Параллельные вычисления с использованием библиотеки PVM
Министерство образования и науки РФ
Федеральное государственное бюджетное образовательное учреждение высшего
профессионального образования «Смоленский государственный университет»
Факультет экономики и управления
Кафедра математики и информатики
Курсовая работа
ПАРАЛЛЕЛЬНЫЕ ВЫЧИСЛЕНИЯ С ИСПОЛЬЗОВАНИЕМ БИБЛИОТЕКИ PVM
Выполнил
студент 3 курса очной формы обучения
МАРКЕЛОВ Владислав Сергеевич
Научный руководитель:
БЛАКУНОВ Игорь Олегович
Смоленск - 2014
ОГЛАВЛЕНИЕ
ВВЕДЕНИЕ
ГЛАВА 1.ОПИСАНИЕ КЛАСТЕРНЫХ СИСТЕМ И ХАРАКТЕРИСТИКА БИБЛИОТЕК ПАРАЛЛЕЛИЗМ
.1 ТИПЫ КЛАСТЕРНЫХ СИСТЕМ
.2 ПОПУЛЯРНЫЕ БИБЛИОТЕКИ ПАРАЛЛЕЛИЗМА. АНАЛОГИ PVM
.3 ОПИСАНИЕ СИСТЕМЫ PVM
ГЛАВА 2. ОРГАНИЗАЦИЯ ПАРАЛЛЕЛЬНЫХ ВЫЧИСЛЕНИЙ
.1 ОПИСАНИЕ ОБОРОДУВАНИЯ И ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
.2 УСТАНОВКА И НАСТРОЙКА ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ КЛАСТЕРА
.3 ГИПОТЕЗА ГОЛЬДБАХА
.4 ПРОЦЕСС КОМПИЛЯЦИИ СОБСТВЕННОЙ ПРОГРАММЫ ДЛЯ РАБОТЫ С PVM
.5 ВЫПОЛНЕНИЕ ПРОГРАММЫ
ЗАКЛЮЧЕНИЕ
СПИСОК ЛИТЕРАТУРЫ
ПРИЛОЖЕНИЕ
ВВЕДЕНИЕ
Данная исследовательская работа посвящена ознакомлению
с программированием параллельных вычислительных процессов с использованием
пакета программ PVM (Parallel Virtual Machine).
Параллельной машиной называют набор процессоров,
памяти и некоторые методы коммуникации между ними. Это может быть двухядерный
процессор в ноутбуке, многопроцессорный сервер или, например, кластер
(суперкомпьютер). Компьютеры, входящие в кластер, вместе намного быстрее, чем
по отдельности. Это основное преимущество кластера, но не единственное.
Более глубокое определение можно представить так: PVM
(параллельная виртуальная машина) - часть средств реального вычислительного
комплекса (процессоры, память, периферийные устройства и т.д.), предназначенные
для выполнения множества задач, участвующих в получении общего результата вычислений.
Главная цель использования PVM - это повышение скорости вычислений за счет их
параллельного выполнения.
Верхняя граница желаемого эффекта оценивается очень
просто - если для вычислений использовать N однотипных процессоров вместо
одного, то время вычислений уменьшится не более чем в N раз. Параллельной
Виртуальной Машиной может стать как отдельно взятый ПК, так и локальная сеть,
включающая в себя суперкомпьютеры с параллельной архитектурой, универсальные
ЭВМ, графические рабочие станции и все те же маломощные ПК. На самом деле,
ускорение вычислений зависит от специфики задачи и характеристик аппаратных и
программных средств PVM.
Данное исследование ставит перед собой цель
рассмотреть возможности PVM на примере конкретной задачи, разобраться из чего
состоит PVM, каким образом работать в ней, какие преимущества и недостатки
имеет эта библиотека?
ГЛАВА 1. ОПИСАНИЕ КЛАСТЕРНЫХ СИСТЕМ И
ХАРКТЕРИСТИКА БИБЛИОТЕК ПАРАЛЛЕЛИЗМА
.1 ТИПЫ КЛАСТЕРНЫХ СИСТЕМ
В первую очередь следует дать определение кластера. Кластер
- это модульная многопроцессорная система, созданная на базе стандартных
вычислительных узлов, соединенных высокоскоростной коммуникационной средой.
Кластеры позволяют уменьшить время расчетов, по
сравнению с одиночным компьютером, разбивая задание на параллельно
выполняющиеся программы. Такой способ организации компьютерных вычислений, при
котором программы разрабатываются как набор взаимодействующих вычислительных
процессов, работающих параллельно (одновременно) на кластерах называется
параллельные вычисления.
Разберемся в типах кластерных систем. Они различаются
по типу памяти - общая (shared) или распределенная (distributed), и по типу
управления - один управляющий узел(SIMD) и несколько(MIMD). Получается, четыре
вида кластерных систем.
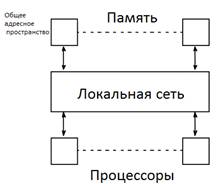
Рис.
1 Общая
Вместо одного процессора - несколько, памяти
соответственно больше. Получается, все процессоры делят общую память и если
процессору 2 нужна какая-то информация, над которой работает процессор 3, то он
получит ее из общей памяти с той же скоростью (рис.1).
Распределенная.
В этом случае у каждого процессора «своя» память (речь
идет не о внутренней памяти процессора, а об оперативной памяти каждого
компьютера в кластере).
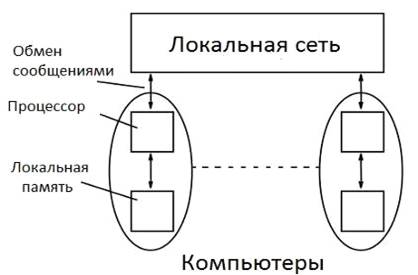
Рис.
2
Примером может служить Рис. 2: Кластер является
множеством отдельных компьютеров, каждый из которых имеет свою память. В таком
случае если процессору (или компьютеру) 2 нужна информация от компьютера 3, то
это займет уже больше времени: нужно будет запросить информацию и передать ее
(в случае кластера - по локальной сети). Топология сети будет влиять на
скорость обмена информацией, поэтому были разработаны разные типы структур.
SIMD.
SIMD - Singe Instruction stream,
Multiple Data stream. Управляющий
узел один, он отправляет инструкции всем остальным процессорам. Каждый
процессор имеет свой набор данных для работы.
SIMD-системы обычно используются для конкретных задач,
требующих, как правило, не столько гибкости и универсальности вычислительной
машины, сколько самой вычислительной силы. Например, обработка видео, научные
исследования (те же симуляции и моделирование).
MIMD.
MIMD - Multiple Instruction stream,
Multiple Data Stream. Каждый
процессор имеет свой собственный управляющий модуль, каждый процессор может
выполнять разные инструкции.машины обладают более широким функционалом, поэтому
в наших пользовательских компьютерах используются именно они. Любые устройства,
использующие хотя бы двухъядерный процессор - MIMD-машины с общей памятью. MIMD
с распределенной памятью это суперкомпьютеры вроде IBM Blue Gene или кластеры.
Чтобы заставить работать описанные типы кластеров по
назначению используют программные инструменты параллелизма, например, PVM
.2 ПОПУЛЯРНЫЕ БИБЛИОТЕКИ
ПАРАЛЛЕЛИЗМА. АНАЛОГИ PVM
Безусловно, даже у такого на первый взгляд непонятного
и неоднозначного для рядового пользователя программного пакета PVM существуют
свои аналоги. И прежде чем говорить о программной системе PVM следует упомянуть
некоторые из них.
Message Passing Interface.
В 1994 г. был принят стандарт механизма передачи
сообщений MPI (Message Passing Interface). Он готовился с 1992 по 1994 гг.
группой Message Passing Interface Forum, в которую вошли представители более
чем 40 организаций из Америки и Европы. Основная цель, которую ставили перед
собой разработчики MPI - это обеспечение полной независимости приложений,
написанных с использованием MPI, от архитектуры многопроцессорной системы, без
какой-либо существенной потери производительности. По замыслу авторов это
должно было стать мощным стимулом для разработки прикладного программного
обеспечения и стандартизованных библиотек подпрограмм для многопроцессорных
систем с распределенной памятью. Подтверждением того, что эта цель была
достигнута, служит тот факт, что в настоящее время этот стандарт поддерживается
практически всеми производителями многопроцессорных систем. Реализации MPI
успешно работают не только на классических MPP системах, но также на SMP
системах и на сетях рабочих станций (в том числе и неоднородных).- это библиотека
функций, обеспечивающая взаимодействие параллельных процессов с помощью
механизма передачи сообщений. Поддерживаются интерфейсы для языков C и FORTRAN.
В последнее время добавлена поддержка языка C++. Библиотека включает в себя
множество функций передачи сообщений типа точка-точка, развитый набор функций
для выполнения коллективных операций и управления процессами параллельного
приложения. Основное отличие MPI от предшественников в том, что явно вводятся
понятия групп процессов, с которыми можно оперировать как с конечными
множествами, а также областей связи и коммуникаторов, описывающих эти области
связи. Это предоставляет программисту очень гибкие средства для написания
эффективных параллельных программ.является наиболее распространённым стандартом
интерфейса обмена данными в параллельном программировании, также существуют его
реализации для большого числа компьютерных платформ. MPI используется при разработке программ для разнородных
наборов компьютеров и суперкомпьютеров. Основным средством коммуникации между
процессами в MPI является передача сообщений друг другу.
В
первую очередь MPI ориентирован на системы с распределенной памятью, то есть
когда затраты на передачу данных велики, в то время как OpenMP
<#"786777.files/image003.jpg">
Рис. 3 - Графический интерфейс Red Hat Enterprise Linux 6.5
2)Установка и настройка PVM.
PVM
версии 3.4.6. была скачана с официального сайта:
<#"786777.files/image004.jpg">
Рис.
5 - Содержание файла.bashrc.
В
каталоге (usr/share/pvm3/) выполняем команду для сборки:
make
По
окончании ее работы PVM будет готова к использованию. (На одном из этапов
выполнения, команда завершилась выходом с ошибкой из-за отсутствия библиотеки
m4_1.4.13-2_х64_х86.rpm, которую необходимо установить с локального
репозитория.)
На
этом процесс установки и настройки PVM завершен. Для продолжения
работы, данная конфигурация была скопирована на второй узел кластера.
)
Установка и конфигурирование RSH.
Для
коммуникаций, PVM использует RSH.расшифровывается как Remote
SHell - протокол, позволяющий подключаться удаленно к устройству и выполнять на
нем команды. Обычно RSH-клиент запускается в консоли, и ответ на команду выводит
прямо в экран консоли. Протокол RSH не является защищенным - данные об
авторизации и передаваемые данные не шифруются.
1. Менеджером пакетов в графическом интерфейсе
был установлен xinet.d из локального репозитория Red Hat Linux 6.5 Enterprise
. Через консоль пользователем root был установлен пакет rsh-клиент из дистрибутива Red Hat Linux 6.5 Enterprise: rpm -i rsh-0.17-14.х64_х86.rpm
. Через консоль пользователем root был установлен пакет rsh-сервер из дистрибутива Red Hat Linux 6.5 Enterprise: rpm -i rsh-server-0.17-14.х64_х86.rpm
. Пользователем root сконфигурированы файлы /etc/xinet.d/rexec, /etc/xinet.d/rlogin, /etc/xinet.d/rsh следующим
образом: опция disable
установлена в значение no.
. Пользователем master в его домашнем каталоге создан файл.rhosts (пример строки файла: redhatpc-1master). Имена узлов и имена пользователей должны быть
разделены табуляцией. Файл должен обязательно заканчивать символом конца файла.
Для этого последняя строка файла должна быть пустой.
. Установите на файл.rhosts следующие права:600 /home/master/.rhosts
. В файле /etc/hosts
указаны все узлы кластера.(redhatpc-1, redhatpc-2).
. Пользователем master проверена работоспособность rsh (команда rsh redhatpc-1 должна
пропускать на redhatpc-1 без запроса пароля).
После настройки и проверки работоспособности RSH, PVM была вызвана в командной строке:
>pvm
Командой add redhatpc-2 был
добавлен 2 узел в кластер. (Рис.4).
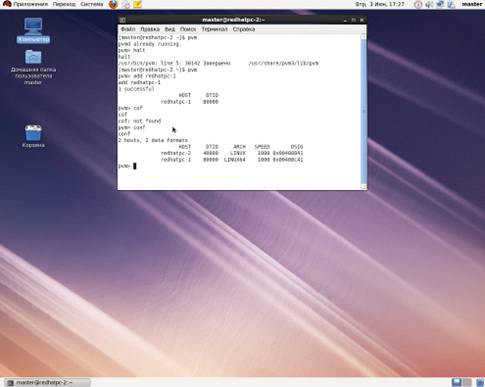
Рис. 5 - Кластер готов к работе.
2.3 ГИПОТЕЗА ГОЛЬДБАХА
Тестирование работы PVM было проведено на основе работы программы, которая
повторяет гипотезу Гольдбаха. Она гласит: любое чётное число, начиная с 4,
можно представить в виде суммы двух простых чисел. В программе мы находим
множество простых чисел, затем сумму двух простых чисел из множества проверяем
на равенство с четным числом. Данные, которые удовлетворяют определению
гипотезы Гольдбаха, заносятся в массив. В конце программы выводится время
выполнения, затраченное на выполнения алгоритма до заданного числа.
Для того, чтобы программа работала на кластере, ее
необходимо распараллелить. Распараллеливание производится с использованием
библиотеки PVM и ее функций.
.4 ПРОЦЕСС КОМПИЛЯЦИИ СОБСТВЕННОЙ
ПРОГРАММЫ ДЛЯ РАБОТЫ С PVM
Библиотечные функции PVM легко интегрировать в С++ среду. Префикс pvm_ в имени каждой функции позволяет не
забыть о ее принадлежности соответствующему пространству имен. Для
использования PVM-функций необходимо включить в
программу заголовочный файл “pvm3.h” и скомпоновать ее с библиотекой libpvm. Чтобы скомпилировать программу с
данной библиотекой, необходимо ввести команду:
>gcc -o mypvm_program -I $PVM_ROOT/include mypvm_program.c -I$PVM_ROOT/lib -lpvm3
Самыми распространенными PVM-функциями являются pvm_mytid(),
pvm_spawn(), pvm_initsend(), pvm_pkint(),
pvm_send(), pvm_recv(), pvm_exit().
Функция pvm_mytid() возвращает индентификатор вызывающей задачи. PVM-система связывает идентификатор
задачи с каждым процессом, который ее создает. Идентификатор задачи
используется для отправки сообщений задачам, получения сообщений от других
задач и т. п.. Любая PVM-задача может связываться с любой другой PVM-задачей до
тех пор, пока не получит доступ к ее идентификатору. Функция pvm_spawn( )
предназначена для запуска нового PVM-процесса. В программе master функция pvm_spawn() используется для
запуска программы slave. Идентификатор новой задачи возвращается в параметре &Tid вызова
функции pvm_spawn (). В PVM-среде для передачи данных между задачами
используются буферы сообщений. Каждая задача может иметь один или несколько
таких буферов. При этом только один из них считается активным. Перед отправкой
каждого сообщения вызывается функция pvm_initsend(), которая позволяет
подготовить или инициализировать активный буфер сообщений. Функция pvm_pkint() используется для упаковки
числового значения. Функции pvm_send() и pvm_recv() используются для отправки и
приема сообщений соответственно. Функции pvm_send() и pvm_recv() содержат
идентификатор задачи, получающей данные, и идентификатор задачи, отправляющей
данные, соответственно. Функция pvm_upkint() извлекает полученное сообщение из активного буфера сообщений и
распаковывает его, сохраняя в массиве типа int.
Обязательным условием для кластеров является
компиляция исходных кодов ПО для каждой системы в отдельности, в нашем случае LINUX64. Далее следует разослать на все
узлы кластера исполняемый файл, т.е. скопировать его в каталог usr/share/pvm3/bin/LINUX64 на каждом узле.
2.5 ВЫПОЛНЕНИЕ ПРОГРАММЫ
В начале программа выполняется на одном узле. Проверка
производится с разными числами от 2 до n. После выполнения алгоритма, программа возвращает время,
которое было затрачено:
Таблица 1 - Выполнение программы на одном узле
кластера.
|
№
|
N
|
Время, с.
|
|
1
|
50000
|
1,49
|
|
2
|
100000
|
5,23
|
|
3
|
250000
|
30,43
|
|
4
|
500000
|
143,39
|
Как видно из таблицы с увеличением числа N время, которое затрачено на
выполнение алгоритма, весьма ощутимо увеличивается, что вызывает некоторые
неудобства. Числа 10000, 50000 вычисляются быстро, поэтому их тестирование на
кластере не имеет смысла, так как даже 1 узел отлично справляется с
поставленной задачей.
После этого программа была запущена на всех узлах
кластера:
Таблица 2 - Выполнение программы на всех узлах
кластера.
|
№
|
N
|
Время, с.
|
|
1
|
100000
|
4,69
|
|
2
|
250000
|
23,67
|
|
3
|
500000
|
112,53
|
Как видно из таблицы, производительность в вычислениях
с крупными числами выросла примерно на 12%, что немного. Дело в том, что на
одном узле кластера происходит большое количество вычислений, так как имеется
всего два узла в кластере, и программа распараллелена всего на две подзадачи.
Для того, чтобы программа работала быстрее, нужно
добавить в кластер узлов и еще сильнее распараллелить задачу, то есть разбить
ее на большее количество параллельных подзадач, чтобы иметь возможность использовать
в процессе подсчета большее количество узлов, на которых происходит малое
количество вычислений. Чем меньше вычислений на одном узле, тем быстрее
работает программа.
Таким образом, тест программы Гипотеза Гольдбаха
показал, что процессорное время работы кластера над данной задачей уменьшается,
отсюда можно сделать вполне обоснованный вывод, что кластерная система работает
быстрее, чем один компьютер. Производительность кластерной системы растет с
увеличением количества узлов в ней.
ЗАКЛЮЧЕНИЕ
В ходе работы были изучены основные принципы
построения распределенных вычислительных систем, была установлена и система PVM, завершена настройка RSH, а также изучены принципы
параллельного программирования с использованием основных функций PVM.
СПИСОК ЛИТЕРАТУРЫ
PVM User’s Guide.
Руководство пользователя PVM, Adam Beguelin 1994: сайт. URL: http://www.netlib.org (дата обращения 16.02.2014).
Linux кластер - практическое руководство, Юрий Сбитнев
2011: сайт. URL : <http://cluster.linux-ekb.info/> (дата обращения
15.03.2014).
Высокопроизводительные
вычисления, Виктор Датсюк, 2012: сайт. URL: <http://rsusu1.rnd.runnet.ru/>
(23.04.2014).
Хабраха́бр - коллективный блог, пользователь Intel8086 2013:
сайт. URL: <http://habrahabr.ru/> (дата обращения
15.03.2014).
Сборка кластера Beowulf
на основе PVM и Linux, Блог Алексея Медведева, Алексей Медведев: сайт. URL:
<http://aleks37.blogspot.ru/> (дата обращения 19.02.2014).
Знакомство с компилятором gcc,
Дмитрий Пантелеичев: сайт. URL: http://www.linuxcenter.ru/ (дата обращения 21.02.2014).
ПРИЛОЖЕНИЕ
ПРИЛОЖЕНИЕ А
Листинг программы Гипотеза Гольдбаха.
Текст родительской программы master.c
#include
<stdio.h>
#include <stdlib.h>
#include <time.h>
#include
</usr/share/pvm3/include/pvm3.h> ]
#include "/home/master/gold/tags.h"
{_t time;mytid;gold_tid;
int golds[NUM_SLAVES]; //массив для хранения данных ID
задач с golditems[SIZE]; // данные для обработки
int result, i,
kp;results[NUM_SLAVES];= clock();= pvm_mytid();(i = 0; i < SIZE; i++) //делаем массив[i]
= i;= pvm_spawn("gold", (char**)0, PvmTaskDefault, "", 1,
&gold_tid);(i = 0; i < NUM_SLAVES; i++)
{_initsend(PvmDataDefault);_pkint(items
+ i*DATA_SIZE, DATA_SIZE, 1);_send(golds[i], MSG_DATA);
}
/* получаем результат от программ slave */
for(i = 0; i < NUM_SLAVES; i++)
{bufid, bytes, type, source;
int slave_no;
//получаем информацию о сообщении
pvm_bufinfo(bufid, &bytes,
&type, &source);
// получаем номер slave, которая послала данное
сообщение
gold_no = get_gold_no(golds, source);
// распаковываем результат в правильную позицию
pvm_upkint(results + gold_no, 1,
1);
}
// находим окончательный результат
kp = 0;
for(i = 0;
i < NUM_SLAVES;
i++)
kp += results[i];= clock() - time;("Time
= %f sec.", (double)time/CLOCKS_PER_SEC);
//выходим из PVM
pvm_exit();
exit(EXIT_SUCCESS);
} // конец main()
Листинг дочерней программы gold.c:
#include <stdio.h>
#include "commons.h"main
(void)
{p[SIZE/2];kp;i, j, k;mytid,
parent_tid;= pvm_mytid();_tid = pvm_parent();_recv(parent_tid,
MSG_DATA);_upkint(items, DATA_SIZE, 1);= 0;[0]=1;++;(i=3; i<SIZE; i+=2)
{(j=1; j<kp; j++) if (i%p[j]==0) break;(j==kp) {p[kp] = i; kp++;}
}(i=2; i<=SIZE; i+=2) {(j=0;
j<kp; j++) {(k=j; k<kp; k++) {(p[j]+p[k]==i) {=kp;;
}
}(k<kp) break;(j==kp)
printf("Исключения = %d\n",
i);_pkint(items, DATA_SIZE, 1);_send(golds[i], MSG_DATA);();0;