Создание электронного тезауруса по дисциплине 'Компьютерные сети'
Министерство сельского хозяйства Российской Федерации
Бузулукский
гидромелиоративный техникум
Филиал ФГБОУ
ВПО Оренбургский ГАУ
КУРСОВАЯ РАБОТА
По дисциплине: «Эксплуатация
информационных систем»
На тему: «Создание электронного
тезауруса по дисциплине «Компьютерные сети»
Выполнил:
студент 31 группы ИС:
Русяев С.С
Проверил:
Дурнев П.В
г. Бузулук,
2014 г
ВВЕДЕНИЕ
В настоящее время в связи с возрастанием объема информации, необходимой
для принятия решений, и возможностями, предоставляемые компьютерными
технологиями, автоматизированные тезаурусы стали широко использоваться в
различных сферах деятельности человека. Организация быстрого и эффективного
поиска информации становится все более не разрешимой проблемой. Цель
документального поиска - нахождение и выдача соответствующих запросу
пользователя документов или их описаний.
Традиционно информационно-поисковые системы применяются для тематического
поиска научно-технической информации в крупных библиотеках, научно-технических
центрах, архивах. Таким образом, сфера приложения для технологий
информационно-поисковых систем представляется достаточно широкой. При
автоматизации поиска документальной информации важнейшей является задача
формализации содержания документа и запроса. При этом поиск происходит по всему
тексту документа или по его поисковому образу, а в качестве запроса чаще всего
выступают отдельные ключевые слова или их логические комбинации. Именно на этой
технологии основано действие информационно-поискового тезауруса. Целью курсовой
работы является разработка электронного тезауруса по дисциплине «Компьютерные
сети».
Основные этапы технологии разработки:
. Предварительная обработка текстов;
. Построение множества предпочтительных дескрипторов (ключевых понятий
предметной области) и концептов;
. Выбор языка программирования или конструктора;
. Выбор шаблона;
. Выбор типа тезауруса;
. Создание тезауруса.
1. ОСНОВЫ
РАЗРАБОТКИ ТЕЗАУРУСОВ
1.1 Понятие тезаурусов
Теза́урус (от греч. θησαυρός - сокровище), в общем смысле -
специальная терминология, более строго и предметно - словарь, собрание
сведений, корпус или свод, полномерно охватывающие понятия, определения и
термины специальной области знаний или сферы деятельности, что должно
способствовать правильной лексической, корпоративной коммуникации (пониманию в
общении и взаимодействии лиц, связанных одной дисциплиной или профессией); в
современной лингвистике - особая разновидность словарей, в которых указаны
семантические отношения (синонимы, антонимы, паронимы, гипонимы, гиперонимы и
т. п.) между лексическими единицами. Тезаурусы являются одним из действенных
инструментов для описания отдельных предметных областей.
) Тезаурус (от греч. thesuarus "сокровище, сокровищница") -
словарь, в котором максимально полно представлены все слова языка с исчерпывающим
перечнем примеров их употребления в текстах;
) Идеологический словарь, в котором показаны семантические отношения
(родовидовые, синонимические и др.) между лексическими единицами.
Тезаурус в первом значении в полном объеме осуществим лишь для мертвых
языков. Структурной основой для тезауруса во втором значении обычно служит
иерархическая система понятий, обеспечивающая поиск от смыслов к лексическим
единицам, т.е. поиск слов, исходя из понятия.
Тезаурус - библиотека с набором словарей синонимов, антонимов,
родственных слов и родовидовых связей, которая служит для расширения поискового
запроса, позволяющего находить релевантные текстовые фрагменты по смысловой
близости к запросу. Высокая ценность Тезауруса заключается в большом объеме
словарной базы и правильном ранжировании замен.
В широком понимании тезаурус обозначает систему знаний, которой
располагает какой-либо субъект или группа субъектов, о действительности.
Субъект также способен принимать новую информацию, за счет чего исходный
тезаурус будет изменяться. В тезаурусе содержится не только информация о
действительности, но и дополнительная информация, за счет которой появляется
возможность приема новых сведений. В 1970-х годах распространились
информационно-поисковые тезаурусы. В их состав входит лексическая единица,
называемая дескриптором. Она служит для поиска информации в автоматическом
режиме. Каждому слову тезауруса сопоставляется синонимичный дескриптор, для
которого задаются семантические отношения. Выделяют иерархические (родовидовые)
отношения и ассоциативные. В лингвистике семантическими отношениями, которые
входят в тезаурус, могут быть антонимы, гипонимы, синонимы, паронимы и т.п.
Тезаурусы, выраженные в электронном формате, могут быть эффективными
инструментами, с помощью которых можно описывать конкретные предметные области.
Если толковый словарь направлен на выявление смысла слова исключительно при
помощи определения, то тезаурус помогает его выявить, используя соотношения
слова с другими словами и их группами. Это позволяет использовать тезаурус для
работы с заполнением баз знаний на основе искусственного интеллекта. В
приложении Microsoft Word существует средство, которое называется «Тезаурус». С
его помощью можно просматривать синонимы для любого слова, либо осуществлять
поиск его определений. Это позволяет расширять свой словарный запас, узнать
синонимы для уже известных слов. Чтобы воспользоваться данным средством,
необходимо выделить в документе желаемое слово, после чего кликнуть по нему
правой кнопкой мыши, выбрать пункт «Синонимы», после чего «Тезаурус».
тезаурус анализ язык
семантизация
1.2 Классификация тезаурусов
В настоящее время существует значительное число информационно-поисковых
тезаурусов, разработанных как у нас в стране, так и за рубежом. В 70-90-ые годы
ХХ века в нашей стране было разработано большое количество ИПТ - свыше 200. В
рамках программы кооперации между странами Евросоюза в области научной и
технической информации была создана база данных Thesaurus Guide, содержащая
сведения о тезаурусах западноевропейских государств, а также США, Канады, Южной
Америки, ЮАР и Австралии. По данным эта БД содержит сведения о 654 тезаурусах,
действовавших в 1985 г. и доступных на одном из официальных языков Европейского
сообщества. Несмотря на некоторое снижение интереса к ИПТ в 90-е годы ХХ в., в
настоящее время наблюдается активизация исследований и разработок в сфере ИПТ,
расширяются области их применения. Поэтому важно знать о том, какие виды
отечественных и зарубежных ИПТ существуют.
Все многообразие ИПТ можно проанализировать, воспользовавшись такими их
параметрами, как широта тематического охвата, назначение в АИС, системность
построения, особенности состава лексики и внутриструктурного построения,
количество естественных языков, форма представления и знаковая природа
информации. В соответствии с выбранными основаниями деления выделяются
следующие виды ИПТ:
. По широте тематического охвата:
) Политематические (многоотраслевые). Примером одного из первых
отечественных политематических тезаурусов может служить «Тезаурус
научно-технических терминов», подготовленный и изданный в 1972 г. под
руководством доктора технических наук Ю. И. Шемакина. Этот ИПТ содержал 19000
терминов по прикладным областям знания и был предназначен для использования в
автоматизированных системах управления и обработки информации. В настоящее
время крупнейшим русскоязычным политематическим тезаурусом является
информационно-поисковый тезаурус по общественно-политической тематике для
автоматического индексирования в Университетской информационной системе
«РОССИЯ» (УИС «Россия»). Он был разработан в 1995 г. Научно-исследовательским
вычислительным центром МГУ им. М. В. Ломоносова (#"786124.files/image001.gif">

Рисунок 1.1 - Информационно-поисковая система «Thesaurus.com»
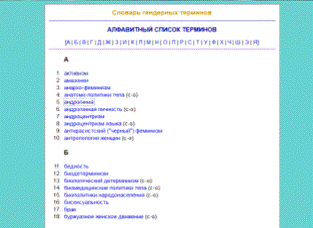
Рисунок 1.2 - Словарь гендерных терминов
После собрания нужной информации, началось создание тезауруса. Для
создания тезауруса был выбран язык программирования - HTML. Hyper Text Markup Language - «HTML» (язык разметки гипертекста)
многие уже давно перестали его считать просто языком программирования. Так как
само понятие HTML включает в себя различные методы оформления гипертекстовых
документов, дизайн, гипертекстовые редакторы, браузеры и много всего другого.
Пользователь, освоивший этот язык, приобретает возможность делать серьезные
вещи простыми методами и, главное, быстро, что в современном мире считается
очень хорошо!
На языке HTML можно создавать собственные мультимедийные продукты и
распространять их на любых носителях информации, и все эти продукты,
выполненные в виде наборов HTML-страниц, не требуют разработки
специализированных программных средств, так как все необходимое для работы с
данными (Web-браузеры) стали частью стандартного программного обеспечения большинства
персональных компьютеров.
Код будущей Web-страницы
обычно набирается в стандартном текстовом редакторе, но есть и другие
программы, и языки программирования, например: Adobe Dreamweaver CS3, JavaScript, Паскаль, С, С++, Бейсик, Пролог.
Начнем с того, что тезаурус будет состоять из трех фреймов: фрейм с
заголовком, фрейм со ссылками и фрейм для содержимого, как показано на рисунке
1.3.
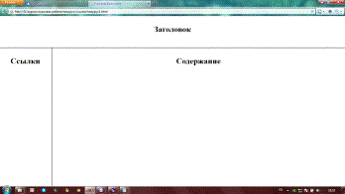
Рисунок 1.3 - Схема тезауруса
Для создания эскиза тезауруса использовали следующие теги и атрибуты
языка HTML:
<title> текст </title> - заголовок сайта;
<frameset rows="120,*"> - два фрейма по горизонтали
размером в 120px и оставшееся пространство;
<frame src="new.html”>- ссылка на документ;
<noresize="noresize"> - отмена возможности
растягивать границы фрейма;
<frameset cols="200,*"> - фреймы по вертикали;
<frame NAME="main">
- указывает имя фрейма для возможности направления информации в этот фрейм.
Для заполнения фреймов информацией, пишем код в документах: «new.txt» - фрейм «Заголовок», «nav.txt» -
фрейм «Ссылки», «main.txt» - фрейм «Содержание».
В документе «new.txt» находится код, отвечающий за
название самого тезауруса. Основные теги:
<style type="text/css"> - применение стилей css;
<background-image: url('images/i2.jpg')> -
установка фонового рисунка;
<text=white> - настройка белого цвета текста;
<p align="center"> - расположение текста по центру;
<h1> - размер текста.
Документ «nav.txt» содержит ссылки в виде букв
алфавита русского языка на конкретные документы, с определениями, начинающимися
на эти буквы, которые будут открываться во фрейме «Содержание». Основные теги:
<background-size: 200%> - масштаб картинки по отношению к фрейму;
<B><A href="A.html" target="main">А</A></B> - ссылка документа А.html на открытие его во фрейме main;
<style="color:red>
- цвет текста красный;
<br> - отступ с красной строчки;
<text-decoration: none"> - отмена стилей (в нашем случае отсутствие
подчеркнутости ссылки).
Каждая ссылка имеет свой документ, содержащий определения, всего их 24.
Для примера, рассмотрим основной тег выделения главного слова:
<font color="red">Верификация</font> - применение цвета к одному
слову.
Документ «main.txt» представляет собой код, из-за
которого во фрейм «Содержание» будут открыться ссылки. Основной тег:
<FRAME NAMЕ="main"/>
- присвоение фрейму имени main.
Чтобы все ссылки работали, надо поменять разрешение всех документов с «txt» на «html». Теперь тезаурус имеет вид как на рисунках 1.4 и
1.5.
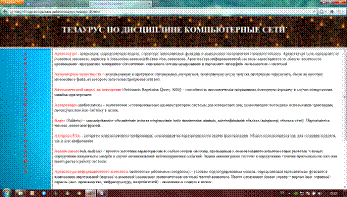
Рисунок 1.4 - Рабочий тезаурус
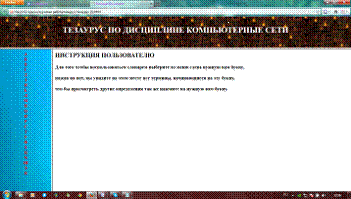
Рисунок 1.5 - Главная страница
2.4 Инструкция администратору
Данный тезаурус разрабатывался с помощью языка программирования HTML, поэтому администратору необходимо
знать основные теги этого языка (смотрите приложение №1).
ТЕЗАУРУС
nav new main
документа (А, Б, В, Г и т.д.) ссылка для открытия документов во
фрейме «main»
Рисунок 1.6 - Связь между документами
Если администратор захочет поменять картинки на сайте во фрейме «Ссылки»
или «Заголовок», то ему надо открыть документы отвечающие за эти фреймы
соответственно: «nav» и «new». Для примера откроем документ «nеw» и рассмотрим код:
<html>
<head>
<title>frame_A</title>
<style type="text/css">{image:
url('images/i2.jpg');
}
</style>
<body text=white>
<h1><p align="center">ТЕЗАУРУС ПО ДИСЦИПЛИНЕ КОМПЬЮТЕРНЫЕ СЕТИ</p></h1>
</head>
</body>
</html>
За открытие картинки во фрейме отвечает лишь часть кода:
<style type="text/css"> - применение стилей css;
body {
- определяет видимую часть документа;
background-image: url('images/i2.jpg'); - ссылка на картинку, которая будет фоном на нашем
сайте;
}
</style> - закрытие тега определяющего
стили.
Чтобы поменять картинку, надо лишь изменить название изображения, в нашем
случае картинка имеет имя «i2.jpg» и находится в папке «images», но если изображение в другой
папке, то замене подлежит и имя папки. Картинки или рисунки должны находится в
папке, которая будет вместе с документами тезауруса, иначе ссылка не найдет
изображение.
Чтобы добавить новое слово в тезаурус, например «Автоматизация», надо
открыть документ, отвечающий за слова на букву «А» «А.html»:
<html> - указывает программе просмотра,
что это HTML документ;
<head> - определяет место, где
помещается информация не отображаемая в теле документа;
<title>html</title>
- Помещает название документа в оглавление программы просмотра страниц;
<body> - определяет видимую часть документа;
<font color="red">Авторизация</font> - текст. - настройка цвета
выделенного слова;
<br> - вставляет перевод строки;
</head> - закрытие тега;
</body> - закрытие тега;
</html> - закрытие тега.
И после тега «br» вставляем тег
настройки цвета выделенного слова. Выделенным словом будет «Автоматизация» и
после тире пишем само определение. Это будет выглядеть так:
<html>
<head>
<title>html</title>
<body>
<font color="red">Авторизация</font> - текст.
<br>
<font color="red">Автоматизация</font> - текст.
</head>
</body>
</html>
ЗАКЛЮЧЕНИЕ
В настоящее время в связи с возрастанием объема информации, необходимой
для принятия решений, и возможностями, предоставляемые компьютерными технологиями,
автоматизированные тезаурусы стали широко использоваться в различных сферах
деятельности человека.
Было прочитано и изучено много теоретического материала, просмотрено
большое количество тезаурусов, их сравнение, выяснение плюсов и минусов. Выбор
языка программирования или программы для создания сайтов, тип строения и
интерфейс тезауруса. Так же мы выяснили, что тезаурусов по учебным дисциплинам
не так уж и много, поэтому это был еще один плюс к разработке собственного
тезауруса терминов по дисциплине «Компьютерные сети».
Язык программирования HTML
был выбран, потому что по сравнению с другими языками он более прост в изучении
и использовании, так же у меня имеется опыт работы с ним. По сравнению с
конструкторами сайтов в нем присутствует большая свобода действий и выбора.
Пользователь, освоивший этот язык, приобретает возможность делать
серьезные вещи простыми методами и, главное, быстро, что в современном мире
считается очень хорошо! На языке HTML можно создавать собственные
мультимедийные продукты и распространять их на любых носителях информации, и
все эти продукты, выполненные в виде наборов HTML-страниц, не требуют
разработки специализированных программных средств, так как все необходимое для
работы с данными (Web-браузеры) стали частью стандартного программного
обеспечения большинства персональных компьютеров. При написании сайта на чистом
HTML языке на странице не будет ничего лишнего, она быстро загружается, хорошо
доступна для поисковых роботов, легче оптимизируется. В HTML можно продумать свою
иерархию страниц, выделить главные и провести добротную внутреннюю оптимизацию
сайта.
СПИСОК
ИСПОЛЬЗУЕМОЙ ЛИТЕРАТУРЫ
1. Лукашевич
Н.В. Тезаурусы в задачах информационного поиска / Н.В. Лукашевич. - И.: МГУ
имени М.В. Ломоносова, 2011, - 512 с.;
2. Джесси
Рассел. Тезаурус / Джесси Рассел. - И.: VSD, 2012, - 66с.;
. Иванов
В.В. Онтологии и тезаурусы: модели, инструменты, приложения: учебное пособие /
В.В. Иванов, Б.В. Добров. - И.: Бином. Лаборатория знаний, 2013, - 173 с.;
. Хольцшлаг
М. Языки HTML и CSS: для создания Web-сайтов: учебное пособие / М. Хольцшлаг, Е. Молли;
пер, с англ. А. Климович. - М.: ТРИУМФ, 2007, - 304 с.;
. Петюшкин
А.В. HTML в Web-дизайне / А.В. Петюшкин. - И.: БХВ-Петербург, 2005, - 400 с.;
. Богомолова
О.Б. Web-конструирование на HTML: Практикум / О.Б. Богомолова. - И.: Бином.
Лаборатория знаний, 2013, - 192 с.;
. Кеннеди
Б. HTML и XHTML: подробное руководство / Кеннеди Б., Муссиано Ч. - И.:
Символ-Плюс, 2013, - 752 с.;
. Матросов
А.В. HTML 4.0 / А.В. Матросов, М.П. Чаунин, А.О. Сергеева. И.: БХВ-Петербург,
2008, - 672 с.;
. Йен
Ллойд. Создай свой Web-сайт с помощью
HTML и CSS / Йен Ллойд. - И.: Питер, 2013, - 416 с.;
. Дакетт.
Д. HTML и CSS. Разработка и создание Web-сайтов / Дакетт Д. И.: Иксмо, 2013, - 480 с.;
ПРИЛОЖЕНИЕ
Таблица 1 - Основные теги языка программирования HTML
|
<body vlink=?>
|
Устанавливает цвет гиперссылок на которых вы уже побывали,
используя значение цвета в виде RRGGBB - пример: 333333 - серый цвет
|
|
<body alink=?>
|
Устанавливает цвет гиперссылок при нажатии
|
|
Теги для форматирования текста
|
|
Создает САМЫЙ БОЛЬШОЙ заголовок
|
|
<h6></h6>
|
Создает самый маленький заголовок
|
|
<b></b>
|
Создает жирный текст
|
Создает наклонный текст
|
|
<tt></tt>
|
Создает текст - имитирующий стиль печатной машинки
|
|
<cite></cite>
|
Используется для цитат, обычно наклонный текст
|
|
<em></em>
|
Используется для выделения из текста слова (наклонный или
жирный текст)
|
|
<strong></strong>
|
Используется для выделения наиболее важных частей текста
(наклонный или жирный текст)
|
|
<font size=?></font>
|
Устанавливает размер текста в пределах от 1 до 7
|
|
<font color=?></font>
|
Устанавливает цвет текста, используя значение цвета в виде
RRGGBB
|
|
Гиперссылки
|
|
<a href="URL"></a>
|
Создает гиперссылку на другие документы или часть текущего
документа
|
|
<a
href="mailto:EMAIL"> </a>
|
Создает гиперссылку вызова почтовой программы для написания
письма автору документа
|
|
<a name="NAME"></a>
|
Отмечает часть текста как цель для гипперссылок в документе
|
|
<a href="#NAME"></a>
|
Создает гиперссылку на часть текущего документа
|
|
Форматирование
|
|
<p>
|
Создает новый параграф
|
|
<p align=?>
|
Выравнивает параграф относительно одной из сторон
документа, значения: left, right, или center
|
|
<br>
|
Вставляет перевод строки
|
|
<blockquote> </blockquote>
|
Создает отступы с обеих сторон текста
|
|
<ol></ol>
|
Создает нумерованный список
|
|
<li>
|
Определяет каждый элемент списка и присваивает номер
|
|
<ul></ul>
|
Создает ненумерованный список
|
|
<div align=?>
|
Важный тег используемый для форматирования больших блоков
текста HTML документа, также используется в таблицах стилей
|
|
Графические элементы
|
|
<img
src="http://hardline.ru/download/name">
|
Добавляет изображение в HTML документ
|
|
<img
src="http://hardline.ru/download/name" align=?>
|
Выравнивает изображение к одной из сторон документа,
принимает значения: left, right, center; bottom, top, middle
|
|
<img
src="http://hardline.ru/download/name" border=?>
|
Устанавливает толщину рамки вокруг изображения
|
|
<hr>
|
Добавляет в HTML документ горизонтальную линию
|
|
<hr size=?>
|
Устанавливает высоту (толщину) линии
|
|
<hr width=?>
|
Устанавливает ширину линии, можно указать ширину в пикселях
или процентах
|
|
<hr noshade>
|
Создает линию без тени
|
|
<hr color=?>
|
Задает линии определенный цвет. Значение RRGGBB
|
|
Кадры
|
|
<frameset></frameset>
|
Предваряет тег <body> в документе, содержащем кадры
|
|
<frameset rows="value,value">
|
Определяет строки в таблице кадров, высота которых
определена кол-вом пикселей или в процентном соотношении к высоте таблицы
кадров
|
|
<frameset cols="value,value">
|
Определяет столбцы в таблице кадров, ширина которых
определена кол-вом пикселей или в процентном соотношении к ширине таблицы
кадров
|
|
<frame>
|
Определяет единичный кадр или область в таблице кадров
|
|
<noframes></noframes>
|
Определяет, что будет показано в окне браузера, если он не
поддерживает кадры
|
|
Атрибуты кадров
|
|
<frame
src="http://hardline.ru/download/URL">
|
Определяет, какой из HTML документов будет показан в кадре
|
Указывает Имя кадра или области, что позволяет
перенаправлять информацию в этот кадр или область из других кадров
|
|
<frame marginwidth=#>
|
Определяет величину отступов по левому и правому краям
кадра; должно быть равно или больше 1
|
|
<frame marginheight=#>
|
Определяет величину отступов по верхнему и нижнему краям
кадра; должно быть равно или больше 1
|
|
<frame scrolling=VALUE>
|
Указывает будет ли выводится линейка прокрутки в кадре;
значение value может быть "yes," "no," или
"auto". Значение по умолчанию для обычных документов - auto
|
|
<frame noresize>
|
Препятствует изменению размеров кадра
|
|
Формы
|
|
<form></form>
|
Создает формы
|
|
<select multiple
name="NAME" size=?></select>
|
Создает скролируемое меню. Size устанавливает кол-во
пунктов меню, которое будет показано на экране, остальные будут доступны при
использовании прокрутки
|
|
<option>
|
Указывает каждый отдельный элемент меню
|
|
<select name="NAME"></select>
|
Создает ниспадающее меню
|
|
<option>
|
Указывает каждый отдельный элемент меню
|
|
<textarea name="NAME"
cols=40 rows=8></textarea>
|
Создает окно для ввода текста. Columns указывает ширину
окна; rows указывает его высоту
|
|
<input type="checkbox"
name="NAME">
|
Создает checkbox. За тегом следует текст
|
|
<input type="radio"
name="NAME" value="x">
|
Создает radio кнопку. За тегом следует текст
|
|
<input type=text
name="foo" size=20>
|
Создает строку для ввода текста. Параметром Size указывается
длина в символах
|