Параллельный алгоритм поиска косяком рыб
Введение
Алгоритм поиска косяком рыб, разработанный в 2002 году, -
стохастический алгоритм оптимизации, основанный на поведении косяка рыб. Со
временем стало понятно, что, с ростом измерений и популяций, время выполнения
неуклонно растёт.
Современные графические процессоры превратились в сильно
распараллеленные, многопотоковые и многоядерные процессоры с невероятной
вычислительной мощностью и пропускной способностью памяти. В связи с этим,
инженеры и ученые заинтересовались тем, чтобы использовать графические
процессоры для вычислений общего назначения. Для облегчения выполнения данной
задачи были разработаны некоторые технологии, такие как CUDA (Compute Unified Device Architecture), поддерживаемая NVIDIA.
В данной работе представлен неизведанный ранее способ запуска
алгоритма поиска косяком рыб на параллельных графических процессорах и
выполнение его в CUDA.
программа графический
алгоритм
1.
Введение в CUDA
В последнее время возможностью для ускорения работы
приложений стали графические процессоры (ГПУ), которые, в первую очередь,
благодаря своему параллельному вычислительному механизму и быстрым выполнением
операций с плавающей точкой, были успешно использованы в различных приложениях
для самых разных областей, начиная физикой и заканчивая финансами.
Несмотря на усилия по созданию интерфейса программирования
приложений на ГПУ, программирование на CUDA так и оставалось
довольно трудозатратным. Для преодоления сложностей, связанных с
программированием на ГПУ, компания NVIDIA представила параллельную вычислительную
платформу общего пользования, называющуюся CUDA. CUDA позволяет автоматически
распределять и управлять потоками в ГПУ.
CUDA позволяет программам напрямую взаимодействовать
с командами ГПУ, используя при этом минимальный набор расширений. У CUDA есть 3 главные
абстракции: иерархия групп потоков, разделяемая память и барьеры для
синхронизации NVIDIA. Эти абстракции позволяют разделить задачу на подзадачи, которые,
в свою очередь, могут быть решены независимо и параллельно. Каждая подзадача
затем может быть разбита на операции, решаемые параллельно всеми потоками из
блока.
Главным узким местом в архитектуре CUDA является передача данных
между хостом (ЦПУ) и ГПУ. Любая передача данных от ЦПУ к ГПУ снижает
производительность, таким образом нужно стараться избегать данной операции. В
частности, в качестве альтернативы можно назвать перемещение некоторых операций
из ЦПУ на ГПУ. Даже если такой подход кажется нелогичным или не обеспечивающим
достаточное распараллеливание задачи, генерация данных на ГПУ будет выполняться
быстрее, нежели передача данных.
Платформа CUDA представляет вполне определенную иерархию
памяти, которая включает в себя различные типы памяти ГПУ, при этом время
доступа к этим различным типам памяти разнится. Каждый поток имеет свою встроенную
память, а каждый блок поток имеет разделяемую память, доступную всем потокам
внутри блока. Также все потоки имеют доступ к одной и той же глобальной памяти.
Все эти пространства для памяти подчинены следующим правилам: самой быстрой
является встроенная память, а самой медленной глобальная; наименее
вместительной, соответственно, будет встроенная, а наибольшим объёмом обладает
глобальная память.
Очень важным аспектом является необходимость установки
барьеров синхронизации. Его суть состоит в том, что он заставляет поток ждать,
пока все потоки из блока достигнут барьер. Это гарантирует правильность
выполнения алгоритма на ГПУ, но может ухудшить показатели производительности.
2.
Выполнение алгоритма с использованием CUDA
Нашей целью является ускорение процесса выполнения алгоритма
посредством запуска оптимизационного процесса на параллельных графических
процессорах.
Объявление
переменных и констант
Положим, что:
) значения фитнесс функции, которую мы обозначим как f(X), лежат в области [-r; r];
) размерности задачи D;
) размер популяции N.
Тогда объявим переменные:
· X: массив состояний рыбки
· ХР: массив состояний добычи рыбок
· XS: массив состояний роя
рыбок
· XF: массив перемещений рыбки
· DIST: массив расстояний,
преодоленных рыбкой
· TESTF: массив фитнесс-функции
рыбки.
Размер X, XP, XS и XF равны 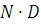 ; размер DIST равен
; размер DIST равен 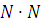 ; размер TESTF равен
; размер TESTF равен 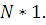 Переменные X,
XP,
XS, XF можно представить в виде
матрицы с N
строками и D
столбцами.
Переменные X,
XP,
XS, XF можно представить в виде
матрицы с N
строками и D
столбцами.
Важнейшим фактором, определяющим параллельную работу ядра,
является объявление размера блока и размера сетки. Уместным будет считать их
следующими:
· Block1
= (BS, BS, 1)
· Grid1 =
(WIDTH/BS + 1, HEIGHT/BS + 1,1)
· Grid2 =(N/BS
+ 1, N/BS + 1,1)
Здесь BS является шириной и длиной потокового блока, WIDTH и HEIGHT числом потоков Grid1 в направлении x и направлении y соответственно. С
глобальной точки зрения, алгоритму также понадобится переменная Ymin, которая будет использоваться
для хранения оптимального значения фитнесс функции. Также введем переменную iterNum, служащую ограничением
для максимального числа итераций запуска алгоритма на графических процессорах.
.
Генерация случайных чисел
Алгоритм требует большое количество случайных чисел во
времяего выполнения. К сожалению, графический процессор не имеет генератора
случайных чисел. В связи с тем, что передача данных от ЦПУ к ГПУ занимает
довольно много времени, верным с практической точки зрения решением будет
сгенерировать большое количество случайных чисел на ЦПУ и передать их в
качестве массива на ГПУ. Решается эта задача следующим образом: M случайных чисел
генерируются на ЦПУ до запуска алгоритма. Затем они один раз передаются на ГПУ,
а для хранения этих данных используется массив RAND, находящийся в
глобальной памяти. Когда функции ядра требуется случайное число, она может
получить его из массива RAND, передав указатель в качестве параметра, где
указатель 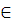 [0; M-N] - случайное целое
число, генерируемое на хосте.
[0; M-N] - случайное целое
число, генерируемое на хосте.
.
Структура алгоритма на ГПУ
Структура алгоритма на ГПУ представлена алгоритмом 1.
Подпроцессы в цикле for используются в качестве 7 функций ядра.
Алгоритм 1:
Инициализация случайных состояний рыб
Инициализация массива случайных чисел
Инициализация параметров алгоритма
Передача данных от ЦПУ к ГПУ
Ymin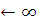
For iter 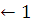 to iterNum
to iterNum
Do Рассчитать значения фитнесс функций всех рыб: TESTF
Обновить результат оптимизации: Ymin
Рассчитать расстояние между рыбами: DIST
Выполнить процесс кормления
Выполнить процесс индивидуального движения
Выполнить процесс коллективного движения
Обновить состояние каждой рыбы: Х
Передать Ymin обратно в ЦПУ и вывести
A. Объявления
ядер
Расчет значений фитнесс функций всех рыб
Мы устанавливаем значения размера сетки и размера блока
равными grid1 и block1 соответственно. Это означает, что при запуске ядра будет
выполнено N
потоков и каждый из них рассчитывает фитнесс функцию для рыбы.
Приведем описание алгоритма:
) Определяем, какое из значений фитнесс функции будем
рассчитывать: i
) Применяем арифметические операции к X[i] и храним посчитанные
значения фитнесс функции в TESTF[i].
Обновление результатов оптимизации
Устанавливаем размер сетки и блока равным 1, это означает,
что после запуска ядра будет выполняться только 1 поток. Это ядро сканирует
массив TESTF[i]
и записывает максимальную фитнесс функцию в Ymin
Расчет расстояния между рыбами
Размер сетки и размер блока принимаются grid2 и block1 соответственно. С
запуском ядра параллельно будут выполняться потоков, каждый поток
ссылается на уникальную пару рыбок и рассчитывает расстояние между ними. Для
преодоления латентности доступа к глобальной памяти, мы привязываем X к текстуре для
кэширования элементов X и получения их из текстуры в тот момент, когда нам это
нужно.
Приведём алгоритм:
) Определяем, для какой пары рыб необходимо найти
расстояние: (i1, i2)
2) If i1 ≥ N or i2 ≥
N or i2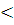 i1 then return
i1 then return
Рассчитываем расстояние между двумя рыбами (i1,
i2)
) Сохраняем результат в массив DIST: DIST[i1] [i2] и DIST[i2] [i1] соответственно.
Процесс добычи
Для реализации процесса добычи, каждой рыбе нужно 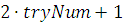 случайных чисел и, в
связи с этим, нужно подготовить такое же число случайных целых чисел, которые
будут служить указателями для массива RAND, хранящего большое число случайных чисел в
глобальной памяти ГПУ.
случайных чисел и, в
связи с этим, нужно подготовить такое же число случайных целых чисел, которые
будут служить указателями для массива RAND, хранящего большое число случайных чисел в
глобальной памяти ГПУ.
Приведём алгоритм процесса добычи:
) Определяем, для какой рыбы будет осуществлён процесс
добычи: i
2) 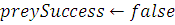
3) For 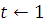 to tryNum
to tryNum
Do PREY(pr2t-1, pr2t, XP, i)
If preySuccess=falseXP[i]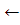 X[i] + RAND [r+i]
X[i] + RAND [r+i] 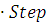
Процесс инстинктивно-коллективного перемещения
Приведём описание для алгоритма для функции, осуществляющей
коллективно-инстинктивное движение. Xc и nf здесь вляются центром
позиции спутников рыбы и числом спутников рыбы соответственно. Xc-X[i]
Алгоритм:
) Определяем процесс добычи для исполнения: i
2) 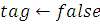
3) If i≥ N
Then return
Рассчитываем. Xc и nf
Then 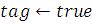
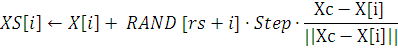
If
Then продолжать процесс добычи
Процесс инстинктивно-волевого перемещения
Приведем описание алгоритма для функции инстинктивно-волевого
перемещения. Здесь Xmin используется для записи состояния рыб с
минимальной фитнесс функцией, а Fmin - минимальная фитнесс функция компаньонов
данной рыбы.
Алгоритм:
) Определяем процесс добычи для выполнения
2)
3) If i≥ N
Then return
4) Находим компаньона рыбы с минимальной фитнесс
функцией
) Рассчитываем число компаньонов рыбы nf
If nf!= 0 and Fmin <
TESTF[i] and nf/N < д
Then
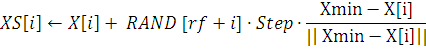
If 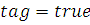 then выполнить процесс добычи
then выполнить процесс добычи
Обновление состояний всех рыб
Устанавливаем размер сетки и размера блока равным grid1 и block1 соответственно. После
запуска ядра будет выполнено N потоков, каждый из которых обновит состояние одной рыбы.
Приведём алгоритм функции.
Алгоритм:
) Определяем, позицию какой рыбы обновить: i
) Вычисляем фитнесс-значение XP[i] и храним результат в
разделяемой памяти pF[i]
) Вычисляем фитнесс-значение XS[i] и храним результат в
разделяемой памяти sF[i]
) Вычисляем фитнесс-значение XF[i] и храним результат в
разделяемой памяти fF[i]
) Сохраняем лучшее состояние из трёх вышеперечисленных
в переменную X[i]
.
Оценка производительности
Эксперименты для оценки производительности были запущены на
системе со следующей конфигурацией: Intel(R) Core(TM) 2 Duo CPU E7500 2.93 Ггц, с 4.0 ГБ RAM. Графический процессор -
NVIDIA GTX 260. Сравнение
производительности основано на четырех стандартных тестовых функциях (см.
таблицу 1)
Таблица 1. Тестовые функции
|
Название функции
|
Уравнение функции
|
Область поиска
|
|
Сфера
|
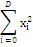
|
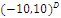
|
|
Растригина
|
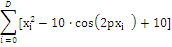
|
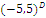
|
|
Гривонка
|
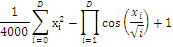
|
|
|
Розенброка
|
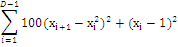
|
|
Время выполнения и ускорение в зависимости от размера популяции
Для измерения времени выполнения и ускорения в зависимости от
размера популяции, установим D=50 для всех экспериментов, а количество итераций iterNum положим равным 100. Шаг
и д положим 3.5 и 0.618 соответственно. Результаты представлены ниже, см.
таблицы 2,3,4,5.
Таблица 2. Результаты выполнения алгоритма на функции сферы
|
N
|
Время выполнения ЦПУ
|
Время выполнения ГПУ
|
Ускорение
|
Результат на ЦПУ
|
Результат на ГПУ
|
|
1500
|
140.042
|
5.810
|
24.103
|
1.28е-005
|
1.16е-005
|
|
2000
|
254.140
|
8.754
|
29.031
|
4.23е-006
|
3.37е-006
|
|
2500
|
358.110
|
12.778
|
28.025
|
1.95е-006
|
1.77е-006
|
|
3000
|
561.158
|
17.431
|
32.192
|
2.39е-007
|
Таблица 3. Результаты выполнения алгоритма на функции
Растригина
|
N
|
Время выполнения ЦПУ
|
Время выполнения ГПУ
|
Ускорение
|
Результат на ЦПУ
|
Результат на ГПУ
|
|
1500
|
147.859
|
5.881
|
25.140
|
1.69e-001
|
1.80e-001
|
|
2000
|
237.621
|
8.822
|
26.933
|
1.22e-001
|
1.12e-001
|
|
2500
|
382.117
|
12.854
|
29.728
|
6.35e-002
|
5.85e-002
|
|
3000
|
515.869
|
17.498
|
29.481
|
2.45e-002
|
2.45e-002
|
Таблица 4. Результаты выполнения алгоритма на функции
Гринвонка
|
N
|
Время выполнения ЦПУ
|
Время выполнения ГПУ
|
Ускорение
|
Результат на ЦПУ
|
Результат на ГПУ
|
|
1500
|
154.799
|
5.886
|
26.301
|
1.79e-007
|
1.19e-007
|
|
2000
|
249.339
|
8.823
|
28.260
|
2.55e-010
|
2.59e-010
|
|
2500
|
387.780
|
12.831
|
30.218
|
2.61e-010
|
0
|
|
3000
|
555.247
|
17.460
|
31.801
|
0
|
0
|
Таблица 5. Результаты выполнения алгоритма на функции
Розенброка
|
N
|
Время выполнения ЦПУ
|
Время выполнения ГПУ
|
Ускорение
|
Результат на ЦПУ
|
Результат на ГПУ
|
134.151
|
5.872
|
4.844
|
1.63e-003
|
1.78 e -003
|
|
2000
|
248.331
|
8.811
|
28.183
|
1.31e-003
|
1.28 e -003
|
|
2500
|
367.370
|
12.834
|
28.623
|
2.05e-004
|
1.98 e -004
|
|
3000
|
523.468
|
17.487
|
29.934
|
2.27e-005
|
3.71 e -005
|
Время
выполнения и ускорение в зависимости от размерности пространства
Проведем еще одну группу тестов, с фиксированным размером
популяции (N=1000).
Шаг и д положим 3.5 и 0.618 соответственно. Результаты приведены ниже, см.
таблицы 6,7,8,9.
Таблица 6. Результаты выполнения алгоритма на функции сферы
|
D
|
Время выполнения ЦПУ
|
Время выполнения ГПУ
|
Ускорение
|
Результат на ЦПУ
|
Результат на ГПУ
|
|
20
|
25.282
|
1.852
|
13.650
|
1.00e-003
|
3.04 e-003
|
|
30
|
40.018
|
2.463
|
16.248
|
1.40 e-005
|
4.95 e-005
|
|
40
|
51.108
|
2.978
|
17.161
|
9.25 e-006
|
9.97 e-006
|
|
50
|
59.856
|
3.536
|
16.927
|
2.67 e-004
|
2.28 e-004
|
Таблица 7. Результаты выполнения алгоритма на функции
Растригина
|
DВремя выполнения
ЦПУВремя выполнения ГПУУскорениеРезультат на ЦПУРезультат на ГПУ
|
|
|
|
|
|
|
20
|
24.978
|
1.878
|
13.297
|
8.93 e-003
|
5.67 e-003
|
|
30
|
40.664
|
2.497
|
16.281
|
1.54 e-002
|
4.72 e-002
|
|
40
|
3.030
|
17.218
|
2.18 e-002
|
1.82 e-002
|
|
50
|
66.542
|
3.613
|
18.413
|
2.85 e-001
|
3.14 e-001
|
Таблица 8. Результаты выполнения алгоритма на функции
Гринвонка
|
D
|
Время выполнения ЦПУ
|
Время выполнения ГПУ
|
Ускорение
|
Результат на ЦПУ
|
Результат на ГПУ
|
|
20
|
27.405
|
1.892
|
14.480
|
3.26 e-004
|
3.65 e-004
|
|
30
|
43.653
|
2.514
|
17.361
|
1.78 e-007
|
1.54 e-007
|
|
40
|
55.574
|
3.046
|
18.242
|
2.38 e-006
|
0
|
|
50
|
66.044
|
3.630
|
18.188
|
6.20 e-006
|
1.79 e-006
|
Таблица 8. Результаты выполнения алгоритма на функции
Розенброка
|
D
|
Время выполнения ЦПУ
|
Время выполнения ГПУ
|
Ускорение
|
Результат на ЦПУ
|
Результат на ГПУ
|
|
20
|
27.405
|
1.892
|
14.480
|
3.26 e-004
|
3.65 e-004
|
|
30
|
43.653
|
2.514
|
17.361
|
1.78 e-007
|
1.54 e-007
|
|
40
|
55.574
|
3.046
|
18.242
|
2.38 e-006
|
0
|
|
50
|
66.044
|
3.630
|
18.188
|
1.79 e-006
|
Анализ результатов
Из результатов экспериментов можно сделать следующие выводы:
· Алгоритм, выполненный с помощью ЦПУ, и
алгоритм, выполненный с помощью ГПУ, дают примерно одинаковые результаты. Таким
образом, наше реализация эффективна и надежна.
· Алгоритм на ГПУ выполняется гораздо
быстрее, чем на ЦПУ. К примеру, в первом эксперименте лучшая производительность
была отмечена при запуске алгоритма для функции сферы: ускорение дошло до
отметки в 32 раза. Во втором эксперименте лучшая производительность была
отмечена при запуске алгоритма для функции Растригина: ускорение достигло
отметки в 18.4.
Важно будет отметить, что в нашей реализации показатели
ускорения всегда будут выше для первого эксперимента, в силу того, что наше
решение ориентировано на выполнение параллельно оптимизационного процесса для
каждой рыбы. Таким образом, при увеличении количества измерений ГПУ требуется
больше последовательных вычислений.
Заключение
В данной работе мы представили базовые блоки, необходимые для
выполнения алгоритма поиска косяком рыб на ГПУ с использованием CUDA. Результаты показали,
что такая реализация алгоритма гораздо более эффективна в план
производительности, нежели оная на ЦПУ. Наш алгоритм очень эффективен в решении
задач реального мира, в случае их большой размерности или наличия большой
популяции.
Список литературы
1. Yifan Hu, Baozhong Yu, Jianliang
Ma, Tianzhou Chen, Parallel Fish Swarm Algorithm Based on GPU-Acceleration //
College of Computer Science and Technology, Zhejiang University, Hangzhou, P.R.
China, Intelligent Systems and Applications (ISA), 2011
. Anthony J.C.C. Lins, Carmelo J.A.
Bastos-Filho, Débora N.O.
Nascimento, Marcos A.C. Oliveira Junior and Fernando B. de Lima-Neto, Analysis
of the Performance of the Fish School Search Algorithm Running in Graphic
Processing Units // Polytechnic School of Pernambuco, University of Pernambuco,
Brazil, Theory and New Applications of Swarm Intelligence, 2012, pp. 18-31.