное число файлов, с которыми выполнялось
сравнение.
КОЛИЧЕСТВО ИССЛЕДОВАННЫХ ФАЙЛОВ =
Приводится список файлов с плагиатом, взятым из
предыдущих лет обучения:
КОЛИЧЕСТВО ФАЙЛОВ с плагиатом, взятым из
предыдущих лет обучения:=
Приводится список файлов с плагиатом, на одном
году обучения:
КОЛИЧЕСТВО ФАЙЛОВ с плагиатом на одном году
обучения:=
Фрагмент итогового отчета по реальной базе
данных работ студентов:
ИТОГОВЫЙ ОТЧЕТ
КРИТЕРИИ ПЛАГИАТА:
Доля длины (в %) совпавшей последовательности
операторов ко всей длине программы -> 50% (по умолчанию)
% практически идентичных типов операторов при
частотном анализе -> 70% (по умолчанию)
Arh\Unit2.pas-202.txt 2004 1 37 1 1
8 1 0 1 0 282\Kam_Lab_2004.pas-272.txt 2004 3 1 1 3 1 1 0 0 0
282\Unit1.pas-670.txt 2004 2 1 1 2 1 1 0 0 0 282\Kop_Lab_2004.pas-318.txt 2004
3 14 1 3 2 1 0 0 0 282\Unit1.pas-70.txt 2004 2 0 0 1 0 0 0 0 0 282\Unit1.pas-840.txt
2004 2 1 1 2 1 1 0 0 0 282
…\Unit1.pas-154.txt 2007 18 13 0 14
12 0 3 1 0 282\Unit1.pas-39.txt 2007 12 16 3 9 15 3 3 1 0 282
КОЛИЧЕСТВО ИССЛЕДОВАННЫХ ФАЙЛОВ = 283
==============================
Список файлов с явным подозрением на плагиат:
файлы, в которых есть заимствованный код из
предыдущих лет
Arh\Unit2.pas-202.txt 2004 1 37 1 1
8 1 0 1 0 282\Unit1.pas-140.txt 2007 5 0 0 4 0 0 1 0 0 282\Unit1.pas-143.txt
2007 19 6 6 12 5 5 1 0 0 282\Unit2.pas-31.txt 2006 0 6 0 0 0 0 0 3 0
282\ZUnit1.pas-0.txt 2011 5 2 2 3 2 2 2 0 0 282\ZUnit1.pas-4.txt 2011 6 0 0 3 0
0 3 0 0 282\ZUnit1.pas-6.txt 2011 2 0 0 0 0 0 2 0 0 282\ZUnit1.pas-8.txt 2011 0
13 0 0 0 0 0 13 0 282\Unit1.pas-773.txt 2008 22 7 1 4 1 1 17 6 0
282\zki6RSA.pas-329.txt 2005 1 13 0 1 0 0 0 1 0 282
….\Unit1.pas-979.txt 2007 16 13 0 14
12 0 0 1 0 282\Unit1.pas-154.txt 2007 18 13 0 14 12 0 3 1 0 282\Unit1.pas-39.txt
2007 12 16 3 9 15 3 3 1 0 282
КОЛИЧЕСТВО ФАЙЛОВ С ПЛАГИАТОМ ИЗ ПРЕДЫДУЩИХ ЛЕТ
= 168
==============================
Список файлов с подозрением на плагиат, но с
неизветным авторством
файлы, в которых есть заимствованный код на
одном году обучения
В данном случае нельзя достоверно определить,
кто писал сам, а кто списывал.
Arh\Unit2.pas-202.txt 2004 1 37 1 1
8 1 0 1 0 282\Kam_Lab_2004.pas-272.txt 2004 3 1 1 3 1 1 0 0 0
282\Unit1.pas-670.txt 2004 2 1 1 2 1 1 0 0 0 282\Kop_Lab_2004.pas-318.txt 2004
3 14 1 3 2 1 0 0 0 282\Unit1.pas-70.txt 2004 2 0 0 1 0 0 0 0 0
282\Unit1.pas-840.txt 2004 2 1 1 2 1 1 0 0 0 282
...\Unit1.pas-879.txt 2007 10 14 1 8
13 1 2 1 0 282\Unit1.pas-713.txt 2007 13 14 1 9 13 1 2 1 0
282\Unit1.pas-438.txt 2007 5 14 1 5 13 1 0 1 0 282\Unit1.pas-979.txt 2007 16 13
0 14 12 0 0 1 0 282\Unit1.pas-154.txt 2007 18 13 0 14 12 0 3 1 0
282\Unit1.pas-39.txt 2007 12 16 3 9 15 3 3 1 0 282
КОЛИЧЕСТВО ФАЙЛОВ С ПЛАГИАТОМ НА ОДНОМ ГОДУ
ОБУЧЕНИЯ = 236
.3.5 Экспорт
итогового протокола в Excel
В таблице 2 (получена после экспорта в Excel)
приведены данные в абсолютных величинах (верхняя часть) и в относительных
величинах (в нижней части). Абсолютные величины - это число работ студентов в
данном году с определенным признаком. Относительные величины приводятся в
процентах к числу работ студентов в данном году.
Пояснение к названиям столбцов:
· С - ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО ЧАСТОТЕ
ОПЕРАТОРОВ БЕЗ УЧЕТА ГОДОВ
· D - ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО
СОВПАДЕНИЮ ПОСЛЕДОВАТЕЛЬНОСТИ ОПЕРАТОРОВ БЕЗ УЧЕТА ГОДОВ
· E - ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ
ОДНОВРЕМЕННО ПО ОБОИМ КРИТЕРИЯМ БЕЗ УЧЕТА ГОДОВ
· F - ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО
ЧАСТОТЕ ОПЕРАТОРОВ В ОДНОМ И ТОМ ЖЕ ГОДУ
· G - ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО
СОВПАДЕНИЮ ПОСЛЕДОВАТЕЛЬНОСТИ ОПЕРАТОРОВ В ОДНОМ И ТОМ ЖЕ ГОДУ
· H - ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ
ОДНОВРЕМЕННО ПО ОБОИМ КРИТЕРИЯМ В ОДНОМ И ТОМ ЖЕ ГОДУ
· I - ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО
ЧАСТОТЕ ОПЕРАТОРОВ ПРИ СРАВНЕНИИ С ПРОГРАММАМИ ПРЕДЫДУЩИХ ЛЕТ
· J - ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО
СОВПАДЕНИЮ ПОСЛЕДОВАТЕЛЬНОСТИ ОПЕРАТОРОВ ПРИ СРАВНЕНИИ С ПРОГРАММАМИ ПРЕДЫДУЩИХ
ЛЕТ
· K - ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ
ОДНОВРЕМЕННО ПО ОБОИМ КРИТЕРИЯМ ПРИ СРАВНЕНИИ С ПРОГРАММАМИ ПРЕДЫДУЩИХ ЛЕТ
Таблица 2 Таблица обработки базы данных,
структурированных по годам и признакам плагиата
|
Код
|
Кол-во
|
C
|
D
|
E
|
F
|
G
|
H
|
I
|
J
|
K
|
|
2002
|
1
|
1
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
2004
|
69
|
54
|
50
|
27
|
46
|
50
|
25
|
0
|
3
|
0
|
|
2005
|
41
|
38
|
30
|
16
|
33
|
10
|
10
|
11
|
17
|
0
|
|
2006
|
11
|
9
|
7
|
3
|
4
|
2
|
2
|
9
|
5
|
1
|
|
2007
|
100
|
98
|
93
|
85
|
96
|
91
|
82
|
71
|
76
|
21
|
|
2008
|
37
|
36
|
22
|
18
|
31
|
14
|
13
|
25
|
11
|
4
|
|
2009
|
4
|
4
|
1
|
1
|
0
|
0
|
0
|
4
|
1
|
1
|
|
2010
|
3
|
3
|
0
|
0
|
0
|
0
|
0
|
3
|
0
|
0
|
|
2011
|
17
|
12
|
9
|
3
|
9
|
5
|
3
|
9
|
6
|
0
|
|
Отношение
|
100,00%
|
0,00%
|
0,00%
|
0,00%
|
0,00%
|
0,00%
|
0,00%
|
0,00%
|
|
|
78,26%
|
72,46%
|
39,13%
|
66,67%
|
72,46%
|
36,23%
|
0,00%
|
4,35%
|
0,00%
|
|
|
92,68%
|
73,17%
|
39,02%
|
80,49%
|
24,39%
|
24,39%
|
26,83%
|
41,46%
|
0,00%
|
|
|
81,82%
|
63,64%
|
27,27%
|
36,36%
|
18,18%
|
18,18%
|
81,82%
|
45,45%
|
9,09%
|
|
|
98,00%
|
93,00%
|
85,00%
|
96,00%
|
91,00%
|
82,00%
|
71,00%
|
76,00%
|
21,00%
|
|
|
97,30%
|
59,46%
|
48,65%
|
83,78%
|
37,84%
|
35,14%
|
67,57%
|
29,73%
|
10,81%
|
|
|
100,00%
|
25,00%
|
25,00%
|
0,00%
|
0,00%
|
0,00%
|
100,00%
|
25,00%
|
25,00%
|
|
|
100,00%
|
0,00%
|
0,00%
|
0,00%
|
0,00%
|
0,00%
|
100,00%
|
0,00%
|
0,00%
|
|
|
70,59%
|
52,94%
|
17,65%
|
52,94%
|
29,41%
|
17,65%
|
52,94%
|
35,29%
|
0,00%
|
Относительные значения в виде столбиковых
диаграмм показаны на рисунке 21:
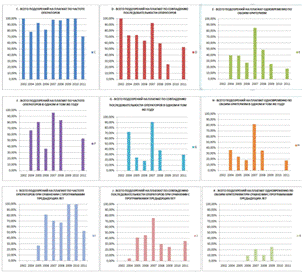
Рисунок 21 Относительные значения в виде
столбиковых диаграмм
6.3.5.1 Исследование итогового
протокола по полученным диаграммам Excel
Проанализируем полученные результаты. При этом
мы не будем учитывать годы 2002, 2006,2009,2010,2011, так как мы имеем
недостаточное количество работ по этим годам. Будем учитывать только 2004,
2005, 2007,2008 год.
· С - ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО ЧАСТОТЕ
ОПЕРАТОРОВ БЕЗ УЧЕТА ГОДОВ: незначительный пик процента подозрительных программ
к общему числу проанализированных программ наблюдается в 2007 году.
· D - ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО
СОВПАДЕНИЮ ПОСЛЕДОВАТЕЛЬНОСТИ ОПЕРАТОРОВ БЕЗ УЧЕТА ГОДОВ: ярко выраженный пик
процента подозрительных программ к общему числу проанализированных программ
наблюдается в 2007 году.
· E - ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ
ОДНОВРЕМЕННО ПО ОБОИМ КРИТЕРИЯМ БЕЗ УЧЕТА ГОДОВ: ярко выраженный пик процента
подозрительных программ к общему числу проанализированных программ наблюдается
в 2007 году.
· F - ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО
ЧАСТОТЕ ОПЕРАТОРОВ В ОДНОМ И ТОМ ЖЕ ГОДУ: ярко выраженный пик процента
подозрительных программ к общему числу проанализированных программ наблюдается
в 2007 году. Видимо курс был либо очень «дружный» либо очень слабый, и поэтому
студенты активно списывали друг у друга.
· G - ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО
СОВПАДЕНИЮ ПОСЛЕДОВАТЕЛЬНОСТИ ОПЕРАТОРОВ В ОДНОМ И ТОМ ЖЕ ГОДУ: ярко выраженный
пик процента подозрительных программ к общему числу проанализированных программ
наблюдается в 2007 году. Видимо, курс был либо очень «дружный» либо очень
слабый, и поэтому студенты активно списывали друг у друга.
· H - ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ
ОДНОВРЕМЕННО ПО ОБОИМ КРИТЕРИЯМ В ОДНОМ И ТОМ ЖЕ ГОДУ: ярко выраженный пик
процента подозрительных программ к общему числу проанализированных программ
наблюдается в 2007 году. Видимо, курс был либо очень «дружный» либо очень
слабый, и поэтому студенты активно списывали друг у друга.
· I - ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО
ЧАСТОТЕ ОПЕРАТОРОВ ПРИ СРАВНЕНИИ С ПРОГРАММАМИ ПРЕДЫДУЩИХ ЛЕТ: пик процента
подозрительных программ к общему числу проанализированных программ наблюдается
в 2007 году.
· J - ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ ПО
СОВПАДЕНИЮ ПОСЛЕДОВАТЕЛЬНОСТИ ОПЕРАТОРОВ ПРИ СРАВНЕНИИ С ПРОГРАММАМИ ПРЕДЫДУЩИХ
ЛЕТ: пик процента подозрительных программ к общему числу проанализированных
программ наблюдается в 2007 году.
· K - ВСЕГО ПОДОЗРЕНИЙ НА ПЛАГИАТ
ОДНОВРЕМЕННО ПО ОБОИМ КРИТЕРИЯМ ПРИ СРАВНЕНИИ С ПРОГРАММАМИ ПРЕДЫДУЩИХ ЛЕТ: пик
процента подозрительных программ к общему числу проанализированных программ
наблюдается в 2007 году.
6.3.6 Экспорт
списка первоисточников в Excel
Ниже (таблица 10 в Приложении 5) приведен список
первоисточников в первоначальном виде и без дубликатов, полученный после
экспорта в Excel. Красным
цветом выделены (но здесь показаны не все) программы студентов, которые явно (с
большой долей вероятности) были списаны с других программ.
6.3.6.1 Исследование списка
первоисточников в Excel
Число первоисточников без дубликатов - 211, а
число изучаемых файлов - 283. Отсюда можно сделать вывод о том, что хотя
плагиат присутствует в работах студентов, но он достаточно невелик (около 25%).
B
75% случаев студент сам пишет программы.
Полученное число первоисточников равное 211 хорошо
согласуется с другими данными проведенного анализа. А именно, если посмотрим на
сумму в столбце E, равную 144: в
этом столбце приведены данные о числе работ, в которых найдены признаки
плагиата по двум критериям. Учтем, что фактически число работ с плагиатом здесь
учтены дважды, поэтому реальное число списанных работ равно 72. Если вычесть
это число из общего числа работ, то как раз и получим полученное число
первоисточников равное 211.
Отметим еще, что не надо рассматривать очень
короткие программы, которые, по сути дела, представляют собой просто шаблонные
заготовки, генерируемые инструментальной средой (такой как Delphi).
.4 Пример работы
модуля
Примеры работа программы даны на основе базы
работ студентов по предмету «Защита информации», сданных в ВУЗе. База содержит
не все работы прошлых лет, а только некоторые, сохранившиеся у преподавателя,
однако это не помешало обнаружить плагиат.
.4.1 Пример 1
анализа последовательности операторов
Пример 1 анализа последовательности операторов
приведен на рисунке 22.
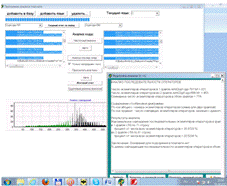
Рисунок 22 Пример 1 анализа последовательности
операторов
Отчет программы:
Максимальное совпадение последовательности
операторов в файлах обнаружено в 1 файле с 50 по 71 строку, во 2 файле c
59 по 81 строку.
*************** 1 Файл:
***************(Static3!=NULL)
Static3->Create("Результат",WS_CHILD|WS_VISIBLE|SS_CENTER,
CRect(495,5,880,20),this);= new CEdit();(Edit3!=NULL)
Edit3->Create(WS_CHILD|WS_VISIBLE|WS_BORDER|ES_MULTILINE, CRect(60,530,590,550),this,IDC_EDIT3);=
new CStatic();(Static1!=NULL)
Static1->Create("Ключ",WS_CHILD|WS_VISIBLE|SS_CENTER,
CRect(10,530,60,550),this);= new CButton();(Button1!=NULL)
Button1->Create("Шифрование",WS_CHILD|WS_VISIBLE|SS_CENTER,
CRect(60,560,230,580),this,IDC_BUTTON1);= new CButton();(Button2!=NULL)
Button2->Create("Выход",WS_CHILD|WS_VISIBLE|SS_CENTER,
CRect(610,600,780,620),this,IDC_BUTTON2);= new CButton();(Button3!=NULL)
Button3->Create("Таблица Вижинера",WS_CHILD|WS_VISIBLE|SS_CENTER,
CRect(610,530,780,550),this,IDC_BUTTON3);= new CButton();(Button4!=NULL)
Button4->Create("Расшифровать
ключом",WS_CHILD|WS_VISIBLE|SS_CENTER,
CRect(240,560,410,580),this,IDC_BUTTON4);= new CButton();(Button6!=NULL)
Button6->Create("<<",WS_CHILD|WS_VISIBLE|SS_CENTER,
CRect(400,250,490,300),this,IDC_BUTTON6);
*************** 2 Файл:
***************(Static2!=NULL) Static2->Create("Исходный
текст",WS_CHILD|WS_VISIBLE|SS_CENTER, CRect(10,5,395,20),this);3
= new CStatic();
// это заголовок правого окна - "Результат"
if (Static3!=NULL) Static3->Create("Результат",WS_CHILD|WS_VISIBLE|SS_CENTER,
CRect(495,5,880,20),this);3 = new
CEdit();
// аналогично Edit1 - это
текстовое поле для ключа
if (Edit3!=NULL)
Edit3->Create(WS_CHILD|WS_VISIBLE|WS_BORDER|ES_MULTILINE,
CRect(60,530,590,550),this,IDC_EDIT3);1 = new
CStatic();
// аналогично для Static2
- это поле "Ключ" справа от текстового поля для ключа
if (Static1!=NULL)
Static1->Create("Ключ",WS_CHILD|WS_VISIBLE|SS_CENTER,
CRect(10,530,60,550),this);
// Кнопка Шифрование - делается аналогично
предыдущим элеменат, только создается объекст CButton
Button1 = new
CButton();
// создаем объект и рисуем его функцией Create
и связываем с константой IDC_BUTTON1
if (Button1!=NULL)
Button1->Create("Шифрование",WS_CHILD|WS_VISIBLE|SS_CENTER,
CRect(60,560,230,580),this,IDC_BUTTON1);2 = new
CButton();
// создаем объект и рисуем его функцией Create
и связываем с константой IDC_BUTTON2
if (Button2!=NULL)
Button2->Create("Выход",WS_CHILD|WS_VISIBLE|SS_CENTER,
CRect(610,600,780,620),this,IDC_BUTTON2);3 = new
CButton();
// создаем объект и рисуем его функцией Create
и связываем с константой IDC_BUTTON3
if (Button3!=NULL)
Button3->Create("Генерация ключа",WS_CHILD|WS_VISIBLE|SS_CENTER,
CRect(610,530,780,550),this,IDC_BUTTON3);4 = new
CButton();
// создаем объект и рисуем его функцией Create
и связываем с константой IDC_BUTTON4
if (Button4!=NULL)
Button4->Create("Расшифровать
ключом",WS_CHILD|WS_VISIBLE|SS_CENTER,
CRect(240,560,410,580),this,IDC_BUTTON4);
+++ Информация о файлах +++
_______________ 1 Файл: _______________
С
Группа: ВВ-5-02
Тема: Крипт2
Автор: Боловинцев
Дополнительная информация:
Путь: C:\Documents
and
Settings\Владимир\Рабочий
стол\BAZA\Лабы\VV-5-02\bolovincev\Crypt2\Crypt.cpp
Размер: 7288 Байт
Изменен: 18.04.2006 13:00:44
_______________ 2 Файл: _______________
С
Группа: ВВ-5-02
Тема: крипт1
Автор: Ахметов
Дополнительная информация:
Путь: C:\Documents
and
Settings\Владимир\Рабочий
стол\BAZA\Лабы\VV-5-02\KomissandAhmetov\мис
зки\1Crypt(comment)\Crypt(comment)\Crypt.cpp
Размер: 17448 Байт
Изменен: 24.03.2006 14:53:34
Очевидно, что во втором файле в совпавшем
фрагменте добавлены комментарии, и судя по датам последних изменений в файлах,
можно предположить, что Боловинцев списал у Ахметова.
.4.2 Пример 2
автоматического анализа частот появления операторов
Пример 2 автоматического анализа частот
появления операторов показан на рисунке 23.
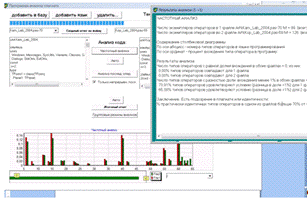
Рисунок 23 Пример 2 автоматического анализа
частот появления операторов
7
ПРОГРАММНАЯ РЕАЛИЗАЦИЯ МОДУЛЯ PLAGIATSEARCH
ПОИСКА ПЛАГИАТА МЕТОДАМИ СРАВНЕНИЯ ПРОИЗВОЛЬНЫХ ТЕКСТОВ
.1 Интерфейс модуля
PlagiatSearch
поиска плагиата методами сравнения произвольных текстов
.1.1 Главное окно
модуля PlagiatSearch
поиска плагиата методами сравнения произвольных текстов
Модуль PlagiatSearch
поиска плагиата методами сравнения произвольных текстов реализован на языке
программирования - Delphi.
В верхней части диалогового окна (рисунок 24) находится панель меню (1), ниже
панель быстрого доступа к наиболее важным функциям меню (2), в правом верхнем
углу после выполнения некоторых действий. Главное окно в средней части - это
тексты сравниваемых текстовых файлов с номерами строк (3). В самом низу
находятся информация с некоторыми комментариями по выполненным действиям (4).
Важным элементом интерфейса является checkbox
‘Текст’ в левой верхней части окна: если флажок установлен, то сравниваемые
файлы рассматриваются как произвольные тексты (рисунок 24, a)
и тогда их выбор можно осуществлять либо через опцию меню “Файл” или через
пиктораммы ‘1’ или ‘2’ на панели быстрого доступа (5).
Меню «Файл» позволяет выполнять основные функции
работы с файлами: открыть сравниваемые файлы (6), сравнить по Левенштейну (7) и
методом шинглов (8). Для исходных кодов можно также выполнить операцию
токенизации (смотрите раздел 4.8). Меню «Просмотр» предлагает удобные средства
перемещения по файлу («Перемещается по измененным частям сравниваемых файлов» и
на указанные строки в файлах). Меню «Опции и параметры» позволяют задать
параметры сравнения файлов по Левенштейну (игнорировать - Регистры и пробелы),
задать весовые коэффициенты Дамерау и размер шинглов. Меню «Методы сравнения»
задает один из реализованных алгоритмов вычисления дистанции Левенштейна (O(NP)
[29] или O(ND)
[28]).
Если флажок не установлен (как на рисунке 24, b),
то сравниваемые файлы рассматриваются как тексты исходных кодов и тогда выбор
возможен только из базы данных исходных кодов (8). При этом можно выбрать язык
программирования (9).
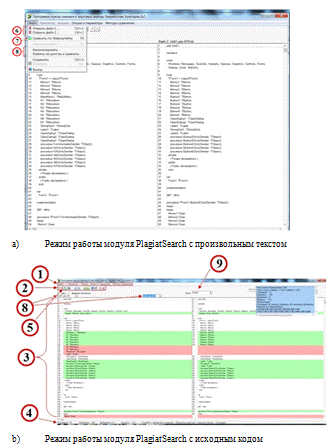
Рисунок 24 Главное окно модуля PlagiatSearch
поиска плагиата методами сравнения произвольных текстов
Первый и основной алгоритм O(NP)
[29], реализованный в дипломе и являющийся модификацией алгоритма
Вагнера-Фишера, позволяет в большинстве случаев почти в два раза сократить
время выполнения по сравнению с алгоритмом O(ND)
[28]. Пусть A и B
будет две последовательности длины M
и N соответственно,
где без потери общности N
>=M, и пусть D
- длина кратчайшего сценария редактирования между ними (shortest
edit
script).
Параметр P, связанный с D
- это количество удалений в таком сценарии, P
= D/2 −(N
−M)/2.
Алгоритм нахождения кратчайшего расстояния редактирования A
и B имеет в худшем
случае время выполнения O(NP)
и чьи ожидаемое время O (N
+PD). Алгоритм прост и
является очень эффективным, особенно когда A
похож на B. То есть, как раз
в случае подозрений на плагиат.
Второй алгоритм O(ND)
[28], реализованный в дипломе и являющийся модификацией алгоритма
Вагнера-Фишера, имеет ожидаемое время выполнения O(ND),
где N - сумма длин
последовательностей A и B,
а D - длина
кратчайшего сценария редактирования между ними.
7.1.2 Меню «Анализ»
и его возможности для поиска плагиата в произвольных текстах
Меню «Анализ» (рисунок 25) становится доступным
и применяется после выполнения сравнения произвольных текстов по Левенштейну.
Рисунок 25 Меню «Анализ»
Это меню включает следующие опции:
· Вычислить расстояние Левенштейна;
Результат вычисления этого расстояния может
интерпретироваться следующим образом: если оно мало, то можно предположить, что
второй файл получается из первого файла за минимальное число действий
(удаление-изменение-добавление).
· Вычислить расстояние Дамерау;
Результат вычисления этого расстояния может
интерпретироваться следующим образом: если оно мало, то можно предположить, что
второй файл получается из первого файла за минимальное число действий с
весовыми коэффициентами (удаление-изменение-добавление). В отличие от простого
расстояния Левенштейна расстояние Дамерау позволяет учитывать при поиске
плагиата разный вес действий. Например, можно считать, что «добавление» имеет
меньшее значение с точки зрения поиска плагиата, чем изменение. Поэтому в этом
случае весовой коэффициент операции «добавления» должен быть больше, чем
весовой коэффициент операции «изменение». Чем больше операций «добавление» при
сравнении файлов и вычислении для них расстояния Дамерау, тем больше будет
значение расстояния Дамерау. Следовательно, тем менее похожими можно считать
сравниваемые файлы.
· Вычислить длину LCS (наибольшей
общей подпоследовательности, longest common subsequence)
· Показать все совпадающие строки
Смысл введения этой опции следующий: показать,
для каждой строки в файле 1 ее дубликаты, которые есть во втором файле. В
информационном окне наличие дубликатов представляется следующим образом: если
для строки файла 1 есть идентичные строки в файле 2, то они указаны в
квадратных скобах через знак равенства. Например, для строки с номером 71 в
файле 1 есть идентичная строка в файле 2 с номером 34: [71]=[34] . Кроме того,
после выполнения операции поиска совпадающих строк вычисляется длина и место
максимального непрерывного фрагмента совпадающих строк (Максимальная длина в
строках непрерывного фрагмента совпадающих строк ->5 со строки 33) и фокус в
главном окне модуля переводится на это место (рисунок 26). В нашем случае этот
фрагмент начинается со строки 33 и имеет длину 5 строк.
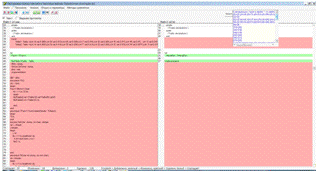
Рисунок 26 Поиск всех совпадающих строк в файлах
и показ максимального непрерывного фрагмента совпадающих строк
Пример результата в информационном
окне показан ниже (синим цветом).
Совпадающие строки в файле 1 и в файле 2:
[2]=[2] [2]=[4] [2]=[7] [2]=[23] [2]=[26]
[2]=[28] [2]=[30] [2]=[32] [2]=[38]
[3]=[3]
[4]=[2] [4]=[4] [4]=[7] [4]=[23] [4]=[26]
[4]=[28] [4]=[30] [4]=[32] [4]=[38]
[8]=[2] [8]=[4] [8]=[7] [8]=[23] [8]=[26]
[8]=[28] [8]=[30] [8]=[32] [8]=[38]
[9]=[8]
[13]=[22]
[33]=[18]
[34]=[19]
[35]=[20]
[36]=[21]
[37]=[22]
[41]=[2] [41]=[4] [41]=[7] [41]=[23] [41]=[26]
[41]=[28] [41]=[30] [41]=[32] [41]=[38]
[42]=[2] [42]=[4] [42]=[7] [42]=[23] [42]=[26]
[42]=[28] [42]=[30] [42]=[32] [42]=[38]
[43]=[24]
[45]=[2] [45]=[4] [45]=[7] [45]=[23] [45]=[26]
[45]=[28] [45]=[30] [45]=[32] [45]=[38]
[51]=[2] [51]=[4] [51]=[7] [51]=[23] [51]=[26]
[51]=[28] [51]=[30] [51]=[32] [51]=[38]
[52]=[31]
[55]=[34]
[61]=[2] [61]=[4] [61]=[7] [61]=[23] [61]=[26]
[61]=[28] [61]=[30] [61]=[32] [61]=[38]
[63]=[37]
[65]=[34]
[67]=[37]
[71]=[34]
[76]=[2] [76]=[4] [76]=[7] [76]=[23] [76]=[26]
[76]=[28] [76]=[30] [76]=[32] [76]=[38]
[77]=[2] [77]=[4] [77]=[7] [77]=[23] [77]=[26]
[77]=[28] [77]=[30] [77]=[32] [77]=[38]
[78]=[2] [78]=[4] [78]=[7] [78]=[23] [78]=[26]
[78]=[28] [78]=[30] [78]=[32] [78]=[38]
[79]=[37]
[82]=[34]
[85]=[2] [85]=[4] [85]=[7] [85]=[23] [85]=[26]
[85]=[28] [85]=[30] [85]=[32] [85]=[38]
[86]=[37]
[88]=[34]
[90]=[37]
[91]=[2] [91]=[4] [91]=[7] [91]=[23] [91]=[26]
[91]=[28] [91]=[30] [91]=[32] [91]=[38]
[93]=[34]
[101]=[37]
[102]=[2] [102]=[4] [102]=[7] [102]=[23]
[102]=[26] [102]=[28] [102]=[30] [102]=[32] [102]=[38]
[109]=[2] [109]=[4] [109]=[7] [109]=[23]
[109]=[26] [109]=[28] [109]=[30] [109]=[32] [109]=[38]
[125]=[2] [125]=[4] [125]=[7] [125]=[23]
[125]=[26] [125]=[28] [125]=[30] [125]=[32] [125]=[38]
[131]=[2] [131]=[4] [131]=[7] [131]=[23]
[131]=[26] [131]=[28] [131]=[30] [131]=[32] [131]=[38]
[132]=[2] [132]=[4] [132]=[7] [132]=[23]
[132]=[26] [132]=[28] [132]=[30] [132]=[32] [132]=[38]
[134]=[37]
[135]=[2] [135]=[4] [135]=[7] [135]=[23]
[135]=[26] [135]=[28] [135]=[30] [135]=[32] [135]=[38]
[139]=[34]
[151]=[2] [151]=[4] [151]=[7] [151]=[23]
[151]=[26] [151]=[28] [151]=[30] [151]=[32] [151]=[38]
[154]=[37]
[155]=[2] [155]=[4] [155]=[7] [155]=[23]
[155]=[26] [155]=[28] [155]=[30] [155]=[32] [155]=[38]
[156]=[39]
Всего найдено совпадающих строк в файле 1 и в
файле 2 ->215
Максимальная длина в строках непрерывного
фрагмента совпадающих строк ->5 со строки 33
· Показать все удаленные в файле 1
строки, которые были добавлены в файле 2.
Смысл введения этой опции следующий: некоторые
удаленные из файла 1 строки могут быть просто перемещены в другое место в файле
2. При сравнении файлов по Левенштейну это подозрительное с точки зрения поиска
плагиата действие не будет обнаружено. В информационном окне это представляется
следующим образом: если для удаленной строки файла 1 есть добавленные строки в
файле 2, то они указаны в квадратных скобах через знак равенства. Например, для
удаленной строки с номером 52 в файле 1 есть добавленная строка в файле 2 с
номером 31: [52]=[31].
Пример результата в информационном окне показан
ниже (синим цветом).
Удаленные строки в файле 1 среди добавленных в
файле 2:
[41]=[2] [41]=[4] [41]=[7] [41]=[23] [41]=[26]
[41]=[28] [41]=[30] [41]=[32] [41]=[38]
[51]=[2] [51]=[4] [51]=[7] [51]=[23] [51]=[26]
[51]=[28] [51]=[30] [51]=[32] [51]=[38]
[52]=[31]
[55]=[34]
[61]=[2] [61]=[4] [61]=[7] [61]=[23] [61]=[26]
[61]=[28] [61]=[30] [61]=[32] [61]=[38]
[63]=[37]
[65]=[34]
[67]=[37]
[71]=[34]
[76]=[2] [76]=[4] [76]=[7] [76]=[23] [76]=[26]
[76]=[28] [76]=[30] [76]=[32] [76]=[38]
[77]=[2] [77]=[4] [77]=[7] [77]=[23] [77]=[26]
[77]=[28] [77]=[30] [77]=[32] [77]=[38]
[78]=[2] [78]=[4] [78]=[7] [78]=[23] [78]=[26]
[78]=[28] [78]=[30] [78]=[32] [78]=[38]
[79]=[37]
[82]=[34]
[85]=[2] [85]=[4] [85]=[7] [85]=[23] [85]=[26]
[85]=[28] [85]=[30] [85]=[32] [85]=[38]
[86]=[37]
[88]=[34]
[90]=[37]
[91]=[2] [91]=[4] [91]=[7] [91]=[23] [91]=[26]
[91]=[28] [91]=[30] [91]=[32] [91]=[38]
[93]=[34]
[101]=[37]
[102]=[2] [102]=[4] [102]=[7] [102]=[23]
[102]=[26] [102]=[28] [102]=[30] [102]=[32] [102]=[38]
[109]=[2] [109]=[4] [109]=[7] [109]=[23]
[109]=[26] [109]=[28] [109]=[30] [109]=[32] [109]=[38]
[125]=[2] [125]=[4] [125]=[7] [125]=[23]
[125]=[26] [125]=[28] [125]=[30] [125]=[32] [125]=[38]
[135]=[2] [135]=[4] [135]=[7] [135]=[23]
[135]=[26] [135]=[28] [135]=[30] [135]=[32] [135]=[38]
[139]=[34]
[151]=[2] [151]=[4] [151]=[7] [151]=[23]
[151]=[26] [151]=[28] [151]=[30] [151]=[32] [151]=[38]
[154]=[37]
Всего найдено удаленных строк в файле 1 среди
добавленных в файле 2 ->132
7.1.3
Информационное окно модуля PlagiatSearch
поиска плагиата в произвольных текстах с результатами вычисления дистанции
Левенштейна
Результаты вычисления дистанции Левенштейна в
информационном окне имеют следующую структуру (покажем на конкретном примере):
Расстояние Левенштейна =254
Число строк: в файле 1 =332; в файле 2 =227
Совпадает : 73;
Изменено : 146;
Добавлено : 8;
Удалено : 113;
Комментарий к средней части главного окна:
Совпадает (N,
белый), Изменено (M, зеленый),
Добавлено (A, голубой),
Удалено (D, красный)
Решение (по
Левенштейну)
[1]N [2]N [3]N [4]N [5]N [6]N [7]M
[8]N [9]N [10]N
[11]N [12]N [13]N [14]N [15]M [16]M
[17]M [18]M [19]M [20]M
[21]D [22]D [23]D [24]D [25]N [26]N
[27]M [28]M [29]M [30]M
[31]M [32]M [33]M [34]M [35]N [36]N
[37]N [38]N [39]N [40]N
[41]N [42]N [43]N [44]N [45]N [46]N
[47]N [48]M [49]N [50]D
[51]D [52]D [53]D [54]D [55]D [56]D
[57]D [58]N [59]N [60]N
[61]N [62]N [63]M [64]D [65]D [66]N
[67]N [68]A [69]N [70]N
[71]M [72]M [73]D [74]N [75]D [76]D
[77]D [78]D [79]D [80]D
[81]D [82]N [83]M [84]A [85]N [86]D
[87]D [88]D [89]D [90]D
[91]D [92]D [93]D [94]D [95]D [96]D
[97]D [98]D [99]D [100]D
[101]D [102]D [103]D [104]D [105]D
[106]D [107]D [108]D [109]N [110]M
[111]M [112]M [113]M [114]M [115]M
[116]M [117]D [118]D [119]D [120]D
[121]D [122]D [123]D [124]N [125]D
[126]D [127]D [128]D [129]D [130]D
[131]N [132]N [133]M [134]N [135]N
[136]N [137]N [138]N [139]N [140]N
[141]N [142]N [143]N [144]N [145]N
[146]N [147]N [148]M [149]M [150]M
[151]M [152]M [153]M [154]M [155]M
[156]M [157]M [158]M [159]M [160]M
[161]M [162]M [163]M [164]M [165]M
[166]M [167]M [168]M [169]D [170]D
[171]D [172]D [173]D [174]D [175]D
[176]D [177]D [178]D [179]D [180]D
[181]D [182]D [183]D [184]D [185]D
[186]N [187]M [188]M [189]M [190]M
[191]M [192]M [193]M [194]M [195]M
[196]M [197]M [198]A [199]A [200]A
[201]N [202]M [203]M [204]M [205]A
[206]N [207]N [208]M [209]N [210]M
[211]M [212]M [213]M [214]M [215]N
[216]N [217]M [218]M [219]M [220]M
[221]M [222]M [223]M [224]M [225]M
[226]M [227]M [228]M [229]M [230]M
[231]M [232]M [233]M [234]M [235]M
[236]M [237]M [238]M [239]M [240]M
[241]M [242]M [243]D [244]D [245]D
[246]D [247]N [248]M [249]M [250]D
[251]D [252]D [253]N [254]M [255]M
[256]M [257]M [258]M [259]M [260]M
[261]M [262]M [263]M [264]M [265]M
[266]M [267]M [268]M [269]M [270]M
[271]M [272]M [273]M [274]M [275]M
[276]M [277]M [278]D [279]D [280]D
[281]D [282]D [283]D [284]D [285]D
[286]D [287]D [288]D [289]D [290]D
[291]D [292]D [293]D [294]D [295]D
[296]D [297]D [298]D [299]D [300]D
[301]D [302]D [303]D [304]D [305]D
[306]D [307]D [308]N [309]M [310]M
[311]M [312]M [313]M [314]M [315]M
[316]M [317]M [318]M [319]M [320]M
[321]M [322]M [323]M [324]M [325]M
[326]M [327]M [328]M [329]M [330]M
[331]M
[332]M [333]M
[334]A [335]N
[336]D [337]N
[338]N [339]N
[340]A
Результаты имеют следующий смысл: показаны
последовательные действия со строками (начиная с первой и до последней),
которые выполняются над строками первого текстового файла для того, чтобы
получить второй текстовый файл:
· Cимволом N (и белым цветом в главном окне
модуля) обозначается строка в первом файле, которая переносится во второй файл
без изменений. Число таких строк - это длина наибольшей общей
подпоследовательности (longest common subsequence, LCS). Также это число
показано в строке «Совпадает» (в нашем примере - 73).
· Cимволом M (и зеленым цветом в
главном окне модуля) обозначается строка в первом файле, которая переносится во
второй файл с изменениями;
· Cимволом A (и голубым цветом в
главном окне модуля) обозначается добавленная к первому файлу строка (которой,
естественно, не было в первом файле, но которая была во втором файле ), которая
переносится во второй файл без изменений;
· Cимволом D (и красным цветом в
главном окне модуля) обозначается строка в первом файле, которая была из него
удалена и которой теперь не будет во втором файле
Как нетрудно видеть, число номеров (в нашем
случае - 340) в результате вычисления дистанции Левенштейна равно сумме числа
строк в первом файле (в нашем примере - 332) плюс число добавленных строк (в
нашем случае 8).
7.1.4 Представление
результатов нахождения наибольшей общей подпоследовательности (longest common
subsequence, LCS)
При вычислении дистанции Левенштейна
одновременно получается наибольшая общая подпоследовательность (longest
common
subsequence,
LCS)
двух сравниваемых файлов. В основном окне модуля наибольшая общая
подпоследовательность - это все строки белого цвета. То есть все строки,
которые одновременно входят без каких-либо изменений в оба файла. Длина LCS
- это число строк белого цвета в главном окне модуля. Также это число показано
в строке «Совпадает» (в нашем примере на - 73).
7.1.5 Представление
метода шинглов для сравнения произвольных текстов
Результатом сравнения файлов методом шинглов
является одно число - процент одинаковых шинглов в обеих файлах. Если этот
процент велик (например, 50%), то возникает подозрение на плагиат. При этом,
конечно, этот процент зависит от длины шингла и показывается в информационном
окне при применении метода. В реализованном модуле можно самостоятельно
выбирать длину шингла (Рисунок 27).
Рисунок 27 Выбор длины шинглов
.1.6 Применение
метода шинглов для сравнения исходных кодов
Метод шинглов для сравнения исходных кодов может
применяться как к самим исходным текстам (рисунок 28), так и к
токенизированному представлению (рисунки 29, 30). Белым цветом показаны шинглы,
которые имеют дубликаты в другом сравниваемом файле.
Рисунок 28 Сравнение исходных кодов методом
шинглов
Рисунок 29 Токенизированное представление
исходных кодов

Рисунок 30 Сравнение токенизированного
представления исходных кодов методом шинглов
ЗАКЛЮЧЕНИЕ
В результате выполнения магистерской диссертации
автором выполнены следующие работы и получены следующие результаты:
1) Усовершенствованы инструментальные средства
анализа исходных кодов программ в части реализации возможностей наглядной
визуальной оценки проверяющим;
2) Реализован набор инструментов анализа
исходных кодов программ, который состоит из двух взаимно дополняющих модулей:
первый анализирует исходный код методами анализа исходных кодов, а второй
позволяет анализировать этот же исходный код методами анализа произвольных
текстов.
) В работе предложен и реализован в виде
самостоятельного модуля алгоритм поиска заимствованных фрагментов в исходных
кодах программ, интегрирующий структурный анализ кодов (на основе токенов) и
методы шинглов, дистанции Левенштейна и наибольшей общей подпоследовательности
(longest common subsequence, LCS) для анализа произвольных текстов.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
(БИБЛИОГРАФИЧЕСКИЙ СПИСОК)
1. Макаров
В.В. Идентификация заимствований в прикладных программах, ИПУ РАН, УДК 001(06),
Телекоммуникационные и новые информационные технологии.
2. Макаров
В.В. Идентификация дублирования и плагиата в исходном тексте прикладных
программ - Москва: Институт
проблем управления РАН, 1999.
3. Красс
А. Обзор автоматических детекторов плагиата в программах.
#"787347.files/image042.gif">