Нейросетевой механизм
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ
РОССИЙСКОЙ ФЕДЕРАЦИИ
Федеральное государственное бюджетное
образовательное учреждение
высшего профессионального образования
“КУБАНСКИЙ ГОСУДАРСТВЕННЫЙ
УНИВЕРСИТЕТ”
(ФГБОУ ВПО “КубГУ”)
Кафедра информационных технологий
ВЫПУСКНАЯ КВАЛИФИКАЦИОННАЯ РАБОТА
БАКАЛАВРА
НЕЙРОСЕТЕВОЙ МЕХАНИЗМ
Работу выполнил Р.Б. Ревякин
Факультет Компьютерных Технологий и Прикладной Математики
Направление 010501 “ Прикладная математика и информатика ”
Научный руководитель преп. А.В. Уварова
Нормоконтролер ст. преп. А.В.Харченко
Краснодар 2014
СОДЕРЖАНИЕ
ВВЕДЕНИЕ
1
Теоретические сведения об аппроксимации и нейронных сетях
1.1
Многослойные сети прямого распространения
1.2
Обобщающая способность многослойного персептрона
1.2.1
Достаточный объём примеров обучения для корректного обобщения
1.3
Аппроксимация функций
1.3.1
Теорема об универсальной аппроксимации.
1.3.2
Пределы ошибок аппроксимации
1.3.3
Ограничение размерности
1.3.4
Практические соображения
1.4 Нормализация
входных данных нейронной сети
1.5
Математический метод аппроксимации
2 Постановка
задачи и проектное решение
2.1
Постановка задачи
2.2 Сервис
OpenWeatherMap
2.2.1
OpenWeatherMap API
2.3
Получение, обработка и нормализация исходных данных
2.3.1
Получение и обработка данных
2.3.2
Проблемы возникшие на этапе получения и обработки данных
2.3.4
Обучающая и тестовая выборка
2.4
Нейронная сеть
2.4.1 Подбор
конфигурации сети.
2.4.2
Оптимизация и дообучение нейронной сети
2.4.3
Обучение и тестирование нейронной сети
2.5
Аппроксимация
2.5.1
Результат работы нейронной сети
2.5.2
Сравнение с математическим методом
3 Реализация
программной системы
3.2 JSON и
возможности фреймворка JSON-Simple
3.4
Программная реализация
3.4.3
Описание проекта WebWeatherView
4
Графический интерфейс пользователя
ЗАКЛЮЧЕНИЕ
СПИСОК
ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
ВВЕДЕНИЕ
В настоящее время интернет стал неотъемлемой частью жизни большого числа
людей, каждый человек ежедневно пользуется множеством различных приложений и
сервисов. И погодные сервисы занимают не последнее место по популярности. Люди
привыкли знать какая будет погода за окном и всегда могут с лёгкостью получить
требуемое. Но, в основном, сайты и приложения дающие погодную сводку обладают
информацией лишь о городах и крупных населённых пунктах. Также они не дают
возможности получить погодные сведения, например, на каком-либо маршруте
движения, что не позволяет человеку иметь полную картину об интересующих его
погодных условиях.
В связи с этим возрастает значимость сервисов отображающих погодные
сведения на карте и позволяющих узнать, что приблизительно будет происходить в
любой интересующей точке. Поскольку точные сведения доступны лишь в городах и
населённых пунктах обладающих метеорологическими станциями, а распространение
полученных с этих станций данных по карте возможно лишь с помощью
аппроксимации, эти данные носят приблизительный характер. И чем точнее
аппроксимация, тем выше практическая применимость таких сервисов. А нужда в
максимально точных данных имеется, например, для агропромышленной индустрии,
тут потребность в точных локальных прогнозах очень высока.
На основании имеющейся информации, в данный момент для решения задачи
аппроксимации используются стандартные математические методы. Перспективным, в
смысле увеличения точности аппроксимации, может оказаться использование
нейронной сети. В частности, для многослойного персептрона доказана теорема об
универсальной аппроксимации, являющаяся математическим доказательством
возможности аппроксимации любой непрерывной функции.
Целью дипломной работы является разработка нейросетевой технологии,
решающей задачу аппроксимации погодных данных на примере температуры, и веб
представления, отображающего результат аппроксимации и позволяющего получить
погодные данные в любой интересующей пользователя точке.
Первая глава дипломной работы содержит теоретическое обоснование
применения нейросетевого механизма к задаче аппроксимации.
Вторая глава посвящена постановке задачи и проектному решению.
Третья глава содержит реализацию программного продукта.
Четвёртая глава содержит интерфейс пользователя.
1 ТЕОРЕТИЧЕСКИЕ СВЕДЕНИЯ ОБ АППРОКСИМАЦИИ И НЕЙРОННЫХ СЕТЯХ
.1
Многослойные сети прямого распространения
Класс многослойных нейронных сетей прямого распространения
характеризуется наличием одного или нескольких скрытых слоёв, узлы которых
называются скрытыми нейронами, или скрытыми элементами. Функция последних
заключается в посредничестве между внешним входным сигналом и выходом нейронной
сети. Добавляя один или несколько скрытых слоёв, мы можем выделить статистики
высокого порядка. Такая сеть позволяет выделять глобальные свойства данных с
помощью локальных соединений за счёт наличия дополнительных синаптических
связей и повышения уровня взаимодействия нейронов. Способность скрытых нейронов
выделять статистические зависимости высокого порядка особенно существенна,
когда размер входного слоя достаточно велик [1].
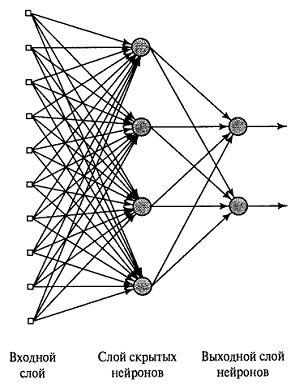
Рисунок
1.1 - Многослойная сеть прямого распространения
Узлы источника входного слоя сети формируют соответствующие элементы
шаблона активации (входной вектор), которые составляют входной сигнал,
поступающий на нейроны (вычислительные элементы) второго слоя. Выходные сигналы
второго слоя используются в качестве входных для третьего слоя и т.д. Обычно
нейроны каждого из слоёв сети используют в качестве входных сигналов выходные
сигналы нейронов только предыдущего слоя. Набор выходных сигналов нейронов
выходного слоя сети определяет общий отклик сети на данный входной образ,
сформированный узлами источника входного слоя. Сеть, показанная на рисунке 1.1,
называется сеть 10-4-2, так как она имеет 10 входных, 4 скрытых, и 2 выходных
нейрона. Нейронная сеть, показанная на рисунке 1.1, считается полносвязной в
том смысле, что все узлы каждого конкретного слоя соединены со всеми узлами смежных
слоёв. Если некоторые из синаптических связей отсутствуют, такая сеть
называется неполносвязной [2].
.2 Обобщающая
способность многослойного персептрона
При обучении методом обратного распространения ошибки в сеть подают
обучающую выборку и вычисляют синаптические веса многослойного персептрона,
загружая в сеть максимально возможное количество примеров. При этом разработчик
надеется, что обученная таким образом сеть будет способна к обобщению.
Считается, что сеть обладает хорошей обобщающей способностью, если отображение
входа на выход, осуществляемое ею, является корректным (или близким к этому)
для данных, никогда ранее не «виденных» сетью в процессе обучения [1].
Процесс обучения нейронной сети можно рассматривать как задачу
аппроксимации кривой. Сама сеть при этом выступает как один нелинейный
оператор. Такая точка зрения позволяет считать обобщение результатом хорошей
нелинейной интерполяции входных данных.
Сеть осуществляет корректную интерполяцию в основном за счёт того, что
непрерывность отдельных функций активации многослойного персептрона
обеспечивает непрерывность общей выходной функции [1].
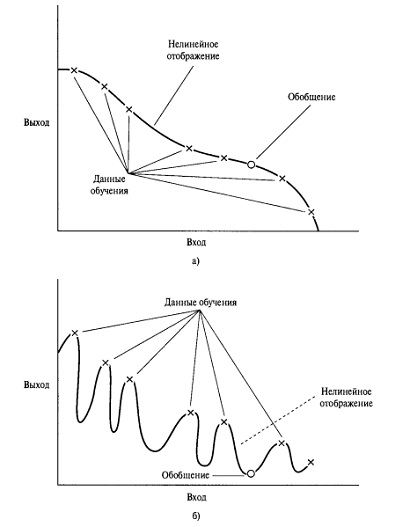
На рисунке 1,a показано, как происходит обобщение в гипотетической сети.
Нелинейное отображение входа на выход, показанное на этом рисунке, определяется
сетью в результате обучения по дискретным точкам (обучающим данным). Точку,
полученную в процессе обобщения и обозначенную незаштрихованным кружочком,
можно рассматривать как результат выполняемой сетью интерполяции.
Нейронная сеть, спроектированная с учётом хорошего обобщения, будет
осуществлять корректное отображение входа на выход даже тогда, когда входной
сигнал слегка отличается от примеров, использованных для обучения сети (что и
показано на рисунке). Однако, если сеть обучается на слишком большом количестве
примеров, всё может закончиться только запоминанием данных обучения. Это может
произойти за счёт нахождения таких признаков (например, благодаря шуму),
которые присутствуют в примерах обучения, но не свойственны самой моделируемой
функции отображения. Такое явление называют избыточным обучения, или
переобучением. Если сеть «переучена», она теряет свою способность к обобщению
на аналогичных входных сигналах.
Обычно загрузка данных в многослойный персептрон таким способом требует
использования большого количества скрытых нейронов, чем действительно
необходимо. Это выливается в нежелательное изменение входного пространства
из-за шума, который содержится в синаптических весах сети. Пример плохого
обобщения вследствие простого запоминания обучающих образов показан на рисунке
1.2,б для тех же данных, которые показаны на рисунке 1.2,а. Результат
запоминания, в сущности, представляет собой справочную таблицу - список пар
«вход-выход», вычисленных нейронной сетью. При этом отображение теряет свою
гладкость. Гладкость отображения входа на выход непосредственно связана с
критерием моделирования, который получил название бритвы Оккама. Сущность этого
критерия состоит в выборе простейшей функции при отсутствии каких-либо
дополнительных априорных знаний. В контексте предыдущего обсуждения
«простейшей» является самая гладкая из функций, аппроксимирующих отображение
для данного критерия ошибки, так как такой подход требует минимальных
вычислительных ресурсов. Гладкость свойственна многим приложениям и зависит от
масштаба изучаемого явления. Таким образом, для плохо обусловленных отношений
важно искать гладкое нелинейное отображение. При этом сеть будет способна
корректно классифицировать новые сигналы относительно примеров обучения [1].
1.2.1
Достаточный объём примеров обучения для корректного обобщения
Способность к обобщению определяется тремя факторами: размером обучающего
множества и его представительностью, архитектурой нейронной сети и физической
сложностью рассматриваемой задачи. Естественно, последний фактор выходит за
пределы нашего влияния. В контексте остальных факторов вопрос обобщения можно
рассматривать с двух различных точек зрения.
Архитектура сети фиксирована и вопрос сводится к определению размера
обучающего множества, необходимого для хорошего обобщения.
Размер обучающего множества фиксирован, и вопрос сводится к определению
наилучшей архитектуры сети, позволяющей достичь хорошего обобщения.
Обе точки зрения по-своему правильны. До сих пор мы фокусировали внимание
на первом аспекте проблемы [1].- измерение обеспечивает теоретический базис для
принципиального решения задачи определения адекватности размера обучающей
выборки. В частности, получены независимые от распределения пессимистические
формулы оценки размера обучающего множества, достаточного для хорошего
обобщения. К сожалению, часто оказывается, что между действительно достаточным
размером обучения и этими оценками может существовать большой разрыв. Из-за
этого расхождения возникает задача сложности выборки, открывающая новую область
исследований.
На практике оказывается, что для хорошего обобщения достаточно, чтобы
размер обучающего множества N удовлетворял следующему соотношению:
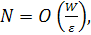 (1)
(1)
где
W - общее количество свободных параметров (т.е. синаптических весов и порогов)
сети; 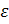 -
допустимая точность ошибки классификации; O(ю) - порядок заключенной в скобки
величины. Например, для ошибки в 10% количество примеров обучения должно в 10
раз превосходить количество свободных параметров сети.
-
допустимая точность ошибки классификации; O(ю) - порядок заключенной в скобки
величины. Например, для ошибки в 10% количество примеров обучения должно в 10
раз превосходить количество свободных параметров сети.
Выражение
(1) получено из эмпирического правила Видроу для алгоритма LMS, утверждающего,
что время стабилизации процесса линейной адаптивной временной фильтрации
примерно равно объёму памяти линейного адаптивного фильтра в задаче фильтра на
линии задержки с отводами, делённому на величину рассогласования.
Рассогласование в алгоритме LMS выступает в роли ошибки из
выражения (1).
.3
Аппроксимация функций
Многослойный персептрон, обучаемый согласно алгоритму обратного
распространения ошибки, можно рассматривать как практический механизм
реализации нелинейного отображения «вход-выход» общего вида. Например, путь m0
- количество входных узлов многослойного персептрона, M = mL -
количество нейронов выходного слоя сети. Отношение «вход-выход» для такой сети
определяет отображение m0-мерного Евклидова пространства входных данных в M-мерное Евклидово пространство
выходных сигналов, непрерывно дифференцируемое бесконечное число раз (если
этому условию удовлетворяют и функции активации). При рассмотрении свойств
многослойного персептрона с точки зрения отображения «вход-выход» возникает
следующий фундаментальный вопрос: «Какое минимальное количество скрытых слоёв
многослойного персептрона, обеспечивающего аппроксимацию некоторого
непрерывного отображения?» [1].
1.3.1 Теорема
об универсальной аппроксимации.
Ответ на этот вопрос обеспечивает теорема об универсальной аппроксимации
для нелинейного отображения «вход-выход», которая формулируется следующим
образом:
Пусть φ(.) - ограниченная, не постоянная монотонно возрастающая
непрерывная функция. Пусть Im0 - m0-мерный единичный гиперкуб [0, 1]m0. Пусть пространство непрерывных на Im0 функций обозначается символом C(Im0). Тогда для любой функции f ⊂ (Im0) и ε > 0 существует такое целое число
m1 и множество действительных констант αi, bi и ωij, где I =
1,…,m1, j = 1,…,m0,
что
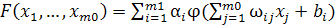 (2)
(2)
является
реализацией аппроксимации функции f(.), то есть
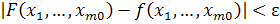 (3)
(3)
для
всех 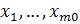 ,
принадлежащих входному пространству [1].
,
принадлежащих входному пространству [1].
Универсальную
теорему аппроксимации можно рассматривать как естественное расширение теоремы
Вейерштрасса. Эта теорема утверждает, что любая непрерывная функция на
замкнутом интервале действительной оси может быть представлена абсолютно и
равномерно сходящимся рядом полиномов.
Теорема
об универсальной аппроксимации непосредственно применима к многослойному
персептрону. Во-первых, в модели многослойного персептрона в качестве функции
активации используется ограниченная, монотонно возрастающая логистическая
функция 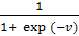 ,
удовлетворяющая условиям, накладываемым теоремой на функцию φ(.).Во-вторых, выражение (2) описывает выходной сигнал
персептрона следующего вида:
,
удовлетворяющая условиям, накладываемым теоремой на функцию φ(.).Во-вторых, выражение (2) описывает выходной сигнал
персептрона следующего вида:
Сеть
содержит m0 входных узлов и один скрытый слой, состоящий из m1
нейронов. Входы обозначены .
Скрытый
нейрон i имеет синаптические веса 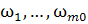 и порог
bi.
и порог
bi.
Выход
сети представляет собой линейную комбинацию выходных сигналов скрытых нейронов,
взвешенных синаптическими весами выходного нейрона - 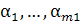 .
.
Теорема
об универсальной аппроксимации является теоремой существования, т.е.
математическим доказательством возможности аппроксимации любой непрерывной
функции. Выражение, составляющее стержень теоремы, просто обобщает описание
аппроксимации функции конечным рядом Фурье. Таким образом, теорема утверждает,
что многослойного персептрона с одним скрытым слоем достаточно для построения
равномерной аппроксимации с точностью ε для любого обучающего множества, представленного
набором входов и
желаемых откликов f(). Тем не
менее из теоремы не следует, что один скрытый слой является оптимальным в
смысле времени обучения, простоты реализации и, что более важно, качества
обобщения [1].
.3.2 Пределы
ошибок аппроксимации
Были исследованы аппроксимирующие свойства многослойного персептрона для
случая одного скрытого слоя с сигмоидальной функцией активации и одного
выходного нейрона. Эта сеть обучалась с помощью алгоритма обратного
распространения ошибки, после чего тестировалась на новых данных. Во время
обучения сети предъявлялись выбранные точки аппроксимируемой функции f, в
результате чего была получена аппроксимирующая функция F, определяемая
выражением (2). Если сети предъявлялись не использованные ранее данные, то
функция F «оценивала» новые точки целевой функции.
Гладкость
целевой функции f выражалась в терминах её разложения Фурье. В частности, в
качестве предельной амплитуды функции f использовалось среднее значение нормы
вектора частоты, взвешенного значениями амплитуды распределения Фурье. Пусть g(ω) - многомерное преобразование Фурье функции 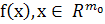 , где ω - вектор частоты. Функция f(x), представленная в
терминах преобразования Фурье g(ω),
определяется следующей инверсной формулой:
, где ω - вектор частоты. Функция f(x), представленная в
терминах преобразования Фурье g(ω),
определяется следующей инверсной формулой:
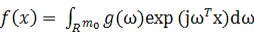 (4)
(4)
где
j = 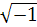 . Для
комплекснозначной функции g(ω) с интегрируемой
функцией ωg(ω) первый
абсолютный момент распределения Фурье функции f можно
определить следующим образом:
. Для
комплекснозначной функции g(ω) с интегрируемой
функцией ωg(ω) первый
абсолютный момент распределения Фурье функции f можно
определить следующим образом:
 (5)
(5)
где
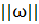 -
Евклидова норма вектора ω; |g(ω )| -
абсолютное значение функции g(ω).
Первый абсолютный момент Cf является мерой гладкости функции f
[1].
-
Евклидова норма вектора ω; |g(ω )| -
абсолютное значение функции g(ω).
Первый абсолютный момент Cf является мерой гладкости функции f
[1].
Первый
абсолютный момент Cf является основой для вычисления пределов ошибки,
которая возникает вследствие использования многослойного персептрона,
представленного функцией отображения «вход-выход» F(x), аппроксимирующей
функцию f(x). Ошибка аппроксимации измеряется интегральной квадратичной ошибкой
по произвольной мере вероятности µ для шара Br = {x: ||x|| ≤
r} радиуса r > 0. На этом основании можно
сформулировать следующее утверждение для предела ошибки аппроксимации:
Для
любой непрерывной функции f(x) с конечным первым моментом Cf и
любого m1 ≥ 1 существует некоторая линейная комбинация
сигмоидальных функций F(x) вида (2), такая, что
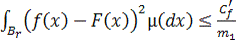 (6)
(6)
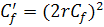 .
.
Если
функция f(x) наблюдается на множестве значений 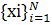 входного
вектора x, принадлежащего шару Br, этот результат определяет следующее ограничение для
эмпирического риска:
входного
вектора x, принадлежащего шару Br, этот результат определяет следующее ограничение для
эмпирического риска:
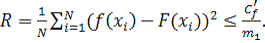 (7)
(7)
Этот
результат использовался для описания границ риска R, возникающего при
использовании многослойного персептрона с m0 входными
узлами и m1 скрытыми нейронами:
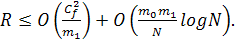 (8)
(8)
Два
слагаемых в этом определении границ риска R отражают
компромисс между двумя противоречивыми требованиями к размеру скрытого слоя.
Точность
наилучшей аппроксимации. В соответствии с теоремой об универсальной
аппроксимации для удовлетворения этого требования размер скрытого слоя m1
должен быть большим.
Точность
эмпирического соответствия аппроксимации. Для того чтобы удовлетворить этому
требованию, отношение  должно
иметь малое значение. Для фиксированного объёма N обучающего множества размер
скрытого слоя
должно
иметь малое значение. Для фиксированного объёма N обучающего множества размер
скрытого слоя 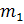 должен
оставаться малым, что противоречит первому требованию [1].
должен
оставаться малым, что противоречит первому требованию [1].
Ограничение
для риска R, описанное формулой (8), имеет ещё одно применение. Дело в том, что
для точной оценки целевой функции не требуется экспоненциально большого
обучающего множества и большой размерности входного пространства m0,
если первый абсолютный момент Cf остаётся конечным. Это ещё больше повышает
практическую ценность многослойного персептрона, используемого в качестве
универсального аппроксиматора.
Ошибку
между эмпирическим соответствием и наилучшей аппроксимацией можно рассматривать
как ошибку оценивания. Пусть ε - среднеквадратическое
значение ошибки оценивания. Тогда, игнорируя логарифмический множитель во
втором слагаемом неравенства (8), можно вделать вывод, что размер N
обучающего множества, необходимый для хорошего результата аналогична
эмпирическому правилу (1), если произведение m0m1 соответствует
общему количеству свободных параметров W сети. Другими
словами, можно утверждать, что для хорошего качества аппроксимации размер
обучающего множества должен превышать отношение общего количества свободных
параметров сети к среднеквадратическому значению ошибки оценивания [1].
.3.3
Ограничение размерности
Из ограничения (8) вытекает ещё один результат. Если размер скрытого слоя
выбирается по следующей формуле (т.е. риск R минимизируется по N):
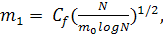 (9)
(9)
то
риск R ограничивается величиной 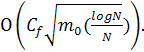 Неожиданный
аспект этого результата состоит в том, что в терминах поведения риска R
скорость сходимости, представленная как функция от размера обучающего множества
N, имеет порядок (1/N)1/2 (умноженный на логарифмический член). В то же
время обычная гладкая функция (например, тригонометрическая и полиномиальная)
демонстрирует несколько другое поведение. Пусть s - мера
гладкости, определяемая как степень дифференцируемости функции (количество
существующих производных). Тогда для обычной гладкой функции минимаксная
скорость сходимости общего риска R имеет порядок
Неожиданный
аспект этого результата состоит в том, что в терминах поведения риска R
скорость сходимости, представленная как функция от размера обучающего множества
N, имеет порядок (1/N)1/2 (умноженный на логарифмический член). В то же
время обычная гладкая функция (например, тригонометрическая и полиномиальная)
демонстрирует несколько другое поведение. Пусть s - мера
гладкости, определяемая как степень дифференцируемости функции (количество
существующих производных). Тогда для обычной гладкой функции минимаксная
скорость сходимости общего риска R имеет порядок
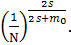 (10)
(10)
Зависимость
этой скорости от размерности входного пространства m0 называют
«проклятием размерности», поскольку это свойство ограничивает практическое
использование таких функций. Таким образом, использование многослойного
персептрона для решения задач аппроксимации обеспечивает определённые
преимущества перед обычными гладкими функциями. Однако это преимущество
появляется при условии, что первый абсолютный момент Cf остаётся
конечным. В этом состоит ограничение гладкости.
Термин
«проклятие размерности» был введён Ричардом Белманом в 1961 году в работе,
посвящённой процессам адаптивного управления. Для геометрической интерпретации
этого понятия рассмотрим пример, в котором x - m0-мерный входной вектор, а
множество {(xi,di)}, i = 1,2,…,N, задаёт обучающую выборку.
Плотность дискретизации пропорциональна значению 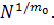 Пусть
f(x) - поверхность в m0 - мерном входном пространстве, проходящая около точек
данных {(xi,di)}, i = 1,2,…,N. Если функция f(x)
достаточно сложна и (по большей части) абсолютно неизвестна, необходимо
уплотнить точки данных для более полного изучения поверхности. К сожалению, в
многомерном пространстве из-за «проклятия размерности» очень сложно найти
обучающую выборку с высокой плотность дискретизации. В частности, в результате
увеличения размерности наблюдается экспоненциальный рост сложности, что, в свою
очередь, приводит к ухудшению пространственных свойств случайных точек с
равномерным распределением [1].
Пусть
f(x) - поверхность в m0 - мерном входном пространстве, проходящая около точек
данных {(xi,di)}, i = 1,2,…,N. Если функция f(x)
достаточно сложна и (по большей части) абсолютно неизвестна, необходимо
уплотнить точки данных для более полного изучения поверхности. К сожалению, в
многомерном пространстве из-за «проклятия размерности» очень сложно найти
обучающую выборку с высокой плотность дискретизации. В частности, в результате
увеличения размерности наблюдается экспоненциальный рост сложности, что, в свою
очередь, приводит к ухудшению пространственных свойств случайных точек с
равномерным распределением [1].
Функция,
определённая в пространстве большой размерности, скорее всего, является
значительно более сложной, чем функция, определённая в пространстве меньше
размерности, и эту сложность трудно разглядеть.
Единственной
возможностью избежать «проклятия-размерности» является получение корректных
априорных знаний о функции, определяемой данными обучения.
Можно
утверждать, что для практического получения хорошей оценки в пространствах
высокой размерности необходимо обеспечить возрастание гладкости неизвестной
функции наряду с увеличением размерности входных данных.
.3.4
Практические соображения
Теорема об универсальной аппроксимации является очень важной с
теоретической точки зрения, так как она обеспечивает необходимый математический
базис для доказательства применимости сетей прямого распространения с одним
скрытым слоем для решения задач аппроксимации. Без такой теоремы можно было бы
безрезультатно заниматься поисками решения, которого на самом деле не
существует. Однако эта теорема не конструктивна, поскольку она не обеспечивает
способ нахождения многослойного персептрона, обладающего заданными свойствами
аппроксимации.
Теорема об универсальной аппроксимации предполагает, что аппроксимируемая
непрерывная функция известна, и для её приближения можно использовать скрытый
слой неограниченного размера. В большинстве практических применений
многослойного персептрона оба эти предположения нарушаются.
Проблема многослойного персептрона с одним скрытым слоем состоит в том,
что нейроны могут взаимодействовать друг с другом на глобальном уровне. В
сложных задачах такое взаимодействие усложняет задачу повышения качества
аппроксимации в одной точке без явного ухудшения в другой. С другой стороны,
при наличии двух скрытых слоёв процесс аппроксимации становится более
управляемым [1]. В частности, можно утверждать следующее:
а) Локальные признаки извлекаются в первом скрытом слое, т.е. некоторые
скрытые нейроны первого слоя можно использовать для разделения входного
пространства на отдельные области, а остальные нейроны слоя обучать локальным
признакам, характеризующим эти области.
б) Глобальные признаки извлекаются во втором скрытом слое. В частности,
нейрон второго скрытого слоя «обобщает» выходные сигналы нейронов первого
скрытого слоя, относящихся к конкретной области входного пространства. Таким
образом он обучается глобальным признакам этой области, а в остальных областях
его выходной сигнал равен нулю.
Этот двухэтапный процесс аппроксимации по своей философии аналогичен
сплайновому подходу к аппроксимации кривых, поскольку нейроны работаю в
изолированных областях. Сплайн является примером такой кусочной полиномиальной
аппроксимации.
В трудах Эдуардо Сонтага предложено дальнейшее обоснование использования
двух скрытых слоёв в контексте обратных задач. В частности, рассматривается
следующая обратная задача [1]:
Для
данной непрерывной вектор-функции 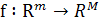 ,
компактного подмножества
,
компактного подмножества 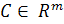 , которое
содержится в пространстве образов функции f, и некоторого
положительного ε > 0 требуется найти вектор-функцию
, которое
содержится в пространстве образов функции f, и некоторого
положительного ε > 0 требуется найти вектор-функцию 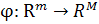 ,
удовлетворяющую условию ||φ(f)(u) - u|| < ε для любого u
,
удовлетворяющую условию ||φ(f)(u) - u|| < ε для любого u 
Эта
задача относится к области обратной кинематики или динамики, где наблюдаемое
состояние x(n) системы является функцией текущих действий u(n) b
предыдущего состояния x(n-1) системы
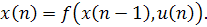 (11)
(11)
Здесь
предполагается, что функция f является обратимой, т.е. u(n) можно
представить как функцию от x(n) для любого x(n - 1). Функция f
описывает прямую кинематику, а функция φ - обратную. В контексте излагаемого материала
необходимо простроить такую функцию φ, которая может быть реализована многослойным
персептроном. В общем случае для решения обратной задачи кинематики функция φ должна быть разрывной. Для решения таких обратных
задач одного скрытого слоя недостаточно, даже при использовании нейронной
модели с разрывными активационными функциями, а персептрона с двумя скрытыми
слоями вполне достаточно для любых возможных C, f и ε.
Рассмотрим
нелинейное отображение типа «вход-выход», заданное следующим соотношением:
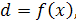 (12)
(12)
где
вектор x - вход, а вектор d - выход. Векторная функция f(ю) считается
неизвестной. Чтобы восполнить пробел в знаниях о функции f(.), нам
предоставляется множество маркированных примеров:
 (13)
(13)
К
структуре нейронной сети, аппроксимирующей неизвестную функцию f(.),
предъявляется следующее требование: функция F(.),
описывающая отображение входного сигнала в выходной, должна быть достаточно
близка к функции f(.) в смысле Евклидовой нормы на множестве всех входных
векторов x, т.е.
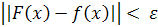 для всех
векторов x,
для всех
векторов x,
где
-
некоторое малое положительное число. Если количество N элементов обучающего
множества достаточно велико и в сети имеется достаточное число свободных
параметров, то ошибку аппроксимации можно
сделать достаточно малой.
Описанная
задача аппроксимации является отличным примером задачи для обучения с учителем.
Здесь xi играет роль входного вектора, а di -
роль желаемого отклика. Исходя из этого, задачу обучения с учителем можно
свести к задаче аппроксимации [1].
Способность
нейронной сети аппроксимировать неизвестное отображение входного пространства в
выходное можно использовать для решения следующих задач.
а)
Идентификация систем. Пусть формула (12) описывает соотношение между входом и
выходом в неизвестной системе с несколькими входами и выходами без памяти.
Термин «без памяти» подразумевает инвариантность системы во времени. Тогда
множество маркированных примеров (13) можно использовать для обучения нейронной
сети, представляющей модель этой системы. Пусть yi - выход
нейронной сети, соответствующий входному вектору xi. Разность
между желаемым откликом di и выходом сети yi составляет
вектор сигнала ошибки ei, используемый для корректировки свободных параметров
сети с целью минимизации среднеквадратической ошибки - суммы квадратов разностей
между выходами неизвестной системы и нейронной сети в статистическом смысле
(т.е. вычисляемой на множестве всех примеров).
Рисунок 1.3 - Блочная диаграмма решения задачи идентификации системы
б) Инверсные системы. Предположим, что существует некая система без
памяти, для которой преобразование входного пространства в выходное описывается
соотношением (12). Требуется построить инверсную систему, которая в ответ на
вектор d генерирует отклик в виде вектора x.
Инверсную систему можно описать следующим образом:
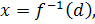
где
вектор-функция  является
инверсной к функции f(.). Обратим внимание, что функция не
является обратной к функции . Здесь
верхний индекс -1 используется только как индикатор инверсии. Во многих
ситуациях на практике функция f(.) может быть достаточно сложной, что делает
практически невозможным формальный вывод обратной функции . Однако
на основе множества маркированных примеров (13) можно построить нейронную сеть,
аппроксимирующую обратную функцию С
помощью схемы, изображённой на рисунке 1.3. В данной ситуации роли векторов xi и di
меняются: вектор di используется как входной сигнал, а вектор xi -
как желаемый отклик. Пусть вектор сигнала ошибки определяется как разность
между вектором xi и выходом нейронной сети yi, полученным в
ответ на возмущение di. Как и в задаче идентификации системы, вектор сигнала
ошибки используется для корректировки свободных параметров нейронной сети с
целью минимизации суммы квадратов разностей между выходами неизвестной
инверсной системы и нейронной сети в статистическом смысле (т.е. вычисляемой на
всём множестве примеров обучения).
является
инверсной к функции f(.). Обратим внимание, что функция не
является обратной к функции . Здесь
верхний индекс -1 используется только как индикатор инверсии. Во многих
ситуациях на практике функция f(.) может быть достаточно сложной, что делает
практически невозможным формальный вывод обратной функции . Однако
на основе множества маркированных примеров (13) можно построить нейронную сеть,
аппроксимирующую обратную функцию С
помощью схемы, изображённой на рисунке 1.3. В данной ситуации роли векторов xi и di
меняются: вектор di используется как входной сигнал, а вектор xi -
как желаемый отклик. Пусть вектор сигнала ошибки определяется как разность
между вектором xi и выходом нейронной сети yi, полученным в
ответ на возмущение di. Как и в задаче идентификации системы, вектор сигнала
ошибки используется для корректировки свободных параметров нейронной сети с
целью минимизации суммы квадратов разностей между выходами неизвестной
инверсной системы и нейронной сети в статистическом смысле (т.е. вычисляемой на
всём множестве примеров обучения).
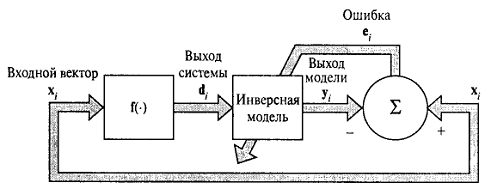
Рисунок 1.4 - Блочная диаграмма моделирования инверсной системы
1.4 Нормализация
входных данных нейронной сети
Нормализация входных данных - это процесс, при котором все входные данные
проходят процесс "выравнивания", т.е. приведения к определённому
интервалу, например [0,1] или [-1,1]. Нормализация позволяет значительно
повысить скорость сходимости алгоритма обучения нейронной сети. Если не
провести нормализацию, то входные данные будут оказывать дополнительное влияние
на нейрон, что может привести к неверным решениям. Другими словами, нельзя
сравнивать величины разных порядков [2].
Простейшие методы нормализации входных данных:
. Нормализация с использованием математического ожидания и
дисперсии.
Выполним
предобработку данных - нормировку исходных данных 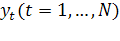 , для
этого воспользуемся стандартной формулой:
, для
этого воспользуемся стандартной формулой:
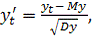 (14)
(14)
где
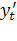 - новая
переменная;
- новая
переменная; 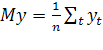 -
выборочная оценка математического ожидания;
-
выборочная оценка математического ожидания; 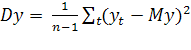 -
выборочная оценка дисперсии.
-
выборочная оценка дисперсии.
Чтобы
полученный выход сети соответствовал реальному используется формула 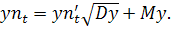
2. Нормализация с использованием минимаксной функции.
Минимаксная функция, выполняет линейное преобразование после определения
минимального и максимального значений функции так, чтобы получаемые значения
находились в нужном диапазоне.
В общем виде формула нормализации выглядит так [3]:
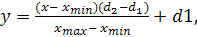 (15)
(15)
где:-
значение, подлежащее нормализации;
[xmin,
xmax] - интервал значений x;
[d1, d2] -
интервал, к которому будет приведено значение x.
Есть
и более основательные и трудоёмкие подходы к нормализации, вот например:
Все
входные переменные должны быть предварительно обработаны так, чтобы среднее
значение по всему обучающему множеству было близко к нулю, иначе их будет сложно
сравнивать со стандартным отклонением. Для оценки практической значимости этого
правила рассмотрим экстремальный случай, когда все входные переменные
положительны. В этом случае синаптические веса нейрона первого скрытого слоя
могут либо одновременно увеличиваться, либо одновременно уменьшаться.
Следовательно, вектор весов этого нейрона будет менять направление, что
приведёт к зигзагообразному движению по поверхности ошибки. Такая ситуация
обычно замедляет процесс обучения и, таким образом, неприемлема [1].
Чтобы
ускорить процесс обучения методом обратного распространения, входные векторы
необходимо нормализовать в двух следующих аспектах:
а)
Входные переменные, содержащиеся в обучающем множестве, должные быть
некоррелированны. Этого можно добиться с помощью анализа главных компонентов.
б)
Некоррелированные входные переменные должны быть масштабированы так, чтобы их
ковариация была приблизительно равной. Тогда различные синаптические веса сети
будут обучаться приблизительно с одной скоростью.
На
рисунке 1.5 показан результат трёх шагов нормализации: смещения среднего,
декорреляции и выравнивания ковариации, применённых в указанном порядке.
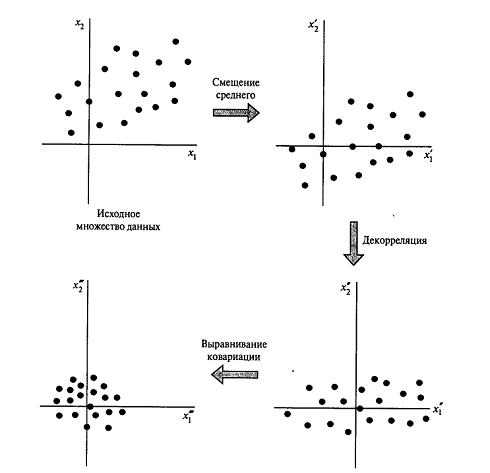
Рисунок 1.5 - Результаты трёх шагов нормализации: смещения среднего,
декорреляции и выравнивания ковариации
.5
Математический метод аппроксимации
Рассмотрим стандартные методы аппроксимации на примере Эрмитовой
интерполяции.
Эрмитова интерполяция строит многочлен, значения которого в выбранных
точках совпадают со значениями исходной функции в этих точках, и производные
многочлена в данных точках совпадают со значениями производных функции (до
некоторого порядка m). Это означает, что n(m+1) величин [4]:
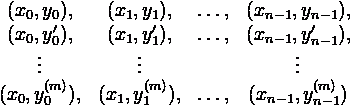
должны быть известны, тогда как для ньютоновской интерполяции необходимы
только первые n значений. Полученный многочлен может иметь степень не более,
чем n(m+1)−1, максимальная степень многочлена Ньютона же равна n−1.
(В общем случае m не обязательно должно быть фиксировано, то есть в одних
точках может быть известно значение большего количества производных, чем в
других. В этом случае многочлен будет иметь степень N−1, где N - число
известных значений) [4].
Простой случай:
При
использовании разделенных разностей для вычисления многочлена Эрмита, первым
шагом является копирование каждой точки m раз. (Здесь рассматривается простой
случай, когда для всех точек m=1.) Поэтому, дана n+1 точка x0,…,xn, и значения f(x0),…,f(xn)
и f(x0),…,f(xn) 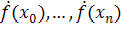 функции
f, которую необходимо интерполировать. Определяется новый набор данных: z0, …,
z2n+1, такой, что z2i = z2i+1 = xi. Теперь определяется таблица разделенных разностей
для точек z0, …, z2n+1. Однако, для некоторых разделенных разностей
функции
f, которую необходимо интерполировать. Определяется новый набор данных: z0, …,
z2n+1, такой, что z2i = z2i+1 = xi. Теперь определяется таблица разделенных разностей
для точек z0, …, z2n+1. Однако, для некоторых разделенных разностей 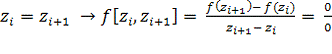
что
является неопределенностью. В этом случае происходит замена этой разделенной
разности значением 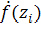 , а
другие вычисляются обычным способом.
, а
другие вычисляются обычным способом.
Общий случай:
В
общем случае полагаем, что в данных точках 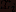 известны
производные функции f до порядка k включительно. Тогда набор данных z0, …, zN содержит
k копий xi. При создании таблицы, разделенных разностей при j = 2, 3, …, k
одинаковые значения будут вычислены как
известны
производные функции f до порядка k включительно. Тогда набор данных z0, …, zN содержит
k копий xi. При создании таблицы, разделенных разностей при j = 2, 3, …, k
одинаковые значения будут вычислены как 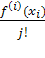 [4].
[4].
Например,
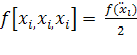 ,
, 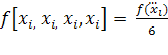 и так
далее.
и так
далее.
2 ПОСТАНОВКА
ЗАДАЧИ И ПРОЕКТНОЕ РЕШЕНИЕ
.1 Постановка
задачи
В рамках выполнения дипломной работы передо мной стояла задача разработки
нейросетевой технологии, решающей задачу аппроксимации погодных данных на
примере температуры, и веб представления, отображающего результат аппроксимации
и позволяющего получить погодные данные в любой интересующей пользователя
точке.
Важнейшим элементом в рамках выполнения дипломной работы стал сервис
OpenWeatherMap, который выступал как поставщик данных и, вообще, стал причиной,
по которой я взялся за нейросетевую аппроксимацию погодных данных.
2.2 Сервис
OpenWeatherMap
OpenWeatherMap это онлайн сервис, который предоставляет бесплатное API к
погодным данным, включающим текущие погодные сведения, прогнозы и историю
наблюдений для разработчиков веб сервисов и мобильных приложений. В качестве
источников данных он использует официальные метеорологические сервисы, данные с
метеорологических станций аэропортов и официальных метеорологических станций.
Также сервис предлагает различные погодные карты, такие как карта облачности
или карта давления.
Сервис OpenWeatherMap получает данные от профессиональных и частных
погодных станций. На сегодня таких станций более 40 тысяч. Большая часть из них
это профессиональные станции, которые установлены в аэропортах и крупных
городах мира. Но также не менее важным для сервиса являются данные от
непрофессиональных станций, которые собирают и устанавливают любители везде,
где это возможно [7].исповедует идею OpenStreetMap и Wikipedia о свободном,
бесплатном предоставлении данных любому желающему, на любые нужды.
OpenWeatherMap использует карты OpenStreetMap для отображения собственных
погодных карт.
Основателями сервиса является команда разработчиков из России.
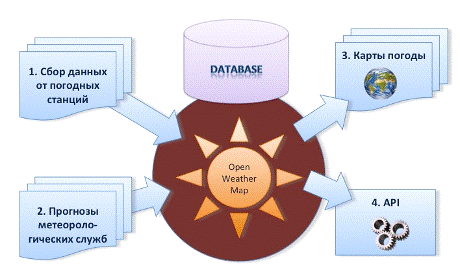
Рисунок
2.1 - Схема сервиса
Основным критерием выбора темы дипломной работы стали следующие слова
разработчиков сервиса, написанные ими в обзорной статье:
«Если вам интересна математика - очень много задач вокруг этого. К
примеру - одна из наиболее важных задач в системе это определение текущей
погоды. Как уже говорилось выше, мы получаем оперативные данные от
метеостанций, которые нужно интерполировать в сетку важных для географических
точек - городов или отдельных районов. Данные от станций разнородны и поступают
не регулярно. Более того, поступает много мусора из ошибочных и неверных
измерений, их надо отсеивать. Причем ошибки могут появляться и в данных от
вполне надежных метеостанций.
Сейчас мы используем достаточно жёсткий и не адаптивный алгоритм. Очень
хотелось бы попробовать в этой задаче какой-либо обучающийся алгоритм.
Очень интересно попробовать в схожей задаче нейросеть.» [7]
2.2.1
OpenWeatherMap API
Сервис OpenWeatherMap предоставляет бесплатный API ко всем данным о
погоде, к их истории, прогнозам и всему многообразию погодных карт.есть двух
видов - JSON для получения данных и Tile / WMS для картографии.
Используя JSON можно получать [7]:
Данные о погоде в более чем 120 тысячах городов. При этом города не нужно
выбирать из жестко ограниченного списка, их можно найти на карте и увидеть
оценочные прогнозы погоды как в самом городе, так и в ближайших регионах.
Данные о текущей погоде в выбранной точке по координатам lat/lon
Прогноз на 7 дней в компактной или в полной форме
«Сырые» данные, полученные от метеостанций
Данные о погоде за прошедшие периоды
.3 Получение,
обработка и нормализация исходных данных
.3.1
Получение и обработка данных
Для аппроксимации мною был выбран участок на карте с координатами 45 - 49
градусов широты, 0 - 4 градуса восточной долготы. Этот участок в центре Франции
выбран не случайно, в обзорной статье об OpenWeatherMap сказано, что «группа
французских энтузиастов развернула систему обработки данных на своих домашних
серверах и предоставляет детальные и точные прогнозы по всей территории
Франции» [7]. В то же время как по поводу России сказано следующее «давайте
посмотрим, что происходит с погодными станциями и погодным энтузиазмом в России.
На иллюстрации ниже можно увидеть текущую картину распределения погодных
станций. По сравнению с плотным покрытием всей европейской части, Россия
выглядит более чем скромно. И это одна из причин неточности прогнозов погоды на
нашей бескрайней территории.» [7]

Рисунок 2.2 - Распределение погодных станций
Так как мне были необходимы наиболее точные данные для обучения сети я
остановился именно на территории государства Франция.
Было принято решение использовать историю наблюдений как источник
погодных данных для обучения сети. Основная часть работы происходила с историей
наблюдения за промежуток: 1 мая 2013 - 1 сентября 2013. Позднее для получения
полной картины погодных явлений использовался временной промежуток: 1 мая 2013
- 1 марта 2014.
В начале выбираются 25 городов обладающих метеорологическими станциями,
данные из которых будут аппроксимироваться на всю поверхность квадрата. По ним
получается история наблюдения за заданный промежуток времени.
Затем получается история наблюдения по всем оставшимся городам и селениям
предоставляющим такие данные. Это делается для получения наибольшего числа
примеров для обучения сети.
Далее отсекается неиспользуемая информация, остаются лишь температурные
данные, координаты и время наблюдения.
Температура представлена в шкале Кельвина, переводим её к шкале Цельсия.
Далее из разрозненных данных формируем примеры вида:
lat, lon, lat0, lon0, T0, lat1, lon1, T1,…, lat24,
lon24, T24 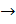 T,
T,
где
lat, lon - координаты точки, на которой будет обучаться сеть.,
loni, i=0,…,24 - координаты точек, относительно которых
происходит аппроксимация.i, i=0,…,24 - температура в конкретный рассматриваемый
момент времени в точках с координатами lati, loni.
Такому
примеру соответствует значение T - температура в точке с координатами lat, lon в
этот же момент времени.
В
итоге получилось около 200 тысяч примеров для обучения сети, что достаточно
много. К сожалению, данную выборку нельзя назвать до конца репрезентативной
поскольку по некоторым городам в ней представлено информации гораздо больше чем
по другим, из-за того, что сервис даёт именно такую неполную информацию. Этот
недостаток ещё предстоит преодолеть.
«Можно получать данные о текущей погоде в выбранной точке по координатам
lat/lon»
Но, к сожалению, эта возможность реализована довольно странно. Вместо
данных в конкретной точке результат http запроса выдаёт информацию о городе
находящемся наиболее близко к указанным координатам. Притом сервис обладает
информацией не обо всех городах и населённых пунктах, а лишь в части из них.
Описанные выше недостатки сильно ограничивали и замедляли разработку. К
примеру, если бы была информация о большем числе городов, то обучающая выборка
была бы более полной, что, вполне вероятно, позволило бы лучше обучить сеть и
получить лучшие результаты аппроксимации.
Также сильно помешал тот факт, что при использовании истории наблюдений я
столкнулся с тем, что о каких-то городах хранится гораздо более насыщенная
история наблюдений за определённый период чем о других (во много раз). Эта
проблема непосредственно влияет на репрезентативность выборки. Причём если
исключить города с более объёмной историей наблюдений, чтобы выровнять
количество информации обо всех городах, то обучающая выборка оказывается
слишком малой и, из-за этого, сеть обучается только хуже.
Пока пришлось оставить выборку с разным объёмом наблюдений о разных
городах. Такая выборка получается довольно большой, что даёт возможность сети
обучиться и показывать достаточно неплохие результаты даже на не совсем
репрезентативной выборке.
.3.3 Нормализация данных
Было применено два типа нормализации:
а) Нормализация с использованием математического ожидания и дисперсии.
Для
температуры и координат отдельно считается математическое ожидание и дисперсия
по формулам: 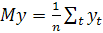 и
и 
Затем
рассчитываются новые нормализованные значения по формуле
(16)
И
записываются в файл в таком же виде
lat, lon, lat0, lon0, T0, lat1, lon1, T1,…, lat24,
lon24, T24 T,
После чего данные можно подавать на обучение.
Чтобы
полученный выход сети соответствовал реальному используется формула [8]
б) Нормализация с использованием минимаксной функции.
Отдельно для координат и температуры считаются максимальные и минимальные
значения в выборке. На основе этого данные нормализуются по формуле:
(17)
где:-
значение, подлежащее нормализации;
[xmax,
xmin] - интервал значений x;
[d1, d2] -
интервал, к которому будет приведено значение x.
Мною
использовался стандартный интервал [0, 1]. [8]
.3.4
Обучающая и тестовая выборка
Обучающая выборка представляет собой совокупность примеров следующего
вида:
latNorm, lonNorm, latNorm0, lonNorm0, TNorm0,
latNorm1, lonNorm1, TNorm1,…, latNorm24, lonNorm24, TNorm24
TNorm,
где
latNorm, lonNorm - нормализованные одним из двух представленных выше
алгоритмов координаты точки, на которой будет обучаться сеть., lonNormi,
i=0,…,24 - нормализованные координаты точек, относительно которых происходит
аппроксимация.i, i=0,…,24 - нормализованная температура в конкретный
рассматриваемый момент времени в точках с координатами lati, loni.
Такому
примеру соответствует значение TNorm - нормализованная температура в точке с координатами lat, lon в
этот же момент времени.
Тестовая
выборка представляется в таком же самом виде.
Было
использовано два вида тестовых выборок:
Выборка
основанная на истории наблюдений
Выборка
представляющая температурное распределение в данный момент времени.
.4 Нейронная
сеть
В качестве нейронной сети для решения задачи аппроксимации использовался
многослойный персептрон. Эксперименты по обучению и тестированию проводились
как для одного, так и для двух скрытых слоёв. В качестве алгоритма обучения
применялся алгоритм обратного распространения ошибки. В качестве функции
активации была выбрана логистическая функция - нелинейная функция, задаваемая
следующим выражением:
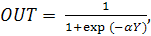 (18)
(18)
где
α - параметр
наклона сигмоидальной функции [3].
Величина
ошибки подсчитывалась следующим образом:
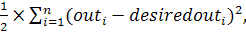 (19)
(19)
где
outi это реальный выход нейрона, а desiredouti
это желаемый выход нейрона.
2.4.1 Подбор
конфигурации сети
Сначала подбор конфигурации сети производился эмпирическим путём, то есть
выбиралась конфигурация, производилось обучение, а на основе полученных
результатов выбиралась та, которая давала наилучшие результаты.
Затем было решено провести более точную подборку конфигурации. Сначала
были проведены исследования с одним скрытым слоем. Был написан метод, который в
цикле примерно от 20 нейронов в скрытом слое до 120 для каждого шага создавал
сеть с указанным числом нейронов. Затем сеть обучалась и тестировалась,
результаты записывались в файл. Этап обучения и тестирования повторялся трижды
для каждой конфигурации сети. На основе полученных данных выбиралась сеть с
наилучшими результатами.
Далее было произведено подобное исследование для двух скрытых слоёв.
В итоге я остановился на конфигурации с двумя скрытыми слоями - 20
нейронов в первом слое, 10 во втором.
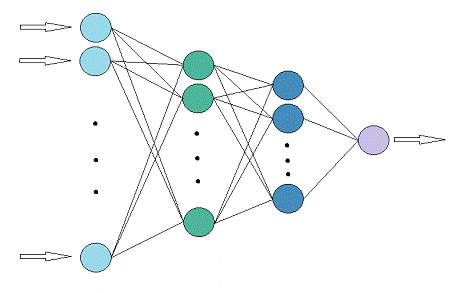
Рисунок 2.3 - Структура нейронной сети
В первом слое нейронной сети содержится 77 нейронов:
городов, для каждого по три значения (широта, долгота, температура) итого
75, плюс 2 значения (широта, долгота) для аппроксимируемой точки.
Затем скрытый слой с 20 нейронами, скрытый слой с 10 нейронами и 1 выходной
нейрон выдающий температуру в аппроксимируемой точке.
.4.2
Оптимизация и дообучение нейронной сети
При первых попытках обучить сеть на имеющемся множестве примеров возникла
проблема, что каждый обучающий проход занимает слишком много времени (около минуты).
Встал вопрос о необходимости ускорения работы сети. Путём анализа и замеров
времени исполнения использующихся методов был вычислен метод выполняющийся
гораздо дольше других. Затем он был переписан, что привело к тому, что скорость
обучения возросла приблизительно в 20 раз (около 3-х секунд).
К имеющейся функциональности нейронной сети была добавлена возможность
дообучения. Сеть обучается, затем веса и все необходимые параметры сохраняются
в файл, а при повторном запуске есть возможность выбора между продолжением
обучения и обучением с нуля. При дообучении веса и параметры берутся из
указанного файла и инициализация сети происходит с использованием этих
значений.
.4.3 Обучение
и тестирование нейронной сети
При использовании нормализации входных данных с помощью математического
ожидания и дисперсии попытки обучить сеть не увенчались успехом.
Когда же использовалась нормализация с помощью минимаксной функции сеть
достаточно неплохо обучалась и давала неплохие результаты при тестировании.
Обучение сети проходило не идеально - сети не удавалось обучиться на всех
без исключения примерах:
При задании максимально допустимой ошибки величиной в 0.01 (что
составляет около 0.7 градуса по Цельсию) сети удаётся научиться давать
правильный результат для 263 тысяч примеров из 264 тысяч. Для ошибки величиной
в 0.001 - около 230 тысяч из 264. То есть процесс обучения заканчивался не по
распознаванию всех примеров, а по достижении максимального числа итераций. Если
сделать число итераций очень большим, то сеть постепенно улучшает показания в
том смысле, что распознает всё большее число примеров, но при тестировании в
лучшую сторону это не сказывается, скорее даже сказывается в худшую.
Тестирование проходило на двух наборах данных:
а) Выборка основанная на истории наблюдений
б) Выборка представляющая температурное распределение в данный момент
времени.
Первая гораздо больше второй. На выборке основанной на истории наблюдений
сеть показывала результаты лучше, чем на данных за текущий момент. Для первой
лучшим показателем является около 1.4 градуса расхождения с реальностью. Для
второй около 1.7.
.5
Аппроксимация
аппроксимация нейронный
сеть
2.5.1
Результат работы нейронной сети
После обучения сети происходит формирование сетки аппроксимации
рассматриваемого квадрата. На вход сети подаются координаты с некоторым шагом,
полностью покрывающие квадрат. Сеть выдаёт результат - предполагаемую
температуру в этой точке. Затем по полученным данным формируется матрица.
Данные из этой матрице впоследствии должны отображаться в веб представлении.

Рисунок 2.4 - Температурное распределение на рассматриваемом участке
карты полученное нейронной сетью
На представленном выше графике отображено температурное распределение на
участке на карте с координатами 45 - 49 градусов широты, 0 - 4 градуса
восточной долготы. По оси Z
откладывается температура в шкале Цельсия.
.5.2
Сравнение с математическим методом
Для сравнения результатов работы нейронной сети с некоторым стандартным
математическим методом аппроксимации использовалась система компьютерной
алгебры Wolfram Mathematica. На том
же наборе данных, который использовался при аппроксимации нейронной сетью, была
произведена аппроксимация методом Эрмитовой интерполяции. Затем было
произведено тестирование.
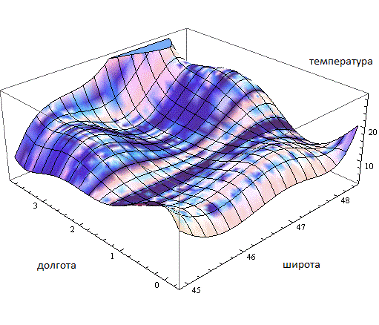
Рисунок 2.5 - Температурное распределение полученное Эрмитовой
интерполяцией
Аппроксимация получилась отличной от ожидаемой, средняя ошибка составила
около 17-ти градусов расхождения с реальностью. Я связываю это со слишком малым
набором известных данных - всего 25 известных точек. Поскольку стандартные
методы не могут обучаться им приходится делать свои суждения только по
имеющимся сведениям, которые, как в данном случае, могут быть не достаточными
для приемлемой аппроксимации.
3 РЕАЛИЗАЦИЯ ПРОГРАММНОЙ СИСТЕМЫ
В процессе реализации программной системы были применены следующие
технологии и программное обеспечение:
язык программирования Java
текстовый формат обмена данными JSON
среда разработки Eclipse
OpenWeatherMap API
фреймворк JSON-Simple для работы с JSON в Java
фреймворк JavaServer Faces для разработки веб-приложений на Java
система компьютерной алгебры Wolfram Mathematica
.1 Основные возможности OpenWeatherMap API
Как уже было сказано ранее, сервис OpenWeatherMap предоставляет
бесплатный API ко всем данным о погоде, к их истории, прогнозам и всему
многообразию погодных карт. API обладает следующими возможностями:
Можно узнать текущие погодные сведения в некотором городе. Это делается с
помощью http запроса следующим образом [9]:
а) По названию города:.openweathermap.org/data/2.5/weather?q=London,uk
б) По географическим координатам:.openweathermap.org/data/2.5/weather?lat=35&lon=139
в) По идентификатору города:.openweathermap.org/data/2.5/weather?id= 2172797
Пример выдаваемого ответа в JSON формате:
{"coord":{"lon":-0.13,"lat":51.51},"sys":
{"message":0.0038,"country":"GB","sunrise":1400213168,"sunset":1400269657},"weather":[{"id":800,"main":"Clear","description":"Sky
is Clear","icon":"01d"}],"base":
"cmcstations","main":{"temp":282.38,"pressure":1034,"humidity":87,"temp_min":279.26,"temp_max":284.82},"wind":{"speed":1.5,"deg":60},"clouds":{"all":0},"dt":1400218487,"id":2643743,"name":"London","cod":200}
В некоторых запросах поддерживается выдача результата в XML формате, для
этого достаточно добавить к запросу параметр «mode=xml».
Получение прогноза погоды на 5 дней за каждые три часа:
api.openweathermap.org/data/2.5/forecast?q=London,us&mode=xml
Прогноз на 10 дней, с одним наблюдением за день:
api.openweathermap.org/data/2.5/forecast/daily?lat=35&lon=139&cnt=10&mode=json
Получение истории наблюдений за определённый промежуток времени:
api.openweathermap.org/data/2.5/history/city?id=2885679&type=hour&start=1369728000&end=1369789200,
Здесь поиск города идёт по его идентификатору, промежуток времени
указывается с использованием UNIX-времени [9].
.2 JSON и возможности фреймворка JSON-Simple
(англ. JavaScript Object Notation) - текстовый формат обмена данными,
основанный на JavaScript и обычно используемый именно с этим языком. Как и
многие другие текстовые форматы, JSON легко читается людьми.
Несмотря на происхождение от JavaScript, формат считается
языконезависимым и может использоваться практически с любым языком программирования.
Для многих языков существует готовый код для создания и обработки данных в
формате JSON.
Пусть text это строковая переменная хранящая представленный в предыдущем
пункте JSON текст. Приведём пример простой программы иллюстрирующей работу фреймворка
[10]:
JSONParser parser = new JSONParser();
Object obj = parser.parse(text);jsonObject = (JSONObject)
obj;name = (String) jsonObject.get("name");weather = (JSONArray)
jsonObject.get("main");<String> iterator =
weather.iterator();(iterator.hasNext()) {.out.println(iterator.next());
}
Здесь все классы имеющие приставку JSON являются классами фреймворка.
В программе создаётся парсер, который парсит JSON текст в объект класса Object. На его основе
формируется объект класса JSONObject. Теперь из этого объекта можно извлекать необходимую информацию - в
программе в строковую переменную «name» помещается имя города. Далее создаётся
объект «weather» класса JSONArray, являющийся
аналогом java.util.List в Java,
хранящий сведения о температуре, давлении, влажности и т.п. После этого
создаётя итератор, с помощью которого осуществляется проход по всем полям «weather» с выводом значений этих полей на
экран.
.3 Библиотека Leaflet
- библиотека с открытым исходным кодом, написанная российским
разработчиком Владимиром Агафонкиным на JavaScript, предназначенная для
отображения карт на веб-сайтах.
Библиотека пользуется очень большой популярностью, так например
библиотека используется на сайтах Flickr, Foursquare, Craigslist, Data.gov,
IGN, проектах Викимедиа, OpenStreetMap, Meetup, WSJ, MapBox, CloudMade, CartoDB
и других.
Приведём пример простой программы иллюстрирующей работу с библиотекой
[11]:
// создаётся карта в заданном месте и определённой степенью приближения
var map = L.map('map').setView([51.505, -0.09], 13);
// добавляется OpenStreetMap слой.tileLayer(
'#"785954.files/image065.gif">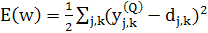 (20)
(20)
Где
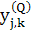 -
реальное выходное состояние нейрона j-го выходного слоя нейронной
сети при подаче на её входы k-го образа,
-
реальное выходное состояние нейрона j-го выходного слоя нейронной
сети при подаче на её входы k-го образа, 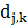 -
требуемое выходное состояние этого нейрона.
-
требуемое выходное состояние этого нейрона.
Далее
происходит вызов метода обучающего нейронную сеть:
net.teachOffLine();
Этот
метод выполняет обучение сети. Раз за разом выполняя прямой и обратный проход
метод стремится к минимизации ошибки, подстраивая веса соответственно методу
обратного распространения. Выход из метода происходит, либо если ошибка сети
станет меньше заданной пользователем, либо при достижении максимально допустимого
числа итераций.
Затем, уже обученной сети предъявляются неоцененные тесты следующим
образом:.compute(patternIn);
Метод compute() вычисляет «выход» сети на
подаваемый тестовый экземпляр. А конкретно он вычисляет и помещает «реакцию»
нейронной сети - число от 0 до 1, в поле output каждого выходного нейрона..getOutput(i);
Приведённая выше конструкция, считывает значение поля output.
.4.2 Описание проекта NetApproximationпроект, осуществляющий получение,
обработку данных, вызов методов нейронной сети и формирование матрицы
аппроксимации.
Проект обладает следующей структурой пакетов:
netapproximation.dao.domain.errors.log.service- состоит из одного класса
Main, содержащего точку в входа в приложение - метод main(). Не содержит в себе какой-либо иной функциональности.
Перед тем как описывать пакет netapproximation.dao напишем о том,
что означает аббревиатура DAO:
В программном обеспечении data access object (DAO) - это объект, который
предоставляет абстрактный интерфейс к какому-либо типу базы данных или механизму
хранения. Определённые возможности предоставляются независимо от того, какой
механизм хранения используется и без необходимости специальным образом
соответствовать этому механизму хранения. Этот шаблон проектирования применим
ко множеству языков программирования, большинству программного обеспечения,
нуждающемуся в хранении информации и к большей части баз данных, но традиционно
этот шаблон связывают с приложениями на платформе Java Enterprise Edition,
взаимодействующими с реляционными базами данных через интерфейс JDBC, потому
что он появился в рекомендациях от фирмы Sun Microsystems.
Таким образом netapproximation.dao содержит класс для взаимодействия с
источниками хранения информации. В моём случае в качестве таковых выступают
файлы. Класс называется CommonDao. Все его методы статические. Они реализуют
помещение списков, множеств и хеш-таблиц в файл, а также извлечение списков и
хеш-таблиц из файлов.
netapproximation.domain - цель
этого пакета - содержать в себе классы представляющие объекты рассматриваемой
предметной области. Содержит один класс Coordinates, соответствующий объекту
«географические координаты».
netapproximation.errors - содержит
определённые мною классы исключений. То есть определив эти исключения я могу
где-либо в коде вызвать их. Например можно обработать какое-либо общее
исключение и взамен него вызвать своё, точно поясняющее что произошло:
try {
// код разбора JSON объекта
} catch (ParseException e) {
throw new JSONParseError("Ошибка разбора JSON объекта: " + e.toString(), e);
}
Вместо достаточно общего ParseException будет получено JSONParseError, что может облегчить поиск и устранение неполадок.
netapproximation.log - отвечает за
логирование. Содержит класс Log.
netapproximation.service - этот
пакет обладает основной функциональностью пакета. Содержит 4 класса:
GetDataService
NormalizeMinMaxService
NormalizeMxDxService
TeachService
GetDataService - содержит методы для получения данных с сервиса
OpenWeatherMap и их обработку.
NormalizeMinMaxService - отвечает за нормализацию данных для подачи на вход
нейронной сети с использованием минимаксной функции.
NormalizeMxDxService - отвечает за нормализацию данных для подачи на вход
нейронной сети с использованием математического ожидания и дисперсии.- содержит
методы для запуска обучения, тестирования, инициализации нейронной сети. Также
отвечает за формирование матрицы аппроксимации на основе обученной нейросети.
.4.3 Описание
проекта WebWeatherView
JavaServer Faces проект
реализующий веб представление температурных данных.
С помощью возможностей Javascript библиотеки Leaflet
отрисовывается карта. С помощью неё же организована возможность получения
температурных данных в некоторой точке путём щелчка по карте. Происходит
обращение к серверу, он по координатам вычисляет результат и возвращает его
клиенту. Происходит отрисовка маркера с аппроксимированной температурой в этой
точке.
Также с использованием JSF компонент, организована возможность поиска
температуры в конкретном городе или по конкретным координатам. После введения
данных и нажатия кнопки «Поиск» происходит обращение к серверу за температурой.
Получив данные программа отрисовывает маркер используя Leaflet API.
4 ГРАФИЧЕСКИЙ ИНТЕРФЕЙС ПОЛЬЗОВАТЕЛЯ
Для отображения температурных данных полученных путём аппроксимации
нейронной сетью было разработано веб-представление.

В возможности пользователя входит получение температуры путём:
нажатия мышкой на карте
указания интересующего города
указания интересующих координат
Данные пользователю отображаются с помощью маркера, отображающегося на
карте в интересующей точке и содержащего в себе аппроксимированную текущую
температуру в этой точке.
ЗАКЛЮЧЕНИЕ
В рамках выполнения дипломной работы были изучены основы аппроксимации функций,
теория обосновывающая применение нейронных сетей к аппроксимации функций.
Также были изучены и применены такие технологии как формат представления
данных JSON, библиотека для работы с этим форматом в Java, API погодного сервиса OpenWeatherMap. Для разработки программной системы
был успешно применён объектно-ориентированный язык Java, изученный ранее. Также
в ходе работы был получен опыт разработки веб приложений.
Была разработана нейронная сеть. В дипломной работе сеть применялась для
аппроксимации температурных данных и показала достаточно неплохие результаты -
ошибка всего около 1.4 градуса Цельсия.
Данные полученные на выходе нейронной сети отображаются пользователю с
помощью веб представления, позволяющего узнать температуру в любой интересующей
его точке.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
1. Саймон
Хайкин Нейронные сети: полный курс, 2-е издание. Пер. с англ. - М.:
Издательский дом «Вильямс», 2006. - 1104 с.: ил.
2. Круглов
В.В., Борисов В. В. Искусственные нейронные сети. Теория и практика. - 2-е
изд., стереотип. - М.: Горячая линия - Телеком, 2002. - 382 с.: ил.
. Яхъяева
Г.Э. Нечёткие множества и нейронные сети: Учебное пособие. М.:
Интернет-Университет Информационных Технологий; БИНОМ. Лаборатория знаний,
2006. - 316с.: ил.
4. Эрмитова интерполяция
[Электронный ресурс] / Статья - Электрон. дан.
<http://dic.academic.ru/dic.nsf/ruwiki/1896283> - Режим доступа:
свободный - Загл. с экрана - Яз. рус. (дата обращения 18.05.2014)
5. Хортсманн
К.С., Корнелл Г. Библиотека профессионала. Java 2.
Том 1.
Основы.: Пер. с англ. - М.: Издательский дом "Вильямc", 2003. - 848 с: ил.
6. Гери Д. М., Хортсманн К.С. JavaServer Faces. Библиотека профессионала, 3-е изд.:
Пер. с англ. - М.: ООО «И,Д, Вильямс», 2011. - 544 c.: ил. - Парал. тит. англ.
7. OpenWeatherMap - как
энтузиасты делают погоду [Электронный ресурс] / Статья - Электрон. дан.
<http://habrahabr.ru/post/164045/> - Режим доступа: свободный - Загл. с
экрана - Яз. рус. (дата обращения 15.02.2014)
. Т.В. Филатова
Применение нейронных сетей для аппроксимации данных API [Электронный ресурс] /
Статья - Электрон. Дан.
<http://sun.tsu.ru/mminfo/000063105/284/image/284_121-125.pdf> - Режим
доступа: свободный - Загл. с экрана - Яз. рус. (дата обращения 20.03.2014)
. OpenWeatherMap API
[Электронный ресурс] / Статья - Электрон. дан.
<http://openweathermap.org/API> - Режим доступа: свободный - Загл. с
экрана - Яз. англ. (дата обращения 18.02.2014)
. JSON.simple example
- Read and write JSON [Электронный ресурс] / Статья - Электрон. Дан.
<http://www.mkyong.com/java/json-simple-example-read-and-write-json/> -
Режим доступа: свободный - Загл. с экрана - Яз. англ. (дата обращения
02.03.2014)
. Leaflet Quick Start
Guide [Электронный ресурс] / Статья - Электрон. дан.
http://leafletjs.com/examples/quick-start.html#leaflet-quick-start-guide
<http://leafletjs.com/examples/quick-start.html> - Режим доступа:
свободный - Загл. с экрана - Яз. англ. (дата обращения 25.03.2014)